1. Introduction
Causal directed acyclic graphs (DAGs) can effectively represent the inter-relationships between variables, which providing a powerful tool for uncertainty inference systems. In recent years, the research of DAGs has become a popular research area in artificial intelligence and machine learning [
1,
2,
3]. Also, DAGs have been successfully applied in many fields such as social science [
4,
5], biomedicine [
6,
7] and economics [
8,
9]. Before utilizing DAGs for causal inference and uncertainty reasoning, it is important to learn the structure of DAGs from empirical data.
The domain of causal structure learning is broadly delineated into two principal categories, that constraint-based learning and score-based learning methodologies. Constraint-based learning methods generally apply the conditional independence (CI) tests or mutual information to identify dependence relationships between variables, and then build DAGs that satisfy these interactions. Typical constraint-based algorithms include Peter–Clark algorithm (PC) [
10], Recursive Autonomy Identification (RAI) [
11], Optimized Zero-First-Order Super-Structure (Opt01SS) [
12], and so on. However, the constraint-based DAGs learning process is highly sensitive to test errors, and while one CI test is wrong it can directly influence the results of subsequent tests.
Therefore, compared to constraint-based learning methods, score-based learning methods are currently in more widespread usage. The score-based learning methods address the structural learning problems as model selection programs, which consist of three components: score function, search algorithm, and search space. The score function is used to evaluate the likelihood of the candidate structure fitting the empirical data. The search algorithm performs a searching strategy for the highest score structure in the candidate structures space and it adopts the heuristic search algorithm mostly. The search space is generally divided into three kinds: space composed of DAGs, space composed of DAG-equivalent class, and space composed of variable topological sorts. Traditional algorithms derived from the combinatorial optimization programs include K2 algorithm [
13], Minimum Description Length and Evolutionary Programming (MDLEP) [
14], PC-Particle Swarm Optimization (PC-PSO) [
15], etc.
Furthermore, researchers gradually introduce deep learning methods into score-based DAGs learning, and transform the traditional combinatorial optimization problem into a continuous optimization process [
16,
17]. Search algorithms have also changed from heuristic search to deep generative model. This continuous optimization approach consists of two components: acyclicity characterization and deep generative model. On the one hand, the matrix acyclicity characterization is a precondition for the continuous optimization of DAGs, and mathematically, the adjacency matrix of DAG must be the nilpotent matrix. On the other hand, within the DAGs learning continuous optimization framework, more deep generative models are deployed for DAGs learning and show significant improvements, such as graph neural network, generative adversarial network, reinforcement learning, and generative flow network. But, in the face of larger data and higher accuracy requirements, there are still some challenges:
Most DAGs continuous optimization are performed by searching in the DAG space. Once the number of DAG variables increases, the DAG space increases exponentially and the generative networks with large parameters cannot find a satisfactory DAG in finite time.
Mathematically, the nilpotent matrix is always used to achieve the acyclicity characterization. In practice, each power operation indicates that it takes a step forward in the directed edge on the graph. However, as the graph size grows, the calculated power number increases, the complexity of the operation rises, and the efficiency of the model decreases.
For the first problem of super-exponential expansion of the DAG space faced by most of the methods, this paper adopts the topological sorts space solving algorithm. By transforming the adjacency matrix into an upper triangular matrix through a congruent transformation guided by the topological sorts, and then the parameters update during the training process only needs to be performed on half of the matrix elements. As the second problem, for continuous optimization based DAGs learning using nilpotent matrices to inscribe acyclic constraints, we decompose the adjacency matrices in training by using QR factorization and design the least-square penalty function instead of the nilpotent matrices, which makes the computation simpler and more efficient.
In this paper, we consider migrating the continuous optimization from the DAG space to the topological sorts space. The space of topological sorts is significantly smaller than the space of DAG or of the equivalence classes. Furthermore, we propose adopt congruent transformation and QR factorization to create an optimization strategy based on the topological sorts. In addition, we employ our method in a graph autoencoder network framework and generate satisfactory DAGs from the data. A summary of the main contributions of this paper is as follows:
We propose continuous optimization DAGs learning in the topological sorts space. We express the topological sorts matrixically, and subsequently use a matrix congruent transformation to convert the initial adjacency matrix into an sort-based adjacency matrix, which enables the continuous optimization DAGs learning to be intervened with the topological sorts.
Based on the topological sorts, we further improve the optimization strategy by using QR factorization. We perform a QR factorization of the sort-based adjacency matrix and utilize the upper triangular attribute of the decomposed matrix to construct the least-square penalty function as constraints for optimization.
We employ our DAGs learning optimization strategy in a graph autoencoder network as the deep generative model framework. And we investigate a comparative analysis of our proposed method against a selection of contemporary algorithms on both synthetic datasets and real-world datasets. The results of our experiments demonstrate the effectiveness of our proposed method.
The subsequent sections of this paper are structured as follows. In
Section 2, we introduce a thorough review of related works.
Section 3 is dedicated to introducing the foundational preliminaries underpinning our study. And in
Section 4, we propose a new DAGs learning method DAGOR.
Section 5 reports our experiments and results. Finally, the conclusions of this study are summarized in
Section 6.
2. Related Works
DAGs learning based on continuous optimization has become a popular research topic. There are two technological lines of research. One is the mathematical acyclicity characterization for DAGs constraint, and the other is the deep generative model for DAGs generation. The former focuses on matrix theoretical analysis for DAGs acyclicity, and the latter adopts deep learning approaches as DAGs generative models.
For acyclicity characterization studies, NO TEARS [
16] is firstly solving the combinatorial graph search challenge into a continuous optimization paradigm through the utilization of trace exponential and nilpotent matrix methodologies. It is based on the gradient computation of the continuous score function. However, a notable limitation of this approach is the computationally intensive property of matrix exponential calculations, which require
operations. In response to this high computational complexity, NO BEARS [
17] offers a different reformulation by leveraging the spectral radius of the adjacency matrix to bound DAGs acyclicity, effectively reducing computational complexity to
. Furthermore, NO FEARS [
18] introduces an innovative acyclicity characterization based on absolute values, which instead the Hadamard product in NO TEARS. This facilitates a practical solution for augmented Lagrangian optimization convergence. Building upon this foundation, GOLEM [
19] proposes a likelihood-based score mechanism augmented with
regularization and soft acyclicity constraints. And NO TEARS+ [
20] extends the acyclicity characterization to accommodate nonparametric general models. LEAST [
21] presents a novel acyclicity constraint paradigm, enhancing upon NO BEARS by leveraging least-square objectives and
regularization, achieving computational efficiency closer to
. DAGMA [
22] eliminates NO TEARS power series and introduces a log-determinant acyclicity characterization. However, these above methods are calculating in the DAG space and with strict limitations for acyclic characterization, which means they are always stuck in a local optimum. But our proposed method, DAGOR, which operates in a topological sorts space with a global modification to the hypothesis, avoids local optima and does not require consideration of acyclicity, reducing computational costs significantly.
As for the DAGs deep generative models, CGNN [
23] firstly represents an integration of continuous optimization for DAG learning with neural networks. Subsequent innovations include Graphite [
24], which employs a generative neural network framework to reconstruct DAGs parameterized by weighted adjacency matrices. But its initial output is an undirected graph. SAM [
25] introduces adversarial training strategies to optimize end-to-end DAG learning, enhancing model robustness. DAG-GNN [
26] integrates neural network functions and black-box variational inference into DAGs learning methods, leveraging evidence lower bound (ELBO) [
27,
28] as the score criterion. Expanding upon this paradigm, GAE [
29] extends DAG-GNN formalisms to a graph autoencoder framework, facilitating the incorporation of non-linear structural interactions and vector-valued variables. RL-BIC [
30] adopts a reinforcement learning approach to DAGs learning and causal discovery, where the reward function consists of a BIC scoring function and an acyclic constraint function with a penalty term. In addition, DAG-GAN [
31] devises an adversarial framework for DAGs structure detection. DAG-GFlowNet [
32] proposes to use the generative flow networks for approximating the posterior distribution over the structure of DAGs. GraN-DAG [
33] learns the conditional independent relationship of the neural network model between variables and transforms the problem into the maximum likelihood optimization problem. It utilizes a multilayer perceptron and a continuous acyclic constraint function as a loss function to constrain its acyclicity.
In particular, we investigate the characteristics of the above methods in
Table 1, as they are the latest advancements in the domain of DAGs learning. We also compare them to the above deep generative models, including NOTEARS, GraN-DAG, DAG-GNN, and RL-BIC. DAGOR has an efficient performance because after the topological sorts based upper triangularization, the adjacency matrix in training only needs to be updated with half of the parameter values.
According to the above analysis, we conclude mostly DAGs learning research concentrates on acyclicity characterization and deep generative models. However, precisely learning DAGs from data is still a challenging problem.
3. Preliminaries
3.1. Directed Acyclic Graphs
A graph is fundamentally composed of vertices and edges, and the edges establish connections between pairs of vertices. The vertices can also represent a myriad of entities, which are linked together in pairs through the intermediary of edges. In the directed graphs, each edge possesses a distinct orientation, which represents a directional flow from one vertex to another. Formally, a path within a directed graph comprises a sequence of edges, where each subsequent edge commences from the vertex of its predecessor. It is worth noting that directed acyclic graphs are characterized by the absence of cycles or closed loops, distinguishing them as structures devoid of cyclical dependencies.
As for directed graphs, the notion of reachability between vertices assumes significance. A vertex
v is reachable from another vertex
u if there exists a path originating at
u and concluding at
v. It follows that if a vertex can traverse a nontrivial path to reach itself, then this path necessarily constitutes a cycle. Consequently, an alternative characterization of DAGs emerges: the graphs wherein no vertex can traverse a nontrivial path to reach itself [
34].
In addition, the DAG is a significant tool for portraying causal effects and causality. The directed edges represent vertices from cause to effect, which reflects causal effects cannot be bidirectional.
3.2. Topological Sorts
A DAG can be topologically sorted by arranging its vertices in a sequence, which ensures a logical flow of information and makes it easier to understand the relationships between the vertices. In the graph theory, a discernible characteristic of a topological sort is its inherent prohibition of cycles, as the directional orientation of edges makes a unidirectional flow that precludes the existence of cycles. Conversely, every DAG has at least one topological sort. Hence, the presence of a topological sort emerges as an equivalent criterion for DAGs. It is important to acknowledge that the uniqueness of this sort is not universal; a DAG owns a singular topological sort exclusively when it has a directed path encompassing all vertices. In such instances, the sequential arrangement of vertices within the topological sort reflects their sort along the aforementioned path, thereby illuminating a distinct correlation between the topology of the graph and the linear arrangement of its vertices [
35].
Moreover, the family of DAGs topological sorts coincide with the family of linear extensions derived from its reachability relation [
36], which representing the intrinsic relationship between the structural properties of the graphs and the resultant arrangements yielded by their topological sorts.
3.3. Determine Acyclicity Based on DAGs Adjacency Matrix
The DAG consists of its vertex set
and edge set
, where the elements of
are all binary subsets of
. Let
represents the
-position element of matrix
A. For a graph
G with
n vertices, its adjacency matrix
is an
matrix whose elements are defined as
Based on the attributes of DAGs, the adjacency matrix has the following three properties:
The diagonal coefficients of matrix
are all zeros;
Matrix
is an asymmetric matrix;
Matrix
is a nilpotent matrix.
Specifically, each exponentiation of the adjacency matrix symbolizes a singular step in the vertex transition process within the graph. Consequently, the resultant nilpotent matrix signifies a state wherein all elements of are rendered as zeros after taking n consecutive power operations. This denotes that the vertices within the graph fail to cyclically return to their initial states following n steps of transition, thereby unequivocally indicating the absence of any closed-loop structures within the graph.
4. Proposed Method
In this section, we introduce our method DAGOR. In this method, we firstly conduct adjacency matrix congruent transformation based on the topological sort vector. Secondly, we perform the QR factorization of the transformed adjacency matrix and propose a least-square penalty function with the upper triangular matrix as constraints for the DAGs learning process. Finally, we employ the DAGOR algorithm with a graph autoencoder framework.
Learning DAGs using topological sorts and QR factorization is carried out because we fin that during the training process of learning DAGs based on deep generative models, the adjacency matrix is normally the one that needs to be updated iteratively for all matrix elements. This is very inefficient for complex datasets with more vertices. Therefore, we consider designing a topological sorts based contract matrix transformation to upper triangularize the adjacency matrix so that only half of the matrix parameters need to be updated for each training. Further, we find that upper triangular matrices also exist in QR factorization, which is consistent with the adjacency matrix in training. Therefore, we introduce QR factorization into the training objective to construct least-square penalty function as constraints for optimization.
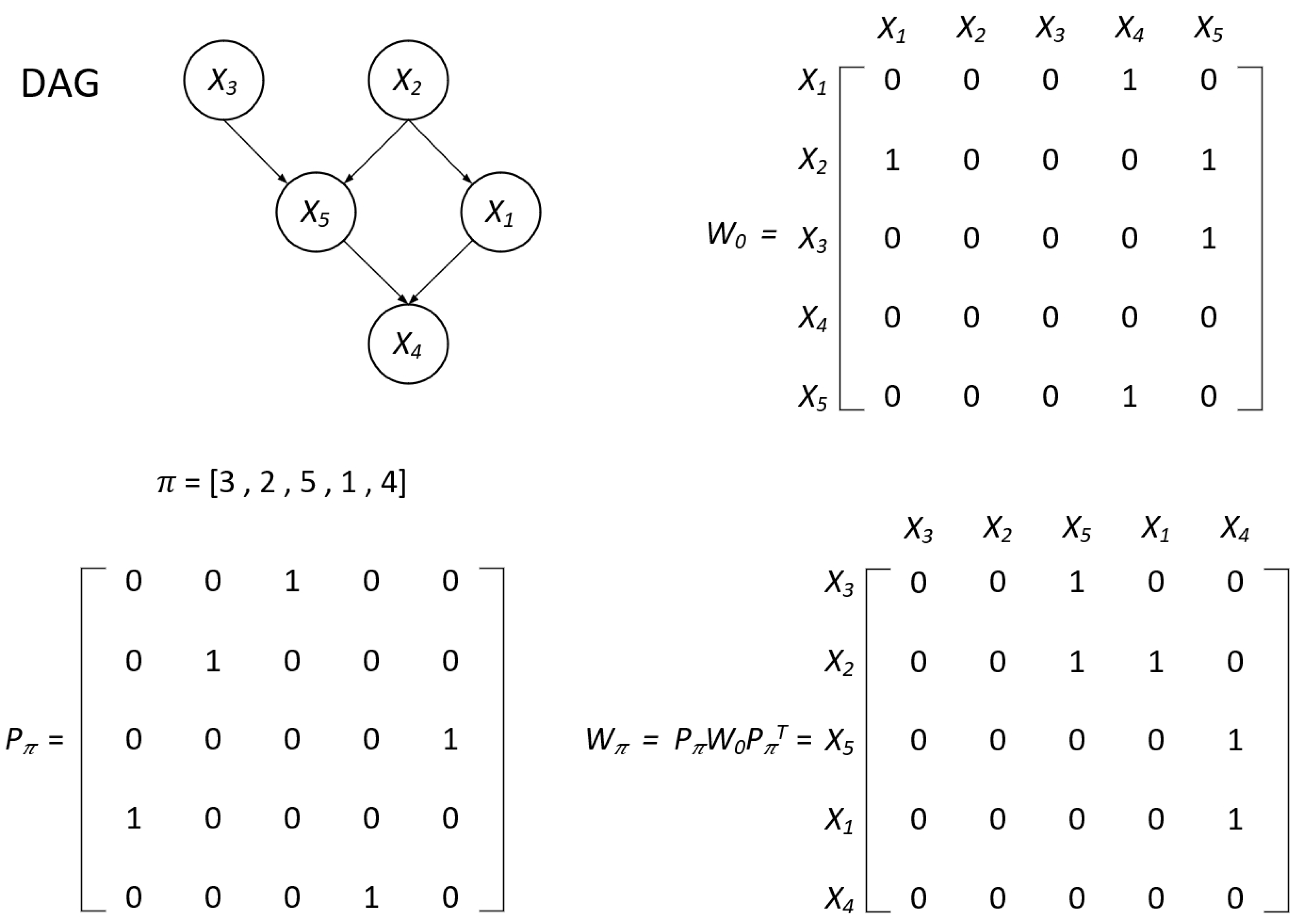
4.1. Adjacency Matrix Congruent Transformation with Topological Sorts
In the context of graph theory, a topological sort for a directed graph G is a partial ordering denoted as ≺ on its vertex set . This sort corresponds to the condition that for any vertices and in V, the presence of a directed edge from to () implies . The symbol denotes the existence of an edge between vertices i and j.
A topological sort, denoted by ≺, defines a permutation
on the vertex set
V of graph
G. This permutation assigns
to the vertex at the
i-th position in the ordering specified by ≺. Importantly, a topological sort yields a unique arrangement of vertices in
G.
Moreover, a directed graph is acyclic if and only if it possesses a topological sort. It is important that the topological sort need not be unique for a given acyclic directed graph. Thus, the existence of a topological sort serves as a decisive criterion for identifying the acyclic characterization of a directed graph, emphasizing its key role in graph theory.
In mathematics, the congruence of two square matrices, denoted as
A and
B, defined over a field, is established when there exists an invertible matrix
P over the same field. This congruence relationship is expressed as
where
denotes the transpose of the matrix
P.
Therefore, we conduct the DAGs adjacency matrix congruent transformation with topological sorts. For each permutation
on the set
, we correspondingly establish a permutation matrix
, with its
i-th row being denoted as
. Given a vector
, we observe that the operation
results as:
signifying that
systematically rearranges the entries of vector
v in accordance with the permutation
and
. Thus, we perform a congruent transformation of the original adjacency matrix
of
, let
Subsequently, the matrix
takes on the form of a strictly upper triangular matrix if and only if
represents the topological sort of the directed acyclic graph
G, denoted by
in
for
. A visual representation is provided in
Figure 1 for enhanced clarity. Consequently, the acyclicity condition on
translates to the requirement that
assumes a strictly upper triangular form for a specific permutation sort
. And we can further utilize
for next DAGs optimization.
4.2. QR Factorization for the Transformed Adjacency Matrix
A recognized matrix factorization refers to a linear transformation that analyses an acknowledged matrix into a product of two or three matrices, typically of standard types. One prominent instance of such factorization is the QR factorization. This factorization entails breaking down the matrix into the product of an orthogonal matrix and a triangular matrix. Specifically, the QR factorization of a real square matrix
A is characterized by the expression
In this factorization, Q represents an orthogonal matrix with columns comprising orthogonal unit vectors, denoted by , and R is an upper triangular matrix. In the case of a nonsingular matrix A, this factorization is uniquely determined. Conversely, for a complex square matrix A, an analogous factorization exists, but with Q being a unitary matrix, characterized by the property that its conjugate transpose, denoted as , is equal to its inverse, i.e., .
Various methodologies exist for computing the QR factorization, including the Gram–Schmidt process [
37], Householder transformations [
38], and Givens rotations [
39]. In our DAGOR framework, we employ the Gram–Schmidt process. The procedure involves considering the vectors to be processed as columns of the matrix
A. That is,
Note that
is the
norm. The resulting QR factorization is
Note that once we find , it is not hard to write the QR factorization.
In the training phase of the depth generation model, the resultant adjacency matrix is denoted as
W. Following the acquisition of the topological sort
through the topological sorts learning methods [
40,
41], a matrix
is introduced to represent
, and a contracted matrix operation is applied:
The primary objective of the training process is to ensure that
W accurately reflects the adjacency matrix of DAGs, while
is specifically represented as the upper triangular matrix. Based on the QR factorization, the adjacency matrix
where
Q is the orthogonal matrix and
R is the upper triangle matrix. By the definition of an orthogonal matrix
Q, an orthogonal matrix must be an invertible matrix:
Then we can also express the upper triangle matrix
R as follows:
Thus, when
,
Q converges to the unit matrix, i.e.,
. Therefore, we propose to set the training optimization satisfying
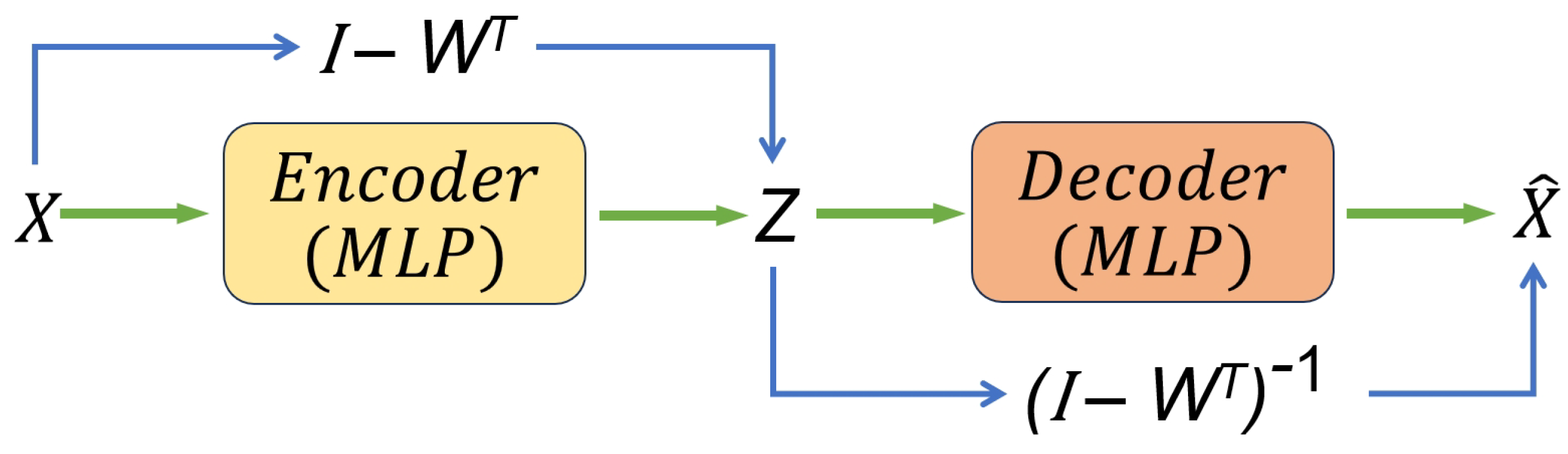
4.3. Algorithm with the Graph Autoencoder Framework
We use a deep generative model based on graph autoencoder (GAE) as a generative model framework. The GNNs framework for DAGs generation is designed as a variational autoencoder (VAE),
Here,
can represent any parameterized graph neural network such as Graph Convolutional Network (GCN), Multilayer Perceptron (MLP), etc. Because a simple MLP is sufficiently effective for the generation of fitting data distributions, more complex models are not necessary. We define the MLP as
and the identity mapping as
. Let
be the MLP and
be the constant mapping of the generative model.
where
and
are the parameters of the neural network. By aggregating the samples
to assess the distributional specification of
Z, the Kullback–Leibler (KL) divergence serves as a metric for quantifying the disparity between the variational distribution
and the true posterior distribution
. Consequently, this methodology enables the inference of the generative model for the DAGs by maximizing the lower bound of evidence, known as the Evidence Lower Bound (ELBO).
The encoder module operates by transforming a given sample denoted as into a representation characterized by the probability density function . Subsequently, the decoder module endeavors to reverse this process by reconstructing the original data from the latent variable Z, with the probability density . The objective is to ensure that the generated sample is virtually indistinguishable from the true data X.
In this goal, the iterative training of the generative model is performed, facilitating the generation of synthetic data
that closely approximates the true distribution
X. This iterative generative training process ultimately culminates in the derivation of a highly satisfactory DAG adjacency matrix denoted as
W. The matrix
W encapsulates the relationships and dependencies within the data, thereby providing a robust and accurate representation of the underlying data structure. The model architecture is shown as
Figure 2.
Hence, the final optimization problem is to minimize the reconstruction error of the GAE (with
penalty) within the least-square penalty function based on QR factorization as constraints:
Further derive its Lagrange function as
is the Lagrange multiplier, so its dual function is
Therefore, by iteratively descending the gradient to further solve its dual function, the solution of the original problem can be obtained. And as the GAE’s empirical default settings, we keep the coefficient to 1.0.
5. Experiments
To assess the effectiveness of our proposed methodology, we systematically evaluate its performance through comparative analyses with established DAGs learning approaches on meticulously constructed simulated synthetic datasets and on benchmark datasets obtained from the Bayesian Network (BN) repository (
https://www.bnlearn.com/bnrepository/, accessed on 6 February 2024).
In this section, the compared methods include NOTEARS [
16], GraN-DAG [
33], DAG-GNN [
26] and RL-BIC [
30]. NOTEARS firstly conduct continuous optimization on acyclic constraint, and GraN-DAG algorithm is an improvement of NOTEARS based on the neural network model. Similar to GraN-DAG, DAG-GNN is an enhancement of the NOTEARS algorithm based on variational inference and graph neural networks. And the RL-BIC algorithm is the first model to introduce reinforcement learning into DAG learning domain.
In
Section 5.2, we conduct experiments on the simulated synthetic datasets, which include linear Gaussian SEM datasets from an Erdős–Rényi (ER) graph and non-linear multilayer perceptron (MLP) SEM datasets from a scale-free (SF) graph. Evaluation metrics include True Positive Rate (TPR), precision, F1 score, and Structural Hamming Distance (SHD), which is used to determine the gap between learned and true structure.
In
Section 5.3, we analyse the capability of our model on the benchmark datasets, including SACHS [
42], INSURANCE [
43], ALARM [
44], and HAILFINDER [
45]. We specially compared all methods with groundtruth. We further utilize the Bayesian Dirichlet equivalent uniform (BDeu), Bayesian Information Criterion (BIC) scores as evaluation criteria to judge the ability of the DAGOR model to search for optimally DAGs structure.
All algorithms are implemented and executed in Pytorch in a PC with 12th Gen Intel(R) Core(TM) i9-12900H @2.50 GHz, 64 bits, and 16.0 GB of memory. The code can be found at
https://github.com/haozuo17/DAGOR, accessed on 6 February 2024.
5.1. Experiment Details
5.1.1. Datasets
Erdős–Rényi (ER) graph: Let be the probability value and let n be a positive integer. The undirected graph on n vertices, with an edge connecting each pair of vertices with probability p, is defined as the graph .
Scale-free (SF) graph: A scale-free network is a connected graph wherein the number of links, denoted as
k, emanating from a specific vertex follows a power-law distribution, represented as
. The construction of a scale-free network involves the iterative addition of vertices to an existing network. In the procedure, connections are added to vertices that already have preferred attachment, making sure that the likelihood of connecting to a certain vertex
i is exactly proportional to the quantity of links that vertex already has,
, i.e.,
5.1.2. Metrics
True Positive Rate (TPR) denotes the proportion of samples that were actually positive classes that were correctly predicted to be positive classes.
Precision indicates the ratio of the total number of positive pairs to the total number of positive pairs predicted.
F1 score can be seen as a kind of reconciled average of model precision and TPR.
Structure Hamming distance (SHD) is a common metric for measuring structure learning and it counts the total number of additions, deletions, and reversals of edges that are required to transform the estimated graph into the genuine graph.
5.1.3. Score Functions
Bayesian Information Criterion (BIC) score: The likelihood estimate of the probability distribution
given the observed data and the BIC score function added penalties regarding the complexity of the model to the likelihood estimates:
where
denotes the number of times the random variable
in the observed data
takes the
k-th value and its parent set of vertices takes the
j-th combination of values.
Bayesian Dirichlet equivalence uniform (BDeu) score: When the prior distribution of the parameters
is assumed to satisfy the product Dirichlet distribution, the following can be derived:
where
denotes the gamma function,
n denotes the number of random variables,
denotes the number of possible values of the set of parents of the
i-th random variable
,
denotes the number of possible values of the random variable
,
denotes the number of samples when the random variable
is taken to be
k, and the set of parents of the random variable
is taken to be
j, and
is the Dirichlet parameter.
5.2. Synthetic Datasets Experiments
5.2.1. Linear Datasets Experiments
For linear structural equation models, it can be expressed as
where
is the weighted adjacency matrix, and
represents the Gaussian noise.
Then, considering the ground-truth DAG derived from an ER2 graph, which encompasses d vertices and edges, we assigned independent edge weights from a uniform distribution of to create a weight matrix W. Gaussian noise, . Under these conditions, we generated random linear datasets . Each simulation involved generating samples and conducting experiments on four graph sizes .
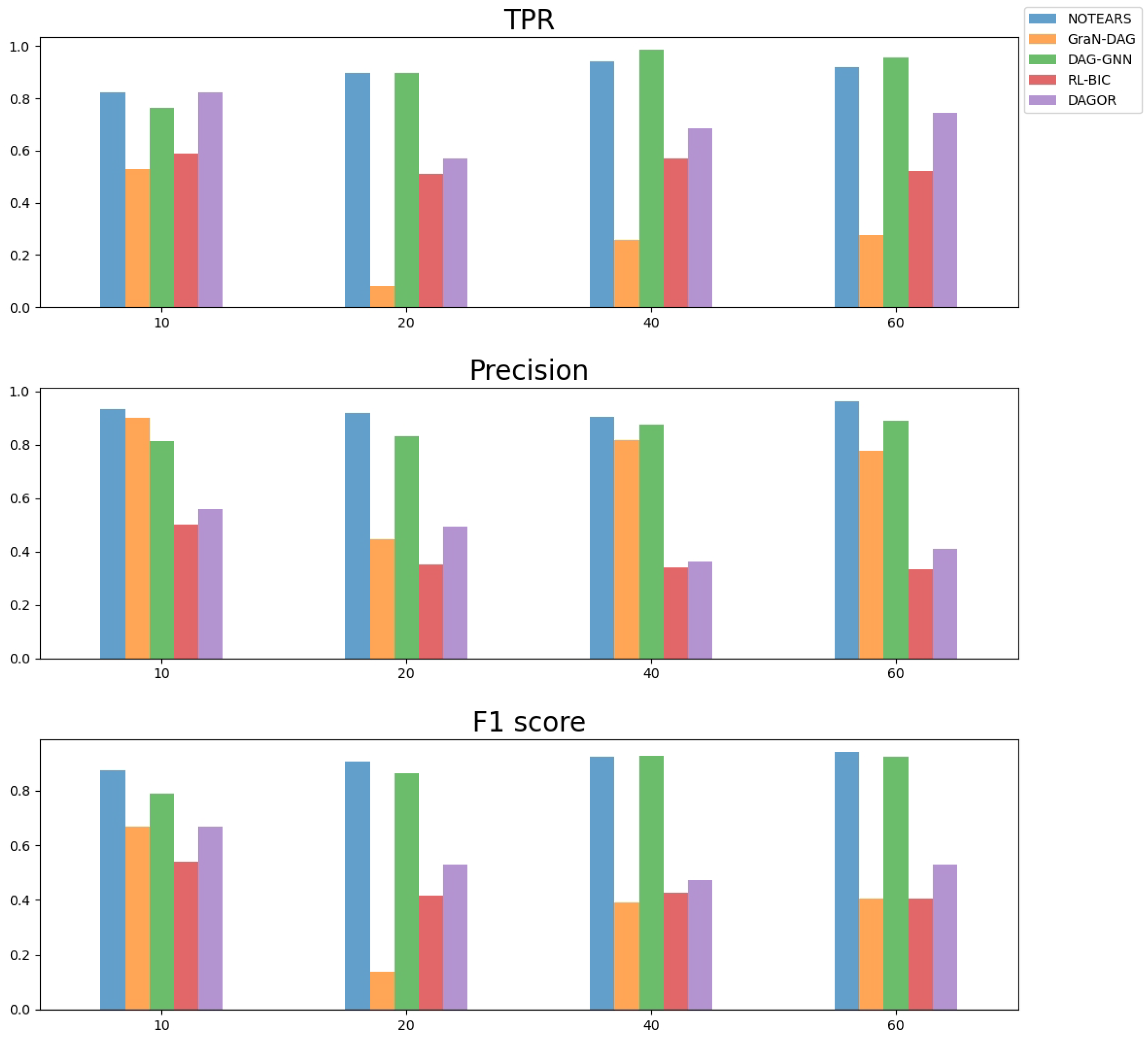
As illustrated in
Figure 3, we find that DAGOR performs at a moderate level on the synthetic linear Gaussian SEM ER2 dataset. In the TPR figure, at 10 vertices, DAGOR has a high value, but as the number of vertices increases to 20, 40, 60, the performance of DAGOR begins to fluctuate and generally decreases. Moreover, the precision of DAGOR is not high, which suggests that there are some edges that are misdirected. For the F1 score, DAGOR has better performances than the reinforcement learning based algorithm RL-BIC and the neural network based algorithm GraN-DAG.
The reason why our DAGOR gets negative performance on ER2 graphs is because the performance of the DAGOR algorithm partially depends on the reliability of the topological sorts. If the topological order is not exact, it will have an impact on the DAGOR search algorithm. However, in the ER2 graphs structure, there are a lot of juxtaposed vertices, which disturbing to the topological sorts and resulting a fuzzy search space. This always reduces the ability of DAGOR to discover DAGs from the vertex topological sorts.
5.2.2. Non-Linear Datasets Experiments
For non-linear structural equation models, we simulate as
where
represents a multilayer perceptron (MLP) that has been randomly initialized, one hidden layer, size 100, and sigmoid activation.
represents the set of parent vertices and
is a standard Gaussian noise.
In this part, we take scale-free (SF) graph as ground-truth DAG derivation. Similar to linear experiments, we generate datasets from SF2, with i.i.d. samples and graph size .
As presented in
Figure 4, our method DAGOR has a really favorable performance on the non-linear synthetic MLP SEM SF2 datasets, and in particular, DAGOR shows a high level in TPR metrics. For the TPR metrics, our method DAGOR achieves better performance than the other four algorithms on all the different vertex datasets. But in terms of the precision, the performance of DAGOR is not that good. For example, DAGOR’s precision is lower than the other four algorithms at 40 and 60 vertices SF2 datasets. But for F1 score metrics, DAGOR performs generally well, which means the DAGs learning ability of DAGOR is still promising.
In particular, the efficiency of our method DAGOR does not decrease obviously in the case of higher number of vertices in SF2. These results further prove that DAGOR can be used in discovering more realistic nonlinear causal relationships.
5.3. Benchmark Datasets Experiments
We also demonstrate the DAGOR model on four discrete real datasets: SARCH, INSURANCE, ALARM, and HAILFINDER.
Table 2 describes the details about four datasets.
The results in
Table 3 show our model’s DAGs structure attains a superior BIC score comparing with the other four alternative methods, which means our method is effective on these four real datasets.
In addition, the results in
Table 4 further prove the findings, where the BDeu score of DAGOR exhibiting superiority over other methods. This outperformance reflects the effectiveness of our model in structure learning to the causality of the discrete real data.
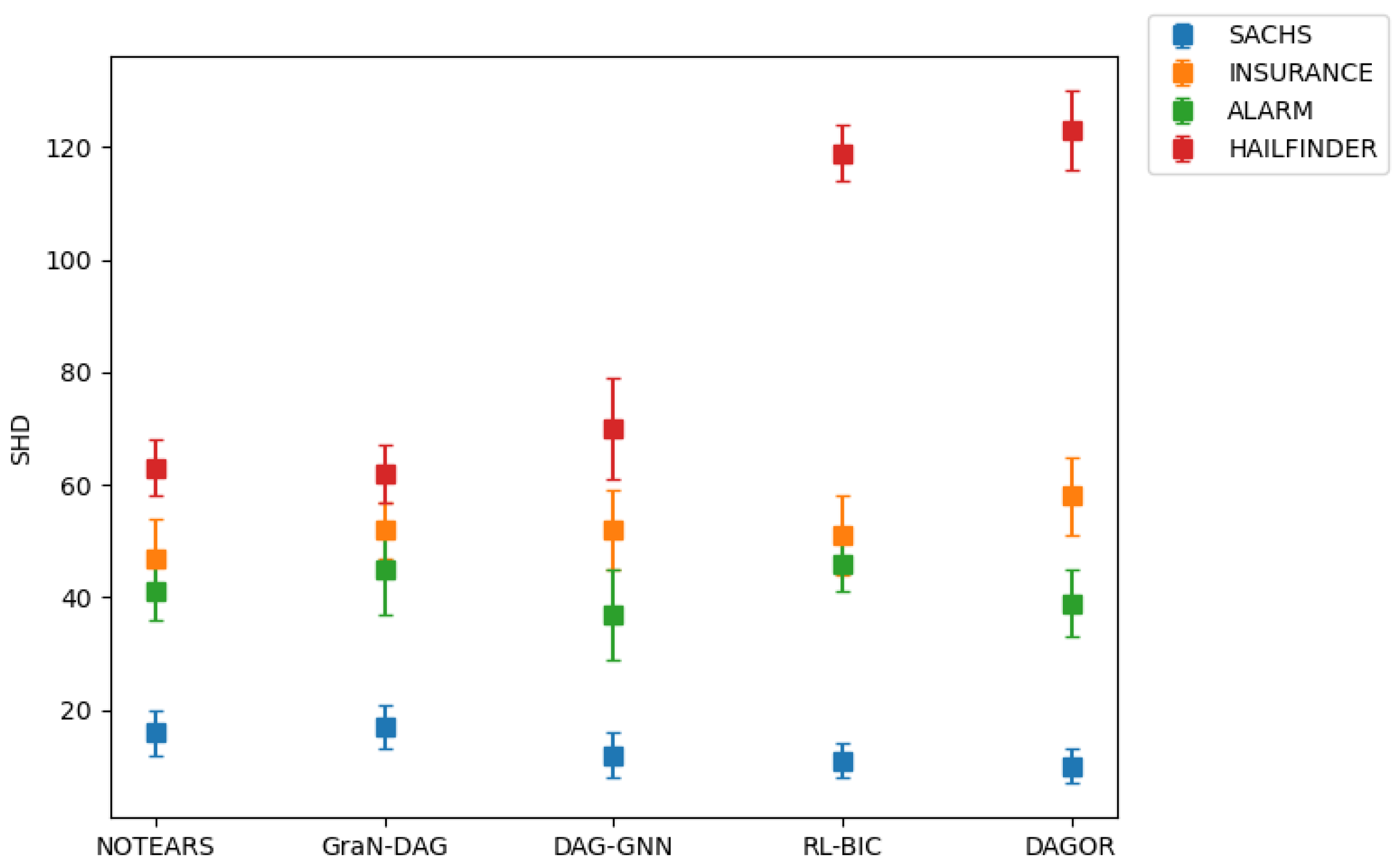
Furthermore,
Figure 5 shows the results of the Structural Hamming distances associated with DAGs learnt by various methods across the four benchmark datasets. We find that DAGOR can perform well on SACHS, INSURANCE and ALARM, but the performance on HAILFINDER is worse than other algorithms, which suggests that DAGOR fails to get a good structure when dealing with very large networks. However, most real world networks do not have such large vertices and edges, which means using our DAGOR is enough in most cases.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}