Abstract
This work focuses on making Bayesian inferences for the two-parameter Birnbaum–Saunders (BS) distribution in the presence of right-censored data. A flexible Gibbs sampler is employed to handle the censored BS data in this Bayesian work that relies on Jeffrey’s and Achcar’s reference priors. A comprehensive simulation study is conducted to compare estimates under various parameter settings, sample sizes, and levels of censoring. Further comparisons are drawn with real-world examples involving Type-II, progressively Type-II, and randomly right-censored data. The study concludes that the suggested Gibbs sampler enhances the accuracy of Bayesian inferences, and both the amount of censoring and the sample size are identified as influential factors in such analyses.
MSC:
62F15; 62N02; 62M86
1. Introduction
The Birnbaum–Saunders (BS) distribution is a two-parameter lifetime distribution that was originally introduced by [1] to model the failure time due to the growth of a dominant crack that is subjected to cyclic stress, which causes a failure upon reaching the threshold level. The BS distribution has gone through various developments and generalizations and is found to be suitable for life testing applications. The distribution was originally derived to model the fatigue life of metals that are subject to periodic stress; this is sometimes referred to as the fatigue life distribution. Interestingly, it can also be obtained by using a monotone transformation on the standard normal distribution [2]. Moreover, as [3] indicated, the BS distribution can be viewed as an equal mixture of an inverse Gaussian (IG) distribution and its reciprocal. These relations are useful in deriving important properties of the BS distribution based on well-known properties of the normal and IG distributions. Ref. [4] showed that the BS distribution can be used as an approximation of the IG distribution. In practice, both the BS and IG distributions are often considered very competitive lifetime models for right-skewed data [5,6].
The distribution function of the BS failure time T with parameters and , denoted by , is given by
where and are the shape and scale parameters, respectively. Here, represents the distribution function of the standard normal distribution. Since , the scale parameter is the median of the BS distribution. The probability density function (pdf) of the is given by
It can be easily shown that and . Interestingly, Ref. [7] indicates that , and therefore the reciprocal variable also belongs to the same family.
The parameter estimation for the BS distribution, including the maximum likelihood estimation (MLE), is largely discussed in its literature. For complete data, Ref. [8] derived the MLE’s of the BS parameters. Ref. [9] introduced modified moment estimators (MMEs), a bias reduction method and a Jackknife technique to reduce the bias of both MMEs and MLEs. Ref. [10] introduced alternative estimators with a smaller bias compared to that for Ref. [9]. Point and interval estimations of the BS parameters under Type-II censoring are discussed in [11]. Ref. [12] suggested a modified censored moment estimation method to estimate its parameters under random censoring. Ref. [13] suggested using a fiducial inference on BS parameters for right-censored data.
Bayesian approaches have also been used to make inferences on the BS parameters. Ref. [14] used both Jeffrey’s prior and a reference prior to derive marginal posteriors using Laplace’s approximation; while [15] employed only the reference priors and considered an approximate Bayesian approach using Lindley’s method. Ref. [16] justified that Jeffrey’s reference prior results in an improper posterior for the scale parameter and suggested employing the reference priors that incorporate some partial information. In this situation, they suggested applying the slice sampling method to obtain a proper posterior for the case of censored data. A work by [17] adopted inverse-gamma priors for the shape and scale parameters and proposed an efficient sampling algorithm using the generalized ratio-of-uniforms method to compute Bayesian estimates. Ref. [18] also adapted the inverse-gamma priors for both the BS parameters and applied Markov Chain Monte Carlo (MCMC)-based conditional and joint sampling methods to handle censored data.
The censored data appear in life-time experiments due to various reasons; the nature of censoring plays a vital role in its analysis. In this study, we focus on the right-censored data that occurs when the test start time of each unit is known, but the test end time is unknown. This includes the random right, Type-II, and progressively Type-II censoring schemes. The progressively Type-II censoring scheme allows one to remove a pre-specified number of uncensored units from the remaining experimental units at the observed failure times [19]. As such, it is a more general form of Type-II censoring, where censoring takes place progressively in r stages. In this scheme, a total of n units are placed on a life-test, only r are completely observed until failure and the rest of units are rightly censored. However, at the time of the first failure, say , of the surviving units are randomly withdrawn from the experiment; at the time of the next failure, say , of the surviving units are censored, and so on. At the time of the last (rth) failure, say , all the remaining surviving units are censored. Therefore, in progressively Type-II censoring experiments with pre-specified r and , the data will take the form .
In this work, we focus on estimating both BS parameters in the presence of right-censored units as well as the average remaining test time of the censored units. For instance, let us consider n non-repairable units and assume we observe failures in r progressively censored stages with censored times . If the experiment were to continue so that all -censored values could be observed, then we let be the set of true observed values of the censored values at the ith progressive stage. Then, the remaining total test time for these censored elements is , where 1 is a column vector of 1’s of length . As such, the estimated and average remaining test time for all the censored units from all r progressive stages is
The rest of the article is organized as follows: In Section 2, we discuss the parameter estimation of the BS distribution using both the maximum likelihood method and the Bayesian method. Section 3 covers the Gibbs sampling procedure for handling censored data. In Section 4, we conduct a Monte–Carlo simulation study to compare the performance of the aforementioned methods. Illustrative examples are included in Section 5, and we conclude with remarks and recommendations in Section 6.
2. BS Parameter Estimation
In this section, we focus on the Bayesian parameter estimation with two different prior specifications: Jeffrey’s and Achcar’s priors for the BS parameters and . We discuss some of the practical challenges of these procedures while summarizing their methodological foundations.
On the other hand, the MLE of BS parameters, and , were heavily discussed in the literature; see [2,8] for details. Consider an experiment with n random failure times = {} that follow the BS distribution. Then, its log-likelihood function, without the additive constant, becomes
By differentiating Equation (4) with respect to and solving it for zero, one can obtain
where and are the sample arithmetic and harmonic means of the observed data. Next, when differentiating Equation (4) with respect to and substituting from Equation (5), the following can be obtained to determine the MLE of .
where . The MLE of is the unique positive root of Equation (6), in which . With this estimate, the MLE of becomes .
2.1. Bayesian Inference
Here, we consider the Bayesian work that was originally suggested by [14] by employing non-informative priors that include Jeffrey’s and Achcar’s reference priors. Jeffrey’s prior density for and is given by
where is the Fisher information matrix of the BS distribution, , and is the standard normal distribution function.
Using the Laplace approximation, it can be shown that Jeffrey’s prior takes the following form
where .
Assuming independence between and , [14] suggested a reference prior that takes the following form
In our discussion, we called this Achcar’s reference prior.
2.2. Posterior Inference
For Jeffrey’s prior, the joint posterior distribution of and becomes [14]
where .
Then, using the Laplace approximation (see Appendix A), the approximate marginal posterior distributions of and for Jeffrey’s prior can be written as
and
respectively.
Then, for Achcar’s reference prior, the joint posterior becomes the same as Equation (7) except where and the approximate marginal posterior distributions of and become
and
respectively.
As both Jeffrey- and Achcar-based posteriors do not have closed-form distributions, the Bayes estimates of and cannot be obtained in an explicit form. However, [14] proposed that the mode of the corresponding posteriors may be used as the Bayes estimates for and .
The work by [16] has shown that the above Achcar’s reference prior based posterior given in Equation (11) becomes improper when . In practice, both posteriors given in Equations (9) and (11) are numerically intractable for larger and n values due to the increments of the products in their numerators. However, as , the parameter in the BS distribution is solely a scale parameter which represents the median. Therefore, we suggest a simple and computationally efficient scaler transformation to reduce this inflation and to avoid the situation that . As a result, the median of the transformed data and the posteriors of will be centered around one.
3. Application of Gibbs Sampler
In this section, we introduce a Gibbs sampling procedure that can be used to estimate the parameters of the BS distribution in the presence of censored data. The procedure uses Markov Chain Monte Carlo (MCMC) techniques to generate data samples that replace the censored portion of the data set.
Here, we propose using Bayesian inference for BS parameters and , employing marginal posteriors obtained using both Jeffrey’s and Achcar’s priors via the Gibbs sampler. Moreover, upon sampling from a BS distribution for unknown realizations of censored units, the remaining average lifetime is also estimated.
The Gibbs sampler requires suitable initial values for and to achieve its convergence. Often the MLE’s from the observed data given censoring are preferred for this purpose. Ignoring the additive constant, the BS log-likelihood function for the progressively Type-II-censored data of the form can be written as
where is the pdf of the BS distribution given in Equation (2), and .
The MLEs of the BS parameters cannot be obtained in the closed form for this censoring scheme. Using the property that the BS distribution can be written as an equal mixture of an IG distribution and its reciprocal [20] outlined an EM algorithm to obtained its MLEs. In this work, we use a computational tool introduced in [21] that is freely available in [22], which can be used to obtain MLEs of the BS parameters with all major censoring schemes.
Below, we outline the major steps of the Gibbs sampler, which employs progressively Type-II-censored BS data.
- Calculate the MLE and from the available right-censored data. Set and .
- Generate random variates from a uniform distribution bounded by the BS CDF value of the respective censored observation and one. Then, use the inverse CDF () value of the newly sampled random variate to replace the censored value. For instance, for the jth censored observation in ,
- Generate: , where .
- Then, set: .
- Repeat Step 2 for all censored units in all r censored stages. The censored data will be replaced by the the newly simulated data (), for each and will be combined with the observed failure times to form an updated and complete sample of size n.
- Using the updated sample in Step 3, sample and from their respective posterior distributions.
- Repeat Steps 2–4 starting with the newly sampled parameters, and . This procedure will continue for k total iterations and conclude with the results for and . A new set of simulated BS observations should be picked in the same manner as in Step 3 using the and as newly updated parameters.
- At the conclusion of Step 5, the average remaining life of censored units defined in Equation (3) shall be calculated using the newly sampled data and is designated as .
- Repeat the above process in Step 2–6 a large number of times, say m total replications. This will result:
In the Gibbs sampler, we guarantee the convergence of the sampled data using both numerical and graphical summaries. This includes monitoring the scalar summary and the scale reduction statistic defined in [23]. As suggested in [24], we confirm that this scale reduction statistic is well below 1.1 and the trace plots behave appropriately to ensure the convergence of the Gibbs samples in all situations considered. After confirming the convergence, we report both point and interval estimates. This includes mean and its stand error estimates as well as the 95% equal-tailed credible intervals for all the parameters including . Moreover, we use the Kernel density estimation procedure to make visual comparisons between estimation methods. A sample R code to exhibit this algorithm is included in the Supplementary Materials.
4. Monte–Carlo Simulation
We conduct a simulation study to compare the performance of the discussed Bayesian estimates. The data are generated from the distribution with four different sample sizes and four different Type-II right-censoring percentages (CEP) at 10%(10%)40%. Without a loss of generality, we kept the scale parameter fixed at 1.0 while varying the shape parameter . In each experimental condition, we repeatedly generated 2000 BS data sets and applied the proposed Gibbs sampler.
We noticed that the Gibbs sampler converges in iterations for both Bayesian priors, and the scale reduction factor for both parameters is less than 1.1. After assessing the convergence, we replicate the Gibbs sampler times to obtain the point and 95% equal-tailed credible intervals for , , and for each generated data set. Then for each parameter, the overall average of the posterior mean estimates (PE), its standard error (SE), and the coverage probability (CP) for 1000 randomly generated BS samples are acquired. To compare posterior point estimates, we refer to an observed bias as the difference between the true BS parameter and its PE. These results are shown in Table 1, Table 2, Table 3 and Table 4.

Table 1.
Mean and standard error of the point estimates and probability coverages of 95% credible intervals based on Monte–Carlo simulation ().
Table 2.
Mean and standard error of the point estimates and probability coverages of 95% credible intervals based on Monte–Carlo simulation ().
Table 3.
Mean and standard error of the point estimates and probability coverages of 95% credible intervals based on Monte–Carlo simulation ().
Table 4.
Mean and standard error of the point estimates and probability coverages of 95% credible intervals based on Monte–Carlo simulation ().
As shown in Table 1, for , Jeffrey’s method slightly underestimates the true value, and the size of the bias increases with the amount of the censoring percentage. The difference is more apparent for higher values. Achcar’s method slightly overestimates the true value of the regardless of the censoring percentage, except for high censoring cases. The standard errors of the estimates are somewhat similar for both methods. Interestingly, Achcar’s prior maintains the coverage probability at the nominal 95% level while Jeffrey’s prior becomes slightly liberal, as its coverage probability is around 93%. The estimates for both the methods are somewhat consistent for all values. The coverage probability comparison for the estimates is quite similar to that of the .
For the average remaining time, Achcar’s estimates provide somewhat higher estimates than Jeffrey’s estimates. Again, the differences are greater for larger values than for the smaller s. As far as the standard error is concerned, both methods are equally good and proportional to the true value. The coverage probability comparison is quite similar to that of the and comparisons.
Based on the estimates shown in Table 2, when , the comparisons we made earlier are still valid for all estimates, but the differences between estimates and the effects of high censoring are not as pronounced as in cases, and their standard errors are also now lower. When the sample size increases to and 50 (see Table 3 and Table 4), both the methods provide better results with increasing precision. The differences between the point estimates for lower values are further narrowing and the coverage probabilities of all estimates approach the nominal 95% level, showing greater precision in the interval estimations for large samples.
5. Illustrative Examples
In this section, we consider three examples to illustrate the Gibbs sampler procedure described in Section 3. These examples exhibit the parameter estimation in randomly right, Type-II, and progressively Type-II-censored data.
- Example 01 (Cancer Patients Data): This data set was originally presented in [25] and consists of lifetimes (in months) of 20 cancer patients who received a new treatment. The complete lifetime of only 17 cancer patients was recorded and the rest of the three patients were right-censored and denoted by “+” in the following data set.
| 3 | 5 | 6 | 7 | 8 | 9 | 10 | 10+ | 12 | 15 |
| 15+ | 18 | 19 | 20 | 22 | 25 | 28 | 30 | 40 | 45+ |
The Kolmogorov–Smirnov goodness-of-fit test indicates that these data adequately follow a BS distribution, and its MLEs are and . For these data, represents the average remaining lifetime for each of three patients censored during the experiment until they die. With only three observations out of 20 being censored, the number of iteration was found to be sufficient to ensure the convergence, and m = 10,000 Gibbs sample chains were used for the parameter estimation. The resulting estimates are shown in Table 5.
Table 5.
Parameter estimates on cancer data.
In addition, in the lower portion of Table 5, we report both point and interval estimates obtained in [25] Bayesian work (A-M 2010) and also the [18]’s Bayesian and MLE results (S-N MLE and S-N Bayesian), where they applied a generalized Birnbaum–Saunders distribution for the same data.
We note that both the initial MLEs, and , fall well within all the corresponding 95% credible interval bounds (see Table 5). Both Jeffre’s and Achcar’s estimates compare favorably to one another. Lengths of the credible intervals are somewhat narrower for when compared to the [18,25] results. The estimated average remaining lifetime for the censored patients ranges from 18 to 20 months after their observation period was completed.
- Example 02 (Fatigue Life): This example consists of the fatigue life of 6061-T6 aluminum coupons cut parallel to the direction of rolling and oscillated at 18 cycles per second, with a maximum stress per cycle of 31,000 psi reported in [8]. We reconfirmed that these data can be adequately modeled using the BS distribution, and the MLEs for complete data are and .
| 70 | 90 | 96 | 97 | 99 | 100 | 103 | 104 | 104 | 105 | 107 | 108 | 108 | 108 | 109 |
| 109 | 112 | 112 | 113 | 114 | 114 | 114 | 116 | 119 | 120 | 120 | 120 | 121 | 121 | 123 |
| 124 | 124 | 124 | 124 | 124 | 128 | 128 | 129 | 129 | 130 | 130 | 130 | 131 | 131 | 131 |
| 131 | 131 | 132 | 132 | 132 | 133 | 134 | 134 | 134 | 134 | 134 | 136 | 136 | 137 | 138 |
| 138 | 138 | 139 | 139 | 141 | 141 | 142 | 142 | 142 | 142 | 142 | 142 | 144 | 144 | 145 |
| 146 | 148 | 148 | 149 | 151 | 151 | 152 | 155 | 156 | 157 | 157 | 157 | 157 | 158 | 159 |
| 162 | 163 | 163 | 164 | 166 | 166 | 168 | 170 | 174 | 196 | 212 |
We applied the Type-II right-censoring scheme with censoring percentages (CEP) at 10%(10%)60% for these data, and the estimated MLEs at different censoring levels are shown in Table 6. Due to the relatively larger and sample size, first, we transform these data using the scale transformation suggested in Section 2.2 and adjust the MLEs accordingly to be used in the Gibbs sampler. We observed that the Gibbs sampler adequately converged with iterations and obtained m = 10,000 Gibbs sample chains to obtain estimates.
Table 6.
Initial Parameter estimates on Type-II-censored fatigue life data.
Also, Figure 1 shows the kernel density estimates of the parameters for Jeffrey’s and Achcar’s priors at 10%, 30%, and 60% censoring levels. The plots seem adequate and both methods seem to provide very similar estimates. However, as [26] indicated, the Gibbs output may not detect improper posteriors; the scale transformation we suggested should have scaled-down to prevent such possible divergences.
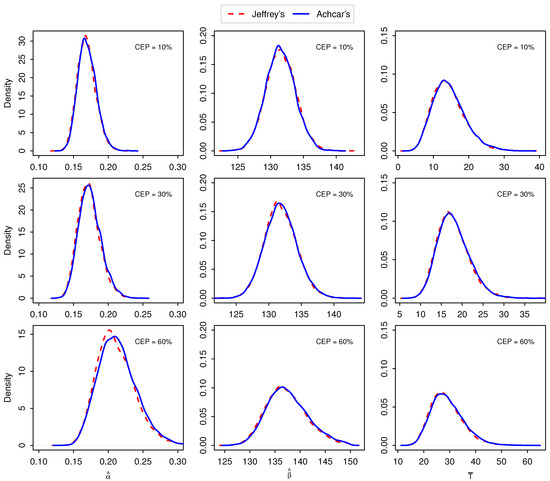
Figure 1.
Kernel density estimates of Achcar’s and Jeffrey’s priors for censored fatigue life data. Top panel, middle, and bottom panels are for 10%, 30%, and 60% censoring schemes, respectively.
The resulting point estimates along with the widths of the 95% credible intervals for both the priors are reported in Table 7. Interestingly, both and estimates for both the methods for lower to mid-censoring percentages 10%, 20%, and 30% are very close to their uncensored MLEs for complete data ( and ). However, when censoring percentage increases, both and overestimate the true values. As expected, the average remaining time is also increased with respect to the censoring percentages. It is also noted that all six estimates overestimated the true average remaining time; the increments are proportional to the true values for increasing the censoring percentages reported in Table 6.
Table 7.
Point estimates (, , and ) and widths of the corresponding credible intervals for different censoring percentages.
- Example 03 (Ball Bearings’ Data): This data set was originally presented in [27] and provides the fatigue life in hours of ten ball bearings of a certain type:
| 152.7 | 172.0 | 172.5 | 173.3 | 193.0 | 204.7 | 216.5 | 234.9 | 262.6 | 422.6 |
Ref. [9] used the full data set and fitted BS distribution and reported that unbiased MLEs of and are 0.314 and 211.528, respectively. Ref. [20] used these data to generate three different progressively Type-II-censored samples and estimated BS parameters. We use somewhat similar progressively Type-II-censored samples, as shown below.
- Scheme I:
- Scheme II: .
The resulting parameter estimates, along with their 95% credible intervals, are reported in Table 8. Due to censoring in this small dataset, both Bayesian priors underestimate the unbiased MLEs. However, the credible intervals adequately capture these values. Achcar’s estimates become slightly better, as they are closer to the unbiased MLEs obtained from the complete data. This example indicates that the suggested method can be used effectively even for small datasets, yielding decent results.
Table 8.
Parameter estimates on Type-II progressively censored ball bearings’ data.
6. Conclusions
This study reveals that the suggested Gibbs sampler performs reasonably well with both Bayesian priors. Achcar’s priors appear to provide better coverage probability than Jeffrey’s prior in the considered cases of this simulation study. Additionally, Achcar’s priors tend to slightly overestimate the true parameter value, while Jeffrey’s tends to underestimate it. The amount of censoring and sample size has an impact on the performance of both methods, and therefore, one should be aware of this limitation in practice. With an increase in sample size, all methods perform better, although the amount of censoring seems to slightly affect the estimates. Care must be taken regarding the size of the parameter and the sample size when applying non-informative priors. The suggested scale transformation may need to be adopted to guarantee proper posteriors when using Achcar’s reference prior. Also, because the marginal posterior distributions relied on the Laplace approximation, there may be limitations on estimating the average lifetime because the BS density is an approximation to its true underlying distribution. However, this study reveals that the Gibbs sampler is capable enough to provide accurate remaining average lifetime estimates.
The simulation results indicate that the method considered shows some improvements with regards to point estimates and coverage probabilities when compared to [15] Bayesian results. In particular, our algorithm shows no substantial effect on the coverage probability by the amount of censoring. Also, the posterior distributions discussed here have tractable closed forms that require no partial or hyper-prior information. Also, our results are consistent with regards to the bias and coverage probability for all parameter combinations we considered; this shows a clear improvement when compared to the simulation results shown in [18].
With the Gibbs sampler, there is less restriction on the type of prior distribution that can be chosen. However, caution must be exercised in programming to ensure the well-behaved nature of both prior and posterior distributions. If posterior distributions, whether conditional or otherwise, cannot be precisely determined, asymptotic distributions may be employed. The Gibbs sampler procedures offer a high degree of flexibility in implementation, allowing the adjustment of the number of iterations based on the trade-off between the speed and desired accuracy. Undoubtedly, the Gibbs sampler finds its place in developing complex models, particularly when dealing with censored data. Its computation involves a series of calculations that are easy to understand, and its implementation is relatively straightforward.
Supplementary Materials
The following supporting information can be downloaded at: https://www.mdpi.com/article/10.3390/math12060874/s1. Supplementary File: “R code for Fatigue Life data Analysis.R”.
Funding
This research received no external funding.
Data Availability Statement
Data are contained within the article and Supplementary Materials.
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A
The Laplace’s method for integrals provides an approximate to the integral of the form
where is a smooth function of , having its maximum at . Then, the Laplace’s approximate for integral I becomes
where .
Now, as outlined in [14], assuming Jeffrey’s prior, the joint posterior distribution of and becomes
where and .
For Achcar’s prior , and the marginal posterior of can be written as
where and . The maximum of the occurs at and therefore, and .
Then, using the Laplace approximation, the integral can be approximated by
By neglecting all but terms in , the approximate marginal posterior distribution of becomes
References
- Birnbaum, Z.W.; Saunders, S.C. A new family of life distributions. J. Appl. Probab. 1969, 6, 319–327. [Google Scholar] [CrossRef]
- Balakrishnan, N.; Kundu, D. Birnbaum-Saunders distribution: A review of models, analysis, and applications. Appl. Stoch. Model. Bus. Ind. 2019, 35, 4–49. [Google Scholar]
- Desmond, A.F. On the relationship between two fatigue-life models. IEEE Trans. Reliab. 1986, 35, 167–169. [Google Scholar] [CrossRef]
- Bhattacharyya, G.; Fries, A. Fatigue Failure Models—Birnbaum-Saunders vs. Inverse Gaussian. IEEE Trans. Reliab. 1982, 31, 439–441. [Google Scholar] [CrossRef]
- Owen, W.J.; Ng, H.K.T. Revisit of relationships and models for the Birnbaum-Saunders and inverse-Gaussian distributions. J. Stat. Distrib. Appl. 2015, 2, 11. [Google Scholar]
- Ng, H.K.T. Discussion of “Birnbaum-Saunders distribution: A review of models, analysis, and applications”. Appl. Stoch. Model. Bus. Ind. 2019, 35, 64–71. [Google Scholar] [CrossRef]
- Saunders, S.C. A family of random variables closed under reciprocation. J. Am. Stat. Assoc. 1974, 69, 533–539. [Google Scholar] [CrossRef]
- Birnbaum, Z.W.; Saunders, S.C. Estimation for a family of life distributions with applications to fatigue. J. Appl. Probab. 1969, 6, 328–347. [Google Scholar] [CrossRef]
- Ng, H.; Kundu, D.; Balakrishnan, N. Modified moment estimation for the two-parameter Birnbaum–Saunders distribution. Comput. Stat. Data Anal. 2003, 43, 283–298. [Google Scholar] [CrossRef]
- Balakrishnan, N.; Zhu, X. An improved method of estimation for the parameters of the Birnbaum–Saunders distribution. J. Stat. Comput. Simul. 2014, 84, 2285–2294. [Google Scholar] [CrossRef]
- Ng, H.; Kundu, D.; Balakrishnan, N. Point and interval estimation for the two-parameter Birnbaum–Saunders distribution based on Type-II censored samples. Comput. Stat. Data Anal. 2006, 50, 3222–3242. [Google Scholar] [CrossRef]
- Wang, Z.; Desmond, A.F.; Lu, X. Modified censored moment estimation for the two-parameter Birnbaum–Saunders distribution. Comput. Stat. Data Anal. 2006, 50, 1033–1051. [Google Scholar] [CrossRef]
- Jayalath, K.P. Fiducial Inference on the Right Censored Birnbaum–Saunders Data via Gibbs Sampler. Stats 2021, 4, 385–399. [Google Scholar] [CrossRef]
- Achcar, J.A. Inferences for the Birnbaum—Saunders fatigue life model using Bayesian methods. Comput. Stat. Data Anal. 1993, 15, 367–380. [Google Scholar] [CrossRef]
- Xu, A.; Tang, Y. Reference analysis for Birnbaum–Saunders distribution. Comput. Stat. Data Anal. 2010, 54, 185–192. [Google Scholar] [CrossRef]
- Xu, A.; Tang, Y. Bayesian analysis of Birnbaum–Saunders distribution with partial information. Comput. Stat. Data Anal. 2011, 55, 2324–2333. [Google Scholar] [CrossRef]
- Wang, M.; Sun, X.; Park, C. Bayesian analysis of Birnbaum–Saunders distribution via the generalized ratio-of-uniforms method. Comput. Stat. 2016, 31, 207–225. [Google Scholar] [CrossRef]
- Sha, N.; Ng, T.L. Bayesian inference for Birnbaum–Saunders distribution and its generalization. J. Stat. Comput. Simul. 2017, 87, 2411–2429. [Google Scholar] [CrossRef]
- Balakrishnan, N.; Cramer, E. The art of progressive censoring. In Statistics for Industry and Technology; Springer: Berlin/Heidelberg, Germany, 2014. [Google Scholar]
- Pradhan, B.; Kundu, D. Inference and optimal censoring schemes for progressively censored Birnbaum–Saunders distribution. J. Stat. Plan. Inference 2013, 143, 1098–1108. [Google Scholar] [CrossRef]
- Delignette-Muller, M.; Dutang, C. An R Package for Fitting Distributions. J. Stat. Softw. 2015, 61, 1–34. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2019. [Google Scholar]
- Brooks, S.P.; Gelman, A. General methods for monitoring convergence of iterative simulations. J. Comput. Graph. Stat. 1998, 7, 434–455. [Google Scholar]
- Gelman, A.; Carlin, J.B.; Stern, H.S.; Dunson, D.B.; Vehtari, A.; Rubin, D.B. Bayesian Data Analysis; Chapman and Hall/CRC: Boca Raton, FL, USA, 2013. [Google Scholar]
- Achcar, J.A.; Moala, F.A. Use of MCMC methods to obtain Bayesian inferences for the Birnbaum-Saunders distribution in the presence of censored data and covariates. Adv. Appl. Stat. 2010, 17, 1–27. [Google Scholar]
- Hobert, J.P.; Casella, G. The effect of improper priors on Gibbs sampling in hierarchical linear mixed models. J. Am. Stat. Assoc. 1996, 91, 1461–1473. [Google Scholar]
- McCool, J. Inferential Techniques for Weibull Populations. Aerospace Research Laboratories Report; Technical Report, ARL TR 74-0180; Wright-Patterson AFB: Fairborn, OH, USA, 1974. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).