1. Introduction
The demand for wireless data has shown exponential growth over the past few decades, and it is expected to increase even further in the future. Simultaneously, user equipment (UE) demands high data rates, wide coverage, and low-latency services [
1,
2]. To meet these requirements, massive MIMO has been presented as a breakthrough technology in 5G [
3,
4]. Massive MIMO based on a large antenna array enables directional transmission to each UE, serves multiple UEs in the same cell at different locations, and leads to a significant increase in spectral efficiency (SE) performance. However, the received signal power is rapidly attenuated with the propagation distance. Therefore, even with the use of massive MIMO at the cell edge UEs may receive signals of low power and poor quality, including interference from neighboring APs located far away [
5,
6].
To address this, the concept of a CF-MIMO network has emerged. A CF-MIMO network is a network where geographically distributed APs jointly serve UEs, and APs are connected to the CPU by front-haul links. The advantage of a CF-MIMO network is that it reduces the propagation distance between APs and UEs, ensuring good signal quality regardless of UE location [
6,
7,
8,
9].
Serving all UEs by every AP in the CF network is not scalable. If a distant AP serves a UE, it uses wireless resources, but it does not contribute to the useful signal power of the UE. Therefore, it is essential to perform clustering in a practical way to allow limited APs to serve UEs [
10,
11]. Among the CF clustering options, scalable user-centric clustering is widely adopted. This approach conducts clustering based on the channel gain between APs and UEs, ensuring that UEs receive signals of good quality only from serving APs.
This paper focuses on the scenario where UEs outnumber antennas, unlike most papers that consider more antennas than UEs. In practice, due to the installation cost constraints of APs, a CF-MIMO network that exceeds the number of antennas is challenging. Additionally, it is expected that the number of UEs will grow at a faster rate than the number of antennas in the future [
12,
13]. Consequently, not all users can be scheduled in the same time slot.
Resource allocation, such as scheduling and power allocation, is crucial in wireless communication due to random or bursty traffic. Furthermore, it is anticipated that the demand for low latency will increase in 6G networks. In this paper, we implement scheduling that satisfies low latency while maximizing the throughput using Lyapunov optimization in the CF-MIMO network, providing an environment where UEs can achieve consistent quality performance regardless of their location. Lyapunov optimization is employed to stabilize the queue in queueing networks and minimize the penalty function. The penalty function is associated with network utility, such as time-average power, packet drop, and throughput. In this paper, the penalty function is configured with a negative value for throughput, creating a trade-off relationship with queue stabilization. The non-negative control parameter serves as the weight of the penalty function. The value of can be chosen to influence the desired performance. Since the parameter V is fixed in most papers, scheduling is conducted regardless of the current queue state and traffic conditions. However, in this paper, we provide a flexible scheduling approach by adjusting the value of the parameter V for each time slot.
1.1. Related Works
There has been some research on Lyapunov optimization [
13,
14,
15,
16,
17,
18]. The authors of [
14] provided a comprehensive methodology for Lyapunov drift-plus-penalty optimization, aiming to stabilize the queue while minimizing the penalty function defined in the system. The authors of [
15] established a trade-off relationship between queue stability and throughput and employed Lyapunov optimization for resource allocation in LTE-based systems. Additionally, they addressed the maximum weighted sum-rate power allocation problem in the physical layer using a branch-and-bound algorithm. However, the approach utilizes a scheduling algorithm using a fixed parameter
V and a power allocation method that has the drawback of high complexity due to iterative power allocation optimization. The authors of [
16] focused on stabilizing virtual queues through Lyapunov optimization in a cell-free network and used a simple block-coordinate descent algorithm to converge to the local optimal for power allocation, similar to [
15]. The approach restricts the scenario to cases where the arrival rate is smaller than the generated data rates. Its scheduling technique does not consider scenarios with high arrival rates. The authors of [
17] employed Lyapunov optimization for delay control by setting the penalty function as the negative value of the reward for format selection. They introduced a novel approach that separates the terms for format selection and transmission scheduling decisions, allowing the optimization to proceed independently for the two decisions. The approach establishes a trade-off relationship between information quality and scheduling. However, it is not suitable for systems aiming to maximize data rates. The authors of [
18] conducted scheduling to prevent packet drops by configuring the
value for each time slot. They addressed environments where the queue’s capacity is limited or a hard delay constraint exists and considered both single-queue and multi-queue models. However, the determination of the optimal value of the parameter
V for the system is challenging due to the cost of quantized packet drops.
Scheduling problems in CF networks have been discussed in previous papers [
12,
13,
19,
20], which conducted scheduling considering throughput fairness for each time slot in environments where the number of antennas is similar to the number of UEs. The authors of [
13] considered active UEs to achieve maximum system performance. Similarly, in this paper, we adopt active UEs that can lead to maximum performance in a dense user-centric scalable cell-free environment. This paper also utilizes a fixed parameter
V to derive the results. The authors of [
12,
19,
20] optimized scheduling, power allocation, and beamforming in a cell-free environment. In addition, the authors of [
19] utilized the signal-to-leakage-plus-interference-plus-noise ratio (SLINR) metric for optimization in a multiple-CU environment and provided three methods for calculating leakage values. The authors of [
20] proposed a method for solving the resource allocation optimization problem in a massive MIMO cell-free system using semidefinite relaxation (SDR) and sequential convex approximation (SCA) approaches within polynomial time. Since the authors of [
12,
19,
20] did not consider scheduling with the queue backlog, applying their approaches to delay-sensitive systems may pose challenges.
The authors of [
21] optimized the receive beamforming and the reflecting coefficient matrix in an active RIS (Reconfigurable Intelligent Surface) to maximize the received signal power. They also suggested the number of reflecting elements that amplify the signal. The approach showed superior achievable rates compared to passive RIS. The authors of [
22] optimized the pilot length and pilot transmission power to maximize data error probability and throughput under limited power. They solved the problem using truncated channel inversion and an iterative optimization algorithm. The authors of [
23] discussed the utilization of MEC (mobile edge computing) in latency-sensitive systems within CF massive MIMO networks. They presented the SECP (successful edge computing probability) for target latency and examined the impact of the SECP and AP density on energy efficiency. The authors of [
24] introduced a method for estimating 2D DOA in mmWave polarized massive MIMO systems using compressive sampling. They proposed an approach suitable for real-time implementations due to its low complexity. The authors of [
25] optimized transmission power and NOMA pairing using the A3C (asynchronous advantage actor-critic)-based ESSO (energy-efficiency secure offloading) scheme, a deep reinforcement learning-based solution. The approach resulted in improved energy consumption and average secrecy probability. However, the above-mentioned papers did not consider scheduling to reduce latency.
1.2. Contributions
In this paper, the number of UEs clustered on an AP is less than the number of antennas on the AP, making it impossible to serve them simultaneously in a time slot. Therefore, active UEs should be scheduled in each time slot.
First, in this paper, in a dense user-centric scalable CF MIMO network, dynamic scheduling is performed on the CPU based on the queue backlog and instantaneous channel state information (CSI) of each user using the drift-plus-penalty method. During scheduling, the number of active UEs that can achieve maximum system performance is selected. Additionally, the value of the parameter is adaptively set based on the queue backlog of each UE to efficiently handle bursty traffic. The proposed method is analyzed by comparing it with the scheduling method using a fixed parameter .
Since the scheduling is performed on the CPU using the drift-plus-penalty method, the number of UEs scheduled to APs can exceed the number of antennas on each AP. Therefore, the CPU utilizes the SUS algorithm for APs to reschedule UEs when the number of scheduled UEs exceeds the number of antennas.
Furthermore, the local maximum ratio (MR) precoder is simply designed at each AP to verify the performance. In distributed operations, APs locally perform power allocation. We introduce two power allocation methods: FPA is suitable for all traffic scenarios and has outstanding throughput performance, and queue-based FPA is capable of satisfying low-latency requirements in low-traffic situations. Therefore, we combine FPA with queue-based FPA to ensure proper operation across all traffic intervals. We provide simulation results of these two methods compared with the computationally complex MMF and sum SE maximization.
1.3. Paper Structure and Notations
The rest of this paper is organized as follows.
Section 2 describes the downlink CF-MIMO network model and the K-queue network model. In
Section 3, we present the CPU scheduling method using Lyapunov optimization and the SUS algorithm. Then, the heuristic FPA and queue-based FPA power allocation methods are proposed.
Section 4 evaluates the simulation results. Finally, the conclusions of this paper are presented in
Section 5.
In this paper, vectors and matrices are denoted with bold letters. , , , , and denote the transpose, conjugate, conjugate transpose, inverse, and norm, respectively. denotes the expectation value, and denotes the circularly symmetric complex Gaussian distribution. and represent an all-zero matrix and an identity matrix, respectively.
4. Performance Evaluation
In this section, we present simulation results based on the power allocation method described in
Section 3.2. Then, we compare the scheduling strategy that uses a fixed
V value with the dynamic
V approach proposed in this paper. The conventional approach in the Lyapunov optimization phase employs a fixed scheduling strategy with a constant
V value. However, this method lacks flexibility, as the fixed
V value does not adapt to changes in traffic and does not consider the current queue backlog. Therefore, the proposed dynamic
V approach takes into account the queue backlog, arrival rate, and effective rate for adaptive scheduling. We also briefly compare the SUS algorithm with random selection in
Section 4.3.
The simulation setup and conditions were as follows:
We established a dense user-centric scalable CF-MIMO network with L = 45 APs, M = 4 antennas per AP, and K = 200 UEs with a single antenna. Additionally, the following parameters were assumed: a coherence interval symbol length of = 200, and a pilot signal length of = 10. Each UE transmitted pilot signals at a power of = 100 mW, and the downlink maximum power of APs was assumed to be = 200 mW.
When Lyapunov optimization was applied in the CPU scheduler, was configured to to maximize network capacity utilization.
The arrival rate was set as , where = 0.3, and every 4000 time slots, changed to 4, 3, 2, 1.5, and 1, gradually reducing the arrival rate. This meant that the traffic changed every 4000 time slots. It allowed us to verify how each scheduling algorithm and power allocation method operated in all traffic intervals. Assuming = 10,000 and = 100,000, each scheduling algorithm was simulated while varying traffic over 20,000 slots to obtain the simulation results.
Based on the estimated channels, precoding was performed at the APs. In this paper, a simple MR precoder was adopted to reduce the burden of APs. AP
l simply obtained the precoder of UE
k as follows:
4.1. Power Allocation Comparison
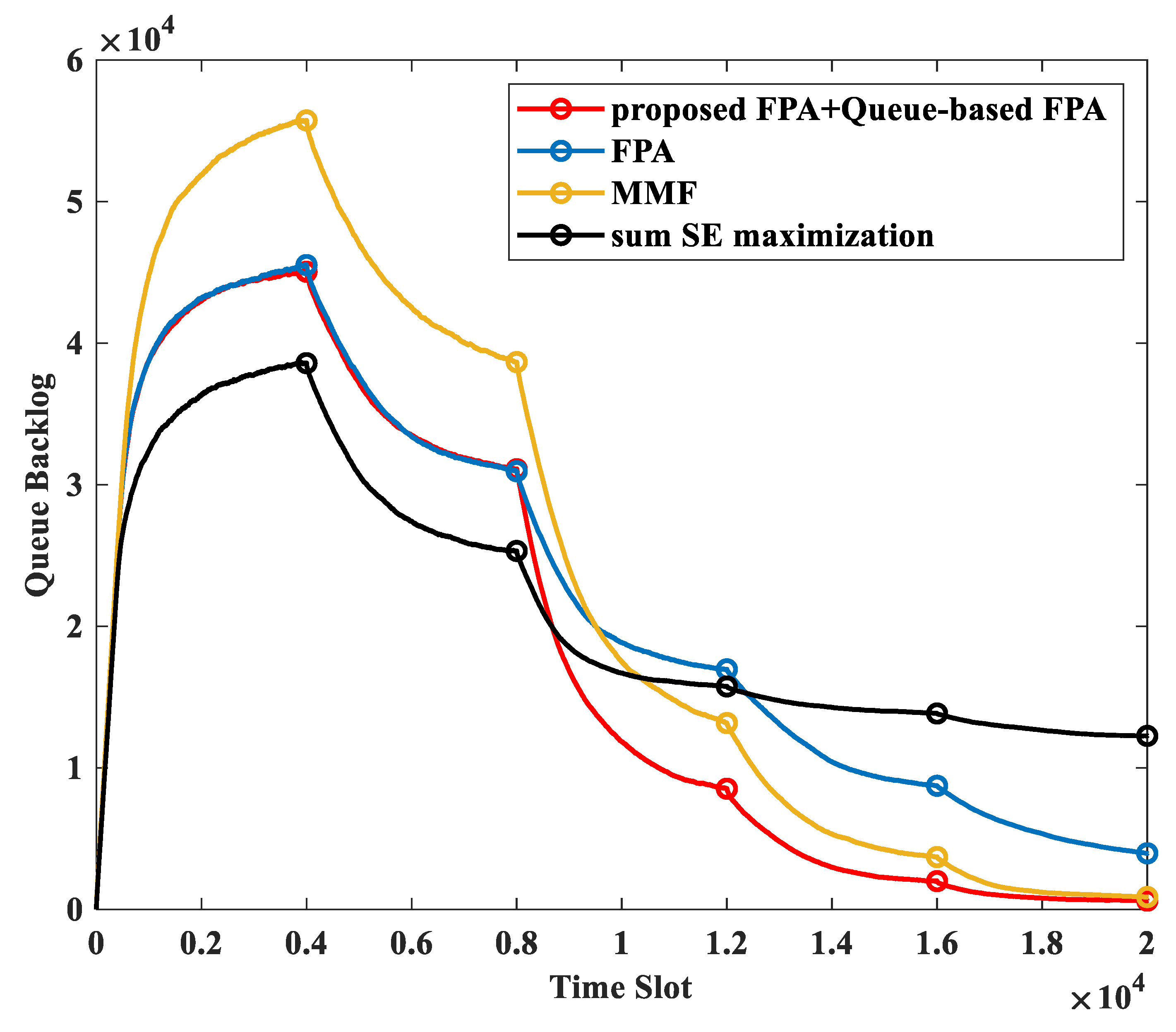
Figure 4 and
Figure 5 compare the performance of queue stabilization across time slots and the cumulative distribution function (CDF) of the throughput performance for various power allocation methods.
In
Figure 4, the MMF allocation, optimizing user fairness from the SE perspective, is more effective for queue elimination in low-traffic intervals than in high-traffic intervals. Sum SE maximization aims to maximize network SE and exhibits the best performance in high-traffic intervals but does not guarantee sufficient performance in low-traffic intervals. When FPA with
= 0.5 is utilized, it provides a simple power allocation that ensures appropriate performance for queue stabilization. FPA + queue-based FPA with
= 0.5 utilizes FPA with
= 0.5 in high-traffic scenarios and switches to queue-based FPA in low-traffic scenarios. It enters a low-traffic period starting from time slot 8000. Then, queue-based FPA, which allocates more power to UEs with a high queue backlog, is applied. Consequently, it removes the queue backlog faster than FPA with v = 0.5. In low-traffic intervals, it outperforms MMF by exhibiting lower queue backlogs, making it a viable power allocation method in systems where low latency is crucial.
Figure 5 shows that MMF exhibits good user fairness performance but low throughput performance. However, due to good user fairness, the variation in throughput among UEs is not significant. The sum SE maximization method exhibits the best performance for intermediate UEs, with throughput performance ranging from 20% to 80%. FPA with
= 0.5 also demonstrates appropriate throughput performance compared to other power allocations. The 95%-likely throughput performance is 6.2 times greater than that of sum SE maximization. The throughput performance of FPA + queue-based FPA with
= 0.5 is similar to that of MMF because it considers queue stabilization power allocation in low-traffic intervals.
4.2. Comparison of Scheduling Algorithms
We compare the performance of scheduling algorithms using dynamic
V and fixed
V, and we also evaluate a modified scheduling method where UEs with
are not scheduled. If a UE with
is scheduled, it may incur a loss in system throughput. Therefore, we combine it with scheduling considering throughput
V = 10,000 and perform a performance comparison. This scheduling method is represented as modified
V = 10,000 in the performance graph.
Figure 6 and
Figure 7 illustrate this comparison using FPA with
= 0.5. The fixed
V approach is compared with
V = 1 and
V = 10,000.
Figure 6 compares the queue stabilization performance of the four scheduling methods. When traffic is high, the performance of dynamic
V is similar to that of
V = 10,000. However, in the case of modified
V = 10,000, UEs with an effective rate larger than the queue backlog are not scheduled, leading to more efficient removal of the system queue backlog. When traffic is low, the performance of dynamic
V is similar to that of
V = 1, indicating that the proposed dynamic
V approach flexibly performs queue stabilization scheduling depending on traffic conditions. However, modified
V = 10,000 exhibits lower performance in low-traffic scenarios. In low-traffic situations, there are fewer UEs with queue backlogs larger than their effective rates, reducing the ability to remove the queue backlog.
Figure 7 compares the throughput performance of the four scheduling methods. For
V = 1, the weight of the penalty component reflecting the throughput is very low. Therefore, most UEs with high queue backlogs are scheduled, limiting the maximum throughput performance and resulting in poor throughput performance. For
V = 10,000, the CPU scheduler considers throughput performance, but UEs with
are scheduled, leading to a loss in throughput performance. The dynamic
V approach minimizes this throughput loss. It can be observed that dynamic
V shows throughput performance that is approximately 90% of
V = 10,000. However, modified
V = 10,000 shows degraded throughput performance in low-traffic scenarios due to not scheduling UEs with
, resulting in a significant loss in throughput performance.
4.3. SUS Algorithm versus Random Selection
We compare the SUS algorithm with random selection in terms of queue stabilization performance and throughput performance. To ensure a fair comparison, both methods utilize the dynamic
V algorithm and FPA.
Figure 8 shows a comparison of queue stabilization performance between the SUS algorithm and random selection, while
Figure 9 shows a CDF comparing their throughput performance.
In random selection, when UEs scheduled using Lyapunov optimization exceed the number of antennas at the AP, the UEs are randomly selected to match the number of antennas. UEs scheduled via the SUS algorithm typically have good channel quality and are semiorthogonal to each other. Therefore, when using MR precoding, the overall throughput performance is superior compared to random selection, as depicted in
Figure 9. This is advantageous for effectively clearing queue backlogs and maintaining queue stability, particularly in high-traffic scenarios. As shown in
Figure 8, the decrease in traffic results in a reduction in the amount of queue backlog. Hence, employing the SUS algorithm for UE scheduling at the AP is essential.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}