
Application of Hyperspectral Technology with Machine Learning for Brix Detection of Pastry Pears


Abstract
:1. Introduction
- (1)
- A crisp pear sugar content dataset was developed and published using hyperspectral imaging technology;
- (2)
- The feasibility and ideal model of the optimized genetic algorithm were investigated for predicting the sugar content in pear.
2. Related Studies
2.1. Hyperspectral Technology
2.2. Genetic Algorithm (GA)
2.3. Support Vector Machine (SVM)
3. Materials and Methods
3.1. Data Production
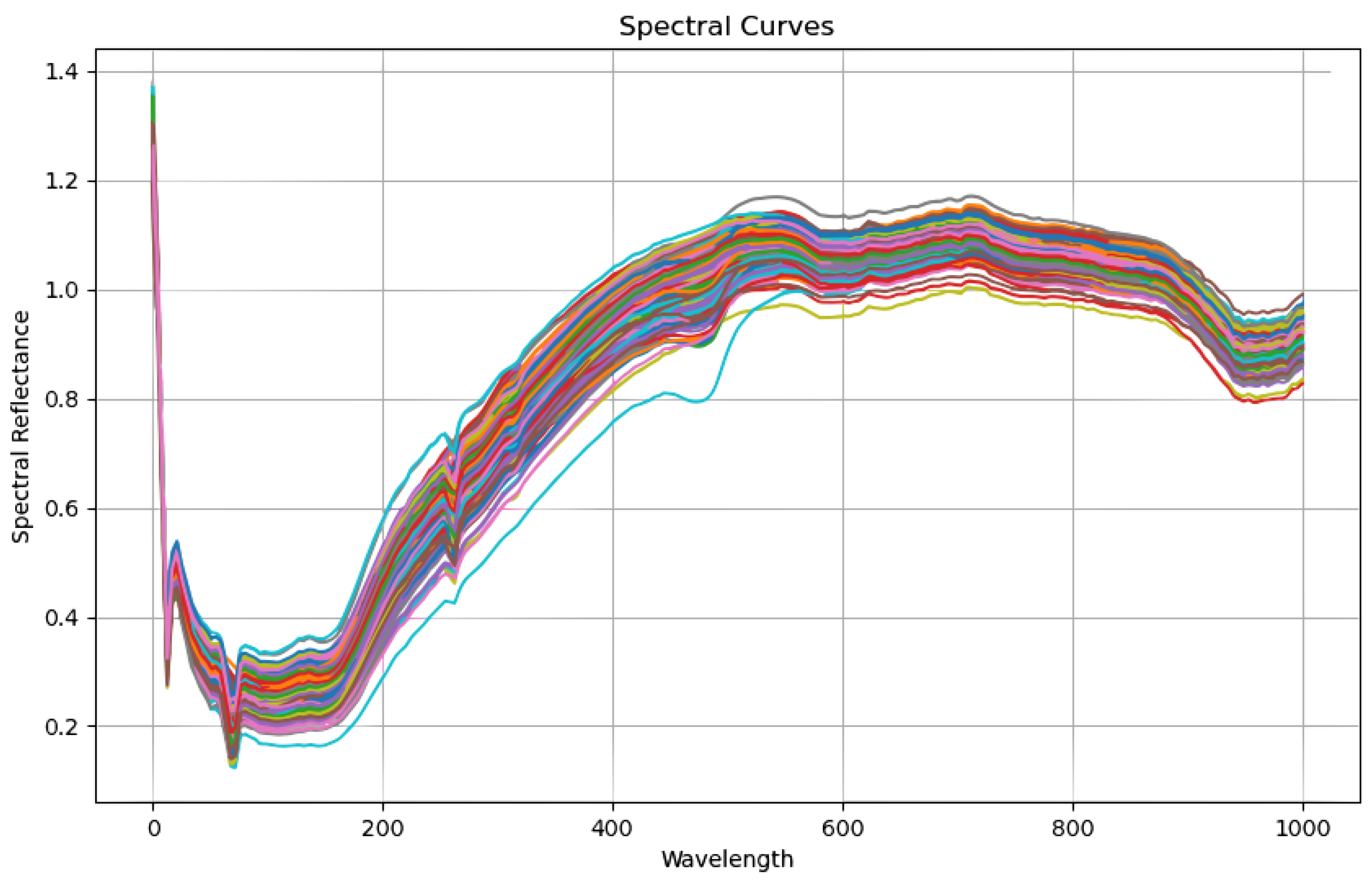
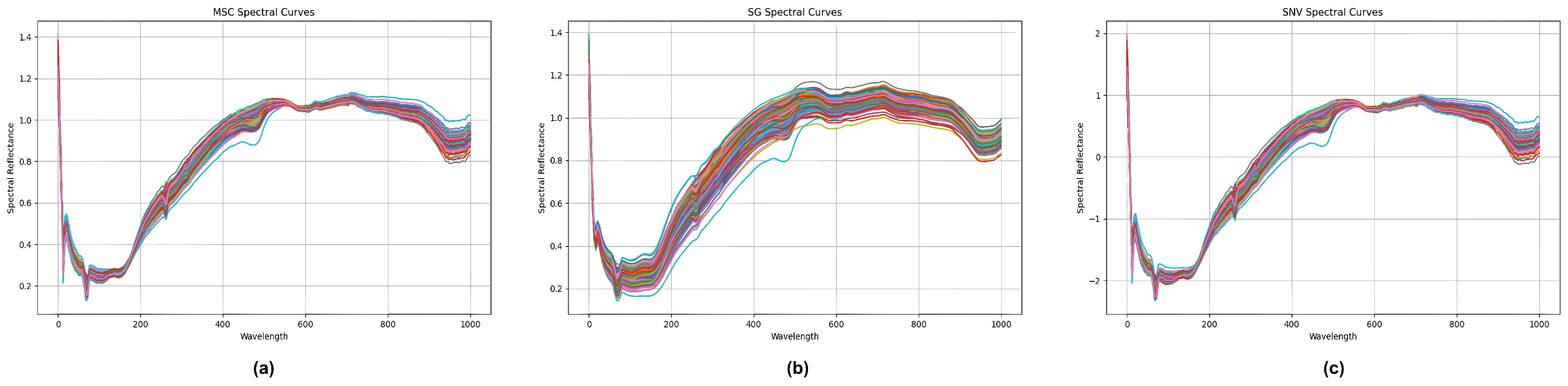
3.2. Data Preprocessing
3.3. Feature Selection Method
3.4. Principle of Genetic Algorithm
| Algorithm 1 Genetic algorithm optimization |
| Input: Problem definition (including chromosome representation, fitness function, etc.) Population size: Crossover probability: Mutation probability: Maximum iterations: Output: Best chromosome or near-optimal chromosome function Initialize return [RandomChromosome() for _ in range()] end function function SelectParents() return two chromosomes based on fitness from end function function CrossoverAndMutate() if then combine and end if mutate resulting chromosomes with return two offspring end function function Execute Initialize for to do for to do SelectParents(population) (CrossoverAndMutate(parent1, parent2)) end for end for return highest fitness chromosome from end function |
3.5. Principle of Support Vector Machine Algorithm
3.6. Improved Support Vector Machine Based on Genetic Algorithm
4. Experimental Results
4.1. Evaluation Indicators
4.2. Basic Experiments and Settings
4.3. Data Processing Effectiveness
4.4. Optimization Algorithm Effectiveness
- (1)
- Performance comparison of SVR and GASVR modelsThe SG-preprocessed full-wavelength data were used to build a genetic-algorithm-optimized support vector machine regression (GASVR) model. The outcomes of this method were compared with those from the classic support vector machine regression (SVR) model. Table 5 displays the specific outcomes.The results in Table 4 show that, compared with the SVR model, GASVR exhibited stabler and superior fitting on the training set (). Specifically, the determination coefficient () on the prediction set was 0.0321 higher than that of the SVR model (). The root mean square error on the prediction set was 0.0267 lower than that of the SVR model (). This verified that optimization using the genetic algorithm substantially improved the performance of the support vector regression prediction model;
- (2)
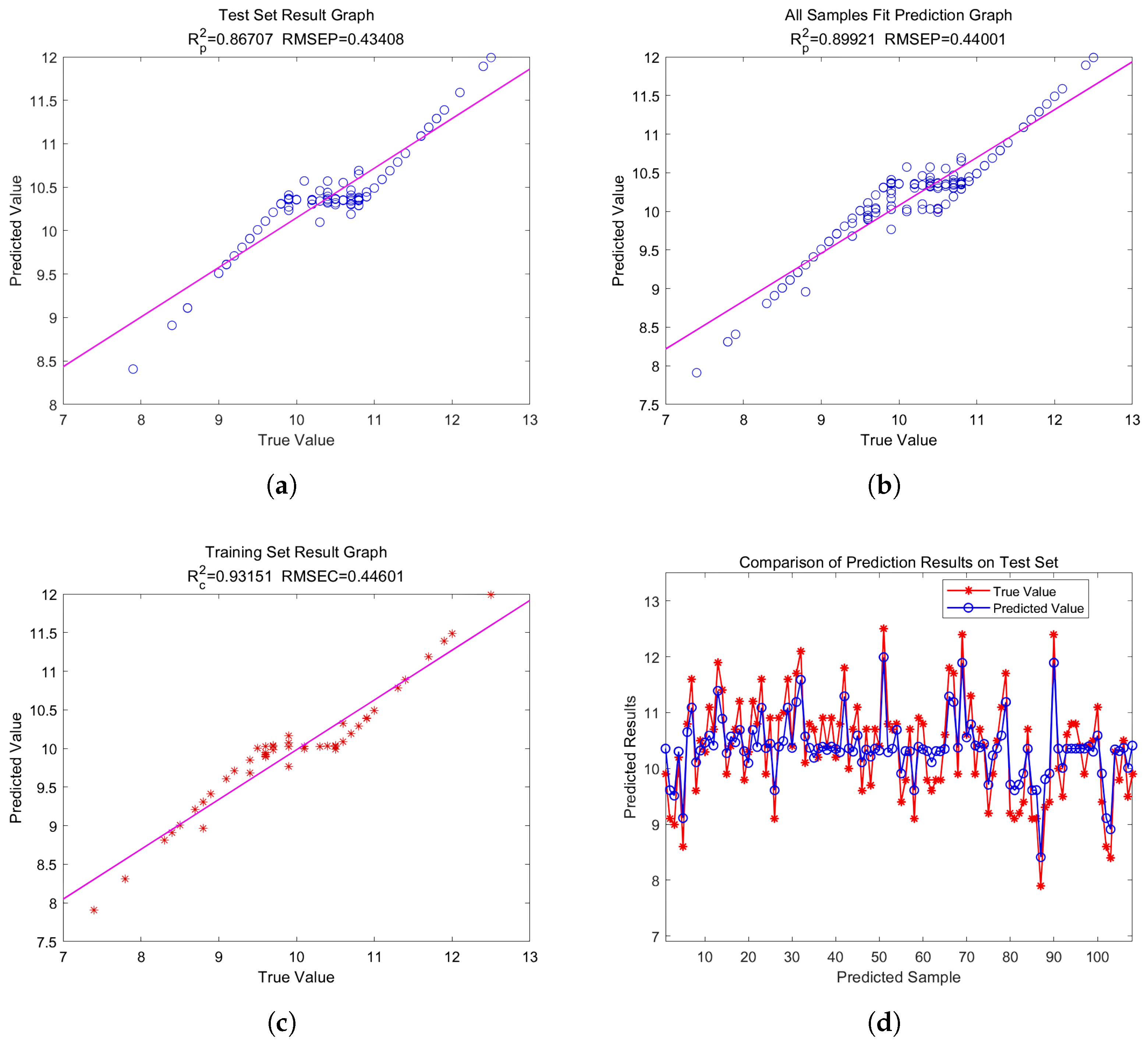
- Construction of GASVR regression modelTo find the best model for predicting crisp pear sugar content, we built a GASVR model using the 48 and 10 distinctive wavelengths screened using CARS and SPA, respectively. We then used the full-wavelength GASVR model prediction findings as the reference standard. Table 6 shows the prediction impacts of the GASVR model for these three different preprocessed wavelength inputs.Table 6 shows that most of the final performance indicators of the GASVR model established using the wavelengths processed via feature engineering were better than those of the GASVR model established using the original wavelengths. The final performance index of the GASVR model established after CARS characteristic wavelength extraction was generally higher than that of the model established after SPA characteristic wavelength extraction. Therefore, the optimal model was the SG-CARS-GASVR model established using the characteristic wavelengths filtered with CARS, which achieved an . Ranked second was the MSC–CARS–GASVR model, established using the characteristic wavelengths filtered with CARS, which achieved an . The results on the calibration set ( ) were substantially improved compared with those of the full-wavelength model. To summarize, the GASVR model produced more accurate predictions, and the SG–CARS–GASVR model produced the best prediction performance overall. Scatter plots of the overall evaluation of the CARS–GASVR model, the test set evaluation, the training set evaluation, and the fitting diagrams of the test and true values in the test set are shown in Figure 12.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- García, J.S.; Hurtado-Salazar, A.; Ceballos-Aguirre, N. Current overview of Hass avocado in Colombia. Challenges and opportunities: A review. Cienc. Rural. 2021, 51, e20200903. [Google Scholar] [CrossRef]
- Reiland, H.; Slavin, J. Systematic Review of Pears and Health. Nutr. Today 2015, 50, 301–305. [Google Scholar] [CrossRef]
- Chang, J.; Song, D. Detection of sugar content in food based on the electrochemical method with the assistance of partial least square method and deep learning. J. Food Meas. Charact. 2023, 17, 4864–4869. [Google Scholar] [CrossRef]
- Yildiz, F.; Özdemir, A.T.; Uluışık, S. Evaluation performance of ultrasonic testing on fruit quality determination. J. Food Qual. 2019, 2019, 6810865. [Google Scholar] [CrossRef]
- Prakash, A.J.; Prakasam, P. An intelligent fruits classification in precision agriculture using bilinear pooling convolutional neural networks. Vis. Comput. 2023, 39, 1765–1781. [Google Scholar] [CrossRef]
- Ye, W.; Xu, W.; Yan, T.; Yan, J.; Gao, P.; Zhang, C. Application of Near-Infrared Spectroscopy and Hyperspectral Imaging Combined with Machine Learning Algorithms for Quality Inspection of Grape: A Review. Foods 2023, 12, 132. [Google Scholar] [CrossRef]
- Bhargava, A.; Bansal, A. Fruits and vegetables quality evaluation using computer vision: A review. J. King Saud-Univ.-Comput. Inf. Sci. 2021, 33, 243–257. [Google Scholar] [CrossRef]
- Castro, W.; Mejía, J.; De-la-Torre, M.; Acevedo-Juárez, B.; Tech, A.R.; Avila-George, H. Radial grid reflectance correction for hyperspectral images of fruits with rounded surfaces. Comput. Electron. Agric. 2023, 213, 108179. [Google Scholar] [CrossRef]
- Cubero, S.; Lee, W.S.; Aleixos, N.; Albert, F.; Blasco, J. Automated systems based on machine vision for inspecting citrus fruits from the field to postharvest—A review. Food Bioprocess Technol. 2016, 9, 1623–1639. [Google Scholar] [CrossRef]
- Fernandes, A.M.; Franco, C.; Mendes-Ferreira, A.; Mendes-Faia, A.; da Costa, P.L.; Melo-Pinto, P. Brix, pH and anthocyanin content determination in whole Port wine grape berries by hyperspectral imaging and neural networks. Comput. Electron. Agric. 2015, 115, 88–96. [Google Scholar] [CrossRef]
- Munera, S.; Besada, C.; Blasco, J.; Cubero, S.; Salvador, A.; Talens, P.; Aleixos, N. Astringency assessment of persimmon by hyperspectral imaging. Postharvest Biol. Technol. 2017, 125, 35–41. [Google Scholar] [CrossRef]
- Rajkumar, P.; Wang, N.; EImasry, G.; Raghavan, G.S.; Gariepy, Y. Studies on banana fruit quality and maturity stages using hyperspectral imaging. J. Food Eng. 2012, 108, 194–200. [Google Scholar] [CrossRef]
- Nanyam, Y.; Choudhary, R.; Gupta, L.; Paliwal, J. A decision-fusion strategy for fruit quality inspection using hyperspectral imaging. Biosyst. Eng. 2012, 111, 118–125. [Google Scholar] [CrossRef]
- Gómez-Sanchis, J.; Martín-Guerrero, J.D.; Soria-Olivas, E.; Martínez-Sober, M.; Magdalena-Benedito, R.; Blasco, J. Detecting rottenness caused by Penicillium genus fungi in citrus fruits using machine learning techniques. Expert Syst. Appl. 2012, 39, 780–785. [Google Scholar] [CrossRef]
- ElMasry, G.; Wang, N.; ElSayed, A.; Ngadi, M. Hyperspectral imaging for nondestructive determination of some quality attributes for strawberry. J. Food Eng. 2007, 81, 98–107. [Google Scholar] [CrossRef]
- Li, J.; Tian, X.; Huang, W.; Zhang, B.; Fan, S. Application of Long-Wave Near Infrared Hyperspectral Imaging for Measurement of Soluble Solid Content (SSC) in Pear. Food Anal. Methods 2016, 9, 3087–3098. [Google Scholar] [CrossRef]
- Zhang, D.; Xu, L.; Liang, D.; Xu, C.; Jin, X.; Weng, S. Fast Prediction of Sugar Content in Dangshan Pear (Pyrus spp.) Using Hyperspectral Imagery Data. Food Anal. Methods 2018, 11, 2336–2345. [Google Scholar] [CrossRef]
- Xu, M.; Sun, J.; Cheng, J.; Yao, K.; Wu, X.; Zhou, X. Non-destructive prediction of total soluble solids and titratable acidity in Kyoho grape using hyperspectral imaging and deep learning algorithm. Int. J. Food Sci. Technol. 2023, 58, 9–21. [Google Scholar] [CrossRef]
- Ye, S.F.; Wang, D.; Min, S.G. Successive projections algorithm combined with uninformative variable elimination for spectral variable selection. Chemom. Intell. Lab. Syst. 2008, 91, 194–199. [Google Scholar] [CrossRef]
- Zou, X.; Zhao, J.; Povey, M.J.; Holmes, M.; Mao, H. Variables selection methods in near-infrared spectroscopy. Anal. Chim. Acta 2010, 667, 14–32. [Google Scholar]
- Nørgaard, L.; Saudland, A.; Wagner, J.; Nielsen, J.P.; Munck, L.; Engelsen, S.B. Interval partial least-squares regression (i PLS): A comparative chemometric study with an example from near-infrared spectroscopy. Appl. Spectrosc. 2000, 54, 413–419. [Google Scholar] [CrossRef]
- Choi, J.H.; Chen, P.A.; Lee, B.; Yim, S.H.; Kim, M.S.; Bae, Y.S.; Lim, D.C.; Seo, H.J. Portable, non-destructive tester integrating VIS/NIR reflectance spectroscopy for the detection of sugar content in Asian pears. Sci. Hortic. 2017, 220, 147–153. [Google Scholar] [CrossRef]
- Khaled, A.Y.; Abd Aziz, S.; Bejo, S.K.; Nawi, N.M.; Seman, I.A.; Onwude, D.I. Early detection of diseases in plant tissue using spectroscopy—Applications and limitations. Appl. Spectrosc. Rev. 2018, 53, 36–64. [Google Scholar] [CrossRef]
- Manley, M. Near-infrared spectroscopy and hyperspectral imaging: Non-destructive analysis of biological materials. Chem. Soc. Rev. 2014, 43, 8200–8214. [Google Scholar] [CrossRef] [PubMed]
- Lu, B.; Dao, P.D.; Liu, J.; He, Y.; Shang, J. Recent Advances of Hyperspectral Imaging Technology and Applications in Agriculture. Remote Sens. 2020, 12, 2659. [Google Scholar] [CrossRef]
- Min, D.; Zhao, J.; Bodner, G.; Ali, M.; Li, F.; Zhang, X.; Rewald, B. Early decay detection in fruit by hyperspectral imaging-Principles and application potential. Food Control. 2023, 152, 109830. [Google Scholar] [CrossRef]
- Raj, R.; Cosgun, A.; Kulic, D. Strawberry Water Content Estimation and Ripeness Classification Using Hyperspectral Sensing. Agronomy 2022, 12, 425. [Google Scholar] [CrossRef]
- Hayes-Roth, F. Review of “Adaptation in Natural and Artificial Systems by John H.Holland”, The U. of Michigan Pres. Acm Sigart Bull. 1975, 15. [Google Scholar] [CrossRef]
- Zhou, Y.; Fan, H. Research on multi objective optimization model of sustainable agriculture industrial structure based on genetic algorithm. J. Intell. Fuzzy Syst. 2018, 35, 2901–2907. [Google Scholar] [CrossRef]
- Khan, M.A.; Lali, M.I.; Sharif, M.; Javed, K.; Aurangzeb, K.; Haider, S.I.; Altamrah, A.S.; Akram, T. An Optimized Method for Segmentation and Classification of Apple Diseases Based on Strong Correlation and Genetic Algorithm Based Feature Selection. IEEE Access 2019, 7, 46261–46277. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Kok, Z.H.; Shariff, A.R.; Alfatni, M.S.; Khairunniza-Bejo, S. Support Vector Machine in Precision Agriculture: A review. Comput. Electron. Agric. 2021, 191, 106546. [Google Scholar] [CrossRef]
- Tang, J.-L.; He, D.-J.; Jing, X. Maize seedling/weed multiclass detection in visible/near infrared image based on SVM. J. Infrared Millim. Waves 2011, 30, 97–103. [Google Scholar] [CrossRef]
- Wu, D.; Shi, H.; He, Y.; Yu, X.; Bao, Y. Potential of hyperspectral imaging and multivariate analysis for rapid and non-invasive detection of gelatin adulteration in prawn. J. Food Eng. 2013, 119, 680–686. [Google Scholar] [CrossRef]
- NY/T 2637-2014; Refractometric Method for Determination of Total Soluble Solids in Fruits and Vegetables. Available online: https://www.chinesestandard.net/PDF/English.aspx/NYT2637-2014 (accessed on 5 March 2024).
- Chen, H.; Pan, T.; Chen, J.; Lu, Q. Waveband selection for NIR spectroscopy analysis of soil organic matter based on SG smoothing and MWPLS methods. Chemom. Intell. Lab. Syst. 2011, 107, 139–146. [Google Scholar] [CrossRef]
- Li, H.; Liang, Y.; Xu, Q.; Cao, D. Key wavelengths screening using competitive adaptive reweighted sampling method for multivariate calibration. Anal. Chim. Acta 2009, 648, 77–84. [Google Scholar] [CrossRef]
- Hsu, C.-W.; Lin, C.-J. A comparison of methods for multiclass support vector machines. IEEE Trans. Neural Netw. 2002, 13, 415–425. [Google Scholar] [PubMed]
- He, L.-M.; Yang, X.-B.; Kong, F.-S. Support vector machines ensemble with optimizing weights by genetic algorithm. In Proceedings of the 2006 International Conference on Machine Learning and Cybernetics, Dalian, China, 13–16 August 2006. [Google Scholar]
- Phan, A.V.; Nguyen, M.L.; Bui, L.T. Feature weighting and SVM parameters optimization based on genetic algorithms for classification problems. Appl. Intell. 2017, 46, 455–469. [Google Scholar] [CrossRef]
- Piepho, H.P.; Edmondson, R.N. A tutorial on the statistical analysis of factorial experiments with qualitative and quantitative treatment factor levels. J. Agron. Crop. Sci. 2018, 204, 429–455. [Google Scholar] [CrossRef]
- Heckler, C.E. Applied Multivariate Statistical Analysis. Technometrics 2005, 47, 517. [Google Scholar] [CrossRef]
- Genuer, R.; Poggi, J.M.; Genuer, R.; Poggi, J.M. Random Forests; Springer: Cham, Switzerland, 2020. [Google Scholar]
- Zhang, L.; An, D.; Wei, Y.; Liu, J.; Wu, J. Prediction of oil content in single maize kernel based on hyperspectral imaging and attention convolution neural network. Food Chem. 2022, 395, 133563. [Google Scholar] [CrossRef] [PubMed]
- Mishra, P.; Biancolillo, A.; Roger, J.M.; Marini, F.; Rutledge, D.N. New data preprocessing trends based on ensemble of multiple preprocessing techniques. TrAC Trends Anal. Chem. 2020, 132, 116045. [Google Scholar] [CrossRef]
- Bai, Z.; Xie, M.; Hu, B.; Luo, D.; Wan, C.; Peng, J.; Shi, Z. Estimation of soil organic carbon using vis-nir spectral data and spectral feature bands selection in Southern Xinjiang, China. Sensors 2022, 22, 6124. [Google Scholar] [CrossRef] [PubMed]
- Abiodun, E.O.; Alabdulatif, A.; Abiodun, O.I.; Alawida, M.; Alabdulatif, A.; Alkhawaldeh, R.S. A systematic review of emerging feature selection optimization methods for optimal text classification: The present state and prospective opportunities. Neural Comput. Appl. 2021, 33, 15091–15118. [Google Scholar] [CrossRef] [PubMed]
- Wei, X.; He, J.; Zheng, S.; Ye, D. Modeling for SSC and firmness detection of persimmon based on NIR hyperspectral imaging by sample partitioning and variables selection. Infrared Phys. Technol. 2020, 105, 103099. [Google Scholar] [CrossRef]
- Kim, M.J.; Yu, W.H.; Song, D.J.; Chun, S.W.; Kim, M.S.; Lee, A.; Kim, G.; Shin, B.S.; Mo, C. Prediction of Soluble-Solid Content in Citrus Fruit Using Visible-Near-Infrared Hyperspectral Imaging Based on Effective-Wavelength Selection Algorithm. Sensors 2024, 24, 1512. [Google Scholar] [CrossRef]
- Zhao, Y.R.; Yu, K.Q.; He, Y. Hyperspectral Imaging Coupled with Random Frog and Calibration Models for Assessment of Total Soluble Solids in Mulberries. J. Anal. Methods Chem. 2015, 2015, 343782. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Sample Size | Minimum Value | Maximum Value | Average Value | (Statistics) Standard Deviation | |
|---|---|---|---|---|---|---|
| Hyperspectral sample set | Training set | 118 | 7.4 | 12.5 | 10.5 | 2.83 |
| Segmentation | Test set | 50 | 8.4 | 10.5 | 9.7 | 1.52 |
| Preprocessing | RMSEC | RMSEP | ||
|---|---|---|---|---|
| Support Vector Machine | 0.6985 | 0.6358 | 0.7093 | 0.5619 |
| Random Forest | 0.8986 | 0.3648 | 0.5047 | 0.7832 |
| Linear Regression | 0.1050 | 0.1579 | 0.3703 | 0.7975 |
| Preprocessing | RMSEC | RMSEP | ||
|---|---|---|---|---|
| Raw Data | 0.6985 | 0.6358 | 0.7093 | 0.5619 |
| Standard Normal Transformation | 0.7163 | 0.5288 | 0.7573 | 0.4490 |
| Multivariate Scattering Correction | 0.7114 | 0.5562 | 0.7402 | 0.4793 |
| Convolution Smoothing | 0.7475 | 0.5212 | 0.7835 | 0.4442 |
| Feature Extraction Method | Number of Characteristic Variables | RMSEC | RMSEP | |
|---|---|---|---|---|
| CARS | 42 | 0.4550 | 0.7433 | 0.6912 |
| SPA | 10 | 0.6542 | 0.7278 | 0.6915 |
| Pretreatment | Developed Model | Training Set | Test Set | ||
|---|---|---|---|---|---|
| RMSEC | RMSEP | ||||
| SG | SVR | 0.7475 | 0.5212 | 0.7835 | 0.4442 |
| SG | GASVR | 0.8945 | 0.4067 | 0.8156 | 0.4175 |
| Pretreatment | Optimal Parameters C, g | Model Developed | Final | RMSE | |
|---|---|---|---|---|---|
| Raw Data | 2.8/0.13 | GASVR | 0.8550 | 0.4709 | |
| SNV | CARS | 3.22/0.51 | 0.8774 | 0.4287 | |
| MSC | 0.8812 | 0.4310 | |||
| SG | 0.8992 | 0.4400 | |||
| SNV | SPA | 7.83/1.38 | 0.6259 | 0.6203 | |
| MSC | 0.8705 | 0.4226 | |||
| SG | 0.8409 | 0.4428 | |||
| Author | Study Target | Model | |
|---|---|---|---|
| Ours | Sugar content in crispy pears | SG–CARS–GASVR | 0.8992 |
| Wei et al. [48] | Persimmon Brix | Savitzky–Golay– RS–CARS–PLS | 0.757 |
| Kim et al. [49] | Soluble solids content in citrus fruits | CARS–PLSR | 0.75 |
| Zhao, Yu, and He [50] | Total soluble solids in mulberry | LS–SVM–linear | 0.857 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ouyang, H.; Tang, L.; Ma, J.; Pang, T. Application of Hyperspectral Technology with Machine Learning for Brix Detection of Pastry Pears. Plants 2024, 13, 1163. https://doi.org/10.3390/plants13081163
Ouyang H, Tang L, Ma J, Pang T. Application of Hyperspectral Technology with Machine Learning for Brix Detection of Pastry Pears. Plants. 2024; 13(8):1163. https://doi.org/10.3390/plants13081163
Chicago/Turabian StyleOuyang, Hongkun, Lingling Tang, Jinglong Ma, and Tao Pang. 2024. "Application of Hyperspectral Technology with Machine Learning for Brix Detection of Pastry Pears" Plants 13, no. 8: 1163. https://doi.org/10.3390/plants13081163
APA StyleOuyang, H., Tang, L., Ma, J., & Pang, T. (2024). Application of Hyperspectral Technology with Machine Learning for Brix Detection of Pastry Pears. Plants, 13(8), 1163. https://doi.org/10.3390/plants13081163