1. Introduction
The process of allocating mixed data with several possible outcomes begins with the identification of the data. This includes identifying the type of data, the source of the data, and any relevant characteristics. Once the data have been identified, the next step is to determine the type of allocation that will be used. There are several different types of allocation, including random, manual, and automated allocation. Moreover, there are multiple methods for examining data with categorical outcomes. These methods include descriptive statistics, bivariate analyses, log-linear regression, multinomial logistic regression, discriminant analyses and quadratic discriminant analysis.
Descriptive statistics are used to summarize the characteristics of a data set.
Bivariate analysis is used to examine the relationship between two variables. In the case of categorical data, bivariate analysis consists of calculating the frequency or percentage of one variable for each category of the other variable.
The purpose of log-linear models is to study the relationship between an outcome variable and one or more explanatory variables, where the outcome variable is expressed as the logarithm of a linear combination of the explanatory variables. The log-linear model is a frequently used and simple structure for a contingency table, see Hand and Christen [
1]. It is based on the same principle as the analysis of variance models, as outlined in Birch [
2], Fienberg and Rinaldo [
3] or Goodman [
4], and is formed by calculating the logarithms of the cell probabilities. Examples of log-linear models with frequency tables can be found in Haberman [
5].
On the other hand, Multinomial logistic regression is a generalized linear model that models the log-odds of the categorical response being true as a linear combination of predictor variables. It is a significant tool in statistical modelling and prediction, extending the capabilities of the binary logistic regression model to situations with more than two outcomes.
The goal of discriminant analysis is to classify individuals into distinct groups, maximizing the difference between groups and minimizing the variation within groups. Discriminant analysis has many advantages over the other mentioned methods. For example, it is able to identify and measure the effects of one or more independent variables on a dependent variable, making it a more powerful tool for predicting the outcome of a certain event. This method was first introduced by Sir Ronald Fisher in 1936, in Fisher [
6], and is a popular research topic. Just to give a few examples over time, Rao [
7] applied discriminant analysis to two types of problems confronted in biological research, while Friedman [
8] proposed alternatives to the usual maximum likelihood estimates for the covariance matrices in linear and quadratic discriminant analysis, in small sample high-dimensional settings. McFarland et al. [
9] used the theory of Bessel functions to derive stochastic representations for the exact distributions of the “plug-in” quadratic discriminant functions for classifying a newly obtained observation. Discriminant analysis was used in Perriere and Thioulouse [
10] to separate Gram negative bacteria proteins according to their subcellular location. The problem of classifying an individual into one of several populations based on mixed nominal, continuous, and ordinal data was studied in Flury, Bourkai and Flury [
11]. Modern research continues to find discriminant analysis helpful in problem-solving. For example, using dynamic feature extraction along with quadratic discriminant analysis classifier can significantly enhance fault classification and diagnosis in dynamic nonlinear processes, as demonstrated by Li, Jia, and Mao [
12]. Furthermore, Tong et al. [
13] demonstrated the effectiveness of discriminant analysis in their work on bearing fault diagnosis, representing a crucial development in fault diagnosis for dynamic nonlinear processes. For more information on discriminant analysis, see McLachlan [
14].
Discriminant analysis can be divided into two categories: continuous and discrete. In the continuous case, the predictor variables are continuous and the output of the analysis is a continuous function. In the discrete case, the predictor variables are discrete and the output of the analysis is a classification. In both cases, discriminant analysis is used to find the optimal allocation rules. In the continuous case, the optimal allocation rule is determined by finding the optimal separating hyperplane which maximizes the difference between the groups. In the discrete case, the optimal allocation rule is determined by finding the optimal decision tree, which maximizes the accuracy of the classification.
A unified approach, providing optimal allocation rules to minimize expected costs for both continuous and mixed cases, is presented in Ferreira et al. [
15]. We will follow this last approach.
Our goal is to obtain confidence ellipsoids for the vector of probabilities,
, of getting particular results in an experiment with
m possible outcomes. Through duality, we will also test hypotheses. In addition, we will use support planes for ellipsoids, see Schott [
16], to obtain simultaneous confidence intervals for these probabilities. Moreover, we will generalize these results to vectors
where
is a known matrix. Furthermore, we will show how to obtain optimal allocation rules, in order to reduce the allocation costs, first for the discrete case and then for the continuous case.
The rest of this paper is organized as follows. The next section, for preliminary results, is divided in two subsections. In the first one, we provide a simplified form of the continuous mapping theorem, CMT, based on Kallenberg [
17]. This theorem will grant us the ability to derive confidence ellipsoids from the
distribution in the second subsection, where we will follow the approach of Scheffé [
18].
Section 3 begins with the study of individual samples, followed by the study of pairs and structured families of independent samples. These samples refer to the treatments of a fixed effects experiment. The optimal allocation rules will be obtained in
Section 4.
Section 5 contains two numerical applications. The first, referring to the discrete case and using real data; the second, referring to the continuous case and using simulated data. We end the paper with some conclusions.
3. Inference
In statistical inference, we often encounter experiments with multiple possible outcomes, each associated with a certain probability. To quantify the likelihood of obtaining specific results in such experiments, given the probabilities
of each outcome, and the observed frequencies
in
n trials, we can employ the following probability function:
where
M represents a singular multivariate distribution.
Consider the probability vector
, and define the vector of estimators:
with
for
. These estimators represent the observed probabilities of each outcome. As the number of trials
n approaches infinity, Wilks’ theorem, in Wilks [
19], provides insight into the asymptotic behavior of the estimators:
where
denotes convergence in distribution, and
represents a normal distribution with zero mean vector and covariance matrix
.
The covariance matrix
is defined as
where
is a diagonal matrix with the components of
along its diagonal. The probabilities in the initial distribution can be estimated from the observed frequencies through maximum likelihood estimation, where each
for
. This result indicates that as the sample size grows, the distribution of the estimated probabilities becomes approximately normal, facilitating the application of classical statistical inference techniques. The covariance matrix
characterizes the variability in the estimates, and its asymptotic normality allows for the construction of confidence intervals and hypothesis tests based on the estimated probabilities
.
3.1. One Sample
Let
constitute an orthonormal basis for the orthogonal complement,
, of
. Then, we can write
where
is the eigenvalue associated with
, see Horn [
20]. We can further decompose the matrix
as
Let
be the eigenvector associated with the largest eigenvalue
. Then, we can write
where + denotes the Moore–Penrose inverse, expressed as
According to Schott [
16] and attending to the continuity of the Moore–Penrose inverse, if
where
denotes convergence in probability, then
Moreover, the continuity of the Moore–Penrose inverse implies that the covariance matrix of the vector
,
will converge in probability to
,
Furthermore, the continuity of the Moore–Penrose inverse implies that, if
is a vector, the inner product
will converge in probability to the inner product
, i.e.,
and the variance of the vector
will also converge in probability to the inner product
, i.e.,
These properties of the Moore–Penrose inverse can be used to draw statistical inference from the data. For example, the covariance matrix of the vector
can be used to estimate the variance of the vector
, and the inner product
can be used to estimate the inner product
. Besides this, we have
see Tsui [
21]. We can then make use of the central limit theorem to show that
Using this result, we can construct a confidence interval for
, with confidence level
, given by
We may then use duality to test the hypothesis
at the limit
q. This method is useful for testing hypotheses about parameters in a variety of different models, including linear mixed models.
3.2. Pair of Samples
We denote as the singular multivariate distribution for a pair of independent samples, , with and . Thus, distributions and the corresponding statistics, such as estimators, will be independent.
We can also take the difference between each of the
and
,
, and end up with unbiased estimators for
, as follows:
If
, we will have
with
. So,
and, given the independence of the two samples,
When
, the variance of
tends to zero, so it becomes an unbiased estimator. The same is true for
. To compare the two multivariate distributions,
and
, we can use the Hotelling’s
statistic to measure the distance between the two distributions:
It is well known that if
then
Now, reasoning as in the previous subsection, it may be shown that
and so
Thus, through duality, we get a
limit level test for
In addition,
as
, so that
and that
And, using duality once again, we can obtain limit level
q tests for
3.3. Structured Families of Samples
Let us consider
d treatments of fixed-effects designs, with a total of
individuals, and
d independent samples. This configuration is referred to as a structured family, and the distributions of the samples,
with
,
, and
,
,
, characterize it. Moreover, consider
Now, we will have
where
is the gamma distribution with a shape parameter of
and a scale parameter of 1. So, with
, given the independence of the
,
, we have
with
whenever
.
We now study the action of the factors in the base design, assuming that the hypotheses of absence of effects and interactions are linked to an orthogonal partition,
and that the row vectors of
constitute an orthonormal basis for
,
. This leads to the hypotheses
where
.
So, we will have
where
is the diagonal matrix, with
along its diagonal, and the estimator is given by
Moreover,
will be the critical value for a limit level
q test for
4. Optimal Allocation Rules
4.1. The Discrete Case
Consider a set of populations combined together, each placed into different groups. A randomly selected sample of n elements from this mixture belongs to a specified population and class, denoted as for elements in class and population , with to w and to m.
Our objective is to determine an allocation rule that minimizes the overall cost of assigning elements to their respective populations. The cost of assigning an element from to is represented by .
Let
be the event that a randomly chosen element belongs to
and
, with
[
] representing the event that a randomly chosen element belongs to
[
]. Define
for
and
. Additionally, introduce conditional probabilities
for
and
.
If the elements located in
are assigned to
,
,
, the average cost is given by
This leads to consistent estimators
as the sample size increases, and the estimated average cost
An optimum allocation for
occurs if there exists a
such that
for
, in which case
Furthermore, if there is an optimum allocation for all
,
,
Discriminant analysis is consistent, indicating that the probability of the allocation rule being optimal increases as the initial sample size grows to infinity. This holds true for all , with i ranging from 1 to w.
The global average cost of assigning elements of
,
, to
is given by
with the consistent estimator
and the limit level
confidence interval
where
is the critical value of a standard normal distribution at level
, and
is the vector with all components null except the one with index
,
, which is 1.
4.2. The Continuos Case
For each event , , that occurs when an element of is randomly chosen to belong to , , the probability of the event is . To determine the allocation, a partition of the observations vector is created such that each element is assigned to when , . The probability of assigning to an element of is denoted as , and , and is calculated from the densities of in the , . The expected cost of the decision is then determined by summing the product of the costs of each pair of events and their associated probabilities.
The average cost incurred by the decision will be equal to the sum of the probabilities multiplied by the expected cost for each action multiplied by the probability of that action. This can be expressed as the sum of integrals for each possible action over the region where that action is the optimal choice. That is,
with
To minimize the expected cost, one must take the regions where each action is the optimal choice,
In the situation of identical decision costs, for which
,
, this is especially noteworthy. This means that
and the sets
are applicable. In addition, if
,
, then
This means that, given , the population with the greatest probability will be chosen.
In summary, the expected cost associated with the decision can be expressed as a sum of integrals over the regions where each action is the optimal choice. This decision can be further simplified when the costs for each action are equal and the probabilities are the same. In this situation, the decision is simply to choose the population with the greatest probability.
5. Numerical Applications
5.1. The Discrete Case—An Application to Real Data
The purpose of this subsection is to illustrate the theory, relative to the discrete case. To do this, we use an application with real data, obtained from Instituto Superior Dom Bosco [
22], related to the impact of four economic policies on greenhouse gas emissions: Policy A, Policy B, Policy C, and Policy D. The data were provided by the Instituto Superior Dom Bosco, and will be used to highlight the effectiveness of the discrimination rule in guiding resource allocation decisions.
Let us assume that for each region, the four policies have four distinct categories. This would create possible combinations. If our null hypothesis is true and all of the combinations are equally likely, then any given combination should have a probability of .
We present a discrimination rule, which will classify regions into two groups, “High Emission” (Population 1) and “Low Emission” (Population 2), based on the values of the statistic:
where each policy category has a value of 1, 2, 3, or 4.
The choice of this statistic is based on its ability to capture the differences between the four economic policies in terms of their impact on greenhouse gas emissions. By calculating the absolute differences between the categories of each policy and summing them, we obtain a single value that represents the overall dissimilarity between the policies. In addition, the use of the absolute differences ensures that the magnitude of the differences is taken into account, regardless of their direction. This is important in the context of evaluating policy effectiveness, as both positive and negative differences can contribute to the overall impact.
The collection of potential values for v is . We use the values of of the conditional probabilities and allocate to population 2 or 1 those with or , respectively.
Suppose
denotes the number of elements with
in population
l. We can obtain the sample size for each population as follows:
and the probability of obtaining
in a randomly chosen element from that sample as
The overall sample size will be
while the number of its elements, with
, will be
The probability of a randomly chosen element of the global sample having
[belonging to population
l] will be
and
We begin by finding the ratios , , of the conditional probabilities, and set , allocating to population 2 [population 1] those with , therefore to those with .
Table 1 displays the results, which indicate that
should be chosen and
, thus giving to population 1, the elements with
, and to population 2, the elements with
.
By computing
the outcomes are summarized in
Table 2.
The cost of wrong decisions for both populations was calculated to be
and
The global average cost of wrong decisions can be estimated by the sum of the product of the probability of randomly chosen elements for the mixture,
and
, and the respective population average costs, which is
5.2. The Continuous Case—An Application to Simulated Data
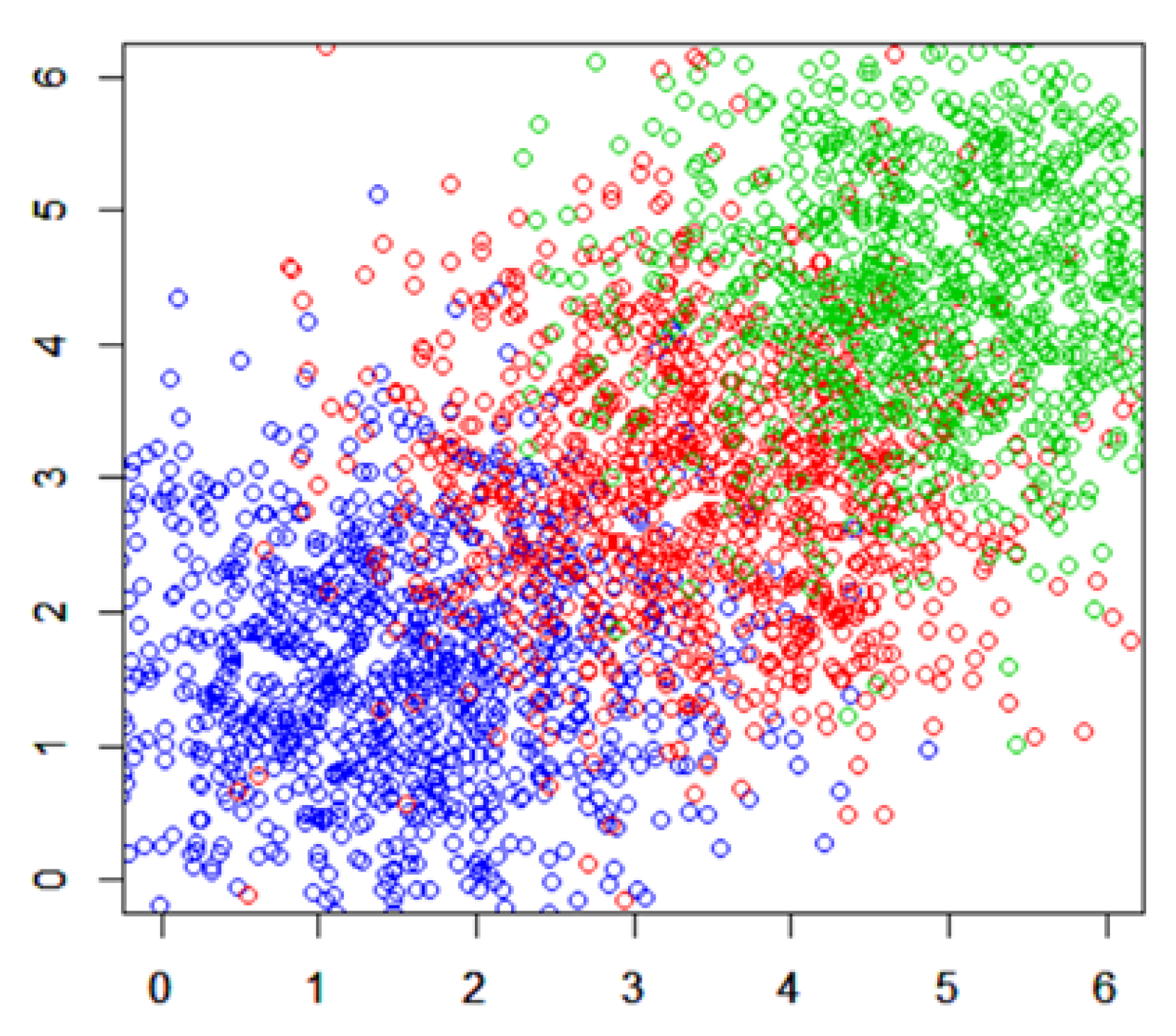
In this subsection, we used R software, version 4.3.0, to simulate and compute a mixture of three populations with mean vectors
and identical covariance matrices
. All measures were taken based on the corresponding normal homocedastic distributions. These values were assumed based on a reasonable assumption for the data generation process, taking into account the need for clear separation between the populations for effective simulation and analysis. In a real-world context, such as in the field of botany, these could, for example, represent averages of certain measurable traits, such as the lengths of petals from three different types of plants.
Simulated samples, with dimension 1000 were generated. These samples are presented in
Figure 1.
Table 3 shows the costs of misallocation. The rows represent the real population of the elements and the columns the populations they were allocated to.
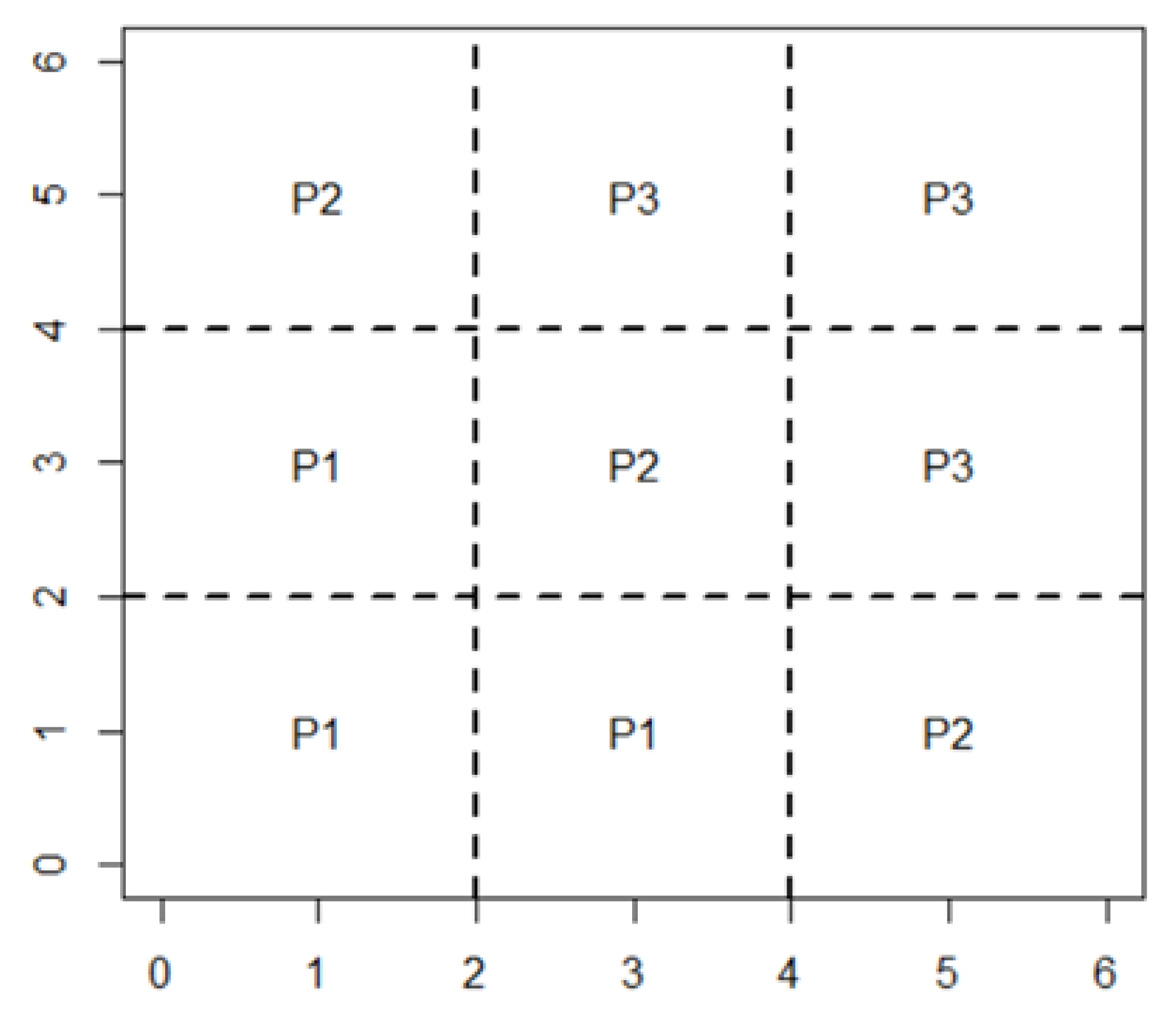
The shapes for the areas of distribution for the elements were established as illustrated in
Figure 2. These are appropriate for normally distributed data with identical covariance matrices. The selected rectangular regions aligned with the axes allowed for efficient calculation of the probabilities of allocation and cost of misallocation.
The average cost will depend on the amount of elements that are allocated to from and to from , as the probabilities of allocating to one element of and to one element of are very small.
With
,
and
representing the regions in which the elements are allocated to populations
,
and
, respectively, we must minimize
As shown in
Figure 2, our approach was to optimize the points where the horizontal and vertical lines intersect the x-axis at
and
and the y-axis at
and
, respectively. These intersection points act as delineations for the designated regions. The selection of those initial points was based on an informed estimation leveraging the mean vectors of the three populations. Noting the fact that the mean vectors for the three populations are
,
, and
, the initial points were chosen to lie approximately midway between these centroids. Taking into account that the populations are distributed normally with identical covariance matrices, this ensures that the initial delineations for the partitioning areas
in the clustering process are not skewed towards one or more populations. Once these initial parameters were set, the optimization process was run, using the ‘stats’ package of R software, version 4.3.0. in R, particularly the ‘optim’ function, continually adjusting the parameters in order to find the values that minimized the objective function, which, in this case, was the cost of misallocation.
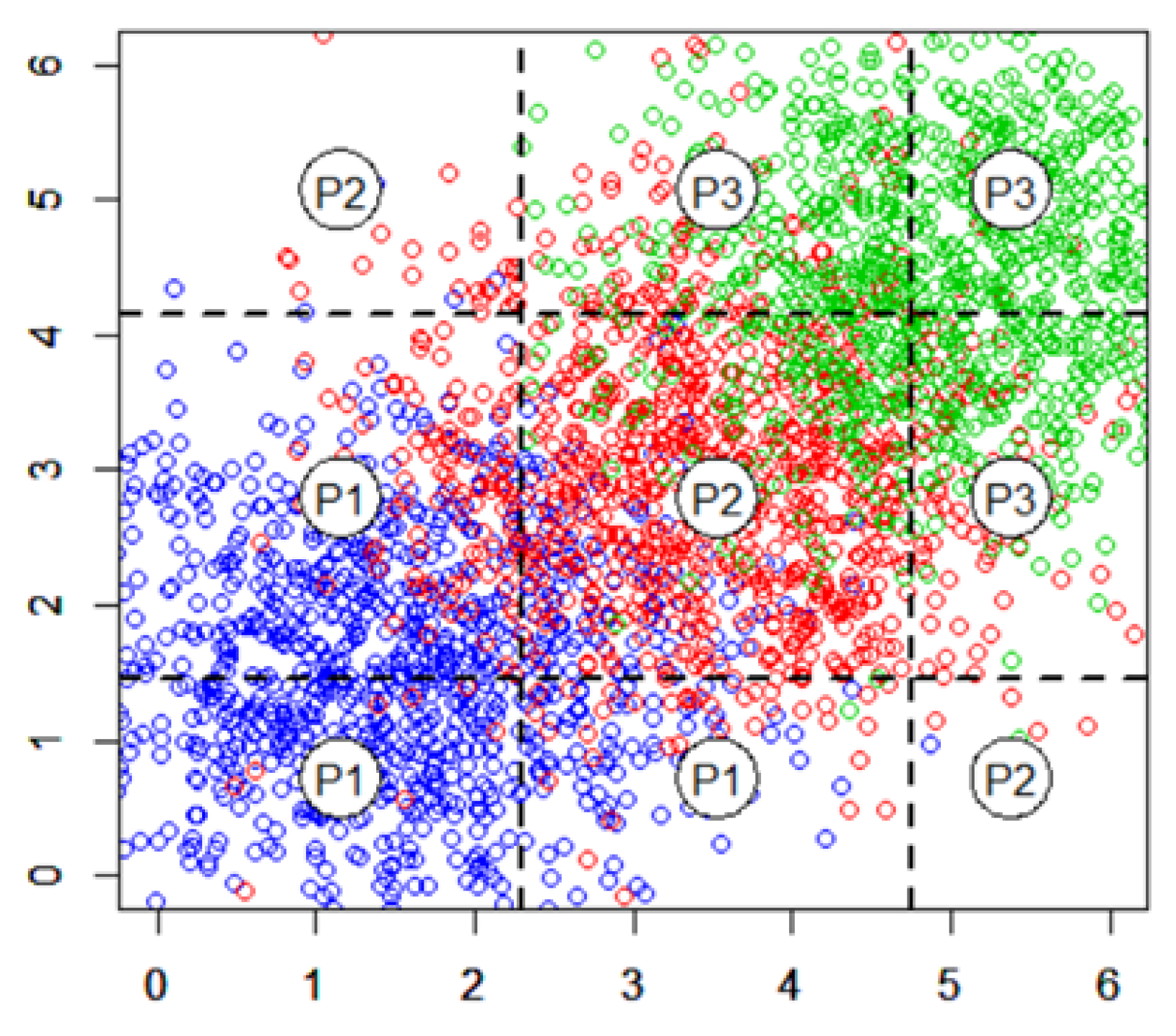
After 1000 repetitions of this optimization process, the suitable partitions displayed in
Figure 3 were obtained. These partitions represent the areas of allocation for the elements within the three populations that produced the minimum misallocation cost, and, therefore, the most efficient allocation of elements within the identified clusters.
The cuts that are most cost-efficient can be represented by the straight lines
Table 4 shows the number of elements in each area.
The corresponding obtained total minimum cost was 638.
So, using simulated samples and different partitions of the sample, we were able to obtain the most cost-efficient cuts and the corresponding total minimum cost.
6. Conclusions
The paper discusses a comprehensive method to obtain optimal allocation rules for fixed-effect experiments. The study process is divided into four sections, namely, asymptotic distributions, confidence ellipsoids, inference, and optimal allocation rules.
Under the section of asymptotic distributions, the Central Limit Theorem (CLT) is accredited for providing valuable insights in terms of the behavior of sample averages.
In confidence ellipsoids, the ellipsoid properties are studied in developing a comprehensive understanding of the distribution of observations. The convex shape of the ellipsoid allows every point within the ellipsoid to be a convex combination of points on its boundary. Simultaneous confidence intervals can be constructed using these ellipsoids.
In the section on inference, the probability functions are detailed. These functions quantify the likelihood of obtaining specific results in experiments. As the number of trials increases, the asymptotic behavior of estimators is established. The distribution of estimated probabilities becomes approximately normal as the sample size grows.
The section on optimal allocation rules further elaborates on the methods for determining an allocation rule that minimizes the overall cost of assigning elements to their respective populations.
The paper concludes with two numerical applications. The first is a real data application showcasing the employment of computational techniques throughout the paper to analyze the real data. The second application undertakes the simulation of data to validate the findings of the study.






{kind=link}
{kind=link}
{kind=link}