
Using Markov Models to Characterize and Predict Process Target Compliance


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Background
3. Phase-Type Models
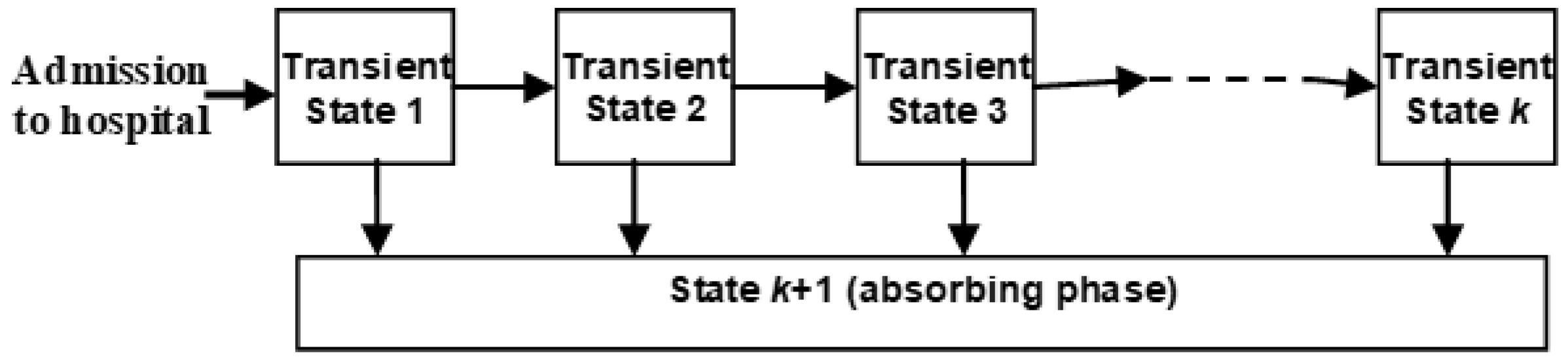
3.1. The Basic Phase-Type Model
3.2. Multiple Absorbing States with Different Targets
3.3. Poisson Arrivals
4. Results
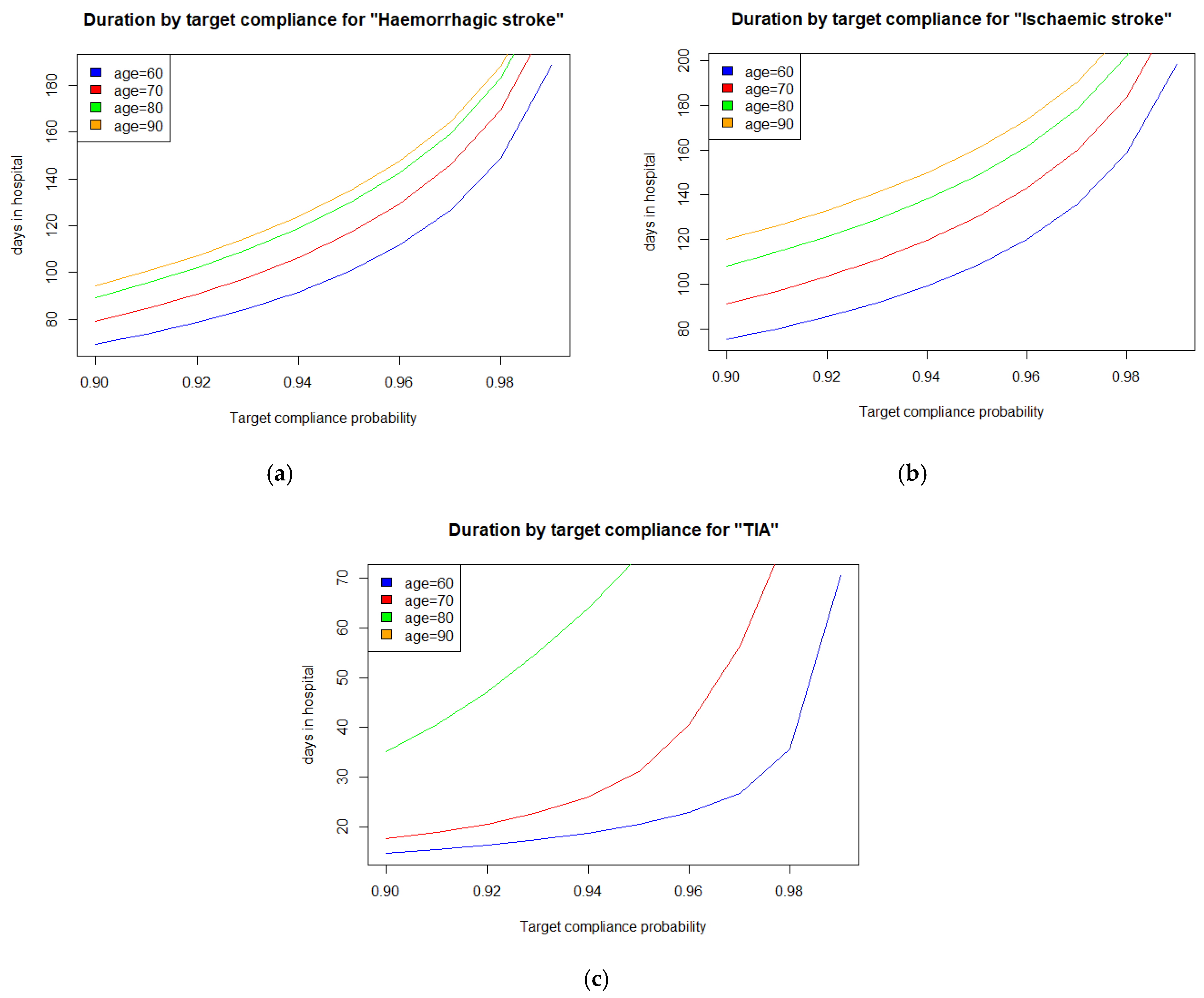
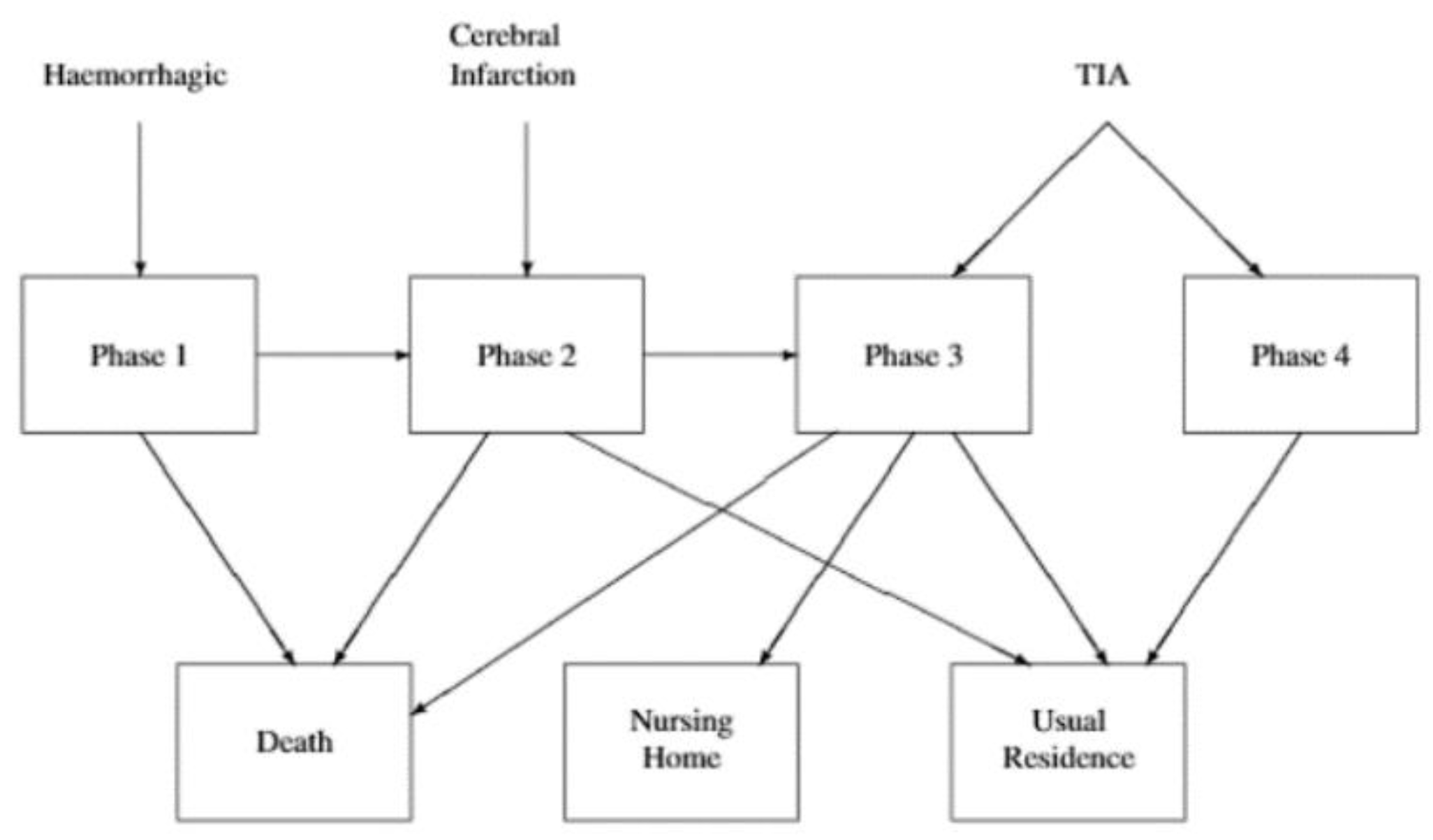
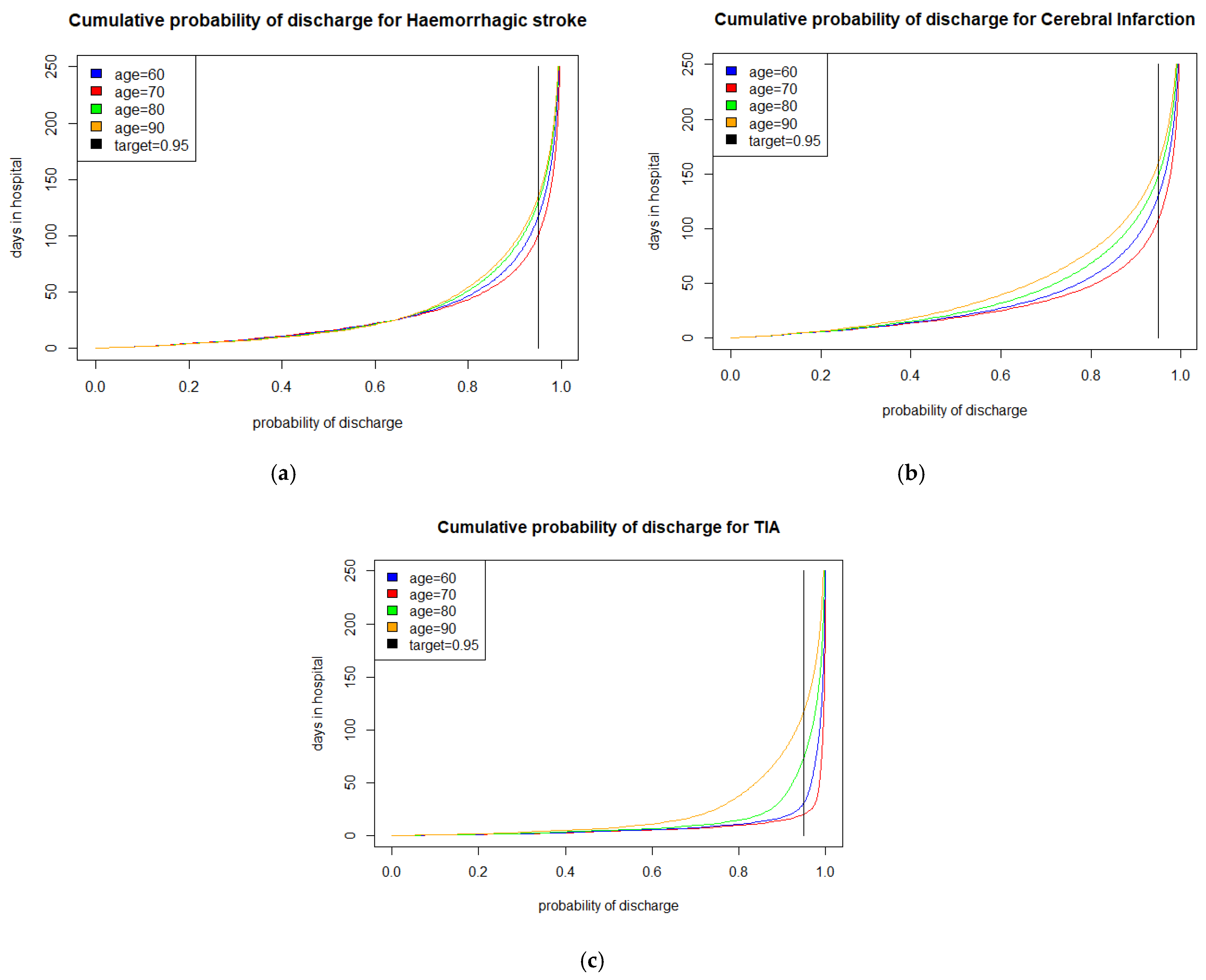
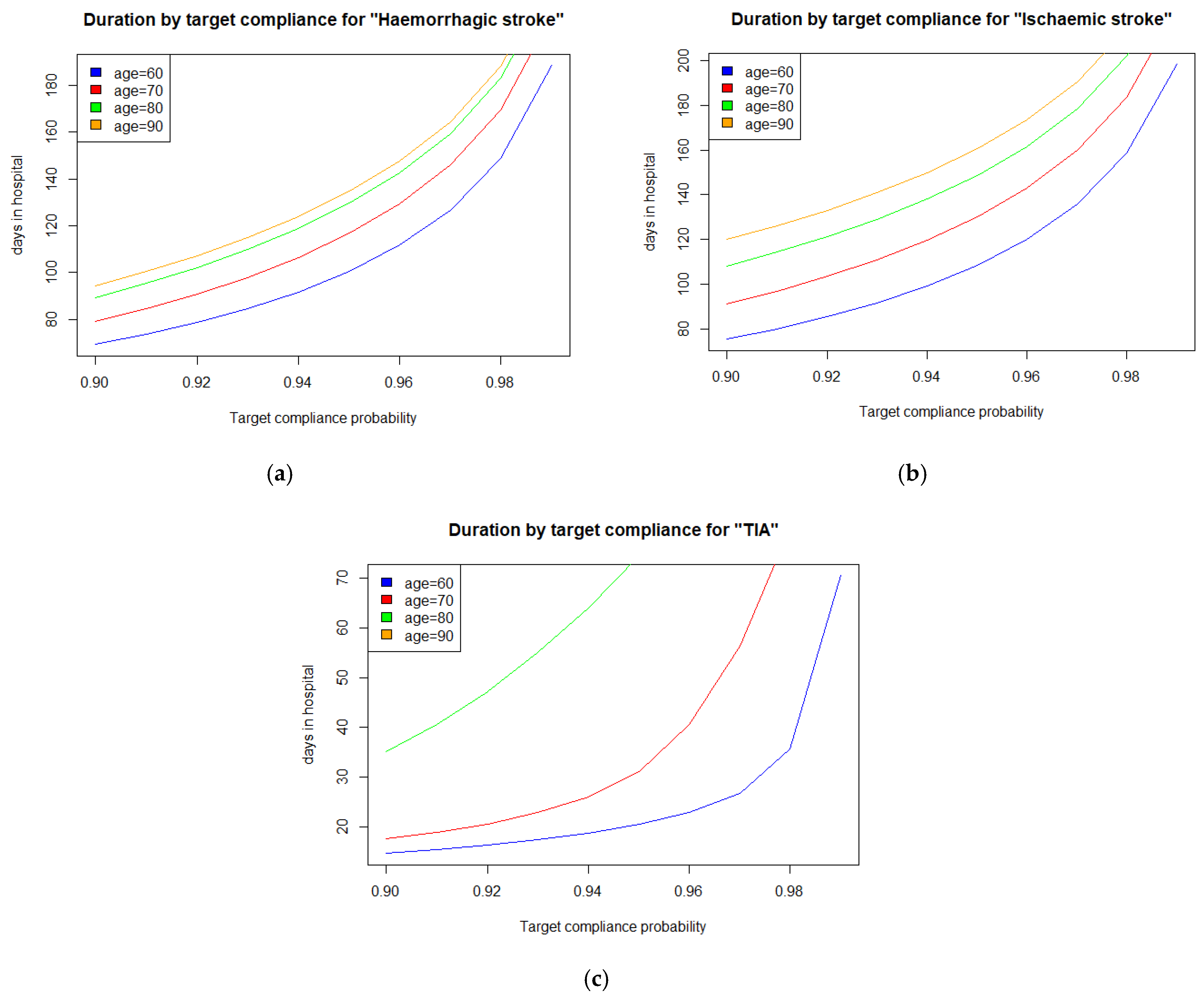
4.1. The Stroke Care Case Study
4.2. Findings
5. Discussion
6. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Van der Aalst, W. Process mining: Overview and opportunities. ACM TMIS 2012, 3, 7. [Google Scholar] [CrossRef]
- Van der Aalst, W.; Reijers, H.; Weijters, A.; van Dongen, B.; de Medeiros, A.A.; Song, M.; Verbeek, H. Business process mining: An industrial application. Inf. Syst. 2007, 32, 713–732. [Google Scholar] [CrossRef]
- Taylor, P. Autonomic Business Processes. Ph.D. Thesis, University of York, York, UK, 2015. [Google Scholar]
- Agrawal, R.; Imieliński, T.; Swami, A. Mining association rules between sets of items in large databases. ACM SIGMOD Rec. 1993, 22, 207–216. [Google Scholar] [CrossRef]
- McClean, S.; Barton, M.; Garg, L.; Fullerton, K. A modeling framework that combines markov models and discrete-event simulation for stroke patient care. ACM Trans. Model. Comput. Simul. 2011, 21, 1–26. [Google Scholar] [CrossRef]
- Peterson, J.L. Petri Net Theory and the Modeling of Systems; Prentice Hall PTR: Hoboken, FL, USA, 1981. [Google Scholar]
- McChesney, I. Process support for continuous, distributed, multi-party healthcare processes—applying workflow modelling to an anticoagulation monitoring protocol. In Proceedings of the 10th International Conference on Ubiquitous Computing and Ambient Intelligence, Las Palmas de Gran Canaria, Spain, 29 November—2 December 2016; Springer: Berlin/Heidelberg, Germany, 2016; p. 255. [Google Scholar]
- Haas, P.J. Stochastic Petri Nets: Modelling, Stability, Simulation; Springer Science & Business Media: Berlin/Heidelbaerg, Germany, 2016; p. 10. [Google Scholar]
- Garg, L.; McClean, S.I.; Barton, M.; Meenan, B.J.; Fullerton, K. Intelligent Patient Management and Resource Planning for Complex, Heterogeneous, and Stochastic Healthcare Systems. IEEE Trans. Syst. Man Cybern. Part A Syst. Humans 2012, 42, 1332–1345. [Google Scholar] [CrossRef]
- Gillespie, J.; McClean, S.; Garg, L.; Barton, M.; Scotney, B.; Fullerton, K. A multi-phase des modelling framework for pa-tient-centred care. JORS 2016, 67, 1239–1249. [Google Scholar]
- Garg, L.; McClean, S.; Meenan, B.; Millard, P. Non-homogeneous Markov models for sequential pattern mining of healthcare data. IMA J. Manag. Math. 2008, 20, 327–344. [Google Scholar] [CrossRef]
- McClean, S.; Stanford, D.; Garg, L.; Khan, N. Using Phase-type Models to Monitor and Predict Process Target Compliance. Proc. Int. Conf. Oper. Res. Enterpr. Syst. 2019, 2019, 82–90. [Google Scholar] [CrossRef]
- Dudin, A.; Kim, C.; Dudina, O.; Dudin, S. Multi-server queueing system with a generalized phase-type service time dis-tribution as a model of call center with a call-back option. Ann. Oper. Res. 2016, 239, 401–428. [Google Scholar] [CrossRef]
- Dudin, S.A.; Lee, M.H. Analysis of Single-Server Queue with Phase-Type Service and Energy Harvesting. Math. Probl. Eng. 2016, 2016, 1–16. [Google Scholar] [CrossRef] [Green Version]
- Vishnevskii, V.M.; Dudin, A.N. Queueing systems with correlated arrival flows and their applications to modeling tele-communication networks. Autom. Remote Control 2017, 78, 1361–1403. [Google Scholar] [CrossRef]
- Barron, Y.; Perry, D.; Stadje, W. A make-tostock production/inventory model with map arrivals and phase-type demands. Ann. Oper. Res. 2016, 241, 373–409. [Google Scholar] [CrossRef]
- McClean, S.; Gillespie, J.; Garg, L.; Barton, M.; Scotney, B.; Kullerton, K. Using phase-type models to cost stroke patient care across health, social and community services. Eur. J. Oper. Res. 2014, 236, 190–199. [Google Scholar] [CrossRef]
- Fackrell, M. Modelling healthcare systems with phase-type distributions. Heal. Care Manag. Sci. 2008, 12, 11–26. [Google Scholar] [CrossRef] [PubMed]
- Tang, X.; Luo, Z.; Gardiner, J.C. Modeling hospital length of stay by Coxian phase-type regression with heterogeneity. Stat. Med. 2012, 31, 1502–1516. [Google Scholar] [CrossRef]
- Marshall, A.H.; Zenga, M. Experimenting with the Coxian Phase-Type Distribution to Uncover Suitable Fits. Methodol. Comput. Appl. Probab. 2010, 14, 71–86. [Google Scholar] [CrossRef]
- Griffiths, J.; Williams, J.; Wood, R. Modelling activities at a neurological rehabilitation unit. Eur. J. Oper. Res. 2013, 226, 301–312. [Google Scholar] [CrossRef]
- Xie, H.; Chaussalet, T.; Millard, P. A Model-Based Approach to the Analysis of Patterns of Length of Stay in Institutional Long-Term Care. IEEE Trans. Inf. Technol. Biomed. 2006, 10, 512–518. [Google Scholar] [CrossRef] [Green Version]
- Knight, V.A.; Harper, P.R. Modelling emergency medical services with phase-type distributions. Heal. Syst. 2012, 1, 58–68. [Google Scholar] [CrossRef]
- Duong, T.; Phung, D.; Bui, H.H.; Venkatesh, S. Efficient duration and hierarchical modeling for human activity recogni-tion. Artif. Intell. 2009, 173, 830–856. [Google Scholar] [CrossRef] [Green Version]
- Faddy, M.J.; McClean, S.I. Markov Chain Modelling for Geriatric Patient Care. Methods Inf. Med. 2005, 44, 369–373. [Google Scholar] [CrossRef] [PubMed]
- Jones, B.; McClean, S.; Stanford, D. Modelling mortality and discharge of hospitalized stroke patients using a phase-type recovery model. HCMS 2018, 22, 1–19. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- McClean, S.; Gribbin, O. A non-parametric competing risks model for manpower planning. Appl. Stoch. Model. Data Anal. 1991, 7, 327–341. [Google Scholar] [CrossRef]
- Vassiliou, P.-C.G. Rate of Convergence and Periodicity of the Expected Population Structure of Markov Systems that Live in a General State Space. Mathematics 2020, 8, 1021. [Google Scholar] [CrossRef]
- Dobson, A.J.; Barnett, A.G. An Introduction to Generalized Linear Models; CRC Press: Boca Raton, FL, USA, 2008. [Google Scholar]
- Otten, M.; Timmer, J.; Witteveen, A. Stratified breast cancer follow-up using a continuous state partially observable Markov decision process. Eur. J. Oper. Res. 2020, 281, 464–474. [Google Scholar] [CrossRef] [Green Version]


Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
McClean, S. Using Markov Models to Characterize and Predict Process Target Compliance. Mathematics 2021, 9, 1187. https://doi.org/10.3390/math9111187
McClean S. Using Markov Models to Characterize and Predict Process Target Compliance. Mathematics. 2021; 9(11):1187. https://doi.org/10.3390/math9111187
Chicago/Turabian StyleMcClean, Sally. 2021. "Using Markov Models to Characterize and Predict Process Target Compliance" Mathematics 9, no. 11: 1187. https://doi.org/10.3390/math9111187
APA StyleMcClean, S. (2021). Using Markov Models to Characterize and Predict Process Target Compliance. Mathematics, 9(11), 1187. https://doi.org/10.3390/math9111187