Abstract
As one of the most widely used applications in domain adaption (DA), Cross-domain sentiment analysis (CDSA) aims to tackle the barrier of lacking in sentiment labeled data. Applying an adversarial network to DA to reduce the distribution discrepancy between source and target domains is a significant advance in CDSA. This adversarial DA paradigm utilizes a single global domain discriminator or a series of local domain discriminators to reduce marginal or conditional probability distribution discrepancies. In general, each discrepancy has a different effect on domain adaption. However, the existing CDSA algorithms ignore this point. Therefore, in this paper, we propose an effective, novel and unsupervised adversarial DA paradigm, Global-Local Dynamic Adversarial Learning (GLDAL). This paradigm is able to quantitively evaluate the weights of global distribution and every local distribution. We also study how to apply GLDAL to CDSA. As GLDAL can effectively reduce the distribution discrepancy between domains, it performs well in a series of CDSA experiments and achieves improvements in classification accuracy compared to similar methods. The effectiveness of each component is demonstrated through ablation experiments on different parts and a quantitative analysis of the dynamic factor. Overall, this approach achieves the desired DA effect with domain shifts.
Keywords:
adversarial domain adaption; cross-domain sentiment analysis; global-local dynamic adversarial learning MSC:
68T01
1. Introduction
Deep neural networks have led to impressive improvements in data mining. However, it is always time-consuming and expensive to acquire sufficient data, and especially to label them. The emergence of domain adaption [1] has significantly reduced the difficulty of labeling data and transferring knowledge between different domains. One of the most challenging problems in domain adaption is how to reduce or even eliminate the differences between the source domain and target domain [2]. In CDSA, these differences are reflected as domain discrepancies owing to the distinct expression of the reviewers’ emotions from various domains [3]. In recent years, adversarial domain adaption [4] has been widely used to reduce different domains’ distribution discrepancies. Most of them depend on either global domain discriminator to reduce marginal probability distribution discrepancy, or several local domain discriminators to reduce conditional probability distribution discrepancy. For example, DANN [4] only implements global adversarial adaption to align global distributions from different domains. Analogously, MADA [5] only utilizes a series of local domain discriminators to align subdomains. In true application scenarios, the global alignment and every single local alignment always contribute differently to the entire domain adaption. When two domains’ marginal probability distributions are more dissimilar, it is obvious that global alignment plays a bigger role. Otherwise, local alignment is more important. Similarly, each local alignment makes different contributions to the total local alignment.
Due to the issues of domain transfer and concept drift, a sentiment classification model trained in one domain may not effectively generalize to other domains. The expressions of sentiment, viewpoints, and emotionally charged words evolve over time, making it challenging to maintain effective sentiment classification models across different domains. Therefore, employing domain adaptation methods can help reduce the drift of sentiment expression [6]. The main purpose of this study is to reduce the data distribution gap between the two emotion domains to enhance the generalization ability of cross-domain emotion classification data models. We want to achieve this goal by utilizing the global-domain discriminator and local-domain discriminator commonly used in traditional natural-language-processing text classifiers to minimize the difference between data margins and global distribution, thereby improving the generalization ability of cross-domain sentiment classification.
In this paper, we propose a novel domain adaption method Global–local Dynamic Adversarial Learning (GLDAL) for unsupervised adaption. GLDAL captures the multi-mode structure of data dynamically through adversarial learning. In CDSA, GLDAL is able to amplify the influence of the pivot words to learn domain-invariant features. The core components of GLDAL are the Global Dynamic Adversarial Factor (GDAF) and Local Dynamic Adversarial Factors (LDAF). The former has the ability to evaluate the relative significance of the marginal and conditional distributions both dynamically and quantitatively. Similarly, the latter plays the same role in the relationship between each conditional distribution. Therefore, GLDAL is able to improve the generalization of adversarial domain adaption.
In the following text, we detail the use of our proposed approach in deep neural network architectures, and experiment on popular sentiment classification datasets (SST, IMDB), where our proposed approach shows improvements compared to the previous state-of-the-art accuracy.
2. Related Work
2.1. Unsupervised Domain Adaption in Transfer Learning
Unsupervised domain adaptation (UDA) is an important branch of transfer learning. There are two main forms of UDA: traditional machine learning and deep learning. UDA based on traditional machine learning can be divided into two categories: (1) Subspace Alignment (SA) [7] and CORAL [8] use the subspace statistical characteristics to eliminate domain differences. (2) Distribution alignments TCA [9], JDA [10], BDA [11] and MEDA [12] are proposed to align the marginal probability distributions or conditional probability distributions between domains.
In the last few years, deep neural networks have been widely used in domain adaption [13,14,15]. Domain adversarial learning, as a branch of deep domain adaption, has been popular in recent years. The idea of adversarial learning comes from Generative Adversarial Networks (GAN) [16,17]. DANN [4] aligns the source and target distributions with only a single global domain discriminator. MADA [5] is able to execute the fine-grained alignment of different data distributions using multi-mode discriminators. DAAN [18] dynamically evaluates the relationship between the marginal and conditional distributions. Our GLDAL is also based on adversarial learning and global attention mechanism. By evaluating the relationship between every local subdomain and the relative importance of the marginal and conditional distributions, GLDAL significantly outperforms existing methods.
2.2. Cross-Domain Sentiment Analysis
Sentiment analysis is also called opinion mining or tendency analysis. It is the process of analyzing and reasoning about subjective texts with emotions. Text representation is an important step in sentiment analysis. In recent years, the most representative work has been the BERT pre-trained model [19], Transformer-XL [20]. However, thegeneral sentiment analysis studies mentioned above only consider the performanc e in a single domain, ignoring the generalization ability, so cross-domain sentiment analysis has quickly become a research hotspot. BERT-DAAT [21] is a pre-trained model based on adversarial training methods that aims to provide the trained BERT with domain awareness. ADS-SAL [22] can dynamically learn an alignment weight for each word, so more important words will obtain higher alignment weights to achieve fine-grained adaptation.
3. Method
3.1. Problem Definition
In CDSA tasks about domain adaption, there are a source domain and a target domain , where and is the set of sentences and are the corresponding sentiment polarity labels. The goal of CDSA is to predict the target label and minimize the target risk , where represents the Softmax output and refers to the feature representation.
3.2. Backbones for Cross-Domain Sentiment Analysis
3.2.1. Bidirectional Gate Recurrent Units with Attention
A Gate Recurrent Unit (GRU) with the attention mechanism [23] is an effective recurrent neural network for sentiment analysis. For a given -dimensional input , the hidden layer of Bi-GRU outputs at time . The calculation process is as follows:
, W is the weight matrix and b is the bias vector; is the activation function; and are the outputs of positive and negative GRU, respectively. ⊕ represents the element-wise summation. The simplification method is to construct a single vector c from the whole sequence, as follows:
3.2.2. Capsule Neural Network Based on BERT
The BERT [19] model is a language model based on two-way Transformer. We directly use the feature representation of BERT as the word-embedding feature of the task and regard BERT as the upstream network. The Capsule Network [24] is composed of a group of neurons, which are used to represent the parameters of a specific type of object. We regard this network as a downstream network. The unique activation function (“squashing”) is formulated as:
is its total input and is the output of capsule . For capsule , the input is determined by multiplying the output of a capsule in the former layer by a weight matrix , , which are coefficients for coupling determined by the dynamic routing:
3.3. Domain Adaption with Adversarial Learning
This adversarial training is like a game with two parts: feature extractor and domain discriminator . Through maximizing the loss of , the parameters of are trained while the parameters of are trained by minimizing the loss of the domain discriminator. The total loss can be formalized as:
Update the parameters of each part as the following equations:
Due to the adversarial relationship with parameter updating, the parameters , , will deliver a saddle point of Equation (6) after the training converges.
3.4. Global-Local Dynamic Adversarial Adaption Network
At present, the mainstream adversarial adaption methods reduce marginal or conditional probability distribution discrepancies. However, it is quite difficult to evaluate the importance of each contribution. Therefore, we should find a novel method that can quantitatively evaluate their importance and dynamically adjust the parameters of the neural network.
In this paper, we propose the Global–local Dynamic Adversarial Learning (GLDAL) shown in Figure 1 to make key improvements. GLDAL can effectively evaluate every single distribution’s importance, aiming to better learn the domain-invariant features through adversarial learning. In GLDAL, the Global domain discriminator and a series of Local domain discriminators play a role in the domain adaption of marginal and conditional distributions, respectively. The most important innovation point is that we propose a novel, global-local dynamic training strategy using the Global Dynamic Factor and Local Dynamic Factors.
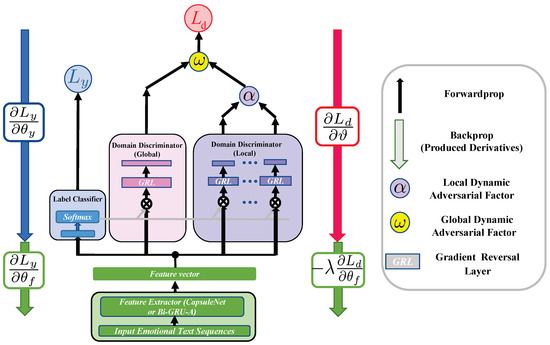
Figure 1.
The architecture of the proposed Global–local Dynamic Adversarial Learning (GLDAL). First, input the Text Sequences into the Feature Extractor to obtain the feature vector distributed in the feature space. Next, there are two main loss functions, namely and . is the classification loss. is the loss combination of the global domain discriminator and local domain discriminators.
3.4.1. Label Classifier
The label classifier (The blue part in Figure 1) in trained by samples from the source domain to implement label classification. The loss of is formulated as:
where represents samples and their labels from the source domain; is the feature extractor.
3.4.2. Global Domain Discriminator
Global domain discriminator (The pink part in Figure 1) is wisely implemented to align the marginal probability distributions between two domains (source domain and target domain) in the feature space. We define the loss of global domain discriminator as:
In this formula, represents the loss of domain discriminator. is the domain label of the sample and is the feature extractor.
3.4.3. Local Domain Discriminator
The local domain discriminator (The purple part in Figure 1) is composed of a series of U class-wise discriminators ; each is used to match the source domain and target domain data associated with class u. The output of the label classifier to each data point is a probability distribution of the U classes. Therefore, we utilize the probability distribution to measure how many data points should be attended to the U domain . The loss function of the local domain discriminator is defined as:
3.5. Global and Local Adversarial Factors
In this part, we introduce how to quantitively evaluate the global distributions and each local distribution. Due to the adversarial characteristic, it is tricky to determine a concrete scheme. Generally, there are two straightforward ideas: Random Setting and Average Step Searching. The former randomly sets the value of dynamic factors and the latter picks the value of these factors with the same step size. For instance, if the scope of factor is [0, 1], the latter strategy will pick the value of = 0, 0.1, …, 0.9, 1.0 to perform training. However, both strategies are computation-consuming and time-consuming.
Therefore, in this paper, we propose two kinds of factors: global dynamic adversarial factor and local dynamic adversarial factors in order to dynamically and quantitively evaluate the importance of each distribution. This strategy has two significant advantages. Firstly, we utilize deep adversarial representations instead of shallow representations to learn these two kinds of factors, making GLDAL more robust. Secondly, every single dynamic factor is determined by the (not hinge loss) of the discriminators, which is more efficient and convenient. In order to calculate the dynamic factors, we denote the global of the global domain discriminator as:
We also denote the local subdomain as:
These two kinds of distances can measure the distribution similarity of the source and target domain to some extent. and denote samples from class , and is the local subdomain discriminator loss over the class .
3.5.1. The Global Dynamic Adversarial Factor
The global dynamic adversarial factor is used to calculate the weighted sum of global domain loss and local domain loss. is initialized as 1 in the first training epoch. After each training epoch, this factor can be estimated through global and local domain discriminators as:
3.5.2. The Local Dynamic Adversarial Factors
The local domain loss is composed of a series of local subdomain loss by weighted summation. The local dynamic adversarial factors act as coefficients in the weighted sum. The importance of the alignment of each subdomain is different, so we assign different weights to every subdomain. In general, if the difference between the source subdomain and the target subdomain regarding class u is larger, we should pay more attention to this subdomain, which is manifested by the fact that the weight of the alignment of this subdomain should be increased. Since is an important parameter used to measure the similarity of the probability distributions of two subdomains and , the parameter can be estimated as:
Each subdomain dynamic adversarial factor is initialized as 1 in the first training epoch. This factor-updating strategy follows the principle: If the (Generally less than 0) between the subdomains about class u is larger, the weight for the alignment of subdomains about u will be greater. In this case, the domain discriminator of the subdomain u can more easily discriminate the domain label information of the sample in the subdomain, which indicates that the difference between domains about class u is large. Therefore, we need to increase the proportion of in the total local loss to ensure a better alignment effect about class u.
4. Experiments
In this section, we implement experiments to evaluate the proposed GLDAL against several previous state-of-the-art domain adaption methods. Our method GLDAL is validated on several popular standard datasets regarding cross-domain sentiment analysis. The training process is shown in Algorithm 1.
| Algorithm 1 GLDAL |
| Input: |
| —samples and , , , , |
| Output: Neural Network |
while stopping criterion is not meet do calculate the global domain loss : Equation (8) calculate the global : Equation (10) acquire classification probability vector from : calculate the sum of all local loss of sample : Equation (9) calculate each local : Equation (11) if then calculate the classification loss of: Equation (7) Backpropagation: Update dynamic factor : return Output |
4.1. Datasets
The Amazon Product Review dataset includes product reviews and metadata from Amazon; due to the uneven distribution of the samples, we set rating 0–1 as negative sentiment, 2–3 as medium and 5 as positive. We chose the following two datasets: Amazon reviews for clothing (C) and Amazon reviews for instant video (I).
SST-5 (S5), SST-2 (S2) are two versions of The Stanford Sentiment Treebank (SST); the former is (S5), with five categories (Very Positive, Positive, Neural, Negative), and the latter is (S2) with two categories (Positive, Negative).
IMDB (IM) is a review rating dataset for movie sentiment analysis, containing the same number of positive and negative sentiment samples. The COVID-19 Review dataset (COR) contains a sample of comments about COVID-19 and the corresponding sentiment scores (Very Positive, Positive, Neural, Negative). Tweet Review dataset TR contains daily comments and sentiment ratings scraped from tweets, with three categories (Positive, Neural, Negative).
We used these domain combinations and built six transfer learning tasks: (C → TR), (TR → I), (COR → S5), (S5 → COR), (IM → S2), (S2 → IM).
4.2. Baselines
Based on two previously mentioned backbones: Bi-GRU-A (Section 3.2.1) and CapsuleNet (Section 3.2.2),We compare our proposed Global–local Dynamic Adversarial Learning (GLDAL) with several state-of-the-art unsupervised deep domain adaption methods: DDC [25], DaNN [26], DANN [4], D-CORAL [15], JAN [27] MADA [5] and DAAN [18].
4.3. Implementation
We implement all methods on the PyTorch framework. For feature extractor backbones CapsuleNet and Bi-GRU-A, we fine-tune all word vectors and all attention layers and train the feature extraction layers with a learning rate of and , respectively. We use approximately 2–5 times the learning rate of the feature extractor to train the label classifier, and use 2–10 times the learning rate to train the local discriminator and global discriminator. The update of the important trade-off factor follows the Warm Start principles: . We set as 0, as 1, N as 100. Other hyperparameters are tuned via transfer cross-validation. The source code is available at https://github.com/killer2-1/GLDAL-for-CDSA (accessed on 20 May 2023).
4.4. Results
The classification accuracy (%) is shown in Table 1 and Table 2. GLDAL outperforms all comparison methods on most CDSA tasks. It is also remarkable that our GLDAL has better effects than similar approaches such as DANN, MADA and DAAN. From the results, we can obtain some conclusions: (1) Generally, the methods based on adversarial learning (DANN, DAAN) perform better than non-adversarial learning methods (DaNN, DDC), which means that adversarial adaption is more effective. (2) Adversarial methods with an attention mechanism such as GLDAL achieves a better performance than DANN and MADA(no attention). (3) Compared with other methods, GLDAL outperforms almost all traditional comparison methods (DDC, DaNN, DANN) on most transfer tasks, which proves the proposed method is effective. For some of the more advanced methods, such as DAAN, GLDAL slightly outperforms these methods, which verifies our method’s benefits.

Table 1.
Accuracy (%) for unsupervised domain adaptation based on Bi-GRU-A(The bold stands for the best performance).
Table 2.
Accuracy (%) of unsupervised domain adaptation based on CapsuleNet.
4.5. Effectiveness Analysis and Ablation Study
4.5.1. Analysis of the Importance of the Global Dynamic Adversarial Factor (GDAF) in GLDAL
In this section, the importance of GDAF in GLDAL is evaluated. The evaluation involves two key points: (1) Whether we should pay attention to the different effects of marginal and conditional probability in adverarial domain adaption. (2) The effectiveness of our evaluation for .
To illustrate the first point, we chose several transfer tasks and analyzed the results of GLDAL under different values of , as shown in in Figure 2. It is obvious that paying attention to the different effects of marginal and conditional distribution is important. The value of optimal varies on different tasks. This is because different feature representations are obtained under different .
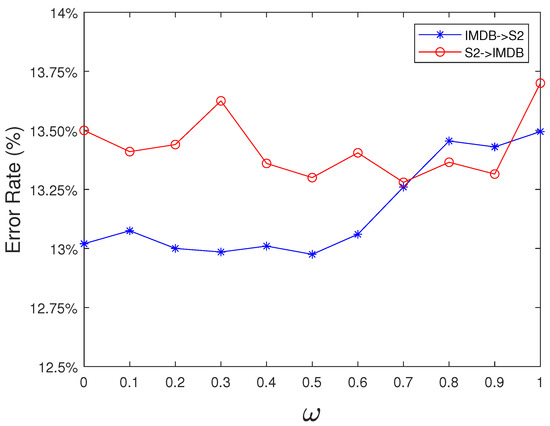
Figure 2.
Performance of several tasks when searching .
To illustrate the second point, we compared the accuracy of transfer tasks under different calculation methods for : Random Guessing, Average Searching (10 times) and our GLDAL. We also executed an ablation study with DANN ( = 1) and MADA ( = 0). Combining the results from Table 3, we can conclude that our method outperforms other four methods.
Table 3.
Accuracy (%) for the effective analysis and ablation study of based on CapsuleNet.
4.5.2. Analysis of the Importance of the Local Dynamic Adversarial Factor (LDAF) in GLDAL
In this section, based on the point oof whether we should pay attention to the different effect of each local subdomain, we analyze the importance of the local dynamic adversarial factor in GLDAL. Like the analysis of , we also chose a series of tasks, and adopted the three methods shown below to conduct verification experiments: (1) A series of random number that are greater than 0, and the sum is fixed to U (RNSF); (2) DAAN (all LDAFs are fixed to 1); (3) Our GLDAL. We used [28] as a measure of cross-domain discrepancy. In general, the smaller the , the better the domain adaption effect. The average results in each dataset are shown in Table 4.
Table 4.
for all unsupervised domain adaptation tasks based on backbone CapsuleNet and Bi-GRU-A.
5. Conclusions
In this paper, we proposed a novel Global–local Dynamic Adversarial Learning (GLDAL) for cross-domain sentiment analysis. Through quantitatively evaluating the relative importance of global distribution and all local distributions, GLDAL is able to dynamically adjust the learning weights of the global discriminator and local discriminators during training. This domain adaption strategy is based on the attention mechanism and has excellent effects on experimental tasks. As a general transfer learning strategy, GLDAL can also be applied to tasks in computer vision and the recommended system. In the future, we plan to extend GLDAL to more challenging transfer learning problems.
Author Contributions
Methodology, Z.Z. and X.F.; Resources, Z.Z.; Data curation, J.L. and S.C.; Writing—original draft, J.L.; Writing—review & editing, Z.Z.; Supervision, X.F. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
There are the url links for our used dataset: IMDB: https://huggingface.co/datasets/imdb (accessed on 20 May 2023); SST: https://huggingface.co/datasets/sst2 (accessed on 20 May 2023); GloVe: https://nlp.stanford.edu/projects/glove/ (accessed on 20 May 2023); IMDB: https://huggingface.co/datasets/imdb (accessed on 20 May 2023).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A Comprehensive Survey on Transfer Learning. Proc. IEEE 2021, 109, 43–76. [Google Scholar] [CrossRef]
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Gupta, B.; Awasthi, S.; Singh, P.; Ram, L.; Kumar, P.; Prasad, B.R.; Agarwal, S. Cross domain sentiment analysis using transfer learning. In Proceedings of the 2017 IEEE International Conference on Industrial and Information Systems (ICIIS), Peradeniya, Sri Lanka, 15–16 December 2017. [Google Scholar]
- Ganin, Y.; Lempitsky, V.S. Unsupervised Domain Adaptation by Backpropagation. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 1180–1189. [Google Scholar]
- Pei, Z.; Cao, Z.; Long, M.; Wang, J. Multi-Adversarial Domain Adaptation. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 3934–3941. [Google Scholar]
- Zhang, M.; Li, X.; Wu, F. Moka-ADA: Adversarial domain adaptation with model-oriented knowledge adaptation for cross-domain sentiment analysis. J. Supercomput. 2023, 79, 13724–13743. [Google Scholar] [CrossRef]
- Sun, B.; Saenko, K. Subspace Distribution Alignment for Unsupervised Domain Adaptation. In Proceedings of the 26th British Machine Vision Conference, Swansea, UK, 7–10 September 2015; pp. 24.1–24.10. [Google Scholar]
- Sun, B.; Feng, J.; Saenko, K. Return of Frustratingly Easy Domain Adaptation. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 2058–2065. [Google Scholar]
- Pan, S.J.; Tsang, I.W.; Kwok, J.T.; Yang, Q. Domain Adaptation via Transfer Component Analysis. IEEE Trans. 2011, 22, 199–210. [Google Scholar] [CrossRef] [PubMed]
- Long, M.; Wang, J.; Ding, G.; Sun, J.; Yu, P.S. Transfer Feature Learning with Joint Distribution Adaptation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Sydney, Australia, 1–8 December 2013; pp. 2200–2207. [Google Scholar]
- Wang, J.; Chen, Y.; Hao, S.; Feng, W.; Shen, Z. Balanced Distribution Adaptation for Transfer Learning. In Proceedings of the 2017 IEEE International Conference on Data Mining (ICDM), New Orleans, LA, USA, 18–21 November 2017. [Google Scholar]
- Wang, J.; Feng, W.; Chen, Y.; Yu, H.; Huang, M.; Yu, P.S. Visual Domain Adaptation with Manifold Embedded Distribution Alignment. In Proceedings of the 26th ACM International Conference on Multimedia, Seoul, Republic of Korea, 22–26 October 2018; pp. 402–410. [Google Scholar]
- Zhu, Y.; Zhuang, F.; Wang, J.; Chen, J.; Shi, Z.; Wu, W.; He, Q. Multi-representation adaptation network for cross-domain image classification. Neural Netw. 2019, 119, 214–221. [Google Scholar] [CrossRef] [PubMed]
- Zhuang, F.; Cheng, X.; Luo, P.; Pan, S.J.; He, Q. Supervised Representation Learning: Transfer Learning with Deep Autoencoders. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015; pp. 4119–4125. [Google Scholar]
- Sun, B.; Saenko, K. Deep CORAL: Correlation Alignment for Deep Domain Adaptation. In Proceedings of the ECCV: European Conference on Computer Vision, Amsterdam, The Netherlands, 8–10 and 15–16 October 2016. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.C.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics, Baltimore, ML, USA, 22–27 June 2014; pp. 2672–2680. [Google Scholar]
- Durugkar, I.P.; Gemp, I.; Mahadevan, S. Generative Multi-Adversarial Networks. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, 24–26 April 2017. [Google Scholar]
- Yu, C.; Wang, J.; Chen, Y.; Huang, M. Transfer Learning with Dynamic Adversarial Adaptation Network. In Proceedings of the 2019 IEEE International Conference on Data Mining (ICDM), Beijing, China, 8–11 November 2019; pp. 778–786. [Google Scholar]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the NAACL, Minneapolis, Minnesota, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Dai, Z.; Yang, Z.; Yang, Y.; Carbonell, J.G.; Le, Q.V.; Salakhutdinov, R. Transformer-XL: Attentive Language Models beyond a Fixed-Length Context. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 2978–2988. [Google Scholar]
- Du, C.; Sun, H.; Wang, J.; Qi, Q.; Liao, J. Adversarial and Domain-Aware BERT for Cross-Domain Sentiment Analysis. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 4019–4028. [Google Scholar]
- Li, Z.; Li, X.; Wei, Y.; Bing, L.; Zhang, Y.; Yang, Q. Transferable End-to-End Aspect-based Sentiment Analysis with Selective Adversarial Learning. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing, Hong Kong, China, 3–7 November 2019; pp. 4589–4599. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Dong, Y.; Fu, Y.; Wang, L.; Chen, Y.; Dong, Y.; Li, J. A Sentiment Analysis Method of Capsule Network Based on BiLSTM. IEEE Access 2020, 8, 37014–37020. [Google Scholar] [CrossRef]
- Tzeng, E.; Hoffman, J.; Zhang, N.; Saenko, K.; Darrell, T. Deep Domain Confusion: Maximizing for Domain Invariance. arXiv 2014, arXiv:1412.3474. [Google Scholar]
- Ghifary, M.; Kleijn, W.B.; Zhang, M. Domain Adaptive Neural Networks for Object Recognition. In Proceedings of the 13th Pacific Rim International Conference on Artificial Intelligence, Gold Coast, QLD, Australia, 1–5 December 2014; pp. 898–904. [Google Scholar]
- Long, M.; Zhu, H.; Wang, J.; Jordan, M.I. Deep Transfer Learning with Joint Adaptation Networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, NSW, Australia, 6–11 August 2017; pp. 2208–2217. [Google Scholar]
- Ben-David, S.; Blitzer, J.; Crammer, K.; Pereira, F. Analysis of Representations for Domain Adaptation. In Proceedings of the Neural Information Processing Systems 19 (NIPS 2006), Vancouver, BC, Canada, 4–7 December 2006; Schölkopf, B., Platt, J.C., Hofmann, T., Eds.; MIT Press: Cambridge, MA, USA, 2006; pp. 137–144. [Google Scholar]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).