(Divergent) Participation in the California Vowel Shift by Korean Americans in Southern California



Abstract
1. Introduction
1.1. Ethnicity and Participation in Local Sound Change
1.2. California Vowel Shift
1.3. Vowels in Korean and Comparison between Korean and American English Vowel Systems
2. The Present Study
2.1. Participants
2.2. Data Collection and Analysis
3. Results
3.1. Phonemic Status of English Vowels
3.2. Lowering and Retraction of IH, EH, and AE
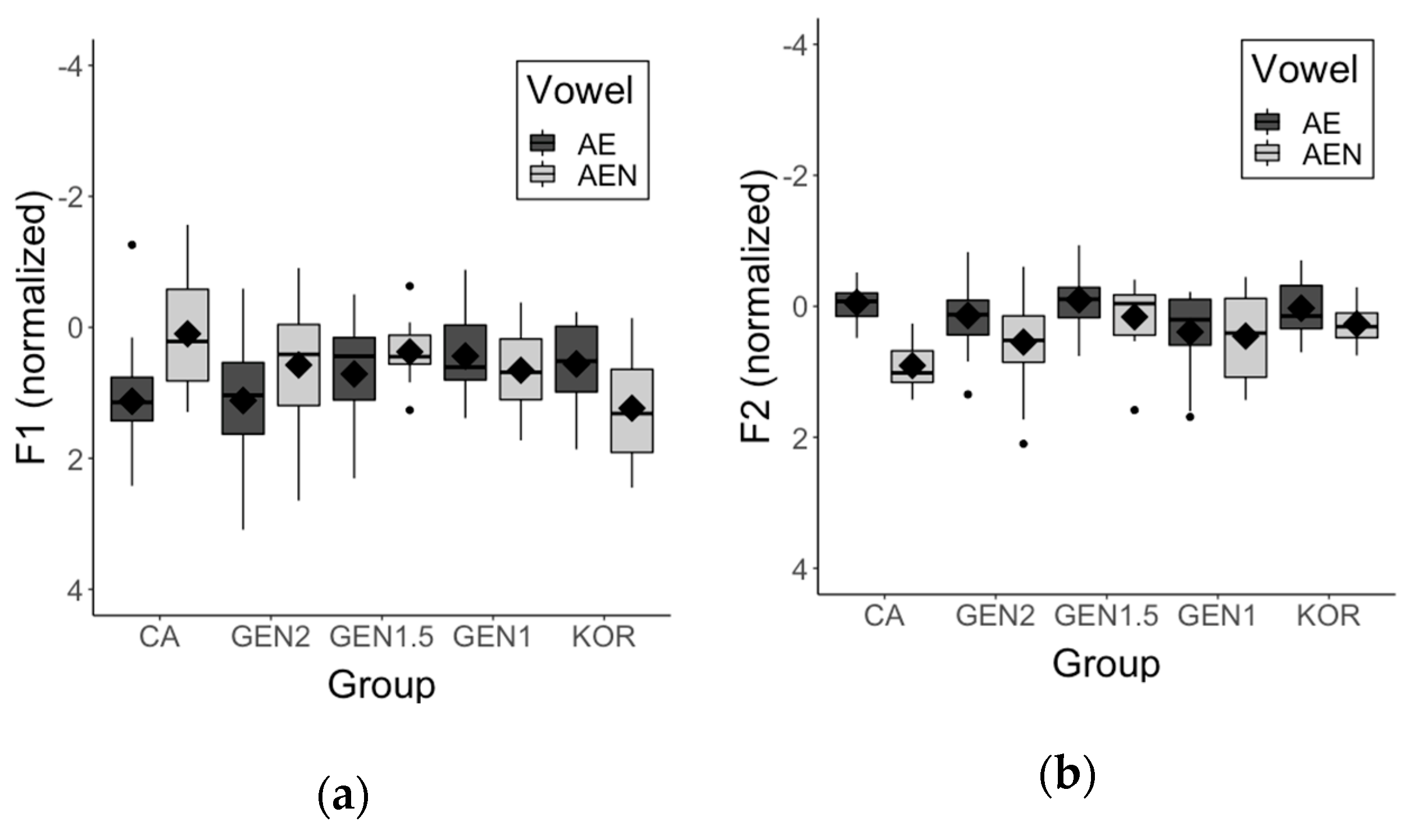
3.3. AE-AEN Split
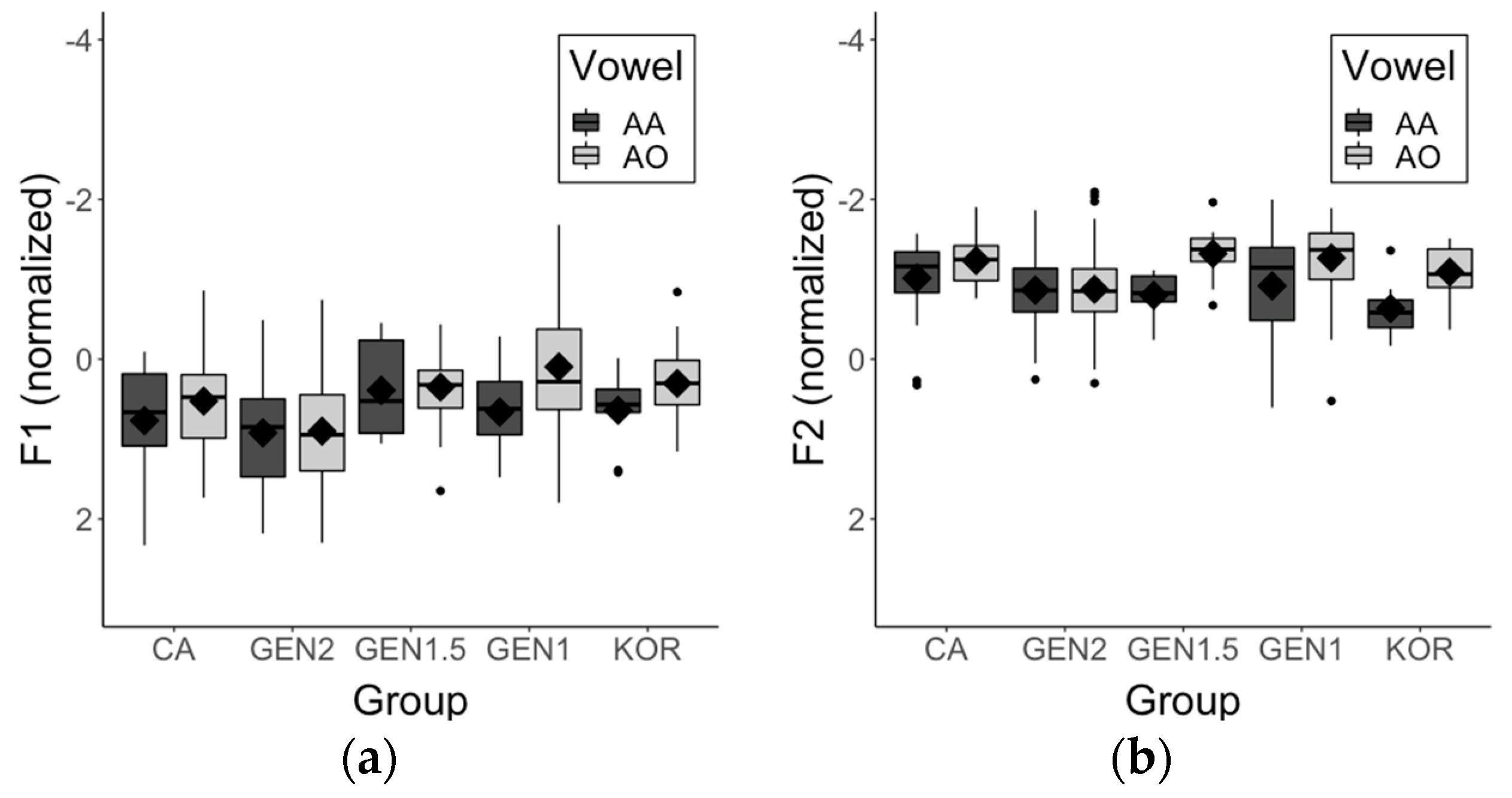
3.4. AA-AO Merger
3.5. Fronting of UW, UH, and AH
4. Discussion
4.1. Effect of Age of Arrival on the Participation in Local Sound Change
4.2. Second-Generation Korean Americans’ Divergent Participation in the California Vowel Shift
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Ahn, Sang-Cheol, and Gregory K. Iverson. 2007. Structured imbalances in the emergence of the Korean vowel system. In Historical Linguistics 2005: Selected Papers from the 17th International Conference on Historical Linguistics. Edited by Joseph C. Salmons and Shannon Dubenion-Smith. Amsterdam and Philadelphia: John Benjamins, pp. 275–93. [Google Scholar]
- Baker, Wendy, and Pavel Trofimovich. 2005. Interaction of Native- and Second-Language Vowels System(s) in Early and Late Bilinguals. Language and Speech 48: 1–27. [Google Scholar] [CrossRef]
- Baker, Wendy, Pavel Trofimovich, Molly Mack, and James E. Flege. 2002. The Effect of Perceived Phonetic Similarity on Non-Native Sound Learning by Children and Adults. In Proceedings of the 26th Annual Boston University Conference on Language Development. Edited by Barbora Skarabela, Sarah Fish and Anna H.-J. Do. Somerville: Cascadilla Press, pp. 36–47. [Google Scholar]
- Bates, Douglas, Martin Maechler, Bon Bolker, and Steve Walker. 2015. Fitting Linear Mixed-effects Models Using lme4. Journal of Statistical Software 67: 1–48. [Google Scholar] [CrossRef]
- Best, Catherine T., and Michael D. Tyler. 2007. Nonnative and Second-language Speech Perception: Commonalities and Complementarities. In Language Experience in Second Language Speech Learning: In Honor of James Emil Flege. Edited by Ocke-Schwen Bohn and Murray J. Munro. Amsterdam and Philadelphia: John Benjamins, pp. 13–34. [Google Scholar]
- Boberg, Charles. 2004. Ethnic Patterns in the Phonetics of Montreal English. Journal of Sociolinguistics 8: 538–68. [Google Scholar] [CrossRef]
- Boersma, Paul, and David Weenink. 2020. Praat: Doing Phonetics by Computer. Computer Program. Version 5.1.31. Available online: http://www.praat.org/ (accessed on 3 July 2020).
- Brown, Janice. 2011. Re-framing “Kawaii”: Interrogating Global Anxieties Surrounding the Culture of ‘Cute’ in Japanese Art and Consumer Products. International Journal of the Image 1: 1–10. [Google Scholar] [CrossRef]
- Carter, Phillip E., Lydda L. Valdez, and Nandi Sims. 2020. New Dialect Formation through Language Contact: Vocalic and Prosodic Developments in Miami English. American Speech 95: 119–48. [Google Scholar] [CrossRef]
- Casillas, Joseph V., and Miquel Simonet. 2016. Production and Perception of the English/æ/-/ɑ/Contrast in Switched-dominance Speakers. Second Language Research 32: 171–95. [Google Scholar] [CrossRef]
- Chang, Charles B., Yao Yao, Erin F. Haynes, and Russell Rhodes. 2011. Production of Phonetic and Phonological Contrast by Heritage Speakers of Mandarin. The Journal of the Acoustical Society of America 129: 3964–80. [Google Scholar] [CrossRef] [PubMed]
- Cheng, Andrew. 2016. A Survey of English Vowel Spaces of Asian American Californians. UC Berkeley Phonetics and Phonology Lab Annual Report 12: 348–84. [Google Scholar]
- Cheshire, Jenny, Paul Kerswill, Sue Fox, and Eivind Torgersen. 2011. Contact, the Feature Pool and the Speech Community: The Emergence of Multicultural London English. Journal of Sociolinguistics 15: 151–96. [Google Scholar] [CrossRef]
- Chou, Rosalind S., and Joe R. Feagin. 2010. The Myth of the Model Minority: Asian Americans Facing Racism. Boulder: Paradigm Publishers. [Google Scholar]
- Clarke, Sandra, Ford Elms, and Amani Youssef. 1995. The Third Dialect of English: Some Canadian Evidence. Language Variation and Change 7: 209–28. [Google Scholar] [CrossRef]
- Clyne, Michael G., Edina Eisikovits, and Laura F. Tollfree. 2001. Ethnic varieties of Australian English. In English in Australia. Edited by David Blair and Peter Collins. Amsterdam: John Benjamins, pp. 223–38. [Google Scholar]
- Coates, Jennifer. 1993. Women, Men, and Language: A Sociolinguistic Account of Gender Differences in Language, 2nd ed. London: Longman. [Google Scholar]
- D’Onofrio, Annette, Penelope Eckert, Robert J. Podesva, Teresa Pratt, and Janneke Van Hofwegen. 2016. The Low Vowels in California’s Central Valley. Publication of the American Dialect Society 101: 11–32. [Google Scholar] [CrossRef]
- D’Onofrio, Annette, Teresa Pratt, and Janneke Van Hofwegen. 2019. Compression in the California Vowel Shift: Tracking Generational Sound Change in California’s Central Valley. Language Variation and Change 31: 193–217. [Google Scholar] [CrossRef]
- Eckert, Penelope. 1989. Jocks and Burnouts: Social Categories and Identity in the High School. New York: Teachers College Press. [Google Scholar]
- Eckert, Penelope. 2008. Where Do Ethnolects Stop? International Journal of Bilingualism 12: 25–42. [Google Scholar] [CrossRef]
- Escudero, Paola, Paul Boersma, Adréia Schurt Rauber, and Ricardo A. H. Bion. 2009. A Cross-dialect Acoustic Description of vowels: Brazilian and European Portuguese. The Journal of the Acoustical Society of America 126: 1379–93. [Google Scholar] [CrossRef]
- Farris, Catherine S. 1994. A Semiotic Analysis of Sajiao as a Gender Marked Communication Style in Chinese. In Unbound Taiwan: Closeups from a Distance, Select Papers 8. Edited by Marshall Johnson and Fred Y. L. Chiu. Chicago: Center for East Asian Studies, University of Chicago, pp. 2–29. [Google Scholar]
- Flege, James. E. 1995. Second-language Speech Learning: Theory, Findings, and Problems. In Speech Perception and Linguistic Experience: Issues in Cross-Language Research. Edited by Winifred Strange. Timonium: York Press, pp. 229–73. [Google Scholar]
- Flege, James. E. 1999. Age of Learning and Second-language Speech. In Second Language Acquisition and the Critical Period Hypothesis. Edited by David Birdsong. Mahwah: Lawrence Erlbaum Press, pp. 101–32. [Google Scholar]
- Flege, James E., and Ian R. A. MacKay. 2011. What Accounts for “Age” Effects on Overall Degree of Foreign Accent? In Achievements and Perspectives in the Acquisition of Second Language Speech. New Sounds. Edited by Magdalena Wrembel, Malgorzata Kul and Katarzyna Dziubalska-Kołaczyk. Bern: Peter Lang, vol. 2, pp. 65–82. [Google Scholar]
- Flege, James. E., Murray Munro, and Ian R. A. MacKay. 1995. Factors Affecting Strength of Perceived Foreign Accent in a Second Language. Journal of the Acoustical Society of America 97: 3125–34. [Google Scholar] [CrossRef]
- Flege, James. E., Ocke-Schewen Bohn, and Sunyoung Jang. 1997. Effects of Experience on Non-native Speakers’ Production and Perception of English Vowels. Journal of Phonetics 25: 437–70. [Google Scholar] [CrossRef]
- Flemming, Edward. 1996. Evidence for Constraints on Contrast: The Dispersion Theory of Contrast. UCLA Working Papers in Phonology 1: 86–106. [Google Scholar]
- Fought, Carmen. 1999. A Majority Sound Change in a Minority Community:/u/-Fronting in Chicano English. Journal of Sociolinguistics 3: 5–23. [Google Scholar] [CrossRef]
- Fought, Carmen. 2003. Chicano English in Context. New York: Macmillan. [Google Scholar]
- Gnevsheva, Ksenia. 2020. The Role of Style in the Ethnolect: Style-Shifting in the Use of Ethnolectal Features in the First- and Second-generation Speakers. International Journal of Bilingualism, 1–20. [Google Scholar] [CrossRef]
- Goffman, Erving. 1979. Gender Advertisements, 2nd ed. Cambridge: Harvard University Press. [Google Scholar]
- Gordon, Matthew. 2011. Methodological and Theoretical Issues in the Study of Chain Shifting. Language and Linguistics Compass 5: 784–94. [Google Scholar] [CrossRef]
- Hagiwara, Robert. 1997. Dialect Variation and Formant Frequency: The American English Vowels Revisited. Journal of the Acoustical Society of America 102: 655–8. [Google Scholar] [CrossRef]
- Hall-Lew, Lauren. 2009. Ethnicity and Sound Change in San Francisco English. Proceedings of the Annual Meeting of the Berkeley Linguistics Society 35: 111–22. [Google Scholar] [CrossRef][Green Version]
- Hall-Lew, Lauren. 2011. The Completion of a Sound Change in California English. Proceedings of the International Congress of Phonetic Sciences 17: 807–10. [Google Scholar]
- Hall-Lew, Lauren, and Rebecca L. Starr. 2010. Beyond the 2nd Generation: English Use Among Chinese Americans in the San Francisco Bay Area. English Today 26: 12–19. [Google Scholar] [CrossRef]
- Hall-Lew, Lauren, Amanda Cardoso, Yova Kemenchedjieva, Kieran Wilson, Ruaridh Purse, and Julie Saigusa. 2015. San Francisco English and the California Vowel Shift. Paper presented at 18th International Conference of the Phonetic Sciences, Glasgow, UK, 10–14 August 2015. [Google Scholar]
- Hinton, Leanne, Birch Moonwomon, Sue Bremner, Herb Luthin, Mary Van Clay, Jean Lerner, and Hazel Corcoran. 1987. It’s Not Just the Valley Girls: A study of California English. Paper presented at Thirteenth Annual Meeting of the Berkeley Linguistics Society, Berkeley, CA, USA, 14–16 February 1987; pp. 117–28. [Google Scholar]
- Hoffman, Michol F. 2010. The Role of Social Factors in the Canadian Vowel Shift: Evidence from Toronto. American Speech 85: 121–40. [Google Scholar] [CrossRef]
- Hoffman, Michol F., and James A. Walker. 2010. Ethnolects and the City: Ethnic Orientation and Linguistic Variation in Toronto English. Language Variation and Change 22: 37–67. [Google Scholar] [CrossRef]
- Ito, Rika. 2010. Accommodation to the Local Majority Norm by Hmong Americans in the Twin Cities, Minnesota. American Speech 85: 141–62. [Google Scholar] [CrossRef]
- Jacewicz, Ewa, Robert Allen Fox, and Joseph Salmons. 2007. Vowel Space Areas across Dialects and Gender. In Proceedings of the 16th International Congress of Phonetic Sciences. Edited by Jürgen Trouvain and William John Barry. Saarbrücken: University of Saarland, pp. 1465–68. [Google Scholar]
- Jang, Hyejin, Jiyoung Shin, and Hosung Nam. 2015. Aspects of Vowels by Ages in Seoul Dialect. Studies in Phonetics, Phonology, and Morphology 21: 341–58. [Google Scholar] [CrossRef]
- Jia, Gisela, and Doris Aaronson. 2003. A Longitudinal Study of Chinese Children and Adolescents Learning English in the United States. Applied Psycholinguistics 24: 131–61. [Google Scholar] [CrossRef]
- Johannessen, Janne Bondi, and Signe Laake. 2015. On two myths of the Norwegian language in America: Is it old-fashioned? Is it approaching the written Bokmål standard? In Germanic Heritage Languages in North America. Edited by Janne Bondi Johannessen and Joseph C. Salmons. Amsterdam and Philadelphia: John Benjamins, pp. 299–322. [Google Scholar]
- Kang, Yoonjung. 2014. A Corpus-based Study of Positional Variation in Seoul Korean Vowels. Japanese/Korean Linguistics 23: 1–20. [Google Scholar]
- Kang, Jieun, and Eun Jong Kong. 2016. Static and Dynamic Spectral Properties of the Monophthong Vowels in Seoul Korean: Implication on Sound Change. Phonetics and Speech Sciences 8: 39–47. [Google Scholar] [CrossRef][Green Version]
- Kawai, Yuko. 2005. Stereotyping Asian Americans: The Dialectic of the Model Minority and the Yellow Peril. The Howard Journal of Communications 16: 109–30. [Google Scholar] [CrossRef]
- Kennedy, Robert, and James Grama. 2012. Chain Shifting and Centralization in California Vowels: An Acoustic Analysis. American Speech 87: 39–56. [Google Scholar] [CrossRef]
- Kim, Jungeun, and Monika Stodolska. 2013. Impacts of Diaspora Travel on Ethnic Identity Development among 1.5 Generation Korean American College Students. Journal of Tourism and Cultural Change 11: 187–207. [Google Scholar] [CrossRef]
- Kuhl, Patricia K., Karern A. Williams, Francisco Lacerda, Kenneth N. Stevens, and Björn Lindblom. 1992. Linguistic Experience Alters Phonetic Perception in Infants by 6 Months of Age. Science 255: 606–8. [Google Scholar] [CrossRef]
- Kuznetsova Alexandra, Brockhoff Per B., and Christensen Rune H. B. 2017. LmerTest Package: Tests in Linear Mixed Effects Models. Journal of Statistical Software 82: 1–26. [Google Scholar] [CrossRef]
- Kwak, Chung-gu. 2003. The Vowel System of Contemporary Korean and Direction of Change. Journal of Korean Linguistics 41: 59–91. [Google Scholar]
- Labov, William. 1972. Language in the Inner City: Studies in Black English Vernacular. Philadelphia: University of Pennsylvania Press. [Google Scholar]
- Labov, William. 1990. The Intersection of Sex and Social Class in the Course of Linguistic Change. Language Variation and Change 2: 205–54. [Google Scholar] [CrossRef]
- Labov, William. 2001. Principles of Linguistic Change: Social Factors. Malden: Wiley-Blackwell, vol. 2. [Google Scholar]
- Labov, William. 2010. Principles of Linguistic Change: Cognitive and Cultural Factors. Malden: Wiley-Blackwell, vol. 3. [Google Scholar]
- Labov, William, Sharon Ash, and Charles Boberg. 2006. The Atlas of North American English: Phonetics, Phonology, and Sound Change. New York: Mouton de Gruyter. [Google Scholar]
- Lee, Hikyong. 2000. Korean Americans as Speakers of English: The Acquisition of General and Regional Features. Ph.D. dissertation, University of Pennsylvania, Philadelphia, PA, USA. [Google Scholar]
- Lee, Jinsok. 2016. The Participation of a Northern New Jersey Korean American Community in Local and National Language Variation. American Speech 91: 327–60. [Google Scholar] [CrossRef]
- Lee, Jess. 2019. Many Dimensions of Asian American Pan-ethnicity. Sociology Compass 13: 1–16. [Google Scholar] [CrossRef]
- Lee, Ki-Moon, and S. Robert Ramsey. 2011. A History of the Korean Language. Cambridge: Cambridge University Press. [Google Scholar]
- Lee, Hyangwon, Woobong Shin, and Jiyoung Shin. 2017. A Sociophonetic Study on High/Mid Back Vowels in Korean. Phonetics and Speech Sciences 9: 39–51. [Google Scholar]
- Lenth, Russell. 2020. Emmeans: Estimated Marginal Means, aka Least-Squares Means. R Package Version 1.5.0. Available online: https://CRAN.R-project.org/package=emmeans (accessed on 8 September 2020).
- Liljencrants, Johan, and Björn Lindblom. 1972. Numerical Simulation of Vowel Quality Systems: The Role of Perceptual Contrast. Language 48: 839–62. [Google Scholar] [CrossRef]
- Lindblom, Björn. 1990. Explaining Phonetic Variation: A Sketch of the H&H Theory. In Speech Production and Speech Modelling. Edited by William J. Hardcastle and Alain Marchal. Dordrecht: Springer, pp. 403–39. [Google Scholar]
- Lindblom, Björn, and Olle Engstrand. 1989. In What Sense is Speech Quantal? Journal of Phonetics 17: 107–21. [Google Scholar] [CrossRef]
- Lloyd-Smith, Anika, Marieke Einfeldt, and Tanja Kupisch. 2020. Italian-German Bilinguals: The Effects of Heritage Language Use on Accent in Early-Acquired Languages. International Journal of Bilingualism 24: 289–304. [Google Scholar] [CrossRef]
- Lobanov, Boris. 1971. Classification of Russian Vowels Spoken by Different Speakers. Journal of the Acoustical Society of America 49: 606–8. [Google Scholar] [CrossRef]
- Madge, Leila. 1998. Capitalizing on ‘Cuteness’: The Aesthetics of Social Relations in a New Postwar Japanese Order. Japanstudien 9: 155–74. [Google Scholar] [CrossRef][Green Version]
- Martinet, André. 1952. Function, Structure, and Sound Change. Word 8: 1–32. [Google Scholar] [CrossRef]
- Mayer, Mercer. 1969. Frog, Where Are You? New York: Dial Press. [Google Scholar]
- McAuliffe, Michael, Michaela Socolof, Sarah Mihuc, Michael Wagner, and Morgan Sonderegger. 2017. Montreal Forced Aligner [Computer Program]. Version 0.9.0. Available online: http://montrealcorpustools.github.io/Montreal-Forced-Aligner/ (accessed on 17 January 2017).
- McCloy, Daniel R. 2016. PhonR: Tools for Phoneticians and Phonologists. R Package Version 1.0-7. Available online: https://CRAN.R-project.org/package=phonR (accessed on 8 September 2020).
- Mendoza-Denton, Norma. 1999. Fighting Words: Latina Girls, Gangs, and Language Attitudes. In Speaking Chicana: Voice, Power, and Identity. Edited by D. Letticia Galindo and María D. Gonzales. Tucson: University of Arizona Press, pp. 39–56. [Google Scholar]
- Mendoza-Denton, Norma, and Melissa Iwai. 1993. They Speak more Caucasian: Generation Differences in the Speech of Japanese-Americans. In Texas Linguistics Forum, Number 33. Austin: University of Texas, Department of Linguistics, pp. 58–67. [Google Scholar]
- Milroy, James, and Lesley Milroy. 1985. Linguistic Change, Social Network and Speaker Innovation. Journal of Linguistics 21: 339–84. [Google Scholar] [CrossRef]
- Ohara, Yumiko. 1998. Two Languages, Two Cultures, and Two Vocal Apparati? Sociolinguistic Explanation for Phonetic Phenomena in Bilingual Speakers of Korean and Japanese. In The Life of Language, the Language of Life: Selected Papers from the First College-Wide Conference for Students in Languages, Linguistics, and Literature. Edited by Dina Yoshimi and Marilyn Plumlee. Honolulu: University of Hawaii at Manoa, pp. 124–33. [Google Scholar]
- Parodi, Claudia. 2014. El español de Los Ángeles: Koineización y diglosia. In Lenguas, Estructuras y Hablantes: Estudios en Homenaje a Thomas C. Smith Stark. Edited by R. Barriga Villanueva and E. Herrera Zendejas. Tlalpan: El Colegio de México, Centro de Estudios Lingüísticos y Literarios, pp. 1101–23. [Google Scholar]
- Pennock-Speck, Barry. 2005. The Changing Voice of Women. In Actas del XXVIII Congreso Internacional de AEDEAN. Edited by Juan José Calvo García de Leonardo, Jesús Tronch Pérez, Milagros del Saz Rubio, Carme Manuel Cuenca, Barry Pennock Speck and Maria José Coperías Aguilar. Valencia: Dept. de Filologia Anglesa i Alemanya, Univ. de València, pp. 407–15. [Google Scholar]
- Pisanski, Katarzyna, Emanual C. Mora, Annette Pisanski, David Reby, Piotr Sorokowski, Tomasz Frackowiak, and David R. Feinberg. 2016. Volitional Exaggeration of Boday Size through Fundamental and Formant Frequency Modulation in Humans. Scientific Reports 6: 34389. [Google Scholar] [CrossRef]
- Podesva, Robert J. 2011. The California Vowel Shift and Gay Identity. American Speech 86: 32–51. [Google Scholar] [CrossRef]
- Podesva, Robert J., Annette D’Onofrio, Janneke Van Hofwegen, and Seung Kyung Kim. 2015. Country Ideology and the California Vowel Shift. Language Variation and Change 27: 157–86. [Google Scholar] [CrossRef]
- Polinsky, Maria. 2018. Heritage Languages and Their Speakers. Cambridge: Cambridge University Press, vol. 159. [Google Scholar]
- Pratt, Teresa, and Annette D’Onofrio. 2017. Jaw Setting and the California Vowel Shift in Parodic Performance. Language in Society 46: 283–312. [Google Scholar] [CrossRef]
- Puzar, Aljosa, and Yewon Hong. 2018. Korean Cuties: Understanding Performed Winsomeness (Aegyo) in South Korea. The Asia Pacific Journal of Anthropology 19: 333–49. [Google Scholar] [CrossRef]
- R Development Core Team. 2020. R Development Core Team, R: A Language and Environment for Statistical Computing. Available online: https://www.r-project.org/ (accessed on 8 September 2020).
- Roeder, Rebecca V. 2010. Northern Cities Mexican American English: Vowel Production and Perception. American Speech 85: 163–84. [Google Scholar] [CrossRef]
- Simpson, Adrian P. 2002. Gender-specific Articulatory-acoustic Relations in Vowel Sequences. Journal of Phonetics 30: 417–35. [Google Scholar] [CrossRef]
- Sohn, Ho-min. 1999. The Korean Language. Cambridge: Cambridge University Press. [Google Scholar]
- Stevens, Gillian. 1999. Age at Immigration and Second Language Proficiency among Foreign-born Adults. Language in Society 28: 555–78. [Google Scholar] [CrossRef]
- Thomas, Erik R. 2000. Spectral Differences in/ai/Offsets Conditioned by Voicing of the Following Consonant. Journal of Phonetics 28: 1–25. [Google Scholar] [CrossRef]
- Thomas, Erik R. 2001. An Acoustic Analysis of Vowel Variation in New World English. In Publication of the American Dialect Society 85. Durham: Duke University Press. [Google Scholar]
- Traunmüller, Hartmut. 1997. Auditory Scales of Frequency Representation. Stockholm: Department of Linguistics, Stockholm University. Available online: http://www.ling.su.se/staff/hartmut/bark.htm (accessed on 8 September 2020).
- Trofimovich, Pavel, Wendy Baker, and Molly Mack. 2011. Context- and Experience-based Effects on the Learning of Vowels in a Second Language. Studies in the Linguistics Sciences 31: 167–86. [Google Scholar]
- Trudgill, Peter. 1972. Sex, Covert Prestige and Linguistic Change in the Urban British English of Norwich. Language in Society 1: 179–95. [Google Scholar] [CrossRef]
- Tseng, Amelia. 2015. Vowel Variation, Style, and Identity Construction in the English of Latinos in Washington, D.C. Ph.D. dissertation, Georgetown University, Washington, DC, USA. [Google Scholar]
- Tsukada, Kimiko, David Birdsong, Ellen Bialystok, Molly Mack, Hyekyung Sung, and James E. Flege. 2005. A Developmental Study of English Vowel Production and Perception by Native Korean Adults and Children. Journal of Phonetics 33: 263–90. [Google Scholar] [CrossRef]
- Van Bezooijen, Reneé. 1995. Sociocultural Aspects of Pitch Differences between Japanese and Dutch Women. Language and Speech 38: 253–65. [Google Scholar] [CrossRef]
- Wei, William. 1993. The Asian American Movement. Philadelphia: Temple University Press. [Google Scholar]
- Weinfeld, Morton. 1985. Myth and Reality in the Canadian Mosaic: Affective ethnicity. In Ethnicity and Ethnic Relations in Canada: A Book of Readings, 2nd ed. Edited by Rita M. Bienvenue and Jay E. Goldstein. Toronto: Butterworths, pp. 65–86. [Google Scholar]
- Werker, Janet F., and Richard C. Tees. 1984. Cross-language Speech Perception: Evidence for Perceptual Reorganization during the First Year of Life. Infant Behavior and Development 7: 49–63. [Google Scholar] [CrossRef]
- Yang, Byunggon. 1996. A Comparative Study of American English and Korean Vowels Produced by Male and Female Speakers. Journal of Phonetics 24: 245–61. [Google Scholar] [CrossRef]
- Yeni-Komshian, Grace H., James E. Flege, and Serena Liu. 2000. Pronunciation Proficiency in the First and Second Languages of Korean-English Bilinguals. Bilingualism: Language and Cognition 3: 131–49. [Google Scholar] [CrossRef]
- Yoon, Kyuchul, and Soonok Kim. 2015. A Comparative Study on the Male and Female Vowel Formants of the Korean Corpus of Spontaneous Speech. Phonetics and Speech Sciences 7: 131–38. [Google Scholar] [CrossRef][Green Version]
- Yuasa, Ikuko Patricia. 2010. Creaky Voice: A New Feminine Voice Quality for Young Urban-oriented Upwardly Mobile American Women? American Speech 85: 315–37. [Google Scholar] [CrossRef]
- Zampini, Mary. 2008. L2 Speech Production Research: Findings, Issues and Advances. In Phonology and Second Language Acquisition. Edited by Jette. G. Hansen Edwards and Mary Zampini. Amsterdam: John Benjamins, pp. 219–50. [Google Scholar]
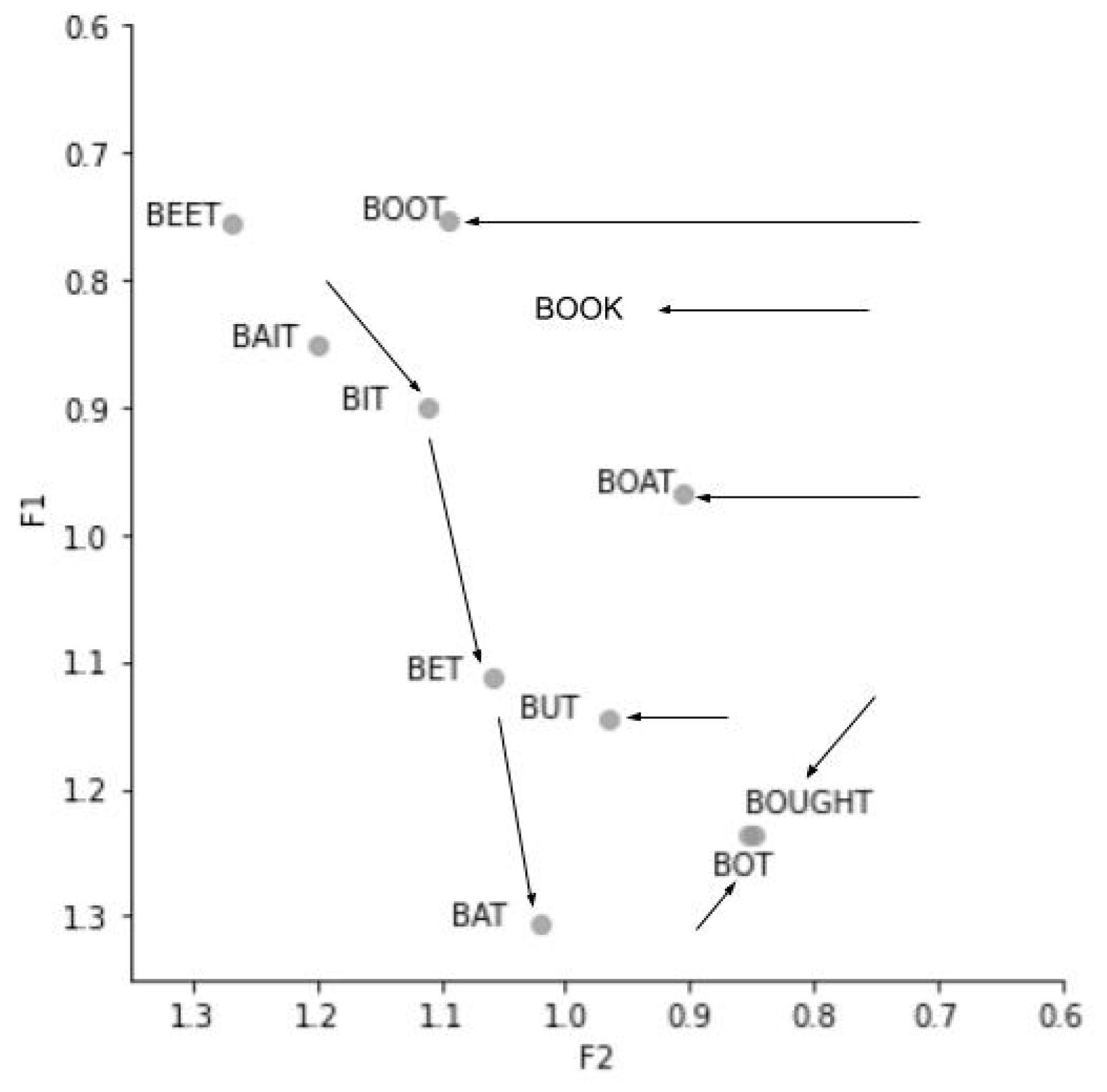
| 1 | Figure 1 was created based on the data of millennial speakers reported in Table A1 in D’Onofrio et al. (2019). Note that BOOK-type tokens (i.e., /ʊ/) were not examined in D’Onofrio et al. (2019), thus, we added the fronting of /ʊ/ in Figure 1 based on previous studies on the California Vowel Shift (e.g., Podesva et al. 2015; Pratt and D’Onofrio 2017). |
| 2 | In some cases, front rounded vowels /y/ and /ø/ may be additionally observed in the speech of older generation speakers, but in modern South Korean these sounds are mostly replaced by the diphthongs [we] and [wi], respectively (Ahn and Iverson 2007; Kwak 2003; Jang et al. 2015). |
| 3 | Kang (2014) specified these speakers as male speakers born before 1962 (i.e., birth-year-based), while in Jang et al. (2015), these speakers were male and female speakers in their 60s (i.e., age-based). Since the data in Jang et al. (2015) were collected between 2014 and 2015, we speculate that these speakers were born between 1945 and 1955. |
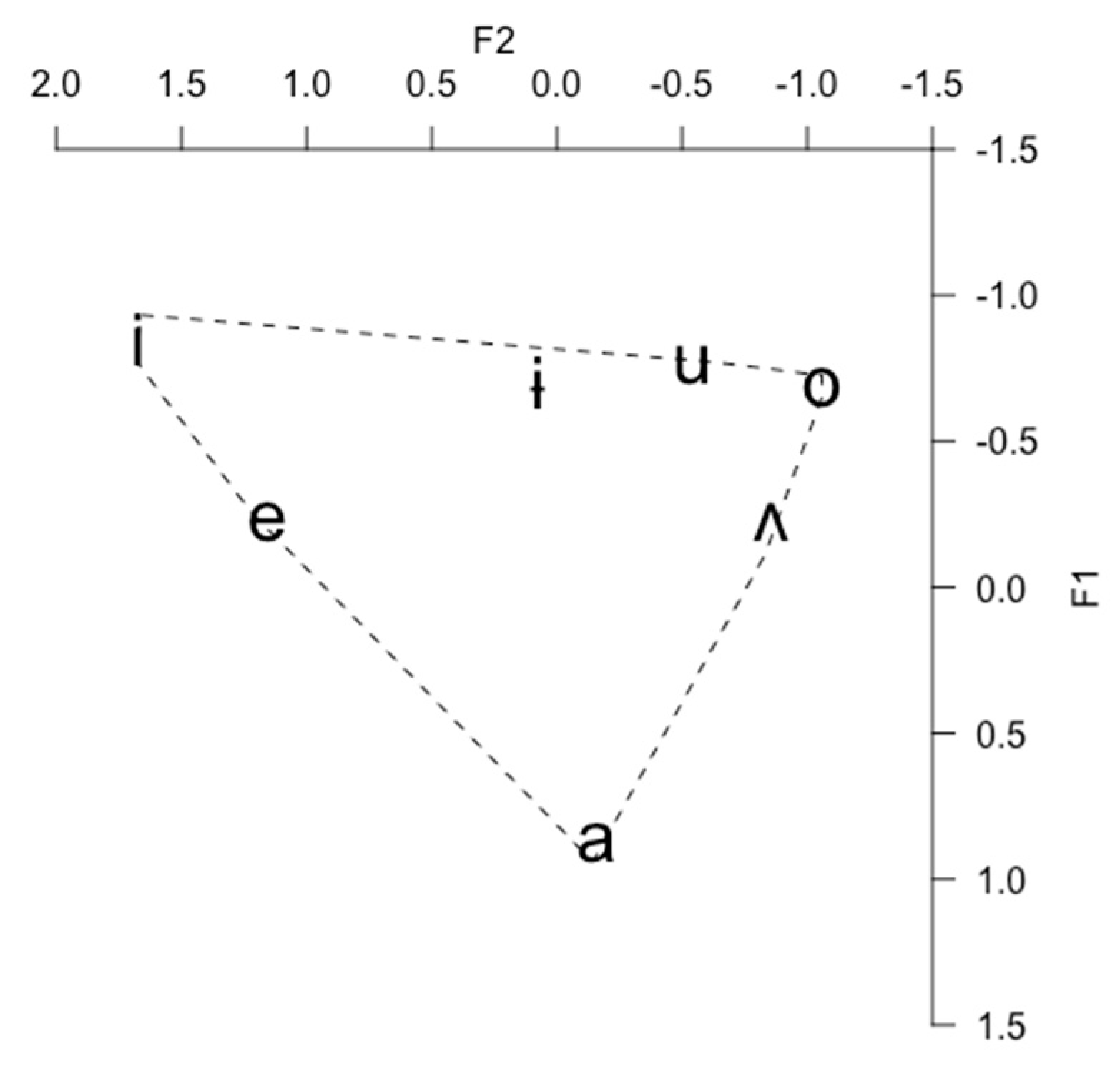
| 4 | Figure 2 was created by averaging the data of male and female speakers in their 20s reported in Table 1 in Kang and Kong (2016). |
| 5 | In a cross-dialectal study, Lee et al. (2017) found that speakers of other Korean dialects (i.e., South Jeolla, South Gyeongsang, and Jaeju) showed converging patterns to Seoul Korean. |
| 6 | Despite dialectal differences, Lee et al. (2017) showed that the /o/-raising in other Korean dialects demonstrates converging patterns to the Seoul dialect, similar to the case of the fronting of /ɨ/ and /u/. |
| 7 | Both Daegu and Yeongju are cities in North Gyeongsang region in South Korea. |
| 8 | The areas are divided by regions, indicated by the suffix Do in Korean, in which different varieties of Korean are spoken. |
| 9 | The two KOR speakers and the CA speaker had spent 2 years, 2 years, and 1 year, respectively, in Illinois at the time of data collection. |
| 10 | The CA speaker was temporarily visiting Arizona at the time of data collection, but was residing in Los Angeles County. |
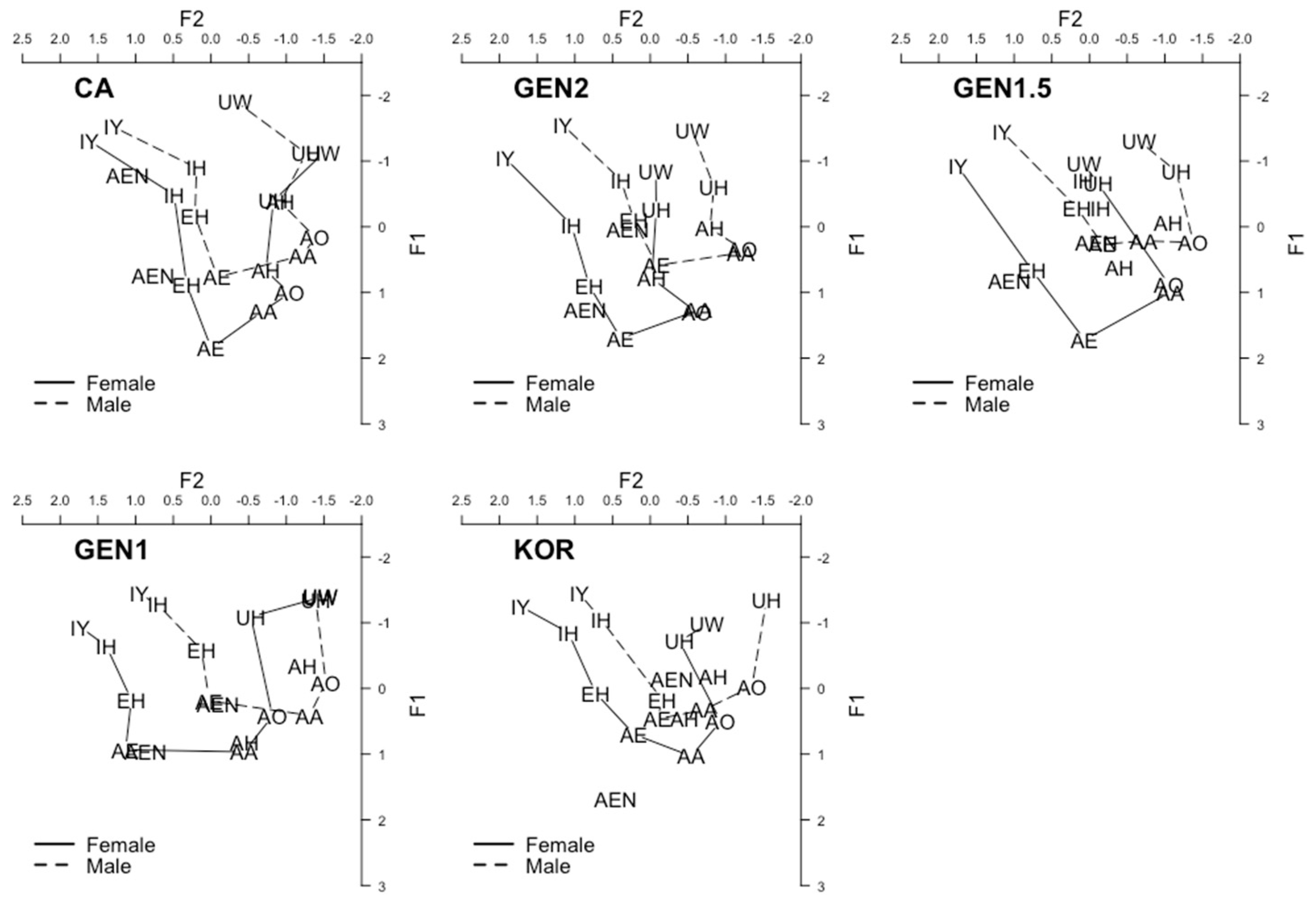
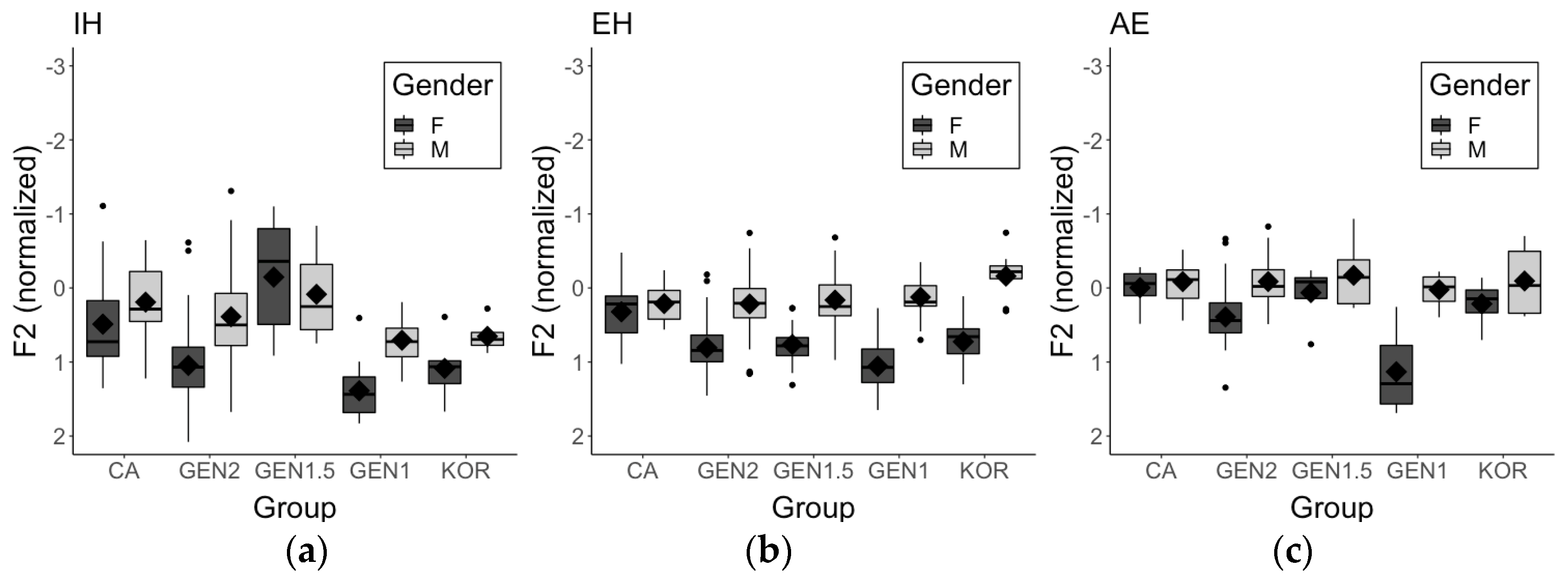
| 11 | In fact, among the five groups, GEN2 speakers’ IH was produced with the lowest vowel height. Results of the same model with the GEN2 speakers as the reference group (instead of the CA speakers) confirmed that, except for the GEN1.5 speakers, the GEN2 speakers produced IH significantly lower than the other groups (CA: β = −0.375, SE = 0.151, t = −2.48, p < 0.05; GEN1: β = −0.699, SE = 0.124, t = −5.622, p < 0.001; KOR: β = −0.603, SE = 0.17, t = −3.556, p < 0.001). |
| 12 | It is noteworthy that the CA speakers and the early bilinguals did not use vowel frontedness to distinguish the UW-UH contrast, whereas they used both vowel height and frontedness when distinguishing other contrasts (see Table 2). We suspect that this is linked to the lack of a main effect of previous consonant on the production of UW and UH. The findings of this study differed from previous research (D’Onofrio et al. 2019; Hall-Lew 2009; Podesva et al. 2015) in that the production of UW and UH was not conditioned by the phonological context that encourages fronting (i.e., post-coronal position). Although our data do not have enough tokens in post-coronal position to further examine its effect on individual speakers, these findings seem to indicate that the fronting of UW and UH is well established among the CA speakers and the early bilinguals. A similar claim has been made by Hall-Lew (2009, 2011) that back vowel fronting is nearing completion in Northern California. |
| 13 | The only gender difference in the CA group was found in the vowel height of EH. That is, the CA female speakers produced EH lower than the male speakers. Kennedy and Grama (2012) found similar results in that female and male Californians in Santa Barbara (Southern California) differed in the height of AE (i.e., women produced it lower than men), but did not show any significant difference in vowel frontedness. Since women in general are leaders of sound changes (Coates 1993; Milroy and Milroy 1985; Labov 1990; Trudgill 1972), it appears that the lowering of mid and low front vowels EH and AE is still in progress in California English, whereas changes in the front-back dimension (i.e., retraction of front vowels and fronting of back vowels) may be nearing stability for the CA speakers. |
| 14 | According to Puzar and Hong (2018), aegyo is not a direct emulation of child behaviors, but a performative repertoire of secondary infantilisation (Goffman 1979, pp. 72–77) used for various purposes (e.g., playfulness, seduction, negotiation, pleasing superiors). Thus, performers of aegyo, particularly young women, use this speech style to “negotiate the imbalance of power within patriarchal, androcentric and ageist/gerontocratic environments” (Puzar and Hong 2018). Similar concepts exist in other East Asian cultures, such as sajiao in China (Farris 1994) and kawaii in Japan (Brown 2011; Madge 1998). |







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| GEN1 (N = 8) | GEN1.5 (N = 4) | GEN2 (N = 25) | KOR (N = 4) | CA (N = 5) | |
|---|---|---|---|---|---|
| Gender | 4F, 4M | 1F, 3M | 15F, 10M | 2F, 2M | 2F, 3M |
| Age (years) | 49.5 (9.3) | 23.8 (3.8) | 24.7 (4.4) | 26.8 (6.1) | 30.8 (15.4) |
| Age of arrival (years) | 25.8 (5) | 10.5 (1.7) | 0.5 (0.9) | 22.8 (7.1) | - |
| Length of residence (years) | 26.8 (10.6) | 13.3 (4.9) | - | 4 (4.3) | - |
| English use | 53.7% (24.5) | 90% (4) | 83.2% (15.8) | 47.5% (5) | 82% (18.3) |
| Korean use | 46.3% (2.4) | 10% (4) | 16.8% (15.8) | 52.5% (5) | - |
| English proficiency 1–5 (=Native) | 2.7 (0.8) | 5 (0) | 5 (0.1) | 3.7 (0.6) | 5 (0) |
| Korean proficiency 1–5 (=Native) | 5 (0) | 4.3 (1) | 2.9 (0.7) | 5 (0) | - |
| IY vs. IH | EH vs. AE | UH vs. UW | AH vs. AO | |
|---|---|---|---|---|
| CA | F1: ***/F2: *** | F1: ***/F2: ** | F1: ***/F2: n.s. | F1: ***/F2: ** |
| GEN2 | F1: ***/F2: *** | F1: ***/F2: *** | F1: ***/F2: n.s. | F1: ***/F2: *** |
| GEN1.5 | F1: ***/F2: *** | F1: ***/F2: *** | F1: **/F2: n.s. | F1: */F2: p = 0.057 |
| GEN1 | F1: n.s./F2: * | F1: ***/F2: n.s. | F1: n.s./F2: n.s. | F1: n.s./F2: n.s. |
| KOR | F1: n.s./F2: * | F1: */F2: n.s. | F1: n.s./F2: n.s. | F1: n.s./F2: n.s. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, J.Y.; Wong, N. (Divergent) Participation in the California Vowel Shift by Korean Americans in Southern California. Languages 2020, 5, 53. https://doi.org/10.3390/languages5040053
Kim JY, Wong N. (Divergent) Participation in the California Vowel Shift by Korean Americans in Southern California. Languages. 2020; 5(4):53. https://doi.org/10.3390/languages5040053
Chicago/Turabian StyleKim, Ji Young, and Nicole Wong. 2020. "(Divergent) Participation in the California Vowel Shift by Korean Americans in Southern California" Languages 5, no. 4: 53. https://doi.org/10.3390/languages5040053
APA StyleKim, J. Y., & Wong, N. (2020). (Divergent) Participation in the California Vowel Shift by Korean Americans in Southern California. Languages, 5(4), 53. https://doi.org/10.3390/languages5040053