Abstract
Early fire detection is the key to saving lives and limiting property damage. Advanced technology can detect fires in high-risk zones with minimal human presence before they escalate beyond control. This study focuses on providing a more advanced model structure based on the YOLOv8 architecture to enhance early recognition of fire. Although YOLOv8 is excellent at real-time object detection, it can still be better adjusted to the nuances of fire detection. We achieved this advancement by incorporating an additional context-to-flow layer, enabling the YOLOv8 model to more effectively capture both local and global contextual information. The context-to-flow layer enhances the model’s ability to recognize complex patterns like smoke and flames, leading to more effective feature extraction. This extra layer helps the model better detect fires and smoke by improving its ability to focus on fine-grained details and minor variation, which is crucial in challenging environments with low visibility, dynamic fire behavior, and complex backgrounds. Our proposed model achieved a 2.9% greater precision rate, 4.7% more recall rate, and 4% more F1-score in comparison to the YOLOv8 default model. This study discovered that the architecture modification increases information flow and improves fire detection at all fire sizes, from tiny sparks to massive flames. We also included explainable AI strategies to explain the model’s decision-making, thus adding more transparency and improving trust in its predictions. Ultimately, this enhanced system demonstrates remarkable efficacy and accuracy, which allows additional improvements in autonomous fire detection systems.
Keywords:
fire detection; modified YOLOv8; deep learning; computer vision; explainable artificial intelligence; EigenCAM MSC:
68T07
1. Introduction
Natural disasters like earthquakes and floods, along with man-made crises such as industrial accidents, have long posed significant challenges to societies worldwide. Among these, fire is one of the most dangerous and unpredictable. Fire can spread incredibly fast, turning a small flame into a large, uncontrollable blaze within minutes, destroying everything in its path. This not only threatens people’s lives and homes but also causes long-term damage to the environment, leading to deforestation, air pollution, and the release of harmful chemicals. Fires also have serious economic impacts, with billions of dollars lost every year due to fire-related damage [1]. Fires can have lasting effects on communities, forcing people to leave their homes, destroying jobs, and causing deep psychological harm [2]. These effects can last for generations, changing the way entire regions function socially and economically [1,3]. Given the rapid spread of fires, early detection is essential; it can mean the difference between successfully controlling the fire and allowing it to escalate into a major disaster. Traditional tools like smoke detectors and heat sensors are helpful, but they often do not detect fires until the heat or smoke reaches the sensors, especially in large or open areas. These systems also have trouble detecting fires in complex environments like thick forests or large industrial sites, where early detection is crucial [4]. To better prevent fire disasters, we need more advanced and accurate systems that can spot fires just as they are starting, allowing for quicker intervention.
There are many computer vision techniques, such as BEMRF-Net, which uses a special module to improve detection accuracy by combining features from different scales. Other methods include a global–local context-aware (GLCA) module that enhances detection and reidentification, a network that transfers context between slices and calibrates uncertain areas, RMU-Net for extracting high-resolution images, and a two-branch module that extracts features at multiple scales with a classifier for better supervision. Along with these techniques, many other image detection technologies are currently available [5,6,7,8,9].
Image-based systems hold promise, but existing models often lack the necessary precision in critical situations [10]. These systems face significant challenges, including low detection accuracy in changing lighting conditions, difficulty distinguishing between fire and non-fire objects, and inefficiencies in processing real-time data [11]. In high-stakes scenarios where every second is crucial, these shortcomings can have devastating consequences. False alarms pose a serious problem because they can desensitize response teams, resulting in delays when responding to actual emergencies [12]. Moreover, in areas where fire detection is crucial, such as densely populated urban centers or remote forest regions, the failure of these systems can result in catastrophic outcomes. The increasing threat posed by fires, combined with the limitations of current detection technologies, highlight the need for a more advanced solution. As climate change intensifies and urbanization continues to expand, the frequency and severity of fire incidents are expected to rise. This reality underscores the urgency of developing a fire detection system that is not only accurate but also robust enough to operate effectively in diverse environments. In response to this critical need, we have developed a state-of-the-art deep learning approach tailored to meet these demands. By utilizing computer vision, our solution offers a more precise and reliable method of fire detection, ensuring that fires are identified and managed before they cause significant harm.
Previous research has explored various frameworks such as YOLOv3, YOLOv5, R-CNN, vanilla CNN, and dual CNN models for fire detection [2]. However, these models often face challenges related to accuracy and speed, particularly in high-pressure situations [2,13]. Several studies have pointed out the limitations of these fire detection models. For instance, the YOLOv3 algorithm-based fire detection method was introduced, which was adapted for real-time high-speed detection on a Banana Pi M3 board [2]. The researchers used data augmentation techniques like rotating labeled images and adding fire-like images to the dataset to enhance training. Independent logistic classifiers and binary cross-entropy loss were also employed for class predictions [2]. However, the method sometimes misclassified non-fire objects like neon signs and headlights as fires, especially at night. Nighttime blurring also caused errors, making it difficult to distinguish between actual fires and other light sources [2]. The YOLOv2-based model was utilized for real-time fire and smoke detection in various environments [1]. Research was conducted with indoor and outdoor fire and smoke image sets, using a Ground Truth Labeler app for data labeling and also implemented on a low-cost embedded device, Jetson Nano, for real-time processing [1]. However, background objects with similar color properties caused false detections, and performance might be limited by the capabilities of the embedded device used, according to the research [1]. Additionally, a fire detection method was proposed using an improved YOLOv4 network and was adapted for real-time monitoring on a Banana Pi M3 board [4]. The dataset was expanded using image transformation techniques to improve detection accuracy. Despite improvements, the method encountered false positives, especially in scenarios with fire-like lights and larger image sizes, which increased processing time, which could be a limitation for real-time applications [4]. Furthermore, a study proposed a fire and smoke detection method using dilated convolutional neural networks to enhance feature extraction and reduce false alarms. A custom dataset of fire and smoke images was created and used for training and evaluation. Despite this, the method struggled with early-stage detection when fire and smoke pixel values were similar to the background, especially in cloudy weather [14]. In another study, a dual deep learning framework utilized two deep CNNs to extract image-based features such as color, texture, and edges and motion-based features like optical flow. Researchers also utilized Superpixel Segmentation for smoke regions in images to extract features and support vector machine combined features from both frameworks for classification. Despite this, the method struggled with environmental scenarios like fog, clouds, and sandstorms, and the dataset was also limited, according to the researchers [15]. These inconsistencies made it challenging to rely on these models in critical situations where reliability is always necessary. Furthermore, in a different study, researchers utilized aerial 360-degree cameras to capture wide-field-of-view images. The DeepLab V3+ networks were applied for flame and smoke segmentation. They also implemented an adaptive method to reduce false positives by analyzing environmental appearance. However, the method was affected by weather conditions, the aerial device required frequent recharging, and the system was not capable of detecting fires at night [3]. In other studies, some researchers utilized a multifunctional AI framework and the Direct-MQTT protocol to enhance fire detection accuracy and minimize data transfer delays. This approach also applied a CNN algorithm for visual intelligence and used the Fire Dynamics Simulator for testing. However, it did not consider sensor failures and used static thresholds [16]. In another study, researchers utilized the ELASTIC-YOLOv3 algorithm to quickly and accurately detect fire candidate areas and combined it with a random forest classifier to verify fire candidates. Additionally, they used a temporal fire-tube and bag-of-features histogram to reflect the dynamic characteristics of nighttime flames. However, the approach faced limitations in real-time processing due to the computational demands of combining CNN with RNN or LSTM, and it struggled with distinguishing fire from fire-like objects in nighttime urban environments [17]. The Intermediate Fusion VGG16 model and the Enhanced Consumed Energy-Leach protocol were utilized in a study for the early detection of forest fires. Drones were employed to capture RGB and IR images, which were then processed using the VGG16 model. However, the study faced limitations due to the lack of real-world testing and resource constraints that hindered comprehensive evaluation [10]. In another computer vision-based study, researchers utilized a YOLOv5 fire detection algorithm based on an attention-enhanced ghost model, mixed convolutional pyramids, and flame-center detection. It incorporated Ghost bottlenecks, SECSP attention modules, GSConv convolution, and the SIoU loss function to enhance accuracy. However, the limitations included potential challenges in real-time detection due to high computational complexities and the need for further validation in diverse environments [11]. In a different study based on CNN, the researchers modified the CNN for forest fire recognition, integrating transfer learning and a feature fusion algorithm to enhance detection accuracy. The researchers utilized a diverse dataset of fire and non-fire images for training and testing. However, the study faced limitations due to the small sample size of the dataset and the need for further validation in real-world scenarios to ensure robustness and generalization. In a different study to detect fire and smoke, the researchers utilized a capacitive particle-analyzing smoke detector for very early fire detection, employing a multiscale smoke particle concentration detection algorithm. This method involved capacitive detection of cell structures and time-frequency domain analysis to calculate particle concentration. However, the study faced limitations in distinguishing particle types and struggled with false alarms in complex environments.
In our pursuit of a more reliable solution, we turned to the robust capabilities of YOLOv8, a model renowned for its superior object detection abilities. Our goal was to enhance fire detection performance by optimizing the architecture of YOLOv8 to better identify fire-specific visual cues. Through extensive training on a comprehensive fire and smoke image dataset, the modified YOLOv8 model demonstrated improved accuracy. This advanced model excels at detecting not only flames but also smoke, which is often an early indicator of larger fires, thereby providing an early warning that can prevent a small incident from escalating into a full-blown disaster.
To further enhance the interpretability of our YOLOv8 model, we utilized EigenCAM, a technique within explainable AI that generates class activation maps. EigenCAM allows us to visualize the regions of the input images that the model focuses on to make predictions [18]. By highlighting these areas, we gain insights into which features the model considers critical for detecting fire and smoke. This transparency is essential for building trust in AI-based systems, particularly in crucial applications like fire detection. With these technologies in place, the issue of false alarms will be effectively reduced. Our approach not only aims to reduce false positives but also ensures that fire detection remains accurate and reliable across a wide range of environments and scenarios. The development of this cutting-edge deep learning solution marks a significant leap forward in the field of fire detection. By capitalizing on the strengths of YOLOv8 and enhancing its capabilities with EigenCAM, we have created a system that is both highly accurate and interpretable. This innovative approach addresses the shortcomings of previous models and provides a robust tool for early fire detection, which is crucial for minimizing damage and safeguarding lives and property globally. This breakthrough paves the way for ultra-reliable fire monitoring in homes, industries, and beyond. The modified YOLOv8 fire detection technique is ushering in a new era of fire safety innovations. It is crucial to take a stand against fire devastation. Together, armed with smarter AI, we can make a real difference, saving lives and property while forging a safer future. The main contributions of this research are as follows:
- In this work, we modified the YOLOv8 architecture for the development of an efficient automated fire and smoke detection system, achieving impressive accuracy in fire and smoke detection. Moreover, a comprehensive fire dataset was created, consisting of 4301 labeled images. Each image was carefully annotated, providing a valuable resource for improving the performance of models in identifying fire and smoke in various conditions.
- We also utilized EigenCAM to explain and visualize the results of the proposed model, highlighting the image areas that most influenced the model’s decisions. This approach enhances the understanding of the model’s behavior, thereby improving the interpretability and transparency of its predictions.
The rest of this research paper is organized as follows: Firstly, Section 2 discusses the background and related work in this field. Additionally, we present the methodology and a detailed description of the dataset in Section 3. Experimental results analysis of these methods are discussed in Section 4. In Section 5, we introduce the explainable AI to interpret our proposed model and its results. Finally, Section 6 and Section 7 include the discussion, summary, and feasible future directions for this research.
2. Related Works
Deep learning-based methods for fire and smoke detection in smart cities have been receiving increasing attention recently. Hybrid techniques that incorporate multiple deep-learning algorithms for fire detection have been proposed in several studies.
Ahn et al. [19] proposed a computer vision-based fire detection model using CCTV footage and leveraged the YOLO algorithm for early fire identification in buildings. Their model achieved high performance with a recall of 97%, precision of 91%, and mAP@0.5 of 96%. The system detects fires within 1 s, significantly faster than traditional fire detectors, which showed delays of up to 307 s. Although the results are promising, the study suggests the need for future improvements by incorporating additional features to enhance model robustness and accuracy.
Researchers have explored several approaches in the realm of vision-based fire and smoke detection. Pincott et al. [13] incorporated Faster R-CNN InceptionV2 and SSD MobileNetV2, achieving 95% and 62% accuracy for fire detection, respectively, and 88% and 77% for smoke detection using both models. However, these techniques are currently only applied in indoor settings, and further research is needed to assess their performance in outdoor environments. Similarly, Avazov et al. [4] proposed a fire detection model using the Improved YOLOv4 Network, designed for smart city environments, achieving an accuracy of up to 98.8%. Despite its efficiency, this method relies on specific hardware like digital cameras and a Banana Pi M3 board, limiting its applicability in complex areas such as forests or industrial zones. Additionally, it faces challenges in identifying hidden fires. Abdusalomov et al. [2] used the YOLOv3 algorithm for real-time fire detection with surveillance cameras, achieving 98.9% detection accuracy, but the technique struggles with false positives, particularly confusing electric lamps with night fires. Saponara et al. [1] proposed a real-time fire and smoke detection system based on YOLOv2, optimized for low-cost devices like the Jetson Nano, achieving high detection accuracy of up to 96.82%. However, its performance is constrained by a small training dataset and challenges with false positives under conditions like clouds and sunlight.
Yunsov et al. [20] presented a YOLOv8 model enhanced with transfer learning for detecting large forest fires and a TranSDet model for smaller fires, also utilizing transfer learning. Their approach achieved a total accuracy rate of 97%, but challenges remain in detecting fires when only smoke is present and in avoiding misidentifications of non-fire elements like the sun and electric lights. In another study, Pu Li and Wangda Zhao [21] compared multiple CNN-based models, with YOLOv3 emerging as the most accurate and fastest. Despite this, they highlighted issues in recognizing small fire regions and the computational intensity of some methodologies.
Many deep learning techniques have been proposed to enhance fire detection accuracy and reduce false alarms. Muhammad et al. [22] utilized two datasets and achieved an overall accuracy of 98.5% based on a CNN, emphasizing the need for better balance between accurate predictions and false alarms. Khan Muhammad [14] employed a GoogleNet architecture, which proved cost-effective with nearly 94.43% accuracy for classification, though it performed poorly in later-stage smoke–fire detection and requires further refinement. Kim and Lee [23] combined region-based CNN with LSTM to extract temporal features of fire. The model improved detection accuracy but had false-positive issues in cases involving clouds and sunsets. Yakun Xia et al. [24] applied dynamic motion-flicker-based features with deep static features, surpassing competitors in complex video data but still facing robustness challenges.
Valikhujaev et al. [25] improved fire and smoke detection using CNNs with dilated convolutions for better feature extraction and reduced false alarms, but the model struggled when smoke pixel values resembled the background, particularly in cloudy weather. Sheng et al. [26] combined super-pixel segmentation with convolutional neural networks to detect smoke in complex environments, enhancing accuracy but increasing false positives due to high sensitivity. Lin and Zhang [27] focused on early smoke detection with a joint framework combining Faster R-CNN for localization and 3D CNN for recognition, showing impressive results but suffering from data scarcity and overfitting risks.
Other advancements in feature extraction include Pundir et al. [28], who presented a dual deep learning framework combining image-based and motion-based features, achieving high accuracy but facing difficulties distinguishing smoke from similar phenomena like fog and sandstorms. Zhao et al. [29] introduced target awareness and depthwise separability to enhance detection speed and accuracy, though their method showed decreased performance under varying conditions due to potential information loss. Devenancio et al. [15] optimized CNN-based fire detection for resource-constrained devices using filter pruning techniques, which reduced computational and memory costs while maintaining performance but struggled with false alarms and environmental generalization.
Naqqash Dilshad et al. [30] developed E-FireNet, a deep learning framework for real-time fire detection in complex environments, adapting the VGG16 network with modifications to improve detail extraction. E-FireNet achieved an accuracy of 98%, precision of 100%, recall of 99%, and an F1-score of 99%, demonstrating superior performance in accuracy, model size, and execution speed, though the authors noted the need for a more diverse dataset and further exploration of vision transformers. Table 1 summarizes the key methods and findings of these studies, highlighting gaps and areas for further research in fire and smoke detection.

Table 1.
Summary of related works on fire detection.
3. Methodology
Fires can cause significant harm and substantial damage to both people and their properties. An efficient fire detection system is crucial to reducing these dangers by facilitating quicker response times. To create an advanced computer vision model for this purpose, we undertook a series of systematic steps.
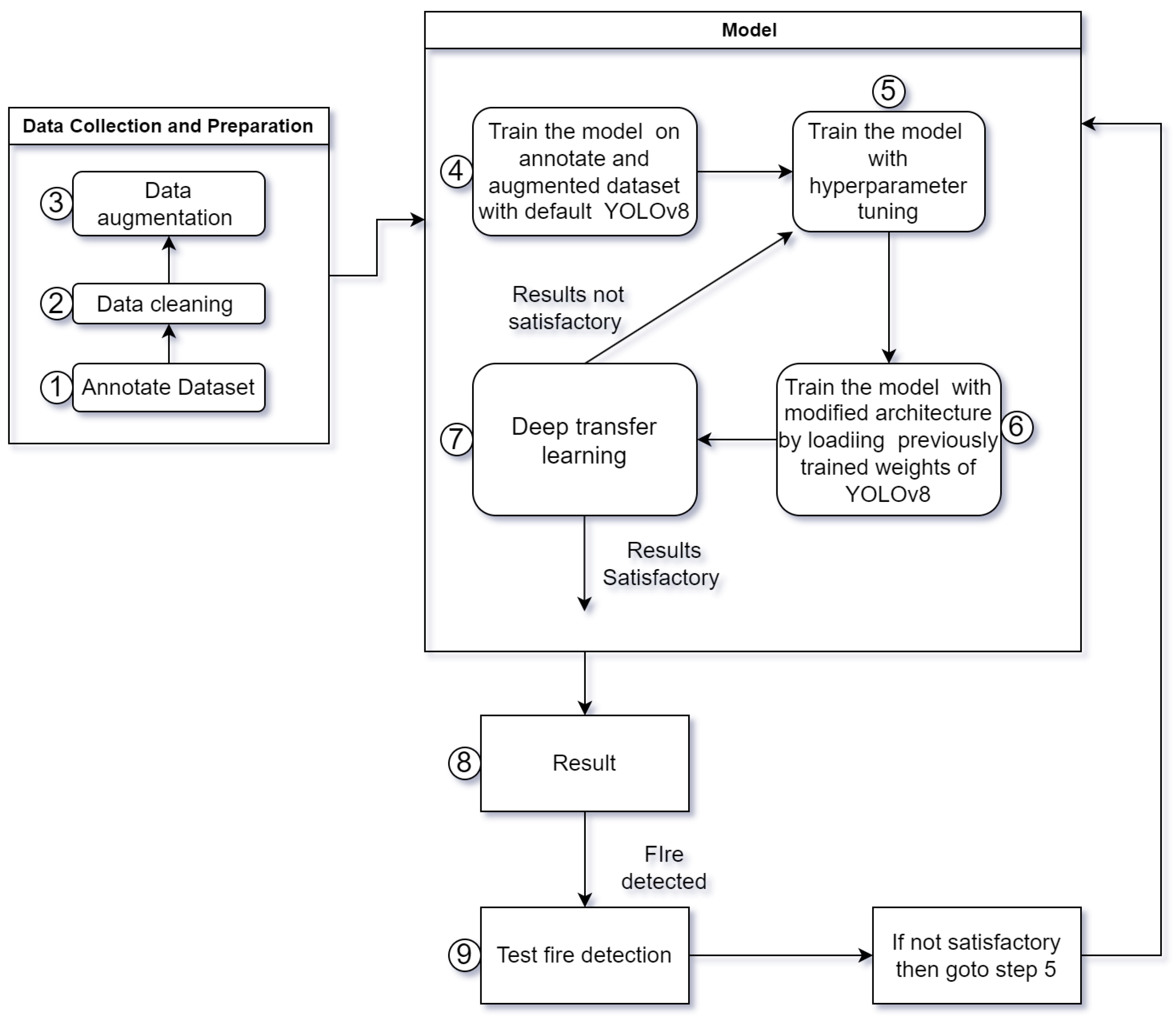
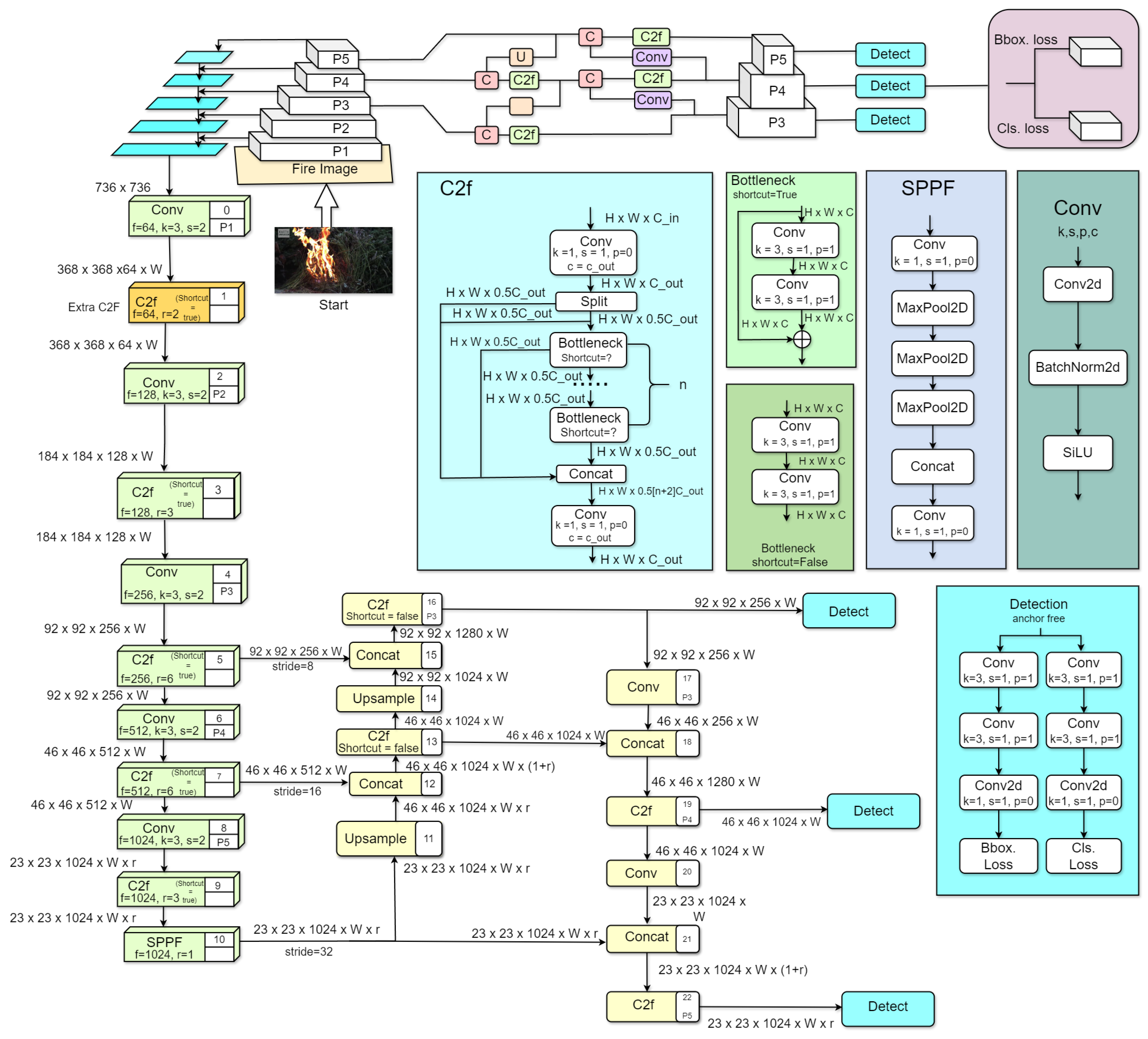
Initially, we gathered and labeled a robust dataset, enhancing it further through data augmentation techniques to ensure its comprehensiveness. Our initial training phase employs the standard YOLOv8 [31] architecture, serving as our baseline. We then delve into hyperparameter tuning, exploring a variety of parameters to identify the optimal set for peak performance. This involves multiple training iterations, each time tweaking the hyperparameters to achieve the best results. With the optimal hyperparameters identified, we retrain our model using a modified version of the YOLOv8 architecture, incorporating the previously trained weights from the initial model. This step is crucial for leveraging the learned features from the earlier training phase, a process known as deep transfer learning. Further refinement is achieved through additional training phases, continuously using the improved weights and our adjusted architecture. To ensure transparency in the model’s decision-making process, we apply EigenCAM, enabling us to visualize and interpret how the model makes its predictions. This detailed methodology, which is visually summarized in Figure 1, outlines our approach to developing an effective fire detection system. The algorithm for the fire detection workflow is shown in Algorithm 1.
| Algorithm 1 Fire Detection Model Workflow |
|
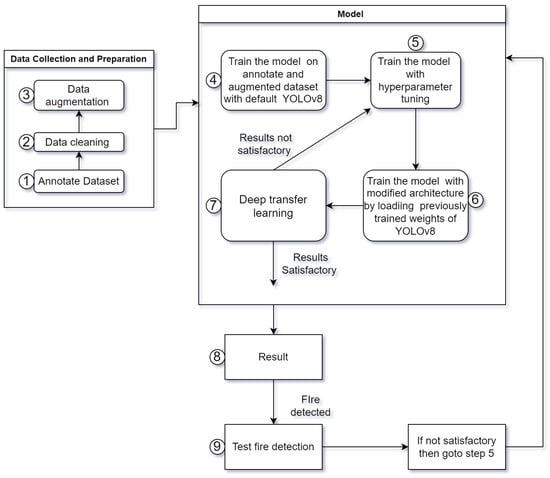
Figure 1.
Detailed workflow of the proposed fire detection model development using YOLOv8.
3.1. Dataset Description and Preprocessing
The initial dataset we collected consists of 4301 labeled fire and smoke images. In 4301 images, 3363 images are outdoor and 938 images are indoor images. To ensure diversity, we collected a wide range of images, including fire on cars, buses, forests, large and small trees, grass, and even leaves. Additionally, we gathered images of fire on large houses, small houses, buildings, and warehouses, as well as fire on waste, paper, clothes, chairs, sofas, tables, stoves, wires, and even rubber balls. Each image has multiple fire and smoke labels. To draw the bounding boxes with the names “fire” and “smoke”, we used the CVAT tool. Subsequently, the dataset was randomly partitioned into two separate sets, one designated for training purposes (80%) and the other allocated for validation (20%). Figure 2 includes several fire and smoke images that are clearly annotated, providing precise labels that highlight the specific areas associated with fire and smoke.

Figure 2.
Examples of labeled fire and smoke images from the dataset.
Initially, we obtained a collection of 4301 photos depicting both indoor and outdoor scenes. After that, we replicated and pasted 1362 more random indoor and outdoor photographs to the dataset, bringing the total to 5663. Following that, we separated the data into 4122 training and 1541 testing image sets. Most of the images in the dataset had more than one label of fire or smoke. The instances of fire and smoke were not totally the same, but the number of instances for both classes was very close. This huge amount of data was critical for showing a significant improvement in our model since it offers a reliable indication of how well the model will perform on larger datasets. We expanded the dataset to encompass a broader range of scenarios with various conditions for types of fire and smoke. As a result, the model was exposed to a wider range of circumstances during training, allowing it to generalize more effectively to completely new data. This suggests that the model improved its ability to recognize fires and smoke in scenarios other than the training images. This strategy was also effective at reducing overfitting. Overfitting happens when a model memorizes specific patterns in training data instead of generalizing to new situations. To circumvent this, we expanded the dataset’s complexity by including more photos rather than depending on a restricted subset of data. The larger dataset allowed the model to generalize across a broader range of circumstances, resulting in less overfitting and a more suitable model for high-dimensional data.
Furthermore, the larger dataset improved the model’s generalization capacity by giving it a broader range of real-world instances for each class. With a wider and more diversified dataset, the model was better able to handle unexpected circumstances outside of the original parameter space. As a result, the high accuracy values we found are consistent with this approach, illustrating how well the model adjusts to various conditions.
3.2. Model Architecture and Modifications
Our suggested method provides a significant improvement to the YOLOv8 design by carefully adding an extra context-to-flow (C2F) layer to the backbone network. The goal of this change is to enhance the model’s ability to capture contextual information about fire, refine features, and improve fire detection accuracy [32]. Figure 3 shows the overall architecture of our proposed model. Here, we present an outline of our suggested method. It is based on the YOLOv8 model, which was chosen due to its superior accuracy and efficiency compared to previous versions of the YOLO model. The C2F module was introduced to provide the model with enhanced capabilities to capture both contextual and flow information crucial for accurate fire detection [32]. We added an extra C2F module after the first conventional layer, which facilitates the model in gathering both environmental and flow data necessary for accurate fire detection, as shown in Figure 3. In the original YOLOv8 backbone, the first two convolutional layers were able to extract simple low-level features like edges, textures, and gradients. The context-to-flow (C2F) layer was missing, which means the model likely did not have a lot of capacity to capture and propagate contextual information early on, which could inhibit its ability to learn complex spatial relationships in data. By inserting a C2F layer between two convolutional layers, how to capture the complex cross-scale features, compounds, and spatial dependencies at the beginning of the network was solved. It resulted in a better distribution of features, which made the network more capable of distinguishing between useful and non-useful patterns, resulting in significant enhancements in accuracy, robustness, and generalization. The C2F layer increases feature extraction ability and guarantees that more context-aware representations are obtained earlier in the network, enabling it to achieve good performance on tasks such as fire detection.
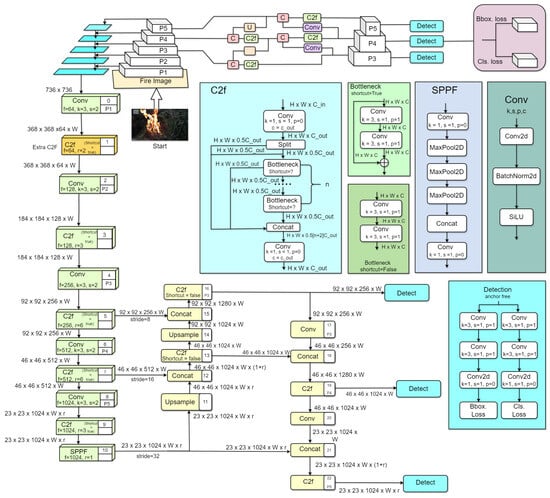
Figure 3.
Overall architecture of the proposed model, highlighting the addition of the C2F module.
3.3. Changes to the YOLOv8 Backbone
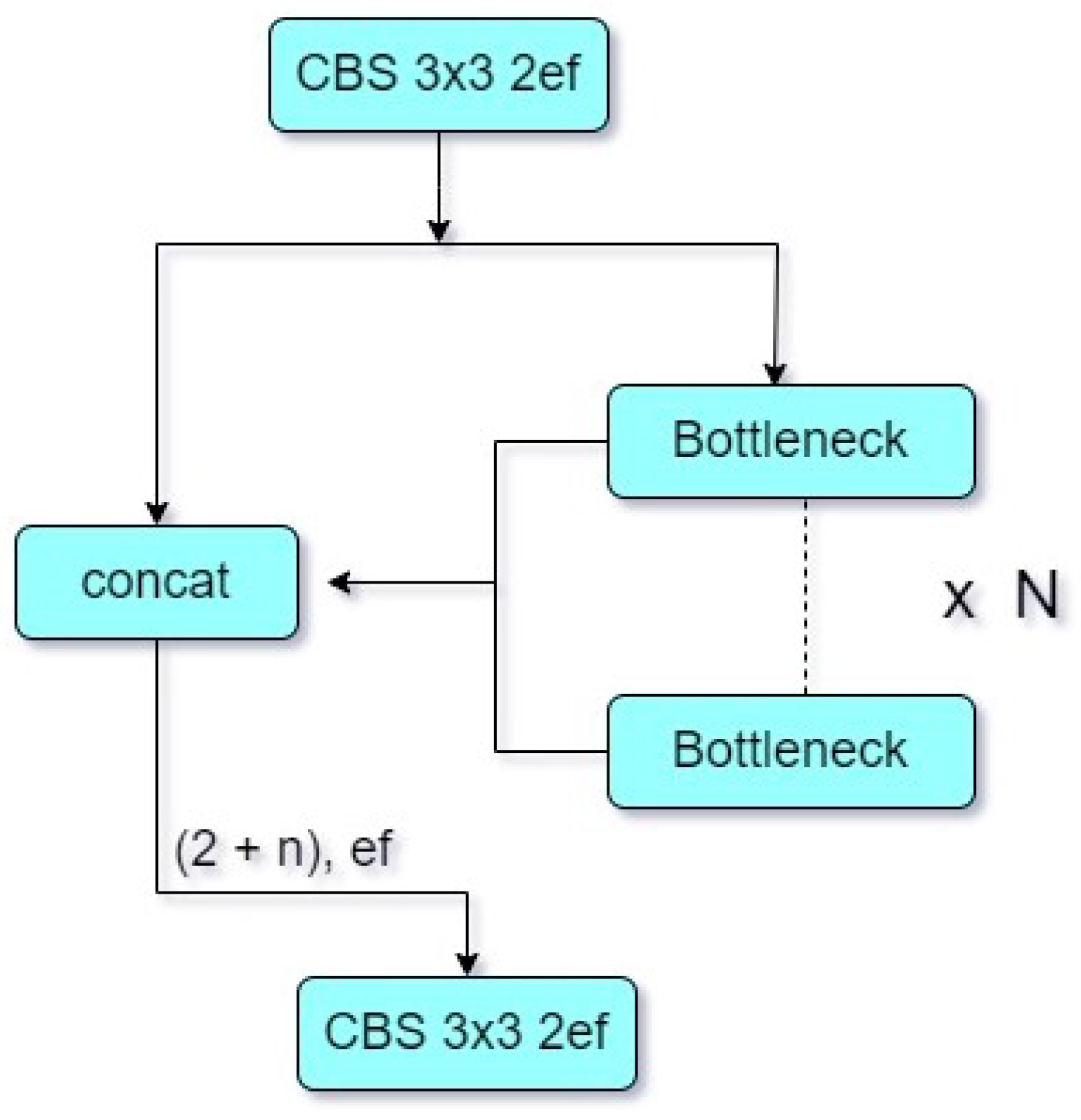
The context-to-flow (C2F) module for the deep learning architecture, as shown in Figure 4, is composed of two parallel branches: the context and flow branch. More specifically, the context branch captures contextual information from the input data and performs convolutions on it [33]. Therefore, we add a C2F layer in the backbone after the first convolutional layer to begin merging contextual information immediately. This layer, C2F, is presented in Figure 4 and serves as a link between feature extraction and the later stages. It locates the useful context in features where the model can make sense of what is happening around it and extract relevant features. The flow branch aims to capture the flow of knowledge based on data. Spatiotemporal changes in the input are analyzed using convolutional layers [33]. This latter branch helps the model capture the dynamics of the data. Those common representations are then concatenated across the branches into robust feature representations of the input. The model fit with context and flow features increased its capabilities to understand more advanced patterns, which in turn helps the model predict accurately. While a higher computational cost came from this extra C2F layer, the improvements in feature extraction and model accuracy make the trade-off worthwhile. The augmented model does better than the base YOLOv8 in working with more intricate, pattern-full information and fluid features present in complex datasets by allowing both functional and flow cues to be integrated into the network sooner. This way, the increased computational load also directly leads to a model that is more novel and able to perform better than older alternatives when it comes to harder real-world detection tasks such as fire or smoke.
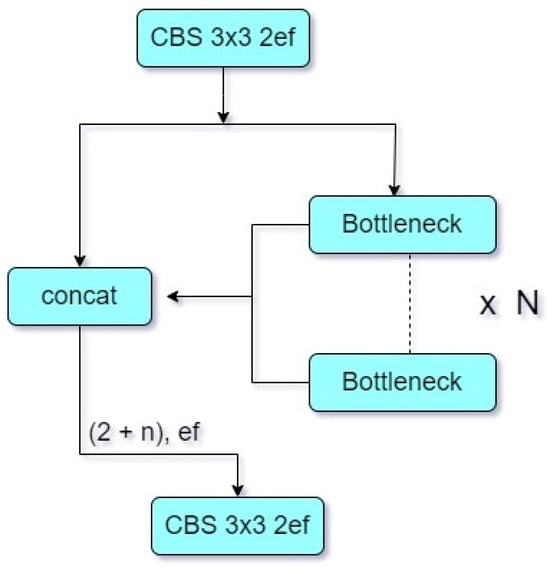
Figure 4.
The structure of the C2F module, showing the context and flow branches.
3.4. The Training and Success Measure Process
The training process is separated into several steps to achieve better output. Initially, the default YOLOv8 framework is used to train a model with a variety of hyperparameters and activation functions, such as LeakyReLU, ReLU, Sigmoid, Tanh, Softmax, and Mish. After that, training is performed on the modified architecture by loading the default YOLOv8 with the best-performing hyperparameters, as shown in Table 2. In particular, the model with the LeakyReLU activation function and the given hyperparameters performs exceptionally well. Moreover, we retrain the model using the same hyperparameters on our modified architecture by loading the previously trained weights. This method of training is essentially a form of deep transfer learning, where the knowledge obtained from the previous model is utilized by the next model to enhance its performance.
Table 2.
Hyperparameters used in the training.
3.5. Improvements after Using C2f Layer
In the C2F layer, contextual information is added early on, allowing the model to capture global characteristics from the very first layers of the backbone. This additional background information helps the network understand the connections between different parts of the input image. By refining features through the C2F layer, the network gains improved discriminatory power. The C2F layer adapts to focus on important traits while ignoring noise and irrelevant data. By combining features from the first convolutional layer with those from subsequent layers, the C2F layer facilitates multi-scale fusion. This fusion enhances the model’s ability to handle objects of varying sizes and scales in the input image, thereby improving detection accuracy. Adding the C2F layer aids in establishing spatial ordering in the feature maps, which is crucial for accurate object detection and recognition. It enables the network to better understand the surrounding context more quickly during training by providing detailed background information earlier on. The YOLOv8 architecture is improved by incorporating an additional context-to-flow (C2F) layer. This enhancement resulted in a more comprehensive model, now comprising 387 layers, 81,874,710 parameters, and 81,874,694 gradients, compared to the default YOLOv8 model, which includes 365 layers, 43,631,382 parameters, and 43,631,366 gradients. The computational intensity of the model significantly increased from 165.4 GFLOPs to 373.1 GFLOPs. The change in architecture demonstrates how the additional C2F layer improved the network’s feature representation, making it more effective in capturing contextual and dynamic information. As a result, the model’s overall accuracy significantly improved. As previously mentioned, our modified model consists of 387 layers, 81,874,710 parameters, and 81,874,694 gradients. This increase in parameters and gradients enables the model to learn complex patterns and nuances in the data, highlighting the potential of this modified YOLOv8 architecture in advancing object detection performance. Our proposed model demonstrates a substantial improvement in accuracy for object detection tasks. The C2F layer plays a key role in enhancing the detection capabilities of the YOLOv8 architecture by gathering more contextual and flow information from the input images. This proposed approach appears to be a promising direction for further advancement in deep learning-based object detection research.
4. Result Analysis
This section provides an in-depth analysis of the overall performance of the proposed model, evaluating its effectiveness across various metrics, including accuracy, precision, recall, and computational efficiency.
4.1. Evaluation Metrics
The average value between recall percentages and precision percentages is known as the F1-score. This metric takes into account both false positives and false negatives, making it a comprehensive measure of a model’s performance. While accuracy is a widely used metric, it can be misleading when the costs of false positives and false negatives are significantly different. In such cases, it is better to consider both recall and precision alongside accuracy.
Precision is the proportion of correctly predicted positive observations to the total predicted positives. Recall, on the other hand, is the proportion of correctly predicted positive observations to all actual positives. The recall can be calculated using Equation (1) [34]:
In these equations, TP stands for “true positive”, FP stands for “false positive”, TN stands for “true negative”, and FN stands for “false negative”. The F1-score, which is a harmonic mean of precision and recall, can be calculated using Equation (3) [34]:
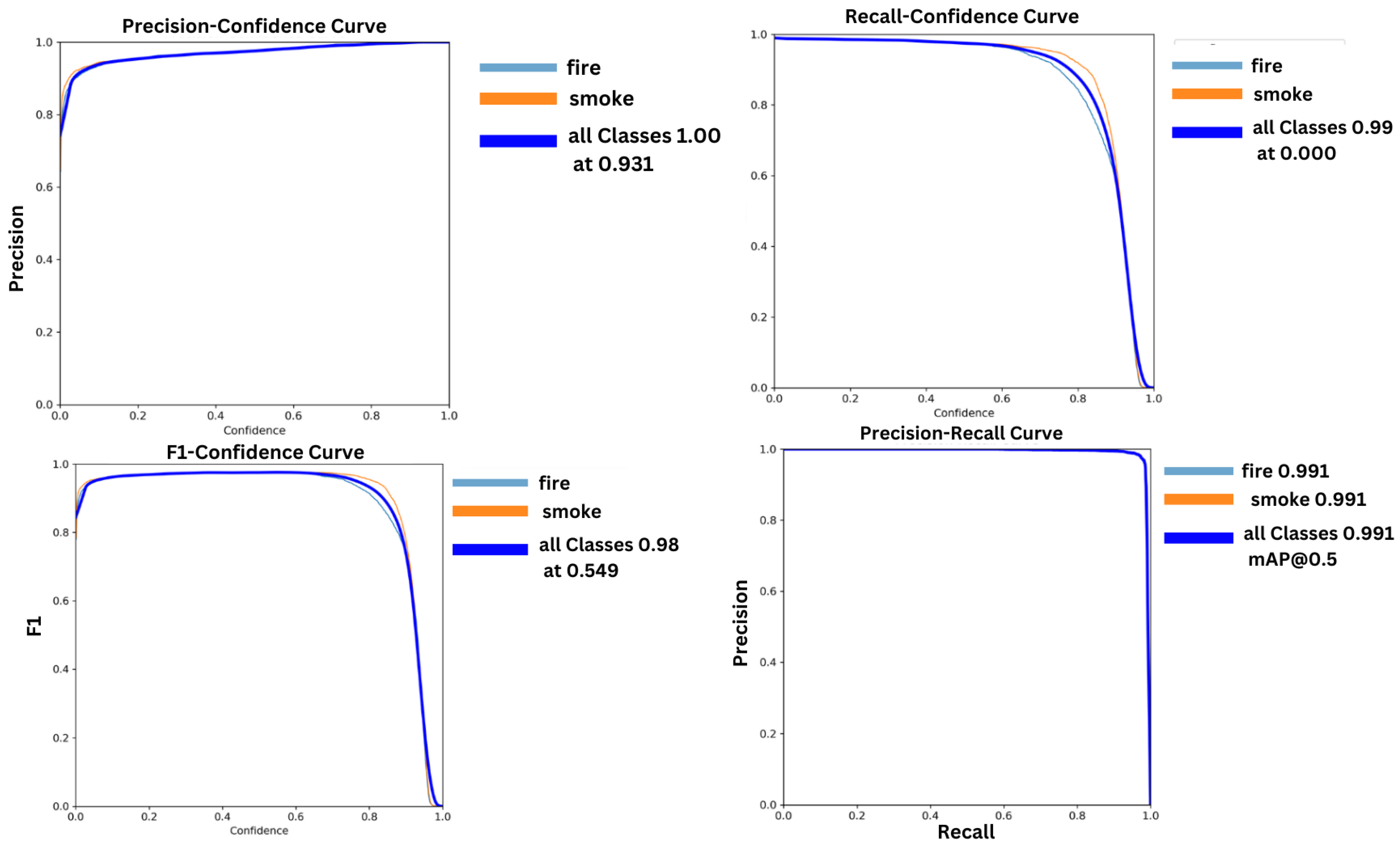
The precision confidence curve, recall confidence curve, F1-score confidence curve, and mAP@50 confidence curve are shown in Figure 5.
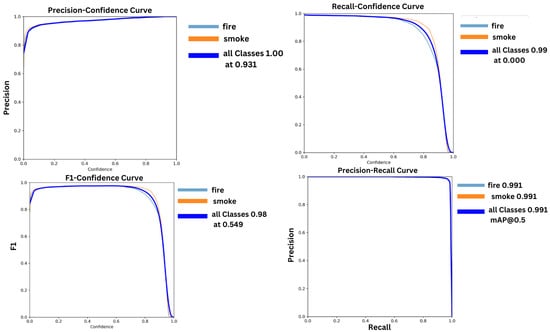
Figure 5.
The evacuation matrix precision, recall, F1-score, and mAP@50 of the proposed model.
4.2. Results of the Proposed Model
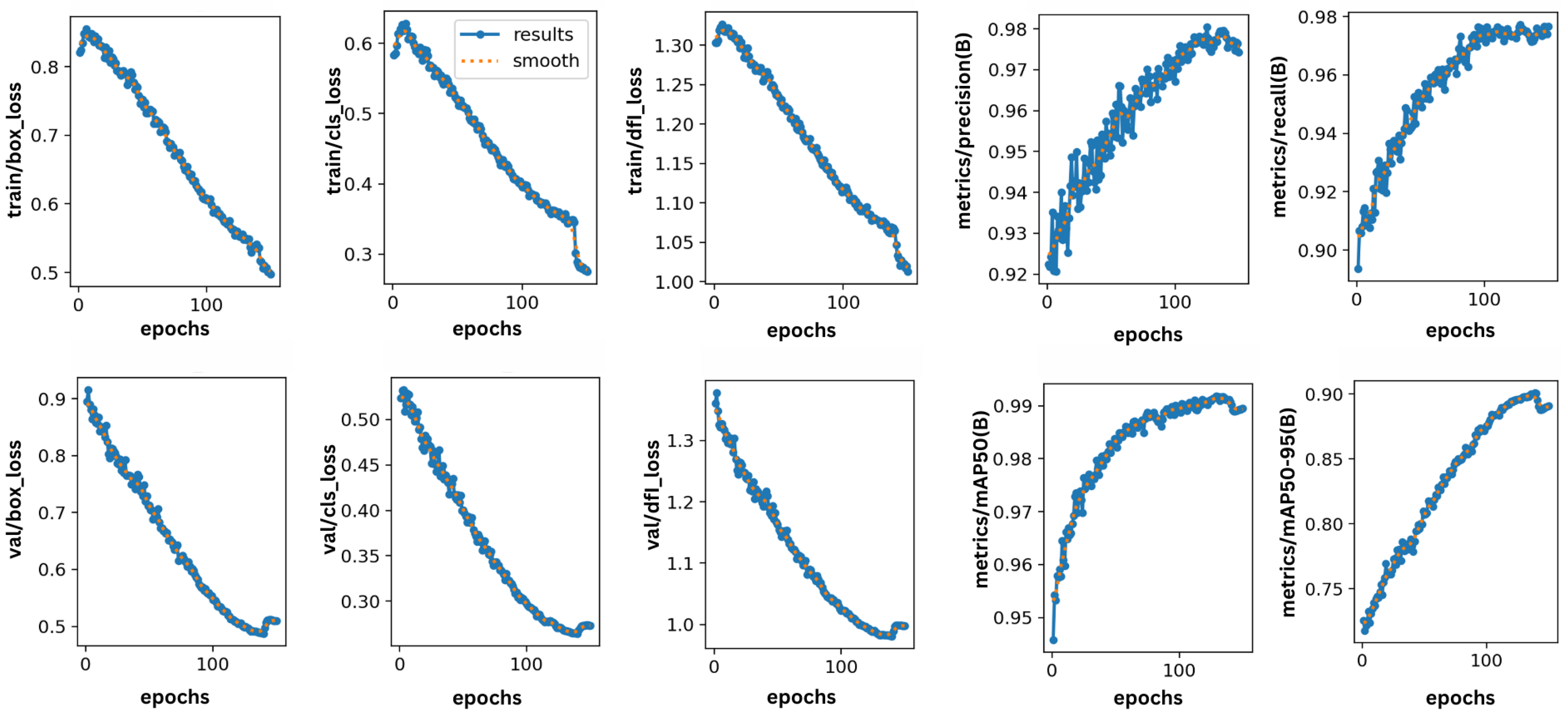
Our findings reveal that the proposed model accurately detects 98% of fires and 97.8% of smoke. The recall rate for fire is 97.1%, and the recall rate for smoke is 97.4%. The mean average precision (mAP) for both classes was 99.1%. The loss, precision, and recall metrics, which reflect the overall performance of the proposed model, are illustrated in Figure 6.
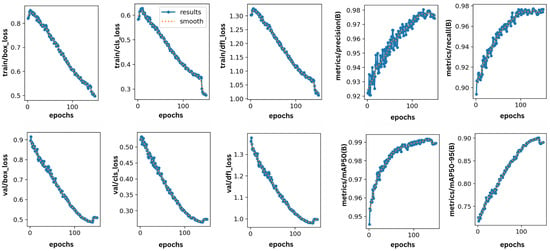
Figure 6.
Training and validation performance metrics for proposed fire detection model.
4.3. Comparing at YOLOv7 and YOLOv8
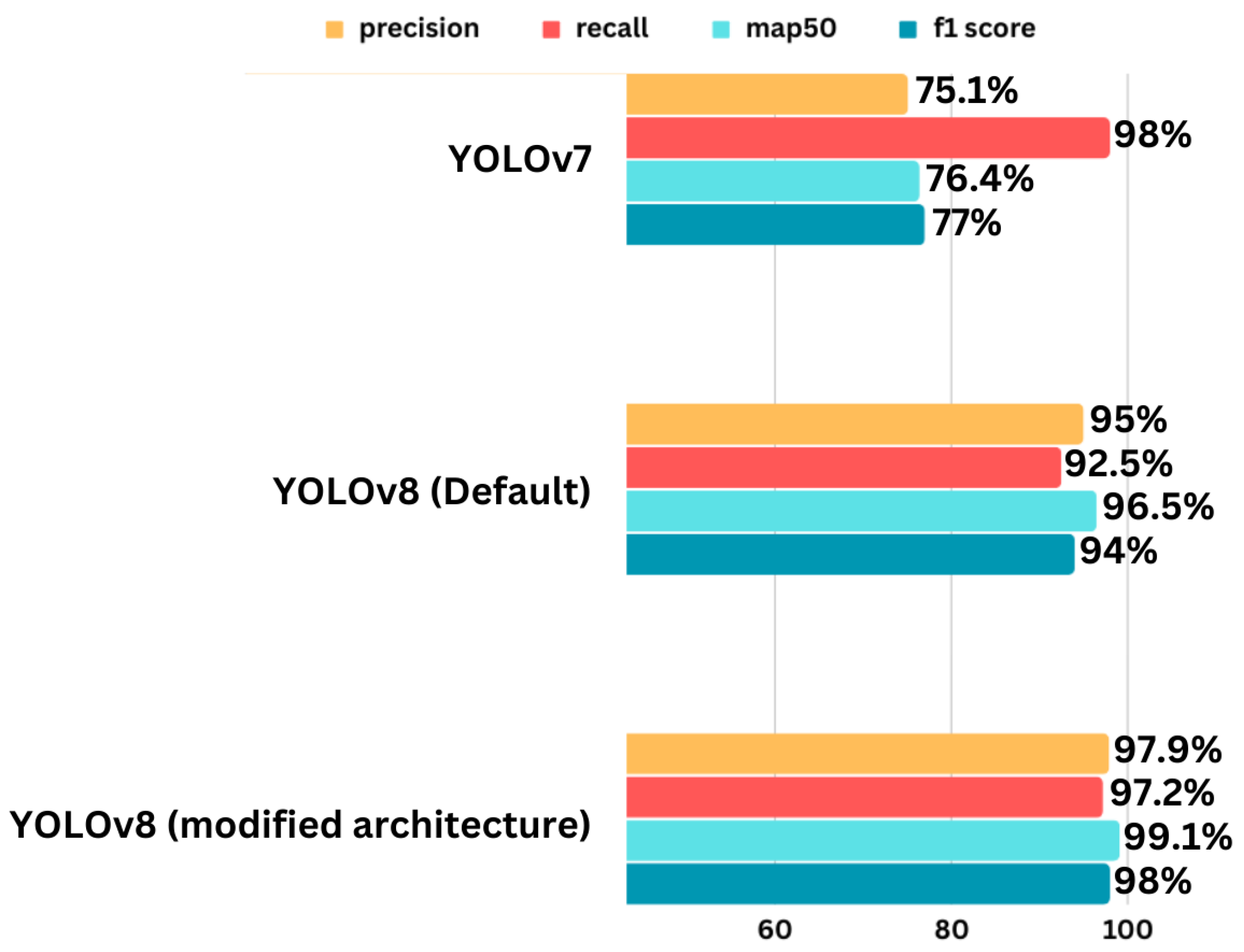
We compare our modified YOLOv8 model against the standard YOLOv7 and YOLOv8 models to evaluate its performance improvements. While comparing precision, recall, mAP@50, and F1-scores between YOLOv7, default YOLOv8, and our modified YOLOv8 model, we observe significant improvements. The bar chart in Figure 7 and values in Table 3 visually demonstrate these improvements, highlighting that our modified YOLOv8 outperforms across key metrics. In comparison with YOLOv7, our proposed model achieved 22.8% more precision rate, 22.7% more mAP@50 rate, and 21% more F1-score. Also, in comparison to the YOLOv8 default model, our proposed model achieved 2.9% more precision rate, 4.7% more recall rate, and 4% more F1-score, as shown in Figure 7 and Table 3.
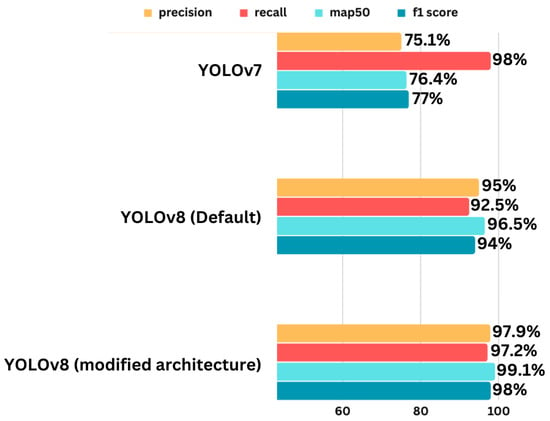
Figure 7.
Comparison of YOLOv7, default YOLOv8, and modified YOLOv8.
Table 3.
Performance comparison of YOLOv7, default YOLOv8, and modified YOLOv8.
4.4. Impact of Hyperparameter Tuning on YOLOv8
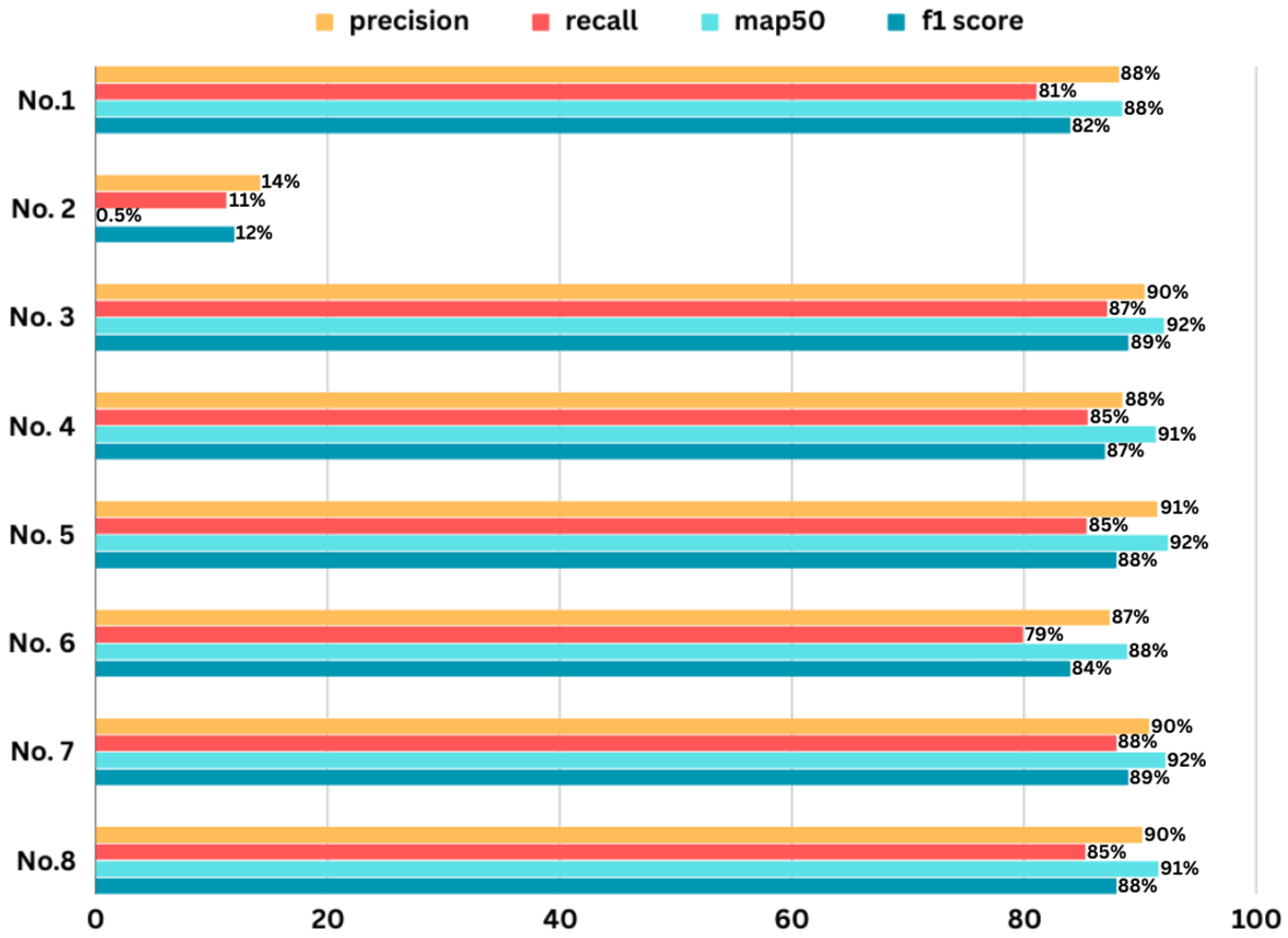
In this analysis, we delve into the details of hyperparameter tuning. We provide a comprehensive table that outlines the outcomes obtained through different configurations of parameters, such as batch size, image size, learning rate (set to 0.001 for all combinations), momentum, activation function, layer count, optimizer choice, and epochs, which are all integral components of this process. Different F1-scores are obtained for various parameter configurations, as shown in Table 4. The most impactful parameters used in hyperparameter tuning are highlighted in Table 4. The YOLOv8 large performed better in comparison to the YOLOv8 nano in every case except in the case of the Softmax activation function. In most cases, where we used AdamW or Adamax as optimizers, YOLOv8l with the SGD optimizer achieved the highest F1-score. However, this highest F1-score was achieved from a model that was using the default YOLOv8 model with different hyperparameters, and the F1-score of the model is 9% less than our proposed model’s F1-score. This comparison shows that our model outperforms the default model. The results of this tuning process are displayed in Figure 8. The impact of hyperparameter tuning on the overall performance of the model is illustrated in the bar chart, which provides a comparison of precision, recall, mAP@50, and F1-scores.
Table 4.
Different parameters used in hyperparameter tuning. In this table, YOLOv8l and YOLOv8n stand for YOLOv8 large and YOLOv8 nano.
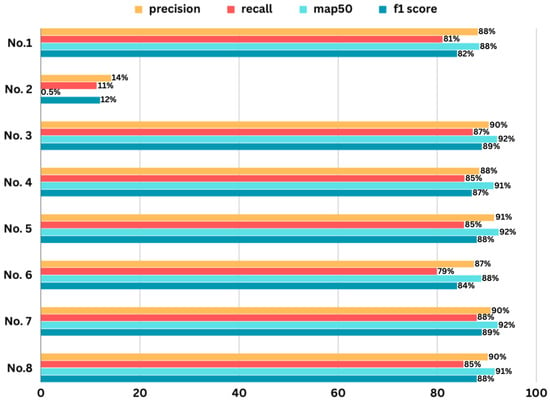
Figure 8.
Performance charts of the precision, recall, map50, and F1-scores for the combinations shown in Table 3.
4.5. Activation Function
Activation functions are mathematical functions that act as gateways for input values. For an artificial neural network to perform complex calculations, it requires more than just a linear representation. Activation functions introduce non-linearity to the network, enabling it to handle complex tasks. Without activation functions, neural networks would be reduced to simple linear regression models [35].
Among all the tested combinations of hyperparameters, the combination used in Model No. 1 in Figure 6 is chosen to train our modified model. This decision was influenced by the behavior of different activation functions. The Tanh function, for instance, performs complex calculations but also has limitations. ReLU neurons can be forced into inactive states, where they remain unresponsive to almost all inputs [35]. When in an unresponsive state, no gradients propagate backward through the neuron, rendering it perpetually inactive and entirely unusable [35]. In some cases, a significant portion of neurons within a network may become trapped in these unresponsive states.
Mish, the default activation function of the YOLOv8 model, also performs complex calculations. However, LeakyReLU addresses the problem of unusable states in ReLU neurons and is not as computationally complex as Tanh or Mish. This balance between simplicity and effectiveness is why we selected the LeakyReLU activation function for our proposed model.
4.6. Performance in a Range of Fire Situations
To start our evaluation, we presented some images from the inferencing data in Figure 9. These images illustrate both small and large fires as well as smoke. The model demonstrates a strong ability to detect and classify these different fire-related traits, indicating that it can effectively handle a wide range of fire situations.

Figure 9.
Sample images of inferencing.
5. Explainability with EigenCAM
The YOLOv8 is a CNN-based framework, and the interpretability of convolutional neural networks (CNNs) remains a critical area of research, particularly for applications in safety-critical domains such as fire and smoke detection. To provide visual explanations of our modified YOLOv8 model’s predictions, we utilized EigenCAM, a method for generating class activation maps that highlight important regions in the input image contributing to the model’s decision. In any CNN classifier, the learning process can be considered a mapping function, where a transformation matrix captures salient features from images using convolutional layers [18]. Optimizers adjust the weights of these convolutional filters to learn important features, as well as the weights of fully connected layers to determine the non-linear decision boundary [18]. The hierarchical representation mapped onto the last convolutional layer provides a basis for visual explanations of CNN predictions.
5.1. Eigen Class Activation Maps (EigenCAM)
The exceptional performance of CNNs on various computer vision tasks is attributed to their ability to extract and preserve relevant features while discarding irrelevant ones. EigenCAM leverages this capability by identifying features that maintain their relevance through all local linear transformations and remain aligned with the principal components of the learned representation. Given an input image I of size , represented as , and the combined weight matrix W of the first k layers with size , the class activation output O is obtained by projecting the input image onto the last convolutional layer [18]:
To compute the principal components of , we factorize using singular value decomposition (SVD) [18]:
Here, U is an orthogonal encoding matrix with columns as the left singular vectors, is a diagonal matrix of size with singular values along the diagonal, and V is an orthogonal matrix with columns as the right singular vectors. The class activation map for EigenCAM, , is derived by projecting O onto the first eigenvector [18]:
where is the first eigenvector in the V matrix.
5.2. Implementation and Results of EigenCAM
In our study, we trained a modified YOLOv8 model on a custom dataset of fire and smoke images. To explain the model’s predictions, we applied EigenCAM to generate heatmaps for the test images. The heatmap, shown in Figure 10, visually highlights regions of the image that the model focused on when making predictions. For instance, when the model detects fire in an image, the heatmap typically shows red regions corresponding to the areas with flames or smoke, indicating that the model correctly identifies these critical features. By overlaying the heatmaps on the original images, we can visually verify that the model’s focus aligns with the expected regions, thereby providing an interpretable explanation of its decision-making process.

Figure 10.
Heatmap generated using EigenCAM, highlighting regions of the image that the model focused on for prediction.
The use of EigenCAM in our research not only enhances the interpretability of our modified YOLOv8 model but also adds an additional layer of validation by confirming that the model’s attention is correctly placed on the relevant features in the input images. This explainability is crucial for trust and reliability in real-world applications, particularly in fire and smoke detection systems. In addition to the qualitative perspective on visual insights from EigenCAM heatmaps, we also provided a quantitative analysis where we utilized our modified YOLOv8 predictions as being interpretable. The pixel intensities of the heatmap were used to calculate several metrics, such as mean, median, and standard deviation. This allows for more quantitative measurements of the activation regions we see in this heatmap. The mean pixel intensity is 110.0977, which shows how much the model focuses while detecting burning-associated important areas. A median pixel intensity of 112.0 is close to the split in the distribution of pixels and tells us that half of the activations were concentrated around this value. The standard deviation was 38.9370, which tells us how spread out the activations are across the image. All the values for these quantitative metrics provide statistical evidence to back up some visual patterns that can be noticed in the heatmaps. Having a low standard deviation and a median close to the mean implies that the model consistently puts its attention on certain regions of high predictive relevance, strengthening heatmap reliability as interpretative for the proposed model decision-making process. EigenCAM is extremely effective when working with complex backdrops since it highlights the most significant aspects that the model concentrates on. This helps to distinguish things from cluttered backgrounds. EigenCAM provides visual explanations for each detected object in an image, making YOLOv8’s predictions more understandable [18]. It is also useful for error analysis because it helps identify the source of errors. It can identify whether the issue is with the model’s design or with the data annotations. EigenCAM also provides visual explanations by projecting learned features onto principle components, allowing us to see what the model focuses on during object detection. This helps us understand how YOLOv8 makes decisions. It is also robust since the explanations remain reliable even when the model produces classification errors [18]. EigenCAM can locate flaws by producing heatmaps indicating which attributes are most significant. This explains why YOLOv8 misclassified an object. Using EigenCAM in conjunction with YOLOv8 increases model interpretability and provides valuable insights for performance evaluation and debugging.
6. Discussion
The results demonstrate that using YOLOv8 improves accuracy, recall, mAP@50, and F1-scores, underscoring the significance of the architectural changes made in the most recent version. The enhanced YOLOv8 model exhibits exceptional object detection performance, particularly in recognizing fires, showcasing its proficiency in this domain. The hyperparameters were finely tuned through extensive effort, yielding insightful results. The detailed table and bar chart illustrate how different configurations impact performance metrics, providing both researchers and practitioners with a framework for optimizing model parameters, thereby enabling better customization of the model for specific use cases. Our data analysis indicates that YOLOv8 is more proficient at detecting fires compared to its predecessors. Additionally, the data obtained from hyperparameter adjustments highlight the importance of careful configuration in achieving superior results. Furthermore, EigenCAM validates that the model focuses on the most relevant features for identifying fire and smoke. Our research makes a significant contribution to the ongoing discourse on object detection in both academic and practical contexts.
7. Conclusions
In our research, we successfully optimized the YOLOv8 model to enhance its effectiveness in detecting fire and smoke. We trained the model using a custom dataset and employed EigenCAM, an explainable AI tool, to ensure that our model focuses on the most relevant features when identifying fire and smoke. This validation step is crucial, as it not only confirms the accuracy of our model but also builds trust in its decision-making process. While the model performs accurately most of the time, it may sometimes make mispredictions when the image is blurry. However, most of the model’s predictions remain accurate despite this limitation. We will try to overcome this limitation in our future studies. We will also try to apply the proposed technique to the other deep learning models. The findings of this study are pivotal for the future of autonomous fire detection technologies. These advancements have the potential to save lives and minimize property damage by enabling quicker and more reliable fire detection. By accurately identifying fire and smoke, these technologies can trigger faster emergency responses, thereby improving safety and reducing risks. Additionally, this research opens up new possibilities in artificial intelligence and computer vision. Our methodology and results provide valuable insights for other researchers tackling similar challenges, offering a foundation for further development. The combination of advanced machine learning models like YOLOv8 with explainability tools like EigenCAM can drive innovation, leading to the creation of smarter and more efficient safety systems.
Author Contributions
Conceptualization, M.W.H., S.S., J.N., R.R. and T.H.; Formal analysis, M.W.H., S.S. and J.N.; Funding acquisition, Z.R. and S.T.M.; Investigation, M.W.H., S.S. and J.N.; Methodology, M.W.H., S.S., J.N., T.H., R.R. and S.T.M.; Supervision, R.R. and T.H.; Validation, R.R., T.H., S.T.M. and Z.R.; Visualization, M.W.H., S.S. and J.N.; Writing—original draft, M.W.H., S.S. and J.N.; Writing—review and editing, M.W.H., S.T.M., T.H., R.R. and Z.R. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The data presented in this manuscript are available on request.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| Adam | Adaptive Moment Estimation |
| CCTV | Closed-Circuit Television |
| C2F | Context-To-Flow |
| CNN | Convolutional Neural Networks |
| CVAT | Computer Vision Annotation Tool |
| DBSCAN | Density-Based Spatial Clustering Of Applications With Noise |
| EigenCAM | Eigen Class Activation Maps |
| GFLOPS | Giga Floating-Point Operations Per Second |
| IR | Infrared |
| LeakyReLU | Leaky Rectified Linear Unit |
| LSTM | Long Short-Term Memory |
| mAP | Mean Average Precision |
| MQTT | Message Queuing Telemetry Transport |
| R-CNN | Region-Based Convolutional Neural Network |
| ReLU | Rectified Linear Unit |
| RNN | Recurrent Neural Network |
| SECSP | Spatially Enhanced Contextual Semantic Parsing |
| SGD | Stochastic Gradient Descent |
| SIoU | Scylla Intersection over Union |
| SLIC | Simple Linear Iterative Clustering |
| Softmax | Softargmax Or Normalized Exponential Function |
| SPPF | Spatial Pyramid Pooling Fast |
| SRoFs | Suspected Regions Of Fire |
| SSD | Single-Shot Detector |
| SVD | Singular Value Decomposition |
| Tanh | Hyperbolic Tangent |
| VGG | Visual Geometry Group |
| YOLO | You Only Look Once |
| BEMRF | Boundary Enhancement and MultiScale Refinement Fusion |
| GLCA | Global–Local Context Aware |
References
- Saponara, S.; Elhanashi, A.; Gagliardi, A. Real-time video fire/smoke detection based on CNN in antifire surveillance systems. J. Real-Time Image Process. 2021, 18, 889–900. [Google Scholar] [CrossRef]
- Abdusalomov, A.; Baratov, N.; Kutlimuratov, A.; Whangbo, T. An improvement of the fire detection and classification method using YOLOv3 for surveillance systems. Sensors 2021, 21, 6519. [Google Scholar] [CrossRef] [PubMed]
- Barmpoutis, P.; Stathaki, T.; Dimitropoulos, K.; Grammalidis, N. Early fire detection based on aerial 360-degree sensors, deep convolution neural networks and exploitation of fire dynamic textures. Remote Sens. 2020, 12, 3177. [Google Scholar] [CrossRef]
- Avazov, K.; Mukhiddinov, M.; Makhmudov, F.; Cho, Y. Fire detection method in smart city environments using a deep-learning-based approach. Electronics 2022, 11, 73. [Google Scholar] [CrossRef]
- Xu, W.; Feng, Z.; Wan, Q.; Xie, Y.; Feng, D.; Zhu, J.; Liu, Y. Building Height Extraction From High-Resolution Single-View Remote Sensing Images Using Shadow and Side Information. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 6514–6528. [Google Scholar] [CrossRef]
- Chen, H.; Feng, D.; Cao, S.; Xu, W.; Xie, Y.; Zhu, J.; Zhang, H. Slice-to-slice context transfer and uncertain region calibration network for shadow detection in remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2023, 203, 166–182. [Google Scholar] [CrossRef]
- Zhu, J.; Zhang, J.; Chen, H.; Xie, Y.; Gu, H.; Lian, H. A cross-view intelligent person search method based on multi-feature constraints. Int. J. Digit. Earth 2024, 17, 2346259. [Google Scholar] [CrossRef]
- Cao, S.; Feng, D.; Liu, S.; Xu, W.; Chen, H.; Xie, Y.; Zhang, H.; Pirasteh, S.; Zhu, J. BEMRF-Net: Boundary Enhancement and MultiScale Refinement Fusion for Building Extraction from Remote Sensing Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 16342–16358. [Google Scholar] [CrossRef]
- Xie, Y.; Zhan, N.; Zhu, J.; Xu, B.; Chen, H.; Mao, W.; Luo, X.; Hu, Y. Landslide extraction from aerial imagery considering context association characteristics. Int. J. Appl. Earth Obs. Geoinf. 2024, 131, 103950. [Google Scholar] [CrossRef]
- Ibraheem, M.K.I.; Mohamed, M.B.; Fakhfakh, A. Forest Defender Fusion System for Early Detection of Forest Fires. Computers 2024, 13, 36. [Google Scholar] [CrossRef]
- Liu, J.; Yin, J.; Yang, Z. Fire Detection and Flame-Centre Localisation Algorithm Based on Combination of Attention-Enhanced Ghost Mode and Mixed Convolution. Appl. Sci. 2024, 14, 989. [Google Scholar] [CrossRef]
- Wang, B.; Zhao, X.; Zhang, Y.; Song, Z.; Wang, Z. A capacitive particle-analyzing smoke detector for very early fire detection. Sensors 2024, 24, 1692. [Google Scholar] [CrossRef] [PubMed]
- Pincott, J.; Tien, P.; Wei, S.; Calautit, J. Indoor fire detection utilizing computer vision-based strategies. J. Build. Eng. 2023, 61, 105154. [Google Scholar] [CrossRef]
- Muhammad, K.; Ahmad, J.; Mehmood, I.; Rho, S.; Baik, S.W. Convolutional neural networks based fire detection in surveillance videos. IEEE Access 2018, 6, 18174–18183. [Google Scholar] [CrossRef]
- de Venancio, P.; Lisboa, A.; Barbosa, A. An automatic fire detection system based on deep convolutional neural networks for low-power, resource-constrained devices. Neural Comput. Appl. 2022, 34, 15349–15368. [Google Scholar] [CrossRef]
- Park, J.H.; Lee, S.; Yun, S.; Kim, H.; Kim, W.T. Dependable fire detection system with multifunctional artificial intelligence framework. Sensors 2019, 19, 2025. [Google Scholar] [CrossRef]
- Park, M.; Ko, B.C. Two-step real-time night-time fire detection in an urban environment using Static ELASTIC-YOLOv3 and Temporal Fire-Tube. Sensors 2020, 20, 2202. [Google Scholar] [CrossRef] [PubMed]
- Muhammad, M.B.; Yeasin, M. Eigen-CAM: Visual Explanations for Deep Convolutional Neural Networks. SN Comput. Sci. 2021, 2, 47. [Google Scholar] [CrossRef]
- Ahn, Y.; Choi, H.; Kim, B. Development of early fire detection model for buildings using computer vision-based CCTV. J. Build. Eng. 2023, 65, 105647. [Google Scholar] [CrossRef]
- Yunusov, N.; Islam, B.M.S.; Abdusalomov, A.; Kim, W. Robust Forest Fire Detection Method for Surveillance Systems Based on You Only Look Once Version 8 and Transfer Learning Approaches. Processes 2024, 12, 1039. [Google Scholar] [CrossRef]
- Li, P.; Zhao, W. Image fire detection algorithms based on convolutional neural networks. Case Stud. Therm. Eng. 2019, 19, 100625. [Google Scholar] [CrossRef]
- Muhammad, K.; Ahmad, J.; Baik, S. Early fire detection using convolutional neural networks during surveillance for effective disaster management. Neurocomputing 2019, 288, 30–42. [Google Scholar] [CrossRef]
- Kim, B.; Lee, J. A video-based fire detection using deep learning models. Appl. Sci. 2019, 9, 2862. [Google Scholar] [CrossRef]
- Xie, Y.; Zhu, J.; Cao, Y.; Zhang, Y.; Feng, D.; Zhang, Y.; Chen, M. Efficient video fire detection exploiting motion-flicker-based dynamic features and deep static features. IEEE Access 2020, 8, 81904–81917. [Google Scholar] [CrossRef]
- Valikhujaev, Y.; Abdusalomov, A.; Cho, Y. Automatic fire and smoke detection method for surveillance systems based on dilated CNNs. Atmosphere 2020, 11, 1241. [Google Scholar] [CrossRef]
- Sheng, D.; Deng, J.; Xiang, J. Automatic smoke detection based on SLIC-DBSCAN enhanced convolutional neural networks. Sensors 2020, 20, 5608. [Google Scholar] [CrossRef]
- Lin, G.; Zhang, Y.; Xu, G.; Zhang, Q. Smoke detection on video sequences using 3D convolutional neural networks. Fire Technol. 2019, 55, 1827–1847. [Google Scholar] [CrossRef]
- Pundir, A.; Raman, B. Dual deep learning model for image based smoke detection. Fire Technol. 2019, 55, 2419–2442. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhang, H.; Zhang, X.; Chen, X. Fire smoke detection based on target-awareness and depthwise convolutions. Multimed. Tools Appl. 2020, 80, 27407–27421. [Google Scholar] [CrossRef]
- Dilshad, N.; Khan, T.; Song, J. Efficient deep learning framework for fire detection in complex surveillance environment. Comput. Syst. Sci. Eng. 2023, 46, 749–764. [Google Scholar] [CrossRef]
- Jacob, S.; Francesco. What is YOLOv8? A Complete Guide. Roboflow Blog. Available online: https://blog.roboflow.com/what-is-yolov8 (accessed on 1 September 2024).
- Fahy, R.; Petrillo, J. Firefighter Fatalities in the US in 2022. 2022. Available online: https://www.usfa.fema.gov/downloads/pdf/publications/firefighter-fatalities-2022.pdf (accessed on 1 June 2024).
- Solawetz, J.; Francesco. What is YOLOv8? The Ultimate Guide. 2023. Available online: https://blog.roboflow.com/whats-new-in-yolov8/ (accessed on 19 July 2024).
- Mehedi, S.T.; Anwar, A.; Rahman, Z.; Ahmed, K. Deep transfer learning based intrusion detection system for electric vehicular networks. Sensors 2021, 21, 4736. [Google Scholar] [CrossRef] [PubMed]
- Inside, A.I. Introduction to Deep Learning with Computer Vision—Learning Rates & Mathematics—Part 1. 2020. Available online: https://medium.com/hitchhikers-guide-to-deep-learning/13-introduction-to-deep-learning-with-computer-vision-learning-rates-mathematics-part-1-4973aacea801 (accessed on 3 September 2024).



Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).