Relationships between Iraqi Rice Varieties at the Nuclear and Plastid Genome Levels



Abstract
:1. Introduction
2. Results
2.1. DNA Sequencing and Data Processing
2.2. Chloroplast Genome Assembly
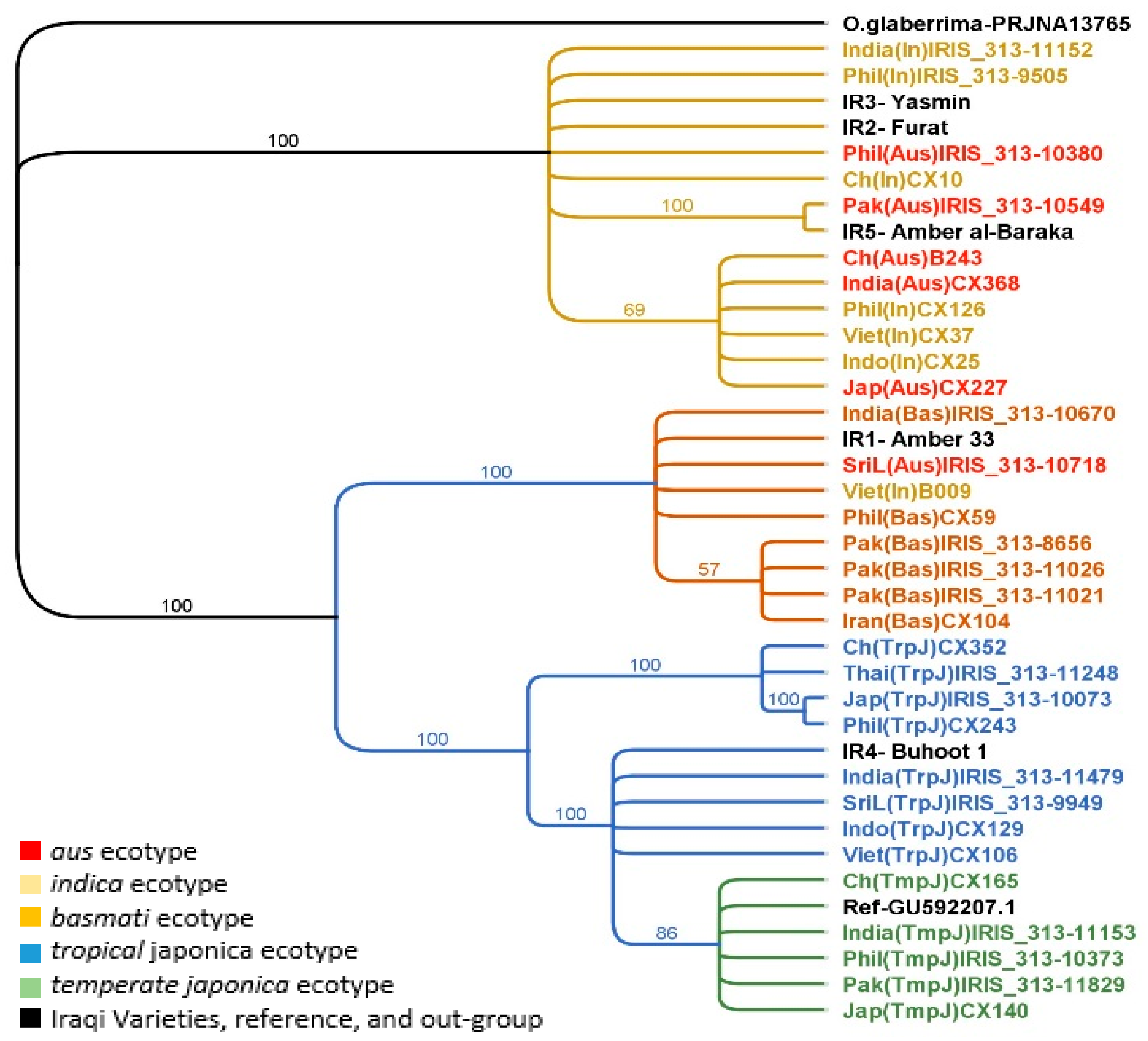
2.3. Phylogenetic Analysis of the Chloroplast Genome
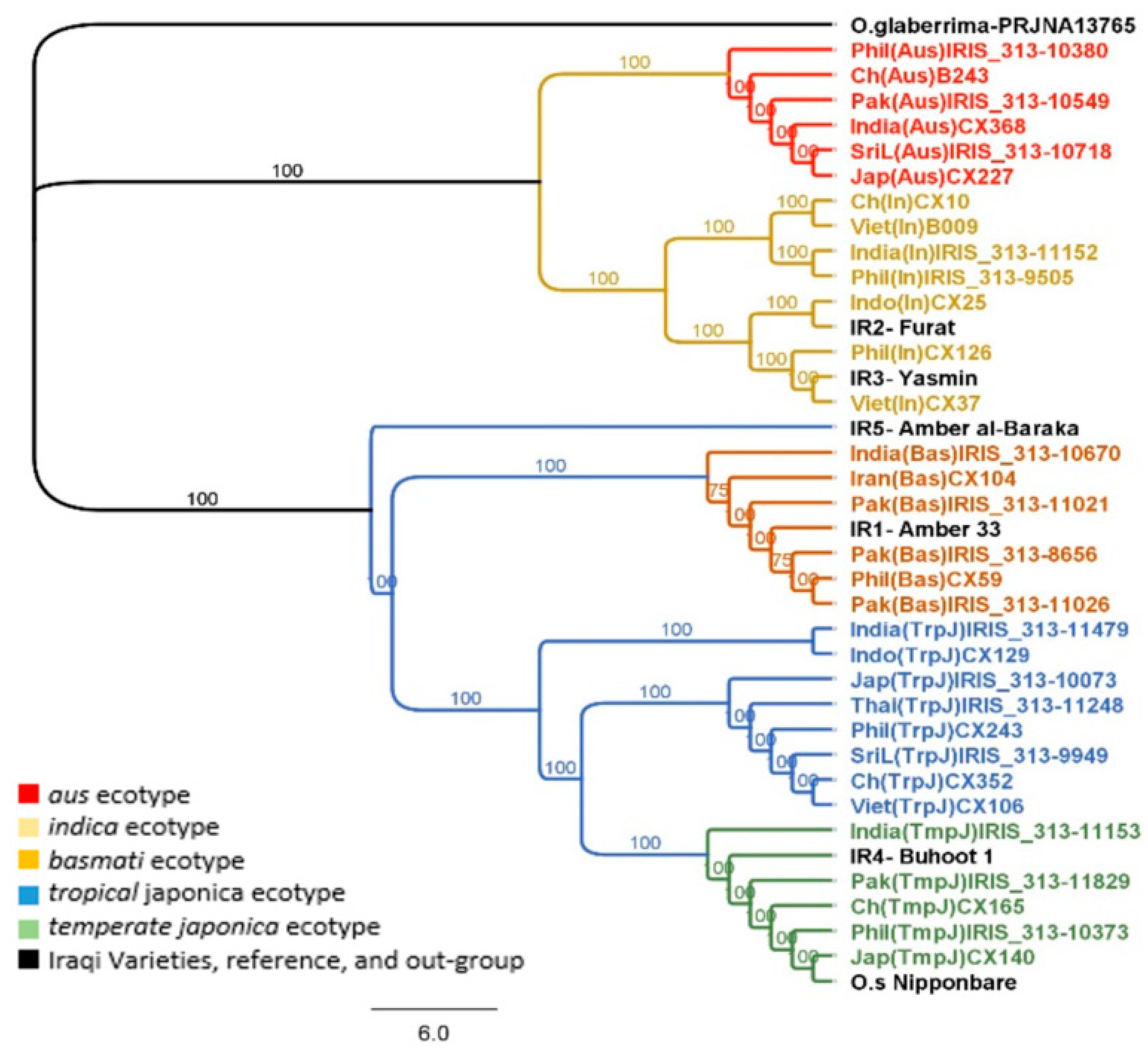
2.4. Phylogenetic Analysis of the Nuclear Genome
3. Discussion
4. Conclusions
5. Materials and Methods
5.1. Plant Materials
5.2. Seed Germination and Growth
5.3. DNA Extraction and Sequencing
5.4. Data Downloaded for Sequence Comparisons
5.5. Data Processing
5.6. Chloroplast Genome Assembly
5.7. Phylogenetic Analysis
5.8. Phylogenetic Analysis of the Nuclear Genome
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Data Availability Statement
References
- Chakravarty, H. Plant Wealth of Iraq: A Dictionary of Economic Plants; Botany Directorate, Ministry of Agriculture & Agrarian Reform: Baghdad, Iraq, 1976.
- Chakravarthi, B.K.; Naravaneni, R. SSR marker based DNA fingerprinting and diversity study in rice (Oryza sativa L.). Afr. J. Biotechnol. 2006, 5, 684–688. [Google Scholar]
- Rabbani, M.A.; Pervaiz, Z.H.; Masood, M.S. Genetic diversity analysis of traditional and improved cultivars of Pakistani rice (Oryza sativa L.) using RAPD markers. Electron. J. Biotechnol. 2008, 11, 52–61. [Google Scholar] [CrossRef]
- Younan, H.Q.; Al-Kazaz, A.A.; Sulaiman, B.K. Investigation of Genetic Diversity and Relationships among a Set of Rice Varieties in Iraq Using Random Amplified Polymorphic DNA (RAPD) Analysis. Jordan J. Biol. Sci. 2011, 4, 249–256. [Google Scholar]
- Al-Zahery, N.; Pala, M.; Battaglia, V.; Grugni, V.; Hamod, M.A.; Kashani, B.H.; Olivieri, A.; Torroni, A.; Santachiara-Benerecetti, A.S.; Semino, O. In search of the genetic footprints of Sumerians: A survey of Y-chromosome and mtDNA variation in the Marsh Arabs of Iraq. BMC Evol. Biol. 2011, 11, 288. [Google Scholar] [CrossRef] [PubMed]
- Chao, L. Rice Production; Report No. 1081 to the Government of Iraq; FAO: Rome, Italy, 1959. [Google Scholar]
- Kovach, M.J.; Calingacion, M.N.; Fitzgerald, M.A.; Mccouch, S.R. The origin and evolution of fragrance in rice (Oryza sativa L.). Proc. Natl. Acad. Sci. USA 2009, 106, 14444–14449. [Google Scholar] [CrossRef] [PubMed]
- Al-Judy, N. Detecting of DNA Fingerprints and Genetic Relationship Analysis in Local and Improved Rice (Oryza sativa L.) Varieties in Iraq. Ph.D. Thesis, College of Science-Baghdad University, Baghdad, Iraq, 2004. [Google Scholar]
- Al-Kazaz, A.K.A. Sequence Variation and Phylogenetic Relationships Among Ten Iraqi Rice Varieties Using RM171 Marker. Iraqi J. Sci. 2014, 55, 145–150. [Google Scholar]
- Patwardhan, A.; Ray, S.; Roy, A. Molecular Markers in Phylogenetic Studies—A Review. J. Phylogenet. Evol. Biol. 2014, 2, 131. [Google Scholar]
- Liu, X.; Zhang, H. Advance of molecular marker application in the tobacco research. Afr. J. Biotechnol. 2008, 7, 4827–4831. [Google Scholar]
- Sotowa, M.; Ootsuka, K.; Kobayashi, Y.; Hao, Y.; Tanaka, K.; Ichitani, K.; Flowers, J.; Purugganan, M.; Nakamura, I.; Sato, Y.-I.; et al. Molecular relationships between Australian annual wild rice, Oryza meridionalis and two related perennial forms. Rice 2013, 6, 26. [Google Scholar] [CrossRef]
- Nock, C.J.; Waters, D.L.E.; Edwards, M.A.; Bowen, S.G.; Rice, N.; Cordeiro, G.M.; Henry, R.J. Chloroplast genome sequences from total DNA for plant identification. Plant Biotechnol. J. 2011, 9, 328–333. [Google Scholar] [CrossRef]
- Straub, S.C.K.; Parks, M.; Weitemier, K.; Fishbein, M.; Cronn, R.C.; Liston, A. Navigating the tip of the genomic iceberg: Next-generation sequencing for plant systematics. Am. J. Bot. 2012, 99, 349–364. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mcpherson, H.; Van Der Merwe, M.; Delaney, S.K.; Edwards, M.A.; Henry, R.J.; Mcintosh, E.; Rymer, P.D.; Milner, M.L.; Siow, J.; Rossetto, M. Capturing chloroplast variation for molecular ecology studies: A simple next generation sequencing approach applied to a rainforest tree. BMC Ecol. 2013, 13, 8. [Google Scholar] [CrossRef] [PubMed]
- Waters, D.L.E.; Nock, C.J.; Ishikawa, R.; Rice, N.; Henry, R.J. Chloroplast genome sequence confirms distinctness of Australian and Asian wild rice. Ecol. Evol. 2012, 2, 211–217. [Google Scholar] [CrossRef] [PubMed]
- Yang, J.-B.; Tang, M.; Li, H.-T.; Zhang, Z.-R.; Li, D.-Z. Complete chloroplast genome of the genus Cymbidium: Lights into the species identification, phylogenetic implications and population genetic analyses. BMC Evol. Biol. 2013, 13, 84. [Google Scholar] [CrossRef] [PubMed]
- Tong, W.; He, Q.; Wang, X.Q.; Yoon, M.Y.; Ra, W.H.; Li, F.; Yu, J.; Oo, W.H.; Min, S.K.; Choi, B.W.; et al. A chloroplast variation map generated using whole genome re-sequencing of Korean landrace rice reveals phylogenetic relationships among Oryza sativa subspecies. Biol. J. Linn. Soc. 2015, 115, 940–952. [Google Scholar] [CrossRef]
- Tong, W.; Kim, T.-S.; Park, Y.-J. Rice Chloroplast Genome Variation Architecture and Phylogenetic Dissection in Diverse Oryza Species Assessed by Whole-Genome Resequencing. Rice 2016, 9, 57. [Google Scholar] [CrossRef]
- Parks, M.; Cronn, R.; Liston, A. Increasing phylogenetic resolution at low taxonomic levels using massively parallel sequencing of chloroplast genomes. BMC Biol. 2009, 7, 84. [Google Scholar] [CrossRef]
- Moore, M.J.; Pamela, S.S.; Charles, D.B.; Burleigh, J.G.; Douglas, E.S. Phylogenetic analysis of 83 plastid genes further resolves the early diversification of eudicots. Proc. Natl. Acad. Sci. USA 2010, 107, 4623–4628. [Google Scholar] [CrossRef] [Green Version]
- Brozynska, M.; Omar, E.S.; Furtado, A.; Crayn, D.; Simon, B.; Ishikawa, R.; Henry, R.J. Chloroplast Genome of Novel Rice Germplasm Identified in Northern Australia. Trop. Plant Biol. 2014, 7, 111–120. [Google Scholar] [CrossRef] [Green Version]
- Huang, X.; Kurata, N.; Wang, Z.X.; Wang, A.; Zhao, Q.; Zhao, Y.; Liu, K.; Lu, H.; Li, W.; Guo, Y.; et al. A map of rice genome variation reveals the origin of cultivated rice. Nature 2012, 490, 497–501. [Google Scholar] [CrossRef] [Green Version]
- Kim, H.; Jeong, E.; Ahn, S.-N.; Doyle, J.; Singh, N.; Greenberg, A.; Won, Y.; Mccouch, S. Nuclear and chloroplast diversity and phenotypic distribution of rice (Oryza sativa L.) germplasm from the democratic people’s republic of Korea (DPRK North Korea). Rice 2014, 7, 7. [Google Scholar] [CrossRef] [PubMed]
- Brozynska, M.; Copetti, D.; Furtado, A.; Wing, R.A.; Crayn, D.; Fox, G.; Ishikawa, R.; Henry, R.J. Sequencing of Australian wild rice genomes reveals ancestral relationships with domesticated rice. Plant Biotechnol. J. 2017, 15, 765–774. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.; Mauleon, R.; Hu, Z.; Chebotarov, D.; Tai, S.; Wu, Z.; Li, M.; Zheng, T.; Fuentes, R.R.; Zhang, F.; et al. Genomic variation in 3,010 diverse accessions of Asian cultivated rice. Nature 2018, 557, 43–49. [Google Scholar] [CrossRef] [PubMed]
- Sims, D.; Ian, S.; Nicholas, E.I.; Andreas, H.; Chris, P.P. Sequencing depth and coverage: Key considerations in genomic analyses. Nat. Rev. Genet. 2014, 15, 121. [Google Scholar] [CrossRef]
- Wambugu, P.W.; Brozynska, M.; Furtado, A.; Waters, D.L.; Henry, R.J. Relationships of wild and domesticated rices (Oryza AA genome species) based upon whole chloroplast genome sequences. Sci. Rep. 2015, 5, 13957. [Google Scholar] [CrossRef]
- Civáň, P.; Craig, H.; Cox, C.J.; Brown, T.A. Three geographically separate domestications of Asian rice. Nat. Plants 2015, 1, 15164. [Google Scholar] [CrossRef]
- Garris, A.J.; Tai, T.H.; Coburn, J.; Kresovich, S.; Mccouch, S. Genetic Structure and Diversity in Oryza sativa L. Genetics 2005, 169, 1631–1638. [Google Scholar] [CrossRef]
- Ahuja, S.C.; Panwar, D.V.S.; Uma, A.; Gupta, K.R. Basmati Rice: The Scented Pearl, Hisar, Directorate of Publications; CCS Haryana Agricultural University: Hisar, India, 1995. [Google Scholar]
- Akram, M. Aromatic rices of Pakistan: A review. Pak. J. Agric. Res. 2009, 22, 154–160. [Google Scholar]
- Glaszmann, J.C. Isozymes and classification of Asian rice varieties. Tag. Theor. Appl. Genet. Theor. Angew. Genet. 1987, 74, 21–30. [Google Scholar] [CrossRef]
- Caicedo, A.L.; Williamson, S.H.; Hernandez, R.D.; Boyko, A.; Fledel-Alon, A.; York, T.L.; Polato, N.R.; Olsen, K.M.; Nielsen, R.; McCouch, S.R.; et al. Genome-wide patterns of nucleotide polymorphism in domesticated rice. PLoS Genet. 2007, 3, e163. [Google Scholar] [CrossRef]
- Furtado, A. DNA extraction from vegetative tissue for next-generation sequencing. Methods Mol. Biol. 2014, 1099, 1–5. [Google Scholar] [PubMed]
- Moner, A.M.; Furtado, A.; Henry, R.J. Chloroplast phylogeography of AA genome rice species. Mol. Phylogenet. Evol. 2018, 127, 475–487. [Google Scholar] [CrossRef] [PubMed]
- Katoh, K.; Misawa, K.; Kuma, K.; Miyata, T. MAFFT: A novel method for rapid multiple sequence alignment based on fast Fourier transform. Nucleic Acids Res. 2002, 30, 3059–3066. [Google Scholar] [CrossRef] [PubMed]
- Huelsenbeck, J.P.; Ronquist, F. MRBAYES: Bayesian inference of phylogenetic trees. Bioinformatics 2001, 17, 754–755. [Google Scholar] [CrossRef] [Green Version]



{kind=link}
{kind=link}
| Varieties | History | Varietal Group | BioProject ID | BioSample Accessions |
|---|---|---|---|---|
| Amber33 | Local (Iraq) | Aromatic, medium grain type | PRJNA576935 | SAMN13014963 |
| Furat | Introduced from (Vietnam) in 1996 | Aromatic, medium grain type | PRJNA576935 | SAMN13014964 |
| Yasmin | Introduced from (Vietnam) in 1998 | Aromatic, medium grain type | PRJNA576935 | SAMN13014965 |
| Buhooth1 | Improved | Non-Aromatic, long grain type | PRJNA576935 | SAMN13014966 |
| Amber al-Baraka | Improved | Aromatic, long grain type | PRJNA576935 | SAMN13014967 |
| No | Sample Unique ID | Project Accession | Species | Country of Origin | Ecotype * | Alignment Name (in Figure 1 and Figure 2) * |
|---|---|---|---|---|---|---|
| 1 | B243 | ERP005654 | O. sativa | China | Aus | Ch(Aus)B243 |
| 2 | CX165 | ERP005654 | O. sativa | China | TmpJ | Ch(TmpJ)CX165 |
| 3 | CX352 | ERP005654 | O. sativa | China | TrpJ | Ch(TrpJ)CX352 |
| 4 | CX10 | ERP005654 | O. sativa | China | In | Ch(In)CX10 |
| 5 | CX368 | ERP005654 | O. sativa | India | Aus | India(Aus)CX368 |
| 6 | IRIS_313–10670 | ERP005654 | O. sativa | India | Bas | India(Bas)IRIS_313-10670 |
| 7 | IRIS_313–11153 | ERP005654 | O. sativa | India | TmpJ | India(TmpJ)IRIS_313-11153 |
| 8 | IRIS_313–11479 | ERP005654 | O. sativa | India | TrpJ | India(TrpJ)IRIS_313-11479 |
| 9 | IRIS_313–11152 | ERP005654 | O. sativa | India | In | India(In)IRIS_313-11152 |
| 10 | CX129 | ERP005654 | O. sativa | Indonesia | TrpJ | Indo(TrpJ)CX129 |
| 11 | CX25 | ERP005654 | O. sativa | Indonesia | In | Indo(In)CX25 |
| 12 | CX104 | ERP005654 | O. sativa | Iran | Bas | Iran(Bas)CX104 |
| 13 | CX227 | ERP005654 | O. sativa | Japan | Aus | Jap(Aus)CX227 |
| 14 | CX140 | ERP005654 | O. sativa | Japan | TmpJ | Jap(TmpJ)CX140 |
| 15 | IRIS_313–10073 | ERP005654 | O. sativa | Japan | TrpJ | Jap(TrpJ)IRIS_313-10073 |
| 16 | IRIS_313–10549 | ERP005654 | O. sativa | Pakistan | Aus | Pak(Aus)IRIS_313-10549 |
| 17 | IRIS_313–11021 | ERP005654 | O. sativa | Pakistan | Bas | Pak(Bas)IRIS_313-11021 |
| 18 | IRIS_313–11026 | ERP005654 | O. sativa | Pakistan | Bas | Pak(Bas)IRIS_313-11026 |
| 19 | IRIS_313–8656 | ERP005654 | O. sativa | Pakistan | Bas | Pak(Bas)IRIS_313-8656 |
| 20 | IRIS_313–11829 | ERP005654 | O. sativa | Pakistan | TmpJ | Pak(TmpJ)IRIS_313-11829 |
| 21 | IRIS_313–10380 | ERP005654 | O. sativa | Philippines | Aus | Phil(Aus)IRIS_313-10380 |
| 22 | CX59 | ERP005654 | O. sativa | Philippines | Bas | Phil(Bas)CX59 |
| 23 | IRIS_313–10373 | ERP005654 | O. sativa | Philippines | TmpJ | Phil(TmpJ)IRIS_313-10373 |
| 24 | CX243 | ERP005654 | O. sativa | Philippines | TrpJ | Phil(TrpJ)CX243 |
| 25 | IRIS_313–9505 | ERP005654 | O. sativa | Philippines | In | Phil(In)IRIS_313-9505 |
| 26 | CX126 | ERP005654 | O. sativa | Philippines | In | Phil(In)CX126 |
| 27 | IRIS_313–10718 | ERP005654 | O. sativa | Sri Lanka | Aus | SriL(Aus)IRIS_313-10718 |
| 28 | IRIS_313–9949 | ERP005654 | O. sativa | Sri Lanka | TrpJ | Sril(TrpJ)IRIS_313-9949 |
| 29 | IRIS_313–11248 | ERP005654 | O. sativa | Thailand | TrpJ | Thai(TrpJ)IRIS_313-11248 |
| 30 | CX106 | ERP005654 | O. sativa | Vietnam | TrpJ | Viet(TrpJ)CX106 |
| 31 | B009 | ERP005654 | O. sativa | Vietnam | In | Viet(In)B009 |
| 32 | CX37 | ERP005654 | O. sativa | Vietnam | In | Viet(In)CX37 |
| 33 | O.glaberrima-PRJNA13765 | SRP038750 | O. glaberrima | - | - | O. glaberrima |
| Varieties | Chloroplast Genome | Length of Nuclear Genome (bp) | |
|---|---|---|---|
| Length of Genome (bp) | Coverage (×) | ||
| Amber33 | 134,536 | 2909 | 616,371 |
| Furat | 134,500 | 7819 | 616,190 |
| Yasmin | 134,502 | 5495 | 616,301 |
| Buhooth1 | 134,550 | 4759 | 616,393 |
| Amber al-Baraka | 134,493 | 3651 | 616,310 |
| B243 | 134,497 | 2203 | 616,278 |
| CX165 | 134,542 | 8818 | 616,377 |
| CX352 | 134,553 | 5305 | 616,324 |
| CX10 | 134,503 | 11,466 | 616,274 |
| CX368 | 134,504 | 3674 | 616,236 |
| IRIS_313–10670 | 134,535 | 1669 | 616,369 |
| IRIS_313–11153 | 134,551 | 1639 | 616,360 |
| IRIS_313–11479 | 134,259 | 2726 | 616,367 |
| IRIS_313–11152 | 134,503 | 1413 | 616,271 |
| CX129 | 134,535 | 6076 | 616 337 |
| CX25 | 134,503 | 5830 | 616,210 |
| CX104 | 134,532 | 6784 | 616,348 |
| CX227 | 134,504 | 4267 | 616,314 |
| CX140 | 134,547 | 5185 | 616,393 |
| IRIS_313–10073 | 134,556 | 2036 | 616,355 |
| IRIS_313–10549 | 134,495 | 1636 | 616 324 |
| IRIS_313–11021 | 134,531 | 1978 | 616,383 |
| IRIS_313–11026 | 134,532 | 1723 | 616,358 |
| IRIS_313–8656 | 134,532 | 2334 | 616 380 |
| IRIS_313–11829 | 134,539 | 4164 | 616,389 |
| IRIS_313–10380 | 134,496 | 1857 | 616,331 |
| CX59 | 134,536 | 5913 | 616,370 |
| IRIS_313–10373 | 134,551 | 1464 | 616,363 |
| CX243 | 134,556 | 4375 | 616,362 |
| IRIS_313–9505 | 134,503 | 968 | 616,283 |
| CX126 | 134,503 | 3510 | 616,220 |
| IRIS_313–10718 | 134,531 | 2332 | 616,324 |
| IRIS_313–9949 | 134,532 | 3041 | 616 385 |
| IRIS_313–11248 | 134,413 | 974 | 616,336 |
| CX106 | 134,529 | 6145 | 616,339 |
| B009 | 134,528 | 839 | 616,231 |
| CX37 | 134,503 | 4836 | 616,258 |
| O.glaberrima- PRJNA13765 | 134,542 | 2567 | 616,099 |
| Variation Type | SNPs | MNPs | Del | Ins | Total | |
|---|---|---|---|---|---|---|
| Group | ||||||
| Indica | 37 | 5 | 10 | 9 | 61 | |
| Japonica | 1 | 0 | 1 | 1 | 3 | |
| Basmati | 4 | 1 | 0 | 1 | 6 | |
| Indica & Basmati | 3 | 2 | 3 | 0 | 8 | |
| Indica and Basmati and Japonica | 3 | 0 | 1 | 3 | 7 | |
| Total | 48 | 8 | 15 | 14 | 85 | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Badro, H.; Furtado, A.; Henry, R. Relationships between Iraqi Rice Varieties at the Nuclear and Plastid Genome Levels. Plants 2019, 8, 481. https://doi.org/10.3390/plants8110481
Badro H, Furtado A, Henry R. Relationships between Iraqi Rice Varieties at the Nuclear and Plastid Genome Levels. Plants. 2019; 8(11):481. https://doi.org/10.3390/plants8110481
Chicago/Turabian StyleBadro, Hayba, Agnelo Furtado, and Robert Henry. 2019. "Relationships between Iraqi Rice Varieties at the Nuclear and Plastid Genome Levels" Plants 8, no. 11: 481. https://doi.org/10.3390/plants8110481
APA StyleBadro, H., Furtado, A., & Henry, R. (2019). Relationships between Iraqi Rice Varieties at the Nuclear and Plastid Genome Levels. Plants, 8(11), 481. https://doi.org/10.3390/plants8110481