Abstract
With the advancement of the large language model (LLM), the demand for data labeling services has increased dramatically. Big models are inseparable from high-quality, specialized scene data, from training to deploying application iterations to landing generation. However, how to achieve intelligent labeling consistency and accuracy and improve labeling efficiency in distributed data middleware scenarios is the main difficulty in enhancing the quality of labeled data at present. In this paper, we proposed an asynchronous federated learning optimization method based on the combination of LLM and digital twin technology. By analysising and comparing and with other existing asynchronous federated learning algorithms, the experimental results show that our proposed method outperforms other algorithms in terms of performance, such as model accuracy and running time. The experimental validation results show that our proposed method has good performance compared with other algorithms in the process of intelligent labeling both in terms of accuracy and running solves the consistency and accuracy problems of intelligent labeling in a distributed data center.
Keywords:
large language model; digital twins; intelligent labeling; asynchronous federated learning MSC:
68W15
1. Introduction
In the data center, the label is its core component. With the development of intelligence, labels are also gradually developing in the direction of intelligent labeling. How to realize the intelligence of tags in the distributed data center and improve the accuracy of intelligent labeling is the focus of current research. However, Digital Twins (DT) and the Large Language Model (LLM) are cutting-edge technologies that have attracted much attention in recent years. In traditional digital twin technology, commonly used AI algorithms include Reinforcement Learning(RL), Graph Neural Networks(GNN), and so on. With the continuous emergence of large model technology, LLM provides new ideas and methods for the training of digital twin models. Digital Twins provide support for the full life cycle management of entities by constructing digital models of physical entities and mapping their states and behaviors in real time. LLM is capable of learning semantic knowledge from massive unstructured text data and has natural language understanding and content generation capabilities close to the human level. If the two can be organically combined and applied to the smart labeling system, it will inevitably lead to a significant increase in labeling accuracy and labeling management level. The synergy of DT and LLM will promote the labeling technology to a higher level of intelligent development.
There are a number of major applications of large language models combined with digital twin technology. Primarily, the training of large models usually requires a large amount of data and computational resources. By constructing a digital twin simulation environment connected to real-world data streams, complex interaction scenarios can be simulated during training. Furthermore, in the inference stage of the large model, digital twin technology can monitor the inference process in real time and dynamically adjust the inference path and parameters of the model according to the actual situation. For example, in the cloud computing environment, digital twin can adjust the computational resource allocation of the large model according to the real-time load of the server to optimize the reasoning efficiency. In edge computing scenarios, digital twins can also help achieve dynamic load balancing to ensure an efficient and stable inference process. Furthermore, by combining the user’s digital twin model, the big model can generate more personalized and accurate services. For example, in a personalized recommendation system, the user’s behavioral data can be updated in real time into their digital twin model and, through interaction with the big model, generate recommendation results that are more in line with the user’s preferences. The digital twin can also simulate long-term changes in user preferences and habits, making recommendations more predictive. Eventually, DT technology can also be used to validate the security and reliability of the big model. By simulating potential attacks and anomalies, DT can help identify the vulnerabilities of a model and adjust the model in a timely manner through a feedback mechanism to improve its security in a real environment.
The main results and contributions of this paper are as follows:
- (1)
- In order to solve the problems of poor quality of labeled data, missing labeled data need to be filled in, and it is not possible to introduce a priori knowledge; in this paper, a combination of the large language model (LLM) and the digital twin (DT) model is proposed to design a mechanism based on DT and LLM, which utilizes the mechanism model of DT to realize the completion of the missing labeled information, as well as using the large model technology to realize the trend information The prediction of trend information is realized by using the mechanism model of digital twin.
- (2)
- In order to solve the problem of heterogeneity of labeling data in distributed data middle grounds, in this paper digital twin technology and big model technology are introduced in asynchronous federated learning scenarios, so that each local client interacts with the information, and this ultimately results in a stable convergence of the accuracy of the intelligent labeling model to about 99%.
- (3)
- Finally, the feasibility of our proposed method and future challenges are reported through experimental data validation and qualitative and quantitative analysis.
2. Related Work
This section provides an in-depth study of the combined application and analysis of big language modeling techniques and digital twin technologies in asynchronous federated learning. The relevant domain studies on big language modeling and digital twin technology are first introduced, respectively. Subsequently, asynchronous federated learning is explored in detail. Lastly, the relationship with this paper is analyzed by comparison, highlighting the unique contributions and progress in research progress made by this study.
2.1. Digital Twins
As the development trend of all industries towards informationization and intelligence is gradually highlighted [1], DT technology has begun to receive attention and is gradually being applied in a variety of fields, such as aerospace and healthcare. The core of DT lies in creating a virtual digital mapping of a physical entity. Currently, there are many more advanced and detailed digital twin related studies. Wang et al. [2] proposed a comprehensive investigation of human DT. Organically, they interact with and combine the virtual entities of digital twins with the human body, and study and explore their applications. Torzoni et al. [3] proposed a DT framework to advance the safety prediction and maintenance of civil engineering with respect to safety issues. Tao et al. [4] designed a DT architecture, makeTwin, for a software platform, and analyzed its top ten core functions and information interaction mechanisms. This research provides new ideas and conceptual support for the research of text. In terms of bibliometrics, Wang et al. [5] summarized in detail the use of bibliometrics for DT technology in existing scientific fields. In the construction industry, digital twin technology also plays an active role. Specifically, Long et al. [6] made a systematic literature review of the application of DT in building construction to develop an integrated framework and postulated three research gaps. Piras et al. [7] proposed the use of DTs in the construction industry for framing and analyzed the key enablers for the same.
The development of digital twin technology also brings a series of challenges. Cheng et al. [8] applied DT technology to resource management based on reinforcement learning and analyzed the opportunities and challenges. Tripathi et al. [9] analyzed the application of DT in ecosystems and its challenges. AIBalkhy et al. [10] analyzed the opportunities and challenges of DT technology in the field of construction. Moreover, DT technology still faces challenges in terms of interpretability, such as cybersecurity automation and trustworthiness [11]. Digital twins play a key role in cybersecurity issues, but there are still technical challenges in terms of the complexity of AI models. In conclusion, there are still limitations in DT technology in terms of maturity, complexity of modeling, accuracy of prediction, and security, and how to improve its technical difficulties and realize its great potential is the new hotspot in current research.
2.2. Large Language Model (LLM)
The rise of LLM has led to unprecedented new breakthroughs in the field of Natural Language Processing (NLP). LLMs, referred to as Big Models, have stirred up a wave of artificial intelligence with their powerful semantic comprehension and content generation capabilities, and have attracted extensive research and attention from the academic community. The Big Language Model is developed based on the Transformer-based NLP architecture proposed by Google and has gone through the following stages: language model, pre-training model, large-scale pre-training model. In the Big Language Model, the main technologies are word embedding technology, positional coding technology, and attention mechanism technology. Among these, the attention mechanism focus can be categorized into self-attention mechanism and multi-head attention.
The development of large language models has gone through several important stages. Early models, such as Word2Vec [12], GloVe [13], and FastText [14], focused on capturing the basic units of a language, but could not fully understand the complex relationships between words in context. Subsequently, models such as BERT [15] and GPT introduced the Transformer architecture, which significantly improved machine reading comprehension and text generation. In 2021 and 2022, models such as Jurassic-1 [16], GPT-Neo [17], and Chinchilla [18] appeared, which handle large-scale datasets with food performance. In June 2021, GPT-3 was released, demonstrating the potential of the model to accomplish multiple complex tasks without task-specific training. In 2023, models such as LLaMA-2 [19], GPT-4 [20], and Claude-2 [21] appeared, which made technical advances and pushed forward the development of LLM at the application level.
Semantic comprehension ability is a core task in big language modeling, which involves in-depth understanding and analysis of words, phrases, sentences, and connotative gist in text. In big models, pre-training and instruction fine-tuning are two key steps. Firstly, the pre-trained model learns the generic features of the text through unsupervised methods, and masters the basic semantic information and language structure. Then, through the instruction fine-tuning process, the pre-trained model is fine-tuned for specific tasks to improve performance. LLM’s semantic understanding capability shows outstanding performance in practical applications. Specifically, in the process of relational task extraction, by identifying and extracting the relationships between entities, structured key information can be extracted from unstructured text data, which can be formed into keywords or labels, thus updating and enriching the knowledge vector base. If the specific relationships of these entities are linked and analyzed, a relational knowledge graph can be constructed, and at the same time feed the big model to improve its semantic understanding and text generation capabilities, and enhance the effectiveness of information retrieval. Currently, big language modeling has been applied to medicine and has made outstanding contributions [22], improving the efficiency and effectiveness of medical clinics, education and research.
The technical challenges faced by big language models include high consumption of resources for model training and inference, compliance issues for model-generated content, etc. Kasneci et al. [23] studied the challenges of big language modeling in education and analyzed the potential bias in the outputs, the need for continuous human supervision, and the fact that potential misuse is not limited to the education industry. These challenges are not insurmountable and the exploration of solutions will be the focus of future research.
2.3. Asynchronous Federated Learning
Aiming at the problem of smart labeling data heterogeneity in the distributed data middleware, which is the application scenario of this paper, the asynchronous federation learning (AFL) method is selected for the applied research. AFL allows multiple clients to train a model together without sharing raw data. With the development of computing and communication technologies, AFL has shown its unique advantages in dealing with the challenges of heterogeneous devices and uneven data distribution. The origin of AFL can be traced back to the proposal of Federated Learning (FL), proposed by Google 2016. With the improvement of data privacy protection regulations and the development of digital economy, FL is rapidly gaining attention. AFL, as a variant of FL, aims to solve the problem of synchronous updating in traditional FL by allowing clients to asynchronously update the model during the training process to adapt to the computational and communication capabilities of different clients. Xu et al. [24] completed a survey and analytical study of AFL for heterogeneous devices from the aspects of efficiency, performance, privacy, and security. Wang et al. [25], in a wireless network, designed an AFL framework and found that it adapts well to the heterogeneity of users, communication environments and learning. Liu et al. [26] designed an adaptive AFL scheme for the problem of resource-constrained edge computing to solve the resource allocation optimization problem.
Despite the obvious advantages of AFL in terms of efficiency and privacy protection, it also faces some challenges. These are categorized into four aspects: data heterogeneity, model heterogeneity, communication heterogeneity, and device heterogeneity. Future research directions may include improving communication efficiency, ensuring fairness in federated learning, enhancing privacy protection, improving robustness to attacks, and developing a unified benchmarking framework.
3. Model
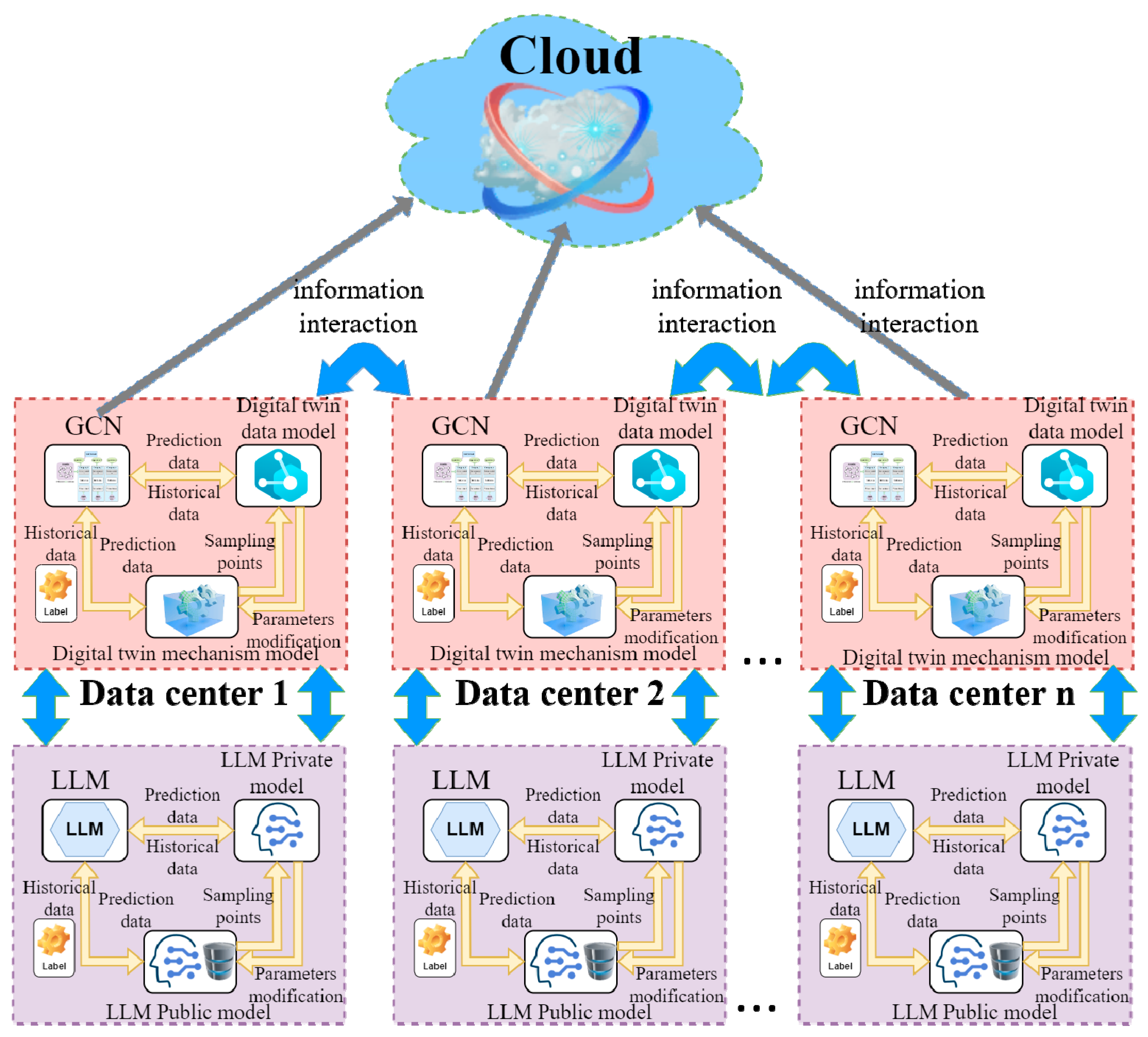
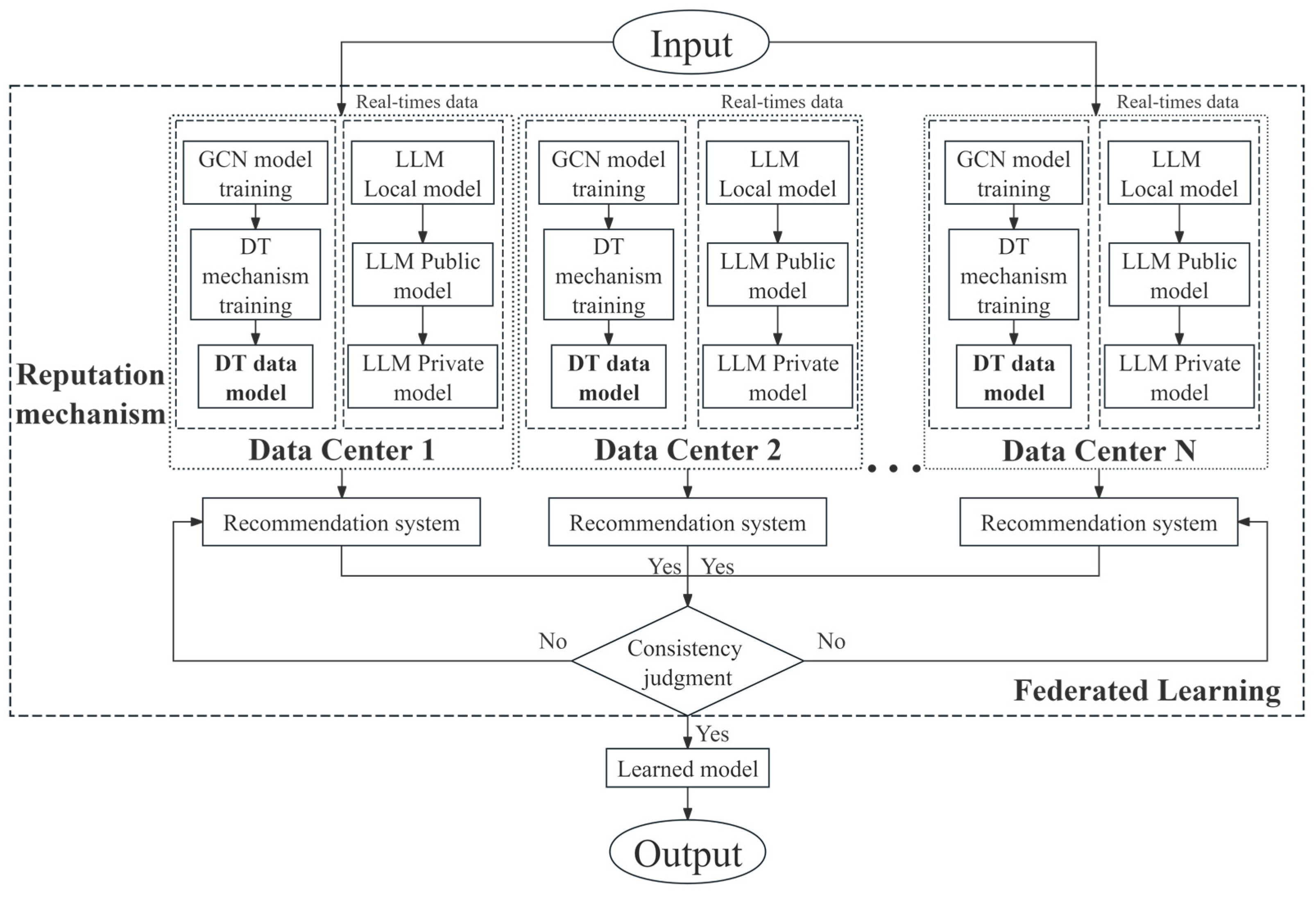
In this section, we describe the system architecture, specifically mapping its core ideas, as shown in Figure 1.
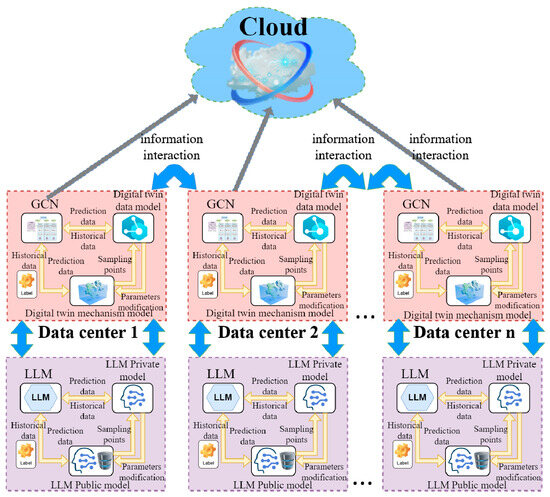
Figure 1.
Architecture of a Distributed Intelligent Annotation System Based on the Combination of Big Model and Digital Twin.
The system framework diagram of the combination of digital twin technology and large language modeling technology for intelligent labeling process is shown. It is explained as follows. Firstly, each of them performs data annotation locally to facilitate the previous GCN model in order to train the labeled data, and the information interacts with the digital twin mechanistic model through the historical data and predictive data. At the same time, private data and public data are used to design the mechanism model of the large language model, and the large language model system formed by it interacts with the local intelligent data center for intelligent labeling model. Finally, each local data center interacts with the others and shares the model parameters, so that its intelligent labeling model maintains labeling accuracy and labeling consistency.
3.1. Intelligent Labeling Mechanisms Based on Large Language Models and Digital Twins
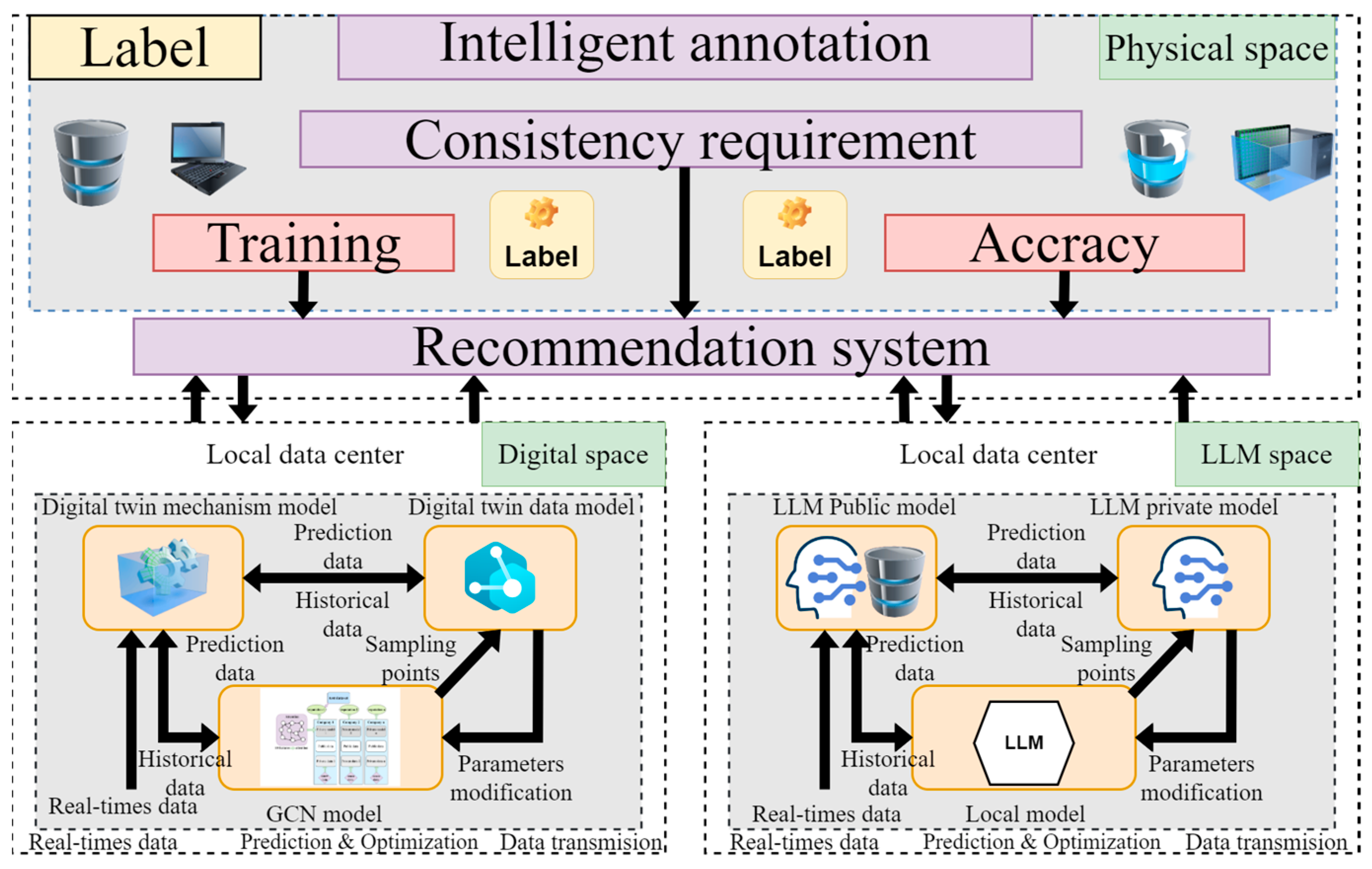
In order to realize the intelligence of labels, the combination of DT and LLM is used to enhance the accuracy and intelligence of the intelligent labeling system. On the one hand, the big model can provide deeper data analysis and insights to help the DT make more accurate predictions and decisions. On the other hand, DT technology greatly enhances the accuracy of model labeling by virtue of its accurate, reliable, and high-fidelity virtual models. Finally, the dynamic information interaction between each local client is carried out through the model heterogeneous approach, which deeply mines the data value, increases the generalization ability of the model, improves its prediction ability, and enhances its fairness. The details are shown in Figure 2.
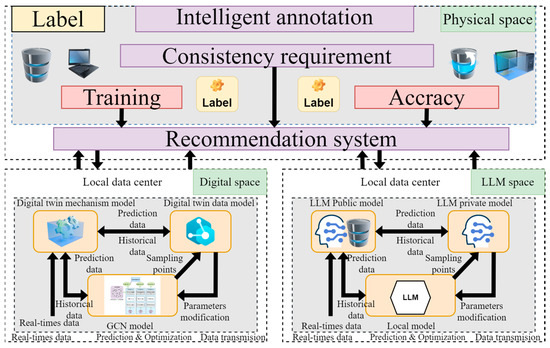
Figure 2.
Framework Diagram of Local Intelligent Marking Model Combining Digital Twin Model and Large Model.
3.1.1. DT System Model
DT technology has a strong interdependence with big data analytics. Cloud computing provides powerful computing and storage resources that can support real-time data processing and analog computation of digital twin technology. Big data analytics technology can help digital twin technology mine valuable information from a large amount of data, thus improving the accuracy and reliability of DT technology. In the distributed data center intelligent labeling system, DT technology can provide real-time, accurate, scalable and visualized functional characteristics for intelligent labeling, which can simulate the state and behavior of the physical model of intelligent labeling in real time and stand on multiple physical counterparts to form a digital twin system for intelligent labeling.
Digital twin technology is the key for the realization of digital upgrading and transformation, and it is an important technology for the realization of intelligent marking. In order to accurately describe the core of the local intelligent marking model, digital twin technology is used for modeling, through the mechanism model, to make up for defects, such as incomplete labels in the local physical intelligent labeling model, through data collection, data aggregation, data preprocessing and data governance, to data pre-training, data intelligent decision-making and labeling, data updating and optimization, and finally the output of intelligent labeling data. In distributed data centers, each virtual twin can improve the intelligent decision-making capability of the whole system by utilizing the information that each twin possesses and achieving better semantic reconfiguration performance. In order to achieve effective information communication interactions, standardized communication protocols and interfaces need to be defined and implemented to ensure that data can flow seamlessly between physical entities, digital twins, and the network. The digital twin mechanism model runs through the whole process. Specifically:
DT: The number of local intelligent labeling models participating in the training of the information interaction model is At this point, the client model
is represented as follows:
where denotes contextual semantic understanding, represents the service sent by the local client m at time t, represents the computational power of the local intelligent marking model at moment t, and represents the packet loss rate of the local smart marking client model at moment t. Their error values are and . Therefore, the calibrated digital twin model is:
3.1.2. Large Language Model
LLM is a deep learning neural network model based on Transformer’s self-attention mechanism, which focuses on extracting and labeling keywords and summaries from unstructured text data using the semantic understanding and content generation capabilities of large language modeling technology. Large language models go through data cleaning and preprocessing stages for data preparation, selecting model architectures, and then pre-training through the use of unsupervised learning. Instruction fine-tuning is performed on specific tasks to adapt to the page count task requirements. Finally, model optimization and evaluation is performed.
First of all, knowledge base construction is performed. The knowledge base is the core component of intelligent marking driven by the digital twin large language model. After pre-processing the public data by collecting, filtering, integrating, data conversion from unstructured to structured data format, data cleaning and standardization, the public data are constructed into a knowledge base through vectorization. The core technology includes word vector representation, word embedding and high dimensional vector representation of documents. At the same time, through contextual semantic understanding and cue engineering, the public data are provided to the large language model for summarization, so as to improve the interpretability and updatability of the labeling results.
- (1)
- Based on the self-attention mechanism formula as follows:
- (2)
- Pre-training
In the pre-training process, the first vectorized representation is performed, which can be divided into two dimensions. On the one hand, the labels are vectorized to represent the existing labels in the label library, which can be referred to the word vector approach. By pre-training on a large language model, word vectors containing semantics can be learned. The word vectors are word embeddings (Word Embeddings) using the Word2Vec method, which is trained on neural networks to obtain word embeddings that capture the moral and grammatical relationships between words. The pre-trained word vectors are migrated to the task, which in turn improves the subsequent results.
The training time can be reduced by turning a one-time V-classification task of label classification into a two-time classification task concerning logV times. The random probabilistic noise representation is N. The positive example is N+ and the negative example is N−. Context is denoted by c. Therefore, the minimized log-likelihood function of the word vector is F(N). The formula is expressed as follows:
On the other hand, the unstructured text is subjected to text vectorization representation. The Tern Frequency–Inverse Document Frequency method (TF–IDF) is used to vec-torize the document by evaluating the importance of feature words in the document.
- (3)
- Command fine-tuning process: fine-tuning can be achieved by changing the model weights with the formula:
- (4)
- Design Prompt Project:
Then, based on the task prompts, an embedding model, specifically labeled entity embedding, is introduced to transform the knowledge extraction into labels for the embedding model and assign tasks.
where
stands for entity labeling.
- (5)
- Mean Average Precision (MAP)
For each query Q, the average accuracy for correct retrieval for labeling is calculated and the obtained labels are de-averaged for all queries. The average accuracy of retrieved result labels, obtained by measuring the results of multiple labeling queries, is suitable for evaluating the accuracy of results.
where denotes the total number of times the label was queried, represents the order of inquiry, and represents the accuracy of the label obtained from the i-th query.
3.1.3. Local Labeling Model
The local intelligent labeling model uses the previous graph convolutional neural network base model for intelligent labeling, and 10 feature nodes are selected as 10 labels for intelligent labeling, and represented by the regularization model, where is the regular term parameter which can be used to denote the known label according to the semi-supervised learning approach , and is the Laplace operator:
We give the graph with 10 feature nodes . The adjacency matrix is
and the node identity matrix is . At this time, the normalized adjacency matrix
, D is the diagonal matrix. The semi-supervised learning-based graph convolutional neural network model is based on each layer:
where is the vertex feature layer and each row uses the feature layer, employing the normalized adjacency matrix, and finally the labels are classified.
3.1.4. GCN+DT+LLM
GCN, as a local intelligent marking model, is combined first with DT first to enhance the interpretability of the intelligent marking model. Meanwhile, combining LLM with DT as an a priori mechanism model and interacting information with GCN and DT combined with the local intelligent labeling model to form a global model enhances the semantic information of the graph data structure and textual data, and enhances the representation capability. Additionally, LLM can generate additional auxiliary information for sparse data through its powerful text generation capability, which enhances the understanding of text by the intelligent labeling model and improves the generalization capability of the model. Consequently, the final global model is:
3.2. Reputation Based on Large Language Modeling with Digital Twins
In the distributed data center smart labeling system, there are still problems of data quality, model efficiency, and reliability and security in the process of information interaction between each local smart labeling model. Therefore, for the existence of dynamic model parameter information interaction in the global smart labeling model and to deal with the security interaction problems in the process, the smart labeling model is combined with asynchronous federated learning to improve the accuracy and consistency of the distributed smart labels in the whole domain. First of all, the GCN model is combined with DT to form a local smart labeling model, which has accuracy limitations and mechanism limitations. Then, the current hot LLM technology is introduced to combine with DT and externalize the knowledge base information, which is used as a tuning mechanism model to interact with the former. Furthermore, an incentive-based reputation mechanism is introduced to ensure the overall performance and security of the distributed intelligent labeling system by evaluating the reliability and data quality of the data providers, and to utilize the computational resources of each local model more efficiently.
3.2.1. Asynchronous Federated Learning Framework
Both asynchronous federated learning mechanisms and reputation mechanisms play important roles in distributed intelligent labeling systems. Asynchronous federated learning allows individual clients to train and update models at different rates, while the reputation mechanism ensures the quality of data and the reliability of participants.
AFL allows each local client to perform model updates at its own time and rate, uploading the model and then globally aggregating it in a cloud-level data center. In order to measure the status of the updates of each local smart labeling model, the difference between the gradient of local accumulation and global aggregation is utilized for measurement. The cosine similarity is chosen as the parameter for measuring the difference.
where and denote the difference between the two global model aggregations before and after. The denotes the parameters of the i-th global model training. The updated weights are . The interference of asynchronous strategies is determined by calculating the cosine similarity between the measurement weights and the dissimilarity. denotes the trained dataset. Thus, the aggregation weights can be finally expressed as:
The minimization loss function is:
3.2.2. Trust Labeling Model
In order to evaluate the user’s trust in the LLM and DT participating in the distributed smart marking training, the virtual twin is required to record the smart marking behavior in real time.
where represents the trust set of the context.
In the function of reputation mechanism, represents the behavior of the intelligent marking model, the trust profile is , and the non-trust profile is set to . Because of the limited computational resources and communication overhead between each local intelligent labeling model in the distributed data center, a length of is set for the behavior of intelligent labeling model as , is the behavior of each model information interaction, represents the delay after the interaction behavior is uploaded, is the number of behaviors , and represents the degree of anomaly checking test for the accuracy of the information interaction of the virtual twin through the local model, where . The smaller the value, the greater the degree of anomaly, and the more inaccurate the intelligent labeling.
where represents the recommended value of the context when the digital twin interacts, represents the behavioral interaction reputation value when the large language model performs smart labeling, and represents the local smart labeling model reputation value.
Therefore, the trust value of the global model consists of three parts, namely, the trust value of the local smart labeling model , the trust value of the behavioral model recommended by the DT, and the interactors of the big language model after it has been smart labeled by the public and private data models, respectively, which together constitute the reputation value of the final global model’s smart labeling and their interactions with the historical model and the current model, respectively. As a result, the local trust value is expressed as follows:
3.3. The Diagram of the Proposed Method
The proposed method is shown in Figure 3. Firstly, the text and other data are inputted into the intelligent marking system and tagged in the local intelligent marking model GCN to obtain the predicted label data, and the prior knowledge is acquired through the corresponding digital twin of the local model. Then, part of the historical data is returned to the GCN intelligent labeling model as an incentive, while the other part of the predicted labels is input into the DT model. Meanwhile, the combination of LLM and DT as a marking mechanism model interacts with the local GCN and DT combined model for information to enhance the accuracy and interpretability of the global labeling model. The public data are used as standard labels for the labeling knowledge base for externalization, and the other LLM uses the private data for model labeling training. Again, the whole model combining each group of GCN and DT interacts with the model of the knowledge base of the LLM externalized with public data and the whole model of the LLM is trained with private data only in each local data center, and then the information interacts between each local model. Then, each local model is uploaded to the cloud of the first-level data middleware for global model aggregation, and sent down to each local data center.
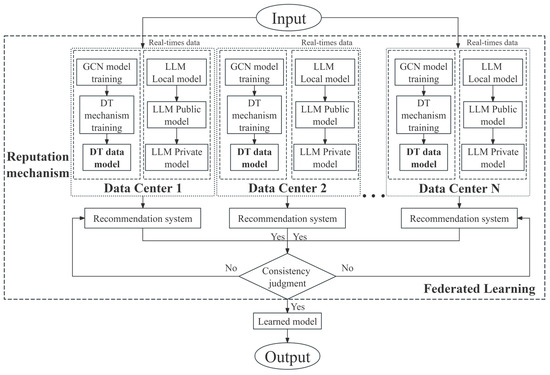
Figure 3.
The diagram of the proposed method.
3.4. Data Sharing Process
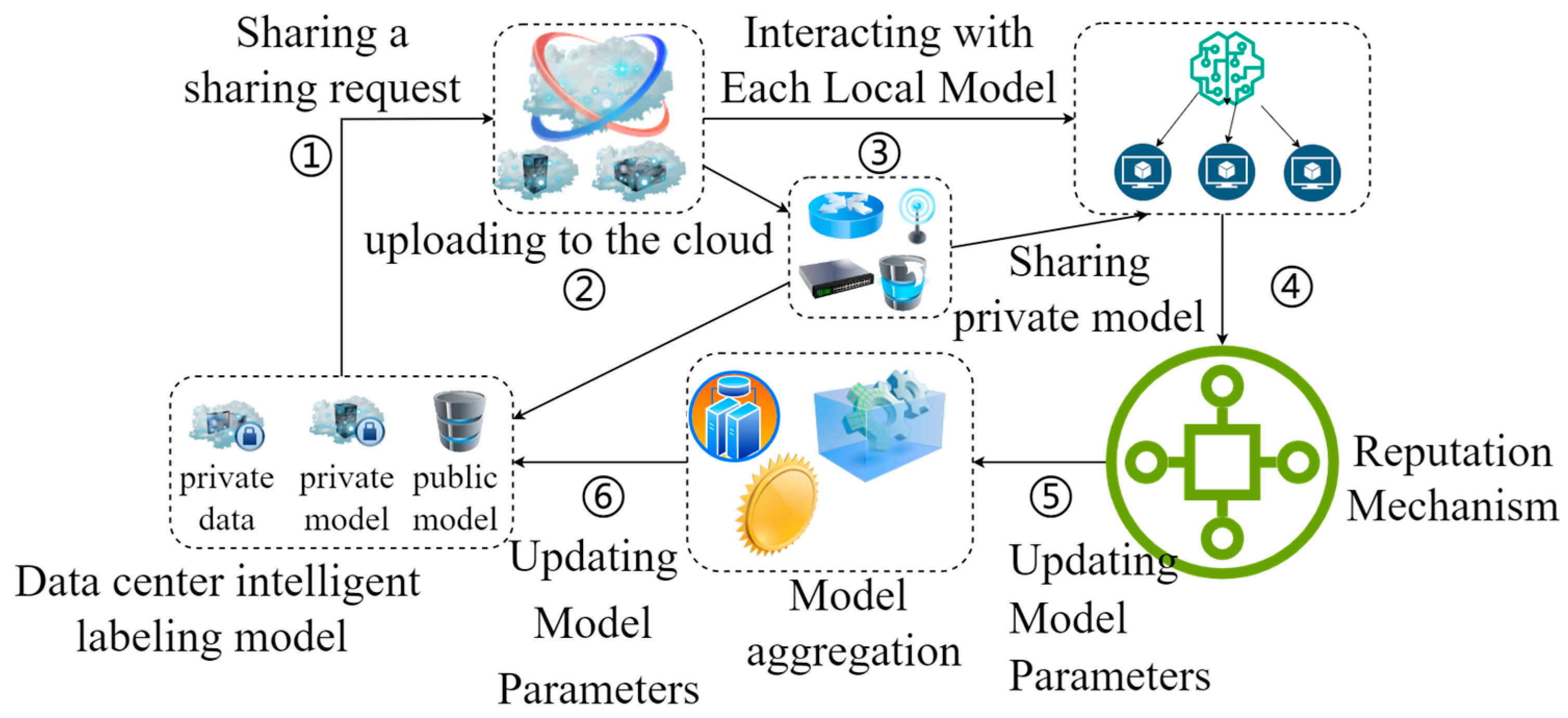
In the intelligent labeling scenario of the distributed data center in this paper, asynchronous federated learning as the main algorithmic strategy is particularly important for its data flow and shared transmission process. Especially, after the introduction of the large language model and DT technology, the asynchronous federated learning strategy is further optimized while improving the accuracy of intelligent marking. The data sharing process is shown in Figure 4 and the specific steps are as follows:
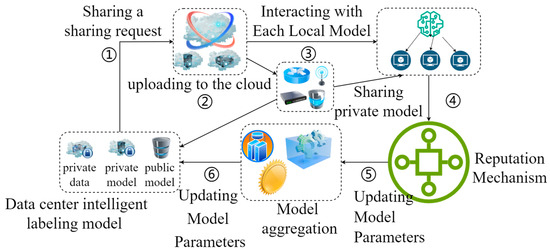
Figure 4.
Diagram of data sharing process.
Step 1: Local Intelligent Labeling Model Training
First of all, each local data center intelligent labeling model uses local private data for labeling private model training, and the trained private model parameters are saved locally. In this paper, GCN is initially selected for intelligent labeling model training. Simultaneously, DT technology is used to establish the mechanism model, and will be used with the GCN model for the dynamic interaction between the data prediction data and historical data.
Step 2: Sending a Sharing Request
The local data center uploads the sharing request to the cloud level data center and, when the permitted command is accepted, the local data center uploads the trained private model parameters to the cloud for global model parameter aggregation. The aggregated data is then distributed to the local data centers.
Step 3: Interacting with Each Local Model
Separately, the local data center is equipped with a system for intelligent labeling of large language models as an optimization scheme. Specifically, a system of large language model intelligent labeling is first established. At the same time, on the one hand, local private data are selected to be labeled as the LLM private model by using the large language model. On the other hand, public data standards are selected as the external knowledge base, and the LLM public model is obtained by training with the big language model. Then, the two interact with the intelligent labeling model of the large language model. Finally, each local LLM intelligent labeling system interacts with the labeling system constructed by the GCN model in the local data center.
Step 4: Reputation Mechanism
During the model interaction between the intelligent labeling system of the large language model and the local intelligent labeling model guided by the digital twin technology, an essential reputation mechanism exists to coordinate the processing of the number of interactions, so that the model as a whole is in a state of high efficiency and economy.
Step 5: Updating Model Parameters
The training of each local intelligent labeling model parameter is optimized based on the differences in the parameters of each local model after information interaction.
Step 6: Updating Model Parameters
The optimized smart labeling model of each local data center uploads its parameters to the cloud-level data center for global model aggregation and calculates the final global model aggregation parameters.
4. Experiment
4.1. Datasets
In this paper the experimental dataset is chosen as the London Smart Meter Dataset [27], which classifies electrical energy consumption into classes as a labeling metric. The London Smart Meter Dataset (LSMD) is a series of datasets that record the energy consumption of households in London. These datasets typically contain the electricity and gas usage of households, and are typically recorded at half-hourly intervals. The dataset contains energy consumption readings from approximately 5567 households participating in the Low Carbon London program led by UK Power Networks. For the experiments in this paper, we specify that the dataset is divided into 20 classes at 5% intervals, i.e., the set corresponds to 20 labels. For example, an energy consumption of 3% is categorized as belonging to the 0–5% interval and is labeled as “level 1”.
4.2. Experiment
To evaluate our proposed algorithm, this experiment comprehensively analyzes and compares several algorithms that are more advanced, including classic AFL, FedAvg [28], FedProx [29], i-MMD [30], FedAdam [31], KAFL [32], FedAsync [33], FedProx-Async, and DBAFL [34]. The classical AFL algorithm is a federated learning framework that allows the participating clients to update the global model in an asynchronous manner. The method is particularly suitable for those scenarios where the performance of client devices varies widely and the network connection is unstable. In AFL, the server can instantly aggregate those model updates that have been uploaded without waiting for all clients to finish local training and upload updates. This design reduces the waiting time and improves the overall learning efficiency. It is characterized by asynchronous updating, adaptability, efficiency and flexibility.
However, in classic AFL algorithms, the heterogeneity of data and devices, privacy and security issues, and unreliability, such as that associated with network instability, are research difficulties and challenges. FedAvg algorithm is an optimization algorithm used for FL, which is particularly suitable for scenarios in which the data is distributed over a large number of devices (e.g., mobile devices, IoT devices, etc.) FedAvg has problematic challenges, such as large data bias, high communication overhead consumption, and privacy protection [28]. FedProx (Federated Proximal Learning) is a variant of Federated Learning (FL) that introduces an L2 regularization term to the standard FedAvg algorithm, which means that a weight difference-based penalty is added. a penalty term based on weight differences. Its core idea is to consider the stability of the global model during local updating to prevent overfitting to local data and moving away from the global optimal solution [29]. FedProx enhances the consistency of the model, solves the problem of non-independent homogeneous distribution, and provides good convergence and robustness. The index maximum mean discrepancy algorithm (i-MMD) is used to measure the data distribution differences between different stations. The smaller the i-MMD value between two distributions, the more similar the data distributions are, which means less impact on model accuracy [30].
FedAdam is a combination of FedSGD and the Adam optimizer applied to Federated Learning (FL) in distributed machine learning. FedAdam employs adaptive learning rates and momentum by using the data from local updates from the client to efficiently update the global model [31]. However, there are still difficulties in hyper-parameter tuning and there will be data heterogeneity problems, etc. The KAFL algorithm is a fast-K asynchronous federated learning algorithm [32], which enhances the efficiency of the federated learning system and the rate of convergence through an improved weighted aggregation approach. The FedAsync (Asynchronous Federated Optimization) algorithm is targeted at the Asynchronous Federated Optimization algorithm for non-IID training data, which has better proof on a class of constrained non-convex problems and its convergence rate is more advantageous. FedProx-Async algorithm is an asynchronous optimization on FedProx algorithm, which improves FedProx algorithm’s problems, such as data heterogeneity, but at the same time brings side effects, such as the communication overhead [33]. The DBAFL algorithm is an AFL scheme with dynamic scaling factors based on blockchain [34].
In this paper, our proposed algorithm will be compared with the above improved algorithm. In the experiments, the regular term weight hyperparameter is chosen and set to 0.1.
4.2.1. Comparison of the Results of the Algorithms for Different Participating Individuals
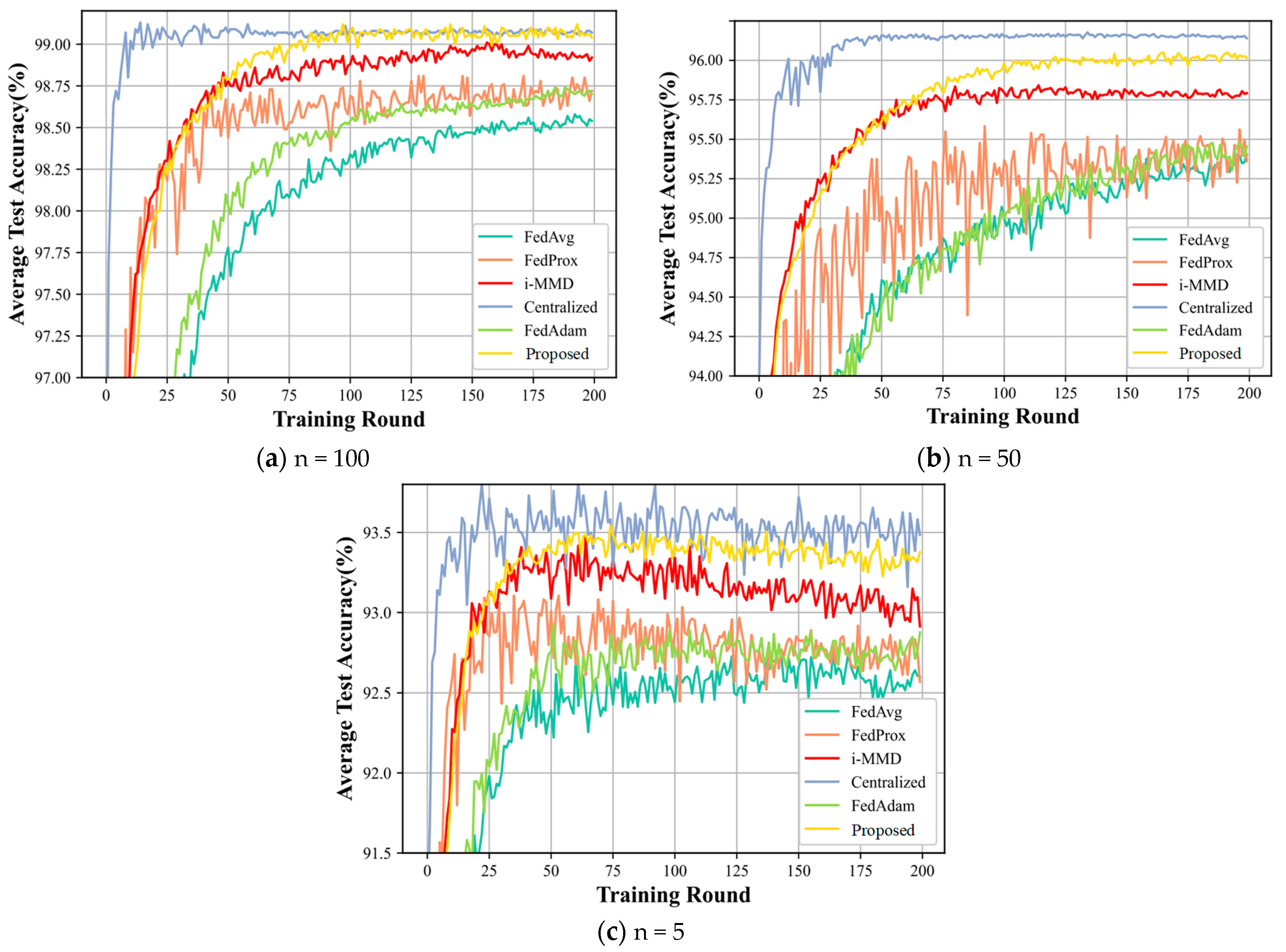
Model accuracy and model runtime are important metrics in the validation of intelligent marking in distributed data centers. In this section, we first explore the impact of the number of individuals locally participating in the intelligent labeling model on the performance of the designed algorithm. Firstly, the heterogeneity parameter is set to , which indicates that the model heterogeneity is adjusted to be small and close to the centralized learning in Figure 5.
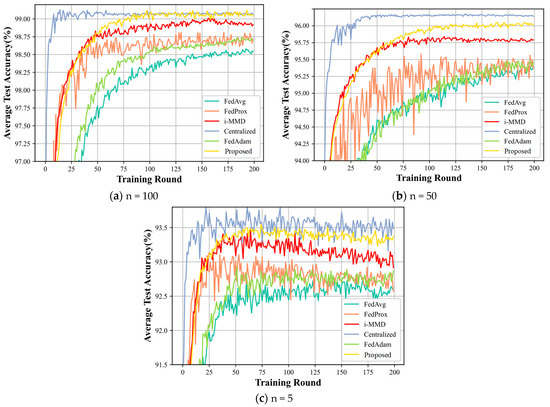
Figure 5.
(a–c) shows a comparison of the accuracy of the model’s six algorithms for different individuals involved in the intelligent labeling model.
Analyzing and observing Figure 5, it shows that our proposed method has more obvious advantages. Specifically, it is analyzed from two perspectives: horizontal and vertical. First of all, for vertical comparison, the model accuracy of the centralized training method is the highest, and all other algorithms converge more slowly than the centralized Centralized method, because centralizing the training of each local intelligent labeling model data will merge the data of each local model, unify the intelligent labeling model training and make the consistency of its labeling results close to perfect, and this is definitely better than the distributed training. From Figure 5a–c, we can see that the general case accuracy is in the following order: Centralized > Proposed > i-MMD > FedProx > FedAdam > FedAvg. Taking the figure in (a) as an example, with the increasing number of Training Rounds, the accuracy of intelligent labeling model training for each algorithm is increasing extremely fast, and the accuracy of each algorithm is increasing rapidly. Accuracy increases extremely quickly and finally levels off. Obviously, the Centralized approach is the first to stabilize, has the fastest convergence speed and the highest accuracy. Although our proposed data sharing method is slower than the Centralized method in terms of convergence speed, the final convergence accuracy is close to the number of participating training models at n = 100, while there is a large gap at n = 50 and n = 5.
In terms of side-by-side comparisons, in the (a) plot in Figure 5, the model accuracy at the number of participating model trainings n = 100 is the highest, smoothed at approximately 99.1%. In graph (b), the model accuracy for the number of participating models training n = 50 is the highest, smoothing to approximately 96.2%. In the figure (c), the model accuracy for the number of participating models n = 5 is finally smooth at approximate 93.5%, but with larger fluctuation. This indicates that, the more local intelligent labeling models are involved in training, the better the intelligent labeling accuracy and, the more models are involved in training, the smoother it is.
4.2.2. Comparison of Algorithmic Rresults for Cases with Different Degrees of Model Heterogeneity
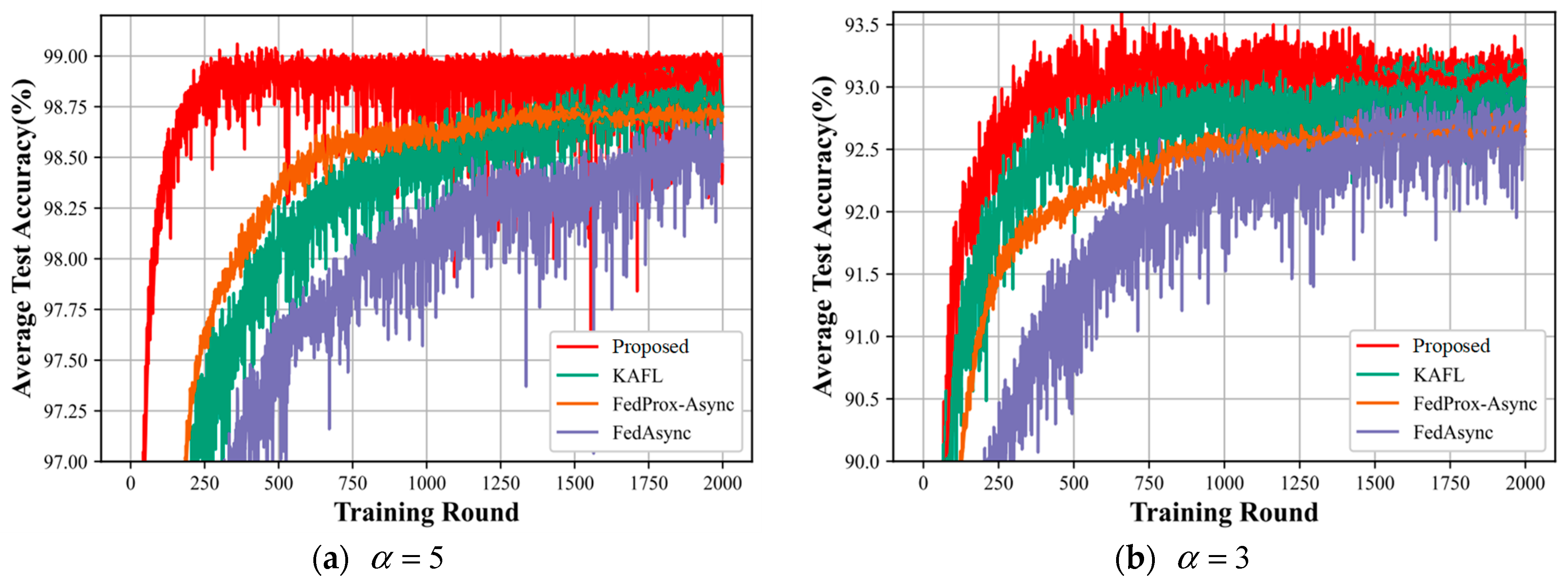
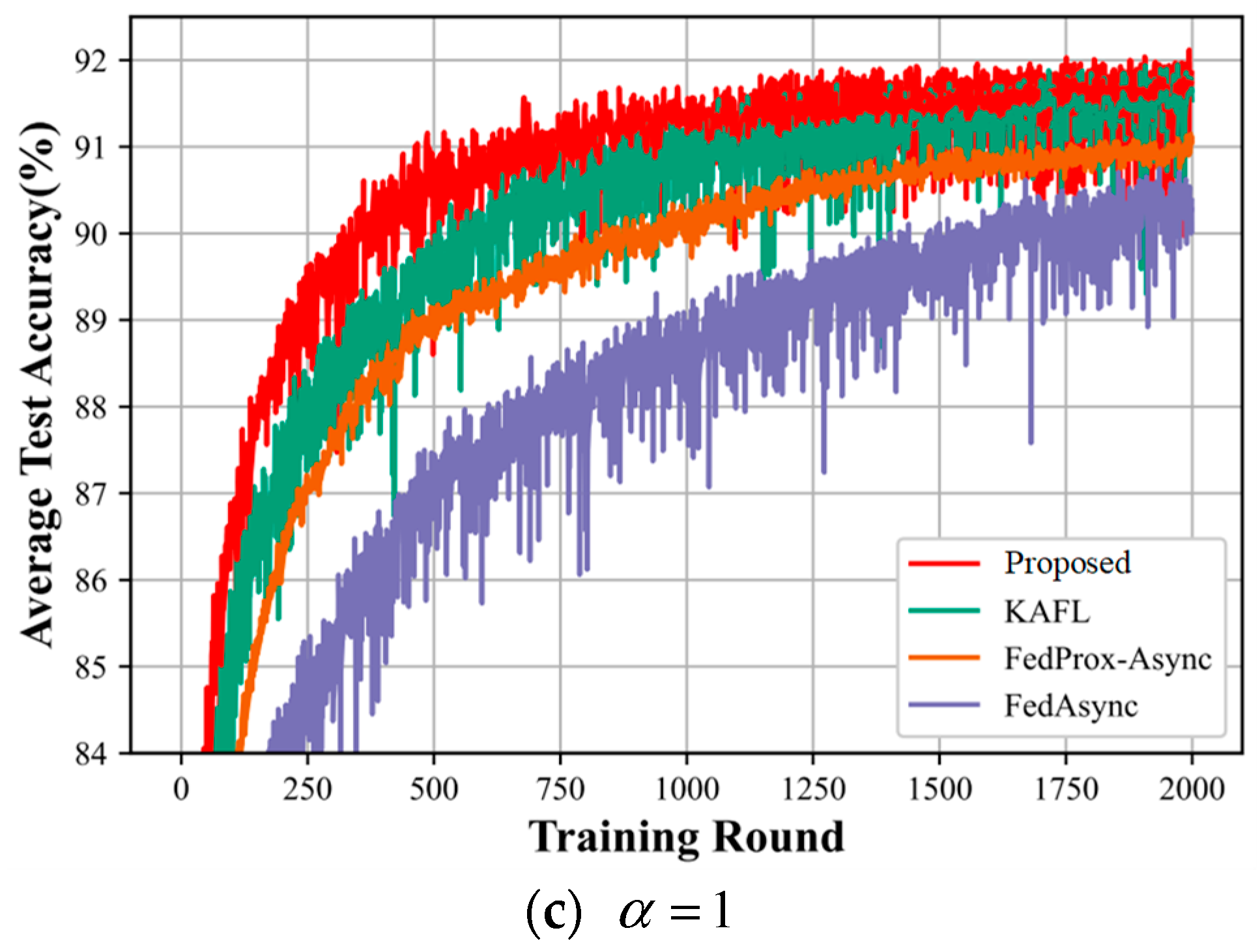
In this subsection, we compare various asynchronous federated learning algorithms for different degrees of heterogeneity. The heterogeneity we set as higher, a, is 1,3,5, as shown in Figure 6.
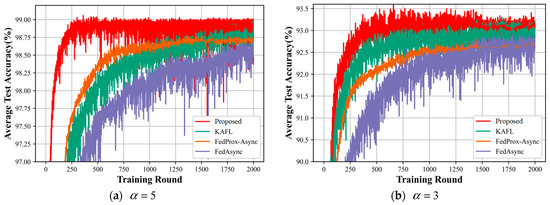
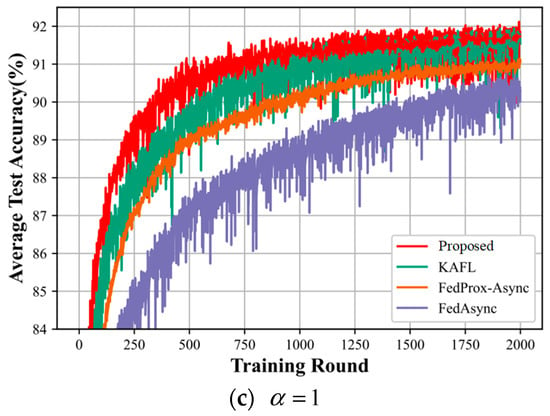
Figure 6.
(a–c) shows a comparison of the accuracy of the four algorithms of the model for different degrees of heterogeneity.
Figure 6 shows the algorithmic performance of all the compared algorithms. From the three plots (a), (b), and (c) in Figure 5, it can be seen that our proposed method outperforms the KAFL algorithm, FedProx-Async, and FedAsync algorithm, both in terms of the convergence speed and the accuracy of convergence of the final intelligent labeling model. Comparing the three graphs together, as a gets smaller, the accuracy of the intelligent labeling model that our proposed method eventually converges to becomes lower and lower: in Figure 6a, the accuracy of the intelligent labeling model training eventually converges to 99%; in Figure 6b, the accuracy of the intelligent labeling model training eventually converges to 93.2%; in Figure 6c, the accuracy of the intelligent labeling model training eventually converges to 92%. This indicates that, the higher the value of a, the less heterogeneous the degree of heterogeneity, resulting in the higher accuracy of the intelligent labeling model.
4.2.3. Comparison of Model Runtimes at Different Numbers of Participants
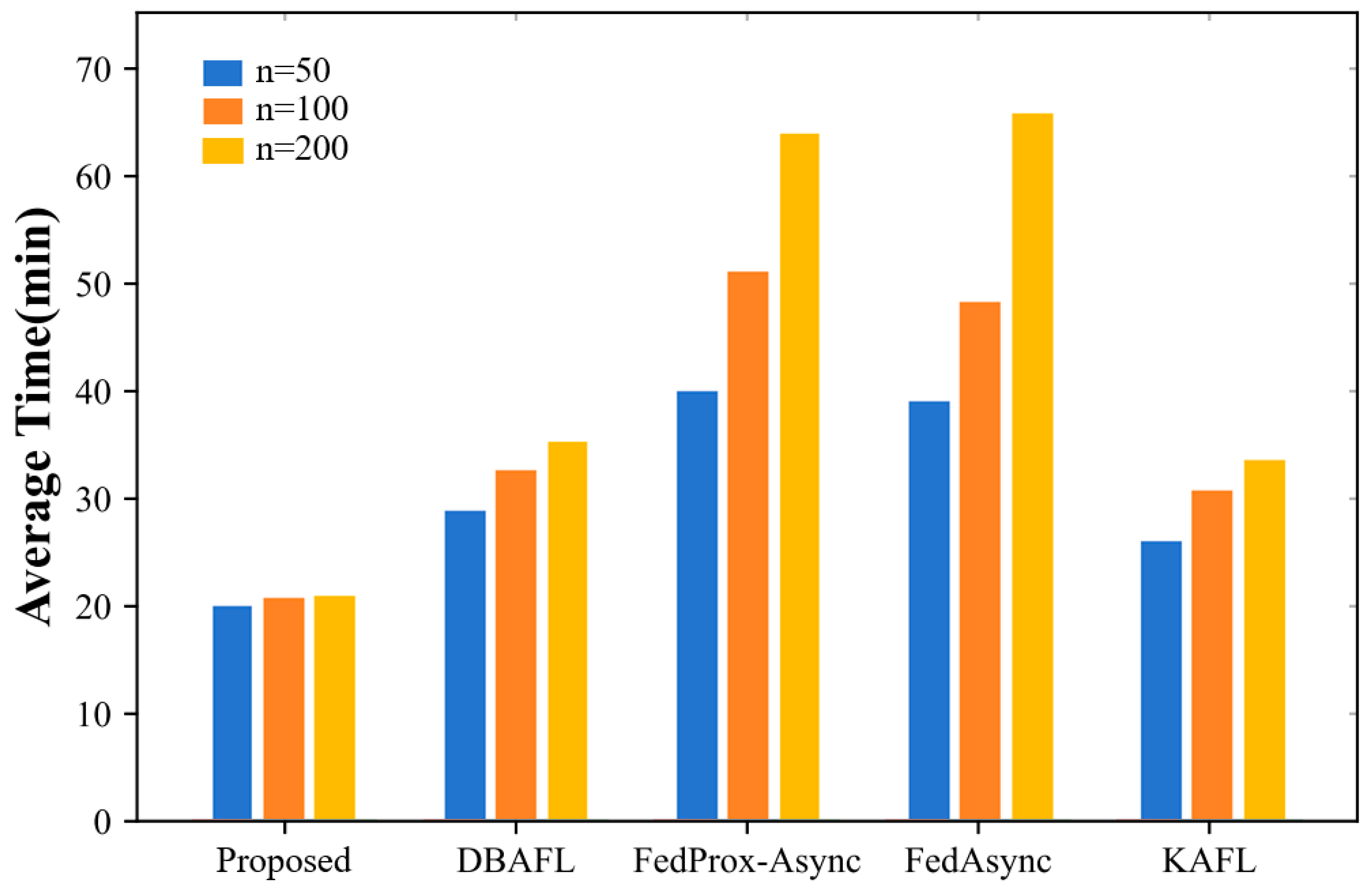
In this subsection, we compare the runtime of various asynchronous federated learning algorithms for the number of participants in the local intelligent labeling model.
Figure 7 shows that the running time of our proposed method is better than the other four algorithms regardless of the number of participating asynchronous federated learning models, with the shortest running time being the Proposed algorithm, followed by the KAFL algorithm, then the DBAFL algorithm, and finally the FedProx-Async algorithm with a similar running time to the FedProx-Async algorithm. Simultaneously, the number of intelligent labeling models involved in the training shows that the training time in order is the least for n = 50, followed by a longer training time for n = 100. n = 200 has the longest running time. It is not difficult to conclude that the higher the number of participating local models, the longer the running time.
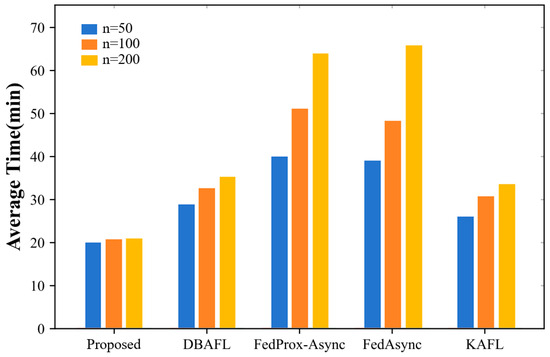
Figure 7.
This figure represents the running time of each algorithm with different numbers of participants.
4.2.4. Comparison of Different Levels of Invasion
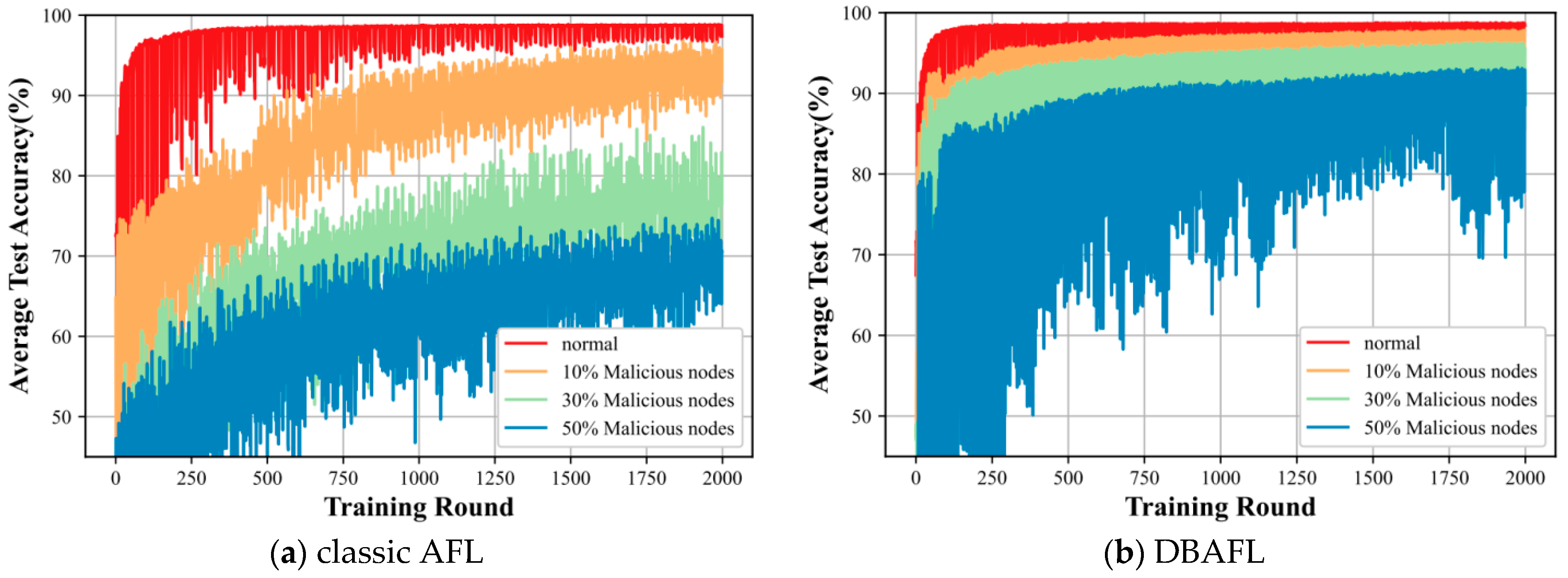
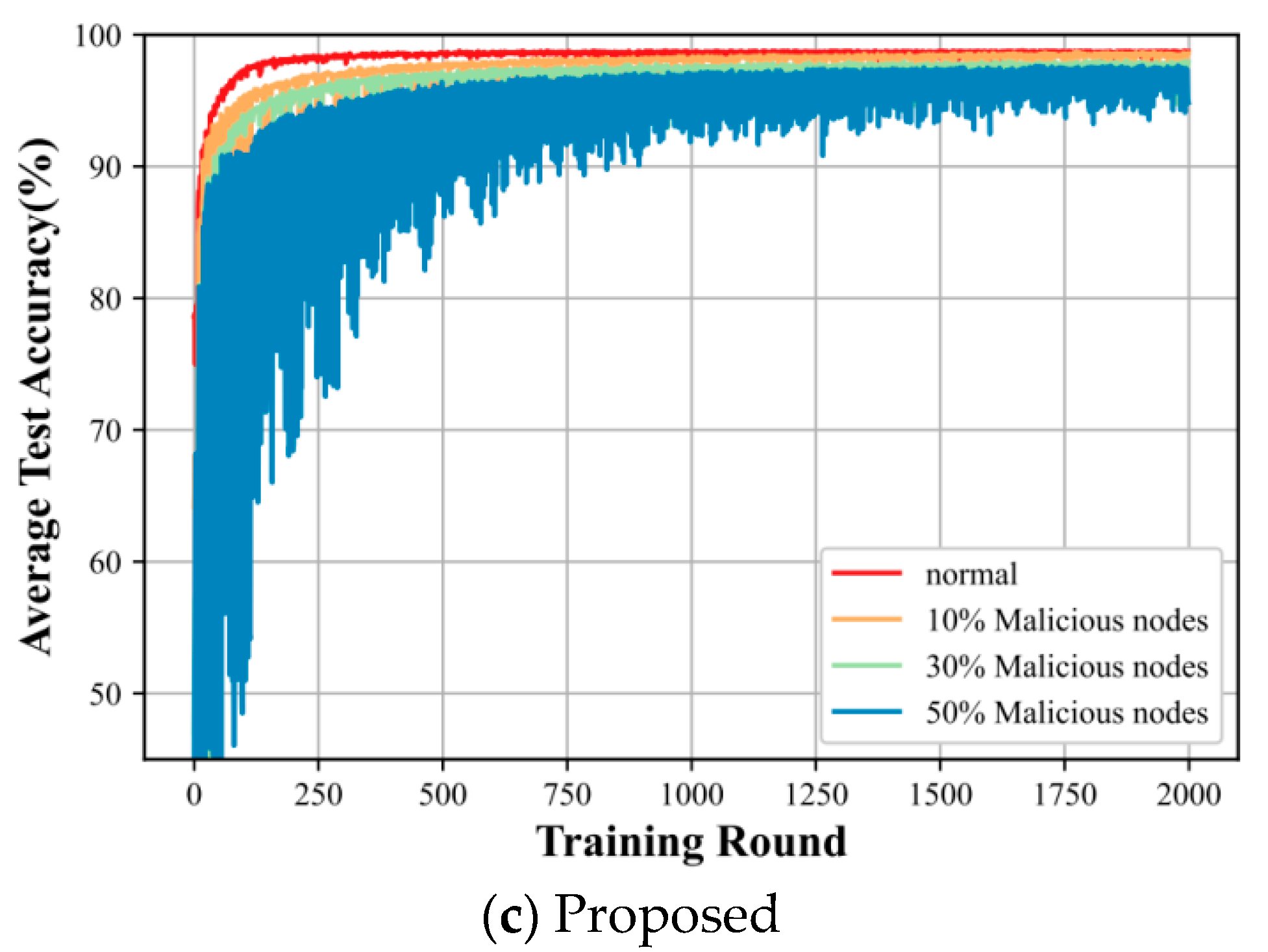
In this subsection, we consider the impact of different levels of intrusion on the three algorithms.
In Figure 8, plots (a), (b), and (c) reflect the comparison of the average training accuracies of our proposed algorithm with the traditional AFL algorithm and the DBAFL algorithm at different levels of intrusion. In figures, the proposed algorithm is less affected by the degree of intrusion, and the model test accuracy is smoother, almost until the degree of intrusion is below 30%. It is only when the degree as before reaches 50% that the test accuracy shows a more obvious fluctuation magnitude. However, for both the classic AFL algorithm and the DBAFL algorithm, the average test accuracy of the intelligent labeling model fluctuates more, and it is obvious that the accuracy fluctuation of the DBAFL algorithm is better than that of the classic AFL algorithm.
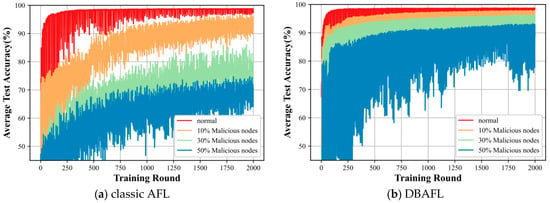
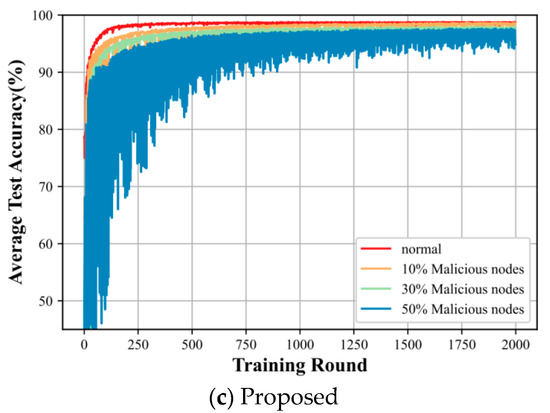
Figure 8.
The figure represents the average training runtime of different algorithms at the level of intrusion.
4.2.5. Performance of Algorithms with Different Numbers of Participating Nodes
The optimization of our proposed algorithm is compared with four other federated learning methods, as shown in Table 1. Our proposed algorithm and the other three algorithms are analyzed in terms of six parameters for comparison. This shows that our proposed method outperforms the other three algorithms in each parameter performance. With the increase of the number of models participating in the local intelligent labeling training, all four algorithms show better performance results. This indicates that our proposed algorithms are in an advantageous position in the performance of each parameter index.

Table 1.
This table shows the performance of the algorithm with different number of participating nodes.
5. Conclusions
In this paper, the optimized asynchronous federated learning strategy we propose is a scheme that combines large language models with digital twins to interact with local intelligent labeling models for information interaction, which is applied in distributed data middleware scenarios to solve the problem of distributed data middleware intelligent labeling, as well as that of the cross-domain efficient interaction process. Our proposed method uses public data as an external knowledge base and private data for local intelligent labeling through the introduction of large language modeling technology and combines the mechanism model with the local intelligent labeling model through digital twin technology to interact historical data and parameter information, and, finally, performs the aggregation of the global model. The experimental results show that our proposed method outperforms other algorithms in terms of intelligent marking model accuracy and running time. Our proposed algorithm still shows significant advantages, even with the presence of interference, such as malicious nodes.
The limitations are as follows:
- (1)
- Data diversity and complexity: the form and complexity of data varies in different application scenarios, from simple text annotation to complex video annotation and analysis, and the difficulty and cost of data annotation increases.
- (2)
- Demand for high computing power and resources: the large model training of generative AI relies on high-performance hardware and large-scale datasets, and the data annotation process also requires higher-scale computing power support.
In the future, new developments in digital history can be explored, and advanced data analytics, machine learning, and artificial intelligence technologies can be utilized to equip models with self-learning, reasoning, and decision-making capabilities, thus realizing more advanced digital twin applications.
There may be several practical application directions in the future:
- Intelligent data annotation and processing: large language models (LLMs) can be used for automated data labeling to improve the efficiency and accuracy of data labeling. Combined with digital twin technology, real-world data can be simulated in virtual environments for training and optimizing models, reducing dependence on real data while protecting data privacy.
- Intelligent Manufacturing and Quality Control: In manufacturing, intelligent labeling models can be used to automatically identify product defects and improve the automation of quality control. Digital twin technology can simulate the production process to optimize productivity and reduce waste.
- Smart city management: Combining large language models and digital twin technology, various cithy data can be intelligently labeled and analyzed to achieve real-time monitoring and management of urban infrastructure, traffic flow, environmental quality and so on.
- Personalized Recommendation System: In e-commerce and content recommendation platforms, intelligent labeling models can analyze user behaviors and preferences to provide personalized product or content recommendations to enhance user experience and satisfaction.
Author Contributions
Conceptualization, X.S.; methodology, C.Y.; software, X.S.; formal analysis, C.Y.; resources, X.C.; writing—original draft preparation, X.S. and C.Y.; writing—review and editing, X.C.; visualization, X.C.; supervision, X.C.; funding acquisition, Y.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by National Natural Science Foundation of China, grant number 62303296.
Data Availability Statement
No new data were created.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Jin, L.; Zhai, X.; Wang, K.; Zhang, K.; Wu, D.; Nazir, A.; Jiang, J.; Liao, W.H. Big data, machine learning, and digital twin assisted additive manufacturing: A review. Mater. Des. 2024, 244, 113086. [Google Scholar]
- Wang, B.; Zhou, H.; Li, X.; Yang, G.; Zheng, P.; Song, C.; Yuan, Y.; Wuest, T.; Yang, H.; Wang, L. Human Digital Twin in the context of Industry 5.0. Robot. Comput.-Integr. Manuf. 2024, 85, 102626. [Google Scholar] [CrossRef]
- Torzoni, M.; Tezzele, M.; Mariani, S.; Manzoni, A.; Willcox, K.E. A digital twin framework for civil engineering structures. Comput. Methods Appl. Mech. Eng. 2024, 418, 116584. [Google Scholar] [CrossRef]
- Tao, F.; Sun, X.; Cheng, J.; Zhu, Y.; Liu, W.; Wang, Y.; Xu, H.; Hu, T.; Liu, X.; Liu, T.; et al. makeTwin: A reference architecture for digital twin software platform. Chin. J. Aeronaut. 2024, 37, 1–18. [Google Scholar] [CrossRef]
- Wang, J.; Li, X.; Wang, P.; Liu, Q. Bibliometric analysis of digital twin literature: A review of influencing factors and conceptual structure. Technol. Anal. Strateg. Manag. 2024, 36, 166–180. [Google Scholar] [CrossRef]
- Long, W.; Bao, Z.; Chen, K.; Ng, S.T.; Wuni, I.Y. Develo an integrative framework for digital twin applications in the building construction industry: A systematic literature review. Adv. Eng. Inform. 2024, 59, 102346. [Google Scholar] [CrossRef]
- Piras, G.; Agostinelli, S.; Muzi, F. Digital twin framework for built environment: A review of key enablers. Energies 2024, 17, 436. [Google Scholar] [CrossRef]
- Cheng, N.; Wang, X.; Li, Z.; Yin, Z.; Luan, T.; Shen, X.S. Toward enhanced reinforcement learning-based resource management via digital twin: Opportunities, applications, and challenges. In IEEE Network; IEEE: Piscataway, NJ, USA, 2024. [Google Scholar] [CrossRef]
- Tripathi, N.; Hietala, H.; Xu, Y.; Liyanage, R. Stakeholders collaborations, challenges and emerging concepts in digital twin ecosystems. Inf. Softw. Technol. 2024, 169, 107424. [Google Scholar] [CrossRef]
- AlBalkhy, W.; Karmaoui, D.; Ducoulombier, L.; Lafhaj, Z.; Linner, T. Digital twins in the built environment: Definition, applications, and challenges. Autom. Constr. 2024, 162, 105368. [Google Scholar] [CrossRef]
- Sarker, I.H.; Janicke, H.; Mohsin, A.; Gill, A.; Maglaras, L. Explainable AI for cybersecurity automation, intelligence and trustworthiness in digital twin: Methods, taxonomy, challenges and prospects. ICT Express 2024, 10, 935–958. [Google Scholar] [CrossRef]
- Adewumi, T.; Liwicki, F.; Liwicki, M. Word2Vec: Optimal hyperparameters and their impact on natural language processing downstream tasks. Open Comput. Sci. 2022, 12, 134–141. [Google Scholar] [CrossRef]
- Ning, G.; Bai, Y. Biomedical named entity recognition based on Glove-BLSTM-CRF model. J. Comput. Methods Sci. Eng. 2021, 21, 125–133. [Google Scholar] [CrossRef]
- Kováčiková, J.V.; Šuppa, M. Thinking, fast and slow: From the speed of FastText to the depth of retrieval augmented large language models for humour classification. In Proceedings of the Working Notes of the Conference and Labs of the Evaluation Forum (CLEF 2024), Grenoble, France, 9–12 September 2024; CEUR Workshop Proceedings. pp. 1862–1867. [Google Scholar]
- Koroteev, M.V. BERT: A review of applications in natural language processing and understanding. arXiv 2021, arXiv:2103.11943. [Google Scholar]
- Lieber, O.; Sharir, O.; Lenz, B.; Shoham, Y. Jurassic-1: Technical details and evaluation. In White Paper; AI21 Labs: Tel Aviv-Yafo, Israel, 2021; Volume 1. [Google Scholar]
- Huang, S.H.; Chen, C.Y. Combining LoRA to GPT-Neo to Reduce Large Language Model Hallucination. 2024. Available online: https://www.researchsquare.com/article/rs-4515250/v1 (accessed on 4 June 2024).
- Hoffmann, J.; Borgeaud, S.; Mensch, A.; Buchatskaya, E.; Cai, T.; Rutherford, E.; de Las Casas, D.; Hendricks, L.A.; Welbl, J.; Clark, A.; et al. An empirical analysis of compute-optimal large language model training. Adv. Neural Inf. Process. Syst. 2022, 35, 30016–30030. [Google Scholar]
- Katlariwala, M.; Gupta, A. Product Recommendation System Using Large Language Model: Llama-2. In Proceedings of the 2024 IEEE World AI IoT Congress (AIIoT), Seattle, WA, USA, 29–31 May 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 0491–0495. [Google Scholar]
- Zhang, J.; Sun, K.; Jagadeesh, A.; Falakaflaki, P.; Kayayan, E.; Tao, G.; Haghighat Ghahfarokhi, M.; Gupta, D.; Gupta, A.; Gupta, V.; et al. The potential and pitfalls of using a large language model such as ChatGPT, GPT-4, or LLaMA as a clinical assistant. J. Am. Med. Inform. Assoc. 2024, 31, 1884–1891. [Google Scholar] [CrossRef] [PubMed]
- Eisele-Metzger, A.; Lieberum, J.L.; Toews, M.; Siemens, W.; Heilmeyer, F.; Haverkamp, C.; Boehringer, D.; Meerpohl, J.J. Exploring the potential of Claude 2 for risk of bias assessment: Using a large language model to assess randomized controlled trials with RoB 2. medRxiv 2024. [Google Scholar] [CrossRef]
- Thirunavukarasu, A.J.; Ting, D.S.J.; Elangovan, K.; Gutierrez, L.; Tan, T.F.; Ting, D.S.W. Large language models in medicine. Nat. Med. 2023, 29, 1930–1940. [Google Scholar] [CrossRef]
- Kasneci, E.; Seßler, K.; Küchemann, S.; Bannert, M.; Dementieva, D.; Fischer, F.; Gasser, U.; Groh, G.; Günnemann, S.; Hüllermeier, E.; et al. ChatGPT for good? On opportunities and challenges of large language models for education. Learn. Individ. Differ. 2023, 103, 102274. [Google Scholar] [CrossRef]
- Xu, C.; Qu, Y.; Xiang, Y.; Gao, L. Asynchronous federated learning on heterogeneous devices: A survey. Comput. Sci. Rev. 2023, 50, 100595. [Google Scholar] [CrossRef]
- Wang, Z.; Zhang, Z.; Tian, Y.; Yang, Q.; Shan, H.; Wang, W.; Quek, T.Q. Asynchronous federated learning over wireless communication networks. IEEE Trans. Wirel. Commun. 2022, 21, 6961–6978. [Google Scholar] [CrossRef]
- Liu, J.; Xu, H.; Wang, L.; Xu, Y.; Qian, C.; Huang, J.; Huang, H. Adaptive asynchronous federated learning in resource-constrained edge computing. IEEE Trans. Mob. Comput. 2021, 22, 674–690. [Google Scholar] [CrossRef]
- Sheng, X.; Zhou, Y.; Cui, X. Graph Neural Network Based Asynchronous Federated Learning for Digital Twin-Driven Distributed Multi-Agent Dynamical Systems. Mathematics 2024, 12, 2469. [Google Scholar] [CrossRef]
- Collins, L.; Hassani, H.; Mokhtari, A.; Shakkottai, S. Fedavg with fine tuning: Local updates lead to representation learning. Adv. Neural Inf. Process. Syst. 2022, 35, 10572–10586. [Google Scholar]
- Su, L.; Xu, J.; Yang, P. A non-parametric view of FedAvg and FedProx: Beyond stationary points. J. Mach. Learn. Res. 2023, 24, 1–48. [Google Scholar]
- Gretton, A.; Borgwardt, K.M.; Rasch, M.J.; Schölkopf, B.; Smola, A. A kernel two-sample test. J. Mach. Learn. Res. 2012, 13, 723–773. [Google Scholar]
- Ju, L.; Zhang, T.; Toor, S.; Hellander, A. Accelerating fair federated learning: Adaptive federated adam. IEEE Trans. Mach. Learn. Commun. Netw. 2024, 2, 1017–1032. [Google Scholar] [CrossRef]
- Wu, X.; Wang, C.L. KAFL: Achieving high training efficiency for fast-k asynchronous federated learning. In Proceedings of the 2022 IEEE 42nd International Conference on Distributed Computing Systems (ICDCS), Bologna, Italy, 10–13 July 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 873–883. [Google Scholar]
- Xie, C.; Koyejo, S.; Gupta, I. Asynchronous federated optimization. arXiv 2019, arXiv:1903.03934. [Google Scholar]
- Xu, C.; Qu, Y.; Luan, T.H.; Eklund, P.W.; Xiang, Y.; Gao, L. An efficient and reliable asynchronous federated learning scheme for smart public transportation. IEEE Trans. Veh. Technol. 2022, 72, 6584–6598. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).