A Hybrid Forward–Backward Algorithm and Its Optimization Application


{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Preliminaries
- (i)
- B is a -Lipschitz continuous and monotone operator;
- (ii)
- if ν is any constant in , then is nonexpansive, where stands for the identity operator on H.
- (i)
- where t and s are any positive real numbers with
- (ii)
- , .
3. Main Results
| Algorithm 1: The hybrid forward–backward algorithm |
 |
| Algorithm 2: The hybrid forward–backward algorithm without the inertial term |
 |
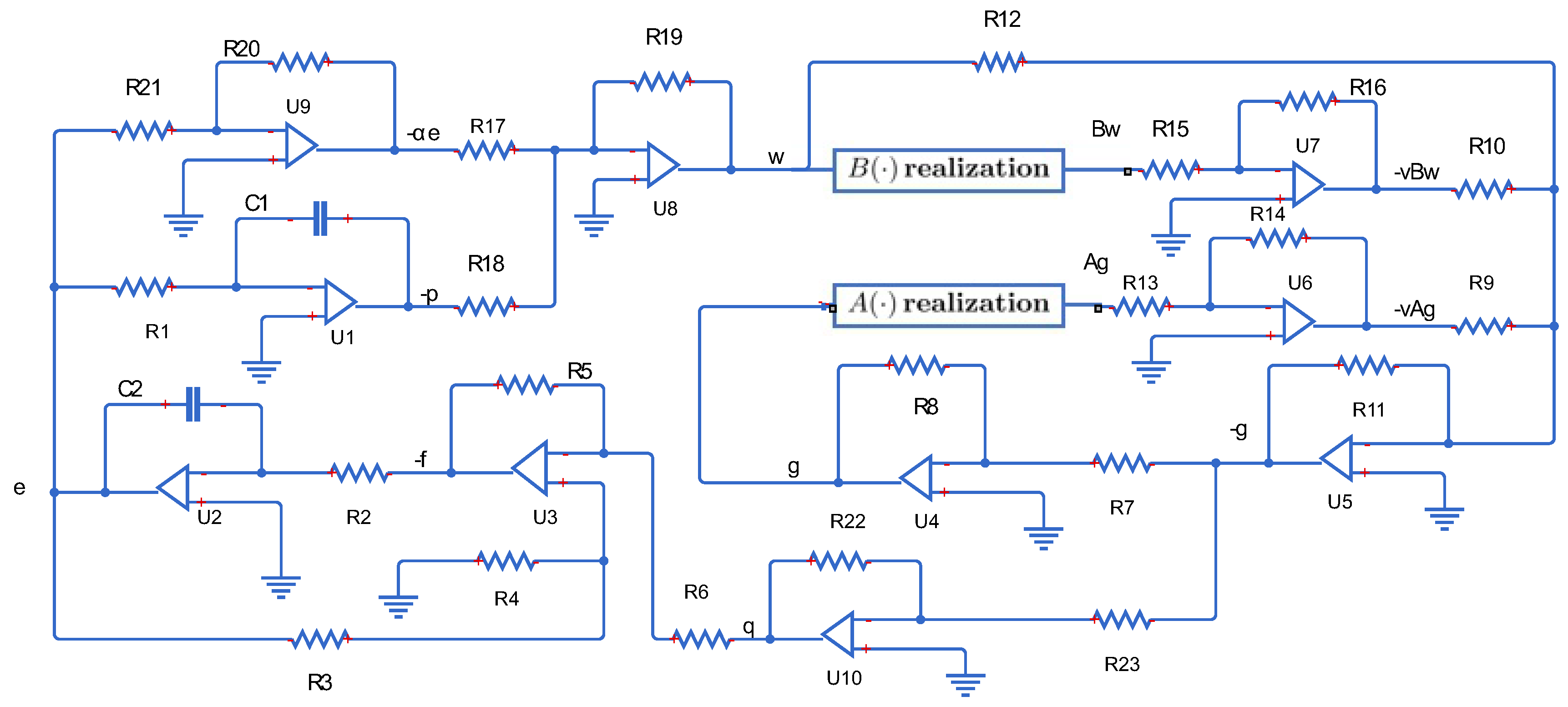
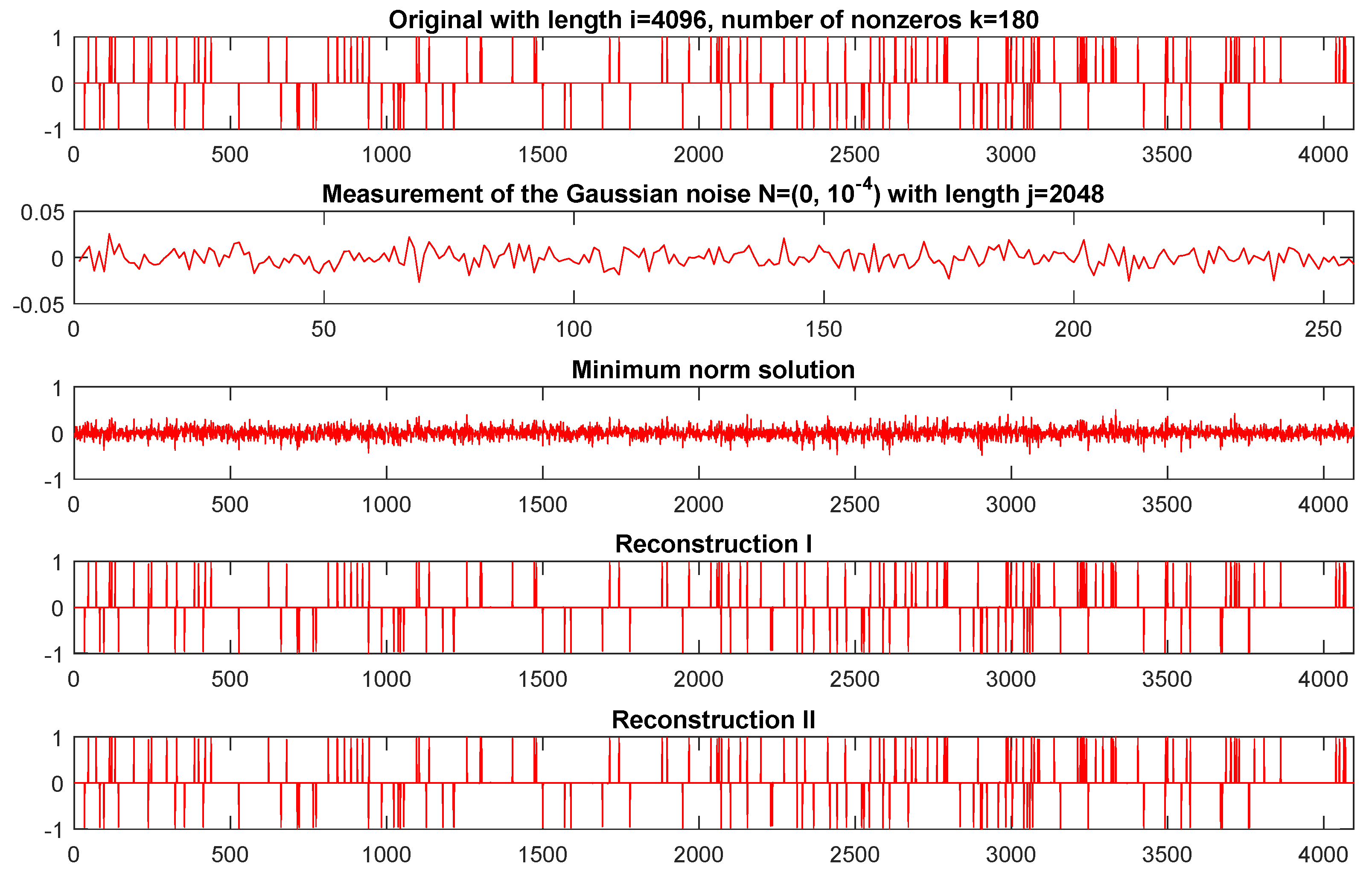
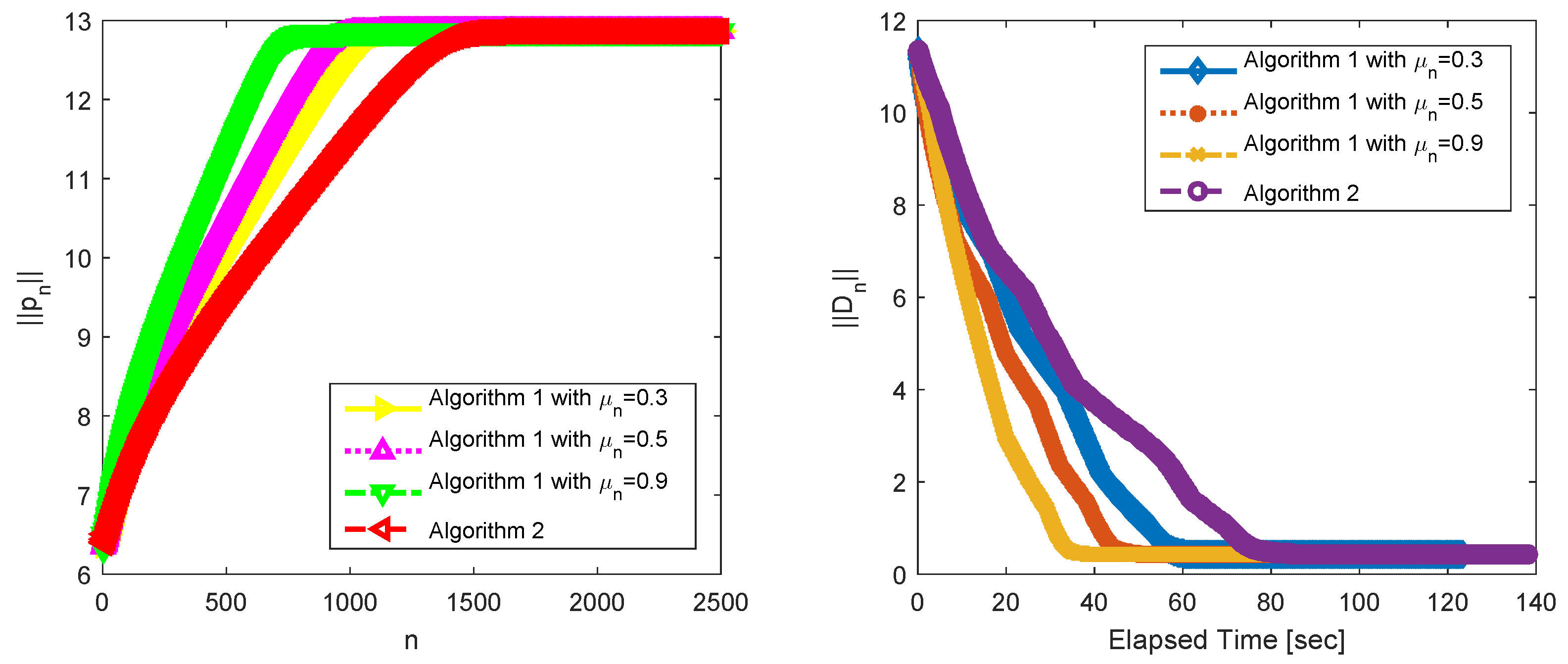
4. Numerical Experiment
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Moudafi, A. Split monotone variational inclusions. J. Optim. Theory Appl. 2011, 150, 275–283. [Google Scholar] [CrossRef]
- Iiduka, H. Two stochastic optimization algorithms for convex optimization with fixed point constraints. Optim. Methods Softw. 2019, 34, 731–757. [Google Scholar] [CrossRef] [Green Version]
- Ansari, Q.H.; Bao, T.Q. A limiting subdifferential version of Ekeland’s variational principle in set optimization. Optim. Lett. 2019, 1–5. [Google Scholar] [CrossRef]
- Al-Homidan, S.; Ansari, Q.H.; Kassay, G. Vectorial form of Ekeland variational principle with applications to vector equilibrium problems. Optimization 2020, 69, 415–436. [Google Scholar] [CrossRef]
- Li, X.; Huang, N.; Ansari, Q.H.; Yao, J.C. Convergence rate of descent method with new inexact line-search on Riemannian manifolds. J. Optim. Theory Appl. 2019, 180, 830–854. [Google Scholar] [CrossRef]
- Polyak, B.T. Some methods of speeding up the convergence of iteration methods. USSR Comput. Math. Math. Phys. 1964, 4, 1–17. [Google Scholar] [CrossRef]
- Rockafellar, R.T. Monotone operators and the proximal point algorithm. SIAM J. Control Optim. 1976, 14, 877–898. [Google Scholar] [CrossRef] [Green Version]
- Moreau, J.J. Proximité et dualité dans un espace hilbertien. Bull. De La Société Mathématique De Fr. 1965, 93, 273–299. [Google Scholar] [CrossRef]
- Bruck, R.E.; Reich, S. Nonexpansive projections and resolvents of accretive operators in Banach spaces. Houst. J. Math. 1977, 3, 459–470. [Google Scholar]
- Lions, P.L.; Mercier, B. Splitting algorithms for the sum of two nonlinear operators. SIAM J. Numer. Anal. 1979, 16, 964–979. [Google Scholar] [CrossRef]
- Cho, S.Y.; Kang, S.M. Approximation of fixed points of pseudocontraction semigroups based on a viscosity iterative process. Appl. Math. Lett. 2011, 24, 224–228. [Google Scholar] [CrossRef]
- Bot, R.I.; Csetnek, E.R. Second order forward-backward dynamical systems for monotone inclusion problems. SIAM J. Control Optim. 2016, 54, 1423–1443. [Google Scholar] [CrossRef]
- Cho, S.Y.; Kang, S.M. Approximation of common solutions of variational inequalities via strict pseudocontractions. Acta Math. Sci. 2012, 32, 1607–1618. [Google Scholar] [CrossRef]
- Cho, S.Y.; Li, W.; Kang, S.M. Convergence analysis of an iterative algorithm for monotone operators. J. Inequal. Appl. 2013, 2013, 199. [Google Scholar] [CrossRef] [Green Version]
- Luo, Y.; Shang, M.; Tan, B. A general inertial viscosity type method for nonexpansive mappings and its applications in signal processing. Mathematics 2020, 8, 288. [Google Scholar] [CrossRef] [Green Version]
- Alvarez, F.; Attouch, H. An inertial proximal method for maximal monotone operators via discretization of a nonlinear oscillator with damping. Set-Valued Anal. 2001, 9, 3–11. [Google Scholar] [CrossRef]
- Lorenz, D.A.; Pock, T. An inertial forward-backward algorithm for monotone inclusions. J. Math. Imaging Vis. 2015, 51, 311–325. [Google Scholar] [CrossRef] [Green Version]
- He, S.; Liu, L.; Xu, H.K. Optimal selections of stepsizes and blocks for the block-iterative ART. Appl. Anal. 2019, 1–14. [Google Scholar] [CrossRef]
- Cho, S.Y. Generalized mixed equilibrium and fixed point problems in a Banach space. J. Nonlinear Sci. Appl. 2016, 9, 1083–1092. [Google Scholar] [CrossRef] [Green Version]
- Liu, L. A hybrid steepest descent method for solving split feasibility problems involving nonexpansive mappings. J. Nonlinear Convex Anal. 2019, 20, 471–488. [Google Scholar]
- Kassay, G.; Reich, S.; Sabach, S. Iterative methods for solving systems of variational inequalities in reflexive Banach spaces. SIAM J. Optim. 2011, 21, 1319–1344. [Google Scholar] [CrossRef]
- Censor, Y.; Gibali, A.; Reich, S.; Sabach, S. Common solutions to variational inequalities. Set-Valued Var. Anal. 2012, 20, 229–247. [Google Scholar] [CrossRef]
- Gibali, A.; Liu, L.W.; Tang, Y.C. Note on the modified relaxation CQ algorithm for the split feasibility problem. Optim. Lett. 2018, 12, 817–830. [Google Scholar] [CrossRef]
- Cho, S.Y. Strong convergence analysis of a hybrid algorithm for nonlinear operators in a Banach space. J. Appl. Anal. Comput. 2018, 8, 19–31. [Google Scholar]
- Yamada, I. The hybrid steepest descent method for the variational inequality problem over the intersection of fixed point sets of nonexpansive mappings. Inherently Parallel Algorithms Feasibility Optim. Their Appl. 2001, 8, 473–504. [Google Scholar]
- Attouch, H.; Maingé, P.E. Asymptotic behavior of second-order dissipative evolution equations combining potential with non-potential effects. ESAIM Control Optim. Calc. Var. 2011, 17, 836–857. [Google Scholar] [CrossRef] [Green Version]
- Iiduka, H.; Takahashi, W. Strong convergence theorems for nonexpansive mappings and inverse-strongly monotone mappings. Nonlinear Anal. 2005, 61, 341–350. [Google Scholar] [CrossRef]
- Opial, Z. Weak convergence of the sequence of successive approximations for nonexpansive mappings. Bull. Am. Math. Soc. 1967, 73, 591–597. [Google Scholar] [CrossRef] [Green Version]
- Maingé, P.E. Inertial iterative process for fixed points of certain quasi-nonexpansive mappings. Set-Valued Anal. 2007, 15, 67–79. [Google Scholar] [CrossRef]
- Maingé, P.E. The viscosity approximation process for quasi-nonexpansive mappings in Hilbert spaces. Comput. Math. Appl. 2010, 59, 74–79. [Google Scholar] [CrossRef] [Green Version]
- Peypouquet, J.; Sorin, S. Evolution equations for maximal monotone operators: Asymptotic analysis in continuous and discrete time. arXiv 2009, arXiv:0905.1270. [Google Scholar]
- He, X.; Huang, T.; Yu, J.; Li, C.; Li, C. An inertial projection neural network for solving variational inequalities. IEEE Trans. Cybern. 2016, 47, 809–814. [Google Scholar] [CrossRef] [PubMed]



© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, L.; Qin, X.; Yao, J.-C. A Hybrid Forward–Backward Algorithm and Its Optimization Application. Mathematics 2020, 8, 447. https://doi.org/10.3390/math8030447
Liu L, Qin X, Yao J-C. A Hybrid Forward–Backward Algorithm and Its Optimization Application. Mathematics. 2020; 8(3):447. https://doi.org/10.3390/math8030447
Chicago/Turabian StyleLiu, Liya, Xiaolong Qin, and Jen-Chih Yao. 2020. "A Hybrid Forward–Backward Algorithm and Its Optimization Application" Mathematics 8, no. 3: 447. https://doi.org/10.3390/math8030447
APA StyleLiu, L., Qin, X., & Yao, J.-C. (2020). A Hybrid Forward–Backward Algorithm and Its Optimization Application. Mathematics, 8(3), 447. https://doi.org/10.3390/math8030447