

Mapping Gross Domestic Product Distribution at 1 km Resolution across Thailand Using the Random Forest Area-to-Area Regression Kriging Model


Abstract
:1. Introduction
2. Materials and Methods
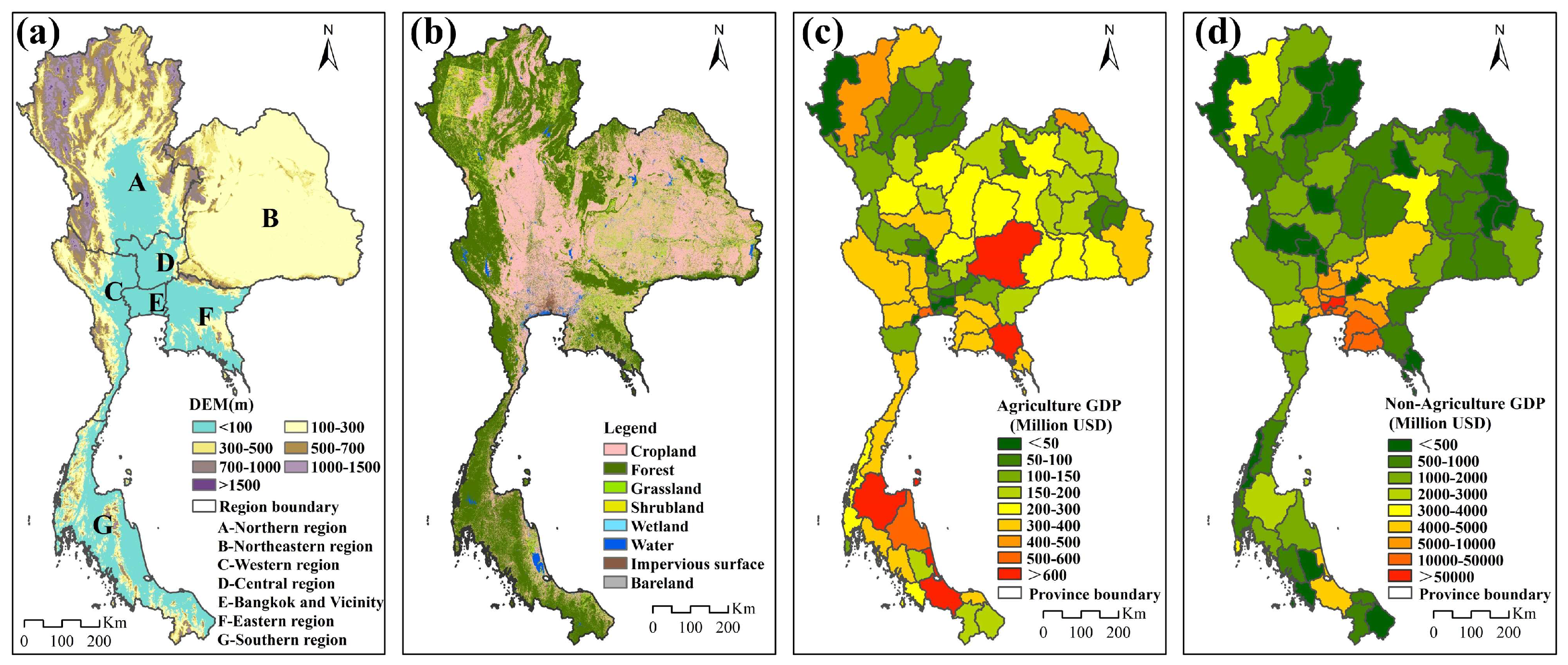
2.1. Study Area
2.2. Materials
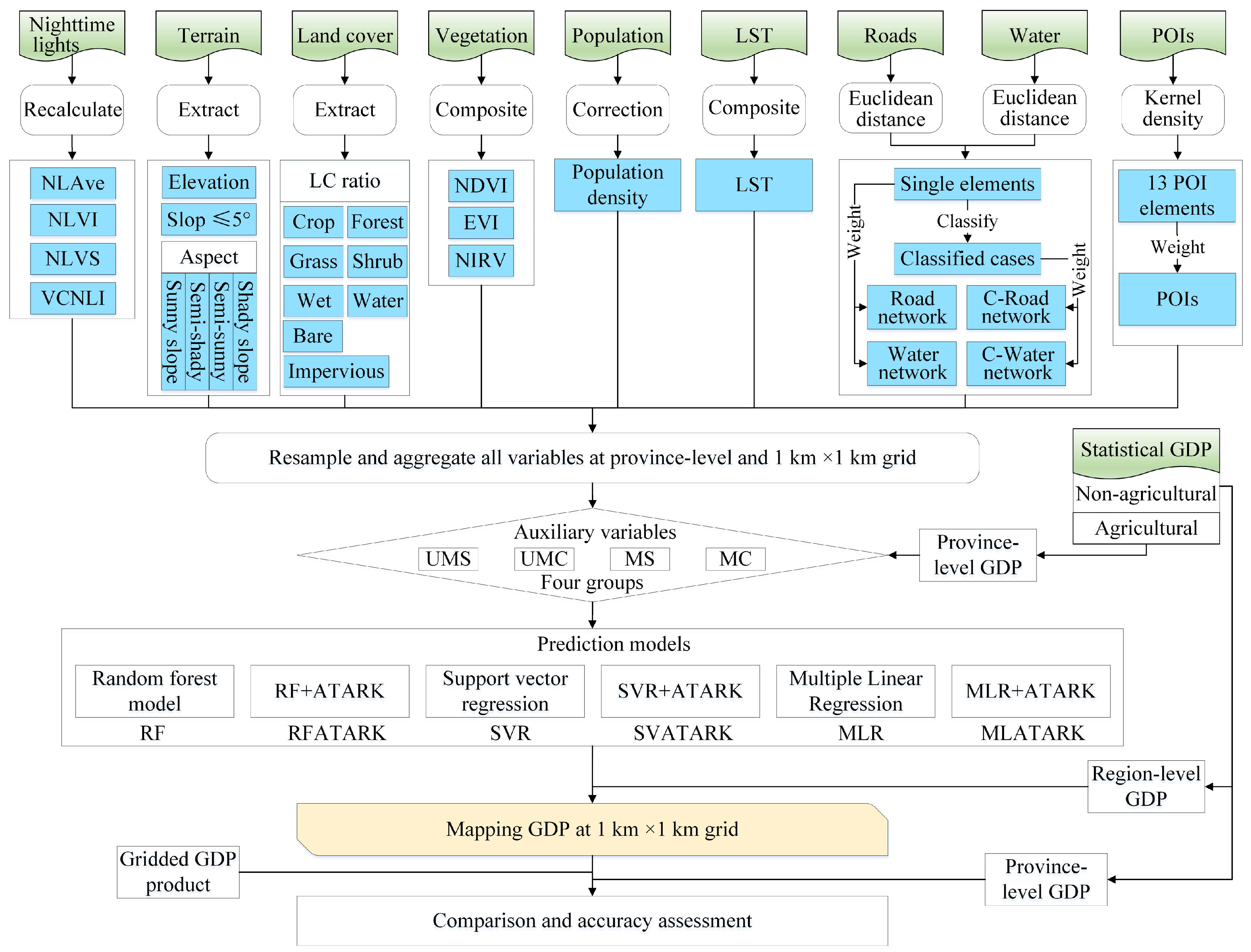
2.3. Data Processing
2.3.1. NTL Data Processing
2.3.2. OSM Data Processing
2.3.3. Other Processing
2.4. Downscaling Methodology
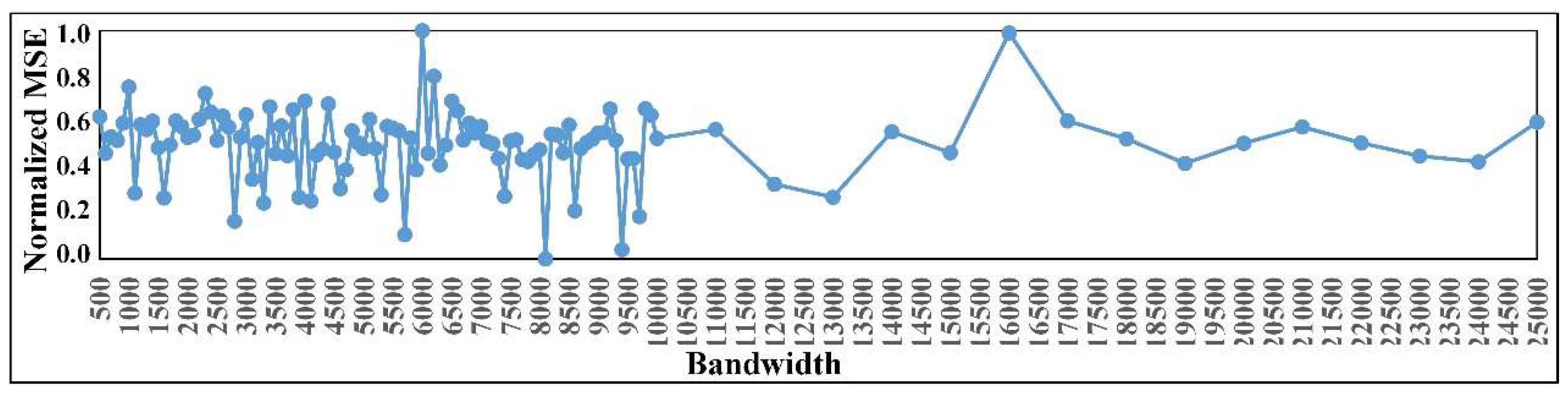
2.4.1. Downscaling Model
2.4.2. Downscaling Strategy
3. Results
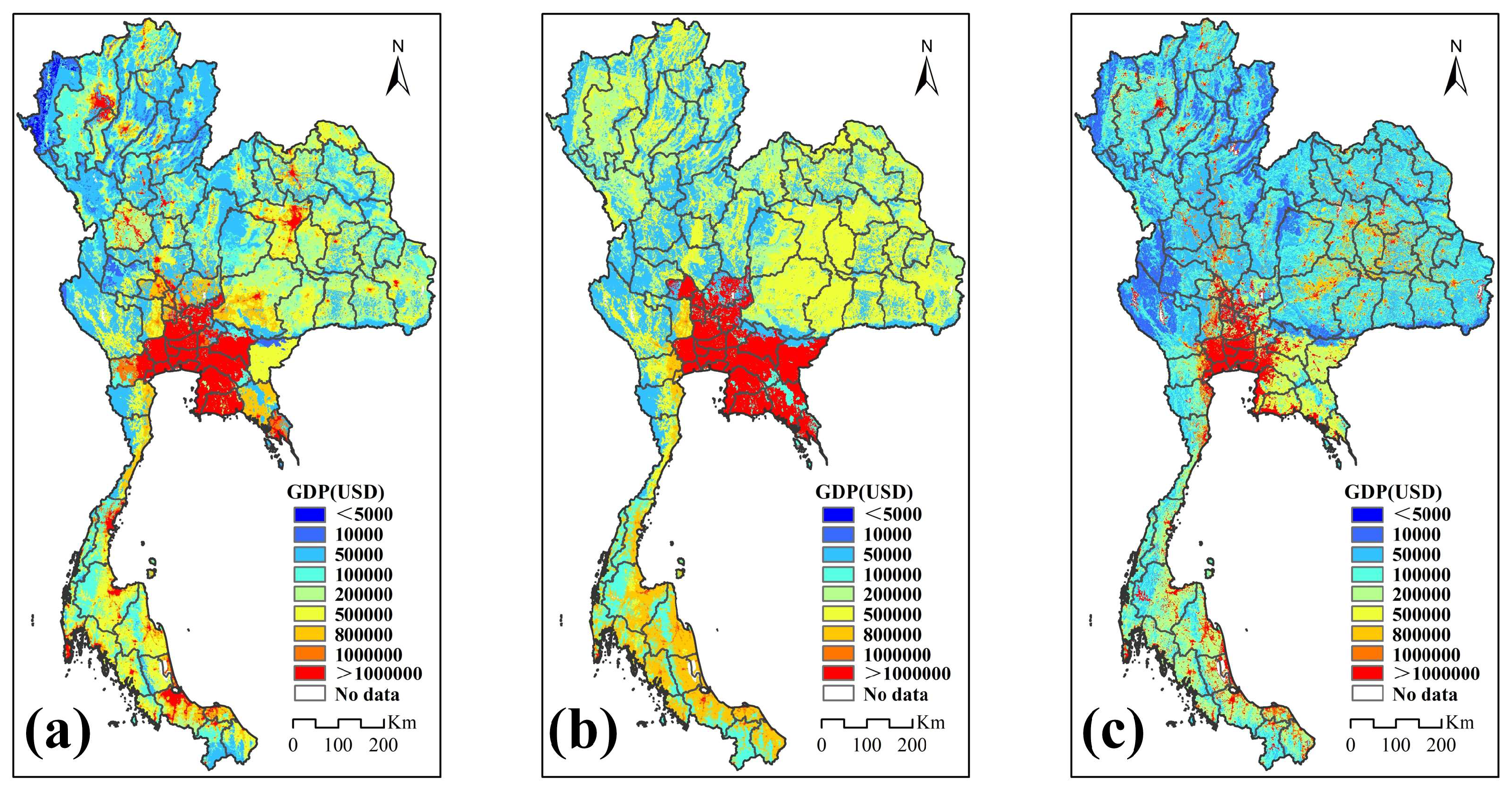
3.1. Gridded GDP Mapping
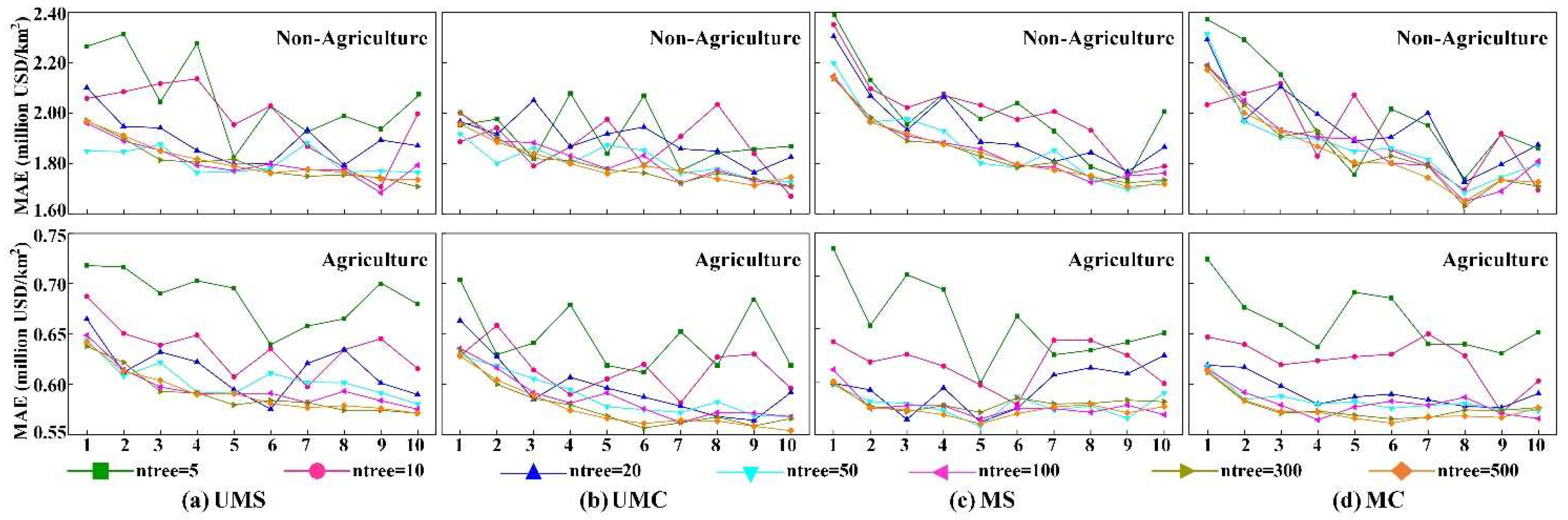
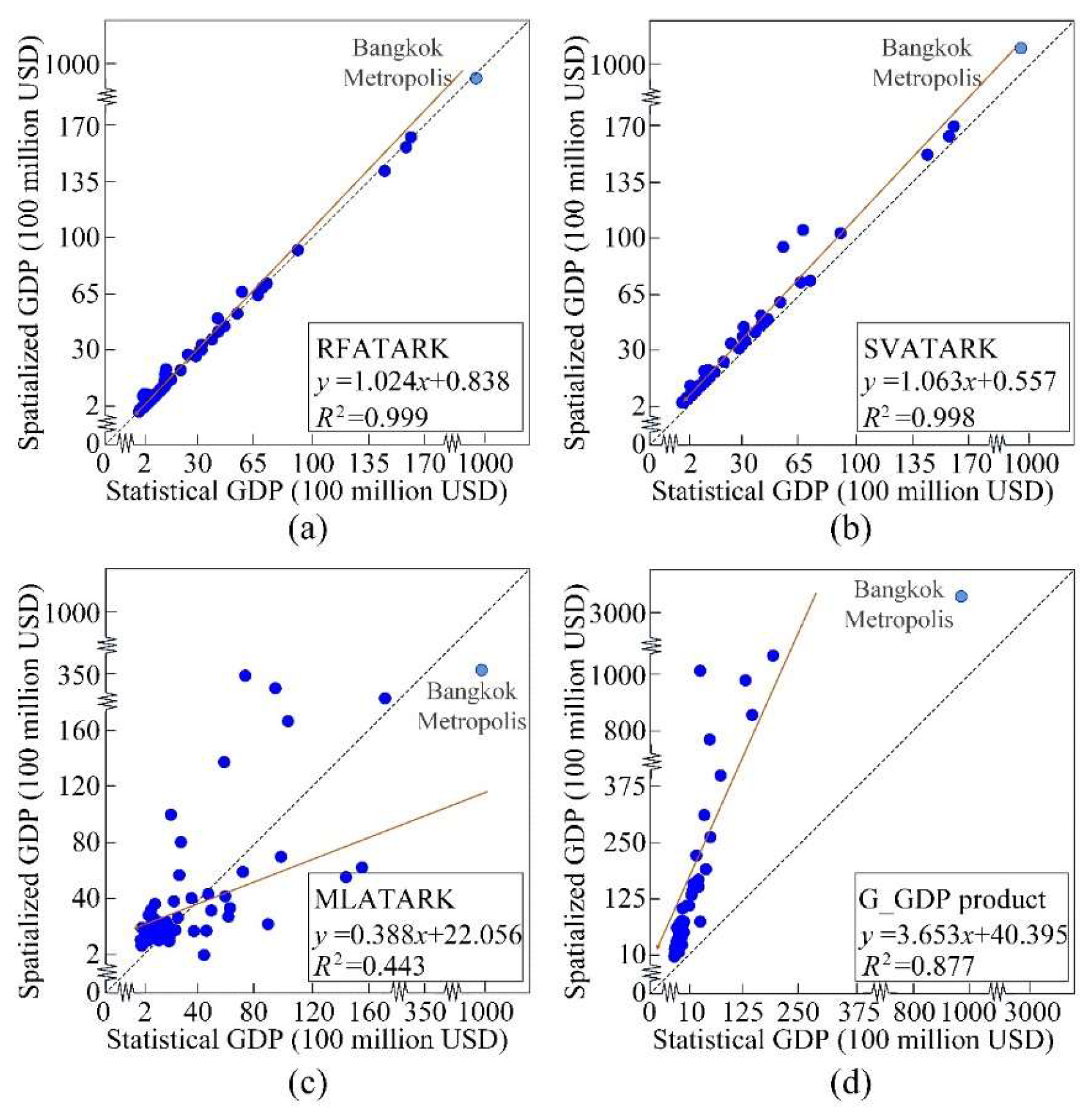
3.2. Accuracy Assessment
4. Discussion
4.1. GDP Spatialization for Different Sectors
4.2. Data Used for GDP Spatialization
4.3. GDP Spatialization Methods
4.4. Impact of Residual Predictions
4.5. Additional Factors Potentially Impacting Accuracy
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Liu, Z.; He, C.; Zhang, Q.; Huang, Q.; Yang, Y. Extracting the Dynamics of Urban Expansion in China Using DMSP-OLS Nighttime Light Data from 1992 to 2008. Landsc. Urban Plan. 2012, 106, 62–72. [Google Scholar] [CrossRef]
- Jean, N.; Burke, M.; Xie, M.; Davis, W.M.; Lobell, D.B.; Ermon, S. Combining Satellite Imagery and Machine Learning to Predict Poverty. Science 2016, 353, 790–794. [Google Scholar] [CrossRef] [PubMed]
- Zhao, N.; Currit, N.; Samson, E. Net Primary Production and Gross Domestic Product in China Derived from Satellite Imagery. Ecol. Econ. 2011, 70, 921–928. [Google Scholar] [CrossRef]
- Zhao, S.; Liu, Y.; Zhang, R.; Fu, B. China’s Population Spatialization Based on Three Machine Learning Models. J. Clean. Prod. 2020, 256, 120644. [Google Scholar] [CrossRef]
- Li, F.; Mi, X. Spatialization of GDP in Beijing Using NPP-VIIRS Data. Remote Sens. Nat. Resour. 2016, 28, 19–24. [Google Scholar] [CrossRef]
- Yue, W.; Gao, J.; Yang, X. Estimation of Gross Domestic Product Using Multi-Sensor Remote Sensing Data: A Case Study in Zhejiang Province, East China. Remote Sens. 2014, 6, 7260–7275. [Google Scholar] [CrossRef]
- Elvidge, C.D.; Baugh, K.E.; Kihn, E.A.; Kroehl, H.W.; Davis, E.R.; Davis, C.W. Relation between Satellite Observed Visible-near Infrared Emissions, Population, Economic Activity and Electric Power Consumption. Int. J. Remote Sens. 1997, 18, 1373–1379. [Google Scholar] [CrossRef]
- Huang, Q.; Yang, X.; Gao, B.; Yang, Y.; Zhao, Y. Application of DMSP/OLS Nighttime Light Images: A Meta-Analysis and a Systematic Literature Review. Remote Sens. 2014, 6, 6844–6866. [Google Scholar] [CrossRef]
- Bennett, M.M.; Smith, L.C. Advances in Using Multitemporal Night-Time Lights Satellite Imagery to Detect, Estimate, and Monitor Socioeconomic Dynamics. Remote Sens. Environ. 2017, 192, 176–197. [Google Scholar] [CrossRef]
- Doll, C.H.; Muller, J.-P.; Elvidge, C.D. Night-Time Imagery as a Tool for Global Mapping of Socioeconomic Parameters and Greenhouse Gas Emissions. Ambio 2000, 29, 157–162. [Google Scholar] [CrossRef]
- Elvidge, C.D.; Zhizhin, M.; Hsu, F.-C.; Baugh, K.E. VIIRS Nightfire: Satellite Pyrometry at Night. Remote Sens. 2013, 5, 4423–4449. [Google Scholar] [CrossRef]
- Zhao, M.; Zhou, Y.; Li, X.; Cao, W.; He, C.; Yu, B.; Li, X.; Elvidge, C.D.; Cheng, W.; Zhou, C. Applications of Satellite Remote Sensing of Nighttime Light Observations: Advances, Challenges, and Perspectives. Remote Sens. 2019, 11, 1971. [Google Scholar] [CrossRef]
- Zhao, M.; Cheng, W.; Zhou, C.; Li, M.; Wang, N.; Liu, Q. GDP Spatialization and Economic Differences in South China Based on NPP-VIIRS Nighttime Light Imagery. Remote Sens. 2017, 9, 673. [Google Scholar] [CrossRef]
- Elvidge, C.D.; Zhizhin, M.; Ghosh, T.; Hsu, F.-C.; Taneja, J. Annual Time Series of Global VIIRS Nighttime Lights Derived from Monthly Averages: 2012 to 2019. Remote Sens 2021, 13, 922. [Google Scholar] [CrossRef]
- Chen, Y.; Wu, G.; Ge, Y.; Xu, Z. Mapping Gridded Gross Domestic Product (GDP) Distribution of China Using Deep Learning With Multiple Geospatial Big Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 1791–1802. [Google Scholar] [CrossRef]
- Gibson, J.; Boe-Gibson, G. Nighttime Lights and County-Level Economic Activity in the United States: 2001 to 2019. Remote Sens. 2021, 13, 2741. [Google Scholar] [CrossRef]
- Hutasavi, S.; Chen, D. Estimating District-Level Electricity Consumption Using Remotely Sensed Data in Eastern Economic Corridor, Thailand. Remote Sens. 2021, 13, 4654. [Google Scholar] [CrossRef]
- Hutasavi, S.; Chen, D. Exploring the Industrial Growth and Poverty Alleviation through Space-Time Data Mining from Night-Time Light Images: A Case Study in Eastern Economic Corridor (EEC), Thailand. Int. J. Remote Sens. 2022, 1–23. [Google Scholar] [CrossRef]
- McCord, G.C.; Rodriguez-Heredia, M. Nightlights and Subnational Economic Activity: Estimating Departmental GDP in Paraguay. Remote Sens. 2022, 14, 1150. [Google Scholar] [CrossRef]
- Pérez-Sindín, X.S.; Chen, T.-H.K.; Prishchepov, A.V. Are Night-Time Lights a Good Proxy of Economic Activity in Rural Areas in Middle and Low-Income Countries? Examining the Empirical Evidence from Colombia. Remote Sens. Appl. 2021, 24, 100647. [Google Scholar] [CrossRef]
- Weidmann, N.B.; Theunissen, G. Estimating Local Inequality from Nighttime Lights. Remote Sens. 2021, 13, 4624. [Google Scholar] [CrossRef]
- Zhang, X.; Gibson, J. Using Multi-Source Nighttime Lights Data to Proxy for County-Level Economic Activity in China from 2012 to 2019. Remote Sens. 2022, 14, 1282. [Google Scholar] [CrossRef]
- Doll, C.N.H.; Muller, J.-P.; Morley, J.G. Mapping Regional Economic Activity from Night-Time Light Satellite Imagery. Ecol. Econ. 2006, 57, 75–92. [Google Scholar] [CrossRef]
- Han, X.; Zhou, Y.; Wang, S.; Liu, R.; Yao, Y. GDP Spatialization in China Based on Nighttime Imagery. Geo-Inf. Sci. 2012, 14, 128–136. [Google Scholar] [CrossRef]
- Chen, Q.; Hou, X.; Zhang, X.; Ma, C. Improved GDP Spatialization Approach by Combining Land-Use Data and Night-Time Light Data: A Case Study in China’s Continental Coastal Area. Int. J. Remote Sens. 2016, 37, 4610–4622. [Google Scholar] [CrossRef]
- Zhao, N.; Liu, Y.; Cao, G.; Samson, E.L.; Zhang, J. Forecasting China’s GDP at the Pixel Level Using Nighttime Lights Time Series and Population Images. GIsci Remote Sens. 2017, 54, 407–425. [Google Scholar] [CrossRef]
- Liang, H.; Guo, Z.; Wu, J.; Chen, Z. GDP Spatialization in Ningbo City Based on NPP/VIIRS Night-Time Light and Auxiliary Data Using Random Forest Regression. Adv. Space Res. 2020, 65, 481–493. [Google Scholar] [CrossRef]
- Sun, J.; Di, L.; Sun, Z.; Wang, J.; Wu, Y. Estimation of GDP Using Deep Learning With NPP-VIIRS Imagery and Land Cover Data at the County Level in CONUS. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 1400–1415. [Google Scholar] [CrossRef]
- Ghosh, T.; Powell, R.L.; Elvidge, C.D.; Baugh, K.E.; Sutton, P.C.; Anderson, S. Shedding Light on the Global Distribution of Economic Activity. Open Geogr. J. 2010, 3, 147–160. [Google Scholar] [CrossRef]
- Li, G.; Fang, C. Global Mapping and Estimation of Ecosystem Services Values and Gross Domestic Product: A Spatially Explicit Integration of National ‘Green GDP’ Accounting. Ecol. Indic. 2014, 46, 293–314. [Google Scholar] [CrossRef]
- Wang, X.; Rafa, M.; Moyer, J.D.; Li, J.; Scheer, J.; Sutton, P. Estimation and Mapping of Sub-National GDP in Uganda Using NPP-VIIRS Imagery. Remote Sens. 2019, 11, 163. [Google Scholar] [CrossRef]
- Keola, S.; Andersson, M.; Hall, O. Monitoring Economic Development from Space: Using Nighttime Light and Land Cover Data to Measure Economic Growth. World Dev. 2015, 66, 322–334. [Google Scholar] [CrossRef]
- Ustaoglu, E.; Bovkır, R.; Aydınoglu, A.C. Spatial Distribution of GDP Based on Integrated NPS-VIIRS Nighttime Light and MODIS EVI Data: A Case Study of Turkey. Environ. Dev. Sustain. 2021, 23, 10309–10343. [Google Scholar] [CrossRef]
- Chen, Q.; Ye, T.; Zhao, N.; Ding, M.; Ouyang, Z.; Jia, P.; Yue, W.; Yang, X. Mapping China’s Regional Economic Activity by Integrating Points-of-Interest and Remote Sensing Data with Random Forest. Environ. Plan. B Urban. Anal. City Sci. 2021, 48, 1876–1894. [Google Scholar] [CrossRef]
- Sutton, P.C.; Costanza, R. Global Estimates of Market and Non-Market Values Derived from Nighttime Satellite Imagery, Land Cover, and Ecosystem Service Valuation. Ecol. Econ. 2002, 41, 509–527. [Google Scholar] [CrossRef]
- Sutton, P.; Elvidge, C.; Tilottama, G. Estimation of Gross Domestic Product at Sub-National Scales Using Nighttime Satellite Imagery. Int. J. Ecol. Econ. Stat. 2007, 8, 5–21. [Google Scholar]
- Punyaratabandhu, P.; Swaspitchayaskun, J. The Political Economy of China–Thailand Development Under the One Belt One Road Initiative: Challenges and Opportunities. Chin. Econ. 2018, 51, 333–341. [Google Scholar] [CrossRef]
- Apipattanavis, S.; Ketpratoom, S.; Kladkempetch, P. Water Management in Thailand. Irrig. Drain. 2018, 67, 113–117. [Google Scholar] [CrossRef]
- Ariyapruchya, K.; Sanchez Martin, M.E.; Reungsri, T.; Luo, X. Publication: Thailand Economic Monitor, June 2016: Aging Society and Economy. 2016. Available online: http://hdl.handle.net/10986/24940 (accessed on 22 December 2022).
- Wang, Z.; Schaaf, C.B.; Sun, Q.; Shuai, Y.; Román, M.O. Capturing Rapid Land Surface Dynamics with Collection V006 MODIS BRDF/NBAR/Albedo (MCD43) Products. Remote Sens. Environ. 2018, 207, 50–64. [Google Scholar] [CrossRef]
- Badgley, G.; Field, C.B.; Berry, J.A. Canopy Near-Infrared Reflectance and Terrestrial Photosynthesis. Sci. Adv. 2017, 3, e1602244. [Google Scholar] [CrossRef] [PubMed]
- Huete, A.; Didan, K.; Miura, T.; Rodriguez, E.P.; Gao, X.; Ferreira, L.G. Overview of the Radiometric and Biophysical Performance of the MODIS Vegetation Indices. Remote Sens. Environ. 2002, 83, 195–213. [Google Scholar] [CrossRef]
- Wan, Z. New Refinements and Validation of the Collection-6 MODIS Land-Surface Temperature/Emissivity Product. Remote Sens. Environ. 2014, 140, 36–45. [Google Scholar] [CrossRef]
- Li, C.; Gong, P.; Wang, J.; Zhu, Z.; Biging, G.S.; Yuan, C.; Hu, T.; Zhang, H.; Wang, Q.; Li, X.; et al. The First All-Season Sample Set for Mapping Global Land Cover with Landsat-8 Data. Sci. Bull. 2017, 62, 508–515. [Google Scholar] [CrossRef] [PubMed]
- Tachikawa, T.; Hato, M.; Kaku, M.; Iwasaki, A. Characteristics of ASTER GDEM Version 2. In Proceedings of the 2011 IEEE International Geoscience and Remote Sensing Symposium, Vancouver, BC, Canada, 24–29 July 2011; IEEE: Vancouver, BC, Canada, 2011; pp. 3657–3660, ISBN 978-1-4577-1005-6. [Google Scholar]
- Kummu, M.; Taka, M.; Guillaume, J.H.A. Gridded Global Datasets for Gross Domestic Product and Human Development Index over 1990–2015. Sci. Data 2018, 5, 180004. [Google Scholar] [CrossRef] [PubMed]
- Tatem, A.J. WorldPop, Open Data for Spatial Demography. Sci. Data 2017, 4, 170004. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Huang, C.; Zhao, M.; Hou, J.; Zhang, Y.; Gu, J. Mapping the Population Density in Mainland China Using NPP/VIIRS and Points-Of-Interest Data Based on a Random Forests Model. Remote Sens. 2020, 12, 3645. [Google Scholar] [CrossRef]
- Sun, M.; Wang, T.; Xu, X.; Zhang, L.; Li, J.; Shi, Y. Ecological Risk Assessment of Soil Cadmium in China’s Coastal Economic Development Zone: A Meta-Analysis. Ecosyst. Health Sustain. 2020, 6, 1733921. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Cutler, A.; Stevens, J.R. Random Forests for Microarrays. Methods Enzymol. 2006, 411, 422–432. [Google Scholar] [CrossRef]
- Ham, J.; Chen, Y.; Crawford, M.M.; Ghosh, J. Investigation of the Random Forest Framework for Classification of Hyperspectral Data. IEEE Trans. Geosci. Remote Sens. 2005, 43, 492–501. [Google Scholar] [CrossRef]
- Goovaerts, P. Kriging and Semivariogram Deconvolution in the Presence of Irregular Geographical Units. Math. Geosci. 2008, 40, 101–128. [Google Scholar] [CrossRef]
- Jin, Y.; Ge, Y.; Liu, Y.; Chen, Y.; Zhang, H.; Heuvelink, G.B.M. A Machine Learning-Based Geostatistical Downscaling Method for Coarse-Resolution Soil Moisture Products. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 1025–1037. [Google Scholar] [CrossRef]
- Smola, A.J.; Schölkopf, B. A Tutorial on Support Vector Regression. Stat. Comput. 2004, 14, 199–222. [Google Scholar] [CrossRef]
- Wu, J. Landscape Sustainability Science: Ecosystem Services and Human Well-Being in Changing Landscapes. Landscape Ecol. 2013, 28, 999–1023. [Google Scholar] [CrossRef]
- Wu, J.; Wang, Z.; Li, W.; Peng, J. Exploring Factors Affecting the Relationship between Light Consumption and GDP Based on DMSP/OLS Nighttime Satellite Imagery. Remote Sens. Environ. 2013, 134, 111–119. [Google Scholar] [CrossRef]
- Wang, X.; Sutton, P.C.; Qi, B. Global Mapping of GDP at 1 Km2 Using VIIRS Nighttime Satellite Imagery. ISPRS Int. J. Geoinf. 2019, 8, 580. [Google Scholar] [CrossRef]
- Henderson, J.V.; Storeygard, A.; Weil, D.N. Measuring Economic Growth from Outer Space. Am. Econ. Rev. 2012, 102, 994–1028. [Google Scholar] [CrossRef]
- Natras, R.; Soja, B.; Schmidt, M. Ensemble Machine Learning of Random Forest, AdaBoost and XGBoost for Vertical Total Electron Content Forecasting. Remote Sens. 2022, 14, 3547. [Google Scholar] [CrossRef]
- Zamani Joharestani, M.; Cao, C.; Ni, X.; Bashir, B.; Talebiesfandarani, S. PM2.5 Prediction Based on Random Forest, XGBoost, and Deep Learning Using Multisource Remote Sensing Data. Atmosphere 2019, 10, 373. [Google Scholar] [CrossRef]
- Yu, J.-W.; Yoon, Y.-W.; Baek, W.-K.; Jung, H.-S. Forest Vertical Structure Mapping Using Two-Seasonal Optic Images and LiDAR DSM Acquired from UAV Platform through Random Forest, XGBoost, and Support Vector Machine Approaches. Remote Sens. 2021, 13, 4282. [Google Scholar] [CrossRef]
- Wang, S.; Zhuang, J.; Zheng, J.; Fan, H.; Kong, J.; Zhan, J. Application of Bayesian hyperparameter optimized random forest and XGBoost model for landslide susceptibility mapping. Front. Earth Sci. 2021, 9, 712240. [Google Scholar] [CrossRef]
- Kiangala, S.K.; Wang, Z.H. An effective adaptive customization framework for small manufacturing plants using extreme gradient boosting-XGBoost and random forest ensemble learning algorithms in an Industry 4.0 environment. Mach. Learn. Appl. 2021, 4, 100024. [Google Scholar] [CrossRef]
- Ge, Y.; Jin, Y.; Stein, A.; Chen, Y.; Wang, J.; Wang, J.; Cheng, Q.; Bai, H.; Liu, M.; Atkinson, P.M. Principles and Methods of Scaling Geospatial Earth Science Data. Earth-Sci. Rev. 2019, 197, 102897. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Dataset | Description | Source |
|---|---|---|---|
| ① | NTL | Annual composited NPP/VIIRS nighttime light data Spatial resolution: 15 arc-seconds | Earth Observation Group at Payne Institute for Public Policy, Colorado School of Mines |
| Vegetation index | Annual synthetic NDVI, EVI, and MODIS near-infrared vegetation reflectance index Spatial resolution: 250 m | Maximum value composite based on MODIS product (MOD13A3) or MODIS-based data calculated by MODIS Surface reflectance product (MOD43) | |
| Land surface temperature (LST) | Annual synthetic LST Spatial resolution: 1000 m | Maximum value composite based on MODIS product (MYD11A1) | |
| LULC | Finer Resolution Observation and Monitoring—Global Land Cover Spatial resolution: 30 m | FROM-GLC at Tsinghua University | |
| ② | Terrain data: digital elevation model (DEM) | ASTER/GDEM Spatial resolution: 30 m | Earth Remote Sensing Data Analysis Center of Japan |
| Boundary information | Provincial boundaries | Database of Global Administrative Areas | |
| Road, water, and point of interest (POI) | Road network, water bodies, and water roads, and 13 types of POIs of Thailand | Open Street Map (OSM) from Geofabrik GmbH | |
| ③ | GDP statistical and census data | Total GDP and population of the 77 provinces in Thailand | Office of the Thailand Economic and Social Development Council |
| Gridded GDP data | GDP of each grid cell Spatial resolution: 30 arc-seconds | Kummu et al. (2018) | |
| Population (Worldpop) | Grided population count datasets Spatial resolution: 100 m | University of Southampton |
| Class | Content | Group | Weight (Class) | Weight (Group) |
|---|---|---|---|---|
| Major roads | Motorways, primary roads, secondary roads, tertiary roads. | Road1 | 0.148 | 0.263 |
| Rail | Railways. | Road1 | 0.131 | |
| Highway links | Roads that connect from one road to another. | Road2 | 0.133 | 0.247 |
| Subway | Subways. | Road2 | 0.092 | |
| Minor roads | Smaller local roads, roads in residential areas, streets. | Road3 | 0.147 | 0.251 |
| Paths | Paths unsuitable for cars. | Road3 | 0.113 | |
| Small roads | Paths for cycling, footpaths, gravel roads, etc. | Road4 | 0.135 | 0.239 |
| Unknown | Unknown type of road or path. | Road4 | 0.101 | |
| River | Large rivers. | Water1 | 0.137 | 0.231 |
| Reservoir | Artificial lakes. | Water1 | 0.111 | |
| Stream | Smaller rivers or streams. | Water2 | 0.124 | 0.294 |
| Canal | Canals. | Water2 | 0.125 | |
| Wetland | Swamp, bog, or marsh land. | Water3 | 0.153 | 0.204 |
| Water | Unspecified bodies of water. | Water3 | 0.104 | |
| Drain | Small drainage ditches or similar structures. | Water4 | 0.124 | 0.271 |
| Dock | Docks. | Water4 | 0.122 |
| Class | Content | Weight |
|---|---|---|
| Accommodation | Hotels, motels, guesthouses, hostel, etc. | 0.092 |
| Catering | Restaurants, bars, cafes, etc. | 0.102 |
| Health | Pharmacies, hospitals, veterinaries, etc. | 0.084 |
| Leisure | Theaters, playgrounds, parks, cinemas, stadiums, etc. | 0.093 |
| Fuel and parking | Gas stations, service areas, car parks, etc. | 0.056 |
| Money | Banks, ATMs, etc. | 0.104 |
| Public | Police posts, fire stations, post offices, libraries, schools, etc. | 0.064 |
| Village and hamlet | Villages and hamlets. | 0.031 |
| Tourism | Tourist attractions, museums, monuments, zoos, ruins, etc. | 0.077 |
| Pofw | Buddhist temples, churches, synagogues, mosques, Muslim places, etc. | 0.050 |
| Miscpoi | Toilets, fountains, fire hydrants, towers, etc. | 0.066 |
| Shopping | Supermarkets, bakeries, malls, travel agencies, vending machines, etc. | 0.094 |
| Transport | Railway stations, bus stops, subway stations, airports, etc. | 0.087 |
| Model | Category | RMSE | MAE | R2 |
|---|---|---|---|---|
| RF | UMS | 7550.438 | 2198.005 | 0.578 |
| UMC | 7093.521 | 2124.864 | 0.642 | |
| MS | 7431.198 | 2163.931 | 0.598 | |
| MC | 7065.877 | 2107.321 | 0.647 | |
| Average | 7285.259 | 2148.53 | 0.616 | |
| SVR | UMS | 8756.371 | 2597.505 | 0.391 |
| UMC | 8424.893 | 2464.847 | 0.443 | |
| MS | 8747.029 | 2559.936 | 0.393 | |
| MC | 8414.596 | 2461.994 | 0.445 | |
| Average | 8585.722 | 2521.071 | 0.418 | |
| MLR | UMS | 17,259.112 | 4397.361 | 0.551 |
| UMC | 16,309.466 | 4695.980 | 0.363 | |
| MS | 51,242.087 | 13,478.187 | 0.607 | |
| MC | 184,033.264 | 40,547.569 | 0.611 | |
| Average | 67,210.980 | 15,779.77 | 0.533 | |
| RFATARK | UMS | 987.344 | 326.345 | 0.981 |
| UMC | 987.006 | 328.335 | 0.965 | |
| MS | 420.958 | 196.956 | 0.993 | |
| MC | 402.082 | 174.195 | 0.998 | |
| Average | 699.348 | 256.458 | 0.984 | |
| SVATARK | UMS | 1031.165 | 294.517 | 0.972 |
| UMC | 1027.465 | 297.735 | 0.998 | |
| MS | 936.841 | 308.826 | 0.977 | |
| MC | 915.298 | 288.899 | 0.996 | |
| Average | 977.692 | 297.494 | 0.986 | |
| MLATARK | UMS | 9174.452 | 2782.196 | 0.328 |
| UMC | 8771.900 | 2704.327 | 0.388 | |
| MS | 9159.387 | 2779.289 | 0.331 | |
| MC | 8363.801 | 2621.250 | 0.451 | |
| Average | 8867.385 | 2721.766 | 0.375 | |
| G_GDP | / | 36,042.271 | 13,657.988 | 0.877 |
| Model | RMSE | MAE | R2 |
|---|---|---|---|
| RFIDW | 1528.675 | 460.424 | 0.578 |
| RF_MC | 8673.488 | 2672.458 | 0.503 |
| XGBoost | 8679.099 | 2615.605 | 0.504 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jin, Y.; Ge, Y.; Fan, H.; Li, Z.; Liu, Y.; Jia, Y. Mapping Gross Domestic Product Distribution at 1 km Resolution across Thailand Using the Random Forest Area-to-Area Regression Kriging Model. ISPRS Int. J. Geo-Inf. 2023, 12, 481. https://doi.org/10.3390/ijgi12120481
Jin Y, Ge Y, Fan H, Li Z, Liu Y, Jia Y. Mapping Gross Domestic Product Distribution at 1 km Resolution across Thailand Using the Random Forest Area-to-Area Regression Kriging Model. ISPRS International Journal of Geo-Information. 2023; 12(12):481. https://doi.org/10.3390/ijgi12120481
Chicago/Turabian StyleJin, Yan, Yong Ge, Haoyu Fan, Zeshuo Li, Yaojie Liu, and Yan Jia. 2023. "Mapping Gross Domestic Product Distribution at 1 km Resolution across Thailand Using the Random Forest Area-to-Area Regression Kriging Model" ISPRS International Journal of Geo-Information 12, no. 12: 481. https://doi.org/10.3390/ijgi12120481
APA StyleJin, Y., Ge, Y., Fan, H., Li, Z., Liu, Y., & Jia, Y. (2023). Mapping Gross Domestic Product Distribution at 1 km Resolution across Thailand Using the Random Forest Area-to-Area Regression Kriging Model. ISPRS International Journal of Geo-Information, 12(12), 481. https://doi.org/10.3390/ijgi12120481