1. Introduction
Stance detection is a fundamental task in the field of natural language processing (NLP), where the aim is to categorize the attitudes expressed towards a particular target based on opinionated input texts [
1]. This task has garnered significant interest in recent years due to its relevance in various domains, including political analysis, social media monitoring, and customer feedback analysis. In the initial phases of stance detection research, the focus was predominantly on online debates characterized by a uniform sentence structure, wherein the user’s attitude is generally expressed in a direct fashion [
2,
3]. With the rapid expansion of the Internet, platforms like Twitter have witnessed remarkable growth in popularity. This surge has prompted researchers to explore the potential of social media as a rich resource for stance detection [
4,
5].
Stance detection methods are usually formulated as sentence-level classification tasks based on a specific target and can be broadly categorized as non-pretrained or pretrained language models (PLMs). Non-pretrained models predominantly utilize deep neural networks (DNNs), such as long short-term memory (LSTM), graph convolutional networks (GCN), and attention-based models for the purpose of stance classification. For example, Du et al. [
6] used an attention model leveraging target information, while Du et al. [
6] developed separate LSTMs to filter non-neutral text and classify attitudes. Sun et al. [
7] proposed hierarchical attention to learn text representations via linguistic features, and Liang et al. [
8] introduced a GCN approach to distinguish target-specific and invariant features. Furthermore, Devi and Kannimuthu [
9] incorporated focal-loss and context-embedding-based data augmentation to handle the data imbalance. Inspired by promising PLM results, fine-tuning strategies have been developed to enhance the accuracy of stance detection [
10]. These methods entail the adaptation of pretrained models, such as BERT [
11] and RoBERTa [
12], using datasets specific to stance detection, thereby tailoring the models to this particular task. In summary, these approaches predominantly conceptualize stance detection as a target-oriented, sentence-level text classification task. Nonetheless, the challenge of data sparsity, exacerbated by the informal and abbreviated nature of social media content, remains a significant obstacle to the efficacy of these methods. Recently, some research has addressed the issue of data sparsity by integrating external knowledge, thus enhancing both the performance and the interpretability of stance detection processes. For example, He et al. [
13] augmented text classifiers by supplementing them with relevant Wikipedia documents about the target. Diaz et al. [
14] constructed a stance tree using external knowledge extracted from a knowledge base and utilized it as evidence to enhance stance prediction and detection precision.
While these works demonstrated enhancements in performance and interpretability, the practical application of these methods encounters several challenges: (i) Deep neural networks (DNNs) are often perceived as “black box” mechanisms, due to their inability to furnish explicit rationales for their decision-making processes. As a result, DNNs may not be suitable for applications where interpretability is a crucial requirement. (ii) Existing methods in stance detection largely rely on extensive datasets that require manual annotation, a process that is time-consuming and labor-intensive. Although zero-shot learning settings have been introduced, they still necessitate significant data annotation within the source domain, complicating the direct application to unseen targets. (iii) The impracticality of deploying very large language models (VLLMs) with interpretative capabilities in stance detection arises from their substantial resource consumption and local deployment complexities, alongside potential data privacy concerns associated with techniques like chain-of-thought (COT) processing, especially in areas like business decision-making and political analysis. The issue in question has been reported and has raised concerns. Consequently, it is imperative to propose a novel technique for transferring stance detection capabilities from VLLM to smaller, locally deployable models that can effectively address these concerns.
In response, this study aimed to develop a stance detection method that can simultaneously achieve interpretability, local deployment, and high accuracy with limited annotation. (1) To satisfy the interpretability requirement, we aimed to develop an understandable stance detection method that can generate the reasoning process of the stance predictor. (2) To meet the limited annotation requirement, we aimed to develop a method that can rely on only a small number of manual labels, while achieving comparable accuracy to state-of-the-art baselines. (3) To satisfy the local deployment requirement, our objective was to develop a method that can be trained on seen data and enable direct prediction on unseen data. In particular, the method should approximate the predictive performance of large-scale models.
To achieve this goal, in this paper, we proposed a distantly supervised explainable stance detection framework (DS-ESD). The DS-ESD model consists of three modules: an instruction-based chain-of-thought (CoT) method, generative network, and transformer-based stance predictor. The CoT method involves using manually designed prompt templates to extract the stance detection analysis process from VLLM in a CoT manner. This method was inspired by Wei et al. [
15], who demonstrated the ability of large-scale models to comply with prompt instructions without requiring parameter training updates. Furthermore, a generative network is utilized to learn the mapping between input and inference process, with the expectation that it can generate the inference process independently of the VLLM during the prediction process. Finally, we constructed a stance classifier that takes as input the tweet and the generated inference process, and that is trained with VLLM-annotated stance labels, thus making it a form of distant supervision. Notably, for the stance classifier, we proposed a label rectification strategy to mitigate the impact of erroneous labels by controlling the probability distribution of the labels.
We summarize our contributions as follows:
To the best of our knowledge, we present the first study on a distantly supervised stance detection framework, which also facilitates the generation of explanations for the stance analysis process. Our approach has advanced the field of stance detection.
We propose a DS-ESD framework, which uses an instruct-based chain-of-thought approach to construct the supervised signal, upon which a generative model is subsequently built to generate explanations.
We propose a novel label-rectification strategy for correcting label errors that arise from the distantly supervised approach.
In order to evaluate the effectiveness of our proposed model, we conducted extensive experiments on three benchmark datasets. Our experimental results demonstrated that our model consistently outperformed the state-of-the-art methods in terms of predictive accuracy. Moreover, we conducted a manual evaluation of the generated explanations, which revealed that they were highly effective in providing clear and intuitive justifications for the model’s predictions.
The remainder of this paper is structured as follows:
Section 2 provides a comprehensive review and discussion of the related literature, including some traditional and recent methods of stance detection.
Section 3 presents a detailed description of the proposed model. In
Section 4, we describe the experimental setup, comprising the datasets employed for evaluation, the methods used for comparison, and report the quantitative evaluation results.
Section 5 presents the conclusions and discusses future work.
3. Our Methodology
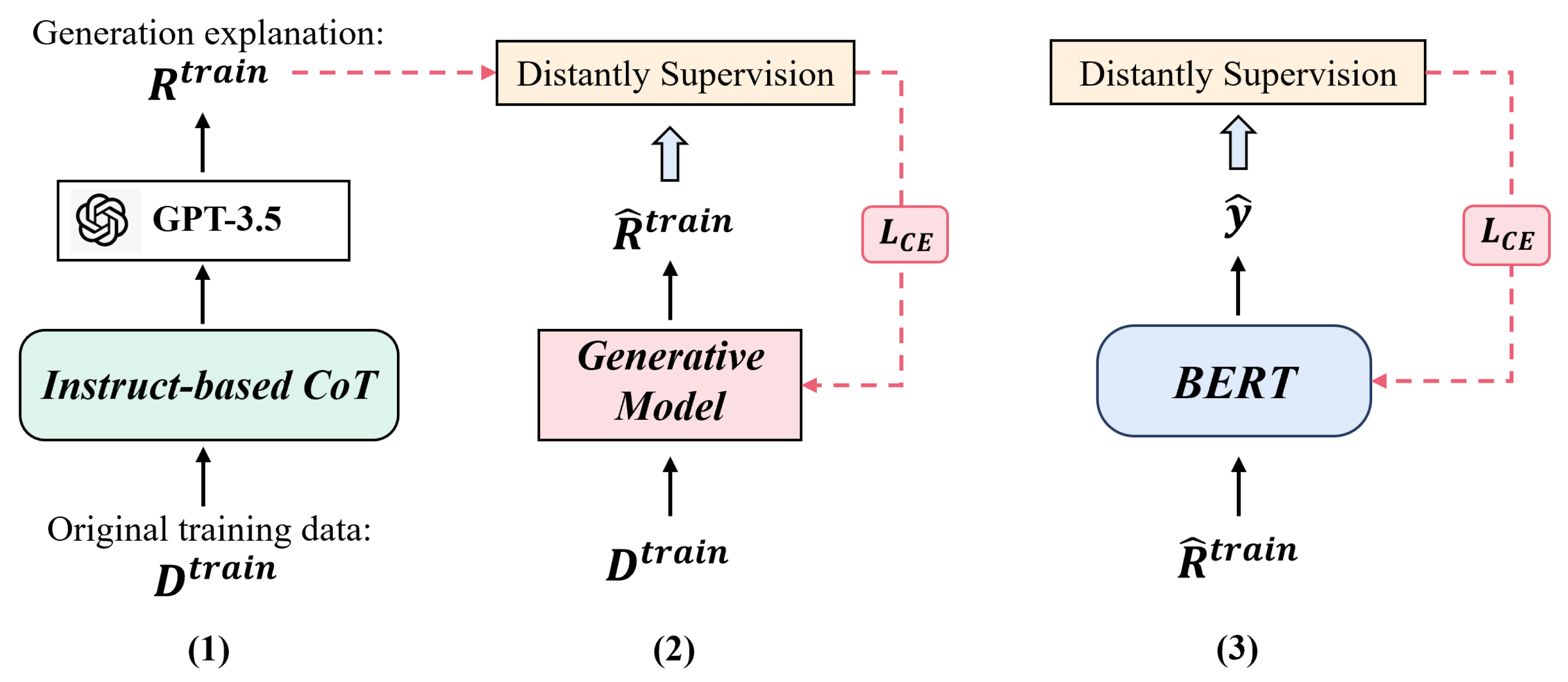
As illustrated in
Figure 1, our method mainly consists of three modules: instruct-based CoT, generative model, and the transformer-based stance network.
3.1. Problem Formulation
We use to denote the collection of labeled data, where x and p denote the input text and the corresponding target, respectively. Each pair in is assigned a stance label y. Given an input sentence and a corresponding target as a test set (unseen target), this study aimed to predict the rationale of prediction r with a stance label for the input sentence towards a given target by using the proposed DS-ESD method.
3.2. Model Process
Our method is divided into two stages: training and prediction. During training, we incorporate the VLLM to aid in model training. In the prediction stage, we aim to achieve high accuracy using a generative model to produce explanations independently of large models.
For the training stage, given , we first perform instruct-based CoT to collect retrieved explanations . Then, we pack and as the training sample for training the generation model. After training the generation model, we can feed the predicted , which is predicted by the generation model, into the transformer-based model to train the stance classification model.
During the inference process, we simply feed the test data into the generative model to generate the corresponding inference process . Subsequently, we feed both and into the stance classifier to automatically predict the stance.
3.3. Instruct-Based CoT
Traditional distantly supervised methods are mostly based on knowledge graphs to construct weak supervision signals. Due to the remarkable knowledge and understanding ability emerging from VLLM in recent years, this paper proposes a method based on CoT to construct weak supervision signals.
The CoT methodology has revealed the potential of VLLM multi-hop reasoning, wherein an VLLM is capable of impressive chain-style reasoning when given some input prompts or instructions. We devised a methodology that leverages a large model to extract pseudo-labels via instruction. Moreover, we aimed to utilize the analytical capabilities of the VLLM to extract the reasoning process of the model. To this end, we engineered a
1-shot instructional framework, as depicted in
Figure 2. This framework is designed to facilitate the large-scale model in generating a logical sequence of the new samples along with their associated stance labels, provided that an instruction and a reference sample are supplied as inputs.
Specifically, we send the API call (instruction) to the VLLM to acquire the explanation.
Figure 3 provides a concrete example, where an instruction and a single sample are given, and the large model is fed with the input sentence “She’s smarter and works harder”. The large model then extracts the specific reasoning process, which is “IF (
Hillary is smarter and works harder) THEN (the attitude towards Hillary is
favor)”.
Subsequently, we leverage the extracted inference process, “Hillary is smarter and works harder” as the reasoning process, which is denoted as r, and “favor” in the explanation as the pseudo-labels. Finally, the instruct-based CoT approach can be employed to obtain the inference process and the pseudo-labels of the training data .
3.4. Fine-Tuning the Generative Model with a New Dataset
Although it is possible to directly extract r from VLLM, in applications such as business decision-making, we prefer to use smaller models that can be deployed locally, to prevent data leakage when predicting stances. Therefore, we designed a generative model to learn the mapping between x and r. During practical deployment, the generation model can directly generate r for unseen targets without the need for VLLM involvement.
The generator component can be modeled using any encoder–decoder architecture. In this study, we adopted BART-large, a pretrained sequence-to-sequence transformer comprising 400 million parameters, as our choice. We concatenate the target p with the input x. This context matrix is then given as memory to the decoder. We trained the model to minimize the negative log-likelihood of the target utterance r.
In summary, our proposed model employs a pretrained BART architecture to extract pertinent knowledge of the given input and generate an explanation. When provided with a training corpus consisting of input/output pairs, denoted as and , respectively, for the purpose of fine-tuning, we employ stochastic gradient descent with the Adam optimizer to minimize the negative marginal log-likelihood of each target . This approach allows us to effectively optimize the network’s parameters and improve its ability to predict the correct outputs for a given set of inputs and parameters.
3.5. Text Representation Method
After obtaining the explanations of the reasoning process r, we proposed the transformer-based network as the stance predictor. The input of the transformer is the reasoning process r and text x, and the output is the stance label.
Formally, we combine
r and tweet
x as the input. Given the hidden states of the representation, which correspond to the BERT model’s output, as
H. The hidden states are subsequently fed into the multi-head self-attention mechanism (MHsA) to compute the output of the transformer layer, expressed as:
where the matrices
Q,
K, and
V represent the query, key, and value, respectively, as per the standard MHSA mechanism. Next, we implement a conventional residual structure that fuses the higher-level representation
H and the current
and applies layer normalization (
LN) to normalize the resultant output.
The transformer block’s ultimate output is obtained by passing
through a feed-forward layer based on attention mechanisms.
Subsequently, the attentive sentence representation
e is learned by aggregating the embeddings of
using the attention vector
:
3.6. Label Rectification Strategy
In order to prevent the model from becoming overconfident and assigning excessively high probabilities to a single-label class, we leverage a label smoothing strategy, which entails assigning a fixed small probability to alternative classes. However, in our specific scenario, the pseudo-labels themselves are not reliable and cannot be used directly. To solve the problem, we introduced a novel label rectification strategy that can dynamically adjust noisy labels. Essentially, we modify the distribution of the original labels to steer them in the correct direction in the presence of potential errors, thus improving the overall accuracy of the model predictions.
More specifically, in the rectification module, a linear transformation is applied to the representation of the sentence
e by the transformer layer, which results in a distributional representation
that is unique to the rectifier (
has the same dimensions as
e). Subsequently, the rectifier takes
as input and outputs a rectification matrix
M, as follows:
Here,
K denotes the total number of stance labels, and
possesses the same dimensions as
. The rectified label distribution is subsequently computed as:
where
denotes the normalized function.
denotes the extent to which the
i-th class is misclassified as the
j-th class.
Let denote the i-th row of M. Assuming that the label corresponding to noise is k, such that = 1 and = 0 for , we obtain = , which is equivalent to (where denotes the k-th column of matrix T). As such, quantifies the extent to which the true label is i but the labeled noise is k. Through this approach, matrix M enables modification of the original label distribution l to a new distribution q.
3.7. Adaptive Training Mechanism
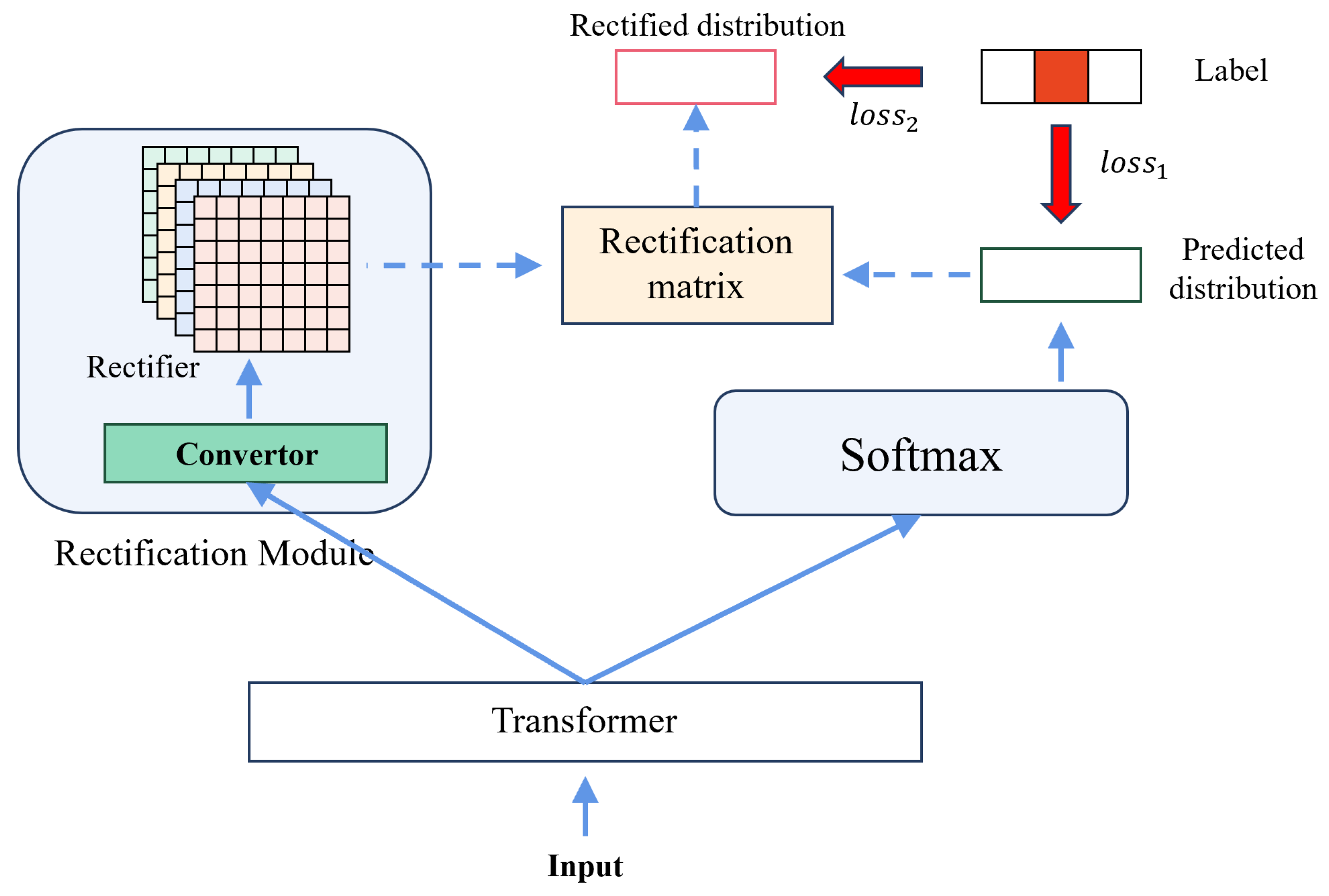
As illustrated in
Figure 4, our approach consists of two distinct losses. Notably, training the rectification module (
) without any direct human guidance or involvement poses a significant challenge. To overcome this challenge, we introduced a novel adaptive mechanism based on curriculum learning. Curriculum learning simulates the human learning process by starting with simpler tasks and gradually increasing the difficulty level. In our approach, we first concentrate on the prediction module (
) to minimize the discrepancy between the predicted distribution and the ground truth distribution. We then gradually increase the level of complexity to enable the model to learn to cope with the noise present in the data. In the second step, we balance the two losses and obtain the final loss function
, where
is the balancing coefficient. We dynamically compute the coefficient using the available information. Specifically, we use
as the coefficient, where
k denotes the annotated label. We validate this strategy in two scenarios: (1) A value of
approaching 1 signifies a high level of confidence that
k is the appropriate label, resulting in reduced emphasis on the rectification module. Given the initially small value of
, the overall loss remains relatively low, and the (
) term restricts the magnitude of the second component. (2) Conversely, a value of
approaching 0 implies that the annotated label may be incorrect, necessitating greater attention towards the rectification module to rectify it.
In fact, q is utilized to explore the entire space and identify the true distribution of the labels. The search process commences with the labeled distribution l and adopts as the loss function. This approach allows q to assimilate information from the labeled distribution l, predicted distribution p, and specific context x. The matrix T is initially initialized as the identity matrix, signifying that noise is not considered.
Finally, the first loss function can be effectively implemented through the utilization of the standard cross-entropy method:
Every ground-truth label,
, pertaining to the
i-th individual sample, is represented in one-hot format. To optimize the network, the standard gradient descent algorithm is employed. The second loss is utilized to automatically adjust the distribution of incorrect categories. Finally, we combine this as follows:
4. Experiments
4.1. Experimental Data
This paper presents experimental results on robust benchmark datasets, including SemEval-2016 Task 6 (SEM16) [
35], COVID-19 [
36], and VAST [
27]. Their statistics are shown in
Table 1 and
Table 2.
SEM16. The SEM16 dataset contains 4870 tweets, each targeting various subjects and annotated with one of three stance labels: “
favor”, “
against”, or “
neutral”. Following the framework suggested by [
24], four specific targets—
Donald Trump (D),
Hillary Clinton (H),
Legalization of Abortion (L), and
Feminist Movement (F)—were selected for the analysis of stance detection efficacy in our research. For the cross-target configuration [
8,
24,
25], we formulated four distinct cross-target stance detection tasks (
D→H, H→D, F→L, L→F), indicating the source target on the left and the destination target on the right of the arrow.
COVID-19. The COVID-19 Stance dataset comprises 6133 tweets that pertain to users’ stance towards four targets related to COVID-19 health mandates. The tweets were manually annotated for stance based on three categories: in-favor, against, and neither.
VAST. Introduced by Allaway and Mckeown [
27], the VAST dataset incorporates a wide array of targets across different sectors, including politics, education, and public health, and features three stance labels: ”pro”, ”neutral”, and ”con”. It consists of 4003 samples for training, with the development and test sets containing 383 and 600 samples, respectively. In alignment with Liang et al. [
8], our model’s performance is assessed on topics in a zero-shot learning context.
4.2. Compared Baseline Methods
To evaluate the performance of our proposed model, a comprehensive analysis and comparison with existing baseline models was conducted. These baseline models are delineated as follows:
Statistics-based methods:
Fine-tuning based methods:
BERT [
11] employs a pretrained BERT model for stance detection, adapting the input format to “[CLS] + text + [SEP] + target + [SEP]” to facilitate the model training and fine-tuning processes.
BERT-NS [
43] represents a semi-supervised approach that applies self-training and knowledge distillation to improve the efficacy of a teacher model through the use of unlabeled data.
BERT-DAN [
44] is designed to explicitly capture both subjective and objective elements within tweets and allows the use of labeled data from related tasks to inform the training of a model for the target task.
PT-HCL [
8] introduces an innovative method for cross-target and zero-shot stance detection employing contrastive learning. This model uses a BERT-based framework to create a unified representation space for various targets.
Prompt-tuning based methods:
MPT [
45] provides a prompt-tuning based method for stance detection, which employs a verbalizer defined by human experts.
KPT [
46] incorporates external lexical resources to define the verbalizer component within the prompt engineering framework.
PIN-POM [
47] puts forth a soft prompt approach tailored for short text categorization, an adaptation readily amenable to stance detection tasks.
TAPD [
48] uses a prompt setting method for position detection, using PLM to learn effective representations for stance detection tasks.
Knowledge-enhanced methods:
SEKT [
25] provides a graph convolutional network enhanced with semantic knowledge to detect attitudes.
WS-BERT-Dual [
28] introduces target-related wiki knowledge to enhance stance detection ability.
TarBK [
29] incorporates the targeted background knowledge for stance detection.
Variants of DS-ESD:
S-ESD refers to supervised learning using backpropagation with a small set of labeled training samples. In contrast, DS-ESD does not require manual annotation and is applicable to more open real-world scenarios, while S-ESD is suited for current in-target and cross-target task settings.
4.3. Implementation Details
In the experimental configuration, we opted for the BART-large architecture with 400 million parameters for the generator component. Subsequently, for the stance classification model, we elected to utilize pretrained language models based on the BERT-base architecture with 340 parameters. To train the model, we utilized the Adam optimizer with a mini-batch size of 32 and a learning rate of 0.0002. The hardware environment for these experiments was provisioned with an A100 40G GPU. To further improve on the current state of the art, we comprehensively describe the templates used to fine-tune pretrained language models throughout this paper.
As per the recommendations of previous works [
8,
25], we employed the micro-average F1 score as our primary evaluation metric. Our first step in this process involved calculating the F1 scores for the categories “favor” and “against”:
The F1-score could be computed based on precision and recall.
4.4. Overall Performance
4.4.1. In-Target Setup
Table 3 and
Table 4 present the results of in-target stance detection using diverse robust benchmarks. Our DS-ESD model consistently outperformed most of the baseline models across all datasets, thereby validating the efficacy of our proposed approach for stance detection. Moreover, the significance tests conducted on DS-ESD relative to the top-performing competitor demonstrated that DS-ESD yielded a statistically significant enhancement in terms of most evaluation metrics, with
p-value < 0.05 (indicated as
†). Specifically, compared with the static-based model (GCAE) that performed poorly, our DS-ESD improved on it by 18.8% on average for the COVID-19 dataset. Compared to KPT and MT, the best competitors of the BERT-based model, our DS-ESD improved by 1.9% and 1.04% on average over SEM16 and COVID-19, respectively.
It is noteworthy that utilizing the method of distant supervision, which obviates the need for manual data annotation, achieved significant improvements in effectiveness across multiple settings compared to strong baselines. This finding indicates the effectiveness of our proposed approach, which leverages VLLM to annotate labels and conducts distant supervision.
4.4.2. Cross-Target Setup
The procurement of a comprehensively annotated large dataset necessitates substantial time and resources. Consequently, we proposed to evaluate the efficacy of our method within a cross-target framework. The objective of this framework was to predict the stance towards the target destination using labeled data from the source target. The F1 scores are detailed in
Table 5. According to these findings, our proposed methodologies (DS-ESD and S-ESD) surpassed the competing baselines by a notable margin. Specifically, DS-ESD exhibited an average enhancement of 12.85% in F1 score over the top-performing statistical method (TPDG), affirming the efficiency of employing a distantly supervised approach in a cross-target context. Furthermore, when compared to the leading fine-tuning-based method (PT-HCL), DS-ESD registered an average improvement of 12.05% in F1 score.
4.4.3. Zero-Shot Stance Detection
In instances where the text’s target was not present in the training dataset, we undertook a comparative analysis against the foremost competitors in the domain. The outcomes of these analyses are documented in
Table 6. It is crucial to note that, given the intrinsic challenges and constraints associated with zero-shot stance detection, all techniques manifested a diminished performance relative to the in-target configuration. In particular, methods predicated exclusively on statistical analysis exhibited inferior results. In contrast, fine-tuning-based strategies, such as PT-HCL, TarBK, and TTS, consistently surpassed those reliant on statistical analyses. This phenomenon underscored the substantial advantages of harnessing knowledge derived from extensive corpora. Despite the inherent difficulties of zero-shot stance detection, our DS-ESD model showcased notable efficacy, rivaling the performance of the leading benchmark methods. When equipped with labeled data from the source domain, our approach (S-ESD) recorded the highest F1 score. Consequently, our findings suggest that DS-ESD constitutes an effective approach for navigating the complex task of zero-shot stance detection through distantly supervised methods.
4.5. Ablation Study
To investigate the impact of each part on our model, we performed an ablation test by discarding the label rectification strategy (denoted as w/o LRS) and the adaptive training mechanism (denoted as w/o ATM), respectively. Specifically, for the w/o LRS, the model was trained using standard cross-entropy. Additionally, following [
49], we constructed a method that relied solely on ChatGPT to verify performance without LRS, denoted as “ChatGPT”.
The ablation study results are summarized in
Table 7. The findings reveal that both the LRS and the ATM contributed significantly to enhancing the performance of the proposed approach. In particular, the performance significantly dropped when LRS was removed. This is because using ChatGPT’s results as pseudo-labels directly introduced a considerable amount of noise, thereby adversely affecting performance. The empirical outcomes additionally corroborated the efficacy of the proposed LRS. Not unexpectedly, integrating all components yielded the optimal outcomes across all experimental setups.
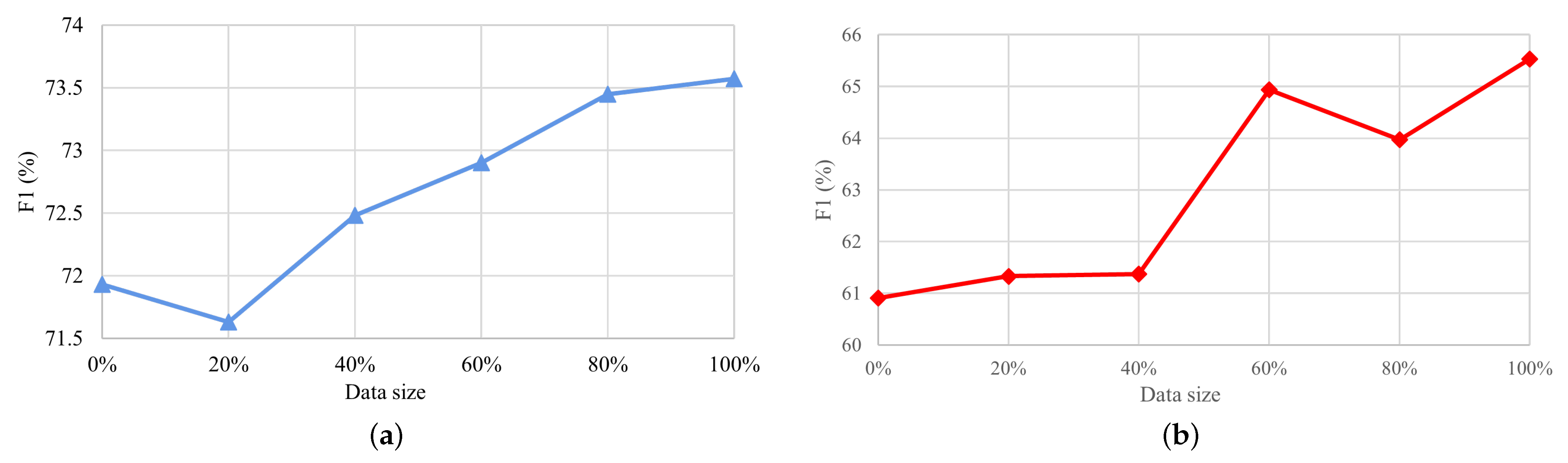
Experimental Results on Varying Amounts of Labeled Data. The size of the labeled samples is crucial for the proposed method, as it significantly impacts both the model’s performance and running time. In this experiment, we conducted tests on the F and L task in the SEM16 dataset, with varying amounts of labeled data, ranging from 0% to 100%.
Figure 5 shows the results. Notably, when using 0% labeled data, we refer to our method as DS-ESD, while using 100% labeled samples represents S-ESD. The results are shown in
Figure 5. The empirical findings illustrate that the performance, as expected, progressively improved with the volume of annotated data, an outcome that aligned with our expectations. Specifically, the results when using 0% labeled data exceeded the baseline method in most settings, indicating the effectiveness of our distant supervision method.
4.6. Case Study
Table 8 presents three explanation examples generated by DS-ESD. The selected samples were accurately predicted by DS-ESD, whereas the baseline failed to predict the correct category.
In the first and fourth examples, it is evident that the DS-ESD model possessed a profound understanding of stance-aware symbols. For instance, the hashtag “#ropegate” was associated with a negative news event during Hillary Clinton’s presidential campaign, and “#thisoppresseswomen” signified opposition to women’s rights. The explanations generated by the DS-ESD model illustrate its capacity to grasp the contextual significance of these tags. In the second example, when conflicting stance-bearing words appeared in the text, DS-ESD could effectively identify the correct words that describe the target. The third example shows that DS-ESD could effectively understand semantic content that requires a deep understanding. For example, the comparison between the long queues to vote for Hillary and the Free Burrito Day queue was accurately categorized by DS-ESD as “implicitly expresses support for Hillary”.
At present, due to constraints on model parameters, the generated explanations are relatively concise and lack detailed elaboration. Future research endeavors may consider expanding the model’s parameter space to generate more comprehensive explanations.
4.7. Manual Evaluation
As the evaluation metrics for the generative model score (e.g., BLEU score) only considered the word-level similarity between ground truth and predicted outputs, we conducted a manual evaluation of the quality of the explanations produced.
Specifically, we asked three annotators to rank these explanations using three different criteria: (1) The generated explanation contains important, salient information and does not omit any essential points that contributed to the stance prediction. (2) The generated explanation does not contain any redundant, repeated, or irrelevant information to the input and the stance detection. (3) The generated explanation does not contain any contradictory pieces of information to the input and the stance detection.
We randomly selected a small set of 100 instances from the test set, and the evaluators scored them according to the above evaluation criteria with a range of . The average scores of the three evaluators all exceeded 80, demonstrating that the generated explanations could effectively explain the rationale of the prediction.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}