Abstract
This study addresses the challenges that high-noise environments and complex multi-speaker scenarios present in civil aviation radio communications. A novel radiotelephone communications speaker diffraction network is developed specifically for these circumstances. To improve the precision of the speaker diarization network, three core modules are designed: voice activity detection (VAD), end-to-end speaker separation for air–ground communication (EESS), and probabilistic knowledge-based text clustering (PKTC). First, the VAD module uses attention mechanisms to separate silence from irrelevant noise, resulting in pure dialogue commands. Subsequently, the EESS module distinguishes between controllers and pilots by levying voice print differences, resulting in effective speaker segmentation. Finally, the PKTC module addresses the issue of pilot voice print ambiguity using text clustering, introducing a novel flight prior knowledge-based text-related clustering model. To achieve robust speaker diarization in multi-pilot scenarios, this model uses prior knowledge-based graph construction, radar data-based graph correction, and probabilistic optimization. This study also includes the development of the specialized ATCSPEECH dataset, which demonstrates significant performance improvements over both the AMI and ATCO2 PROJECT datasets.
1. Introduction
In the field of civil aviation, ensuring flight safety and efficiency necessitates the establishment of effective communication at aerodromes and within airspace. The Very High Frequency Communication System (VHF COMM) plays a crucial role in civil aviation communications, using voice as the medium and VHF radio signals as the carrier for information transmission. Air traffic controllers use the air traffic control system to communicate with and coordinate multiple aircraft in the airspace. As shown in Figure 1, the voice commands of controllers are transmitted via wire from the air traffic control system to interphone systems, which are then broadcasted via VHF COMM in the very high frequency band through wireless transmission to the airspace. When aircraft receive commands, they wirelessly transmit them back to the aerodrome, where they are stored in interphone systems and relayed back to the air traffic controller [1].
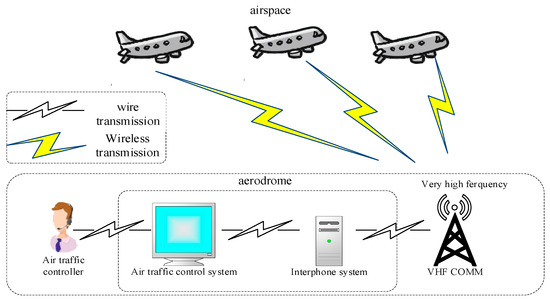
Figure 1.
Civil aviation communication system and interphone system.
The Very High Frequency Communication System (VHF COMM) operates in the 30–3000 MHz frequency band, primarily serving the A1 sea area of the Global Maritime Distress and Safety System (GMDSS), and is an important system for communicating between air traffic controllers and pilots in aviation. The frequencies used in civil aviation range from 118.000 to 151.975 MHz, according to International Civil Aviation Organization standards, with a channel spacing of 25 kHz. Specifically, the 121.600 to 121.925 MHz band is primarily used for ground control. VHF COMM features semi-duplex amplitude modulation, a minimum transmission power of 20 W, the rapid attenuation of surface waves, a communication distance limited by line of sight, propagation primarily through space waves, and susceptibility to the troposphere and terrain. Additionally, communication can be affected by noise interference, channel compression, and voice signal distortion due to weather, encoders, and channel noise [2].
In the civil aviation system, the Very High Frequency (VHF) Communication System serves as the primary network for aircraft communication, and it is critical, particularly in ensuring the accuracy of two-way voice communication between aircraft crew members and various control positions. It is critical to continuously record dialogues between different pilots and controllers during critical operations with a high complexity and risk of accidents, such as takeoff and landing. This allows for the detection of any missed or incorrect control information by comparing repeated instructions from controllers and pilots. It is evident that the structured recording of voice communication between air traffic control and crew is critical [3].
Since the crew in the airspace cannot effectively perceive the specific situation of the entire airspace, such as drone conflicts and potential navigation conflicts, it is necessary to rely on the ground air traffic management units for control services. The process of providing services, according to the standard air traffic control procedures published by ICAO, can be divided into the following three steps:
- Surveillance and Identification: Controllers identify aircraft through surveillance facilities or air–ground dialogues.
- Issuance and Execution of Commands: Controllers issue commands to aircraft after a reasonable analysis of airspace dynamics and aircraft dynamics, and pilots execute the commands effectively upon receiving them.
- Monitoring of Commands: Controllers use dialogues with pilots to further monitor the implementation of commands.
These three steps form a cycle, achieving the entire air traffic management service. It is evident that surveillance and communication constitute the entire air traffic management process To achieve effective air traffic safety management, effective surveillance and communication are essential.
In the air traffic surveillance of general large airports, secondary radar (SSR) and ADS-B surveillance equipment are often used to achieve the effective monitoring of aircraft status. However, in the air traffic surveillance of most medium and small airports, due to the lack of sufficient surveillance equipment, procedural control based on position reports is adopted. Compared with the highly automated and visualized radar control method, procedural control relies on pilots reporting their positions, and controllers build a model of the entire airspace through dialogues with pilots. At this time, the air traffic management service heavily depends on the controllers’ understanding of the airspace and their communication abilities, making air–ground cooperation (AGC) the most critical high-risk human-in-the-loop (HITL) segment. Whether AI-based methods can be used to assist in surveillance becomes the key to improving procedural control services.
Correspondingly, achieving voice-based assisted surveillance can also be roughly divided into the following three steps:
- Voice Segmentation: Real-time voice is processed into individual meaningful voice segments that computers can understand, achieving “when speak”.
- Voice Understanding: Voice is recognized as text, identifying who said the corresponding command, achieving command identification, and reaching “who speak when”.
- Semantic Analysis and Display: The text content is understood and abstracted into a specific command vector, representing the specific meaning of the command, and a modeling analysis to determine whether the command affects future flights or achieves a visual effect similar to radar control, achieving “who speak what at when”.
Therefore, in the research of civil aviation air–ground communication, how to achieve automated voice segmentation and accurately match the corresponding speakers, solving the “who speak when” problem, has become a focus of research in this field [4,5].
The task of mapping voices to speakers is a classic “Who Spoke When” problem, addressed through speaker diarization networks. Researchers have extensively investigated various network architectures for automating voice segmentation and clustering tasks, yielding significant achievements. Tae Jin Park et al. reviewed the development of speaker diarization, noting its early use in air traffic control dialogue segmentation and clustering [6]. Federico Landini et al. utilized a Bayesian Hidden Markov Model for the speaker clustering of x-vector sequences in the VBx system [7]. Hervé Bredin and others [5,8,9] developed pyannote.audio, a neural network processing system for speaker identification and diarization that used advanced machine learning and deep learning techniques to achieve a top performance in multiple competitions and datasets. Zuluaga-Gomez et al. [10] combined voice activity detection with the BERT model to detect speaker roles and changes by segmenting the text of voice recognition software. Bonastre et al. [11] introduced the ALIZE speaker diarization system, which is written in C++ and designed and implemented using traditional method-based models. In practical applications, speaker diarization technology has been used in scenarios such as telephone customer service, where the use of deep learning has strengthened the technology, with a focus on modular and end-to-end approaches [12].
In summary, the current speaker-logging process typically consists of two steps: first, slicing the input long speech data, which is typically implemented using a voice activity detection (VAD) algorithm; second, clustering the sliced audio to achieve a one-to-one correspondence between the audio and the speaker. Currently, VAD algorithms frequently employ endpoint discrimination algorithms based on statistical models, such as ALIZE [11], and machine learning endpoint discrimination algorithms based on waveform recognition, such as pyan-note.audio [8]. In noisy environments, statistically based endpoint discrimination algorithms typically perform poorly. Although waveform recognition-based machine learning endpoint discrimination algorithms can improve silence detection techniques under complex background noise by enhancing neural networks, simple machine learning networks are overly sensitive to speaker breathing gaps, resulting in too many small segments being cut from a continuous piece of audio. Currently, mainstream clustering algorithms are based on x-vector speaker recognition technology, including VBx [7] and pyan-note.audio [8]. The main idea is to augment variable-length speech with noise and reverb, then map it through deep neural networks into fixed-length vectors, and finally recognize the speaker by clustering the vectors after a secondary mapping. However, such algorithms have high requirements for speech quality, requiring distinct voiceprints from different speakers. The traditional modulation, transmission, and demodulation operations used in radiotelephone communications using very high frequency (VHF) systems not only cause voiceprint blurring (filtering by filters in analog signal processing), but also introduce strong noise (poor communication environments), all of which can have a significant impact on the performance of current speaker-logging systems.
While speaker diarization technology originated in the context of voice segmentation for radiotelephone communications, its application and development in civil aviation face challenges due to high noise interference from radiotelephone conversations and complex multi-party communication scenarios. The existing research has used text processing methods for speaker detection, but it has not fully integrated the characteristics of civil aviation radiotelephone communications with speaker voiceprint features. This paper aims to optimize for the semi-duplex nature of radiotelephone communications, multi-speaker environments, and complex background noise by developing a comprehensive radiotelephone communication speaker diarization system to meet the application needs of speaker diarization in radiotelephone communications.
Given the complex nature of radiotelephone half-duplex communications, which are characterized by multiple speakers and noisy environments, this study proposes a novel speaker diffraction network suitable for airports with aircraft that are not equipped with CPDLC or do not prioritize CPDLC as the primary communication method.
2. Contribution
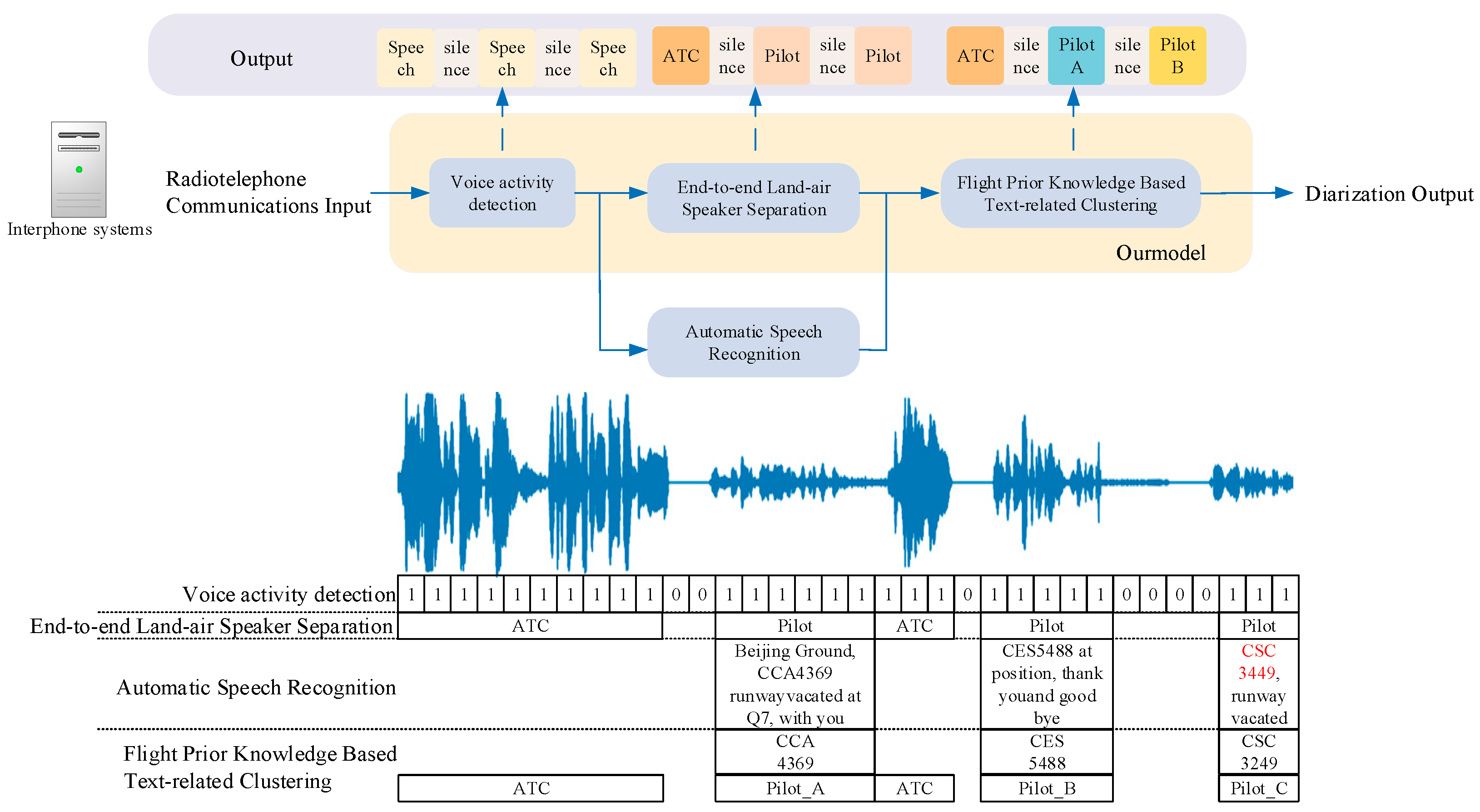
As shown in Figure 2., our network is comprised of three main components: voice activity detection (VAD), end-to-end radiotelephone speaker separation (EESS), and flight prior knowledge-based text-related clustering (PKTC).

Figure 2.
Radiotelephone Communications Speaker Diarization Network. The red data in the graph represents the changes made to this data.
The VAD model used in this study has been redesigned with an attention mechanism to filter out the silence and background noises common in radiotelephone communications. The difference in voice signal transmission pathways between controllers and pilots—wired into the intercom system for controllers and wireless for pilots—has resulted in distinct voice signal characteristics. Using current advanced end-to-end speaker segmentation models based on voiceprints enables an effective separation and pre-clustering of communications between the two parties. As a result, the EESS model is an adaptation of the radiotelephone speaker segmentation model based on [5], fine-tuned to pre-cluster voice signals into two categories: pilots and controllers. The PKTC model is innovative in that it introduces a text-feature speaker-clustering model based on the textual content of radiotelephone communications and prior flight knowledge. This includes graph construction based on prior knowledge, graph correction with radar data, and probability optimization to cluster pilot voices into speaker classes identified by call signs. In summary, this paper presents a novel Radiotelephone Communications Speaker Diarization Network that is tailored to the unique characteristics of radiotelephone communications.
To assess the effectiveness of the network, this paper compiled a collection of real and continuous radiotelephone communication voice data. Based on this, the ATCSPEECH dataset was constructed to train and test speaker diarization tasks. The dataset contains 5347 voice recordings from 106 speakers, including 11 air traffic controllers who held the same position at different times and 95 pilots. The data includes 14 h of recordings from a specific airport, from 7 a.m. to 9 p.m.
The remainder of this paper is organized as follows. Section 2 uses a piece of typical voice data from real radiotelephone communication to demonstrate three features of the Radiotelephone Communication Speaker Diarization Network, as well as the challenges in extracting these features. Based on these challenges, Section 3 proposes a novel radiotelephone communication speaker diarization system made up of three modules: voice activity detection (VAD), end-to-end radiotelephone speaker separation (EESS), and flight prior knowledge-based text-related clustering (PKTC). Section 4 introduces the ATCSPEECH database, which we created for the radiotelephone communication speaker diarization task. Section 5 trains and compares the network using the public AMI and ATCO2 PROJECT databases, followed by ablation studies on various network modules. Finally, Section 6 summarizes the contents of this article.
3. Preliminary Analysis
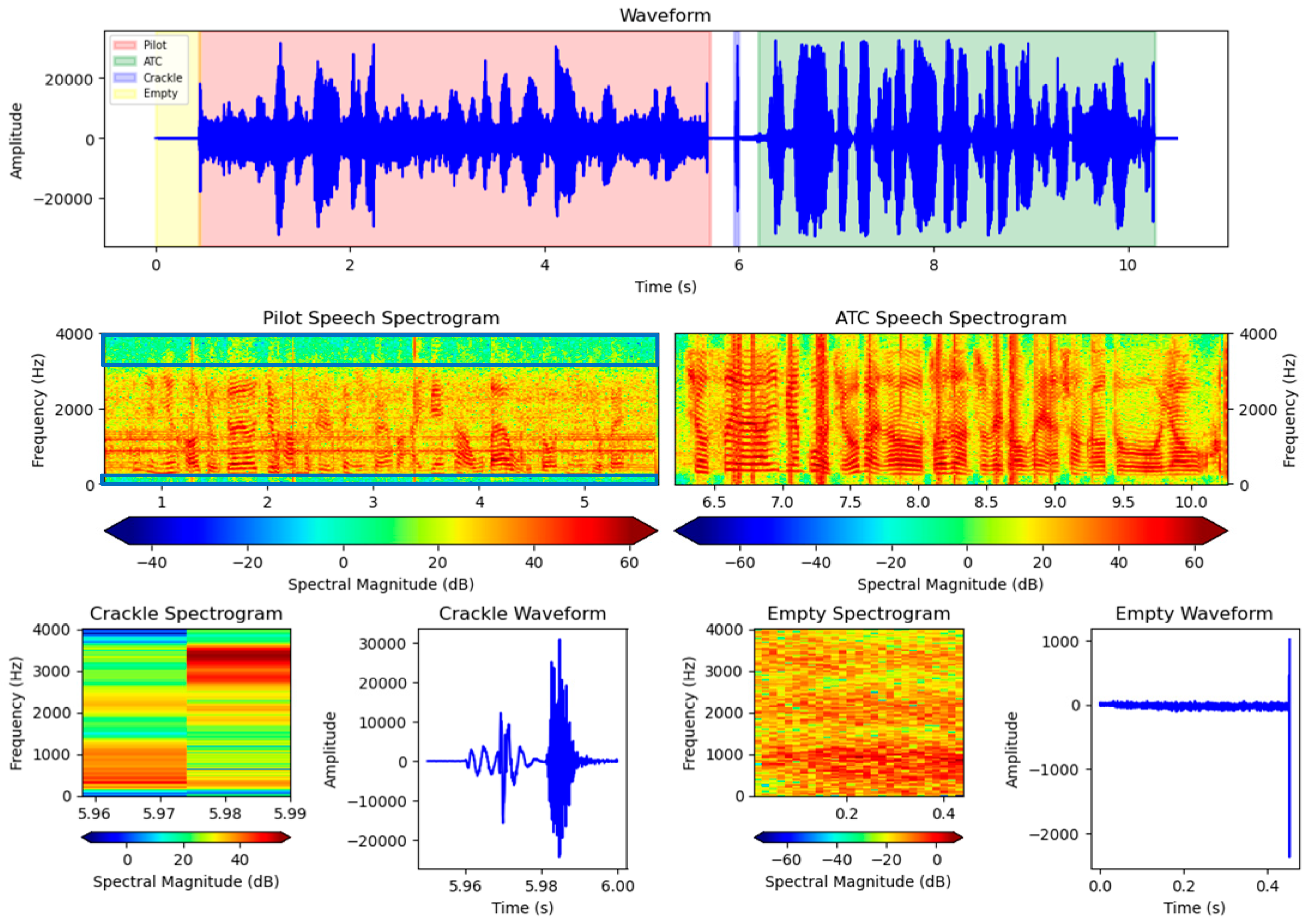
In radiotelephone communication, a single controller in one location communicates with multiple pilots via the Very High Frequency Communication System (VHF COMM). Figure 2 depicts a segment of real radiotelephone communication voice data captured from the airport intercom system. As shown in Figure 3, voice communication has the following characteristics during transmission:

Figure 3.
A waveform and spectrum graph of a radiotelephone communication audio.
Characteristic 1: Radiotelephone communication operates in half-duplex mode, which requires speakers to press the Push to Talk (PIT) device button to speak, allowing only one speaker to speak at a time. When neither party presses the talk button, the intercom system records absolute silence, as shown in the figures with the empty waveform and empty spectrogram. When both parties press the talk button at the same time, they are unable to communicate effectively, and the system records a segment of chaotic noise that does not belong to any speaker. The duration of this noise is typically correlated with the time both parties press the button simultaneously, and it is usually very brief, with its waveform and spectrogram shown in the figures as Crackle Waveform and Crackle Spectrogram, respectively. Such conflicts are common at congested airports.
Characteristic 2: The audio processed during speaker logging is collected from the intercom system. The controller’s voice is transmitted from the control tower to the intercom system via wired transmission, resulting in minimal noise and a clear voiceprint, as shown by the waveform green marker and ATC speech spectrogram in the figure. However, because the controller uses the microphone at such a close distance, “popping” may occur. In the waveform, this is represented by an overly full and enlarged shape. Pilots’ voices enter the intercom system via wireless transmission, as indicated by the waveform red marker and pilot speech spectrogram in the figures. The pilots’ end voice introduces noise that varies with communication distance, the presence of obstacles in the channel, flight phases, and weather conditions, making the pilots’ end voice noisier. This noise appears in the spectrogram as a series of red lines spanning from left to right, indicating constant noise in those frequency bands.
Characteristic 3: During transmission, pilots’ voices are filtered through a band-pass filter, which is represented by wave cancellation in the blue box of the pilot speech spectrogram. This results in a sparse and blurry voiceprint for the pilots, which differs significantly from that of the controllers. When a controller communicates with multiple pilots, their voices exhibit a weakened voiceprint, causing their voiceprints to become similar and making it difficult for voiceprint-based speaker-clustering models to distinguish between them [12].
The challenges associated with Characteristic 1 include the need for the voice activity detection (VAD) module to distinguish not only silence but also noise generated during conflicts between the parties in conversation. The challenge with Characteristic 2 stems from the significant differences in voiceprints between controllers and pilots, with a focus on how to use this feature to create an effective speech separation model. For Characteristic 3, the challenge is that relying solely on acoustic models to distinguish pilots’ voices may be ineffective. Thus, in order to aid in speech separation, additional features such as text must be incorporated into the speaker diarization system design. To address these challenges in air–ground communication scenarios, this paper proposes a speaker diarization system consisting of three modules: voice activity detection (VAD), end-to-end radiotelephone speaker separation (EESS), and flight prior knowledge-based text-related clustering (PKTC). The VAD module has been enhanced with an attention mechanism to effectively filter out silence and noise, as described in Characteristic 1. The EESS model fine-tunes an end-to-end speaker segmentation model to distinguish between controller and pilot voiceprints by pre-clustering voices into two categories: pilots and controllers. Given Characteristics 2 and 3, a text-related clustering model based on flight prior knowledge is designed to accurately cluster pilot voices to the corresponding call sign, effectively resolving speaker identification errors in speaker diarization logs caused by blurred voiceprints.
4. Proposed Framework
The model proposed in this paper consists of three components: voice activity detection (VAD), end-to-end radiotelephone speaker separation (EESS), and flight prior knowledge-based text-related clustering (PKTC).
4.1. Voice Activity Detection
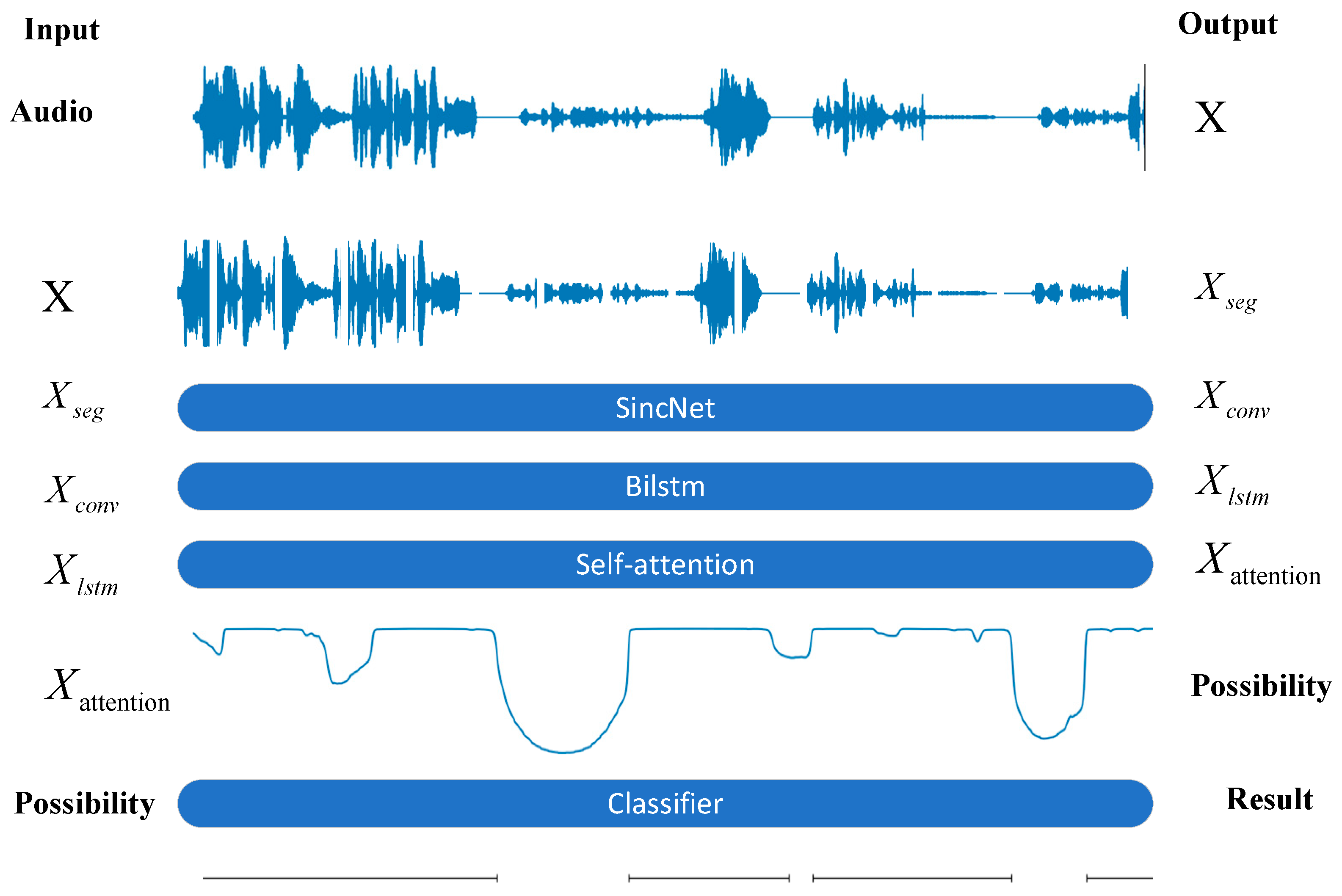
The voice activity detection (VAD) model attempts to slice the input speech signal and filter out noise caused by equipment conditions to the greatest extent possible. The VAD model developed in this paper serves as the system’s entry point and is optimized for radiotelephone communication scenarios. Figure 4 shows how the model uses a local temporal network based on Bi-LSTM to filter out noise-generated intervals [13]. It also includes a global temporal network based on self-attention that preserves silent intervals caused by the speaker’s breathing [14]. This network enables the segmentation of long speech signals into individual radiotelephone command speech segments.

Figure 4.
Architecture diagram of a VAD model.
Due to the use of Push to Talk (PTT) devices, air–ground communication can be seen as a polling speech, meaning that only one person speaks at a time. In the design of the VAD system, the fundamental reason we needed to change the VAD architecture is that in air–ground communication, there is “silence” when no one is speaking, but there are also some “crackle” sounds caused by button presses. These segments should be filtered out and removed by the VAD system. Traditional energy spectrum-based VAD models are very effective at filtering “silence”, but when filtering “crackle”, since “crackle” itself has a non-zero energy spectrum, energy-based segmentation models will treat “crackle” as a valid sentence and retain it. Therefore, we chose a waveform-based VAD framework. Although “crackle” itself carries energy, it appears as isolated, sharp spikes in the waveform spectrum. Thus, the waveform-based VAD model can effectively identify and remove it. Additionally, as to the silent intervals caused by breathing, Bi-LSTM-based VAD systems cannot effectively recognize these intervals due to the characteristics of the Bi-LSTM model, leading to the segmentation of a continuous speech segment into two or more sentences. Therefore, we designed a self-attention global temporal network to extend the model’s “receptive field” to retain the silent intervals caused by the speaker’s breathing.
Assume that the audio input here consists of sample points, denoted as . Then, this speech segment is sliced with a stride of ,
First, each audio segment is convolved using the SincNet convolution method mentioned in [15], resulting in :
where represents the convolution operation and denotes a convolutional band-pass filter with a length of , where represents learnable parameters, as defined below:
In this context, and represent each convolutional band-pass filter’s upper and lower frequency limits, respectively, while represents a Hamming window function defined to have the same length as the original signal and utilized to mitigate the effects of spectral leakage.
After being convolved with SincNet, the signal is absolute value-pooled and normalized before being activated using the Leaky ReLU function. The processed audio signal is then fed into a two-layer Bi-LSTM network to extract short-term features. Assuming that the feature extracted is vector , the specific steps are as follows:
where represents the index for each timestep, stands for the sigmoid function, represent the input, forget, and output gates, respectively, and denote the cell state and hidden output, respectively. and represent trainable weight matrices and bias vectors, while indicates the element-wise multiplication of corresponding vectors. Finally, by concatenating the feature vector obtained from the forward computation and the vector derived from the backward sequence, we obtain the result of the feature extraction for this layer, which is
To address the issues of gradient explosion and vanishing encountered by the Bi-LSTM network when processing long-duration data [16,17], as well as the network’s oversensitivity to silent gaps caused by speaker breathing, this paper introduces a self-attention-based network for the further processing of time-related features. The input sequence data are embedded in a vector space of dimension to track the relative order of each part within the sequence, which is then concatenated with the original -dimensional data prior to encoding. The encoder consists primarily of two parts: the Multi-Head Attention (MHA) and the feed-forward layer. The MHA mechanism consists of several scaled dot-product attention units. Given a sequence vector, each attention unit computes contextual information about a specific token and combines it with a weighted set of similar tokens. During encoding, the network mainly learns three weight matrices: key weight , value weight , and query weight . These three weight matrices enable us to compute the attention representation of all vectors.
where is the transpose of matrix and represents the dimensionality of vector features aimed at stabilizing the gradient. The SoftMax function is used for weight normalization. During computation, the weights are dot-multiplied with each head’s attention vectors, then summed and fed through a linear layer activated by the Gelu function.
where represents the attention mechanism generated by the -th head.
Finally, the processed feature vectors undergo a binary classification task to determine whether each stride contains a valid human voice signal. At this point, the network outputs the audio segmented into units based on this determination.
4.2. End-to-End Radiotelephone Speaker Separation
The end-to-end radiotelephone speaker separation model requires processing the audio segments divided by the voice activity detection model, clustering pilots and controllers into two groups based on the acoustic characteristics of each command segment. The Pyannote-based end-to-end speaker segmentation model [9] is fine-tuned to cluster speech.
With simple pre-training, the binary clustering model based on voiceprint features can easily cluster pilot and controller voices. In actual long-duration radiotelephone communication, the communication time established between individual pilots and controllers is short, particularly in scenarios where multiple pilots communicate with controllers. Given the high volume of flights at airports, with numerous and unknown speakers, conventional speaker diarization systems struggle to handle the audio. As a result, this model incorporates the flight prior knowledge-based text-related clustering model to improve the robustness of the speaker diarization task in multi-pilot scenarios.
4.3. Flight Prior Knowledge Based Text-Related Clustering
To address the challenges of dealing with a large and indeterminate number of speakers in long-duration radiotelephone communication, as well as the fuzziness of pilot voiceprints, which makes designing a voiceprint-based speaker clustering system difficult, this system introduces flight prior knowledge-based text-related clustering. It re-clusters speakers based on radiotelephone command texts, which include call signs.
In standard radiotelephone communications, commands from the pilot’s side should contain the aircraft’s call sign, and if a command includes multiple call signs, the last call sign is definitively that of the aircraft [18,19]. Additionally, airlines coordinate flights through the Air Coordination Council, with coordination cycles measured in years divided into spring and autumn seasons, resulting in flights appearing in fixed cycles. Martin Kocour et al. [20] found that airport radar data can be used to correct the textual results of voice recognition when extracting call signs. Therefore, based on prior knowledge, pilot call signs can be matched and corrected to address errors caused by voice recognition systems [21]. This paper presents a flight prior knowledge-based text-related clustering model, which performs call sign recognition, correction, and extraction for clustering. The algorithm’s specific process is as follows:
First, the call sign recognition task is defined as follows: given an acoustic observation , the process involves finding the most likely corresponding sequence of call sign strings . The specific process is described as follows:
where represents the probability constraints of the acoustic model, while represents the probability constraints of the language model.
Secondly, the call sign correction task is defined as follows: given a string , by correcting a few characters , the required string sequence is determined.
The algorithm’s primary workflow is divided into three parts: graph construction based on prior information, graph correction based on radar data, and probability optimization.
4.3.1. Graph Construction Based on Prior Knowledge
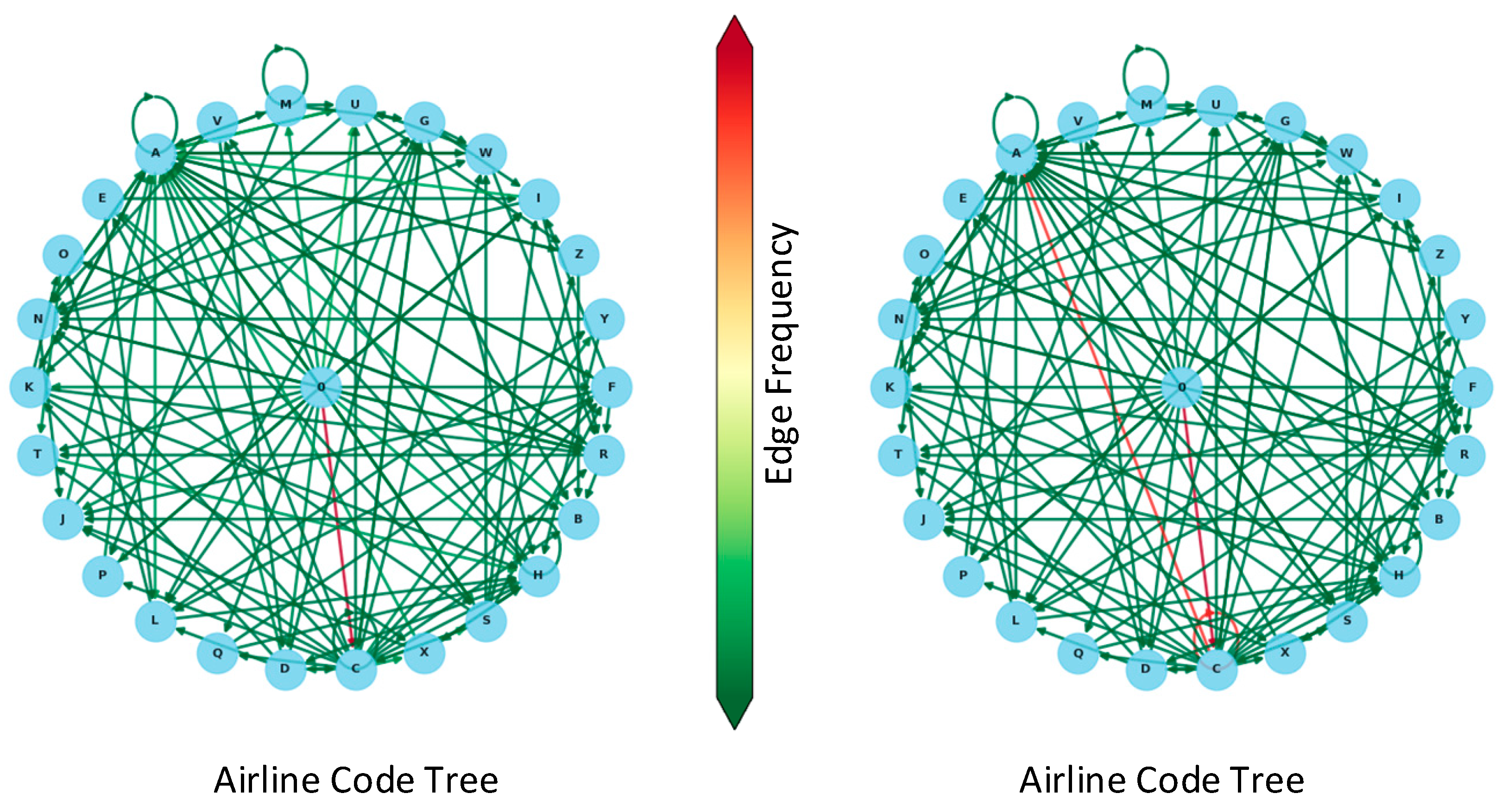
The algorithm begins with aviation data that have been revised by the aviation coordination council, and it constructs a dictionary graph as follows: Initially, it collects all possible flight call signs that may appear at the airport, splitting them into three-letter airline codes and four-digit flight numbers. Separate graphs are generated for airline codes and flight numbers. The processed call signs are then organized by the character sequence, with the preceding letter as the head and the following letter as the tail, forming a directed edge. Finally, the outdegree of each node’s letter is tallied, and the results are normalized to determine the transition probabilities for each character state.
where represents the probability of transitioning from the current state to state , denotes the outdegree of transitioning from state to state , and represents the outdegree from any state to state
The final output is depicted on the left side of Figure 5.
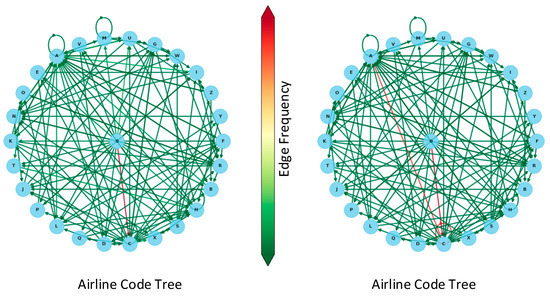
Figure 5.
Call sign character state transition probability diagram. (In the dictionary graph, each node represents a different transition state, with the character ‘0’ representing the initial nodes. Each edge represents the transition from the current state to the next, with the color changing from green to red, indicating the probability of the state transitioning from low to high. The left side of the diagram is based on prior knowledge mapping, while the right side shows changes to the diagram based on radar data). Red lines represent high-probability states, green lines represent low-probability state transitions, and circles represent self-state transitions.
4.3.2. Graph Correction Based on Radar Data
The algorithm begins with data obtained from radar to correct the dictionary graph, with the following procedure: It updates the graph with the most recent flight call signs from the radar at the time of query. Similarly, the call signs are first split into the three-letter airline code and the four-digit flight number, and each is inserted into the graphs separately. It updates all transition probabilities for the current head node based on the character sequence, with the preceding letter serving as the head and the following letter as the tail. The transition probability for states ending with the tail node is updated by multiplying it by weight and adding weight , while the transition probability for states not ending with the tail node is multiplied by weight . The sum of weights and equals 1.
where
represents the degree of correlation between the radar data and control commands, with a positive correlation between the call signs appearing in the radar data and those in the control commands when ; the larger is, the smaller the correlation. In different scenarios, the correlation between the most recent radar data call signs and control command call signs varies. For example, in busy airports with a high volume of aircraft movements, the correlation between the most recent radar data call signs and control command call signs is weaker, necessitating a higher value for . Therefore, the value of should be adjusted during pre-training in real-world test scenarios. In this experiment, the value is set to .
4.3.3. Probability Optimization
During a call sign-decoding operation, assuming that character has already been decoded and character is awaiting decoding, the potential decoding results for character form the character set . In this context, the probability of decoding to is . Therefore, multiplying the decoding probability by the corresponding state transition probability in the graph represents the potential decoding outcome at that moment.
Therefore, the speech recognition task is updated as follows:
Similarly, for the correction task, assume that the call sign character to be corrected is with the character value being , and the potential correction result set being . The preceding character to this character is , and the succeeding character is . In the dictionary graph, the transition probability from character state to state is , and from character state to state is . In a scenario where occurs, it indicates an erroneous call sign sequence; thus, a correction should be made, with the corrected character ensuring that is maximized. Thus
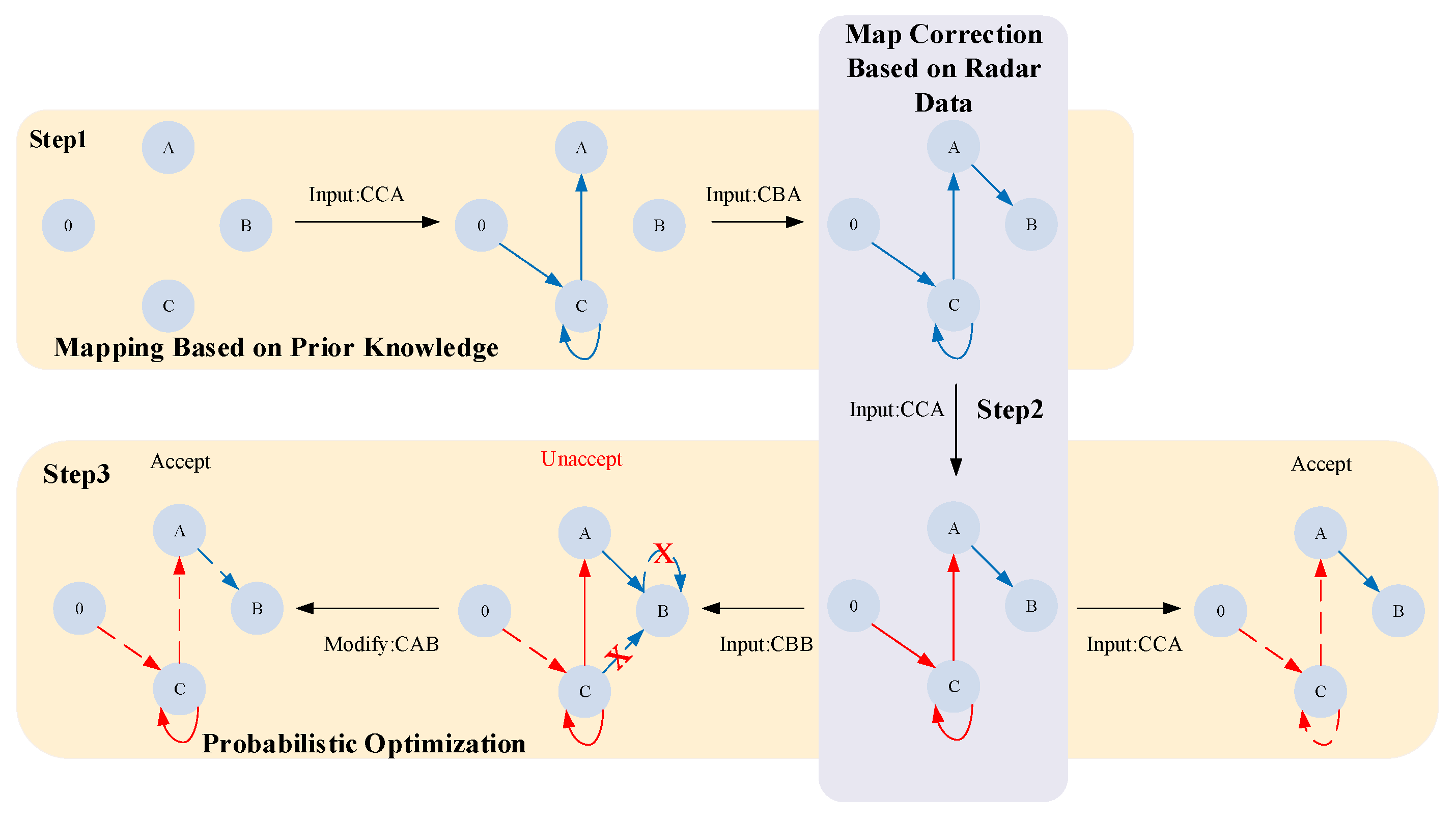
Figure 5 (right) shows that the flight CCA4369 has now been added to the simulated radar information. After probability optimization, call sign characters will tend to select characters that have appeared in prior information, with a greater emphasis on call sign characters that have recently appeared in radar information. Figure 6 illustrates the specific operational process of this algorithm using a simple example.

Figure 6.
Algorithm example diagram. The first step is to map based on prior knowledge, using two flights identified as CCA and CBA. In the second step, which involves a map correction using radar data, a flight with the value CCA is used. The third step, probabilistic optimization, involves two queries. One query specifies the value CCA, which the model accepts and returns as a string. The other query is for the value CBB, which the model initially rejects. After changing the second character, ‘B’, to ‘A’, the model accepts and returns the string with the value CAB. The solid line represents the state transition paths generated during the graph construction, and the dashed lines represent the state transition paths generated during the query and modification.
This algorithm enhances the accuracy of call signs in the text.
Finally, for processed speech text, call sign matching is performed. In radiotelephone communication, pilots often append the aircraft’s call sign to the end of a command. As shown in Figure 7, by first reversing the text and then matching the airline code in reverse order, adding the first four characters before reversing it again, a call sign recognized from speech can be obtained.

Figure 7.
Schematic diagram of the call sign-matching algorithm.
Re-clustering based on call sign texts allows us to easily overcome the clustering challenges caused by the sparsity of pilot voiceprints, as well as the difficulties of clustering in scenarios involving multiple pilots.
5. Dataset and Experimentation
5.1. ATCSPEECH Dataset
This section designs the proprietary ATCSPEECH dataset for network training and testing.
We created the ATCSPEECH dataset, which consists of voice data annotated for speaker diarization by air traffic controllers with control licenses and over two years of experience working at airports. The data are derived from complete voice command recordings at airports, which include comprehensive contextual content such as command text labels, speaker labels, and command start and end timestamp labels.
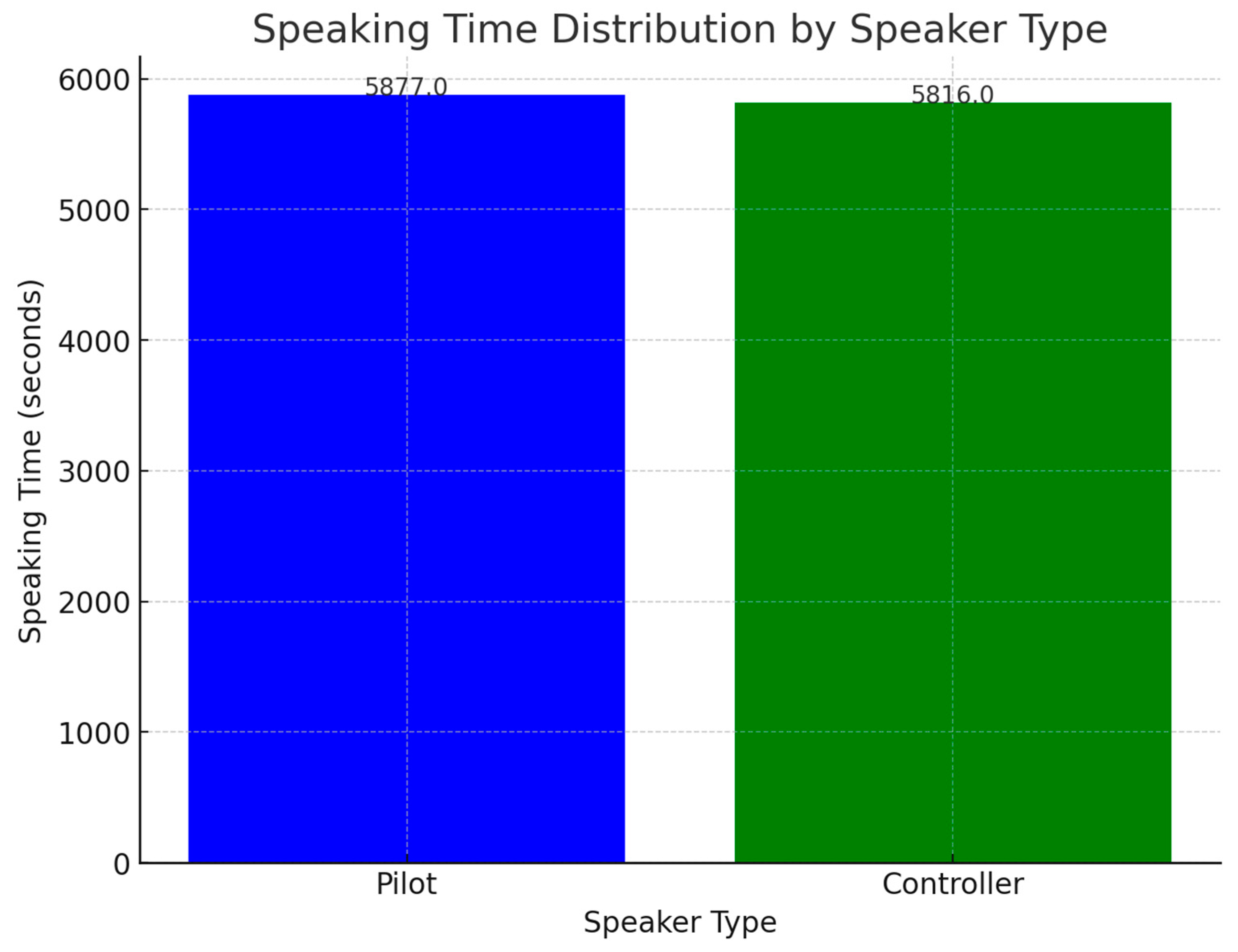
As shown in Figure 8, This dataset contains 5347 voice recordings that cover 14 h of ground-to-air communication at the airport, from 7 a.m. to 9 p.m. It has 106 speakers, including eleven different air traffic controllers and 95 pilots. Pilots have a total speaking time of about 1 h, 37 min, and 57 s, while air traffic controllers have about 1 h, 36 min, and 56 s.

Figure 8.
ATCSPEECH dataset speaking time and number of speakers.
5.2. Expermental Settings
The model in this paper compares and performs ablation studies on three datasets: two public datasets, the AMI and ATCO2 PROJECT datasets, and one proprietary dataset, ATCSPEECH. The AMI dataset [22] was extracted from the AMI Meeting Corpus, and a corpus contains approximately 100 h of meeting recordings. These recordings document a variety of meetings, including project meetings, design reviews, and research discussions. The ATCO2 PROJECT dataset collects, organizes, and preprocesses ground-to-air communication data for air traffic control (ATC). The project collected data from a number of airports, including Prague and Brno in the Czech Republic, Zurich, Bern, and Sion in Switzerland, Sydney in Australia, Bratislava in Slovakia, and Tallinn in Estonia. This dataset contains real communications between air traffic controllers (ATCs) and pilots, which have been used by other researchers to train speech recognition and speaker diarization models [23,24]. It contains 20 h and 35 min of ground-to-air communication recordings, totaling 2657 dialogues. Because of confidentiality concerns, the dialogue content is not continuous, preventing the model from accessing quality contextual information and associated ADS-B data. ATCSPEECH, a dataset we created, contains 5347 ground-to-air communication data entries and includes 107 speakers. All three datasets are processed in RTTM format, which includes audio duration, speaker ID, a speaker voice start timestamp, and speech duration.
The network proposed in this paper consists of three parts: voice activity detection (VAD), end-to-end radiotelephone speaker separation (EESS), and flight prior knowledge-based text clustering (PKTC). To effectively adapt the model to voice data from various airports, the first two parts use the diarization error rate (DER) as the loss function during training. The third part is fine-tuned using the top 10% of the data in the dataset.
The DER calculation consists of three components: missed speaker error, false alarm error, and speaker error. The DER is calculated by adding the three errors and dividing the total duration of reference (or actual) speaker activity. The specific calculation formula is as follows:
In the analysis, ‘Missed Speaker Error’ denotes the cumulative time that speakers in the data are omitted from the system’s output. The term ‘False Alarm Error’ refers to the total time of speakers that the system incorrectly identifies as being present in the output but are not found in the actual data. ‘Speaker Labeling Error’ is the total number of time segments incorrectly attributed to another speaker in the system’s output. The ‘Total Reference Speaker Duration’ indicates the aggregate speaking time of the reference speakers within the speech data. The network is developed using Python 3.8.17’s PyTorch2.1.0 library, with experiments conducted on an RTX 4090 GPU. The hyperparameters are shown in Table 1.

Table 1.
ATC-SD Net network hyperparameter settings.
6. Results
To validate the optimal performance of our network across different datasets, the diarization error rate (DER) is employed as the evaluation metric. The calculation method for the DER is as follows:
Among the audio files tested, there are files in total, for which the speaker diarization system processes each audio file to produce a result . The final test result of the speaker diarization system is the average of the system’s processing results across all the audio files in the test dataset.
6.1. Quantitative Results
Our experiments compared several publicly available speaker diarization algorithms, including VBx [7] and Pyannote [9]. Among these, the Pyannote model was selected as our baseline model, as it demonstrated the best and most stable performance.
The VBx model does not include a trainable voice activity detection (VAD) model, so Pyannote [9] was used instead. In the AMI dataset testing, our model did not use the flight prior knowledge-based text-related clustering model.
As shown in Table 2, although the VBx model performed best in the AMI dataset, it did not perform well in the ATCO2 PROJECT dataset or the ATCSPEECH dataset, which contain background noise from radio communications. Moreover, models based solely on voiceprint clustering, such as VBx and Pyannote, perform poorly on the ATCSPEECH dataset, which contains complex backgrounds and unknown speakers.
Table 2.
Performance of the speaker diarization system on different datasets.
6.2. Ablation Study
To demonstrate the impact of parameter settings across the three modules of our network on overall performance, ablation experiments were conducted. First, various model parameters and training epochs in the voice activity detection (VAD) module were adjusted using a VAD model without the transformer module as the baseline. Experiments were conducted on the AMI dataset, the ATCO2 PROJECT dataset, and the ATCSPEECH dataset, using the diarization error rate (DER) as the evaluation metric and ignoring speaker error. The results are as follows:
As shown in Table 3, the experiments used the Pyannote VAD system as the baseline model and selected Silero VAD [25] as a comparative model. The experiments found that the Silero VAD system achieved the best results on the AMI dataset but performed poorly on the ATCO2 PROJECT and ATCSPEECH datasets. We speculate that this is because the Silero VAD model does not fully adopt a waveform-based VAD architecture and is too sensitive to certain noises. Perhaps using a dedicated dataset for fine-tuning could improve the model’s performance. In addition, the experiments found that the Silero VAD model is overly sensitive to the breathing intervals of speakers, causing a single sentence to be split into multiple sentences. From the perspective of VAD system performance, such interval sensitivity can improve system performance. However, for the entire ATC-SD system, this is detrimental. Splitting a complete voice command into multiple short segments makes it difficult for the subsequent end-to-end speaker segmentation model to extract enough features to classify controllers and pilots. This may also lead to some commands without call signs, increasing the overall error rate of the speaker diarization system. This is one of the reasons why we chose to develop a new VAD model.
Table 3.
Performance of the VAD model with different model parameters and epochs on the AMI dataset and ATCO2 PROJECT dataset. (Arrows represent that the lower the DER the better the model performance).
It is observed that increasing the depth of the model can improve the performance of the VAD model, but this comes with an increased number of parameters and a tendency towards overfitting during training, resulting in poor performance on test sets, which lacks practical application significance (as indicated by the NAN column in Table 3). Excessively high dropout rates degrade the model training results. Moreover, too many heads in the attention mechanism reduce model performance, while also increasing the number of model parameters. Increasing the training frequency appropriately for different datasets can improve training outcomes, but excessive training frequencies can lead to overfitting, wasting computational resources while not improving model performance.
To validate the effectiveness of the flight prior knowledge-based text-related clustering model in binary classification, experiments were carried out on the ATCO2 project dataset and the ATCSPEECH dataset. The diarization error rate (DER) was used as a metric to assess experimental results.
To ensure experimental consistency, the baseline model from Table 3 was selected for voice activity detection. The model generates a missed speaker error and a false alarm error, which contribute approximately 12.0% and 8.9% of the diarization error rate, respectively. As shown in the experimental results in Table 4, it is evident that the voiceprint-based end-to-end speaker segmentation model can easily distinguish between pilot and controller voices after simple pre-training.
Table 4.
Performance of the end-to-end speaker segmentation model after fine-tuning on the ATCO2 PROJECT dataset (Arrows represent that the lower the DER the better the model performance).
Finally, the call signs in the ATCSPEECH dataset’s textual data were perturbed to simulate the recognition errors that occur when voice recognition systems process noisy speech data. This was done to test the robustness of the flight prior knowledge-based text-related clustering (PKTC) model against erroneous speech recognition data. The experiment also used the diarization error rate (DER) as the measurement metric, ignoring the missed speaker error and false alarm error. The network with an uncorrected call sign-matching algorithm served as the baseline model.
As demonstrated by the experimental results in Table 5, it is evident that, under various perturbation scenarios, the flight prior knowledge-based text-related clustering (PKTC) model proposed in this paper is robust to erroneous call signs and provides some corrective effects on incorrect call signs.
Table 5.
Performance of the Radiotelephone Communications Speaker Diarization Network on ATCSPEECH data after different text perturbation processing (performance metric is DER).
As shown in Table 5, the baseline model does not include the flight prior knowledge-based text-related clustering algorithm, meaning it extracts the last call sign from a command as the speaker. In contrast, the other model incorporates the flight prior knowledge-based text-related clustering algorithm for call sign correction. In fact, when the transcription text accuracy is 100%, the DER of both models is equal. The DER shown in Table 5 is entirely produced by the VAD system and the EESS system, approximately 6.6%. However, when ASR transcription errors begin to occur, the system starts to make errors, and the DER increases as the ASR error rate increases, because the call sign is not corrected using the flight prior knowledge-based text-related clustering algorithm. In fact, the ASR error rate does not exceed 10%, but to simulate extreme conditions, the experiment chose error rates of 10% and 20% for testing. As shown in Table 5, under high error rates, the flight prior knowledge-based text-related clustering algorithm performed the call sign correction task under high transcription error rates, reducing the DER of the entire system and improving its performance.
7. Conclusions
This study introduces a novel radiotelephone communications speaker diffraction network that is based on the unique characteristics of air–ground communication scenarios. The network is comprised of three major components: voice activity detection (VAD), end-to-end air–ground speaker separation (EESS), and prior knowledge-based text-related clustering (PKTC). The VAD module uses attention mechanisms to effectively filter out silence and noise during air–ground communications. The end-to-end speaker segmentation model precisely segments speech and divides it into two categories: pilots and controllers. One of this paper’s novel features is the prior knowledge-based text-related clustering model, which accurately clusters the segmented pilot speech to the corresponding call sign-identified speakers.
Furthermore, to train and test speaker diarization tasks, this study collected real, continuous air–ground communication voice data, resulting in the ATCSPEECH dataset. This dataset contains 5347 voice recordings from 106 speakers, including 11 controllers and 95 pilots, for a total duration of approximately 14 h.
After fine-tuning and training on the proprietary ATCSPEECH dataset, as well as the public ATCO2 PROJECT and AMI datasets, the network outperformed the baseline models significantly. Ablation studies confirmed the strong robustness of each network module. Overall, the model proposed in this study is effectively optimized for the characteristics of air–ground communication and performed exceptionally well in speaker diarization tasks, providing valuable references for future research and applications in the aviation communication field. In addition, this system can also adapt to significant changes in voiceprints caused by inconsistencies in VHF COMM equipment or handle data from the auxiliary VHF COMM receiver, by fine-tuning the End-to-End Land–Air Speaker Separation module or through an unbalanced fine-tuning training method (where the data for the controller class are much larger than those for the pilot class during fine-tuning).
In future research, we plan to investigate integrating automatic speech recognition (ASR) and speaker diarization into an end-to-end design to reduce the model’s training loss and improve overall performance. Additionally, the network’s design could be jointly optimized with downstream tasks, such as pilot profiling and controller career lifecycle monitoring, to improve the model’s overall task performance. We will also consider the direction of the joint training of speaker diarization and speech recognition systems. Additionally, we can integrate large language models to directly input speech vectors into the model, bypassing speech recognition, and directly obtain downstream results, thereby reducing the system’s response time.
Author Contributions
Conceptualization, W.P. and Y.W.; methodology, Y.W.; software, Y.W.; validation, Y.W. and Y.Z.; formal analysis, Y.Z. and Y.W.; investigation, Y.W.; resources, W.P.; data curation, B.H.; writing—original draft preparation, Y.W.; writing—review and editing, W.P. and Y.W.; visualization, Y.W.; supervision, Y.W. and B.H.; project administration, Y.W.; funding acquisition, W.P. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China (U2333209), National Key R&D Program of China (No.2021YFF0603904), National Natural Science Foundation of China (U1733203) and Safety Capacity Building Project of Civil Aviation Administration of China (TM2019-16-1/3), the Fundamental Research Funds for the Central Universities (PHD2023-044), and the 2024 Annual Central University Fundamental Research Funds Support Project (24CAFUC10184).
Data Availability Statement
The data presented in this study are available on request from the corresponding author. The data are not publicly available due to privacy.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| VAD | Voice activity detection |
| EESS | End-to-end speaker separation for air–ground communication |
| PKTC | Probabilistic Knowledge-Based Text Clustering |
| VHF COMM | Very High Frequency Communication System |
| VHF | Very high frequency |
| GMDSS | Global Maritime Distress and Safety System |
| PIT | Push To Talk |
| ATC | Air traffic controller |
| Bi-LSTM | Bidirectional Long Short-Term Memory Network |
| MHA | Multi-Head Attention |
| ADS-B | Automatic Dependent Surveillance—Broadcast |
| DER | Diarization error rate |
| VBx | Bayesian HMM clustering of x-vector sequences |
| ASR | Automatic Speech Recognition |
References
- 4444 ATM/501; Procedures for Air Navigation Services–Air Traffic Management (PANS-ATM). International Civil Aviation Organization: Montreal, QC, Canada, 2001.
- Delpech, E.; Laignelet, M.; Pimm, C.; Raynal, C.; Trzos, M.; Arnold, A.; Pronto, D. A Real-Life, French-Accented Corpus of Air Traffic Control Communications. In Proceedings of the Language Resources and Evaluation Conference (LREC), Miyazaki, Japan, 7–12 May 2018. [Google Scholar]
- Helmke, H.; Ohneiser, O.; Buxbaum, J.; Kern, C. Increasing Atm Efficiency with Assistant Based Speech Recognition. In Proceedings of the 13th USA/Europe Air Traffic Management Research and Development Seminar, Seattle, WA, USA, 27–30 June 2017. [Google Scholar]
- Lin, Y. Spoken Instruction Understanding in Air Traffic Control: Challenge, Technique, and Application. Aerospace 2021, 8, 65. [Google Scholar] [CrossRef]
- Plaquet, A.; Bredin, H. Powerset Multi-Class Cross Entropy Loss for Neural Speaker Diarization. arXiv 2023, arXiv:2310.13025. [Google Scholar]
- Park, T.J.; Kanda, N.; Dimitriadis, D.; Han, K.J.; Watanabe, S.; Narayanan, S. A Review of Speaker Diarization: Recent Advances with Deep Learning. Comput. Speech Lang. 2022, 72, 101317. [Google Scholar] [CrossRef]
- Landini, F.; Profant, J.; Diez, M.; Burget, L. Bayesian HMM Clustering of X-Vector Sequences (VBx) in Speaker Diarization: Theory, Implementation and Analysis on Standard Tasks. Comput. Speech Lang. 2022, 71, 101254. [Google Scholar] [CrossRef]
- Bredin, H.; Yin, R.; Coria, J.M.; Gelly, G.; Korshunov, P.; Lavechin, M.; Fustes, D.; Titeux, H.; Bouaziz, W.; Gill, M.-P. Pyannote. Audio: Neural Building Blocks for Speaker Diarization. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 7124–7128. [Google Scholar]
- Bredin, H. Pyannote. Audio 2.1 Speaker Diarization Pipeline: Principle, Benchmark, and Recipe. In Proceedings of the 24th INTERSPEECH Conference (INTERSPEECH 2023), Dublin, Ireland, 20–24 August 2023. [Google Scholar]
- Zuluaga-Gomez, J.; Sarfjoo, S.S.; Prasad, A.; Nigmatulina, I.; Motlicek, P.; Ondrej, K.; Ohneiser, O.; Helmke, H. Bertraffic: Bert-Based Joint Speaker Role and Speaker Change Detection for Air Traffic Control Communications. In Proceedings of the 2022 IEEE Spoken Language Technology Workshop (SLT), Doha, Qatar, 9–12 January 2023; pp. 633–640. [Google Scholar]
- Bonastre, J.-F.; Wils, F.; Meignier, S. ALIZE, a Free Toolkit for Speaker Recognition. In Proceedings of the (ICASSP ‘05). IEEE International Conference on Acoustics, Speech, and Signal Processing, Philadelphia, PA, USA, 23 March 2005; Volume 1, pp. 1–737. [Google Scholar]
- Jiao, X.; Chen, Y.; Qu, D.; Yang, X. Blueprint Separable Subsampling and Aggregate Feature Conformer-Based End-to-End Neural Diarization. Electronics 2023, 12, 4118. [Google Scholar] [CrossRef]
- Gelly, G.; Gauvain, J.-L. Optimization of RNN-Based Speech Activity Detection. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 26, 646–656. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Ravanelli, M.; Bengio, Y. Speaker Recognition from Raw Waveform with Sincnet. In Proceedings of the 2018 IEEE spoken language technology workshop (SLT), Athens, Greece, 18–21 December 2018; pp. 1021–1028. [Google Scholar]
- Hu, Y.; Huber, A.; Anumula, J.; Liu, S. Overcoming the Vanishing Gradient Problem in Plain Recurrent Networks. arXiv 2018, arXiv:1801.06105. [Google Scholar]
- Ribeiro, A.H.; Tiels, K.; Aguirre, L.A.; Schön, T. Beyond Exploding and Vanishing Gradients: Analysing RNN Training Using Attractors and Smoothness. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Online, 26–28 August 2020; pp. 2370–2380. [Google Scholar]
- International Civil Aviation Organization Manual of Radiotelephony, 4th ed.; International Civil Aviation Organization: Montreal, QC, Canada, 2007.
- Annex, I. Aeronautical Telecommunications. Volume III Part I Digital Data Communication Systems, 10. Available online: https://scholar.google.com/scholar?hl=zh-CN&as_sdt=0%2C5&q=Aeronautical+Telecommunications+Volum&btnG= (accessed on 1 July 2024).
- Kocour, M.; Veselỳ, K.; Blatt, A.; Zuluaga-Gomez, J.; Szöke, I.; Cernockỳ, J.; Klakow, D.; Motlicek, P. Boosting of Contextual Information in ASR for Air-Traffic Call-Sign Recognition. In Proceedings of the Interspeech, Brno, Czechia, 30 August–3 September 2021; pp. 3301–3305. [Google Scholar]
- Kasttet, M.S.; Lyhyaoui, A.; Zbakh, D.; Aramja, A.; Kachkari, A. Toward Effective Aircraft Call Sign Detection Using Fuzzy String-Matching between ASR and ADS-B Data. Aerospace 2023, 11, 32. [Google Scholar] [CrossRef]
- Carletta, J. Unleashing the Killer Corpus: Experiences in Creating the Multi-Everything AMI Meeting Corpus. Lang. Resour. Eval. 2007, 41, 181–190. [Google Scholar] [CrossRef]
- Zuluaga-Gomez, J.; Veselỳ, K.; Blatt, A.; Motlicek, P.; Klakow, D.; Tart, A.; Szöke, I.; Prasad, A.; Sarfjoo, S.; Kolčárek, P.; et al. Automatic Call Sign Detection: Matching Air Surveillance Data with Air Traffic Spoken Communications. Proceedings 2020, 59, 14. [Google Scholar] [CrossRef]
- Kocour, M.; Veselỳ, K.; Szöke, I.; Kesiraju, S.; Zuluaga-Gomez, J.; Blatt, A.; Prasad, A.; Nigmatulina, I.; Motlíček, P.; Klakow, D.; et al. Automatic Processing Pipeline for Collecting and Annotating Air-Traffic Voice Communication Data. Eng. Proc. 2021, 13, 8. [Google Scholar] [CrossRef]
- Team, S. Silero Vad: Pre-Trained Enterprise-Grade Voice Activity Detector (Vad), Number Detector and Language Classifier. Retrieved March 2021, 31, 2023. [Google Scholar]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).