
Q-Sorting: An Algorithm for Reinforcement Learning Problems with Multiple Cumulative Constraints




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. RL Problems with Multiple Cumulative Constraints
- MDP is finite-time and episodic, which means that all discount rates are 1.
- MDP as well as the policy are deterministic.
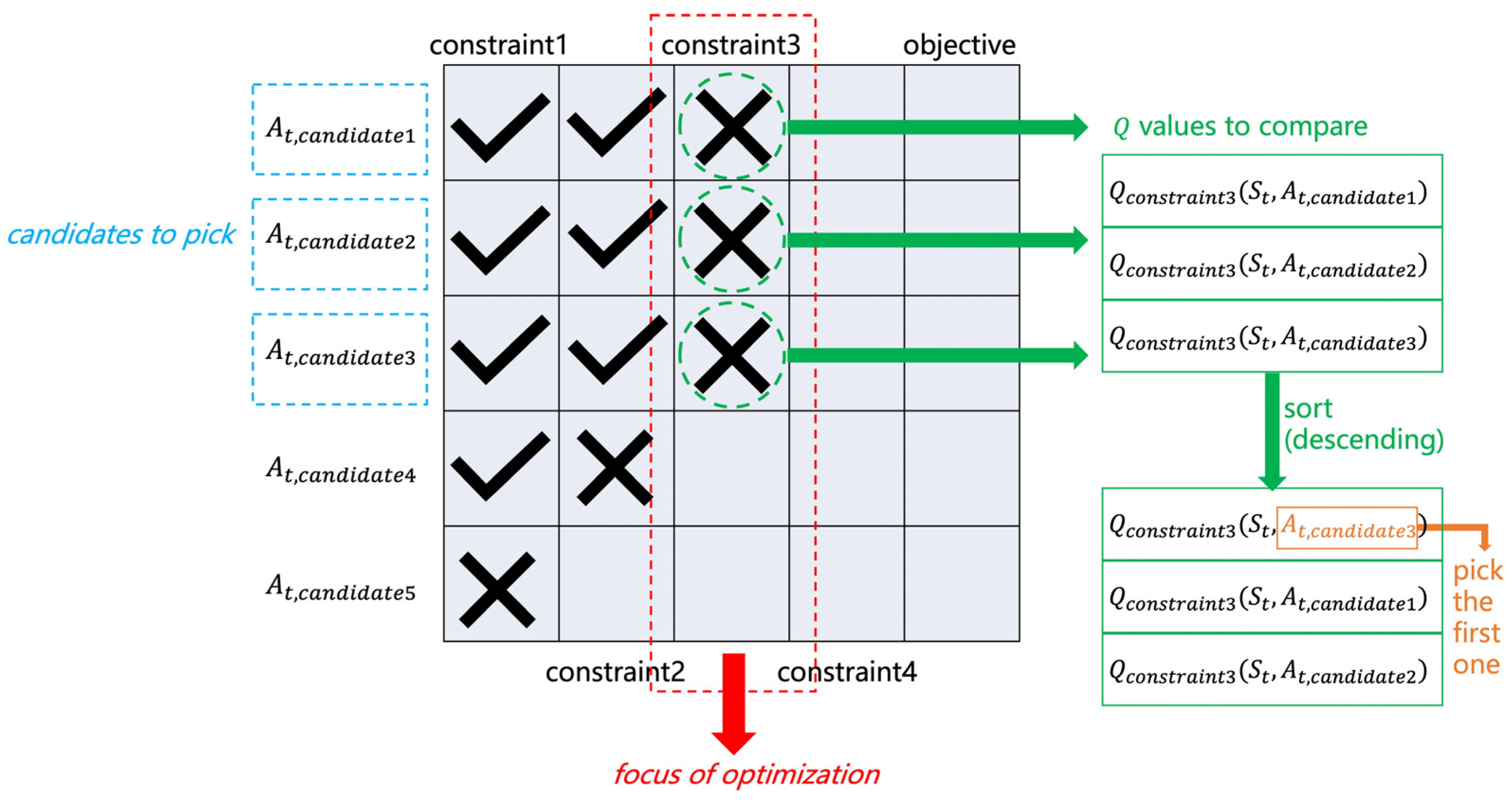
3. Q-Sorting
| Algorithm 1. Q-sorting |
| Algorithm parameter: small |
| Initialize for the objective and each constraint arbitrarily except that , for all , |
| Loop for each episode: |
| Initialize |
| Initialize an empty array |
| Loop for each step of the episode: |
| Generate a uniform random number |
| IF |
| Randomly pick |
| ELSE |
| 1. Test and filter action candidates, starting from the first constraint, until no candidates pass a specific test or all tests are passed. If all candidates fail on a constraint, the constraint becomes the focus of optimization; on the other hand, if there is at least one candidate satisfying all constraints (passing all the tests), the objective becomes the focus of optimization. Record the index of focus as , . 2. Record indices of candidates reaching as , . 3. Sort in descending order and pick the action corresponding to the first as . If multiple actions attain the maximum value at the same time, randomly pick one from them. |
| Take , observe and |
| Append the vector to : |
| Update the current state: |
| until the terminal state is reached |
| Update with Monte Carlo, according to the trajectory recoded |
4. Simulation Results
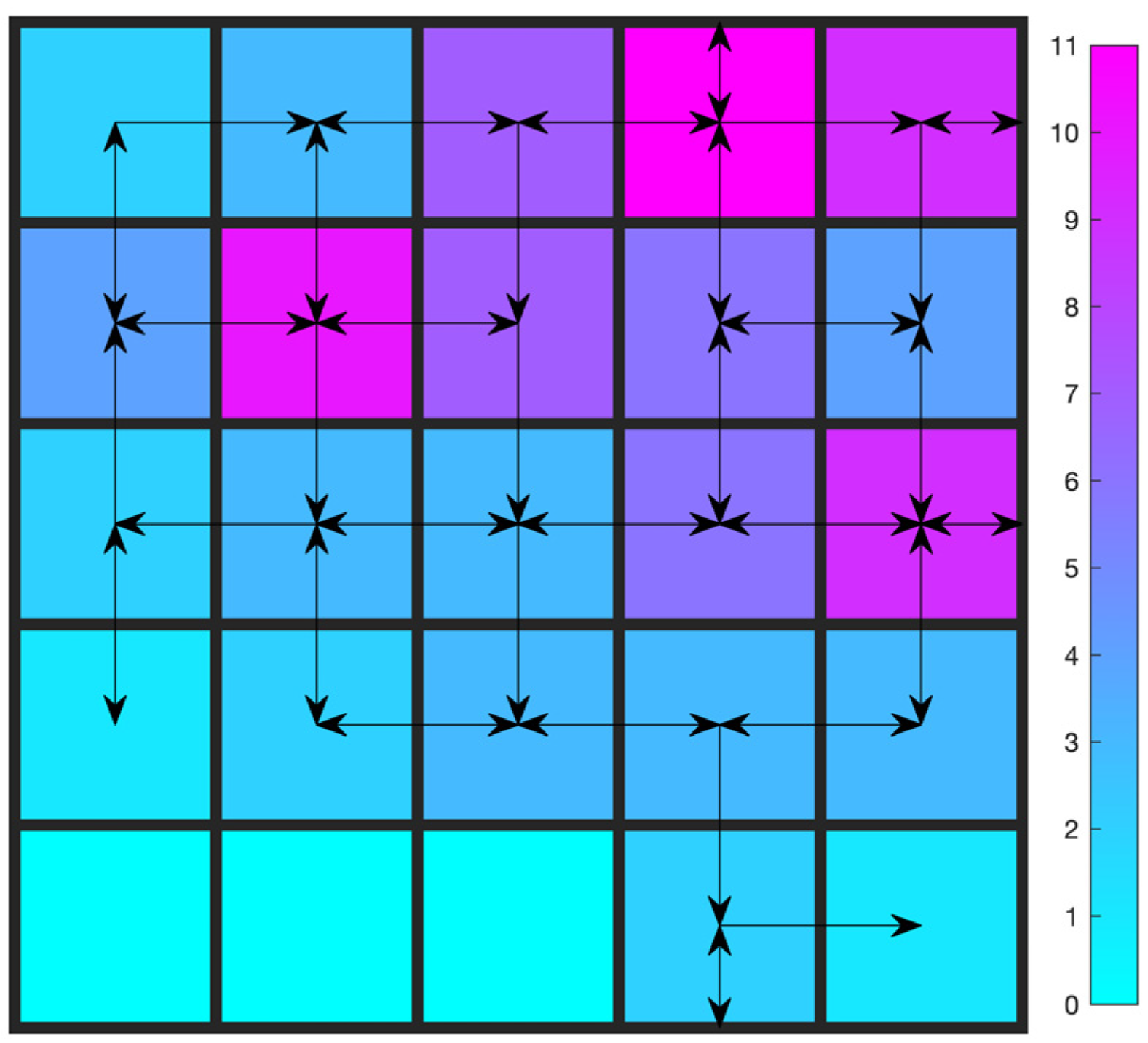
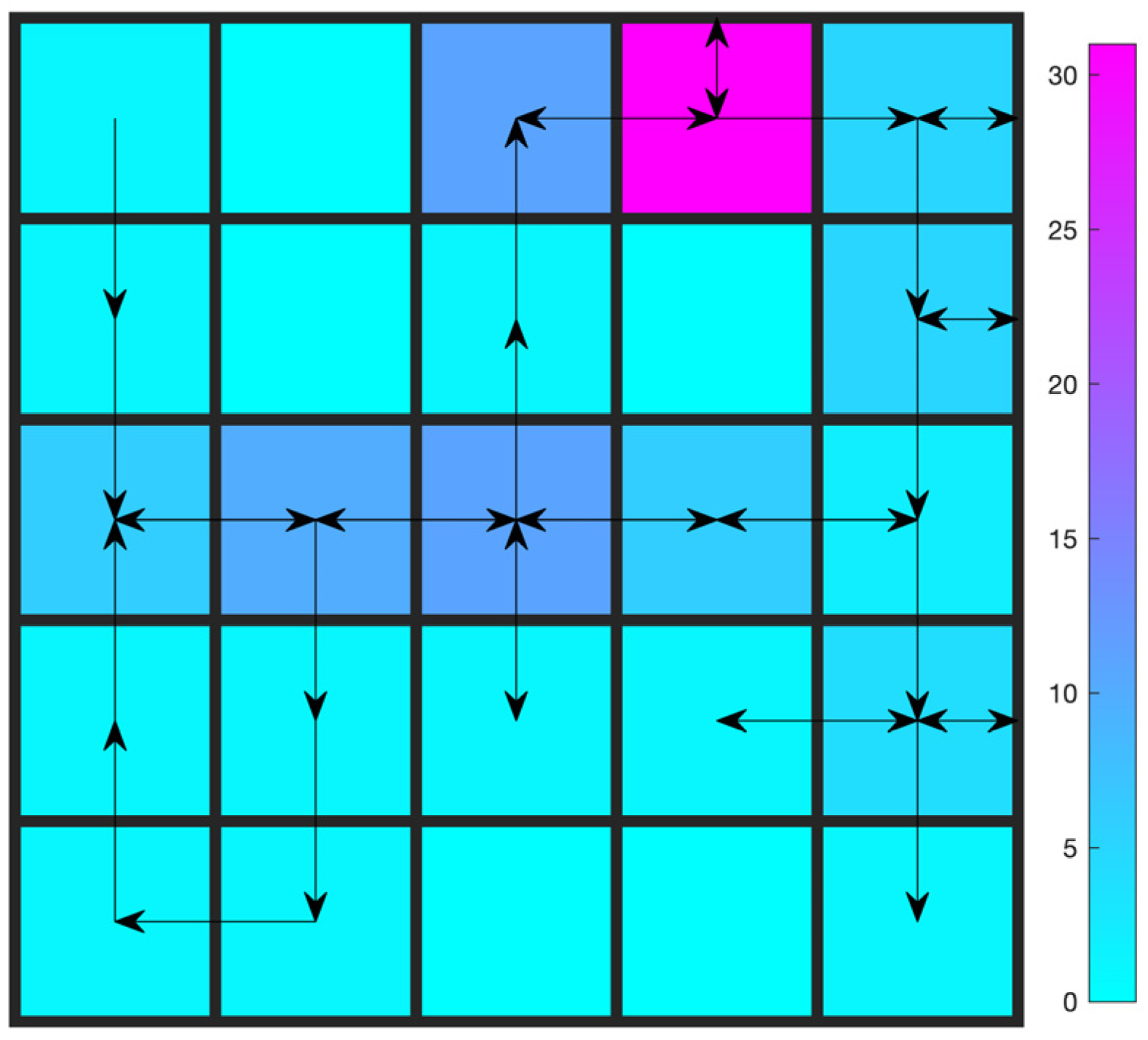
4.1. Gridworld
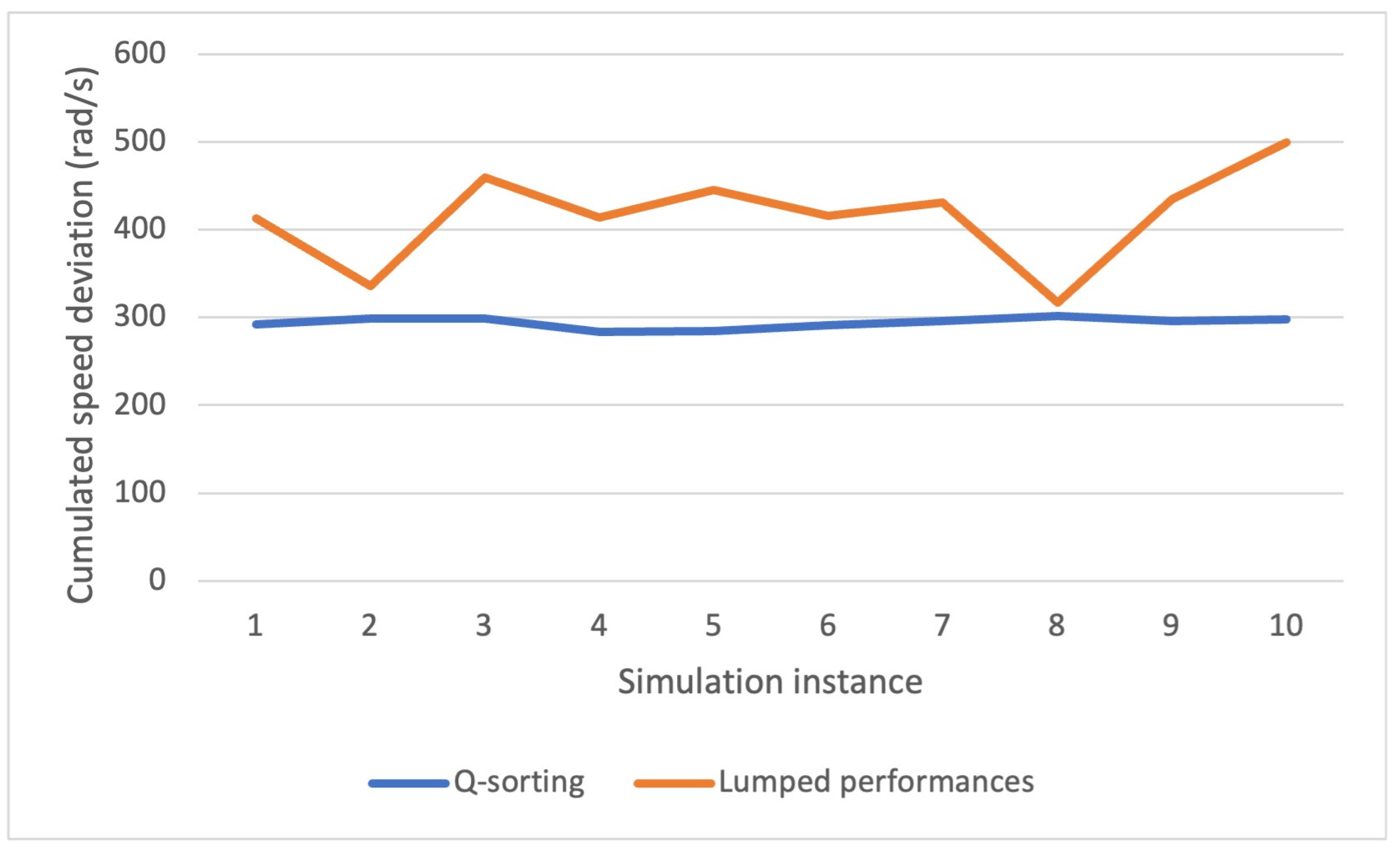
4.2. Motor Speed Synchronization Control
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018; ISBN 978-0-262-19398-6. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing Atari with Deep Reinforcement Learning. Nature 2013, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; Van Den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the Game of Go with Deep Neural Networks and Tree Search. Nature 2016, 529, 484. [Google Scholar] [CrossRef] [PubMed]
- Geibel, P. Reinforcement Learning for MDPs with Constraints; Lecture Notes in Computer Science (including Subseries Lecture Notes in Artificial Intelligence Lecture Notes Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2006; Volume 4212, pp. 646–653. [Google Scholar] [CrossRef]
- Julian, D.; Chiang, M.; O’Neill, D.; Boyd, S. QoS and Fairness Constrained Convex Optimization of Resource Allocation for Wireless Cellular and Ad Hoc Networks. In Proceedings of the Twenty-First Annual Joint Conference of the IEEE Computer and Communications Societies, New York, NY, USA, 23–27 June 2002; IEEE: Piscataway, NJ, USA, 2002; Volume 2, pp. 477–486. [Google Scholar]
- Yuan, J.; Yang, L. Predictive Energy Management Strategy for Connected 48V Hybrid Electric Vehicles. Energy 2019, 187, 115952. [Google Scholar] [CrossRef]
- Zhang, R.; Xiong, K.; Lu, Y.; Fan, P.; Ng, D.W.K.; Letaief, K.B. Energy Efficiency Maximization in RIS-Assisted SWIPT Networks with RSMA: A PPO-Based Approach. IEEE J. Sel. Areas Commun. 2023, 41, 1413–1430. [Google Scholar] [CrossRef]
- Zhang, R.; Xiong, K.; Lu, Y.; Gao, B.; Fan, P.; Letaief, K. Ben Joint Coordinated Beamforming and Power Splitting Ratio Optimization in MU-MISO SWIPT-Enabled HetNets: A Multi-Agent DDQN-Based Approach. IEEE J. Sel. Areas Commun. 2022, 40, 677–693. [Google Scholar] [CrossRef]
- Liu, Y.; Halev, A.; Liu, X. Policy Learning with Constraints in Model-Free Reinforcement Learning: A Survey. In Proceedings of the IJCAI International Joint Conference on Artificial Intelligence, Montreal, QC, Canada, 19–27 August 2021; pp. 4508–4515. [Google Scholar] [CrossRef]
- Altman, E. Constrained Markov Decision Processes; Routledge: Oxfordshire, UK, 1999; ISBN 1315140225. [Google Scholar]
- Chow, Y.; Ghavamzadeh, M.; Janson, L.; Pavone, M. Risk-Constrained Reinforcement Learning with Percentile Risk Criteria. J. Mach. Learn. Res. 2018, 18, 6070–6120. [Google Scholar]
- Tessler, C.; Mankowitz, D.J.; Mannor, S. Reward Constrained Policy Optimization. In Proceedings of the 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, 6–9 May 2019; pp. 1–15. [Google Scholar]
- Bohez, S.; Abdolmaleki, A.; Neunert, M.; Buchli, J.; Heess, N.; Hadsell, R. Value Constrained Model-Free Continuous Control. arXiv 2019, arXiv:1902.04623. [Google Scholar]
- Jayant, A.K.; Bhatnagar, S. Model-Based Safe Deep Reinforcement Learning via a Constrained Proximal Policy Optimization Algorithm. Adv. Neural Inf. Process. Syst. 2022, 35, 24432–24445. [Google Scholar]
- Panageas, I.; Piliouras, G.; Wang, X. First-Order Methods Almost Always Avoid Saddle Points: The Case of Vanishing Step-Sizes. Adv. Neural Inf. Process. Syst. 2019, 32, 6474–6483. [Google Scholar]
- Vidyasagar, M. Nonlinear Systems Analysis; SIAM: Philadelphia, PA, USA, 2002; ISBN 0898715261. [Google Scholar]
- Glynn, P.W.; Zeevi, A. Bounding Stationary Expectations of Markov Processes; Institute of Mathematical Statistics: Waite Hill, OH, USA, 2008; Volume 4, pp. 195–214. [Google Scholar] [CrossRef]
- Chow, Y.; Nachum, O.; Duenez-Guzman, E.; Ghavamzadeh, M. A Lyapunov-Based Approach to Safe Reinforcement Learning. Adv. Neural Inf. Process. Syst. 2018, 31, 8092–8101. [Google Scholar]
- Chow, Y.; Nachum, O.; Faust, A.; Duenez-Guzman, E.; Ghavamzadeh, M. Lyapunov-Based Safe Policy Optimization for Continuous Control. arXiv 2019, arXiv:1901.10031. [Google Scholar]
- Satija, H.; Amortila, P.; Pineau, J. Constrained Markov Decision Processes via Backward Value Functions. In Proceedings of the 37th International Conference on Machine Learning, ICML 2020, Virtual, 13–18 July 2020; pp. 8460–8469. [Google Scholar]
- Achiam, J.; Held, D.; Tamar, A.; Abbeel, P. Constrained Policy Optimization. In Proceedings of the International Conference on Machine Learning; PMLR, Sydney, Australia, 6–11 August 2017; pp. 22–31. [Google Scholar]
- Schulman, J.; Levine, S.; Abbeel, P.; Jordan, M.; Moritz, P. Trust Region Policy Optimization. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 7–9 July 2015; Volume 67, pp. 1889–1897. [Google Scholar]
- Liu, Y.; Ding, J.; Liu, X. IPO: Interior-Point Policy Optimization under Constraints. In Proceedings of the AAAI 2020-34th AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 4940–4947. [Google Scholar] [CrossRef]
- Boyd, S.P.; Vandenberghe, L. Convex Optimization; Cambridge University Press: Cambridge, UK, 2004; ISBN 0521833787. [Google Scholar]
- Liu, Y.; Ding, J.; Liu, X. A Constrained Reinforcement Learning Based Approach for Network Slicing. In Proceedings of the 2020 IEEE 28th International Conference on Network Protocols (ICNP), Madrid, Spain, 13–16 October 2020. [Google Scholar] [CrossRef]
- Liu, Y.; Ding, J.; Liu, X. Resource Allocation Method for Network Slicing Using Constrained Reinforcement Learning. In Proceedings of the 2021 IFIP Networking Conference (IFIP Networking), Espoo and Helsinki, Finland, 21–24 June 2021; pp. 1–3. [Google Scholar] [CrossRef]
- Wei, H.; Liu, X.; Ying, L. Triple-Q: A Model-Free Algorithm for Constrained Reinforcement Learning with Sublinear Regret and Zero Constraint Violation. Proc. Mach. Learn. Res. 2022, 151, 3274–3307. [Google Scholar]
- Rummery, G.; Niranjan, M. On-Line Q-Learning Using Connectionist Systems (Technical Report); University of Cambridge, Department of Engineering Cambridge: Cambridge, UK, 1994; Volume 37. [Google Scholar]
- Wei, C.Y.; Jafarnia-Jahromi, M.; Luo, H.; Sharma, H.; Jain, R. Model-Free Reinforcement Learning in Infinite-Horizon Average-Reward Markov Decision Processes. In Proceedings of the 37th International Conference on Machine Learning ICML 2020, Virtual, 13–18 July 2020; pp. 10101–10111. [Google Scholar]
- Singh, R.; Gupta, A.; Shroff, N.B. Learning in Constrained Markov Decision Processes. IEEE Trans. Control Netw. Syst. 2023, 10, 441–453. [Google Scholar] [CrossRef]
- Bura, A.; HasanzadeZonuzy, A.; Kalathil, D.; Shakkottai, S.; Chamberland, J.F. DOPE: Doubly Optimistic and Pessimistic Exploration for Safe Reinforcement Learning. Adv. Neural Inf. Process. Syst. 2022, 35, 1047–1059. [Google Scholar]
- Yang, T.Y.; Rosca, J.; Narasimhan, K.; Ramadge, P.J. Projection-Based Constrained Policy Optimization. In Proceedings of the 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, 26–30 April 2020; pp. 1–24. [Google Scholar]
- Morimura, T.; Peters, J. Derivatives of Logarithmic Stationary Distributions for Policy Gradient Reinforcement Learning. Neural Comput. 2010, 22, 342–376. [Google Scholar] [CrossRef] [PubMed]
- Pankayaraj, P.; Varakantham, P. Constrained Reinforcement Learning in Hard Exploration Problems. In Proceedings of the 37th AAAI Conference on Artificial Intelligence, AAAI 2023, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 15055–15063. [Google Scholar] [CrossRef]
- Calvo-Fullana, M.; Paternain, S.; Chamon, L.F.O.; Ribeiro, A. State Augmented Constrained Reinforcement Learning: Overcoming the Limitations of Learning with Rewards. IEEE Trans. Automat. Control, 2023; early access. [Google Scholar] [CrossRef]
- McMahan, J.; Zhu, X. Anytime-Constrained Reinforcement Learning. Proc. Mach. Learn. Res. 2024, 238, 4321–4329. [Google Scholar]
- Bai, Q.; Bedi, A.S.; Agarwal, M.; Koppel, A.; Aggarwal, V. Achieving Zero Constraint Violation for Constrained Reinforcement Learning via Primal-Dual Approach. In Proceedings of the 36th AAAI Conference on Artificial Intelligence, AAAI 2022, Virtually, 22 February–1 March 2022; Volume 36, pp. 3682–3689. [Google Scholar] [CrossRef]
- Ma, Y.J.; Shen, A.; Bastani, O.; Jayaraman, D. Conservative and Adaptive Penalty for Model-Based Safe Reinforcement Learning. In Proceedings of the 36th AAAI Conference on Artificial Intelligence, AAAI 2022, Virtually, 22 February–1 March 2022; Volume 36, pp. 5404–5412. [Google Scholar] [CrossRef]
- Xu, H.; Zhan, X.; Zhu, X. Constraints Penalized Q-Learning for Safe Offline Reinforcement Learning. In Proceedings of the 36th AAAI Conference on Artificial Intelligence, AAAI 2022, Virtually, 22 February–1 March 2022; Volume 36, pp. 8753–8760. [Google Scholar] [CrossRef]
- Huang, J.; Zhang, J.; Huang, W.; Yin, C. Optimal Speed Synchronization Control with Disturbance Compensation for an Integrated Motor-Transmission Powertrain System. J. Dyn. Syst. Meas. Control 2018, 141, 041001. [Google Scholar] [CrossRef]
- Huang, J.; Zhang, J.; Yin, C. Comparative Study of Motor Speed Synchronization Control for an Integrated Motor–Transmission Powertrain System. Proc. Inst. Mech. Eng. Part D J. Automob. Eng. 2020, 234, 1137–1152. [Google Scholar] [CrossRef]













Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, J.; Lu, G.; Li, Y.; Wu, J. Q-Sorting: An Algorithm for Reinforcement Learning Problems with Multiple Cumulative Constraints. Mathematics 2024, 12, 2001. https://doi.org/10.3390/math12132001
Huang J, Lu G, Li Y, Wu J. Q-Sorting: An Algorithm for Reinforcement Learning Problems with Multiple Cumulative Constraints. Mathematics. 2024; 12(13):2001. https://doi.org/10.3390/math12132001
Chicago/Turabian StyleHuang, Jianfeng, Guoqiang Lu, Yi Li, and Jiajun Wu. 2024. "Q-Sorting: An Algorithm for Reinforcement Learning Problems with Multiple Cumulative Constraints" Mathematics 12, no. 13: 2001. https://doi.org/10.3390/math12132001
APA StyleHuang, J., Lu, G., Li, Y., & Wu, J. (2024). Q-Sorting: An Algorithm for Reinforcement Learning Problems with Multiple Cumulative Constraints. Mathematics, 12(13), 2001. https://doi.org/10.3390/math12132001