
Tuning Machine Learning Models Using a Group Search Firefly Algorithm for Credit Card Fraud Detection

 ,
,  , ,
, ,  , and
, and 
Abstract
:1. Introduction
- The development of the novel improved version of the well-known FA metaheuristic that addresses the known drawbacks of the original implementation.
- The application of the devised algorithm for tuning three machine learning classifiers for the particular task of fraud detection, with a goal to enhance the classifiers’ accuracy, as well as other performance metrics.
- The comprehensive comparative analysis of different swarm intelligence metaheuristics for ML tuning against practical credit card fraud challenge.
2. Literature Review and Background
2.1. Support Vector Machine
2.2. Extreme Learning Machine
2.3. The XGBoost Algorithm
2.4. Swarm Intelligence
2.5. Machine Learning Model Tuning by Swarm Intelligence Metaheuristics
2.6. Credit Card Fraud Detection Overview
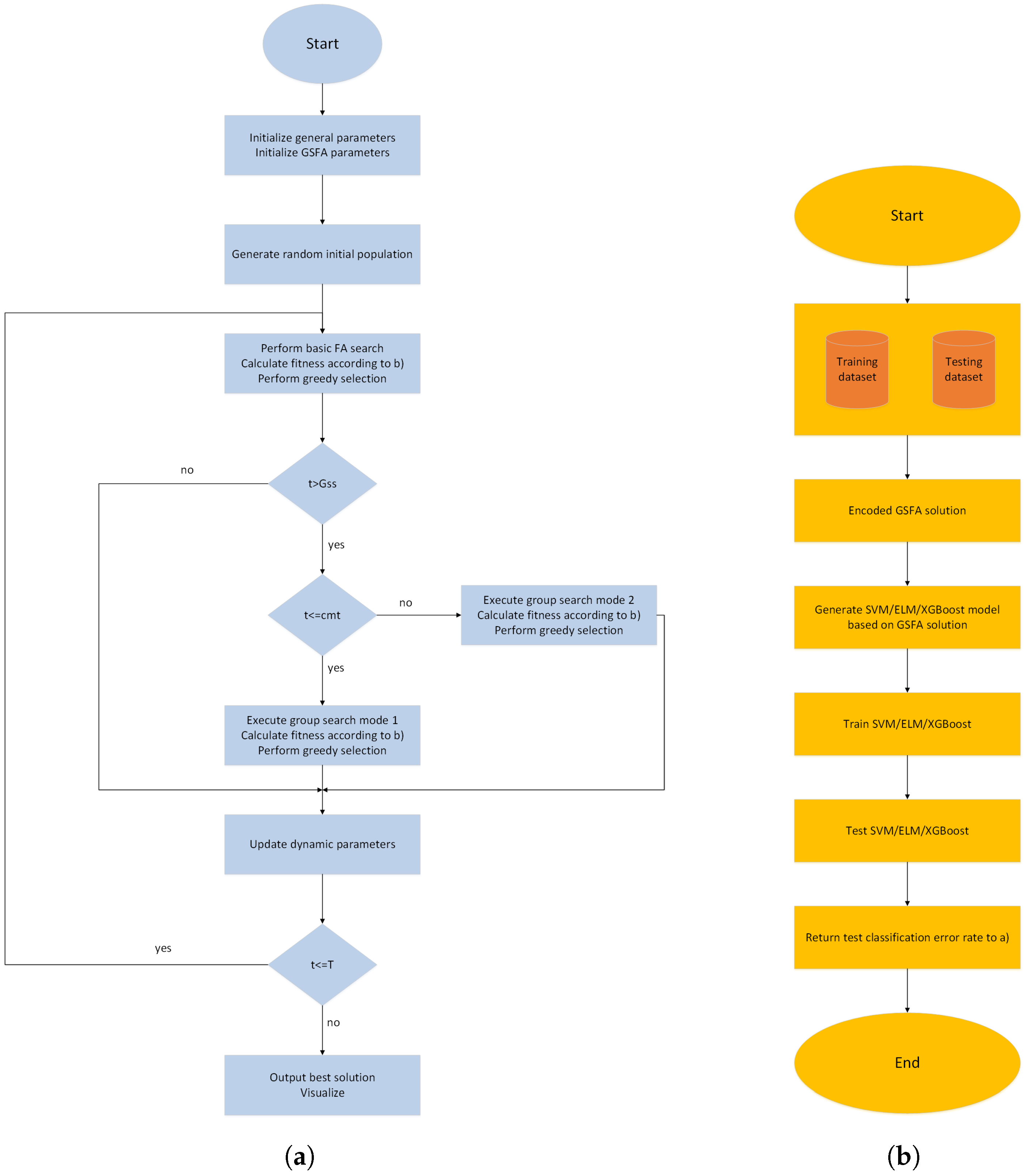
3. Proposed Method
3.1. Original Firefly Algorithm
3.2. Motivation and Proposed Improved Group Search Firefly Algorithm
| Algorithm 1 The GSFA pseudo-code. |
Define global parameters N and T Generate the initial population of solutions , () Define basic FA control parameters Define specific GSFA control parameters Set initial values of dynamic parameters whiledo for to N do for to i do if then Move the firefly j in the direction of the firefly i in D dimension Attractiveness changes with distance r as exp[] Evaluate the new solution, replace the worst solution with better one and update intensity of light end if end for end for Sort population according to fitness in descending order and determine solution with index -1 () if then if then Generate new solution by group search mode 1 operator else Generate new solution by group search mode 2 operator end if Perform greedy selection between and end if All solution are ranked in order to find the current best solution end while Output the global best solution Post-process results and perform visualization |
4. Experimental Findings, Comparative Analysis, and Discussion
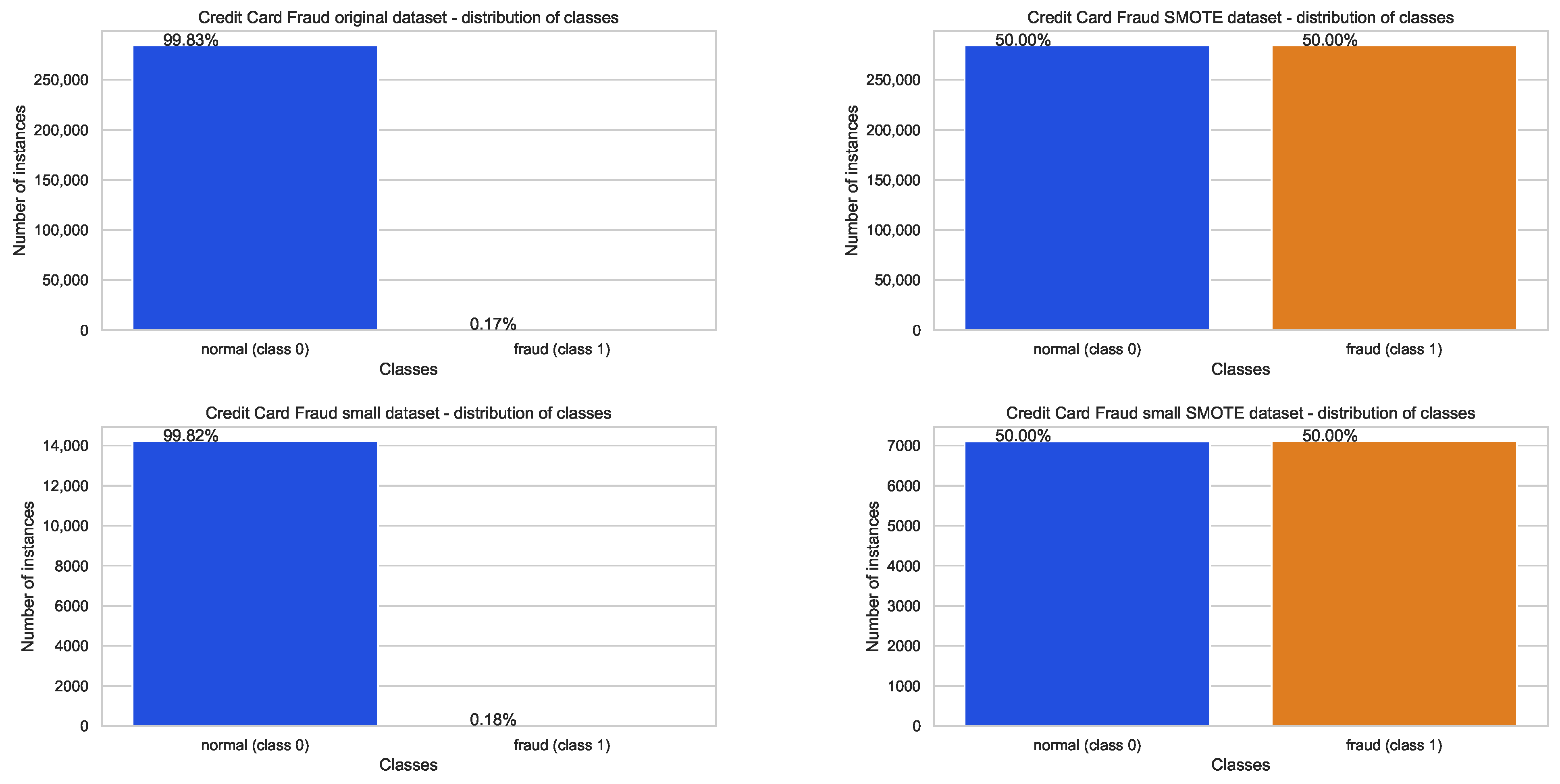
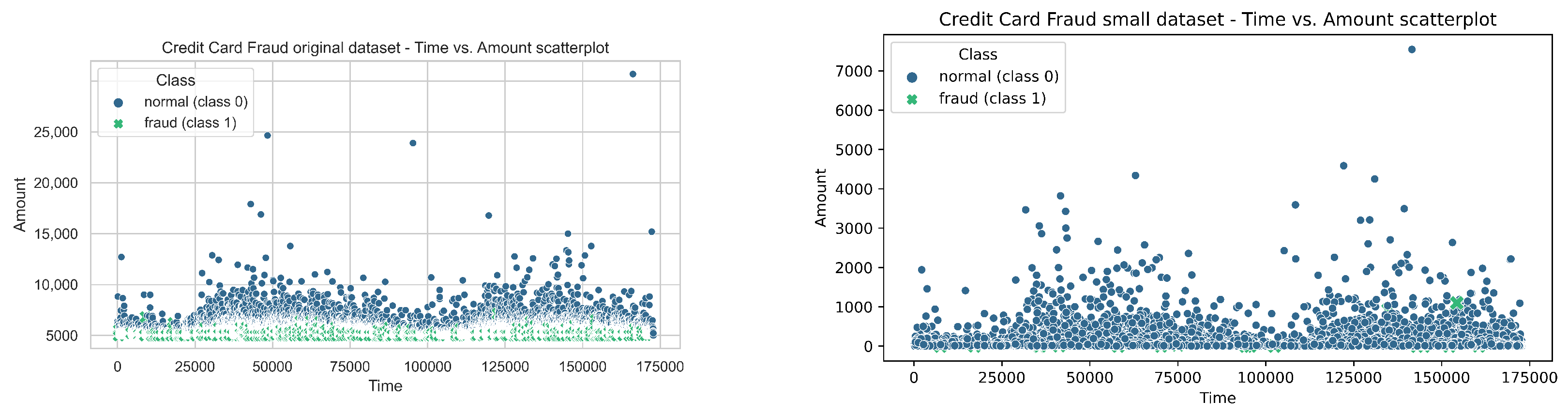
4.1. Datasets Used in Experiments
4.2. Experimental Setup, Proposed Encoding Scheme, and Flow-Chart Diagram
- C, boundaries: , type: continuous,
- , boundaries: , type: continuous, and
- kernel type, boundaries: , type: integer, where value 0 denotes polynomial (poly), 1 marks radial basis function (rbf), 2 represents sigmoid, and finally 3 represents linear kernel type.
- learning rate (), boundaries: , type: continuous,
- , boundaries: , type: continuous,
- subsample, boundaries: ,type: continuous,
- collsample_bytree, boundaries: , type: continuous,
- max_depth, boundaries: , type: integer and
- , boundaries: , type: continuous.
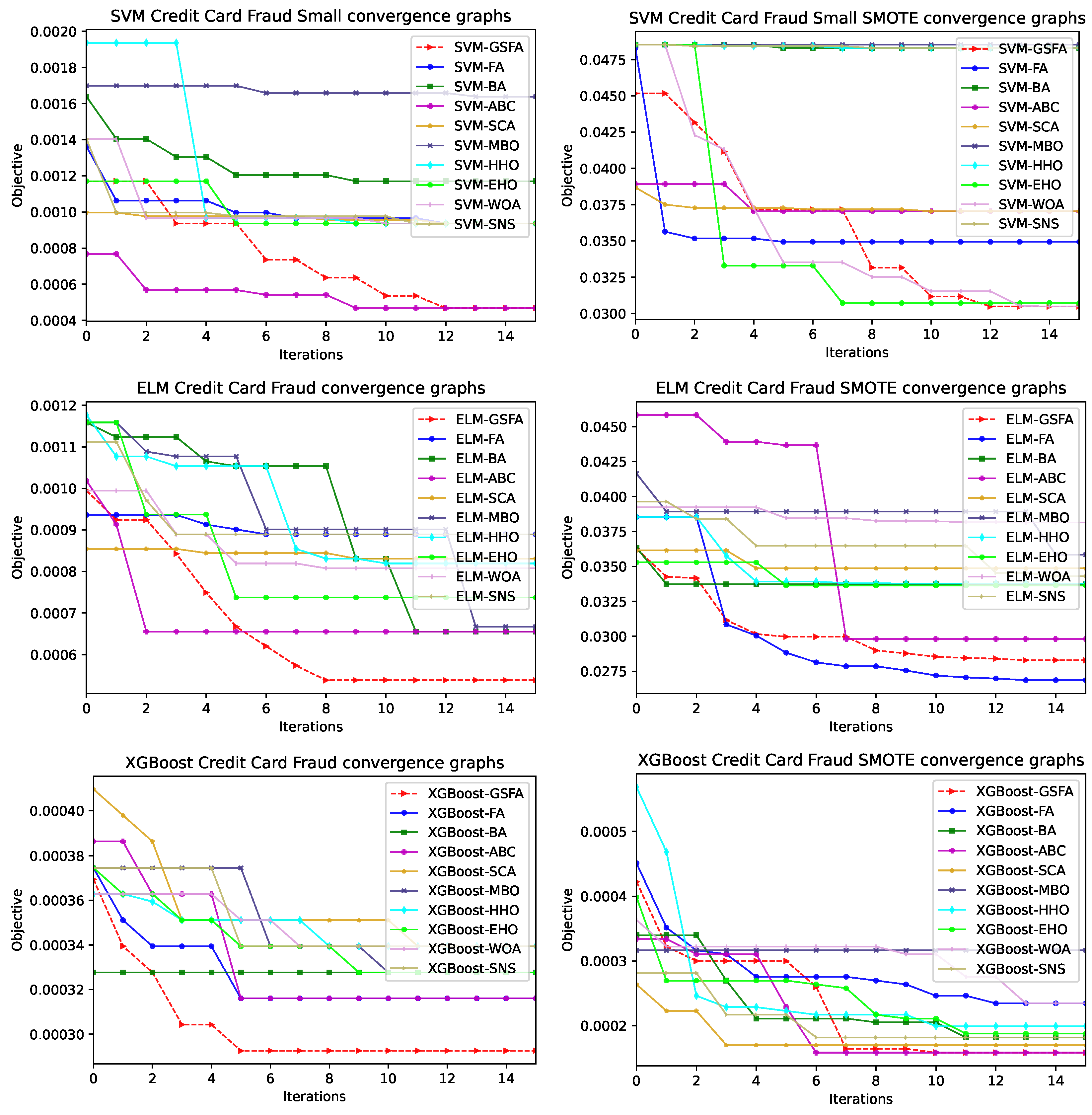
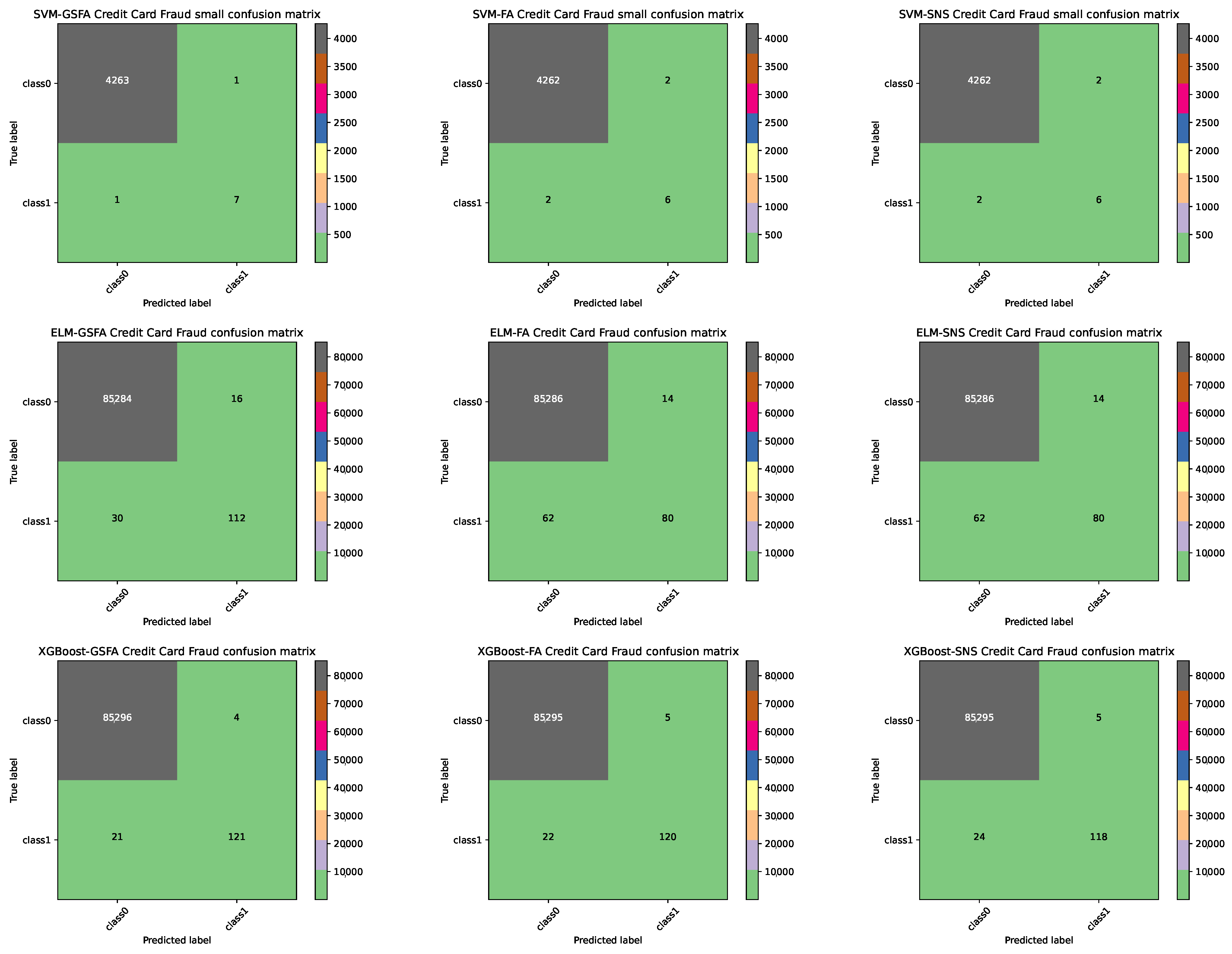
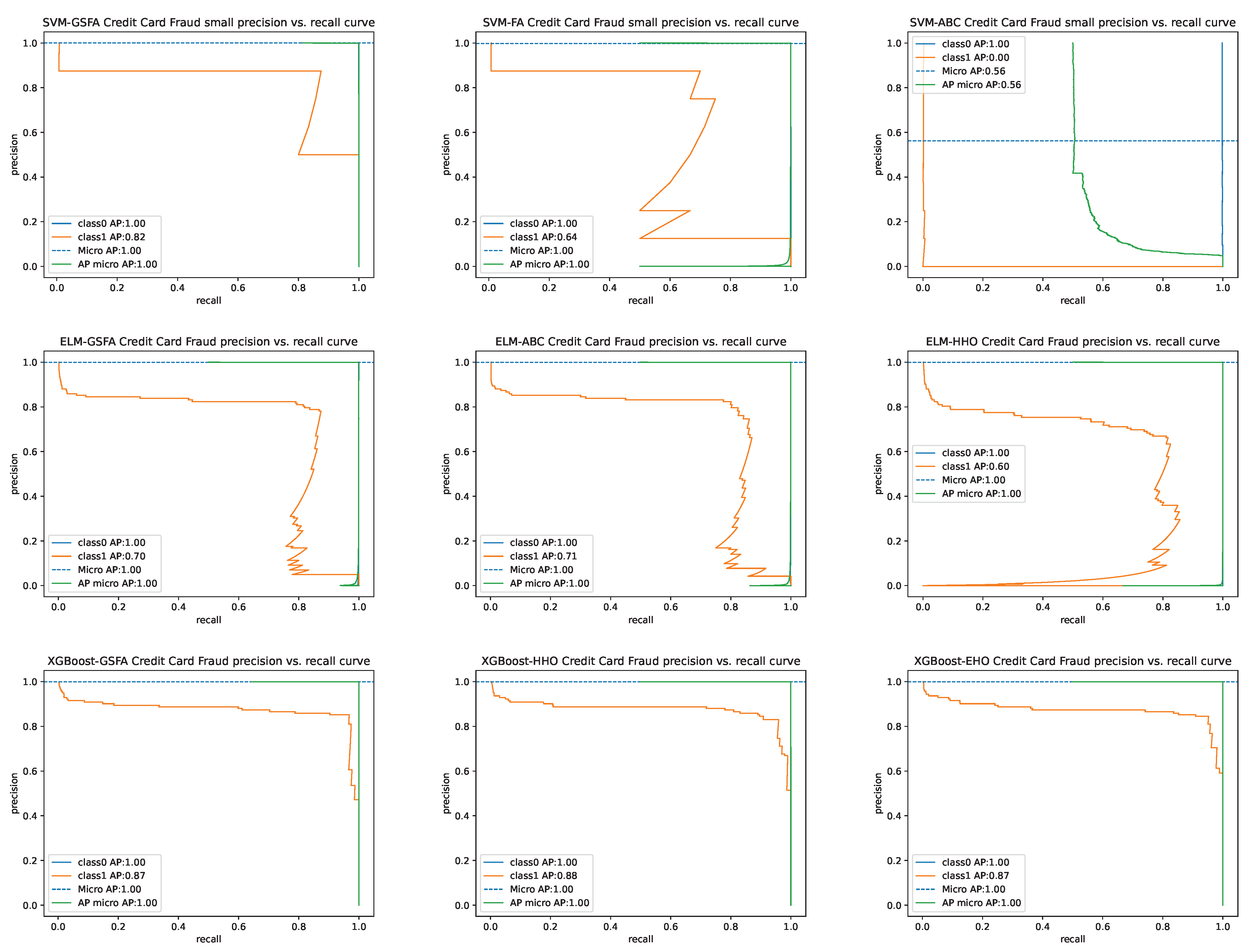
4.3. Comparative Analysis and Discussion
4.4. Statistical Tests
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Elreedy, D.; Atiya, A.F. A Comprehensive Analysis of Synthetic Minority Oversampling Technique (SMOTE) for handling class imbalance. Inf. Sci. 2019, 505, 32–64. [Google Scholar] [CrossRef]
- Nematzadeh, S.; Kiani, F.; Torkamanian-Afshar, M.; Aydin, N. Tuning hyperparameters of machine learning algorithms and deep neural networks using metaheuristics: A bioinformatics study on biomedical and biological cases. Comput. Biol. Chem. 2022, 97, 107619. [Google Scholar] [CrossRef] [PubMed]
- Bacanin, N.; Bezdan, T.; Venkatachalam, K.; Zivkovic, M.; Strumberger, I.; Abouhawwash, M.; Ahmed, A. Artificial Neural Networks Hidden Unit and Weight Connection Optimization by Quasi-Refection-Based Learning Artificial Bee Colony Algorithm. IEEE Access 2021, 9, 169135–169155. [Google Scholar] [CrossRef]
- Bacanin, N.; Bezdan, T.; Tuba, E.; Strumberger, I.; Tuba, M. Optimizing Convolutional Neural Network Hyperparameters by Enhanced Swarm Intelligence Metaheuristics. Algorithms 2020, 13, 67. [Google Scholar] [CrossRef] [Green Version]
- Al-Andoli, M.; Tan, S.C.; Cheah, W.P. Parallel stacked autoencoder with particle swarm optimization for community detection in complex networks. Appl. Intell. 2022, 52, 3366–3386. [Google Scholar] [CrossRef]
- Gajic, L.; Cvetnic, D.; Zivkovic, M.; Bezdan, T.; Bacanin, N.; Milosevic, S. Multi-layer Perceptron Training Using Hybridized Bat Algorithm. In Computational Vision and Bio-Inspired Computing; Smys, S., Tavares, J.M.R.S., Bestak, R., Shi, F., Eds.; Springer: Singapore, 2021; pp. 689–705. [Google Scholar]
- Yang, X.S. Firefly Algorithms for Multimodal Optimization. In Stochastic Algorithms: Foundations and Applications; Watanabe, O., Zeugmann, T., Eds.; Springer: Berlin/Heidelberg, Germany, 2009; pp. 169–178. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme learning machine: A new learning scheme of feedforward neural networks. In Proceedings of the IEEE International Joint Conference on Neural Networks (IEEE Cat. No.04CH37541), Budapest, Hungary, 25–29 July 2004; Volume 2, pp. 985–990. [Google Scholar] [CrossRef]
- Serre, D. Matrices: Theory and Applications; Springer: Berlin/Heidelberg, Germany, 2002. [Google Scholar]
- Huang, G.B. Learning capability and storage capacity of two-hidden-layer feedforward networks. IEEE Trans. Neural Netw. 2003, 14, 274–281. [Google Scholar] [CrossRef] [Green Version]
- Raslan, A.F.; Ali, A.F.; Darwish, A. 1—Swarm intelligence algorithms and their applications in Internet of Things. In Swarm Intelligence for Resource Management in Internet of Things; Intelligent Data-Centric Systems; Academic Press: Cambridge, MA, USA, 2020; pp. 1–19. [Google Scholar] [CrossRef]
- Rostami, M.; Berahmand, K.; Nasiri, E.; Forouzandeh, S. Review of swarm intelligence-based feature selection methods. Eng. Appl. Artif. Intell. 2021, 100, 104210. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the ICNN’95—International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995; Volume 4, pp. 1942–1948. [Google Scholar] [CrossRef]
- Karaboga, D.; Basturk, B. On the performance of artificial bee colony (ABC) algorithm. Appl. Soft Comput. 2008, 8, 687–697. [Google Scholar] [CrossRef]
- Yang, X.; Hossein Gandomi, A. Bat algorithm: A novel approach for global engineering optimization. Eng. Comput. 2012, 29, 464–483. [Google Scholar] [CrossRef] [Green Version]
- Wang, G.G.; Deb, S.; Coelho, L.d.S. Elephant Herding Optimization. In Proceedings of the 3rd International Symposium on Computational and Business Intelligence (ISCBI), Bali, Indonesia, 7–9 December 2015; pp. 1–5. [Google Scholar] [CrossRef]
- Mirjalili, S.; Lewis, A. The Whale Optimization Algorithm. Adv. Eng. Softw. 2016, 95, 51–67. [Google Scholar] [CrossRef]
- Mirjalili, S. Dragonfly algorithm: A new meta-heuristic optimization technique for solving single-objective, discrete, and multi-objective problems. Neural Comput. Appl. 2016, 27, 1053–1073. [Google Scholar] [CrossRef]
- Dorigo, M.; Birattari, M. Ant Colony Optimization. In Encyclopedia of Machine Learning; Springer US: Boston, MA, USA, 2010; pp. 36–39. [Google Scholar] [CrossRef]
- Mucherino, A.; Seref, O. Monkey search: A novel metaheuristic search for global optimization. AIP Conf. Proc. 2007, 953, 162–173. [Google Scholar] [CrossRef]
- Mirjalili, S.; Mirjalili, S.M.; Lewis, A. Grey Wolf Optimizer. Adv. Eng. Softw. 2014, 69, 46–61. [Google Scholar] [CrossRef] [Green Version]
- Gandomi, A.H.; Yang, X.S.; Alavi, A.H. Cuckoo search algorithm: A metaheuristic approach to solve structural optimization problems. Eng. Comput. 2013, 29, 17–35. [Google Scholar] [CrossRef]
- Yang, X.S. Flower Pollination Algorithm for Global Optimization. In Unconventional Computation and Natural Computation; Springer: Berlin/Heidelberg, Germany, 2012; pp. 240–249. [Google Scholar]
- Mirjalili, S.; Gandomi, A.H.; Mirjalili, S.Z.; Saremi, S.; Faris, H.; Mirjalili, S.M. Salp Swarm Algorithm: A bio-inspired optimizer for engineering design problems. Adv. Eng. Softw. 2017, 114, 163–191. [Google Scholar] [CrossRef]
- Heidari, A.A.; Mirjalili, S.; Faris, H.; Aljarah, I.; Mafarja, M.; Chen, H. Harris hawks optimization: Algorithm and applications. Future Gener. Comput. Syst. 2019, 97, 849–872. [Google Scholar] [CrossRef]
- Wang, G.G.; Deb, S.; Cui, Z. Monarch butterfly optimization. Neural Comput. Appl. 2019, 31, 1995–2014. [Google Scholar] [CrossRef] [Green Version]
- Dhiman, G.; Kumar, V. Emperor penguin optimizer: A bio-inspired algorithm for engineering problems. Knowl.-Based Syst. 2018, 159, 20–50. [Google Scholar] [CrossRef]
- Mirjalili, S.Z.; Mirjalili, S.; Saremi, S.; Faris, H.; Aljarah, I. Grasshopper optimization algorithm for multi-objective optimization problems. Appl. Intell. 2018, 48, 805–820. [Google Scholar] [CrossRef]
- Bezdan, T.; Zivkovic, M.; Tuba, E.; Strumberger, I.; Bacanin, N.; Tuba, M. Multi-objective Task Scheduling in Cloud Computing Environment by Hybridized Bat Algorithm. In Proceedings of the International Conference on Intelligent and Fuzzy Systems, Istanbul, Turkey, 24–26 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 718–725. [Google Scholar]
- Bacanin, N.; Zivkovic, M.; Bezdan, T.; Venkatachalam, K.; Abouhawwash, M. Modified firefly algorithm for workflow scheduling in cloud-edge environment. Neural Comput. Appl. 2022, 34, 9043–9068. [Google Scholar] [CrossRef] [PubMed]
- Zivkovic, M.; Bacanin, N.; Tuba, E.; Strumberger, I.; Bezdan, T.; Tuba, M. Wireless Sensor Networks Life Time Optimization Based on the Improved Firefly Algorithm. In Proceedings of the 2020 International Wireless Communications and Mobile Computing (IWCMC), Limassol, Cyprus, 15–19 June 2020; pp. 1176–1181. [Google Scholar]
- Bacanin, N.; Tuba, E.; Zivkovic, M.; Strumberger, I.; Tuba, M. Whale Optimization Algorithm with Exploratory Move for Wireless Sensor Networks Localization. In International Conference on Hybrid Intelligent Systems; Springer: Berlin/Heidelberg, Germany, 2019; pp. 328–338. [Google Scholar]
- Bacanin, N.; Sarac, M.; Budimirovic, N.; Zivkovic, M.; AlZubi, A.A.; Bashir, A.K. Smart wireless health care system using graph LSTM pollution prediction and dragonfly node localization. Sustain. Comput. Inform. Syst. 2022, 35, 100711. [Google Scholar] [CrossRef]
- Bezdan, T.; Stoean, C.; Naamany, A.A.; Bacanin, N.; Rashid, T.A.; Zivkovic, M.; Venkatachalam, K. Hybrid Fruit-Fly Optimization Algorithm with K-Means for Text Document Clustering. Mathematics 2021, 9, 1929. [Google Scholar] [CrossRef]
- Stoean, R. Analysis on the potential of an EA—Surrogate modelling tandem for deep learning parametrization: An example for cancer classification from medical images. Neural Comput. Appl. 2018, 32, 313–322. [Google Scholar] [CrossRef]
- Bacanin, N.; Bezdan, T.; Zivkovic, M.; Chhabra, A. Weight Optimization in Artificial Neural Network Training by Improved Monarch Butterfly Algorithm. In Mobile Computing and Sustainable Informatics; Springer: Berlin/Heidelberg, Germany, 2022; pp. 397–409. [Google Scholar]
- Bacanin, N.; Alhazmi, K.; Zivkovic, M.; Venkatachalam, K.; Bezdan, T.; Nebhen, J. Training Multi-Layer Perceptron with Enhanced Brain Storm Optimization Metaheuristics. Comput. Mater. Contin. 2022, 70, 4199–4215. [Google Scholar] [CrossRef]
- Salb, M.; Zivkovic, M.; Bacanin, N.; Chhabra, A.; Suresh, M. Support Vector Machine Performance Improvements for Cryptocurrency Value Forecasting by Enhanced Sine Cosine Algorithm. In Computer Vision and Robotics; Springer: Berlin/Heidelberg, Germany, 2022; pp. 527–536. [Google Scholar]
- Bezdan, T.; Milosevic, S.; Venkatachalam, K.; Zivkovic, M.; Bacanin, N.; Strumberger, I. Optimizing Convolutional Neural Network by Hybridized Elephant Herding Optimization Algorithm for Magnetic Resonance Image Classification of Glioma Brain Tumor Grade. In Proceedings of the 2021 Zooming Innovation in Consumer Technologies Conference (ZINC), Novi Sad, Serbia, 26–27 May 2021; pp. 171–176. [Google Scholar]
- Basha, J.; Bacanin, N.; Vukobrat, N.; Zivkovic, M.; Venkatachalam, K.; Hubálovskỳ, S.; Trojovskỳ, P. Chaotic Harris hawks optimization with quasi-reflection-based learning: An application to enhance CNN design. Sensors 2021, 21, 6654. [Google Scholar] [CrossRef]
- Tair, M.; Bacanin, N.; Zivkovic, M.; Venkatachalam, K. A Chaotic Oppositional Whale Optimisation Algorithm with Firefly Search for Medical Diagnostics. Comput. Mater. Contin. 2022, 72, 959–982. [Google Scholar] [CrossRef]
- Zivkovic, M.; Bacanin, N.; Venkatachalam, K.; Nayyar, A.; Djordjevic, A.; Strumberger, I.; Al-Turjman, F. COVID-19 cases prediction by using hybrid machine learning and beetle antennae search approach. Sustain. Cities Soc. 2021, 66, 102669. [Google Scholar] [CrossRef]
- Bezdan, T.; Zivkovic, M.; Bacanin, N.; Chhabra, A.; Suresh, M. Feature Selection by Hybrid Brain Storm Optimization Algorithm for COVID-19 Classification. J. Comput. Biol. 2022. [Google Scholar] [CrossRef]
- Mohammed, S.; Alkinani, F.; Hassan, Y. Automatic computer aided diagnostic for COVID-19 based on chest X-ray image and particle swarm intelligence. Int. J. Intell. Eng. Syst. 2020, 13, 63–73. [Google Scholar] [CrossRef]
- Abd Elaziz, M.; Ewees, A.A.; Yousri, D.; Alwerfali, H.S.N.; Awad, Q.A.; Lu, S.; Al-Qaness, M.A. An improved Marine Predators algorithm with fuzzy entropy for multi-level thresholding: Real world example of COVID-19 CT image segmentation. IEEE Access 2020, 8, 125306–125330. [Google Scholar] [CrossRef]
- Alshamiri, A.K.; Singh, A.; Surampudi, B.R. Two swarm intelligence approaches for tuning extreme learning machine. Int. J. Mach. Learn. Cybern. 2018, 9, 1271–1283. [Google Scholar] [CrossRef]
- Bui, D.T.; Ngo, P.T.T.; Pham, T.D.; Jaafari, A.; Minh, N.Q.; Hoa, P.V.; Samui, P. A novel hybrid approach based on a swarm intelligence optimized extreme learning machine for flash flood susceptibility mapping. Catena 2019, 179, 184–196. [Google Scholar] [CrossRef]
- Faris, H.; Mirjalili, S.; Aljarah, I.; Mafarja, M.; Heidari, A.A. Salp swarm algorithm: Theory, literature review, and application in extreme learning machines. In Nature-Inspired Optimizers; Springer: Berlin/Heidelberg, Germany, 2020; pp. 185–199. [Google Scholar]
- Gu, Q.; Chang, Y.; Li, X.; Chang, Z.; Feng, Z. A novel F-SVM based on FOA for improving SVM performance. Expert Syst. Appl. 2021, 165, 113713. [Google Scholar] [CrossRef]
- Makki, S.; Assaghir, Z.; Taher, Y.; Haque, R.; Hacid, M.S.; Zeineddine, H. An experimental study with imbalanced classification approaches for credit card fraud detection. IEEE Access 2019, 7, 93010–93022. [Google Scholar] [CrossRef]
- Carcillo, F.; Le Borgne, Y.A.; Caelen, O.; Kessaci, Y.; Oblé, F.; Bontempi, G. Combining unsupervised and supervised learning in credit card fraud detection. Inf. Sci. 2021, 557, 317–331. [Google Scholar] [CrossRef]
- Taha, A.A.; Malebary, S.J. An intelligent approach to credit card fraud detection using an optimized light gradient boosting machine. IEEE Access 2020, 8, 25579–25587. [Google Scholar] [CrossRef]
- Randhawa, K.; Loo, C.K.; Seera, M.; Lim, C.P.; Nandi, A.K. Credit card fraud detection using AdaBoost and majority voting. IEEE Access 2018, 6, 14277–14284. [Google Scholar] [CrossRef]
- Ileberi, E.; Sun, Y.; Wang, Z. Performance Evaluation of Machine Learning Methods for Credit Card Fraud Detection Using SMOTE and AdaBoost. IEEE Access 2021, 9, 165286–165294. [Google Scholar] [CrossRef]
- Bezdan, T.; Cvetnic, D.; Gajic, L.; Zivkovic, M.; Strumberger, I.; Bacanin, N. Feature Selection by Firefly Algorithm with Improved Initialization Strategy. In Proceedings of the 7th Conference on the Engineering of Computer Based Systems (ECBS 2021), Novi Sad, Serbia, 26–27 May 2021; Association for Computing Machinery: New York, NY, USA, 2021. [Google Scholar] [CrossRef]
- Bacanin, N.; Bezdan, T.; Venkatachalam, K.; Al-Turjman, F. Optimized convolutional neural network by firefly algorithm for magnetic resonance image classification of glioma brain tumor grade. J. Real Time Image Process. 2021, 18, 1085–1098. [Google Scholar] [CrossRef]
- Wang, H.; Zhou, X.; Sun, H.; Yu, X.; Zhao, J.; Zhang, H.; Cui, L. Firefly algorithm with adaptive control parameters. Soft Comput. 2017, 21, 5091–5102. [Google Scholar] [CrossRef]
- Wang, J.; Liu, Y.; Feng, H. IFACNN: Efficient DDoS attack detection based on improved firefly algorithm to optimize convolutional neural networks. Math. Biosci. Eng. 2022, 19, 1280–1303. [Google Scholar] [CrossRef]
- Talatahari, S.; Bayzidi, H.; Saraee, M. Social Network Search for Global Optimization. IEEE Access 2021, 9, 92815–92863. [Google Scholar] [CrossRef]
- Goldanloo, M.J.; Gharehchopogh, F.S. A hybrid OBL-based firefly algorithm with symbiotic organisms search algorithm for solving continuous optimization problems. J. Supercomput. 2022, 78, 3998–4031. [Google Scholar] [CrossRef]
- Yang, X.S.; Xingshi, H. Firefly Algorithm: Recent Advances and Applications. Int. J. Swarm Intell. 2013, 1, 36–50. [Google Scholar] [CrossRef] [Green Version]
- Yang, X.S. Bat algorithm for multi-objective optimisation. Int. J.-Bio Inspired Comput. 2011, 3, 267–274. [Google Scholar] [CrossRef]
- Mirjalili, S. SCA: A sine cosine algorithm for solving optimization problems. Knowl.-Based Syst. 2016, 96, 120–133. [Google Scholar] [CrossRef]
- Eftimov, T.; Korošec, P.; Seljak, B.K. Disadvantages of statistical comparison of stochastic optimization algorithms. In Proceedings of the Bioinspired Optimizaiton Methods and Their Applications, BIOMA, Bled, Slovenia, 18–20 May 2016; pp. 105–118. [Google Scholar]
- Derrac, J.; García, S.; Molina, D.; Herrera, F. A practical tutorial on the use of nonparametric statistical tests as a methodology for comparing evolutionary and swarm intelligence algorithms. Swarm Evol. Comput. 2011, 1, 3–18. [Google Scholar] [CrossRef]
- García, S.; Molina, D.; Lozano, M.; Herrera, F. A study on the use of non-parametric tests for analyzing the evolutionary algorithms’ behaviour: A case study on the CEC’2005 special session on real parameter optimization. J. Heuristics 2009, 15, 617–644. [Google Scholar] [CrossRef]
- Shapiro, S.S.; Francia, R. An approximate analysis of variance test for normality. J. Am. Stat. Assoc. 1972, 67, 215–216. [Google Scholar] [CrossRef]
- LaTorre, A.; Molina, D.; Osaba, E.; Poyatos, J.; Del Ser, J.; Herrera, F. A prescription of methodological guidelines for comparing bio-inspired optimization algorithms. Swarm Evol. Comput. 2021, 67, 100973. [Google Scholar] [CrossRef]
- Glass, G.V. Testing homogeneity of variances. Am. Educ. Res. J. 1966, 3, 187–190. [Google Scholar] [CrossRef]
- Friedman, M. The use of ranks to avoid the assumption of normality implicit in the analysis of variance. J. Am. Stat. Assoc. 1937, 32, 675–701. [Google Scholar] [CrossRef]
- Friedman, M. A comparison of alternative tests of significance for the problem of m rankings. Ann. Math. Stat. 1940, 11, 86–92. [Google Scholar] [CrossRef]
- Sheskin, D.J. Handbook of Parametric and Nonparametric Statistical Procedures; Chapman and Hall/CRC: Boca Raton, FL, USA, 2020. [Google Scholar]
- Iman, R.L.; Davenport, J.M. Approximations of the critical region of the fbietkan statistic. Commun. Stat. Theory Methods 1980, 9, 571–595. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Expression | Description |
|---|---|---|
| dynamic group search parameter, starting value 2 | ||
| group search start | ||
| change mode trigger |
| Metrics | SVM-GSFA | SVM-FA | SVM-BA | SVM-ABC | SVM-SCA | SVM-MBO | SVM-HHO | SVM-EHO | SVM-WOA | SVM-SNS |
|---|---|---|---|---|---|---|---|---|---|---|
| best (%) | 99.9552 | 99.9064 | 99.8830 | 99.9532 | 99.9064 | 99.8361 | 99.9064 | 99.9064 | 99.9064 | 99.9064 |
| worst (%) | 99.9064 | 99.8596 | 99.8596 | 99.9064 | 99.9064 | 99.8127 | 99.9064 | 99.8127 | 99.9064 | 99.8596 |
| mean (%) | 99.9220 | 99.8752 | 99.8674 | 99.9298 | 99.9064 | 99.8283 | 99.9064 | 99.8752 | 99.9064 | 99.8908 |
| median (%) | 99.9064 | 99.8596 | 99.8596 | 99.9298 | 99.9064 | 99.8361 | 99.9064 | 99.9064 | 99.9064 | 99.9064 |
| std | 0.000270 | 0.000270 | 0.000135 | 0.000234 | 0.000000 | 0.000135 | 0.000000 | 0.000541 | 0.000000 | 0.000270 |
| Metrics | ELM-GSFA | ELM-FA | ELM-BA | ELM-ABC | ELM-SCA | ELM-MBO | ELM-HHO | ELM-EHO | ELM-WOA | ELM-SNS |
|---|---|---|---|---|---|---|---|---|---|---|
| best (%) | 99.9462 | 99.9111 | 99.9345 | 99.9345 | 99.9169 | 99.9333 | 99.9181 | 99.9263 | 99.9192 | 99.9111 |
| worst (%) | 99.9427 | 99.8841 | 99.9134 | 99.8947 | 99.9029 | 99.8982 | 99.8947 | 99.9075 | 99.9075 | 99.8947 |
| mean (%) | 99.9442 | 99.8947 | 99.9207 | 99.9058 | 99.9105 | 99.9099 | 99.9081 | 99.9160 | 99.9160 | 99.9029 |
| median (%) | 99.9438 | 99.8917 | 99.9175 | 99.8970 | 99.9111 | 99.9040 | 99.9099 | 99.9151 | 99.9157 | 99.9029 |
| std | 0.000018 | 0.000123 | 0.000095 | 0.000192 | 0.000059 | 0.000163 | 0.000109 | 0.000077 | 0.000136 | 0.000070 |
| Metrics | XGBoost-GSFA | XGBoost-FA | XGBoost-BA | XGBoost-ABC | XGBoost-SCA | XGBoost-MBO | XGBoost-HHO | XGBoost-EHO | XGBoost-WOA | XGBoost-SNS |
|---|---|---|---|---|---|---|---|---|---|---|
| best (%) | 99.9707 | 99.9684 | 99.9672 | 99.9684 | 99.9661 | 99.9672 | 99.9661 | 99.9672 | 99.9661 | 99.9661 |
| worst (%) | 99.9696 | 99.9649 | 99.9625 | 99.9661 | 99.9649 | 99.9649 | 99.9649 | 99.9649 | 99.9661 | 99.9637 |
| mean (%) | 99.9704 | 99.9668 | 99.9649 | 99.9668 | 99.9653 | 99.9664 | 99.9657 | 99.9657 | 99.9661 | 99.9649 |
| median (%) | 99.9707 | 99.9672 | 99.9649 | 99.9661 | 99.9649 | 99.9672 | 99.9661 | 99.9649 | 99.9661 | 99.9649 |
| std | 0.000007 | 0.000018 | 0.000023 | 0.000014 | 0.000007 | 0.000014 | 0.000007 | 0.000014 | 0.000000 | 0.000012 |
| Metrics | SVM-GSFA | SVM-FA | SVM-BA | SVM-ABC | SVM-SCA | SVM-MBO | SVM-HHO | SVM-EHO | SVM-WOA | SVM-SNS |
|---|---|---|---|---|---|---|---|---|---|---|
| best (%) | 96.9519 | 96.5064 | 95.1700 | 96.2954 | 96.2954 | 95.1465 | 95.1700 | 96.9285 | 96.9519 | 95.1700 |
| worst (%) | 96.8039 | 96.2704 | 94.0674 | 96.0005 | 95.9408 | 94.6151 | 94.1505 | 96.2706 | 96.4701 | 94.3300 |
| mean (%) | 96.8643 | 96.3557 | 94.4115 | 96.0875 | 96.0431 | 94.8514 | 94.4080 | 96.6505 | 96.6271 | 94.9307 |
| median (%) | 96.8504 | 96.3691 | 94.5049 | 96.0651 | 96.0251 | 94.8352 | 94.3261 | 96.5141 | 96.7155 | 94.9480 |
| std | 0.001050 | 0.007410 | 0.056500 | 0.002150 | 0.008980 | 0.010500 | 0.045500 | 0.007450 | 0.006660 | 0.074500 |
| Metrics | ELM-GSFA | ELM-FA | ELM-BA | ELM-ABC | ELM-SCA | ELM-MBO | ELM-HHO | ELM-EHO | ELM-WOA | ELM-SNS |
|---|---|---|---|---|---|---|---|---|---|---|
| best (%) | 97.1716 | 97.3140 | 96.6270 | 97.0186 | 96.5133 | 96.4165 | 96.6229 | 96.6364 | 96.1867 | 96.5695 |
| worst (%) | 97.1046 | 97.2455 | 96.4971 | 97.0046 | 96.3211 | 96.3961 | 96.4708 | 96.5071 | 95.8648 | 96.3695 |
| mean (%) | 97.1440 | 97.2669 | 96.5881 | 97.0126 | 96.3971 | 96.4055 | 96.5207 | 96.6044 | 96.0175 | 96.4710 |
| median (%) | 97.1595 | 97.261 | 96.5794 | 97.0069 | 96.4671 | 96.4087 | 96.4981 | 96.5951 | 96.0266 | 96.4898 |
| std | 0.000321 | 0.000355 | 0.004440 | 0.000456 | 0.000059 | 0.000429 | 0.084200 | 0.025200 | 0.023600 | 0.003450 |
| Metrics | XGBoost-GSFA | XGBoost-FA | XGBoost-BA | XGBoost-ABC | XGBoost-SCA | XGBoost-MBO | XGBoost-HHO | XGBoost-EHO | XGBoost-WOA | XGBoost-SNS |
|---|---|---|---|---|---|---|---|---|---|---|
| best (%) | 99.9842 | 99.9766 | 99.9818 | 99.9842 | 99.9830 | 99.9683 | 99.9818 | 99.9812 | 99.9766 | 99.9818 |
| worst (%) | 99.9841 | 99.9740 | 99.9786 | 99.9803 | 99.9810 | 99.9642 | 99.9793 | 99.9762 | 99.9743 | 99.9756 |
| mean (%) | 99.9841 | 99.9750 | 99.9800 | 99.9836 | 99.9823 | 99.9662 | 99.9800 | 99.9795 | 99.9757 | 99.9794 |
| median (%) | 99.9841 | 99.9751 | 99.9801 | 99.9841 | 99.9824 | 99.9669 | 99.9801 | 99.9786 | 99.9756 | 99.9786 |
| std | 0.000001 | 0.000020 | 0.000095 | 0.000034 | 0.000034 | 0.000072 | 0.000084 | 0.000085 | 0.000067 | 0.000105 |
| Metrics | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Metaheuristic | Accuracy (%) | Precision 0 | Precision 1 |
M.Avg.
Precision | Recall 0 | Recall 1 |
M.Avg.
Recall | F1 Score 0 | F1 Score 1 |
M.Avg.
F1 Score |
M.Avg.
ROC AUC |
M.Avg.
PR AUC |
| SVM-GSFA | 99.9532 | 0.999765 | 0.875000 | 0.999532 | 0.999765 | 0.875000 | 0.999532 | 0.999765 | 0.875000 | 0.999532 | 1.00 | 1.00 |
| SVM-FA | 99.9064 | 0.999531 | 0.750000 | 0.999064 | 0.999531 | 0.750000 | 0.999064 | 0.999531 | 0.750000 | 0.999064 | 1.00 | 1.00 |
| SVM-BA | 99.8830 | 0.999063 | 0.800000 | 0.998690 | 0.999765 | 0.500000 | 0.998830 | 0.999414 | 0.615385 | 0.998695 | 1.00 | 1.00 |
| SVM-ABC | 99.9532 | 0.998251 | 0.002015 | 0.996385 | 0.535413 | 0.500000 | 0.535346 | 0.696993 | 0.004014 | 0.695695 | 0.52 | 0.56 |
| SVM-SCA | 99.9064 | 0.999531 | 0.750000 | 0.999064 | 0.999531 | 0.750000 | 0.999064 | 0.999531 | 0.750000 | 0.999064 | 1.00 | 1.00 |
| SVM-MBO | 99.8361 | 0.998127 | 0.000000 | 0.996258 | 0.999765 | 0.000000 | 0.997893 | 0.998946 | 0.000000 | 0.997075 | 0.50 | 0.50 |
| SVM-HHO | 99.9064 | 0.999531 | 0.750000 | 0.999064 | 0.999531 | 0.750000 | 0.999064 | 0.999531 | 0.750000 | 0.999064 | 1.00 | 1.00 |
| SVM-EHO | 99.9064 | 0.999297 | 0.833333 | 0.998986 | 0.999765 | 0.625000 | 0.999064 | 0.999531 | 0.714286 | 0.998997 | 1.00 | 1.00 |
| SVM-WOA | 99.9064 | 0.999531 | 0.750000 | 0.999064 | 0.999531 | 0.750000 | 0.999064 | 0.999531 | 0.750000 | 0.999064 | 1.00 | 1.00 |
| SVM-SNS | 99.9064 | 0.999531 | 0.750000 | 0.999064 | 0.999531 | 0.750000 | 0.999064 | 0.999531 | 0.750000 | 0.999064 | 1.00 | 1.00 |
| Metrics | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Metaheuristic | Accuracy (%) | Precision 0 | Precision 1 |
M.Avg.
Precision | Recall 0 | Recall 1 |
M.Avg.
Recall | F1 Score 0 | F1 Score 1 |
M.Avg.
F1 Score |
M.Avg.
ROC AUC |
M.Avg.
PR AUC |
| ELM-GSFA | 99.9462 | 0.999648 | 0.875000 | 0.999441 | 0.999812 | 0.788732 | 0.999462 | 0.999730 | 0.829630 | 0.999448 | 1.00 | 1.00 |
| ELM-FA | 99.9111 | 0.999274 | 0.851064 | 0.999027 | 0.999836 | 0.563380 | 0.999111 | 0.999555 | 0.677966 | 0.999020 | 1.00 | 1.00 |
| ELM-BA | 99.9345 | 0.999637 | 0.816176 | 0.999332 | 0.999707 | 0.781690 | 0.999345 | 0.999672 | 0.798561 | 0.999338 | 1.00 | 1.00 |
| ELM-ABC | 99.9345 | 0.999555 | 0.852459 | 0.999310 | 0.999789 | 0.732394 | 0.999345 | 0.999672 | 0.787879 | 0.999320 | 1.00 | 1.00 |
| ELM-SCA | 99.9169 | 0.999332 | 0.858586 | 0.999098 | 0.999836 | 0.598592 | 0.999169 | 0.999584 | 0.705394 | 0.999095 | 1.00 | 1.00 |
| ELM-MBO | 99.9333 | 0.999578 | 0.834646 | 0.999304 | 0.999754 | 0.746479 | 0.999333 | 0.999666 | 0.788104 | 0.999314 | 1.00 | 1.00 |
| ELM-HHO | 99.9181 | 0.999402 | 0.827273 | 0.999116 | 0.999777 | 0.640845 | 0.999181 | 0.999590 | 0.722222 | 0.999129 | 1.00 | 1.00 |
| ELM-EHO | 99.9263 | 0.998338 | 0.000000 | 0.996679 | 1.000000 | 0.000000 | 0.998338 | 0.999168 | 0.000000 | 0.997508 | 0.50 | 0.50 |
| ELM-WOA | 99.9192 | 0.999391 | 0.841121 | 0.999128 | 0.999801 | 0.633803 | 0.999192 | 0.999596 | 0.722892 | 0.999136 | 1.00 | 1.00 |
| ELM-SNS | 99.9111 | 0.999274 | 0.851064 | 0.999027 | 0.999836 | 0.563380 | 0.999111 | 0.999555 | 0.677966 | 0.999020 | 1.00 | 1.00 |
| Metrics | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Metaheuristic | Accuracy (%) | Precision 0 | Precision 1 |
M.Avg.
Precision | Recall 0 | Recall 1 |
M.Avg.
Recall | F1 Score 0 | F1 Score 1 |
M.Avg.
F1 Score |
M.Avg.
ROC AUC |
M.Avg.
PR AUC |
| XGBoost-GSFA | 99.9707 | 0.999754 | 0.968000 | 0.999701 | 0.999953 | 0.852113 | 0.999707 | 0.999853 | 0.906367 | 0.999698 | 1.00 | 1.00 |
| XGBoost-FA | 99.9684 | 0.999742 | 0.960000 | 0.999676 | 0.999941 | 0.845070 | 0.999684 | 0.999842 | 0.898876 | 0.999674 | 1.00 | 1.00 |
| XGBoost-BA | 99.9672 | 0.999730 | 0.959677 | 0.999664 | 0.999941 | 0.838028 | 0.999672 | 0.999836 | 0.894737 | 0.999661 | 1.00 | 1.00 |
| XGBoost-ABC | 99.9684 | 0.999742 | 0.960000 | 0.999676 | 0.999941 | 0.845070 | 0.999684 | 0.999842 | 0.898876 | 0.999674 | 1.00 | 1.00 |
| XGBoost-SCA | 99.9661 | 0.999719 | 0.959350 | 0.999652 | 0.999941 | 0.830986 | 0.999661 | 0.999830 | 0.890566 | 0.999648 | 1.00 | 1.00 |
| XGBoost-MBO | 99.9672 | 0.999730 | 0.959677 | 0.999664 | 0.999941 | 0.838028 | 0.999672 | 0.999836 | 0.894737 | 0.999661 | 1.00 | 1.00 |
| XGBoost-HHO | 99.9661 | 0.999719 | 0.959350 | 0.999652 | 0.999941 | 0.830986 | 0.999661 | 0.999830 | 0.890566 | 0.999648 | 1.00 | 1.00 |
| XGBoost-EHO | 99.9672 | 0.999742 | 0.952381 | 0.999663 | 0.999930 | 0.845070 | 0.999672 | 0.999836 | 0.895522 | 0.999663 | 1.00 | 1.00 |
| XGBoost-WOA | 99.9661 | 0.999730 | 0.952000 | 0.999651 | 0.999930 | 0.838028 | 0.999661 | 0.999830 | 0.891386 | 0.999650 | 1.00 | 1.00 |
| XGBoost-SNS | 99.9661 | 0.999719 | 0.959350 | 0.999652 | 0.999941 | 0.830986 | 0.999661 | 0.999830 | 0.890566 | 0.999648 | 1.00 | 1.00 |
| Metrics | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Metaheuristic | Accuracy (%) | Precision 0 | Precision 1 |
M.Avg.
Precision | Recall 0 | Recall 1 |
M.Avg.
Recall | F1 Score 0 | F1 Score 1 |
M.Avg.
F1 Score |
M.Avg.
ROC AUC |
M.Avg.
PR AUC |
| SVM-GSFA | 96.9519 | 0.945285 | 0.996530 | 0.970913 | 0.996717 | 0.942335 | 0.969520 | 0.970320 | 0.968675 | 0.969497 | 0.99 | 0.99 |
| SVM-FA | 96.5064 | 0.943228 | 0.989151 | 0.966195 | 0.989681 | 0.940459 | 0.965064 | 0.965896 | 0.964191 | 0.965043 | 0.99 | 0.99 |
| SVM-BA | 95.1700 | 0.911891 | 1.000000 | 0.955956 | 1.000000 | 0.903422 | 0.951700 | 0.953915 | 0.949261 | 0.951587 | 0.99 | 0.98 |
| SVM-ABC | 96.2954 | 0.931381 | 0.999494 | 0.965446 | 0.999531 | 0.926394 | 0.962954 | 0.964253 | 0.961557 | 0.962905 | 1.00 | 1.00 |
| SVM-SCA | 96.2954 | 0.931381 | 0.999494 | 0.965446 | 0.999531 | 0.926395 | 0.962954 | 0.964253 | 0.961557 | 0.962905 | 1.00 | 1.00 |
| SVM-MBO | 95.1465 | 0.536780 | 0.533067 | 0.534923 | 0.506567 | 0.563057 | 0.534818 | 0.521236 | 0.547652 | 0.534447 | 0.54 | 0.53 |
| SVM-HHO | 95.1700 | 0.911891 | 1.000000 | 0.955956 | 1.000000 | 0.903422 | 0.951700 | 0.953915 | 0.949261 | 0.951587 | 0.99 | 0.98 |
| SVM-EHO | 96.9285 | 0.946054 | 0.995054 | 0.970560 | 0.995310 | 0.943272 | 0.969285 | 0.970057 | 0.968472 | 0.969264 | 0.99 | 0.99 |
| SVM-WOA | 96.9519 | 0.946875 | 0.994568 | 0.970727 | 0.994841 | 0.944210 | 0.969519 | 0.970265 | 0.968735 | 0.969500 | 0.99 | 0.99 |
| SVM-SNS | 95.1700 | 0.911891 | 1.000000 | 0.955956 | 1.000000 | 0.903422 | 0.951700 | 0.953915 | 0.949261 | 0.951587 | 0.99 | 0.98 |
| Metrics | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Metaheuristic | Accuracy (%) | Precision 0 | Precision 1 |
M.Avg.
Precision | Recall 0 | Recall 1 |
M.Avg.
Recall | F1 Score 0 | F1 Score 1 |
M.Avg.
F1 Score |
M.Avg.
ROC AUC |
M.Avg.
PR AUC |
| ELM-GSFA | 97.1716 | 0.961894 | 0.982012 | 0.971931 | 0.982475 | 0.960909 | 0.971716 | 0.972076 | 0.971346 | 0.971712 | 1.00 | 1.00 |
| ELM-FA | 97.3140 | 0.967921 | 0.978501 | 0.973200 | 0.978837 | 0.967418 | 0.973140 | 0.973349 | 0.972928 | 0.973139 | 1.00 | 1.00 |
| ELM-BA | 96.6270 | 0.966703 | 0.965835 | 0.966270 | 0.965957 | 0.966584 | 0.966270 | 0.966330 | 0.966209 | 0.966270 | 0.99 | 0.99 |
| ELM-ABC | 97.0186 | 0.958294 | 0.982770 | 0.970506 | 0.983294 | 0.957020 | 0.970186 | 0.970633 | 0.969724 | 0.970180 | 0.99 | 0.99 |
| ELM-SCA | 96.5133 | 0.948796 | 0.982790 | 0.965755 | 0.983493 | 0.946692 | 0.965132 | 0.965833 | 0.964403 | 0.965119 | 0.99 | 0.99 |
| ELM-MBO | 96.4165 | 0.949218 | 0.980219 | 0.964685 | 0.980966 | 0.947291 | 0.964165 | 0.964831 | 0.963474 | 0.964154 | 0.99 | 0.99 |
| ELM-HHO | 96.6229 | 0.952841 | 0.980501 | 0.966641 | 0.981165 | 0.951227 | 0.966229 | 0.966796 | 0.965642 | 0.966220 | 0.99 | 0.99 |
| ELM-EHO | 96.6364 | 0.957048 | 0.976114 | 0.966560 | 0.976708 | 0.955974 | 0.966364 | 0.966778 | 0.965939 | 0.966359 | 0.99 | 0.99 |
| ELM-WOA | 96.1867 | 0.958182 | 0.965630 | 0.961898 | 0.966062 | 0.957654 | 0.961867 | 0.962106 | 0.961626 | 0.961866 | 0.99 | 0.99 |
| ELM-SNS | 96.5695 | 0.960938 | 0.970575 | 0.965746 | 0.971011 | 0.960357 | 0.965695 | 0.965948 | 0.965439 | 0.965694 | 0.99 | 0.99 |
| Metrics | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Metaheuristic | Accuracy (%) | Precision 0 | Precision 1 |
M.Avg.
Precision | Recall 0 | Recall 1 |
M.Avg.
Recall | F1 Score 0 | F1 Score 1 |
M.Avg.
F1 Score |
M.Avg.
ROC AUC |
M.Avg.
PR AUC |
| XGBoost-GSFA | 99.9842 | 0.999988 | 0.999695 | 0.999842 | 0.999696 | 0.999988 | 0.999842 | 0.999842 | 0.999841 | 0.999842 | 1.00 | 1.00 |
| XGBoost-FA | 99.9766 | 0.999965 | 0.999565 | 0.999766 | 0.999567 | 0.999965 | 0.999766 | 0.999766 | 0.999765 | 0.999766 | 1.00 | 1.00 |
| XGBoost-BA | 99.9818 | 0.999988 | 0.999648 | 0.999818 | 0.999649 | 0.999988 | 0.999818 | 0.999819 | 0.999818 | 0.999818 | 1.00 | 1.00 |
| XGBoost-ABC | 99.9842 | 0.999965 | 0.999718 | 0.999842 | 0.999719 | 0.999965 | 0.999842 | 0.999842 | 0.999841 | 0.999842 | 1.00 | 1.00 |
| XGBoost-SCA | 99.9830 | 0.999965 | 0.999695 | 0.999830 | 0.999696 | 0.999965 | 0.999830 | 0.999830 | 0.999830 | 0.999830 | 1.00 | 1.00 |
| XGBoost-MBO | 99.9683 | 0.999941 | 0.999425 | 0.999684 | 0.999427 | 0.999941 | 0.999683 | 0.999684 | 0.999683 | 0.999683 | 1.00 | 1.00 |
| XGBoost-HHO | 99.9818 | 0.999965 | 0.999671 | 0.999818 | 0.999672 | 0.999965 | 0.999818 | 0.999819 | 0.999818 | 0.999818 | 1.00 | 1.00 |
| XGBoost-EHO | 99.9812 | 0.999965 | 0.999660 | 0.999812 | 0.999661 | 0.999965 | 0.999812 | 0.999813 | 0.999812 | 0.999812 | 1.00 | 1.00 |
| XGBoost-WOA | 99.9766 | 0.999930 | 0.999601 | 0.999766 | 0.999602 | 0.999930 | 0.999766 | 0.999766 | 0.999765 | 0.999766 | 1.00 | 1.00 |
| XGBoost-SNS | 99.9818 | 0.999977 | 0.999659 | 0.999818 | 0.999661 | 0.999976 | 0.999818 | 0.999819 | 0.999818 | 0.999818 | 1.00 | 1.00 |
| Method/Parameters | No SMOTE | With SMOTE | ||||
|---|---|---|---|---|---|---|
| C | Kernel Type | C | Kernel Type | |||
| SVM-GSFA | 1816.0411 | 0.0492 | 1 | 0.031 | 0.1015 | 0 |
| SVM-FA | 16316.8042 | 0 | 0.031 | 1.6601 | 1 | |
| SVM-BA | 32768 | 0.1172 | 2 | 2106.3912 | 7.6593 | 0 |
| SVM-ABC | 6064.1918 | 0.0142 | 1 | 8512.3559 | 2 | |
| SVM-SCA | 15,430.8553 | 0 | 8591.6538 | 2 | ||
| SVM-MBO | 14,167.7370 | 1.9988 | 2 | 631.3854 | 5.1329 | 0 |
| SVM-HHO | 22,160.9077 | 0 | 500.4590 | 2.3178 | 0 | |
| SVM-EHO | 0.031 | 2.3360 | 0 | 2425.9645 | 0.0234 | 0 |
| SVM-WOA | 22,320.8262 | 0 | 0.0353 | 0.0912 | 0 | |
| SVM-SNS | 32,768 | 0 | 8277.7914 | 0.6790 | 0 |
| Method/ | No SMOTE | With SMOTE |
|---|---|---|
| Parameters | Number of Neurons | Number of Neurons |
| ELM-GSFA | 88 | 67 |
| ELM-FA | 60 | 74 |
| ELM-BA | 30 | 85 |
| ELM-ABC | 85 | 86 |
| ELM-SCA | 53 | 150 |
| ELM-MBO | 97 | 135 |
| ELM-HHO | 50 | 48 |
| ELM-EHO | 56 | 79 |
| ELM-WOA | 64 | 133 |
| ELM-SNS | 64 | 90 |
| Method/ | No SMOTE | |||||
|---|---|---|---|---|---|---|
| Parameters | eta | min_child_weight | Subsample | colsample_bytree | max_depth | Gamma |
| XGBoost-GSFA | 0.6109 | 5.3438 | 0.6276 | 0.7093 | 8.0268 | 0.4437 |
| XGBoost-FA | 0.8330 | 7.1837 | 0.9261 | 0.7303 | 3.7943 | 0.1307 |
| XGBoost-BA | 0.7028 | 6.7516 | 0.6247 | 0.6904 | 5.7910 | 0.3833 |
| XGBoost-ABC | 0.8340 | 7.7698 | 0.5957 | 0.7957 | 6.2033 | 0.0021 |
| XGBoost-SCA | 0.5143 | 1.5846 | 1 | 0.7242 | 6.6324 | 0.4547 |
| XGBoost-MBO | 0.6572 | 3.9720 | 0.5423 | 0.7891 | 5.3727 | 0.1232 |
| XGBoost-HHO | 0.6329 | 2.2029 | 0.9299 | 0.9118 | 7.8752 | 0.5 |
| XGBoost-EHO | 0.6274 | 10 | 1 | 0.6247 | 5.1698 | 0.5 |
| XGBoost-WOA | 0.5940 | 5.5582 | 0.5548 | 0.6715 | 6.0848 | 0.4435 |
| XGBoost-SNS | 0.6841 | 1 | 0.9168 | 1 | 5.8061 | 0.1113 |
| With SMOTE | ||||||
| Parameters | eta | min_child_weight | Subsample | colsample_bytree | max_depth | Gamma |
| XGBoost-GSFA | 0.8753 | 5.5543 | 0.9998 | 0.7219 | 9.5889 | 0.3941 |
| XGBoost-FA | 0.7744 | 5.7581 | 0.9646 | 0.4266 | 8.9161 | 0.0730 |
| XGBoost-BA | 0.8889 | 1 | 1 | 0.4705 | 9.9235 | 0.3647 |
| XGBoost-ABC | 0.8581 | 3.9509 | 0.7588 | 0.3775 | 10 | 0.0874 |
| XGBoost-SCA | 0.9 | 1 | 0.9368 | 0.5866 | 10 | 0 |
| XGBoost-MBO | 0.7940 | 2.1121 | 0.4077 | 0.7334 | 8.7939 | 0.2791 |
| XGBoost-HHO | 0.8227 | 5.0387 | 0.9566 | 0.4330 | 9.6767 | 0.4883 |
| XGBoost-EHO | 0.9 | 3.9113 | 0.8527 | 0.7699 | 10 | 0.5 |
| XGBoost-WOA | 0.8606 | 2.5538 | 0.9666 | 0.9613 | 9.5649 | 0.1993 |
| XGBoost-SNS | 0.9 | 1 | 0.8993 | 0.5963 | 10 | 0.0858 |
| Methods | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Problem | GSFA | FA | BA | ABC | SCA | MBO | HHO | EHO | WOA | SNS |
| SVM | ||||||||||
| SVM Smote | ||||||||||
| ELM | ||||||||||
| ELM Smote | ||||||||||
| XGB | ||||||||||
| XGB Smote | ||||||||||
| Methods | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| GSFA | FA | BA | ABC | SCA | MBO | HHO | EHO | WOA | SNS | |
| p-value | ||||||||||
| Functions | GSFA | FA | BA | ABC | SCA | MBO | HHO | EHO | WOA | SNS |
|---|---|---|---|---|---|---|---|---|---|---|
| SVM | 1 | 7.5 | 9 | 2 | 4 | 10 | 4 | 7.5 | 4 | 6 |
| SVM Smote | 1 | 4 | 9 | 5 | 6 | 8 | 10 | 2 | 3 | 7 |
| ELM | 1 | 10 | 2 | 8 | 4 | 6 | 7 | 3 | 5 | 9 |
| ELM Smote | 2 | 1 | 4 | 6 | 9 | 8 | 5 | 3 | 10 | 7 |
| XGB | 1 | 2.5 | 9.5 | 2.5 | 8 | 4 | 6.5 | 6.5 | 5 | 9.5 |
| XGB Smote | 1 | 7 | 4 | 2 | 3 | 10 | 9 | 8 | 6 | 5 |
| Average Ranking | 1.17 | 5.33 | 6.25 | 4.25 | 5.67 | 7.67 | 6.92 | 5.00 | 5.50 | 7.25 |
| Rank | 1 | 4 | 7 | 2 | 6 | 10 | 8 | 3 | 5 | 9 |
| Functions | GSFA | FA | BA | ABC | SCA | MBO | HHO | EHO | WOA | SNS |
|---|---|---|---|---|---|---|---|---|---|---|
| SVM | 9 | 46.5 | 49 | 11 | 13 | 50 | 13 | 46.5 | 13 | 24 |
| SVM Smote | 1 | 5 | 59 | 7 | 8 | 58 | 60 | 2 | 3 | 57 |
| ELM | 10 | 48 | 16 | 43 | 35 | 38 | 40 | 21 | 36 | 44 |
| ELM Smote | 6 | 4 | 42 | 52 | 55 | 54 | 51 | 15 | 56 | 53 |
| XGB | 20 | 25.5 | 32.5 | 25.5 | 31 | 27 | 29.5 | 29.5 | 28 | 32.5 |
| XGB Smote | 17 | 37 | 22 | 18 | 19 | 45 | 41 | 39 | 34 | 23 |
| Average Ranking | 10.50 | 27.67 | 36.75 | 26.08 | 26.83 | 45.33 | 39.08 | 25.50 | 28.33 | 38.92 |
| Rank | 1 | 5 | 7 | 3 | 4 | 10 | 9 | 2 | 6 | 8 |
| Comparison | p-Value | Rank | 0.05/() | 0.1/() |
|---|---|---|---|---|
| GSFA vs. MBO | 0 | 0.005556 | 0.011111 | |
| GSFA vs. SNS | 1 | 0.006250 | 0.012500 | |
| GSFA vs. HHO | 2 | 0.007143 | 0.014286 | |
| GSFA vs. BA | 3 | 0.008333 | 0.016667 | |
| GSFA vs. SCA | 4 | 0.010000 | 0.020000 | |
| GSFA vs. WOA | 5 | 0.012500 | 0.025000 | |
| GSFA vs. FA | 6 | 0.016667 | 0.033333 | |
| GSFA vs. EHO | 7 | 0.025000 | 0.050000 | |
| GSFA vs. ABC | 8 | 0.050000 | 0.100000 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jovanovic, D.; Antonijevic, M.; Stankovic, M.; Zivkovic, M.; Tanaskovic, M.; Bacanin, N. Tuning Machine Learning Models Using a Group Search Firefly Algorithm for Credit Card Fraud Detection. Mathematics 2022, 10, 2272. https://doi.org/10.3390/math10132272
Jovanovic D, Antonijevic M, Stankovic M, Zivkovic M, Tanaskovic M, Bacanin N. Tuning Machine Learning Models Using a Group Search Firefly Algorithm for Credit Card Fraud Detection. Mathematics. 2022; 10(13):2272. https://doi.org/10.3390/math10132272
Chicago/Turabian StyleJovanovic, Dijana, Milos Antonijevic, Milos Stankovic, Miodrag Zivkovic, Marko Tanaskovic, and Nebojsa Bacanin. 2022. "Tuning Machine Learning Models Using a Group Search Firefly Algorithm for Credit Card Fraud Detection" Mathematics 10, no. 13: 2272. https://doi.org/10.3390/math10132272
APA StyleJovanovic, D., Antonijevic, M., Stankovic, M., Zivkovic, M., Tanaskovic, M., & Bacanin, N. (2022). Tuning Machine Learning Models Using a Group Search Firefly Algorithm for Credit Card Fraud Detection. Mathematics, 10(13), 2272. https://doi.org/10.3390/math10132272