1. Introduction
The Internet of Things (IoT) represents a vast network of interconnected devices, objects, or “things” that communicate and exchange data with each other. These devices can connect and interact with the external environment [
1]. The increase in wireless connectivity in recent years has resulted in extensive research in Resource Allocation (RA) for wireless networks. With Next Generation Wireless (NGW) networks needing to support more connected devices and resource-intensive applications, there is a renewed focus on developing more efficient User Association policies [
2,
3].
Figure 1 displays a network with multiple Base Stations (BSs) and a collection of IoT devices and cell phones that represent users. These devices need to be associated with the most suitable BS to optimize the system’s utility function. The User Association problem involves formulating strategies for this association process, which becomes complex and challenging in high-traffic or congested environments. The figure illustrates the complexity of these associations, highlighting the need for advanced methods to achieve efficient and effective User Association. The primary objective is to optimize the system’s utility function, commonly associated with throughput. In scenarios of low traffic, basic heuristic methods can yield satisfactory results. However, these simplistic methods fail to deliver optimal solutions in high-traffic or congested environments. Therefore, identifying the ultimate association policy represents a complex and challenging problem. Allocating and managing resources in wireless networks is a difficult and complex task that requires significant effort to achieve the desired outcomes [
4]. This issue can be tackled by treating the UA problem as a sequence of decisions and applying Deep Reinforcement Learning (DRL) strategies to create more effective policies [
5].
Mathematics plays a fundamental role in machine learning by providing the theoretical foundations, algorithms, and tools necessary for understanding and analyzing complex data patterns [
6]. Concepts from probability theory, optimization, and linear algebra are applied to formulate and solve the mathematical models underlying machine learning algorithms. Furthermore, mathematical analysis allows researchers to prove convergence properties, stability, and optimality guarantees for ML methods. Reinforcement Learning (RL) is a form of machine learning. It involves an agent that learns to make optimal decisions by interacting with its environment and getting feedback as rewards or penalties. The agent aims to master a policy, which is a set of rules directing states to actions for the maximal cumulative reward over time. This learning technique is iterative, with the agent continually refining its actions based on past experiences to better future outcomes. It is a versatile tool for solving complex issues [
7]. In recent years, RL research has been focusing on applying its concepts to real-world problems. To emulate human learning, RL uses designs based on trial and error [
8,
9]. Deep Reinforcement Learning is an advanced variant of Reinforcement Learning that employs a Deep Q-Network to compute the Q value-action function [
10]. By leveraging neural networks, it approximates the Q-function in Q-learning, which allows it to proficiently manage high-dimensional state spaces [
11]. This approach has found applications in wireless networks, where it has been used to significantly boost their performance [
12]. DRL has demonstrated its potential in dealing with complex problems by navigating large state spaces and improving decision-making processes.
A Graph Neural Network is a neural network variant that is specifically engineered to handle graph data structures, making it capable of understanding and inferring intricate relationships among various entities [
13]. Within a GNN, each graph node is linked with a feature vector that encapsulates the node’s characteristics. These vectors are processed through multiple layers of the neural network, each layer modifying the vectors according to the attributes of the neighboring nodes in the graph [
14]. This mechanism empowers GNNs to gather and disseminate information across the graph, thereby facilitating reasoning about inter-entity relationships. The ultimate output of the GNN can serve various purposes, such as node categorization, link forecasting, and graph-oriented classification [
15].
Combining DRL and GNN can enable the development of more advanced intelligent systems that can reason and act in complex environments with graph-structured data [
16]. By using GNNs to encode and process graph-structured data, DRL agents can better understand the relationships between entities in their environment, allowing them to make more informed decisions and take actions that lead to better performance [
17]. Furthermore, the combination of DRL and GNN can enhance the ability of these intelligent systems to make generalizations, enabling them to perform well in unseen or partially observed environments with similar graph structures [
18].
The main contribution of our work is to develop a deep reinforcement learning framework for the user association problem using graph representations. It is a DQN-GNN-based approach designed for wireless networks to effectively associate wireless users with the network.
In this paper, we present the following key contributions:
A novel DQN with a GNN-based approach is proposed for efficient user-to-base station association in wireless networks.
A comprehensive evaluation of our proposed method is conducted in terms of (a) average rewards, (b) average returns, and (c) success rate.
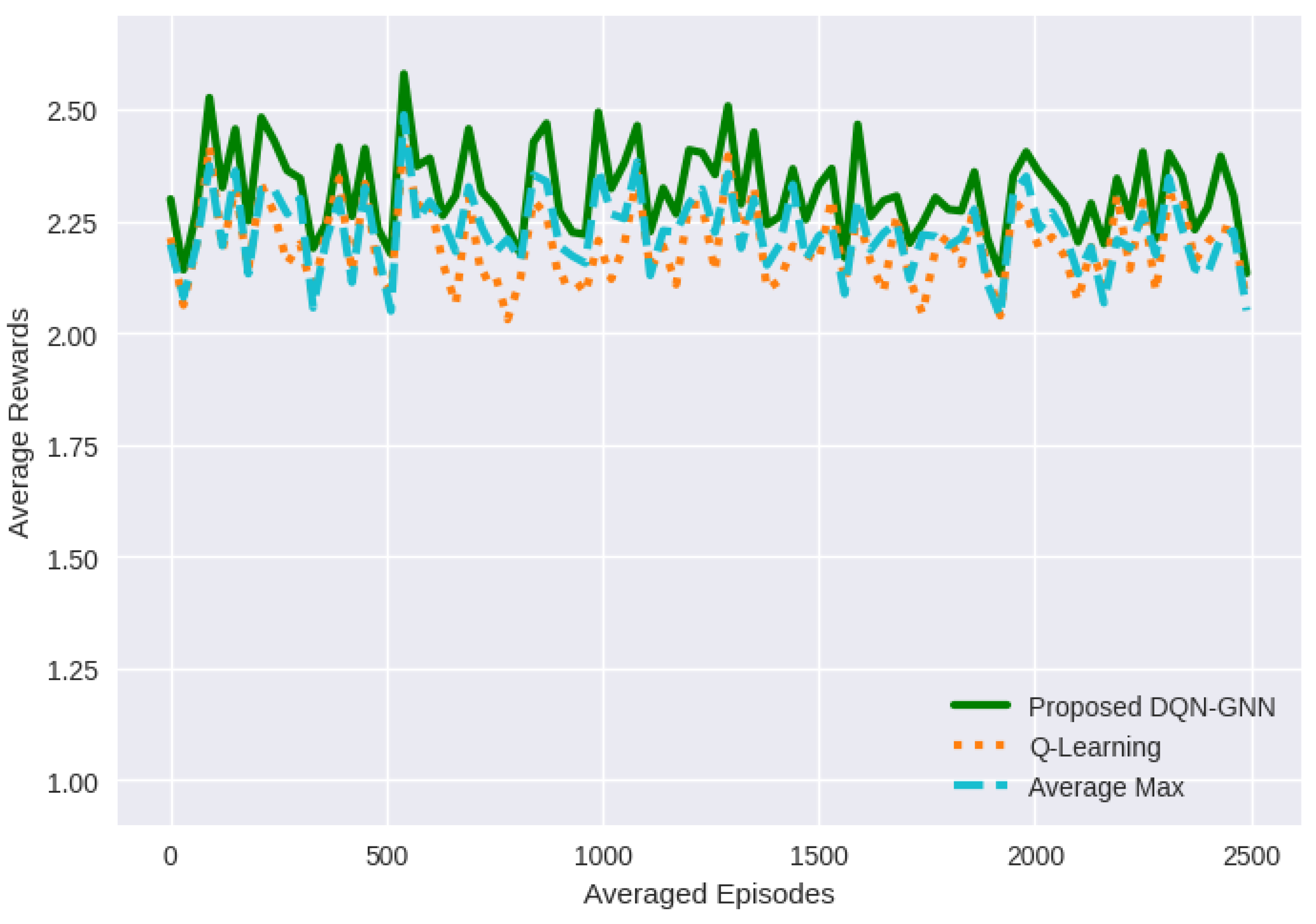
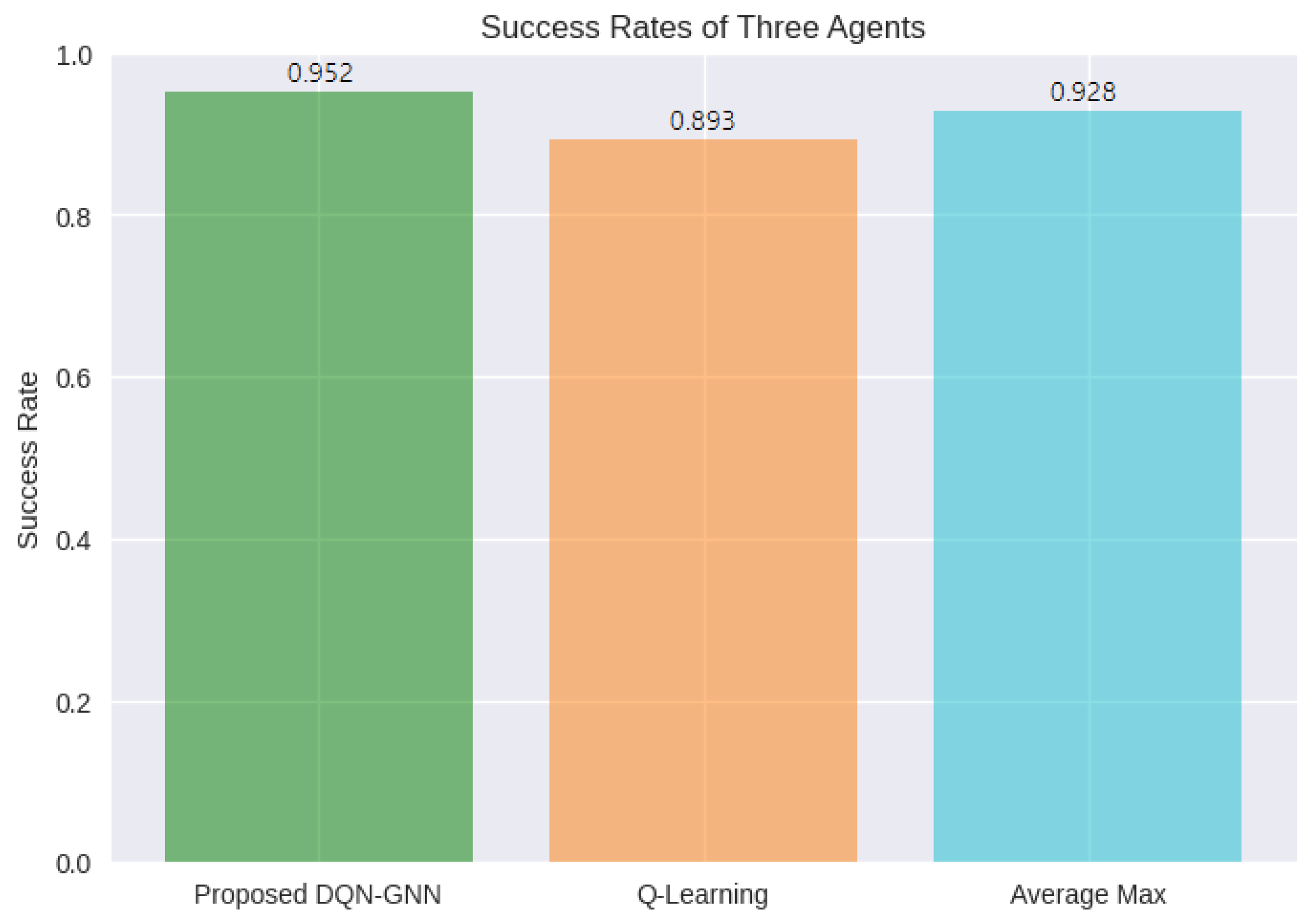
The DQN-GNN approach outperforms current recent work, such as Q-learning and max average approaches, achieving a success rate of 95.2%, which is higher than other methods by up to 5.9%.
The combination of DQN and GNN enhances performance by capturing complex relationships and spatial dependencies in wireless networks, leading to more accurate and efficient associations.
The remainder of this paper is structured as follows:
Section 2 provides a mathematical perspective of the DQN-GNN approach. A comprehensive examination of related studies is offered in
Section 3. A detailed explanation of the proposed method and the system model can be found in
Section 4. The mathematical formulation and optimization of our proposed DQN-GNN approach are discussed in
Section 5. The effectiveness of the proposed user association strategy is assessed in
Section 6. The qualitative analysis and comparison are given in
Section 7. Finally, the paper wraps up in
Section 8, with conclusions and potential future work.
2. DQN and GNN: A Mathematical Perspective
In this section, we provide a mathematical perspective of the Deep Q-Network algorithm and explore its connection to Graph Neural Networks. DQN is a reinforcement learning algorithm that combines deep neural networks with the Q-learning algorithm to solve complex decision-making problems [
19]. The core idea behind DQN is to approximate the Q-value function using a deep neural network and iteratively update the network parameters to improve the Q-value estimates [
20].
Let us define the Q-value function for a given state-action pair as represented in Equation (
1).
where
s represents the current state,
a represents the action taken in that state,
denotes the immediate reward received after taking action
a in state
s at time
t,
represents the next state, and
is the discount factor that determines the importance of future rewards.
The goal of DQN is to learn an optimal Q-value function
that maximizes the expected cumulative reward. To achieve this, DQN utilizes a deep neural network parameterized by
to approximate the Q-value function. Let
represent the output of the neural network when the state-action pair
is passed through the network with parameters
[
21].
The DQN algorithm uses a loss function to measure the discrepancy between the predicted Q-values and the target Q-values. The target Q-value for a state-action pair
is given by Equation (
2).
where
r is the immediate reward obtained after taking action
a in state
s,
is the next state, and
represents the parameters of a separate target network that are updated less frequently than the online network. The loss function used in DQN is the mean squared error (MSE) between the predicted Q-values and the target Q-values [
22], given in Equation (
3).
To update the parameters of the neural network, DQN employs gradient descent to minimize the loss function. The weights
are updated according to Equation (
4), where
is the learning rate.
By iteratively applying the Q-learning updates and optimizing the neural network parameters, DQN learns an optimal policy that maximizes the expected cumulative reward.
GNNs are a class of neural networks designed specifically to operate on graph-structured data. They have gained significant attention due to their ability to capture complex relationships and dependencies within graphs.
Let us consider a graph , where V represents the set of nodes and E represents the set of edges connecting the nodes. Each node in the graph is associated with a feature vector , which represents the input features of the node. Additionally, each edge can have an associated edge attribute , which represents the characteristics of the edge.
The goal of GNNs is to learn a node-level or graph-level representation that captures the structural information and the interactions between nodes and edges in the graph. GNNs achieve this by iteratively aggregating information from neighboring nodes and updating the node representations. The propagation rule of a GNN can be expressed using Equation (
5).
where
represents the hidden representation of node
at layer
l,
represents the set of neighbors of node
,
and
are learnable weight matrices at layer
l, and
is a normalization factor that depends on the degree of node
and
. The function
represents a non-linear activation function, such as rectified linear unit (ReLU) or sigmoid.
By stacking multiple layers of GNNs, the model can capture increasingly complex graph patterns and dependencies. The final node representations can be used for various downstream tasks, such as node classification, link prediction, or graph classification.
3. Related Work
In this section, related studies that used reinforcement learning to solve the user association problem in wireless networks are discussed, along with their limitations.
In [
23], Li, Z. et al. presented a distributed user association algorithm known as Online Reinforcement Learning Approach (ORLA). This innovative approach utilizes online RL to optimize load balancing within vehicular networks. ORLA leverages historical association experiences to adapt to dynamic vehicular environments and achieve superior association solutions. It also effectively handles network dynamics through real-time feedback and consistent traffic association patterns. When tested with the QiangSheng taxi movement dataset, comprising genuine taxi movement data from Beijing, ORLA outperformed other prevalent association methodologies in terms of load-balancing quality.
In their study, Li, Q. et al. built an intelligent user association algorithm, named reinforcement learning handoff (RLH), intended to minimize unnecessary handoffs in UAV networks [
24]. Furthermore, they devised two distinct UAV mobility control strategies to work in tandem with the RLH algorithm to improve system throughput. The RLH algorithm motivates user handoffs through rewards obtained from the reinforcement learning process. The two suggested UAV mobility control strategies are based on the estimation of the SNR and the K-Means method. As demonstrated by simulation results, the RLH algorithm can effectively lower handoffs by as much as 75%, thus proving its efficacy in diminishing unneeded handoffs.
In their research, Zhao et al. [
2] introduced a reinforcement learning strategy to maximize network utility and maintain quality of service in diverse cellular networks. This method employs a dueling double deep Q-network (D3QN) strategy within a multi-agent reinforcement learning framework to tackle the issue of expansive action spaces. The distributed user equipment (UEs) gains access to the global state space via message passing, enabling the D3QN approach to quickly reach a subgame perfect Nash equilibrium. Simulations reveal that the D3QN surpasses other reinforcement learning methods in addressing large-scale learning challenges.
Ding et al. in [
25] presented a multi-agent deep Q-learning network methodology to simultaneously enhance user association and power regulation in uplink heterogeneous networks (HetNets) utilizing orthogonal frequency division multiple access (OFDMA). They successfully tackled the non-convex and non-linear issue using this multi-agent DQN approach, which demands less environmental communication information compared to conventional methods such as game theory, fractional programming, and convex optimization. This proposed technique ensures maximum long-term overall network utility through a novel reward function while also maintaining the quality of service (QoS) for users. Simulations have shown the multi-agent DQN approach to surpass traditional Q-learning in terms of energy efficiency and convergence.
Chou et al. introduced an algorithm rooted in the Deep Deterministic Policy Gradient (DDPG) in [
26] as a solution to the user association issue in wireless networks. They redefined the problem as a Markov Decision Process (MDP) and employed their proposed algorithm to take advantage of the supply-demand understanding of the Lagrange dual problem. The simulated outcomes reveal that their approach notably enhances the quality of experience (QoE), especially in situations with limited wireless resources and a high user count, in comparison to other baseline methods.
Guan et al. introduced a solution for dynamically optimizing user association and power allocation in each time slot in [
27] to minimize the long-term average transmission power consumed by users. Such a joint problem can be formulated as a Markov decision process, which suffers from the curse of dimensionality when there are many users. The authors proposed a distributed relative value iteration (RVI) algorithm that reduces the dimensions of the MDP problem, enabling it to be broken down into multiple solvable small-scale MDP problems. Simulation results indicate that the proposed algorithm performs better than both the conventional RVI algorithm and a baseline algorithm with myopic policies in terms of long-term average transmission power consumption.
In [
28], Zhang et al. developed two deep reinforcement learning algorithms for Internet of Things device association in wireless networks. The centralized DRL algorithm makes decisions for all devices simultaneously, using global information, while the distributed DRL algorithm makes decisions for one device at a time, using local information. Both algorithms use historical information to infer current information and achieve performance comparable to optimal user association policies that require real-time information. The distributed DRL algorithm is shown to have the advantage of scalability in simulations.
Sana et al. proposed a multi-agent reinforcement learning approach in [
29] to address the issue of user association in wireless networks. Users act as independent agents and learn to coordinate their actions based on their local observations to optimize the network sum-rate. The proposed approach limits signaling overhead since there is no direct information exchange among the agents. Simulation results show that the algorithm is scalable, flexible, and able to adapt to rapid changes in the radio environment, resulting in a large sum-rate gain compared to state-of-the-art solutions.
Dinh et al. in [
30] investigated the problem of optimizing joint user-to-access points (AP) association and beamforming in an integrated sub-6GHz/mmWave system to maximize the system’s long-term throughput while meeting various user quality-of-service requirements. The proposed method is based on Deep Q-Networks, where each user optimizes its AP association and interface requests and can be served by multiple APs simultaneously to support multiple applications. Each AP selects its associated users and applications served on each interface while optimizing its millimeter wave (mmWave) beamforming parameters. Simulation results demonstrate that the proposed method outperforms baseline DQN schemes, achieving high global throughput and reducing user outage probabilities.
In [
31], Hsieh et al. propose a novel approach for user association in heterogeneous networks that directly operates in the hybrid space, using a parameterized deep Q-network (P-DQN) to maximize the average cumulative reward while considering constraints on wireless backhaul capacity and quality-of-service for each user device. The proposed P-DQN outperforms traditional approaches such as DQN and distance-based association in terms of energy efficiency while satisfying the QoS and backhaul capacity constraints. Simulation results show that in a HetNet with three small base stations (SBS) and five UEs, the proposed P-DQN improves energy efficiency by up to 77.6% and 140.6% compared to DQN and distance-based association, respectively.
In [
32], Chen et al. proposed a decentralized method to adjust the flight paths of multiple Unmanned Aerial Vehicles (UAVs) over diverse Ground Users (GUs). Their aim was to maximize total data transfer and energy efficiency while maintaining fairness. They redefined the problem as a Decentralized Partially Observed Markov Decision Process (DEC-POMDP) and tackled it using a Coalition Formation Game (CFG) and Multi-Agent Deep Reinforcement Learning (MADRL). The CFG algorithm was employed to acquire a decentralized solution that converges to the Nash equilibrium. Subsequently, a MADRL-based procedure was utilized to perpetually optimize the UAVs’ trajectories and energy usage in a centralized-training yet decentralized-execution manner. Simulations showed that their proposed method surpassed current methods in terms of fairness in data transfer and energy usage in a distributed way.
Joda et al. proposed strategies for placing network functions in cloud nodes and associating users with radio units (RUs) in [
33] to minimize end-to-end delay and deployment cost in Open Radio Access Networks (O-RANs). The problem is formulated as a multi-objective optimization problem with a large number of constraints and variables. To solve the problem, a Markov Decision Problem was developed, and a DQN-based algorithm was proposed. The simulation results show that the proposed scheme reduces the average user delay by up to 40% and the deployment cost by up to 20% compared to the baselines.
Alizadeh and Vu in [
34] developed a central load balancer designed to maintain equal distribution across all base stations at every stage of learning. Their proposed methodology introduces two different association vectors, allowing users to participate in background learning while simultaneously engaging in optimal data transmission. They also presented a measurement model designed to swiftly account for channel fluctuations and user mobility within dynamic networks. To minimize the rate of handover, they distinguish between the costs of transmission handover and learning handover, introducing a learning handover cost that decreases with the duration of stay. Simulation results reveal that the proposed algorithms not only converge quickly but also surpass the Third Generation Partnership Project (3GPP) handover, approaching near-optimal benchmarks for worst connection swapping.
In [
35], Khoshkbari et al. proposed a novel deep Q-learning approach in which a satellite serves as an operative agent. This agent is responsible for scheduling each user to a terrestrial base station (TBS) or a high-altitude platform station (HAPS) within each time slot, utilizing channel state information (CSI) obtained from the preceding time slot. This proposed approach yields results that almost mirror those achieved via the exhaustive search action selection method. Moreover, it outperforms a convex optimization-based user association scheme in scenarios where the CSI is noisy. The researchers further delve into the implications of imperfect CSI and highlight the superior performance of their proposed method under such circumstances.
Moon et al. proposed a decentralized user association technique based on a multi-agent actor-critic (AC) method in [
36] to maximize the energy efficiency of an ultra-dense network (UDN). This technique aims to enhance the energy efficiency of ultra-dense networks. The actor network of the proposed technique decides the user association of the small base station, guided by local observations. Simultaneously, the critic network communicates the energy-efficient user association decision to the actor network. This mechanism allows each small base station’s deep reinforcement learning agent to identify the user association decision, which optimizes network energy efficiency. According to the simulation results, the proposed method provides an average improvement in energy efficiency of more than 50% compared to traditional user association techniques.
In [
37], Kim et al. proposed a curriculum learning technique to improve the accuracy of a reinforcement learning agent in solving the challenging problem of resource allocation in wireless networks, particularly in scenarios with high user mobility, such as the Internet of Vehicles (IoV). The proposed technique involves gradually increasing the mobility of each user during learning to enhance the model’s accuracy. Simulation results demonstrate that the proposed method achieves faster convergence and better performance compared to traditional reinforcement learning techniques.
Table 1 displays a comparison among recent related works in terms of the used RL methods and main goals.
The limitations of the recent related reinforcement learning-based user association schemes are:
Limited scalability: Some of the related works face scalability issues when applied to large-scale wireless networks due to the high computational complexity and communication overhead of the proposed algorithms.
Limited generalization: Many of the related works are not generalized well to different wireless network scenarios, as the performance relies heavily on the quality and quantity of training data or may only address specific problems, such as load balancing or power allocation.
Limited flexibility: Some of the related works lack flexibility in adapting to rapid changes in the radio environment or may require high signaling overhead due to the direct information exchange among agents or nodes.
Limited efficiency: Some of the related works suffer from inefficient resource allocation or may not fully utilize available resources, leading to suboptimal performance in terms of energy efficiency or network throughput.
4. The Proposed Approach
4.1. Building the Proposed DQN-GNN Approach
In this section, we describe the details of building our proposed DQN-GNN approach for user association in wireless networks. The design of the GNN and DQN models, the training process, and the integration of the two models for user association are discussed.
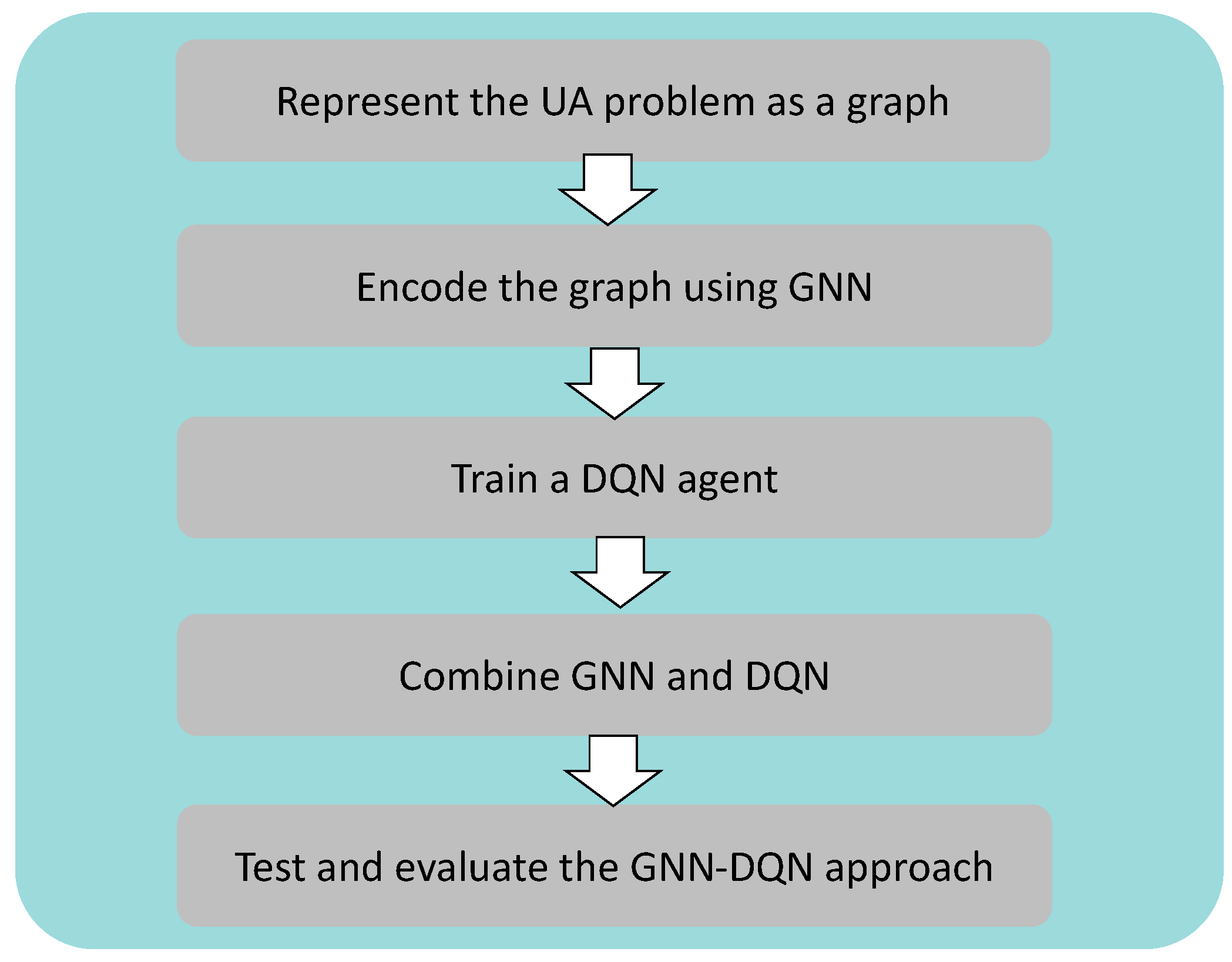
The proposed model building phase goes through five phases, as shown in
Figure 2.
Represent the UA problem as a graph: The user association problem is represented as a graph, where each node corresponds to a user or a base station, and the edges represent the wireless connections between them.
Encode the graph using GNN: A GNN is used to encode the graph structure of the network and learn a representation for each node that captures its importance and connectivity within the network. This allows the system to reason about the relationships between users and BSs and make more informed decisions about user association. In this work, we use a GNN model called LocalGNN for both the policy network and the target network, which was proposed by Shaddad et al. in [
39]. A notable feature of the LocalGNN is its ability to locally aggregate information for each node, and this aggregation is also extended to include neighboring nodes within K hops. This means that the feature extraction and computation for each node can be performed locally, which greatly supports the scalability of the proposed algorithm.
Train a DQN agent: A DQN agent is trained to learn a policy that selects the best BS for each user to connect to based on the current state of the network. The state can be defined as the current set of user-BS associations, as well as additional network parameters such as signal strength, traffic load, and interference levels. The DQN agent can learn to optimize the network performance by selecting the best user-BS associations.
Combine GNN and DQN: The GNN and DQN models are combined by using the GNN to encode the graph structure of the network and provide input to the DQN agent. The DQN agent can then use the learned representation of each node to make more informed decisions about user association. This combination of models can lead to more efficient and effective user-BS associations and better overall network performance.
Test and evaluate the GNN-DQN approach: Once the models are trained, the system can be tested and evaluated using wireless network data. To assess the effectiveness of our proposed GNN-DQN approach for user association, we compared its results to those obtained using other user association methods. This comparison allows us to evaluate the performance of our approach relative to existing methods and determine its efficacy in solving the user association problem in wireless networks.
Figure 3 shows the diagram of the proposed DQN-GNN-based approach. There are two entities: intelligent DQN-GNN agent and 5G network environment. The DQN and GNN work together to provide an adaptive and efficient approach to User Association in 5G networks, with the DQN making real-time allocation decisions based on the current network state and the GNN providing predictions of future network states to improve the DQN’s decision-making ability.
4.2. The System Model
Suppose we have N base stations in a 5G network environment, each of which possesses a finite number of frequency resources. According to the 5G framework, these resources are called Resource Blocks (RB). During each time interval t, there is a chance that a user may arrive, with the arrival probability following a certain distribution. If a user does arrive, one of the k base stations with the highest signal-to-noise-and-interference ratio (SNIR) and available resources is required to form an association with the new user. In our proposed reinforcement learning model, a tuple is formed by (s, a, T, r, ).
The current state in the agent-environment system, denoted as
s, is a fusion of the condition of the base station and the user situation, according to [
40]. The state of the base station encapsulates the number of linked users and the average utility achieved thus far, along with the existing state of the system and the features of the new user. The user’s state, on the other hand, includes the Received Signal Strength Indicator (RSSI) from the associated base stations and a specific demand that must be met.
The action that the agent takes in a particular state, symbolized as
a, involves choosing a base station from the options available, according to [
41]. However, an action is not necessary at every time interval. To ensure a well-defined Markov process, decision-making is incorporated into the state. If no user is present, the demand drops to zero, and the only task required is to update the system state without any action needed.
T denotes the succeeding state in which the environment transitions after the agent executes a specific action, as described in [
42]. The descriptors of the base station are updated to reflect the effects of the action, which could be an increase in the number of connected users and a new mean utility, as well as the impact of time, which could be a decrease in the number of connected users if a user’s demand has been satisfied. The characteristics of the new user are revised every time a new user joins. It is important to note that while the transitions over the base station’s features are deterministic, given the action
a and the state
s, they are stochastic for the new user’s features.
The reward that the agent earns for executing a particular action in a specific state is represented as
r, as per [
43]. In the context of our research, the reward is the logarithm of the sum of the throughput between users, which supports equity in resource allocation and is commonly used in related literature.
The parameter
signifies the discount factor utilized to prioritize future rewards in the agent’s decision-making process, as per [
44]. The agent aims to optimize the expected discounted cumulative reward by updating a policy (
) using one of Bellman’s equations. The action-value function for policy
is utilized, and the state-action value function is refreshed using the optimality equation.
Table 2 displays the parameters of the proposed DQN-GNN model.
Algorithm 1 provides the complete pseudocode for the proposed DQN-GNN user association approach for wireless networks, where
and
are the parameters of the Q-network and GNN, respectively. The replay memory buffer is represented by
D, which contains the experiences of the agent.
is the epsilon-greedy policy used by the agent to select actions in the current state.
is the next state, and
indicates whether the episode has terminated. The learning rate used to update the Q-network and GNN parameters is represented by
. The target Q-value (
) is used to update the Q-network parameters.
L is the loss function used to compute the difference between the predicted and target Q-values.
is the gradient of the loss function with respect to the Q-network parameters.
is the gradient of the GNN output with respect to the GNN parameters, while
is the gradient of the Q-network output with respect to the Q-network parameters. The algorithm iteratively updates the Q-network and GNN parameters based on the observed transitions and their corresponding target Q-values, with the goal of maximizing the cumulative reward over a sequence of time steps. By learning the optimal user association policy, this approach can improve user experience and network efficiency in wireless networks.
| Algorithm 1: DQN-GNN User Association Approach |
![Mathematics 11 04286 i001]() |
The data in the environment are generated dynamically based on the specified parameters and actions. To store the agent’s experiences, a replay memory buffer called D is utilized. This buffer contains transitions in the form of , representing the state, action, reward, next state, and termination information at each time step during an episode. During the training phase, the algorithm selects a mini-batch of transitions from the replay memory buffer D. These transitions are then used to compute the target Q-values and update the Q-network and GNN parameters. In the testing phase, the algorithm does not rely on a specific dataset or replay memory buffer. Instead, it assesses the performance of the trained policy by executing it within the environment and evaluating the achieved outcomes based on predefined metrics.
5. Mathematical Formulation and Optimization
In this section, we delve into the mathematical aspects of our proposed DQN-GNN approach for user association in wireless networks. The formulation provides the mathematical groundwork for the DQN-GNN model, setting up the problem in a way that allows for the application of reinforcement learning techniques. Then, we discuss the optimization process of the DQN-GNN model.
5.1. Problem Formulation
The User Association problem can be formulated as a Markov Decision Process with the state space S, action space A, transition probability P, and reward function R. In our problem context:
The state at time t is defined by the current user-BS associations and network conditions, such as the number of connected users and the average utility achieved up to time t.
The action at time t is the decision made by the DQN-GNN agent to associate a user with a specific BS.
The transition probability is determined by the dynamics of the wireless network, such as the arrival and departure of users and changes in network conditions.
The reward is the utility of the system after taking action in state , which is defined as the logarithm of the sum of the throughput between users.
The goal of the DQN-GNN agent is to learn a policy that maximizes the expected cumulative discounted reward , where is the discount factor.
Our DQN-GNN approach is particularly relevant in the context of wireless networks and the Internet of Things. In wireless IoT networks, a large number of interconnected devices are continuously interacting, leading to dynamic and complex network conditions. The state space (S) in our approach, which represents the current user-BS associations and network conditions, can effectively capture the complex dynamics of such networks. The action space (A), which represents the decision to associate a user with a specific BS, allows for efficient resource allocation in these networks, where resources are often scarce and need to be judiciously allocated. The transition probability (P) and the reward function (R) can model the impact of these decisions on the network’s performance, providing a way to navigate the complex and dynamic IoT environment.
Moreover, the policy learned by the DQN-GNN agent, which aims to maximize the expected cumulative discounted reward, can guide the decision-making process in these networks. This policy essentially provides a strategy for efficient user association in the face of dynamic network conditions and limited resources, which are typical characteristics of wireless IoT networks. Therefore, our DQN-GNN approach provides a mathematical framework for optimizing user association in wireless IoT networks and can significantly enhance network performance in these environments.
5.2. Optimization Process
The optimization process is a crucial component of our proposed DQN-GNN approach. It refers to the iterative method of adjusting the parameters of the DQN and GNN models to minimize the difference between the predicted Q-values and the actual rewards. This process is key to improving the model’s performance in the user association task over time.
This process can be visualized in the context of the Markov Decision Process, as shown in
Figure 4. The diagram illustrates the interaction between the DQN-GNN agent and the wireless network environment over multiple time steps. Starting from an initial state (s), the agent takes an action (a), which leads to a new state (s′) and a reward (r). This cycle repeats as the agent continues to interact with the environment, with the agent taking another action (a′) in state (s′), leading to another new state (s″) and another reward (r′).
Formally, the optimization process of our DQN-GNN model can be mathematically formulated as follows:
In this equation, , and are the parameters of the policy network (DQN) and the target network (GNN), respectively. The policy network is responsible for making the decisions (i.e., choosing the actions), while the target network is used to generate the target Q-values for the update of the policy network. The replay memory buffer (D) stores the agent’s experiences in the form of state-action-reward-next state tuples. These experiences are sampled during the training process to update the model parameters. and are the estimated Q-values of the current and next state-action pairs, respectively. These are the outputs of the DQN, which estimates the maximum expected future rewards for taking action a in state s.
The objective of the optimization process is to find the optimal parameters and that minimize the expectation of the squared difference between the predicted Q-values and the actual rewards (plus the discounted maximum Q-value of the next state). This difference represents the temporal difference error, which measures the discrepancy between the current Q-value estimate and the more accurate estimate obtained after observing the reward and the next state. Optimization is performed using an optimizer, which iteratively adjusts the parameters in the direction that reduces the error. Through this optimization process, the DQN-GNN model learns to make more accurate predictions and better decisions, leading to improved performance in the user association task.
7. Qualitative Analysis and Comparison
The DQN-GNN approach offers a robust solution to user association in wireless networks due to its inherent ability to adapt to dynamic network conditions. In comparison, the Online Reinforcement Learning Approach presented by Li, Z. et al. [
23] focuses on load balancing in vehicular networks. Although ORLA is effective in its specific context, it may not fully capture the complex network topologies and spatial dependencies that exist between users and base stations. The incorporation of GNNs in the DQN-GNN approach allows it to efficiently model these relationships, leading to improved user association and overall network performance.
In comparison to the Reinforcement Learning Handoff (RLH) approach proposed by Li, Q. et al. [
24], the DQN-GNN approach provides a more comprehensive solution to the user association problem. Although RLH is effective in reducing redundant handoffs in UAV networks, it does not optimize the overall network utility, particularly in diverse cellular networks. The DQN-GNN approach, on the other hand, aims to optimize network performance through better user association, demonstrating its versatility in addressing different aspects of the user association problem.
On the other hand, the Dueling Double Deep Q-Network approach by Zhao et al. [
38] applies multi-agent RL to optimize network utility in heterogeneous cellular networks. Although D3QN is a novel approach, it may face scalability issues with increasing network size due to its high computational complexity. Owing to the scalable nature of deep learning models, the DQN-GNN approach can be extended more efficiently to large wireless networks, thereby making it a more feasible solution for real-world applications.
Table 4 shows a qualitative analysis and comparison of the proposed DQN-GNN approach with three other approaches: ORLA, RLH, and D3QN. The comparison is conducted based on several key factors, namely spatial dependencies, scalability, communication overhead, and optimization objective.
8. Conclusions and Future Work
In this paper, we propose a deep reinforcement learning approach that uses a Graph Neural Network to estimate the q-value function for the user association problem in wireless networks. Our approach is able to model the network topology and capture spatial dependencies between users and base stations, resulting in more accurate and efficient associations. It outperforms existing techniques, such as Q-learning and max-average approaches, in terms of average rewards and returns. Furthermore, it achieves a success rate of 95.2%, which is higher than other techniques by up to 5.9%. There are several reasons for this superior performance. First, the incorporation of GNNs into our approach allows for the accurate representation of the complex network topology and facilitates the learning of dependencies between users and BSs. By considering these factors, our approach can make more informed and context-aware decisions, which ultimately lead to better rewards and returns. Second, the use of deep reinforcement learning allows our approach to learn from past experiences and optimize the user association process over time. The DQN framework, combined with GNNs, enables our approach to estimate the q-value function more accurately, leading to more optimal and efficient associations. Additionally, the ability of GNNs to propagate information across the network graph enhances the understanding of the underlying structure and relationships, enabling our approach to exploit this information for improved decision-making. Overall, the integration of GNNs into the DQN framework empowers our approach to outperform traditional techniques by leveraging the network topology, capturing spatial dependencies, and effectively learning from past experiences, resulting in superior average rewards and returns.
In future work, we plan to extend our approach to address more complex scenarios, such as larger network topologies and dynamic environments. This expansion will allow us to explore the scalability and adaptability of our method in a broader context. We are also interested in investigating the application of transfer learning, which has shown promise in enabling knowledge transfer between tasks or domains. By leveraging pre-existing knowledge and fine-tuning GNN models, we can potentially enhance the efficiency and generalization capabilities of our approach across different network topologies. Furthermore, we recognize the importance of evaluating the robustness of our approach to uncertainties and noise sources inherent in wireless networks.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}