Abstract
Considering the advantages of trapezoid fuzzy two-dimensional linguistic variables (TrF2DLVs), which can not only accurately describe the qualitative evaluation but also use qualitative linguistic variables (LVs) to describe the confidence level of this evaluation in the second dimension, this paper proposes a novel method based on trapezoidal fuzzy two-dimensional linguistic information to solve multiple attribute decision-making (MADM) problems with unknown attribute weight. First, a combination weight model is constructed, which covers a subjective weight determination model based on the proposed trapezoidal fuzzy two-dimensional linguistic best-worst method (TrF2DL-BWM) and an objective weight determination model based on the proposed CRITIC method. Then, in order to accurately rank the alternatives, an extended VIKOR-QUALIFLEX method is proposed, which can measure the concordance index of each ranking combination by means of group utility and individual maximum regret value of each evaluation alternative. Finally, a practical problem of lean management assessment for industrial residential projects is solved by the proposed method, and the effectiveness and advantages of the method are demonstrated by comparative analysis and discussion.
1. Introduction
With the continuous development of society, management decision-making has become increasingly important. How to make a wise decision on some major issues is related to the long-term development of the government, enterprises, and individuals. In this way, the multiple attribute decision-making (MADM) method, that is to evaluate and make decisions on multiple alternatives through multiple attributes of objectives, plays a key role. Scholars have also been studying and discussing this topic for a long time [1,2,3,4,5].
For MADM, the representation model of decision information is a primary and crucial research topic. Generally, decision attributes are divided into two forms: quantitative attributes and qualitative attributes. In quantitative evaluation, crisp number is the initial evaluation tool to express the exact information. However, in the complex decision-making process, some evaluation information may be uncertain. Therefore, Zadeh [6] put forward a novel concept, fuzzy set (FS), which is used to describe the quantitative evaluation of an objective in the form of membership degree. With the rise of fuzzy sets, all kinds of extended fuzzy information begin to appear, such as interval fuzzy number, triangular fuzzy number, and trapezoidal fuzzy number (TrFN). Among them, TrFN is the most generalized and accurate form, which can be reduced to other fuzzy information forms by adjusting membership function, so it has been paid great attention [7,8]. In addition, in terms of qualitative evaluation, the linguistic variables (LVs) introduced by Zadeh [9] promote the convenient expression of qualitative information, which is more in line with human evaluation habits. Then, some scholars point out that a single linguistic term (LT) is not enough to accurately model the qualitative evaluation information, so some extended linguistic information forms begin to emerge, such as two-dimensional linguistic variables (2DLVs) [10], hesitant fuzzy linguistic term sets [11], probabilistic linguistic term sets [12,13], and so on. However, it is worth noting that in the real complex decision-making environment, if people want to describe some uncertain information more accurately and completely, it is necessary to consider both qualitative and quantitative expressions. Inspired by 2DLVs, Li et al. [14] put forward the trapezoid fuzzy two-dimensional linguistic variables (TrF2DLVs), which can describe the evaluation information through two dimensions. In the first dimension, the TrFN is used to present the qualitative evaluation of the object, and in the second dimension, the LV is used to describe the degree of certainty of the evaluation produced by the first dimension. In this way, the TrF2DLVs can model the uncertain evaluation information more accurately through the combination of quantitative and qualitative tools. Based on the unique advantages of TrF2DLVs, they have been gradually concerned and studied in recent years [14,15,16].
The determination of attribute weight is the second problem and challenge of MADM. In most of the MADM problems, the weight of attributes is given directly, which is not only unscientific but also relatively reckless, because of which the evaluation results cannot reflect the real evaluation situation. Therefore, many scholars began to study the weight model, which can be divided into two categories, one is the determination of subjective attribute weight, whereas the other is the determination of objective attribute weight. The research of subjective weight model mainly focuses on AHP method [17], SWARA method [18], and BWM [4]. In particular, it is necessary to point out that the SWARA method is used because of its simplicity and a small number of steps. However, it does not have the ability to determine the consistency degree of the comparisons. The traditional AHP method determines the priority relationship of attributes by pairwise comparison. However, once the number of attributes is large, the number of pairwise comparison will be more, which will easily lead to the inconsistency of preference matrix. In order to simplify the complexity of AHP and improve the logical rationality of evaluation matrix, Rezaei [4] contributed the best-worst method (BWM), which only needs to determine the best and worst attributes, and then compare with other attributes. In view of the advantages of BWM, it has been widely used in MADM. For example, Guo and Zhao [2] proposed that the fuzzy BWM is to solve the issues under fuzzy environment, and defined the consistency ratio for fuzzy BWM; Brunelli and Rezaei [1] introduced a new metric into the framework of BWM to deal with MADM problems; Kumar et al. [19] presented a hybrid BWM and VIKOR method to evaluate green performance of the airports; and Muravev and Mijic [20] put forward a novel BWM-MABAC Model for integrated provider selection problems. For the determination of objective weight method, there are various weight models, such as entropy weight model [21], deviation maximization model [22], grey correlation analysis model [23], bidirectional projection model [24], and CRITIC model [25]. Among them, the CRITIC method has a very unique advantage, which can quantify contrast intensity and conflict to measure the weight of attributes, and further make the evaluation results easier to distinguish the priority relationship. Thus, CRITIC method has been paid more and more attention in MADM. For example, some TOPSIS-CRITIC models are presented to solve practical application problems in [25,26]; Žižović et al. [27] proposed a modified CRITIC method to determine criteria weight coefficients, and so forth.
For the research of MADM method, the core research point is about the ranking method. Generally speaking, ranking methods are divided into two types: one is based on information aggregation operators, and the other is traditional ranking method based on various information measures. With the increasing functions and features of information aggregation operators, the first kind of ranking methods have received special attention because they are easy to operate. For instance, Liu et al. [28] studied the MADM method based on the interval type-2 fuzzy partitioned Bonferroni mean operator for green supplier selection problem, which can consider the complex correlation between two attributes in different class groups; Liu and Li introduced the trapezoidal fuzzy two-dimensional linguistic power generalized Hamy mean operator considering the correlation among multiple attributes to deal with MADM problem. However, it is undeniable that although the MADM methods based on aggregation operator are simple, it may cause information loss in the decision-making process. Therefore, this study advocates to use the traditional ranking method. For example, the TOPSIS [23], MABAC [29], and VIKOR [19,30] methods can consider the distance from the alternatives to the positive and negative ideal solutions; the MAIRCA method [31] can reflect in determining the gap between the ideal and the empirical ponders; the MARCOS method [32] can determine the utility functions on the basis of the defined relationships between alternatives and reference values (ideal and anti-ideal alternatives), and the COPRAS method [33] can determine the relative significance values of alternatives based on the relationships between maximizing and minimizing indexes. Among these methods, the VIKOR method has an obvious advantage, i.e., it can use the group utility value and individual maximum regret value to find a compromise solution. In addition, the ELECTRE [7], PROMETHEE [34], and QUALIFLEX [35] method can measure the priority of alternatives by considering the possibility degree, preference index, and concordance index between alternatives, respectively, and then get the ranking results. Although these traditional methods have many steps, the evaluation results obtained by them are more accurate and more stable than those obtained by those methods based on aggregation operators.
Although TrF2DLVs have unique advantages in information expression, its research and application in MADM has not attracted enough attention from experts and scholars. Some of the existing research results have some positive highlights, but there are still some shortcomings that need to be improved. For example, the existing MADM methods based on trapezoidal fuzzy two-dimensional linguistic information do not consider the determination model of subjective weight. Although the power aggregation operator used by Li et al. in [14] and Liu and Li [15] can calculate the objective weight of attribute value, its main purpose is to deal with the problem that the evaluation information contains extreme evaluation values. The corresponding problem is that all evaluation values tend to be the same, which weakens the differentiation of priority among different alternatives. In addition, it is not scientific to merely rely on the subjective weight or objective weight of attributes to rank the alternatives. This is because the subjective weight combines the experience, preference and knowledge background of decision-makers (DMs), while the objective weight represents some objective information of the evaluation data itself. Moreover, for the research of ranking methods, the existing MADM methods based on the TrF2DLVs are constructed based on various aggregation operators, and they are extremely unstable in response to the attribute weights, which is not desirable for some evaluation problems. Through the literature review, we can find that BWM can effectively calculate the subjective weights of attributes in MADM problems, while CRITIC method has outstanding advantages in obtaining objective weights of attributes. However, the application results of these methods in fuzzy environment are relatively few. In addition, the VIKOR method is a very effective sorting tool, but it still needs some improvement because it cannot get the unique solution. In view of these motivations, the innovation and contributions of this study mainly focuses on the following aspects:
- (1)
- Some basic concepts about TrF2DLVs are introduced, including expectation value based on scale function, distance measure, and trapezoidal fuzzy two-dimensional linguistic preference relation (TrF2DLPR).
- (2)
- A combination weight model based on trapezoidal fuzzy two-dimensional linguistic information is proposed to solve the MADM problems with unknown attribute weights, which includes proposing a trapezoidal fuzzy two-dimensional linguistic best-worst method (TrF2DL-BWM) to determine the subjective attribute weight, proposing a CRITIC method to determine the objective attribute weight, and proposing a method based on the maximum comprehensive evaluation value to determine the combination weight.
- (3)
- An extended VIKOR-QUALIFLEX method based on TrF2DLVs is presented to solve MADM problems, which can measure the concordance index of each ranking combination by means of group utility and individual maximum regret value of each evaluation alternative, and get more stable evaluation result.
- (4)
- A practical application of lean management assessment for industrial residential projects is solved by the proposed method.
The following sections of this study can be presented as below. Section 2 introduces some basic concepts needed in this study. Section 3 proposes the model of the weights of attributes for MADM based on trapezoidal fuzzy two-dimensional linguistic information. Section 4 presents an extended VIKOR-QUALIFLEX method for TrF2DLVs to deal with MADM problems. Section 5 solves the practical problems of lean management evaluation of the industrial residential projects, verifies the effectiveness of the proposed method, and demonstrates its advantages. In Section 6, the conclusions are given.
2. Preliminaries
This section will introduce some basic concepts needed in this study, including TrFNs, linguistic term sets (LTSs), TrF2DLV, and TrF2DLPRs.
2.1. Trapezoidal Fuzzy Numbers
Definition 1.
[36] Let which meets the condition , and its membership degree function :is defined as below:
then can be called as a trapezoidal fuzzy number (TrFN), where the element of is real number, and its membership function , a regular and continuous convex function, stands for the degree of element x to the FS . Obviously, when , then the TrFN reduces to a triangular fuzzy number; when , then the TrFN reduces to a crisp number.
Suppose and are any two TrFNs, then their operational rules are presented as below [14,36]:
The distance measure between and is presented as below:
2.2. Linguistic Term Sets
Let be a finite and totally ordered discrete LTS with odd cardinality, where represents a possible value for a LV; the term must satisfy these properties [37]:
- (i)
- The set is ordered: if and only if ;
- (ii)
- There is a negation operator: Neg () = ;
- (iii)
- If , then ;
- (iv)
- If , then .
Definition 2.
[38]: For an LTS , the linguistic scale function is expressed as:
where and the linguistic scale function can construct a mapping relationship between the linguistic variable and a crisp number.
Note: the linguistic scale function has been widely studied at this stage 5. To simplify the operation, this study selects the simplest linguistic scale function for application. In addition, different DMs can also choose the appropriate linguistic scale function for some actual problems.
2.3. Trapezoidal Fuzzy Two-Dimensional Linguistic Variables
TrFNs can accurately describe the evaluation information of an objective thing, but sometimes people’s confidence in this evaluation information is not absolute. Inspired by two-dimensional linguistic information [10], Li et al. [14] put forward trapezoidal fuzzy two-dimensional linguistic information to describe the evaluated things. In a TrF2DLV, the first dimension can describe the evaluation information by a TrFN, and the second dimension can model the degree of confidence in this evaluation by a LV. Therefore, TrF2DLVs can express fuzzy information accurately and concretely, thus reducing the distortion of information.
Definition 3.
[14]: Let be a TrFN and be a LT. If is used to evaluate alternatives by a DM and is used to express the reliability of the evaluation given by the DM, then the can be called as a TrF2DLV.
Suppose and are any two TrF2DLVs, where and , then their operational rules can be expressed as below:
For any three TrF2DLVs , , and , they have these properties:
- (i)
- ;
- (ii)
- ;
- (iii)
- ;
- (iv)
- ;
- (v)
- ;
- (vi)
- ;
- (vii)
- .
Definition 4.
Supposeis a TrF2DLV, then the expected value ofcan be defined as below:
whereis the subscript of LTand, y is the linguistic scale function, andin this study. Obviously,.
Suppose and are any two TrF2DLVs. The comparison rules between and can be described as below:
- (i)
- If , the ;
- (ii)
- If , the ;
- (iii)
- If , the .
Definition 5.
Supposeandare any two TrF2DLVs, the distance measure of these TrF2DLVs is defined as below:
whereandare the expected values ofand, respectively.
Clearly, the distance of TrF2DLVs can satisfy these conditions:
- (i)
- ;
- (ii)
- If , then ;
- (iii)
- ;
- (iv)
- .
2.4. Trapezoidal Fuzzy Two-Dimensional Linguistic Preference Relation
Usually, experts can compare the evaluation subjects in pairs through fuzzy numbers to form a fuzzy preference relationship (FPRs) [39].
For FPRs, Rf, on a set of alternatives A = {A1, A2, …, An} are represented by a FS on the product set A × A and described by a membership function [40]:
FPRs can be defined as a matrix with , and expressed as
We use to represent the preference degree of an alternative Ai prefer to Aj:
For the FPRs, some properties need to be satisfied in Rf: (1) , (2) , and (3) .
Fuzzy preference relation can be more convenient to evaluate things, but fuzzy numbers are not enough to describe the evaluation information in reality accurately. Therefore, TrF2DLVs is introduced into fuzzy preference relation hereof and the concept of TrF2DLPR is given.
Definition 6.
The TrF2DLPR, RT, on a set of alternatives A are represented by a matrix on the set A × A, whose elements are formulated by
The matrix is defined as
where TrF2DLVs , , and .
Example 1.
Suppose that a DM evaluates three alternatives,, andby pairwise comparison, and he/she uses a TrF2DLPR to express decision-making information. The LV in the second dimension comes from the LTSThen, the evaluation matrixcan be expressed as follows:
Note: For the trapezoidal fuzzy numbers in the first dimension of TrF2DLVs, they mainly come from the transformation of linguistic terms. The evaluator can use the original linguistic terms to describe the evaluation information. Then, in order to calculate the information more accurately, the DMs use the transformation rules between linguistic terms and trapezoidal fuzzy numbers introduced in reference [41] to preprocess the data and obtain the above accurate results.
3. Models of the Weights of Attributes for MADM Based on Trapezoidal Fuzzy Two-Dimensional Linguistic Information
One of the biggest challenges in MADM models is determining attributes weights, i.e., most of MADM problem solution utility functions need importance values of attributes. It is essential part of the problem solution, since weight coefficients in some methods crucially influence the final decision-making result. Weights of attributes express an attitude of DMs on achieving goals in real problem. Considering the complexity and uncertainty of MADM problems, the weights of attributes are usually unknown. The simplest way to obtain the attribute weights is to assign the attribute weight subjectively based on the characteristics of the decision-making problem and the importance of the attribute. On the other hand, in order to obtain the decision results more conveniently, we can also use the evaluation data to measure the importance of attributes, which is called objective weight. This is because the evaluation data can indirectly and objectively reflect how to allocate the importance of attributes so that DMs can achieve the evaluation goals they are seeking. To consider both the subjective preference of DMs and the objectivity of evaluation data, this paper uses the maximum expected value of evaluation method to combine the subjective weights obtained by TrF2DL-BWM and objective weights obtained based on CRITIC method.
3.1. Subjective Weight Model Based on TrF2DL-BWM
In order to study the logical rationality of preference relation, Tanino [39] introduced the concept of additive consistency for FPRs. In an FPR, , if , then the FPR can be called additively consistent FPRs. Inspired by literature [39], we introduce a definition of additive consistency for TrF2DLPRs in the following.
Definition 7.
A TrF2DLPRcan be converted into an expected FPRusing Equation (15). Suppose, thenis an additively consistent TrF2DLPR if
whereis the excepted value of TrF2DLVs.
If the matrix is an additively consistent TrF2DLPR, then the element and the weights and have the following relationship:
Note: The reasonable value of is as follows:
Supposing that the information obtained by DMs is considered highly credible, we let in this study.
Inspired by the traditional BWM, we propose the TrF2DL-BWM in this paper. Suppose the set of attributes of a decision problem are expressed as . The first step is to determine the best and the worst attributes.
Then, we can determine the preference of the best attribute over all the other attributes by TrF2DLV and obtain the Best-to-Others vector . Similarly, the Others-to-Worst vector can be obtained by determining the preference of all attributes over the worst attribute. According to Definition 7, the vector and can be converted into and , respectively. It is clear that and . If the pairwise comparison is additively consistent, then
Then, element and weights and have the following relationship:
Similarly, the relationship between element and weights and can be expressed as
where the value of is selected according to Equation (23), and n in Equation (23) is the number of criteria.
In MADM, the weights of the attribute are crucial for ranking alternatives. Inspired by the idea in [3,4], we can minimize the maximum absolute differences of and to obtain the priority weight vectors.
Thus, to obtain the weight of each attribute, a mathematical model is constructed as follows:
In order to facilitate the solution, the model (27) is transferred into the following linear programming model:
where n denotes the number of attributes. The weights vector and objective function value can be obtained by solving the model (28).
The specific steps of TrF2DL-BWM method are summarized as below:
- Step 1
- determine the best and the worst attributes.
- Step 2
- obtain the Best-to-Others vector and the Others-to-Worst vector .
- Step 3
- convert the vector and to and , respectively.
- Step 4
- obtain the subjective weight vector by solving the model (28).
It should be noted that the consistency ratio also can be calculated in different methods, but the value closer to 0 can be desired. The pairwise comparison can be highly consistent only in this way.
3.2. Objective Weight Model Based on CRITIC Method
To determine the weight of attributes, Diakoulaki et al. [42] introduced a method in 1995, referred to as CRITIC. In this method, there is no contradiction between attributes, and attribute weight is determined by decision matrix. In addition, CRITIC method is related to both contrast intensity and conflict of the decision criteria and can get the attribute weights with obvious discrimination. For MADM problems with unknown weights, the CRITIC method has great advantages and can be used to obtain objective weights of attributes.
Suppose the initial decision matrix is expressed as , where is the evaluation value of the alternative according to the attribute represented by a TrF2DLV . The specific steps of using CRITIC method to calculate the attribute weight are as below:
- Step 1
- Normalize the decision matrix into () by the following formulas:For benefit attributes, we haveFor cost attributes, we have
- Step 2
- Calculate the correlation coefficient between the jth and the lth attributes by the following Equation (31) and obtain the correlation coefficient matrix :where and are the mean of jth and lth attributes. can be calculated by the following Equation (32). Similarly, can also be obtained.
- Step 3
- Calculate the standard deviation of the attribute by the following formula:
- Step 4
- Calculate the index () of the attribute by the following formula:
- Step 5
- Obtain the objective weight vector , where
3.3. Combination Weight Model Based on Maximum Expected Value of Evaluation
Suppose the subjective weight vector is , and . Additionally, the objective weight vector is , and . Let combination weight vector be and satisfy these conditions: , . In respect to combination weight vector , the expected value of weighted evaluation for alternative is as follows:
where is the excepted value of TrF2DLVs and can be calculated according to Equation (15).
Liu [41] points out that the choice of , i.e., the choice of and , should make the expected value of weighted evaluation of each alternative reach the maximum. Since there is no preference relationship among the alternatives, thus the following mathematical programming model can be constructed to obtain the combination weights:
To solve the model (37), the Lagrange multiplier function is constructed as:
and we have
By solving above equation, we get
Then, we can get the combination weight vector , where (j = 1, 2…., n).
4. Extended VIKOR-QUALIFLEX Method Based on TrF2DLVs for MADM with Unknown Attribute Weight
4.1. Problem Description of MADM with Unknown Attribute Weight
It is assumed that the DMs need to rank the m alternatives for decision-making, in order to consider the alternatives comprehensively, n evaluation attributes are selected. To express the information accurately, the evaluation information is represented by TrF2DLVs. In addition, the attribute weights of the MADM problem are unknown, which need to be obtained through expert experience and evaluation information.
4.2. Extended VIKOR-QUALIFLEX Method Based on TrF2DLVs
To solve above MADM problems, an extended VIKOR-QUALIFLEX method based on trapezoidal fuzzy two-dimensional linguistic information is established in this section. This method is mainly divided into three stages, including obtaining evaluation information, obtaining attribute weight, and ranking alternatives. In stage 1, the DM try to use TrF2DLVs to evaluate alternatives based on different attributes and gives an evaluation matrix . In stage 2, in order to obtain unknown attribute weight, a weight determination model is constructed. It mainly includes three parts: (1) the TrF2DL-BWM is employed to calculate the subjective weight vector, (2) the CRITIC method is employed to calculate the objective weight vector, and (3) calculate the combination weight vector. In stage 3, the QUALIFLEX method is employed to rank the alternatives, in which a VIKOR method is employed to measure the concordance index of alternatives for pairwise comparison based on the weighted evaluation information. The specific steps of this decision method are as follows:
- Step 1
- Establish decision matrix , where is the evaluation value of the alternative according to the attribute represented by a TrF2DLV . Then, normalize the decision-making unit according to the attribute of benefit type or cost type. The normalized matrix can be obtained from Equations (29) and (30) in Section 3.2.
- Step 2
- Calculate the weight vector of attributes using the weight determination model.
- Step 2.1
- Calculate the subjective weight vector using TrF2DL-BWM in Section 2.1, where ,;
- Step 2.2
- Calculate the objective weight vector using the CRITIC method in Section 2.2, where , ;
- Step 2.3
- Calculate the combination weight vector by a mathematical programming model in Section 2.3, where , .
Note: If the experts have enough information and knowledge reserves when acquiring the subjective weight, the proposed decision-making method can be further simplified, and the DMs may not need to calculate the objective weights and combination weights.
- Step 3
- Determine positive and negative ideal solutions of each subattribute.The positive ideal solution and the negative ideal solution .Note: the comparison rules of are described in Section 2.3.
- Step 4
- Calculate the group utility value and individual regret value of each evaluation alternative, where
- Step 5
- List all possible ranking of m evaluation alternatives .
- Step 6
- The alternatives in each possible permutation are compared in pairs in order, and the concordance index of each comparison ( over ) is calculated by the following Equation (43). Then, the concordance index matrix is established.where , , , and . is the decision-making mechanism coefficient, which can balance the weights between group utility and individual regret. When , it indicates that DMs prefer to maximize group utility; when , it indicates that DMs prefer to minimize individual regret. In this study, we suppose that the “the maximum group utility” and “minimum individual regret” have the same importance, that is, .
- Step 7
- Calculate the overall concordance index for each possible ranking .
- Step 8
- The ranking with the largest overall concordance index is selected as the final ranking result.
The process of the proposed method can be described by Figure 1.
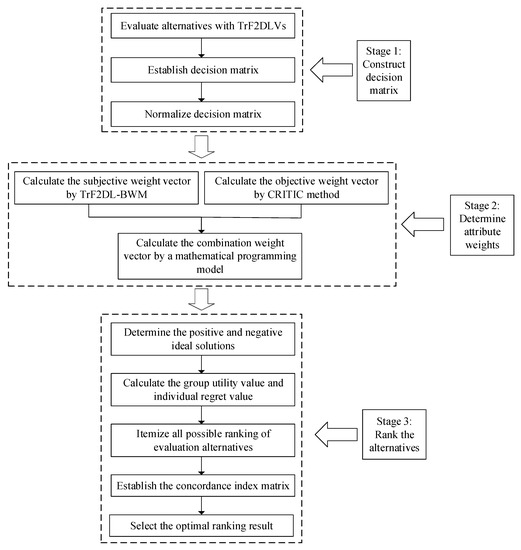
Figure 1.
The flow chart of the proposed method.
5. Practical Case Application
Industrialized residential project is the trend of housing construction in the future, but the current project management system matching with the construction mode of industrialized residential project is relatively backward. It is urgent to create a management system and evaluation method suitable for the construction of industrialized residential projects, so as to give full play to the advantages of industrialized residential project. A research institute in China is ready to evaluate the lean management level of industrialized residential project in M city. Based on the previous literature review, expert interviews, and questionnaire survey, combined with the scientific principle, goal oriented principle, comparability principle, systematic principle, operability principle, and independence principle of index system construction, this research institute has determined the following evaluation index system for lean management of industrialized residential project. This index system is mainly developed from two levels: project process level and organization level. Based on the project process level, three primary attributes are determined, which are design lean management, component production and logistics lean management, and construction lean management. Based on the organization level, two primary attributes are determined, namely, organizational collaborative lean management and information collaborative lean management. In addition, each primary attribute is subdivided into multiple subattributes. The specific evaluation attribute system of lean management level of industrialized residential project is shown in Table 1. Note: this index system has been tested by questionnaire, reliability and validity, exploratory factor analysis, and confirmatory factor analysis, which has been proved that it has good applicability. Due to the space limitation, this paper does not introduce the process and results of the test and analysis.

Table 1.
Evaluation attribute system.
With the strong support of leaders and peers, this study selected three industrialized residential projects (P1, P2, and P3) as the alternatives of this quantitative analysis. Note: P1, P2, and P3 are now officially completed. As the content of the project involves many professional terms, in order not to affect the readability of the article, the specific content of each project is not detailed here. In this evaluation study, several experts who have participated in (or understood) the above three projects were selected as the main DMs, and lean management evaluation data of the three projects were obtained by on-site questionnaire scoring. The TrF2DLVs are employed to evaluate the three projects. It should be noted that DMs use the LTS with five LTs to express the subjective trust in the second dimension of TrF2DLVs. In addition, for the trapezoidal fuzzy numbers in the first dimension of TrF2DLVs, they mainly come from the transformation of linguistic terms based on the reference [41]. The DMs use the information form of linguistic terms to express the evaluation information of the first dimension, and then, they are transformed into trapezoidal fuzzy numbers based on the relevant transformation rules in [41]. After the data preprocessing, the following evaluation matrix is obtained in Table 2.
Table 2.
Decision matrix based on trapezoid fuzzy two-dimensional linguistic variables (TrF2DLVs).
5.1. Method Implementation Process
To solve the above practical application case through the proposed method, the specific steps are as follows:
- Step 1.
- Since all attribute types are benefit type, the normalization can be omitted.
- Step 2.1.
- Calculate the subjective weight vector using TrF2DL-BWM.
- Step 2.1.1.
- First, the best attribute and the worst attribute are determined among all the primary attributes. Then, the best attribute and the worst attribute among the subattributes of each primary attribute are determined.For the five primary attributes, the DMs determine that the best attribute is and the worst attribute is . For the four subattributes under the primary attribute , DMs determine that the best attribute is , and the worst subattribute is . Similarly, for other primary attributes, the best subattributes are , , , and , and the worst subattributes are , , , and .
- Step 2.1.2.
- For the five primary attributes, DMs give the Best-to-Others vector:= = {([0.500, 0.500, 0.500, 0.500],), ([0.667, 0.733, 0.800, 0.867],), ([0.533, 0.600, 0.667, 0.733],), ([0.733, 0.800, 0.867, 0.933],), ([0.800, 0.867, 0.933, 1.000],)}, and the Others-to-Worst vector:= = {([0.800, 0.867, 0.933, 1.000],), ([0.533, 0.600, 0.667, 0.733],), ([0.667, 0.733, 0.800, 0.867],), ([0.667, 0.733, 0.800, 0.867],), ([0.500, 0.500, 0.500, 0.500],)}.For the four subattributes under the primary attribute , DMs give the Best-to-Others vector:= = {([0.500, 0.500, 0.500, 0.500],), ([0.533, 0.600, 0.667, 0.733],), ([0.800, 0.867, 0.933, 1.000],), ([0.667, 0.733, 0.800, 0.867],)}, and the Others-to-Worst vector:= {([0.800, 0.867, 0.933, 1.000],), ([0.667, 0.733, 0.800, 0.867],), ([0.500, 0.500, 0.500, 0.500],), ([0.667, 0.733, 0.800, 0.867],)}.Similarly, DMs can give the Best-to-Others vectors and the Others-to-Worst vectors of other subattributes under the primary attribute , , , and . For the convenience of reading, they are omitted here.
- Step 2.1.3.
- Convert the vector and to and , respectively.Here, we only take the primary attributes as an example to give the experimental results. = = {0.500, 0.767, 0.633, 0.833, 0.930},= {0.900, 0.633, 0.767, 0.575,0.500}.
- Step 2.1.4.
- For the five primary attributes, we can build the following model based on Equation (28):
We employ the LINGO to solve above model and obtain the subjective weight vector and = 0.003. Similarly, we have the other weight vectors = (0.380, 0.304, 0.126, 0.189)T, = (0.386, 0.282, 0.216, 0.116)T, = (0.240, 0.283,0.135,0.342)T, = (0.387, 0.313, 0.106, 0.194)T, and = (0.403, 0.64, 0.233)T and = 0.019, = 0.018, = 0.022, = 0.022, and = 0.006.
It is easy to find that the value of objective function are very close to 0, so the obtained subjective weights have high reliability.
To obtain the global subjective weights for each subattribute, the subjective weights of corresponding main attribute need be multiplied by the local subjective weights of each subattribute. Thus, we can obtain the global subjective weight vector of all subattributes:
w = (0.119, 0.095, 0.040, 0.059, 0.069, 0.050, 0.039, 0.021, 0.059, 0.070, 0.033, 0.084, 0.058, 0.047, 0.016, 0.029, 0.045, 0.041, 0.026)T.
- Step 2.2.
- Calculate the objective weight vector using the CRITIC method in Section 2.2.
- Step 2.2.1.
- For the four subattributes under the primary attribute , we calculate the correlation coefficient (j, l = 1, 2, 3, 4) between the jth and the lth attributes by the Equations (31) and (32), and the following correlation coefficient matrix: can be determined:
Similarly, the other correlation coefficient matrices can be obtained:
For the correlation coefficient matrix of primary attributes, we first aggregate the subattributes under each primary attribute for each alternative using the following Equation (45).
Then, we obtain the following matrix using the similar method mentioned above.
- Step 2.2.3.
- For the primary attributes, calculate the standard deviation of the (j = A, B, C, D, E) primary attribute by Equation (33). Similarly, the standard deviation (j = 1, 2, 3, 4 when and j = 1, 2, 3 when ) of subattributes under each primary attribute can also be obtained.
- Step 2.2.4.
- According to Equations (34) and (35), the objective weight vector for primary attributes and the objective weight vector can be obtained as below:
To obtain the global objective weights for each subattribute, the objective weights of corresponding main attribute need to be multiplied by the local objective weights of each subattribute. Thus, we can obtain the global objective weight vector of all subattributes:
ω = (0.014, 0.012, 0.008, 0.009, 0.089, 0.209, 0.063, 0.113, 0.036, 0.050, 0.040, 0.019, 0.031, 0.038, 0.043, 0.038, 0.066, 0.077, 0.045)T.
- Step 2.3.
- Calculate the combination weight vector of all subattributes by the mathematical programming model in Section 2.3 and Equation (40). The result is as follows:ϖ = (0.092, 0.074, 0.032, 0.046, 0.074, 0.091, 0.045, 0.045, 0.053, 0.065, 0.035, 0.067, 0.051, 0.044, 0.023, 0.031, 0.051, 0.050, 0.031)T.
- Step 3.
- Determine positive and negative ideal solutions of each subattribute.
- Step 4.
- Calculate the group utility value and individual regret value of each evaluation alternative based on Equations (41) and (42),
- Step 5.
- All possible ranking of 3 evaluation alternatives can be listed:
- Step 6.
- The concordance index matrix is established by Equation (43),
- Step 7.
- Calculate the overall concordance index for each possible ranking by Equation (44),
- Step 8.
- The largest overall concordance index is , thus the ranking result is .
Thus, the project has the best level of lean management.
5.2. Parameter Sensitivity Analysis
The parameter is involved in the method of obtaining subjective weight. Therefore, in this section, we will analyze the influence of different values of parameter on subjective weight, combination weight, and ranking result. Let , , and employ the method proposed in Section 3.1 to obtain local subjective weights of each subattribute and five primary attributes and then obtain global subjective weights of 19 subattributes. The experimental results are shown in Figure 2 and Figure 3. Then, let , , and to obtain the combination weights of 19 subattributes by the method proposed in Section 3.1. The experimental results are shown in Figure 4. In addition, based on different values of , the ranking results are shown in Table 3.
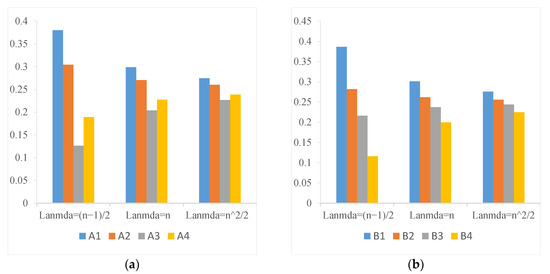
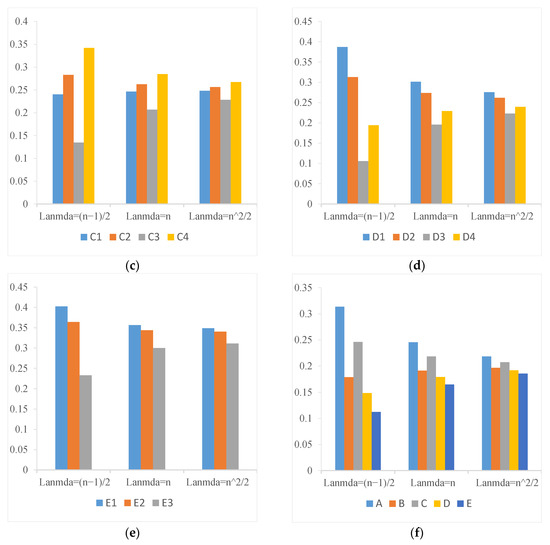
Figure 2.
The local subjective weights of each subattribute from different parameter . (a) The subjective weights of subattributes in attribute A; (b) The subjective weights of subattributes in attribute B; (c) The subjective weights of subattributes in attribute C; (d) The subjective weights of subattributes in attribute D; (e) The subjective weights of subattributes in attribute E; (f) The subjective weights of attributes A–E.
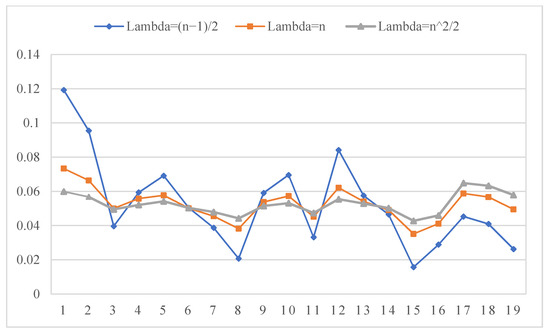
Figure 3.
The global subjective weights of 19 subattributes from different parameter .
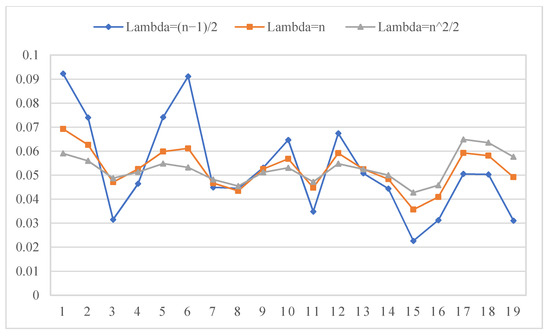
Figure 4.
The combination weights of 19 subattributes from different parameter .
Table 3.
Ranking obtained from different parameter .
From Figure 2, it is easy to find that parameter has obvious influence on local subjective weight of subattributes. When , the weight differentiation of each local attribute is obvious, but when gradually increases ( and ), the local weight difference of each subattribute decreases, which is close to each other in numerical value. However, it should be noted that regardless of the value of , the priority relationship of attributes at each level is unchanged. For example, for the five primary attributes, no matter what value takes, the priority relationships of attribute weight are wA > wC >wB> wD >wE. In addition, the larger the value of , the closer the distribution of attribute weight to uniform distribution. The smaller the parameter , the greater the gap between the weights. From Figure 3 and Figure 4, we can also find that the global weights of 19 subattributes are also affected by the value of . The smaller the is, the more obvious the difference between attribute weights is, and the priority relationship between attributes is easier to distinguish. Besides, it can be seen from the results in Table 3, whether based on subjective weights or combined weights, parameter has no effect on the ranking results from this case. From the analysis of additive consistency Formula (22), it can be found that when is large enough, the weight gap between attribute i and attribute j can be small enough, but the priority relationship between the two attributes is fixed. Therefore, when takes a smaller value, the sequence of attribute priority relation with more obvious discrimination can be obtained. In this case, we believe that the preference evaluation information is highly reliable. When is large, the weight distribution of all attributes is balanced. In this case, the priority of attributes cannot be clearly distinguished. Therefore, parameter can be flexibly applied to different index systems and DMs with different distinguishing ability. For example, parameter should be set to a smaller value when the index system requires that each index has a more obvious discrimination. If the DMs thinks that there should be some fairness between attributes, then they can set a larger value of .
5.3. Weight Sensitivity Analysis
The core of this study is about the determination of attribute weight. We will analyze the impact of weight on the evaluation results. In the following table, we only use subjective weight and objective weight to deal with this evaluation problem. Using this proposed method, the ranking can be shown in Table 4.
Table 4.
Ranking obtained from different weights.
It is easy to find from Table 4 that when only the objective attribute weights are used, the ranking results are the same as that of the combination attribute weights, however, when only subjective weight is used for ranking, although project is the best one, the priority relationship between project and project cannot be distinguished. This shows that different attribute weights may have different effects on the evaluation results. In order to further explore this rule, we make the combination weight , and then observe the influence of parameter on the ranking results. The specific experimental results are shown in Figure 5.
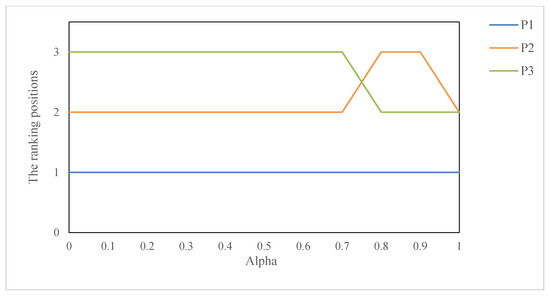
Figure 5.
The ranking results from different parameter .
From Figure 5, we can find that when the combination weight is close to the subjective weight obtained in this study, the ranking results change. However, on the whole, we think that the ranking results obtained from the proposed method are relatively stable in response to the attribute weights. In order to further verify our conjecture, we randomly generate 100 groups of subjective weights for simulation experiments. The experimental results are presented as Figure 6. Based on Figure 6, we can easily find that the proposed ranking method is relatively stable, and the specific advantages will be discussed in detail in the comparative analysis in the next part.
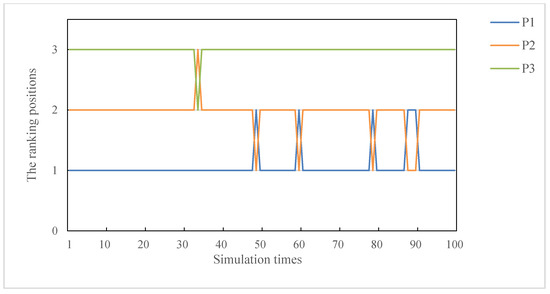
Figure 6.
The fluctuation of ranking order of each project.
5.4. Comparative Analysis and Discussion
To verify the effectiveness and advantages of the proposed method, we compare it with two typical MADM methods based on trapezoidal fuzzy two-dimensional linguistic information. The typical methods mainly include the MADM method based on the trapezoidal fuzzy two-dimensional linguistic power generalized weighted aggregation (TF2DLPGWA) operator in [14] and the MADM method based on the weighted trapezoidal fuzzy two-dimensional linguistic power generalized Hamy mean (WTF2DLPGHM) operator in [15]. We employ the above two methods and our method to cope with the application case in [15]. It is worth noting that the two typical methods all have variable parameters. In order to make these methods give full play to their characteristics and advantages without losing generality, we let in [14] and and in [15]. The specific experimental results are shown in Table 5.
Table 5.
Experimental results obtained from different methods.
From Table 5, we can see that the ranking results obtained by the method in [15] is the same as that obtained by our method. Their best project is all , while the best project obtained by the method in [14] is . This indicates that our novel method is effective. In addition, it should be noted that the expected values obtained by method in [14] and method in [15] are very close and difficult to distinguish. So, we have such a question in the brain, whether the ranking results obtained by methods in [14,15] are easy to be affected by attribute weights. Because the two methods also consider the objective weight of attributes with the help of power mean operator, we use the following experiments to verify our conjecture. Specifically, 100 groups of subjective weights are randomly generated, and the method in [14] and the method in [15] are used to process the evaluation data of this application case, and the ranking results are presented in Figure 6 and Figure 7.
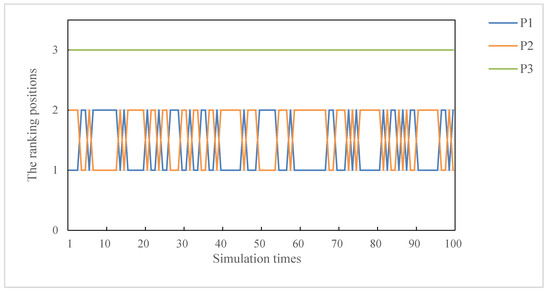
Figure 7.
The fluctuation of ranking order of each project from method in [14].
From Figure 7 and Figure 8, we can find that methods in [14] and [15] are extremely unstable in response to subjective attribute weights, and it is not clear whether the best project is or . On the contrary, the proposed method is relatively more stable than these two methods and the evaluation results are more convincing.
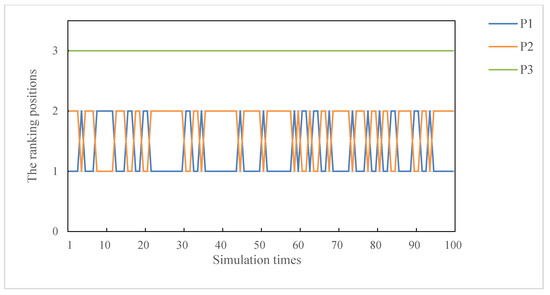
Figure 8.
The fluctuation of ranking order of each project from method A in [15].
In the following points, we compare and discuss with the above two typical methods in terms of characteristics and internal mechanism.
- (1)
- Compared with the method in [14]. The TF2DLPGWA operator in [14] can assign a corresponding weight to each attribute value, and the allocation principle is to adjust the weight of extreme value to a smaller weight. The result of this operation is to reconcile the evaluation value of the alternatives, reduce the differentiation between the alternatives, and make it difficult to distinguish some close alternatives. It is not suitable for those DMs with poor discrimination ability. In addition, the proposed method, which uses a CRITIC method to deal with the objective weight, can measure the contrast intensity and conflict, get a more distinct overall correlation coefficient, and then get a more clear objective weight. In addition, although the method based on TF2DLPGWA operator is simple and easy to operate, it is easy to cause the loss of decision-making information. Our method in this paper can calculate the overall concordance index of different ranking combinations by the group utility value and individual regret value, and then get more scientific and reliable ranking results.
- (2)
- Compared with the method in [15]. The WTF2DLPGHM operator in [15] also uses the power mean operator to change the weight of extreme evaluation value to eliminate the effect of extreme value. However, in this way, it may be difficult to distinguish the priority among the alternatives. In addition, although the method based on the WTF2DLPGHM operator uses the Hamy mean operator which can deal with the relationship between attributes, and contains variable parameters which can adapt to different DMs with different preferences. It also brings the corresponding disadvantage of obtaining unstable evaluation result. However, the ranking obtained by our method are easier to identify and distinguish, and more stable in response to the weights of attributes. More importantly, the results are more convincing. It is worth noting that this paper also proposes a combination weight model to determine the attribute weights, which not only considers the subjective weight of the DMs but also considers the objective weight information contained in the evaluation data; this makes the weights of attribute more real and effective, thus improving the accuracy of decision-making. In addition, the proposed weight model can be flexibly applied to different index systems and DMs with different distinguishing ability based on the flexible parameter .
6. Conclusions
The TrF2DLVs can not only describe the fuzzy information more accurately in the form of trapezoidal fuzzy number but also include the description of the degree of certainty of this evaluation information. Therefore, the MADM based on trapezoidal fuzzy two-dimensional linguistic information has been paid more and more attention. In this study, some new basic theories on TrF2DLVs were first proposed, including expected value, distance measure, and TrF2DLPR. Then, for the MADM problems with unknown attribute weight, this paper constructed a combination weight model. It mainly includes using TrF2DL-BWM to determine the subjective attribute weight, using CRITIC method to determine the objective attribute weight, and using the method based on the maximum comprehensive evaluation value to determine the combination weight. Whereafter, an extended VIKOR-QUALIFLEX method based on TrF2DLVs was proposed to rank alternatives. Finally, in order to verify the effectiveness and advantages of the novel method, this paper applied it to the evaluation of lean management level of industrial residential projects and selected some representative methods for comparative analysis and discussion.
In this article, the basic theory of TrF2DLVs can be further studied, including some operation rules, information measurement, etc. In addition, the prosed method in this paper still has some limitations. For example, the BWM of obtaining subjective weight still needs a lot of pairwise comparison when the number of attributes is too large; the QUALIFLEX method needs to calculate a large number of ranking combinations (m!) when there are too many alternatives (m). Thus, some novel methods can be referenced and applied, such as FUCOM method [32], LBWA method [43], and RAFSI method [44]. It is also worthwhile to apply the novel method to other practical problems, such as evaluations on E-commerce [45], investment selection, talent evaluation, and emergency management.
Author Contributions
Conceptualization, Y.L. (Yisheng Liu) and Y.L. (Ye Li); data curation, Y.L. (Yisheng Liu); formal analysis, Y.L. (Yisheng Liu) and Y.L. (Ye Li); investigation, Y.L. (Ye Li); methodology, Y.L. (Yisheng Liu) and Y.L. (Ye Li); resources, Y.L. (Yisheng Liu); software, Y.L. (Ye Li); supervision, Y.L. (Yisheng Liu); writing—original draft, Y.L. (Ye Li); writing—review and editing, Y.L. (Yisheng Liu). Both authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The authors confirm that the data supporting the findings of this study are available within this article.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Brunelli, M.; Rezaei, J. A multiplicative best–worst method for multi-criteria decision making. Oper. Res. Lett. 2019, 47, 12–15. [Google Scholar] [CrossRef]
- Guo, S.; Zhao, H.R. Fuzzy best-worst multi-criteria decision-making method and its applications. Knowl.-Based Syst. 2017, 121, 23–31. [Google Scholar] [CrossRef]
- Li, J.; Wang, J.; Hu, J. Multi-criteria decision-making method based on dominance degree and BWM with probabilistic hesitant fuzzy information. Int. J. Mach. Learn. Cybern. 2019, 10, 1671–1685. [Google Scholar] [CrossRef]
- Rezaei, J. Best-Worst Multi-Criteria Decision-Making Method. Omega 2015, 53, 49–57. [Google Scholar] [CrossRef]
- Wang, J.; Wu, J.; Wang, J.; Zhang, H.; Chen, X. Interval-valued hesitant fuzzy linguistic sets and their applications in multi-criteria decision-making problems. Inf. Sci. 2014, 288, 55–72. [Google Scholar] [CrossRef]
- Zadeh, L.A. Fuzzy sets. Inf. Control 1965, 8, 338–353. [Google Scholar] [CrossRef]
- Ayyildiz, E.; Gumus, A.T.; Erkan, M. Individual credit ranking by an integrated interval type-2 trapezoidal fuzzy ELECTRE methodology. Soft Comput. 2020, 24, 16149–16163. [Google Scholar] [CrossRef]
- Xie, J.; Zeng, W.; Li, J.; Yin, Q. Similarity measures of generalized trapezoidal fuzzy numbers for fault diagnosis. Soft Comput. 2019, 23, 1999–2014. [Google Scholar] [CrossRef]
- Zadeh, L.A. The concept of a linguistic variable and its application to approximate reasoning-I. Inf. Sci. 1975, 8, 199–249. [Google Scholar] [CrossRef]
- Zhu, W.D.; Zhou, G.Z.; Yang, S.L. An approach to group decision making based on 2-dimension linguistic assessment information. Syst. Eng. 2009, 27, 113–118. [Google Scholar]
- Liu, P.; Zhang, X.; Pedrycz, W. A consensus model for hesitant fuzzy linguistic group decision-making in the framework of Dempster-Shafer evidence theory. Knowl.-Based Syst. 2020, 106559. [Google Scholar] [CrossRef]
- Liu, P.; Wang, P.; Pedrycz, W. Consistency-and consensus-based group decision-making method with incomplete probabilistic linguistic preference relations. IEEE Trans. Fuzzy Syst. 2020, 1–15. [Google Scholar] [CrossRef]
- Wang, P.; Liu, P.; Chiclana, F. Multi-stage consistency optimization algorithm for decision making with incomplete probabilistic linguistic preference relation. Inf. Sci. 2020, 1–28. [Google Scholar] [CrossRef]
- Li, Y.; Wang, Y.; Liu, P. Multiple attribute group decision-making methods based on trapezoidal fuzzy two-dimension linguistic power generalized aggregation operators. Soft Comput. 2016, 20, 2689–2704. [Google Scholar] [CrossRef]
- Liu, Y.; Li, Y. The Trapezoidal Fuzzy Two-Dimensional Linguistic Power Generalized Hamy Mean Operator and Its Application in Multi-Attribute Decision-Making. Mathematics 2020, 8, 122. [Google Scholar] [CrossRef]
- Yin, K.; Yang, B.; Li, X. Multiple attribute group decision-making methods based on trapezoidal fuzzy two-dimensional linguistic partitioned Bonferroni mean aggregation operators. Int. J. Environ. Res. Public Health 2018, 15, 194. [Google Scholar] [CrossRef]
- Saaty, T.L. A scaling method for priorities in hierarchical structures. J. Math. Psychol. 1977, 15, 234–281. [Google Scholar] [CrossRef]
- Zavadskas, E.K.; Stević, Ž.; Tanackov, I.; Prentkovskis, O. A novel multicriteria approach–rough step-wise weight assessment ratio analysis method (R-SWARA) and its application in logistics. Stud. Inform. Control 2018, 27, 97–106. [Google Scholar] [CrossRef]
- Kumar, A.; Aswin, A.; Gupta, H. Evaluating green performance of the airports using hybrid BWM and VIKOR methodology. Tour. Manag. 2020, 76, 103941. [Google Scholar] [CrossRef]
- Muravev, D.; Mijic, N. A Novel Integrated Provider Selection Multicriteria Model: The BWM-MABAC Model. Decis. Mak. Appl. Manag. Eng. 2020, 3, 60–78. [Google Scholar] [CrossRef]
- Cui, Y.; Feng, P.; Jin, J.; Liu, L. Water resources carrying capacity evaluation and diagnosis based on set pair analysis and improved the entropy weight method. Entropy 2018, 20, 359. [Google Scholar] [CrossRef]
- Wu, Z.; Chen, Y. The maximizing deviation method for group multiple attribute decision making under linguistic environment. Fuzzy Sets Syst. 2007, 158, 1608–1617. [Google Scholar] [CrossRef]
- Hu, Y.; Wu, L.; Shi, C.; Wang, Y.; Zhu, F. Research on optimal decision-making of cloud manufacturing service provider based on grey correlation analysis and TOPSIS. Int. J. Prod. Res. 2020, 58, 748–757. [Google Scholar] [CrossRef]
- Liu, Z.; Wang, X.; Li, L.; Zhao, X.; Liu, P. Q-rung orthopair fuzzy multiple attribute group decision-making method based on normalized bidirectional projection model and generalized knowledge-based entropy measure. J. Ambient Intell. Humaniz. Comput. 2020, 1–16. [Google Scholar] [CrossRef]
- Babatunde, M.; Ighravwe, D. A CRITIC-TOPSIS framework for hybrid renewable energy systems evaluation under techno-economic requirements. J. Proj. Manag. 2019, 4, 109–126. [Google Scholar] [CrossRef]
- Abdel-Basset, M.; Mohamed, R. A novel plithogenic TOPSIS-CRITIC model for sustainable supply chain risk management. J. Clean. Prod. 2020, 247, 119586. [Google Scholar] [CrossRef]
- Žižović, M.; Miljković, B.; Marinković, D. Objective methods for determining criteria weight coefficients: A modification of the CRITIC method. Decis. Mak. Appl. Manag. Eng. 2020, 3, 149–161. [Google Scholar] [CrossRef]
- Liu, P.; Gao, H.; Ma, J. Novel green supplier selection method by combining quality function deployment with partitioned Bonferroni mean operator in interval type-2 fuzzy environment. Inf. Sci. 2019, 490, 292–316. [Google Scholar] [CrossRef]
- Liu, P.; Zhu, B.; Wang, P.; Shen, M. An approach based on linguistic spherical fuzzy sets for public evaluation of shared bicycles in China. Eng. Appl. Artif. Intell. 2020, 87, 103295. [Google Scholar] [CrossRef]
- Komazec, N.; Petrović, A. Application of the AHP-VIKOR hybrid model in media selection for informing of endangered in emergency situations. Oper. Res. Eng. Sci. Theory Appl. 2019, 2, 12–23. [Google Scholar] [CrossRef]
- Chatterjee, K.; Pamucar, D.; Zavadskas, E.K. Evaluating the performance of suppliers based on using the R’AMATEL-MAIRCA method for green supply chain implementation in electronics industry. J. Clean. Prod. 2018, 184, 101–129. [Google Scholar] [CrossRef]
- Stević, Ž.; Pamučar, D.; Puška, A.; Chatterjee, P. Sustainable supplier selection in healthcare industries using a new MCDM method: Measurement of alternatives and ranking according to COmpromise solution (MARCOS). Comput. Ind. Eng. 2020, 140, 106231. [Google Scholar] [CrossRef]
- Ghorabaee, M.K.; Amiri, M.; Sadaghiani, J.S.; Goodarzi, G.H. Multiple criteria group decision-making for supplier selection based on COPRAS method with interval type-2 fuzzy sets. Int. J. Adv. Manuf. Technol. 2014, 75, 1115–1130. [Google Scholar] [CrossRef]
- Xu, D.; Wei, X.; Ding, H.; Bin, H. A New Method Based on PROMETHEE and TODIM for Multi-Attribute Decision-Making with Single-Valued Neutrosophic Sets. Mathematics 2020, 8, 1816. [Google Scholar] [CrossRef]
- Liang, Y.; Qin, J.; Martínez, L.; Liu, J. A heterogeneous QUALIFLEX method with criteria interaction for multi-criteria group decision making. Inf. Sci. 2020, 512, 1481–1502. [Google Scholar] [CrossRef]
- Li, R. Theory and Application on the Fuzzy Multiple Attribute Decision Making; Science Press: Beijing, China, 2002. [Google Scholar]
- Herrera, F.; Herrera-Viedma, E. Linguistic decision analysis: Steps for solving decision problems under linguistic information. Fuzzy Sets Syst. 2000, 115, 67–82. [Google Scholar] [CrossRef]
- Xu, Z. Group decision making with triangular fuzzy linguistic variables. In International Conference on Intelligent Data Engineering and Automated Learning; Springer: Berlin/Heidelberg, Germany, 2007; pp. 17–26. [Google Scholar]
- Tanino, T. Fuzzy preference orderings in group decision making. Fuzzy Sets Syst. 1984, 12, 117–131. [Google Scholar] [CrossRef]
- Herrera-Viedma, E.; Herrera, F.; Chiclana, F.; Luque, M. Some issues on consistency of fuzzy preference relations. Eur. J. Oper. Res. 2004, 154, 98–109. [Google Scholar] [CrossRef]
- Liu, P. Study on Evaluation Methods and Application of Enterprise Informatization Level Based on Fuzzy Multi-Attribute Decision Making; Beijing Jiaotong University: Beijing, China, 2009. [Google Scholar]
- Diakoulaki, D.; Mavrotas, G.; Papayannakis, L. Determining objective weights in multiple criteria problems: The CRITIC method. Comput. Oper. Res. 1995, 22, 763–770. [Google Scholar] [CrossRef]
- Žižović, M.; Pamucar, D. New model for determining criteria weights: Level Based Weight Assessment (LBWA) model. Decis. Mak. Appl. Manag. Eng. 2019, 2, 126–137. [Google Scholar] [CrossRef]
- Žižović, M.; Pamučar, D.; Albijanić, M.; Chatterjee, P.; Pribićević, I. Eliminating Rank Reversal Problem Using a New Multi-Attribute Model—The RAFSI Method. Mathematics 2020, 8, 1015. [Google Scholar] [CrossRef]
- Guan, H.J.; Zhao, A.W.; Shi, G.Q. Research on E-Commerce Precision Poverty Alleviation; Economic Science Press: Beijing, China, 2019. [Google Scholar]









Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).