1. Introduction
In recent decades, as a fundamental technique of machine learning, data clustering has been widely applied to various fields [
1,
2,
3,
4,
5,
6]. Technically, data clustering aims to partition a set of samples into different groups in an unsupervised way, so that the samples with high similarity are accumulated into the same group, otherwise into different groups. This provides an effective way to analyze the inner structures of data.
Traditional clustering methods are often designed for data with single views. However, real-world data often have multiple modalities or are collected from multiple sources, thus called multi-view data [
7,
8,
9,
10]. For example, an image dataset can be described using heterogeneous features, e.g., color descriptors, local binary patterns, or local shape descriptors. A web page can be described by images, links, texts, etc. Since data descriptions from different views often have compatible and complementary information, multi-view data are generally more comprehensive than single-view data in data representation. This indicates that it is possible to obtain better clustering performances using multi-view features than using one-view features. Inspired by this, multi-view clustering [
11,
12] has received a lot of attention and has led to efforts to improve clustering performances in past years. For example, Cai et al. [
13] proposed a robust large-scale multi-view clustering method to integrate heterogeneous representations of large-scale data. Chaudhuri et al. [
14] provided a simple and efficient multi-view clustering method, which aims to learn subspaces based on a canonical correlation analysis (CCA). Kumar et al. [
15] proposed a multi-view clustering approach in the framework of spectral clustering, where the philosophy of co-regularization is used to make clustering in different views agree with each other. In addition, due to the powerful capabilities of non-negative matrix factorization (NMF) in feature extraction, NMF has been extended to multi-view clustering. For example, Liu et al. [
16] proposed a joint NMF algorithm, called MultiNMF, by pushing each coefficient matrix (which corresponds to each view) toward a common consensus matrix. Based on this, Kalayeh et al. [
17] developed a weighted multi-view NMF for the problem of dataset imbalance. Motivated by the success of deep learning, many deep matrix decomposition-based algorithms are proposed for improving multi-view clustering by discovering the hierarchical structures of multi-view data, such as in [
18,
19].
Most previous studies of multi-view data, including the above-mentioned, have tended to rely on input data that can be fully observed from each view. However, due to some unavoidable factors in the process of data collection and transmission, there are observation failures with real-world data (from some views). For example, speakers can be described by audio-visual information, while some may lack visual or auditory information [
20]. For bilingual documents (one language as one view), many documents may have only one type of language translation [
21]. Thus, each view may have a different number of instances, which would then bring large challenges for conventional methods in multi-view clustering. For convenience, here, the clustering of incomplete multi-view data is called incomplete multi-view clustering (IMC) [
22,
23].
To overcome the above-mentioned IMC problem, many efforts have been made in recent years. Trivedi et al. [
22] first proposed solving the IMC problem by exploiting the kernel canonical correlation analysis (KCCA) of multi-view data. However, this method can only handle two-view data, which must have one complete view and, thus, greatly limits its application in the real world. To alleviate such a limitation, many advanced methods are subsequently being proposed for the IMC problem, such as matrix factorization-based methods, e.g., partial multi-view clustering (PVC) [
20], incomplete multimodality grouping (IMG) [
24], and partial multi-view subspace clustering (PMSC) [
25], which aims to seek the consensus representation of all views for clustering. However, these methods are still inflexible, since they can only work in two-view data with special incomplete cases where some samples are fully observed from all views while others can only be observed from one view. To improve the generalization of the IMC clustering methods, researchers attempted to propose many flexible methods to deal with various incomplete cases. For example, Shao et al. [
26] proposed a multi-incomplete-view clustering (MIC) MIC via a weighted NMF with the
constraint. Subsequently, an online multi-view clustering algorithm is proposed to deal with large-scale incomplete multi-view data by a joint weighted NMF framework, where multi-view data are processed chunk by chunk [
27]. Moreover, Hu et al. [
28] proposed a doubly aligned incomplete multi-view clustering algorithm (DAIMC) by introducing regression to capture more information among multiple views. Wen et al. [
29] proposed a general framework for incomplete multi-view clustering, where the low-rank representation was adopted to adaptively construct the graph of each view and then learn a common representation for all views by a co-regularization term. In addition, some other incomplete multi-view clustering methods were proposed, such as in references [
30,
31,
32].
These methods attempted to solve the incomplete multi-view clustering problem by learning a consensus representation or graph shared by each view. However, most of them chose to neglect the missing views regarding incomplete multi-view data, which would greatly increase the difficulties in learning consensus representations for clustering, especially in cases of high missing rates. To tackle this issue, recently, Wen et al. [
33] first proposed an adaptive graph completion-based incomplete multi-view clustering (AGC_IMC), attempting to recover the missing connection between the missing and available instances via between-view inferring. For example, assuming multi-view data with
l views, the connection of instance
j with other instances in view
v, i.e., the similarity graph
, can be recovered by exploiting the following between-view information.
To overcome this drawback, here, we propose a novel incomplete multi-view clustering method based on low-rank graph completion (IMC-LGC). Generally, the data are drawn from several low-rank subspaces; thus, the learned graph of the corresponding view should discover the low-rank structure of the data [
34]. This indicates that the incomplete graph of each view can be recovered by exploiting the low-rank structure inside the view. Moreover, different views often admit the same underlying clustering of the data, i.e., corresponding data points in different views should have the same cluster relationship. This means that the learned graph of each view should reflect the same similarity relation; in other words, there are low-rank relationships among different similarity graphs. Thus, the low-rank relationship among graphs can be used to predict the connections between missing instances and available instances. Inspired by these characteristics, we attempt to improve the multi-view clustering performance by recovering the incomplete graphs using the low-rank information within and between views.
Figure 1 presents a flowchart of the proposed method. Specifically, we first stack the similarity graphs of all views into a third-order graph tensor and then exploit the low-rank structure via the low-rank constraint along each mode-unfolding matrix; this process enables the proposed model to capture the low-rank information (within and between views) simultaneously.
In this way, the connection hidden between missing and available instances can be recovered and then further improve the clustering performance. We next learn the consensus representation for clustering from all complete graphs via multi-view spectral clustering. To obtain the optimal multi-view clustering result, the graph completion and consensus representation learning are integrated into a joint optimization framework. A large number of experimental results show that the proposed method obtains better clustering performance than state-of-the-art incomplete multi-view clustering methods. To summarize, our work has the following contributions.
By revealing the low-rank relationship within each graph and between all graphs, it is expected to restore the hidden connections between missing and available instances.
We propose exploring the low-rank relationship of within and between views simultaneously by imposing the matrix nuclear norm regularization on each mode matrization of the third-order graph tensor that is stacked by all similarity graphs.
The graph completion and consensus representation learning were developed to optimize jointly in a unified framework, with the goal of obtaining complete graphs for clustering. Extensive experimental results show that the proposed method outperforms other state-of-the-art IMC methods.
where
is coefficient. However, this inference would miss the significance and become unreliable when sample
j has only one or even no available view.
The rest of the paper is organized as follows.
Section 2 briefly introduces preliminaries, which include notations and two representative multi-view spectral clustering methods.
Section 3 proposes a novel multi-view spectral clustering method based on low-rank graph completion, and then gives its optimization procedure and the computational complexity analysis.
Section 4 analyzes the experimental results conducted on several real-world datasets. Finally, a brief conclusion is offered in
Section 5.
4. Experiments
This section aims to evaluate the proposed method IMC-LGC on several real-world multi-view datasets with samples missing throughout the comparison with the state-of-the-art IMC methods. Moreover, we also conducted experiments to analyze the parameter sensitivity and convergence. For the proposed method and its compared methods, all the parameters were ’tried’ to obtain the best clustering results according to corresponding papers.
4.1. Dataset Description and Incomplete Multi-View Data Construction
(1) BBCSport [
49]: The original BBCSport database contained 737 new articles collected from the BBCSport website. These documents are described by 2–4 views and categorized into 5 classes (i.e., athletics, cricket, football, rugby, and tennis). In our experiments, following the experiment settings in [
33], we adopted a subset with 116 samples described by all 4 views to validate the effectiveness of our method. The feature dimensions of different views are 1991, 2063, 2113, and 2158, respectively.
(2) 3Sources (
http://erdos.ucd.ie/datasets/3Sources.html, accessed on 10 March 2022): A total of 3 sources consisted of 948 texts collected from 3 online news sources: BBC, Reuters, and The Guardian. Following [
33], we experimented on a subset that contained 169 stories that were reported in all 3 sources (to compare the different methods).
(3) Handwritten (
https://archive.ics.uci.edu/ml/datasets/Multiple+Features, accessed on 10 March 2022): The original dataset contained 10 digits, i.e., 0–9, where each digit has 200 handwritten images. In our experiment, considering the limitation of computation resources, we selected a subset that consisted of 0–3 digits and each digit had the first 50 images (200 images in total). A total of 4 kinds of features (i.e., pixel averages, Fourier coefficients, profile correlations, and Karhunen-love coefficient) was selected as 4 views; the feature dimensions were 240, 76, 216, and 64, respectively.
(4) MSRC-v1 (
https://github.com/youweiliang/ConsistentGraphLearning/tree/master/data, accessed on 10 March 2022): The original dataset consisted of 8 categories of images with data points for the object recognition problem [
50]. In the experiment, following [
51], we selected the following widely used categories—cow, airplane, building, face, bicycle, car—and each had 30 images. A total of 5 features, i.e., CENTRIST, color moment, GIST, LBP, and HOG, were selected as 5 views, with feature dimensions of 254, 24, 512, 256, and 576, respectively.
(5) ORL Database (
http://www.cl.cam.ac.uk/research/dtg/attarchive/facedatabase.html, accessed on 10 March 2022): The ORL dataset consisted of 400 facial images from 40 individuals, where each had 10 different images taken at different times with various lighting, facial expressions (open/closed eyes, smiling/not smiling), and facial details (glasses/no glasses). In the experiment, each image was presented as
, and then 3 types of features were extracted: intensity, LBP, and Gabor, with dimensions of 4096, 3304, and 6750, respectively.
Two types of incomplete multi-view datasets were considered in our experiments. For the BBCSport, 3 sources, and handwritten datasets, 10%, 30%, and 50% of samples were randomly selected as the paired samples whose views were fully observed. We randomly select samples of the corresponding remaining samples as the single-view samples, where is the number of views of the dataset. In this way, the incomplete dataset with paired samples was constructed. The MSRC-v1 and ORL datasets, under the condition that each sample contained at least 10%, 30%, and 50% of instances from every view, were randomly removed to construct the incomplete multi-view dataset with different missing-view rates.
4.2. Compared Methods and Evaluation Metric
The following methods, which can handle incomplete multi-view data, were selected to compare with the proposed method.
(1) Best single view (BSV) [
24]: For BSV, the missing instances of each view are first filled in the average of instances; then it implements
k-means on all views separately and reports their best clustering results.
(2) Concat [
24]: For the missing instances, Concat first fills them in the average instances in the corresponding view, and then concatenates all views into a single view with long dimensions; it next reports the clustering results by performing the
k-means on the single view.
(3) Multi-incomplete-view clustering (MIC) [
26]: The MIC method learns the latent feature matrices for all incomplete views via a weighted multi-view matrix factorization framework and pushes them toward a common consensus using a co-regularized approach, where the missing instances are given as the lower weights to minimize the negative influences from the missing instances.
(4) Online multi-view clustering (OMVC) [
27]: Similar to MIC, OMVC also learns the consensus representation for incomplete views by a weighted non-negative matrix factorization framework. To reduce the memory requirements in processing large-scale data, it processes multi-view data chunk-by-chunk.
(5) Graph-regularized partial multi-view clustering (GPMVC) [
21]: GPMVC is an extension of the partial multi-view clustering method for partial view datasets, which learns the common representation from the normalized individual representations of all views by exploiting the intrinsic geometry of the data distribution in each view via the graph constraint.
(6) Adaptive graph completion-based incomplete multi-view clustering (AGC_IMC) [
33]: AGC_IMC borrows the idea of multi-view spectral clustering and jointly performs graph completion and consensus representation learning in a unified framework, obtaining a more reasonable consensus representation for clustering by inferring the intrinsic connective information on the missing instances and available instances.
To evaluate the performance of the proposed method and its compared methods, Four well-known evaluation metrics, i.e., accuracy (ACC), normalized mutual information (NMI), purity, adjusted Rand index (AR), were adopted in our experiment [
52,
53,
54], where ACC, NMI, and purity are reported in the table, and AR is shown in the figure. A higher value of these methods means a better clustering performance. For a fair comparison, we ran the above methods 10 times with respect to different view-missing groups, and then collected their average values (%). In addition, all compared methods were implemented with wide parameter ranges and their best performances were reported.
4.3. Experiment Results and Analysis
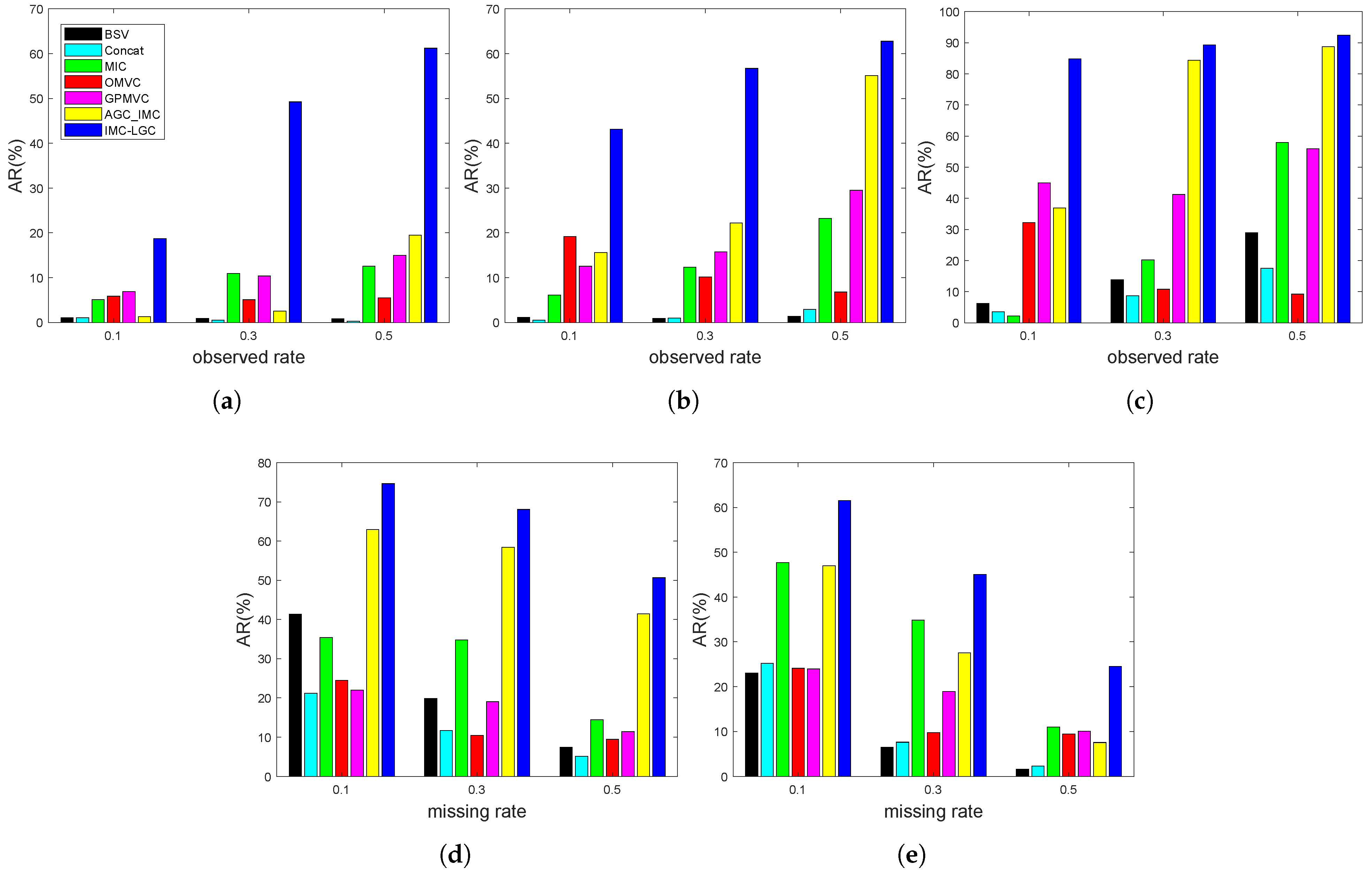
Experimental results of different incomplete multi-view clustering methods on the above two types of incomplete multi-view databases are enumerated in
Table 1,
Table 2,
Table 3,
Table 4 and
Table 5 and
Figure 2. These experimental results reflect the following points:
(1) The proposed method obtains significantly better results than the other methods in the five multi-view datasets under two types of incomplete cases. For example, as observed from
Table 1, compared with the suboptimal method, the ACC value of the proposed method is improved by about 8%. As shown in
Table 2, the ACC achieved by the proposed method is about 7% higher than that of the suboptimal method.
(2) As the observed rate of paired samples increase or the missing rate of view decreases, the BSV and Concat methods fail to obtain obvious improvements in comparison with other methods under our considered cases. For example, the BSV obtains results of 34.05%, 33.71%, and 33.53% of ACC in the BBCSport dataset with observed rates of 0.1, 0.3, and 0.5, respectively; the Concat achieves results of 32.84%, 32.50%, and 32.41% of ACC. These results indicate that the capabilities of BSV and Concat in capturing information are obviously weaker than other methods in dealing with incomplete multi-view data clustering problems, which are mainly caused by their rough processing.
(3) AGC_IMC is most related to our proposed method, IMC-LGC, while it fails to obtain competitive results in most cases, especially when the observed samples are smaller. For example, in
Table 3, AGC_IMC obtains 93.80% and the proposed method achieves 95.85% in ACC under the observed rate of 0.3, while AGC_IMC only obtains 58.35% and the proposed method obtains 93.95% in ACC when the observed rate decreases to 0.1. In
Table 4, when the missing rate of each view is 0.1, the ACC obtained by AGC_IMC is about 6% smaller than that of the proposed method, i.e., AGC_IMC obtains 69.50% and the proposed method obtains 74.95%; when the missing rate achieves 0.5, the ACC obtained by AGC_IMC is about 10% smaller than that of the proposed method, i.e., AGC_IMC obtains 35.63% and the proposed method obtains 45.25%. These results may be caused by the fact that AGC_IMC only learns the between-view inferring of missing instances and available instances, while the proposed method can capture the low-rank information (within and between views) simultaneously.
4.4. Sensitivity Analysis of the Penalty Parameters
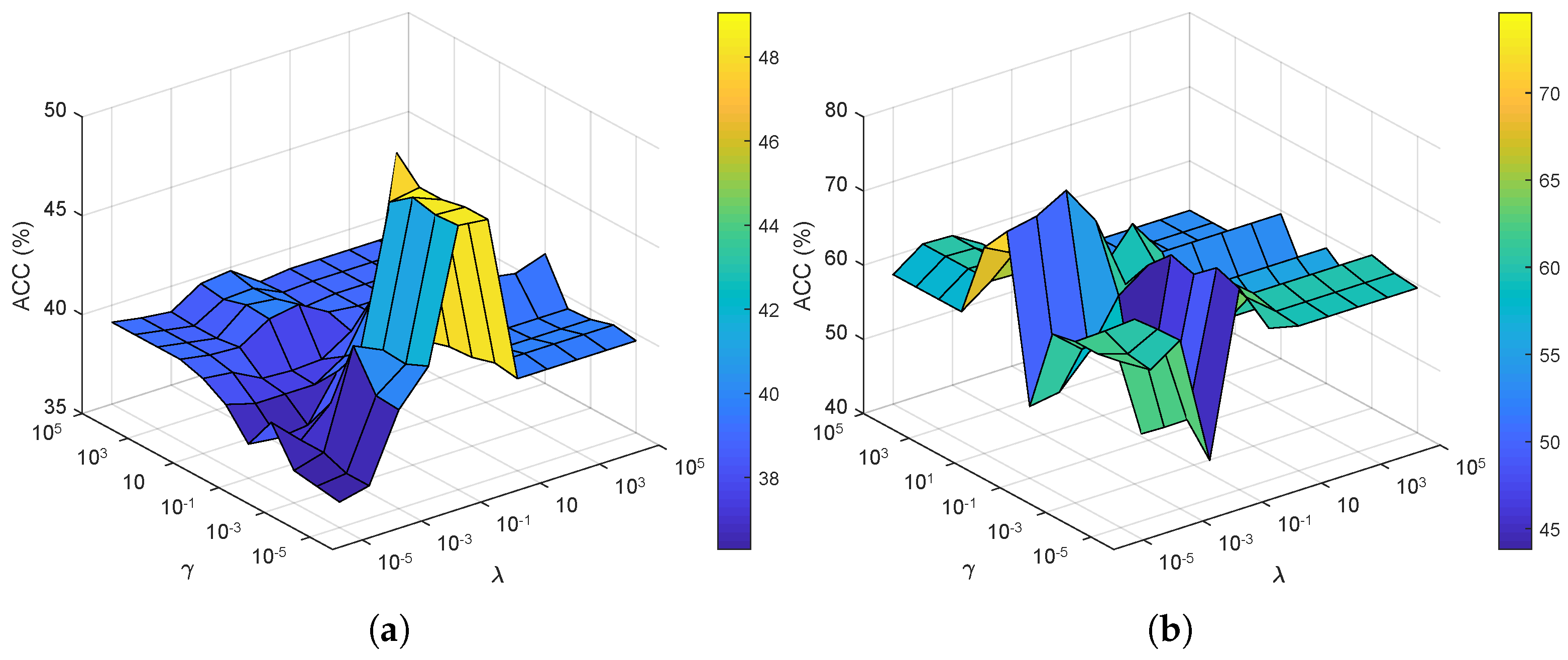
The proposed method has three penalty parameters , where and are the penalty parameters for low-rank constraint terms, and for the multi-view spectral clustering terms. Next, we analyze the sensitivities of these parameters in terms of clustering accuracy.
4.4.1. Parameters and
We experimented on the BBCSport dataset with 10% observed paired samples and the MSRC-v1 dataset with 50% missing instances of each view, under different combinations of parameters
and
, where
is fixed. In the experiment,
and
are selected from a set
and
is simply fixed by
for BBCSport and
for MSRC-v1. The experimental results of the proposed method on the above two datasets are recorded in
Figure 3. As for the BBCSport dataset, a relatively good clustering performance could be achieved when
and
. As for the MSRC-v1 dataset, the proposed method can obtain the best results when
and
satisfy
. These results led us to choose parameters
and
of the proposed method in experiments with high clustering accuracy. According to the above-mentioned analysis, the parameters
and
are often selected from the set of
in our previous experiments.
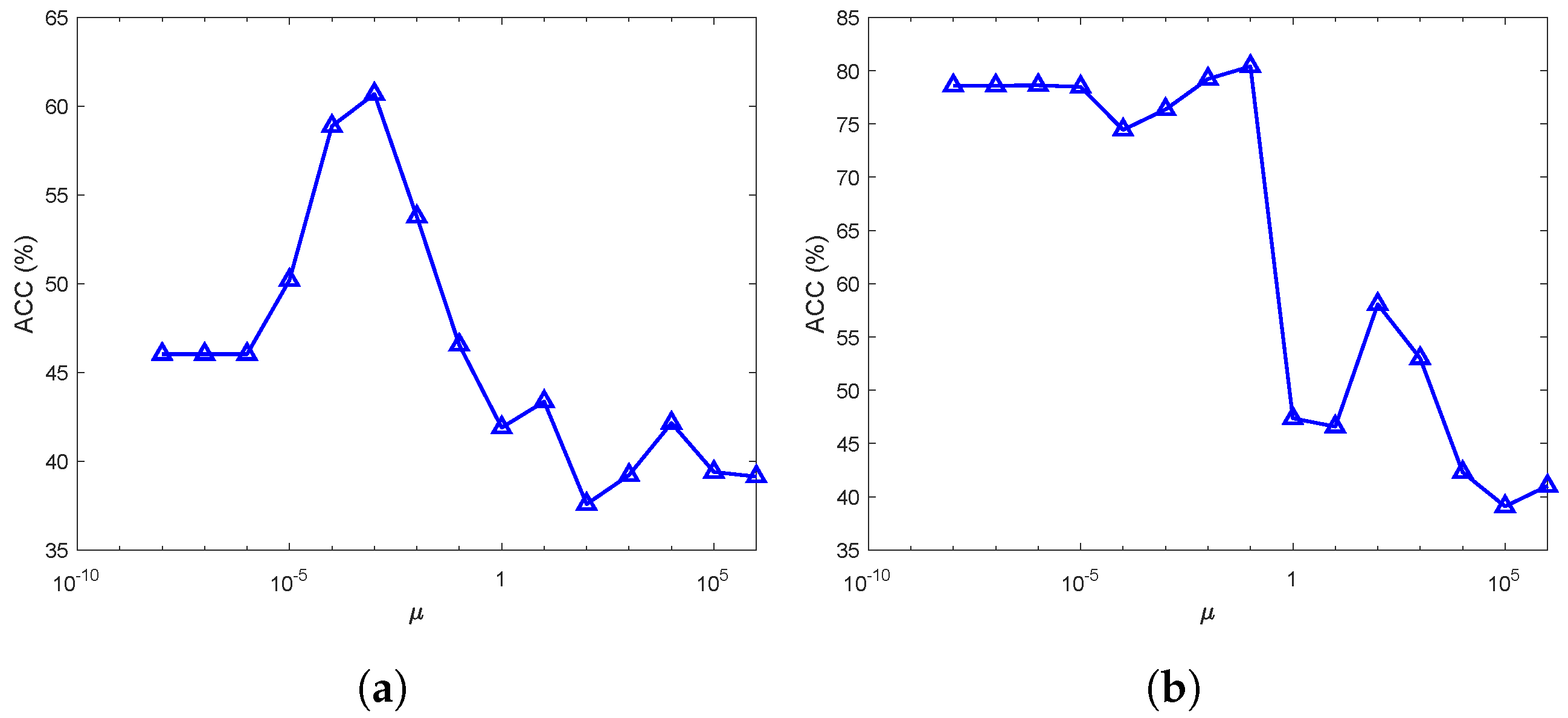
4.4.2. Parameters
We conducted our experiment on the BBCSport dataset with 20% observed paired samples and the MSRC-v1 dataset with 30% missing instances of each view, under different values of parameter
, where
and
are fixed. In the experiment,
is selected from a set
. As for these two datasets,
and
are simply fixed by
and
, respectively. The experimental results of the proposed method are recorded in
Figure 4, from which we can observe that the proposed method can obtain a rather good performance when
is selected from
. Specifically, the proposed method obtained the best results in the BBCSport dataset when
, and in the MSRC-v1 dataset when
. These results led us to choose parameter
of the proposed method in experiments with high clustering accuracy. According to the above analysis, parameter
was experimentally selected from the set of
in our previous experiments.
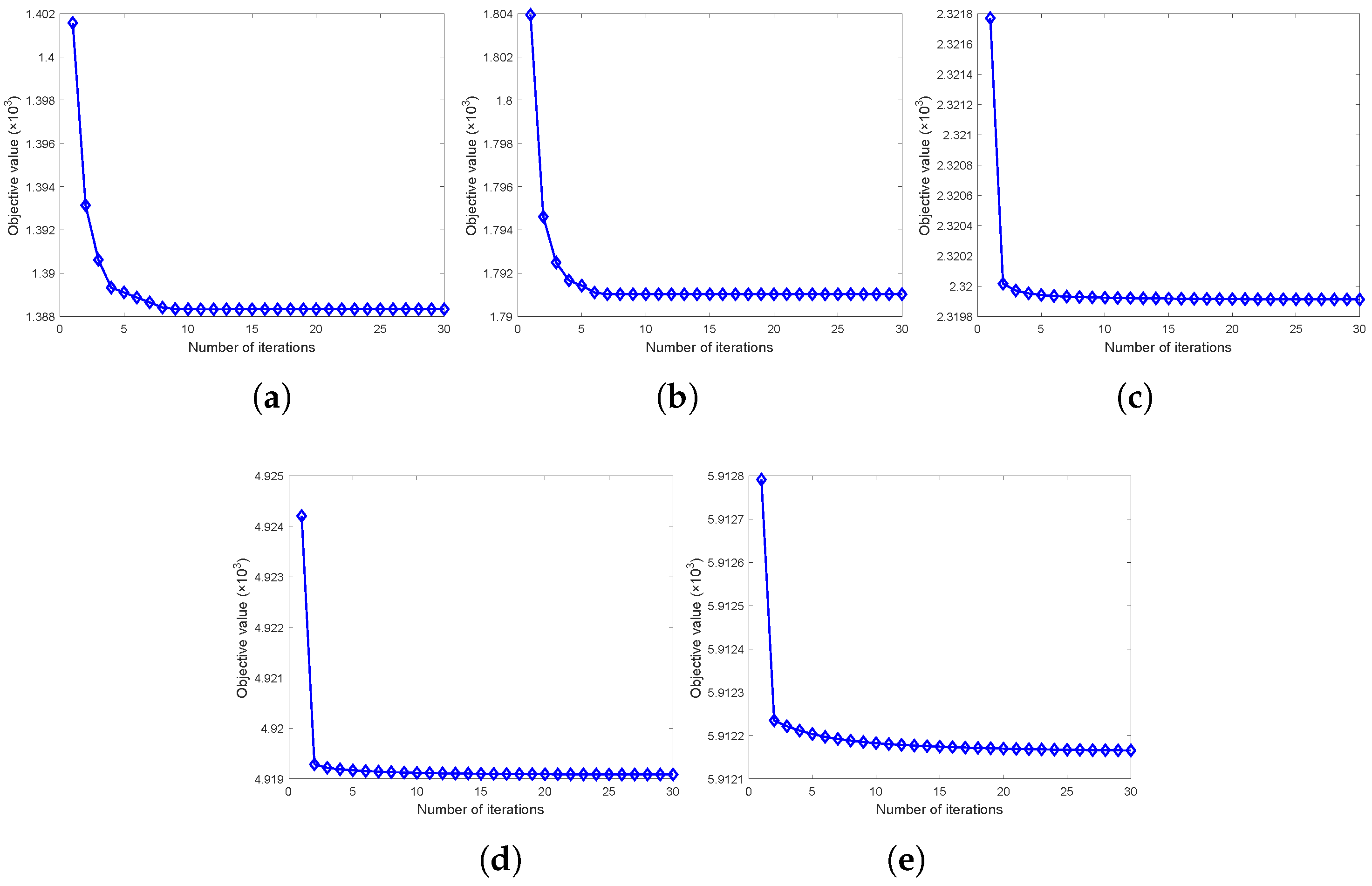
4.5. Convergence Analysis
In this section, we experiment on the BBCSport dataset, the 3-sources dataset, the handwritten dataset with 30% observed paired samples, the MSRC-v1 dataset, and the ORL dataset with 30% missing view rates. We record the objective function value versus the iteration in
Figure 5. From
Figure 5, we can see that the objective function value fast decreased to the stationary point when the iteration increased, which reflects the relatively good convergence property of the proposed method.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}