
Modeling of Hyperparameter Tuned Deep Learning Model for Automated Image Captioning

 ,
, 
Abstract
:1. Introduction
- Develops a novel HPTDL-AIC technique for the automated image captioning process;
- Aims to create correct descriptions for the input images by the use of encoder–decoder structure;
- Employs the Faster SqueezeNet with RMSProp model for the extraction of visual features that exist in the image;
- Presents a BSA with LSTM as a language modeling tool to generate description sentences and decodes the vector into sentences;
- Validate the performance of the HPTDL-AIC technique using two benchmark datasets and inspect the results under several aspects.
2. Literature Review
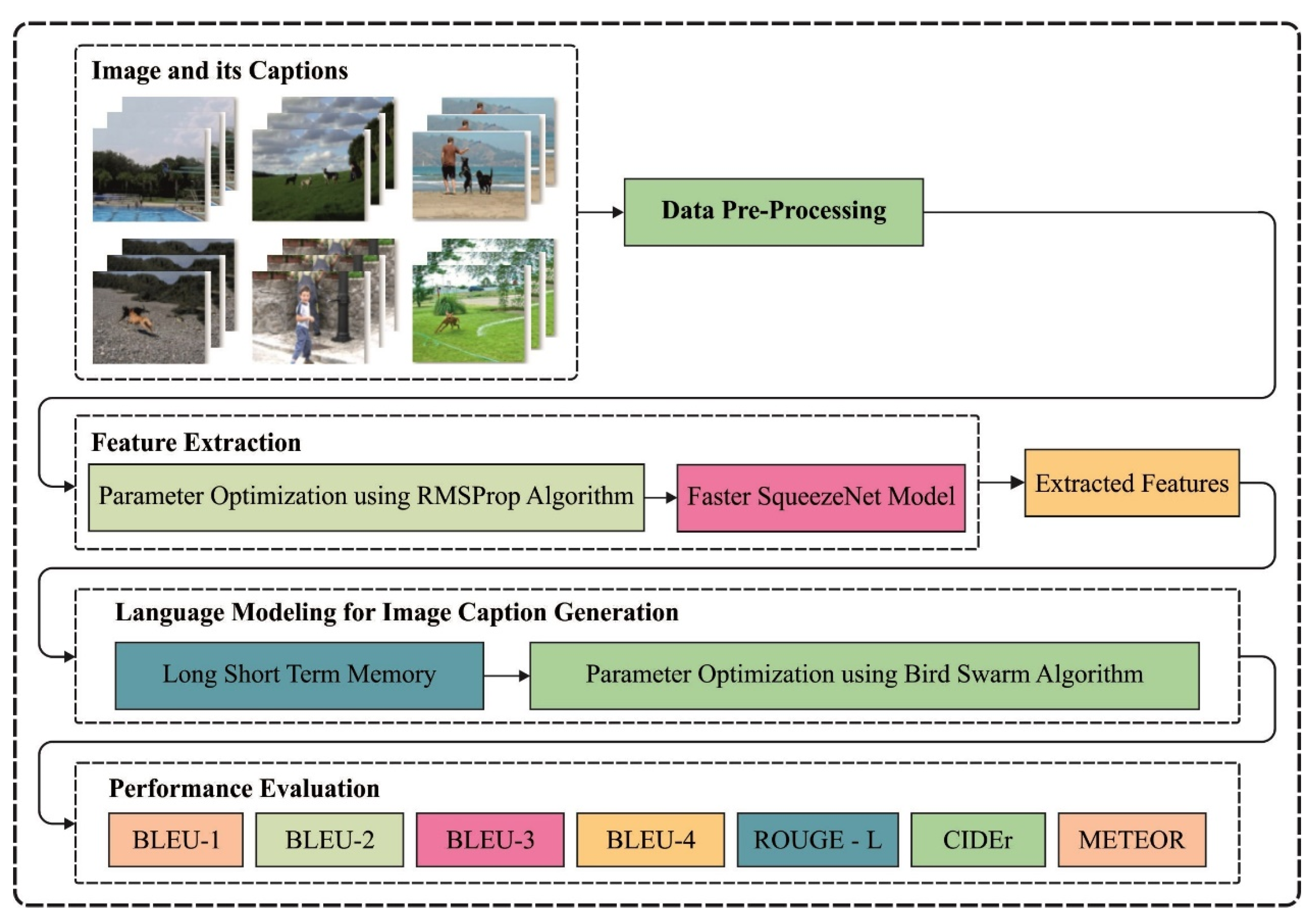
3. The Proposed Image Captioning Model
3.1. Pre-Processing
- The dataset text has words with distinct letter cases, which creates issues to components the same as the words with varying capitalized are regarded as altered. Thus, this improves issue vocabulary and afterward results in complexity. Therefore, it can be essential to alter the entire text to lower case in order to prevent this problem.
- The presence of punctuation improves the complexity of these issues; therefore, they are removed from the dataset.
- Numerical data present from the text retain an issue in the component as it increases the vocabulary that is extracted.
- Indicates initial and final order: word tokens ‘<start>’ and ‘<end>’ are further initial and final of every sentence for representing the initial and last token of the forecast order to the component.
- Tokenization: clean text is separated into constituent words, and a dictionary including the entire vocabulary to word-to-index and index-to-word equivalent are obtained.
- Vectorization: For resolving different sentence lengths, the short sentence is padded to the length of long sentence orders.
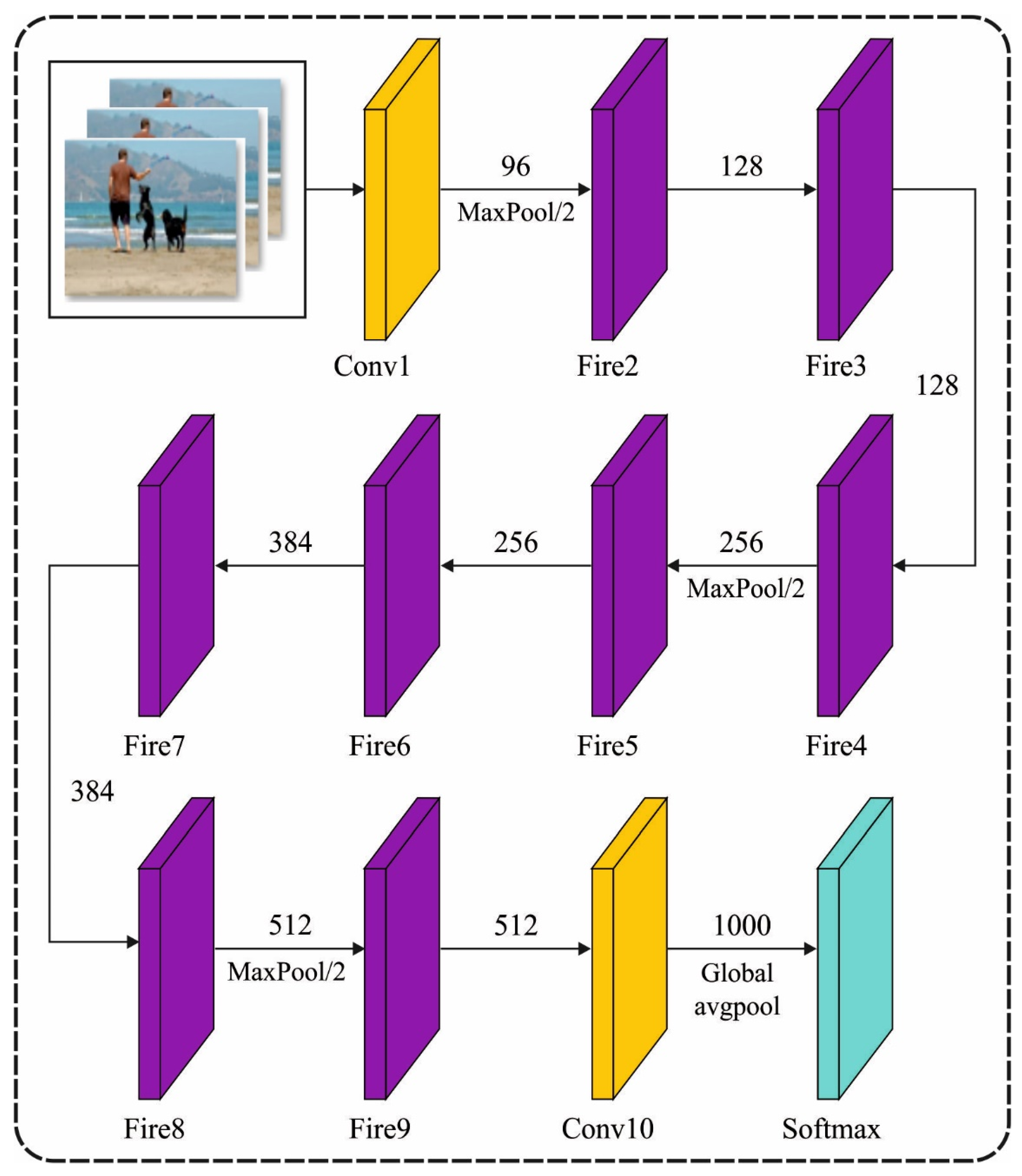
3.2. Feature Extraction: Optimal Faster SqueezeNet Model
3.3. Language Modeling for Image Caption Generation
- Rule1: All birds are switched amongst vigilant as well as foraging behaviors. If a bird forages or retains vigilance, it can be defined as a stochastic decision.
- Rule2: If foraging, all birds record and upgrade their preceding optimum experience and swarm earlier optimum experience. The experience is utilized for searching for food. Social information is distributed concurrently amongst the entire swarm.
- Rule3: While maintaining vigilance, all birds attempt to move nearby the center of swarm. This characteristic can be determined by disturbance due to swarm competitions. the birds with higher reserves further tend towards adjacent swarm centers than birds with lower reserves.
- Rule4: The bird flies to other locations frequently. Upon flying to other places, birds frequently switch amongst production as well as scrounging. The bird with maximum reserves becomes a producer, and others with minimum reserves are scroungers. Another bird with maximal as well as minimal reserves was arbitrarily chosen to be the producer as well as a scrounger.
- Rule5: The producer actively seeks food. The scroungers arbitrarily follow a producer for searching the food.
4. Performance Validation
4.1. Implementation Data
4.2. Performance Measures
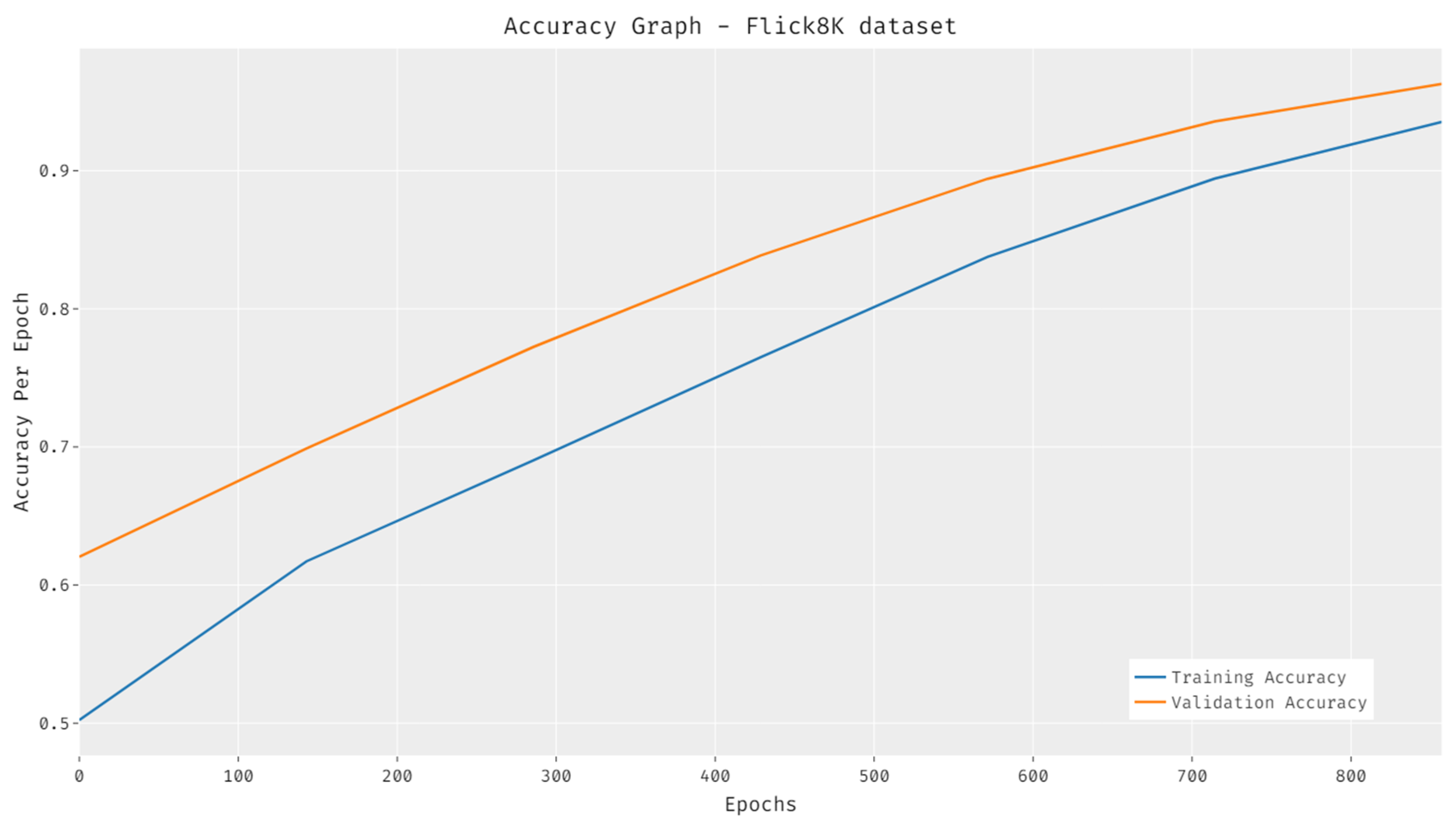
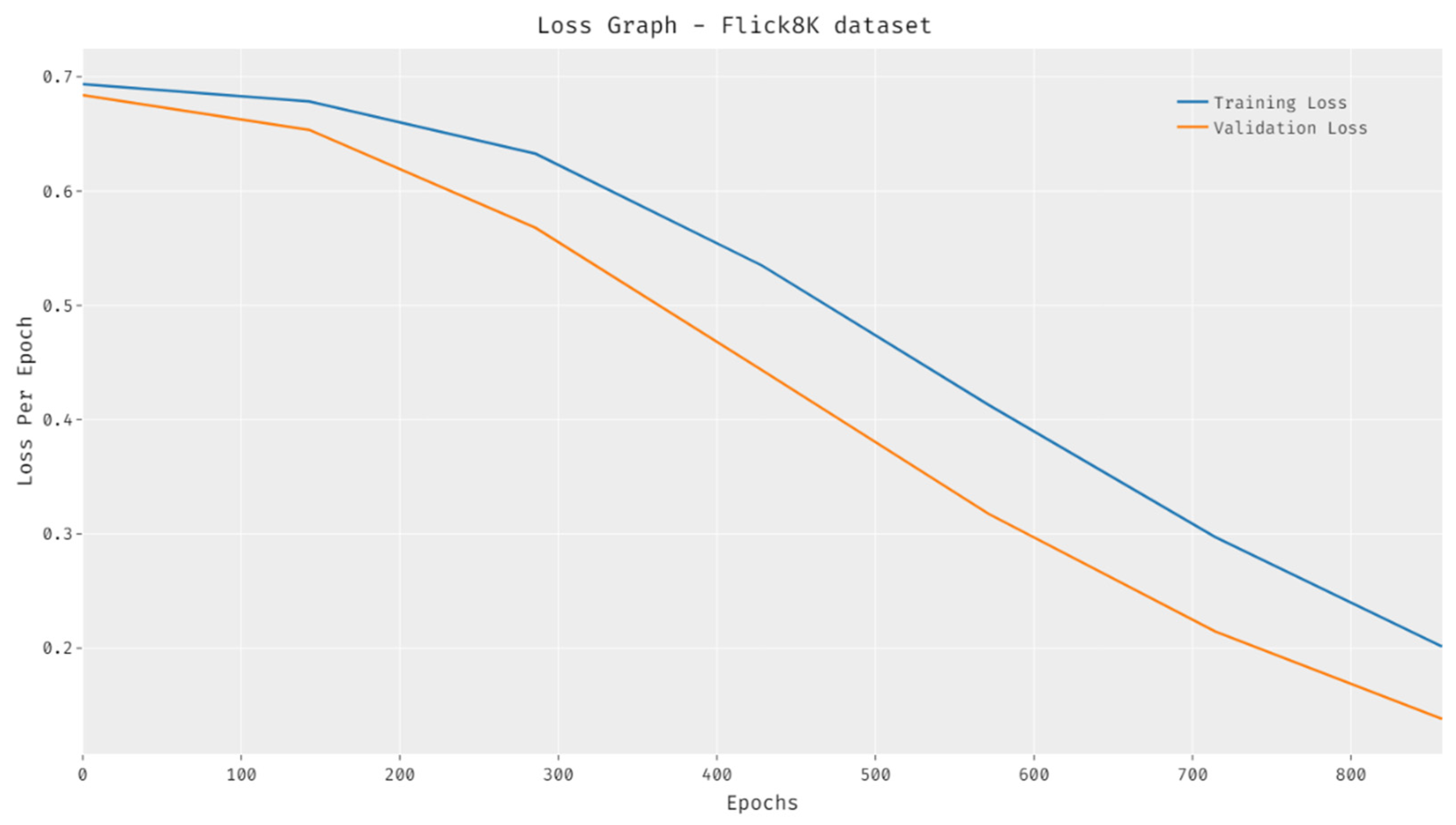
4.3. Visualization Results
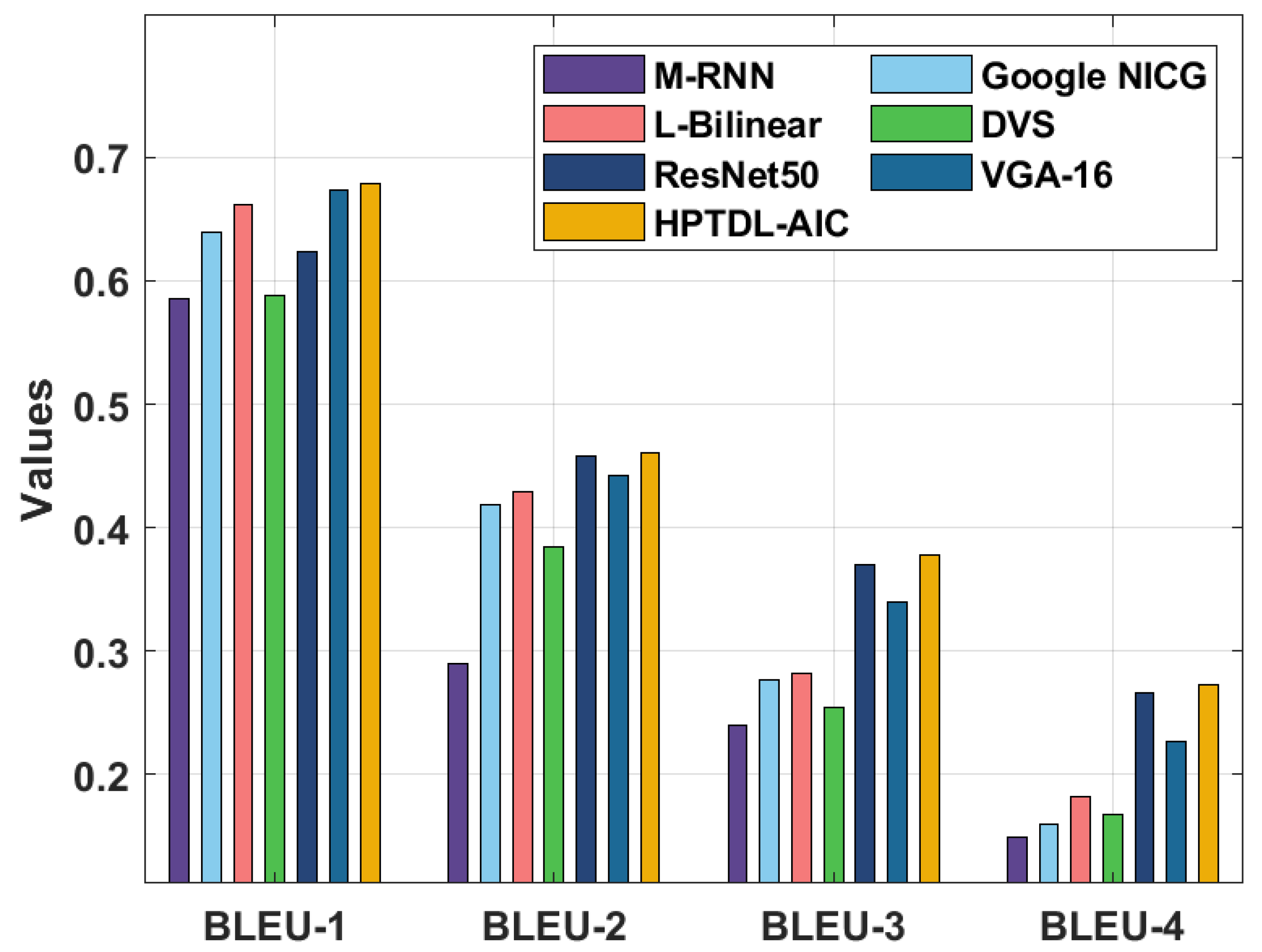
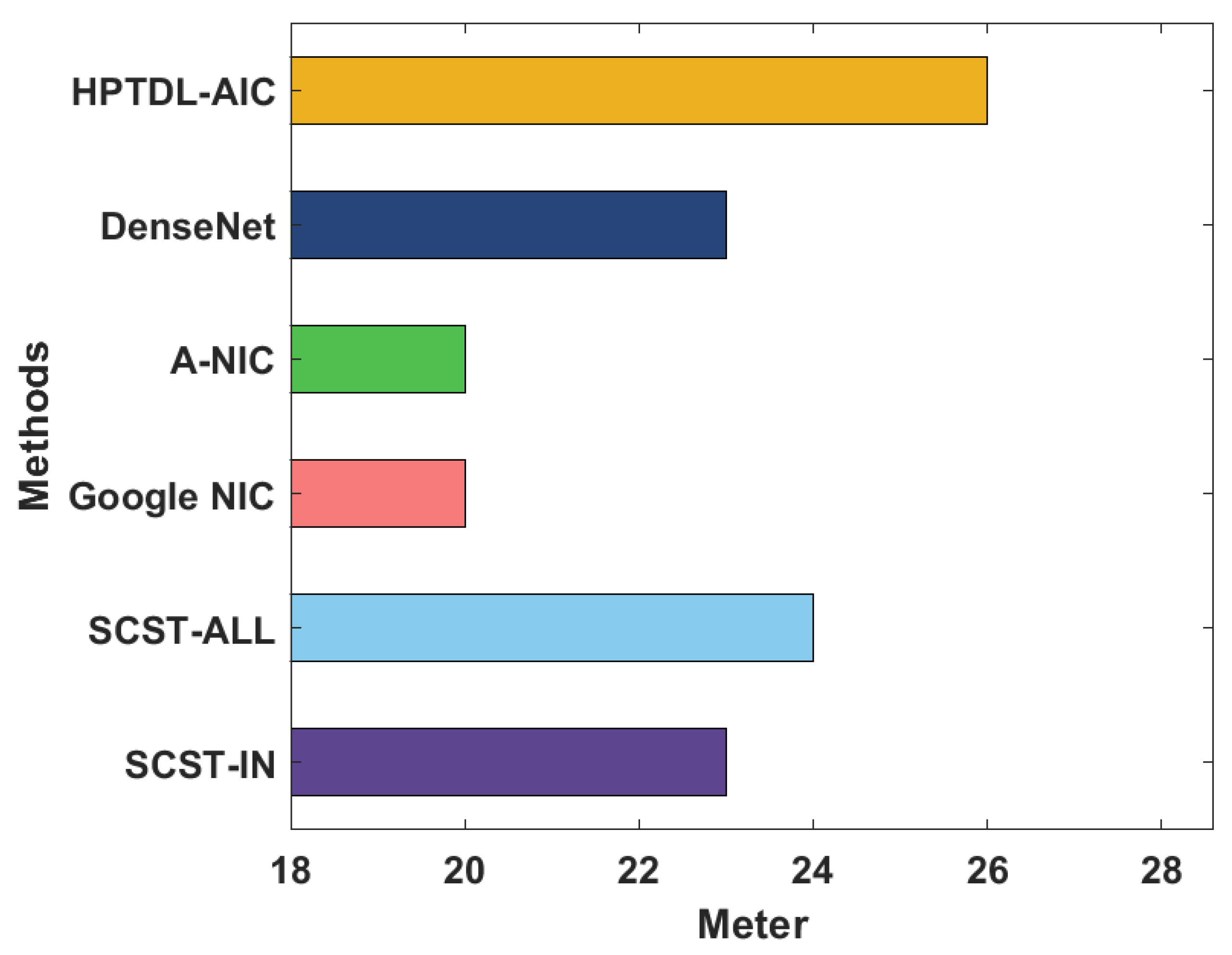
4.4. Results Analysis on Flickr8K Dataset
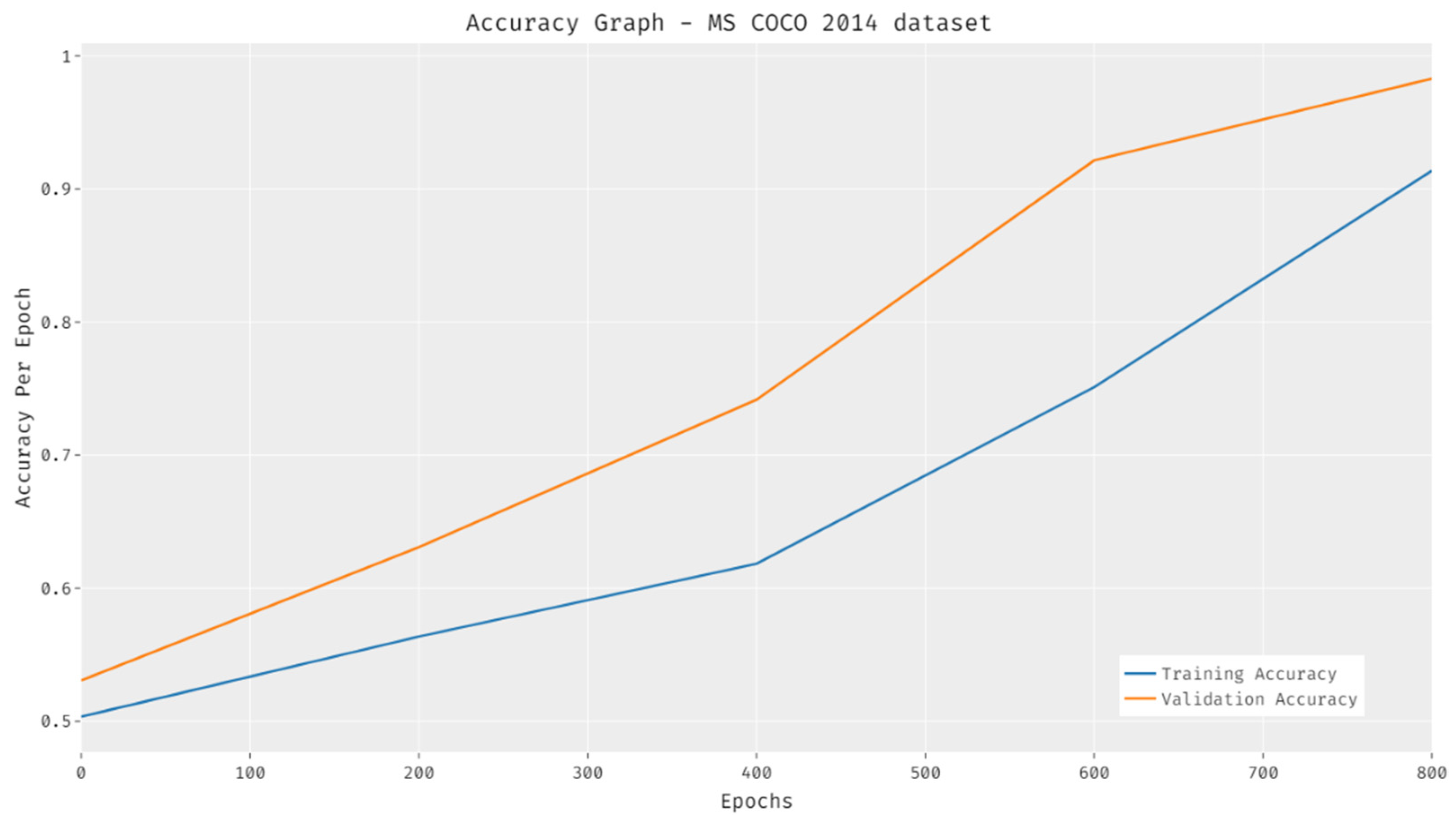
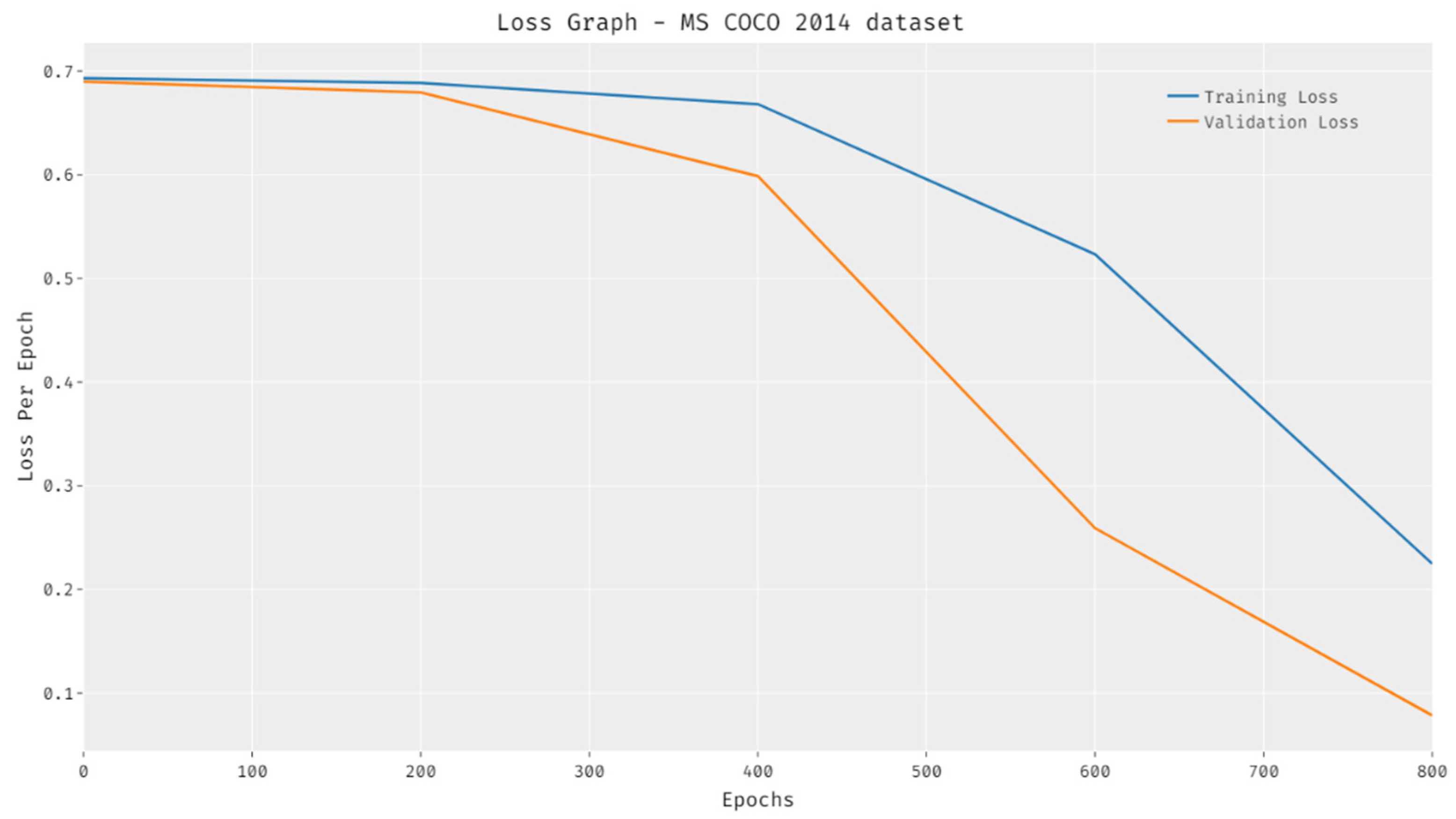
4.5. Results Analysis on MS COCO 2014 Dataset
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Huang, W.; Wang, Q.; Li, X. Denoising-based multiscale feature fusion for remote sensing image captioning. IEEE Geosci. Remote Sens. Lett. 2020, 18, 436–440. [Google Scholar] [CrossRef]
- Hossain, M.Z.; Sohel, F.; Shiratuddin, M.F.; Laga, H. A comprehensive survey of deep learning for image captioning. ACM Comput. Surv. (CsUR) 2019, 51, 1–36. [Google Scholar] [CrossRef] [Green Version]
- Wang, C.; Yang, H.; Bartz, C.; Meinel, C. Image captioning with deep bidirectional LSTMs. In Proceedings of the 24th ACM International Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; pp. 988–997. [Google Scholar]
- Sharma, P.; Ding, N.; Goodman, S.; Soricut, R. Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; Volume 1, pp. 2556–2565. [Google Scholar]
- Yao, T.; Pan, Y.; Li, Y.; Mei, T. Incorporating copying mechanism in image captioning for learning novel objects. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6580–6588. [Google Scholar]
- Hoxha, G.; Melgani, F.; Demir, B. Toward remote sensing image retrieval under a deep image captioning perspective. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 4462–4475. [Google Scholar] [CrossRef]
- Liu, H.; Wang, G.; Huang, T.; He, P.; Skitmore, M.; Luo, X. Manifesting construction activity scenes via image captioning. Autom. Constr. 2020, 119, 103334. [Google Scholar] [CrossRef]
- Li, Y.; Yao, T.; Pan, Y.; Chao, H.; Mei, T. Pointing novel objects in image captioning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12497–12506. [Google Scholar]
- Ren, Z.; Wang, X.; Zhang, N.; Lv, X.; Li, L.J. Deep reinforcement learning-based image captioning with embedding reward. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 290–298. [Google Scholar]
- Kesavan, V.; Muley, V.; Kolhekar, M. Deep Learning based Automatic Image Caption Generation. In Proceedings of the 2019 Global Conference for Advancement in Technology (GCAT), Bangalore, India, 18–20 October 2019; pp. 1–6. [Google Scholar]
- Wang, E.K.; Zhang, X.; Wang, F.; Wu, T.Y.; Chen, C.M. Multilayer dense attention model for image caption. IEEE Access 2019, 7, 66358–66368. [Google Scholar] [CrossRef]
- Sharma, H. A Novel Image Captioning Model Based on Morphology and Fisher Vectors. In Proceedings of International Conference on Communication and Artificial Intelligence; Springer: Singapore, 2021; pp. 483–493. [Google Scholar]
- Cheng, C.; Li, C.; Han, Y.; Zhu, Y. A semi-supervised deep learning image caption model based on Pseudo Label and N-gram. Int. J. Approx. Reason. 2021, 131, 93–107. [Google Scholar] [CrossRef]
- Zeng, X.; Wen, L.; Liu, B.; Qi, X. Deep learning for ultrasound image caption generation based on object detection. Neurocomputing 2020, 392, 132–141. [Google Scholar] [CrossRef]
- Shen, X.; Liu, B.; Zhou, Y.; Zhao, J.; Liu, M. Remote sensing image captioning via Variational Autoencoder and Reinforcement Learning. Knowl.-Based Syst. 2020, 203, 105920. [Google Scholar] [CrossRef]
- Xu, Y.; Yang, G.; Luo, J.; He, J. An Electronic Component Recognition Algorithm Based on Deep Learning with a Faster SqueezeNet. Math. Probl. Eng. 2020, 2020, 2940286. [Google Scholar] [CrossRef]
- Chu, Y.; Yue, X.; Yu, L.; Sergei, M.; Wang, Z. Automatic image captioning based on ResNet50 and LSTM with soft attention. Wirel. Commun. Mob. Comput. 2020, 2020, 8909458. [Google Scholar] [CrossRef]
- Meng, X.B.; Gao, X.Z.; Lu, L.; Liu, Y.; Zhang, H. A new bio-inspired optimisation algorithm: Bird Swarm Algorithm. J. Exp. Theor. Artif. Intell. 2016, 28, 673–687. [Google Scholar] [CrossRef]
- Phan, N.H.; Hoang, V.D.; Shin, H. Adaptive combination of tag and link-based user similarity in flickr. In Proceedings of the 18th ACM International Conference on Multimedia, Firenze, Italy, 25–29 October 2010; pp. 675–678. Available online: https://www.kaggle.com/adityajn105/flickr8k/activity (accessed on 14 August 2021).
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and tell: Lessons learned from the 2015 mscoco image captioning challenge. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 652–663. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; pp. 311–318. [Google Scholar]
- Denkowski, M.; Lavie, A. Meteor 1.3: Automatic metric for reliable optimization and evaluation of machine translation systems. In Proceedings of the Sixth Workshop on Statistical Machine Translation, Edinburgh, UK, 30–31 July 2011; pp. 85–91. [Google Scholar]
- Vedantam, R.; Lawrence Zitnick, C.; Parikh, D. Cider: Consensus-based image description evaluation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4566–4575. [Google Scholar]
- Lin, C.-Y. ROUGE: A package for automatic evaluation of summaries. In Proceedings of the ACL-Workshop, Text Summarization Branches Out, Barcelona, Spain, 25–26 July 2004; pp. 1–8. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 |
|---|---|---|---|---|
| M-RNN | 0.585 | 0.290 | 0.240 | 0.149 |
| Google NICG | 0.639 | 0.419 | 0.277 | 0.160 |
| L-Bilinear | 0.662 | 0.429 | 0.282 | 0.182 |
| DVS | 0.588 | 0.385 | 0.254 | 0.168 |
| ResNet50 | 0.624 | 0.458 | 0.370 | 0.266 |
| VGA-16 | 0.674 | 0.442 | 0.340 | 0.227 |
| HPTDL-AIC | 0.679 | 0.461 | 0.378 | 0.273 |
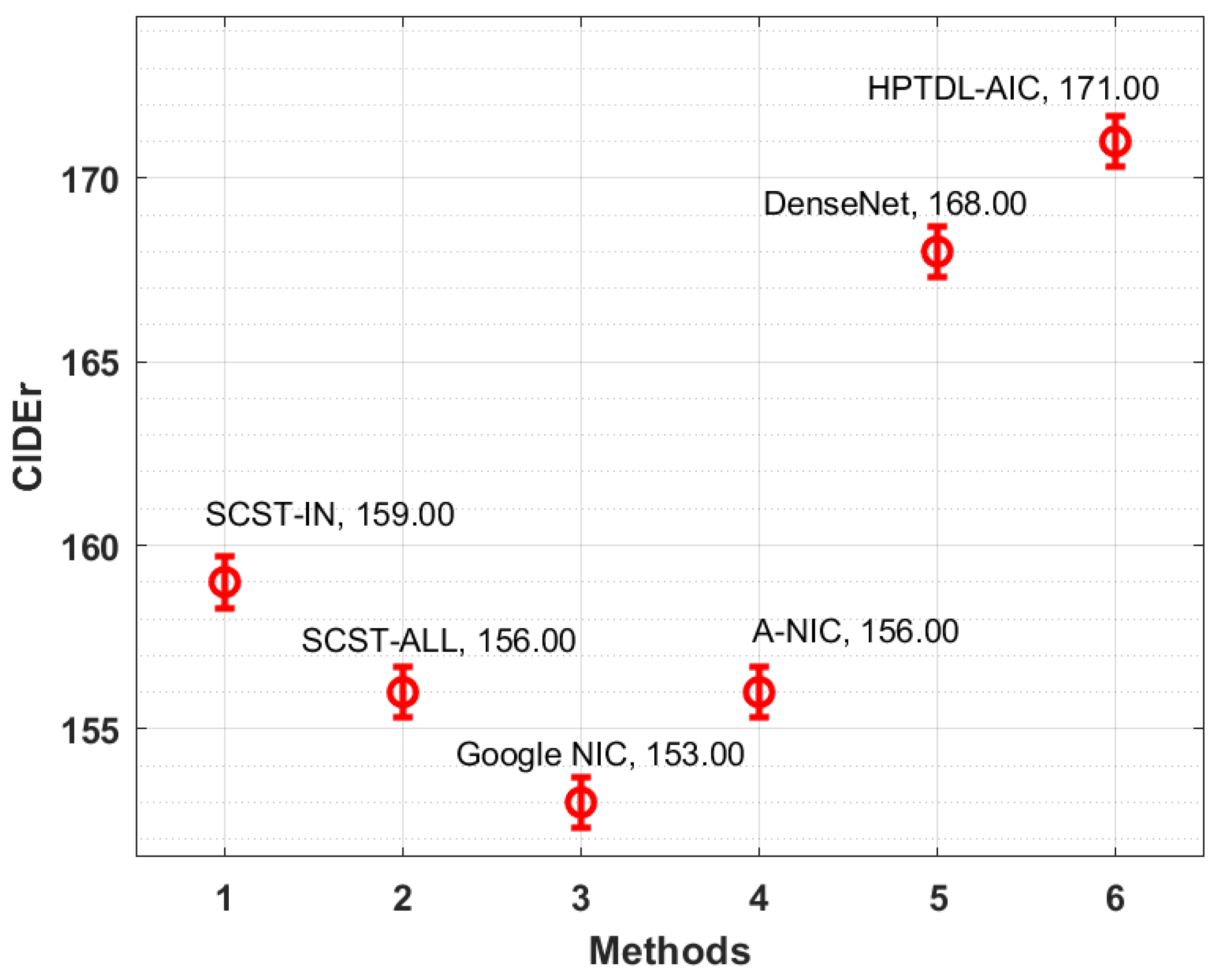
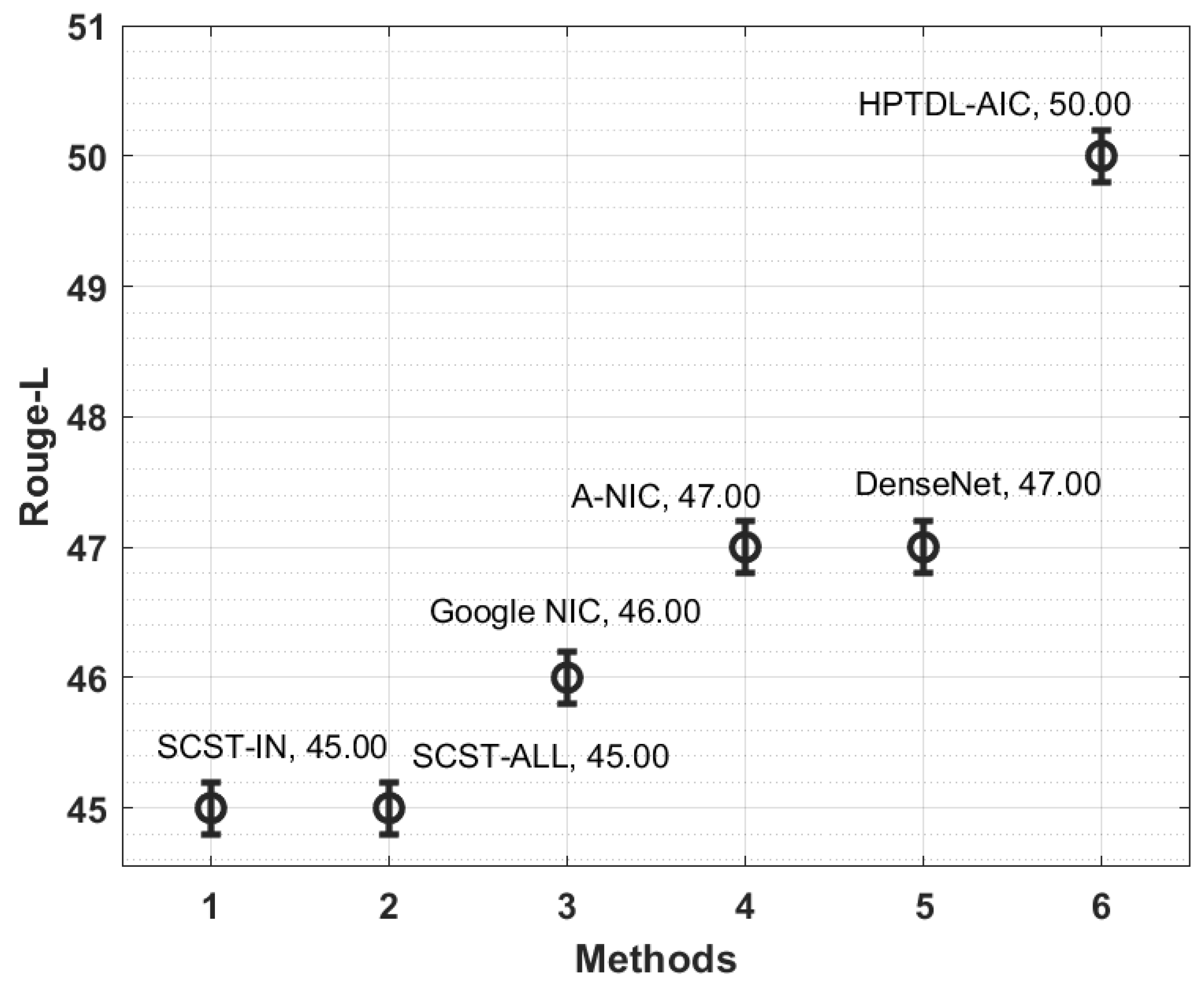
| Methods | Meter | CIDEr | Rouge-L |
|---|---|---|---|
| SCST-IN | 23.00 | 159.00 | 45.00 |
| SCST-ALL | 24.00 | 156.00 | 45.00 |
| Google NIC | 20.00 | 153.00 | 46.00 |
| A-NIC | 20.00 | 156.00 | 47.00 |
| DenseNet | 23.00 | 168.00 | 47.00 |
| HPTDL-AIC | 26.00 | 171.00 | 50.00 |
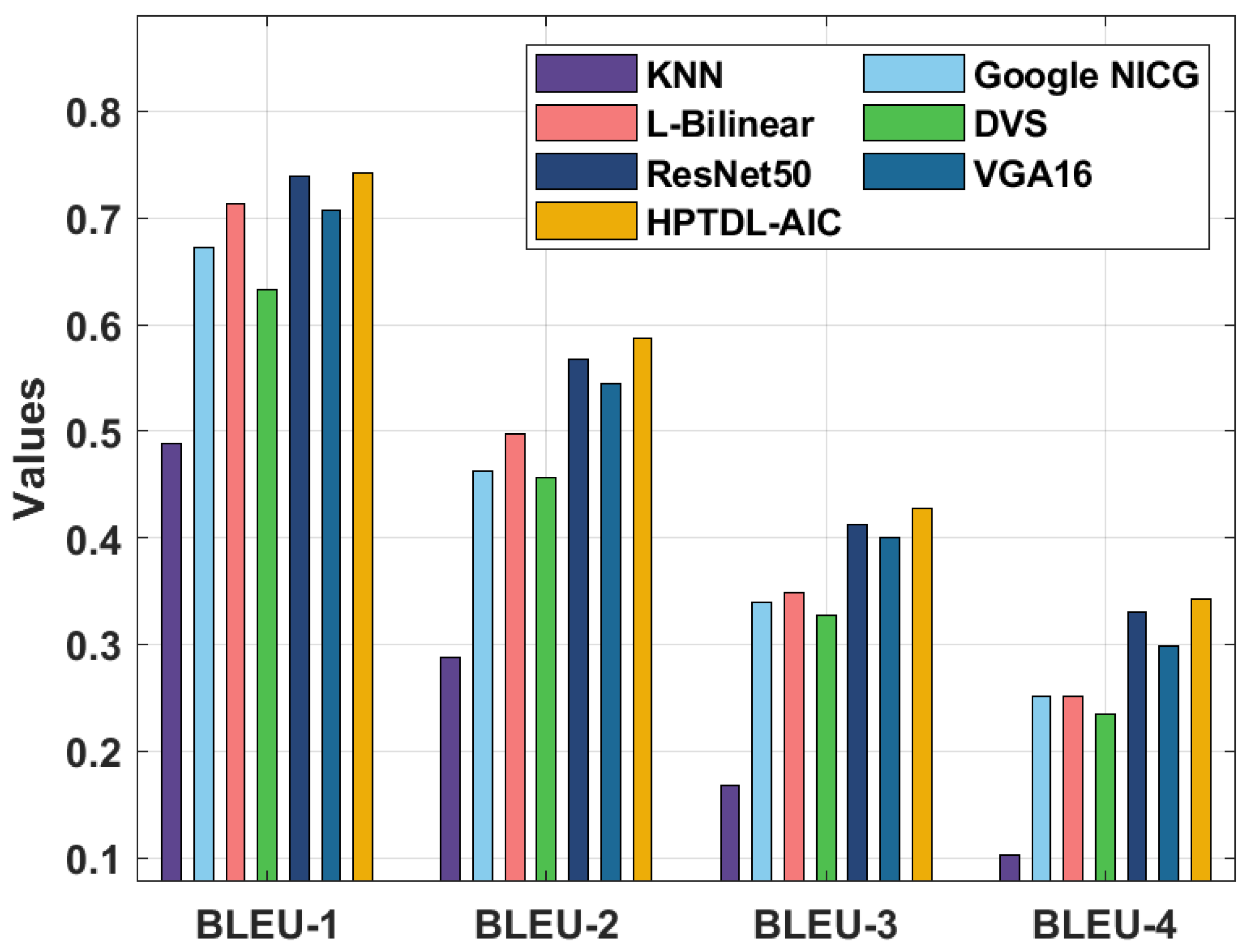
| Methods | BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 |
|---|---|---|---|---|
| KNN | 0.489 | 0.288 | 0.168 | 0.103 |
| Google NICG | 0.673 | 0.463 | 0.339 | 0.252 |
| L-Bilinear | 0.713 | 0.497 | 0.349 | 0.251 |
| DVS | 0.633 | 0.457 | 0.328 | 0.235 |
| ResNet50 | 0.739 | 0.568 | 0.413 | 0.331 |
| VGA16 | 0.707 | 0.544 | 0.400 | 0.299 |
| HPTDL-AIC | 0.742 | 0.587 | 0.428 | 0.343 |
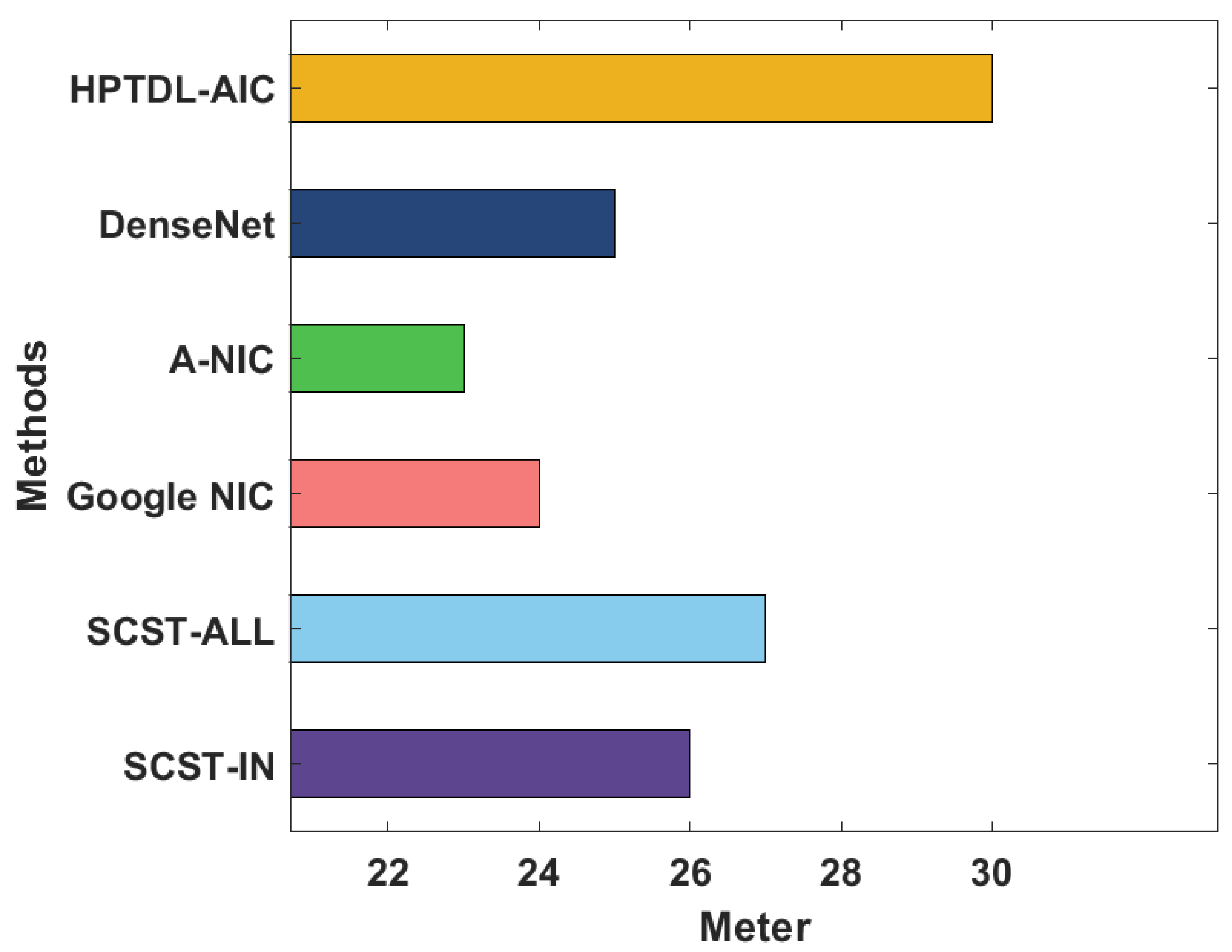
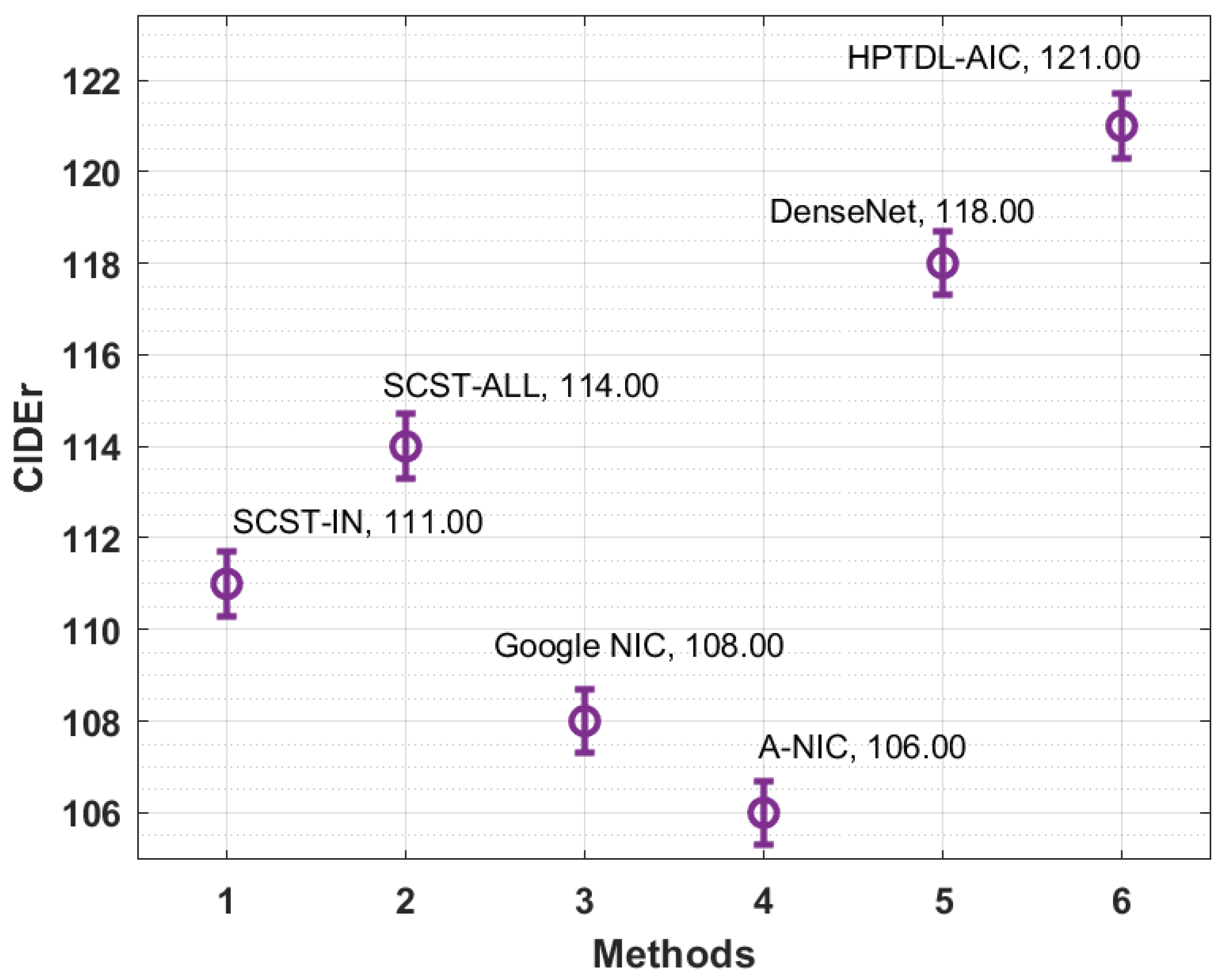
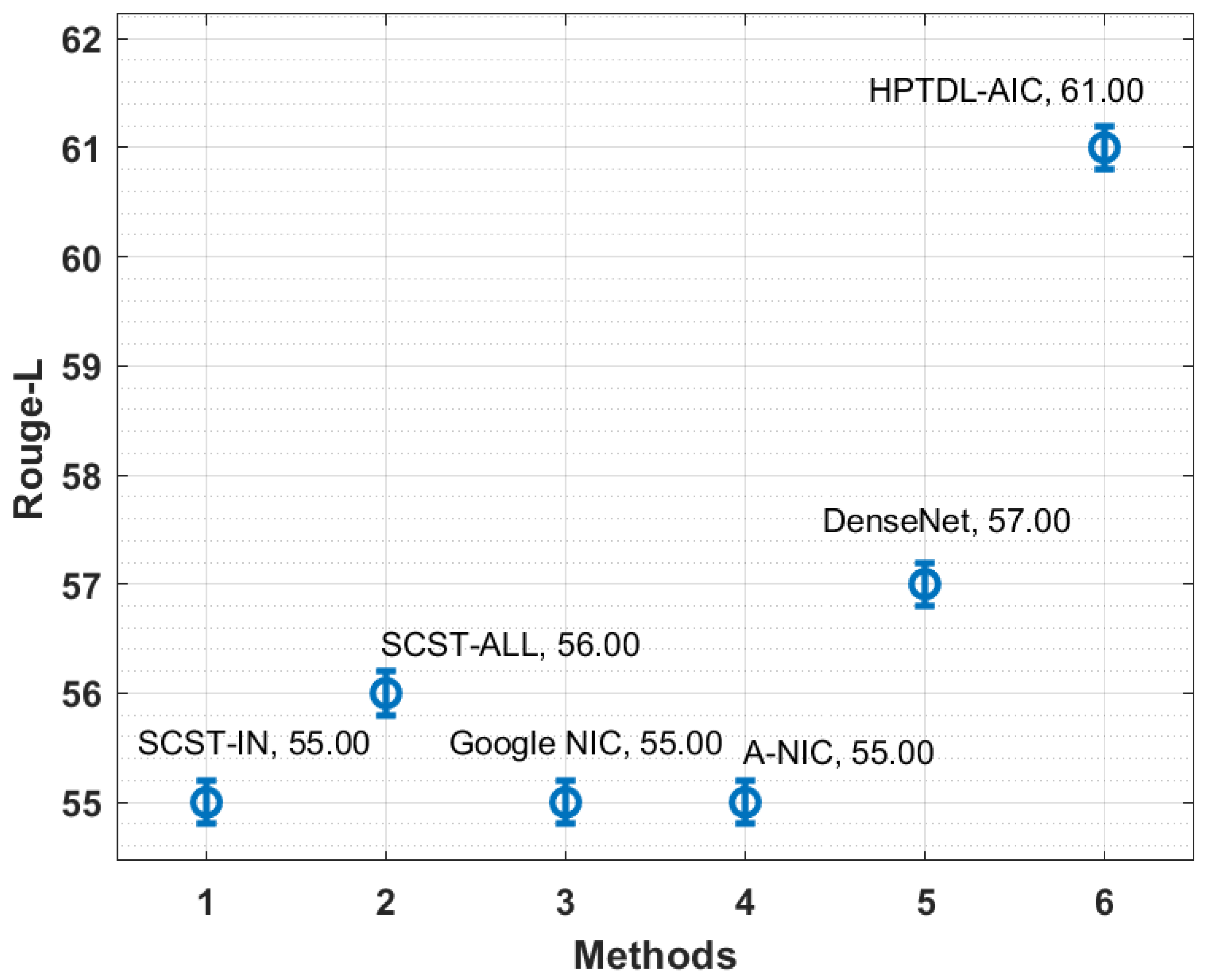
| Methods | Meter | CIDEr | Rouge-L |
|---|---|---|---|
| SCST-IN | 26.00 | 111.00 | 55.00 |
| SCST-ALL | 27.00 | 114.00 | 56.00 |
| Google NIC | 24.00 | 108.00 | 55.00 |
| A-NIC | 23.00 | 106.00 | 55.00 |
| DenseNet | 25.00 | 118.00 | 57.00 |
| HPTDL-AIC | 30.00 | 121.00 | 61.00 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Omri, M.; Abdel-Khalek, S.; Khalil, E.M.; Bouslimi, J.; Joshi, G.P. Modeling of Hyperparameter Tuned Deep Learning Model for Automated Image Captioning. Mathematics 2022, 10, 288. https://doi.org/10.3390/math10030288
Omri M, Abdel-Khalek S, Khalil EM, Bouslimi J, Joshi GP. Modeling of Hyperparameter Tuned Deep Learning Model for Automated Image Captioning. Mathematics. 2022; 10(3):288. https://doi.org/10.3390/math10030288
Chicago/Turabian StyleOmri, Mohamed, Sayed Abdel-Khalek, Eied M. Khalil, Jamel Bouslimi, and Gyanendra Prasad Joshi. 2022. "Modeling of Hyperparameter Tuned Deep Learning Model for Automated Image Captioning" Mathematics 10, no. 3: 288. https://doi.org/10.3390/math10030288
APA StyleOmri, M., Abdel-Khalek, S., Khalil, E. M., Bouslimi, J., & Joshi, G. P. (2022). Modeling of Hyperparameter Tuned Deep Learning Model for Automated Image Captioning. Mathematics, 10(3), 288. https://doi.org/10.3390/math10030288