Abstract
Transformer has emerged as one of the modern neural networks that has been applied in numerous applications. However, transformers’ large and deep architecture makes them computationally and memory-intensive. In this paper, we propose the block g-circulant matrices to replace the dense weight matrices in the feedforward layers of the transformer and leverage the DCT-DST algorithm to multiply these matrices with the input vector. Our test using Portuguese-English datasets shows that the suggested method improves model memory efficiency compared to the dense transformer but at the cost of a slight drop in accuracy. We found that the model Dense-block 1-circulant DCT-DST of 128 dimensions achieved the highest model memory efficiency at 22.14%. We further show that the same model achieved a BLEU score of 26.47%.
MSC:
15B05
1. Introduction
Across a wide range of applications, including chatbots [1], machine translation [2], text summarization [3], video-image processing [4,5,6], etc., transformer neural networks have significantly improved. As demonstrated by [7,8,9,10,11], transformers and their modifications have proven superior, particularly in machine translation. As the amount of computational power required for training and inference increases, one of the more advanced neural networks is the Transformer [12], which has a deeper topology. Conversely, the depth of the transformer architecture gives rise to several constraints and challenges, including high computational complexity [13], substantial demands on computational resources [14], and high memory consumption [15] that quadratic to the input sequence length. Therefore, methods are required to achieve excellent performance, mainly when using them as translation machines. Several approaches have been put forth to address this problem, including weight matrix decomposition, matrix-vector algorithm selection, and weight matrix replacement.
Utilizing a structured weight matrix is considered a crucial tactic among other strategies because of its benefits. According to [16], this may lessen the memory needed for training and storing the model (and optimizer). This alternative approach can also mitigate computational complexity, leveraging the benefits of the selected structured weight matrix [12]. This fact has encouraged the creation of a wide variety of structured matrices, including low-rank matrices [17], Toeplitz-like matrices [18], block-circulant matrices [19,20], fast-food transforms [21], low displacement rank matrices [22], and butterfly matrices [23], among other matrices. One of the Low Displacement Rank (LDR) matrices is the block g-circulant matrix [24,25]. The block g-circulant matrix combines features from block-circulant and g-circulant matrices. Its adoption as a replacement for the transformer weight matrix is believed to enhance transformer performance, building on findings from prior research [26,27]. With a g position shift to the right, this matrix is a generalization of the block circulant matrix. This property makes more intricate patterns and interactions within the matrix possible, expanding the range of potential uses. Among their many benefits is the ability to find efficient algorithms, such as those for multiplying them by any vector to reduce computational complexity [28]. This is why structured matrices are used as transformer weight matrices.
We have found that the Fast Fourier Transform (FFT) algorithm is dependable when the structured matrix is a circulant matrix [29]. The ability of the FFT Transformer to compress model memory up to 100 times has been demonstrated. This transformer is based on the feedforward layer’s block g-circulant weight matrices. Liu [28] discovered the Discrete Cosine Transform-Discrete Sine Transform (DCT-DST) algorithm for circulant matrix-vector products, which can save storage compared to FFT. No text processing system has ever employed the DCT-DST algorithm. Processing photos and videos is its more common usage [30,31]. With a DCT-DST algorithm for the translation machine, we present a novel method for executing a real block g-circulant weight matrix-based transformer in this paper. Our objective is to impose a block g-circulant structure on transformer model topologies through the elegant mathematical characteristic of the block g-circulant matrix. The contributions of this paper are summarized as follows:
- We define the block g-circulant matrix and generate several lemmas and theorems regarding the characteristics and possible eigenvalues, as well as defining the matrices utilized in carrying out the DCT-DST algorithm for multiplication of block g-circulant matrices.
- We propose a new approach in using structured matrices as a replacement for dense weight matrices, combined with matrix multiplication algorithms, in this case, a combination of block g-circulant matrices and the DCT-DST algorithm.
- Our research is the first study that applied the DCT-DST algorithm for weight matrix-vector multiplication in a transformer-based translation machine.
In this article, we present a structured exploration of key concepts. Firstly, we delve into the foundational motivation driving our exploration of block g-circulant matrices and the DCT-DST algorithm. Section 2 explains the theories and characteristics of block g-circulant matrices, including a comprehensive examination of the potential eigenvalues of real block g-circulant matrices. Section 3 describes the workings of the block g-circulant DCT-DST transformer, including a comprehensive explanation of the associated algorithm. Section 4 presents our experimental methodology, results, and a thorough discussion of the research findings. Finally, we summarize our insights in a concise conclusion in the closing section.
2. Block g-Circulant Matrix
Definition 1.
Let be a matrix for each . Then a block-circulant matrix is generated from the ordered set , and is of the form
The set of all such matrices of order will be denoted by , whereas represents the set of all circulant matrices of dimension m.
Theorem 1
([32]). Let has generating elements . If , are generating elements of , then
is a diagonal matrix of dimension with
with and
with .
In case , we can decompose the diagonalization of [26] as follow:
with
where and are real and imaginary parts of columns of and
and for it will be
with
and
where , and denote a real and imaginary part of the eigenvalues of decomposers.
Definition 2
([28]). The Discrete Cosine Transform (DCT) I and V matrices are defined as follows
Definition 3
([28]). The Discrete Sine Transform (DST) I and V matrices are defined as follows
In the following theorem, we will see that the matrix , defined in (5), can be partitioned into a matrix generated by the DCT-DST matrices.
Theorem 2
Definition 4.
Let be a g-circulant matrix, i.e., classical circulant matrix with each row shifted g position to the right. A matrix is a block g-circulant matrix if it is generated by , ; and shifted g position to the right.
Lemma 1.
Let be a block g-circulant matrix with n block, and each block has order m. Then can be denoted as
where is a block g-circulant matrix with and
where
and by (1) we have
Lemma 2.
Let and ., and let , with and are the great common divisor between n, m respectively with g. Then we have
where is the matrix defined in (12) and is the submatrix of obtained by considering only its first rows.
Lemma 3
([33]). Let , then
- (a)
- ,
- (b)
- ,
- (c)
- (d)
where mod n.
Lemma 4.
Lemma 5.
Let . Then where mod . As a consequence we have .
Lemma 6.
In the following lemma, we will see that Lemma (5) also holds for the matrix .
Lemma 7.
If , then with mod .
Proof.
Lemma 8.
Lemma 9.
Let be a g-block circulant matrix and be a h-block circulant matrix. Then is a -block circulant matrix.
Proof.
2.1. Eigenvalues of Block g-Circulant Matrices
In this section, we explore the eigenvalues of a block g-circulant matrix in case , and and .
2.1.1. Case
If , this means that is a matrix that has constant elements along all the rows in each block and, therefore, it has rank 1; then, remembering that the trace (tr(·)) of a matrix is the sum of its eigenvalues, we can conclude that has zero eigenvalues and one eigenvalue different from zero given by
where and is the entry of the ith block and pth column.
2.1.2. Case
If , then the is a “classical” block circulant matrix as defined in Definition 1, and its eigenvalues are given by
2.1.3. Case
The following theorem we will use to calculate the eigenvalues of a singular matrix with rank by calculating the eigenvalues of a smaller matrix with .
Theorem 3
([34]). Let A be a matrix of dimension , , which can be written as , where , with . Then the eigenvalues of the matrix A are given by k eigenvalues of the matrix and zero eigenvalues:
We will apply Theorem (3) while considering that the matrix is singular. By Lemma 2 we can write that
where and is the identity matrix of dimension . Now we can rewrite (11) as bellow
where .
By Theorem (3) we find that the eigenvalues of are equal to those of , plus null eigenvalues:
with geometric multiplicity .
2.1.4. Case
When both and g are coprime, the lemma provides a straightforward formula to compute the modulus of eigenvalues for a g-circulant matrix . This method draws upon the classical eigenvalue computation for the circulant matrix .
Lemma 10.
Let be a g-block circulant such that and denote
with
Then, the modulus of the eigenvalues of are given by
with and . where is such that .
Proof.
By Lemma (9) we have that if is a g-block circulant matrix, then is a -block circulant matrix, . By Lemma (5) is also a -block circulant matrix, where . Since then there is such that , then is a block circulant matrix. Notice that the eigenvalues of are the modulus of the roots of index s of the eigenvalues of the block circulant matrix . From Equations (15) and (20) we obtain that
Since , we have
Using Equation (22) and the fact that , we obtain
Using Lemma (9), Equation (2), and since , we have
Hence, we have that is a diagonal matrix, and its eigenvalues are given by the diagonal elements of , i.e., from (22)
with and . So we have the modulus of the eigenvalues of are the modulus of the roots of index s of the eigenvalues of the block circulant matrix . □
Next, we will see a real block g-circulant matrix decomposition into an orthogonal matrix . We also will define an orthogonal matrix whose multiplication by will be used in the DCT-DST algorithm.
Theorem 4.
Let be a real block g-circulant matrix, and define as:
where is a matrix of dimension t as defined in (5) and denote identity matrix of t dimension whose t and columns are exchanged. A straightforward calculation shows that
where
, , and .
Definition 5.
Let and be the matrices as defined in (5) and Theorem (4) respectively. Matrix orthogonal is denoted as
where
as stated in [28].
3. Block g-Circulant DCT-DST Transformer
The architecture of the transformer network includes one or two multi-head attention units, a position-wise feedforward unit, and sub-layer connections with layer normalization. A layer of an encoder or decoder is composed of these. Learning weight matrices to multiply a matrix is a step in the positionwise feedforward and multihead attention units. In [2], these weight matrices were uncompressed, dense, and random in the original Transformers. Using block g-circulant weight matrices, we compress these weight matrices in this study.
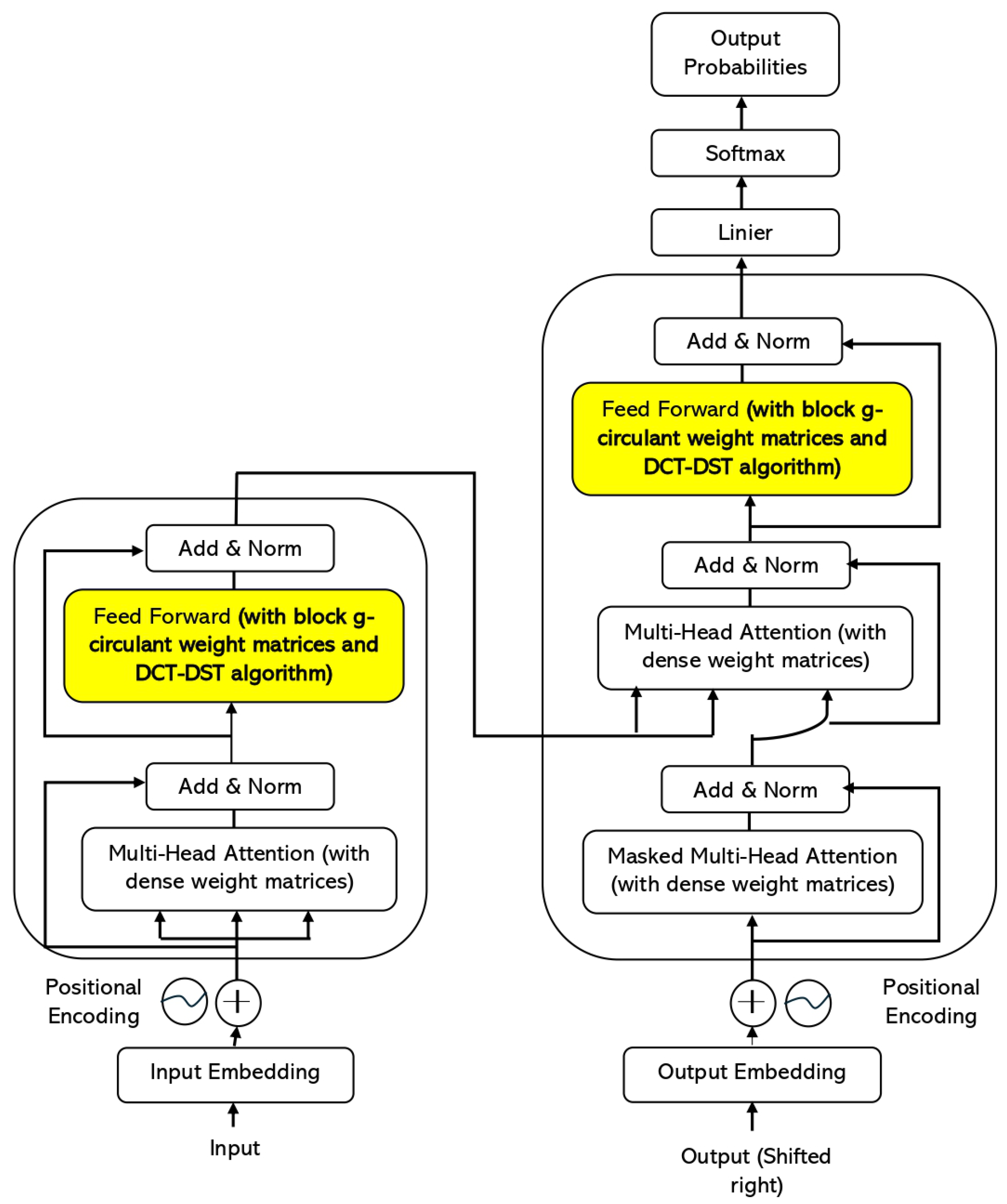
The block g-circulant DCT-DST transformer discussed in this study is a variation of the original transformer model outlined in [2]. This adaptation involves two essential modifications: firstly, the substitution of a block g-circulant matrix for the conventional dense weight matrix, and secondly, the integration of the DCT-DST matrix-vector multiplication algorithm. This integration enables efficient computation when multiplying the block g-circulant matrix with the vector input of each sublayer (Figure 1).
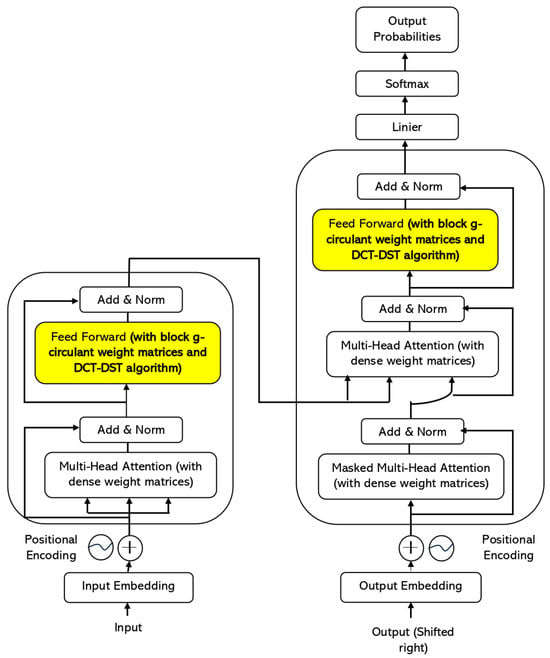
Figure 1.
The encoder-decoder structure of the block g-circulant DCT-DST transformer.
3.1. Multihead Attention Sublayer
Two input sequences are applied to the multi-head attention sublayer: a key/value sequence and a query sequence , with and represent the number of queries and keys/values respectively and denote the dimensionality of input and output. Let the number of attention heads be y. By projecting the query sequence and key/value sequence by dense weight matrices, we create queries, keys, and values in , where . For and , we could learn separate dense weight matrices . Rather, for , we learn a 3-dense weight matrices and slice the resulting products y times. It is important that these weight matrices have block sizes smaller than to avoid correlations between different attention heads. After obtaining these projections, we calculate the dot product of attention for each attention head:
After computing dot-product attention, the output sequences are concatenated into a sequence of shape and projected through a dense projection matrix with block-size . Thus, each dense matrix multihead attention unit learns 4 dense weight matrices of shape and block-size .
3.2. Block g-Circulant Positionwise Feedforward Sublayer
The block g-circulant positionwise feedforward sublayer uses two block g-circulant weight matrices. It applies the transformation:
where, has block-size and has block-size , and represent individual g-circulant block matrices, and by default, , where denote the dimensionality of the inner-layer. When performing matrix multiplication between and and the multiplier vector, the DCT-DST multiplication algorithm is employed.
3.3. Block Sizes
The block-size parameters , and introduce the three-dimensional hyperparameter space. However, we established a single block-size model so that we could test models and iterate quickly. Concerning ,
In this case, the maximum value of is , at which time it is entirely circulant.
3.4. DCT-DST Algorithm
In multiplying block g-circulant weight matrices with any input vector in each transformer layer, we applied the following algorithm, adapted from [28].
- Compute directly, ,
- Compute by DCT and DST
- Form
- Compute directly
- Compute by DCT and DST
- Compute directly
- Compute by DCT and DST
- Compute , i.e.,
4. Experiment and Result
4.1. Data and Experimental Details
This experiment was conducted using data from the TED Talks Open Translation Project’s Portuguese-English datasets, and Tensorflow datasets were then used to load the data. The TED Open Translation Project is a pioneering endeavor by a prominent media platform to subtitle and comprehensively catalog online video content. It represents a groundbreaking initiative in leveraging volunteer translation for public and professional purposes. Among the many talks available within the TED talks transcripts under the Open Translator project, the Portuguese-English transcript is just one of over 2400 talks spanning 109 languages. Portuguese and English are among the top three languages with the highest number of talks in the TED talks collection. It has approximately 52,000 in training examples (Portuguese-English sentence pairs), 1200 in validation examples, and 1800 in test examples.
The dataset was then tokenized using Moses tokenizer as used in the original transformer by [2]. We chose to employ this tokenizer because it is one of the two widely recognized rule-based tokenizers extensively utilized in machine translation and natural language processing experiments. According to [35], the Moses tokenizer has demonstrated superior performance to several other tokenizers, specifically in neural machine translation. We used the code from the TensorFlow.org tutorial on neural machine translation with a transformer and Keras. We utilized the various base model and optimizer setups, which were slightly different from the original transformer model. Distinct from [2], each model applied four layers, not six, as in [2], eight attention heads, and a dropout rate of . We set a batch size of 64, while the number of epochs is 20. The feedforward dimensions are four times larger than those of the model. Like [2], we used an Adam optimizer with ; , and . The details of the experiment are provided in Table 1.

Table 1.
The experiment details of models training.
The model dimensions have various values depending on the size of the weight matrices being tested. The size of the weight matrices is the combinations of n and m values such that a block g-circulant matrix of dimension 128 was obtained. Choosing a 128-dimensional matrix corresponds to the findings derived from [26]. We also experimented with other matrix dimensions for comparative purposes as part of our analysis. We applied some values of g, inter alia, , and other values such that and . denote the greatest common divisor of and g.
The model’s name refers to the types of matrices and algorithms employed in the multi-head attention and feed-forward sublayers. We used two types of matrices (Dense and Real Block Circulant Matrices) in conjunction with the DCT-DST algorithm. For instance, the Dense-Block 2-Circulant DCT-DST transformer model means that in the multi-head attention is applied the Dense Matrix and in the feed-forward sublayer is used the real Block 2-Circulant matrix with the DCT-DST algorithm. In this experiment, we trained 3 (three) transformer models with block g-circulant weight matrices and one original transformer model. In each model, experiments were conducted with matrix sizes across five dimensions: 16, 32, 64, 128, and 256 (Table 2).
Table 2.
The transformer model being tested along with the g value and size of the weight matrix.
4.2. Evaluation
On a held-out set of 500 samples, we evaluated performance using the corpus BLEU (Bilingual Evaluation Understudy) score. This figure corresponds to [36]. Statistically, a sample size of 500 can be classified as significant, making it sufficiently robust for conclusion.
BLEU serves as a metric designed to evaluate machine-translated text automatically. It quantifies the similarity between the machine-translated text and a set of high-quality reference translations, generating a score ranging from zero to one. BLEU’s notable strength is its strong correlation with human judgments. It achieves this by averaging individual sentence judgment errors across a test corpus rather than attempting to precisely determine human judgment for every single sentence [36,37]. In our study, the corpus BLEU score employed the English sentence as its single reference and the top English sentence output of beam search as the hypothesis for each pair of Portuguese and English sentences in the evaluation set. Aggregating references and hypotheses across all pairings produced the corpus BLEU.
4.3. Result and Discussion
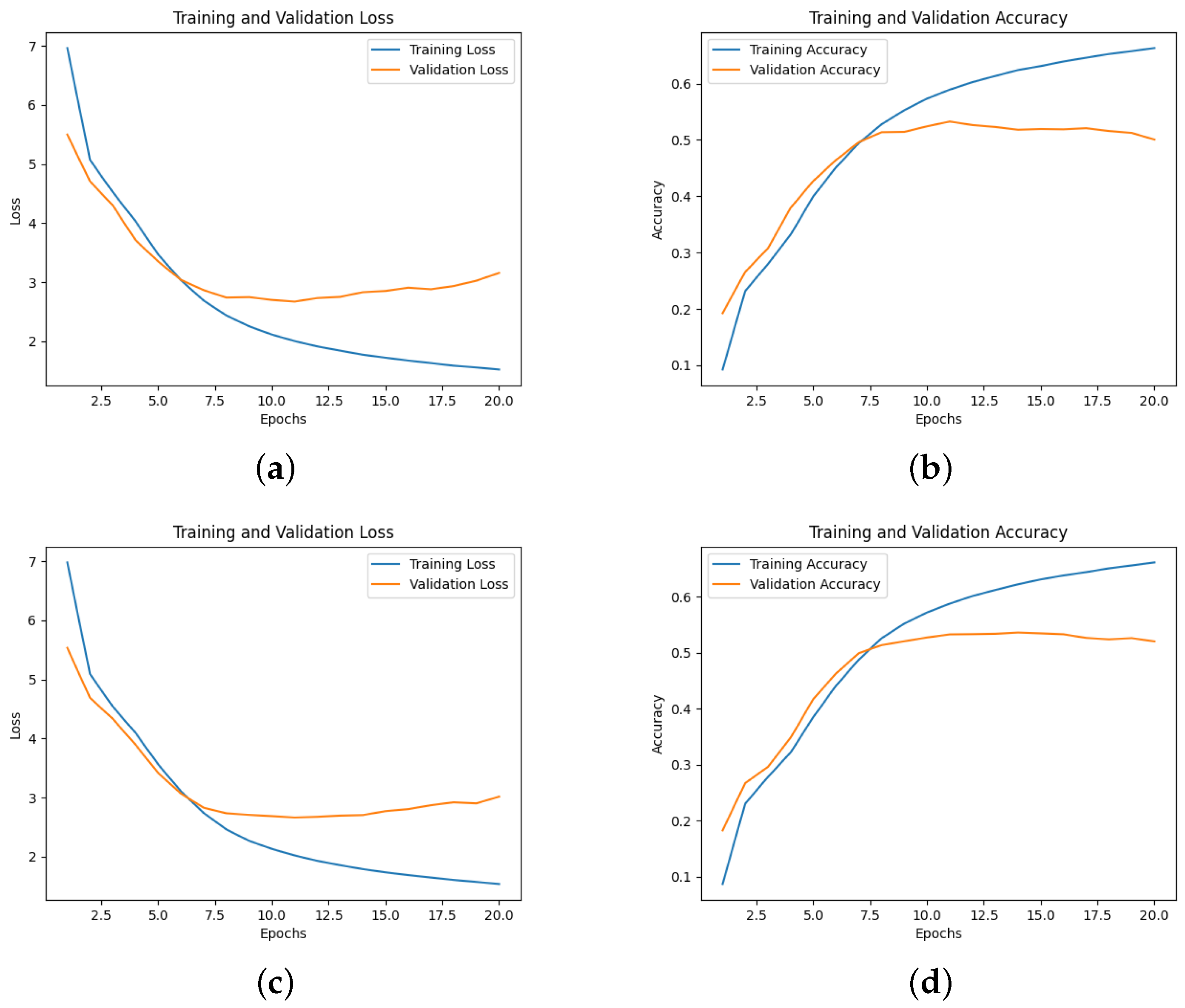
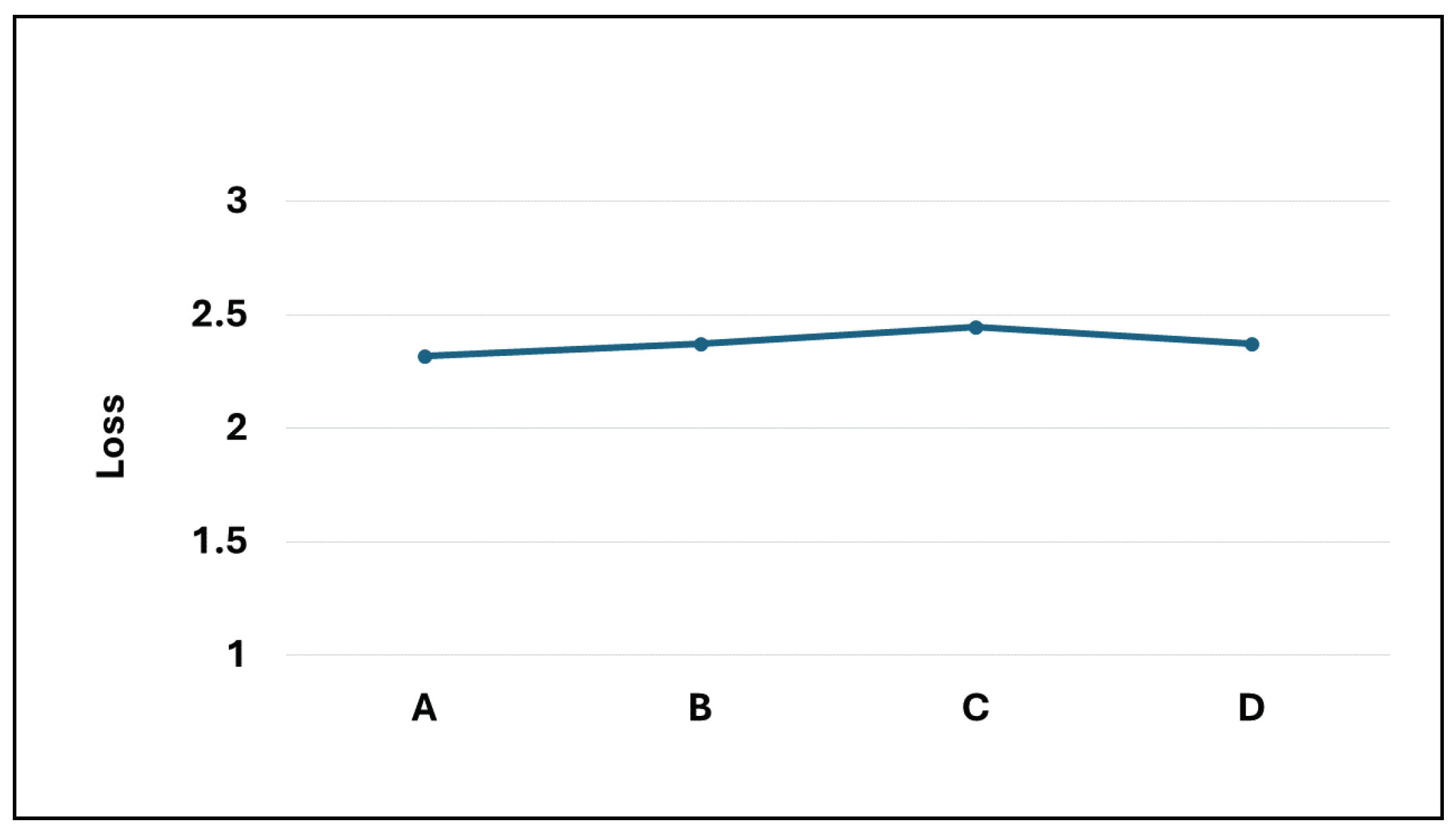
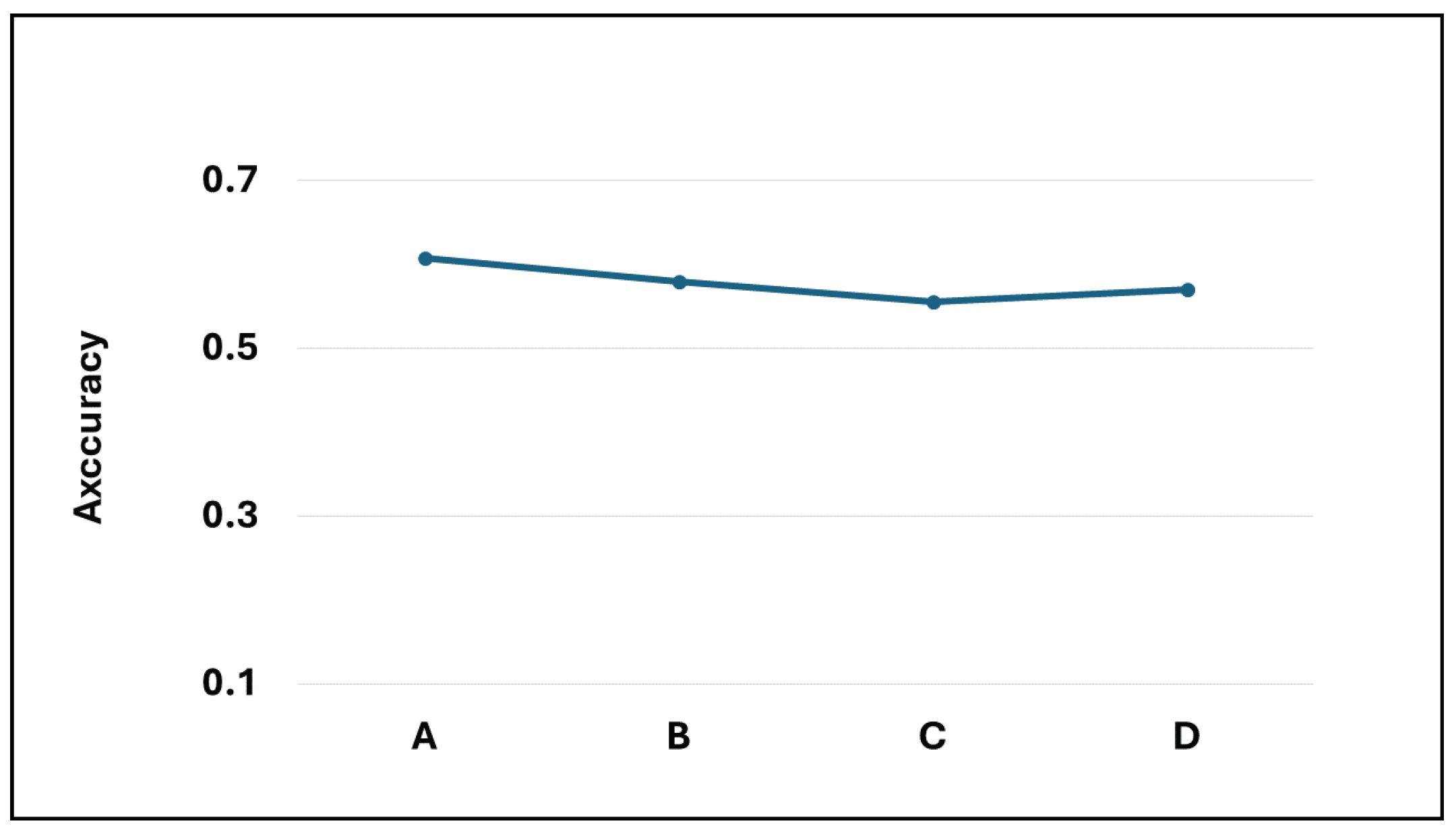
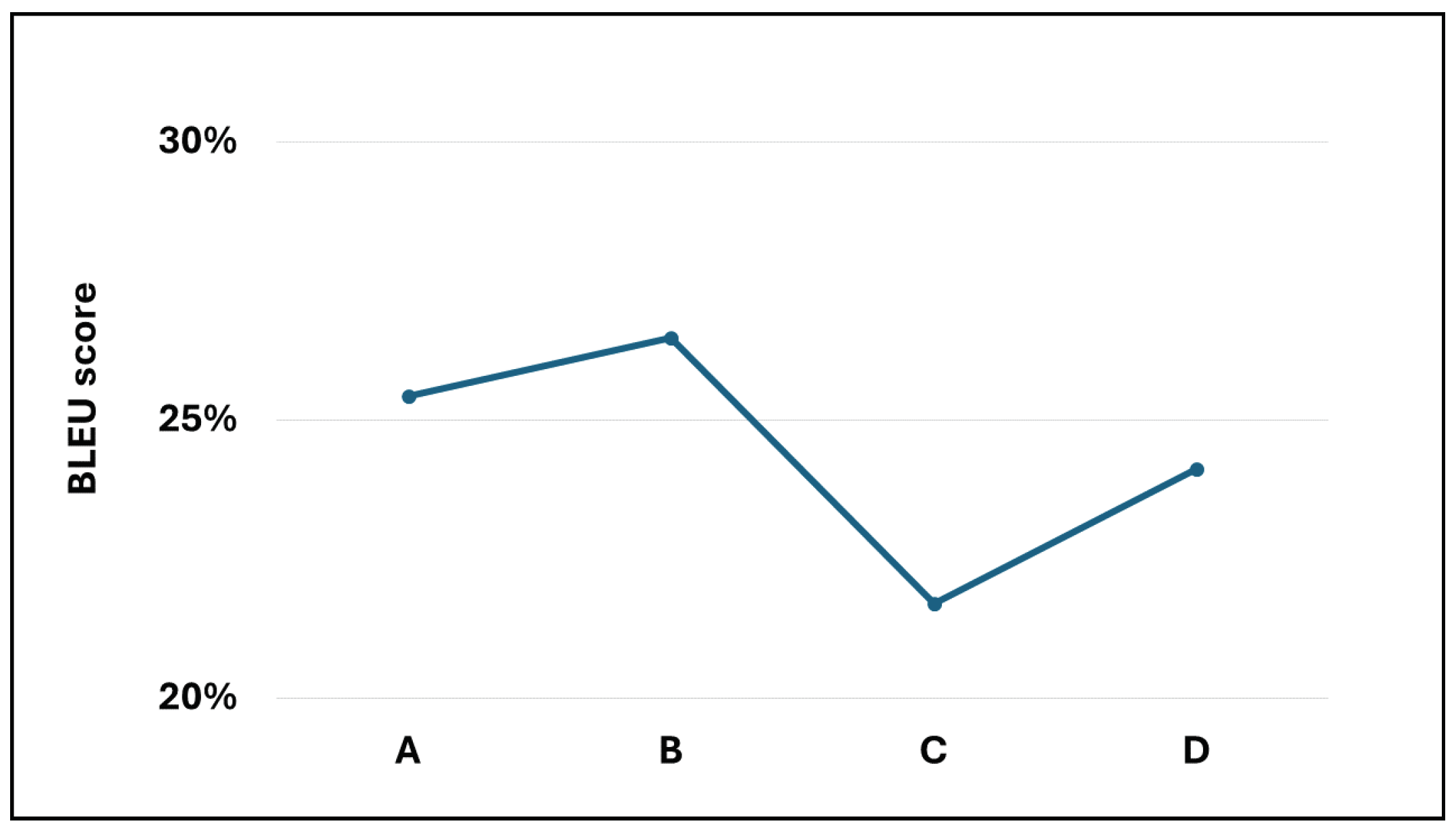
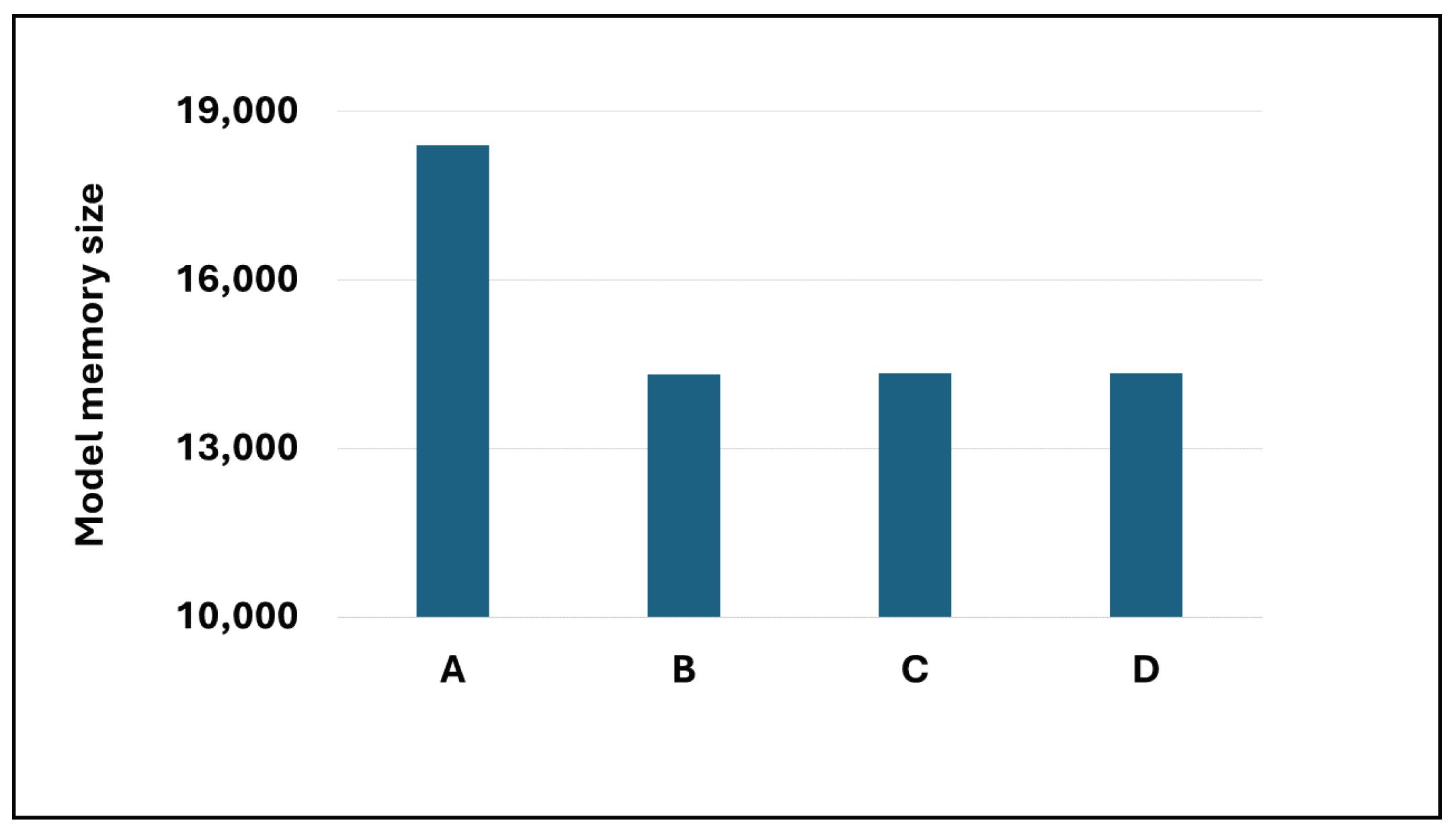
Based on the analysis of multiple model samples displayed in Figure 2, it’s evident that the overall models avoid overfitting, demonstrating their capability for predictive tasks. Reviewing the experimental outcomes outlined in Table 3, the Dense-Block 1-circulant DCT-DST model notably surpasses the Dense-Dense model in BLEU score and model memory efficiency. Specifically, it achieves a higher BLEU score and demonstrates a improvement in model memory utilization. However, across other metrics, the performance of the block g-circulant matrix-based model needs to catch up to the Dense-Dense model. During testing on the test dataset, the Dense-Dense model excels notably in test duration. Furthermore, across similar matrix dimensions, all models achieve loss values that exhibit marginal differences. Notably, the block g-circulant model group with tends to outperform the group where , both in terms of loss and accuracy metrics. Figure 3, Figure 4, Figure 5 and Figure 6 provides a holistic view of the comparison among diverse g values, highlighting the fluctuations in loss, accuracy, BLEU score, and model memory size.
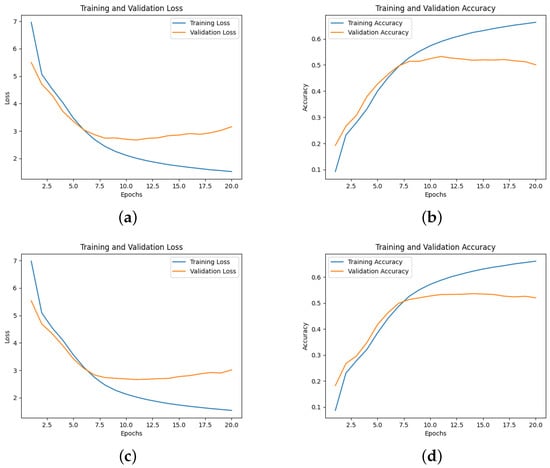
Figure 2.
(a) The loss of Dense-Block 2-Circulant DCT-DST model; (b) The accuracy of Dense-Block 2-Circulant DCT-DST model; (c) The loss of Dense-Block 3-Circulant DCT-DST model; (d) The Accuracy of Dense-Block 3-Circulant DCT-DST model.
Table 3.
The evaluated metrics across the four transformer models include accuracy, loss, test duration, BLEU score, and model memory consumption.
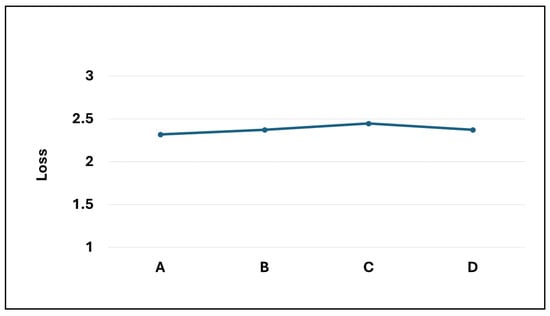
Figure 3.
The loss values for the four transformer models.
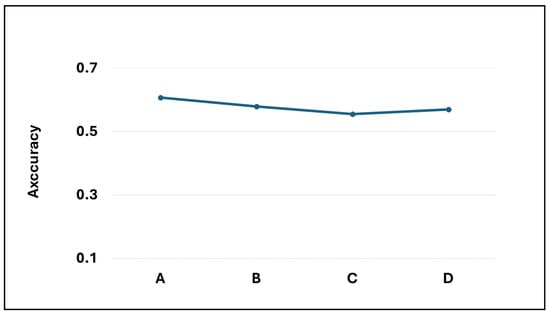
Figure 4.
The accuracy values for the four transformer models.
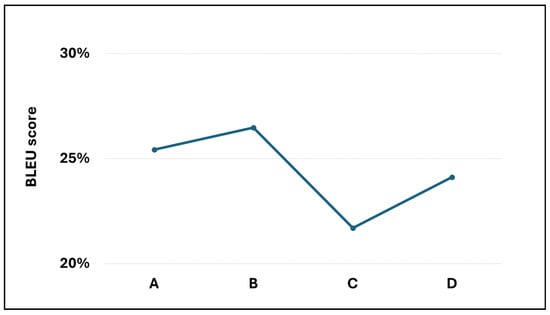
Figure 5.
The BLEU score for the four transformer models.
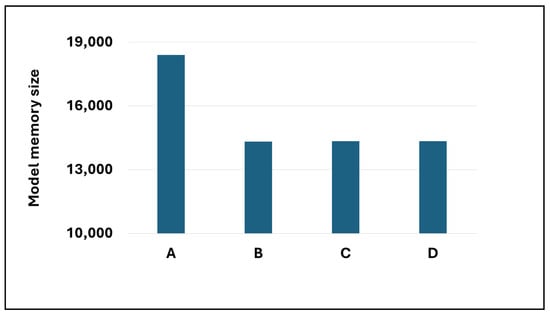
Figure 6.
The Model memory size for the four transformer models.
In general, the transformer model employing the block g-circulant weight matrix boasts a more efficient model memory size than the Dense-Dense model. This enhanced efficiency can be credited to utilizing the block g-circulant matrix, a structured matrix falling within the category of low displacement rank (LDR) matrices [12]. This discovery corroborates earlier research detailed in [26,28,29], which similarly highlighted the benefits of both block circulant matrices and circulant matrices through experimental evidence—the block g-circulant matrices allowing us to leverage the concept of data-sparsity. Data sparsity implies that representing an matrix necessitates fewer than parameters. Unlike traditional sparse matrices, data-sparse matrices aren’t mandated to contain zero entries; instead, a relationship exists among the matrix entries. Moreover, efficient algorithms, such as computing the matrix-vector product with any vector, can be achieved with fewer than operations [12]. This approach is expected to reduce the number of model training parameters utilized in the experiment, consequently diminishing the demand for storage space. Moreover, the reduced storage space requirement is believed to stem from implementing the DCT-DST algorithm, elaborated upon in [28].
Additionally, the relatively prolonged test duration observed in the block g-circulant model experiments likely arises from employing a vector matrix multiplication algorithm involving more intricate procedural steps, such as the algorithm DCT-DST. Initially, some people anticipated that implementing the algorithm would streamline the testing process, but contrary to expectations, the opposite happened. This can be attributed to the algorithm’s relatively intricate structure and the deep transformer architecture, which involves a significant number of weight matrix and input vector multiplication operations.
5. Conclusions
Incorporating a structured block g-circulant matrix as a weight matrix, combined with the DCT-DST algorithm for multiplication with the input vector in the transformer model, effectively elevated the BLEU score and conserved storage space. However, this approach resulted in a slight reduction in accuracy and an extension of testing time. In a mathematical context, the Kronecker product operation plays a pivotal role in defining the matrices used in the algorithm, enabling the execution of the DCT-DST algorithm on the multiplication of the weight matrix with the transformer input vector.
Author Contributions
Conceptualization, I.M.-A., A.P. and E.A.; methodology, I.M.-A.; software, E.A. and A.P.; validation, I.M.-A. and A.P.; formal analysis, E.A.; investigation, E.A.; resources, I.M.-A. and A.P.; data curation, A.P.; writing—original draft preparation, E.A.; writing—review and editing, E.A., I.M.-A. and A.P.; visualization, I.M.-A.; supervision, I.M.-A. and A.P.; project administration, E.A.; funding acquisition, I.M.-A. All authors have read and agreed to the published version of the manuscript.
Funding
This research was financially supported by the Research and Community Service Program of the Indonesian Ministry of Education, Culture, Research and Technology 2023. The doctoral-degree scholarship was supported by the Center for Higher Education Fund (Balai Pembiayaan Pendidikan Tinggi), the Indonesia Endowment Fund for Education (LPDP), and Agency for the Assessment and Application of Technology (BPPT) through the Beasiswa Pendidikan Indonesia (BPI) Kemendikbudristek.
Data Availability Statement
The data presented in this study are available on request from the corresponding author.
Acknowledgments
The authors express their gratitude to Mikhael Martin for his invaluable contribution in conceptualizing the programming language.
Conflicts of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
- Mitsuda, K.; Higashinaka, R.; Sugiyama, H.; Mizukami, M.; Kinebuchi, T.; Nakamura, R.; Adachi, N.; Kawabata, H. Fine-Tuning a Pre-trained Transformer-Based Encoder-Decoder Model with User-Generated Question-Answer Pairs to Realize Character-like Chatbots. In Conversational AI for Natural Human-Centric Interaction: Proceedings of the 12th International Workshop on Spoken Dialogue System Technology, Singapore, IWSDS 2021; Springer Nature: Singapore, 2022; pp. 277–290. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; dan Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Ranganathan, J.; Abuka, G. Text summarization using transformer model. In Proceedings of the 2022 Ninth International Conference on Social Networks Analysis, Management and Security (SNAMS), Milan, Italy, 29 November–1 December 2022; pp. 1–5. [Google Scholar]
- Arnab, A.; Dehghani, M.; Heigold, G.; Sun, C.; Lucic, M.; Schmid, C. Vivit: A video vision transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 6836–6846. [Google Scholar]
- Zeng, P.; Zhang, H.; Song, J.; Gao, L. S2 transformer for image captioning. In Proceedings of the International Joint Conferences on Artificial Intelligence, Vienna, Austria, 23–29 July 2022; pp. 1608–1614. [Google Scholar]
- Bazi, Y.; Bashmal, L.; Rahhal, M.M.A.; Dayil, R.A.; Ajlan, N.A. Vision transformers for remote sensing image classification. Remote Sens. 2021, 13, 516. [Google Scholar] [CrossRef]
- Toral, A.; Oliver, A.; Ballestín, P.R. Machine translation of novels in the age of transformer. arXiv 2020, arXiv:2011.14979. [Google Scholar]
- Araabi, A.; Monz, C. Optimizing transformer for low-resource neural machine translation. arXiv 2020, arXiv:2011.02266. [Google Scholar]
- Tian, T.; Song, C.; Ting, J.; Huang, H. A French-to-English machine translation model using transformer network. Procedia Comput. Sci. 2022, 199, 1438–1443. [Google Scholar] [CrossRef]
- Ahmed, K.; Keskar, N.S.; Socher, R. Weighted transformer network for machine translation. arXiv 2017, arXiv:1711.02132. [Google Scholar]
- Wang, Q.; Li, B.; Xiao, T.; Zhu, J.; Li, C.; Wong, D.F.; Chao, L.S. Learning deep transformer models for machine translation. arXiv 2019, arXiv:1906.01787. [Google Scholar]
- Kissel, M.; Diepold, K. Structured Matrices and Their Application in Neural Networks: A Survey. New Gener. Comput. 2023, 41, 697–722. [Google Scholar] [CrossRef]
- Keles, F.D.; Wijewardena, P.M.; Hegde, C. On the computational complexity of self-attention. In Proceedings of the 34th International Conference on Algorithmic Learning Theory, Singapore, 20–23 February 2022; PMLR:2023. pp. 597–619. [Google Scholar]
- Pan, Z.; Chen, P.; He, H.; Liu, J.; Cai, J.; Zhuang, B. Mesa: A memory-saving training framework for transformers. arXiv 2021, arXiv:2111.11124. [Google Scholar]
- Yang, H.; Zhao, M.; Yuan, L.; Yu, Y.; Li, Z.; Gu, M. Memory-efficient Transformer-based network model for Traveling Salesman Problem. Neural Netw. 2023, 161, 589–597. [Google Scholar] [CrossRef]
- Sohoni, N.S.; Aberger, C.R.; Leszczynski, M.; Zhang, J.; Ré, C. Low-memory neural network training: A technical report. arXiv 2019, arXiv:1904.10631. [Google Scholar]
- Sainath, T.N.; Kingsbury, B.; Sindhwani, V.; Arisoy, E.; Ramabhadran, B. Low-rank matrix factorization for deep neural network training with high-dimensional output targets. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 6655–6659. [Google Scholar]
- Sindhwani, V.; Sainath, T.; Kumar, S. Structured transforms for small-footprint deep learning. arXiv 2015, arXiv:1510.01722. [Google Scholar]
- Cheng, Y.; Yu, F.X.; Feris, R.S.; Kumar, S.; Choudhary, A.; Chang, S. An exploration of parameter redundancy in deep networks with circulant projections. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 2857–2865. [Google Scholar]
- Ding, C.; Liao, S.; Wang, Y.; Li, Z.; Liu, N.; Zhuo, Y.; Wang, C.; Qian, X.; Bai, Y.; Yuan, G.; et al. Circnn: Accelerating and compressing deep neural networks using block-circulant weight matrices. In Proceedings of the 50th Annual IEEE/ACM International Symposium on Microarchitecture, Boston, MA, USA, 14–17 October 2017; pp. 395–408. [Google Scholar]
- Yang, Z.; Moczulski, M.; Denil, M.; Freitas, N.D.; Song, L.; Wang, Z. Deep fried convnets. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Thomas, A.; Gu, A.; Dao, T.; Rudra, A.; Ré, C. Learning compressed transforms with low displacement rank. arXiv 2018, arXiv:1810.02309. [Google Scholar]
- Dao, T.; Gu, A.; Eichhorn, M.; Rudra, A.; Ré, C. Learning fast algorithms for linear transforms using butterfly factorizations. Proc. Mach. Learn. Res. 2019, 97, 1517–1527. [Google Scholar] [PubMed]
- Pan, V. Structured Matrices and Polynomials: Unified Superfast Algorithms; Springer Science and Business Media: Boston, MA, USA; New York, NY, USA, 2001. [Google Scholar]
- Davis, P.J. Circulant Matrices; Wiley: New York, NY, USA, 1979; Volume 2. [Google Scholar]
- Asriani, E.; Muchtadi-Alamsyah, I.; Purwarianti, A. Real Block-Circulant Matrices and DCT-DST Algorithm for Transformer Neural Network. Front. Appl. Math. Stat. 2023, 9, 1260187. [Google Scholar] [CrossRef]
- Asriani, E.; Muchtadi-Alamsyah, I.; Purwarianti, A. g-Circulant Matrices and Its Matrix-Vector Multiplication Algorithm for Transformer Neural Networks. AIP Conf. 2024. post-acceptance. [Google Scholar]
- Liu, Z.; Chen, S.; Xu, W.; Zhang, Y. The eigen-structures of real (skew) circulant matrices with some applications. Comput. Appl. Math. 2019, 38, 1–13. [Google Scholar] [CrossRef]
- Reid, S.; dan Mistele, M. Fast Fourier Transformed Transformers: Circulant Weight Matrices for NMT Compression. 2019. Available online: https://web.stanford.edu/class/archive/cs/cs224n/cs224n.1194/reports/custom/15722831.pdf (accessed on 23 May 2024).
- Saxena, A.; Fernandes, F.C. DCT/DST-based transform coding for intra prediction in image/video coding. IEEE Trans. Image Process. 2013, 22, 3974–3981. [Google Scholar] [CrossRef]
- Park, W.; Lee, B.; Kim, M. Fast computation of integer DCT-V, DCT-VIII, and DST-VII for video coding. IEEE Trans. Image Process. 2019, 28, 5839–5851. [Google Scholar] [CrossRef]
- Olson, B.; Shaw, S.; Shi, C.; Pierre, C.; Parker, R. Circulant matrices and their application to vibration analysis. Appl. Mech. Rev. 2014, 66, 040803. [Google Scholar] [CrossRef]
- Serra-Capizzano, S.; Debora, S. A note on the eigenvalues of g-circulants (and of g-Toeplitz, g-Hankel matrices). Calcolo 2014, 51, 639–659. [Google Scholar] [CrossRef]
- Wilkinson, J.H. The Algebraic Eigenvalue Problem; Clarendon: Oxford, UK, 1965; Volume 662. [Google Scholar]
- Domingo, M.; Garcıa-Martınez, M.; Helle, A.; Casacuberta, F.; Herranz, M. How much does tokenization affect neural machine translation? arXiv 2018, arXiv:1812.08621. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 6–12 July 2002; pp. 311–318. [Google Scholar]
- Post, M. A call for clarity in reporting BLEU scores. arXiv 2018, arXiv:1804.08771. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).