Abstract
Many studies have underlined the importance of the log-normal distribution in the modeling of phenomena occurring in biology. With this in mind, in this article we offer a new and motivated transformed version of the log-normal distribution, primarily for use with biological data. The hazard rate function, quantile function, and several other significant aspects of the new distribution are investigated. In particular, we show that the hazard rate function has increasing, decreasing, bathtub, and upside-down bathtub shapes. The maximum likelihood and Bayesian techniques are both used to estimate unknown parameters. Based on the proposed distribution, we also present a parametric regression model and a Bayesian regression approach. As an assessment of the longstanding performance, simulation studies based on maximum likelihood and Bayesian techniques of estimation procedures are also conducted. Two real datasets are used to demonstrate the applicability of the new distribution. The efficiency of the third parameter in the new model is tested by utilizing the likelihood ratio test. Furthermore, the parametric bootstrap approach is used to determine the effectiveness of the suggested model for the datasets.
1. Introduction
In practice, the log-normal (LN) distribution has a wide variety of applications in an empirical sense for fitting data. In biology, too, there are diverse applications for the LN distribution. The presence of the LN distribution in biological science has been highlighted on numerous occasions. Earlier, in a study of the relationship between genes and characters in quantitative inheritance, [1] utilized the LN theory. The bivariate LN distribution has been examined by [2] in specific references to allometry, the study of biological scaling. In terms of statistical data derived from biological and agricultural sources, [3] provided much more general references. According to [4], a study on the intricacy of the biochemical processes involved in gene expression has induced an emergent LN distribution of expression levels. Again, ref. [5] discovered that a form of the LN distribution fit the postpartum blood loss data from several geographical areas quite well, implying that the LN distribution may fit postpartum blood loss globally.
In real life, the traditional basic distributions often fail to characterize and do not accurately predict most of the real-life datasets arising from complicated phenomena. Since the quality of results by statistical analysis heavily depends on the assumed model, there is huge importance in the selection of an adaptive model for analyzing the data. For this reason, it is necessary to find more allied distributions to get better quality and more accurate results. Since the LN distribution has superior importance in the field of biological sciences, it is inevitable to derive a new extended version of the LN distribution not only for modelling the biological data but also for the variety of datasets from other study areas where the LN distribution has the best fit. Note that, the LN distribution has been utilized in a range of domains which includes most of the applied areas, such as economics, sociology, and meteorology, to name just a few examples. For more applications of LN distribution in biology as well as in various study areas, one can go through the references [6,7].
On the mathematical side, the probability density function (pdf) for a LN random variable W is given by
Thus, the LN distribution depends on two parameters, a scale parameter and a shape parameter . Recently, there has been a surge in interest in the art of adding parameters to well-known existing distributions in order to get different shapes of hazard/failure rate functions (i) for applying them in various real-life situations and (ii) for analyzing data with a high degree of skewness and kurtosis. A fair review of some of the extended models is presented in [8]. As in the context of extending or generalizing baseline distributions, several authors have started to develop families of distributions based on conventional distributions or using some other techniques. Thus, in this article we propose a new extended version of the LN distribution by using a transformation technique that includes an additional shape parameter. We aim to reveal some statistical properties of the proposed model and apply them to real-life data. The chief motivations for introducing this extended lifetime model are to (i) propose a new flexible version of the LN distribution that can be used, especially to model biological data, since the LN distribution has eminent superiority in biological sciences and its related fields, and also to be applied in a wider class of other reliability problems, and (ii) to possess some new additional shapes on the hazard/failure rate.
The remaining part of the article is structured as follows. Section 2 reveals the method of construction of the distribution. In Section 3, we define the considered distribution and examine the hazard rate function. The quantile function and some of its associated measures are derived in Section 4. In Section 5, the maximum likelihood (ML) and Bayesian estimation techniques are used to estimate the unknown parameters of the new model. Furthermore, a parametric bootstrap method of simulation using the ML estimates (MLEs) is presented in Section 6. A parametric regression model associated with the new distribution is defined in Section 7. Again, a Bayesian regression method is presented in Section 8. To analyze the consistency of ML and Bayesian estimates of the model parameters, two types of simulation studies are conducted in Section 9. In Section 10, we compare the potentiality of the proposed distribution to competing distributions using two real datasets, one univariate uncensored dataset, and one censored dataset, both based on biological science. Finally, Section 11 covers the penultimate concluding remarks.
2. Construction of the New Distribution
Ref. [9] suggested a transformation method known as the DUS transformation, which utilizes exponential as the baseline distribution and is termed the DUS exponential () distribution. If is the cumulative distribution function (cdf) of some baseline continuous distribution, then the DUS transformation yields a new cdf given by
The benefit of utilizing this transformed modification is that the new distribution will generate a computation-efficient distribution as it never contains any new parameter other than the parameter(s) involved in the baseline distribution. Again, ref. [10] introduced a new generalized form of DUS transformation and the authors took the exponential distribution as the baseline distribution. The cdf of the generalized DUS (GDUS) transformation is given by
Considering the immense applicability of the LN distribution as specified in the previous section, we propose to apply it as the baseline distribution in the GDUS transformation.
3. Definition of the Distribution
The definition of the new distribution, as well as several key features, are presented in this section. Henceforth, we call the new distribution the generalized DUS transformed log-normal (GDUSLN) distribution, and it is defined as follows:
Definition 1.
We say that a random variable X follows the GDUSLN distribution with parameters and σ if its cdf is given by
and its pdf is given by
where , and . Furthermore, and are the cdf and pdf of the standard normal distribution, respectively. It is understood that for .
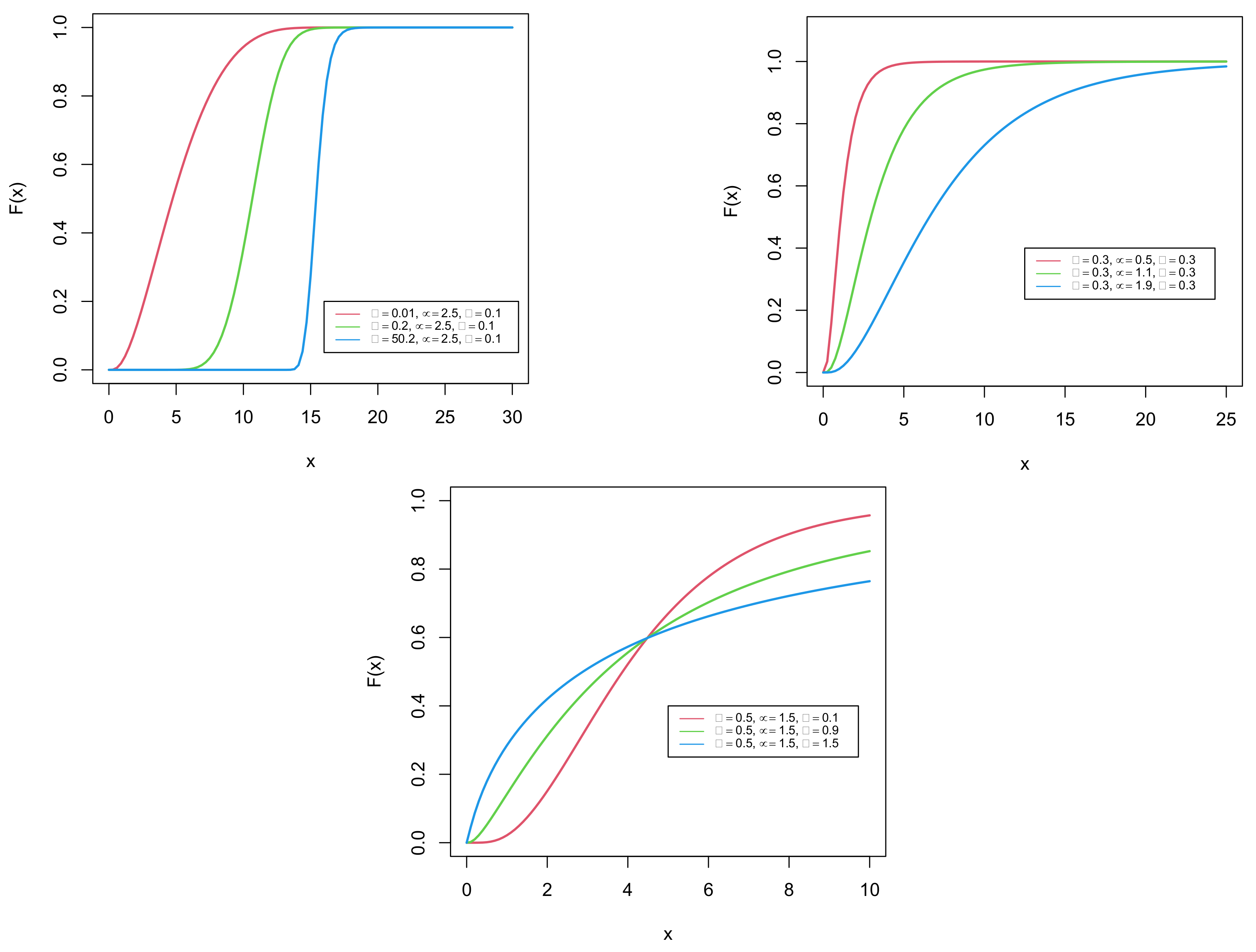
The plots in Figure 1 and Figure 2 portray the corresponding cdf and pdf of the GDUSLN distribution.
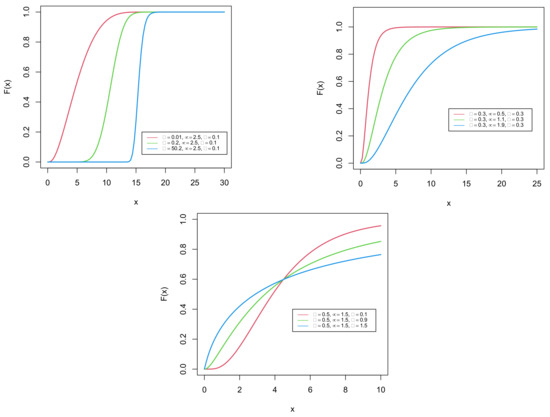
Figure 1.
Plots of the cdf of the GDUSLN distribution.
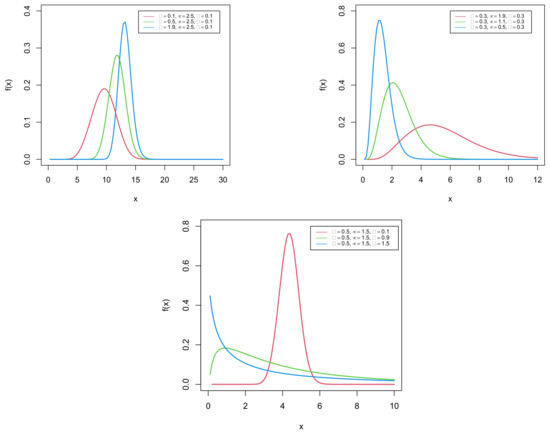
Figure 2.
Plots of the pdf of the GDUSLN distribution.
We observe that the pdf may be decreasing and unimodal with a certain flexibility in the mode and tails. It is, however, mainly right-skewed or almost symmetrical.
The cdf of the GDUSLN distribution in (1) is mitigated to the cdf of the DUS transformed log-normal (DUSLN) distribution, once . It is worth mentioning that the DUSLN distribution is not discussed in the available literature.
Hazard Rate Function
The hazard rate function of the GDUSLN distribution is given by
where is the survival function specified by
Thus, the hazard rate function gets the form
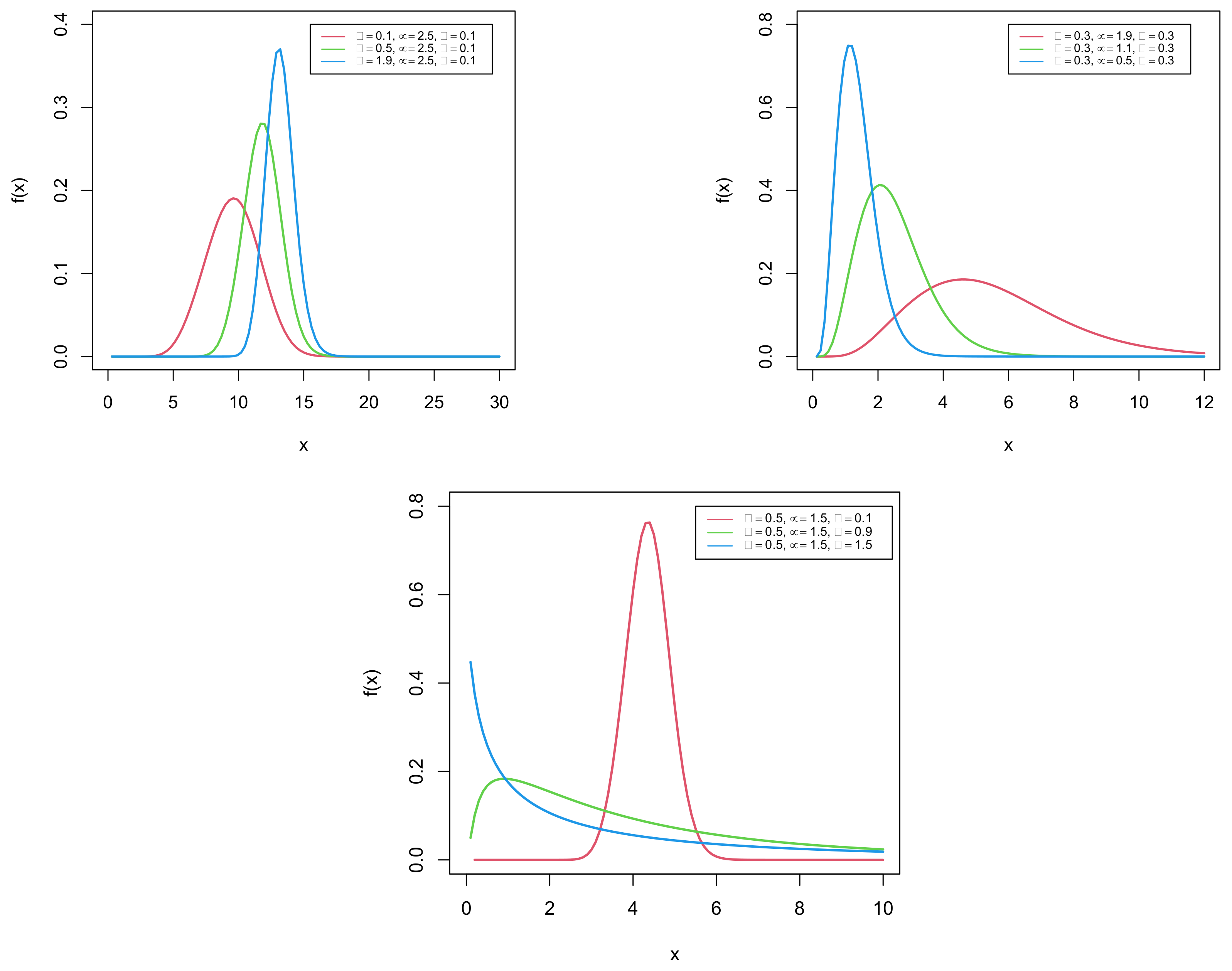
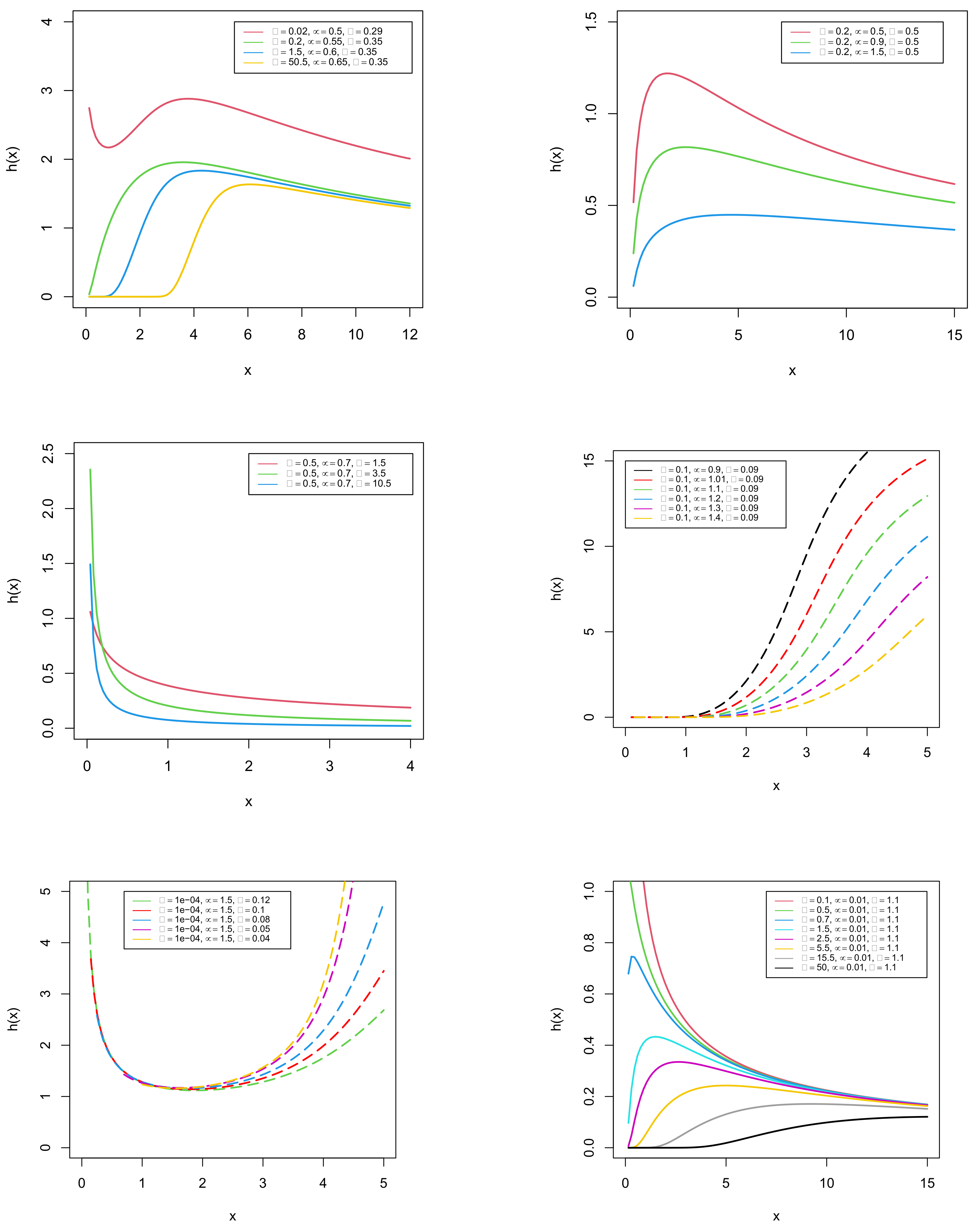
Furthermore, plots in Figure 3 refer to the shapes of the hazard rate function.
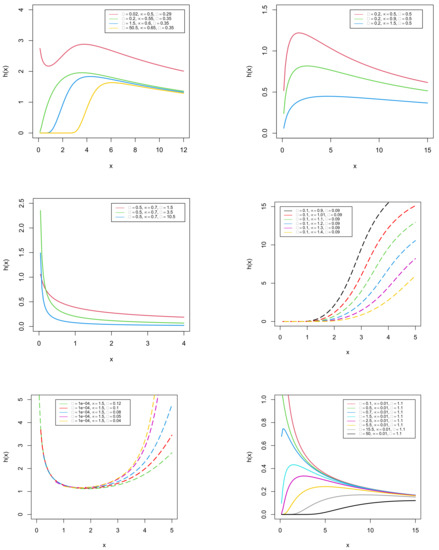
Figure 3.
Plots of the hazard rate function of the GDUSLN distribution.
It is observed that the hazard rate function possesses all the common shapes, such as increasing, decreasing, bathtub, and upside-down bathtub shapes. In this context, one of the innovative features of our model is the ability to design a bathtub-shaped failure rate function with a long flat region. This region, nevertheless, is extremely important in real-world applications, emphasizing the need for proper flat region modeling (see [11]). Furthermore, from Figure 3, it is fascinating to observe that the GDUSLN distribution has a new decreasing–increasing–decreasing shape, which we call the inverted N-shaped hazard rate function, and again possesses a special shape starting with a flat region and continuing with an increasing–decreasing shape, which we call the constant-increasing–decreasing shaped hazard rate function. More elaborately, the following results are observed from Figure 3: The hazard rate function graphs for various combinations of parameters reveal a variety of shapes including increasing (, , ), decreasing (, , ), bathtub (, , ), and upside-down bathtub (, , ). Furthermore, it can be found that the shapes vary from decreasing to increasing via upside-down bathtub when , , and .
4. Quantile Function and Associated Measures
In this section, we derive an analytical expression for the quantile function of the GDUSLN distribution and some of its associated measures.
Theorem 1.
Let . If X follows the GDUSLN distribution as given in (1), then the quantile of the distribution is given by , and, more explicitly,
where is the quantile function of a standard normal distribution.
Proof.
For the GDUSLN distribution, is the solution of the equation
On simplifications, (4) reduces to
As a remark, since is the quantile function of a standard normal distribution, in Equation (3) also gets the form
where is the inverse error function.
Now, by putting , in Equation (5), we get the median of the GDUSLN distribution, and it is given by
Equation (5) delivers the first and third quartiles of the distribution ( and ) for and , respectively. □
5. Estimation of Parameters
In this section, we discuss how to estimate the parameters of the GDUSLN distribution by employing two well-known methods, namely the ML and the Bayesian methods.
5.1. ML Estimation
In this subsection, we consider the ML estimation for the GDUSLN model parameters and . Let symbolize a random sample from the GDUSLN distribution, and let reflect the observed values. Then the log-likelihood function can then be written in the following form:
The score function associated with the log-likelihood function is
Now, the associated nonlinear log-likelihood equations are given by , and , which can be explicated as
and
respectively.
One should get the MLEs () of the GDUSLN model parameters () by synergistically solving the nonlinear Equations (7)–(9).
In this paper, for the numerical optimization, we maximize the log-likelihood function for finding the MLEs. For fixing a lower and upper bound for each parameter, the numerical optimization technique “L-BFGS-B” in fitdistrplus package of the RStudio software is used. The package provides a set of functions such as fitdist and mledist for fitting univariate distributions to various types of datasets. When the log-likelihood is maximized, one should carefully choose the initial values and remove the constraints of parameters (see [12]). Fitdistrplus is a very handy package that gives unique solutions for MLEs whenever there are questions about the initial guesses and convergence of the algorithm. As a result, we use the prefit function of this package, which delivers good starting values for the algorithm. As one of the returning components of the mledist function, the indication of convergence is done by using some integer codes, such that “0” indicates successful convergence, and “1” indicates that the maximum iteration limit has been reached. As such, “10” indicates the degeneracy of the algorithm, and “100” indicates that the algorithm encountered an internal error. For more details on this package, one should go through the link “https://CRAN.R-project.org/package=fitdistrplus (accessed on 4 September 2021)”.
The asymptotic confidence intervals for the parameters , and are now executed. When it comes to the second partial derivatives of taken at , the Hessian matrix of the GDUSLN distribution can be obtained, and it is given by
Now, the observed Fisher’s information matrix can be obtained by taking negative of the Hessian matrix. That is,
In the case of , we derive the second partial derivatives of (6) by concerning the parameters and , and are given as follows:
and
Clearly, , and . Hence, the information matrix is non-singular, thus following the result for the GDUSLN model also. Thus, we verified that the MLEs of the GDUSLN model parameters are unique.
Now, the inverse of the observed Fisher’s information matrix provides the variance-covariance matrix of the MLEs, which is given by
and for .
The asymptotically normal distribution of MLEs have been thoroughly established. That is, follows asymptotically the multivariate normal distribution .
Using the following formulae, we calculate the asymptotic confidence intervals for parameters.
where is the upper percentile of the standard normal distribution.
5.2. Bayesian Estimation
In this subsection, we perform the Bayesian analysis for the GDUSLN model parameters. To do so, each parameter should have a prior density. We employ two types of priors for this: the half-Cauchy () and the normal (N) priors. The pdf of the HC distribution with scale parameter a is defined as
The HC distribution has no mean nor variance. Meanwhile, its mode is equal to 0. Since the pdf of the HC is virtually flat but not totally flat at scale value equals 25, which verges on acquiring adequate information for the numerical approximation algorithm to continue looking at the target posterior pdf, the HC distribution with is recommended as a noninformative prior. Ref. [13] suggested that the uniform distribution, or whether more information is required, is a superior alternative to the HC distribution. As a result, for the parameters and , the HC distribution with is chosen as a noninformative prior distribution in this article. Thus, we set the prior distributions of the parameters to be
The log-likelihood function of the GDUSLN distribution is given in Equation (6). Now, using (6) and (11), we obtain the joint posterior pdf as given by
From (12), it is obvious that there is no analytical solution to find out the Bayesian estimates. Thus, we use a remarkable method of simulation, namely the Metropolis-Hastings algorithm of the Markov Chain Monte Carlo (MCMC) method.
6. Bootstrap Confidence Intervals
In this section, we use the parametric bootstrap method to approximate the distribution of MLEs of the GDUSLN model parameters. Then, we can use the bootstrap distribution to estimate confidence intervals of each parameter for the fitted GDUSLN distribution. Let be a MLE on the set of parameters of interest using a given dataset . The bootstrap is a method to estimate the distribution of statistic by getting a random sample for based on B random samples that are drawn with replacement from , see [14]. The bootstrap sample can be used to construct bootstrap confidence intervals for the parametric set of the GDUSLN distribution.
Thus, using the following formulae, we calculate the bootstrap confidence intervals for parameters:
where denotes the percentile of the bootstrap sample and, for ,
7. GDUSLN Regression Model
In this section, we define a regression model based on the GDUSLN distribution called the GDUSLN regression model. For finding the model based on the GDUSLN distribution, we consider a random variable X following the GDUSLN distribution with pdf as given in (2) and we define another random variable Y as . Then the Y has the following pdf:
where , the shape parameter , the location parameter , and the scale parameter . We allude to Equation (13) as the Log-GDUSLN (Log GDUS log-normal) distribution or otherwise, GDUS normal (GDUSN) distribution. It is worth mentioning that the GDUSN distribution is not covered in any of the existing literature. In this setting, the standardized random variable has the pdf given by
Now, the linear location-scale regression model by linking the response variable, say , and the explanatory variable vector, say , is obtained as:
where is the random error component, has the pdf as given in (14), is the location parameter of , where , and are unknown parameters. The linear model represents the location parameter vector , where is a known model matrix.
Ultimately, in this article, we propose the GDUSLN regression model from (15) and it is given by
Consider a sample of n independent observations. Here, typical likelihood estimation approach can be used. Now, for the vector of parameters from model (16), the total log-likelihood function for right censored has the form
with if survival (uncensored) and , if not (censored). Furthermore, for , and are the pdf and survival function of the GDUSLN distribution taken at , respectively.
8. Bayesian Regression Model
The Bayesian technique is shown to be particularly effective in analyzing survival models in many practical circumstances. Ergo, in this section, we will look at how the Bayesian approach fits the regression model based on the GDUSLN distribution when prior pieces of information about the parameters are taken into account. Accordingly, for the purpose of Bayesian analysis of this model, we implemented a simulation method.
Now, to perform a Bayesian analysis, one should adopt prior distributions for the parameters. Here, similar to Section 5.2, we utilized two different prior distributions, the HC and N priors. The pdf of the HC distribution with a as the scale parameter is given in Equation (10). Now, we write the right censored likelihood function as
with , if survival (uncensored) and , if not (censored). Furthermore, for , and are the pdf and survival function of the GDUSLN distribution taken at , respectively. We use the link function specified by
as a linear combination of explanatory variables. Thus, we set the prior distributions of the parameters to be
Now, using (17)–(19), the joint posterior pdf is obtained as
From Equation (20), it is clear that the analytical solution is not possible to find out the Bayesian estimates. Thus, similar to Section 5.2, we use the method of simulation, namely, the Metropolis–Hastings algorithm of the MCMC method.
9. Performance of the Estimates Using Simulation Study
In this section, we conduct simulation experiments to assess the long-run performances of ML and Bayesian estimates of the GDUSLN distribution parameters for some finite sample sizes. We have generated samples of sizes , and 1000 from the GDUSLN distribution using various values of parameters.
9.1. Simulation Study for the MLE
Here, the iteration is conducted 1001 times. Thus, we computed the average of the biases, mean squared errors (MSEs), coverage probabilities (CPs), and average lengths (ALs) of each parameter estimate for all replications in the respective sample sizes.
The analysis computes the values for the average biases and MSEs of the simulated estimates by the following formulae:
- Average bias = , and
- Average MSE = ,
where i is the number of iterations, and and is the estimate of . The results of each parameter set are reported in Table 1, Table 2, Table 3 and Table 4.

Table 1.
The MLE simulation results for (, , ).
Table 2.
The MLE simulation results for (, , ).
Table 3.
The MLE simulation results for (, , ).
Table 4.
The MLE simulation results for (, , ).
It can be observed that with the increase in sample size, the MSEs and the ALs corresponding to each estimate fall. Furthermore, the CPs of the confidence intervals for each parameter are fairly close to the nominal levels. This confirms the consistent performance of MLEs of the GDUSLN distribution.
9.2. Simulation Study for Bayesian Estimates
We consider the prior distributions for the GDUSLN parameters as given in Section 5.2. Hence, here we iterated each sample 10,001 times. For each parameter set of respective sample sizes, the posterior summary results such as mean, standard deviation (SD), Monte Carlo error (MCE), confidence interval (CI), and median are presented in Table 5, Table 6, Table 7 and Table 8.
Table 5.
Posterior summary results for (, , ).
Table 6.
Posterior summary results for (, , ).
Table 7.
Posterior summary results for (, , ).
Table 8.
Posterior summary results for (, , ).
It is observed that the SD and MCE decrease as the sample size increases, which predicts the consistency of Bayesian estimates of the GDUSLN distribution.
10. Applications and Empirical Study
This section is comprised of demonstrating the empirical importance of the GDUSLN distribution. We consider two real datasets from the area of biological science. One is the univariate cancer survival dataset, which is used to compare the data modeling ability of the GDUSLN distribution over some competitive distributions, and the other is the heart transplant dataset for the regression study. We use the RStudio software for numerical evaluations of these datasets.
10.1. Cancer Survival Data
First, we utilize the dataset from [15] as a biological dataset, which represents an uncensored univariate dataset comprised of the remission times (in months) of a random sample of 128 bladder cancer patients. The descriptive measures of the real dataset, which include sample size (n), minimum (), first quartile (), median (), third quartile (), maximum (), and inter-quartile range (IQR) are given in Table 9.
Table 9.
Descriptive statistics of real dataset.
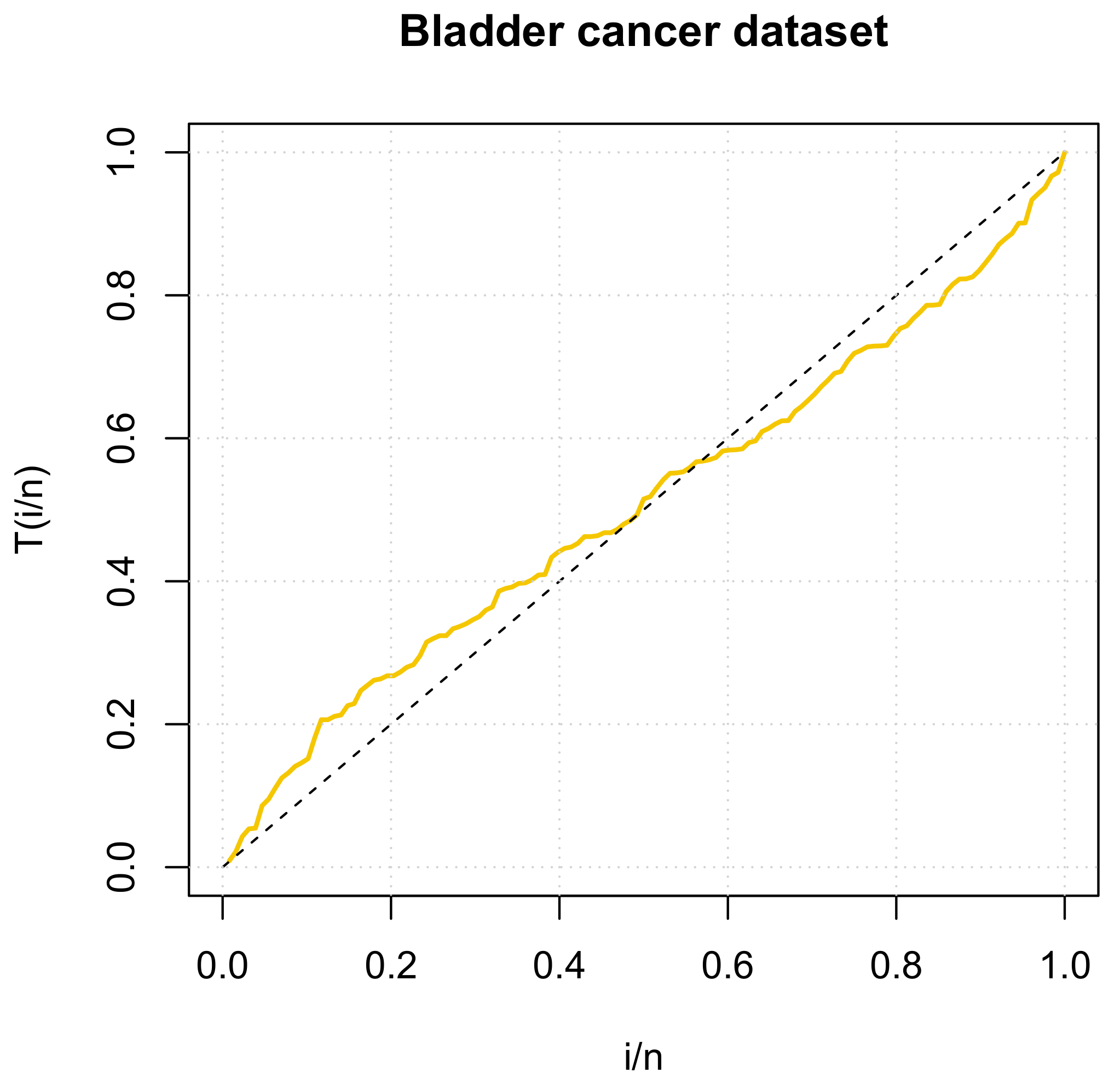
We also investigate the empirical hazard rate function for the biology dataset using the idea of a total time on test (TTT) plot. The TTT plot is a graph being used to distinguish between several types of aging as displayed in the hazard rate shapes. The common shapes of the hazard rate possess constant, increasing, decreasing, bathtub, and upside-down bathtub shapes, and can be identified by using the TTT plot by the following methods:
- A plot around the diagonal indicates a constant hazard rate, that is, the failure times can be considered exponentially distributed.
- A concave plot (above the diagonal) indicates an increasing hazard rate function.
- A convex plot (under the diagonal) indicates a decreasing hazard rate function.
- A plot which first is convex, and then concave indicates a bathtub shaped hazard rate function.
- A plot which first is concave, and then convex indicates an upside-down bathtub shaped hazard rate function.
For more about the TTT plot, see details in [16]. The TTT plot is drawn by plotting
against , where and , are the order statistics of the sample.
Thus, the plot in Figure 4 indicates that this dataset represents an upside-down bathtub shaped hazard rate function. This case is covered by the characteristics of the GDUSLN distribution.
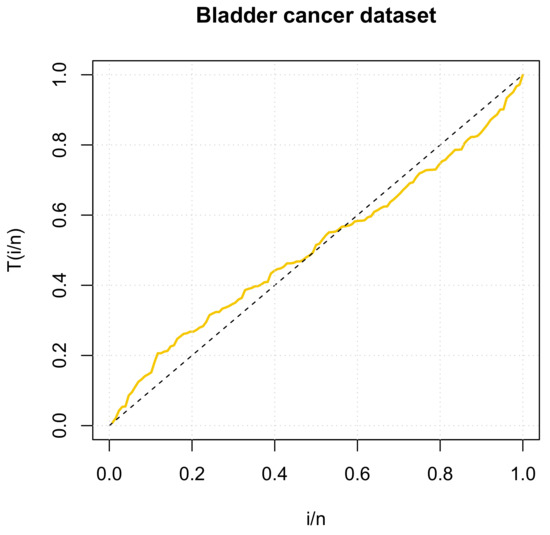
Figure 4.
The TTT plot of bladder cancer dataset.
To show the potential advantage of the GDUSLN distribution, the following distributions are considered for comparison:
- The two-parameter LN distribution.
- The exponentiated LN (ELN) distribution or otherwise, the log-power-normal distribution (see [17]) with pdf
- Generalized half-normal (GHN) distribution (see [18]) with pdf
- The new generalized Lindley distribution (NGLD) (see [19]) with pdfwhere .
- The modified Weibull (MoW) distribution (see [20]) with pdf
- The Weibull distribution with pdf
We compare the competitive models to the proposed models using the following statistical tools: negative log-likelihood (), Kolmogorov–Smirnov (KS), Cramér-von Misses (), Anderson–Darling () statistics, Akaike Information Criterion (AIC), and Bayesian Information Criterion (BIC) values. Table 10 and Table 11 display the corresponding MLEs and goodness-of-fit (GOF) statistics of the considered distributions corresponding to the bladder cancer dataset.
Table 10.
Bladder cancer dataset: MLEs of the parameters.
Table 11.
Bladder cancer dataset: GOF statistics results.
From these tables, we see that the GOF statistics values of the GDUSLN distribution are smaller than those of the other compared distributions. It can also be noted that the optimization algorithm possesses successful convergence as indicated in Section 5.1.
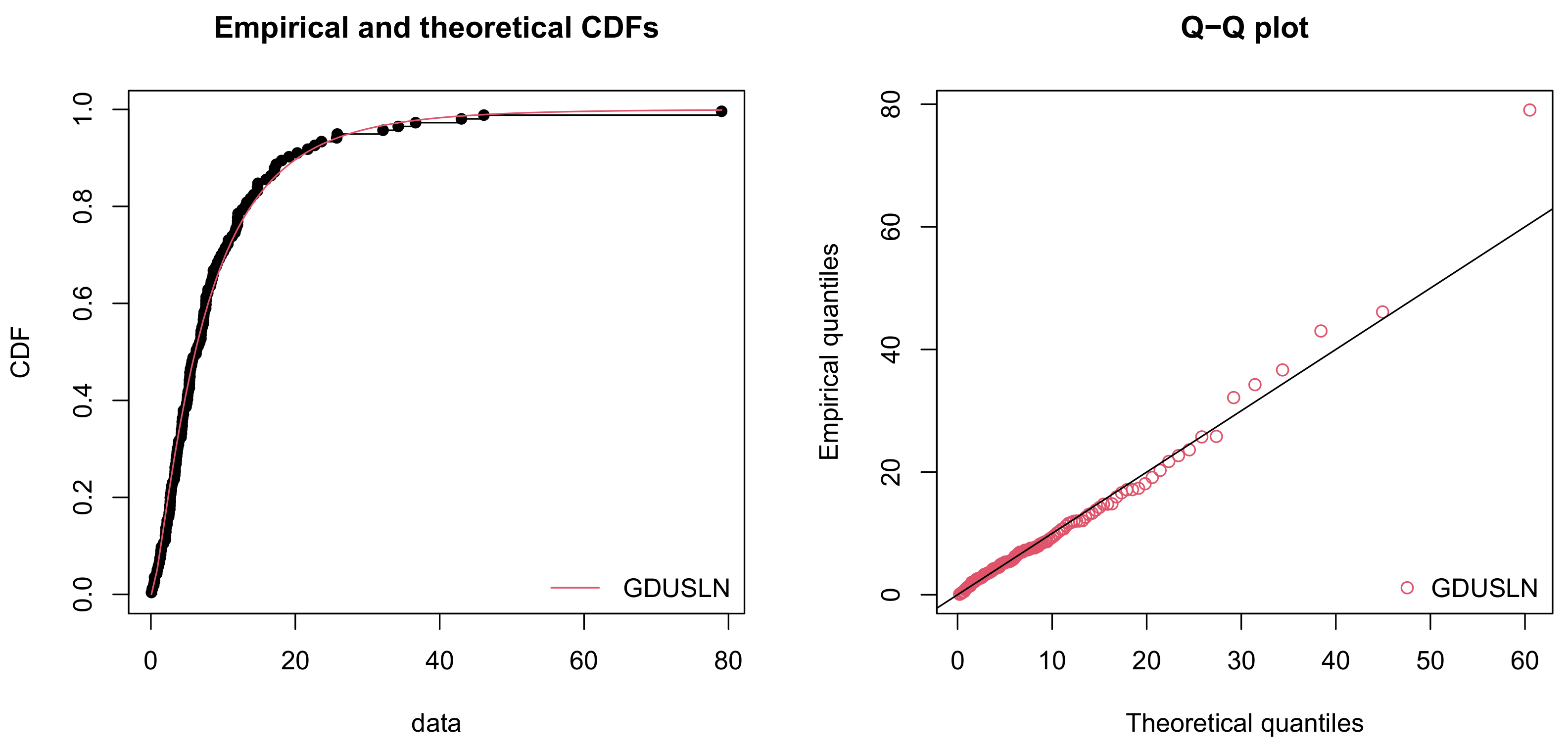
The empirical cdf and quantile-quantile (Q-Q) plots for the real dataset are given in Figure 5.
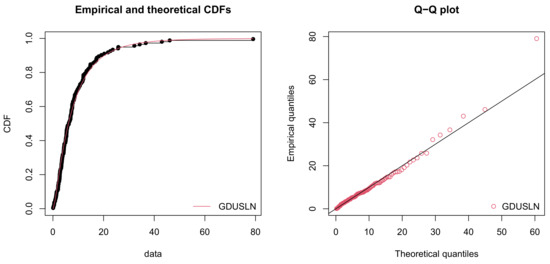
Figure 5.
Empirical plots on bladder cancer dataset.
This figure shows some nice-shaped curves for those empirical and fitted functions. Thus, we conclude that the GDUSLN distribution is the most suitable distribution for this dataset compared to that of the other distributions.
Now, the Hessian matrix corresponding to bladder cancer dataset is obtained as
and the corresponding estimated variance-covariance matrix is
It is observed that the determinant value of the observed information matrix () is non-zero, and hence satisfies the non-singularity condition of the information matrix. Now, Table 12 provides the 95 percent asymptotic confidence intervals for the GDUSLN parameters.
Table 12.
The 95% asymptotic confidence intervals of the GDUSLN parameters based on bladder cancer dataset.
Next, we focus on estimating the parameters of the GDUSLN distribution using the Bayesian procedure based on the above discussed univariate bladder cancer survival dataset. In the context of Bayesian estimation, the analysis was performed using the Metropolis–Hastings algorithm of the MCMC method with 1000 iterations. For comparing Bayes estimates with the MLEs, both the estimates of the GDUSLN parameters for the real dataset are given in Table 13. The numerical computations on Bayesian estimation are done using RStudio software.
Table 13.
MLEs and Bayes estimates of the GDUSLN parameters on bladder cancer dataset.
10.1.1. Results on Bootstrap Confidence Intervals
In this subsection, for the considered dataset, we utilize the computed MLEs to construct the 95 percent bootstrap confidence intervals for the parameters , , and . Based on the GDUSLN distribution, we simulate 1001 samples of the same size as the real dataset, with true values of the parameters chosen as MLEs of the respective parameters. We calculate the MLEs , and , for for each sample obtained. Table 14 shows the median and 95 percent bootstrap confidence interval for the parameters , and of the dataset.
Table 14.
The median and 95% bootstrap confidence interval for the GDUSLN parameters on bladder cancer dataset.
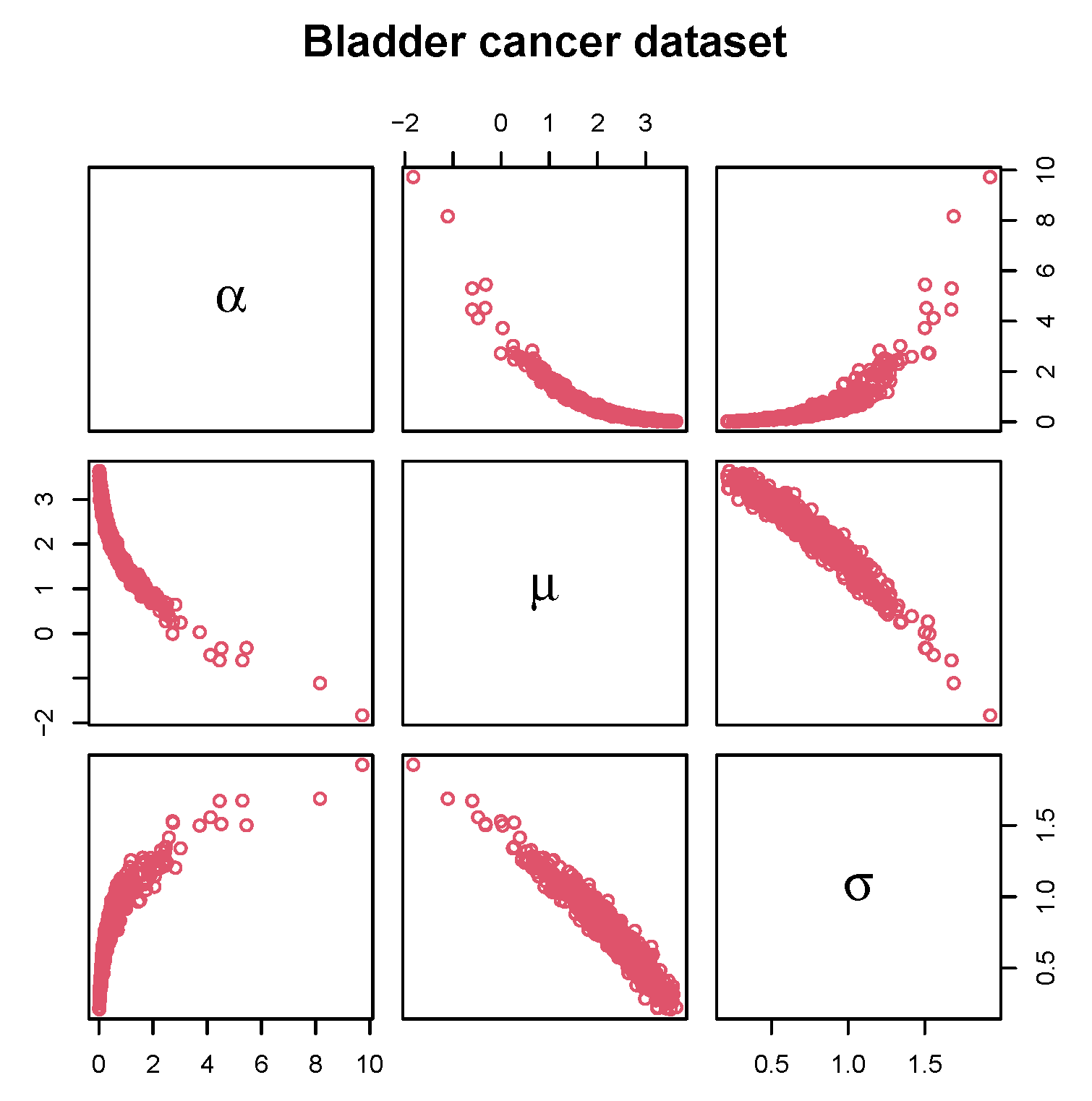
It is also fascinating to look at the joint distribution of the bootstrapped values in a matrix of scatter plots to determine the potential structural correlation among the parameters. The matrix scatterplots of the bootstrapped values of the GDUSLN parameters, which portray the joint uncertainty distribution of the fitted parameters, are displayed in Figure 6.
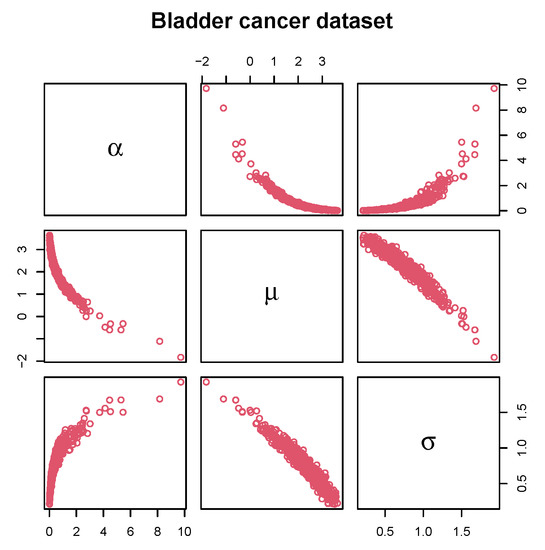
Figure 6.
Matrix scatter plot on bootstrappped values of the GDUSLN parameters due to bladder cancer dataset.
10.1.2. Likelihood Ratio Test
We also utilized the likelihood ratio (LR) test for comparing the GDUSLN distribution, which has an additional parameter with the LN distribution based on the above discussed bladder cancer survival dataset. The LR statistic for comparing the nested model : LN against : GDUSLN is
which asymptotically follows a chi-square distribution having d degrees of freedom, d being the number of additional parameters in the GDUSLN model. By using this result and standard statistical tables, we can obtain critical values for the LR test statistics for the given bladder cancer dataset. Table 15 includes the LR statistic and the corresponding p-value.
Table 15.
Likelihood ratio statistics and their p-values on bladder cancer dataset.
Given, the values of test statistic and the associated p-value, we reject the null hypothesis for the above discussed bladder cancer dataset and conclude that the GDUSLN distribution provides a significantly better representation than the LN distribution.
10.2. Stanford Heart Transplant Data
In this application, we validate the prominence of the GDUSLN regression model by applying it to the real dataset, the renowned Stanford heart transplant data. The dataset is given in [21], which can also be found in the R package p3state.msm. The goal of this study is to investigate the survival times () of patients with covariates -year of acceptance to the program, -age of patient (in years), and -previous surgery status (). In this study, the transplant indicator is used as the censoring variable.
10.2.1. Results Using the GDUSLN Regression Model
The fitted non-linear regression model is given by
where the response variable is observed follows a random variable following the GDUSLN distribution.
In Table 16, we compare the performance of the GDUSLN regression model with that of the LN regression model, as well as the summaries due to the real dataset, which include estimates of all parameters, negative log-likelihood (), and the value of AIC.
Table 16.
Regression results on Stanford heart transplant dataset.
Since its has the smallest AIC, the GDUSLN regression model is the best.
10.2.2. Results Using the GDUSLN Bayesian Regression
Table 17 represents the summary of 1000 times iterated simulated results, due to the censored dataset using Random Dive Metropolis–Hastings (RDMH) algorithm of the MCMC method, which includes the posterior mean, SD, Monte Carlo Standard Error (MCSE), effective sample size due to autocorrelation (ESS), 95% CI and the posterior median.
Table 17.
GDUSLN Bayesian regression results on Stanford heart transplant dataset.
11. Concluding Remarks
In this article, we suggested a new distribution, which is a transformed version of the log-normal distribution, mainly to investigate data in the field of biology in this research. We explored the mathematical and statistical aspects of the new model, which we call the generalized DUS transformed log-normal (GDUSLN) distribution. We delivered specific expressions for the hazard rate function and the quantile function. The hazard rate function possesses all the common shapes such as increasing, decreasing, bathtub, and upside-down bathtub, and also possesses an interesting shape called the inverted N-shaped hazard rate function. The model parameters were estimated by using Bayesian estimation and the method of maximum likelihood, and also, the observed information matrix was presented. Further, we adopted the parametric bootstrap technique to obtain confidence intervals for the model parameters. More importantly, we introduced a parametric regression model and a Bayesian regression method based on the new distribution. Simulation studies were conducted to analyze the performance of ML and Bayesian estimates of the GDUSLN parameters and they confirm their consistency. The usefulness of the new model was illustrated by two applications of real datasets, which are related to the field of biology and used goodness-of-fit tests. The novel model consistently outperforms previous models in the literature in terms of fitting. We anticipate that the suggested model would find a wider range of applications in the modeling of positive real-world datasets, that is, not only in the area of biology but also in many other areas such as physics, astronomy, engineering, survival analysis, hydrology, economics, and so on.
Author Contributions
Conceptualization, M.R.I. and R.M.; methodology, M.R.I., C.C., S.L.N., D.S.S. and R.M.; validation, M.R.I., C.C., S.L.N., D.S.S. and R.M.; software, S.L.N. and D.S.S.; investigation, M.R.I., C.C., S.L.N., D.S.S. and R.M.; data curation, S.L.N. and D.S.S.; writing—original draft preparation, S.L.N. and D.S.S.; writing—review and editing, M.R.I., C.C., S.L.N., D.S.S. and R.M.; visualization, M.R.I., C.C., S.L.N., D.S.S. and R.M. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Acknowledgments
The authors would like to thank the Editor and the unknown reviewers for the constructive comments, which greatly improved the present version of our article.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Sinnott, E.W. The Relation of Gene to Character in Quantitative Inheritance. Proc. Natl. Acad. Sci. USA 1937, 23, 224–227. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kermack, K.A.; Haldane, J.B.S. Organic correlation and allometry. Biometrika 1950, 37, 30–41. [Google Scholar] [CrossRef] [PubMed]
- Bernstein, L.; Weatherall, M. Statistics for Medical and Other Biological Students. Q. Rev. Biol. 1954, 29, 303. [Google Scholar]
- Beal, J. Biochemical complexity drives log-normal variation in genetic expression. Eng. Biol. 2017, 1, 55–60. [Google Scholar] [CrossRef] [Green Version]
- Carvalho, J.; Piaggio, G.; Wojdyla, D.; Widmer, M.; Gülmezoglu, A. Distribution of postpartum blood loss: Modeling, estimation and application to clinical trials. Reprod. Health 2018, 15, 199. [Google Scholar] [CrossRef] [PubMed]
- Aitchison, J.; Brown, J.A.C. The Lognormal Distribution with Special Reference to Its Uses in Economics; Cambridge University Press: Cambridge, UK, 1957. [Google Scholar]
- Jobe, J.; Crow, E.; Shimizu, K. Lognormal Distributions: Theory and Applications. Technometrics 1989, 31, 392. [Google Scholar] [CrossRef]
- Pham, A.; Lai, C.D. On Recent Generalizations of the Weibull Distribution. Reliab. IEEE Trans. 2007, 56, 454–458. [Google Scholar] [CrossRef]
- Dinesh, K.; Umesh, S.; Sanjay Kumar, S. A Method of Proposing New Distribution and its Application to Bladder Cancer Patients Data. J. Stat. Appl. Probab. Lett. 2015, 3, 235–245. [Google Scholar]
- Maurya, S.K.; Kaushik, A.; Singh, S.K.; Singh, U. A new class of distribution having decreasing, increasing, and bathtub-shaped failure rate. Commun. Stat. Theory Methods 2017, 46, 10359–10372. [Google Scholar] [CrossRef]
- Irshad, M.R.; Maya, R.; Krishna, A. Exponentiated Power Muth Distribution and Associated Inference. J. Indian Soc. Probab. Stat. 2021, 1–38. [Google Scholar] [CrossRef]
- MacDonald, I.L. Does Newton-Raphson really fail? Stat. Methods Med. Res. 2014, 23, 308–311. [Google Scholar] [CrossRef] [PubMed]
- Gelman, A.; Hill, J. Data Analysis Using Regression and Multilevel/Hierarchical Models; Analytical Methods for Social Research; Cambridge University Press: Cambridge, UK, 2006. [Google Scholar]
- Wasserman, L. All of Nonparametric Statistics; Springer Texts in Statistics; Springer: New York, NY, USA, 2006. [Google Scholar]
- Lee, E.; Wang, J. Statistical Methods for Survival Data Analysis; Wiley Series in Probability and Statistics; Wiley: New York, NY, USA, 2003. [Google Scholar]
- Aarset, M.V. How to Identify a Bathtub Hazard Rate. IEEE Trans. Reliab. 1987, R-36, 106–108. [Google Scholar] [CrossRef]
- Martínez-Flórez, G.; Bolfarine, H.; Gómez, H.W. The log-power-normal distribution with application to air pollution. Environmetrics 2014, 25, 44–56. [Google Scholar] [CrossRef]
- Cooray, K.; Ananda, M.M.A. A Generalization of the Half-Normal Distribution with Applications to Lifetime Data. Commun. Stat. Theory Methods 2008, 37, 1323–1337. [Google Scholar] [CrossRef]
- Elbatal, I.; Merovci, F.; Elgarhy, M. A new generalized Lindley distribution. Math. Theory Model. 2013, 3, 30–47. [Google Scholar]
- Xie, M.; Tang, Y.; Goh, T. A modified Weibull extension with bathtub-shaped failure rate function. Reliab. Eng. Syst. Saf. 2002, 76, 279–285. [Google Scholar] [CrossRef]
- Crowley, J.; Hu, M. Covariance Analysis of Heart Transplant Survival Data. J. Am. Stat. Assoc. 1977, 72, 27–36. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).