1. Introduction
Improvements in information and communication technologies break down geographical boundaries, allowing for faster connection and communication worldwide [
1]. Further, the proliferation of social networks due to the ubiquity of Web 2.0 revolutionizes the way people present their opinions by providing social interactions [
2,
3]. As a result, consumers from all over the world are sharing their emotions, opinions, evaluations and judgments to a wide ranging audience by connecting themselves to online platforms such as blogs, newsgroups, discussion boards, and social networking sites [
4,
5,
6]. Consequently, the Web consists of huge volumes of publicly available opinion data about different objects, for instance, individuals, government, products, events, organizations, services, education, news [
7,
8]. The volume of opinion data about different entities (individuals, products, events, organizations, services) is growing rapidly on these platforms due to the accessibility, scalability, and enhanced user participation of Web 2.0. The fast-growing opinion data are unstructured, freely available, and decision-oriented to fulfil the need of diverse stakeholders such as corporates and consumers [
9,
10,
11]. Though there are various platforms of electronic word of mouth (e-WOM), the most highly focused are online reviews platforms. Enterprises are now focusing on customer online reviews to support their decision-making process, such as risk management, sale prediction, market intelligence, new product design, trend prediction, advertisement placement, threats from competitors and benchmarking [
12,
13,
14,
15,
16]. From the customer point of view, e-WOM considerably impacts customers’ product choice and adoption, purchase intentions, and use of products [
17,
18]. Moreover, social networks have increased the sophistication of customers, and so customers compare competing products before buying a product [
19,
20]. As a result, positive e-WOM improves the trust, satisfaction and loyalty of customers [
2]. In contrast, negative e-WOM decrease customers’ patronage and loyalty [
3].
The volume of e-WOM has been growing at a remarkable pace as the universality of the Web offers easy users’ participation through different online platforms [
21]. These platforms provide valuable insights into different features of a target product, for instance, a digital camera. Consumers consult these platforms to compare features of different cameras (picture quality, battery life, zoom, flash) from competing brands before making a purchase [
22]. The features of a product play a crucial role in the purchase decision. However, online reviews do not highlight the critical features of a product to facilitate consumers in their decision-making process. Moreover, users need to gravitate through a host of reviews to learn about features that need to be considered before making a purchase due to the varying quality, enormous availability, distributed nature, voluminosity, heterogeneity, and multi-dimensionality of online reviews. As a result, it is a time-consuming and tedious task to analyze and summarize online reviews to get information about competing features between products of different brands [
23,
24]. Further, the nature of the online reviews poses many challenges to the text mining community, such as filtering low-quality reviews from high-quality reviews (information overloading problem), ranking of products’ prominent features and integrated visual views of consumers’ opinions (consumers-to-consumers communication problem) [
25,
26,
27]. The information overload problem has been resolved in literature by a variety of review ranking schemes. To overcome the consumer-consumers communication problem, opinion mining systems have been available in the literature aiming at providing automatic analysis and summarization of online reviews to pinpoint decision-oriented features of a target product [
28].
Due to the characteristics of online reviews, it becomes difficult to identify high-quality reviews which cover a diverse set of opinions. The quality of a review is described by its embedded polarity or opinions [
29] or how helpful a review is [
30]. For example, the Amazon online reputation system in Ref. [
31] asks users to vote for customer reviews they found “helpful” in the form of helpfulness votes and star rating. The helpfulness votes and 5-star rating represent the quality of the product that signifies customers’ endorsement and impact other customers’ shopping intentions [
32,
33,
34]. Currently, high-quality reviews are identified when users explicitly filter reviews based on the star rating and/or their level of helpfulness [
32,
35]. Different review quality evaluation methods have been proposed in the literature that utilize combinations of metadata, textual, and social features [
36,
37,
38]. In contrast to classical rating systems [
39] in which users rate a product, community-driven review systems allow the customers to rate prominent features of a product. The customers rating may vary based on the different features of the product. Consequently, it emphasizes the need to develop mechanisms to identify prominent features of a product in Ref. [
40] about which the customers are concerned and rank products based on identified features by excavating a large number of customer reviews. Commonly, feature frequency, semantic polarities and ratings are used for feature ranking to enhance consumers to consumer communication [
41,
42,
43,
44,
45,
46]. However, these methods overlook important factors that can improve feature ranking by focusing on (i) opinion strength, such as how positive or negative an opinion word is, (ii) quality of reviews, and (iii) consideration of user preferences. Further, the visualization of the opinion summary has the same importance as the assessment of review quality and feature ranking. A feature-based opinion summary with ample visualization may be more valuable than a summary showing only an average rating for features of a target product [
41]. However, existing review quality evaluation methods are not integrated with feature ranking, opinion visualizations, and user preferences and they overlook a few parameters, such as visitor count and title information. Therefore, there is a need for an integrated system that ranks, analyzes, summarizes and visualizes these online reviews to fulfil the requirements of consumers and enterprises.
In the light of above discussion, the motivation of the work is to (i) remove low-quality reviews from feature ranking as suggested by Ref. [
47], (ii) enhancing the feature ranking by incorporating missing parameters, and (iii) improving existing opinion visualization to provide opinion-strength-based summary. Therefore, this study aims to propose and develop a reputation system to provides users a multi-level analysis and summarization of consumer opinions. Specifically, the objectives of this paper are to propose (i) a review ranking method incorporating vital parameters and user preferences, (ii) a feature ranking method based on indispensable parameters, and (iii) opinion strength-based visualization.
The main contributions include:
- (a)
Scheme for the selection of high-quality reviews by incorporating users’ preferences.
- (b)
Feature ranking scheme based on multiple parameters for a deeper understanding of consumers’ opinions.
- (c)
Opinion-strength-based visualization based on high-quality reviews to provide high-quality information for decision-making. The proposed visualization provides a multi-level detail of consumers’ opinions (ranging from −3 to +3) on critical products features at a glance, which allows entrepreneurs and consumers to highlight decisive product features having a key impact on the sale, product choice and adoption.
- (d)
Reputation system is evaluated on a real dataset
- (e)
Usability study for the evaluation of the proposed visualization
The rest of the paper is organized as follows.
Section 2 presents existing work on review quality evaluation, feature ranking and opinion visualizations.
Section 3 presents the proposed system.
Section 4 presents the results and discussion, and finally,
Section 5 concludes the paper.
3. Proposed System
3.1. Theoretical Framework
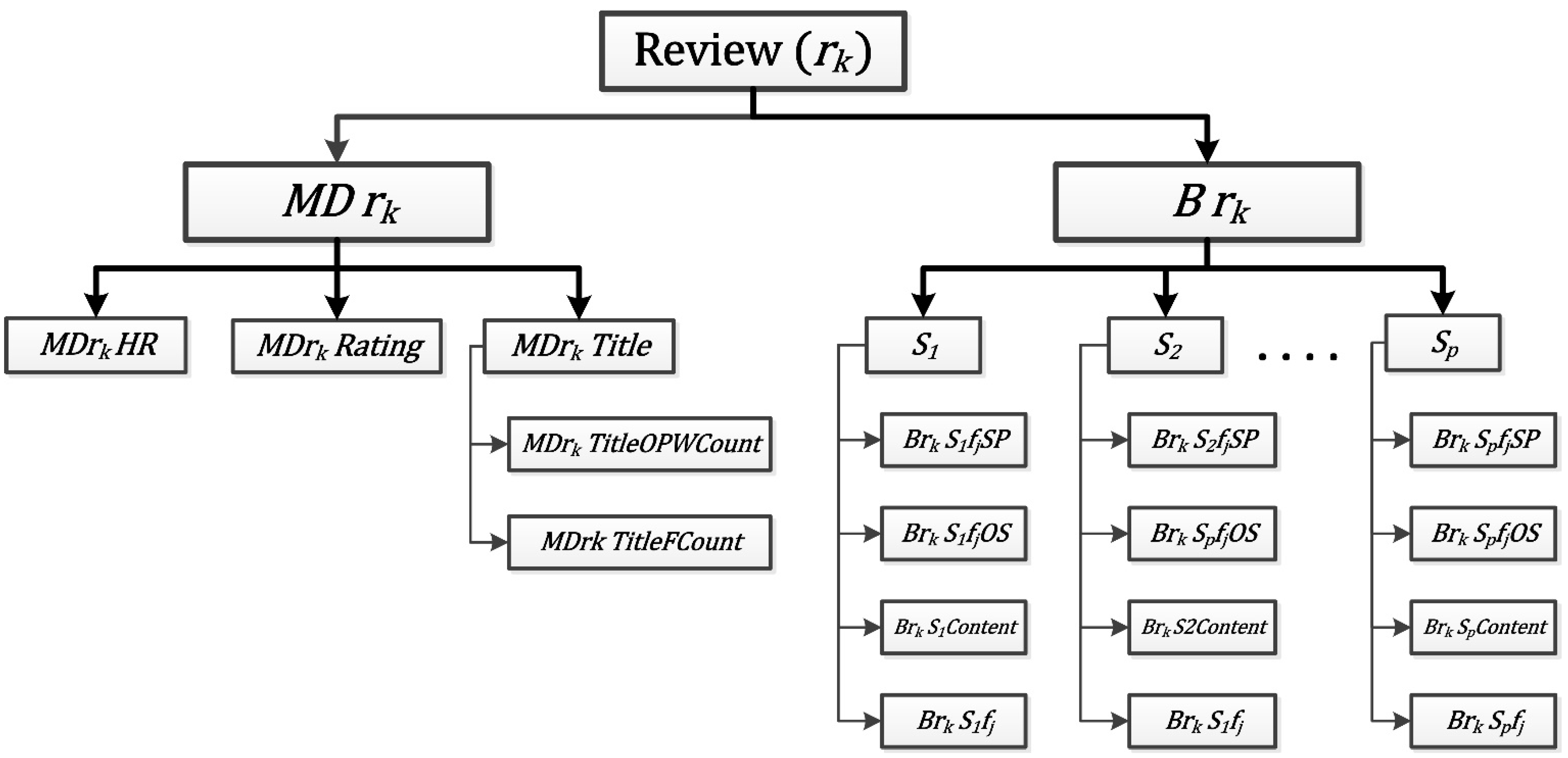
Let document D with product reviews contain n reviews R= [ Every review () is comprised of a set of feature-opinion pair, which consists of a feature and an opinion word . Each feature may pair with more than one opinion words in a single review or over the set of n reviews. In our proposed system, each review is represented by a tuple (termed as review tuple) of two elements . The review tuple is as follows:
where, , , , , ,
The
represents the metadata of a review, and B represents a set of sentences in the body of reviews.
Table 1 depicts the description of the abbreviation used. Each sentence
in
is represented by a proposed tuple. The proposed tuple is an extension of tuples presented in Refs. [
40,
58]. As shown in
Figure 1, each sentence
contains single feature
. The opinion related to the feature
in a sentence can be positive
or negative
). Opinion polarity is estimated in the range of −3 to −1 for negative and +1 to +3 for positive (three for strongest and one for weakest). The opinion with positive semantic polarity can have opinion strength strong positive (
), mildly positive (
) or weak positive (
) [
52,
64,
65]. Similarly, the opinion with negative semantic polarity can have opinion strength strong negative (
), mildly negative (
) or weak negative (
) [
52,
64,
65]. A feature tuple is also proposed in work, as shown below.
The mathematical model of the feature tuple that is part of the review tuple is shown below:
where
= [
= [
Consider the following review shown in
Figure 2.
The helpfulness ratio (
,) of the above-mentioned review is 75 (3/4*100) with a 5-star rating. The title of the review indicates a positive opinion with ‘great’ opinion word in the title having an opinion strength strong positive (
) associated with the weight of +3 (
. The review presents opinions on battery, picture quality, and viewfinder features of a camera. The ‘battery’, ‘picture quality’, and ‘viewfinder’ features are described by the opinion word good, poor, and very good, respectively. The opinion word good is a positive word with the weak positive (
) opinion strength, which is associated with the weight +1 (
). However, the opinion word poor is a negative word with the
strength (associated with the weight −1). The semantic orientation of the opinion word very good is positive with the opinion strength of
(where
. The tuple of the review presented in
Figure 2 is demonstrated in
Figure 3.
Consider the following reviews shown in
Figure 4.
Figure 4 shows three reviews containing opinions on three different features (picture quality, battery, viewfinder) of a digital camera. The resultant feature tuple of the battery feature is presented in
Figure 5. The battery feature was mentioned in all of the reviews three times; therefore, its weight is three. Three opinion words (good, poor, disappointing) are associated with the battery feature. These opinion words are Weakly Positive, Weakly Negative and Mildly Negative with corresponding values of +1, −1, and −2, respectively. One positive opinion word having an opinion strength of +1 is associated with the battery feature, and hence the
value of the battery is +1, while two negative words with −1 and −2 opinion strengths are connected with the feature battery, resulting in the value of
of the feature equals to −3 (−2 + −1).
3.2. Architecture of the System
The proposed system consists of five components: pre-processor, feature and opinion extractor, review ranker, feature ranker, and opinion visualizer (see
Figure 6). This architecture is based on a previous study [
52].
3.2.1. Pre-Processor
A pre-processor prepares a document containing reviews for review and feature ranking. A variety of processes, including conversion of review text to lower case, removal of non-alphabetic characters, tokenization, stop word filter, spell checker, word stemming, and part of speech (POS) tagging, are performed by the component. Firstly, the text of the document is transformed into lower case. Secondly, stop words are eliminated from the document by applying a stop word filter using a defined list of stop words. Thirdly, word-stemming is performed to convert derivationally and inflectional forms of words into a base form. After that, noise is removed from the document by spell checking. Then POS tagging is employed to assign a POS category to each word in the document. In the end, the tokenization returns a list of words.
3.2.2. Feature and Opinion Extractor
Feature and opinion extractor extracts candidate features along with opinion words to generate a list of potential features. An existing study revealed that 60%–70% of the product features are represented by frequent explicit nouns [
55]. The current study considered frequent nouns or noun phrases as candidate features based on the findings of existing studies [
42,
52,
53,
58]. Let us suppose there are q nouns (i.e., features) (
) extracted from all the review tuples and stored in the list. A window based approach [
41] is then utilized to extract opinion words associated with a particular feature in which opinion words discussed within K words of a particular feature are selected as associated opinion words. In contrast to existing studies [
42,
43,
44,
52] which extract nouns based only on feature frequency, we utilized three parameters to extract prominent features from a review document.
The noun j weight (
) is calculated based on the assumption that frequently discussed nouns in a large number of high-quality reviews associated with several opinion words discussed in considerable review titles are significant product features. To identify potential features and associated opinion words from the list of nouns, an algorithm called feature and opinion extractor is proposed and presented in
Figure 7. The inputs to the algorithm are the list of nouns (NounsList[]) extracted from reviews tuples (stored in the list Reviews[]) and review document. NounsList[] is an adjacency list [
10] that can store the associated opinion words with a noun. Associated opinion words for feature
is searched in all reviews, and opinion words that are on a distance of
K words from the selected noun are populated in the NounsList[]. The following five equations are used to calculate
. In Equation (1), the frequency of noun
(
) is calculated based on its occurrence in the review document consisting of m reivews. In other words,
in Equation (1) represents count of
occurrence in reviews.
The number of opinion words associated with noun
in the whole review document is calculated in Equation (2).
(depicted in Equation (2) is the number of opinion words associated with the noun
The numbers of times noun
appeared in the titles of reviews is described by Equation (3) where
is the number of titles in which the noun
discussed. In Equation (3), the bracket value is 1 (using the inversion notation [
10]), if the condition holds otherwise, it is 0 [
10]. The condition
in Equation (3), returns 1, if
exists in the review
title.
Equation (4) computes the numbers of times noun
appeared in reviews.
Equation (5) shows the calculation of feature weight. The values of
,
,
, and
calculated in Equations (1)–(4) are utilized in the Equation (4) to calculated the weight of a feature. Therefore, our proposed method to calculated weight of a noun is based on four paramters: (i) frequency of noun
, (ii) the number of associated opinion words with noun
, and (iii) the number of times noun
appreared in reviews’ title, and number of reviews in which
appeared (
. These parametera are calculated for each noun from (Lines 8–17) of the algorithm.
The noun frequency
,
, and
are then summed up to compute the weight of a review called
in the algorithm (Line 20–21). This
is used to filter the nouns. Nouns having a
above a threshold
are selected as potential features. After this, FeatureOpinionList[] containing the selected (most frequent) features with associated opinion words is built.
3.2.3. Review Ranker
The job of the review ranker is to calculate the rank of reviews stored in the review document. To calculate the rank of a review, first, the weight of each review is calculated based on five parameters. A user can define the contribution of these parameters by assigning them a weight. After assigning the weight to the reviews, the reviews are classified into five classes: (a) excellent, (b) good, (c) average, (d) fair, and (e) poor according to their weights.
To compute the class of each review stored in the review document, a ReviewRanking algorithm is proposed and presented in
Figure 8. The core of the algorithm is to assign weights to reviews. The parameters used to compute the weight of a review tuple are: (i) title score (TitleScore), (ii) number of features in the review body (
), (iii) number of opinion words in the review body (
), (iv) helpfulness ratio (
), and (v) users’ rating
. The Title score depicts the sum of the number of feature and opinion words in the review title. Firstly, for each review tuple, the algorithm computes the number of features (
and opinion words (
) appearing in the review title and then these computations are used to calculated title score (TitleScore) (Line 4–12). In other words, the Title score represents the sum of
, and
Moreover, for each review tuple the number of opinion words (
and features (
appearing in the body are calculated (Line 14-21). Weight of each review (
is computed based on the values of the parameters (
,
,
,
). Users’ preferences are incorporated in review ranking by defining the weight of each parameter (
,
,
, and
by users. User preferences weights (
,
,
, and
and the weights assigned to
(α) are presented in (Line 23-25). Title weight coefficient (α) can be adjusted depending on the size and nature of experimental data. We set the value of α to 10 based on the conclusion of Ref. [
42]. Maximum weight (
among the m reviews is computed in Line 27. After calculating the weights of reviews, class of each review is calculated (based on review own weight and maximum weight (
) among all reviews weights). Based on
can be classified as one of the following review classes: (i) Excellent, (ii) Good, (iii) Average, (iv) Fair, and (v) Poor. We utilized these five review classes of Ref. [
52] to depict the quality of each review in the review document and to distinguish high-quality reviews (HQ_reviews) from low-quality reviews to improve feature ranking. The presented scheme requires the user to decide which of the classes to be selected. The reviews that belong to selected classes (termed as high-quality reviews) are considered for feature ranking and opinion summary. For example, if the user selects classes Excellent, and Good; then all the reviews with
equals Excellent, and Good are declared as high-quality reviews.
Consider the review shown in
Figure 9 as an example. In this review, features are highlighted in red while opinion words are highlighted in green. The
of the review is two as the title of the review comprises of one feature (Picture) and one opinion word (Brilliant). There are four features in the body of the review (picture quality, viewfinder, zoom, battery), and as a result, the
score of the review is four. Four opinion words (excellent, poor, good and fantastic) are expressed in the review, so the
of the review is four. Putting the values of the
computation equation results in 25.4. In the calculation of the
of the review
shown in
Figure 9, assuming the value of 0.20 for all preferences (
,
,
, and
).
3.2.4. Feature Ranker
After discarding low-quality reviews (with
below a certain threshold
) among
reviews, we are left with
high-quality reviews (HQ-Reviews[]). The feature ranker ranks the extracted features (FeatureOpinionList[]) by utilizing high-quality reviews provided by the review ranker. In contrast to Ref. [
52], we are enhancing the feature ranking by incorporating opinion and feature frequency along with opinion strength and orientation. The proposed feature ranker computes four rankings for every feature
based on the information presented in high-quality reviews: (i) feature
weight (
, (depicted in Equation (10)); (ii) positive credence of
(
, (depicted in Equation (12)); (iii) negative credence (
, (depicted in Equation (14)); and (iv) overall credence (
, (depicted in Equation (15)). An algorithm is proposed and presented in
Figure 10 to calculate these ranking of a feature.
The
is calculated based on the idea that frequently discussed features in a large number of high-quality reviews associated with many opinion words that appeared in substantial reviews’ titles are decisive product features. Therefore, the value of
is calculated using four parameters; (i) count of
occurrence in high-quality reviews (
), (ii) the number of opinion words associated with the
(
), (iii) number of reviews which discussed the feature in title or body (
), and (iv) the number of reviews’ titles that contains the feature (
). These parameters are computed using Equations (6)–(9), respectively as shown (Lines 3–10) of the algorithm. Moreover,
and
are exploited in calculating the weight of a feature
on the ground that if a feature
is discussed in many reviews and titles, then it is significant. The calculation of
is depicted in Equation (10).
in Equation (11) represents the count of positive opinions for the feature
in all sentences of
reviews. In Equation (11), the condition
returns to 1 if
is
, otherwise it would return zero. In Equation (12), the condition
returns to 1 if the feature opinion strength in sent
is
, otherwise it would return zero. Moreover,
sums the opinion strength
the number of times it appears in the sentences of all m reviews. Positive credence (
) of a feature
in Equation (12), denotes the number of positive opinion words used to describe a feature
and the accumulated strength of associated positive opinion words. The larger the value of
denotes that the feature
was discussed more positively and many times.
Equation (13) depicts the total number of occurrences of negative opinions of a feature
in the body of m high-quality reviews.
in Equation (14) reflects the number of negative opinion words used to describe a feature and the total strength of these negative opinion words. The idea behind
is that the rank of a feature
should be higher than other features if
is associated with more negative words. The high value of
indicates that the features are discussed negatively by a large number of users.
is subtracted from
of a feature
to obtain an overall rank (
) as shown in Equation (15).
The count of
,
,
in each review is computed (Lines 12–25).
is computed in Line 38 and
is computed in Line 47.
3.2.5. Opinion Visualizer
An extensive literature review followed by a usability study with 146 participants was performed by the authors in their previous work to identify a suitable opinion visualization [
63]. In Ref. [
63], a questionnaire survey was performed to get feedback from users about existing opinion visualizations. Users’ preferred visualization (tree map [
39]) is adapted for the current study based on the findings of a previous study. The proposed visualization provides a multi-dimensional view of consumer opinions. The proposed visualization is discussed in the result section.



 ,
, 

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}