


Predictive Maintenance with Linguistic Text Mining


{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Literature Review
2.1. Maintenance
“The combination of all technical and administrative actions, including supervision, which ensure that a system is in its required functioning state”.[1]
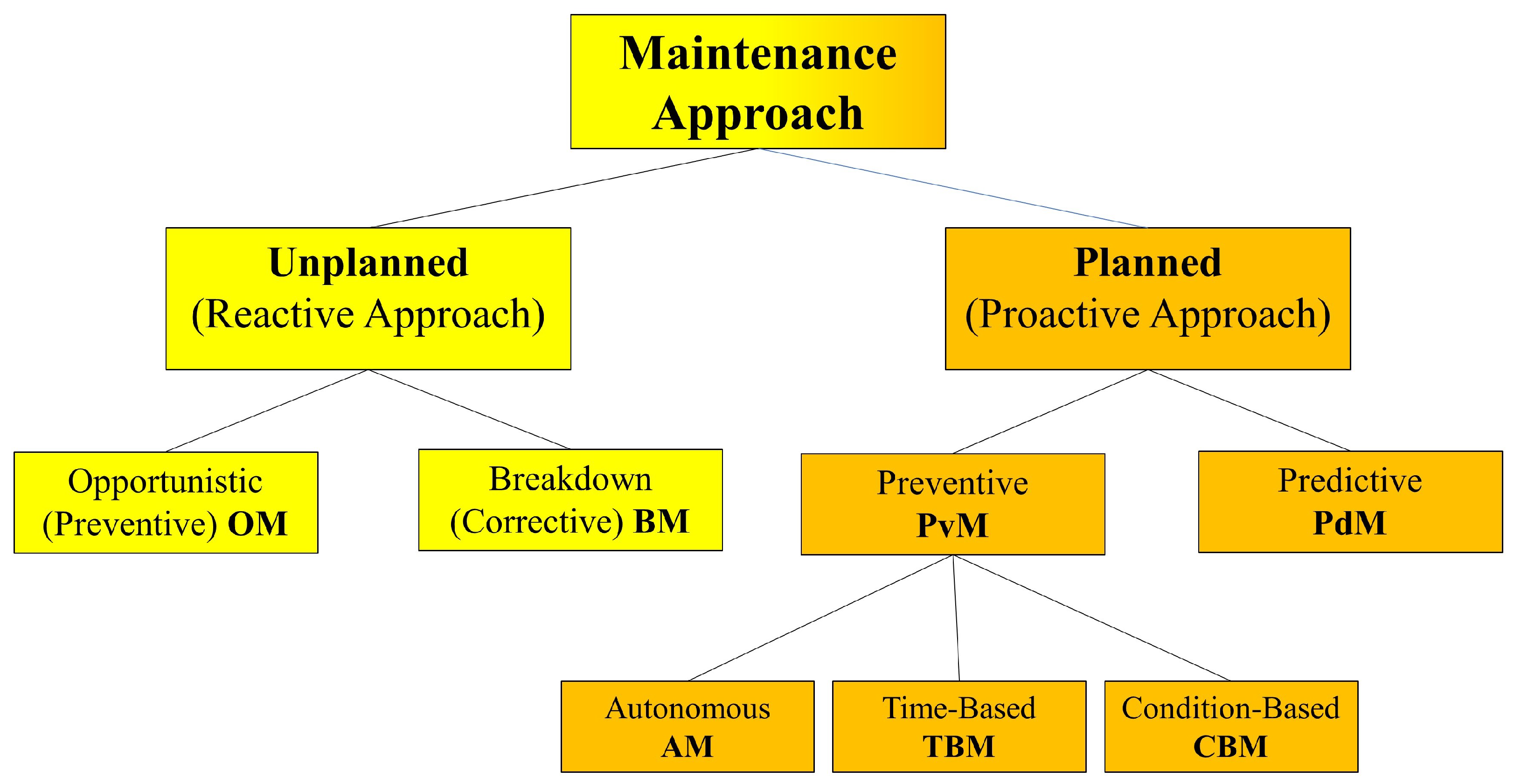
2.2. Maintenance Approaches
2.2.1. Unplanned Maintenance
- Opportunistic maintenance (OM), which strives to turn a failure event into an opportunity for improvement; for instance, if a production line stops because of a machine failure, the maintenance team can conduct inspections on other machines in the line while the repair is underway. A classification of opportunistic maintenance models can be found in Di Dio et al. ([14]).
- Breakdown maintenance (BM), also known as corrective maintenance (CM) or run-to-failure or reactive maintenance, refers to maintenance activities performed on industrial machinery or equipment to identify and rectify the causes of failures in a failed system (Wang et al., 2014). Unlike preventive maintenance, which involves scheduled inspections and servicing to prevent failures, corrective maintenance occurs after a breakdown has occurred and aims to restore the equipment to its normal operating condition. In Wang et al. ([15]), a comprehensive corrective maintenance scheme for engineering equipment is proposed.
2.2.2. Planned Maintenance: Preventive Maintenance (PvM)
- The simplest form of PvM is autonomous maintenance (AM), defined by regular tasks involving equipment monitoring, adjustments, and basic maintenance by machine operators, and the process is commonly referred to as routine activity. A simplified approach to autonomous maintenance is outlined in a study by Gajdzik et al. [16]. Additionally, preventive maintenance (PvM) can utilize time-based methods.
- Time-based maintenance (TBM) is a maintenance strategy based on fixed time intervals, where predefined maintenance tasks are performed regularly according to predetermined schedules. Maintenance decisions in TBM are triggered solely by time, with preventive repairs determined through failure time analysis ([17]). TBM strives to mitigate system degradation by executing preventive maintenance tasks while the system remains operational ([18]).
- Another preventive technique is condition-based maintenance (CBM) [19], which monitors the actual condition of assets to inform maintenance decisions. CBM prescribes maintenance based on physical variables indicating decreasing performance or imminent failure. Introduced as an alternative to TBM, CBM addresses its limitations and serves as a decision-making method covering equipment condition evaluation and maintenance decision processes ([20]).
2.2.3. Planned Maintenance: Predictive Maintenance (PdM)
2.3. Predictive Maintenance Approaches
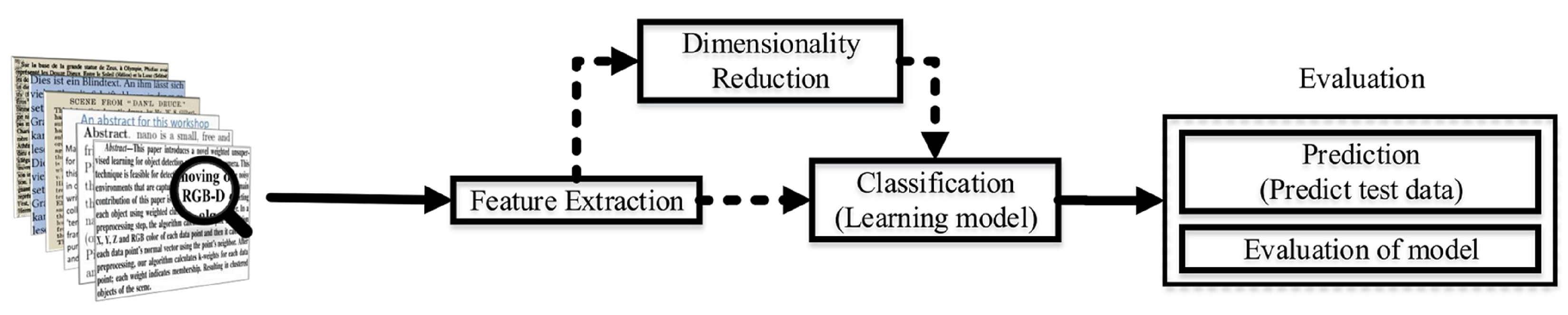
2.4. Text Mining
- Pre-processing;
- Text representation;
- Dimensionality reduction;
- Features extraction;
- Document classification;
- Evaluation.
2.5. Scientific Foundations of the Research
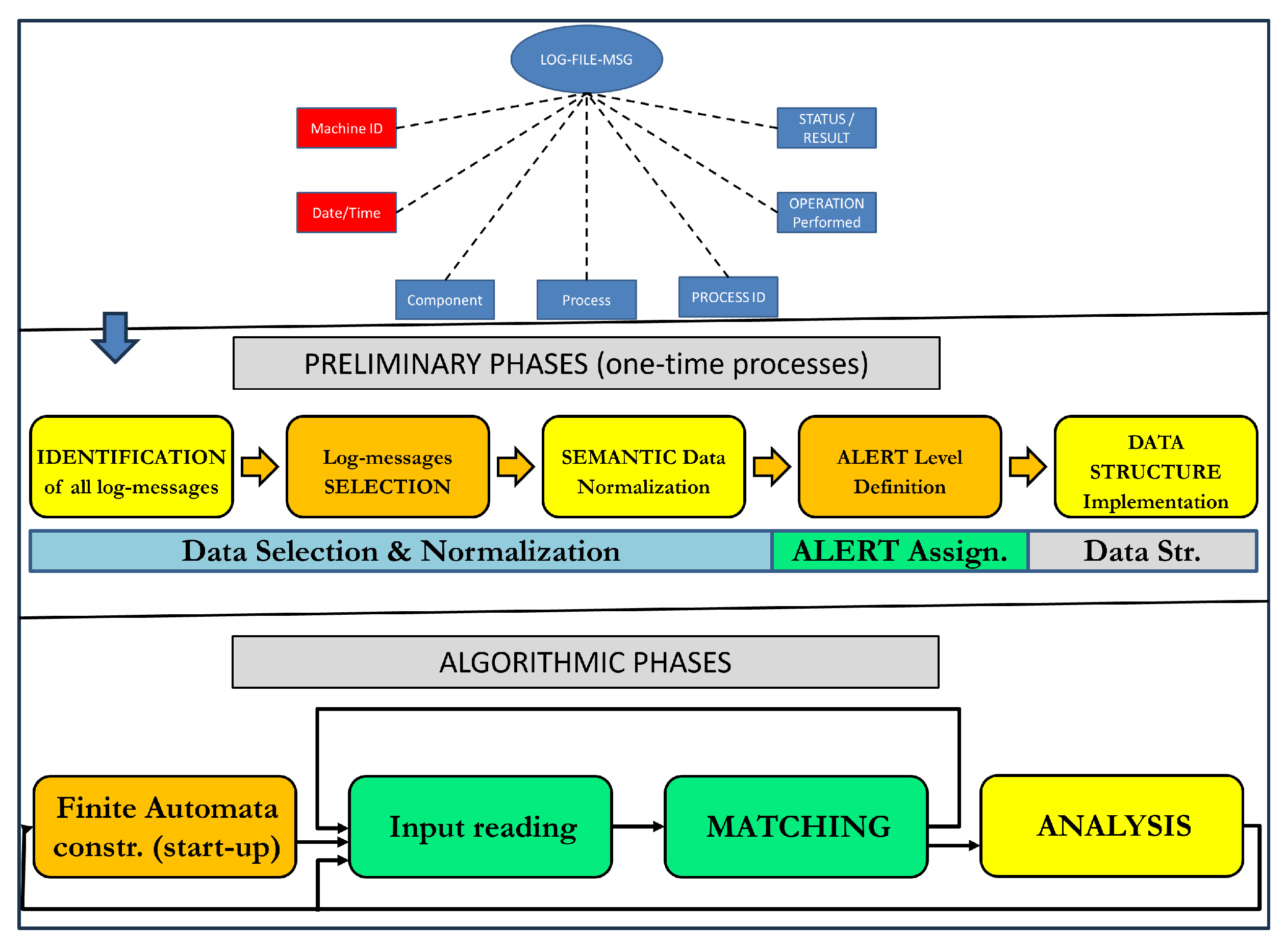
3. System Description
3.1. LOG Messages
| Machine ID: | A unique identifier denotes the machine from which the message originated. |
| Date/time: | The date and time at which the event or message was generated. |
| Component: | Text strings are employed to logically group messages, where components may represent various subsystems or components of the machine, such as “Controller”, “Database Server”, or “Motor Drive”. |
| Process: | Identification of the running process that generated the message, typically including the full path and filename, and sometimes the module name. |
| Process ID (PID): | An integer that uniquely identifies the running process. |
| Operation performed: | Details about the specific operation or event that occurred. This could include commands executed, sensor readings, status updates, or any other relevant information about the machine’s activities. |
| Result or status: | The outcome or status of the operation performed. This could indicate success, failure, warnings, errors, or other relevant states. The result may be presented as a free-form text string or a predefined code indicating the status. |
3.2. System Preliminary Phase
3.2.1. Preliminary Sub-Step 1: Data Selection and Normalization
- Identification of all message types: this initial stage involves identifying every possible type of message that can be generated.
- Relevance-based log messages selection. Each selected message type should contain only relevant information and will constitute the initial segment of every element within the ontology. This stage is carried out in strict collaboration with the machine’s domain experts.
- Semantic data normalization: in this stage, the focus is on aligning the data with standardized semantics and formats.
3.2.2. Preliminary Sub-Step 2: Assigning Alert Level to Each Log Message
| White Level (All Clear): | Signifies that everything is functioning properly. |
| Yellow Level (Minor—Caution): | Indicates occasional anomalies that have occurred, none of which are critical, and the system can continue operating without issues. |
| Orange Level (Moderate—Act Promptly): | Indicates significant anomalies or a grouping of basic anomalies that, if recurring, could impact production continuity. |
| Red Level (Severe—Immediate Action Required): | Signifies the presence of severe anomalies within the system that could significantly disrupt production activities. |
| Black Level (Emergency Shutdown): | Indicates that the system is at risk of irreversible equipment or product failures and requires an immediate halt. |
3.2.3. Preliminary Sub-Step 3: Data Structure Establishment
3.3. System Algorithmic Steps
3.3.1. Pre-Processing
3.3.2. Matching
3.3.3. Analysis
4. System Performances
4.1. Algorithms’ Performances
| Pre-processing: | Initially, the system constructs a finite automaton in the computer’s memory for the entire set of log messages. This process occurs once per session and whenever the reference ontology changes. The time complexity of the pre-processing phase, denoted by the total number of elementary algorithmic steps (and hence the number of state transitions in the finite automaton), is [73], where m is linearly proportional to the sum of the lengths of all entries in the dictionary with n elements, given by . This implies that the time required is linearly proportional to the number of characters in the dictionary. |
| Processing: | The automaton continuously processes lines of input text, character by character, without revisiting previously read characters. Each character guides the automaton through its state transitions, and, upon reaching a state corresponding to the end of a log message, it emits the associated alert. Consequently, analyzing a text of k characters requires k state transitions. All log messages are simultaneously recognized in a single pass, even if they partially or fully overlap, regardless of their length. Thus, the algorithm operates in linear time relative to the number of characters in the input text [73], and its performance remains unaffected by the size of the ontologies (i.e., the set of all possible log messages). Furthermore, it operates entirely within the computer’s main memory. |
| Analysis: | At the conclusion of the matching phase, once the input text has been fully processed, the system tallies the frequency of each alert detected and suggests a classification for the input text. |
4.2. System Architecture
5. Performances Comparison
5.1. Efficiency
5.2. Computational Performance
6. Case Study
6.1. Source Data Description
| Date/time | of event recording (e.g., “13/02/2023 14:25:00”). |
| Process | of the running process that generated the message |
| ID | (e.g., “MSG_SYS”). |
| Operation | performed (e.g., “Scrive”). |
| Execution status/result | of the event (e.g., “Fine corsa asse…, Y+”). |
| Date/Time # Process ID # Operation # Execution status/result # “Alert Level” |
6.2. Simulation Results
6.2.1. Preliminary Phase
6.2.2. Algorithmic Phase 1: Pre-Processing
6.2.3. Algorithmic Phase 2: Processing
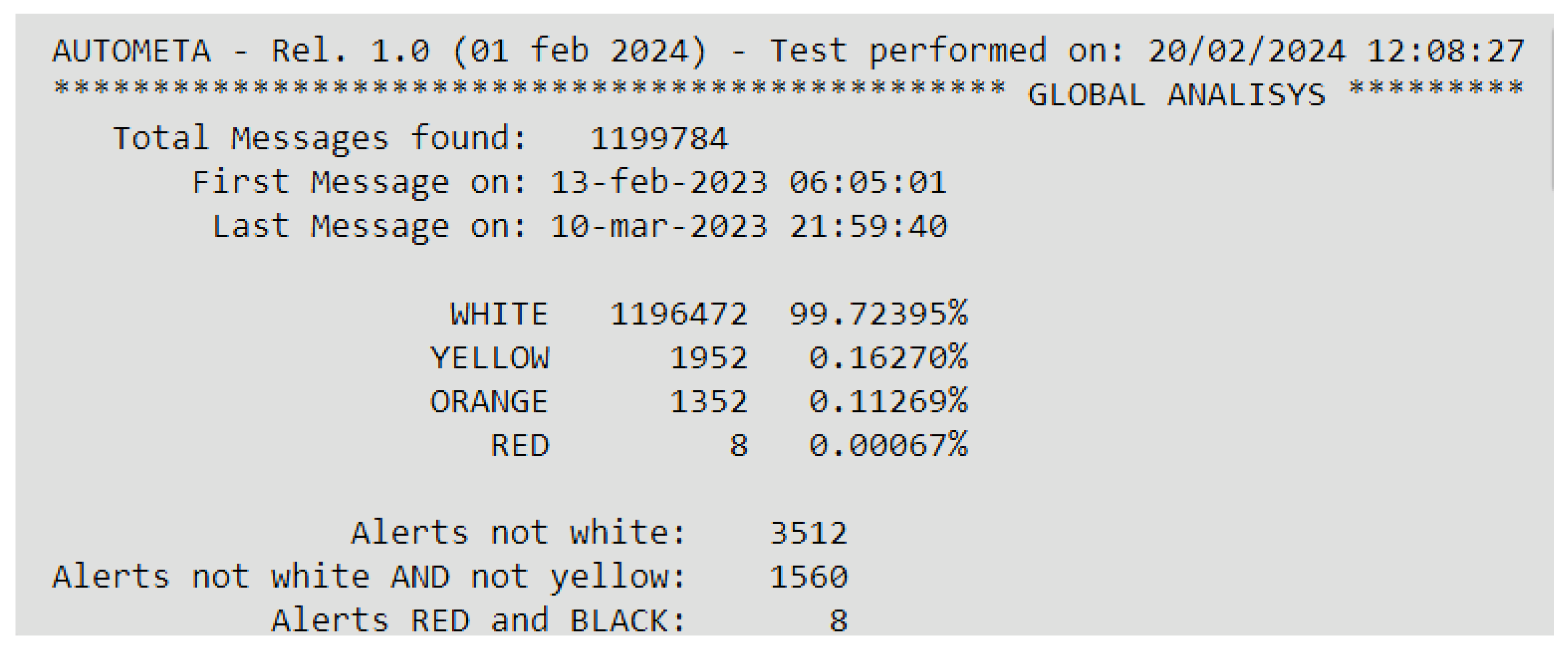
6.2.4. Algorithmic Phase 3: Analysis
- –
- 1,196,472 are white (99.72%) and 3312 are not white (0.28%);
- –
- 1952 are yellow (0.17%) and 1360 (0.13%) are neither white nor yellow;
- –
- 1352 are orange (0.11%);
- –
- 8 are red (0.00067%).
7. Future Research Directions
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Basri, E.I.; Razak, I.H.A.; Ab-Samat, H.; Kamaruddin, S. Preventive Maintenance (PM) Planning: A Review. J. Qual. Maint. Eng. 2017, 23, 114–143. [Google Scholar] [CrossRef]
- Trojan, F.; Marçal, R.F. Proposal of Maintenance-Types Classification to Clarify Maintenance Concepts in Production and Operations Management. J. Bus. Econ. 2017, 8, 560–572. [Google Scholar]
- Rüßmann, M.; Lorenz, M.; Gerbert, P.; Waldner, M.; Justus, J.; Engel, P.; Harnisch, M. Industry 4.0: The Future of Productivity and Growth in Manufacturing Industries. Boston Consult. Group 2015, 9, 54–89. [Google Scholar]
- Silvestri, L.; Forcina, A.; Introna, V.; Santolamazza, A.; Cesarotti, V. Maintenance Transformation through Industry 4.0 Technologies: A Systematic Literature Review. Comput. Ind. 2020, 123, 103335. [Google Scholar] [CrossRef]
- Silva Neto, A.V.; Silva, H.L.; Camargo, J.B.; Almeida, J.R.; Cugnasca, P.S. Design and Assurance of Safety-Critical Systems with Artificial Intelligence in FPGAs: The Safety ArtISt Method and a Case Study of an FPGA-Based Autonomous Vehicle Braking Control System. Electronics 2023, 12, 4903. [Google Scholar] [CrossRef]
- Zonta, T.; da Costa, C.A.; da Rosa Righi, R.; de Lima, M.J.; da Trindade, E.S.; Li, G.P. Predictive Maintenance in the Industry 4.0: A Systematic Literature Review. Comput. Ind. Eng. 2020, 150, 106889. [Google Scholar] [CrossRef]
- Shcherbakov, M.V.; Glotov, A.V.; Cheremisinov, S.V. Proactive and Predictive Maintenance of Cyber-Physical Systems. Stud. Syst. Decis. Control 2020, 259, 263–278. [Google Scholar] [CrossRef]
- Bampoula, X.; Siaterlis, G.; Nikolakis, N.; Alexopoulos, K. A Deep Learning Model for Predictive Maintenance in Cyber-Physical Production Systems Using LSTM Autoencoders. Sensors 2021, 21, 972. [Google Scholar] [CrossRef] [PubMed]
- Nota, G.; Postiglione, A.; Carvello, R. Text Mining Techniques for the Management of Predictive Maintenance. In Proceedings of the 3rd International Conference on Industry 4.0 and Smart Manufacturing, ISM 2021, Linz, Austria, 19–21 November 2021; Longo, F., Affenzeller, M.P.A., Eds.; Elsevier B.V.: Amsterdam, The Netherlands, 2022. [Google Scholar] [CrossRef]
- Sharanya, S. A Cyber Physical System Framework for Industrial Predictive Maintenance Using Machine Learning. In Real-Time Applications of Machine Learning in Cyber-Physical Systems; IGI Global: Hershey, PA, USA, 2022; pp. 241–269. [Google Scholar]
- Duffuaa, S.; Ben-Daya, M.; Al-Sultan, K.; Andijani, A. A Generic Conceptual Simulation Model for Maintenance Systems. J. Qual. Maint. Eng. 2001, 7, 207–219. [Google Scholar] [CrossRef]
- Nyman, D.; Levitt, J. Maintenance Planning, Scheduling, and Coordination; Industrial Press Inc.: New York, NY, USA, 2001. [Google Scholar]
- Patil, A.; Soni, G.; Prakash, A.; Karwasra, K. Maintenance strategy selection: A comprehensive review of current paradigms and solution approaches. Int. J. Qual. Reliab. Manag. 2022, 39, 675–703. [Google Scholar] [CrossRef]
- Di Dio, M.; Iannone, R.; Miranda, S.; Riemma, S. A Framework for the Choice of the Opportunistic Maintenance Policy in Industrial Contexts. In Proceedings of the IEEE International Conference on Industrial Engineering and Engineering Management, Selangor Darul Ehsan, Malaysia, 9–12 December 2014; IEEE Computer Society: Washington, DC, USA, 2014; pp. 1716–1720. [Google Scholar] [CrossRef]
- Wang, Y.; Deng, C.; Wu, J.; Wang, Y.; Xiong, Y. A Corrective Maintenance Scheme for Engineering Equipment. Eng. Fail. Anal. 2014, 36, 269–283. [Google Scholar] [CrossRef]
- Gajdzik, B. Autonomous and Professional Maintenance in Metallurgical Enterprise as Activities within Total Productive Maintenance. Metalurgija 2014, 53, 269–272. [Google Scholar]
- Ahmad, R.; Kamaruddin, S. An Overview of Time-Based and Condition-Based Maintenance in Industrial Application. Comput. Ind. Eng. 2012, 63, 135–149. [Google Scholar] [CrossRef]
- Kim, J.; Ahn, Y.; Yeo, H. A Comparative Study of Time-Based Maintenance and Condition-Based Maintenance for Optimal Choice of Maintenance Policy. Struct. Infrastruct. Eng. 2016, 12, 1525–1536. [Google Scholar] [CrossRef]
- Shin, J.H.; Jun, H.B. On Condition Based Maintenance Policy. J. Comput. Des. Eng. 2015, 2, 119–127. [Google Scholar] [CrossRef]
- Ahmad, R.; Kamaruddin, S. A Review of Condition-Based Maintenance Decision-Making. Eur. J. Ind. Eng. 2012, 6, 519–541. [Google Scholar] [CrossRef]
- Mobley, R.K. An Introduction to Predictive Maintenance; Elsevier: Amsterdam, The Netherlands, 2002. [Google Scholar]
- Frankó, A.; Varga, P. A Survey on Machine Learning Based Smart Maintenance and Quality Control Solutions. Infocommunications J. 2021, 13, 28–35. [Google Scholar] [CrossRef]
- Florian, E.; Sgarbossa, F.; Zennaro, I. Machine Learning-Based Predictive Maintenance: A Cost-Oriented Model for Implementation. Int. J. Prod. Econ. 2021, 236, 108114. [Google Scholar] [CrossRef]
- Drakaki, M.; Karnavas, Y.L.; Tziafettas, I.A.; Linardos, V.; Tzionas, P. Machine Learning and Deep Learning Based Methods toward Industry 4.0 Predictive Maintenance in Induction Motors: A State of the Art Survey. J. Ind. Eng. Manag. 2022, 15, 31–57. [Google Scholar] [CrossRef]
- Rosati, R.; Romeo, L.; Cecchini, G.; Tonetto, F.; Viti, P.; Mancini, A.; Frontoni, E. From Knowledge-Based to Big Data Analytic Model: A Novel IoT and Machine Learning Based Decision Support System for Predictive Maintenance in Industry 4.0. J. Intell. Manuf. 2023, 34, 107–121. [Google Scholar] [CrossRef]
- Higgs, P.A.; Parkin, R.; Jackson, M.; Al-Habaibeh, A.; Zorriassatine, F.; Coy, J. A Survey on Condition Monitoring Systems in Industry. In Proceedings of the 7th Biennial Conference on Engineering Systems Design and Analysis, ESDA, Manchester, UK, 19–22 July 2004; American Society of Mechanical Engineers: New York, NY, USA, 2004; Volume 3, pp. 163–178. [Google Scholar] [CrossRef]
- Zhu, J.; Nostrand, T.; Spiegel, C.; Morton, B. Survey of Condition Indicators for Condition Monitoring Systems. In Proceedings of the PHM 2014—The Annual Conference of the Prognostics and Health Management Society 2014, Spokane, WA, USA, 29 September–2 October 2014; pp. 635–647. [Google Scholar]
- Surucu, O.; Gadsden, S.A.; Yawney, J. Condition Monitoring Using Machine Learning: A Review of Theory, Applications, and Recent Advances. Expert Syst. Appl. 2023, 221, 119738. [Google Scholar] [CrossRef]
- Jung, D.; Zhang, Z.; Winslett, M. Vibration Analysis for Iot Enabled Predictive Maintenance. In Proceedings of the International Conference on Data Engineering, San Diego, CA, USA, 19–22 April 2017; IEEE Computer Society: Washington, DC, USA, 2017; pp. 1271–1282. [Google Scholar] [CrossRef]
- Popescu, T.D.; Aiordachioaie, D.; Culea-Florescu, A. Basic Tools for Vibration Analysis with Applications to Predictive Maintenance of Rotating Machines: An Overview. Int. J. Adv. Manuf. Technol. 2022, 118, 2883–2899. [Google Scholar] [CrossRef]
- Boughardini, I.E.; Mechkouri, M.H.; Reklaoui, K. A Predictive Maintenance System Based on Vibration Analysis for Rotating Machinery Using Wireless Sensor Network (WSN). Lect. Notes Netw. Syst. 2023, 712 LNNS, 93–106. [Google Scholar] [CrossRef]
- Ortega, M.; Ivorra, E.; Juan, A.; Venegas, P.; Martínez, J.; Alcañiz, M. Mantra: An Effective System Based on Augmented Reality and Infrared Thermography for Industrial Maintenance. Appl. Sci. 2021, 11, 385. [Google Scholar] [CrossRef]
- Keartland, S.; Van Zyl, T.L. Automating Predictive Maintenance Using Oil Analysis and Machine Learning. In Proceedings of the 2020 International SAUPEC/RobMech/PRASA Conference, Cape Town, South Africa, 29–31 January 2020; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2020. [Google Scholar] [CrossRef]
- Johansen, R.; Dupont, S.; Christiansen, U.N.; Horning, J.; Catalano, J.; Sorensen, J.L.; Bentien, A. An In-Line, High-Flowrate, and Maintenance Free Ultrasonic Sensor with a High Dynamic Range for Particle Monitoring in Fluids. IEEE Sens. J. 2018, 18, 2299–2304. [Google Scholar] [CrossRef]
- Gouriveau, R.; Medjaher, K.; Zerhouni, N. From Prognostics and Health Systems Management to Predictive Maintenance 1: Monitoring and Prognostics; John Wiley & Sons: Hoboken, NJ, USA, 2016; Volume 4, pp. 1–163. [Google Scholar] [CrossRef]
- Guillén, A.; Crespo, A.; Macchi, M.; Gómez, J. On the Role of Prognostics and Health Management in Advanced Maintenance Systems. Prod. Plan. Control 2016, 27, 991–1004. [Google Scholar] [CrossRef]
- Mancuso, A.; Compare, M.; Salo, A.; Zio, E. Optimal Prognostics and Health Management-driven Inspection and Maintenance Strategies for Industrial Systems. Reliab. Eng. Syst. Saf. 2021, 210, 107536. [Google Scholar] [CrossRef]
- Aggarwal, C.C.; Zhai, C. Mining Text Data; Springer: Boston, MA, USA, 2012; pp. 1–526. [Google Scholar]
- Aggarwal, C.C.; Zhai, C. A Survey of Text Classification Algorithms. In Mining Text Data; Aggarwal, C.C., Zhai, C., Eds.; Springer: Boston, MA, USA, 2012; pp. 163–222. [Google Scholar] [CrossRef]
- Usai, A.; Pironti, M.; Mital, M.; Aouina Mejri, C. Knowledge Discovery out of Text Data: A Systematic Review via Text Mining. J. Knowl. Manag. 2018, 22, 1471–1488. [Google Scholar] [CrossRef]
- Kowsari, K.; Meimandi, K.J.; Heidarysafa, M.; Mendu, S.; Barnes, L.; Brown, D. Text Classification Algorithms: A Survey. Information 2019, 10, 150. [Google Scholar] [CrossRef]
- Tandel, S.S.; Jamadar, A.; Dudugu, S. A Survey on Text Mining Techniques. In Proceedings of the 2019 5th International Conference on Advanced Computing and Communication Systems, ICACCS, Coimbatore, India, 15–16 March 2019; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2019; pp. 1022–1026. [Google Scholar] [CrossRef]
- Zong, C.; Xia, R.; Zhang, J. Text Data Mining; Springer: Singapore, 2021; pp. 1–351. [Google Scholar] [CrossRef]
- Kumar, M.; Kumar, S.; Yadav, S.L. Data Mining for the Internet of Things: A Survey; Apple Academic Press: Palm Bay, FL, USA, 2023; pp. 93–109. [Google Scholar]
- Navathe, S.B.; Ramez, E. Data Warehousing and Data Mining. In Fundamentals of Database Systems; Pearson Education: Singapore, 2000; pp. 841–872. [Google Scholar]
- Gupta, V.; Lehal, G.S. A Survey of Text Mining Techniques and Applications. J. Emerg. Technol. Web Intell. 2009, 1, 60–76. [Google Scholar] [CrossRef]
- Kusakin, I.; Fedorets, O.; Romanov, A. Classification of Short Scientific Texts. Sci. Tech. Inf. Process. 2023, 50, 176–183. [Google Scholar] [CrossRef]
- Danilov, G.; Ishankulov, T.; Kotik, K.; Orlov, Y.; Shifrin, M.; Potapov, A. The Classification of Short Scientific Texts Using Pretrained BERT Model; IOS Press: Amsterdam, The Netherlands, 2021; pp. 83–87. [Google Scholar] [CrossRef]
- Ongenaert, M.; Van Neste, L.; De Meyer, T.; Menschaert, G.; Bekaert, S.; Van Criekinge, W. PubMeth: A Cancer Methylation Database Combining Text-Mining and Expert Annotation. Nucleic Acids Res. 2008, 36, D842–D846. [Google Scholar] [CrossRef] [PubMed]
- Cejuela, J.M.; McQuilton, P.; Ponting, L.; Marygold, S.; Stefancsik, R.; Millburn, G.H.; Rost, B. Tagtog: Interactive and Text-Mining-Assisted Annotation of Gene Mentions in PLOS Full-Text Articles. Database Mag. Electron. Database Rev. 2014, 2014, bau033. [Google Scholar] [CrossRef] [PubMed]
- Cheerkoot-Jalim, S.; Khedo, K.K. A Systematic Review of Text Mining Approaches Applied to Various Application Areas in the Biomedical Domain. J. Knowl. Manag. 2020, 25, 642–668. [Google Scholar] [CrossRef]
- Rodríguez-Rodríguez, I.; Rodríguez, J.V.; Shirvanizadeh, N.; Ortiz, A.; Pardo-Quiles, D.J. Applications of Artificial Intelligence, Machine Learning, Big Data and the Internet of Things to the COVID-19 Pandemic: A Scientometric Review Using Text Mining. Int. J. Environ. Res. Public Health 2021, 18, 8578. [Google Scholar] [CrossRef] [PubMed]
- Baltoumas, F.A.; Zafeiropoulou, S.; Karatzas, E.; Paragkamian, S.; Thanati, F.; Iliopoulos, I.; Eliopoulos, A.G.; Schneider, R.; Jensen, L.J.; Pafilis, E.; et al. OnTheFly2.0: A Text-Mining Web Application for Automated Biomedical Entity Recognition, Document Annotation, Network and Functional Enrichment Analysis. Nar Genom. Bioinform. 2021, 3, lqab090. [Google Scholar] [CrossRef] [PubMed]
- Fenza, G.; Orciuoli, F.; Peduto, A.; Postiglione, A. Healthcare Conversational Agents: Chatbot for Improving Patient-Reported Outcomes. Lect. Notes Netw. Syst. 2023, 661 LNNS, 137–148. [Google Scholar] [CrossRef]
- Abbe, A.; Grouin, C.; Zweigenbaum, P.; Falissard, B. Text Mining Applications in Psychiatry: A Systematic Literature Review. Int. J. Methods Psychiatr. Res. 2016, 25, 86–100. [Google Scholar] [CrossRef] [PubMed]
- Chu, C.Y.; Park, K.; Kremer, G.E. A Global Supply Chain Risk Management Framework: An Application of Text-Mining to Identify Region-Specific Supply Chain Risks. Adv. Eng. Inform. 2020, 45, 101053. [Google Scholar] [CrossRef]
- Kumar, B.S.; Ravi, V. A Survey of the Applications of Text Mining in Financial Domain. Knowl.-Based Syst. 2016, 114, 128–147. [Google Scholar] [CrossRef]
- Gupta, A.; Dengre, V.; Kheruwala, H.A.; Shah, M. Comprehensive Review of Text-Mining Applications in Finance. Financ. Innov. 2020, 6, 1–25. [Google Scholar] [CrossRef]
- Kumar, S.; Kar, A.K.; Ilavarasan, P.V. Applications of Text Mining in Services Management: A Systematic Literature Review. Int. J. Inf. Manag. Data Insights 2021, 1, 100008. [Google Scholar] [CrossRef]
- Irfan, R.; King, C.K.; Grages, D.; Ewen, S.; Khan, S.U.; Madani, S.A.; Kolodziej, J.; Wang, L.; Chen, D.; Rayes, A.; et al. A Survey on Text Mining in Social Networks. Knowl. Eng. Rev. 2015, 30, 157–170. [Google Scholar] [CrossRef]
- Salloum, S.A.; Al-Emran, M.; Monem, A.A.; Shaalan, K. A Survey of Text Mining in Social Media: Facebook and Twitter Perspectives. Adv. Sci. Technol. Eng. Syst. 2017, 2, 127–133. [Google Scholar] [CrossRef]
- Ferreira-Mello, R.; André, M.; Pinheiro, A.; Costa, E.; Romero, C. Text Mining in Education. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2019, 9, e1332. [Google Scholar] [CrossRef]
- Ngai, E.; Lee, P. A Review of the Literature on Applications of Text Mining in Policy Making. In Proceedings of the Pacific Asia Conference on Information Systems, PACIS, Chiayi, Taiwan, 27 June–1 July 2016. [Google Scholar]
- Drury, B.; Roche, M. A Survey of the Applications of Text Mining for Agriculture. Comput. Electron. Agric. 2019, 163, 104864. [Google Scholar] [CrossRef]
- Postiglione, A. Text Mining with Finite State Automata via Compound Words Ontologies. Lect. Notes Data Eng. Commun. Technol. 2024, 193, 194–205. [Google Scholar] [CrossRef]
- Postiglione, A. Finite State Automata on Multi-Word Units for Efficient Text-Mining. Mathematics 2024, 12, 506. [Google Scholar] [CrossRef]
- Elia, A.; Monteleone, M.; Postiglione, A. Cataloga: A Software for Semantic-Based Terminological Data Mining. In Proceedings of the 1st International Conference on Data Compression, Communication and Processing, Palinuro, SA, USA, 21–24 June 2011; IEEE Computer Society: Washington, DC, USA, 2011; pp. 153–156. [Google Scholar] [CrossRef]
- Gross, M. Lexicon-Grammar and the Syntactic Analysis of French. In Proceedings of the 10th International Conference on Computational Linguistics, COLING, 1984 and 22nd Annual Meeting of the Association for Computational Linguistics, ACL, Stanford, CA, USA, 2–6 July 1984; pp. 275–282. [Google Scholar]
- Gross, M. The construction of electronic dictionaries; [La construction de dictionnaires électroniques]. Ann. Télécommun. 1989, 44, 4–19. [Google Scholar] [CrossRef]
- Gross, M. The Use of Finite Automata in the Lexical Representation of Natural Language. Lect. Notes Comput. Sci. (Subser. Lect. Notes Artif. Intell. Lect. Notes Bioinform.) 1989, 377 LNCS, 34–50. [Google Scholar] [CrossRef]
- Monteleone, M. NooJ for Artificial Intelligence: An Anthropic Approach. Commun. Comput. Inf. Sci. 2021, 1389, 173–184. [Google Scholar] [CrossRef]
- Monteleone, M.; Mirto, I.M. NooJ Grammars for Italian Negation System and Sentiment Analysis. Commun. Comput. Inf. Sci. 2021, 1520 CCIS, 39–50. [Google Scholar] [CrossRef]
- Aho, A.V.; Corasick, M.J. Efficient String Matching: An Aid to Bibliographic Search. Commun. ACM 1975, 18, 333–340. [Google Scholar] [CrossRef]
- Boyer, R.S.; Moore, J.S. A Fast String Searching Algorithm. Commun. ACM 1977, 20, 762–772. [Google Scholar] [CrossRef]
- Crochemore, M.; Hancart, C.; Lecroq, T. Algorithms on Strings; Cambridge University Press: Cambridge, UK, 2007; Volume 9780521848992, pp. 1–383. [Google Scholar] [CrossRef]
- Cormen, T.H.; Leiserson, C.E.; Rivest, R.L.; Stein, C. Introduction to Algorithms, 3rd ed.; The MIT Press: Cambridge, MA, USA, 2009. [Google Scholar]
- Harrag, F.; El-Qawasmeh, E.; Salman Al-Salman, A.M. Extracting Named Entities from Prophetic Narration Texts (Hadith). Commun. Comput. Inf. Sci. 2011, 180 CCIS, 289–297. [Google Scholar] [CrossRef]
- Singh, R.; Ghorbani, A.A. EfficientPMM: Finite Automata Based Efficient Pattern Matching Machine. Procedia Comput. Sci. 2017, 108, 1060–1070. [Google Scholar] [CrossRef]
- Hakak, S.I.; Kamsin, A.; Shivakumara, P.; Gilkar, G.A.; Khan, W.Z.; Imran, M. Exact String Matching Algorithms: Survey, Issues, and Future Research Directions. IEEE Access Pract. Innov. Open Solut. 2019, 7, 69614–69637. [Google Scholar] [CrossRef]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Postiglione, A.; Monteleone, M. Predictive Maintenance with Linguistic Text Mining. Mathematics 2024, 12, 1089. https://doi.org/10.3390/math12071089
Postiglione A, Monteleone M. Predictive Maintenance with Linguistic Text Mining. Mathematics. 2024; 12(7):1089. https://doi.org/10.3390/math12071089
Chicago/Turabian StylePostiglione, Alberto, and Mario Monteleone. 2024. "Predictive Maintenance with Linguistic Text Mining" Mathematics 12, no. 7: 1089. https://doi.org/10.3390/math12071089
APA StylePostiglione, A., & Monteleone, M. (2024). Predictive Maintenance with Linguistic Text Mining. Mathematics, 12(7), 1089. https://doi.org/10.3390/math12071089