Abstract
The field of object detection has witnessed significant advancements in recent years, thanks to the remarkable progress in artificial intelligence and deep learning. These breakthroughs have significantly enhanced the accuracy and efficiency of detecting and categorizing objects in digital images. Nonetheless, contemporary object detection technologies have certain limitations, such as their inability to counter white-box attacks, insufficient denoising, suboptimal reconstruction, and gradient confusion. To overcome these hurdles, this study proposes an innovative approach that uses conditional diffusion models to perturb adversarial examples. The process begins with the application of a random chessboard mask to the adversarial example, followed by the addition of a slight noise to fill the masked area during the forward process. The adversarial image is then restored to its original form through a reverse generative process that only considers the masked pixels, not the entire image. Next, we use the complement of the initial mask as the mask for the second stage to reconstruct the image once more. This two-stage masking process allows for the complete removal of global disturbances and aids in image reconstruction. In particular, we employ a conditional diffusion model based on a class-conditional U-Net architecture, with the source image further conditioned through concatenation. Our method outperforms the recently introduced HARP method by 5% and 6.5% in mAP on the COCO2017 and PASCAL VOC datasets, respectively, under non-APT PGD attacks. Comprehensive experimental results confirm that our method can effectively restore adversarial examples, demonstrating its practical utility.
MSC:
68T07
1. Introduction
Deep learning [1] has significantly advanced pattern recognition in fields like image classification [2,3,4], object detection [5,6,7], and semantic segmentation [8,9]. It also plays a crucial role in visual concept discovery [10], image clustering [11], and disease diagnosis. This success is largely due to its ability to automatically extract and learn hierarchical features, which is essential for both supervised and unsupervised tasks [12], directly influencing their accuracy and efficiency. Despite these advancements, recent research has highlighted a significant vulnerability: deep learning models are susceptible to minor perturbations crafted to manipulate input images [13]. This has sparked a burgeoning interest in enhancing the robustness of convolutional neural networks (CNNs) against adversarial attacks. As a result, a variety of defensive strategies have been developed [14,15,16,17,18,19,20,21,22], focusing on improving model resilience. These strategies underscore the importance of robust feature extraction, not only for performance but also for ensuring the security and reliability of deep learning systems in real-world applications.
Presently, multiple defensive strategies are deployed to safeguard against adversarial attacks aimed at object detection and classification systems. Up to now, defenses against adversarial attacks have been developed using three methods: (1) Adversarial training, which involves altering the training data to enhance the classifier’s robustness to attacks, as illustrated by recent research [13,23] that incorporates adversarial examples into the training process. (2) Defensive distillation adjusts the training process of the classifier to lessen the intensity of gradients. Research by [18] has shown that defensive distillation enhances the model’s resilience against adversarial perturbations. (3) Noise removal, which attempts to remove the adversarial noise from the input; these methods [19,24,25] often rely on detecting and filtering out perturbations characteristic of adversarial example samples. Thus far, although the defense effectiveness of target detection authentication is already quite sophisticated, most of these defense measures are targeted defenses. In particular, model-agnostic defenses appear overly simplistic and inadequate for completely eliminating adversarial perturbations in input images. Conversely, model-specific defenses rely on substantial presumptions regarding the characteristics of the adversary. However, recent work [26,27,28,29,30,31] using generative models to purify adversarial images has become a promising and mainstream approach as a counterpart to adversarial training. These techniques strive to convert adversarial images into clean ones by employing a purification model, providing an efficient defense approach as a substitute for adversarial training.
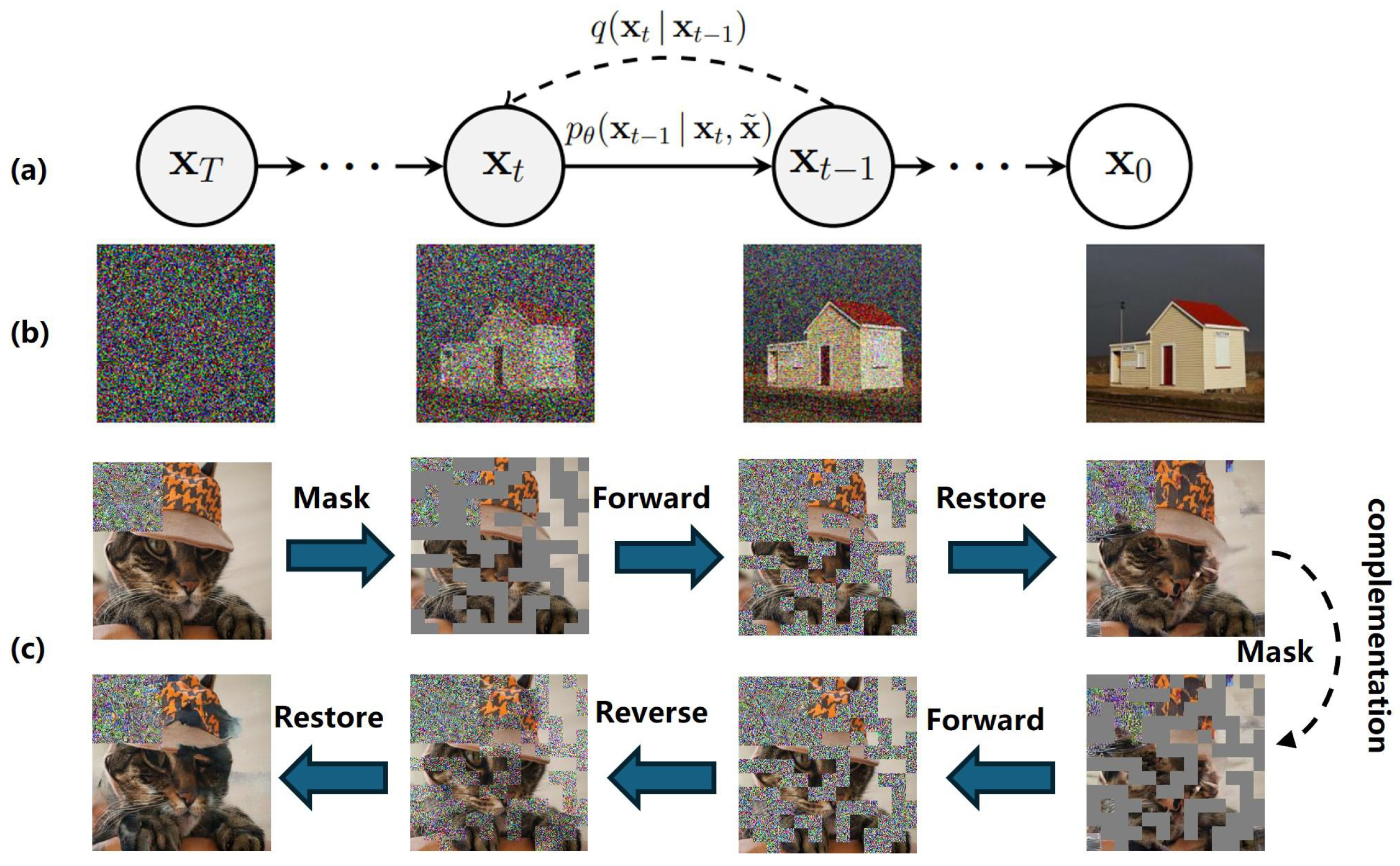
Figure 1 illustrates our motivation. In this study, we put forward a defensive strategy aimed at enhancing the robustness of object detection models. This is achieved by purifying the distribution of perturbation noise and eliminating perturbations from the input images. We utilize the powerful representational abilities of conditional diffusion models to alleviate the effects of adversarial disturbances by purifying adversarial images. This approach provides a robust defense against adversarial attacks in image processing. The proposed method is as follows: (1) We employ the conditional diffusion model [32], which is architecturally grounded in a class-conditional U-Net model [33]. This method diverges from previous works [34,35] in several key aspects. Firstly, it necessitates additional conditioning of the source image through concatenation. Secondly, we reduce class-conditioning and adopt the loss function to more faithfully capture the output distribution. (2) Unlike other diffusion models, we do not add noise to the entire image to render it purely noisy during the forward process. Instead, we employ a full-image reconstruction scheme with two stages of mask occlusion. Specifically, we first generate a chessboardlike random mask to cover the image and add noise within this mask to restore the images at the first stage. Then, we apply a complementary mask to the one used previously and restore the image again. This method can destroy the global perturbation and remove the adversarial perturbation without affecting the target images.
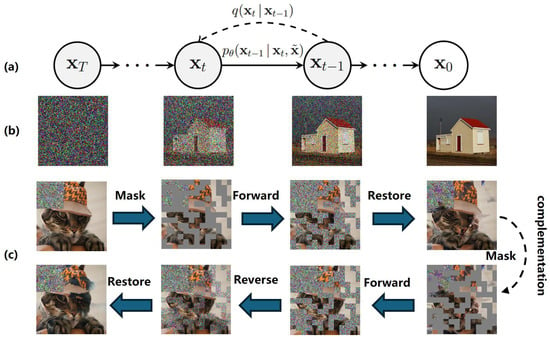
Figure 1.
Diffusion model on defending. (a) A diffusion model is presented where the forward process is and the reverse process is . (b) The diffusion model is then applied to an image generation task. This involves using the model to generate new images that are similar to the input images but have been altered in some way through the diffusion process. (c) We propose formulating the defense method to restore pictures twice using a diffusion model for pictures masked by a two-stage mask.
We encapsulate the key contributions of our research as follows:
- We formulate the defense as restoring images twice using a diffusion model for images masked by a two-stage mask. To our knowledge, this is the inaugural research to utilize diffusion models in the realm of object detection defense.
- In order to dismantle the global perturbation and reconstruct the image, we employ random_mosaic to create mask occlusions for the entire image. The original images serve as the input condition, guaranteeing that the class of the target image remains unaffected. This approach ensures the maximum possible elimination of the anti-disturbance.
- When compared to the HARP method under non-adaptive conditions, our method exhibits an improvement in the mean Average Precision (mAP) by 5% on the COCO2017 dataset and 6.5% on the PASCAL VOC dataset. Furthermore, our method demonstrates greater generalizability across various scenarios. Specifically, it achieves an mAP of 62.4% under the Momentum Iterative Method (MIM) attack and 62.1% under the Projected Gradient Descent (PGD) attack. These results underscore the effectiveness and applicability of our proposed method in defending against adversarial attacks in object detection tasks. Our approach provides a promising direction for future research in this area.
2. Related Work
Object detection. Object detection, a pivotal function in the field of computer vision, is tasked with discerning the presence, pinpointing the location, and classifying the category of one or more objects within a given image. The recent years have witnessed significant advancements, largely attributable to the evolution of convolutional neural networks (CNNs) [5,36,37]. In object detection, feature extraction is crucial, as it directly determines the performance of downstream tasks, whether in supervised classification or unsupervised learning [38,39]. As for object detectors, they can be generally divided into two main categories. The first category encompasses two-stage strategy detectors such as Faster RCNN [7], RCNN [40], SPPNet [41], Fast RCNN [5], RFCN [42], Mask RCNN [43], and Light Head RCNN [44], among others. These detectors initially utilize a Region Proposal Network (RPN) to generate potential bounding boxes or “proposals”. These proposals are then passed through a classification and regression layer to predict the class labels and refine the bounding-box coordinates, respectively. While this approach is known for its superior performance in terms of object localization and recognition accuracy, it does come with the trade-off of speed. The second category comprises one-stage detectors such as DetectorNet [45], OverFeat [37], YOLO [36], and SSD [46]. These methods directly predict the bounding-box coordinates and classes of the object instances from the input images, resulting in faster performance. However, while these methods have advantages in reasoning speed, they may not achieve the same level of accuracy as two-stage detectors. More recently, transformer models [47] have also begun to play a role in computer vision, where they either replace or are used in combination with CNNs. By utilizing self-attention mechanisms, transformers can capture both local and global context within images, introducing a new paradigm for object detection [48].
Diffusion model. Diffusion models [49,50] have recently emerged with impressive results as powerful generative models [49,51] in image generation [35,49,52]. The diffusion model employed in our research is grounded in cutting-edge advancements [32,53,54,55]. However, our investigations revealed a disconcerting trend: diffusion models are predominantly utilized for malicious purposes rather than defensive measures [56,57,58,59]. Specifically, they are often weaponized in sophisticated attacks such as backdoor attacks [60], adversarial attacks [61,62,63], and membership inference attacks [59]. This shift underscores the urgent need for robust countermeasures and defensive strategies to mitigate these emerging threats.
Adversarial Attacks. Adversarial examples demonstrate that deep learning models are more vulnerable to image perturbation. Adversarial perturbations can be classified into two categories: (1) global adversarial perturbations and (2) local adversarial perturbations; both pose threats to deep learning models. An early attack on object detection is DAG [64], which leads to incorrect labels being proposed in the RPN, misleading the Faster R-CNN. However, most previous studies on adversarial attacks [13,65,66] alter the input image pixels, which may not be feasible in the physical world. Therefore, to achieve a universal attack, adversarial patch attacks as proposed in [67,68,69,70,71] also threaten state-of-the-art object detectors.
3. Methodology
Our methods is introduced as a countermeasure against adversarial attacks within object detection frameworks, predicated on a diffusion principle. This principle systematically refines the value of each pixel until the image’s reconstruction aligns with the pristine model’s distribution. The integration of diffusion model modules into the object detection pipeline attenuates the perturbations induced by adversarial inputs. The defense mechanism unfolds in two sequential phases: the initial phase involves a stochastic fill of the masked regions, while the unmasked segments remain invariant during inference. In the inference phase, the diffusion model is deployed to rehabilitate the adversarial instance, thus enhancing the system’s resilience to adversarial perturbations and sustaining the integrity of clean data performance. Our methodology employs a dual restoration process; the inaugural restoration invokes a chessboard masking via random_mosaic, followed by a complementary masking strategy in the subsequent restoration.
3.1. Preliminaries: Diffusion Models
In this approach, we utilized diffusion models (DMs) [49] to obtain high-precision, purified images. Following the forward process of diffusion models, we initially introduce noise into adversarial images, resulting in diffused images. Subsequently, clean images are retrieved through the reverse process.
In the forward process, DMs characterize the forward process as a Markovian process that adds to an input image Gaussian noise via T iterations to obtain . Each iteration of the DM process can be shown as follows:
where is the input image at time step t, while represents the hyperparameters of a predefined scale factor that governs the magnitude of each step t, and the symbol represents the Gaussian distribution. Equation (1) is a forward process with constructed, and is virtually indistinguishable from Gaussian noise. Simply put, at , we have the original image, and at , the image is transformed into one that resembles a Gaussian distribution. This is achieved by progressively adding noise, and then the reverse process denoises it to generate a new image. During this phase, as T increases, it is noteworthy that we can also marginalize the forward process at each step, as shown in Equation (3).
where , and is entirely Gaussian noise.
When we define and , the Gaussian parameterization of the forward process enables a closed-form expression for the posterior distribution of given , shown in Equation (4). This formulation provides a mathematical framework for understanding the behavior of the diffusion model during the forward process.
Learning: Drawing inspiration from the above, we can view the forward process as the act of introducing noise, while the reverse process serves as the denoising inference phase of diffusion. The model learns a reverse process that effectively inverts the forward process. If we give an adversarial input as per Equation (5), the objective is to recover the images . In this process, we need a prediction of the noise vector , which is achieved by optimizing an objective that resembles denoising score matching (as per Equation (6)). In this context, we parameterize the model to condition it on the input y, adversarial example , and the current noise level , and this objective is in [49].
Inference: In the learning stage, the models learned how to output the inverse derivation of the input via the reverse process. The input to the model is a standard normally distributed random noise, and the sampling process can start at a pure Gaussian noise by T steps of iterative refinement, a step-by-step approach to the target output.
Give , we can obtain the target image by rearranging terms in Equation (5) as Equation (7). We use , substituting the posterior distribution of in Equation (4), to parameterize the mean of as Equation (8). Furthermore, with the parameterize, the computed result can be formulated as Equation (9):
To summarize, we can train the reverse process mean function approximator to predict by conditioning the input x, adversarial example , and the current noise level . We have shown that the -prediction parameterization resembles Langevin dynamics. This statement mirrors a single step in Langevin dynamics for which provides an approximation of the gradient of the data log density.
3.2. Architecture
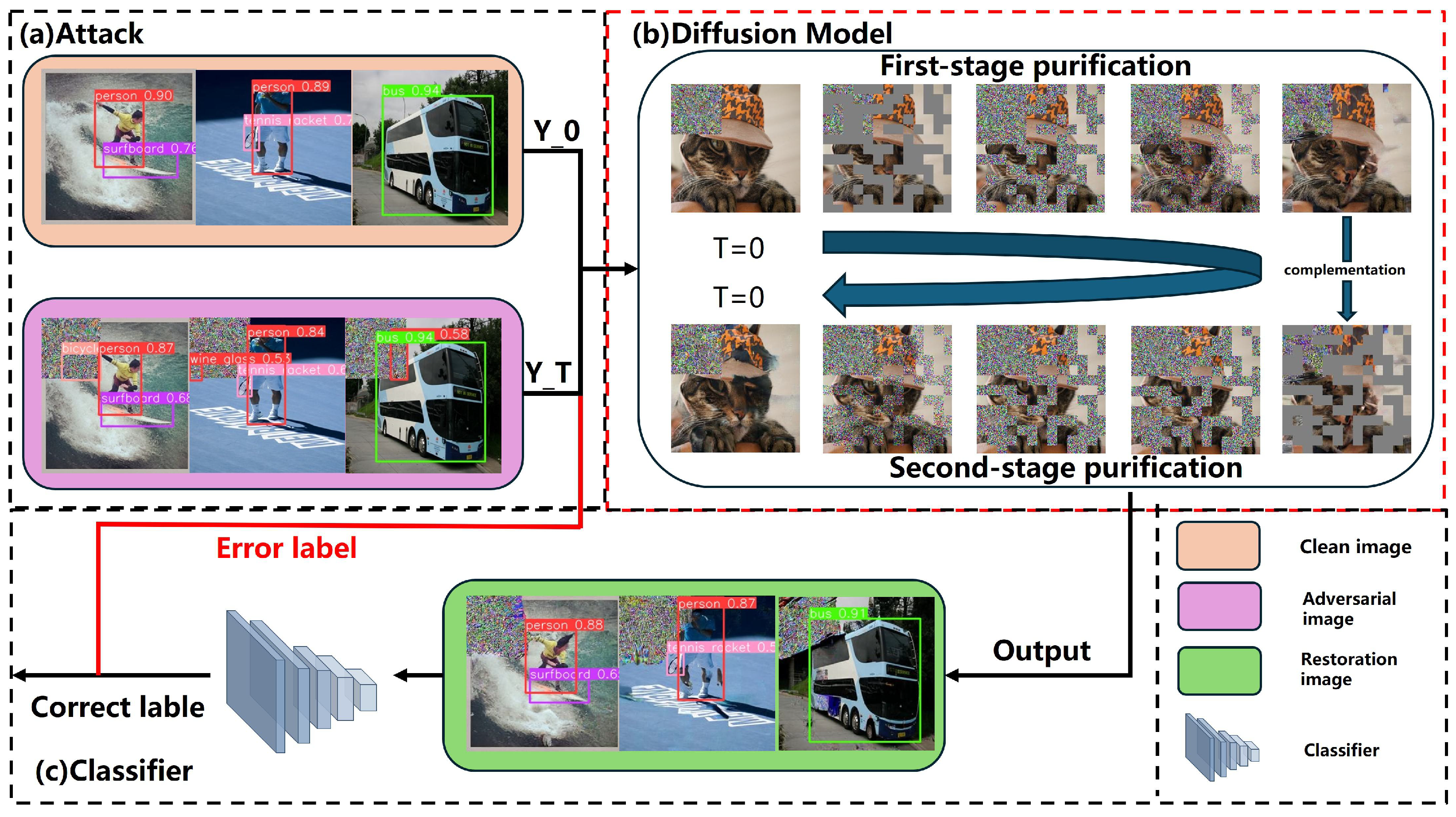
In this research, we introduce a defense framework for adversarial learning that amalgamates methods of adversarial image creation, image assessment, and image reconstruction. The specific steps are as follows and are shown in Figure 2.
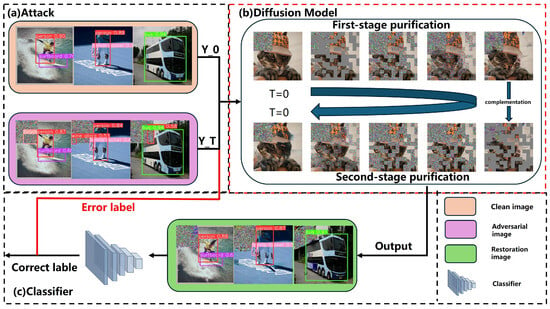
Figure 2.
The overview of the proposed method consists of an attacker, a diffusion model, and a classifier. (a) In the initial phase, the attacker optimizes the attack intensity by focusing solely on correctly classified samples. It first implements the untargeted variant of each attack, followed by the targeted variant against each potential target label. (b) In the subsequent stage, we implement a two-stage restoration method. With a pre-trained diffusion model, the method takes the ground-truth image as input and introduces noise to adversarial images. This guides the diffusion model to restore images through reverse denoising. During this stage, instead of introducing noise to the entire image, we generate a mask and superimpose noise onto the mask. Initially, we employ a random_mosaic to create a chessboardlike mask to overlay the image. Subsequently, we complement the masks used in the first stage to form complementary masks for the second stage. (c) In the final stage, we utilize YOLOv5 to detect the restored images. This comprehensive approach ensures a robust defense against adversarial attacks while maintaining the integrity of the original image.
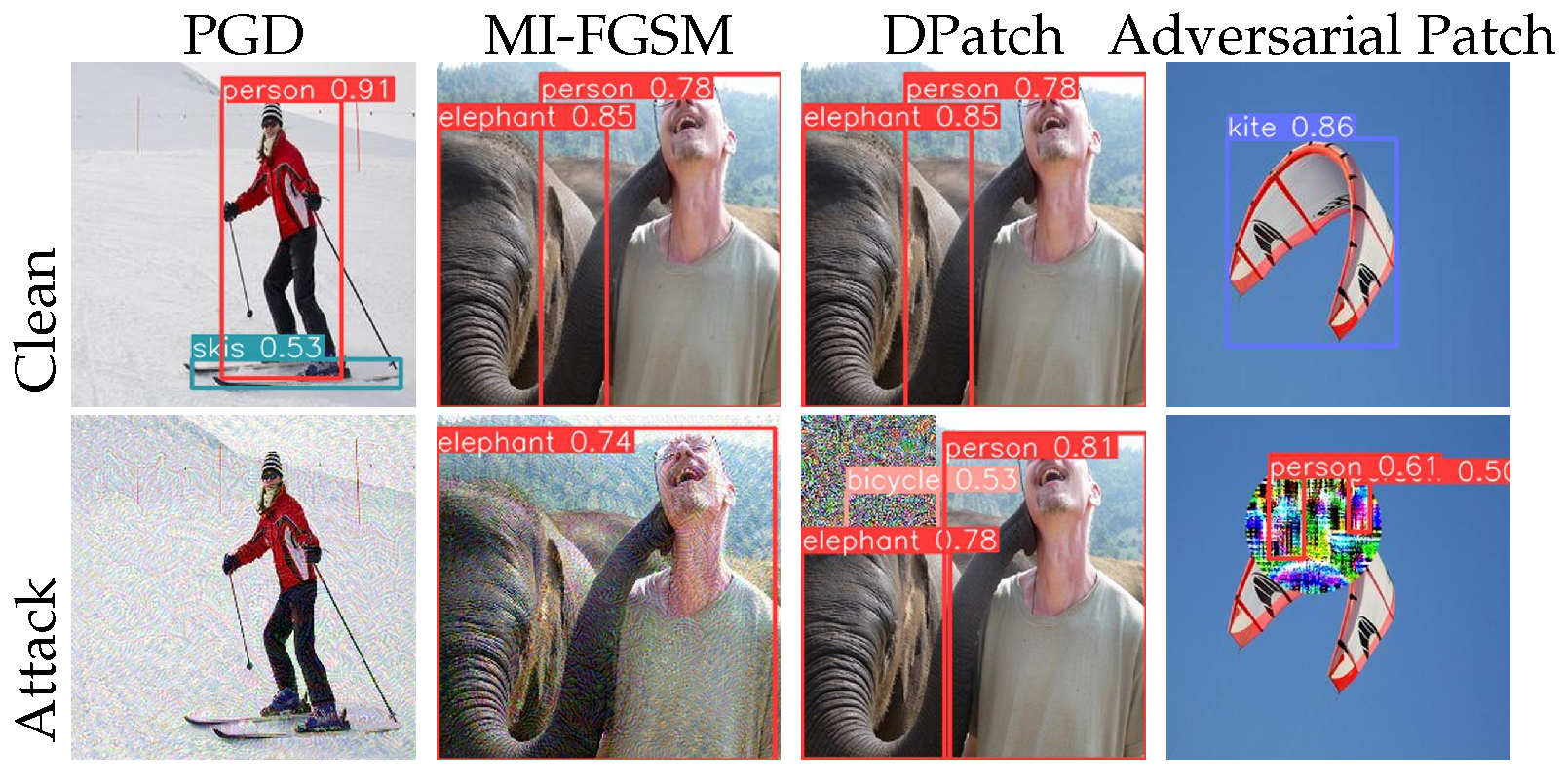
Firstly, the YOLOv5 [72] model performed object detection on the original image, obtaining information on object positions and categories. Based on this, we used the four-attack method to compute the adversarial perturbations. These perturbations were computed and superimposed on the original image to fabricate an adversarial image. The results are shown in Figure 3.
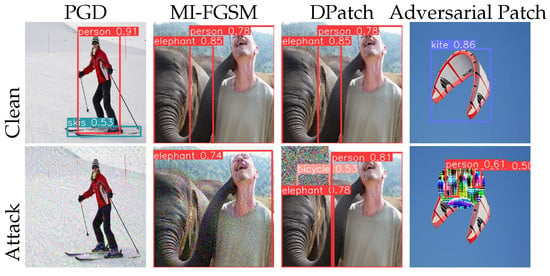
Figure 3.
Visual comparison of four attack method results. Clean image on undefended model (top), adversarial example on undefended model (bottom).
Secondly, our methods employed a pre-trained diffusion model and covered the adversarial image with a mask generated by a random mosaic. We then introduced random noise to the area obscured by the mask during the forward process. The aim was to maximize the restoration of the original image’s features and structure. Specifically, the model in question initiated the process by generating a perturbed sample from a standard Gaussian distribution. This sample, characterized by its inherent noise, underwent a series of denoising iterations. The primary objective of these iterations was to progressively transform the noisy sample into a representation that aligned more closely with the empirical data distribution, which was a reflection of real-world data.
Through an iterative denoising process, the model strove to transform this noisy sample into a sample that was closer to the real data distribution, i.e., the empirical data distribution. This iterative denoising process used Gaussian noise, whose mathematical principles and algorithms have been extensively studied and verified, ensuring the quality and stability of the generated images. Even though there are other types of noise like pink noise, shot noise, and salt-and-pepper noise, the same problem arises in the iterative process: dealing with salt-and-pepper noise may make it difficult to accurately recover image details due to the discrete and random nature of the noise. Therefore, to more effectively handle these different types of noise, it may be necessary to combine other denoising methods or employ more complex models. During this period, the mask we utilized resembled a chessboard, which allowed us to retain most of the image’s information during the restoration process, ensuring that the original target remained unaffected. Subsequently, we employed the complementary mask for a second round of restoration, which aided in eliminating the adversarial perturbation. This two-step restoration process, involving the use of a chessboardlike mask and its complement, was designed to balance the preservation of original image details and the disruption of adversarial noise. It was a suitable approach to enhance the robustness of the model against adversarial attacks.
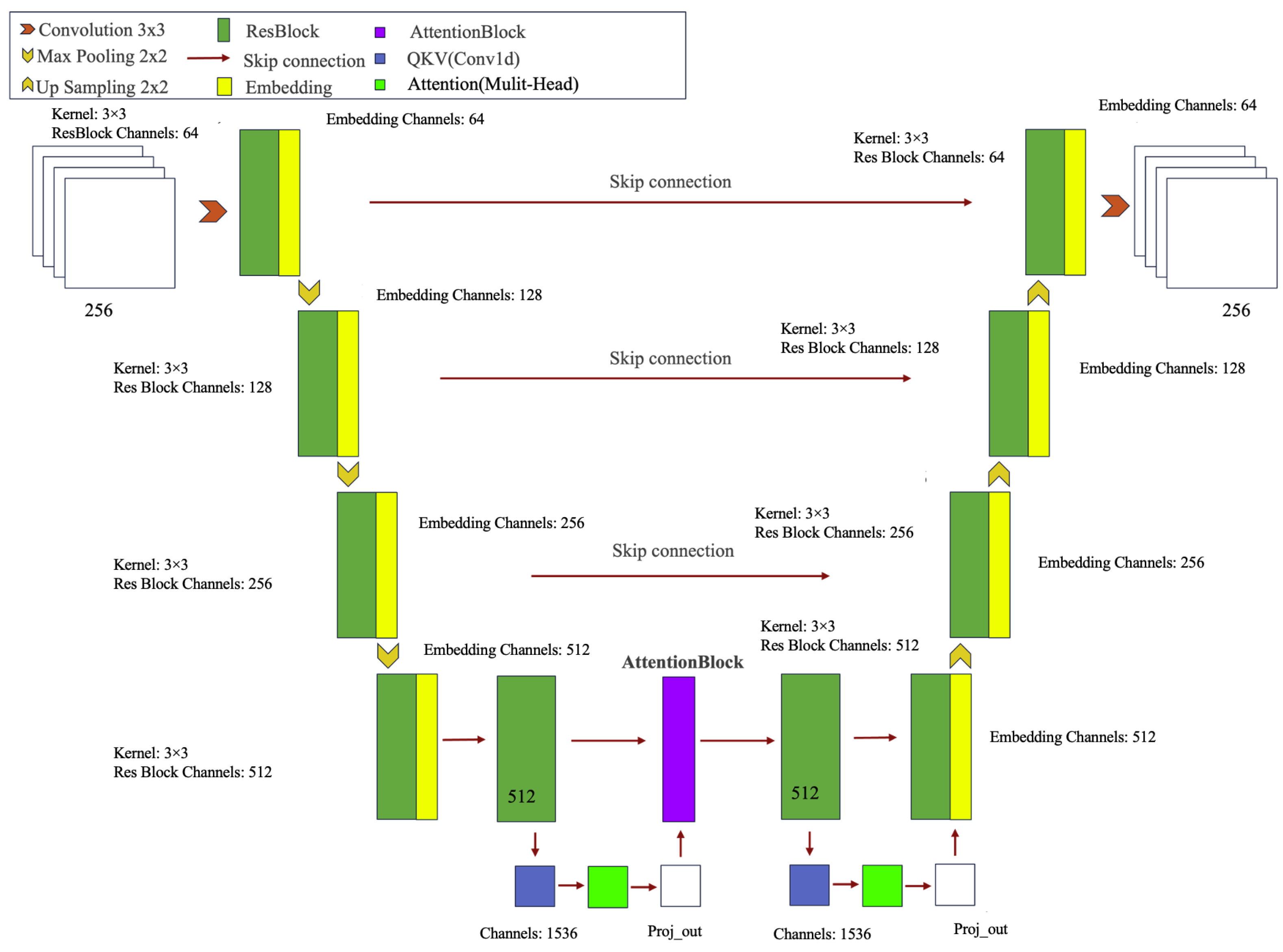
The model employed the U-net architecture, a widely used neural network for image segmentation tasks, characterized by its symmetric encoder–decoder structure. The encoder extracts features through a series of downsampling layers, while the decoder gradually restores the spatial resolution of the image using upsampling layers, incorporating skip connections to retain detail information.
Based on U-net, several improvements were made. First, the SiLU activation function was introduced to enhance the model’s nonlinear expressiveness. Second, the EmbedBlock and EmbedSequential modules were combined to enable more effective transmission and integration of embedded information. Multi-head attention mechanisms (Attention Block) were incorporated in certain layers of the encoder and decoder to enhance the model’s focus on important features by calculating self-attention weights in the feature maps, improving its ability to capture global context.
Additionally, conditional embedding was introduced in each residual block (ResBlock), embedding external conditional information (such as time steps) into the feature maps to help the model better adapt to different input conditions. During the upsampling process in the decoder, a multi-scale feature fusion strategy was employed to merge feature maps of different scales, enhancing the model’s ability to capture details. Finally, the upsampling and downsampling strategies were optimized to further improve the model’s performance and efficiency. The architectural framework of image inpainting models utilizing U-net is shown in Figure 4.
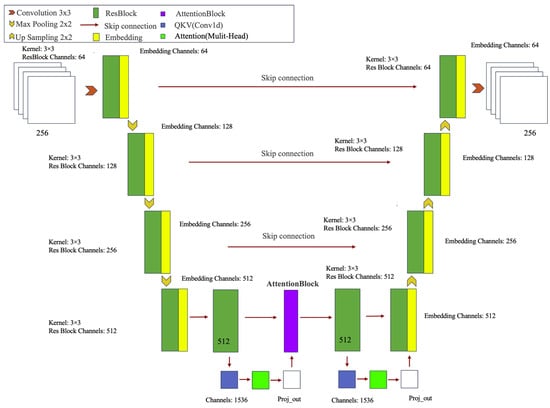
Figure 4.
Architectural framework of image inpainting models utilizing U-net.
During training, we adopted an end-to-end training strategy, using the mean squared error (MSE) as the loss function to minimize the difference between predicted results and true labels. We chose the Adam optimizer with a learning rate set to 0.001, dynamically adjusting it during training. To prevent overfitting, we introduced dropout layers in each residual block and employed data augmentation techniques such as random cropping, rotation, and flipping during training to increase data diversity.
Finally, the reconstructed image was fed back into the object detection model for target detection. The detection results were then compared between the reconstructed and original images.
4. Experiments
In this section, we initially outline the experimental settings (refer to Section 4.1). Following this, we juxtapose our approach with cutting-edge adversarial defense techniques to assess the defense potential and efficiency of our method (see Section 4.2). Subsequently, we conduct ablation studies on the components of the method to elucidate its functioning in warding off adversarial attacks (refer to Section 4.5).
4.1. Experimental Settings
Models: In our experiments, the YOLOv5 model was trained and validated on the COCO 2017 dataset, achieving an outstanding performance of 67.8% on the mAP metric with an IOU threshold of 0.5. Meanwhile, on the VOC2012 dataset, it achieved an 82.4% mAP with the same IOU threshold. The training was conducted using four NVIDIA RTX 3090 GPUs. A learning rate of 0.001, a batch size of 16, and 200 epochs were used. Data augmentation techniques such as random cropping, flipping, and color jittering were applied to enhance model robustness.
Dateset and metric: We conducted our method evaluation on two datasets: COCO2017 [73] and VOC2007 [74]. The model was trained on the COCO2017 dataset, while testing was performed on both VOC2012 and COCO2017 datasets. We assessed the model’s robustness using a test set comprising 500 images from each dataset. The training process spanned approximately 200 epochs with a sample size of 2000. The detector’s performance was evaluated using the box average precision (AP) metric with an Intersection Over Union (IOU) threshold of 0.5.
Attack setting and baselines: Our methods were evaluated under strong attack scenarios. The experiment utilized the Projected Gradient Descent (PGD) [75] and the Momentum Iterative Method (MIM) [76] as loss functions for generating adversarial images to attack YOLOv5. For the PGD patch attack, the experiment used 200 iterations with a step size of and . In the MIM patch attack, 20 iterations with a decay factor and a step size of were used to generate a patch attack. The patch was strategically positioned at the upper left corner of each input image. We implemented both non-adaptive and adaptive attacks. In the adaptive attack scenario, we utilized a parameter-free, computationally economical, and user-independent ensemble of attacks to assess robustness. Conversely, in the non-adaptive attack, the attacker was only privy to the parameters of the object detector. We benchmarked our proposed method against several baselines, including Adversarial Training (AT) [13], JPEG compression [77], Feature Noise Convolution (FNC) [78], Spatial Smoothing [79], Segment Adversarial Camouflage (SAC) [80], and HARP [81].
4.2. Robustness and Efficiency
Table 1 illustrates the performance of various defense methodologies on the VOC and COCO datasets across diverse attack scenarios, comparing accuracy (%) under clean data conditions, non-APT (non-adaptive adversarial patch training), and APT (adaptive adversarial patch training). The results encompassed two types of attacks: Projected Gradient Descent (PGD) and Momentum Iterative Method (MIM). Across both datasets and attack types, “method (ours)” consistently exhibited the most robust defense, excelling in both resilience and accuracy.

Table 1.
Comparative analysis of defense effectiveness and efficiency on YOLOv5: a study across PASCAL VOC2012 and COCO2017 datasets. In the table, the bolded font indicates our experimental results.
For the VOC dataset, all methods showed similar performance on clean data, with accuracies around 82.4% to 82.6%. However, under adversarial attacks, “method (ours)” stood out, particularly in non-APT conditions where it achieved 80.8% (PGD) and 81.0% (MIM), and in APT conditions with 81.1% (PGD) and 80.7% (MIM), surpassing other defenses.
In the COCO dataset, the overall clean accuracy was comparatively lower; however, “method (ours)” once again surpassed the other methodologies, attaining the highest performance under non-APT (PGD: 61.1%, MIM: 60.5%) and APT (PGD: 61.4%, MIM: 61.2%) conditions. When compared to alternative defense strategies, “method (ours)” consistently exhibited superior robustness, particularly in the context of more challenging APT attacks.
Nevertheless, the restoration method exhibited noteworthy efficacy in contexts characterized by a limited number of detected objects, especially those involving large targets. However, it faced considerable challenges in complex scenes, primarily due to the limited size of the COCO dataset. This limitation led to suboptimal performance in more intricate environments. To address this issue, we plan to enhance our training dataset, thereby improving the method’s performance across a broader spectrum of scenes.
In conclusion, we randomly selected a few instances to validate the efficacy of our method. As depicted in Figure 5, we observed the effective resistance to adversarial attacks.

Figure 5.
Given a 256 × 256 image, we visualize the patch results generated by PGD and MIM attack methods. The top is the clean image, the middle is the adversarial image, and the bottom is the restored image.
4.3. Image Recovery Quality Analysis for FID Assessment
To comprehensively evaluate the quality of image restoration, the Fréchet Inception Distance (FID), a widely recognized metric in the field, was adopted. The FID is designed to compare the distribution of recovered images with that of the original images in the feature space, thereby effectively measuring the similarity between the two sets of images. Specifically, the FID quantifies the visual feature differences by calculating the Fréchet distance between the feature vectors extracted from the Inception network for both the recovered and original images. Two representative attack repair methods were employed as the basis for fidelity experiments. The experimental results are presented in Table 2.
Table 2.
Evaluation of FID performance under PGD and patch attacks: a comparative on COCO and VOC datasets.
The experimental results demonstrated that the quality of generated images was generally higher on the VOC dataset compared to the COCO dataset. This situation may be due to the complexity of the COCO dataset, which includes diverse and complex scenes, thus presenting greater challenges for diffusion models in generating images.
4.4. Generalizability of Method
In the previous sections, we used PGD and MIM to create adversarial patches. The method was further evaluated in unseen and physical attacks, including DPatch [71], PGD, Adversarial Patch [82], and MIM attack. In DPatch and Adversarial Patch, T = 200 was used, and the learning rate was 1.99. For PGD and MIM, T = 40 iterations were used with . Additionally, for MIM, a decay factor of was used. The performance is shown in Table 3. Our methods achieved more than 60% under all attacks, providing strong robustness in undefended models. We also found the defense performance in the PGD and MIM attack was higher than the patched attack because we used a two-stage restoration method that covered the images and destroyed the adversarial perturbation, but in the patched attack, we found that sometimes the patch would be restored and detected again. As depicted in Figure 6 and Figure 7, we can observe the effective resistance to other patch attacks and unseen attacks.
Table 3.
Evaluating mAP performance under unseen attack methods: a comparative study of defense techniques on the COCO2017 dataset.

Figure 6.
This is the visualization result of our proposed method to defend against an Adversarial Patch; we can see that the result is better: the first line is the clean picture, the middle line is the attacked picture, and the last line is the result of the defense.

Figure 7.
This is the visualization result of our proposed method to defend against unseen attack; we can see that the result is better, the first line is the clean picture, the middle line is the attacked picture, and the last line is the result of the defense.
4.5. Ablation Study
In this section, the effect of each component of the method is investigated. In all experiments, the attack used was the unseen attack PGD (T = 50).
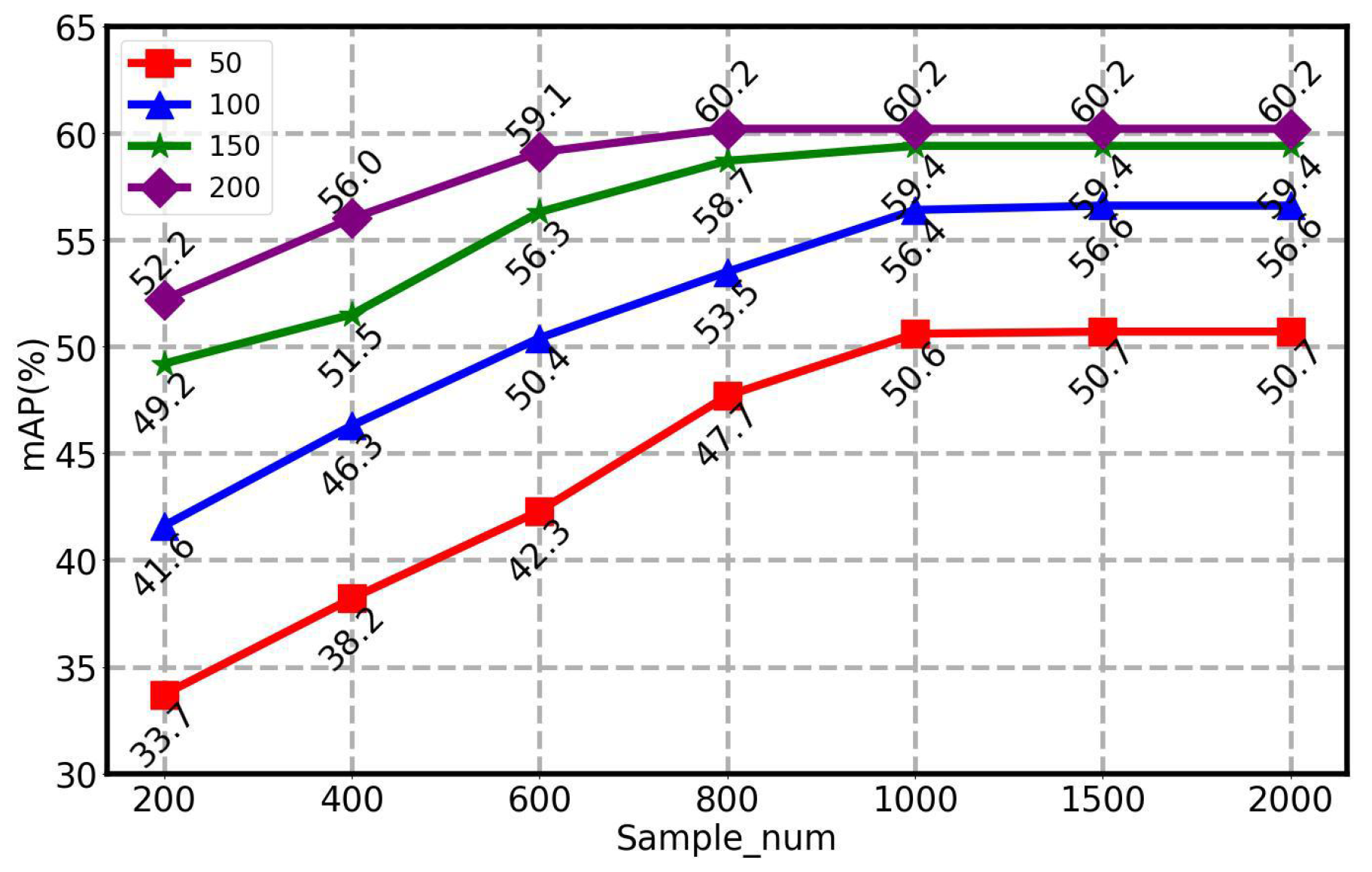
Training epoch and sampling vs. restoration quality: We show how the diffusion model training epoch and sample_num affected the image quality performance in Figure 8 and Figure 9.

Figure 8.
The purification performance was evaluated with varying sampling_num values with epoch = 200. Visually, the results are similar, but the mAP values are quite different.
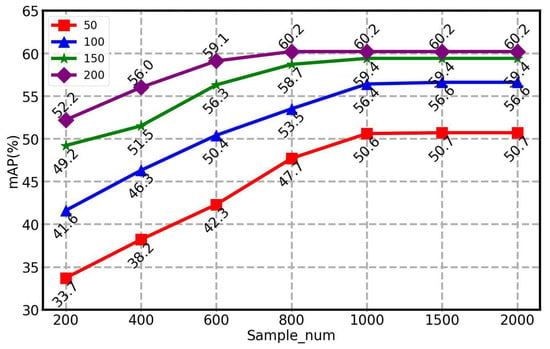
Figure 9.
With different mAP values for sample_num, the results are better with more samples, but a saturation point is reached around sample_num = 1500.
Specifically, as the number of epochs increased, the quality of the images generated by the model also improved. This could be because, as the model was trained over more epochs, it could better capture the complexity of the data, thereby generating more accurate and realistic images. In the restoration method, sample_num determined how often samples were taken during the back-sampling process. This sampling process restored the noise image to the original image. Therefore, the number of samples (i.e., sample_num) may have affected the quality of the recovered image. When the sample_num was larger, more samples were taken, which brought the recovered image closer to the original, thus improving the quality of the image. Conversely, when the sample_num was small, then the number of samples was reduced, which caused the recovered image to differ significantly from the original image, thus reducing the quality of the image. However, when the number of epochs and sample_num exceeded a certain threshold, the performance of the model gradually saturated, which could also increase the complexity and runtime of the calculation.
Impact of mask: In our methods, we employed a strategy known as random masking. This strategy involved randomly forming an irregular checkerboard mask on the image, covering some areas. These masked areas, also called masks, played a crucial role in our experiments. In training, we used random masking to train the data by simulating the damage an image may suffer. In the inference stage, we also added the mask in adversarial images to restore them. However, we found that the mask sizes and generated methods impacted the image quality and model performance, as shown in Table 4 and Figure 10. Maybe when important information in the image was obscured, there was a possibility that it would not be recovered. In an unseen attack, it could be irreparable if the mask covered a smaller object. In a patch attack, if the patch location was at the four corners of the image, the performance was better than in a random location. The reason for this is that our mask position was not fixed, resulting in random recovery results. At the same time, we found that when the size was 20, the recovery result was the best because the restored image could better highlight the content of the target. If the size was too small, the restored content was very miscellaneous, and if the size was too large, the target was occluded. Also, we tried different methods of mask formation in the experiment; the best recovery method was using a white mask because we used the white mask in training, as shown in Figure 11.
Table 4.
Diffusion ablation experiments about the mask. We can see the best mAP used the white method, and the best size was 20 × 20.

Figure 10.
Diffusion ablation experiments about mask sizes. We can see the different performance results with different mask sizes. We found that the effect of a mask size of 20 × 20 was better, most likely because it was adopted in the training phase. However, we also used different sizes to train and found that 20 × 20 made the object detector pay more attention to the object.

Figure 11.
Diffusion ablation experiments about the method of generating the mask. We can see the different performance results with different masks. The white mask used in the training phase is the best at detection, although the visualization shows that the final result is not the best.
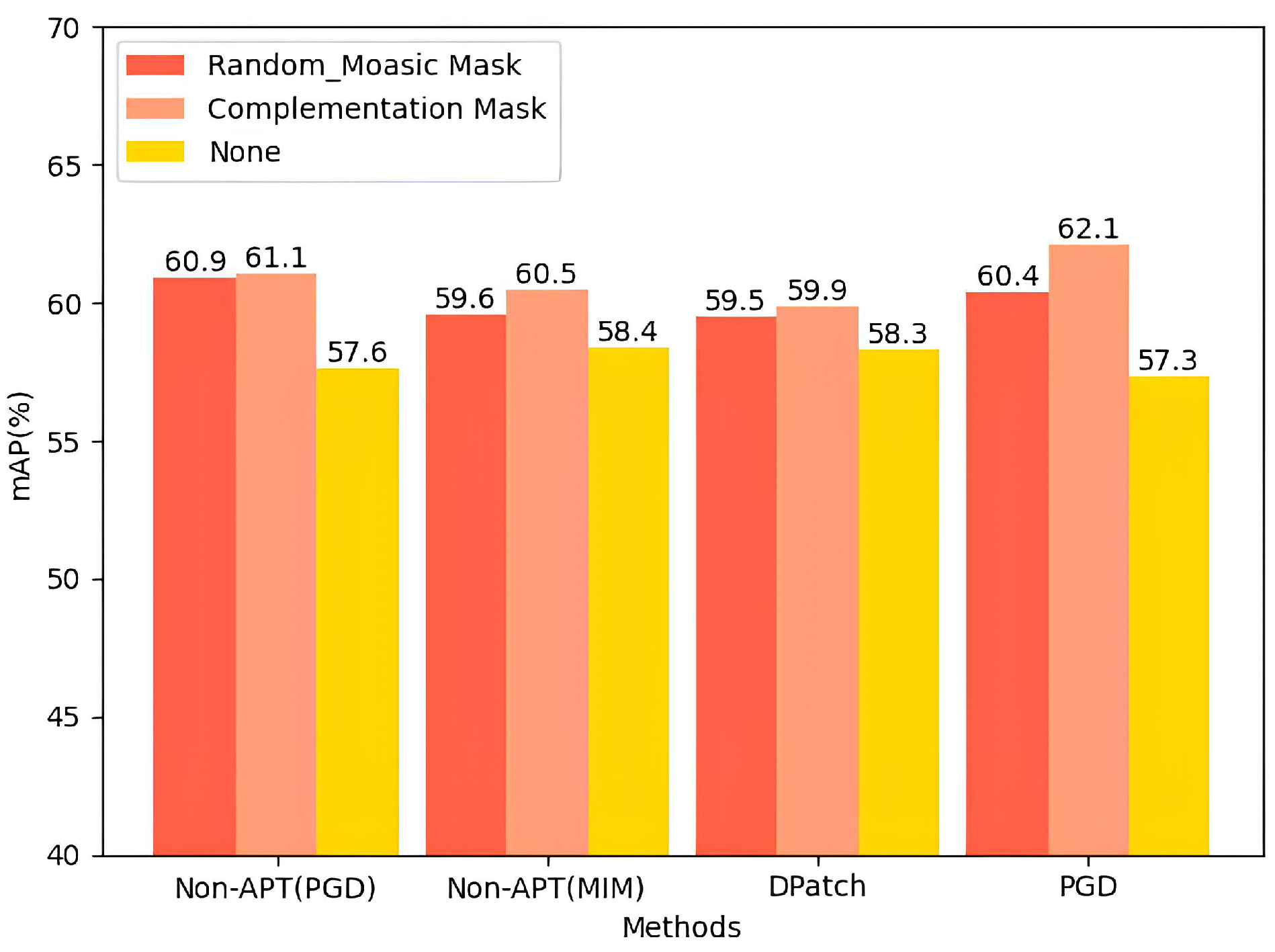
The second masking plan: In the experiment, we adopted the complementary mask in the second stage. We found that the complementary mask could complete the destruction, and the image reconstruction of global perturbations ensured the maximum obliteration of adversarial perturbations without affecting the target image class. This method showed a better effect for unseen attacks but was not better for patch attacks. Thus, in the second stage, we adopted the random_mosaic mask to test its performance. We found that the results of the random_mosaic mask in the patch attack were the same as the complementary mask results. However, in the unseen attack, the results were poorer than those of the patched attack under the complementary mask. The comparison is shown in Figure 12.
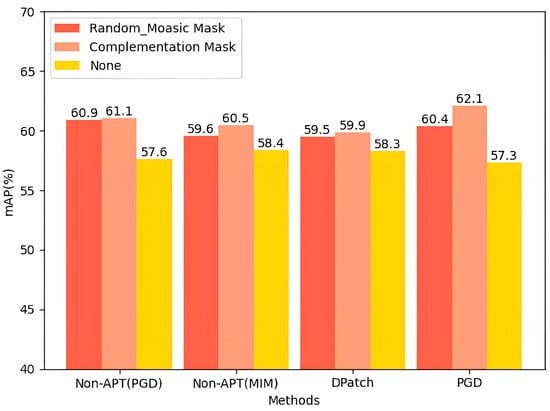
Figure 12.
mAP values of different mask usage strategies under four attacks; we can see the complementary mask is better than other mask-generating methods. Meanwhile, the performance in restoring PGD is better than that of other attack restoration methods.
5. Discussion
To further enhance the practicality and efficiency of the method, our plan is to add a rapid detection algorithm to quickly determine whether an input image is adversarial before it enters the diffusion model, thereby reducing unnecessary computational overhead. Additionally, the exploration of potential neural networks (PlNN) and incorporation of the characteristics of diffusion equations into the loss function will improve the model’s adaptability to adversarial perturbations.
Regarding the comparison with the basic model, the Yolov5 framework was used as the test object, but the comparison with other framework models is lacking. Our plan is to expand this section in future studies by including other popular object detection frameworks such as Faster R-CNN, SSD, and RetinaNet in the comparison. This will allow for a more comprehensive evaluation of the performance of the proposed method under different frameworks, thus verifying its universality and robustness in various environments.
Furthermore, we can consider the potential extension of the proposal to 3D object detection. It is noted that 3D object recognition can also be affected by adversarial attacks. In the future, the exploration of whether diffusion models can be used in 3D object detection to defend against these attacks will be pursued.
6. Conclusions
In this paper, we introduced an innovative approach based on conditional diffusion models to mitigate the vulnerability of object detection systems against adversarial attacks. The method was based on diffusion principles and was divided into two main stages: the initial stage used random checkerboard masks to fill adversarial samples while preserving unmasked regions; the inference stage employed a pre-trained diffusion model to restore adversarial images through a reverse denoising process. Experimental results demonstrated that the proposed method exhibited strong defense capabilities against adversarial attacks across multiple datasets. On the PASCAL VOC dataset, the method achieved an average precision (mAP) of 80.8% and 81.1% under non-APT and APT PGD attacks, respectively. On the COCO dataset, the performance for clear images was 67.8%, and under APTPGD attacks, it scored 61.4%. The Fréchet Inception Distance (FID) evaluation of image restoration quality showed an FID value of 39.95 for the VOC dataset and 45.67 for the COCO dataset, indicating higher-quality generated images on the VOC dataset. Ablation experiments assessed the contribution of different components to overall performance, further validating the effectiveness of the method. In summary, the approach we proposed in this study enhanced the robustness of the target detection framework against adversarial attacks by restoring adversarial sample processing through diffusion modeling, yielding superior empirical outcomes across various datasets.
Author Contributions
Conceptualization, X.Y.; methodology, X.Y.; software, X.Y.; validation, J.S. and S.C.; formal analysis, J.S. and S.C.; investigation, Z.Y., J.S. and S.C.; resources, Z.Y.; data curation, Z.Y., X.D. and S.C.; writing—original draft preparation, X.Y.; writing—review and editing, Q.Z. and X.D.; visualization, X.Y.; supervision, Q.Z. and X.D.; project administration, Q.Z. and X.D.; All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by the FDCT under its General R&D Subsidy Program Fund (grant no. 0038/2022/A), by NSFC-FDCT under its Joint Scientific Research Project Fund (grant no. 0051/2022/AFJ), by the Xiamen Research Project for the Returned Overseas Chinese Scholars (Xiamen Human Resources Society [2022] 205-02), by the Xiamen Science and Technology Plan Project (3502Z20231042), and by the Xiamen University of Technology High-Level Talent Launch Project (YKJ22041R).
Data Availability Statement
The data supporting the results reported in this study are publicly available. The COCO 2017 dataset can be accessed at https://cocodataset.org/#home (accessed on 30 September 2024), and the PASCAL VOC dataset can be accessed at http://host.robots.ox.ac.uk/pascal/VOC/ (accessed on 30 September 2024). These datasets are publicly available and can be downloaded from their respective official websites. No new data were created in this study.
Conflicts of Interest
The authors declare that they have no conflicts of interest.
References
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1–9. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; IEEE: New York, NY, USA, 2016; pp. 770–778. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; IEEE: New York, NY, USA, 2015; pp. 1440–1448. [Google Scholar]
- Zhang, Z.; Qiao, S.; Xie, C.; Shen, W.; Wang, B.; Yuille, A.L. Single-shot object detection with enriched semantics. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; IEEE: New York, NY, USA, 2018; pp. 5813–5821. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 1–9. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; IEEE: New York, NY, USA, 2015; pp. 3431–3440. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Wang, J.; Zhang, Z.; Xie, C.; Zhou, Y.; Premachandran, V.; Zhu, J.; Xie, L.; Yuille, A. Visual concepts and compositional voting. arXiv 2017, arXiv:1711.04451. [Google Scholar] [CrossRef]
- Deng, S.; Wen, J.; Liu, C.; Yan, K.; Xu, G.; Xu, Y. Projective Incomplete Multi-View Clustering. IEEE Trans. Neural Netw. Learn. Syst. 2023, 35, 10539–10551. [Google Scholar] [CrossRef]
- Wen, J.; Liu, C.; Deng, S.; Liu, Y.; Fei, L.; Yan, K.; Xu, Y. Deep Double Incomplete Multi-View Multi-Label Learning With Incomplete Labels and Missing Views. IEEE Trans. Neural Netw. Learn. Syst. 2023, 35, 11396–11408. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Kurakin, A.; Goodfellow, I.; Bengio, S. Adversarial machine learning at scale. arXiv 2016, arXiv:1611.01236. [Google Scholar]
- Tramèr, F.; Kurakin, A.; Papernot, N.; Goodfellow, I.; Boneh, D.; McDaniel, P. Ensemble adversarial training: Attacks and defenses. arXiv 2017, arXiv:1705.07204. [Google Scholar]
- Cao, X.; Gong, N.Z. Mitigating evasion attacks to deep neural networks via region-based classification. In Proceedings of the 33rd Annual Computer Security Applications Conference, Orlando, FL, USA, 4–8 December 2017; ACM: New York, NY, USA, 2017; pp. 278–287. [Google Scholar]
- Feinman, R.; Curtin, R.R.; Shintre, S.; Gardner, A.B. Detecting adversarial samples from artifacts. arXiv 2017, arXiv:1703.00410. [Google Scholar]
- Papernot, N.; McDaniel, P.; Wu, X.; Jha, S.; Swami, A. Distillation as a defense to adversarial perturbations against deep neural networks. In Proceedings of the 2016 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2016; IEEE: New York, NY, USA, 2016; pp. 582–597. [Google Scholar]
- Meng, D.; Chen, H. Magnet: A two-pronged defense against adversarial examples. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017; ACM: New York, NY, USA, 2017; pp. 135–147. [Google Scholar]
- Lu, J.; Sibai, H.; Fabry, E.; Forsyth, D. No need to worry about adversarial examples in object detection in autonomous vehicles. arXiv 2017, arXiv:1707.03501. [Google Scholar]
- Wei, X.; Liang, S.; Chen, N.; Cao, X. Transferable adversarial attacks for image and video object detection. arXiv 2018, arXiv:1811.12641. [Google Scholar]
- Papernot, N.; Faghri, F.; Carlini, N.; Goodfellow, I.; Feinman, R.; Kurakin, A.; Xie, C.; Sharma, Y.; Brown, T.; Roy, A. Technical report on the CleverHans v2.1.0 adversarial examples library. arXiv 2016, arXiv:1610.00768. [Google Scholar]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. arXiv 2013, arXiv:1312.6199. [Google Scholar]
- Hendrycks, D.; Gimpel, K. Early methods for detecting adversarial images. arXiv 2016, arXiv:1608.00530. [Google Scholar]
- Hill, M.; Mitchell, J.; Zhu, S.-C. Stochastic Security: Adversarial Defense Using Long-Run Dynamics of Energy-Based Models. arXiv 2020, arXiv:2005.13525. [Google Scholar]
- Lin, W.-A.; Balaji, Y.; Samangouei, P.; Chellappa, R. Invert and Defend: Model-Based Approximate Inversion of Generative Adversarial Networks for Secure Inference. arXiv 2019, arXiv:1911.10291. [Google Scholar]
- Song, Y.; Kim, T.; Nowozin, S.; Ermon, S.; Kushman, N. PixelDefend: Leveraging Generative Models to Understand and Defend Against Adversarial Examples. arXiv 2017, arXiv:1710.10766. [Google Scholar]
- Du, Y.; Mordatch, I. Implicit Generation and Modeling with Energy Based Models. In Proceedings of the 33rd Conference on Neural Information Processing Systems (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Grathwohl, W.; Wang, K.-C.; Jacobsen, J.-H.; Duvenaud, D.; Norouzi, M.; Swersky, K. Your Classifier is Secretly an Energy Based Model and You Should Treat It Like One. arXiv 2019, arXiv:1912.03263. [Google Scholar]
- Yoon, J.; Hwang, S.J.; Lee, J. Adversarial Purification with Score-Based Generative Models. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 12062–12072. [Google Scholar]
- Song, Y.; Ermon, S. Generative Modeling by Estimating Gradients of the Data Distribution. Adv. Neural Inf. Process. Syst. 2019, 32, 11918–11930. [Google Scholar]
- Saharia, C.; Chan, W.; Chang, H.; Lee, C.; Ho, J.; Salimans, T.; Fleet, D.; Norouzi, M. Palette: Image-to-image diffusion models. In Proceedings of the ACM SIGGRAPH 2022 Conference Proceedings, Vancouver, BC, Canada, 7–11 August 2022; ACM: New York, NY, USA, 2022; pp. 1–10. [Google Scholar]
- Austin, J.; Johnson, D.D.; Ho, J.; Tarlow, D.; Van Den Berg, R. Structured denoising diffusion models in discrete state-spaces. Adv. Neural Inf. Process. Syst. 2021, 34, 17981–17993. [Google Scholar]
- Saharia, C.; Ho, J.; Chan, W.; Salimans, T.; Fleet, D.J.; Norouzi, M. Image super-resolution via iterative refinement. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 4713–4726. [Google Scholar] [CrossRef]
- Dhariwal, P.; Nichol, A. Diffusion models beat GANs on image synthesis. Adv. Neural Inf. Process. Syst. 2021, 34, 8780–8794. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; IEEE: New York, NY, USA, 2016; pp. 779–788. [Google Scholar]
- Sermanet, P.; Eigen, D.; Zhang, X.; Mathieu, M.; Fergus, R.; LeCun, Y. Overfeat: Integrated recognition, localization and detection using convolutional networks. arXiv 2013, arXiv:1312.6229. [Google Scholar]
- Wen, J.; Deng, S.; Fei, L.; Zhang, Z.; Zhang, B.; Zhang, Z.; Xu, Y. Discriminative Regression with Adaptive Graph Diffusion. IEEE Trans. Neural Netw. Learn. Syst. 2022, 35, 1797–1809. [Google Scholar] [CrossRef]
- Liu, C.; Wen, J.; Wu, Z.; Luo, X.; Huang, C.; Xu, Y. Information Recovery-Driven Deep Incomplete Multiview Clustering Network. IEEE Trans. Neural Netw. Learn. Syst. 2023, 1–11. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; IEEE: New York, NY, USA, 2014; pp. 580–587. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object detection via region-based fully convolutional networks. Adv. Neural Inf. Process. Syst. 2016, 29, 1–9. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; IEEE: New York, NY, USA, 2017; pp. 2961–2969. [Google Scholar]
- Li, Z.; Peng, C.; Yu, G.; Zhang, X.; Deng, Y.; Sun, J. Light-head R-CNN: In defense of two-stage object detector. arXiv 2017, arXiv:1711.07264. [Google Scholar]
- Zeng, X. Deep Neural Networks for Object Detection; The Chinese University of Hong Kong: Hong Kong, China, 2016. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single shot multibox detector. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part I 14; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is All You Need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Shah, S.; Tembhurne, J. Object Detection Using Convolutional Neural Networks and Transformer-Based Models: A Review. J. Electr. Syst. Inf. Technol. 2023, 10, 54. [Google Scholar] [CrossRef]
- Ho, J.; Jain, A.; Abbeel, P. Denoising diffusion probabilistic models. Adv. Neural Inf. Process. Syst. 2020, 33, 6840–6851. [Google Scholar]
- Sohl-Dickstein, J.; Weiss, E.; Maheswaranathan, N.; Ganguli, S. Deep unsupervised learning using nonequilibrium thermodynamics. In International Conference on Machine Learning; PMLR: Lille, France, 2015; pp. 2256–2265. [Google Scholar]
- Song, Y.; Sohl-Dickstein, J.; Kingma, D.P.; Kumar, A.; Ermon, S.; Poole, B. Score-based generative modeling through stochastic differential equations. arXiv 2020, arXiv:2011.13456. [Google Scholar]
- Ho, J.; Saharia, C.; Chan, W.; Fleet, D.J.; Norouzi, M.; Salimans, T. Cascaded diffusion models for high fidelity image generation. J. Mach. Learn. Res. 2022, 23, 1–33. [Google Scholar]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; IEEE: New York, NY, USA, 2022; pp. 10684–10695. [Google Scholar]
- Lugmayr, A.; Danelljan, M.; Romero, A.; Yu, F.; Timofte, R.; Van Gool, L. Repaint: Inpainting using denoising diffusion probabilistic models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; IEEE: New York, NY, USA, 2022; pp. 11461–11471. [Google Scholar]
- Xia, B.; Zhang, Y.; Wang, S.; Wang, Y.; Wu, X.; Tian, Y.; Yang, W.; Van Gool, L. Diffir: Efficient diffusion model for image restoration. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; IEEE: New York, NY, USA, 2023; pp. 13095–13105. [Google Scholar]
- Fernandez, V.; Sanchez, P.; Pinaya, W.H.L.; Jacenków, G.; Tsaftaris, S.A.; Cardoso, J. Privacy distillation: Reducing re-identification risk of multimodal diffusion models. arXiv 2023, arXiv:2306.01322. [Google Scholar]
- Matsumoto, T.; Miura, T.; Yanai, N. Membership Inference Attacks against Diffusion Models. In Proceedings of the 2023 IEEE Security and Privacy Workshops (SPW), San Francisco, CA, USA, 22–26 May 2023; IEEE: New York, NY, USA, 2023; pp. 77–83. [Google Scholar]
- An, S.; Chou, S.-Y.; Zhang, K.; Xu, Q.; Tao, G.; Shen, G.; Cheng, S.; Ma, S.; Chen, P.-Y.; Ho, T.-Y.; et al. Elijah: Eliminating Backdoors Injected in Diffusion Models via Distribution Shift. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; Volume 38, Number 10. pp. 10847–10855. [Google Scholar]
- Duan, J.; Kong, F.; Wang, S.; Shi, X.; Xu, K. Are Diffusion Models Vulnerable to Membership Inference Attacks? In Proceedings of the International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2023; PMLR: Cambridge, UK, 2023; pp. 8717–8730. [Google Scholar]
- Chen, W.; Song, D.; Li, B. Trojdiff: Trojan Attacks on Diffusion Models with Diverse Targets. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 4035–4044. [Google Scholar]
- Zhai, S.; Dong, Y.; Shen, Q.; Pu, S.; Fang, Y.; Su, H. Text-to-Image Diffusion Models Can Be Easily Backdoored through Multimodal Data Poisoning. In Proceedings of the 31st ACM International Conference on Multimedia, Ottawa, ON, Canada, 2–6 October 2023; p. 1577. [Google Scholar]
- Liang, C.; Wu, X.; Hua, Y.; Zhang, J.; Xue, Y.; Song, T.; Xue, Z.; Ma, R.; Guan, H. Adversarial Example Does Good: Preventing Painting Imitation from Diffusion Models via Adversarial Examples. arXiv 2023, arXiv:2302.04578. [Google Scholar]
- Liang, C.; Wu, X. Mist: Towards Improved Adversarial Examples for Diffusion Models. arXiv 2023, arXiv:2305.12683. [Google Scholar]
- Xie, C.; Wang, J.; Zhang, Z.; Zhou, Y.; Xie, L.; Yuille, A. Adversarial Examples for Semantic Segmentation and Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; IEEE: New York, NY, USA, 2017; pp. 1369–1378. [Google Scholar]
- Li, Y.; Tian, D.; Chang, M.-C.; Bian, X.; Lyu, S. Robust adversarial perturbation on deep proposal-based models. arXiv 2018, arXiv:1809.05962. [Google Scholar]
- Chow, K.-H.; Liu, L.; Loper, M.; Bae, J.; Gursoy, M.E.; Truex, S.; Wei, W.; Wu, Y. Adversarial objectness gradient attacks in real-time object detection systems. In Proceedings of the 2020 Second IEEE International Conference on Trust, Privacy and Security in Intelligent Systems and Applications (TPS-ISA), Atlanta, GA, USA, 28–31 October 2020; IEEE: New York, NY, USA, 2020; pp. 263–272. [Google Scholar]
- Bao, J. Sparse adversarial attack to object detection. arXiv 2020, arXiv:2012.13692. [Google Scholar]
- Thys, S.; Van Ranst, W.; Goedemé, T. Fooling automated surveillance cameras: Adversarial patches to attack person detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019; IEEE: New York, NY, USA, 2019. [Google Scholar]
- Yang, D.Y.; Xiong, J.; Li, X.; Yan, X.; Raiti, J.; Wang, Y.; Wu, H.; Zhong, Z. Building Towards “Invisible Cloak”: Robust Physical Adversarial Attack on YOLO Object Detector. In Proceedings of the 2018 9th IEEE Annual Ubiquitous Computing, Electronics & Mobile Communication Conference (UEMCON), New York, NY, USA, 8–10 November 2018; IEEE: New York, NY, USA, 2018; pp. 368–374. [Google Scholar]
- Zhao, Y.; Yan, H.; Wei, X. Object hider: Adversarial patch attack against object detectors. arXiv 2020, arXiv:2010.14974. [Google Scholar]
- Liu, X.; Yang, H.; Liu, Z.; Song, L.; Li, H.; Chen, Y. Dpatch: An adversarial patch attack on object detectors. arXiv 2018, arXiv:1806.02299. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Stoken, A.; Borovec, J.; Kwon, Y.; Michael, K.; Fang, J.; Zeng, Y.; Wong, C.; Montes, D.; et al. ultralytics/yolov5: V7.0-yolov5 sota realtime instance segmentation. Zenodo 2022. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollar, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014, Proceedings, Part V 13; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards Deep Learning Models Resistant to Adversarial Attacks. arXiv 2017, arXiv:1706.06083. [Google Scholar]
- Dong, Y.; Liao, F.; Pang, T.; Su, H.; Zhu, J.; Hu, X.; Li, J. Boosting Adversarial Attacks with Momentum. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; IEEE: New York, NY, USA, 2018; pp. 9185–9193. [Google Scholar]
- Dziugaite, G.K.; Ghahramani, Z.; Roy, D.M. A study of the effect of jpg compression on adversarial images. arXiv 2016, arXiv:1608.00853. [Google Scholar]
- Yu, C.; Chen, J.; Xue, Y.; Liu, Y.; Wan, W.; Bao, J.; Ma, H. Defending Against Universal Adversarial Patches by Clipping Feature Norms. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; IEEE: New York, NY, USA, 2021; pp. 16434–16442. [Google Scholar]
- Xu, W.; Evans, D.; Qi, Y. Feature Squeezing: Detecting Adversarial Examples in Deep Neural Networks. arXiv 2017, arXiv:1704.01155. [Google Scholar]
- Liu, J.; Levine, A.; Lau, C.P.; Chellappa, R.; Feizi, S. Segment and Complete: Defending Object Detectors Against Adversarial Patch Attacks with Robust Patch Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; IEEE: New York, NY, USA, 2022; pp. 14973–14982. [Google Scholar]
- Cai, J.; Chen, S.; Li, H.; Xia, B.; Mao, Z.; Yuan, W. HARP: Let Object Detector Undergo Hyperplasia to Counter Adversarial Patches. In Proceedings of the 31st ACM International Conference on Multimedia; ACM: New York, NY, USA, 2023; pp. 2673–2683. [Google Scholar]
- Brown, T.B.; Mané, D.; Roy, A.; Abadi, M.; Gilmer, J. Adversarial Patch. arXiv 2017, arXiv:1712.09665. [Google Scholar]





Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).