1. Introduction
The concept of attraction basins has been used in many fields, such as Economy [
1,
2,
3], Mathematics [
4,
5,
6], Biology [
7,
8,
9], Physics [
10,
11,
12], Computer Science [
13,
14,
15], etc. Their definitions may vary in different degrees (even within the same field), although the underlying idea stays the same. For example, to analyse far-sighted network formation games in Economy, Page et al. [
2] define attraction basin informally as
“… a set of equivalent networks to which the strategic network formation process represented by the game might tend and from which there is no escape”. To analyse the dynamical behaviour of different Steffensen-type methods in Applied Mathematics, Cordero et al. [
5] define attraction basins as follows:
“If a fixed point p of R is attracting, then all nearby points of p are attracted toward p under the action of R, in the sense that their iterates under R converge to p. The collection of all points whose iterates under R converge to p is called the basin of attraction of p.” To study the environmental robustness of biological complex networks, Demongeot et al. [
7] describe an attraction basin as
“the set of configurations that evolve towards an attractor …”. Similarly, in Physics, Isomäki et al. [
10] describe attraction basins as
“the sets of initial conditions approaching particular attractors when time approaches infinity”. In this paper, we are interested in attraction basins used in the field of Computer Science related to metaheuristics [
16]. Informally, the common general definition may be stated as follows. The attraction basin consists of initial configurations that are “attracted” to its attractor. The definition allows arbitrary configurations, an arbitrary attraction mechanism, and arbitrary attractor, as long as it is reachable by the attraction mechanism from the initial configuration(s). The concept of attraction basins helps the users to structure the space under consideration, and, thus, it is applicable to almost any field.
In the field of metaheuristics, the space under consideration is composed of many feasible solutions (configurations) to the optimisation problem. Then, the metaheuristics, such as Evolutionary Algorithms, [
17,
18,
19,
20] are used to find the (sub-)optimal solution(s). The definition of optimality depends on the needs of a concrete user. During the run, the metaheuristic itself structures the problem space to find the (sub-)optimal solution(s). This structuring depends on the internal mechanisms of a metaheuristic, user-defined parameters (if they exist), and the problem to be solved. Therefore, each metaheuristic (with all its user-defined parameters) solving some problem can be analysed with its own attraction basins [
14]. However, as these attraction basins would be stochastic and hard to analyse, researchers mostly do not use metaheuristics for their construction. Researchers rely on a deterministic local search algorithm, usually Best or First Improvement, that operates on some predefined neighbourhood. In this way, each optimisation problem has its attraction basins independent of the metaheuristics used to solve it. For example, see
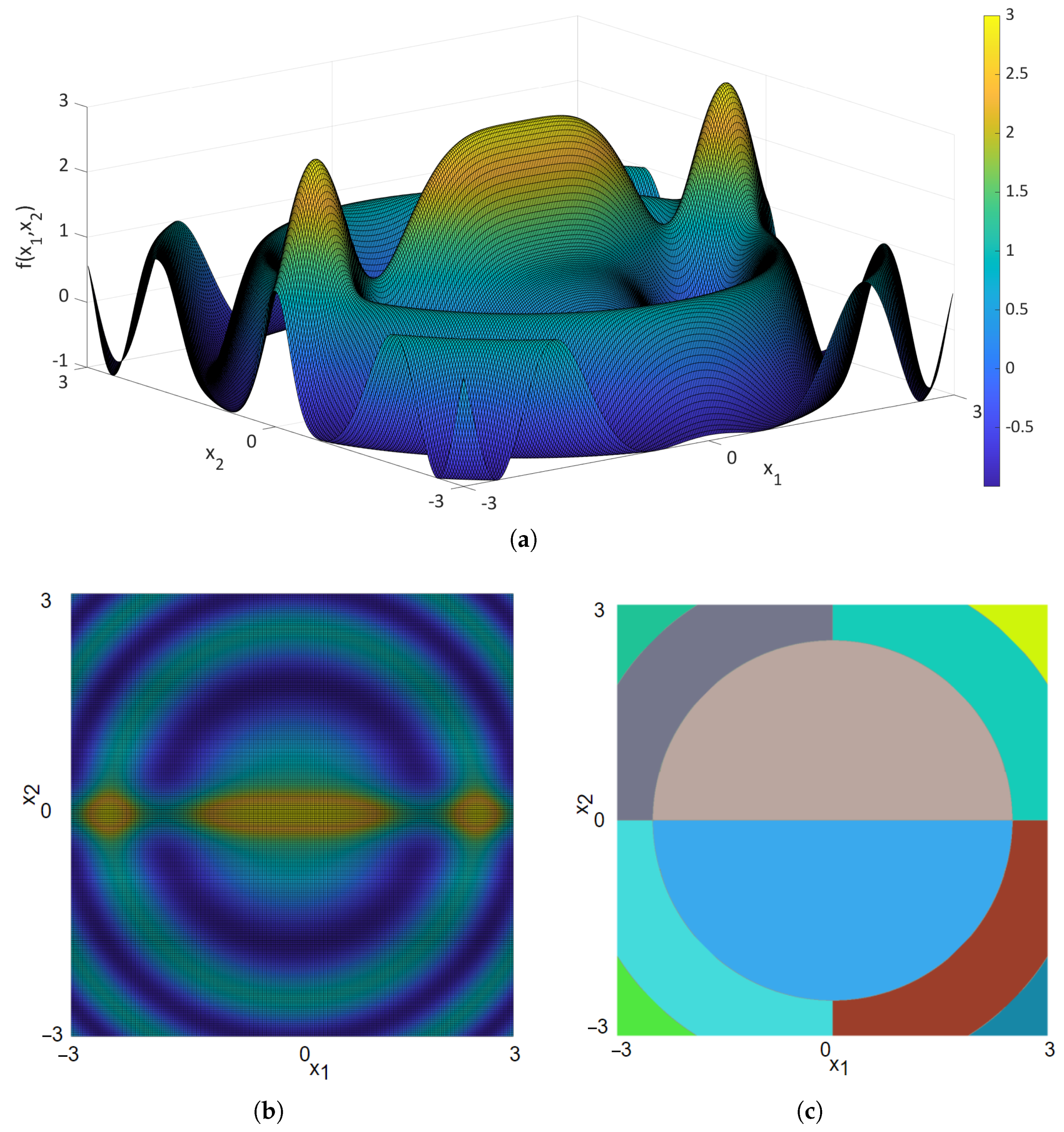
Figure 1, where a landscape (
Figure 1a), heatmap (
Figure 1b), and attraction basins (
Figure 1c) are shown for a two-dimensional Rastrigin function (see Equation (
1)).
In
Figure 1c, the neighbouring points (i.e., solutions and configurations) that belong to the same attraction basin have the same colour, and all points in a particular attraction basin are attracted by the same local optimum. Colours are chosen randomly, however different colour combination classes may have some impact on noticeability in map-based information visualisation as found in [
21]. Here, the attraction basins were computed by a Best Improvement local search that operated on eight neighbours per each point (we used grid sampling). Attraction basins for Split Drop Wave (see Equation (
2)) are not so simple and regular as for the Rastrigin function. Its attraction basins are harder to compute with the previous algorithm, due to thin circular plateaus.
Figure 2 presents a landscape, heatmap, and attraction basins computed correctly with the algorithm from [
22].
Attraction basins are used, for example, to characterise the fitness landscapes (see, e.g., in [
23,
24]), or analyse the metaheuristic (e.g., researchers in [
22,
25] measure exploration). A fitness landscape is an important concept, which was borrowed from biology [
26] to analyse the optimisation problems and the relation of their characteristics to the performance of metaheuristics [
27,
28,
29,
30]. For example, characteristics such as the modality, distribution of attraction basin sizes, global and largest attraction basin ratio, global and largest attraction basin distance, barriers (optimal fitness value needed to reach one optimum from another using an arbitrary path [
29]), ruggedness, etc. were compared with the performance of metaheuristics, to find out which metaheuristic was more suitable for certain characteristics of problems [
31,
32,
33,
34]. Moreover, Machine Learning algorithms were used for automatic selection of metaheuristics based on these characteristics [
35,
36]. Therefore, the characteristics (e.g., attraction basins) should be computed and understood accurately, otherwise such analysis could be misleading. The same holds for the exploration and exploitation, two distinct phases of each metaheuristic that are found to be crucial to understand and use metaheuristics efficiently [
37,
38,
39,
40,
41]. In [
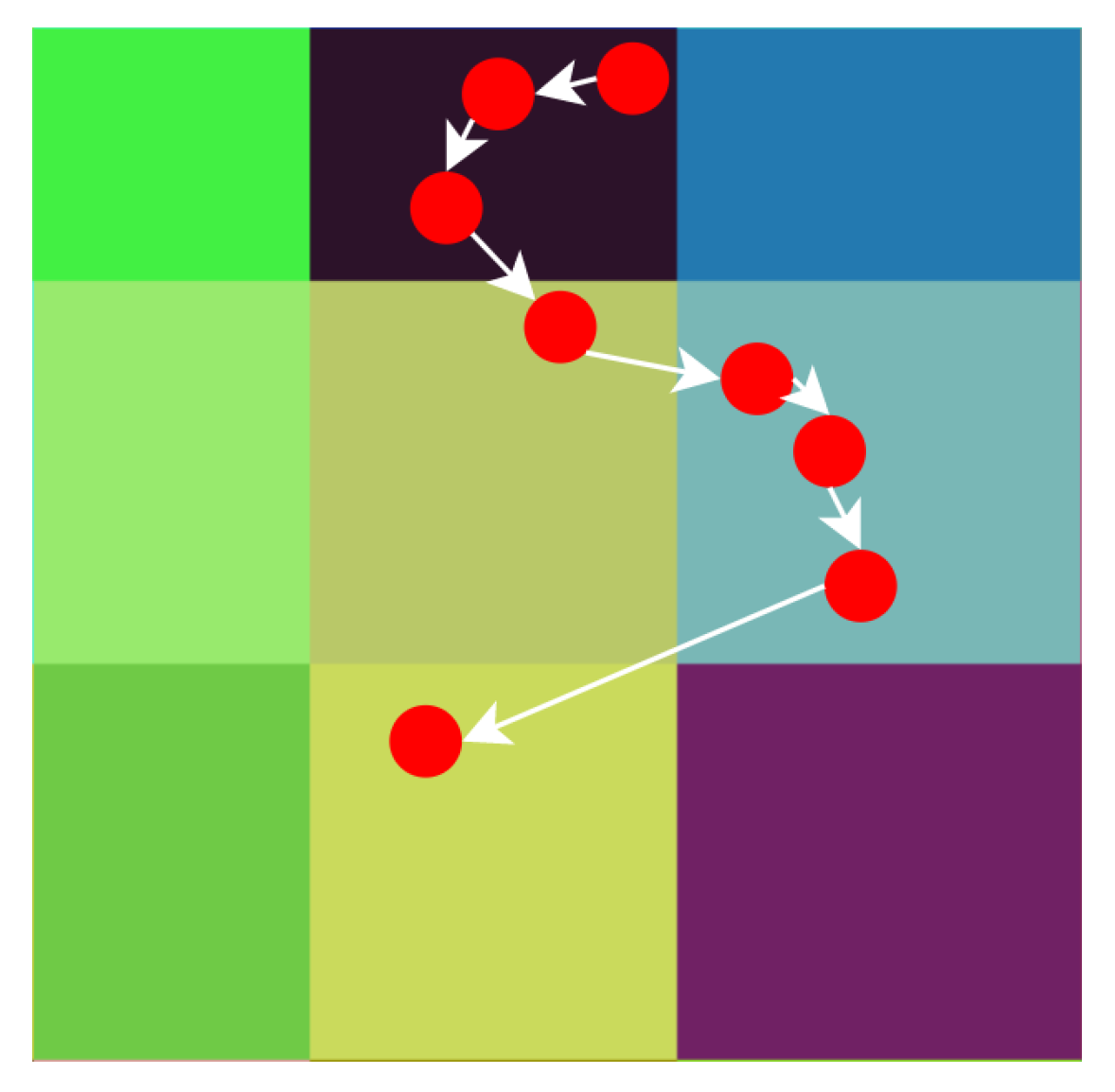
22], attraction basins were used to measure exploration and exploitation directly. For example, in
Figure 3, attraction basins are denoted with different colours, solutions given by a certain metaheuristic are denoted with red circles, and the sequence of solutions is ordered by the white arrows. The first two arrows represent the exploitation phase. The next two arrows represent the exploration phase. Then two arrows represent the exploitation phase again, and, finally, the last arrow represents the exploration phase.
It is obvious that the metric requires unambiguously computed attraction basins, so the exploration and exploitation phases can also be identified unambiguously. Otherwise, the results of the metric may be meaningless.
During our previous work, where we measured the exploration and exploitation of metaheuristics based on attraction basins [
22], we noticed the inconsistencies in the definitions, lack of implementations, and generally the lack of literature that deals appropriately with the attraction basins in the field of metaheuristics, especially within continuous (real-valued domain) problems. To overcome this, we decided to conduct a Systematic Mapping Study (SMS) [
42]. To the best of our knowledge, no SMS, or Systematic Literature Review (SLR) for that matter, exists on this topic in the field. We believe this study could provide a good start and point out open issues to the newcomers, as well as experienced researchers. The main contributions of this work are overviews of
optimisation problem types where attraction basins have been used,
topics and contexts within attraction basins have been used,
definitions of attraction basins,
algorithms to compute attraction basins, and
trends.
The rest of the paper is organised as follows.
Section 2 reviews SMSs and metaheuristics briefly in general. The research method is described in
Section 3. Results are aggregated and discussed in
Section 4. Findings are summarised and some directions are provided in
Section 5. Finally, algorithms that are of secondary importance are included in
Appendix A.
4. Results and Discussion
This section presents and discusses the results obtained by classification of all studies that passed the full-text screening phase.
Many articles did not pass the full-text screening phase because of only mentioning attraction basins without any further elaboration. Scopus found more relevant articles than Web of Science in our case, although the overall number was still small. Therefore, we used iterative forward and backward snowballing to widen our corpus. Eighty new articles were identified in the snowballing phase, in a total of 137 publications. It is intriguing that we found more articles by snowballing than by database search. Does this indicate that snowballing is necessary for some areas? First, we have to investigate why the database search missed so many relevant articles. The reasons for this are presented chronologically in
Figure 6. We missed one paper from 2014 because we assumed the paper was a duplicate (
Duplicate suspicion row). One paper was added to the database in the meantime (
Added recently to Scopus row). Two articles were omitted because they were not found in the database to belong to the field of Computer Science (
Refinement: Research area Computer Science row). Surprisingly, the most papers were missed because of the first part of the search string, that is
TITLE-ABS-KEY (“attraction basin*” OR “basin* of attraction”) (
A problem with the first part of the search string row). Only two papers were missed because of the second part of the search string, that is,
TITLE-ABS-KEY (“optimi*ation” OR “metaheuristic*” OR “heuristic*” OR “evolutionary algorithm*” OR “evolutionary computation” OR “genetic algorithm*” OR “swarm intelligence” OR “swarm algorithm*” OR “search algorithm*” OR “local search”) (
A problem with the second part of the search string row). Ten articles were missed because of their non-existence in the databases (
Scopus and WoS did not have the article row). Obviously, the problem was in the search string, as some synonyms for attraction basins were omitted (see
Figure 6). However, a newcomer to the field is not supposed to know all subtleties in advance, and, thus, some snowballing in some research areas may be still necessary. During this section, we will compare conclusions derived from the database search and conclusions derived from the snowballing. Only then will we know how necessary snowballing was in this particular work.
4.1. RQ1: Attraction Basin Synonyms
Figure 7 presents the different terms used in exchange with attraction basins in relation to publication year.
Basin of attraction was far the most used term, followed by
attraction basin. These two terms were part of the search string, and thus it is not surprising they were the only terms found in the database search. As
Figure 7b suggests, the finding about the most frequent terms did not change after performing snowballing. However, new, but not so frequent, terms were found during snowballing. To see what impact this had on our conclusions, we included these new terms in the search string and perform iterative forward and backward snowballing again. The answer to this question will be part of the answer to the first question posed, that is if the snowballing was necessary. As we will see at the end of this section, this had some important impact. Interestingly, some publications never mentioned
attraction or similar, but only
basin. However, as we found later, including only
“basin” in the search string increased sensitivity, but abnormally reduced precision. To help future researchers find our articles that deal with attraction basins easily, we recommend to authors of new manuscripts using either
“basin of attraction” or
“attraction basin”.
4.2. RQ2: Problem Types
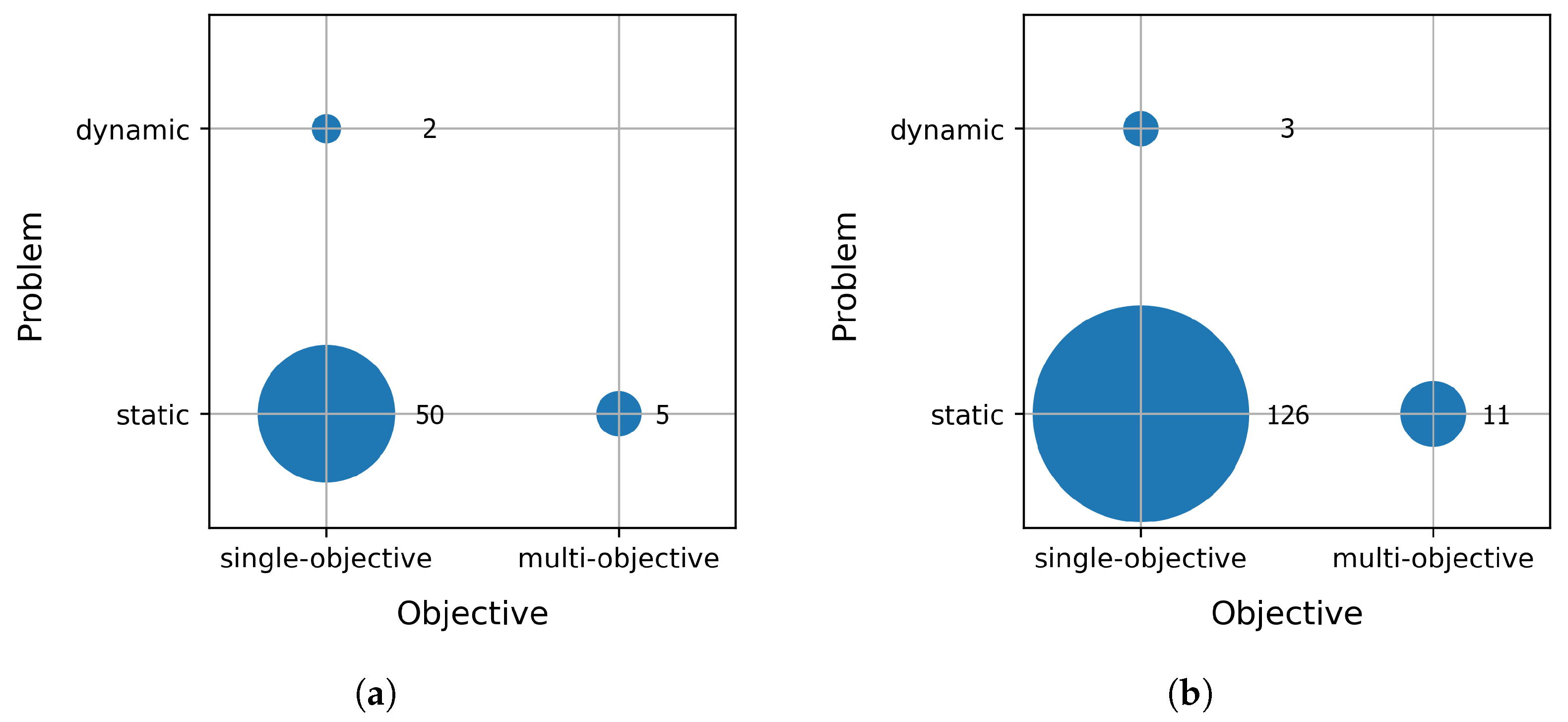
The number of publications per problem type is visualised in
Figure 8. Note that the sum of numbers does not necessarily need to be equivalent to the number of included primary studies, as some publications include multiple problem types. This is the case in other bubble charts as well. Single-objective static discrete problems were the most frequent problems in the literature that dealt with attraction basins. Multi-objective problems were less investigated, although continuous domains were slightly better. Research on dynamic problems is almost non-existent. Multi-objective and dynamic problems are more complex, and thus it is understandable that there is a lack of literature on this. We believe that the reason for the lack of literature on multi-objective functions is the not so apparent notion of fitness landscapes. Generally, the fitness landscape is composed of a solution space, an objective space, and the definition of the neighbourhood [
24]. In the single-objective functions, the objective space consists of scalars, while in the multi-objective functions, the objective space consists of the vectors of scalars [
78]. Therefore, the difficulty in extracting attraction basins in multi-objective functions follows directly from the fact that the attraction basins are derived mainly from fitness landscapes. Interestingly,
Figure 8a implies continuous domains are better investigated, but, using the snowballing procedure, this changes. Findings about multi-objective and dynamic problems did not change fundamentally after snowballing.
The numbers of publications regarding the number of objectives and fitness function are presented in
Figure 9. Note that we classified the papers which dealt with multi-objectivisation of single-objective problems to both classes (single-objective, and multi-objective). Most of the papers that did not specify the problem type exclusively we classified to single-objective static problems. Such types of problems are easier, and, thus, as
Figure 9 suggests, better investigated. Multi-objective dynamic problems were not investigated at all. Including the snowballing procedure or not, this did not have an important impact.
Figure 10 introduces three new classes: An algorithm to compute—meaning the paper provide in some form the algorithm to compute attraction basins; definition—meaning the paper provided a formal definition of attraction basins to some degree; and in-depth—meaning the paper investigated attraction basins more deeply, not just using them. The plot shows the number of publications in relation to the domain of problems (continuous, discrete) and to these new classes. The data show that discrete domains are investigated better. We find this reasonable as it is easier to compute and define attraction basins on discrete problems. Within continuous domains, we rely heavily on discretisation and possibly on a floating-point error. If we choose a better sampling step we risk running out of memory very quickly. Otherwise, it is not easy to obtain sufficient neighbours, while this is quite straightforward within discrete domains. That is, some important neighbours may be missed that lead to another attraction basin. On the other hand, if we decide to sample more neighbours, we risk exceeding the time limit. Nonetheless, attraction basins need to be explored better, especially within continuous domains. As
Figure 10 suggests, snowballing only pointed out the differences better.
4.3. RQ3: Definitions Used for Attraction Basins
We found many informal and a few formal definitions of attraction basins that are (dis)similar to various degrees. Here, we list only those that we found fundamentally different from each other (the listing is ordered chronologically):
Ref. [
79]: “
A local optimum’s region of attraction is the set of all points in S [search space]
which are primarily attracted to it. Regions of attraction may overlap. A local optimum’s strict region of attraction is the set of all points in S which are primarily attracted to it, and are not primarily attracted to any other local optimum. Strict regions of attraction do not overlap.”
Ref. [
80]: “
Goldberg (1991) formally defines basins of attraction to a point as all points x such that a given hillclimber has a non-zero probability of climbing to within some ε of if started within some δ-neigbhorhood of x.”
Ref. [
81]: “
A basin of attraction of a vertex is the set of vertices ”, where
is the set of vertices,
is the neighbourhood obtained by operator
, and
is the objective function to be optimised.
Ref. [
82]: “
The attraction basin of a local optimum is the set of points of the search space such that a steepest ascent algorithm starting from ends at the local optimum .”
The previous definition is generalised, i.e., the steepest ascent algorithm is replaced with the so-called pivot rule (any algorithm can be used, including a stochastic one) [
83],
Ref. [
84]: “[Attraction basin]
… the set of points that can reach the target via neutral or positive mutations.”
Ref. [
85]: “
Given a deterministic algorithm A, the basin of attraction of a point s, is defined as the set of states that, taken as initial states, give origin to trajectories that include point s.”
Ref. [
86]: “
The basin of attraction of the local minima are the set of configurations where the cost of flipping a backbone variable is less than the penalty caused by disrupting the associated block cost and cross-linking cost.”
Ref. [
87]: “
The basin of attraction of a local minimum is the set of initial conditions which lead, after optimisation, to that minimum.”
Ref. [
88]: “
The basin of attraction of a local optimum i is the set .”
Ref. [
32]: “
An attraction basin is a region in which there is a single locally optimal point and all other points have their shortest path to reach the locally optimal point.”
Ref. [
89]: “
The basin of attraction of the local optimum i is the set .”, where
is the probability that
s will end up in
i.
Ref. [
29]: “
Simply put, they are the areas around the optima that lead directly to the optimum when going downhill (assuming a minimisation problem).”—authors distinguish strong (points that lead exclusively to a single optimum), and weak attraction basins (points that can lead to many optima).
Ref. [
90]: “
The attraction basin is defined as the biggest hyper-sphere that contains no valleys around a seed.”
Ref. [
91]: “
The basin of attraction of a local optimum is the set of solution candidates from which the focal local optimum can be reached using a number of local search steps (no diversification steps are allowed).”
Ref. [
14]: “
An attractor associated with an optimisation algorithm is the ultimate optimal point found by the iterative procedure. When the algorithm converges to an answer, the attractor of the algorithm is a single fixed-point, the simplest type of attractors. Otherwise, it is not a fixed-point attractor. The union of all orbits which converge towards an attractor is called its basin of attraction.”
Ref. [
92]: “
Each point in an attraction basin has a monotonic path of increasing (for maxima) or decreasing (for minima) fitness to its local optima.”
Ref. [
15]: “
The basin of attraction of the Pareto local solution p, is the set of solutions for which ”, where maxPLS is the maximal Pareto local search algorithm from [
15].
The listed definitions are essentially different from each other because of
the domain they cover (discrete, real-valued or both),
the number of objectives in the optimisation problem (single-objective, multi-objective, or both),
the attraction mechanism they use (steepest ascent, local search, hill-climbing, stochastic algorithm, deterministic algorithm, monotonic increasing/decreasing, any optimisation algorithm, shortest path, etc.),
the distinguishing between different types of basins (weak or strong, strict or non-strict), or
the degree of generality.
The main problem with some definitions (e.g., Definitions 3–5, 10, and 17) is that they do not take into account the possibility that the attraction mechanism may reach multiple local optima, e.g., steepest ascent can reach multiple local optima if it finds several neighbours with the same maximum fitness on its way (in this case the algorithm must select a neighbour randomly or in a predetermined order; this, in turn, can lead to different local optima). This problem is solved by introducing two types of attraction basins: strict or non-strict (Definition 1), i.e., weak or strong (Definition 13). Although most of the definitions appear to be general in respect to the type of search space (discrete and real-valued), this is not the case in practice. Definitions do not handle the neighbours and the number of neighbours (sampling) in real-valued domains and the impact this may have on resulting attraction basins. However, this may be regarded as a problem of computation and not a problem of definitions. Definition 2 alleviates this problem by introducing parameters and . Some definitions handle plateaus (or saddles) differently, e.g., Definition 17 views the plateau as a single point (solution or configuration), and, consequently, escapes each plateau if possible, and therefore sees the plateau as part of an existing attraction basin, that is, each plateau does not define a new attraction basin. This is not the case with, e.g., Definition 10, where plateaus are not escaped, and the algorithm (local search) stops at the plateau (local optimum), which means a new attraction basin must be defined. We identify the lack of a general theoretical framework of attraction basins that will unite different views/definitions in a meaningful way, and investigate all domains and problem types better. Only then, can the concept be exploited fully. We found that, without snowballing, many important definitions of attraction basins would be missed (Definitions 1, 2, 13, and 14).
4.4. RQ4: Algorithms Used for Attraction Basins
Considering that relatively many definitions have been used so far, we would expect to find efficient algorithms to compute attraction basins, but this is not the case. Only a few algorithms have been developed and are often described poorly. The simplest and most popular algorithm is based on exhaustive enumeration of a search space, where a local search procedure is run for each candidate solution. The most used local search procedures are Best Improvement, and First Improvement (see
Algorithm A1 in Appendix A), e.g., in [
89]. The only difference is that Best Improvement selects the best neighbour, while First Improvement selects the first neighbour better than the current solution, encountered on its way to the optimum. Once all local searches reach their optima, it is easy to determine attraction basins, for example, each candidate solution could be labelled by its optimum. However, this algorithm, without additional sophistication, handles plateaus poorly. Once it reaches a single point from the plateau it will stop and create a new basin if this point is not reached by other runs. This means multiple points on the same plateau may create multiple basins. If we are within the real-valued domains, the number of basins may increase due to the thinner sampling step. Even if we solve this problem, for each plateau we will have one basin, as the algorithm cannot escape the plateau. This may be correct behaviour for some definitions of attraction basins (e.g., Definition 10), but not for others (e.g., Definition 17). In terms of the time complexity, the efficient technique to compute attraction basins comes from T. Jones and G. Rawlins [
93] in 1993 (see
Algorithm A2 in Appendix A). The idea is based on depth-first search and so-called reverse hill climbing, where, starting from the optima, the algorithm builds its attraction basins recursively using the lookup table. This algorithm must be run for each optimum. This is a drawback for problems where it is impossible to know all the optima in advance (real-valued domains). S.W. Mahfoud [
79], in the same year, published the algorithm which returns the set of local optima to which a point is closest, even in the case of large plateaus (see
Algorithm A3 in Appendix A). Once the algorithm finds one or more optima, the result could be used in a similar manner as before, that is, each candidate solution could be labelled by its local optima (notice the plural). M. Van Turnhout and F. Bociort, in their optical system optimisation [
87], report on the use of an algorithm that starts with following the gradient downwards by solving Equation (
3), where the vector
x is a point in the two-dimensional solution space, and
is the arc length along the curved continuous path.
The input to the algorithm is the grid of equally spaced starting points in the plane
. Depending on which local minimum the algorithm obtains, the starting point is coloured with the corresponding colour for that minimum. Using the same input, the authors of [
22] computed attraction basins for real-valued domains in three steps (see
Algorithm A4 in Appendix A). First, the potential borders of the attraction basins are obtained (lines 2–7), followed by a boundary fill step (lines 8–11), and, last, removal of the false borders (lines 12–18). We found that, without snowballing, two algorithms would be missed:
Algorithms A2 and A3 from Appendix A.
Estimation/approximation algorithms have also been used to compute attraction basins. They are based on clustering [
94,
95], the detect-multimodal method followed by hyper-spheres [
90], sampling and area division [
96], tabu zones of different forms and sizes, and with different locations in relation to the corresponding optima [
97], and based on sampling along each dimensional axis until finding a slump in fitness and then creating a hyper-rectangle [
98]. Most of these algorithms assume real-valued domain problems, but, still, there is a lack of exact and efficient algorithms to evaluate them. Therefore, we did not examine them more closely in this work.
4.5. RQ5: Most Popular Topics for Attraction Basins
Table 2 lists the contexts/purposes where attraction basins were investigated. They are used mostly for Fitness Landscape Analysis (i.e., Exploratory Landscape Analysis, search space analysis). Note that attraction basins within the continuous domain were often used for clustering and niching. Different clusters and niches were often considered as approximated attraction basins [
99,
100]; however, this is in contrast with the usual definition. Therefore, we found the “usual” attraction basins to be less investigated within the continuous domain. Recently, attraction basins have received attention for analysis of exploration and exploitation. Moving between different attraction basins was perceived as exploration, and moving within the same attraction basin as exploitation [
22,
76,
101]. Some works altered the inner workings of metaheuristics to control moving between attraction basins, such as the detect multimodal and radius-based methods [
90,
102]. A lot of works used attraction basins to measure problem difficulty, e.g., the number and distribution of attraction basins sizes, ratios between global optima attraction basins sizes, and local optima attraction basins sizes [
30,
75,
94,
103,
104]. We recognised the lack of a general framework that would organise all such approaches within the field in a systematic manner. The only topic found after performing the snowballing was automatic algorithm selection, however, with only one publication. Automatic algorithm selection means, instead of analysis and experimentation with optimisation algorithms, we let software select the best algorithm for concrete problems by learning (e.g., using Machine Learning), based on the features such as number of attraction basins, distribution of their sizes, etc. [
35]. Although, as this SMS reveals, the attraction basins were used for many important topics and purposes in the field of metaheuristics, we found no study that investigates the influence of different definitions and algorithms on the attraction basins and their usability on the topic. The authors of [
87,
89] investigate only the influence of local search algorithms on the resulting attraction basins in certain domains. However, their impact on the purpose for which attraction basins are used is never discussed. This work emphasises the importance of this investigation by highlighting the different definitions and algorithms to compute attraction basins, and the different contexts where attraction basins have been used.
4.6. RQ6: Demographic Data of SMS
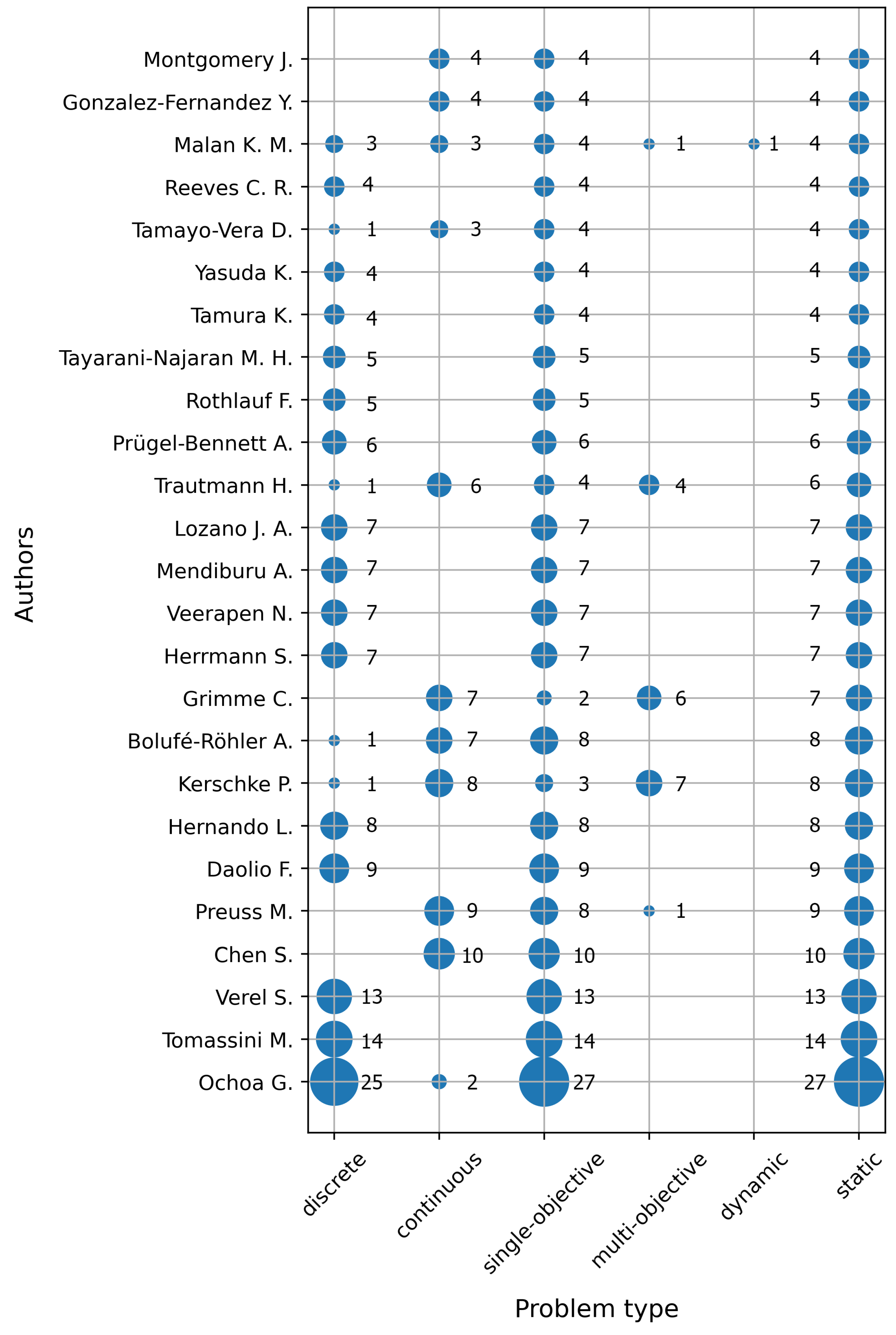
The most prolific authors are Ochoa G., Tomassini M., Verel S., and Chen S. as
Figure 11 suggests. Ochoa G., Tomassini M., and Verel S., usually in a group, published the most papers on Local Optima Networks [
113], while Chen S. on threshold convergence and exploration [
25,
114]. It seems that Local Optima Networks have received a lot of attention in the research community. A local optima network is a graph where each node represents a local optimum, and each edge between two nodes represents the probability to pass from one attraction basin to another [
115].
Next, we show the most popular venues that publish articles relevant to our topic.
Figure 12 shows the publication count per journal. We merged journals that published less than two studies to the category “other” due to space limitations. The Evolutionary Computation journal published the most papers (13), followed immediately by IEEE Transactions on Evolutionary Computation (8).
The Genetic and Evolutionary Computation Conference (GECCO)—19, and the IEEE Congress on Evolutionary Computation (CEC)—18, published the most conference papers on the topic of attraction basins (see
Figure 13). Conferences publish more papers on the topic than journals, as
Figure 13 suggests. In the
Figure 13, we merged conferences that published less than two studies to the category “other”.
Publication count by year is shown in
Figure 14. Note, only papers accepted before July 2021 were considered. The usage of attraction basins increased in the last decade. One of the reasons behind this is the exploitation of high computing capabilities, as the search spaces are too enormous to compute attraction basins exactly.
4.7. Necessity of Snowballing
As indicated earlier in this section, we investigated what happens to the results after the inclusion of new synonyms in the search string, together with iterative forward and backward snowballing. As expected, the number of papers increased enormously, from 201 to 1574 in Scopus, and from 105 to 966 in the Web of Science database. However, only 38 articles remained after screening. This is due to the imprecise term
basin, which is responsible, e.g., for including the papers that deal with rivers and lakes (e.g., geology). Strangely, refinement/filtering did not exclude these papers during the database search. Demographic data followed almost the same distribution as before including the new synonyms. Only one new journal with more than two articles was identified (Journal of Global Optimization). This journal mainly published papers on the important topic of the filled functions.
Filled functions are the auxiliary functions that help algorithms to escape local minima by optimising these new functions. This important topic would not be identified without changing the search string. Interestingly, using the snowballing on the article that deals with
filled functions, we followed the track back to 1987, where attraction basins were mentioned. Again, the topic was
filled functions, which may imply that this is the first context where attraction basins were used. During the full-text read we found that in the paper [
116], the authors wrote:
“The idea about the basin appeared in the 1970s (Dixon et al., 1976)”; however, we did not find this manuscript available in the full-text. Conclusions about problem types stays the same, although the numbers went slightly higher for continuous domains. Almost all these new papers that dealt with continuous domains had
filled functions as their topic. For some reason, the frequency of papers that deal with this newly identified topic dropped in last decade. During the extraction of data, surprisingly, we found the new synonyms as well, although not so often used,
“attraction area”,
“attraction region”,
“basin of convergence”,
“region of convergence”, and
“catchment basin”. The frequency of the term
“basin” increased again, because of the topic of
filled functions. After adding the latest new synonyms to our search string, we did not find any new relevant articles (all of them were from other fields). Overall, we estimate that, in this work, snowballing was important and necessary. Otherwise, some important definitions and algorithms would have been missed. Terms other than
“basin of attraction” and
“attraction basin” would not be found. The important topic of filled functions wouldn’t be identified at all. We found it only after including the new synonyms (first time) and performing snowballing. We would not have found that the idea of attraction basins traces its roots back to the 1970s according to the work in [
116].
5. Conclusions
In this study, we were limited to Computer Science, although the study is useful to other areas as well, such as physics and mathematics, where the attraction basins are examined in the context of dynamical systems. Only two databases—Scopus and ISI Web of Science—were used to construct the seed set. We omitted the papers published in workshops, dissertations, and the rest of the grey literature. Our SMS included categories that are of a similar level of granularity. Specific categories, such as dimensionality of the problem or specific types of discrete spaces (combinatorial, permutation, binary), are not considered in this SMS.
In this paper, we presented the first SMS on attraction basins in the field of metaheuristics. We believe this study will help newcomers, as well as those who are experienced, to dive into the topic more quickly, and therefore enhance the improvement in the field. The main findings on the topic are as follows:
Discrete domains were investigated far better than continuous.
Single-objective static problems dominated. Multi-objective problems were investigated better within the continuous domain, although still very weakly.
Different definitions of attraction basins were used, while the most frequent one was based on a local search. Within the continuous domain researchers often use clusters or niches as approximated attraction basins. There is a lack of a general framework of attraction basins in the field of metaheuristics.
Only a few “exact” algorithms were found, exhaustive enumeration with local search, reverse hillclimbing, and the primary attraction algorithm. No parallel and scalable algorithm was found to compute attraction basins.
Attraction basins were used for many purposes, such as fitness landscape analysis, clustering and niching, comparison of metaheuristics, exploration and exploitation, and analysis of metaheuristics, to enhance the search, problem generation, filled functions, etc. Local Optima Network is the topic that received the most attention in the area regarding the attraction basins.
The notion of attraction basins first appeared in the 1970s.
Regarding the question of whether is it necessary to perform snowballing, we answer ’yes’ for some works (it holds for this work).
We encourage researchers to develop efficient, parallel, and scalable algorithms to compute attraction basins that can run on a cluster [
117,
118,
119,
120,
121]. However, an unambiguous definition of attraction basins is needed to design an algorithm. Unfortunately, often weak definitions are provided that do not take into account all specificities. This is especially a problem within the continuous domain. Attraction basins on the continuous domain are understood poorly. These specificities include the settings, such as the neighbourhood definition, order of neighbours, specific local search variant, and sampling. The bigger impact of these settings on the resulting attraction basins could have huge repercussions on the attraction basin’s applications. Therefore, as our future work, we will investigate the impact of these different settings on the resulting attraction basins. We will investigate the impact of shifting, rotating, and adding more dimensions to problems on attraction basins. Further, we will analyse the influence of different settings on the exploration and exploitation metric proposed in [
22]. If we find out a significant influence, the metric will be revised in one of our future works. Therefore, we encourage researchers to experiment with different definitions/algorithms, and provide a general framework that is independent of an attraction mechanism, attractor, and initial configurations. In this way, the power of the concept may be exploited better.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}