Abstract
The Diminishing-Return (DR)-submodular function maximization problem has garnered significant attention across various domains in recent years. Classic methods often employ continuous greedy or Frank–Wolfe approaches to tackle this problem; however, high iteration and subproblem solver complexity are typically required to control the approximation ratio effectively. In this paper, we introduce a strategy that employs a binary search to find the dynamic stepsize, integrating it into traditional algorithm frameworks to address problems with different constraint types. We demonstrate that algorithms using this dynamic stepsize strategy can achieve comparable approximation ratios to those using a fixed stepsize strategy. In the monotone case, the iteration complexity is , while in the non-monotone scenario, it is , where F denotes the objective function. We then apply this strategy to solving stochastic DR-submodular function maximization problems, obtaining corresponding iteration complexity results in a high-probability form. Furthermore, theoretical examples as well as numerical experiments validate that this stepsize selection strategy outperforms the fixed stepsize strategy.
Keywords:
DR-submodular; approximation algorithm; dynamic stepsizes; computational complexity; stochastic optimization MSC:
90C27; 68W25; 65Y20
1. Introduction
The problem of maximizing DR-submodular functions, which generalizes set submodular functions to more general domains such as integer lattices and box regions in Euclidean spaces, has emerged as a prominent research topic in optimization. Set submodular functions inherently capture the diminishing returns property, where the marginal gain of adding an element to a set decreases as the set expands. DR-submodular functions extend this fundamental property to continuous and mixed-integer domains, enabling broader applications in machine learning, graph theory, economics, and operations research [1,2,3,4]. This extension not only addresses practical problems with continuous variables but also provides a unified framework for solving set submodular maximization through continuous relaxation techniques [5,6].
The problem of deterministic DR-submodular function maximization considered in this paper can be formally written as follows:
where the feasible set is compact and convex, and is a differentiable DR-submodular function. While this problem is generally NP-hard, under certain structural assumptions, approximation algorithms with constant approximation ratios can be developed. For unconstrained scenarios, Niazadeh et al. [7] established a tight -approximation algorithm, aligning with classical results for unconstrained submodular maximization. In constrained settings, monotonicity plays a critical role: convex-constrained monotone DR-submodular maximization admits a -approximation [1], whereas non-monotone cases under down-closed constraints achieve -approximation [1] with recent improvements to [8]. For general convex constraints containing the origin, a -approximation guarantee is attainable [9,10,11].
While deterministic DR-submodular maximization has been extensively studied, practical scenarios often involve uncertainties where the objective function can only be accessed through stochastic evaluations. This motivates the investigation of stochastic DR-submodular maximization problems, which are typically formulated as follows:
where the DR-submodular function is defined as the expectation of stochastic functions with . Building upon the Lyapunov framework established for deterministic problems [10], recent works like [12,13] have developed stochastic variants of continuous greedy algorithms. Specifically, Lian et al. [14] proposed SPIDER-based methods that reduce gradient evaluation complexity from in earlier works [12] to through variance reduction techniques.
The Lyapunov framework proposed by Du et al. [9,10] provides a unified perspective for analyzing DR-submodular maximization algorithms. By modeling algorithms as discretizations of ordinary differential equations (ODEs) in the time domain , this approach establishes a direct connection between continuous-time dynamics and discrete-time implementations. Specifically, the approximation ratio of discrete algorithms differs from their continuous counterparts by a residual term that diminishes as the stepsize approaches zero. However, the use of constant stepsizes in this framework imposes fundamental limitations: the required number of iterations grows inversely with stepsize magnitude, leading to linear computational complexity both in theory and practical implementations.
To address the limitations of fixed stepsize strategies, recent advances have explored dynamic stepsize adaptation for submodular optimization. For box-constrained DR-submodular maximization, Chen et al. [15] developed a -approximation algorithm with adaptive rounds, where stepsizes are selected through enumeration over a candidate set of size . Furthermore, Ene et al. [16] achieved -approximation for non-monotone cases using parallel rounds, and -approximation for monotone cases with rounds. These works inspire our development of binary search-based dynamic stepsizes that achieve comparable approximation guarantees while reducing computational complexity.
The dynamic stepsize strategy in this paper leverages binary search to approximate solutions to univariate equations by selecting intervals based on midpoint function value signs, ensuring convergence via monotonicity and continuity. While stochastic methods like simulated annealing [17] address non-convex/stochastic problems via probabilistic criteria, their guarantees depend on cooling schedules and lack deterministic convergence. In contrast, our binary search framework exploits the monotonicity/continuity of the stepsize equation (Equation (38)), achieving sufficiently precise solutions with guaranteed efficiency, avoiding cooling parameter dependencies and focusing on theoretical foundations for DR-submodular structures.
1.1. Contributions
This paper introduces a novel dynamic stepsize strategy for DR-submodular maximization problems, offering significant improvements over traditional fixed stepsize methods. Our approach achieves state-of-the-art approximation guarantees while reducing computational complexity. Notably, the iteration complexity of our algorithms is independent of the smoothness parameter L. In the monotone case, it is also independent of the variable dimension n. Furthermore, both the gradient evaluation complexity and function evaluation complexity exhibit only a logarithmic dependence on the problem dimension n and the smoothness parameter L. Below, we summarize the key contributions:
- Deterministic DR-Submodular Maximization: For deterministic settings, our dynamic stepsize strategy achieves the following complexity bounds:
- –
- In the monotone case, the iteration complexity is , where reflects the gradient norm at the origin, and denotes the discretization error.
- –
- For non-monotone functions, the iteration complexity increases to , accounting for the added challenge posed by non-monotonicity.
To determine the stepsize dynamically, we employ a binary search procedure, introducing an additional factor of to the evaluation complexity. - Stochastic DR-Submodular Maximization: Extending our approach to stochastic settings, we achieve comparable complexity results with high probability:
- –
- For monotone objective functions, the iteration complexity remains .
- –
- In the non-monotone case, the complexity is .
These results demonstrate that our method maintains efficiency regardless of the smoothness parameter L, making it particularly suitable for large-scale stochastic optimization problems. - Empirical Validation: We validate the effectiveness of our dynamic stepsize strategy through three examples: multilinear extensions of set submodular functions, DR-submodular quadratic functions, and softmax extensions for determinantal point processes (DPPs). The results confirm that our approach outperforms fixed stepsize strategies in terms of both iteration complexity and practical performance.
Table 1 provides a unified overview of our algorithms’ theoretical guarantees and computational complexities (iteration and gradient evaluation bounds) under diverse problem settings, enabling readers to rapidly grasp the efficiency and adaptability of our dynamic stepsize framework.

Table 1.
Algorithms and theoretical guarantees in this paper. D = Deterministic; S = Stochastic; M = Monotone; NM = Non-Monotone; DC = Down-closed; GC = General convex; Grad Eval = Gradient evaluation complexity; S-Grad Eval = Single (per-sample) gradient evaluation complexity.
1.2. Organizations
The organization of the rest of this manuscript is as follows. Section 2 introduces the fundamental concepts and key results that form the basis of our work. In Section 3, we outline the design principles of our dynamic stepsize strategy and establish theoretical guarantees for both monotone and non-monotone deterministic objective functions. Section 4 extends our approach to stochastic settings, presenting algorithms and analyses tailored for monotone and non-monotone DR-submodular functions under uncertainty. In Section 5, we evaluate the computational efficiency of our strategy through its application to three canonical DR-submodular functions, with comprehensive numerical experiments validating the efficacy of the dynamic stepsize approach. Section 6 summarizes our key findings while discussing both limitations and promising future research directions.
2. Preliminaries
We begin by introducing the formal definition of a non-negative DR-submodular function defined on the continuous domain , along with some fundamental properties.
Definition 1.
A function is said to be DR-submodular if for any two vectors satisfying (coordinate-wise) and any scalar such that , the following inequality holds:
for all . Here, represents the i-th standard basis vector in .
This property reflects the diminishing returns behavior of F along each coordinate direction. Specifically, the marginal gain of increasing a single coordinate diminishes as the input vector grows larger.
To facilitate further discussions, we introduce additional notation. Throughout this paper, the inequality for two vectors means that holds for all . Additionally, the operation is defined as , and is defined as .
An important result is that, in the differentiable case, DR-submodular functions are equivalent to the monotonic decrease in the gradient. Specifically, when F is differentiable, F is DR-submodular if and only if [2]
Another essential property for differentiable DR-submodular functions that will be used in this paper is derived from the concavity-like behavior in non-negative directions, as stated in the following proposition.
Proposition 1
([18]). When F is differentiable and DR-submodular, then
In this paper, we also require the function F to be L-smooth, meaning that for any , there holds
where denotes the Euclidean norm unless otherwise specified. An important property of L-smooth functions is that they satisfy the following necessary (but not sufficient) condition:
For the stochastic DR-submodular maximization problem (2), we introduce additional notations to describe the stochastic approximation of the objective function’s full gradient.
- At each iteration j, let denote a random subset of samples drawn from , with m representing the size of .
- The stochastic gradient at x is computed as
- We use an unbiased estimator to approximate the true gradient .
All algorithms and theoretical analyses in this paper for problems (1) and (2) rely on the following foundational assumption:
Assumption 1.
The problems under consideration satisfy these conditions:
- 1.
- is DR-submodular and L-smooth.
- 2.
- and .
- 3.
- A Linear-Objective Optimization (LOO) oracle is available, providing solutions to
The following assumption is essential for the stochastic problem (2).
Assumption 2.
The stochastic gradient is unbiased—i.e.,
This assumption ensures that the mini-batch gradient estimator satisfies
where denotes the random mini-batch sampled at iteration j. This property is critical for deriving high-probability guarantees in stochastic optimization.
Lyapunov Method for DR-Submodular Maximization
As discussed in [10], Lyapunov functions play a crucial role in the analysis of algorithms. Depending on the specific problem, the Lyapunov function can take various parametric forms. Taking the monotone DR-submodular maximization problem for example, the ideal algorithm can be designed as follows:
A unified parameterized form of the Lyapunov function is given by:
where and are time-dependent parameters.
The monotonicity of the Lyapunov function is closely tied to the approximation ratio of the algorithm, as demonstrated by the following inequality:
where represents the optimal solution. The specific values of , , and T depend on the problem under consideration and are chosen accordingly to achieve the desired theoretical guarantees. In this problem, letting can guarantee the monotonicity of and then the approximation ratio for monotone DR-submodular functions is:
For maximizing non-monotone DR-submodular functions with down-closed constraints, the ideal algorithm can be designed as follows:
In this problem, let , , and . Then the best approximation ratio for monotone DR-submodular functions is:
where is down-closed.
For maximizing non-monotone DR-submodular functions with general convex constraints, the ideal algorithm can be designed as follows:
In this problem, let , , and . Then the best approximation ratio for monotone DR-submodular functions is:
where is only convex.
In this paper, we focus on the same algorithmic ODE forms as those discussed above. However, our key improvement lies in the discretization process. Specifically, we aim to enhance the iteration complexity by employing a dynamic stepsize strategy. This approach allows for more efficient approximations while maintaining the desired theoretical guarantees, thereby advancing the state-of-the-art in DR-submodular maximization algorithms.
3. Deterministic Scenarios
In this section, we discuss the dynamic stepsize algorithms for maximizing deterministic DR-submodular functions, considering two cases: monotone and non-monotone. The fixed stepsize versions of the algorithms discussed in this section already exist in the literature, as documented in [6,9,10].
3.1. Monotone Case
In this subsection, we discuss a dynamic stepsize algorithm designed to maximize a monotone DR-submodular function while ensuring an approximation guarantee. To better illustrate the strategy for selecting the stepsize, we first introduce an idealized algorithm that relies on an oracle capable of solving a univariate continuous monotone equation. Subsequently, we propose a practical and implementable version of the algorithm.
3.1.1. An Idealized Algorithm
The ideal version referred to above is depicted as Algorithm 1. Unlike the fixed stepsize approach used in [10] where , our algorithm determines the stepsize by solving Equation (22). In brief, the stepsize is selected to ensure that the directional derivatives along between successive iterations differ precisely by .
| Algorithm 1: Ideal CG |
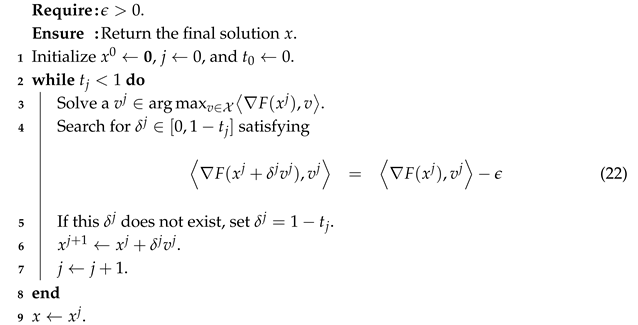 |
Before analyzing the computational complexity and approximation guarantees of Algorithm 1, we must verify the feasibility of its output.
Lemma 1.
Algorithm 1 outputs a solution satisfying .
Proof.
Note that
and . By the feasibility of and the convexity of P, we can prove the conclusion. □
The iteration complexity bound is established as follows.
Lemma 2.
The iteration number K of Algorithm 1 satisfies
Proof.
For , we have
Summing up this inequality from to yields
Noting that by the monotonicity of F, we can conclude that .
By the fact that F is L-smooth and DR-submodular, there holds
Combining these bounds completes the proof. □
As outlined in [10], the iteration complexity of the Frank–Wolfe algorithm for DR-submodular maximization is . We now present the approximation guarantee and complexity results for Algorithm 1.
Theorem 1.
Assume that F is monotone. Then Algorithm 1 returns a solution x satisfying
where denotes the optimal solution, with iteration complexity given by Equation (24).
3.1.2. Algorithm with Binary Search
An oracle for solving Equation (22) exactly is not always feasible in general cases. To address this, we propose employing a binary search technique to compute an approximate solution. This approach preserves the approximation ratio achieved by Algorithm 1, leading to the development of Algorithm 2. The key distinction between these two algorithms lies in the determination of the stepsize at each iteration.
In Algorithm 2, we utilize the bisection method to compute a compensation parameter that satisfies condition (38). The implementation begins by initializing the search interval as . At each iteration, we evaluate the left-hand side of (38) at the midpoint of the current interval and determine whether the value belongs to the right sub-interval. Depending on this evaluation, we systematically discard either the left or right half of the interval and repeat the process. The well-defined nature of this procedure is guaranteed by the monotonicity and continuity of the left-hand side expression with respect to .
| Algorithm 2: Bisection continuous-greedy |
 |
Following a similar analysis to that of Algorithm 1, the number of iterations K in the “while” loop of Algorithm 2 can also be bounded.
Corollary 1.
For Algorithm 2, the iteration number satisfies
To analyze the gradient evaluation complexity of F, it is necessary to examine the number of binary search steps required in each iteration to determine the stepsize.
Lemma 3.
For each iteration , the stepsize can be determined within at most binary search steps.
Proof.
Let represent the exact solution to the equation
Due to the monotonicity and continuity of the univariate function , the binary search process can identify an interval of length that contains . Let denote the right endpoint of this interval. Consequently, we have
By the L-smoothness property of F, it follows that
Thus, we obtain
Additionally, by the monotonicity of , we know
Combining these results with the definition of , the proof is completed. □
The approximation guarantee and oracle complexity of Algorithm 2 can now be derived.
Theorem 2.
Assume F is monotone. Then, Algorithm 2 outputs a solution x satisfying
The LOO oracle complexity is at most , and the gradient evaluation complexity is at most .
Proof.
The complexities of the LOO oracle and gradient evaluations can be established using Corollary 1 and Lemma 3. We now focus on deriving the approximation ratio.
Recall the function defined in (34). For , we have
From the structure of Algorithm 2, the DR-submodularity, and the monotonicity of F, it follows that
Thus, we obtain
Summing up these inequalities for to , we obtain
On the other hand, by the definition of , we have
Combining these results yields the approximation guarantee stated in the theorem. □
3.2. Non-Monotone Case
In this subsection, we discuss the dynamic stepsize strategy for maximizing DR-submodular functions after removing monotonicity, along with its theoretical guarantees. Unlike the monotonic case, here we categorize the constraints into two types: down-closed and general convex types.
3.2.1. Down-Closed Constraint
Algorithm 3 is proposed for scenarios involving down-closed constraints, which means that if and , then . The fundamental framework is inspired by the measured continuous greedy (MCG) algorithm introduced in [6], initially raised for maximizing the multilinear extension relaxation of submodular set functions. In [10], MCG was demonstrated to require iterations to ensure an approximation loss of .
| Algorithm 3: Bisection MCG |
 |
The feasibility of the output produced by Algorithm 3 is ensured by the down-closed property of .
Lemma 4.
The solution x generated by Algorithm 3 satisfies .
The proof of is presented in Appendix A.
The absence of the monotonicity assumption for F necessitates a distinct analysis of the iteration complexity for Algorithm 3 compared to Algorithm 2.
Lemma 5.
For Algorithm 3, the number of iterations K satisfies
Proof.
The upper bound follows analogous reasoning to Corollary 1.
Note that at the -th iteration of the algorithm, we have —i.e., there exists at least one such that , or else we can let and terminate the algorithm.
Now, consider the changing process of the sign of for .
Case I. . In this case, the analysis is analogous to that in Lemma 2 and we have
Case II. . First, we define the iteration index set as the following:
It is obvious that .
For , by the monotonicity of w.r.t. K, we have
since , and are entry-wisely of the same sign. By the monotonicity of , the number of these iterations can be bounded as
The proof is completed. □
Building upon the preceding analysis, we establish the following approximation guarantee and complexity results for Algorithm 3:
Theorem 3.
For any down-closed feasible set , Algorithm 3 produces a solution x satisfying with LOO oracle calls bounded by
and gradient evaluations at most
Proof.
Redefine the potential function as . Then, for , there holds
Similar to the proof of Theorem 2, we need to prove a lower bound on the difference of function values between two adjacent iteration points when F is non-monotone:
where the third inequality is due to Proposition 1 and the fourth inequality is by Lemma 3 in [1], which implies that the following inequality holds:
for . Additionally, for the upper bound on the -norm of , we have the following claim. □
Claim 1.
For all the iteration points , , of Algorithm 3, we have .
The claim can be proved by induction. First, note that . Assume that for some j, then the proof can be finished by showing that
So the above formula yields
By summing Equation (75) over j from 0 to , we obtain
Together with the fact , we obtain the theorem.
3.2.2. General Convex Constraint
This section presents a Frank–Wolfe variant designed for maximizing non-monotone DR-submodular functions under general convex constraints, where stepsizes are determined through binary search operations on Equation (38). A key distinction from prior methods in [10] and earlier approaches lies in our iterative tracking protocol. Specifically, the method requires maintaining records of both parameter vectors and their corresponding function evaluations at each iteration. Upon completing the iteration sequence, the procedure outputs the stored point achieving maximum functional value, contrasting with traditional implementations that directly return the final computed iterate.
The feasibility and approximation characteristics of solution x generated by Algorithm 4 are formally established through the following analytical results.
| Algorithm 4: Bisection Frank-Wolfe |
 |
Lemma 6.
Algorithm 4 produces a feasible solution satisfying .
The proof of is presented in Appendix B.
Theorem 4.
The solution of Algorithm 4 satisfies
with computational complexity characterized by LOO oracle calls and gradient evaluations.
The proof of is presented in Appendix C.
4. Stochastic DR-Submodular Function Maximization
This section investigates stochastic maximization of DR-submodular functions under two distinct settings. Section 4.1 focuses on the monotone case, establishing theoretical guarantees for constrained optimization. Building upon this foundation, Section 4.2 extends the analysis to non-monotone scenarios, addressing both down-closed constraints and generalized convex constraints. For the fixed stepsize implementations of stochastic DR-submodular maximization algorithms, we refer readers to [12,14].
4.1. Stochastic Monotone DR-Submodular Maximization
Algorithm 5 implements a SPIDER-CG framework for continuous monotone DR-submodular optimization, integrating binary search for adaptive stepsize selection. Our approach builds on the recursive gradient estimator from [14], where Lian et al. consider an gradient approximation of by adding an unbiased estimator of to , and is given as an unbiased estimator of . Building upon this variance-reduced foundation, we adopt the binary search method to find out a proper dynamic stepsize.
| Algorithm 5: Bisection Stochastic CG |
 |
We have the following theorem on the theoretical results of Algorithm 5.
Theorem 5.
Assume that F is monotone and set . Under Assumption 2, Algorithm 5 outputs a solution x satisfying
With probability , the LOO oracle complexity is bounded by and the gradient evaluation complexity is bounded by
Proof.
Firstly, we provide the proof of the complexity. For , from the deterministic algorithm, we have
According to the Chernoff bounds, let , , , satisfying
For each iteration, the probability of is at least . For all j, the following inequality holds with a high probability ,
Then
It is noteworthy that
Then we can obtain
Then we can obtain the complexity with probability . According to Taylor expansion, we have
Denote . The number m of set is at most
Let
From the deterministic case, letting the right endpoint of the interval be yields
From the above, for all j, there holds the following inequation in high probability.
Then
Now, we focus on the approximation ratio. Define the function as
For , there holds
By the form of Algorithm 5 and the DR-submodularity and monotonicity of F, we have
Thus, we have
Summing up all the above inequalities from to yields
On the other hand, by the definition of function L, we have
Then
□
4.2. Stochastic Non-Monotone DR-Submodular Maximization
This subsection investigates the stochastic maximization of non-monotone DR-submodular functions under two constraint classes: down-closed convex sets and general convex domains.
4.2.1. Down-Closed Constraint
Algorithm 6 is designed for a stochastic non-monotone DR-submodular function with a down-closed constraint.
| Algorithm 6: Bisection Stochastic MCG |
 |
Theorem 6.
Assume that is down-closed and set . Under Assumption 2, Algorithm 6 outputs a solution x satisfying
With probability , the LOO oracle complexity is bounded by and the gradient evaluation complexity is bounded by
The proof of is presented in Appendix D.
4.2.2. General Convex Constraint
In this subsection, we present the dynamic stepsize algorithm for solving the maximization of stochastic non-monotone DR-submodular functions with general convex constraints.
Theorem 7.
Algorithm 7 outputs a solution x satisfying
With probability , the LOO oracle complexity is bounded by and the gradient evaluation complexity is bounded by .
The proof of is presented in Appendix E.
| Algorithm 7: Bisection Stochastic Frank–Wolfe |
 |
5. Examples
To explore the potential acceleration offered by a dynamic stepsize strategy, we present three illustrative examples in this section.
Multilinear Relaxation for Submodular Maximization. Let V be a finite ground set, and let be a function. The multilinear extension of f is defined as
where . It is well known that the function f is submodular (i.e., for any and ) if and only if F is DR-submodular. Therefore, maximizing a submodular function f can be achieved by first solving the maximization of its multilinear extension and then obtaining a feasible solution to the original problem through a rounding method. Such algorithms are known to provide strong approximation guarantees [5,19].
Let denote the vector whose i-th entry is 1 and all other entries are 0. The upper bound of can be derived as follows.
Lemma 7.
Let F denote of a submodular set function f. Suppose the feasible set satisfies and we have
For the multilinear extension of a submodular set function, the Lipschitz constant L is given by [6].
Softmax Relaxation for DPP MAP Problem. Determinantal point processes (DPPs) are probabilistic models that emphasize diversity by capturing repulsive interactions, making them highly valuable in machine learning for tasks requiring varied selections. Let H denote the positive semi-definite kernel matrix associated with a DPP. The softmax extension of the DPP maximum a posteriori (MAP) problem is expressed as
where I represents the identity matrix. Based on Corollary 2 in [4], the gradient of the softmax extension can be written as follows:
Consequently, the -norm of the gradient at is given by
In practical scenarios involving DPPs, the matrix H is often a Gram matrix, where the diagonal elements are universally bounded. This implies that the asymptotic growth of is upper-bounded by .
DR-Submodular Quadratic Functions. Consider a quadratic function of the form
where (i.e., A is a matrix with non-positive entries). In this case, is DR-submodular. It is straightforward to verify that and the gradient Lipschitz constant is given by
The computational complexities of the algorithms designed to address the three constrained DR-submodular function maximization problems outlined earlier are compiled in Table 2. The results presented in the table reveal that the dynamic stepsize strategy introduced in this work offers a significant advantage in terms of complexity over the constant stepsize approach, both for the MLE and softmax relaxation problems. However, in the quadratic case, a definitive comparison of their complexities cannot be made, because they are determined by the -norm of the linear term vector and the -norm of the quadratic term matrix, respectively, and there is no inherent relationship between the magnitudes of these two quantities.
Table 2.
Comparison of complexities between dynamic and constant stepsizes for three examples (grad.eval: complexity of gradient evaluation).
Numerical Experiments
We conduct numerical experiments to evaluate different stepsize selection strategies for solving DR-submodular maximization problems. Our investigation focuses on two fundamental classes of objective functions: quadratic DR-submodular functions and softmax extension functions. The experimental framework builds upon established methodologies from [9,14], with necessary adaptations for our specific analysis.
Our experimental evaluation considers two problem classes: softmax extension problems and quadratic DR-submodular problems with linear constraints. Since neither problem class inherently satisfies monotonicity, we augment both functions with an additional term, where b is a positive vector with components in appropriate ranges. This modification enables the verification of Algorithms 2 and 5 by ensuring monotonicity preservation.
We evaluate Algorithms 2–4 on the softmax extension problems, while testing the stochastic algorithms (Algorithms 5–7) on quadratic DR-submodular problems with incorporated random variables. The randomization methodology follows the principled approach outlined in [14].
For each problem class, we consider decision space dimensions , with the number of constraints m set as for each dimension. The approximation parameter is fixed at 0.1, and the constant stepsize strategy employs 100 iterations. Each configuration is executed with five independent trials, with averaged results reported.
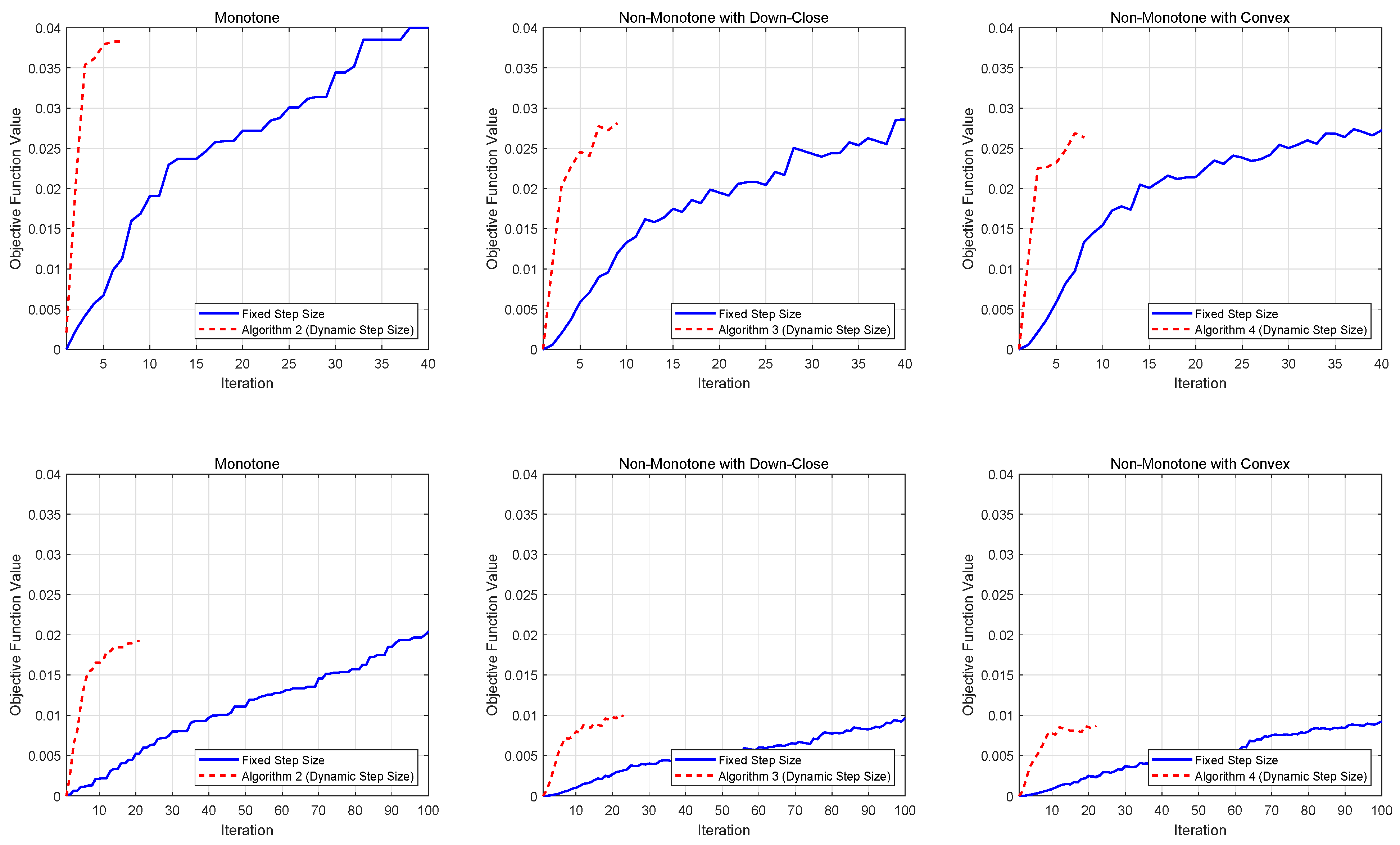
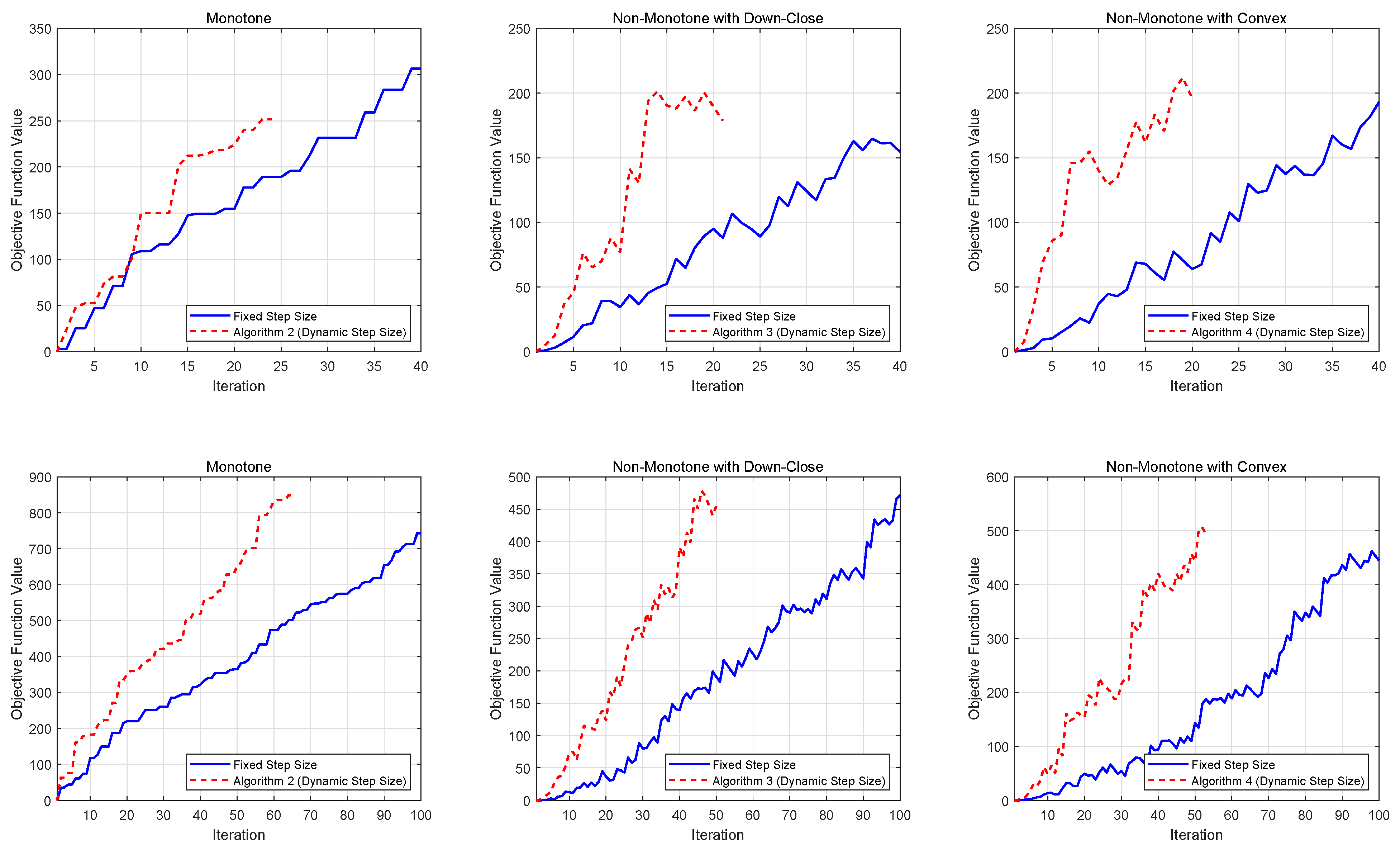
Figure 1 presents the performance comparison for softmax extension problems, while Figure 2 displays the results for stochastic quadratic DR-submodular problems. Both figures demonstrate the evolution of achieved function values across different stepsize strategies, providing empirical insights into algorithmic efficiency.
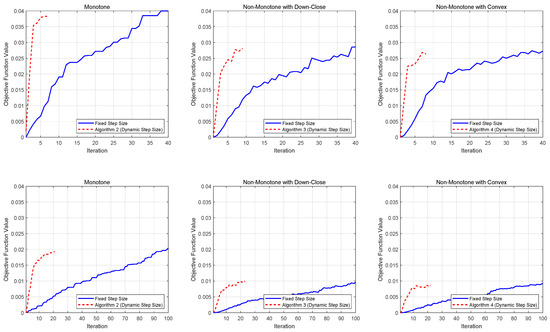
Figure 1.
Numerical results for softmax problems.
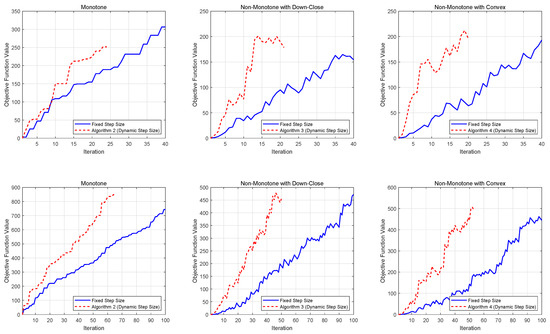
Figure 2.
Numerical results for stochastic quadratic DR-submodular problems.
From the numerical results, we observe that for both deterministic and stochastic problems, dynamic stepsizes generally lead to lower iteration complexity compared to constant stepsizes, especially for larger problem dimensions. This finding highlights the advantages of using dynamic stepsizes in solving DR-submodular maximization problems.
6. Conclusions
This paper introduces a dynamic stepsize strategy for DR-submodular maximization, achieving iteration complexities independent of the smoothness parameter L. In deterministic settings, monotone cases attain -approximation with iterations, while non-monotone problems under down-closed or general convex constraints achieve and -approximations with iterations. For stochastic optimization, variance reduction techniques (e.g., SPIDER) further reduce gradient evaluation complexities while maintaining high-probability guarantees. Empirical results on multilinear extensions, DPP softmax relaxations, and DR-submodular quadratics validate the practical efficiency of our methods compared to fixed stepsize baselines.
Our work has three key limitations: first, while our dynamic strategy matches the iteration complexity of fixed stepsize methods, it does not guarantee superiority for all L-smooth DR-submodular functions. Second, Algorithm 1 avoids the L-smoothness assumption but requires a univariate equation oracle to solve Equation (22), which lacks practical applications as no real-world examples have been identified to support this assumption. Third, our stepsize mechanism heavily relies on the DR-submodularity property, limiting its applicability to non-DR-submodular functions or mixed-integer domains. These limitations highlight opportunities for future research to extend our framework to broader function classes and practical scenarios.
Author Contributions
Conceptualization, Y.Z.; Methodology, Q.L. and Y.Z.; Validation, M.L.; Formal analysis, Y.L. All authors have read and agreed to the published version of the manuscript.
Funding
The author Yang Zhou was supported by the National Natural Science Foundation of China (No. 12371099). This research received no external funding.
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding author.
Conflicts of Interest
The authors declare that they have no known competing financial or non-financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Appendix A. Proof of Lemma 4
Proof.
By the algorithm, we can first obtain the following relations:
The conclusions can then be obtained by the down-closeness of P. □
Appendix B. Proof of Lemma 6
Proof.
The conclusion can be derived by the fact that for , which can be proved by induction. Note that and is a convex combination of and . Thus, if and the proof is completed. □
Appendix C. Proof of Theorem 4
Proof.
For Algorithm 4, we have the claim that for , there holds
We first prove the claim by induction. Note that satisfies the inequality. Assume that for some , the inequality holds; then for , we have
Thus, inequality (A3) is proved. Redefine the potential function ; then
Together by inequalities (73), (A3), and
we obtain
Note that if there exists a such that , then by the form of the output x in Algorithm 4, we have , which satisfies (103). Otherwise, we have
and
Together with the fact that
we complete the proof. □
Appendix D. Proof of Theorem 6
Proof.
Similar to Lemma 5, the difference in the analysis is as follows.
For , by the monotonicity of w.r.t. K, we obtain the following effect with a high probability from Theorem 5:
since , and are entry-wisely of the same sign. By the monotonicity of , the number of these iterations can be bounded as
From Theorem 5, the number m of set is at most .
Now, we present the proof of the approximation ratio. Redefine the potential function as . Then for , the following holds:
We need to prove a lower bound on the difference of function values between two adjacent iteration points when F is non-monotone:
where the fourth inequality is by Lemma 3 in [1], which implies that the following inequality holds:
for . From the deterministic case, for the upper bound on the -norm of , we have the following claim.
Claim 2.
For all the iteration points , , of Algorithm 3, we have .
So, the above formula yields
By summing Equation (A16) over j from 0 to , we obtain
Together with the fact that , we obtain the theorem. □
Appendix E. Proof of Theorem 7
Proof.
For Algorithm 7, we have the claim that for , there holds
Redefine the potential function ; then
Together by inequalities (73), (A3), and
we obtain
Note that if there exists a such that , then by the form of the output x in Algorithm 7, we have , which satisfies (103). Otherwise, we have
and
Together with the fact that
we complete the proof. □
References
- Bian, A.; Levy, K.; Krause, A.; Buhmann, J.M. Continuous DR-submodular maximization: Structure and algorithms. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 486–496. [Google Scholar]
- Bian, A.A.; Mirzasoleiman, B.; Buhmann, J.; Krause, A. Guaranteed non-convex optimization: Submodular maximization over continuous domains. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, PMLR 2017, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 111–120. [Google Scholar]
- Bian, Y.; Buhmann, J.M.; Krause, A. Continuous submodular function maximization. arXiv 2020, arXiv:2006.13474. [Google Scholar]
- Gillenwater, J.; Kulesza, A.; Taskar, B. Near-Optimal MAP Inference for Determinantal Point Processes. In Proceedings of the 25th International Conference on Neural Information Processing Systems, NIPS’12, Lake Tahoe, NV, USA, 3–6 December 2012; Curran Associates Inc.: Red Hook, NY, USA, 2012; Volume 2, pp. 2735–2743. [Google Scholar]
- Calinescu, G.; Chekuri, C.; Pál, M.; Vondrák, J. Maximizing a monotone submodular function subject to a matroid constraint. SIAM J. Comput. 2011, 40, 1740–1766. [Google Scholar] [CrossRef]
- Feldman, M.; Naor, J.; Schwartz, R. A unified continuous greedy algorithm for submodular maximization. In Proceedings of the 2011 IEEE 52nd Annual Symposium on Foundations of Computer Science, FOCS ’11, Palm Springs, CA, USA, 22–25 October 2011; IEEE Computer Society: Washington, DC, USA, 2011; pp. 570–579. [Google Scholar]
- Niazadeh, R.; Roughgarden, T.; Wang, J.R. Optimal Algorithms for Continuous Non-Monotone Submodular and DR-Submodular Maximization. J. Mach. Learn. Res. 2020, 21, 1–31. [Google Scholar]
- Buchbinder, N.; Feldman, M. Constrained submodular maximization via new bounds for dr-submodular functions. In Proceedings of the 56th Annual ACM Symposium on Theory of Computing, Vancouver, BC, Canada, 24–28 June 2024; Association for Computing Machinery: New York, NY, USA, 2024; pp. 1820–1831. [Google Scholar]
- Du, D.; Liu, Z.; Wu, C.; Xu, D.; Zhou, Y. An improved approximation algorithm for maximizing a DR-submodular function over a convex set. arXiv 2022, arXiv:2203.14740. [Google Scholar]
- Du, D. Lyapunov function approach for approximation algorithm design and analysis: With applications in submodular maximization. arXiv 2022, arXiv:2205.12442. [Google Scholar]
- Mualem, L.; Feldman, M. Resolving the Approximability of Offline and Online Non-Monotone DR-Submodular Maximization over General Convex Sets. In Proceedings of the International Conference on Artificial Intelligence and Statistics, PMLR, Valencia, Spain, 25–27 April 2023; pp. 2542–2564. [Google Scholar]
- Mokhtari, A.; Hassani, H.; Karbasi, A. Stochastic Conditional Gradient Methods: From Convex Minimization to Submodular Maximization. arXiv 2018, arXiv:1804.09554. [Google Scholar]
- Hassani, H.; Karbasi, A.; Mokhtari, A.; Shen, Z. Stochastic Conditional Gradient++: (Non)Convex Minimization and Continuous Submodular Maximization. SIAM J. Optim. 2020, 30, 3315–3344. [Google Scholar] [CrossRef]
- Lian, Y.; Xu, D.; Du, D.; Zhou, Y. A Stochastic Non-Monotone DR-Submodular Maximization Problem over a Convex Set. In Proceedings of the Computing and Combinatorics: 28th International Conference, COCOON 2022, Shenzhen, China, 22–24 October 2022; Springer Nature: Berlin/Heidelberg, Germany, 2023; Volume 13595, pp. 1–11. [Google Scholar]
- Chen, L.; Feldman, M.; Karbasi, A. Unconstrained submodular maximization with constant adaptive complexity. In Proceedings of the 51st Annual ACM SIGACT Symposium on Theory of Computing, Phoenix, AZ, USA, 23–26 June 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 102–113. [Google Scholar]
- Ene, A.; Nguyen, H. Parallel algorithm for non-monotone DR-submodular maximization. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 13–18 July 2020; pp. 2902–2911. [Google Scholar]
- Delahaye, D.; Chaimatanan, S.; Mongeau, M. Simulated annealing: From basics to applications. In Handbook of Metaheuristics; Springer: Berlin/Heidelberg, Germany, 2018; pp. 1–35. [Google Scholar]
- Hassani, H.; Soltanolkotabi, M.; Karbasi, A. Gradient Methods for Submodular Maximization. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30, pp. 5843–5853. [Google Scholar]
- Chekuri, C.; Vondrák, J.; Zenklusen, R. Submodular Function Maximization via the Multilinear Relaxation and Contention Resolution Schemes. SIAM J. Comput. 2014, 43, 1831–1879. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).