
The That-Trace Effect: Evidence from Spanish–English Code-Switching


Abstract
:1. Background
- Who do you think that Susana saw twho?
- * Who do you think that twho saw Susana?
- Who do you think ___ Susana saw twho?
- Who do you think ___ twho saw Susana?
1.1. The That-Trace Effect in English and Not in Spanish
| a. | ¿A | quién | crees | que | Susana | vio | ta quién? |
| acc | who | believe.2sg | that | Susana | saw.3sg |
| b. | ¿Quién | crees | que | tquién vio | a | Susana? | |
| who | believe.2sg | that | saw.3sg | acc | Susana | ||
| a. | The | boy | cried. | / | *Cried | the | boy. |
| b. | El | niño | lloró. | / | Lloró | el | niño. |
| The | boy | cried.3sg | cried.3sg | the | boy |
| 4. | ¿Quién | crees | que | vio | tquién | a | Susana? |
| who | believe.2sg | that | saw.3sg | acc | Susana |
| a. | * | ¿A | quién | crees | ___ | Susana | vio | ta quién? |
| acc | who | believe.2sg | Susana | saw.3sg |
| b. | * | ¿Quién | crees | ___ | tquién | vio | a | Susana? |
| who | believe.2sg | saw.3sg | acc | Susana? |
1.2. Code-Switching
1.3. Theoretical Accounts of the That-Trace Effect
1.3.1. Anti-Locality
1.3.2. Criterial Freezing
1.3.3. Prosodic Alignment
1.3.4. Labeling
1.3.5. T-to-C
1.4. Research Questions
- What combinations of C and T permit subject extraction over an overt complementizer in Spanish–English code-switching?
- Which theoretical accounts of the that-trace effect are supported by the code-switching evidence?
2. Materials and Methods
2.1. Participants
2.2. Procedure
2.3. Materials
| 8. | No | recuerdo | how much money | han | robado | those criminals |
| no | remember.1sg | have.3pl | stolen |
| en | la | última | década. |
| in | the | last | decade |
3. Results
3.1. Data Preparation and Analysis
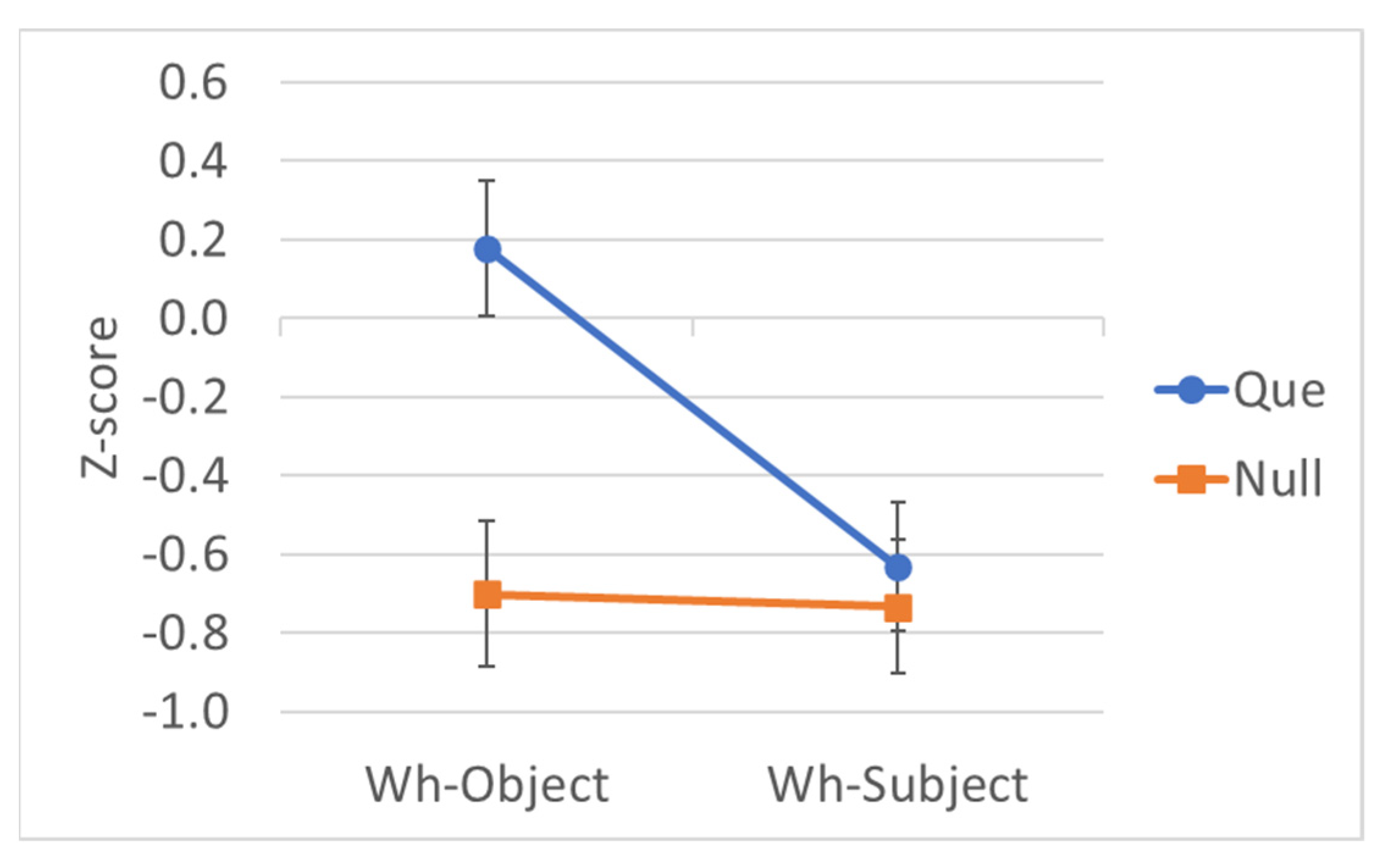
3.2. Preliminary Step 1: Monolingual English Results
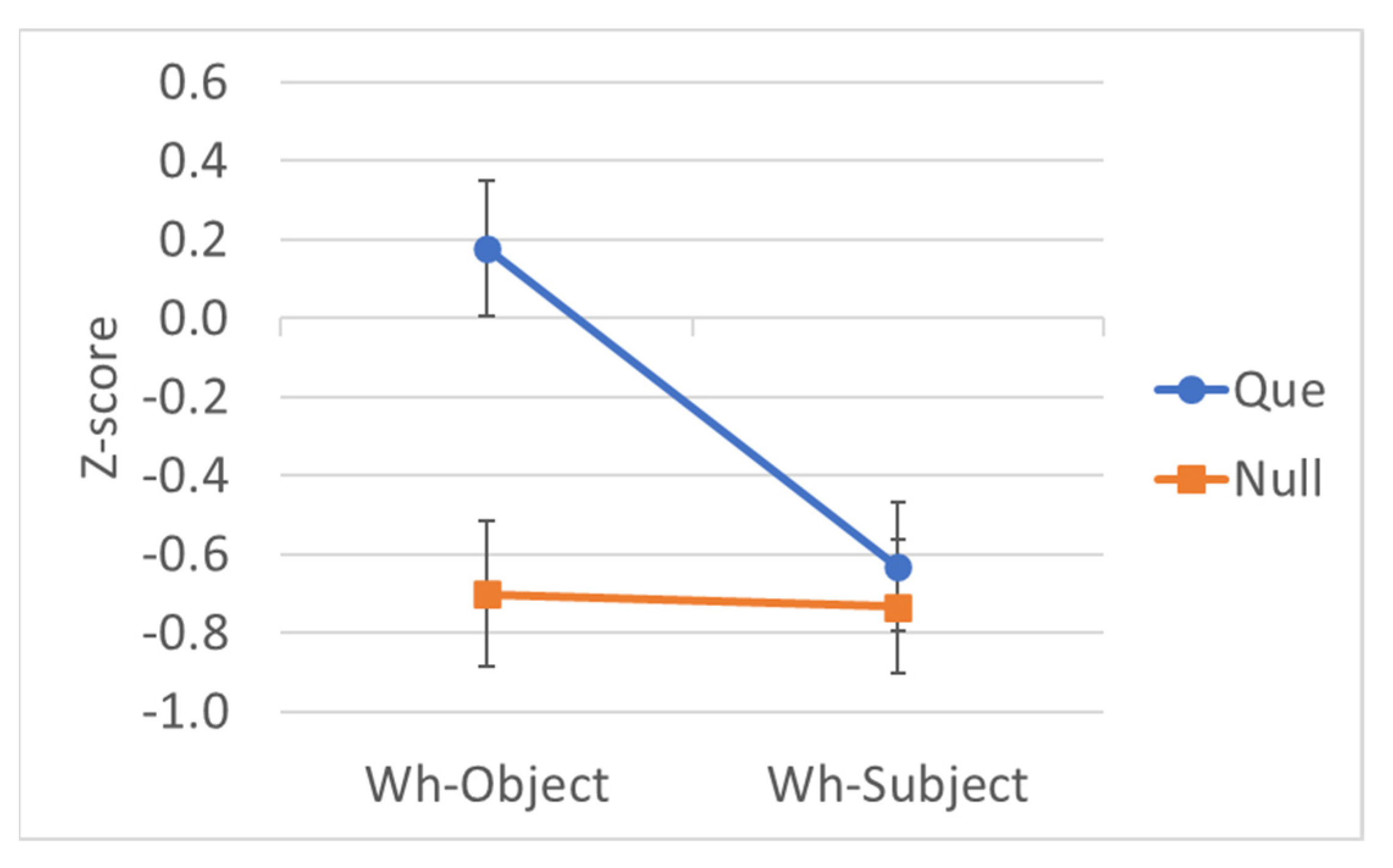
3.3. Preliminary Step 2: Monolingual Spanish Results
| a. | ¿Quién | crees | que | lo | hizo? |
| who | believe.2sg | that | it.acc | did.3sg |
| b. | ¿Quién | no | crees | que | llegue | a tiempo? |
| who | no | believe.2sg | that | arrive.subj.3sg | on-time |
| a. | * | ¿Quién | confirmaron | las | editoras | había | escrito | el | libro |
| who | confirmed.3pl | the | editors | had.3sg | written | the | book | ||
| en | tan solo | una | semana? | ||||||
| in | only | one | week |
| b. | ¿Quién, | confirmaron | las | editoras, | había | escrito |
| who | confirmed.3pl | the | editors | had.3sg | written | |
| el | libro | en | tan solo | una | semana? | |
| the | book | in | only | one | week |
| a. | * | ¿Qué | confirmaron | las | editoras | el | autor | había | escrito |
| what | confirmed.3pl | the | editors | the | author | had.3sg | written | ||
| en | tan solo | una | semana? | ||||||
| in | only | one | week |
| b. | * | ¿Qué, | confirmaron | las | editoras | el | autor | había | escrito |
| what | confirmed.3pl | the | editors | the | author | had.3sg | written | ||
| en | tan solo | una | semana? | ||||||
| in | only | one | week |
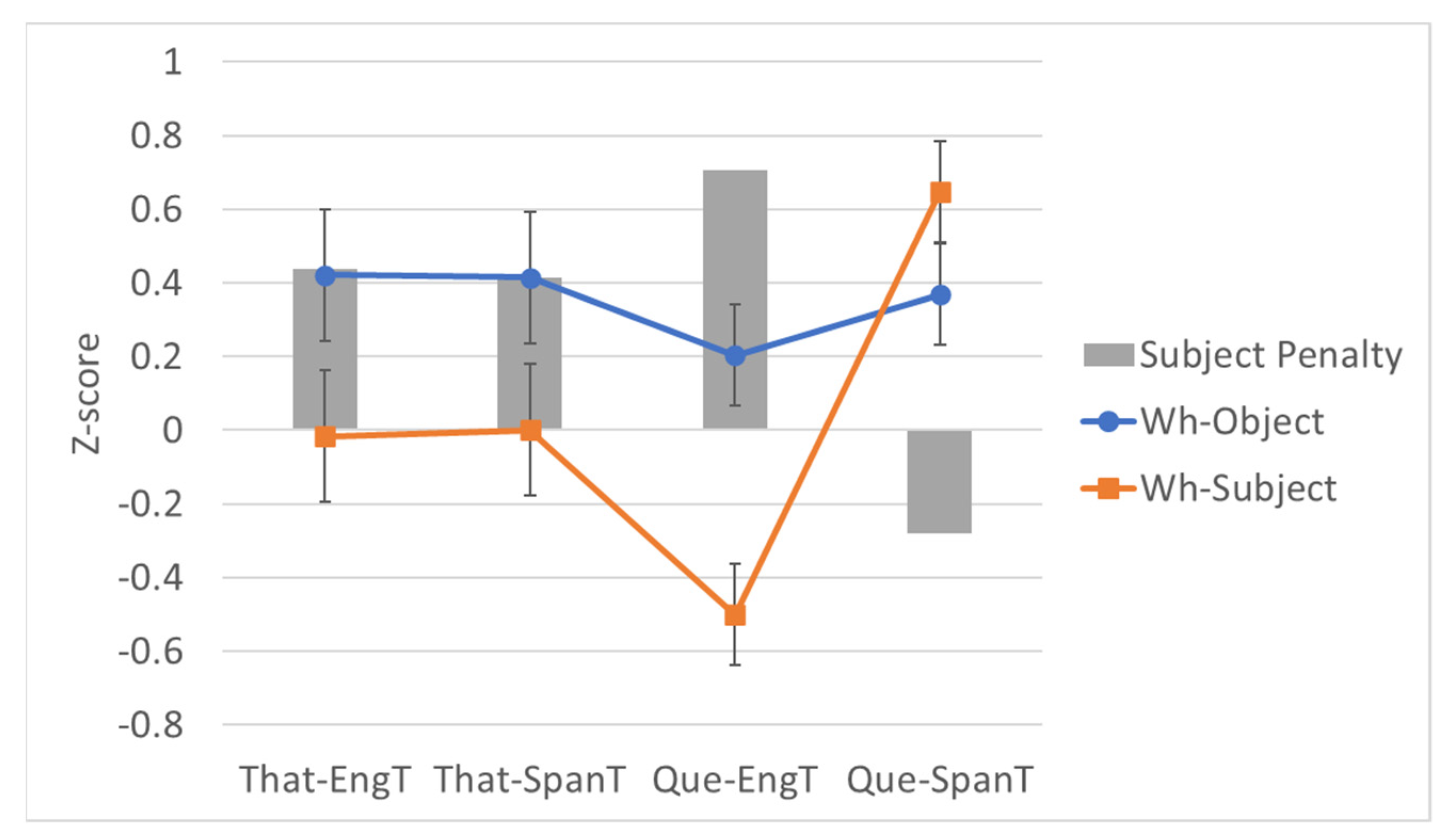
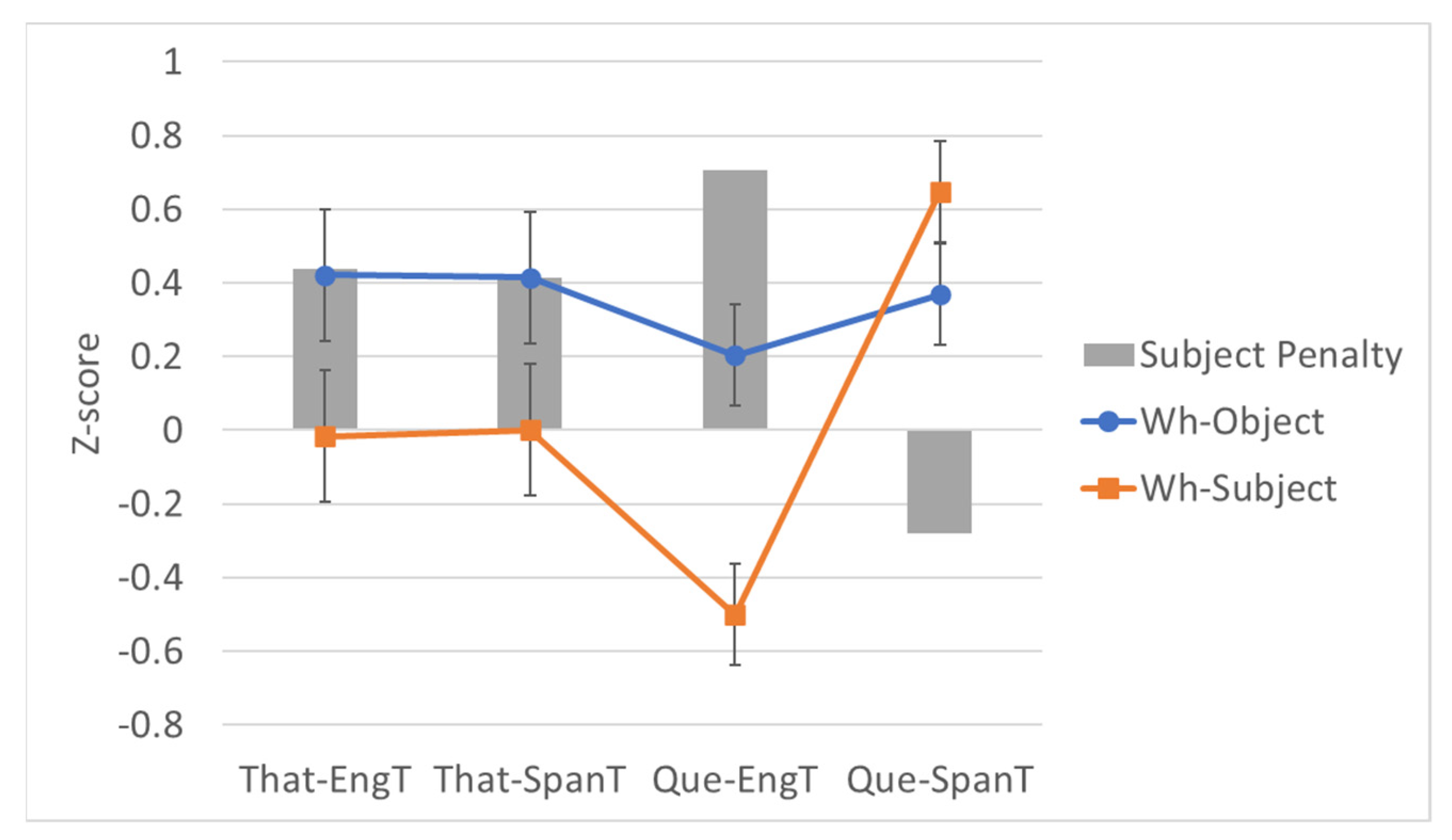
3.4. Code-Switching Results by Type
3.4.1. Extraction over That
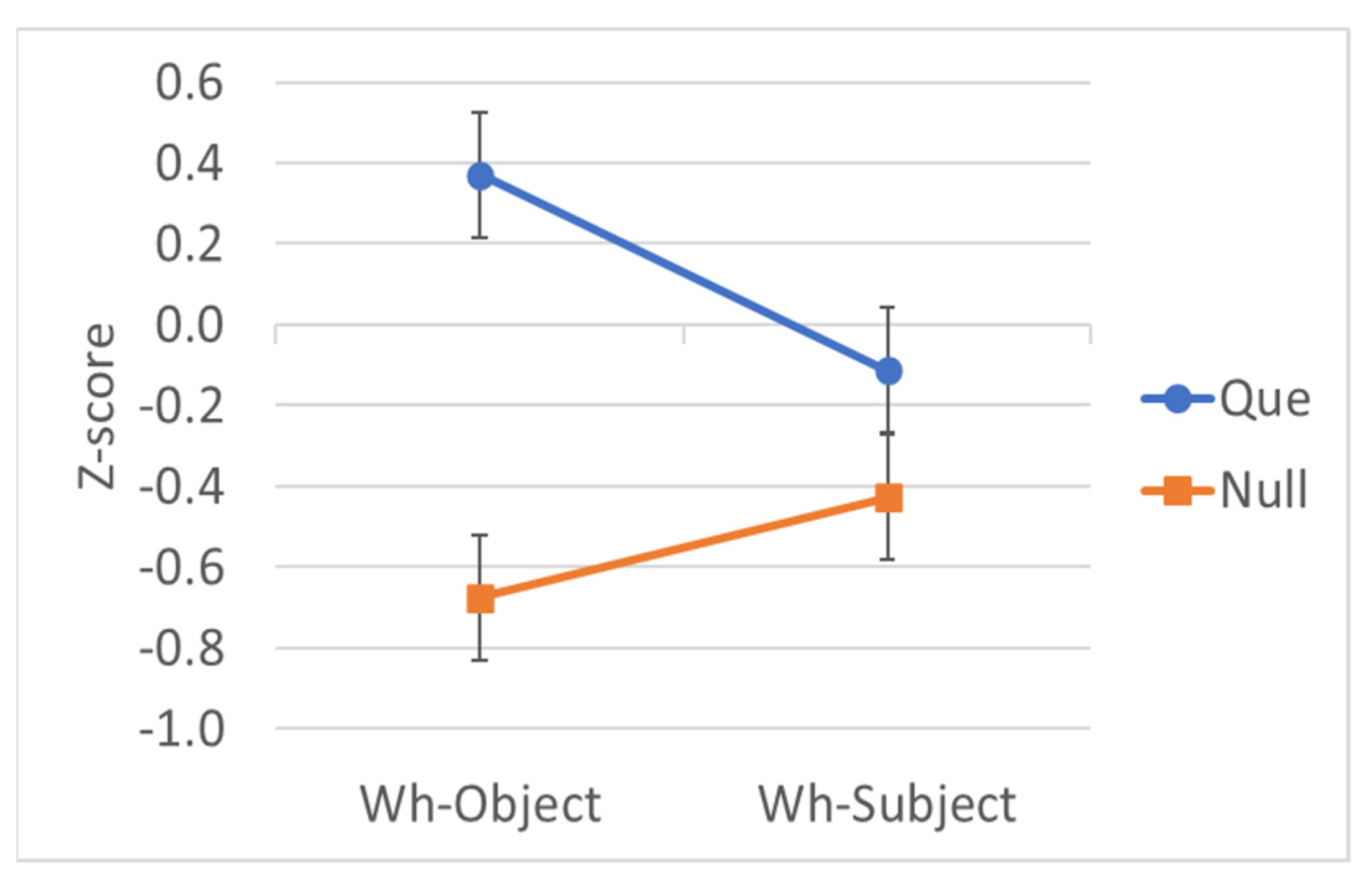
3.4.2. Extraction over Que
3.4.3. Summary of Code-Switching Results
| 12. | Quién | asumieron | los | maestros | que | had read the text before the test? |
| who | assumed.3pl | the | teachers | that |
4. Discussion
4.1. Empirical Findings
4.2. Testing Theoretical Accounts
4.3. Narrowing the Range of Hypotheses
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Follow-Up Monolingual Results

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Wh | C | Example | Mean Rating | EMM Z-Score |
|---|---|---|---|---|
| Object | Que | ¿Qué confirmaron las editoras que el autor había escrito en tan solo una semana? | 4.84 | 0.175 |
| Object | Null | ¿Qué confirmaron las editoras ___ el autor había escrito en tan solo una semana? | 2.70 | −0.701 |
| Subject | Que | ¿Quién confirmaron las editoras que había escrito el libro en tan solo una semana? | 2.88 | −0.630 |
| Subject | Null | ¿Quién confirmaron las editoras ___ había escrito el libro en tan solo una semana? | 2.59 | −0.734 |
| Fixed Effect | Coefficient (β) | SE | 95% CI | t | F | p |
|---|---|---|---|---|---|---|
| C | 0.49 | 0.10 | 0.27–0.71 | 4.69 | 21.98 | <.001 |
| Wh | 0.42 | 0.10 | 0.20–0.63 | 4.00 | 16.01 | <.001 |
| Wh*C | 0.77 | 0.21 | 0.35–1.19 | 3.75 | 14.04 | .001 |
| Random Effects | Variance | SE | ||||
| By-Subject intercept | 0.002 | 0.026 | ||||
| By-Subject slope over C | 0.003 | 0.043 | ||||
| By-Subject slope over Wh*C | 0.083 | 0.050 | ||||
| By-Item intercept | 0.009 | 0.022 | ||||
| By-Item slope over Wh | 0.006 | 0.039 | ||||
| By-Item slope over Wh*C | 0.003 | 0.046 | ||||
| 1 | Some may call this projection Infl, and some posit projections just for subject agreement, like AgrS or Rizzi’s Subj projection. We have chosen to always refer to the highest verbal projection as T and the subject position as Spec-TP for the sake of consistency. | ||||||||||||||||||
| 2 | Post-verbal subjects also widely correlate with null subjects, so it could be that it is not the availability of post-verbal subjects that is crucial, but rather the availability of null subjects, especially of particular types. Nicolis (2008) presents evidence from eight creole languages suggesting that the crucial feature is the existence of null expletives in the language, rather than subject position per se. Nonetheless, the essential insight is the same—something allows the extraction to proceed from post-verbal position—and for Spanish (like Italian) that extraction may well proceed from a post-verbal subject position that exists independently, which is why we focus our description on that fact. | ||||||||||||||||||
| 3 | As mentioned previously, Rizzi’s system has a dedicated functional head Subj that hosts subjects in its specifier, distinct from TP, but we will continue to refer to Spec-TP as the position of all subjects for consistency. | ||||||||||||||||||
| 4 | |||||||||||||||||||
| 5 | An anonymous reviewer points out that this same reasoning cannot be directly applied to their account of English, however. If we assume an English auxiliary occupies the T head, the notion that a phonetically filled T renders extraction possible predicts that *Who do you think that will leave? or *Who do you think that has left? should be grammatical, contrary to fact. McFadden and Sundaresan do not consider this point, but perhaps they could address it by following Sato and Dobashi (2016) in appealing to Truckenbrodt’s (1999) Lexical Category Condition. Under this view, even an English T head filled with an overt auxiliary might be invisible to PF, whereas Spanish T would also contain the lexical verb due to V-to-T raising, yielding the same cross-linguistic contrast in sentences with and without auxiliaries. We will tentatively assume this contrast holds for the sake of the present work, but we agree more research into these details would be valuable. Intriguingly, some evidence from Dutch (den Dikken 2007) shows that the linear order of the auxiliary and verb (T-V vs. V-T) can affect the availability of extraction, suggesting that even within a single language there could be some effect worth exploring of the contents of the T head. | ||||||||||||||||||
| 6 | We choose a relatively low minimum proficiency in part because this task penalizes incorrectly guessing ‘yes’ on a false word, and heritage speakers display a well-known ‘yes-bias;’ they are reluctant to reject unfamiliar linguistic structures due to linguistic insecurity (Polinsky 2018), which pushes their scores on this task lower than they might otherwise be. | ||||||||||||||||||
| 7 | Spanish examples are direct translations of the English sentences in Table 3 which is why they are not glossed. | ||||||||||||||||||
| 8 | All the code-switched examples are versions of the sentences What did the teachers assume that the child had read before the test? or Who did the teachers assume that had read the text before the test?. By convention, one language (here, Spanish) is italicized for readers’ convenience, but nothing was italicized for participants. | ||||||||||||||||||
| 9 | The same experiments found that sentences with post-verbal Spanish subjects, as in (i), were rated very low when T was in English, further suggesting that subject position has more to do with T than with features of the subject itself.
‘I do not remember how much money those criminals have stolen in the last decade.’ | ||||||||||||||||||
| 10 | An anonymous reviewer suggests a clever way to test our conjecture: many parentheticals cannot take negative quantifiers as subjects. For example, Collins and Postal (2014, p. 196) note that sentences like *Cathy will not, nobody asserted/proved/reported/said/wrote, divorce Frank are not possible, while it is certainly possible for a negative quantifier to be a matrix clause subject, as in Nobody asserted Cathy will not divorce Frank. Assuming the same holds for Spanish, we could potentially force a non-parenthetical reading by including a negative quantifier, as in *¿Quién no confirmó nadie ___ había escrito el libro en tan solo una semana? ‘Who did no one confirm had written the book in only one week?’. Because the parenthetical reading is not available, this sentence must be interpreted as subordination with a missing complementizer, our intended reading. We agree this would be a valuable follow-up study, but for the moment we must leave it for future research. | ||||||||||||||||||
| 11 | Further evidence for this interpretation comes from the code-switching results themselves. If these speakers in fact have a that-trace effect in their Spanish just like in English, then we would expect to observe a subject/object asymmetry in all code-switching sentences as well, since both languages would be the same. Instead, we see in Section 3.4 that, when C and T are both in Spanish, subject extraction is at least as acceptable as object extraction. This finding would be puzzling if their Spanish truly prohibited subject extraction, suggesting that the code-switching evidence indeed surfaces the relevant contrast between Spanish and English. | ||||||||||||||||||
| 12 | Importantly, syntactic features still play a role even for accounts that ultimately attribute the that-trace effect to prosodic requirements. Because the syntactic features of a given sentence determine its structure and that syntactic structure must be mapped onto a prosodic structure, those features necessarily play a role in the prosodic structure of the sentence. |
References
- Alexiadou, Artemis, and Elena Anagnostopoulou. 1998. Parametrizing AGR: Word Order, V-Movement and EPP-Checking. Natural Language & Linguistic Theory 16: 491–539. [Google Scholar] [CrossRef]
- Bader, Markus, and Jana Häussler. 2010. Toward a model of grammaticality judgments. Journal of Linguistics 46: 273–330. [Google Scholar] [CrossRef]
- Badiola, Lucia, Rodrigo Delgado, Ariane Sande, and Sara Stefanich. 2018. Code-switching attitudes and their effects on acceptability judgment tasks. Linguistic Approaches to Bilingualism 8: 5–24. [Google Scholar] [CrossRef] [Green Version]
- Barbosa, Pilar P. 2011. Pro-drop and Theories of pro in the Minimalist Program Part 1: Consistent Null Subject Languages and the Pronominal-Agr Hypothesis: Null Subject Languages and the Pronominal-Agr Hypothesis. Language and Linguistics Compass 5: 551–70. [Google Scholar] [CrossRef]
- Barr, Dale J., Roger Levy, Christoph Scheepers, and Harry J. Tily. 2013. Random effects structure for confirmatory hypothesis testing: Keep it maximal. Journal of Memory and Language 68: 255–78. [Google Scholar] [CrossRef] [Green Version]
- Bošković, Željko. 2016. On the timing of labeling: Deducing Comp-trace effects, the Subject Condition, the Adjunct Condition, and tucking in from labeling. The Linguistic Review 33: 17–66. [Google Scholar] [CrossRef]
- Brandi, Luciana, and Patrizia Cordin. 1989. Two Italian dialects and the null subject parameter. In The Null Subject Parameter. Studies in Natural Language and Linguistic Theory 15. Edited by Osvaldo Jaeggli and Kenneth J. Safir. Dordrecht: Kluwer, pp. 111–42. [Google Scholar] [CrossRef]
- Bresnan, Joan. 1977. Variables in the theory of transformations. In Formal Syntax. Edited by Peter W. Culicover, Thomas Wasow and Adrian Akmajian. New York: Academic Press, pp. 157–96. [Google Scholar]
- Camacho, José. 2013. Null Subjects. Cambridge: Cambridge University Press. [Google Scholar]
- Chacón, Dustin Alfonso, Michael Fetters, Margaret Kandel, Eric Pelzl, and Colin Phillips. 2015. Indirect learning and language variation: Reassessing the that-trace effect. Unpublished manuscript. [Google Scholar]
- Chomsky, Noam. 1995. The Minimalist Program. Cambridge: MIT Press. [Google Scholar]
- Chomsky, Noam. 2008. On phases. In Foundational Issues in Linguistic Theory: Essays in Honor of Jean-Roger Vergnaud. Edited by Robert Freidin, Carlos Otero and Maria Luisa Zubizarreta. Cambridge: MIT Press, pp. 134–66. [Google Scholar]
- Chomsky, Noam. 2013. Problems of projection. Lingua 130: 33–49. [Google Scholar] [CrossRef]
- Chomsky, Noam. 2015. Problems of projection: Extensions. In Structures, Strategies, and Beyond. Edited by Elisa Di Domenico, Cornelia Hamann and Simona Matteini. Amsterdam: John Benjamins, pp. 1–16. [Google Scholar] [CrossRef] [Green Version]
- Collins, Chris, and Paul M. Postal. 2014. Classical NEG Raising: An Essay on the Syntax of Negation. Cambridge: MIT Press. [Google Scholar]
- Cowart, Wayne, and Dana McDaniel. 2021. The that-trace effect. In The Cambridge Handbook of Experimental Syntax. Edited by Grant Goodall. Cambridge: Cambridge University Press, pp. 258–77. [Google Scholar]
- Davies, Mark. 2006. A Frequency Dictionary of Spanish: Core Vocabulary for Learners. New York and London: Routledge. [Google Scholar]
- Davies, Mark. 2008. The Corpus of Contemporary American English (COCA): 520 Million Words, 1990-Present. Available online: http://corpus.byu.edu/coca/ (accessed on 6 May 2018).
- den Dikken, Marcel. 2007. Questionnaire Study on Dutch That-Trace Effects: Stimuli and Results. Unpublished Manuscript. Available online: https://www.gc.cuny.edu/CUNY_GC/media/CUNY-Graduate-Center/PDF/Programs/Linguistics/Dikken/dutch_that_trace_results.pdf (accessed on 19 October 2021).
- Douglas, Jamie. 2017. Unifying the that-trace and anti-that-trace effects. Glossa: A Journal of General Linguistics 2: 60. [Google Scholar] [CrossRef] [Green Version]
- Drummond, Alex. 2017. Internet Based EXperiments (Ibex). Available online: http://spellout.net/ibexfarm/ (accessed on 8 September 2020).
- Ebert, Shane. 2014. The Morphosyntax of Wh-Questions: Evidence from Spanish-English Code-Switching. Chicago: University of Illinois at Chicago Dissertation. [Google Scholar]
- Ebert, Shane, and Bradley Hoot. 2018. That-trace effects in Spanish-English code-switching. In Code-Switching—Experimental Answers to Theoretical Questions: In Honor of Kay González-Vilbazo. Edited by Luis López. Issues in Hispanic and Lusophone Linguistics 19. Amsterdam: John Benjamins, pp. 101–45. [Google Scholar] [CrossRef]
- Ebert, Shane, and Bryan Koronkiewicz. 2018. Monolingual stimuli as a foundation for analyzing code-switching data. Linguistic Approaches to Bilingualism 8: 25–66. [Google Scholar] [CrossRef]
- Erlewine, Michael Yoshitaka. 2016. Anti-locality and optimality in Kaqchikel Agent Focus. Natural Language & Linguistic Theory 34: 429–79. [Google Scholar] [CrossRef]
- Erlewine, Michael Yoshitaka. 2020. Anti-locality and subject extraction. Glossa: A Journal of General Linguistics 5: 84. [Google Scholar] [CrossRef]
- Gilligan, Gary Martin. 1987. A Cross-Linguistic Approach to the Pro-Drop Parameter. Los Angeles: University of Southern California Dissertation, Available online: http://www.proquest.com/docview/1664339268/citation/627F44948625453CPQ/1 (accessed on 24 August 2021).
- González-Vilbazo, Kay, Laura Bartlett, Sarah Downey, Shane Ebert, Jeanne Heil, Bradley Hoot, Bryan Koronkiewicz, and Sergio Ramos. 2013. Methodological Considerations in Code-Switching Research. Studies in Hispanic & Lusophone Linguistics 6: 119–38. [Google Scholar]
- González-Vilbazo, Kay, and Luis López. 2011. Some properties of light verbs in code-switching. Lingua 121: 832–50. [Google Scholar] [CrossRef]
- González-Vilbazo, Kay, and Luis López. 2012. Little v and parametric variation. Natural Language & Linguistic Theory 30: 33–77. [Google Scholar] [CrossRef]
- González-Vilbazo, Kay, and Luis López. 2013. Phase switching. Paper presented at the Code-Switching in the Bilingual Child: Within and across the Clause, Center for General Linguistics (ZAS), Berlin, Germany, May 14. [Google Scholar]
- Grosjean, François. 1985. The bilingual as a competent but specific speaker-hearer. Journal of Multilingual and Multicultural Development 6: 467–77. [Google Scholar] [CrossRef]
- Hoot, Bradley, and Shane Ebert. 2021. On the position of subjects in Spanish: Evidence from code-switching. Glossa: A journal of general linguistics 6: 73. [Google Scholar] [CrossRef]
- Izura, Cristina, Fernando Cuetos, and Marc Brysbaert. 2014. Lextale-Esp: A test to rapidly and efficiently assess the Spanish vocabulary size. Psicologica: International Journal of Methodology and Experimental Psychology 35: 49–66. [Google Scholar]
- Juzek, Tom. 2016. Acceptability Judgement Tasks and Grammatical Theory. Oxford: University of Oxford Dissertation. [Google Scholar]
- Juzek, Tom, and Jana Häussler. 2015. Non-cooperative behaviour & acceptability judgement tasks. Paper presented at the Methods and Linguistic Theories Symposium, Bamberg, Germany, November 27–28. [Google Scholar]
- Kandybowicz, Jason. 2006. Comp-trace effects explained away. In Proceedings of the 25th West Coast Conference on Formal Linguistics. Edited by Donald Baumer, David Montero and Michael Scanlon. Somerville: Cascadilla Proceedings Project, pp. 220–28. [Google Scholar]
- Kandybowicz, Jason. 2009. Embracing edges: Syntactic and phono-syntactic edge sensitivity in Nupe. Natural Language & Linguistic Theory 27: 305–44. [Google Scholar] [CrossRef]
- Kenstowicz, Michael. 1989. The null subject parameter in modern Arabic dialects. In The Null Subject Parameter. Studies in Natural Language and Linguistic Theory 15. Edited by Osvaldo Jaeggli and Kenneth J. Safir. Dordrecht: Kluwer, pp. 263–75. [Google Scholar] [CrossRef]
- Kiziak, Tanja. 2010. Extraction Asymmetries: Experimental evidence from German. Amsterdam: John Benjamins. [Google Scholar]
- Larson-Hall, Jenifer. 2010. A Guide to Doing Statistics in Second Language Research Using SPSS. New York and London: Routledge. [Google Scholar]
- López, Luis. 2020. Bilingual Grammar: Toward an Integrated Model. Cambridge: Cambridge University Press. [Google Scholar]
- MacSwan, Jeff. 1999. A Minimalist Approach to Intra-Sentential Code-Switching. New York: Garland. [Google Scholar]
- MacSwan, Jeff. 2004. Code-Switching and Grammatical Theory. In The Handbook of BILINGUALISM, 1st ed. Edited by Tej K. Bhatia and William C. Ritchie. Malden: Blackwell, pp. 415–62. [Google Scholar]
- MacSwan, Jeff. 2013. Code-Switching and Grammatical Theory. In The Handbook of Bilingualism and Multilingualism, 2nd ed. Edited by Tej K. Bhatia and William C. Ritchie. Chichester and Malden: Wiley-Blackwell, pp. 321–50. [Google Scholar]
- McFadden, Thomas, and Sandhya Sundaresan. 2018. What the EPP and comp-trace effects have in common: Constraining silent elements at the edge. Glossa: A Journal of General Linguistics 3: 43.1–43.34. [Google Scholar] [CrossRef] [Green Version]
- Meteyard, Lotte, and Robert A. I. Davies. 2020. Best practice guidance for linear mixed-effects models in psychological science. Journal of Memory and Language 112: 104092. [Google Scholar] [CrossRef] [Green Version]
- Montrul, Silvina. 2008. Incomplete Acquisition in Bilingualism: Re-Examining the Age Factor. Studies in Bilingualism 39. Amsterdam: John Benjamins. [Google Scholar]
- Nicolis, Marco. 2008. The null subject parameter and correlating properties: The case of Creole languages. In The Limits of Syntactic Variation. Edited by Theresa Biberauer. Linguistik Aktuell/Linguistics Today 132. Amsterdam: John Benjamins, vol. 132, pp. 271–94. [Google Scholar] [CrossRef] [Green Version]
- Perlmutter, David. 1968. Deep and Surface Structure Constraints in Syntax. Cambridge: MIT Dissertation, Available online: http://hdl.handle.net/1721.1/13003 (accessed on 17 August 2017).
- Perlmutter, David. 1971. Deep and Surface Structure Constraints in Syntax. New York: Holt, Reinhart, and Wilson. [Google Scholar]
- Pesetsky, David. 2017. Complementizer-trace effects. In The Wiley Blackwell Companion to Syntax, 2nd ed. Edited by Martin Everaert and Henk van Riemsdijk. London: Wiley Blackwell. [Google Scholar]
- Pesetsky, David, and Esther Torrego. 2001. T-to-C movement: Causes and consequences. In Ken Hale: A Life in Language. Edited by Michael Kenstowicz. Cambridge: MIT Press. [Google Scholar]
- Polinsky, Maria. 2018. Heritage Languages and Their Speakers. Cambridge: Cambridge University Press. [Google Scholar] [CrossRef]
- Reis, Marga. 1996. Extractions from verb-second clauses in German? In On Extraction and Extraposition in German. Linguistik Aktuell/Linguistics Today 11. Edited by Uli Lutz and Jürgen Pafel. Amsterdam: John Benjamins, pp. 45–88. [Google Scholar] [CrossRef]
- Ritchart, Amanda, Grant Goodall, and Marc Garellek. 2016. Prosody and the that-trace effect: An experimental study. In Proceedings of the 33rd West Coast Conference on Formal Linguistics. Edited by Kyeong-min Kim, Pocholo Umbal, Trevor Block, Queenie Chan, Tanie Cheng, Kelli Finney, Mara Katz, Sophie Nickel-Thompson and Lisa Shorten. Somerville: Cascadilla Proceedings Project, pp. 320–28. Available online: http://www.lingref.com/cpp/wccfl/33/paper3251.pdf (accessed on 19 October 2021).
- Rizzi, Luigi. 1982. Issues in Italian Syntax. Studies in Generative Grammar 11. Dordrecht: Foris. [Google Scholar]
- Rizzi, Luigi. 2006. On the form of chains: Criterial positions and ECP effects. In Wh-Movement: Moving on. Edited by Lisa Lai Shen Chen and Norbert Corver. Current Studies in Linguistics 42. Cambridge: MIT Press, pp. 97–134. [Google Scholar]
- Rizzi, Luigi. 2015. Notes on labeling and subject positions. In Structures, Strategies and Beyond: Studies in Honour of Adriana Belletti. Edited by Elisa Di Domenico, Cornelia Hamann and Simona Matteini. Linguistik Aktuell/Linguistics Today 223. Amsterdam: John Benjamins, pp. 17–46. [Google Scholar] [CrossRef] [Green Version]
- Rizzi, Luigi, and Ur Shlonsky. 2007. Strategies of subject extraction. In Interfaces + Recursion = Language? Chomsky’s Minimalism and the View from Syntax-Semantics. Edited by Uli Sauerland and Hans-Martin Gärtner. Studies in Generative Grammar [SGG] 89. Berlin: Mouton de Gruyter, pp. 115–60. [Google Scholar]
- Rothman, Jason, and Jeanine Treffers-Daller. 2014. A prolegomenon to the construct of the native speaker: Heritage speaker bilinguals are natives too! Applied Linguistics 35: 93–98. [Google Scholar] [CrossRef] [Green Version]
- Sande, Ariane. 2018. C Plus T as a Necessary Condition for Pro-Drop: Evidence from Code-Switching. Chicago: University of Illinois at Chicago Dissertation. [Google Scholar]
- Sato, Yosuke, and Yoshihito Dobashi. 2016. Prosodic Phrasing and the That-Trace Effect. Linguistic Inquiry 47: 333–49. [Google Scholar] [CrossRef]
- Schütze, Carson T., and Jon Sprouse. 2013. Judgment data. In Research Methods in Linguistics. Edited by Robert J. Podesva and Devyani Sharma. Cambridge: Cambridge University Press, pp. 27–50. [Google Scholar]
- Shim, Ji Young. 2013. Deriving Word Order in Code-Switching: Feature Inheritance and Light Verbs. New York: City University of New York Dissertation. [Google Scholar]
- Shim, Ji Young. 2016. Mixed verbs in code-switching: The syntax of light verbs. Languages 1: 8. [Google Scholar] [CrossRef] [Green Version]
- Sobin, Nicholas. 1987. The variable status of COMP-trace phenomena. Natural Language & Linguistic Theory 5: 33–60. [Google Scholar] [CrossRef]
- Sprouse, Jon. 2011. A validation of Amazon Mechanical Turk for the collection of acceptability judgments in linguistic theory. Behavior Research Methods 43: 155–67. [Google Scholar] [CrossRef] [Green Version]
- Sprouse, Jon, Ivano Caponigro, Ciro Greco, and Carlo Cecchetto. 2016. Experimental syntax and the variation of island effects in English and Italian. Natural Language & Linguistic Theory 34: 307–44. [Google Scholar] [CrossRef]
- Toquero-Pérez, Luis Miguel. 2021. That-Trace Effects: Haplology Is the Answer. Unpublished Manuscript; lingbuzz/005548. Available online: https://ling.auf.net/lingbuzz/005548 (accessed on 8 September 2021).
- Truckenbrodt, Hubert. 1999. On the relation between syntactic phrases and phonological phrases. Linguistic Inquiry 30: 219–55. [Google Scholar] [CrossRef]
- Vanden Wyngaerd, Emma. 2020. C0 and Dutch-English code-switching. Ampersand 7: 100060. [Google Scholar] [CrossRef]
- Villa-García, Julio. 2018. Properties of the extended verb phrase: Agreement, the structure of INFL, and subjects. In The Cambridge Handbook of Spanish Linguistics. Edited by Kimberly L. Geeslin. Cambridge: Cambridge University Press, pp. 329–50. [Google Scholar] [CrossRef]
- Woolford, Ellen. 1983. Bilingual code-switching and syntactic theory. Linguistic Inquiry 14: 520–36. [Google Scholar] [CrossRef]


| Account | Basic Claim | Spanish Is Different Because… | Ban on Extraction from Spec-TP Is… | Prediction for CS |
|---|---|---|---|---|
| Anti-Locality (Douglas 2017; Erlewine 2016, 2020) | Movement from Spec-TP to Spec-CP is too short; extraction from Spec-TP thus universally barred. | It does not have the EPP; Spanish allows extraction from post-verbal position, so movement is not too short. | Universal. | Extraction only from post-verbal position in CS, so whatever determines subject position (C+T?) determines extraction in CS. |
| Criterial Freezing (Rizzi 2006, 2015; Rizzi and Shlonsky 2007) | Positions with interpretive properties (like subjects) are frozen; extraction from Spec-TP thus universally barred. | Null expletive fills the subject position in Spanish, so subject can be extracted from lower position. | Universal. | Null expletives permit extraction, so whatever determines null subject availability (C+T?) determines extraction in CS. |
| Prosodic Alignment (Kandybowicz 2006, 2009; McFadden and Sundaresan 2018; Sato and Dobashi 2016) | Empty Spec-TP cannot align with left edge of intonational phrase (or cannot form phrase with C) so syntax/prosody matching fails; extraction from Spec-TP thus universally barred. | V-to-T movement means V is highest head in intonational phrase and therefore at left edge, which is thus not empty. | Universal. | Assuming V-to-T is a property of T, language of T determines CS behavior. |
| Labeling (Chomsky 2013, 2015) | T is deficient and cannot be labeled alone; can only be labeled with subject, so subject is frozen. | T is not deficient (because of ‘rich agreement’). | Language-specific. | Language of T determines CS behavior. |
| T-to-C (Pesetsky and Torrego 2001) | T raised to C surfaces as that; extracting a subject is more economical and blocks T raising, so *that-t. | Spanish C is a true complementizer, not an instance of T in C. | Language-specific. | Language of C determines CS behavior. |
| Characteristic | Mean (SD, Range) |
|---|---|
| Age | 21.2 (3.2, 18–31) |
| Overall self-rating, English, 1–5, 5 max. | 4.9 (0.3, 4–5) |
| Overall self-rating, Spanish, 1–5, 5 max. | 4.1 (0.9, 2–5) |
| Self-reported English usage, all domains | 69.6% (26.4, 0–100) |
| Self-reported Spanish usage, all domains | 35.9% (29.0, 0–100) |
| LexTALE_Esp score | 28.5 (9.4, 12–49) |
| Wh | C | Example |
|---|---|---|
| Object | That | What did the editors confirm that the author had written in only one week? |
| Object | Null | What did the editors confirm ___ the author had written in only one week? |
| Subject | That | Who did the editors confirm that had written the book in only one week? |
| Subject | Null | Who did the editors confirm ___ had written the book in only one week? |
| Wh | C | Example7 |
|---|---|---|
| Object | Que | ¿Qué confirmaron las editoras que el autor había escrito en tan solo una semana? |
| Object | Null | ¿Qué confirmaron las editoras ___ el autor había escrito en tan solo una semana? |
| Subject | Que | ¿Quién confirmaron las editoras que había escrito el libro en tan solo una semana? |
| Subject | Null | ¿Quién confirmaron las editoras ___ había escrito el libro en tan solo una semana? |
| Wh | C | T | Example8 |
|---|---|---|---|
| Object | That | En | Qué asumieron los maestros that the child had read before the test? |
| Object | That | Sp | What did the teachers assume that el niño había leído antes del examen? |
| Object | Que | En | Qué asumieron los maestros que the child had read before the test? |
| Object | Que | Sp | What did the teachers assume que el niño había leído antes del examen? |
| Subject | That | En | Quién asumieron los maestros that had read the text before the test? |
| Subject | That | Sp | Who did the teachers assume that había leído el texto antes del examen? |
| Subject | Que | En | Quién asumieron los maestros que had read the text before the test? |
| Subject | Que | Sp | Who did the teachers assume que había leído el texto antes del examen? |
| Constraint | Rationale |
|---|---|
| Only one code-switch per sentence. | Avoid single-word switches and awkwardly repeated switches. |
| Arguments and verbs among the 5000 most common Spanish (Davies 2006) and English (Davies 2008) words. | Avoid frequency effects; limit chance of rejection due to unfamiliar words. |
| English C always that and Spanish C always que. | Unambiguously identify the language of C. |
| Matrix clause verbs plural and lower clause verbs singular. | Avoid misinterpretation of extracted wh-word as pertaining to matrix clause. |
| Matrix clause verbs all verbs of assertion or belief that take clausal complements and are unlikely to take human objects (following Ritchart et al. 2016). | Avoid misinterpretation of extracted wh-word as object of matrix verb. |
| Embedded-clause verbs all simple transitives chosen to semantically favor animate subjects and inanimate objects. | Avoid confusion of embedded subjects and objects. |
| Lower clause verb always pluperfect, with auxiliary verb assumed to instantiate T. | Make language of T head unambiguous; three-syllable pluperfect había ‘had’ used rather than one-syllable present perfect ha ‘has’ to make it more salient. |
| Matrix verbs simple preterit. | Consistent tense across items; past-tense verbs sound natural in information-seeking questions. |
| Matrix subjects always definite, animate, human, and plural. | Avoid possible extraneous grammatical effects; make subject clear via subject-verb agreement. |
| Embedded subjects always definite, animate, human, and singular. | Avoid possible extraneous grammatical effects; make subject clear via subject-verb agreement. |
| Embedded objects always definite and inanimate. | Avoid possible extraneous grammatical effects; make object clear via verb semantics. |
| No initial inverted question mark for code-switching. | Make sentences consistent whether the first part is in Spanish or English. |
| Wh | C | Example | Mean Rating | EMM Z-Score |
|---|---|---|---|---|
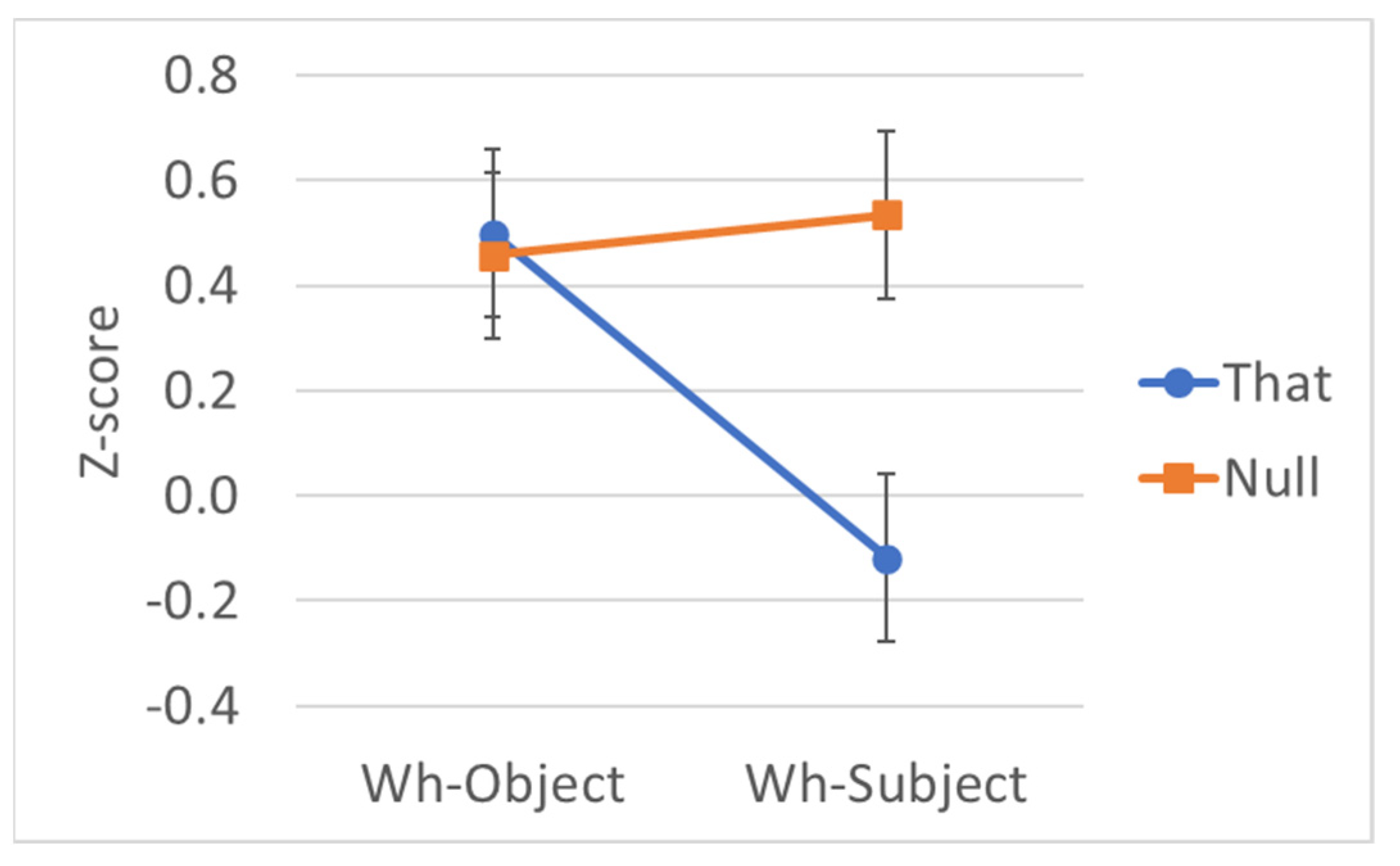
| Object | That | What did the editors confirm that the author had written in only one week? | 5.77 | 0.499 |
| Object | Null | What did the editors confirm ___ the author had written in only one week? | 5.71 | 0.457 |
| Subject | That | Who did the editors confirm that had written the book in only one week? | 4.12 | −0.118 |
| Subject | Null | Who did the editors confirm ___ had written the book in only one week? | 5.93 | 0.535 |
| Fixed Effect | Coefficient (β) | SE | 95% CI | t | F | p |
|---|---|---|---|---|---|---|
| C | −0.31 | 0.07 | −0.44–−0.17 | −4.55 | 20.66 | <.001 |
| Wh | 0.27 | 0.08 | 0.11–0.43 | 3.51 | 12.31 | .002 |
| Wh*C | 0.69 | 0.12 | 0.44–0.95 | 5.58 | 31.18 | <.001 |
| Random Effects | Variance | SE | ||||
| By-Subject intercept | 0.019 | 0.021 | ||||
| By-Subject slope over C | 0.011 | 0.022 | ||||
| By-Subject slope over Wh | 0.017 | 0.023 | ||||
| By-Subject slope over Wh*C | 0.006 | 0.029 | ||||
| By-Item intercept | 0.021 | 0.020 | ||||
| By-Item slope over Wh | 0.021 | 0.024 | ||||
| By-Item slope over Wh*C | 0.011 | 0.021 | ||||
| Wh | C | Example | Mean Rating | EMM Z-Score |
|---|---|---|---|---|
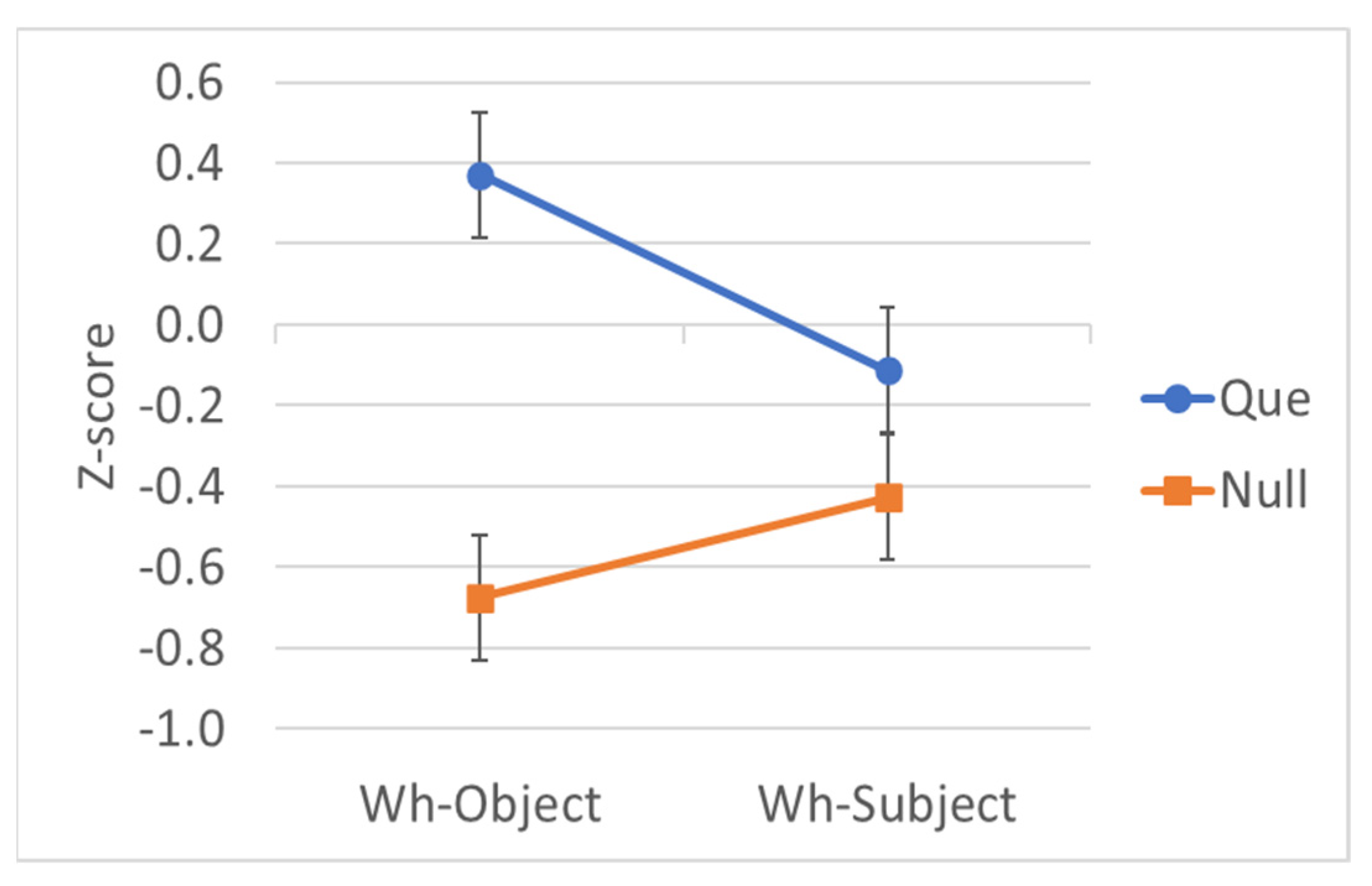
| Object | Que | ¿Qué confirmaron las editoras que el autor había escrito en tan solo una semana? | 5.82 | 0.371 |
| Object | Null | ¿Qué confirmaron las editoras ___ el autor había escrito en tan solo una semana? | 3.28 | −0.675 |
| Subject | Que | ¿Quién confirmaron las editoras que había escrito el libro en tan solo una semana? | 4.60 | −0.113 |
| Subject | Null | ¿Quién confirmaron las editoras ___ había escrito el libro en tan solo una semana? | 3.90 | −0.427 |
| Fixed Effect | Coefficient (β) | SE | 95% CI | t | F | p |
|---|---|---|---|---|---|---|
| C | 0.68 | 0.07 | 0.54–0.82 | 9.25 | 85.61 | <.001 |
| Wh | 0.12 | 0.07 | −0.03–0.26 | 1.61 | 2.59 | .108 |
| Wh*C | 0.73 | 0.15 | 0.44–1.02 | 4.98 | 24.79 | <.001 |
| Random Effects | Variance | SE | ||||
| By-Subject intercept | 0.020 | 0.017 | ||||
| By-Item intercept | 0.004 | 0.012 | ||||
| Wh | T | Example | Mean Rating | EMM Z-Score |
|---|---|---|---|---|
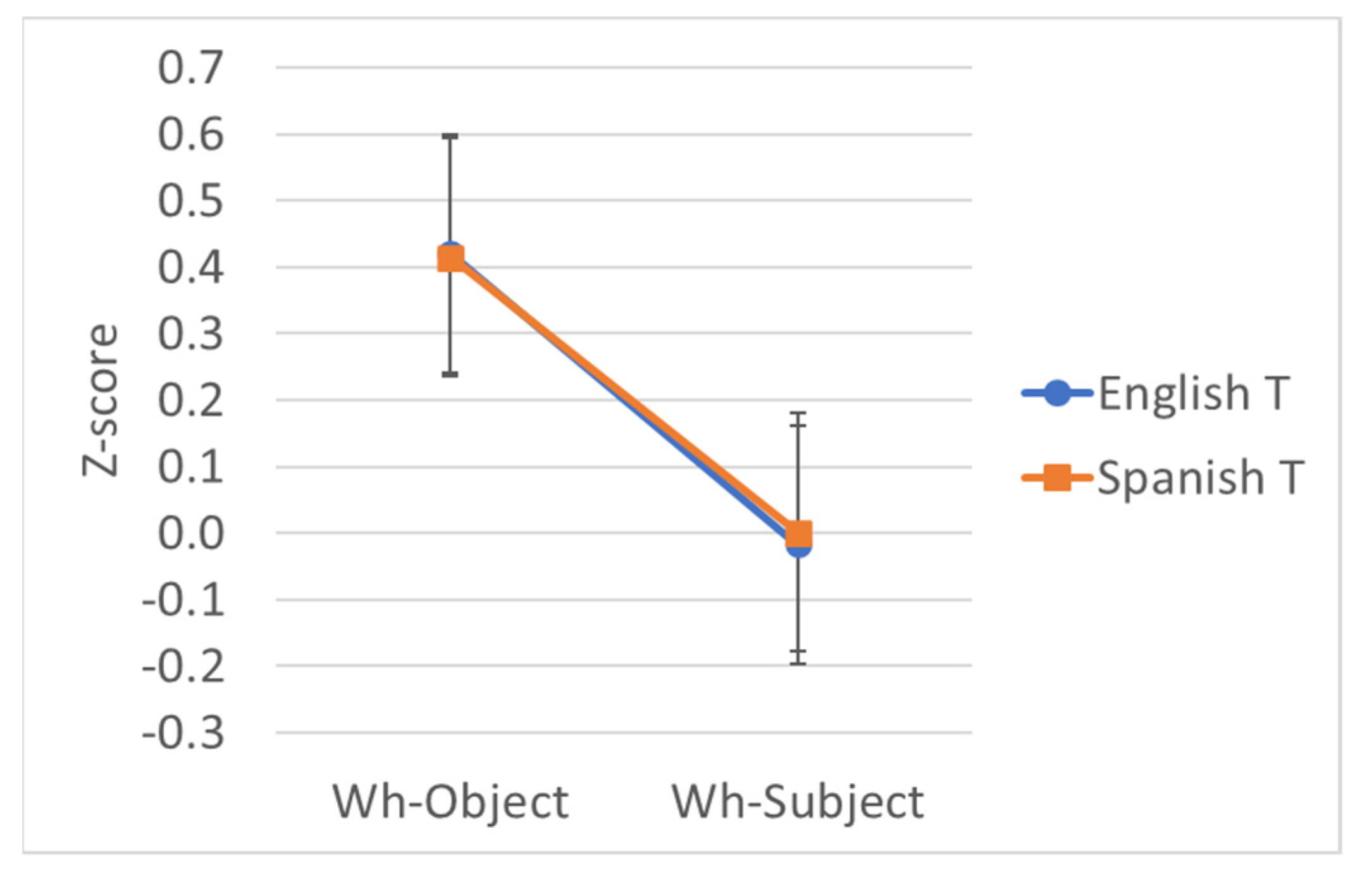
| Object | Eng | Quéasumieron los maestros that the child had read before the test? | 5.48 | 0.421 |
| Object | Span | What did the teachers assume that el niño había leído antes del examen? | 5.41 | 0.414 |
| Subject | Eng | Quiénasumieron los maestros that had read the text before the test? | 4.38 | −0.017 |
| Subject | Span | Who did the teachers assume that había leído el texto antes del examen? | 4.44 | 0.001 |
| Fixed Effect | Coefficient (β) | SE | 95% CI | t | F | p |
|---|---|---|---|---|---|---|
| T | 0.01 | 0.09 | −0.16–0.17 | 0.06 | 0.00 | .949 |
| Wh | 0.43 | 0.09 | 0.25–0.60 | 4.94 | 24.41 | <.001 |
| Wh*T | −0.02 | 0.17 | −0.37–0.32 | −0.14 | 0.02 | .888 |
| Random Effects | Variance | SE | ||||
| By-Subject intercept | 0.006 | 0.019 | ||||
| By-Subject slope over Wh*T | 0.094 | 0.037 | ||||
| By-Item intercept | 0.034 | 0.024 | ||||
| By-Item slope over Wh*T | 0.004 | 0.030 | ||||
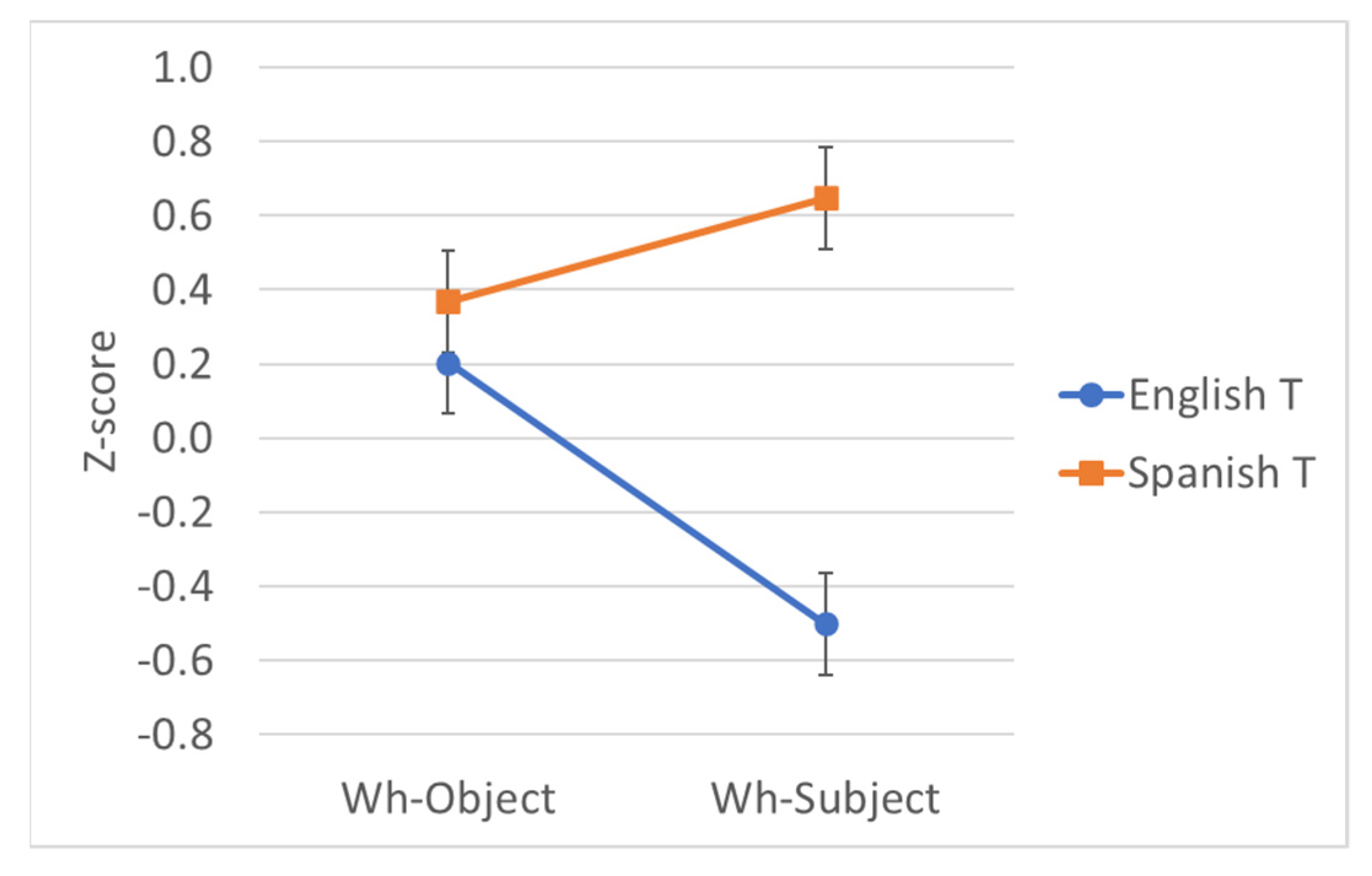
| Wh | T | Example | Mean Rating | EMM Z-Score |
|---|---|---|---|---|
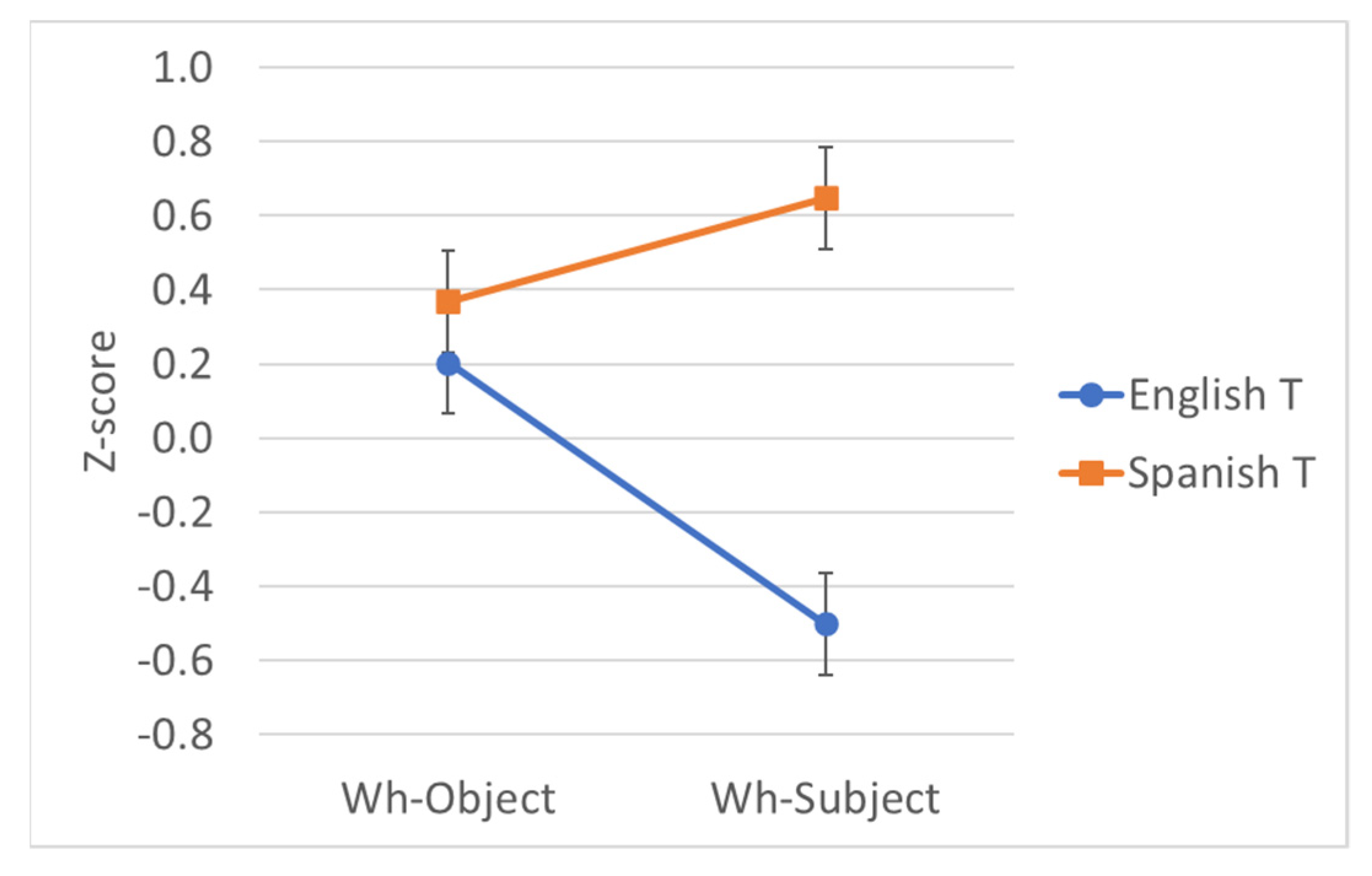
| Object | Eng | Quéasumieron los maestros que the child had read before the test? | 4.93 | 0.203 |
| Object | Span | What did the teachers assume que el niño había leído antes del examen? | 5.26 | 0.368 |
| Subject | Eng | Quiénasumieron los maestros que had read the text before the test? | 3.24 | −0.501 |
| Subject | Span | Who did the teachers assume que había leído el texto antes del examen? | 5.93 | 0.647 |
| Fixed Effect | Coefficient (β) | SE | 95% CI | t | F | p |
|---|---|---|---|---|---|---|
| T | 0.66 | 0.07 | 0.53–0.79 | 9.96 | 99.17 | <.001 |
| Wh | 0.21 | 0.07 | 0.08–0.35 | 3.16 | 9.95 | .003 |
| Wh*T | −0.98 | 0.13 | −1.25–−0.72 | −7.37 | 54.31 | <.001 |
| Random Effects | Variance | SE | ||||
| By-Subject intercept | 0.005 | 0.011 | ||||
| By-Item intercept | 0.012 | 0.018 | ||||
| By-Item slope over Wh | 0.002 | 0.024 | ||||
| Fixed Effect | Coefficient (β) | SE | 95% CI | t | F | p |
|---|---|---|---|---|---|---|
| C | −0.36 | 0.07 | −0.50–−0.21 | −4.93 | 24.34 | <.001 |
| Wh | 0.59 | 0.07 | 0.44–0.73 | 8.10 | 65.59 | <.001 |
| Wh*C | 0.26 | 0.14 | −0.03–0.54 | 1.77 | 3.148 | .077 |
| Random Effects | Variance | SE | ||||
| By-Subject intercept | 0.014 | 0.015 | ||||
| Account | Basic Claim | Spanish Is Different Because… | Ban on Extraction from Spec-TP Is… | Prediction for CS | Account Supported? |
|---|---|---|---|---|---|
| Anti-Locality (Douglas 2017; Erlewine 2016, 2020) | Movement from Spec-TP to Spec-CP is too short; extraction from Spec-TP thus universally barred. | It does not have the EPP; Spanish allows extraction from post-verbal position, so movement is not too short. | Universal. | Extraction only from post-verbal position in CS, so whatever determines subject position (C + T?) determines extraction in CS. | Yes. Recent experimental work suggest C and T together permit post-verbal subjects. |
| Criterial Freezing (Rizzi 2006, 2015; Rizzi and Shlonsky 2007) | Positions with interpretive properties (like subjects) are frozen; extraction from Spec-TP thus universally barred. | Null expletive fills the subject position in Spanish, so subject can be extracted from lower position. | Universal. | Null expletives permit extraction, so whatever determines null subject availability (C + T?) determines extraction in CS. | Yes. Recent experimental work suggest C and T together permit null subjects. |
| Prosodic Alignment (Kandybowicz 2006, 2009; McFadden and Sundaresan 2018; Sato and Dobashi 2016) | Empty Spec-TP cannot align with left edge of intonational phrase (or cannot form phrase with C) so syntax/prosody matching fails; extraction from Spec-TP thus universally barred. | V-to-T movement means V is highest head in intonational phrase and therefore at left edge, which is thus not empty. | Universal. | Assuming V-to-T is a property of T, language of T determines CS behavior. | No. T alone does not obviate the that-trace effect. |
| Labeling (Chomsky 2013, 2015) | T is deficient and cannot be labeled alone; can only be labeled with subject, so subject is frozen. | T is not deficient (because of ‘rich agreement’). | Language specific. | Language of T determines CS behavior. | No. T alone does not obviate the that-trace effect. |
| T-to-C (Pesetsky and Torrego 2001) | T raised to C surfaces as that; extracting a subject is more economical and blocks T raising, so *that-t. | Spanish C is a true complementizer, not an instance of T in C. | Language specific. | Language of C determines CS behavior. | No. C alone does not obviate the that-trace effect. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hoot, B.; Ebert, S. The That-Trace Effect: Evidence from Spanish–English Code-Switching. Languages 2021, 6, 189. https://doi.org/10.3390/languages6040189
Hoot B, Ebert S. The That-Trace Effect: Evidence from Spanish–English Code-Switching. Languages. 2021; 6(4):189. https://doi.org/10.3390/languages6040189
Chicago/Turabian StyleHoot, Bradley, and Shane Ebert. 2021. "The That-Trace Effect: Evidence from Spanish–English Code-Switching" Languages 6, no. 4: 189. https://doi.org/10.3390/languages6040189
APA StyleHoot, B., & Ebert, S. (2021). The That-Trace Effect: Evidence from Spanish–English Code-Switching. Languages, 6(4), 189. https://doi.org/10.3390/languages6040189