
Decoys Deployment for Missile Interception: A Multi-Agent Reinforcement Learning Approach



Abstract
:1. Introduction
1.1. Related Works
1.2. Contribution and Structure of the Paper
2. Problem Definition and Modelling
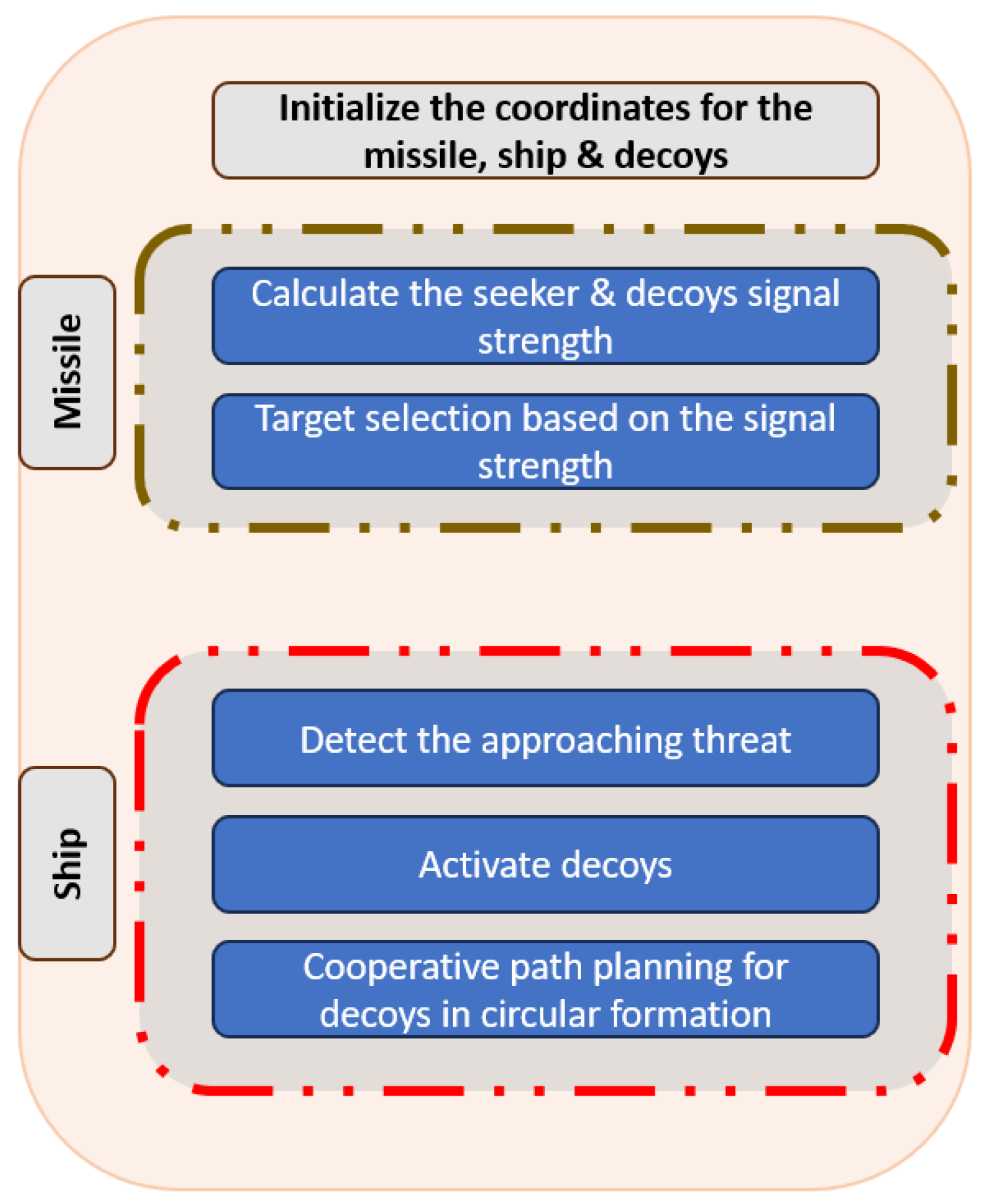
2.1. Problem Definition
2.2. Modelling
2.2.1. Decoy Model
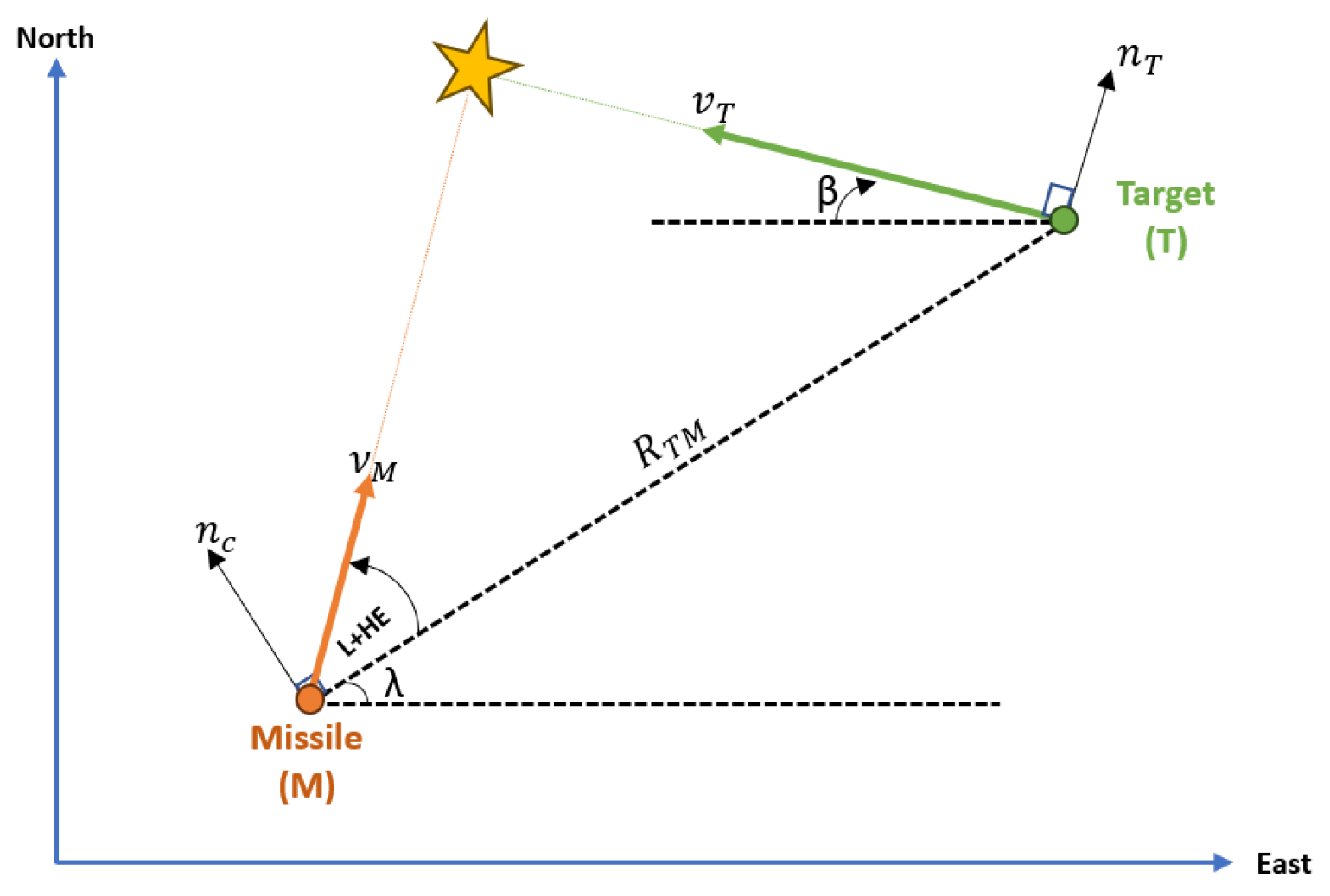
2.2.2. Target Model
2.2.3. Missile Model
3. Reinforcement Learning
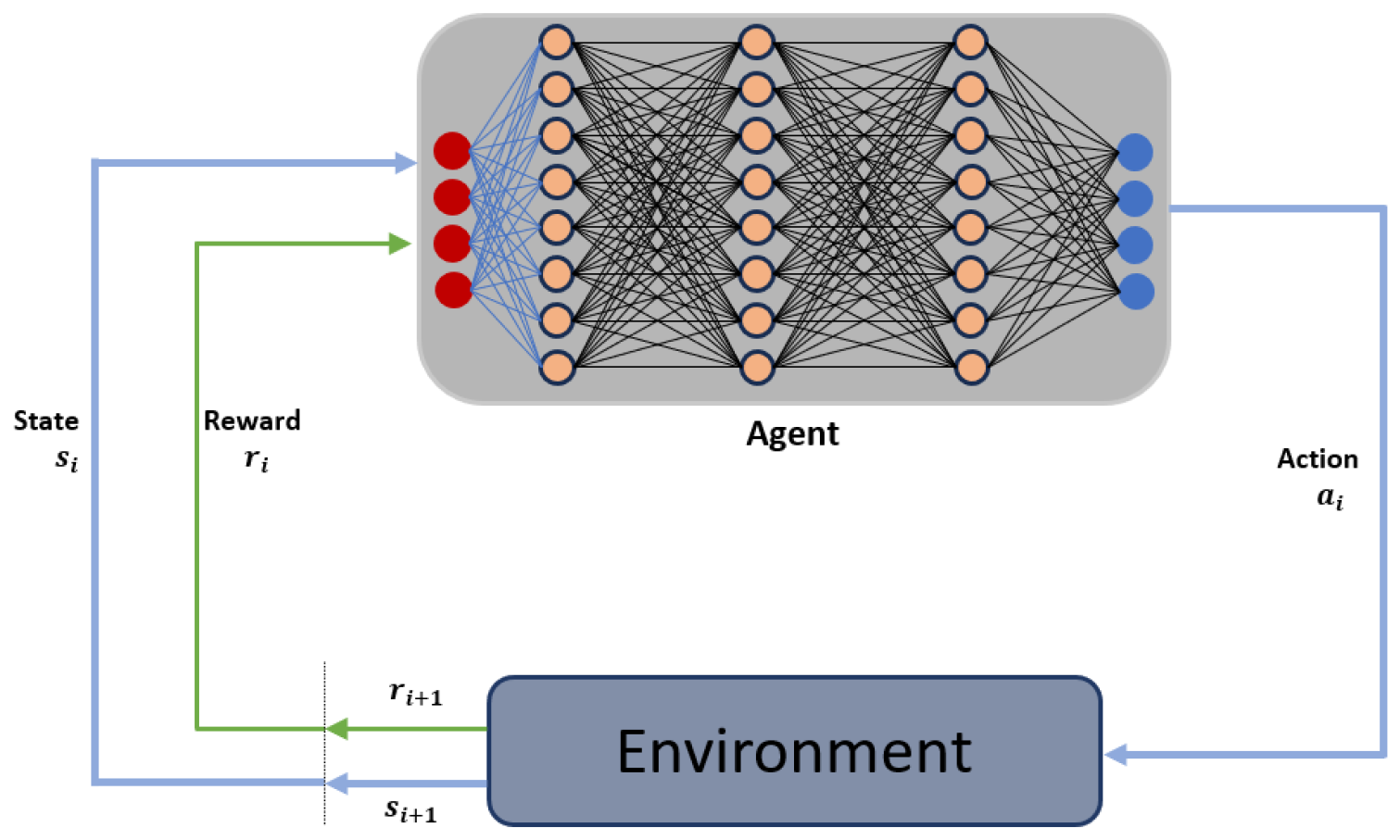
3.1. Basic Concepts of Reinforcement Learning
3.2. Centralized Training Decentralised Execution (CTDE) Framework
| Algorithm 1: Multi-Agent Deep Deterministic Policy Gradient for N agents [25] |
= |
4. Simulation Setup and Training of Agents
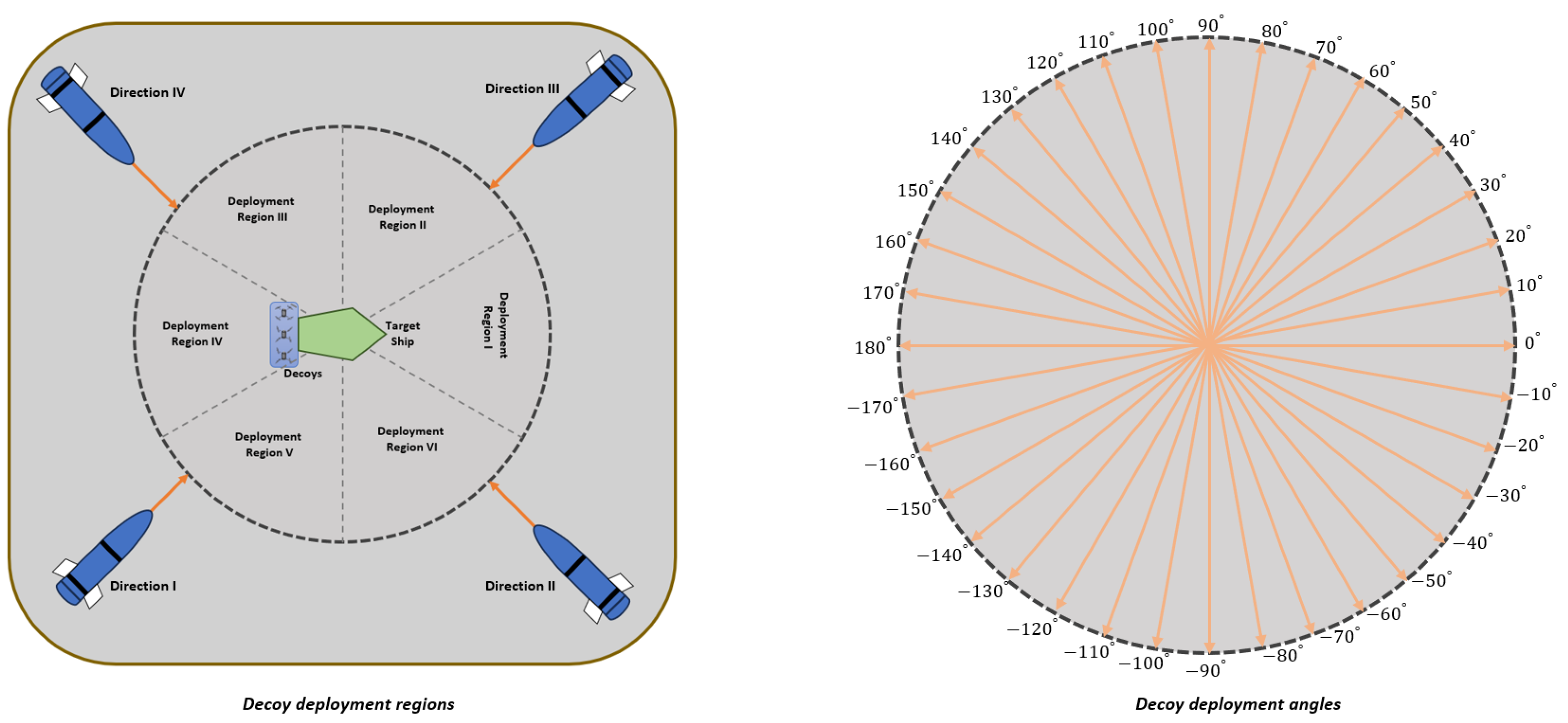
4.1. Defining Observation and Action Spaces
4.1.1. Observation Space
4.1.2. Action Space
4.2. Reward Formulation
4.3. Neural Network Architecture
5. Results and Discussion
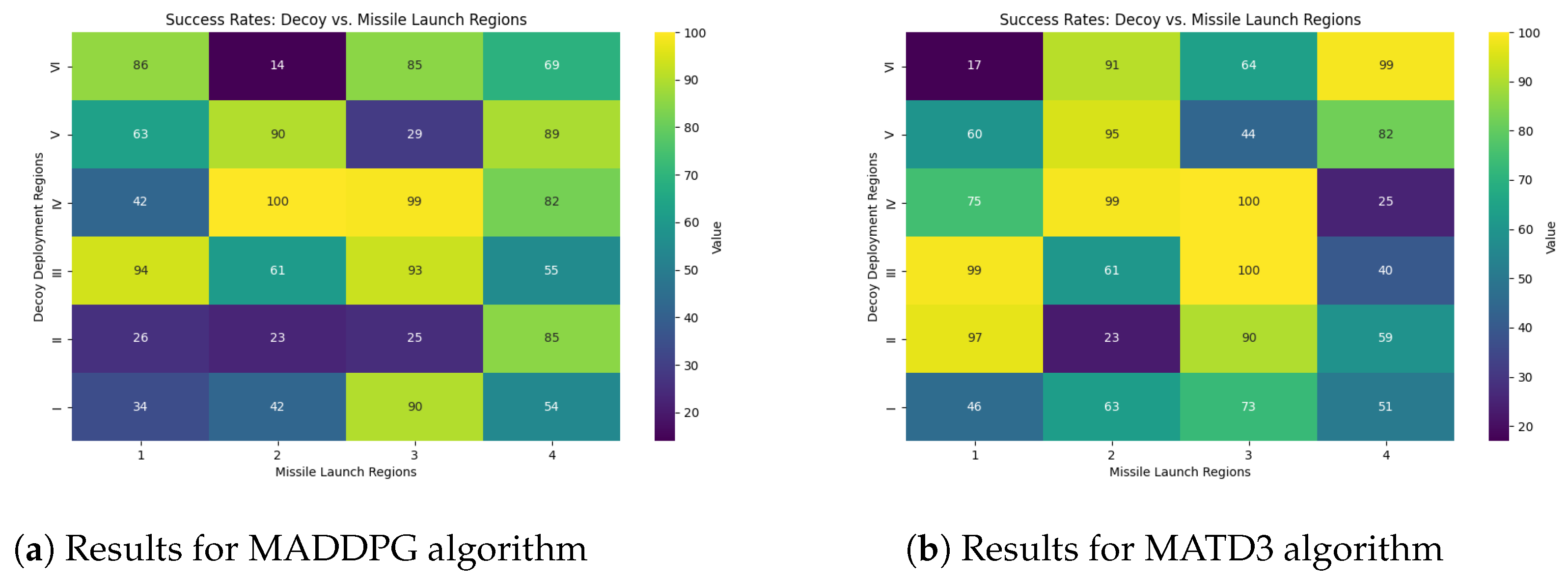
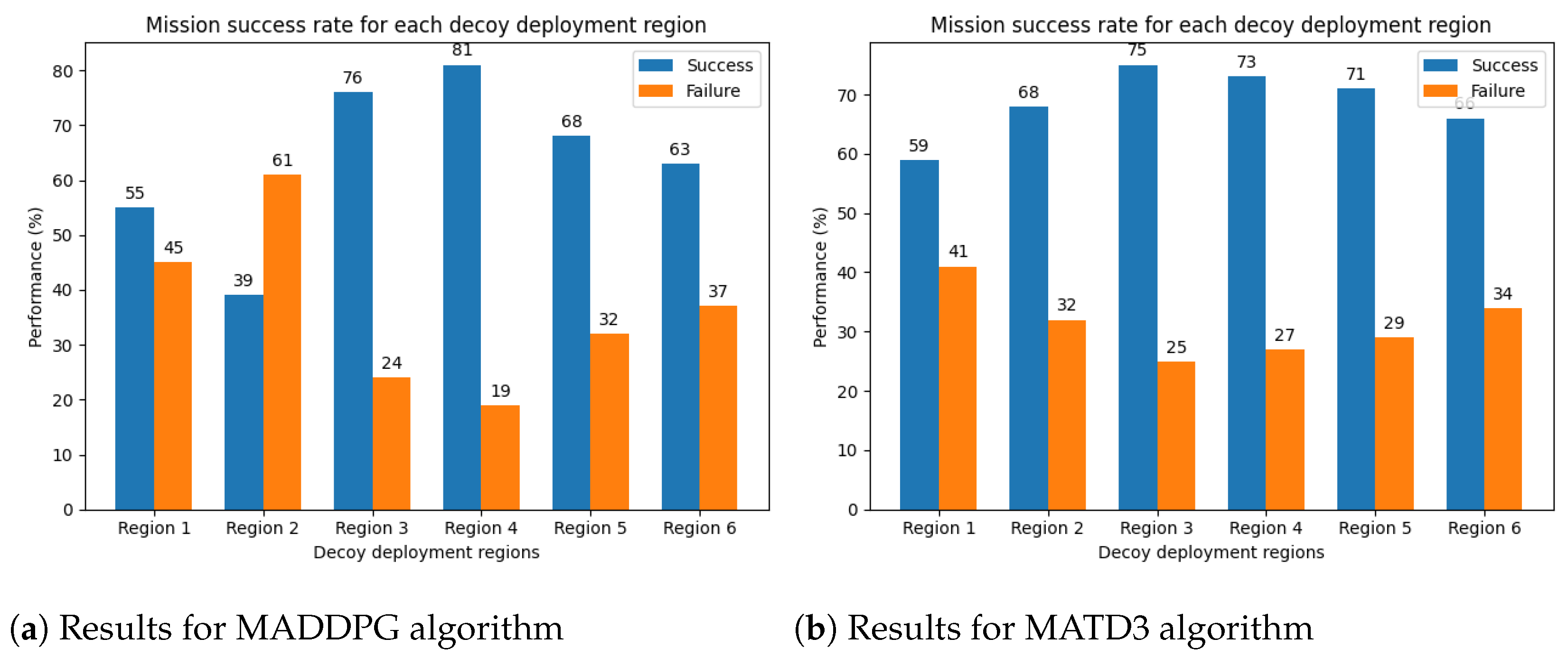
5.1. Evaluation Based on the Variable Decoy Deployment Region and Missile Launch Direction
5.2. Evaluation with Variable Decoys’ Maximum Speed and Missile Speed
5.3. Robustness Evaluation of Trained Decoys under Noisy Conditions
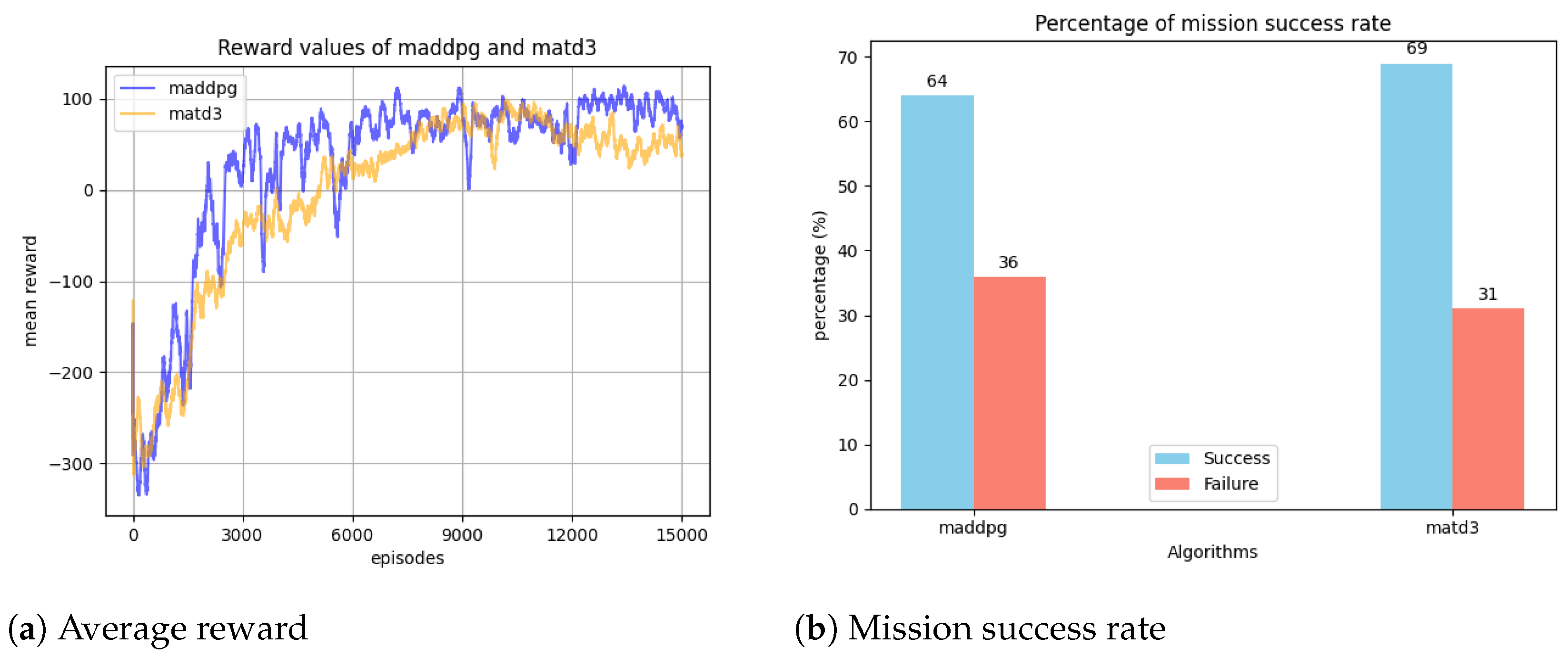
5.4. Comparisons of MADDPG and MATD3 Algorithms
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kerins, W.J. Analysis of towed decoys. IEEE Trans. Aerosp. Electron. Syst. 1993, 29, 1222–1227. [Google Scholar] [CrossRef]
- Yeh, J.H. Effects of Towed-Decoys against an Anti-Air Missile with a Monopulse Seeker. Ph.D. Thesis, Naval Postgraduate School, Monterey, CA, USA, 1995. [Google Scholar]
- Zhou, Y. Correlation parameters simulation for towed radar active decoy. In Proceedings of the 2012 International Conference on Computer Distributed Control and Intelligent Environmental Monitoring, Zhangjiajie, China, 5–6 March 2012; pp. 214–217. [Google Scholar]
- Tan, T.H. Effectiveness of Off-Board Active Decoys against Anti-Shipping Missiles; Technical Report; Naval Postgraduate School: Monterey, CA, USA, 1996. [Google Scholar]
- Lakshmi, E.V.; Sastry, N.; Rao, B.P. Optimum active decoy deployment for effective deception of missile radars. In Proceedings of the 2011 IEEE CIE International Conference on Radar, Chengdu, China, 24–27 October 2011; Volume 1, pp. 234–237. [Google Scholar]
- Butt, F.A.; Jalil, M. An overview of electronic warfare in radar systems. In Proceedings of the 2013 the International Conference on Technological Advances in Electrical, Electronics and Computer Engineering (TAEECE), Konya, Turkey, 9–11 May 2013; pp. 213–217. [Google Scholar]
- Ragesh, R.; Ratnoo, A.; Ghose, D. Analysis of evader survivability enhancement by decoy deployment. In Proceedings of the 2014 American Control Conference, Portland, OR, USA, 4–6 June 2014; pp. 4735–4740. [Google Scholar]
- Rim, J.W.; Jung, K.H.; Koh, I.S.; Baek, C.; Lee, S.; Choi, S.H. Simulation of dynamic EADs jamming performance against tracking radar in presence of airborne platform. Int. J. Aeronaut. Space Sci. 2015, 16, 475–483. [Google Scholar] [CrossRef]
- Ragesh, R.; Ratnoo, A.; Ghose, D. Decoy Launch Envelopes for Survivability in an Interceptor–Target Engagement. J. Guid. Control Dyn. 2016, 39, 667–676. [Google Scholar] [CrossRef]
- Rim, J.W.; Koh, I.S.; Choi, S.H. Jamming performance analysis for repeater-type active decoy against ground tracking radar considering dynamics of platform and decoy. In Proceedings of the 2017 18th International Radar Symposium (IRS), Prague, Czech Republic, 28–30 June 2017; pp. 1–9. [Google Scholar]
- Rajagopalan, A. Active Protection System Soft-Kill Using Q-Learning. In Proceedings of the International Conference on Science and Innovation for Land Power, Australia Defence Science and Technology, online, 5–6 September 2018. [Google Scholar]
- Rim, J.W.; Koh, I.S. Effect of beam pattern and amplifier gain of repeater-type active decoy on jamming to active RF seeker system based on proportional navigation law. In Proceedings of the 2018 19th International Radar Symposium (IRS), Bonn, Germany, 20–22 June 2018; pp. 1–9. [Google Scholar]
- Kim, K. Engagement-Scenario-Based Decoy-Effect Simulation Against an Anti-ship Missile Considering Radar Cross Section and Evasive Maneuvers of Naval Ships. J. Ocean Eng. Technol. 2021, 35, 238–246. [Google Scholar] [CrossRef]
- Chen, Y.; Wang, H.; Zhao, Y. Optimal trajectory for swim-out acoustic decoy to countermeasure torpedo. In Proceedings of the Fourth International Workshop on Advanced Computational Intelligence, Wuhan, China, 19–21 October 2011; pp. 86–91. [Google Scholar]
- Kwon, S.J.; Seo, K.M.; Kim, B.S.; Kim, T.G. Effectiveness analysis of anti-torpedo warfare simulation for evaluating mix strategies of decoys and jammers. In Proceedings of the Advanced Methods, Techniques, and Applications in Modeling and Simulation: Asia Simulation Conference 2011, Seoul, Republic of Korea, 16–18 November 2011; pp. 385–393. [Google Scholar]
- Chen, Y.C.; Guo, Y.H. Optimal combination strategy for two swim-out acoustic decoys to countermeasure acoustic homing torpedo. In Proceedings of the 2017 4th International Conference on Information Science and Control Engineering (ICISCE), Changsha, China, 21–23 July 2017; pp. 1061–1065. [Google Scholar]
- Akhil, K.; Ghose, D.; Rao, S.K. Optimizing deployment of multiple decoys to enhance ship survivability. In Proceedings of the 2008 American Control Conference, Seattle, WA, USA, 11–13 June 2008; pp. 1812–1817. [Google Scholar]
- Conte, C.; Verini Supplizi, S.; de Alteriis, G.; Mele, A.; Rufino, G.; Accardo, D. Using Drone Swarms as a Countermeasure of Radar Detection. J. Aerosp. Inf. Syst. 2023, 20, 70–80. [Google Scholar] [CrossRef]
- Shames, I.; Dostovalova, A.; Kim, J.; Hmam, H. Task allocation and motion control for threat-seduction decoys. In Proceedings of the 2017 IEEE 56th Annual Conference on Decision and Control (CDC), Melbourne, Australia, 12–15 December 2017; pp. 4509–4514. [Google Scholar]
- Jeong, J.; Yu, B.; Kim, T.; Kim, S.; Suk, J.; Oh, H. Maritime application of ducted-fan flight array system: Decoy for anti-ship missile. In Proceedings of the 2017 Workshop on Research, Education and Development of Unmanned Aerial Systems (RED-UAS), Linkoping, Sweden, 3–5 October 2017; pp. 72–77. [Google Scholar]
- Dileep, M.; Yu, B.; Kim, S.; Oh, H. Task Assignment for Deploying Unmanned Aircraft as Decoys. Int. J. Control Autom. Syst. 2020, 18, 3204–3217. [Google Scholar] [CrossRef]
- Li, J.; Zhang, G.; Zhang, X.; Zhang, W. Integrating dynamic event-triggered and sensor-tolerant control: Application to USV-UAVs cooperative formation system for maritime parallel search. IEEE Trans. Intell. Transp. Syst. 2023, 25, 3986–3998. [Google Scholar] [CrossRef]
- Yu, C.; Velu, A.; Vinitsky, E.; Wang, Y.; Bayen, A.; Wu, Y. The Surprising Effectiveness of PPO in Cooperative, Multi-Agent Games. arXiv 2021, arXiv:2103.01955. [Google Scholar]
- Foerster, J.; Farquhar, G.; Afouras, T.; Nardelli, N.; Whiteson, S. Counterfactual Multi-Agent Policy Gradients. arXiv 2018, arXiv:1705.08926. [Google Scholar] [CrossRef]
- Lowe, R.; Wu, Y.I.; Tamar, A.; Harb, J.; Pieter Abbeel, O.; Mordatch, I. Multi-agent actor-critic for mixed cooperative-competitive environments. arXiv 2017, arXiv:1706.02275. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Ackermann, J.; Gabler, V.; Osa, T.; Sugiyama, M. Reducing overestimation bias in multi-agent domains using double centralized critics. arXiv 2019, arXiv:1910.01465. [Google Scholar]
- Fujimoto, S.; Hoof, H.; Meger, D. Addressing function approximation error in actor-critic methods. In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 1587–1596. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Critic Network | Actor Network |
|---|---|---|
| Input layer | obs_dims | |
| Hidden layer 1 | 256 | 256 |
| Hidden layer 2 | 64 | 64 |
| Hidden layer 3 | 256 | 256 |
| Hidden layer 4 | 64 | 64 |
| Output layer | 1 | action_dims |
| Parameters | Value |
|---|---|
| Number of Agents | 3 |
| Maximum episode number | 15,000 |
| Maximum step number | 300 |
| Critic learning rate | |
| Actor learning rate | |
| Experience Buffer Length | |
| Discount Factor | 0.99 |
| Mini Batch Size | 128 |
| Sample Time | 0.1 |
| Missile Speed (in Mach) | |||||
|---|---|---|---|---|---|
| Decoy Speed | 0.7 | 0.8 | 0.9 | 1 | 1.1 |
| 20 | 64.8 | 67.1 | 66.26 | 66.27 | 66.02 |
| 25 | 65.6 | 65.8 | 65.7 | 65.75 | 66.07 |
| 30 | 65.8 | 65.65 | 65.6 | 65.39 | 65.16 |
| 35 | 64.9 | 64.8 | 64.62 | 64.41 | 64.34 |
| 40 | 64.13 | 63.86 | 63.81 | 63.73 | 63.56 |
| Missile Speed (in Mach) | |||||
|---|---|---|---|---|---|
| Decoy Speed | 0.7 | 0.8 | 0.9 | 1 | 1.1 |
| 20 | 69.2 | 69.7 | 69.1 | 68.2 | 68.62 |
| 25 | 68.76 | 69.07 | 69.2 | 69.01 | 68.99 |
| 30 | 68.9 | 69.07 | 68.93 | 69.05 | 69.06 |
| 35 | 68.97 | 68.82 | 68.62 | 68.55 | 68.38 |
| 40 | 68.22 | 68.01 | 67.83 | 67.62 | 67.42 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bildik, E.; Tsourdos, A.; Perrusquía, A.; Inalhan, G. Decoys Deployment for Missile Interception: A Multi-Agent Reinforcement Learning Approach. Aerospace 2024, 11, 684. https://doi.org/10.3390/aerospace11080684
Bildik E, Tsourdos A, Perrusquía A, Inalhan G. Decoys Deployment for Missile Interception: A Multi-Agent Reinforcement Learning Approach. Aerospace. 2024; 11(8):684. https://doi.org/10.3390/aerospace11080684
Chicago/Turabian StyleBildik, Enver, Antonios Tsourdos, Adolfo Perrusquía, and Gokhan Inalhan. 2024. "Decoys Deployment for Missile Interception: A Multi-Agent Reinforcement Learning Approach" Aerospace 11, no. 8: 684. https://doi.org/10.3390/aerospace11080684