
Automatic Evaluation Method for Functional Movement Screening Based on a Dual-Stream Network and Feature Fusion

Abstract
:1. Introduction
- We combined the optical flow technique to extract dynamic information and color information from the RGB data in our data processing. This method not only focuses on the superficial features provided by static images, but also explores the underlying temporal dynamics in image sequences, providing a more accurate and comprehensive data foundation.
- We propose a novel attention fusion strategy specifically designed for the features of dual-stream (optical flow and RGB) data. By introducing an attention mechanism, it effectively integrates two data streams, allowing the model to focus more on the key information while dealing with complex visual tasks. This method not only improves the efficiency of feature fusion, but also enhances the model’s adaptability to different data sources and the accuracy of information extraction.
- Specifically, the comprehensive protocol we propose achieved a 4% increase in accuracy in experiments. This result not only proves the effectiveness of our method, but also provides a reliable means of improving performance in related fields.
2. Relevant Theories
2.1. Dual Streams
2.2. Attention Mechanism
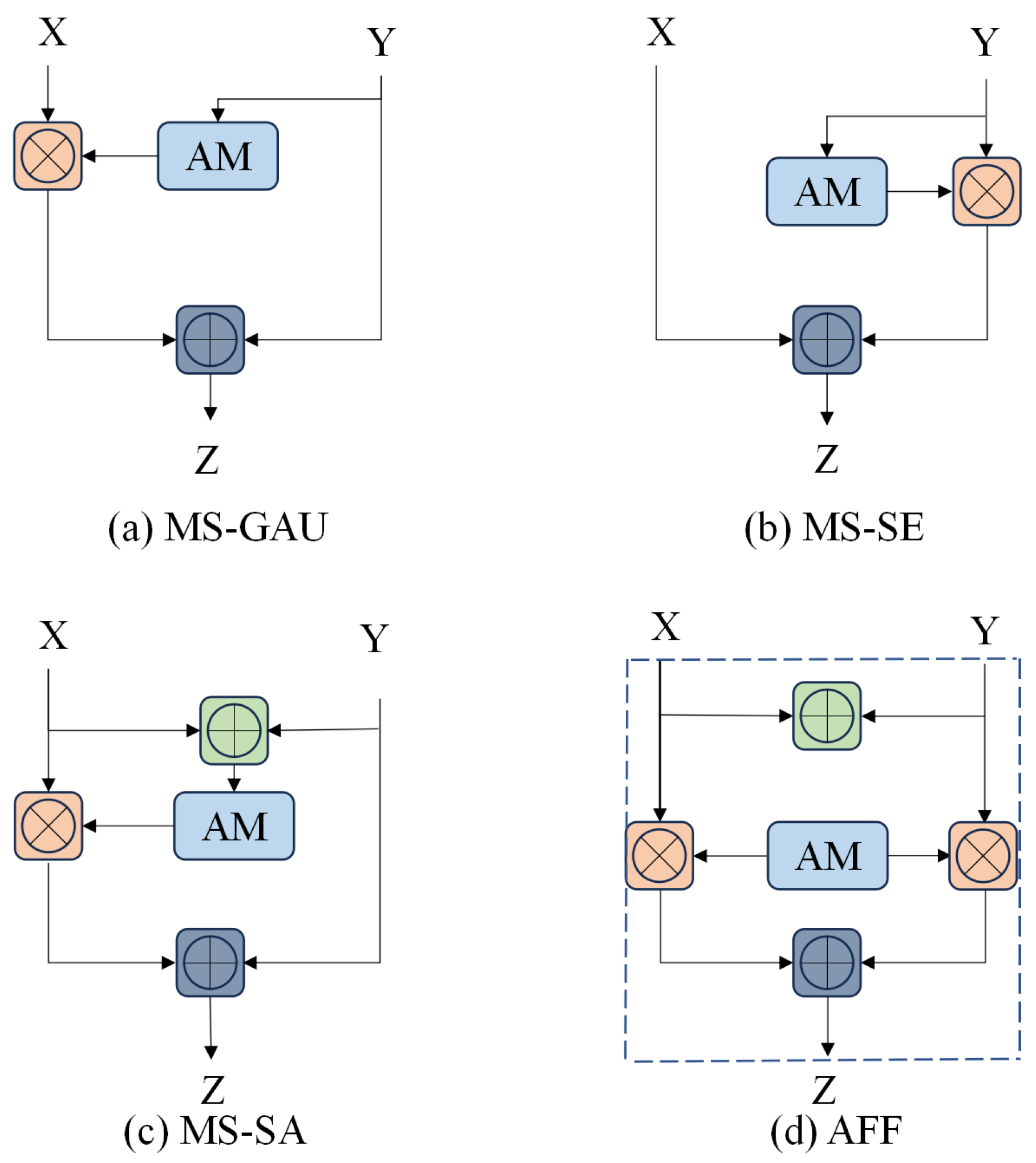
2.3. Feature Fusion
2.4. I3D Infrastructure
3. The Protocol Proposed in This Paper
3.1. Data Preprocessing
3.2. Feature Extraction
3.3. Dual-Stream Fusion Protocol
3.4. Score Prediction
3.4.1. Gaussian Distribution of the Initial Data
3.4.2. Kullback–Leibler (KL) Divergence
4. Experiment
4.1. Data and Experimental Environment
4.2. Evaluation Metrics
- Accuracy: Accuracy serves the purpose of providing a quick and intuitive evaluation of performance, informing us of how well the model performs on the entire test set. As shown in Formula (9), represents the number of correct classes for the i-th classification, 4 represents the number of classes, and N represents the total number of samples.
- Macroscopic (ma): When we are dealing with multiclass problems, we usually need an evaluation metric to measure the average performance of the model across all classes. is the macro score. We first calculate the score for each class and then calculate the mean of these scores. As shown in Formula (10), N represents the total number of classes, and represents the score of the i class.
- Kappa coefficient: It is a statistical measure used to assess the agreement between two evaluators or models in a classification task, taking into account chance agreement. It can be used to measure the consistency between predicted values and actual labels. In classification problems, the most common evaluation metric is Accuracy, which directly reflects the proportion of correct classifications and is computationally straightforward. However, in real-world classification tasks, the number of samples in each class often tends to be imbalanced. When dealing with such imbalanced datasets without adjustment, models can easily be biased towards the majority class at the expense of the minority class. In such cases, a metric is needed that penalizes this “bias” in the model rather than just using accuracy. The kappa coefficient, calculated based on a formula that accounts for chance agreement, provides a lower score for more imbalanced confusion matrices. Consequently, models with a strong “bias” toward the majority class receive lower kappa scores, appropriately reflecting their shortcomings in capturing the minority class. The formula for calculating the kappa coefficient is shown as Formula (11):where represents the observed consistency (namely, proportion of correct predictions for the model, consistent with Formula (7)), and is the expected consistency due to random chance. is calculated based on the probability of random prediction in each class.
4.3. Experiment and Result Analysis
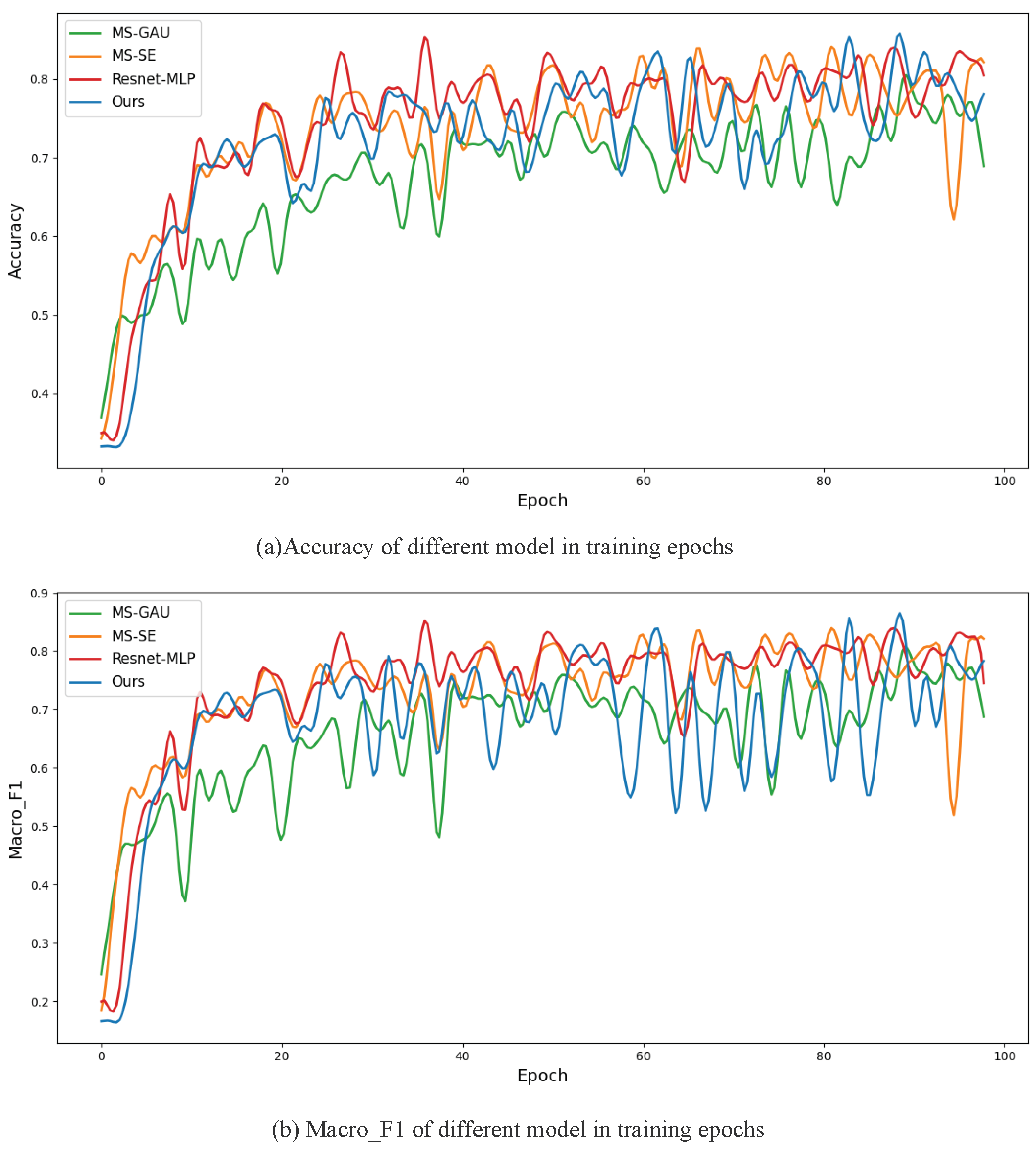
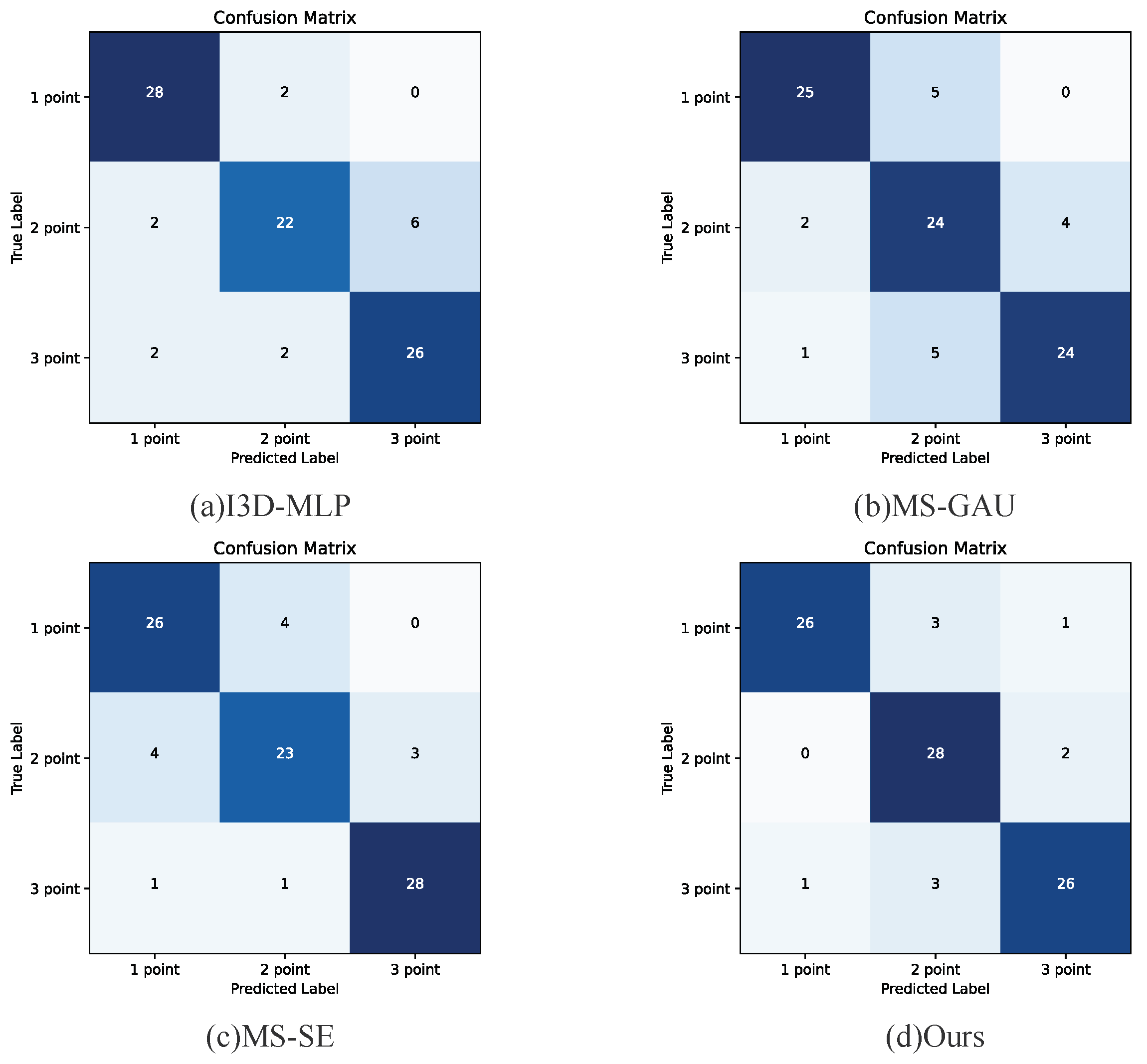
4.3.1. Comparative Experiment Analysis
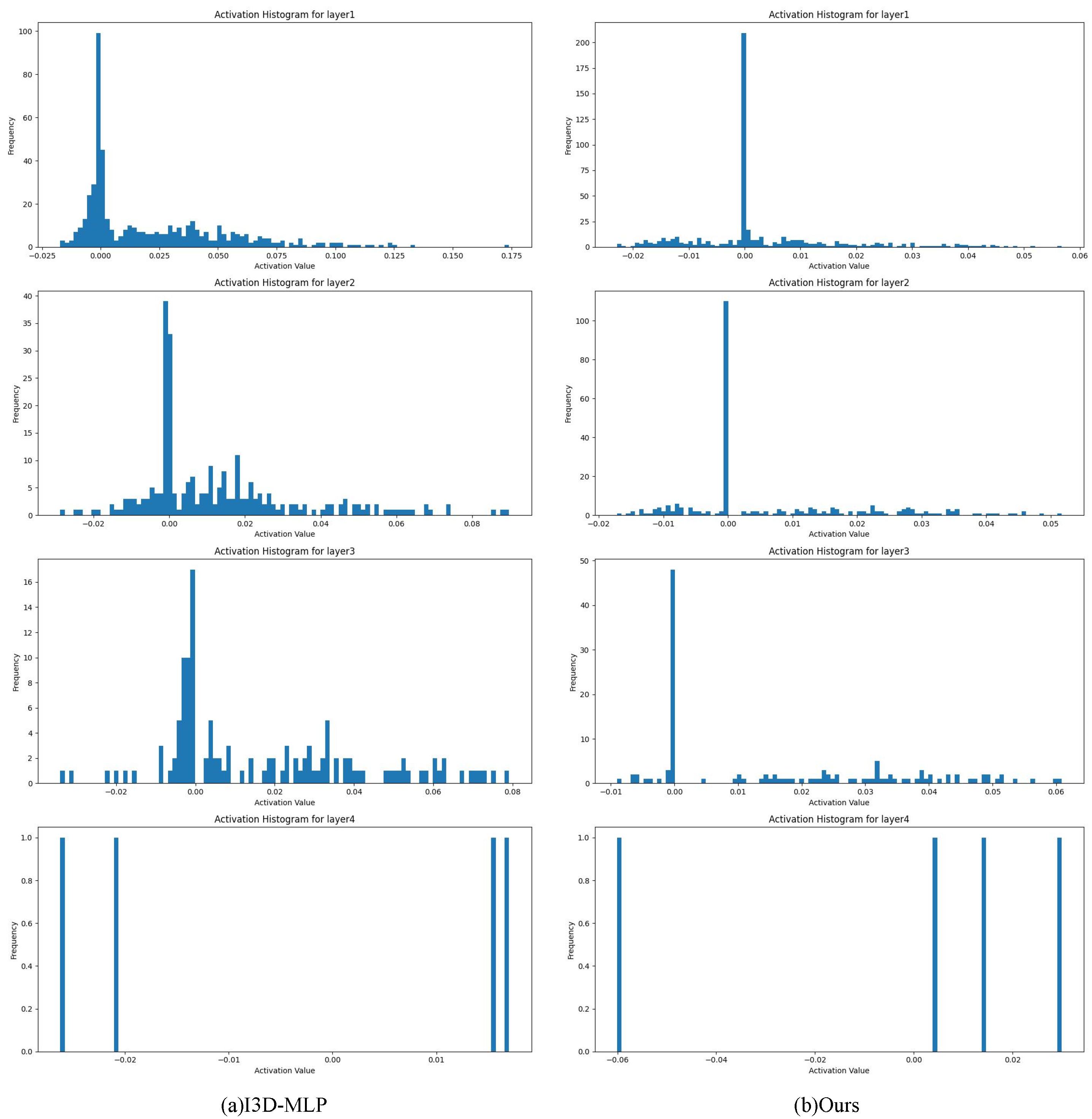
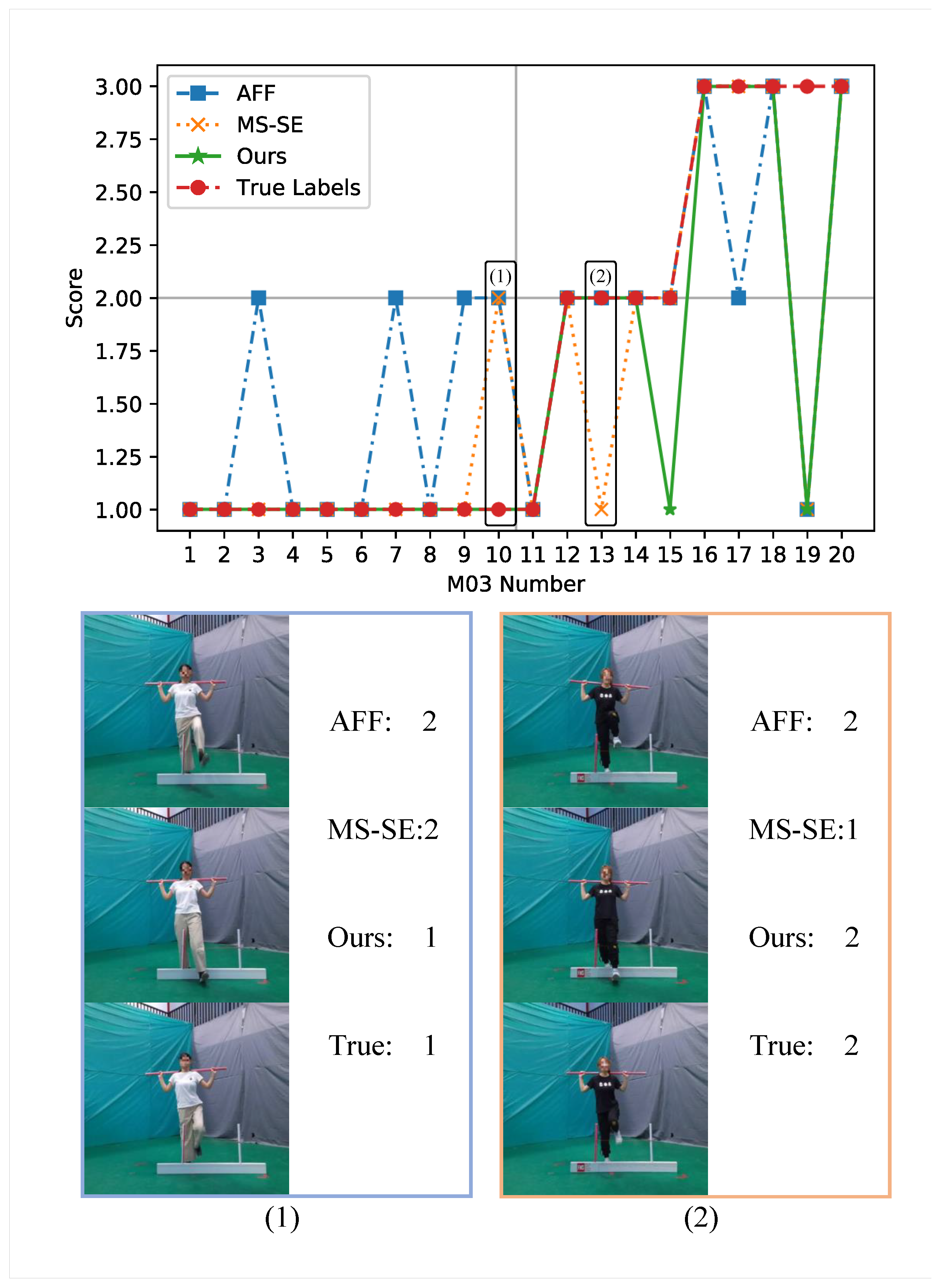
4.3.2. Visualization Experiment Analysis
4.3.3. Ablation Experiment Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Cook, G.; Burton, L.; Hoogenboom, B.J.; Voight, M. Functional movement screening: The use of fundamental movements as an assessment of function-part 2. Int. J. Sport. Phys. Ther. 2014, 9, 549. [Google Scholar]
- Glaws, K.R.; Juneau, C.M.; Becker, L.C.; Di Stasi, S.L.; Hewett, T.E. Intra-and inter-rater reliability of the Selective Functional Movement Assessment (SFMA). Int. J. Sport. Phys. Ther. 2014, 9, 195. [Google Scholar]
- Kim, C.Y.; Kang, T.; Kim, B.H.; Lee, S.Y. Y-balance Test. Korean Soc. Sport Biomech. 2019, 29, 33. [Google Scholar]
- Cook, G.; Burton, L.; Hoogenboom, B. Pre-Participation Screening: The Use of Fundamental Movements as an Assessment of Function—Part 1. N. Am. J. Sports Phys. Ther. NAJSPT 2006, 1, 62–72. [Google Scholar] [PubMed]
- Spilz, A.; Munz, M. Automatic Assessment of Functional Movement Screening Exercises with Deep Learning Architectures. Sensors 2022, 23, 5. [Google Scholar] [CrossRef] [PubMed]
- Huang, Q.; Chen, Y.; Li, C.; Wang, Y.; Li, Q. Dual-Stream Multi-Scale Distillation Network for Human Action Recognition. SSRN, 2023; preprint. [Google Scholar] [CrossRef]
- Hong, R.; Xing, Q.; Shen, Y.; Shen, Y. Effective Quantization Evaluation Method of Functional Movement Screening with Improved Gaussian Mixture Model. Appl. Sci. 2023, 13, 7487. [Google Scholar] [CrossRef]
- Li, R.; Liu, Q.; Gui, J.; Gu, D.; Hu, H. Indoor Relocalization in Challenging Environments with Dual-Stream Convolutional Neural Networks. IEEE Trans. Autom. Sci. Eng. 2017, 15, 651–662. [Google Scholar] [CrossRef]
- Lin, X.; Huang, T.; Ruan, Z.; Yang, X.; Chen, Z.; Zheng, G.; Feng, C. Automatic Evaluation of Functional Movement Screening Based on Attention Mechanism and Score Distribution Prediction. Mathematics 2023, 11, 4936. [Google Scholar] [CrossRef]
- Parmar, P.; Morris, B. Action quality assessment across multiple actions. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa Village, HI, USA, 7–11 January 2019; pp. 1468–1476. [Google Scholar]
- Chang, W.D.; Chou, L.W.; Chang, N.J.; Chen, S. Comparison of functional movement screen, star excursion balance test, and physical fitness in junior athletes with different sports injury risk. BioMed Res. Int. 2020, 2020, 8690540. [Google Scholar] [CrossRef] [PubMed]
- Yu, X.; Rao, Y.; Zhao, W.; Lu, J.; Zhou, J. Group-aware contrastive regression for action quality assessment. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 7919–7928. [Google Scholar]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. In Advances in Neural Information Processing Systems 27, Proceedings of the Annual Conference on Neural Information Processing Systems 2014, Montreal, QC, Canada, 8–13 December 2014; NIPS: Cambridge, MA, USA, 2014; pp. 568–576. [Google Scholar]
- Carreira, J.; Zisserman, A. Quo vadis, action recognition? A new model and the kinetics dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6299–6308. [Google Scholar]
- Zach, C.; Pock, T.; Bischof, H. A Duality Based Approach for Realtime TV-L1 Optical Flow. In Pattern Recognition; Hamprecht, F.A., Schnörr, C., Jähne, B., Eds.; In Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2007; pp. 214–223. [Google Scholar]
- Wang, L.; Qiao, Y.; Tang, X. Action Recognition with Trajectory-Pooled Deep-Convolutional Descriptors. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 4305–4314. [Google Scholar]
- Sun, D.; Yang, X.; Liu, M.-Y.; Kautz, J. Pwc-net: CNNs for optical flow using pyramid, warping, and cost volume. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8934–8943. [Google Scholar]
- Teed, Z.; Deng, J. Raft: Recurrent all-pairs field transforms for optical flow. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020, Proceedings, Part II; Springer: Berlin/Heidelberg, Germany, 2020; pp. 402–419. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Dai, Y.; Gieseke, F.; Oehmcke, S.; Wu, Y.; Barnard, K. Attentional feature fusion. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual, 5–9 January 2021; pp. 3560–3569. [Google Scholar]
- Xing, Q.J.; Shen, Y.Y.; Cao, R.; Zong, S.X.; Zhao, S.X.; Shen, Y.F. Functional movement screen dataset collected with two azure kinect depth sensors. Sci. Data 2022, 9, 104. [Google Scholar] [CrossRef]
- Wang, X.; Miao, Z.; Zhang, R.; Hao, S. I3D-lstm: A new model for human action recognition. IOP Conf. Ser. Mater. Sci. Eng. 2019, 569, 032035. [Google Scholar] [CrossRef]
- Tang, Y.; Ni, Z.; Zhou, J.; Zhang, D.; Lu, J.; Wu, Y.; Zhou, J. Uncertainty-aware score distribution learning for action quality assessment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9839–9848. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Paper | Approach | Contribution | Dataset | Year |
|---|---|---|---|---|
| [4] | FMS | Assess functional movement impairments based on proprioception, mobility, and stability | FMS Dataset | 2006 |
| [8] | Dual-stream CNN | Improved the relocalization accuracy by about 20% compared with the state-of-the-art deep learning method for pose regression, and greatly enhanced the system robustness in challenging scenes | Microsoft 7-Scenes and indoor data sets | 2017 |
| [10] | C3D-LSTM | Showed that there is utility in learning a single model across multiple actions | AQA-7 | 2019 |
| [11] | FMS, SEBT | Assessed the relationships between FMS, SEBT, agility test, and vertical jump test scores and sports injury risk in junior athletes | FMS Dataset | 2020 |
| [12] | Core | Outperformed previous methods by a large margin and established a new state of the art on all three benchmarks | AQA-7, MTL-AQA, and JIGSAW | 2021 |
| [5] | CNN-LSTM | Capable of performing complex motion analytic tasks based on inertial measurement unit data | New dataset and IMU data | 2022 |
| [7] | GMM | Effectively performed the FMS assessment task, and it is potentially feasible to use depth cameras for FMS assessment | FMS Dataset | 2023 |
| [9] | I3D-AM-MLP | I3D model evaluation of FMS combined with attention mechanism | FMS dataset | 2023 |
| Protocol | Accuracy (%) | ma (%) | Kappa (%) |
|---|---|---|---|
| I3D-LSTM [24] | 71.11 | 70.90 | 56.66 |
| I3D-MLP [25] | 84.44 | 84.53 | 76.66 |
| Improved-GMM [7] | 80.00 | 77.00 | 67.00 |
| RESNET-MLP [21] | 84.44 | 84.12 | 76.67 |
| Ours | 88.89 | 88.95 | 83.33 |
| Model | Params | Params |
|---|---|---|
| I3D-MLP [25] | 12.98 M | 27,877.32 M |
| Ours | 13.11 M | 27,877.45 M |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, X.; Chen, R.; Feng, C.; Chen, Z.; Yang, X.; Cui, H. Automatic Evaluation Method for Functional Movement Screening Based on a Dual-Stream Network and Feature Fusion. Mathematics 2024, 12, 1162. https://doi.org/10.3390/math12081162
Lin X, Chen R, Feng C, Chen Z, Yang X, Cui H. Automatic Evaluation Method for Functional Movement Screening Based on a Dual-Stream Network and Feature Fusion. Mathematics. 2024; 12(8):1162. https://doi.org/10.3390/math12081162
Chicago/Turabian StyleLin, Xiuchun, Renguang Chen, Chen Feng, Zhide Chen, Xu Yang, and Hui Cui. 2024. "Automatic Evaluation Method for Functional Movement Screening Based on a Dual-Stream Network and Feature Fusion" Mathematics 12, no. 8: 1162. https://doi.org/10.3390/math12081162