
Home Language Experience Shapes Which Skills Are Used during Unfamiliar Speech Processing

Abstract
:1. Introduction
1.1. Variation in Spoken Word Recognition Accuracy among Children
1.2. Differences in Spoken Language Recognition Based on Linguistic Experience
1.3. Ease of Language Understanding Model
1.4. The Current Study
- Children with exposure to only one variety of English (single-variety exposure group) are expected to rely more on cognitive skills (especially the short-term memory component of working memory) than children who are exposed to multiple languages or varieties of English in the home (multiple-variety exposure group).
- Working memory skills are expected to predict performance more strongly for low-familiarity words compared to high-familiarity words.
- Older children are expected to perform better than younger children.
2. Methods
2.1. Participants
2.2. Materials for the Spoken Word Recognition Task
2.3. Procedure
2.3.1. Spoken Word Recognition
2.3.2. Assessments of Linguistic Skills
2.3.3. Assessments of Cognitive Skills
2.4. Statistical Analysis and Coding
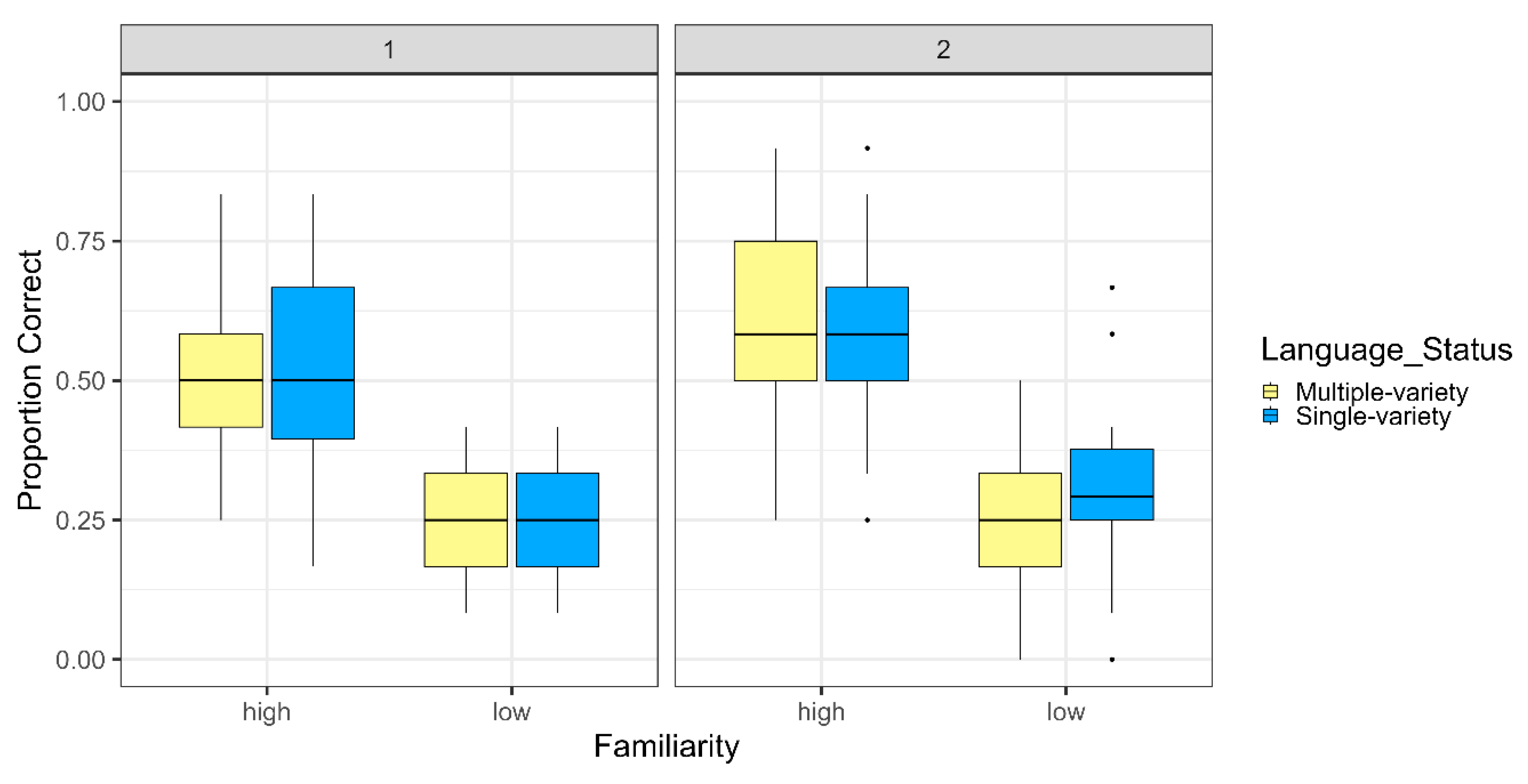
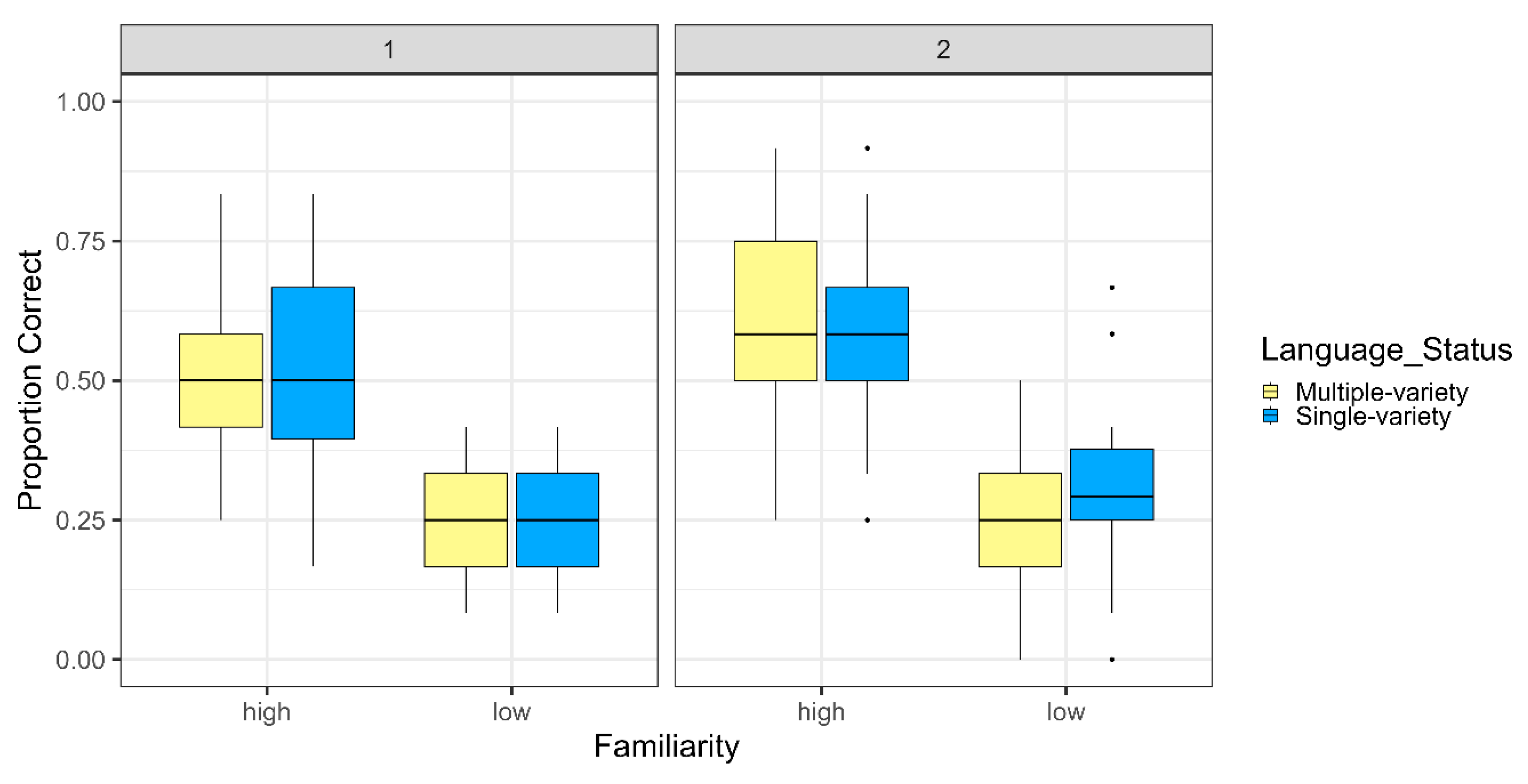
3. Results
4. Discussion and Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
| Omnibus Model | Estimate | Std. Error | z-Value | p-Value |
|---|---|---|---|---|
| (Intercept) | −0.517 | 0.164 | −3.145 | 0.002 |
| Group1 | −0.089 | 0.058 | −1.547 | 0.122 |
| Familiarity1 | 0.801 | 0.109 | 7.363 | <0.001 |
| block1 | −0.190 | 0.060 | −3.182 | 0.001 |
| scale(age) | 0.231 | 0.066 | 3.520 | <0.001 |
| scale(toni_scaled) | −0.032 | 0.067 | −0.477 | 0.633 |
| scale(ppvt) | 0.018 | 0.081 | 0.220 | 0.826 |
| scale(recall_sent_scaled) | 0.178 | 0.093 | 1.925 | 0.054 |
| scale(forward_digit_scaled) | 0.165 | 0.078 | 2.122 | 0.034 |
| scale(back_digit_scaled) | −0.152 | 0.066 | −2.311 | 0.021 |
| scale(block_span_scaled) | 0.117 | 0.063 | 1.856 | 0.063 |
| scale(PA_scaled) | −0.029 | 0.077 | −0.383 | 0.702 |
| Group1:Familiarity1 | 0.023 | 0.049 | 0.466 | 0.641 |
| Single-Variety Exposure/High | Estimate | Std. Error | z-Value | p-Value |
|---|---|---|---|---|
| (Intercept) | 0.331 | 0.172 | 1.925 | 0.054 |
| block1 | −0.168 | 0.108 | −1.549 | 0.121 |
| scale(age) | 0.456 | 0.119 | 3.819 | <0.001 |
| scale(toni_scaled) | 0.012 | 0.116 | 0.103 | 0.918 |
| scale(ppvt) | 0.188 | 0.129 | 1.457 | 0.145 |
| scale(recall_sent_scaled) | −0.076 | 0.163 | −0.467 | 0.641 |
| scale(forward_digit_scaled) | 0.503 | 0.158 | 3.186 | 0.001 |
| scale(back_digit_scaled) | −0.325 | 0.118 | −2.763 | 0.006 |
| scale(block_span_scaled) | 0.154 | 0.103 | 1.497 | 0.134 |
| scale(PA_scaled) | −0.034 | 0.156 | −0.219 | 0.827 |
| Single-Variety Exposure/Low | Estimate | Std. Error | z-Value | p-Value |
|---|---|---|---|---|
| (Intercept) | −1.179 | 0.182 | −6.487 | <0.001 |
| block1 | −0.247 | 0.108 | −2.292 | 0.022 |
| scale(age) | 0.168 | 0.119 | 1.419 | 0.156 |
| scale(toni_scaled) | −0.148 | 0.113 | −1.316 | 0.188 |
| scale(ppvt) | 0.070 | 0.127 | 0.551 | 0.581 |
| scale(recall_sent_scaled) | 0.155 | 0.158 | 0.986 | 0.324 |
| scale(forward_digit_scaled) | 0.400 | 0.156 | 2.563 | 0.010 |
| scale(back_digit_scaled) | −0.281 | 0.119 | −2.356 | 0.019 |
| scale(block_span_scaled) | 0.060 | 0.106 | 0.566 | 0.571 |
| scale(PA_scaled) | −0.284 | 0.159 | −1.786 | 0.074 |
| Multiple-Variety Exposure/High | Estimate | Std. Error | z-Value | p-Value |
|---|---|---|---|---|
| (Intercept) | 0.295 | 0.209 | 1.411 | 0.158 |
| block1 | −0.241 | 0.122 | −1.966 | 0.049 |
| scale(age) | −0.052 | 0.177 | −0.294 | 0.769 |
| scale(toni_scaled) | 0.006 | 0.139 | 0.044 | 0.965 |
| scale(ppvt) | −0.365 | 0.219 | −1.670 | 0.095 |
| scale(recall_sent_scaled) | 0.485 | 0.221 | 2.191 | 0.029 |
| scale(forward_digit_scaled) | 0.067 | 0.146 | 0.461 | 0.645 |
| scale(back_digit_scaled) | −0.177 | 0.145 | −1.221 | 0.222 |
| scale(block_span_scaled) | 0.115 | 0.142 | 0.810 | 0.418 |
| scale(PA_scaled) | 0.053 | 0.135 | 0.393 | 0.694 |
| Multiple-Variety Exposure/Low | Estimate | Std. Error | z-Value | p-Value |
|---|---|---|---|---|
| (Intercept) | −1.356 | 0.200 | −6.774 | <0.001 |
| block1 | −0.154 | 0.122 | −1.271 | 0.204 |
| scale(age) | −0.049 | 0.174 | −0.281 | 0.779 |
| scale(toni_scaled) | 0.046 | 0.133 | 0.346 | 0.729 |
| scale(ppvt) | −0.240 | 0.207 | −1.163 | 0.245 |
| scale(recall_sent_scaled) | 0.438 | 0.217 | 2.022 | 0.043 |
| scale(forward_digit_scaled) | −0.225 | 0.145 | −1.554 | 0.120 |
| scale(back_digit_scaled) | −0.126 | 0.142 | −0.887 | 0.375 |
| scale(block_span_scaled) | −0.027 | 0.140 | −0.193 | 0.847 |
| scale(PA_scaled) | 0.066 | 0.138 | 0.477 | 0.633 |
References
- Akeroyd, Michael A. 2008. Are individual differences in speech reception related to individual differences in cognitive ability? A survey of twenty experimental studies with normal and hearing-impaired adults. International Journal of Audiology 47: S53–S71. [Google Scholar] [CrossRef] [PubMed]
- Akoglu, Haldun. 2018. User’s guide to correlation coefficients. Turkish Journal of Emergency Medicine 18: 91–93. [Google Scholar] [CrossRef] [PubMed]
- Alloway, Tracy Packiam, Susan E. Gathercole, Catherine Willis, and Anne-Marie Adams. 2004. A structural analysis of working memory and related cognitive skills in young children. Journal of Experimental Child Psychology 87: 85–106. [Google Scholar] [CrossRef] [PubMed]
- Baddeley, Alan. 2000. The episodic buffer: A new component of working memory? Trends in Cognitive Sciences 4: 417–23. [Google Scholar] [CrossRef] [PubMed]
- Baddeley, Alan. 2003. Working memory and language: An overview. Journal of Communication Disorders 36: 189–208. [Google Scholar] [CrossRef] [PubMed]
- Baddeley, Alan, and Robert H. Logie. 1999. Working Memory: The Multiple-Component Model. In Models of Working Memory: Mechanisms of Active Maintenance and Executive Control. Edited by Akira Miyake and Priti Shah. Cambridge: Cambridge University Press. [Google Scholar]
- Baese-Berk, Melissa M., Ann R. Bradlow, and Beverly A. Wright. 2013. Accent-independent adaptation to foreign accented speech. The Journal of the Acoustical Society of America 133: EL174–EL80. [Google Scholar] [CrossRef] [PubMed]
- Bates, Douglas, Martin Maechler, Ben Bolker, and Steven Walker. 2010. lme4: Linear Mixed-Effects Models Using Eigen and S4. Version 1.1-35.2. Available online: http://lme4.r-forge.r-project.org/ (accessed on 23 January 2024).
- Benkí, Jose. 2003. Quantitative evaluation of lexical status, word frequency, and neighborhood density as context effects in spoken word recognition. Journal of the Acoustical Society of America 113: 1689–705. [Google Scholar] [CrossRef]
- Bent, Tessa. 2014. Children’s perception of foreign-accented words. Journal of Child Language 41: 1334–55. [Google Scholar] [CrossRef] [PubMed]
- Blomberg, Rina, Henrik Danielsson, Mary Rudner, Göran B. W. Söderlund, and Jerker Rönnberg. 2019. Speech Processing Difficulties in Attention Deficit Hyperactivity Disorder. Frontiers in Psychology 10: 458190. [Google Scholar] [CrossRef] [PubMed]
- Cohen, Jacob. 1988. Statistical Power Analysis for the Behavioral Sciences, 2nd ed. Hillsdale: Lawrence Earlbaum Associates. [Google Scholar]
- Cohen, Jacob, Patricia Cohen, Stephen G. West, and Leona S. Aiken. 2003. Applied Multiple Regression/Correlation Analysis for the Behavioral Sciences, 3rd ed. Mahwah: Lawrence Erlbaum Associates. [Google Scholar]
- Cowan, Nelson. 1988. Evolving conceptions of memory storage, selective attention, and their mutual constraints within the human information-processing system. Psychological Bulletin 104: 163–91. [Google Scholar] [CrossRef]
- Cowan, Nelson. 2017. The many faces of working memory and short-term storage. Psychonomic Bulletin & Review 24: 1158–70. [Google Scholar] [CrossRef] [PubMed]
- Dollaghan, Chris. 1998. Spoken word recognition in children with and without specific language impairment. Applied Psycholinguistics 19: 193–207. [Google Scholar] [CrossRef]
- Dunn, Lloyd M., and Douglas M. Dunn. 2007. PPVT-4: Peabody Picture Vocabulary Test, 4th ed. Minneapolis: NCS Pearson, Inc. [Google Scholar]
- Eisenberg, Laurie S., Robert V. Shannon, Amy Schaefer Martinez, John Wygonski, and Arthur Boothroyd. 2000. Speech recognition with reduced spectral cues as a function of age. The Journal of the Acoustical Society of America 107: 2704–10. [Google Scholar] [CrossRef] [PubMed]
- Elliott, Lois L. 1979. Performance of children aged 9 to 17 years on a test of speech intelligibility in noise using sentence material with controlled word predictability. Journal of the Acoustical Society of America 66: 651–53. [Google Scholar] [CrossRef] [PubMed]
- Erickson, Lucy C., and Rochelle S. Newman. 2017. Influences of Background Noise on Infants and Children. Current Directions in Psychological Science 26: 451–57. [Google Scholar] [CrossRef] [PubMed]
- Evans, Julia L., Ronald B. Gillam, and James W. Montgomery. 2018. Cognitive Predictors of Spoken Word Recognition in Children with and without Developmental Language Disorders. Journal of Speech, Language, and Hearing Research 61: 1409–25. [Google Scholar] [CrossRef] [PubMed]
- Felty, Robert Albert. 2007. Context Effects in Spoken Word Recognition of English and German by Native and Non-Native Listeners. Ph.D. dissertation, University of Michigan, Ann Arbor, MI, USA. [Google Scholar]
- Harrell, Frank E., Jr. 2024. Hmisc: Harrell Miscellaneous. Version 5.1-2. Available online: https://cran.r-project.org/web/packages/Hmisc/index.html (accessed on 23 January 2024).
- Kartushina, Natalia, Julien Mayor, and Audun Rosslund. 2022. Toddlers raised in multi-dialectal families learn words better in accented speech than those raised in monodialectal families. Journal of Child Language 49: 1093–118. [Google Scholar] [CrossRef] [PubMed]
- Klein, Kelsey E., Elizabeth A. Walker, Benjamin Kirby, and Ryan W. McCreery. 2017. Vocabulary Facilitates Speech Perception in Children with Hearing Aids. Journal of Speech, Language, and Hearing Research 60: 2281–96. [Google Scholar] [CrossRef] [PubMed]
- Leibold, Lori J., and Emily Buss. 2019. Masked Speech Recognition in School-Age Children. Frontiers in Psychology 10: 479879. [Google Scholar] [CrossRef] [PubMed]
- Levi, Susannah V. 2014. Individual differences in learning talker categories: The role of working memory. Phonetica 71: 201–26. [Google Scholar] [CrossRef] [PubMed]
- Levi, Susannah V. 2015. Talker familiarity and spoken word recognition in school-age children. Journal of Child Language 42: 843–72. [Google Scholar] [CrossRef] [PubMed]
- Levi, Susannah V., Stephen J. Winters, and David B. Pisoni. 2007. Speaker-independent factors affecting the perception of foreign accent in a second language. Journal of the Acoustical Society of America 121: 2327–38. [Google Scholar] [CrossRef] [PubMed]
- Levy, Helena, Lars Konieczny, and Adriana Hanulíková. 2019. Processing of unfamiliar accents in monolingual and bilingual children: Effects of type and amount of accent experience. Journal of Child Language 46: 368–92. [Google Scholar] [CrossRef] [PubMed]
- Mainela-Arnold, Elina, Julia L. Evans, and Jeffry A. Coady. 2008. Lexical representations in children with SLI: Evidence from a frequency-manipulated gating task. Journal of Speech, Language, and Hearing Research 51: 381–93. [Google Scholar] [CrossRef] [PubMed]
- McCreery, Ryan W., Margaret K. Miller, Emily Buss, and Lori J. Leibold. 2020. Cognitive and linguistic contributions to masked speech recognition in children. Journal of Speech, Language, and Hearing Research 63: 3525–38. [Google Scholar] [CrossRef] [PubMed]
- McCreery, Ryan W., Meredith Spratford, Benjamin Kirby, and Marc Brennan. 2017. Individual differences in language and working memory affect children’s speech recognition in noise. International Journal of Audiology 56: 306–15. [Google Scholar] [CrossRef] [PubMed]
- McMurray, Bob, Vicki M. Samelson, Sung Hee Lee, and J. Bruce Tomblin. 2010. Individual differences in online spoken word recognition: Implications for SLI. Cognitive Psychology 60: 1–39. [Google Scholar] [CrossRef] [PubMed]
- Miller, Margaret K., Lauren Calandruccio, Emily Buss, Ryan W. McCreery, Jacob Oleson, Barbara Rodriguez, and Lori J. Leibold. 2019. Masked English speech recognition performance in younger and older Spanish–English bilingual and English monolingual children. Journal of Speech, Language, and Hearing Research 62: 4578–91. [Google Scholar] [CrossRef] [PubMed]
- Montgomery, James W. 1999. Recognition of Gated Words by Children With Specific Language Impairment. Journal of Speech, Language, and Hearing Research 42: 735–43. [Google Scholar] [CrossRef] [PubMed]
- Munson, Benjamin. 2001. Relationships Between Vocabulary Size and Spoken Word Recognition in Children Aged 3 to 70. Contemporary Issues in Communication Science and Disorders 28: 20–29. [Google Scholar] [CrossRef]
- Pickering, Sue, and Susan E. Gathercole. 2001. Working Memory Test Battery for Children. London: The Psychological Corporation. [Google Scholar]
- Potter, Christine E., and Jenny R. Saffran. 2017. Exposure to multiple accents supports infants’ understanding of novel accents. Cognition 166: 67–72. [Google Scholar] [CrossRef]
- Redmond, Sean M. 2005. Differentiating SLI from ADHD using children’s sentence recall and production of past tense morphology. Clinical Linguistics & Phonetics 19: 109–27. [Google Scholar] [CrossRef]
- Redmond, Sean M., Heather L. Thompson, and Sam Goldstein. 2011. Psycholinguistic profiling differentiates specific language impairment from typical development and from attention-deficit/hyperactivity disorder. Journal of Speech, Language, and Hearing Research 54: 99–117. [Google Scholar] [CrossRef] [PubMed]
- Rönnberg, Jerker. 2003. Cognition in the hearing impaired and deaf as a bridge between signal and dialogue: A framework and a model. International Journal of Audiology 42: 68–76. [Google Scholar] [CrossRef] [PubMed]
- Rönnberg, Jerker, Emil Holmer, and Mary Rudner. 2019. Cognitive hearing science and ease of language understanding. International Journal of Audiology 58: 247–61. [Google Scholar] [CrossRef] [PubMed]
- Rönnberg, Jerker, Thomas Lunner, Adriana Zekveld, Patrik Sörqvist, Henrik Danielsson, Björn Lyxell, Örjan Dahlström, Carine Signoret, Stefan Stenfelt, M. Kathleen Pichora-Fuller, and et al. 2013. The Ease of Language Understanding (ELU) model: Theoretical, empirical, and clinical advances. Frontiers in Systems Neuroscience 7: 31. [Google Scholar] [CrossRef] [PubMed]
- Schober, Patrick, Christa Boer, and Lothar A. Schwarte. 2018. Correlation Coefficients: Appropriate Use and Interpretation. Anesthesia & Analgesia 126: 1763–68. [Google Scholar] [CrossRef] [PubMed]
- Schroeder, Manfred R. 1968. Reference signal for signal quality studies. Journal of the Acoustical Society of America 44: 1735–36. [Google Scholar] [CrossRef]
- Semel, Eleanor, Elisabeth H. Wiig, and Wayne A. Secord. 2003. Clinical Evaluation of Language Fundamentals, 4th Edition (CELF-4). Toronto: The Psychological Corporation/A Harcourt Assessment Company. [Google Scholar]
- Stenfelt, Stefan, and Jerker Rönnberg. 2009. The Signal-Cognition interface: Interactions between degraded auditory signals and cognitive processes. Scandinavian Journal of Psychology 50: 385–93. [Google Scholar] [CrossRef] [PubMed]
- Taft, Marcus, and Lily Tao. 2017. Effects of early home language environment on perception and production of speech. Bilingualism: Language and Cognition 20: 1030–44. [Google Scholar] [CrossRef]
- Venker, Courtney E. 2016. Spoken word recognition in children with autism spectrum disorder: The role of visual disengagement. Autism 21: 821–29. [Google Scholar] [CrossRef]
- Wagner, Richard K., Joseph K. Torgesen, and Carol Alexander Rashotte. 1999. Comprehensive Test of Phonological Processing (CTOPP). Austin: Pro-Ed. [Google Scholar]
| Multiple-Variety | Single-Variety | t-Value | df | p-Value | |
|---|---|---|---|---|---|
| Age (in months) | 80–164 112.3 | 88–141 112.2 | 0.01 | 49.6 | 0.990 |
| Core Language (CELF) | 82–133 101.3 | 82–123 100.6 | 0.15 | 47.2 | 0.877 |
| PPVT (scaled) | 90–144 108.9 | 78–140 105.8 | 0.69 | 50.9 | 0.491 |
| TONI (scaled) | 83–146 109.1 | 81–150 109.8 | −0.13 | 49.9 | 0.890 |
| Forward digit (scaled) | 5–14 9.36 | 3–14 8.6 | 0.99 | 50.9 | 0.326 |
| Backward digit (scaled) | 5–14 9.7 | 6–14 9.21 | 0.71 | 50.5 | 0.477 |
| Block span (scaled) | 69–143 102.6 | 55–141 99.0 | 0.63 | 50.4 | 0.529 |
| Recalling Sentences (scaled) | 6–17 10.4 | 6–16 10.36 | 0.05 | 48.5 | 0.958 |
| Phon awareness composite (scaled) | 73–118 99.64 | 76–127 99.68 | −0.01 | 49.5 | 0.991 |
| Age | PPVT | TONI | Recalling Sentences | Forward Digit Span | Backward Digit Span | Block Span | |
|---|---|---|---|---|---|---|---|
| PPVT | −0.23 | ||||||
| TONI | −0.08 | 0.28 | |||||
| Recalling Sent. | −0.01 | 0.64 | 0.29 | ||||
| Forward Digit | −0.20 | 0.39 | 0.34 | 0.60 | |||
| Backward Digit | −0.15 | 0.21 | 0.37 | 0.23 | 0.33 | ||
| Block Span | −0.13 | 0.07 | 0.34 | 0.14 | 0.13 | 0.38 | |
| Phon. Awareness | −0.37 | 0.56 | 0.35 | 0.54 | 0.48 | 0.25 | 0.18 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Levi, S.V. Home Language Experience Shapes Which Skills Are Used during Unfamiliar Speech Processing. Languages 2024, 9, 159. https://doi.org/10.3390/languages9050159
Levi SV. Home Language Experience Shapes Which Skills Are Used during Unfamiliar Speech Processing. Languages. 2024; 9(5):159. https://doi.org/10.3390/languages9050159
Chicago/Turabian StyleLevi, Susannah V. 2024. "Home Language Experience Shapes Which Skills Are Used during Unfamiliar Speech Processing" Languages 9, no. 5: 159. https://doi.org/10.3390/languages9050159
APA StyleLevi, S. V. (2024). Home Language Experience Shapes Which Skills Are Used during Unfamiliar Speech Processing. Languages, 9(5), 159. https://doi.org/10.3390/languages9050159