Abstract
We propose a stochastic algorithm for global optimisation of a regular function, possibly unbounded, defined on a bounded set with regular boundary; a function that attains its extremum in the boundary of its domain of definition. The algorithm is determined by a diffusion process that is associated with the function by means of a strictly elliptic operator that ensures an adequate maximum principle. In order to preclude the algorithm to be trapped in a local extremum, we add a pure random search step to the algorithm. We show that an adequate procedure of parallelisation of the algorithm can increase the rate of convergence, thus superseding the main drawback of the addition of the pure random search step.
1. Introduction
If we consider the partition of random type algorithms for global optimisation between those that are adaptive, that is, those that have a search distribution, at a given step, to depend on the distributions of previous steps (see [1,2,3] for comprehensive approaches and, for yet another example, [4]) and those algorithms with steps being independent distributed search variables, it seems that only with those of the second class can we expect to escape the curse of being trapped in local extrema. This curse is surely related to the well known slogan global optimisation requires global information first proposed by Stephens and Baritompa (see [5] and illustrated in [6]). One obvious way to counteract the pernicious effect of adaptivity of the algorithms is to include an intermediate pure random search (PRS) step (see [7]) that will overcame the proclivity of the algorithm to be trapped on a possible local extremum. However, this introduction comes with a price, namely the slowing down of the rate of convergence of the adaptive algorithm. As a countermeasure, we can consider the parallelisation of the algorithm at the pure random stage. Let us briefly state our main objectives in order to give some context to the remainder of this introduction. Our first objective in this work is to study the effect of parallelisation on the rate of convergence of a parallelizable stochastic algorithm for global optimisation with no constraints in the search for the maximum of a function. Our second objective is to study a random adaptive algorithm for global optimisation of functions that may be assumed to attain its extremums at the border of the bounded set where these functions are defined. Thorough and fundamental expositions on the general subject of random algorithms requiring familiarity with probability theory, as well as some knowledge of deterministic and stochastic differential equations and Markov chains, are found in [8,9]. A broad introduction to stochastic algorithms for global optimisation is found in [10]. An excellent reference treaty on stochastic methods for global optimisation is found in [11]; the authors lay a solid ground for further studies, for instance, in detailing extreme value theory and its applications to statistical inference in some stochastic optimisation algorithms. The quest for better performing algorithms for stochastic optimisation continues to develop newer approaches aiming at more general applicability, provable convergence, and stability in regard to small changes in the parameters. An interesting example of such a work is [12], where the objective functions are supposed to be weakly convex, having as a particular case compositions of convex losses with smooth functions seen in machine learning algorithms. Another example may be found in the recent work [13]; the algorithm proposed is akin to the zig-zag algorithm first introduced in [14]—further studied in [15] and with its convergence also studied in [6]—and a thorough comparison of the performance of the introduced algorithm with other well known stochastic optimisation algorithms is detailed. Further results on the convergence of global stochastic optimisation algorithms using perturbed Liapunov function methods are presented in [16]. Let us stress that the subject of stochastic optimisation is broad, encompassing many different types of algorithms such as simulated annealing, genetic algorithms, and tabu search; a review of these different types is provided in [17], detailing advantages and disadvantages and summarising the literature on optimal values of the inputs. There are many instances of the idea that the algorithm may, in itself, guide the search into more promising regions; for instance, in [18], modifications of the pure random search algorithm are proposed following this idea—implemented using the regularity of the function to determine the more promising regions—and we quote, ...We think that if the objective function satisfies some conditions such as continuity, the Lipschitz condition or differentiability etc., the regions containing the minimal points are easy to be determined. If the algorithm generates many points in the regions of this kind, the probability of success will be large.
Fruitful ideas to build global optimisation algorithms with stochastic differential equations were previously published in, for instance, [19,20,21,22,23,24,25,26]. For numerical methods in stochastic differential equations, a fundamental reference is [27]. The splendid book [19] provides a well-founded approach to the convergence of algorithms either using functional compactness arguments or weak convergence results; some of the algorithms studied are taken as perturbations of ideal deterministic algorithms by an additive noise, not necessarily Gaussian, satisfying regularity properties. The idea of defining the intensity of the additive noise, the volatility of the stochastic differential equation by an annealing rate decreasing to zero with increasing time, is proposed in [21], and weak convergence is studied. In [25], the convergence of the studied algorithm for global optimisation with constraints is established for general nonconvex, smooth functions; the stochastic differential equation underpinning the algorithm .has as a drift the symmetric of the gradient of the function—a well known approach for obtaining a solution to an unconstrained optimisation problem considering the ordinary differential equation—and for the volatility, the square root of a positive function denominated annealing schedule with a parameter to be chosen according to the problem under analysis. This approach was already studied in [20], where a detailed justification for the choice of the stochastic differential equation is given, alongside many interesting related results. In [26], the authors use Euler discretisation of a stochastic differential equation with mean reversion, in which the volatility is suitably modified in order to reduce the Gaussian noise contribution as the number of iterations increase; the method is tested against 14 classical functions, and the results indicate that the random search guided by the trajectory of a discretised diffusion perform well. The fine study of stochastic algorithms based on stochastic differential equations can be read in [28], where, using perturbed Liapunov function methods, stability results of the algorithms are established. Furthermore, in [16], an algorithm of simulated annealing-type procedure is studied and the following recommendation is stated: ...whenever possible, one can and should use parallel processors....
In this work, we do not need much of a theoretical background on parallel computing, as we use a standard computation tool to take advantage of the processors being able to compute either with the specification of working independently or not. Some general references for the study of parallel algorithms are [29,30,31]. Early efforts on the parallelisation of those stochastic algorithms that may be called by the random search type can be read in [32], where a particular structure of the algorithm is designed using several units capable of processing data independently, notwithstanding communication with the units during the computation. In [29], a collective work, there is an excellent review of the main ideas of parallelisation techniques for global optimisation algorithms. More recently, in [33], the authors propose a framework to estimate the parallel performance of a given algorithm by analysing the runtime behaviour of its sequential version; the goal is achieved by approximating the runtime distribution of the sequential process with statistical methods, and then the runtime behaviour of the parallel process can be predicted by a model based on order statistics. The method we develop in this work bears some resemblance with this general idea.
As we previously observed, some fundamental random search algorithms for global optimisation built using discretised stochastic differential equations have as volatilities—that is, variances—parametrised quantities derived from simulated annealing principles. Parallelisation of simulated annealing type algorithms were studied by several authors. A precursor work is [34], where the simulated annealing algorithm is mapped onto a dynamically structured tree of processors; the algorithm presented achieves speedups between and , N being the number of processors. Another important work is a volume edited by Robert Azencott, from which [35] is a paradigmatic chapter. In [36], five parallel algorithms for global optimisation are studied; these algorithms are categorised by the amount of information exchanged among the different parallel runs with the asynchronous approach, being such that no information is exchanged among parallel runs. The parallelisation we propose is asynchronous, and the parallel runs are independent. In [37], there are three proposals of parallel algorithms for simulated annealing that fall in a similar categorisation for the the amount of information exchanged among the different parallel runs leading to independent, semi-independent, and co-operating searches. An important reference on the same vein is [38], reporting on five conversions of simulated annealing algorithm from sequential-to-parallel forms on high-performance computers and their application to a set of standard function optimisation problems. In the algorithm proposal of [39], a common feature of simulated annealing algorithms, that is, adaptive cooling based on variance, is abandoned; instead, the algorithm resamples the states across processors periodically, and the resampling interval is tuned according to the success rate for each specific number of processors.
We now present in greater detail the contents and main contributions of this work. The first one is to develop and study a novel formal description of parallelisation of random algorithms for global optimisation with no constraints, and the second one is to introduce and study a novel stochastic differential equation-based algorithm suited to functions attaining the extremum at some points of the border of the domain of definition, for instance, unbounded functions. On the first contribution, in Theorem 1, we detail a proof of the convergence of the pure random search algorithm for measurable functions, using simple results of martingale theory in discrete time, with the main purpose of highlighting the perspective used in this work, to wit, a stochastic algorithm may be seen as a sequence of random variables. With this perspective, in Theorem 2, we show that two convergent pure random search algorithms associated with the same function converge to random variables with the same law. We define, in Definition 3, the rate of convergence of a random algorithm and, in Definition 4, the parallelisation of such an algorithm, following the MPI standard, which is designed for distributed memory with multiple kernels of computation. Theorem 3 is another of the main contributions of this work, since we prove an estimate showing the improvement of the rate of convergence of a parallelised algorithm measured with respect to the nonparallelised version of the algorithm. We show that the parallelisation of the pure random search algorithm behaves in conformity with the results of Theorem 3 with examples of standard test functions for global optimisation. For the second main contribution of this work, in Section 4, we introduce a novel algorithm using stochastic differential equations based on a maximum principle, which is specially suited for unbounded functions; we consider an example that we treat both in the parallelised and nonparallelised versions of the algorithm, thus showing again the advantage of parallelising a random algorithm. The proposed algorithm is different from the algorithms proposed in the literature, in particular, in the works referred above in the paragraph on global optimisation algorithms with stochastic differential equations, and we intend to further explore the properties of this new algorithm in future work. Broadly stated, the main difference stems from the fact that the stochastic differential equation is built in order for the algorithm to be a martingale and for a maximum principle to be applied.
2. On the Parallelisation of Random Algorithms
The introduction of a pure random search step in an adaptive stochastic algorithm for global optimisation is an auxiliary device to avoid missing the global extremum. However, keeping in mind that adaptive algorithms are introduced to increase the convergence rates, the pure random search step is counterproductive, since it slows down the whole algorithm.
Thus, we propose parallelisation of the algorithm at the pure random search step level in order to improve the global rate of convergence of the algorithm. For completeness, we first describe a martingale approach to pure random search. Next, in Section 2.2, we show that, with an appropriate definition of the rate of convergence, parallelisation of a stochastic algorithm improves the global rate of convergence.
2.1. Pure Random Search Revisited
A probabilistic description of the pure random search may be defined as follows.
Definition 1
(Pure random search for global optimisation). A pure random search algorithm for the global maximisation of a function f on a compact set K is a sequence of random variables, such that:
- (i)
- The function , defined on K a compact set of , is measurable.
- (ii)
- The sequence is a sequence of independent and identically distributed (IID) random variables with , that is, X is uniformly distributed in K. We recall that, with λ denoting the Lebesgue measure over we have—with the symbol ⌢ denotingwith probability law—that:
- (iii)
- The sequence is a sequence of random variables with values in K defined for almost all by and for :with the consequence that is a nondecreasing sequence for almost all .
Four our purposes, we recall an essential definition.
Definition 2
(The essential supremum of a function over a compact set). The essential supremum of the function f over K is given by:
We next single out Hypothesis 1 with the purpose of focusing on the most interesting cases for our study. In Remark 1, we identify the extension of Theorem 1 to the excluded cases of this hypothesis.
Hypothesis 1.
We will suppose that . This hypothesis implies that, for all , we have that f is of p-power integrable (see for instance ([40], p. 190)).
We now present the convergence result for the random algorithm of pure random search for global optimisation.
Theorem 1
(On the convergence of the pure random search algorithm). Under Hypothesis 1, we have that, for the pure random search algorithm in Definition 1:
- 1.
- The sequence is asubmartingalewith respect to its natural filtration , that is, with: .
- 2.
- The sequence convergesalmost surelyto a random variable such that, with the essential supremum of f over K in Definition 2,that is, the random variable is astrongsolution of the global optimisation problem of f over K.
Proof.
We first observe that the random variables of the sequence are integrable. In fact as we have, by Formula (2) and by the righthand side of Formula (1), that:
and we may conclude by induction. Now, since the conditional expectations are well defined and the sequence is a nondecreasing sequence for almost all , we have that:
and so we have the first statement in Theorem 1. In order to prove that the submartingale converges, we will take advantage of Hypothesis 1 to obtain an uniform bound on the terms in the furthest left-hand side of Formula (5). Since we have that:
we have that, for every , there exists , such that , and such that almost everywhere on K with respect to . This implies the uniform bound:
As a consequence of the bound in Formula (6), we have, by a standard result on martingale theory (see ([41], p. 50)), that the submartingale converges almost surely to a random variable that we denote by . In order to prove that is a strong solution of the maximisation problem for f over K—defined to be a solution such that Formula (4) is satisfied—we consider, for an arbitrary , the fixed set defined by:
and we proceed with the following sequence of observations. Without loss of generality, we may assume, as an Hypothesis 2, that , since, by Hypothesis 1, if it is otherwise, we can always consider a translation of f.
- (j)
- For we have that:We first observe that, by the fact that , and as a consequence of a standard supremum argument, we have that
- (jj)
- Almost surely, we will have for some integer , that is, more precisely,Let us suppose the contrary, that is,Consider, for , the set,which we know, by Formula (8), to have full probability and select according to the condition in Formula (10). Now, by the definition of in Formula (11), there exists , such that , that is such that . However, by the condition in Formula (10), we have that , and so, by the definition of the sequence in Formula (2), we should have that and so , that is, , a statement that contradicts the condition in Formula (10).
- (jjj)
- We have the final conclusion of the second statement in the theorem, Formula (4), that is:Take and satisfying Observation (jj), that is, a set of full probability and such that,Now, since the sequence is almost surely nondecreasing, for all and the adequate , we can write:a condition that implies . We have thus shown thata condition that, by a standard argument, implies Formula (4).
Being so, the proof of the theorem is now complete. □
Remark 1
(On the case of an infinite essential supremum). In order to extend Theorem 1 to the case , we may consider that
a condition that, for any submartingale, is equivalent to , that is, the sequence is bounded in (see ([41], pp. 50–51)). Furthermore, by observing that, if
we have for arbitrary that , and so we can consider, instead of , the set . We then show that with a similar proof, a condition that, in turn, implies that almost surely.
We now state a remark and an important result on the laws of the solution of the global optimisation problem by means of pure random search that we will use in the sequel.
Remark 2
(On the laws of the variables of the algorithm). Consider the two sequences , and of IID random variables with , and let and be the corresponding pure random search algorithms according to Definition 1. Then, for all , we have that and have the same law. In fact, a simple proof by induction shows that, for every , the law of —and consequently, the law of —only depends on the law of .
Theorem 2
(On the unicity of the global optimisation solution of pure random search). Suppose that , the essential supremum of f over the compact K, is finite. Let and be two pure random search algorithms associated with and , two sequences of IID random variables with , as in Remark 2. Suppose that these random algorithms converge to and , respectively. Then, we have that , and so and have the same law.
Proof.
We can consider the sequence defined for by:
Now, we may observe the following. Firstly, we have that, almost surely for , as an immediate consequence of the definition in Formula (12). Then, we have that, almost surely, is a nondecreasing sequence, as it is defined as the pointwise maximum of two nondecreasing sequences. Lastly, since, for all , we have that and have the same law (see Remark 2), and since, by Formula (2), we have that:
then is a pure random search algorithm for global optimisation of f over K that, by Theorem 1, converges almost surely to some random variable . Since we have that, for almost all , the sequences and are subsequences of , we immediately have that almost surely, as claimed. □
2.2. On the Rate of Convergence of a Parallelisation of a Random Algorithm
In this section, we use the Ky Fan distance to define the rate of convergence of a generic random algorithm, and we obtain natural bounds for the rate of convergence of a parallelisation of this random algorithm. The pure random search developed in Section 2.1 is a basic algorithm, to which the following results apply.
Consider a stochastic algorithm for global optimisation—for instance, on what follows, maximisation—of a measurable function f on a regular domain given by the sequence of random variables . We will suppose that converges, at least in probability, to some random variable . We recall that , the Ky Fan metric (see ([42], p. 289)), is defined for two random variables X and Y to be:
and that this distance is the distance of the convergence in probability. Furthermore, we have that .
We now introduce a quantitative notion for the rate of convergence of an algorithm.
Definition 3
(The rate of convergence of a random algorithm). Suppose that the random algorithm converges in probability to some random variable . The rate of convergence of the algorithm is given by the numerical sequence:
that is, the rate of convergence of the algorithm is the rate of convergence to zero of the numerical sequence , with, by definition, .
We now consider a definition of parallelisation of a random algorithm.
Definition 4
(Parallelisation of a random algorithm). Given a random algorithm for global optimisation of a measurable function f on a regular domain , converging in probability to some random variable , we say that this algorithm is parallelisable if, for every integer and for every , there exist r independent copies of the terms of the algorithm sequence and of the random variable —namely and for and every —such that the following two conditions are verified:
- For all , we have that .
- For all , the random variable is a solution of theweakoptimisation problem for f on D, that is, , with the essential supremum of f (see Definition 2).
Remark 3
(PRS as an example of a parallelizable algorithm). The pure random search of a measurable function f on a compact set K studied in Section 2.1 is parallelisable. In fact, given any two samples of , as in Remark 2 and Theorem 2, the correspondent terms of the two algorithms generated by the two samples are independent as a consequence of the fact that, as seen in Remark 2, the law of only depends on the law of the initial segment of the sample of used to define it. It thus follows firstly that the limit random variables are independent, because almost sure limits of term-by-term independent sequences are independent by an application of a standard reasoning using characteristic functions. Moreover, as by Theorem 2, both limits of the two algorithms are equal almost surely if one of these limits is a solution of the (strong) optimisation problem.
We now state the result that compares the parallelisation of a random algorithm with the version of the algorithm without parallelisation. This result can be used to determine stopping criteria for parallelised random algorithms, as detailed in Remark 5.
Theorem 3
(On the rate of convergence of a parallelised random algorithm). Let be a parallelizable random algorithm for global optimisation of a measurable function f on a regular domain and let the limit in probability of the algorithm and solution of the global optimisation problem be the random variable. Let be an integer and let and , for , be the independent copies of the algorithm and of the solution of the optimisation problem according to Definition 4. We then have for all :
and also, for all such that ,
Proof.
For the proof, we will use Lemma 1, which is well known, but which we reproduce next for the reader’s convenience. Since we have, by definition, that:
we also have that, for every integer ,
Without loss of generality, we may assume that the sequence is nondecreasing. Now, the algorithm being parallelisable, by Definition 4, we have the necessary conditions to apply the estimate in Formula (a) of Lemma 1, and so we obtain
For the reader’s convenience, we recall the following well known elementary result that was used in the proof of Theorem 3.
Lemma 1.
Let be a sequence of non-negative, independent and identically distributed with a random variable Z. We then have, for all ϵ:
- (a)
- (b)
Proof.
We have that
and so it follows, by the independence and the identical distributions of , that:
The proof of the second assertion is similar by observing that
which is equivalent to the second stated formula. □
Remark 4
(On the rate of convergence of a parallelised random algorithm). The rate of convergence of an algorithm , as in Definition 3, is the rate of convergence to zero of the sequence , with the terms of the sequence being as in Formula (16). In this formula, the infimum is attained (see again ([42], p. 289)), and so we have that:
If this random algorithm is parallelisable, as in Theorem 3, we may consider that the gain in performance with this parallelisation is observed on the behaviour of
a behaviour that can be assessed in Formula (14), that is,
As a consequence, we should compare this behaviour with the behaviour of the original algorithm in Formula (17). It is clear that, when , there is, for the parallelised algorithm, a remarkable improvement in the probability of a deviation from zero of the random variable in Formula (18) that measures the gain in performance with the parallelisation.
Remark 5
(On the actual implementation of a parallelisation of a random algorithm). One way for an actual implementation of a random algorithm to take advantage of the improvement in the performance gained with the parallelisation, observed in Remark 4, is the following. Let for be the current maximum at step n for each one of the parallel runs of the algorithm. Let be such that is the smallest integer, such that at least one of the current maxima changes. Let for be the changed current maxima at step . Applying the stopping criteria to will accelerate the algorithm stopping.
3. Some Parallel Computations with the Pure Random Search Algorithm
This section is devoted to present a computational study aiming at exhibiting the effects of parallel computing with the pure random search algorithm. Intuitively, asynchronous parallelisation of an algorithm with the parallel runs running independently is tantamount to performing the evaluations of the algorithm in several different machines, not necessarily simultaneously; with this perspective, it seems equivalent to perform four thousand search steps in a single machine or one thousand search steps in each one of four similar distinct machines and then collect the results. It may be observed that, in order to consider the possible performance improvements with the parallelisation of an algorithm, we have to account for the execution times. Moreover, there is evidence of an upper limit for the gain obtained by the parallelisation of an algorithm, namely Amdhal’s Law (see ([43], p. 65)) or the latter refined Gustafson’s Law (see [44]). In Remark 5, we suggested a procedure to take into account the execution time of the best performing copy of the parallelised algorithm in order to stop the algorithm. In the following, we will not stop the algorithm whenever there is a copy of the algorithm satisfying the stopping criteria. Instead, we will stop the parallelised algorithm only when all the copies satisfy the stopping criteria and take the result of the copy—both in the variables time of execution and value attained—having the value attained when stopped that is closest to the maximum. This approach also allows us to study the improvement in the time variable in a simple way.
From Formula (14), in Theorem 3, we have a theoretical upper bound on a tail probability of the parallelised algorithm and the rate of convergence of the nonparallelised algorithm that depends on r, the number of independent copies of the algorithm in the parallelisation. In the study presented in the following, we intend to illustrate a determined quantitative improvement with the parallelisation of the pure random search algorithm.
The proposed method for the study is described in the following steps.
- 1.
- For each of the functions of two real variables studied (see Appendix A for additional information on these functions)—Ackley’s, drop-wave, Keane’s, Goldstein-Price’s, Himmelblau’s, and a nearly unbounded function—we determined, by Monte Carlo simulation, two lists of pairs of numbers, UU and VV. The list VV has 400 pairs of numbers, the first number of the pair being the time in seconds that the nonparallelised PRS algorithm overcomes of the known maximum of the function, at which point the simulation stopped, and the second number being the value attained at the moment the algorithm stopped. The list UU is similar to the list VV, but it contains the pair corresponding to the best performing kernel—among the four kernels of the machine used in the parallelised algorithm—regarding the value attained. In Appendix B, we detail the machine characteristics as well as the main code used in the computations both of the parallelised and the simple algorithms.
- 2.
- We fitted a continuous bivariate distribution to both samples UU and VV, truncated to exact intervals of both time, the first marginal variate, and value, the second marginal variate. Then, using the probability density functions (PDF) of the marginals, denoted and for the first marginal and and for the second marginal of each of the two samples UU and VV, we determined two values of reference one the time reference and the other the value reference, such that:We observe that, in some cases, and were not unique solutions of the equations in the variable v and in the variable t; whenever this situation occurred, we chose the solutions closest to the medians of the two distributions. Furthermore, in at least one of the cases, there was no solution of the equations with the PDF, and we used a solution of a similar equation but with the cumulative distribution functions.
- 3.
- With the determined values of and , we can immediately compute the conditional probabilities given by for the parallelised algorithm, V being the value variable and T the time marginal variable, and similarly, for the nonparallelised algorithm. By analogy with Formula (14) in Theorem 3 and due to the choice of and , we would expect to have:where r is the number of copies in the parallelised algorithm. As a consequence, with:we expect to have in the examples given.
In Table 1, we present the results of the computations just described, with kernels, using the machine and code both presented in Appendix B. A first observation is that the result for the nearly unbounded function is the best among all functions tested. This kind of function will be the object of the results presented in Section 4. A second observation is that the median time values come from samples of repetitions of the algorithm both in the parallelised and nonparallelised versions; in the parallelised version, there are four times more repetitions than in the nonparallelised version, and being so, it is possible for the median times obtained with parallel algorithms to be sometimes worse than with the nonparallelised version.

Table 1.
Results comparing the parallelised and the nonparallelised algorithms.
Remark 6
(Quantitative experimental validation of the advantage of a parallelisation of a pure random search). The results presented in Table 1 seem to substantiate the claim presented in Theorem 3, in Formula (14). In fact, it seems clear that, both for the examples of slightly modified well known test functions having several local maximums—Ackley’s, drop-wave, and Keane’s—and the functions attaining their maximums on a plateau-like surface—Goldstein–Price’s and Himmelblau’s—we obtain estimates of , given by , that can be considered acceptable, taking into account that, in the parallelised algorithm, efficiency losses occur in the distribution of tasks among kernels.
Remark 7
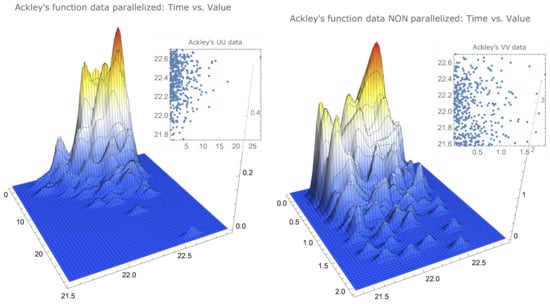
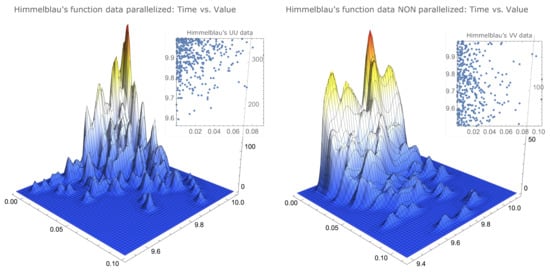
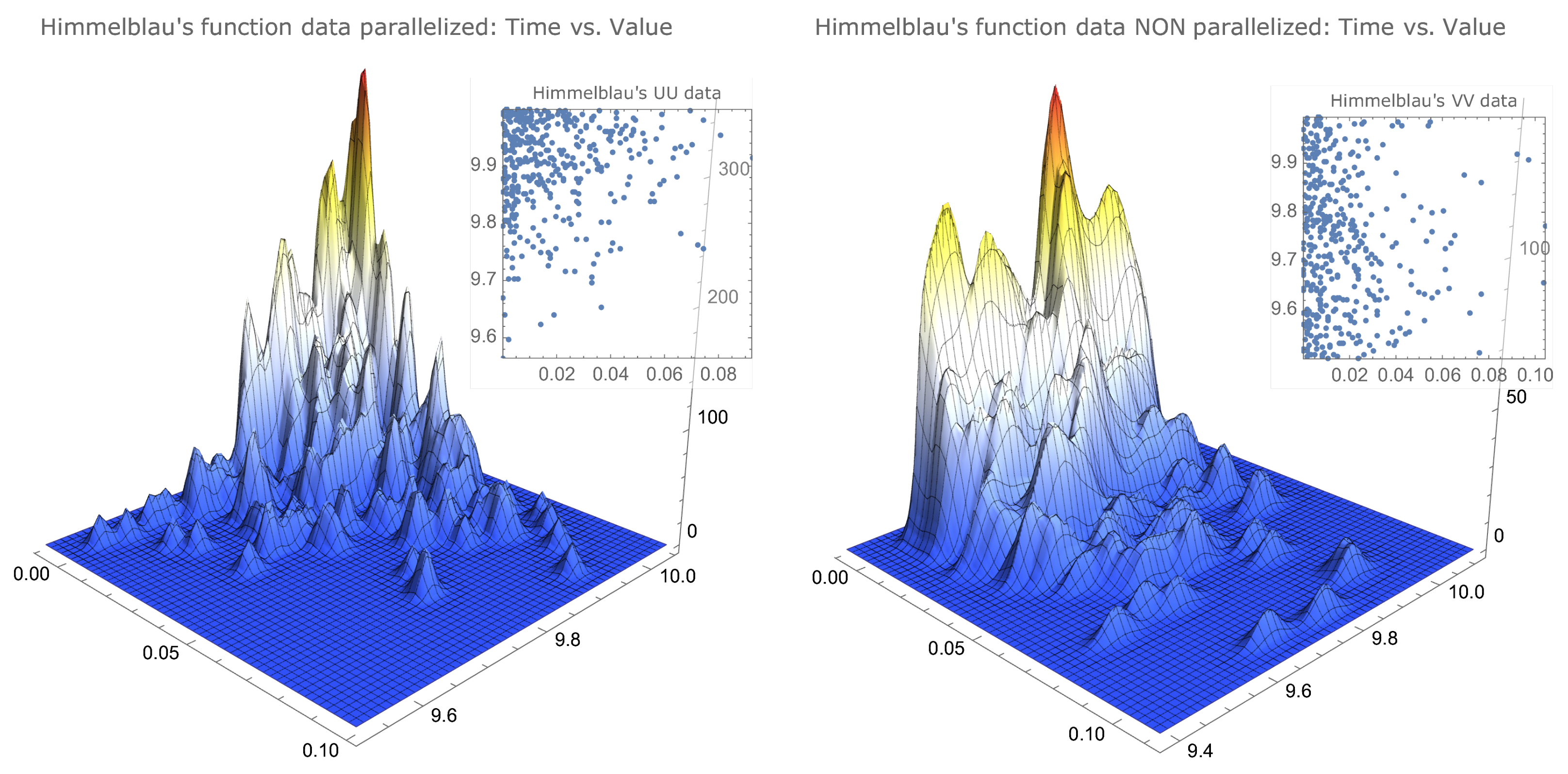
(Simulated data representations for examples of two types of functions). The simulated data that allowed us to determine the values of Table 1 can be visualised to provide a better insight of their characteristics. In Figure 1 and Figure 2, we compare the same data for functions that clearly differ in the maximum localisation characteristics. As already mentioned, the drop-wave function presents several local maxima, with some of these local maxima agglomerated together with the global maximum, and the Himmelblau’s function has its maximum—with four distinct maximisers—in a surface plateau.
Figure 1.
Smoothed histograms and simulation data for Ackley’s function.
Figure 2.
Smoothed histograms and simulation data for Himmelblau’s function.
There is a noticeable similarity between the parallelised data of both functions, as well as between the nonparallelised data of both functions.
However, there is a noticeable difference, for each function, between the parallelised data and the nonparallelised data. The parallelised data for both functions show a concentration on the upper left corner—less accentuated for Ackley’s function—that is, surrounding the best values in a way that can be described as: closest to the true maximum and smallest times—more noticeable for Himmelblau’s function—while the nonparallelised data, for both functions, appear to be uniformly distributed in the interval , also being more scattered in the time variable.
4. On a Martingale Diffusion Type Algorithm for Global Optimisation
In this section, we propose an algorithm for global optimisation based on the maximum principle for strictly elliptic operators. Let us take as an example a harmonic function on an open and bounded domain with regular boundary; this function belongs to the kernel of the Laplacian operator. It is well known that such a function attains its maximum on the boundary. Consider the diffusion naturally associated with the Laplacian. The algorithm we propose consists of running the diffusion on the domain until it touches the boundary; then, by a Feynman–Kǎc-type result, we can obtain the maximum value of the function. This algorithm is suited for nearly unbounded functions. We next detail the general idea of our approach.
4.1. On the Maximum Principle for Strictly Elliptic Operators
Consider a function , where is a bounded open set with a regular boundary . We consider the following two global optimisation goals for the function f over the compact .
- (a)
- Determination of .
- (b)
- Determination of the set of maximisers .
We will consider the following regularity hypothesis of f over .
- (A1)
- (f is twice differentiable on , and the second differential is continuous) and (f is continuous in ).
We consider a complete probability space and and two independent Brownian processes on . Let be the natural filtration generated by both and , which we assume to be complete and right-continuous. The first ingredient in the elaboration of our algorithm is a two-dimensional diffusion process , that is, a strong solution of the following system of stochastic differential equations:
We will suppose that the coefficients and have the necessary regularity to ensure the existence of a strong solution (see Remark 9 on validity of this hypothesis).
In order to guarantee some useful convergence properties, we assume the following hypothesis.
- (A2)
- The process is a -martingale.
As a result of an application of Ito’s formula (as in ([45], pp. 32–33)), we can identify a partial differential operator that will impose further constraints on the coefficients of the diffusions in Formula (21). In fact, we have:
and in order for to be a martingale, the sum of the terms that constitute the coefficient in Formula (22) has to vanish. Furthermore, if we consider the operator defined for , , by:
we should have in ; a condition denominated f is harmonic on (see [46], p. 47).
Now, in order to ensure a Feynman–Kǎc-type representation result, we assume the following hypothesis:
- (A3)
- The operator is strictly elliptic on , that is,
The following result, which we quote from ([46], p. 46), gives a representation of the solutions of a well posed problem with operator using the diffusion .
Theorem 4
(A Feynman–Kǎc-type representation of the solution of a Dirichlet problem). Let u be a solution of the Dirichlet problem for the operator in Formula (23) associated with the function f in , that is:
- and .
- in and in .
Then, with , theexit timeof from , that is, , we have the following representation:
- (a)
- almost surely (see also ([47], p. 324)).
- (b)
- For all , we have that , with being the expectation with respect of the law of given as a solution of the diffusion system in Formula (21) with initial condition .
As a consequence of the statement (b) of Theorem 4, we have the following maximum principle that is crucial for our algorithm proposal.
Theorem 5
(A maximum principle application). Consider the notations and conditions of Theorem 4, and suppose that f is harmonic in , and moreover, that f is a solution of the Dirichlet problem for the operator , associated with the function f in , that is:
- and .
- in , and obviously, in .
We then have, by the conclusion of Theorem 4:
Proof.
Since, by the representation formula, we have for all that , we can conclude that:
and the conclusion now follows the hypothesis . □
Remark 8.
Let us summarise the main ideas we are pursuing. We link the function f to a two-dimensional diffusion by means of a strictly elliptic differential operator of second order having as coefficients the diffusion coefficients, for which f is a solution of a Dirichlet problem. The representation Theorem 4 shows that, if we start the diffusion anywhere on the domain of f, and then we wait until the diffusion hits the boundary, we will have that the value of the function f at this point is a candidate to the maximum of the function in the closure of its definition domain.
4.2. The Practical Implementation of the Algorithm
Following the main idea exposed in Remark 8, we need to determine the coefficients of the diffusions in such a way that we have . For that purpose, we do the following.
- We assume that, as f grows, the volatilities of the diffusions should decrease, and so we consider, for instance,with and to be chosen appropriately depending on f, its domain of definition , and possibly also in an adaptive way in the algorithm.
- We consider two functions , , for , such that:We observe that, by Schwarz’s theorem, we have that .
- In order to determine the drift coefficients of the diffusions, we may observe that, for , we have that if and only if:as a result of Formula (23) and of the previous determinations. This equality can be achieved by taking, for instance, for ,an expression that is determined as soon as the functions are determined.
- We can consider the equally spaced Euler–Maruyama discretisation (see ([48], p. 305) or ([49], p. 152)) of the diffusions in Formula (21), that is, for ,being the discretisation step, with and the sequence being a sequence of independent and identically distributed random variables with a standard Gaussian random variable, that is, .
The effectiveness of the practical implementation of the algorithm is conditioned to the existence of strong solutions of the system of SDE given in Formula (21), having the drifts given by Formula (27) and volatilities given by Formula (25). A first observation is that, as a consequence of Formula (26) and of Formula (27), we have, for , that:
Thus, if is bounded away from zero, that is, if , and if , we have that is a continuous function over the compact and so is both uniformly continuous and bounded in . A second observation is that, with the choice in Formula (25) we have that, for
and so the operator defined in Formula (23) is strictly elliptic—even uniformly strictly elliptic—according to Formula (24). We now need an existence result for the system of stochastic differential equations given in Formula (21) having the drifts given by Formula (27) and volatilities given by Formula (25). For that purpose, we quote the following version of the celebrated Yamada–Watanabe theorem (see ([50], pp. 40–41)).
Theorem 6
(Yamada and Watanabe 1971). Suppose that μ and σ are progressively measurable and bounded and satisfy the following hypothesis.
- (1)
- There exists , anincreasingcontinuous function, such that , such that:
- (2)
- There exists , anincreasing concavefunction, such that , such that:
Then, for any random variable Z, where , the following stochastic differential equation
has a strong solution and uniqueness in law holds.
Remark 9
(On the existence and unicity of the process defining the diffusion algorithm). Despite the fact that, in general, we do not have the sub-linear growth of the coefficients that, together with the Lipschitz character of these coefficients, ensures existence and unicity of a strong solution in the context of the classical Ito’s theorem, we may nevertheless conclude that the system of stochastic differential equations given in Formula (21), having the drifts given by Formula (27) and volatilities given by Formula (25), has a strong solution that is unique in law; this happens as long as we force the solution process to stay on a compact set contained in . In fact, by the regularity properties imposed on f, we have that and ; thus, by the mean value theorem, on any compact set contained in , we have that has a bounded derivative, and so it verifies a Lipschitz condition, which implies that it satisfies hypothesis (1) of Theorem 6. Moreover, as pointed out above, the regularity properties imposed on f also imply that the term not containing in Formula (27) is bounded, and so the drifts are also Lipschitz on any compact set contained in by virtue of the same property that the term —in Formula (27)—has. The practical implementation of the algorithm in Section 4.3 considers that the diffusion process is restrained to a compact set contained in the maximal open set where the function f is defined.
Remark 10
(On the convergence of the Euler–Maruyama discretisation). The equally spaced Euler–Maruyama discretisation that we propose in Formula (28) converges weakly under a very general hypothesis, as stated in Proposition 4.58 in ([49], p. 146). This is a consequence of the regularity of the coefficients— is continuous, and has the same regularity as f—and the fact that the strong solution of a SDE given by an Ito integral, with continuous coefficients, is a continuous function of the Brownian process. Nevertheless, the question of the strong convergence and of the rate of convergence of the Euler–Maruyama discretisation should be addressed for each particular case of the function f studied.
Remark 11
(The martingale diffusion type algorithm). A simplified scheme describing the martingale diffusion-type algorithm is the following. The actual implementations in Mathematica ™(see [51]) for both the parallelised and nonparallelised versions are presented in Listing A4 and Listing A3, respectively.
- STEP 1:
- CHOOSE Tolerance error and upper bound A.
- STEP 2:
- CHOOSE at random uniformly;
- DO:, for and
- STEP 3:
- DO: compute iteratively for according to Formula (28);
- IFDO:
- UNTIL either one of the following stopping criteria is verified:
- stop at such that: or,
- stop at n such that: and
- either or ;
- STOP or GO TO STEP 2 with new that must be compared with .
We observe thatSTEP 2in the algorithm is of the pure random search kind. Being so, if the algorithm is parallelisable, the results of Section 2.2 can be applied. In the parallelised version, there will be an extra step added to the above pseudo-code for collecting the times and values of each of the four copies of the algorithm.
We now prove that the algorithm we just described in the simplified scheme above is parallelizable according to Definition 4.
Theorem 7
(Parallelisation of martingale diffusion-type algorithm). Let the process be given by the set of two diffusions in Formula (21). Suppose that the process is such that Hypothesis (A1), (A2), and (A3) hold. Then, the process is a uniformly integrable martingale, and so it converges, almost surely and in , to a random variable . Moreover, if , we have that:
- (a)
- the well defined random variable is a weak solution of the global optimisation problem for f in ;
- (b)
- the algorithm described in Remark 11 is parallelizable.
Proof.
It is clear that, as that for every , we have that:
and so the process is uniformly integrable (see, for instance, ([41], p. 29)); moreover, this process being a martingale in continuous time it converges almost surely and in to a random variable that closes the martingale (see, for instance, ([41], p. 88)). From statement (b) in Theorem 4, it follows that the random variable is well defined. Now, without loss of generality, we may suppose that . Now, again by Theorem 5 and its proof, we have that:
Since is bounded, we recall Definition 2 of the essential supremum of f over the compact set ,
from which is clear that
and so Assertion (a) of the theorem is proved. From Formula (28), it is clear that, for , the law of depends only on the law of the random variable , and so the same happens with the law of the integer valued hitting time of , that is, ; we observe that, almost surely, we have:
In fact, since we have that , we may state:
- ;
- and for almost all , we have that:
Since , we now have for the hitting time of by the discretised process that by force of Formula (33); moreover, the following dichotomy applies:
and in any case, we have , as claimed. Now, if we redefine the discretised algorithm by:
we will have
Moreover, we observe that:
We have that is a uniformly integrable martingale, and so the stopped process is a uniformly integrable martingale converging in probability to the random variable by reason of Formula (34). As a consequence, we have that:
Finally, as a consequence of Formula (31), we have, for sufficiently small , that
and so the algorithm is parallelisable. □
4.3. An Example of an Application of the Diffusion Optimisation Algorithm with Parallelisation
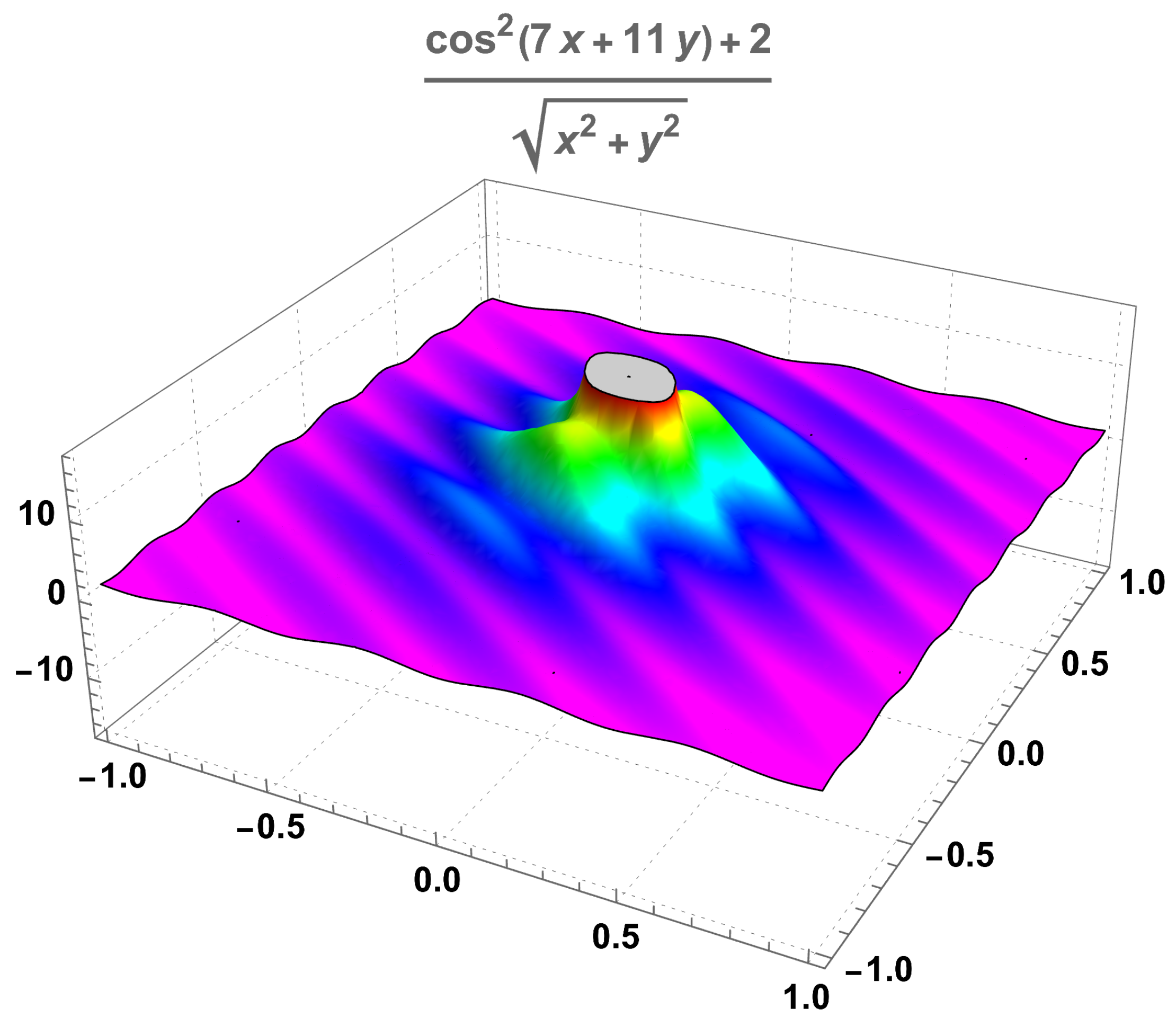
In order to consider an example of a function to apply the diffusion algorithm, we start with
a function that is unbounded at the point . The function f that we analyse may be considered an example of the type of nearly unbounded functions, such as the one studied in Section 4.1 and Section 4.2 if we consider it to be defined in the open set given by:
represented in Figure 3 for , such that for a better visualisation. It is clearly a function that will attain its maximum at a point of the boundary of , more precisely on the set . We observe that the point belongs to this circle, and that ; this value will be used in the implementation of the algorithm. We observe also that numerically, that is, using a standard maximiser function of the software, we have:
with a unique maximiser in the set , that is, a point in the boundary of .
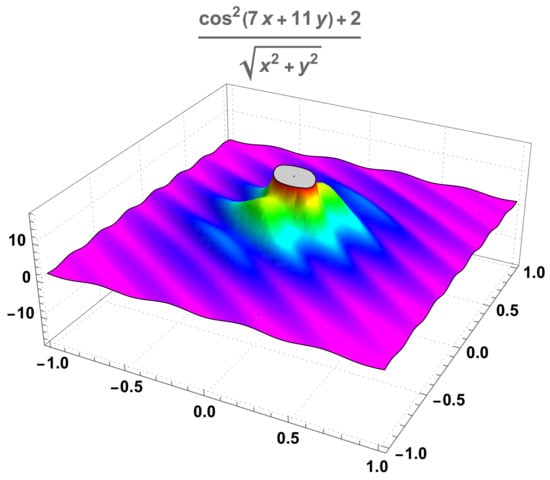
Figure 3.
A nearly unbounded function having several local maxima.
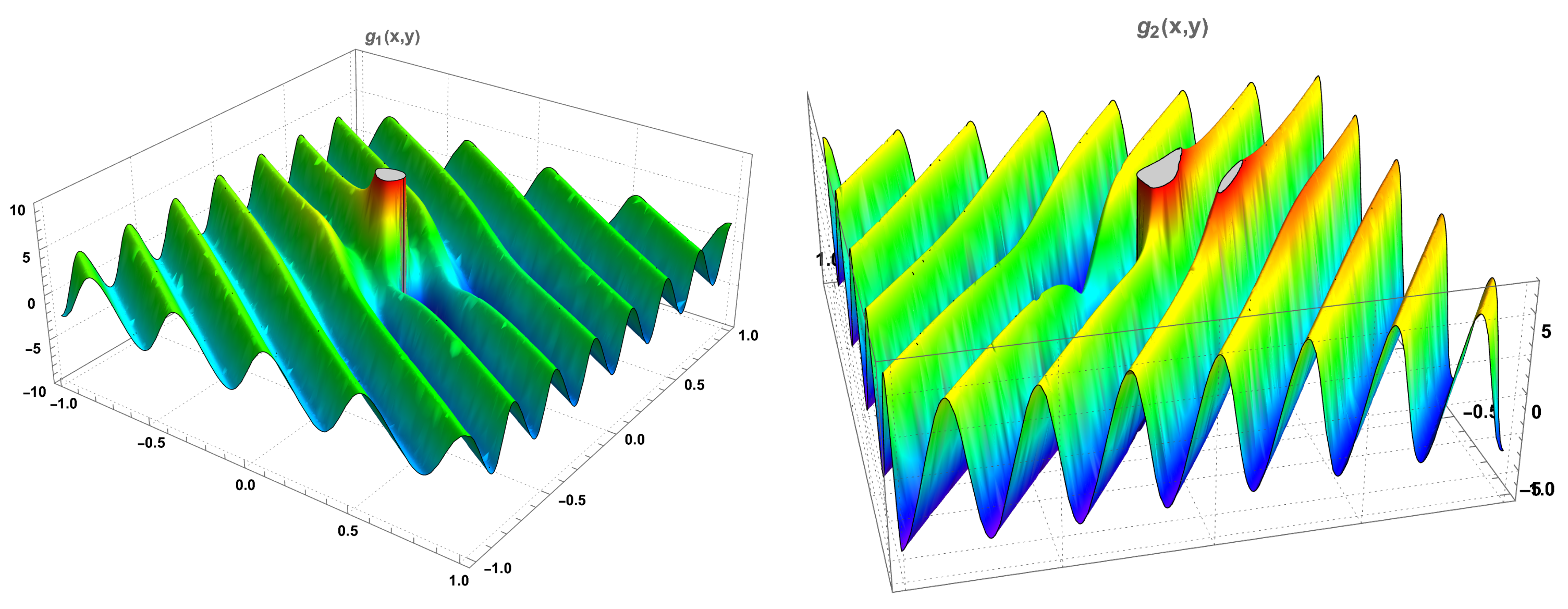
The computation of the coefficients according with the Formulas (25)–(27), allows the determination of the coefficients of the two diffusions. The function , computed according to Formula (26), is given by:
An inspection of Figure 4 and the Taylor series of order one in a neighbourhood of the point
show that there is a singularity at the point , and that the function is well defined in the domain . Similarly, the function , given by:
and the correspondent Taylor series of order one in a neighbourhood of the point ,
also show that the function is well defined in the domain .
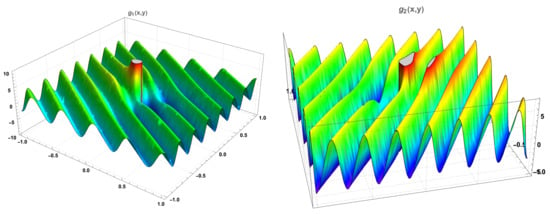
Figure 4.
The functions and .
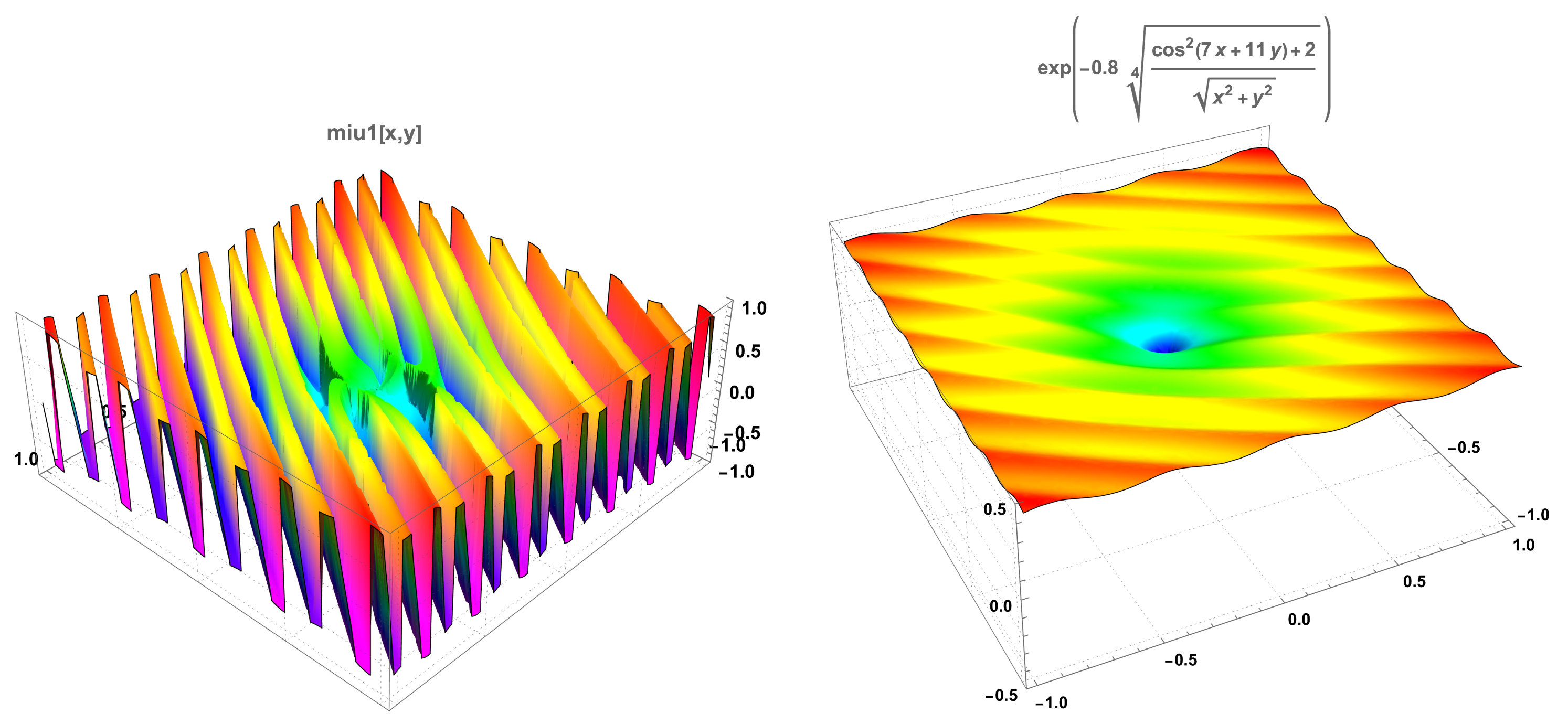
We now detail some aspects of the coefficients , , and used in the numerical computations. Using Formula (25) and Formula (27), we determined the coefficients and , as presented in Formula (35) and in Formula (36), respectively.
and
An immediate inspection of Formula (35) and of Formula (36) shows that there is a possibility of large values that will render the Monte-Carlo simulation unstable. So, for computational purposes, we considered, instead of and , the following coefficients with .
The coefficients of the first diffusion are shown in Figure 5 for . The value of to be taken when applying the method is linked both to the discretisation step and the number of steps of the diffusions, as well as to steepness of the function close to the border where the maximum is attained.
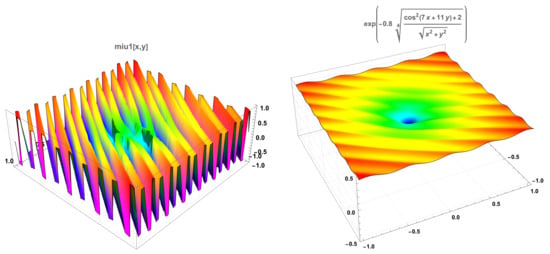
Figure 5.
The coefficients of the first diffusion and .
We considered the algorithm prescribed to run on only one kernel, described in Listing A3, and the parallelised algorithm running in four kernels, described in Listing A4. In the study presented in Section 3, we compared, for the pure random search algorithm, the four kernel parallelised algorithm, with the algorithm being processed without the specification of parallelisation, that is, in its normal usual mode. We also performed a trial running the pure random search algorithm parallelised on one kernel only, as done for the diffusion algorithm, but there were no appreciable changes in the results, for instance, for Himmelblau’s function, the estimate of changed from the already reported to the new value if the parallelisation was run with one only kernel specification. The results for the diffusion algorithm are presented in Table 2. We recall that the parallelisation performance indicator is defined in Formula (20) and that we compare to 4, the maximum number of kernels used in the parallelisation of the algorithm.
Table 2.
Diffusion algorithm example: comparing the parallelised and the nonparallelised versions.
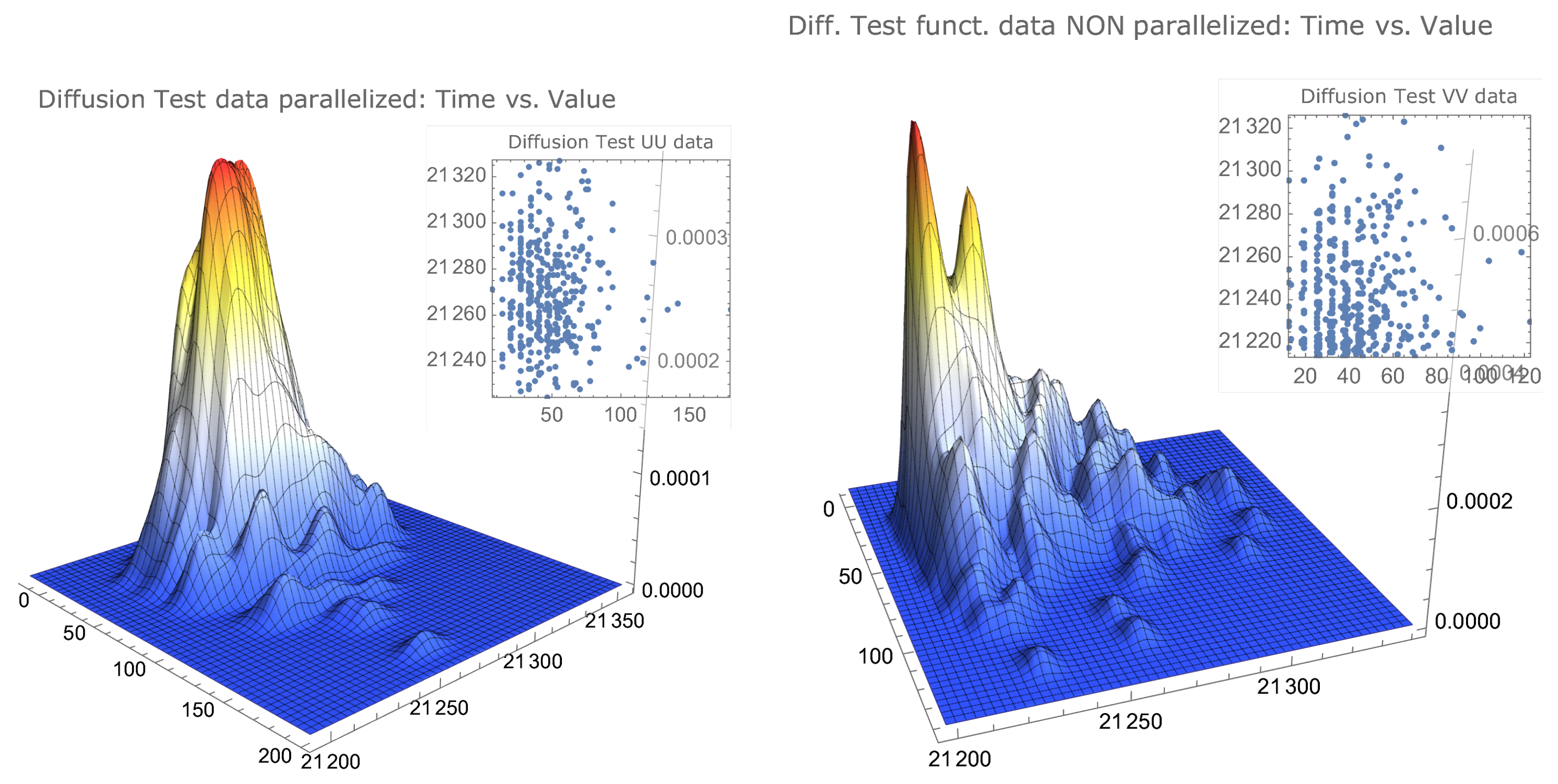
The smoothed bivariate distribution of simulated data for the example function and the diffusion algorithm is presented in Figure 6.
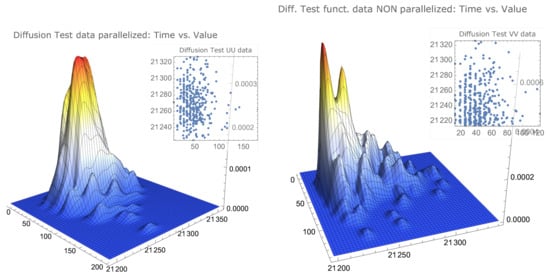
Figure 6.
Smoothed distribution of parallelised and nonparallelised simulated data.
Remark 12
(Some conclusions on the application example of the diffusion algorithm). It is clear from the analysis of the median execution times for both the algorithm running in only one kernel and running in parallel with four kernels, reported in Table 2—respectively, s and s—that the implementation of the diffusion algorithm presented is not efficient when compared with the available implementations of global optimisation algorithms that can find the optimum in less than two seconds. Further studies are required to ascertain if there is some specific class of functions for which the proposed diffusion algorithm presents some noticeable advantages over other algorithms. The estimate in Table 2 clearly shows the advantage of running a parallelised algorithm, especially whenever the algorithm is computationally demanding, as is the diffusion algorithm. The possibility of a substancial gain of efficiency in highly time-consuming algorithms by the proposed parallelisation method of the algorithm requires further study.
5. Conclusions
In this work, we developed and studied a novel formal description of parallelisation of random algorithms for global optimisation with no constraints and we presented a preliminary study for a novel stochastic differential equation based algorithm suited to functions attaining the extremum at some points of the border of the domain of definition, for instance, unbounded functions. There are many practical applications for which this algorithm may be well suited. For instance, it may be used for the study of the temperature in a mathematical model of the heath diffusion in the core of a nuclear reaction in case of a meltdown as in [52]. The full testing of an improved implementation of the algorithm proposed will be the object of future work, encompassing further testing against well-known and well-performing algorithms and against higher dimensional problems.
We introduced a performance indicator defined in Formula (20) motivated by two reasons: the first reason is the parallelisation method and the implementation of this method used. We chose to study the method of parallelisation consisting of sending the algorithm, simultaneously and independently, to the four kernels available in our computer and stopping each kernel as soon as the running maximum was in a previously prescribed neighbourhood of the known maximum of the function recording both the value and the time taken to attain this value. These recorded values were used to define a sample, from which the indicator of Formula (20) was computed. The second and most important reason is the goal of practically verifying the result in Formula (14) of Theorem 3. The study of the variations of performance, measured by the performance indicator of Formula (20), whenever there is an increase in the number of processors/cores used, will also be a subject of future work. The practical work presented confirms the usefulness of this performance indicator, and this conformation, in turn, confirms the advantages of parallelisation, even with a reduced number of processors.
Author Contributions
Conceptualization, M.L.E.; Formal analysis, M.L.E.; Investigation, M.L.E., N.P.K. and P.P.M.; Software, M.L.E. and N.M.; Visualization, M.L.E.; Writing–original draft, M.L.E.; Writing–review and editing, M.L.E., N.P.K., P.P.M. and N.M. All authors have read and agreed to the published version of the manuscript.
Funding
For the second author, this work was undertaken with partial financial support of RFBR (Grant n. 19-01-00451). For the first and third author, this work was partially supported through the project of the Centro de Matemática e Aplicações, UID/MAT/00297/2020, financed by the Fundação para a Ciência e a Tecnologia (Portuguese Foundation for Science and Technology). The APC was by supported the New University of Lisbon through the PhD program in Statistics and Risk Management of the FCT Nova Faculty.
Informed Consent Statement
Not applicable.
Acknowledgments
This work was published with financial support from the New University of Lisbon. The authors express gratitude to the comments, corrections and questions of the referees that lead to a revised and better version of this work.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. The Test Functions for the Pure Random Search Parallelisation Study
In this appendix, we provide information on the test functions studied in Section 3. There are very well-known references on test functions for unconstrained optimisation methods, where a large set of functions—displaying a wide spectrum of features creating obstacles for efficient global optimisation algorithms—can be found (see [53], or [54]). Since our goal is to provide an illustration of the quantitative approach proposed to establish differences with parallelised and nonparallelised random search, we opt to select a set of six functions with essentially three characteristic features: oscillating with several local maxima, a maximum in a plateau like surface, and nearly unbounded. Additional information on this functions is presented in Table A1.
Table A1.
Some characteristics of the slightly modified test functions used.
Table A1.
Some characteristics of the slightly modified test functions used.
| Function | Expression | Maximisers | 95%max |
|---|---|---|---|
| Ackley | 21.5824 | ||
| drop-wave | 0.95 | ||
| Keane | 0.639984 | ||
| nearly unbounded | 9500 | ||
| Goldstein-Price | 6.65 | ||
| Himmelblau | . | 9.5 |
Remark A1
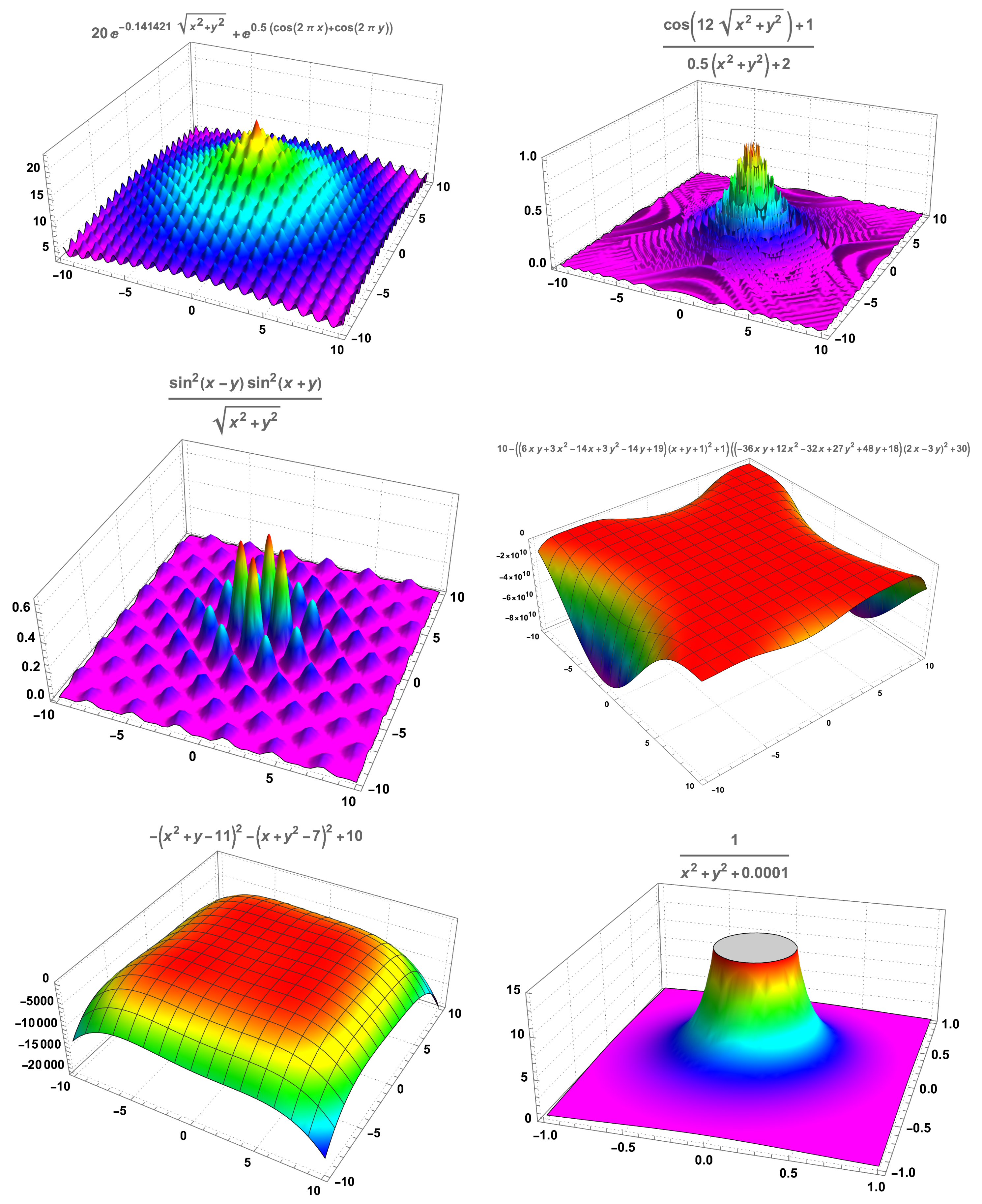
We stress that these functions are modified versions of the homonymous functions in the references mentioned above; the modifications are of two sorts: change of sign in order to have critical points as maximums and adding a constant in order to have an essentially nonnegative function. The graphical representation of these functions is displayed in Figure A1.
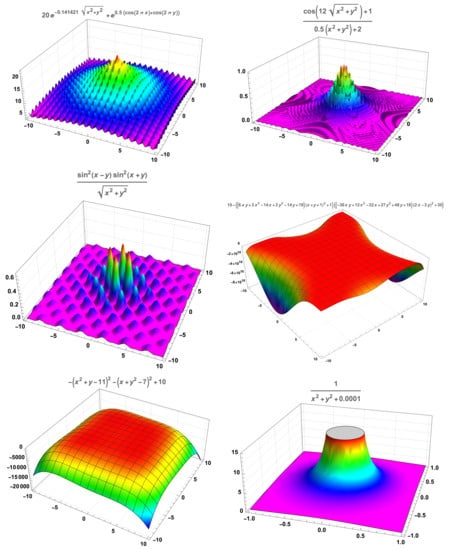
Figure A1.
Test functions, from left to right and top to down: Ackley’s, drop-wave, Keane’s, Goldstein-Price’s, Himmelblau’s and nearly unbounded.
Figure A1.
Test functions, from left to right and top to down: Ackley’s, drop-wave, Keane’s, Goldstein-Price’s, Himmelblau’s and nearly unbounded.
Appendix B. Mathematica ™ Code for Parallel Computation
The details on the machine having four kernels, and on the corresponding operating system (OS), used to perform the parallel computations studies of Section 3, are detailed in Table A2.
Table A2.
Machine, OS and some of the 4 kernel characteristics.
Table A2.
Machine, OS and some of the 4 kernel characteristics.
| KernelID | Machine | OS | Version | Processor | TimeUsed | Memory |
|---|---|---|---|---|---|---|
| 1 | Mac Mini M1 2020 8 Gb | MacOSX-x86-64 | 12.3 | 1289 | 0.809547 | 49401008 |
| 2 | Mac Mini M1 2020 8 Gb | MacOSX-x86-64 | 12.3 | 1290 | 0.809104 | 49401232 |
| 3 | Mac Mini M1 2020 8 Gb | MacOSX-x86-64 | 12.3 | 1291 | 0.773256 | 49401048 |
| 4 | Mac Mini M1 2020 8 Gb | MacOSX-x86-64 | 12.3 | 1292 | 0.828269 | 49403112 |
The determination, in a parallel computation with four kernels, of the table of values UU for the best performing kernel was performed using the code in Listing A1.
| Listing A1. Code for UU table: timing and value of the best performing kernel. |
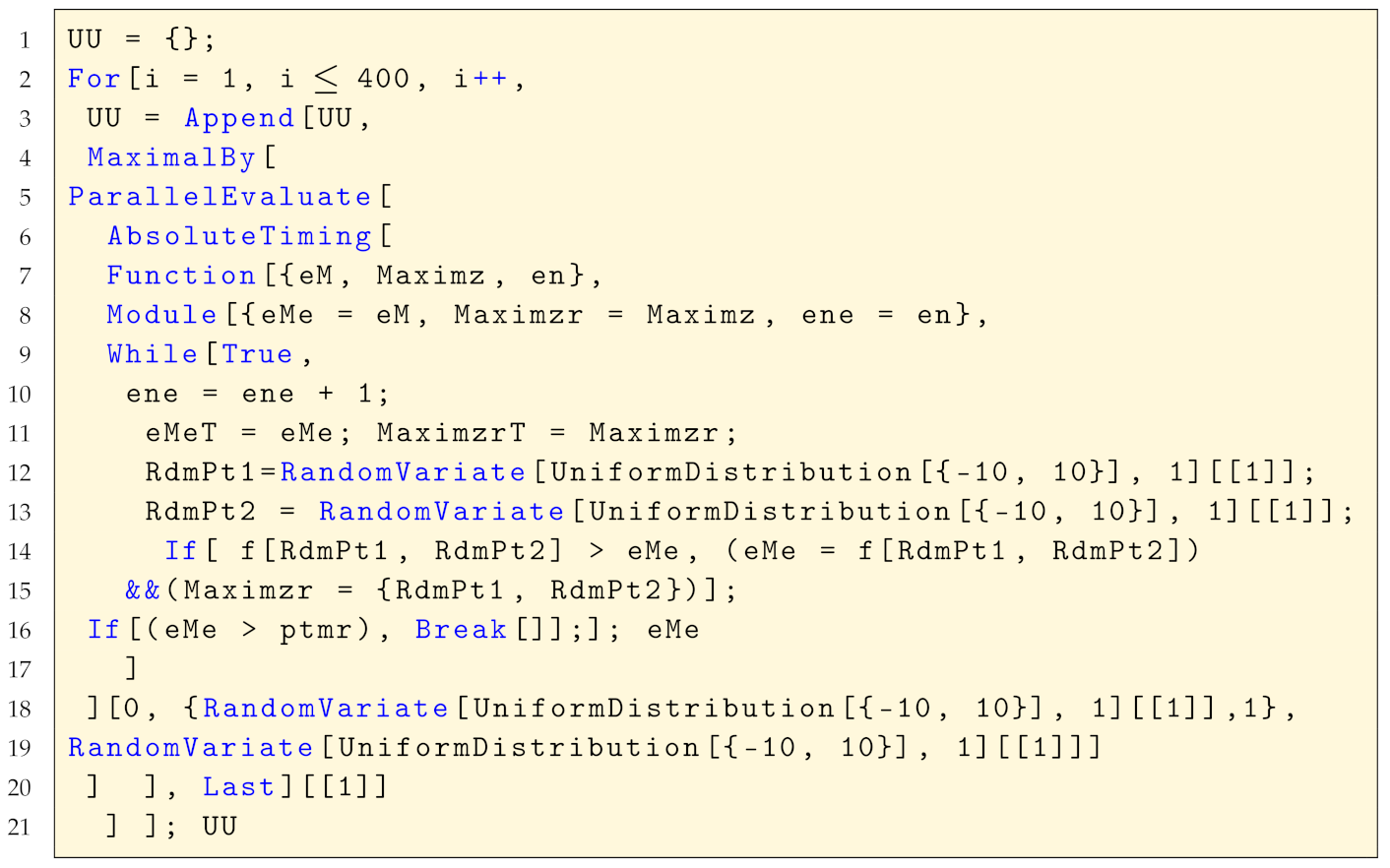 |
The definition domain of all numerical valued functions being maximised was (see lines 12, 13, 18 and 19 of the code in Listing A1).
The determination of the values VV of the nonparallelised computation was performed using the code in Listing A2.
| Listing A2. Code for VV table: timing and value of the nonparallelised computation. |
 |
The code function AbsoluteTiming returns the absolute number of seconds in real time that have elapsed and measures only the time involved in actually evaluating the expression in its argument that is being determined not time involved in formatting the result.
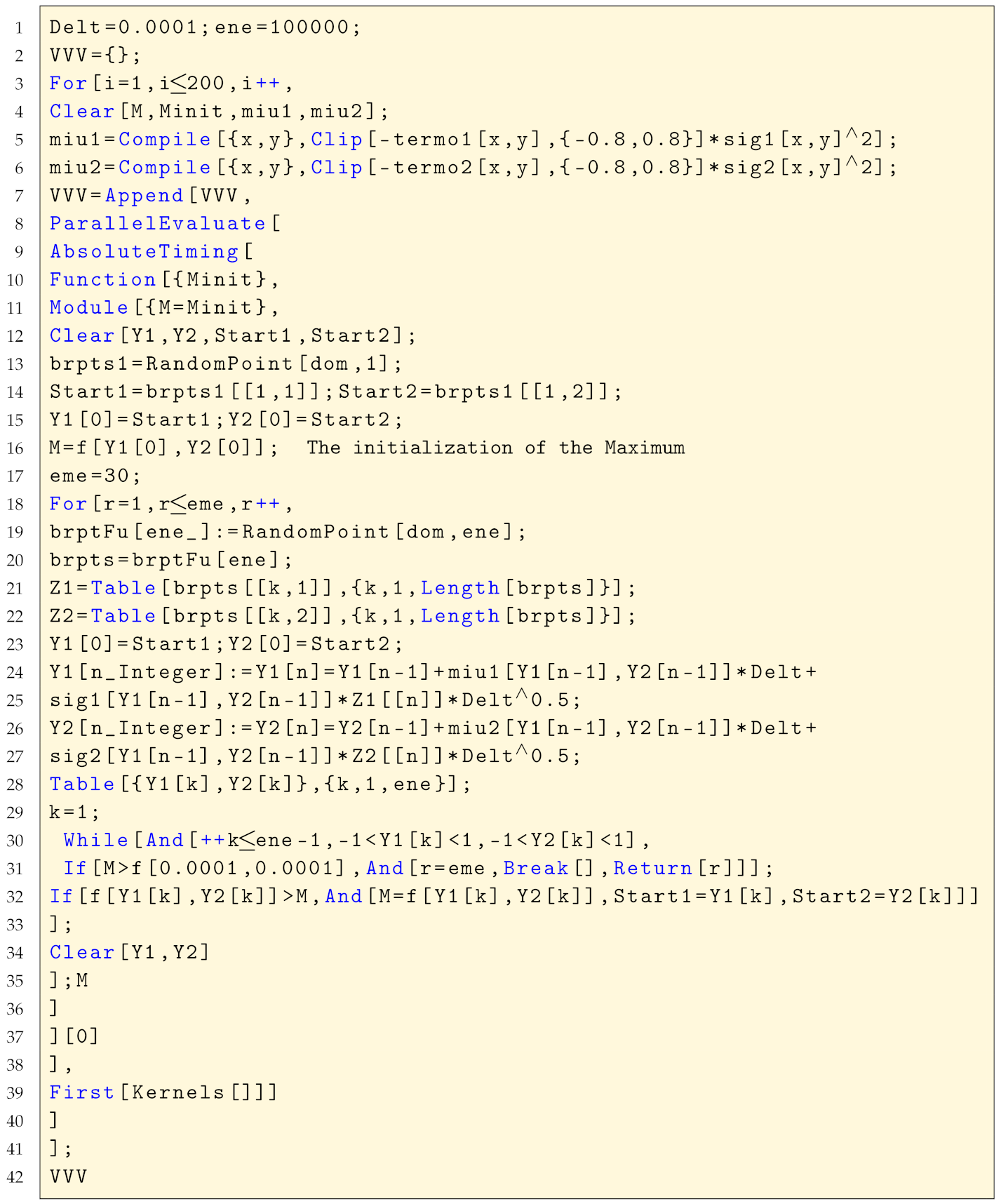
The implementation of the diffusion algorithm with parallelisation restrained to only one kernel, which is tantamount to an algorithm with no parallelisation, is presented in Listing A3.
| Listing A3. The diffusion algorithm with one only kernel. |
 |
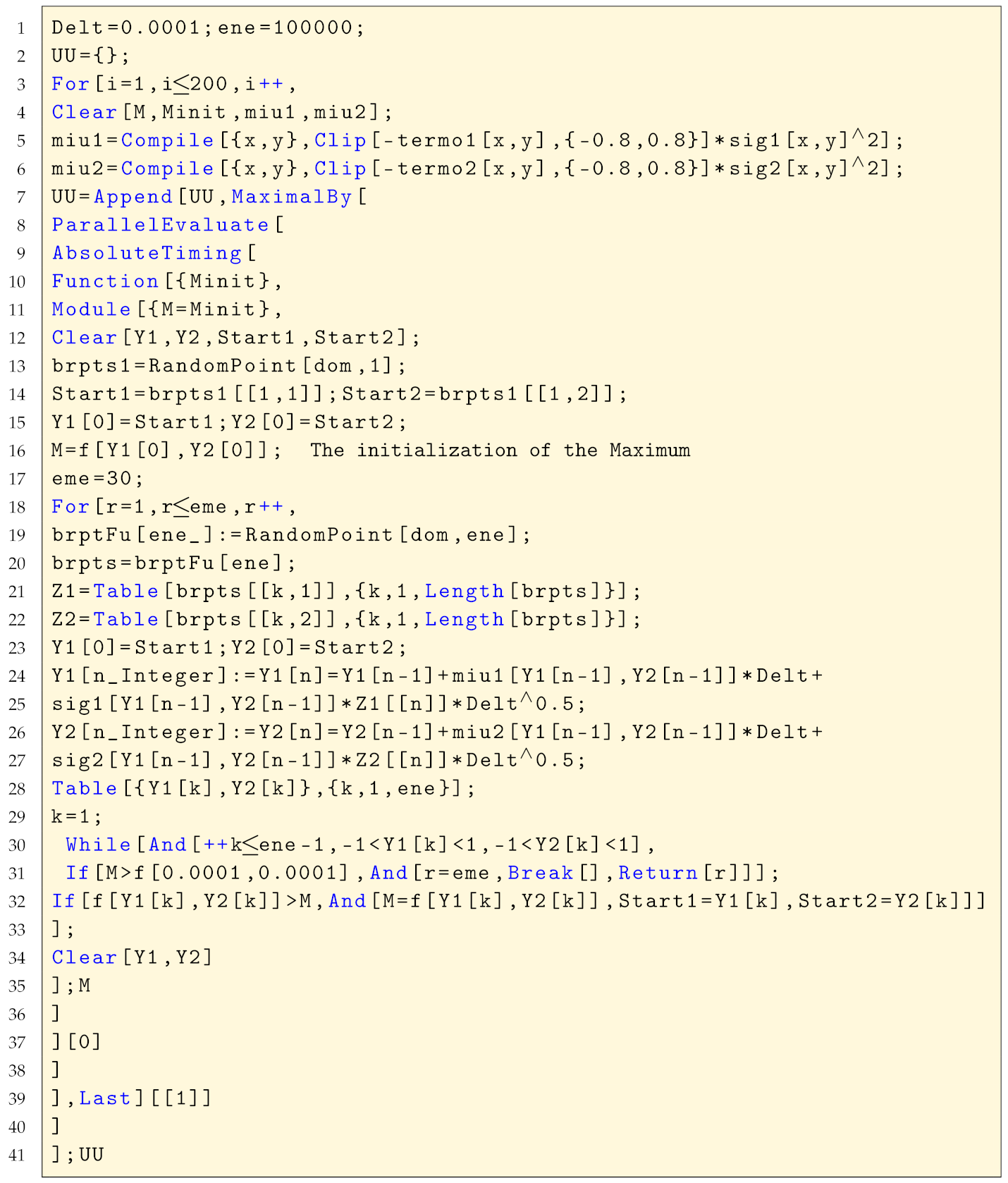
The parallelised diffusion algorithm with four kernels was implemented according to Listing A4. We recall that the computations were achieved with the four kernels running independently, by force of the algorithm, and the result given correspond to the output of the kernel for which the achieved value was higher.
| Listing A4. The diffusion algorithm with result given by the best of 4 kernels. |
 |
References
- Zabinsky, Z.B. Stochastic Adaptive Search for Global Optimization; Nonconvex Optimization and its Applications; Kluwer Academic Publishers: Boston, MA, USA, 2003; Volume 72, p. xviii+224. [Google Scholar]
- Spall, J.C. Stochastic optimization. In Handbook of Computational Statistics; Springer: Berlin, Germany, 2004; pp. 169–197. [Google Scholar]
- Rubinstein, R.Y.; Kroese, D.P. Simulation and the Monte Carlo Method, 2nd ed.; Wiley Series in Probability and Statistics; Wiley-Interscience [John Wiley & Sons]: Hoboken, NJ, USA, 2008; p. xviii+345. [Google Scholar]
- Esquível, M.L. A conditional Gaussian martingale algorithm for global optimization. In Computational Science and Its Applications—ICCSA 2006, PT 3; Gavrilova, M., Gervasi, O., Kumar, V., Tan, C.J.K., Taniar, D., Lagana, A., Mun, Y., Choo, H., Eds.; Lecture Notes in Computer Science; Springer: Berlin, Germany, 2006; Volume 3982, pp. 841–851. [Google Scholar]
- Stephens, C.P.; Baritompa, W. Global optimization requires global information. J. Optim. Theory Appl. 1998, 96, 575–588. [Google Scholar] [CrossRef] [Green Version]
- Esquível, M.L.; Machado, N.; Krasii, N.P.; Mota, P.P. On the Information Content of some Stochastic Algorithms. In Recent Developments in Stochastic Methods and Applications; Albert, N.S., Konstantin, E.S., Dmitry, V.K., Eds.; Springer Proceedings in Mathematics & Statistics; Springer International Publishing: Berlin, Germany; Cham, Switzerland, 2021; pp. 57–75. [Google Scholar]
- Spall, J.C. Introduction to Stochastic Search and Optimization; Wiley-Interscience Series in Discrete Mathematics and Optimization; Estimation, Simulation, and Control; Wiley-Interscience [John Wiley & Sons]: Hoboken, NJ, USA, 2003; p. xx+595. [Google Scholar] [CrossRef]
- Duflo, M. Algorithmes Stochastiques; Mathématiques & Applications (Berlin) [Mathematics & Applications]; Springer: Berlin, Germany, 1996; Volume 23, p. xiv+319. [Google Scholar]
- Duflo, M. Random Iterative Models; Applications of Mathematics (New York); Stephen, S.W., Translator; Springer: Berlin, Germany, 1997; Volume 34, p. xviii+385. [Google Scholar] [CrossRef]
- Bartholomew-Biggs, M.C.; Parkhurst, S.C.; Wilson, S.P. Global Optimization—Stochastic or Deterministic? In Stochastic Algorithms: Foundations and Applications; Albrecht, A., Steinhöfel, K., Eds.; Springer: Berlin/Heidelberg, Germany, 2003; pp. 125–137. [Google Scholar]
- Zhigljavsky, A.; Žilinskas, A. Stochastic Global Optimization; Springer Optimization and Its Applications; Springer: New York, NY, USA, 2008; Volume 9, p. x+262. [Google Scholar]
- Asi, H.; Duchi, J.C. The importance of better models in stochastic optimization. Proc. Natl. Acad. Sci. USA 2019, 116, 22924–22930. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Plevris, V.; Bakas, N.P.; Solorzano, G. Pure Random Orthogonal Search (PROS): A Plain and Elegant Parameterless Algorithm for Global Optimization. Appl. Sci. 2021, 11, 5053. [Google Scholar] [CrossRef]
- Mexia, J.a.T.; Pereira, D.; Baeta, J. L2 environmental indexes. Listy Biom. 1999, 36, 137–143. [Google Scholar]
- Pereira, D.G.; Mexia, J.T. Comparing double minimization and zigzag algorithms in joint regression analysis: The complete case. J. Stat. Comput. Simul. 2010, 80, 133–141. [Google Scholar] [CrossRef]
- Yin, G. Convergence of a global stochastic optimization algorithm with partial step size restarting. Adv. Appl. Probab. 2000, 32, 480–498. [Google Scholar] [CrossRef]
- Fouskakis, D.; Draper, D. Stochastic Optimization: A Review. Int. Stat. Rev./Rev. Int. De Stat. 2002, 70, 315–349. [Google Scholar] [CrossRef]
- Peng, J.p.; Shi, D.h. Improvement of pure random search in global optimization. J. Shanghai Univ. 2000, 4, 92–95. [Google Scholar] [CrossRef]
- Kushner, H.J.; Clark, D.S. Stochastic Approximation Methods for Constrained and Unconstrained Systems; Applied Mathematical Sciences; Springer: New York, NY, USA; Berlin, Germany, 1978; Volume 26, p. x+261. [Google Scholar]
- Aluffi-Pentini, F.; Parisi, V.; Zirilli, F. Global optimization and stochastic differential equations. J. Optim. Theory Appl. 1985, 47, 1–16. [Google Scholar] [CrossRef]
- Chiang, T.S.; Hwang, C.R.; Sheu, S.J. Diffusion for global optimization in Rn. Siam J. Control Optim. 1987, 25, 737–753. [Google Scholar] [CrossRef]
- Aluffi-Pentini, F.; Parisi, V.; Zirilli, F. A global optimization algorithm using stochastic differential equations. ACM Trans. Math. Softw. 1988, 14, 345–365. [Google Scholar] [CrossRef]
- Mohan, C.; Shankar, K. A numerical study of some modified versions of controlled random search method for global optimization. Int. J. Comput. Math. 1988, 23, 325–341. [Google Scholar] [CrossRef]
- Parpas, P.; Rustem, B.; Pistikopoulos, E.N. Linearly constrained global optimization and stochastic differential equations. J. Glob. Optim. 2006, 36, 191–217. [Google Scholar] [CrossRef]
- Parpas, P.; Rustem, B. Convergence analysis of a global optimization algorithm using stochastic differential equations. J. Glob. Optim. 2009, 45, 95–110. [Google Scholar] [CrossRef]
- Vegh, V.; Tieng, Q. Unconstrained real valued optimization based on stochastic differential equations. Int. J. Innov. Comput. Inf. Control 2011, 7, 6235–6246. [Google Scholar]
- Glasserman, P. Monte Carlo Methods in Financial Engineering; Applications of Mathematics (New York); Stochastic Modelling and Applied Probability; Springer: New York, NY, USA, 2004; Volume 53, p. xiv+596. [Google Scholar]
- Yin, G. Rates of convergence for a class of global stochastic optimization algorithms. Siam J. Optim. 1999, 10, 99–120. [Google Scholar] [CrossRef]
- Kontoghiorghes, E.J. (Ed.) Handbook of Parallel Computing and Statistics; Statistics: Textbooks and Monographs; Chapman & Hall/CRC: Boca Raton, FL, USA, 2006; Volume 184, p. xvi+530. [Google Scholar]
- Rajasekaran, S.; Reif, J. Handbook of Parallel Computing: Models, Algorithms and Applications; Chapman & Hall/CRC Computer and Information Science Series; CRC Press: Boca Raton, FL, USA, 2008. [Google Scholar]
- Hamadi, Y.; Sais, L. (Eds.) Handbook of Parallel Constraint Reasoning; Springer: Cham, Switzerland, 2018; p. xxvi+677. [Google Scholar] [CrossRef]
- Price, W.L. Global optimization algorithms for a CAD workstation. J. Optim. Theory Appl. 1987, 55, 133–146. [Google Scholar] [CrossRef]
- Truchet, C.; Arbelaez, A.; Richoux, F.; Codognet, P. Estimating parallel runtimes for randomized algorithms in constraint solving. J. Heuristics 2016, 22, 613–648. [Google Scholar] [CrossRef]
- Chamberlain, R.; Edelman, M.; Franklin, M.; Witte, E. Simulated annealing on a multiprocessor. In Proceedings of the 1988 IEEE International Conference on Computer Design: VLSI, Rye Brook, NY, USA, 3–5 October 1988; pp. 540–544. [Google Scholar] [CrossRef]
- Azencott, R. Parallel simulated annealing: An overview of basic techniques. In Simulated Annealing; Wiley-Interscience Series in Discrete Mathematics; Wiley: New York, NY, USA, 1992; pp. 37–46. [Google Scholar]
- Onbaşoğlu, E.; Özdamar, L. Parallel simulated annealing algorithms in global optimization. J. Glob. Optim. 2001, 19, 27–50. [Google Scholar] [CrossRef]
- Czech, Z.J. Three Parallel Algorithms for Simulated Annealing. In Parallel Processing and Applied Mathematics; Wyrzykowski, R., Dongarra, J., Paprzycki, M., Waśniewski, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2002; pp. 210–217. [Google Scholar]
- Chen, D.J.; Lee, C.Y.; Park, C.H.; Mendes, P. Parallelizing simulated annealing algorithms based on high-performance computer. J. Glob. Optim. 2007, 39, 261–289. [Google Scholar] [CrossRef]
- Lou, Z.; Reinitz, J. Parallel simulated annealing using an adaptive resampling interval. Parallel Comput. 2016, 53, 23–31. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Genet, J. Mesure et Intégration; Librairie Vuibert: Paris, France, 1976; p. 323. [Google Scholar]
- Kopp, P.E. Martingales and Stochastic Integrals; Cambridge University Press: Cambridge, UK, 1984; p. xi+202. [Google Scholar]
- Dudley, R.M. Real Analysis and Probability; Cambridge Studies in Advanced Mathematics; Revised Reprint of the 1989 Original; Cambridge University Press: Cambridge, UK, 2002; Volume 74, p. x+555. [Google Scholar] [CrossRef]
- Pacheco, P.S.; Malensek, M. An Introduction to Parallel Programming, 2nd ed.; Morgan Kaufmann Publishers; Elsevier: Cambridge, MA, USA, 2022; p. xix+468. [Google Scholar]
- Gustafson, J.L. Reevaluating Amdahl’s Law. Commun. ACM 1988, 31, 532–533. [Google Scholar] [CrossRef] [Green Version]
- McKean, H.P. Stochastic Integrals; Reprint of the 1969 Edition, with Errata; AMS Chelsea Publishing: Providence, RI, USA, 2005; p. xvi+141. [Google Scholar] [CrossRef]
- Bass, R.F. Diffusions and Elliptic Operators; Probability and Its Applications (New York); Springer: New York, NY, USA, 1998; p. xiv+232. [Google Scholar]
- Bass, R.F. Stochastic Processes; Cambridge Series in Statistical and Probabilistic Mathematics; Cambridge University Press: Cambridge, UK, 2011; Volume 33, p. xvi+390. [Google Scholar] [CrossRef]
- Kloeden, P.E.; Platen, E. Numerical Solution of Stochastic Differential Equations; Applications of Mathematics (New York); Springer: Berlin, Germany, 1992; Volume 23, p. xxxvi+632. [Google Scholar] [CrossRef] [Green Version]
- Korn, R.; Korn, E.; Kroisandt, G. Monte Carlo Methods and Models in Finance and Insurance; Chapman & Hall/CRC Financial Mathematics Series; CRC Press: Boca Raton, FL, USA, 2010; p. xiv+470. [Google Scholar] [CrossRef]
- Probability Theory III: Stochastic Calculus; Encyclopaedia of Mathematical Sciences, Volume 45; Prokhorov, Y.V.; Shiryaev, A.N. (Eds.) Springer: Berlin, Germany, 1998; Volume 45, p. iv+253. [Google Scholar]
- Wolfram Research, Inc. Mathematica, Version 12.3.1; Wolfram Research, Inc.: Champaign, IL, USA, 2021. [Google Scholar]
- Daniele, C.; Da Vià, R.; Manservisi, S.; Zunino, P. A multiscale heat transfer model for nuclear reactor assemblies. Nucl. Eng. Des. 2020, 367, 110794. [Google Scholar] [CrossRef]
- Moré, J.J.; Garbow, B.S.; Hillstrom, K.E. Testing Unconstrained Optimization Software. ACM Trans. Math. Softw. 1981, 7, 17–41. [Google Scholar] [CrossRef]
- Appel, M.J.; LaBarre, R.; Radulovic, D. On Accelerated Random Search. SIAM J. Optim. 2004, 14, 708–731. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).