Abstract
Deepfake detection is a focus of extensive research to combat the proliferation of manipulated media. Existing approaches suffer from limited generalizability and struggle to detect deepfakes created using unseen techniques. This paper proposes a novel deepfake detection method to improve generalizability. We observe domain-wise independent clues in deepfake images, including inconsistencies in facial colors, detectable artifacts at synthesis boundaries, and disparities in quality between facial and nonfacial regions. This approach uses an interpatch dissimilarity estimator and a multistream convolutional neural network to capture deepfake clues unique to each feature. By exploiting these clues, we enhance the effectiveness and generalizability of deepfake detection. The experimental results demonstrate the improved performance and robustness of this method.
MSC:
68T45
1. Introduction
Deepfakes forge faces by replacing the identity of a target subject with that of another source subject. Over the past few years, deepfake techniques have gained considerable attention in the field of face manipulation, resulting in substantial advancements in methods for generating forged images [,,,,,,,,,,,]. The accessibility of deepfake generation techniques has made it possible for anyone to create highly realistic fake videos that are extremely difficult to distinguish from genuine ones. According to incomplete statistics [], it is estimated that there are close to hundreds of thousands of manipulated facial videos being shared on the Internet. The prevalence of deepfakes has made them a common sight in various contexts. Thus, deepfakes present serious threats, including the propagation of fake news, the defamation of celebrities, and the potential for significant social and political issues. Furthermore, the methods for forging faces continue to evolve incessantly. It has reached a point where discerning the authenticity of altered faces is nearly impossible for the human eye to accomplish.
Extensive research efforts have been dedicated to developing deepfake detectors [,,,,,,,,,,,,,,,,,,,,,,,,,] to address the exploitation of deepfakes. Various approaches based on deep learning have been proposed to address the challenge of deepfake detection. These approaches often treat it as a binary classification problem, training neural networks to distinguish between authentic and manipulated media content. Researchers have predominantly evaluated their models using publicly available datasets, which presents an initial step towards benchmarking the performance of deepfake detection systems in real-world scenarios.
However, with these deep-learning-based approaches to detection, it is seen that most of the methods lean towards overfitting []. Moreover, given the potential for deepfake videos to be generated in real-world scenarios using techniques and data previously unseen, the application of existing deepfake detection systems to real-world situations is likely to result in inevitable performance degradation. Consequently, there exists a practical gap in the current application of deepfake detectors to real-world scenarios.
In response to this challenge, recent endeavors have aimed to enhance the generalizability of deepfake detectors. For instance, some studies have suggested data augmentation as an effective strategy for enhancing generalization. However, both the research by Zhao et al. [] and Chen et al. [], which use augmented data, still face the challenge of dependency on the training data, as the augmented data are generated based on the training set. Another case of study, Nadimpalli et al. [], proposed a hybrid combination of supervised and reinforcement learning to improve generalizability, but their method still faces performance degradation issues in the context of cross-dataset testing, which is a commonly used evaluation method for assessing generalizability.
As illustrated in Figure 1, deepfake images present several clues that can contribute to detecting deepfakes. Owing to the synthesis of another face onto a source image, discrepancies in facial colors may arise. Even if deepfake generators employ color transformation algorithms to make the deepfake image appear plausible, variations in color distribution may persist. Additionally, incorrect synthesis can cause detectable artifacts at the boundaries of the synthesized image. Furthermore, deepfake algorithms often generate images with a specific resolution, necessitating subsequent warping to align the original face in the source video, introducing inherent disparities in image quality compared to the original footage.
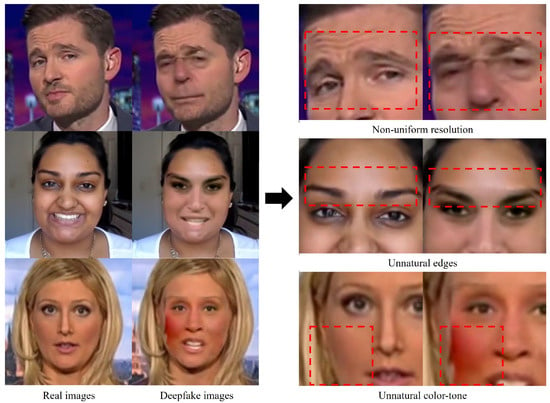
Figure 1.
Forgery pattern examples in deepfake image generation.
Based on these observations, we propose a novel deepfake detection method. First, we employ a patch-by-patch no-reference image quality assessment (NR-IQA) approach within a frame to distinguish deepfake videos based on the interpatch dissimilarity between facial and nonfacial regions. To the best of our knowledge, this approach represents a novel approach in the field of deepfake detection. The purpose of a deepfake is to replace only the identity; thus, the nonfacial region remains unaltered. By leveraging this characteristic, we can discern a deepfake image by detecting differences in patch quality between the nonfacial and facial regions. Additionally, we employ a frequency decomposition block to extract high- and low-frequency components. The high-frequency information aids in detecting artifacts introduced during the forgery process, whereas the low-frequency information captures features related to variations in color between the original and deepfake images. By leveraging these contributions, we aim to improve the effectiveness and robustness of deepfake detection, ensuring better applicability in real-world scenarios. The main contributions of the proposed approach are summarized as follows:
- We observe a common characteristic of images with face forgery applied: a quality difference between patches corresponding to facial and nonfacial regions where the technique is not applied.
- We employ the interpatch dissimilarity estimator within a frame to capture quality differences between patches to enhance the performance and generalizability of deepfake detection.
- We use a multistream CNN that uses high and low frequencies and the original image streams to capture deepfake clues unique to each feature.
2. Related Work
2.1. Deepfake Generation
Deepfake [] generation can be classified into three main categories: complete image synthesis, modification of facial attributes or expressions, and face identity swapping. Various techniques, such as autoencoders [], generative adversarial networks [,], or three-dimensional (3D) models [], are employed to generate the synthetic image segment, which is seamlessly blended with the original image.
2.2. Deepfake Detection
Initially, in the realm of deepfake detection, a deep-learning-based approach was introduced in []. This method employed two inception modules, namely Meso-4 and MesoInception-4, to construct the proposed architecture. The training process used the mean squared error as the loss function to minimize the disparity between the actual and anticipated labels. Wang et al. [] introduced a layerwise neuron behavioral approach for detecting fake faces. Bonettini et al. [] studied the ensembling of differently trained convolutional neural network (CNN) models for deepfake detection. This approach offers the advantage of maximizing detection performance through ensemble learning. However, it comes with the trade-off of increased computational demands and resource usage due to the employment of multiple networks.
Various studies have been conducted with a focus on artifact detection in the field of deepfake detection. Li et al. [] employed CNNs to detect distinctive artifacts in deepfake videos, namely FWA and DSP-FWA. FWA is designed to detect face warping artifacts in deepfake videos, and DSP-FWA builds upon the FWA technique and represents a recent advancement. It incorporates a spatial pyramid pooling module, effectively addressing variations in the resolutions of the original target faces. Notably, DSP-FWA’s training involves the use of self-collected facial images. Yang et al. [] simulated the forgery process using image generation techniques and explored potential traces of forgery using attention mechanisms. Li et al. [] introduced a potent method for deepfake detection by exposing the blending boundaries within manipulated images. However, their approach involves a complex trace generator, which results in a high computational workload. In contrast, Durall et al. [] proposed a straightforward method for deepfake detection based on classical frequency domain analysis followed by a basic classifier.
Similarly, there is active research in the field of deepfake detection that leverages the frequency domain for various purposes [,,,,,,,,,,,]. Durall et al. [] employed the Discrete Fourier Transform (DFT) for deepfake detection. They propose a straightforward approach to detect fake face images by converting the images into the frequency domain using DFT. Afterward, they extract features from a 1D representation of the Fast Fourier Transform power spectrum through logistic regression and Support Vector Machines (SVM). Also, Woo et al. [] applied frequency domain learning in knowledge distillation to improve low-quality compressed deepfake image detection. Their methods exhibit a weakness in detection performance for high-quality deepfake images. Giudice et al. [] proposed a method for detecting abnormal frequencies in the frequency domain using Discrete Cosine Transform (DCT) to identify deepfake videos. Jeong et al. [] detected frequency-level artifacts and considered the image-level irregularities to detect deepfake images of GAN models. While these frequency-utilizing methods, including ours, share the commonality of applying frequency domain transformation, our key distinction is that we solely use it for frequency separation without performing frequency analysis and subsequently extract features in the spatial domain through an inverse process.
These frequency-aware image decomposition studies [,,,,,,] typically applied hand-crafted filters. However, Li et al. [] proposed a single-center loss and an adaptive frequency feature generation module to address the limitations of learned features under softmax loss and the inadequacy of fixed filter banks and hand-crafted features. Qian et al. [] proposed a method that leverages frequency-aware clues, including local frequency statistics and decomposed image components according to a set of learnable frequency filters, for in-depth detection of face forgery patterns by mining frequency clues in a data-driven way.
Younus et al. [] spotted artifacts by examining the edge pixels in the wavelet domain. Wang et al. [] focused on detecting low-quality compressed deepfake images by utilizing frequency features through Haar wavelet transform. Wolter et al. [] proposed a wavelet-packet-based approach for deepfake detection. The wavelet-domain-based deepfake detection models [,,] analyzed wavelet coefficients, which are derived from an image representation in both space and frequency domains. In our case, we do not perform frequency analysis but just separate high- and low-frequency components. Therefore, preserving spatial relations is not meaningful for our approach. Hence, we adopt the computationally efficient frequency transformation method DCT.
There is also research in deepfake detection that considers the temporal dimension [,,,]. Abdul Jamsheed, V and Janet, B [] proposed a combination of CNN and long short-term memory recurrent neural network to detect these manipulations. Savir et al. [] and De et al. [] employed a recurrent neural network to identify manipulation artifacts across video frames. However, these papers consider both spatial and temporal information, which might result in a high computational cost as a disadvantage.
Zhou et al. [] proposed a two-stream network to detect tampering artifacts and to leverage features capturing local noise residuals and camera characteristics. Based on the tendency that sharing information with each other through a multi-task learning approach improves the performance of both sides, Nguyen et al. [] designed a CNN that uses a multi-task learning approach to simultaneously detect manipulated images and videos and find manipulated regions for each query. The problem with this model is that it needs to be fine-tuned using additional data to deal with unseen attacks. Furthermore, these models rely on training data due to the lack of additional effort on generalizability, and they are less effective at detecting deepfake techniques that are not encountered during training.
To make it deployable in real-world applications, it is crucial that the model does not require additional training. Considering this concern, recent efforts have been directed toward enhancing the generalizability of deepfake detection. Zhao et al. [] capitalized on identifying inconsistencies in source features within forged images. Additionally, their method is accompanied by a new image synthesis approach, called "inconsistency image generator", to provide richly annotated training data for pair-wise self-consistency learning. Chen et al. [] addressed generalizable deepfake detection by emphasizing that a versatile representation should be sensitive to diverse forgeries. To achieve this, the study introduces augmented forgeries with diverse configurations and enforces the model to predict these configurations for improved sensitivity. Nadimpalli et al. [] formulated deepfake detection as a hybrid combination of supervised and reinforcement learning (RL) to improve generalizability. The model applies top-k augmentations for each test sample by an RL agent. One weakness of reinforcement learning algorithms is their potential instability due to the absence of guaranteed convergence.
While there is currently an active research effort to enhance the generalization performance of deepfake detectors, there remains considerable room for improvement in the realm of cross-dataset evaluation, a widely employed approach for assessing algorithmic generalizability. We propose to enhance generalizability and reduce reliance on training data; we introduce a model designed to make predictions based on features commonly found in facial forgery images.
2.3. No-Reference Image Quality Assessment
Exchanging image identities while seamlessly achieving a perfect synthesis can be challenging. A key indicator for detecting deepfakes in this process is the quality difference between the synthesized facial region and nonfacial region. To utilize this as a clue, we employ the concept of image quality assessment (IQA) [,,]. The resolution difference between the target and source images occurs while swapping image identities. To quantify this difference and further use it for training, we can use NR-IQA. Unlike the full-reference (FR) IQA methods, NR-IQA methods [,] can only use input images to measure image quality without any reference directly. Yang et al. [] proposed a multi-dimensional attention network to improve the performance of NR-IQA, and we apply this model to estimate the quality by patch.
3. Methods
As illustrated in Figure 2, the overall architecture consists of the interpatch dissimilarity estimator, frequency decomposition block, and multistream CNN. The interpatch dissimilarity estimator independently analyzes the dissimilarity value: comparing facial regions affected by facial forgery techniques with nonfacial regions to estimate the likelihood of a deepfake. The frequency decomposition block decomposes the input into high- and low-frequency components and passes them separately, allowing the multistream CNN to capture unique deepfake clues for each feature. The classification stage aggregates each deepfake clue to make a final decision.

Figure 2.
Overall ClueCatcher framework to capture and detect forgery clues that occur during deepfake image generation.
3.1. Observation
This section presents the empirical observations that motivated the proposed network and substantiates the observations with supporting evidence. Capturing common features of deepfake images is crucial irrespective of the forgery technique employed in order to avoid overfitting to a specific forgery method and to enhance the generalizability of a deepfake detector. Based on the fact that the deepfake technique preserves regions other than the facial part, we compared the quality differences between the synthetic and preserved areas. Our analysis confirmed the presence of quality distinctions between synthetic and preserved areas, a common observation in the majority of existing deepfake images.
Deepfake generation methods are typically designed to generate images with a specific resolution. These methods can be broadly classified into classic computer-graphics-based techniques and deep-learning-based techniques. Among classic computer graphics approaches, face swapping [] focuses on facial angles and employs a defined resolution determined by the distance between the center of the eyes to generate visually plausible synthetic images. Deep-learning-based techniques employ autoencoders to synthesize the source’s face as the target’s original face. A representative deep-learning-based technique, such as Celeb-DF [], generates synthetic faces at a resolution of , which are resized. Although these deepfake generators aim to produce visually pleasing outcomes, they tend not to consider quality harmonization.
We propose an appropriate measurement, interpatch dissimilarity, to capture these quality differences and make them useful for deepfake detection. Figure 3 provides a simple visualization of the interpatch dissimilarity measurement process, which operates based on the NR-IQA method. Detailed equations and explanations regarding interpatch dissimilarity measurement can be found in Section 3.2. Here, we present a conceptual overview. To calculate interpatch dissimilarity, we segment the facial and nonfacial region from the input image, isolating the regions targeted by facial forgery techniques from those that are not. Then, we randomly sample patches of the same size as the face from the nonfacial region for matching resolution and performed NR-IQA on all patches. Finally, we calculate the dissimilarity values based on the measured quality error between the nonfacial and facial patches.
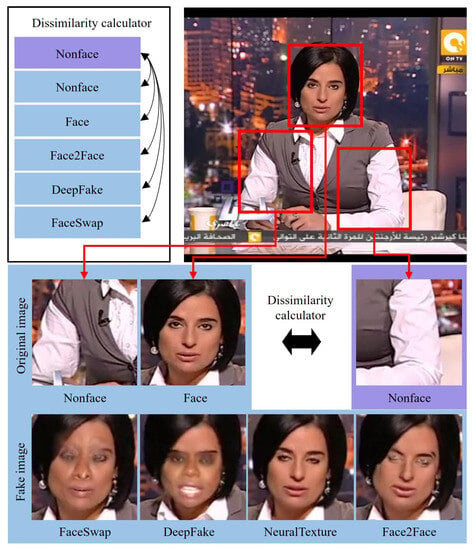
Figure 3.
Illustration of the interpatch dissimilarity operation.
Figure 4 depicts the statistical analysis of interpatch dissimilarity. It presents the distribution of dissimilarity values among different patches within the same image. These statistics were computed based on the FaceForensics++ dataset []. The blue curve is the patch-to-patch dissimilarity corresponding to the nonfacial region without deepfakes applied. Although the locations differ, the dissimilarity values are mostly close to zero because they were extracted from the same image. There is a slight error for the original facial patch (brown curve) due to the difference in the detail represented within the patch because it needs to represent detailed features, such as the eyes, nose, and mouth, despite being the same image quality.
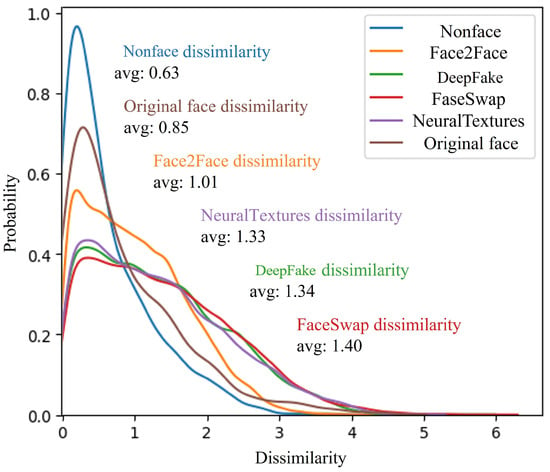
Figure 4.
Distribution plots of dissimilarity between patches.
However, the dissimilarity value increases noticeably for the facial patches with the facial forgery technique applied. For Face2Face (orange curve), which has the smallest error with the original face, the dissimilarity value is relatively small because the technique changes the expression of the original face rather than synthesizing the face of another subject. Nevertheless, it is similar to the dissimilarity distribution of the other facial forgery techniques. These dissimilarity values can be a useful clue for deepfake detection, as demonstrated by the experimental results.
3.2. Interpatch Dissimilarity Estimator
As mentioned, a clear difference in quality exists between the facial areas altered by the deepfake technique and the unaffected nonfacial areas. We propose an intraquality assessment module that improves deepfake detection performance using forgery clues generated during this process. Typically, the resolution is measured by comparing it to the ground truth (GT) for IQA. However, in real-world situations, deepfake images do not have a GT facial image, so the difference in the resolution must be measured by comparing the deepfake facial region to the other regions. We use the NR-IQA model to measure the absolute resolution difference without a comparison target.
As depicted in Figure 5, we first detect faces in the input image and extract five nonfacial patches. All six patches are the same size; thus, no resolution difference occurs due to their size. Each patch is cropped into an 8 × 8 patch and embedded. Then, the patches are input into the vision transformer for extracting the features. These features estimate the quality of the image through attention blocks and weighted sums. This vision transformer was previously trained using PIPAL [] for IQA purposes. The IQA score for each patch quantifies the difference in resolution in the synthesis process by averaging the scores for the nonfacial regions and the difference between the scores for the facial regions. This difference is defined as follows:
where represents the image quality score, denotes the quality score for the facial region, indicates the quality score for nonfacial regions, and indicates the standard deviation over all the patches involved in the computation. If the synthesized image is better or worse in absolute value, this represents the difference. In this process, the interpatch dissimilarity values of the nonfacial and deepfake images are calculated and used for deepfake detection. In addition, the reason for using multiple nonfacial regions is to learn the difference in the image quality score and the distribution, which can mitigate the performance degradation caused by outliers.

Figure 5.
Interpatch dissimilarity estimator framework analyzing the difference in image quality between facial and nonfacial regions.
3.3. Frequency Decomposition Block
Detecting visual differences has become more difficult with the development of deepfake imaging techniques. In high-frequency components, artifacts introduced during the forgery can be detected []. Moreover, low-frequency components can capture color distribution disparities between the original and deepfake images. This paper uses a frequency decomposition block that divides the input image into high- and low-frequency components. We decomposed the frequency through DCT []. An input image of size in the 2D spatial domain can be represented by a DCT in the frequency domain as follows:
We use to represent the pixel value at position in the spatial domain; represents the DCT coefficient value at position in the frequency domain; denotes the cosine basis function; and we utilize and as the regularization constants. The ranges of x, y, u, and v are 0 ≤ < M and 0 ≤ < N. Furthermore, transformation of the image from the frequency domain to the spatial domain can be achieved through the inverse DCT (IDCT), as illustrated in Equation (6). The high- and low-frequency components of the image, obtained by applying the DCT and IDCT operations, can be independently extracted using a feature extractor that operates in a domain-specific manner. The transformed DCT is divided into high-frequency and low-frequency using the mask. The is expressed as follows:
where D represents the zigzag scanning index corresponding to the example shown in Figure 6a, d denotes the parameter for extracting frequency components, and signifies the mask used for extracting high-frequency components. Figure 6a illustrates the use of index D for a zigzag scan on a 10 × 10 pixel grid. When the hyperparameter d is configured to 15, Figure 6b demonstrates the ability to isolate high-frequency elements while excluding those below the threshold of 15. Frequency separation is achieved through the multiplication of the mask with the DCT coefficients, denoted as . We empirically determined the value of d through experiments to optimize performance and set it to fifteen. To indicate the mask used for extracting low-frequency components, we invert the condition in the equation.
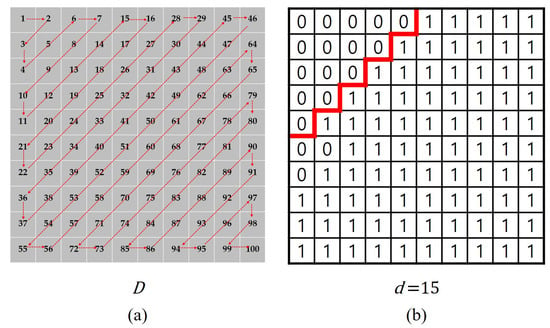
Figure 6.
(a) Index of zigzag scan example for 10 × 10 pixels. (b) A mask obtained from the hyperparameter d of 15.
3.4. Multi-Stream Convolution Neural Network
The proposed approach uses the original image and an image consisting solely of high- and low-frequency components obtained through the frequency decomposition block to capture the fundamental distinctions between original and deepfake images. The high-frequency component plays a crucial role in directing the network attention toward forged traces, aiding in detecting artifacts, such as unnatural edges, that may arise during the synthesis process. Conversely, the low-frequency component is used to learn intrinsic features related to the facial color distribution disparities between original and deepfake patches.
Deepfake images necessitate the synthesis of two faces, each with an inherent skin color. Even if postprocessing techniques, such as Poisson image editing, are employed to smooth out differences in skin color naturally, the distribution of facial colors in deepfake images tends to be relatively more dispersed compared to that of the original images. This characteristic is critical for distinguishing deepfake images from original images and provides crucial clues that facilitate discrimination. Additionally, using the low-frequency component mitigates issues encountered by existing models that overly rely on detecting specific artifacts, leading to overfitting and hindering generalization.
The multisttream CNN architecture incorporates a self-attention structure. By applying self-attention to each image stream, the network can effectively integrate global and local information simultaneously. To clarify, we acquire the key (K), value (V), and query (Q) projections from the features () extracted independently in each stream using the feature extraction network. This operation is achieved through the application of depthwise separable convolution, denoted as W. The self-attention process is defined as follows:
where represents the resulting feature maps, corresponds to the pointwise convolution, and functions as a scaling factor. The dimensions of and are (batch size, 512, 8, 8), and the dimensions of K, Q and V are (batch size, 4, 128, 64).
The multisttream CNN leverages the intrinsic information of each domain, enhancing its performance and generalizability. The individual features and interclass patch similarity errors are fused in the classification stage. We train ClueCatcher with the cross-entropy loss, allowing us to train the entire system end-to-end. The cross-entropy loss function is defined as follows:
where p represents the probability of predicting deepfakes.
4. Experiments
4.1. Experimental Setup
4.1.1. Datasets
Following recent deepfake detection methods [,,,], we conduct these experiments on the FaceForencis++ (FF++) dataset [] and on Celeb-DF []. FF++ is a facial forgery detection video dataset with 1000 real videos. It is the most widely used dataset and consists of four manipulation techniques: deepfakes (DF), Face2Face (F2F), FaceSwap (FS), and Neural Texture (NT). In addition, FF++ has different compression levels: raw (c0), high quality (c23), and low quality (c40), but we experimented with c23, which is typically used. We used 720 videos for training, 140 for validation, and 140 for testing. In addition, Celeb-DF contains 590 real videos and 5639 high-quality fake videos created with an improved deepfake algorithm. All methods are applied to 1000 high-definition real videos downloaded from YouTube and manually selected so that the subjects are nearly front-facing without occlusion.
4.1.2. Implementation Details
We chose 32 frames per video for deepfake discrimination. The choice was based on the fact that using a small number of frames per video has a strong tendency to overfit, and increasing the number of frames does not improve performance in a justifiable way []. We focused the analysis on the facial region. For every real/deepfake video frame, we detected faces using Blazeface [], a face extractor, and stored the aligned face images as inputs of size . We used EfficientNet [] pretrained on ImageNet [] as the backbone network, Albumentation [] as the data augmentation library, and PyTorch as the deep learning framework. Adam [] was used for optimization with a learning rate of 1e-5 and an initial training rate of 1e-5. Finally, we trained the proposed model on an RTX 3080Ti GPU with a batch size of 32.
4.1.3. Evaluation Metrics
The most commonly used metric for deepfake detection results is the area under the curve (AUC). A higher value of AUC indicates better performance. We applied the AUC as an evaluation metric. The evaluation results of the experiments are calculated by averaging the classification scores of the video frames at the video level.
4.2. Comparison with Previous Methods
To compare with existing work, we considered FF++ and Celeb-DF, which are included in the most popular datasets for deepfake detection. Given a dataset, the proposed model is trained on the real and deepfake data from the training split, and performance is evaluated with the corresponding testing set. The results for FF++ and Celeb-DF are provided in Table 1.

Table 1.
Quantitative comparison in terms of AUC(%) on FaceForensics++ and Celeb-DF. The results indicate within-dataset performance, and best performances are bold.
This type of evaluation focuses on specialization, not generalization. Nevertheless, the proposed model performs well on average compared to the state-of-the-art models and demonstrates that interpatch dissimilarity and separated frequency components capture important clues for discriminating deepfakes. In the FF++ dataset, the ClueCatcher and Xception methods may demonstrate minor performance variations attributable to their use of distinct backbone networks. Nonetheless, both models attain AUC scores exceeding 99%, representing a remarkably high level of performance.
4.3. Generalizability Evaluation
The ability to generalize is an important indicator of an algorithm’s superiority. In a real-world setting, a deepfake detector cannot obtain prior knowledge of all forgeries. To evaluate the generalizability of this method to unknown forgeries, we perform fine-grained cross-testing by training on a specific manipulation technique and testing on the others listed in FF++. Table 2 compares the results published in [] for a deepfake detection network trained on FF++ and tested on Celeb-DF with ClueCatcher. We also conduct a comparison by measuring the frames per second (FPS) of both existing algorithms with the provided code and our proposed model. In terms of speed among compared models, Xception-c23 achieved the highest FPS at 62, demonstrating its exceptional speed. In contrast, our model achieved a relatively lower FPS of 18. However, it is important to note that our model compensates for this lower speed with the highest level of AUC among the compared models. The performance of ClueCatcher achieves convincing results with 76.5% in terms of the AUC. The results demonstrate that ClueCatcher can effectively generalize across various source cues without overfitting specific forgery techniques among data from the same generation method. As presented in Table 3, the results reveal that the proposed method outperforms other methods for unknown types of forgeries. These results demonstrate that ClueCatcher can distinguish forgeries with unknown patterns by exploring common features of forged faces. In addition, we further preformed a cross-dataset evaluation, which is a widely used approach to evaluate the generalizability of an algorithm. Cross-dataset evaluation can provide robustness to perturbations. Each dataset has distinct characteristics that can be considered a form of perturbation, such as cropping, rotation, shifting, resolution changes, and more.
Table 2.
Comparison with existing studies on the cross-dataset evaluation of deepfake detection on Celeb-DF, including frames per second (FPS). AUC(%) results from existing methods are taken from []. The best performances are bold.
Table 3.
Generalizability comparison in terms of AUC(%) on different manipulation techniques. Gray background indicates within-dataset results, and the others indicate cross-dataset results (Deepfake (DF), Face2Face (F2F), FaceSwap (FS), and neural texture (NT)). The best results are in bold.
Figure 6 and Figure 7 visualize the results of ClueCatcher tested on two distinct datasets. The DISSIM score is displayed in the upper-right corner. In Figure 7, ClueCatcher accurately detects manipulated images, even when different face forgery techniques (DF, F2F, FS, and NT) are applied to a video. Figure 8 demonstrates deepfake detection in videos synthesized with different identities using deepfake techniques. ClueCatcher also successfully detects deepfake content that is challenging to recognize with the naked eye. These visualizations in Figure 6 and Figure 7 underscore ClueCatcher’s robustness in detecting face-forgery content across diverse datasets and manipulation techniques.

Figure 7.
Visualization of ClueCatcher’s detection results for real and manipulated images (DF, F2F, FS, and NT) for ID 997 on FF++.

Figure 8.
Visualization of ClueCatcher’s detection results for the real and deepfake images for ID 38 on Celeb-DF. The denotation ‘id38’ depicts the real identity, while the others represent other identities applied by the deepfake techniques.
4.4. Ablation Study
We conducted an ablation study to evaluate the influence of two key parts in the deepfake detector: the frequency components and interpatch dissimilarity. Table 4 presents the results of evaluating the individual contributions of each module by testing the model performance with and without it. The network is trained FaceForensics++ and tested on each of the synthesis techniques. First, we examined the effect of incorporating the frequency components. We observed a slight performance improvement when the frequency components were added to the model. This enhancement can be attributed to the network effectively capturing global and local information through high- and low-frequency components. Next, we investigated the influence of interpatch dissimilarity. We also observed a performance improvement with this information. The interpatch dissimilarity represents disparity in the quality value of patches to help detect deepfakes. Finally, we achieved the highest performance levels when the frequency components and interpatch dissimilarity were integrated into the deepfake detector. Overall, the ablation study highlights the importance of both the frequency components and interpatch dissimilarity for enhancing the performance of the deepfake detector. The study emphasizes the complementary nature of these modules and demonstrates their collective effectiveness for detecting and mitigating deepfake manipulations.
Table 4.
Ablation study on FF++ in terms of AUC(%). The hyphen - indicates without, and the check ✓ indicates with the method.
5. Discussion
Interpatch dissimilarity estimator in ClueCatcher effectively improves generalizability for deepfake detection by leveraging nonfacial regions unaffected by deepfake techniques. However, as depicted in Figure 9, leveraging nonfacial regions can be difficult when they contain little texture or edge components on which to base the quality assessment. Consequently, incorporating an additional computation to determine the feasibility of the quality evaluation for nonfacial regions is expected to mitigate potentially misleading results. In our future work, we plan to address the quality assessment challenge by developing a new algorithm specifically designed to handle the quality assessment of smooth nonfacial regions. This algorithm will consider factors such as lighting conditions, color consistency, and overall image coherence to make more-accurate quality assessments for deepfake detection. Furthermore, we plan to enhance the robustness of our model against perturbations such as cropping, rotation, and compression. This reinforcement of our model’s resilience will ensure its stability and effectiveness in real-world scenarios, where images may undergo various transformations.

Figure 9.
Difficult case for interpatch dissimilarity estimator.
Additionally, while our primary focus is on accuracy, it is worth noting that our model currently operates at 18 FPS, which is comparatively slower than some other models documented in the literature. In certain contexts, such as media forensics, where meticulous examination of content is paramount, a slight reduction in speed in favor of improved accuracy is justifiable. However, there are scenarios where real-time detection with minimal latency is essential. To address this concern, we intend to explore potential optimizations in future research. These optimizations will aim to strike a better balance between speed and accuracy without compromising the core objective of reliable deepfake detection.
6. Conclusions
This paper addresses a deepfake detector that improves generalizability for applications in real-world environments. This method focuses on the quality dissimilarity between patches that can occur during the deepfake process, regardless of the forgery techniques, and improves the generalizability by capturing domain-wise independent clues. By effectively identifying and mitigating the risks associated with malicious deepfake media, we can contribute to public safety by effectively identifying and mitigating potential risks posed by maliciously manipulated deepfake media to protect individuals and communities.
Author Contributions
Conceptualization, E.-G.L. and S.-B.Y.; methodology, E.-G.L., I.L. and S.-B.Y.; software, E.-G.L. and I.L.; validation, E.-G.L. and I.L.; formal analysis, E.-G.L., I.L. and S.-B.Y.; investigation, E.-G.L. and I.L.; resources, E.-G.L., I.L. and S.-B.Y.; data curation, E.-G.L. and S.-B.Y.; writing—original draft preparation, E.-G.L. and I.L.; writing—review and editing, E.-G.L. and S.-B.Y.; visualization, E.-G.L. and I.L.; supervision, S.-B.Y.; project administration, S.-B.Y.; funding acquisition, S.-B.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the Industrial Fundamental Technology Development Program (No. 20018699) funded by MOTIE of Korea and the IITP grant funded by the Korean government (MSIT) (No. 2021-0-02068, RS-2023-00256629).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable. All the face images in the paper are open public datasets, so there are no copyright issues.
Data Availability Statement
Publicly available datasets were analyzed in this study. These data can be found here: Celeb-DF https://github.com/yuezunli/celeb-deepfakeforensics (accessed on 11 March 2020) and FaceForensics++ http://niessnerlab.org/projects/roessler2018faceforensics.html (accessed on 25 January 2019).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Tolosana, R.; Vera-Rodriguez, R.; Fierrez, J.; Morales, A.; Ortega-Garcia, J. Deepfakes and beyond: A survey of face manipulation and fake detection. Inf. Fusion 2020, 64, 131–148. [Google Scholar] [CrossRef]
- Bitouk, D.; Kumar, N.; Dhillon, S.; Belhumeur, P.N.; Nayar, S.K. Face Swapping: Automatically Replacing Faces in Photographs. ACM SIGGRAPH 2008, 27, 1–8. [Google Scholar] [CrossRef]
- Korshunova, I.; Shi, W.; Dambre, J.; Theis, L. Fast face-swap using convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 22–25 July 2017; pp. 3677–3685. [Google Scholar]
- Li, Y.; Yang, X.; Sun, P.; Qi, H.; Lyu, S. Celeb-df: A large-scale challenging dataset for deepfake forensics. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3207–3216. [Google Scholar]
- Lee, I.; Lee, E.; Yoo, S.B. Latent-OFER: Detect, mask, and reconstruct with latent vectors for occluded facial expression recognition. arXiv 2023, arXiv:2307.11404. [Google Scholar]
- Nirkin, Y.; Keller, Y.; Hassner, T. Fsgan: Subject agnostic face swapping and reenactment. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27–28 October 2019; pp. 7184–7193. [Google Scholar]
- Liu, K.; Perov, I.; Gao, D.; Chervoniy, N.; Zhou, W.; Zhang, W. Deepfacelab: Integrated, flexible and extensible face-swapping framework. Pattern Recognit. 2023, 141, 109628. [Google Scholar] [CrossRef]
- Vahdat, A.; Kautz, J. NVAE: A deep hierarchical variational autoencoder. Adv. Neural Inf. Process. Syst. 2020, 33, 19667–19679. [Google Scholar]
- Hong, Y.; Kim, M.J.; Lee, I.; Yoo, S.B. Fluxformer: Flow-Guided Duplex Attention Transformer via Spatio-Temporal Clustering for Action Recognition. IEEE Robot. Autom. Lett. 2023, 8, 6411–6418. [Google Scholar] [CrossRef]
- Choi, Y.; Uh, Y.; Yoo, J.; Ha, J.W. Stargan v2: Diverse image synthesis for multiple domains. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8188–8197. [Google Scholar]
- Karras, T.; Laine, S.; Aittala, M.; Hellsten, J.; Lehtinen, J.; Aila, T. Analyzing and improving the image quality of stylegan. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8110–8119. [Google Scholar]
- Thies, J.; Zollhofer, M.; Stamminger, M.; Theobalt, C.; Nießner, M. Face2face: Real-time face capture and reenactment of rgb videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2387–2395. [Google Scholar]
- Masood, M.; Nawaz, M.; Malik, K.M.; Javed, A.; Irtaza, A.; Malik, H. Deepfakes generation and detection: State-of-the-art, open challenges, countermeasures, and way forward. Appl. Intell. 2023, 53, 3974–4026. [Google Scholar] [CrossRef]
- Afchar, D.; Nozick, V.; Yamagishi, J.; Echizen, I. Mesonet: A compact facial video forgery detection network. In Proceedings of the IEEE International Workshop on Information Forensics and Security, Hong Kong, China, 10–13 December 2018; pp. 1–7. [Google Scholar]
- Wang, R.; Juefei-Xu, F.; Ma, L.; Xie, X.; Huang, Y.; Wang, J.; Liu, Y. Fakespotter: A simple yet robust baseline for spotting ai-synthesized fake faces. arXiv 2019, arXiv:1909.06122. [Google Scholar]
- Bonettini, N.; Cannas, E.D.; Mandelli, S.; Bondi, L.; Bestagini, P.; Tubaro, S. Video face manipulation detection through ensemble of cnns. In Proceedings of the 2020 25th International Conference on Pattern Recognition, Milano, Italy, 10–15 January 2021; pp. 5012–5019. [Google Scholar]
- Li, Y.; Lyu, S. Exposing deepfake videos by detecting face warping artifacts. arXiv 2018, arXiv:1811.00656. [Google Scholar]
- Kim, M.H.; Yun, J.S.; Yoo, S.B. Multiregression spatially variant blur kernel estimation based on inter-kernel consistency. Electron. Lett. 2023, 59, e12805. [Google Scholar] [CrossRef]
- Yang, J.; Xiao, S.; Li, A.; Lu, W.; Gao, X.; Li, Y. MSTA-Net: Forgery detection by generating manipulation trace based on multi-scale self-texture attention. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 4854–4866. [Google Scholar] [CrossRef]
- Li, L.; Bao, J.; Zhang, T.; Yang, H.; Chen, D.; Wen, F.; Guo, B. Face x-ray for more general face forgery detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5001–5010. [Google Scholar]
- Durall, R.; Keuper, M.; Pfreundt, F.J.; Keuper, J. Unmasking deepfakes with simple features. arXiv 2019, arXiv:1911.00686. [Google Scholar]
- Le, M.B.; Woo, S. ADD: Frequency attention and multi-view based knowledge distillation to detect low-quality compressed deepfake images. Proc. Aaai Conf. Artif. Intell. 2022, 36, 122–130. [Google Scholar]
- Giudice, O.; Guarnera, L.; Battiato, S. Fighting deepfakes by detecting gan dct anomalies. J. Imaging 2021, 7, 128. [Google Scholar] [CrossRef] [PubMed]
- Jeong, Y.; Kim, D.; Ro, Y.; Choi, J. FrePGAN: Robust deepfake detection using frequency-level perturbations. Proc. Aaai Conf. Artif. Intell. 2022, 36, 1060–1068. [Google Scholar] [CrossRef]
- Yun, J.S.; Na, Y.; Kim, H.H.; Kim, H.I.; Yoo, S.B. HAZE-Net: High-Frequency Attentive Super-Resolved Gaze Estimation in Low-Resolution Face Images. In Proceedings of the Asian Conference on Computer Vision, Macau, China, 4–8 December; pp. 3361–3378.
- Tian, C.; Luo, Z.; Shi, G.; Li, S. Frequency-Aware Attentional Feature Fusion for Deepfake Detection. In Proceedings of the ICASSP 2023–2023 IEEE International Conference on Acoustics, Speech and Signal Processing, Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Kohli, A.; Gupta, A. Detecting deepfake, faceswap and face2face facial forgeries using frequency cnn. Multimed. Tools Appl. 2021, 80, 18461–18478. [Google Scholar] [CrossRef]
- Li, J.; Xie, H.; Li, J.; Wang, Z.; Zhang, Y. Frequency-aware discriminative feature learning supervised by single-center loss for face forgery detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 6458–6467. [Google Scholar]
- Qian, Y.; Yin, G.; Sheng, L.; Chen, Z.; Shao, J. Thinking in frequency: Face forgery detection by mining frequency-aware clues. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 86–103. [Google Scholar]
- Younus, M.A.; Hasan, T.M. Effective and fast deepfake detection method based on haar wavelet transform. In Proceedings of the 2020 International Conference on Computer Science and Software Engineering, Duhok, Iraq, 16–18 April 2020; pp. 186–190. [Google Scholar]
- Wang, B.; Wu, X.; Tang, Y.; Ma, Y.; Shan, Z.; Wei, F. Frequency domain filtered residual network for deepfake detection. Mathematics 2023, 11, 816. [Google Scholar] [CrossRef]
- Wolter, M.; Blanke, F.; Heese, R.; Garcke, J. Wavelet-packets for deepfake image analysis and detection. Mach. Learn. 2022, 111, 4295–4327. [Google Scholar] [CrossRef]
- Lee, I.; Yun, J.S.; Kim, H.H.; Na, Y.; Yoo, S.B. LatentGaze: Cross-Domain Gaze Estimation through Gaze-Aware Analytic Latent Code Manipulation. In Proceedings of the Asian Conference on Computer Vision, Macau, China, 4–8 December 2022; pp. 3379–3395. [Google Scholar]
- Abdul, J.V.; Janet, B. Deep fake video detection using recurrent neural networks. Int. J. Sci. Res. Comput. Sci. Eng. 2021, 9, 22–26. [Google Scholar]
- Masi, I.; Killekar, A.; Mascarenhas, R.M.; Gurudatt, S.P.; AbdAlmageed, W. Two-branch recurrent network for isolating deepfakes in videos. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 667–684. [Google Scholar]
- Sabir, E.; Cheng, J.; Jaiswal, A.; AbdAlmageed, W.; Masi, I.; Natarajan, P. Recurrent convolutional strategies for face manipulation detection in videos. Interfaces 2019, 3, 80–87. [Google Scholar]
- De L., O.; Franklin, S.; Basu, S.; Karwoski, B.; George, A. Deepfake detection using spatiotemporal convolutional networks. arXiv 2020, arXiv:2006.14749. [Google Scholar]
- Zhou, P.; Han, X.; Morariu, V.I.; Davis, L.S. Two-stream neural networks for tampered face detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 1831–1839. [Google Scholar]
- Nguyen, H.H.; Fang, F.; Yamagishi, J.; Echizen, I. Multi-task learning for detecting and segmenting manipulated facial images and videos. In Proceedings of the 2019 IEEE 10th International Conference on Biometrics Theory, Applications and Systems, Tampa, FL, USA, 23–26 September 2019; pp. 1–8. [Google Scholar]
- Rana, M.S.; Nobi, M.N.; Murali, B.; Sung, A.H. Deepfake detection: A systematic literature review. IEEE Access 2022, 10, 25494–25513. [Google Scholar] [CrossRef]
- Zhao, T.; Xu, X.; Xu, M.; Ding, H.; Xiong, Y.; Xia, W. Learning self-consistency for deepfake detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Nashville, TN, USA, 19–21 June 2021; pp. 15023–15033. [Google Scholar]
- Chen, L.; Zhang, Y.; Song, Y.; Liu, L.; Wang, J. Self-supervised learning of adversarial example: Towards good generalizations for deepfake detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 18710–18719. [Google Scholar]
- Nadimpalli, A.V.; Rattani, A. On improving cross-dataset generalization of deepfake detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 91–99. [Google Scholar]
- Ke, J.; Wang, Q.; Wang, Y.; Milanfar, P.; Yang, F. Musiq: Multi-scale image quality transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 5148–5157. [Google Scholar]
- Yang, S.; Wu, T.; Shi, S.; Lao, S.; Gong, Y.; Cao, M.; Wang, J.; Yang, Y. Maniqa: Multi-dimension attention network for no-reference image quality assessment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1191–1200. [Google Scholar]
- Jinjin, G.; Haoming, C.; Haoyu, C.; Xiaoxing, Y.; Ren, J.S.; Chao, D. Pipal: A large-scale image quality assessment dataset for perceptual image restoration. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 633–651. [Google Scholar]
- Rossler, A.; Cozzolino, D.; Verdoliva, L.; Riess, C.; Thies, J.; Nießner, M. Faceforensics++: Learning to detect manipulated facial images. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27–28 October 2019; pp. 1–11. [Google Scholar]
- Ahmed, N.; Natarajan, T.; Rao, K.R. Discrete cosine transform. IEEE Trans. Comput. 1974, 100, 90–93. [Google Scholar] [CrossRef]
- Bazarevsky, V.; Kartynnik, Y.; Vakunov, A.; Raveendran, K.; Grundmann, M. Blazeface: Sub-millisecond neural face detection on mobile gpus. arXiv 2019, arXiv:1907.05047. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; pp. 6105–6114. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Buslaev, A.; Iglovikov, V.I.; Khvedchenya, E.; Parinov, A.; Druzhinin, M.; Kalinin, A.A. Albumentations: Fast and flexible image augmentations. Information 2020, 11, 125. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Nguyen, H.H.; Yamagishi, J.; Echizen, I. Capsule-forensics: Using capsule networks to detect forged images and videos. In Proceedings of the ICASSP 2019–2019 IEEE International Conference on Acoustics, Speech and Signal Processing, Brighton, UK, 12–17 May 2019; pp. 2307–2311. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).