In this section, we present a design-based simulation experiment based on the Mexican Intra Censal Survey of 2015 (Encuesta Intracensal). The purpose of the simulation is to observe the performance of the different methods under more realistic scenarios. The survey is carried out by the Mexican National Institute of Statistics and Geography (Instituto Nacional de Estadistica y Geografia—INEGI). The survey has a sample of 5.9 million households and is representative at the national, state (32 states) and municipal or delegation level (2457 municipalities), as well as for localities with a population of 50,000 or more inhabitants.
The 2015 Intra Censal Survey questionnaire includes the following topics related to the housing unit: dwelling features, size and use of the dwelling, conditions for cooking, ownership and access conditions, access to water, sanitation facilities and sanitation, electric power, solid waste, equipment, appliances and automobile; and information and communication technologies (ICT). It also includes the following demographic information: total population and structure, birth registration, marital status, health services, ethnicity, education, economic characteristics, non-paid work, migration, daily mobility, fertility and mortality, household composition, non-labor household income, food security, agricultural land use, relationship to the household head, indigenous language, occupation, economic activity, and accumulated education. The survey also includes indicators for states, municipalities, and counties.
One of the key features of the survey is its size and the fact that it includes a measure of income at the household level (defined as money received from work performed during the course of the reference week by individuals of age 12 or older within the household). The inclusion of an income measure allows for a design-based validation of the different methods presented above. The next section describes how the survey is modified to create a census data set and how samples are then drawn from the created census data with the goal of obtaining small area estimates of poverty at the municipal level.
4.1. Creating a Census and Survey
Because the goal of this exercise is to test how well the different methods perform under a real world scenario, the Intra Censal Survey is modified to mimic a Census in order to allow for a design-based simulation. The first step consists of randomly removing 90 percent of households that reported an income of 0. This is done to ensure that some households with an income of 0 are included in the population, but not as many as in the original data to make it more realistic (welfare values of 0 and/or missing are a common feature of household surveys). In the second step, all municipalities with less than 500 households are removed. Thus, the number of households by municipality range from 501 to 23,513 and the median municipality has 1613 households. The final “Census” consists of 3.9 million households and 1865 municipalities.
To draw survey samples, primary sampling units (PSU) need to be created. (the Intra Censal Survey has its own PSUs, however many of these have too few observations to properly work as PSUs in the created “Census” data). Within each municipality, the original data’s PSUs are sorted (assumming that the clusters’ numbering is tied to how proximate each cluster is to one and other) and joined until each created PSU has close to 300 households. Under the proposed approach, original PSUs are never split, just joined to others. Additionally, all original PSUs that were larger than 300 households are designated as a created PSU. The entire process yields 16,297 PSUs.
The resulting Census data is used to draw 500 survey samples to conduct a design-based simulation to establish how a method will perform over repeated sampling from a finite population [
7]. The sampling approach reflects standard designs used in most face-to-face household surveys conducted in the developing world, such as those conducted by the Living Standards Measurement Study (LSMS) program of the World Bank [
30], with some simplification for convenience. First, the 32 states that comprise Mexico are treated as the intended domains of the sample. The main indicator of interest for the survey is the welfare measure: household per capita income. The desired level of precision to be achieved in the sample is assumed to be a relative standard error (
) of 7.5 percent for mean per capita income in each state (this is somewhat arbitrary, but corresponds to usual precision targets in similar surveys and yields a sample of reasonable size). A two-stage clustered design is assumed with clusters (defined above) serving as primary sampling units (PSUs) selected in the first stage within each domain and then a sample of 10 households within each cluster is selected in the second stage. With these design features established, the trimmed census data was analyzed to identify the parameter estimates for per capita income (mean and standard deviation) for each state and the target standard error implied by the parameter estimates that corresponds to an
of 7.5 percent. The minimum sample size required for state
s, given these parameters, under simple random sampling (SRS), is then obtained as:
where
is the standard deviation of per capita income in state
s,
is the target standard error of 7.5 percent in state
s, and
is the mean per capita income in state
s. The minimum sample size under SRS must then be adjusted to account for the clustered design. This design effect due to clustering is accounted for by estimating the intra-cluster correlation (
) for per capita income within each state using the trimmed census data. The
estimates can then be applied to the SRS size obtained above to arrive at the minimum sample size for state
s under the clustered design employed here, given by:
where
is the design effect in state
s,
is the number of households selected within each cluster (10 in this case) and
is the intraclass correlation coefficient (ICC) of per capita income in state
s. The minimum number of clusters to achieve
(assuming 10 households per cluster) was calculated, and then the final (household) sample size is obtained by multiplying the number of clusters by 10 (full results for the sample size determination are available upon request).
Taking the sample size requirements from above as fixed, the sample in each simulation is selected in accordance with the two-stage design. PSUs within each state, referred to here as clusters, are selected with probability proportional to size (PPS) without replacement, where the measure of size is the number of households within the cluster. Then 10 households were selected within each cluster via simple random sampling. According to this design, the inclusion probability for household
h in cluster
c and in state
s is approximated as follows:
where
is the total number of households in the census for state
s,
is the number of households in cluster
c from state
s,
is the number of clusters selected in state
s, and
is the number of households selected in cluster
c within state
s, which is fixed at 10. Even though PPS sampling without replacement is used here, the above formula for the inclusion probabilities is obtained for sampling with replacement. In this case, this formula should provide a reasonable approximation, since there are a relatively large number of PSUs present in the frame. The design weight for each household is simply the inverse of the inclusion probability. In a typical survey, the design weights would be further adjusted for non-response and calibrated to known population characteristics. However, since the sampling is only a simulation exercise, there is no non-response and thus no non-response adjustment is required. Calibration or post-stratification could be performed but was not implemented to simplify the process.
The sample size across the 500 samples is roughly 23,540. Under the proposed sampling scenario, not all municipalities are included, and the number of municipalities included varies from sample to sample, ranging between 951 and 1020 municipalities. The median municipality included in a given sample, is represented by a sole PSU and thus its sample size is of 10 households.
4.2. Model Selection
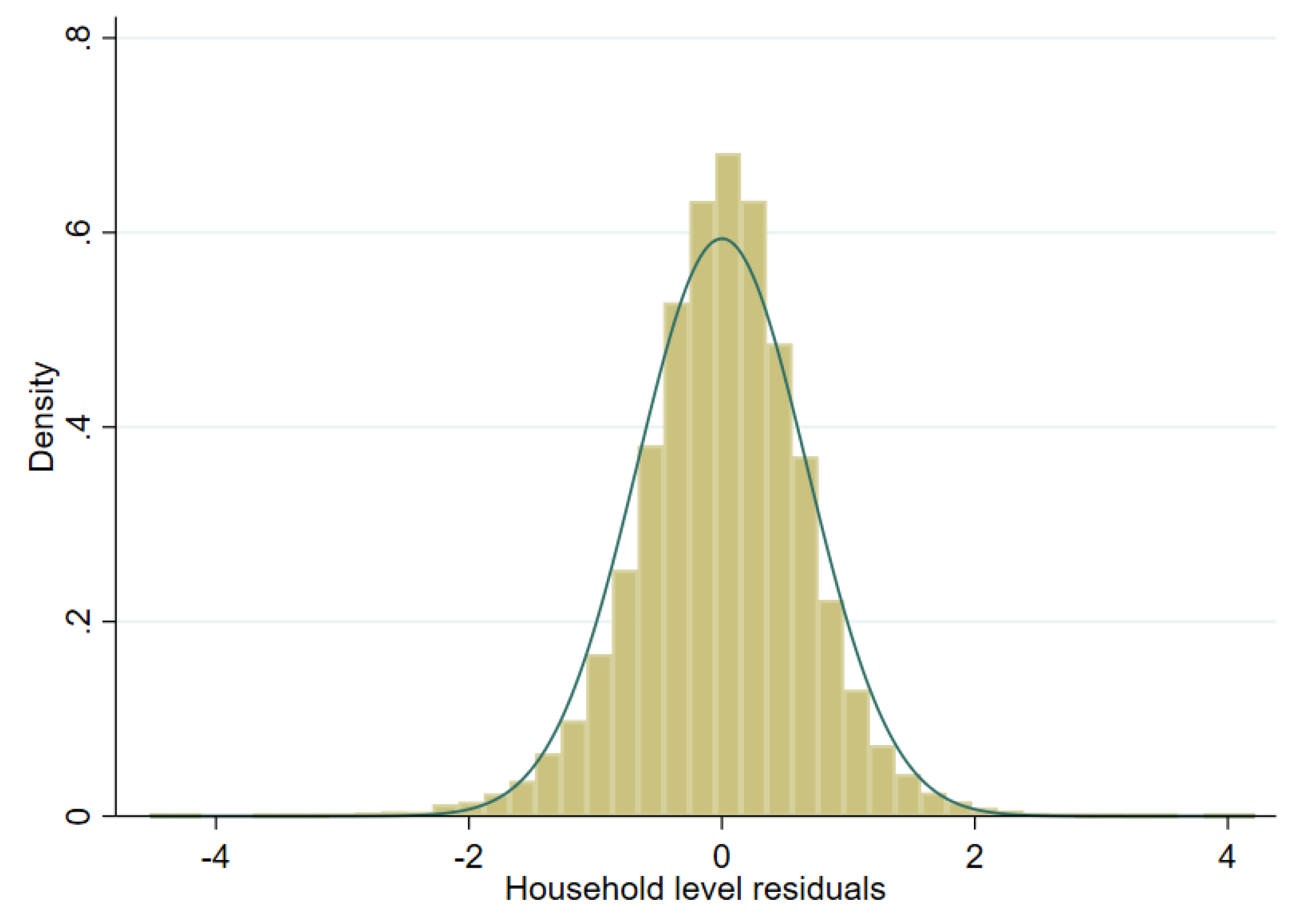
Model selection is conducted using the first sample drawn from the scenario detailed in the previous section. The target variable is household per capita income. However, this variable is highly skewed and to achieve an approximately normal distribution we test three transformations: (i) natural logarithm (in any given sample, roughly 11 observations have an income of 0, these are assigned an income of 1 prior to transformation), (ii) log-shift transformation, and (iii) Box-Cox transformation of the natural logarithm (for further details on transformations, see Tzavidis et al. [
7]). As one can see in
Figure 6,
Figure 7 and
Figure 8 for a single sample (from a two-stage clustered design), the Box-Cox transformation, as well as the log shift, fix the skewness in the distribution of model residuals that appears after taking the natural logarithm of per capita income.
The goal of the model selection process is to arrive at a model that only includes stable covariates. Under each transformation, model selection is done using a least absolute shrinkage and selection operator, commonly known as lasso, where the candidates for covariates include household characteristics and characteristics at the PSU, municipal and state level. The model is selected using 20 fold cross validation and shrinkage parameter
that is within 1 standard error of the one that minimizes the cross validated MSE. Two models are selected: (i) a model that includes household characteristics and characteristics at the PSU, municipal, and state levels and (ii) another model that only includes characteristics at the PSU, municipal and state levels. The second model is used for the unit-context approach. All household level characteristics that are also included as aggregates at the PSU, municipality, and state levels have been previously standardized to ensure that these have mean 0 and standard deviation 1 for each PSU, municipality and state, respectively. Note that aggregated covariates have been obtained from the “census”, thus, the aggregated covariates will be the same within the sample and the census. The lasso model selection process applied here ignores the error structure presented in (
1) and (
2) and does not ensure that selected covariates will be significant under the assumed models. Consequently, after the initial lasso model selection, model (
1) is fit using Henderson’s Method III (with sampling weights) and random effects specified at the municipality level. Because the resulting model may still include covariates that are not significant under the fitted model, all non-significant (at the 1% level) covariates are removed sequentially, starting with the least significant covariate, then the model is fit again without the covariate, and the process is repeated until all covariates in the model are significant at the 1% level. Finally, we check for multicollinearity and remove covariates with a variance inflation factor (VIF) above 3.
Fitted models using the first sample and the described model selection are presented in
Table A1 and
Table A2 in the
Appendix A. Since in small area estimation models are used for prediction, assessing the predictive power of the model is important. This may be measured using the coefficient of determination,
[
7]. For the household level model used in this exercise, the
is close to 0.45 while that of the unit-context model centers around 0.25.
Figure 9,
Figure 10 and
Figure 11 represent checks on the normality assumptions using normal
Q-Q-plots of household level residuals and estimated area effects for the onefold unit level model with random municipality location effects. The resulting plots for the unit-context models can be seen in the
Appendix A Figure A1,
Figure A2 and
Figure A3. The natural logarithm transformation (
Figure 9) presents evidence of deviation from normality. Marhuenda et al. [
8] notes in applications that use real data the exact fit to a distribution is barely met; however, the Box-Cox and log-shift transformations provide considerably better normal approximations, see
Figure 10 and
Figure 11. Box-Cox and log-shift transformations are available under R’s
sae package as well as under Stata’s
sae package. In the World Bank’s
PovMap software, the only available transformation was natural logarithm. However,
PovMap does allow for drawing residuals from the empirical distribution as well as from a Student’s
t distribution.
4.3. Results
Once the models to be used have been selected and
samples under two-stage sampling described in
Section 4.1 have been taken from the “census” created using the Mexican Intra Censal Survey of 2015, we obtain estimates using the different considered models. The target parameters for this simulation are mean welfare and the FGT class of decomposable poverty measures defined by Foster et al. [
29] for
, for the municipalities present in the census. The true values of the target parameters at the municipal level are based on the census data.
As a first step, we compare results using the three transformations discussed in the previous section.
Figure 12 and
Figure 13 show box plots of empirical absolute relative bias and MSE of CensusEB estimates of poverty rates based on model (
1) under each transformation. The Box-Cox and log-shift transformation yield estimates that are not only less biased, but also result with a lower empirical design MSE. As can be seen in the results from the first 3 columns in
Table 2, the log-shift transformation yields aggregate results somewhat preferable to the Box-Cox. Additionally, in
Table 2, it is quite clear that the natural logarithm may actually result in aggregate results that present considerably smaller gains over direct ones and thus model and residual checks should always be done to ensure adequate transformations are used to avoid such an outcome. The rest of the discussion will focus on estimates obtained from the log-shift transformation applied to the two-stage samples (Figures under other transformations are available upon request).
We consider estimators based on one-fold and twofold nested error models, including unit-context (UC) models with only aggregated covariates (all models include a constant term), and direct estimators. Concretely, we consider the following (a table summarizing each method can be found in the
Appendix A):
Direct Estimates:
Direct estimates from the survey samples for each municipality. These are calculated with weights from the considered design. Specifically, the calculation of FGT indicators under the two-stage design detailed in
Section 4.1 using the inclusion probabilities is obtained as:
;
where, is the inclusion probability for household h in cluster c and in municipality a, and is the FGT or welfare measure of interest for household h in cluster c and in municipality a. Note that, depending on the sampling strategy, some areas might have zero sample size, and hence no direct estimates can be obtained for those areas.
Unit-level models:
: Model fit is done using Henderson’s Method III (with sampling weights) and estimates are obtained using CensusEB as noted in CMN Corral et al. [
16]. The fitted model reads:
;
where is a vector of household specific characteristics, contains cluster level characteristics, includes municipality level characteristics and is composed of state level characteristics. The random effects, , are specified at the municipal level.
: Model fit is done using Henderson’s Method III (with sampling weights) and estimates are obtained using Census EB as noted in Corral et al. [
16]. The difference with model (1) is that random effects are specified at the PSU level. That is, the fitted model is:
;
where, , is a random effect for cluster c within municipality a.
: Model fit is done using REML and estimates are obtained using CensusEB as in Marhuenda et al. [
8]. Fitted model follows:
- (a)
; random effects are specified at the municipality and PSU level.
Note that CensusEB estimators based on twofold nested error models are obtained without the use of probability sampling weights and are thus not comparable to those estimators that use survey weights.
: Similar to
, however random effects are specified at the municipal and state level. The goal here is to borrow strength from the state for municipalities that are not in the sample which takes a cue from Marhuenda et al. [
8].
: under the same model as in 2. In cases where we use a transformation different from the natural logarithm, random location effects and household residuals are drawn from their empirical distribution.
Unit-context models:
: Unit-context model originally proposed by Nguyen [
9] but with EB, similar to Masaki et al. [
12]. Model fit is done using Henderson’s Method III (with sampling weights) and estimates are obtained using CensusEB as noted in Corral et al. [
16]. The fitted model follows:
.
: Unit-context model fit is done using REML and estimates are obtained using CensusEB as in Marhuenda et al. [
8]. The fitted model is:
;
: Similar to model ; however, random effects are specified at the municipal and state levels. Just like 5, the goal here is to borrow strength from the state for municipalities that are not in the sample.
:
ELL estimates under model in
, but random effects are specified at the PSU level, as was originally proposed by Nguyen [
9] and then by Lange et al. [
11]. In cases where we use a transformation different from the natural logarithm, random location effects and household residuals are drawn from their empirical distribution.
.
The chosen measures to evaluate performance of the considered predictors are bias, MSE, and root MSE obtained as:
where
j stands for one of the methods:
and
;
denotes the true population parameter for municipality
a. Note that, in design-based simulations, there is only one true population parameter because our census is fixed. In model-based simulations, the target parameters are random. Formal evaluation of the MSE estimators is not undertaken here since it is beyond the scope of the exercise and computationally intensive as it would require obtaining a bootstrap MSE for each of the 500 samples.
In
Section 3.1, like Marhuenda et al. [
8], we noticed how the relative size of the random effects affected the precision of the different methods. The first sample from the simulation experiment under two-stage sampling is used to assess the magnitude of the random effects under the unit level model. The values of
and
under the twofold nested error model with a log shift transformation for this sample are equal to 0.021 and 0.013, respectively. The value of
when specifying random effects only at the cluster level is equal to 0.072, and
is equal to 0.054. When specifying random effects only at the municipality level,
is equal to 0.022, and the
ratio is equal to 0.045.
In
Figure 14, we can clearly see that, in general, all SAE methods outperform the direct estimates in terms of design MSE (see
Figure A6 in the
Appendix A for the untrimmed version of the figure). In terms of design bias (
Figure 15), direct estimators are very close to being unbiased under the design and would likely converge to the true estimate as the number of simulations increase. On the other hand, model-based estimators are all biased under the design. The result is similar to the one presented by Marhuenda et al. [
8], where gains in MSE for model-based estimators are achieved at the expense of design bias. As an additional check, we add simulations where
samples are taken, each consisting of a 1% SRS without replacement in every PSU within the fixed census population. Aggregate results for this scenario are presented in column 4 of
Table 2 and box plots for MSE and bias are presented in
Appendix A Figure A4 and
Figure A5, respectively. The first thing to note in these figures is there are fewer extreme outliers when compared to results from the two-stage sample scenario in
Figure A6 in the
Appendix A. Despite fewer outliers, the results under the additional sampling scenario mimic those from two-stage samples. However, under the two-stage sampling used here, direct estimates for most municipalities are not available across all 500 samples (see
Section 4.1). Consequently, direct estimates are not included under the remaining figures that discuss results from the two-stage samples.
Under the simulation experiment with two-stage sampling, the empirical MSE of
estimates, where the location effect has been specified at the PSU level, appear to have a tighter spread than direct estimates (
Figure 14). Consequently, though ELL appears to perform relatively well, relative to direct estimates, the number of ELL outliers with a high MSE is considerable and
performs worse than all other small area approaches. This result was not expected, as the FGT0 results for
appear to perform better than the traditional
, which has a considerably better model fit (note that, under the MI inspired bootstrap of ELL, a very poor model fit will be heavily penalized and will likely yield noise estimates for
that are fare worse than direct estimates in most applications). Nevertheless,
does very poorly in terms of true MSE for the estimation of mean welfare, with an MSE that is as large as that of direct estimates, and it is also considerably biased, see
Appendix A Table A5. These results also hold under the simulation experiment with the 1% SRS by PSU samples.
As expected,
estimates show a considerably tighter MSE spread than direct estimates, but still with outliers. Another interesting finding is that under CensusEB, but with random effects specified at the PSU level (
), the empirical MSE is tighter than that of the direct estimates and also displays better properties than
as seen in
Table 2. However, given the discussion in the model-based validation and the results shown here, the results with the random effects at the municipality level are preferred over the ones where the effect is specified at the PSU level.
Perhaps the most surprising result is the low MSE of the
method with only contextual variables and the other
variants, as proposed by Masaki et al. [
12]. The results display a tight spread and the results from
Table 2 corroborate the finding. Nevertheless, beyond UC models being an alternative if contemporaneous census data is not available, the method presents a couple of advantages over traditional Fay–Herriot (FH) area level models under sampling scenarios that follow a two-stage design like the one considered here. First, as noted toward the end of
Section 4.1, the majority of municipalities are represented by 1 PSU and thus have quite small sample sizes which makes the likelihood of direct FGT0 estimates being equal to 0 or 1 much higher. Under these cases, the method from Nguyen [
9] is a valid alternative to FH because FH is not applicable in these municipalities with a sampling variance of 0. An additional advantage is that the model can be used for multiple indicators, whereas the FH requires a model for each indicator considered.
Table 2.
Aggregate results for 1865 municipalities in “Census” (FGT0)—results from 500 samples.
Table 2.
Aggregate results for 1865 municipalities in “Census” (FGT0)—results from 500 samples.
| | 1 | 2 | 3 | 4 |
|---|
| Transformation | Box-Cox | Nat. log. | Log. Shift | Log. Shift |
| Direct | | | | |
| AAB () | 11.314 | 11.314 | 11.314 | 9.722 |
| ARMSE () | 14.051 | 14.051 | 14.051 | 11.997 |
| | | | |
| AAB () | 6.277 | 8.642 | 6.273 | 5.393 |
| ARMSE () | 6.580 | 9.169 | 6.574 | 5.964 |
| | | | |
| AAB () | 6.382 | 8.953 | 6.380 | 5.740 |
| ARMSE () | 6.695 | 9.414 | 6.687 | 5.997 |
| | | | |
| AAB () | 6.080 | 8.800 | 6.092 | 5.395 |
| ARMSE () | 6.584 | 9.525 | 6.589 | 6.034 |
| | | | |
| AAB () | 6.253 | 8.690 | 6.277 | 6.054 |
| ARMSE () | 6.363 | 8.847 | 6.384 | 6.181 |
| | | | |
| AAB () | 6.685 | 8.781 | 6.685 | 6.961 |
| ARMSE () | 6.820 | 8.854 | 6.820 | 7.087 |
| | | | |
| AAB () | 6.171 | 7.531 | 6.016 | 5.982 |
| ARMSE () | 6.607 | 8.274 | 6.461 | 6.672 |
| | | | |
| AAB () | 6.121 | 7.596 | 5.998 | 5.926 |
| ARMSE () | 6.446 | 8.186 | 6.332 | 6.652 |
| | | | |
| AAB () | 6.250 | 8.019 | 6.250 | 7.581 |
| ARMSE () | 6.421 | 8.100 | 6.421 | 7.758 |
| | | | |
| AAB () | 6.002 | 7.539 | 5.875 | 5.937 |
| ARMSE () | 6.414 | 8.284 | 6.294 | 6.570 |
A possible explanation for the good performance of unit-context models under the considered experiments could be due to estimated random effects, where
, which coincides with the better performing scenario in
Section 3.1. However, this observation is likely a coincidence, since the performance of unit-context models depends on the particular covariates included in the model and on the shape of the target indicator. Under the Mexican data with the covariates used, the unit-context model performs rather well. However, the method considerably lags behind all others for estimation of the welfare mean by area. A similar result is observed in the results presented in
Section 3.1, see also
Table A5 in the
Appendix A).
Under the simulations of column 3 of
Table 2, the gains in MSE for the unit-context methods appear to come in municipalities with larger populations (similar findings are obtained under the simulations for column 1). This is expected because in our sampling scenarios, municipalities with a larger population are more likely to be included in all the samples. For example, in the census there are 16,293 PSUs spread over 1865 municipalities. The median municipality in the created census has 7 PSUs, and the median municipality in a given two-stage sample is only represented by one PSU. Consequently, it is not surprising the unit-context variants under-perform relative to unit models in terms of bias and MSE in municipalities with smaller populations, as can be observed in
Figure 16. For municipalities with larger populations, and hence those likely to consist of more PSUs and more of these PSUs in the sample, direct estimates for FGT0 are more precise and unit-context models begin to catch up to unit models (see
Figure A7 in the
Appendix A).
Under the simulations from a 1% SRS by PSU, shown in
Table 2, column 4 and in the
Appendix A Figure A4 and
Figure A5, we notice the unit models (
) present a slight upward bias that seems to become more pronounced in more populous municipalities (
Figure 17). Notice that some bias is acceptable since gains in MSE are achieved at the expense of bias, however in this case the presence of outliers seems to lead to increased upward bias that affects more municipalities as we move to more populous deciles (box-plots for
in
Figure 17). Unit-context (
) models on the other hand, appear to have a downward bias. In the box-plots in
Figure 17 for
, the bias in lower deciles is downward and as we move to upper deciles the downward bias is considerably reduced.
As noted in
Section 3.1, the problem faced by unit-context models is an effect that is somehow similar to omitted variable bias, which is manifested as a lack of linearity (see
Figure 18). The true model includes household size at the household level. Consequently, this variable is a determinant of the dependent variable. Household size
can be broken down into
, thus the omitted component,
, is also a determinant of the dependent variable. The unit-context model only includes the PSU average household size
obtained from the census as a covariate.
Figure 19 further presents the issue. Under
, residuals appear to follow a random pattern; however, under
households in municipalities represented by only one PSU in the sample will all have the same linear fit. This manifests itself in the figures for
as a column of vertical dots. The problem can also be observed in
Figure 20 where the households within municipalities with just one PSU in the sample will have the same linear fit. More specifically, all the points corresponding to different households from the same PSU become superposed in
Figure 20 right, and for those municipalities with just one PSU, there is a single point representing the same predicted value for all the households in that municipality.
To check whether the upward bias of estimators based on unit-level models is due to deviations from model assumptions, specifically deviation from normality, we apply a normalization transformation called ordered quantile normalization [
31] (employed also by Masaki et al. [
12]). In the absence of tied values the transformation is guaranteed to produce a normally distributed transformed data. The transformation is of use only for FGT0 because it cannot be fully reversed 1 to 1 without the original data and thus one has to extrapolate values not observed in the original data (
ibid) (the original functional transformation is only defined when a given value is in the observed original data [
31]). The result for this transformation can be seen in
Figure 21, and it shows that the deviation from normality may be an issue in our models. The previously observed upward bias in the
models is less evident in these results. However, now that the deviation from normality is less of an issue, the
models show a clear downward bias. The figure adds further evidence of a possible bias inherent in the
model offsetting the bias due to the deviation from the model’s assumptions—in this case normality. Offsetting of biases is not guaranteed to always occur.
As an additional check, we also performed a hybrid experiment that consists in using the census data created in
Section 4.1 and a 5% SRS from each PSU to construct a synthetic census based on a twofold model. The 5% SRS sample is used to select a model with all eligible covariates (household and aggregate) following the same process described in
Section 4.2. Using the model’s resulting parameter estimates from a twofold model as in (
2), we create a new welfare vector in the census for all households. Then a unit-context model and a new unit model are selected, once again following the process described in
Section 4.2 using the first out of 500 samples where 1% SRS by PSU is selected. This is done to remove the issue of outliers from the data and to ensure that the data generating process follows the one assumed in Equation (
2). The simulation removes the potential misspecification due to deviations from normality in the data and allows us to isolate the problem present in the unit-context model (
).
Results for the new hybrid simulations are presented in
Figure 22 and
Figure 23. Note that in this simulation, where we have removed the normality issue, the upward bias that was present in the unit level model (
) is no longer evident. On the other hand, the previously suspected downward bias of the unit context models (
) is salient, as can be seen in
Figure 22 and by municipality deciles sorted by population in
Figure 24. Note that under the
model more than 75% of the municipalities present a downward bias (
Figure 22). This finding is aligned to what we observed in
Figure 17. However, because there is no deviation from normality in the hybrid simulation, the downward bias of the unit-context models (
) is never offset, and is quite considerable and leading to substantially larger empirical MSEs for the unit context models (
Figure 25). Simulations were repeated, where, instead of performing model selection, the selected model for CEB estimators contains exactly the same covariates as those used to generate the welfare, and considering only the area aggregates for UC models. This was done just to check whether the observed biases could be due to model misspecification, in the sense that the selected covariates are different from those in the true model. Results were very similar to those observed in the previous hybrid simulation with a model selection step. Hence, the results suggest deviations from the assumed model are an issue and the countering of biases is what is driving the seemingly good results for unit-context models in the two-stage sampling scenario, highlighting the importance of proper data transformations and model selection to ensure that model assumptions hold when using Census EB methods.
Given the direction of the bias of unit-context models is not known a priori (see how under the simulations presented in
Figure 1 and
Figure 2, the method appears to be upward biased)—and that these might present high bias—unit-context models are unlikely to be preferred over traditional FH models when the census auxiliary data are not aligned to survey microdata, unless the calculation of variances of direct estimators, to be used in the FH model, is not possible for various locations, as noted before. This bias appears also for other measures of welfare, and particularly for ELL variants of the unit-context models. In this case, benchmarking is not a recommended procedure for correcting the bias, since it may not help. EB estimators are approximately model unbiased and optimal in terms of minimizing the MSE for a given area, thus when adjusted afterwards for benchmarking, that is, so that these match usual estimates at higher aggregation levels, the optimal properties are lost and estimators usually become worse in terms of bias and MSE under the model. When benchmarking adjustments are large, as those likely required by UC variants, it is an indication that the model does not really hold for the data. In the case of UC models, we have shown that the model will not hold due to omitted variable bias.
Furthermore, note bias can lead to considerable re-ranking of locations and thus a limit on the acceptable bias should usually be determined according to need. This is of particular importance when determining priorities across areas based on small area estimates. If an area’s true poverty rate is 50% and the method yields an estimator of 10% due to a biased model, there is a real risk that this area may not be given assistance when needed. Molina [
10] suggests 5 or 10 percent of absolute relative bias as an acceptable threshold. An additional problem for unit-context models in many applications is it is not possible to match census and survey PSUs; in some cases it is due to confidentiality reasons and in others it is due to different sampling frames used for the survey. The latter is something that is likely to affect applications where census and surveys correspond to different years. Under these scenarios, unit-context models are unlikely to be superior to FH and alternative area models.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}