Abstract
We focus on inverse preconditioners based on minimizing , where is the preconditioned matrix and A is symmetric and positive definite. We present and analyze gradient-type methods to minimize on a suitable compact set. For this, we use the geometrical properties of the non-polyhedral cone of symmetric and positive definite matrices, and also the special properties of on the feasible set. Preliminary and encouraging numerical results are also presented in which dense and sparse approximations are included.
1. Introduction
The development of algebraic inverse preconditioning continues to be an active research area since they play a key role in a wide variety of applications that involve the solution of large and sparse linear systems of equations; see e.g., [1,2,3,4,5,6,7,8,9,10,11].
A standard and well-known approach to build preconditioning strategies is based on incomplete factorizations of the coefficient matrix: incomplete LU (ILU), incomplete Choleksy (IC), among others. However, preconditioners built with this approach, while popular and fairly easy to implement, are not suitable for parallel platforms, especially Graphics Processing Units (GPUs) [12], and moreover are not always reliable since the incomplete factorization process may yield a very ill-conditioned factorization (see, e.g., [13]). Even for symmetric positive definite matrices, existence of the standard IC factorization is guaranteed only for some special classes of matrices (see, e.g., [14]). In the symmetric positive definite case, variants of IC have been developed to avoid ill-conditioning and breakdown (see, e.g., [15,16]). Nevertheless, usually these modifications are expensive and introduce additional parameters to be chosen in the algorithm.
For a given square matrix A, there exist several proposals for constructing robust sparse inverse approximations which are based on optimization techniques, mainly based on minimizing the Frobenius norm of the residual over a set P of matrices with a certain sparsity pattern; see e.g., [5,6,15,17,18,19,20,21,22]. An advantage of these approximate inverse preconditioners is that the process of building them, as well as applying them, is well suited for parallel platforms. However, we must remark that when A is symmetric and positive definite, minimizing the Frobenius norm of the residual without imposing additional constraints can produce an inverse preconditioner which is neither symmetric nor positive definite; see, e.g., (p. 312 [15]).
There is currently a growing interest, and understanding, in the rich geometrical structure of the non-polyhedral cone of symmetric and positive semidefinite matrices (); see e.g., [19,22,23,24,25,26,27]. In this work, we focus on inverse preconditioners based on minimizing the positive-scaling-invariant function , instead of minimizing the Frobenius norm of the residual. Our approach takes advantage of the geometrical properties of the cone, and also of the special properties of on a suitable compact set, to introduce specialized constrained gradient-type methods for which we analyze their convergence properties.
The rest of the document is organized as follows. In Section 2, we develop and analyze two different gradient-type iterative schemes for finding inverse approximations based on minimizing , including sparse versions. In Section 3, we present numerical results on some well-known test matrices to illustrate the behavior and properties of the introduced gradient-type methods. Finally, in Section 4 we present some concluding remarks.
2. Gradient-Type Iterative Methods
Let us recall that the cosine between two real matrices A and B is defined as
where is the Frobenius inner product in the space of matrices and is the associated Frobenius norm. By the Cauchy–Schwarz inequality, it follows that
and the equality is attained if and only if for some nonzero real number γ.
To compute the inverse of a given symmetric and positive definite matrix A, we consider the function
for which the minimum value zero is reached at , for any positive real number ξ. Let us recall that any positive semidefinite matrix B has nonnegative diagonal entries and so . Hence, if is symmetric, we need to impose that as a necessary condition for to be in the cone (see [24,26,27]). Therefore, in order to impose uniqueness in the cone, we consider the constrained minimization problem
where and . Notice that is a closed and bounded set, and so problem (3) is well-posed. Notice also that T is convex while S is not.
Remark 2.1.
For any , , and so the function F is invariant under positive scaling.
The derivative of , denoted by , plays an important role in our work.
Lemma 2.1.
Proof.
For fixed matrices X and Y, we consider the function . It is well-known that . We have
and we obtain after differentiating and some algebraic manipulations
and the result is established. ☐
Theorem 2.1.
Problem (3) possesses the unique solution .
Proof.
Notice that for , if and only if for . Now, and so is the global maximizer of the function F on S, but ; however, and . Therefore, is the unique feasible solution of (3). ☐
Before discussing different numerical schemes for solving problem (3), we need a couple of technical lemmas.
Lemma 2.2.
If and , then
Proof.
Since then , and we have
hence
However, , so
since . ☐
Lemma 2.3.
If , then
Proof.
For every X, we have , and so
On the other hand, since , , and hence
and the result is established. ☐
2.1. The Negative Gradient Direction
For the numerical solution of (3), we start by considering the classical gradient iterations that, from an initial guess , are given by
where is a suitable step length. A standard approach is to use the optimal choice i.e., the positive step length that (exactly) minimizes the function along the negative gradient direction. We present a closed formula for the optimal choice of step length in a more general setting, assuming that the iterative method is given by:
where is a search direction in the space of matrices.
Lemma 2.4.
The optimal step length , that optimizes , is given by
Proof.
Consider the auxiliary function in one variable
Differentiating , using that , and also that
and then forcing the result is obtained, after some algebraic manipulations. ☐
Remark 2.2.
For our first approach, , and so for the optimal gradient method (also known as Cauchy method or steepest descent method) the step length is given by
Notice that if instead of using the descent direction , we use the ascent direction , in Lemma 2.4, the obtained that also forces , is given by (4) but with a negative sign in front. Hence, to guarantee that the step length is positive to minimize F along the negative gradient direction to approximate , instead of maximizing F along the gradient direction to approximate , we will choose the step length as the absolute value of the expression in (4).
Since , the gradient iterations can be written as
which can be further simplified by imposing the condition for uniqueness . In that case, we set
and then we multiply the matrix by the factor to guarantee that , i.e., such that .
Concerning the condition that the sequence remains in T, in our next result, we establish that if the step length remains uniformly bounded from above, then for all k.
Lemma 2.5.
Assume that and that . Then,
Proof.
We proceed by induction. Let us assume that
It follows that
and so
Now, since and
we obtain that
Since , then , and we conclude that
Since is obtained as a positive scaling factor of , then , and the result is established. ☐
Now, for some given matrices A, we cannot guarantee that the step length computed as the absolute value of (4) will satisfy for all k. Therefore, if , then we will set in our algorithm to guarantee that , and hence that the cosine between and I is nonnegative, which is a necessary condition to guarantee that remains in the cone (see, e.g., [24,26,27].
We now present our steepest descent gradient algorithm that will be referred as the CauchyCos Algorithm.
| Algorithm 1 : CauchyCos (Steepest descent approach on CauchyCos (Steepest descent approach on ) |
|
We note that if we start from such that then by construction , for all ; for example, is a convenient choice. For that initial guess, and again by construction all the iterates will remain in the cone. Notice also that, at each iteration, we need to compute the three matrix–matrix products: , , and , which, for dense matrices, require floating point operations (flops) each. Every one of the remaining calculations (inner products and Frobenius norms) are obtained with n column-oriented inner products that require n flops each. Summing up, in the dense case, the computational cost of each iteration of the CauchyCos Algorithm is flops. In Section 2.5, we will discuss a sparse version of the CauchyCos Algorithm and its computational cost.
2.2. Convergence Properties of the CauchyCos Algorithm
In spite of the resemblance with the classical Cauchy method for convex constrained optimization, the CauchyCos algorithm involves certain key ingredients in its formulation that splits it apart from the Cauchy method. Therefore, a specialized convergence analysis is required. In particular, we note that the constraint set S on which the iterates are computed, thanks to the scaling step 7, is not a convex set.
We start by establishing the commutativity of all iterates with the matrix A.
Lemma 2.6.
If , then , for all in the CauchyCos Algorithm. Furthermore, if is symmetric, then and are symmetric for all .
Proof.
We proceed by induction. Assume that . It follows that:
and since and differ only by a scaling factor, then . Hence, since , the result holds for all k. The second property is proven similarly by induction. ☐
It is worth noticing that, using Lemma 2.6 and (5), it follows by simple calculations that as well as are symmetric matrices for all k. In turn, if , this clearly implies using Lemma 2.6 that is also a symmetric matrix for all k.
Our next result establishes that the sequences generated by the CauchyCos Algorithm are uniformly bounded away from zero, and hence the algorithm is well-defined.
Lemma 2.7.
If , then the sequences , , and generated by the CauchyCos Algorithm are uniformly bounded away from zero.
Proof.
Using Lemmas 2.2 and 2.6 we have that
which combined with the Cauchy–Schwarz inequality and Lemma 2.3 implies that
for all k. Moreover, since A is nonsingular then
is bounded away from zero for all k. ☐
Theorem 2.2.
The sequence generated by the CauchyCos Algorithm converges to .
Proof.
The sequence , which is a closed and bounded set; therefore, there exist limit points in . Let be a limit point of , and let be a subsequence that converges to . Let us suppose, by way of contradiction, that .
In that case, the negative gradient, , is a descent direction for the function F at . Hence, there exists such that
Consider now an auxiliary function given by
Clearly, θ is a continuous function, and then converges to . Therefore, for all sufficiently large,
Now, since was obtained using Lemma 2.4 as the exact optimal step length along the negative gradient direction, then using Remark 2.1, it follows that
and thus,
for all sufficiently large.
On the other hand, since F is continuous, converges to . However, the whole sequence generated by the CauchyCos Algorithm is decreasing, and so converges to , and since F is bounded below then for large enough
which contradicts (6). Consequently, .
Now, using Lemma 2.1, it follows that implies . Hence, the subsequence converges to . Nevertheless, as we argued before, the whole sequence converges to , and by continuity the whole sequence converges to . ☐
Notice that Theorem 2.2 states that the sequence converges to which is in the cone. Hence, if is symmetric and , then is symmetric (Lemma 2.6), and after a k iterations (k large enough), the eigenvalues of are strictly positive: as a consequence, is in the cone.
Remark 2.3.
The optimal choice of step length , as it usually happens when combined with the negative gradient direction (see e.g., [28,29]), produces an orthogonality between consecutive gradient directions, that in our setting becomes . Indeed, minimizes , which means that
This orthogonality is responsible for the well-known zig-zagging behavior of the optimal gradient method, which in some cases induces a very slow convergence.
2.3. A Simplified Search Direction
To avoid the zig-zagging trajectory of the optimal gradient iterates, we now consider a different search direction:
to move from to the next iterate. Notice that and so can be viewed as a simplified version of the search direction used in the classical steepest descent method. Moreover, the direction in (7) is obtained from the direction used by CauchyCos by multiplying on the right by the matrix , so it can be viewed as a right-preconditioning of the method CauchyCos. Notice also that resembles the residual direction used in the minimal residual iterative method (MinRes) for minimizing in the least-squares sense (see e.g., [6,10]). Nevertheless, the scaling factors in (7) differ from the scaling factors in the classical residual direction at . Note that MinRes here should not be confused with the Krylov method MINRES [10].
For solving (3), we now present a variation of the CauchyCos Algorithm, that will be referred as the MinCos Algorithm, which from a given initial guess produces a sequence of iterates using the search direction , while remaining in the compact set . This new algorithm consists of simply replacing in the CauchyCos Algorithm by .
| Algorithm 2 : MinCos (simplified gradient approach on ) |
|
As before, we note that if we start from then by construction , for all . For that initial guess, and again by construction all the iterates remain in the cone. Notice also that, at each iteration, we now need to compute the two matrix–matrix products: , and , which for dense matrices require flops each. Every one of the remaining calculations (inner products and Frobenius norms) are obtained with n column-oriented inner products that require n flops each. Summing up, in the dense case, the computational cost of each iteration of the MinCos Algorithm is flops. In Section 2.5, we will discuss a sparse version of the MinCos Algorithm and its computational cost.
2.4. Convergence Properties of the MinCos Algorithm
We start by noticing that, unless we are at the solution, the search direction is a descent direction.
Lemma 2.8.
If and , the search direction is a descent direction for the function F at X.
Proof.
We need to establish that, for a given , . Since is symmetric and positive definite, then it has a unique square root which is also symmetric and positive definite. This particular square root will be denoted as . Therefore, since , and using that , for given square matrices and , it follows that
☐
Remark 2.4.
The step length in the MinCos Algorithm is obtained using the search direction in Lemma (2.4). Notice that if we use instead of , the obtained which also forces is the one given by Lemma (2.4) but with a negative sign. Therefore, as in the CauchyCos Algorithm, to guarantee that minimizes F along the descent direction to approximate , instead of maximizing F along the ascent direction to approximate , we choose the step length as the absolute value of the expression in Lemma (2.4).
We now establish the commutativity of all iterates with the matrix A.
Lemma 2.9.
If , then , for all in the MinCos Algorithm.
Proof.
We proceed by induction. Assume that . We have that
and since and differ only by a scaling factor, then . Hence, since , the result holds for all k. ☐
It is worth noticing that using Lemma 2.9 and (5), it follows by simple calculations that , , and in the MinCos Algorithm are symmetric matrices for all k. These three sequences generated by the MinCos Algorithm are also uniformly bounded away from zero, and so the algorithm is well-defined.
Lemma 2.10.
If , then the sequences , , and generated by the MinCos Algorithm are uniformly bounded away from zero.
Proof.
From Lemma 2.3, the sequence is uniformly bounded. For the sequence , using Lemmas 2.2 and 2.9, we have that
where is the unique square root of A, which is also symmetric and positive definite. Combining the previous equality with the Cauchy–Schwarz inequality, and using the consistency of the Frobenius norm, we obtain
Since , then , which combined with (8) implies that
is bounded away from zero for all k. Moreover, since A is nonsingular then
is also bounded away from zero for all k. ☐
Theorem 2.3.
The sequence generated by the MinCos Algorithm converges to .
Proof.
From Lemma 2.8, the search direction is a descent direction for F at X, unless . Therefore, since in the MinCos Algorithm is obtained as the exact minimizer of F along the direction for all k, the proof is obtained repeating the same arguments shown in the proof of Theorem 2.2, simply replacing by for all possible instances Y. ☐
2.5. Connections between the Considered Methods and Sparse Versions
For a given matrix A, the merit function has been widely used for computing approximate inverse preconditioners (see, e.g., [5,6,15,17,18,19,20,22]). In that case, the properties of the Frobenius norm permit in a natural way the use of parallel computing. Moreover, the minimization of can also be accomplished imposing a column-wise numerical dropping strategy leading to a sparse approximation of . Therefore, when possible, it is natural to compare the CauchyCos and the MinCos Algorithms applied to the angle-related merit function with the optimal Cauchy method applied to (referred from now on as the CauchyFro method), and also to the Minimal Residual (MinRes) method applied to (see, e.g., [6,15]). Notice that, as we mentioned before in Section 2.3, with respect to CauchyCos and MinCos, MinRes can be seen as a right-preconditioning version of the method CauchyFro.
The gradient of is given by , and so the iterations of the CauchyFro method, from the same initial guess used by MinCos and CauchyCos, can be written as
where and the step length is obtained as the global minimizer of along the direction , as follows
where is the residual matrix at . The iterations of the MinRes method can be obtained replacing by the residual matrix in (9) and (10) (see [6] for details). We need to remark that in the dense case, the CauchyFro method needs to compute two matrix-matrix products per iteration, whereas the MinRes method by using the recursion needs one matrix-matrix product per iteration.
We now discuss how to dynamically impose sparsity in the sequence of iterates generated by either the CauchyCos Algorithm or the MinCos Algorithm, to reduce their required storage and computational cost.
A possible way of accomplishing this task is to prescribe a sparsity pattern beforehand, which is usually related to the sparsity pattern of the original matrix A, and then impose it at every iteration (see e.g., [4,20,21,22]). At this point, we would like to mention that although there exist some special applications for which the involved matrices are large and dense [30,31], frequently in real applications the involved matrices are large and sparse. However, in general, the inverse of a sparse matrix is dense anyway. Moreover, with very few exceptions, it is not possible to know a priori the location of the large or the small entries of the inverse. Consequently, it is very difficult in general to prescribe a priori a nonzero sparsity pattern for the approximate inverse.
As a consequence, to force sparsity in our gradient related algorithms, we use instead a numerical dropping strategy to each column (or row) independently, using a threshold tolerance, combined with a fixed bound on the maximum number of nonzero elements to be kept at each column (or row) to limit the fill-in. This combined strategy will be fully described in our numerical results section.
In the CauchyCos and MinCos Algorithms, the dropping strategy must be applied to the matrix right after it is obtained at Step 6, and before computing at Step 7. That way, will remain sparse at all iterations, and we guarantee that . The new Steps 7 and 8, in the sparse versions of both algorithms, are given by
- 7:
- Apply numerical dropping to with a maximum number of nonzero entries;
- 8:
- Set , where if , else.
Notice that, since all the involved matrices are symmetric, the matrix-matrix products required in both algorithms can be performed using sparse-sparse mode column-oriented inner products (see, e.g., [6]). The remaining calculations (inner products and Frobenius norms), required to obtain the step length, must be also computed using sparse-sparse mode. Using this approach, which takes advantage of the imposed sparsity, the computational cost and the required storage of both algorithms are drastically reduced. Moreover, using the column oriented approach both algorithms have a potential for parallelization.
3. Numerical Results
We present some numerical results to illustrate the properties of our gradient-type algorithms for obtaining inverse approximations. All computations are performed in MATLAB using double precision. To test the robustness of our methods, we present hereafter a variety of problems with large scale matrices and very badly conditioned ones (non necessarily of big size) but for which the building of an approximate inverse is difficult. Most of the matrices are taken from the Matrix Market collection [32], which contains a large choice of benchmarks that are widely used.
It is worth mentioning that Schulz method [33] is another well-known iterative method for computing the inverse of a given matrix A. From a given , it produces the following iterates , and so it needs two matrix–matrix products per iteration. Schulz method can be obtained applying Newton’s method to the related map , and hence it possesses local q-quadratic convergence; for recent variations and applications see [34,35,36]. However, the q-quadratic rate of convergence requires that the scheme is performed without dropping (see e.g., [34]). As a consequence, Schulz method is not competitive with CauchyCos, CauchyFro, MinRes, and MinCos for large and sparse matrices (see Section 2.5).
For our experiments, we consider the following test matrices in the cone:
- from the Matlab gallery: Poisson, Lehmer, Wathen, Moler, and miij. Notice that the Poisson matrix, referred in Matlab as (Poisson, N) is the finite differences 2D discretization matrix of the negative Laplacian on with homogeneous Dirichlet boundary conditions.
- Poisson 3D (that depends on the parameter N) is the finite differences 3D discretization matrix of the negative Laplacian on the unit cube with homogeneous Dirichlet boundary conditions.
- from the Matrix Market [32]: nos1, nos2, nos5, and nos6.
In Table 1, we report the considered test matrices with their size, sparsity properties, and two-norm condition number . Notice that the Wathen matrices have random entries so we cannot report their spectral properties. Moreover, Wathen (N) is a sparse matrix with . In general, the inverse of all the considered matrices are dense, except the inverse of the Lehmer matrix which is tridiagonal.

Table 1.
Considered test matrices and their characteristics.
3.1. Approximation to the Inverse with No Dropping Strategy
To add understanding to the properties of the new CauchyCos and MinCos Algorithms, we start by testing their behavior, as well as the behavior of CauchyFro and MinRes, without imposing sparsity. Since the goal is to compute an approximation to , it is not necessary to carry on the iterations up to a very small tolerance parameter ϵ, and we choose for our experiments. For all methods, we stop the iterations when .
Table 2 shows the number of required iterations by the four considered algorithms when applied to some of the test functions, and for different values of n. No information in some of the entries of the table indicates that the corresponding method requires an excessive amount of iterations as compared with the MinRes and MinCos Algorithms. We can observe that CauchyFro and CauchyCos are not competitive with MinRes and MinCos, except for very few cases and for very small dimensions. Among the Cauchy-type methods, CauchyCos requires less iterations than CauchyFro, and in several cases the difference is significant. The MinCos and MinRes Algorithms were able to accomplish the required tolerance using a reasonable amount of iterations, except for the Lehmer(n) and minij(n) matrices for larger values of n, which are the most difficult ones in our list of test matrices. The MinCos Algorithm clearly outperforms the MinRes Algorithm, except for the Poisson 2D (n) and Poisson 3D (n) for which both methods require the same number of iterations. For the more difficult matrices and especially for larger values of n, MinCos reduces in the average the number of iterations with respect to MinRes by a factor of 4.
Table 2.
Number of iterations required for all considered methods when .
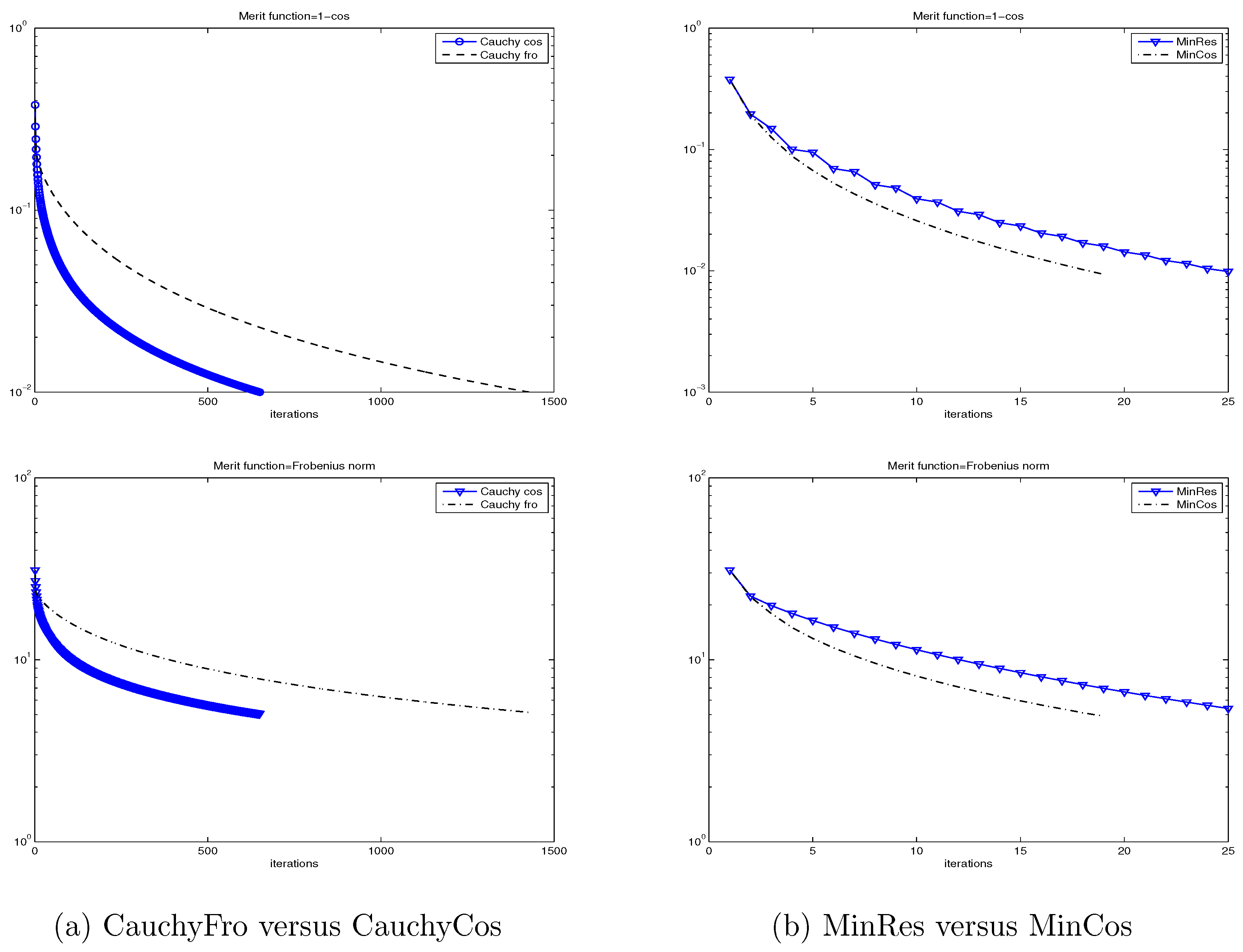
In Figure 1, we show the (semilog) convergence history for the four considered methods and for both merit functions: and , when applied to the Wathen matrix for and . Once again, we can observe that CauchyFro and CauchyCos are not competitive with MinRes and MinCos, and that MinCos outperforms MinRes. Moreover, we observe in this case that the function is a better merit function than in the sense that it indicates with fewer iterations that a given iterate is sufficiently close to the inverse matrix. The same good behavior of the merit function has been observed in all our experiments.
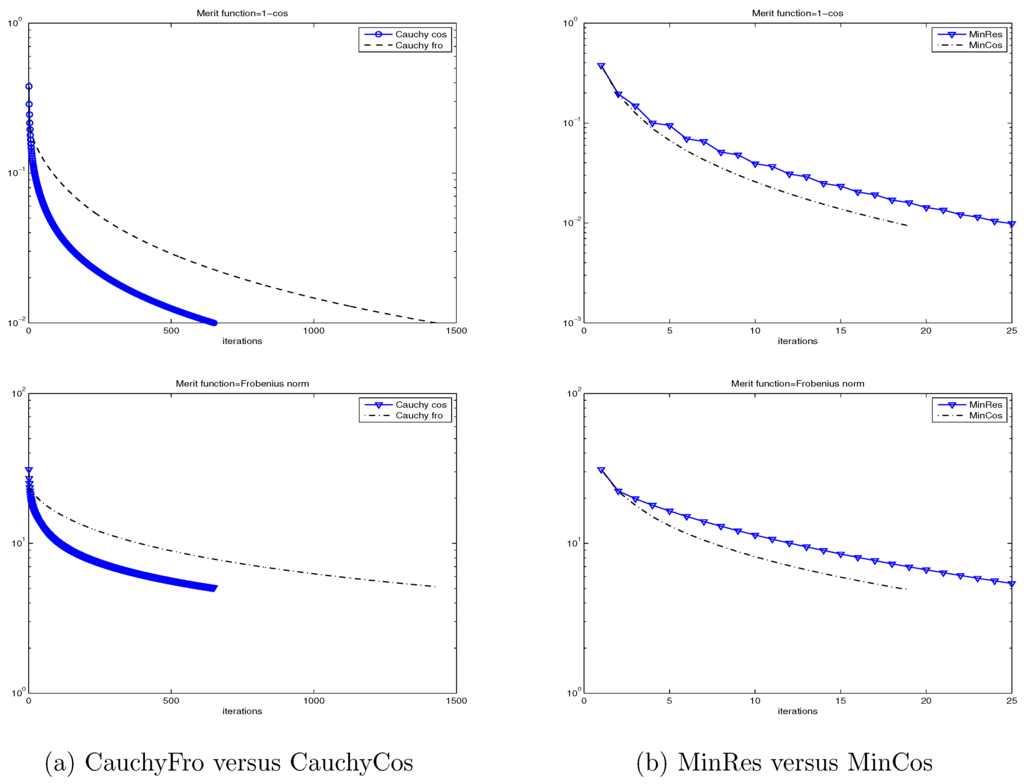
Figure 1.
Convergence history for CauchyFro and CauchyCos (left), and MinRes and MinCos (right) for two merit functions: (up) and (down), when applied to the Wathen matrix for and .
Based on these preliminary results, we will only report the behavior of MinRes and MinCos for the forthcoming numerical experiments.
3.2. Sparse Approximation to the Inverse
We now build sparse approximations by applying the dropping strategy, described in Section 2.5, which is based on a threshold tolerance with a limited fill-in () on the matrix , at each iteration, right before the scaling step to guarantee that the iterate . We define as the percentage of coefficients less than the maximum value of the modulus of all the coefficients in a column. To be precise, for each i-th column, we select at most off-diagonal coefficients among the ones that are larger in magnitude than , where represents the i-th column of . Once the sparsity has been imposed at each column and a sparse matrix is obtained, say , we guarantee symmetry by setting .
We have implemented the relatively simple dropping strategy, described above, for both MinRes and MinCos to make a first validation of the new method. Of course, we could use a more sophisticated dropping procedure for both methods as one can find in [6]. The current numerical comparison is preliminary and indicates the potential of MinCos versus MinRes. We begin by comparing both methods when we apply the numerical described dropping strategy on the Matrix Market matrices.
Table 3 shows the performance of MinRes and MinCos when applied to the matrices nos1, nos2, nos5, and nos6, for , , and several values of . We report the iteration k (Iter) at which the method was stopped, the interval of , the quotient /, and the percentage of fill-in (% fill-in) at the final matrix . We observe that, when imposing the dropping strategy to obtain sparsity, MinRes fails to produce an acceptable preconditioner. Indeed, as it has been already observed (see [6,15]) quite frequently that MinRes produces an indefinite approximation to the inverse of a sparse matrix in the cone. We also observe that, in all cases, the MinCos method produces a sparse symmetric and positive definite preconditioner with relatively few iterations and a low level of fill-in. Moreover, with the exception of the matrix nos6, the MinCos method produces a preconditioned matrix whose condition number is reduced by a factor of approximately 10 with respect to the condition number of A. In some cases, MinRes was capable of producing a sparse symmetric and positive definite preconditioner, but in those cases, the MinCos produced a better preconditioner in the sense that it exhibits a better reduction of the condition number, and also a better eigenvalues distribution. Based on these results, for the remaining experiments, we only report the behavior of the MinCos Algorithm.
Table 3.
Performance of MinRes and MinCos when applied to the Matrix Market matrices nos1, nos2, nos5, and nos6, for , , and different values of .
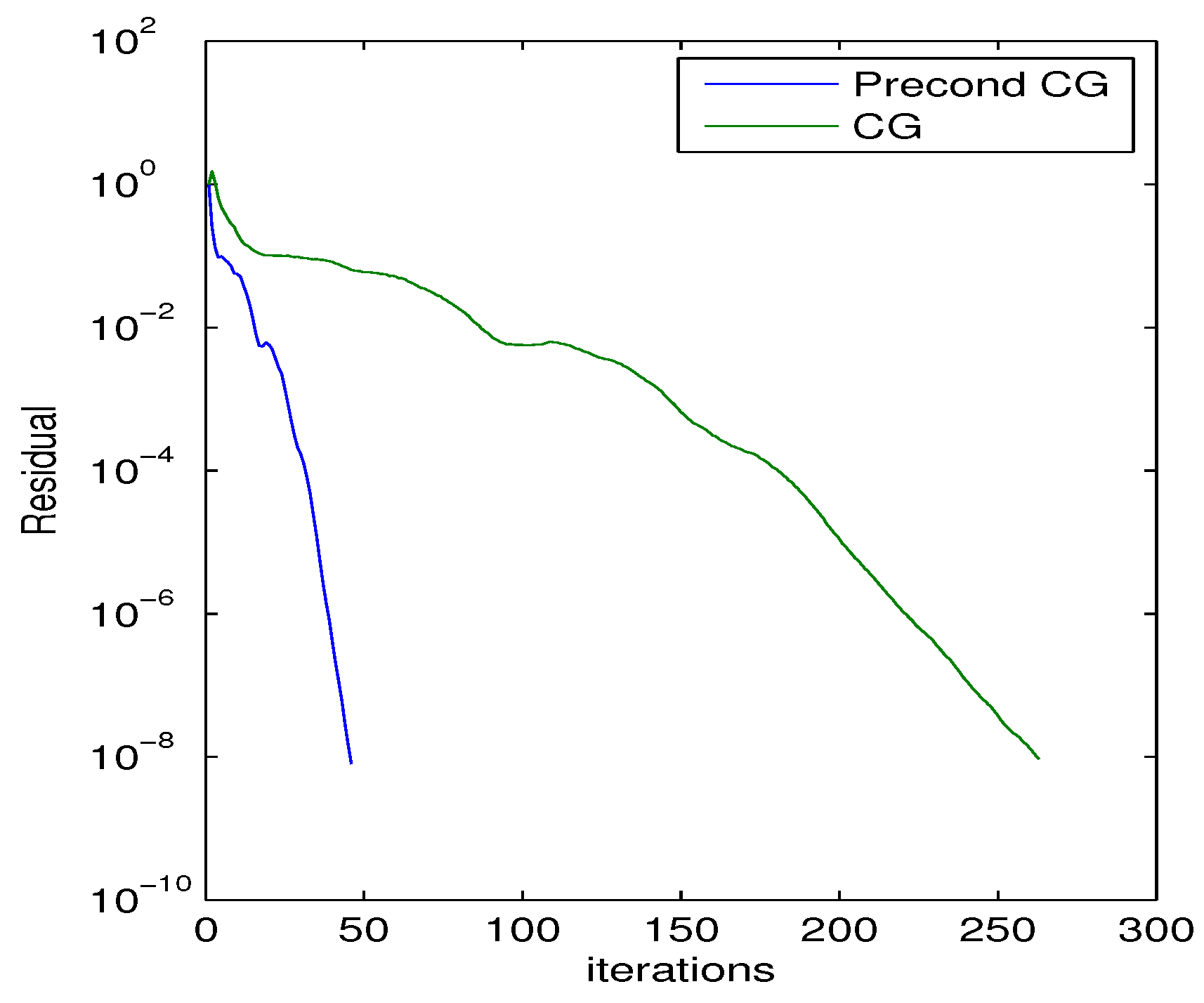
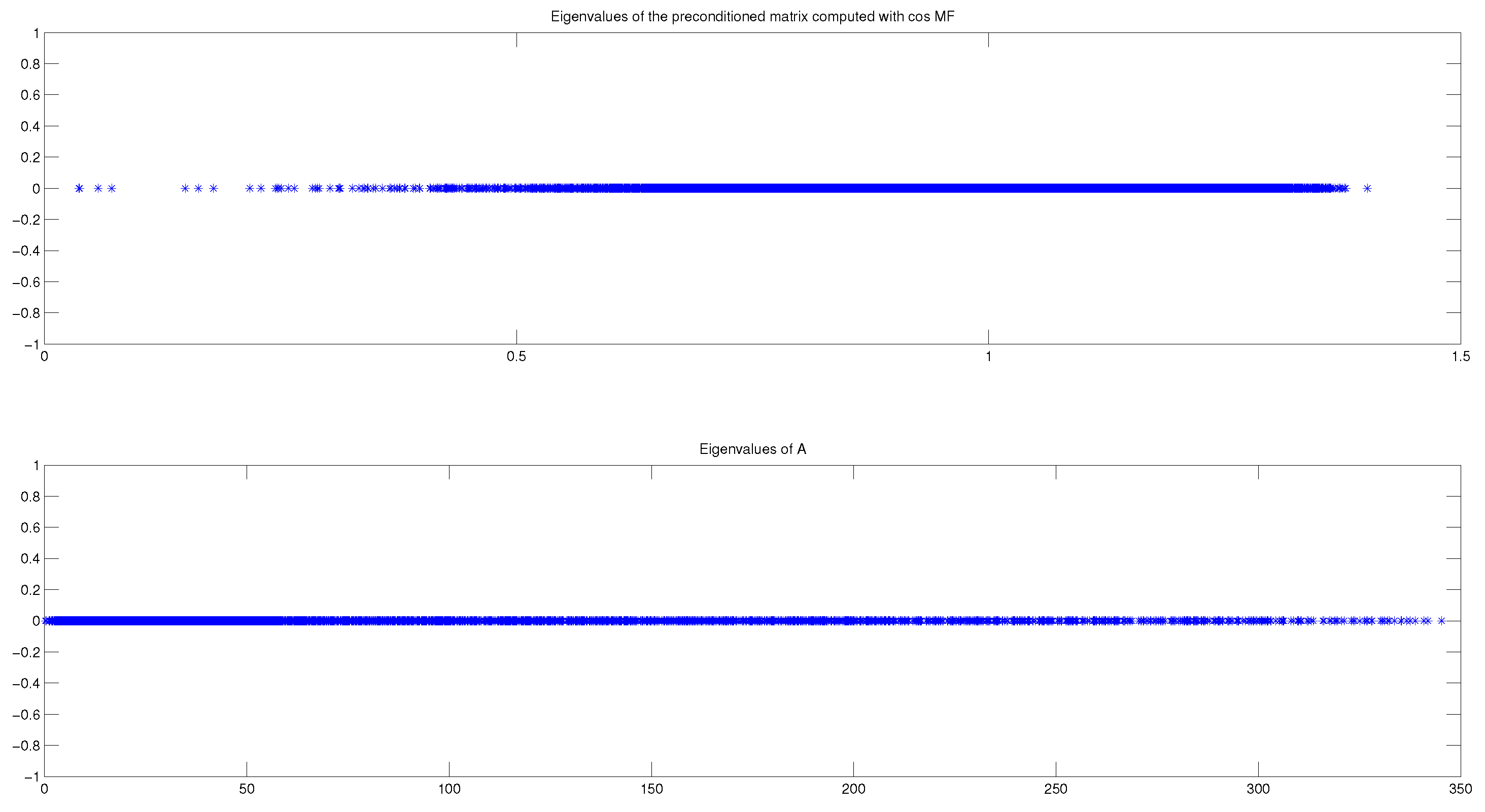
Table 4 shows the performance of the MinCos Algorithm when applied to the Wathen matrix for different values of n and a maximum of 20 iterations. For this numerical experiment, we fix , , and . For the particular case of the Wathen matrix when , we show in Figure 2 that the (semilog) convergence history of the norm of the residual when solving a linear system with a random right-hand side vector, using the Conjugate Gradient (CG) method without preconditioning, and also using the preconditioner generated by the MinCos Algorithm after 20 iterations, fixing , , and . We also report in Figure 3 the eigenvalues distribution of A and of , at , for the same experiment with the Wathen matrix and . Notice that the eigenvalues of A are distributed in the interval , whereas the eigenvalues of are located in the interval (see Table 4). Even better, we can observe that most of the eigenvalues are in the interval , and very few of them are in the interval , which clearly accounts for the good behavior of the preconditioned CG method (see Figure 2).
Table 4.
Performance of MinCos applied to the Wathen matrix for different values of n and a maximum of 20 iterations, when , , and .
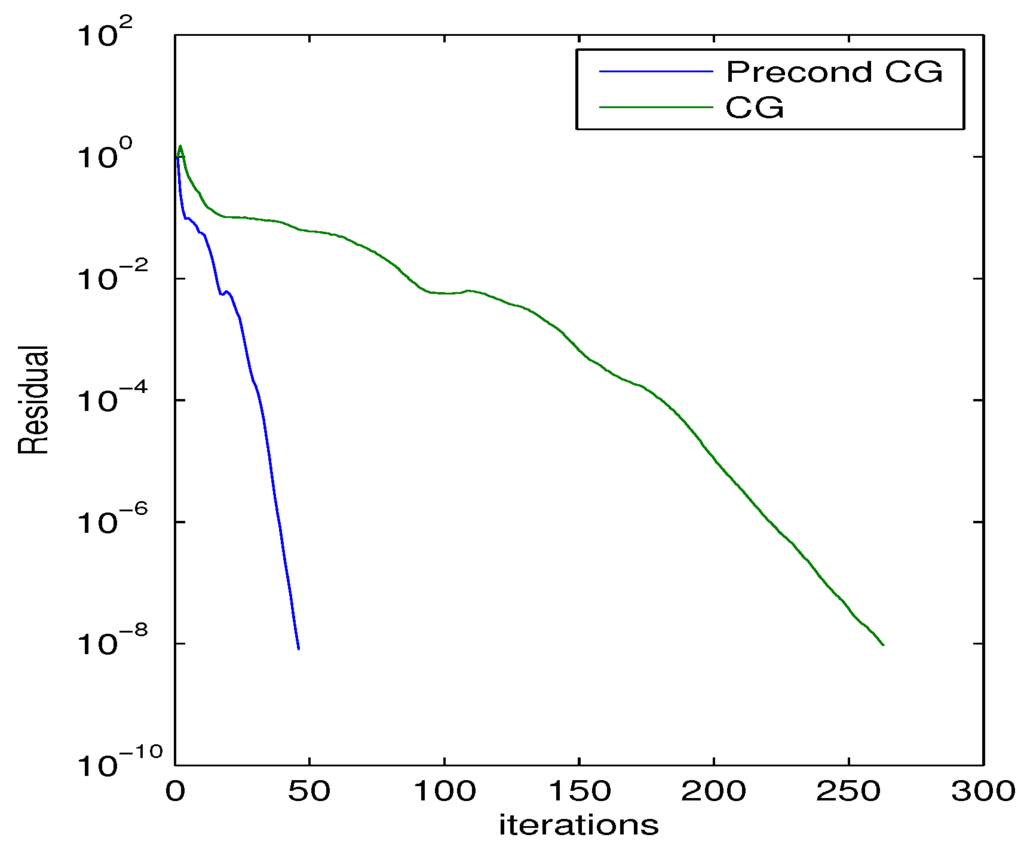
Figure 2.
Convergence history of the CG method applied to a linear system with the Wathen matrix, for , 20 iterations, , , and , using the preconditioned generated by the MinCos Algorithm and without preconditioning.
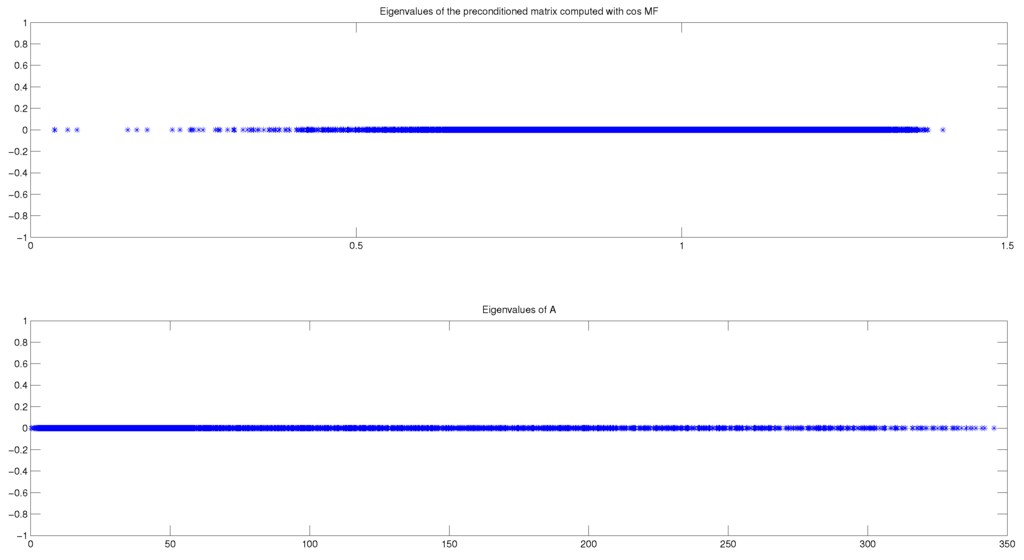
Figure 3.
Eigenvalues distribution of A (down) and of (up) after 20 iterations of the MinCos Algorithm when applied to the Wathen matrix for , , , and .
Table 5, Table 6 and Table 7 show the performance of the MinCos Algorithm when applied to the Poisson 2D, the Poisson 3D, and the Lehmer matrices, respectively, for different values of n, and different values of the maximum number of iterations, ϵ, , and . We can observe that, for the Poisson 2D and 3D matrices, the MinCos Algorithm produces a sparse symmetric and positive definite preconditioner with very few iterations, a low level of fill-in, and a significant reduction of the condition number.
Table 5.
Performance of MinCos applied to the Poisson 2D matrix, for different values of n and a maximum of 20 iterations, when , , and .
Table 6.
Performance of MinCos applied to the Poisson 3D matrix, for different values of n and a maximum of 20 iterations, when , , and .
Table 7.
Performance of MinCos applied to the Lehmer matrix, for different values of n and a maximum of 40 iterations, when , , and .
For the Lehmer matrix, which is one of the most difficult considered matrices, we observe in Table 7 that the MinCos Algorithm produces a symmetric and positive definite preconditioner with a significant reduction of the condition number, but after 40 iterations and fixing , for which the preconditioner accepts a high level of fill-in. If we impose a low level of fill-in, by reducing the value of , MinCos still produces a symmetric and positive definite matrix, but the reduction of the condition number is not significant.
We close this section mentioning that both methods (MinCos and MinRes) produce sparse approximations to the inverse with comparable sparsity as shown in Table 3 (last column). Notice also that MinCos produces a sequence such that the eigenvalues of are strictly positive at convergence, which, in turn, implies that the matrices are invertible after a sufficiently large k. This important property cannot be satisfied by MinRes.
4. Conclusions
We have introduced and analyzed two gradient-type optimization schemes to build sparse inverse preconditioners for symmetric positive definite matrices. For that, we have proposed the novel objective function , which is invariant under positive scaling and has some special properties that are clearly related to the geometry of the cone. One of the new schemes, the CauchyCos Algorithm, is closely related to the classical steepest descent method, and as a consequence, it shows in most cases a very slow convergence. The second new scheme, denoted as the MinCos Algorithm, shows a much faster performance and competes favorably with well-known methods. Based on our numerical results, by choosing properly the numerical dropping parameters, the MinCos Algorithm produces a sparse inverse preconditioner in the cone for which a significant reduction of the condition number is observed, while keeping a low level of fill-in.
Acknowledgments
The second author was supported by the Fédération ARC (FR CNRS 3399) throughout a 3 months stay "Poste Rouge CNRS". The major part of this work was done on this occasion.
Author Contributions
Both authors contributed at exactly the same level in all aspects (theoretical, algorithmic, experimental and redactional) of the paper.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Bertaccini, D.; Filippone, S. Sparse approximate inverse preconditioners on high performance GPU platforms. Comput. Math. Appl. 2016, 71, 693–711. [Google Scholar] [CrossRef]
- Carr, L.E.; Borges, C.F.; Giraldo, F.X. An element based spectrally optimized approximate inverse preconditioner for the Euler equations. SIAM J. Sci. Comput. 2012, 34, 392–420. [Google Scholar] [CrossRef]
- Chehab, J.-P. Matrix differential equations and inverse preconditioners. Comput. Appl. Math. 2007, 26, 95–128. [Google Scholar] [CrossRef]
- Chen, K. An analysis of sparse approximate inverse preconditioners for boundary integral equations. SIAM J. Matrix Anal. Appl. 2001, 22, 1058–1078. [Google Scholar] [CrossRef]
- Chen, K. Matrix Preconditioning Techniques and Applications; Cambridge University Press: Cambridge, UK, 2005. [Google Scholar]
- Chow, E.; Saad, Y. Approximate inverse preconditioners via sparse–sparse iterations. SIAM J. Sci. Computing 1998, 19, 995–1023. [Google Scholar] [CrossRef]
- Chung, J.; Chung, M.; O’Leary, D.P. Optimal regularized low rank inverse approximation. Linear Algebra Appl. 2015, 468, 260–269. [Google Scholar] [CrossRef]
- Guillaume, P.H.; Huard, A.; LeCalvez, C. A block constant approximate inverse for preconditioning large linear systems. SIAM J. Matrix Anal. Appl. 2002, 24, 822–851. [Google Scholar] [CrossRef]
- Labutin, I.; Surodina, I.V. Algorithm for sparse approximate inverse preconditioners in the conjugate gradient method. Reliab. Comput. 2013, 19, 120–126. [Google Scholar]
- Saad, Y. Iterative Methods for Sparse Linear Systems, 2nd ed.; SIAM: Philadelphia, PA, USA, 2010. [Google Scholar]
- Sajo-Castelli, A.M.; Fortes, M.A.; Raydan, M. Preconditioned conjugate gradient method for finding minimal energy surfaces on Powell-Sabin triangulations. J. Comput. Appl. Math. 2014, 268, 34–55. [Google Scholar] [CrossRef]
- Li, R.; Saad, Y. GPU-accelerated preconditioned iterative linear solvers. J. Supercomput. 2013, 63, 443–466. [Google Scholar] [CrossRef]
- Chow, E.; Saad, Y. Experimental study of ILU preconditioners for indefinite matrices. J. Comput. Appl. Math. 1997, 86, 387–414. [Google Scholar] [CrossRef]
- Manteuffel, T.A. An incomplete factorization technique for positive definite linear systems. Math. Comp. 1980, 34, 473–497. [Google Scholar] [CrossRef]
- Benzi, M.; Tuma, M. A comparative study of sparse approximate inverse preconditioners. Appl. Numer. Math. 1999, 30, 305–340. [Google Scholar] [CrossRef]
- Kaporin, I.E. High quality preconditioning of a general symmetric positive definite matrix based on its UTU + UTR + RTU decomposition. Numer. Linear Algebra Appl. 1998, 5, 483–509. [Google Scholar] [CrossRef]
- Chow, E.; Saad, Y. Approximate inverse techniques for block-partitioned matrices. SIAM J. Sci. Comput. 1997, 18, 1657–1675. [Google Scholar] [CrossRef]
- Cosgrove, J.D.F.; Díaz, J.C.; Griewank, A. Approximate inverse preconditioning for sparse linear systems. Int. J. Comput. Math. 1992, 44, 91–110. [Google Scholar] [CrossRef]
- González, L. Orthogonal projections of the identity: spectral analysis and applications to approximate inverse preconditioning. SIAM Rev. 2006, 48, 66–75. [Google Scholar] [CrossRef]
- Gould, N.I.M.; Scott, J.A. Sparse approximate-inverse preconditioners using norm-minimization techniques. SIAM J. Sci. Comput. 1998, 19, 605–625. [Google Scholar] [CrossRef]
- Kolotilina, L.Y.; Yeremin, Y.A. Factorized sparse approximate inverse preconditioning I. Theory. SIAM J. Matrix Anal. Appl. 1993, 14, 45–58. [Google Scholar] [CrossRef]
- Montero, G.; González, L.; Flórez, E.; García, M.D.; Suárez, A. Approximate inverse computation using Frobenius inner product. Numer. Linear Algebra Appl. 2002, 9, 239–247. [Google Scholar] [CrossRef]
- Andreani, R.; Raydan, M.; Tarazaga, P. On the geometrical structure of symmetric matrices. Linear Algebra Appl. 2013, 438, 1201–1214. [Google Scholar] [CrossRef]
- Chehab, J.P.; Raydan, M. Geometrical properties of the Frobenius condition number for positive definite matrices. Linear Algebra Appl. 2008, 429, 2089–2097. [Google Scholar] [CrossRef]
- Hill, R.D.; Waters, S.R. On the cone of positive semidefinite matrices. Linear Algebra Appl. 1987, 90, 81–88. [Google Scholar] [CrossRef]
- Iusem, A.N.; Seeger, A. On pairs of vectors achieving the maximal angle of a convex cone. Math. Program. Ser. B 2005, 104, 501–523. [Google Scholar] [CrossRef]
- Tarazaga, P. Eigenvalue estimates for symmetric matrices. Linear Algebra Appl. 1990, 135, 171–179. [Google Scholar] [CrossRef]
- Bertsekas, D.P. Nonlinear Programming; Athena Scientific: Boston, MA, USA, 1999. [Google Scholar]
- Ribeiro, A.A.; Karas, E.W. Otimização Contínua: Aspectos Teóricos e Computacionais; Cengage Learning Editora: Curitiba, Brazil, 2014. [Google Scholar]
- Forsman, K.; Gropp, W.; Kettunen, L.; Levine, D.; Salonen, J. Solution of dense systems of linear equations arising from integral equation formulations. Antennas Propag. Mag. 1995, 37, 96–100. [Google Scholar] [CrossRef]
- Helsing, J. Approximate inverse preconditioners for some large dense random electrostatic interaction matrices. BIT Numer. Math. 2006, 46, 307–323. [Google Scholar] [CrossRef]
- Matrix Market. Available online: http://math.nist.gov/MatrixMarket/ (accessed on 1 October 2015).
- Schulz, G. Iterative Berechnung der Reziproken matrix. Z. Angew. Math. Mech. 1933, 13, 57–59. [Google Scholar] [CrossRef]
- Cahueñas, O.; Hernández-Ramos, L.M.; Raydan, M. Pseudoinverse preconditioners and iterative methods for large dense linear least-squares problems. Bull. Comput. Appl. Math. 2013, 1, 69–91. [Google Scholar]
- Soleymani, F. On a fast iterative method for approximate inverse of matrices. Commun. Korean Math. Soc. 2013, 28, 407–418. [Google Scholar] [CrossRef]
- Toutounian, F.; Soleymani, F. An iterative method for computing the approximate inverse of a square matrix and the Moore—Penrose inverse of a non-square matrix. Appl. Math. Comput. 2013, 224, 671–680. [Google Scholar] [CrossRef]
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).