
Decentralized and Secure Collaborative Framework for Personalized Diabetes Prediction


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
- Blockchain as the foundation: Blockchain technology provides a decentralized, immutable, and transparent ledger for secure data management and access control. Patient data can be registered on the blockchain, establishing ownership and enabling fine-grained permissions for how the data can be used. Smart contracts on the blockchain automate data-sharing agreements, ensuring compliance and facilitating auditable transactions between healthcare institutions.
- Federated learning for privacy preservation: Federated learning allows machine learning models to be trained on distributed datasets without requiring the movement of sensitive patient data. Instead of sending data to a central server, local models are trained on each institution’s dataset. Only model updates, such as gradients or parameters, are exchanged, significantly reducing privacy risks.
- Blockchain securing federated learning: Blockchain further strengthens federated learning by addressing potential vulnerabilities. It provides a secure channel for model updates, preventing tampering or interception. Additionally, blockchain enables the verification of participating institutions and a transparent audit trail for model training, ensuring trust and accountability within the collaborative network.
2. Materials and Methods
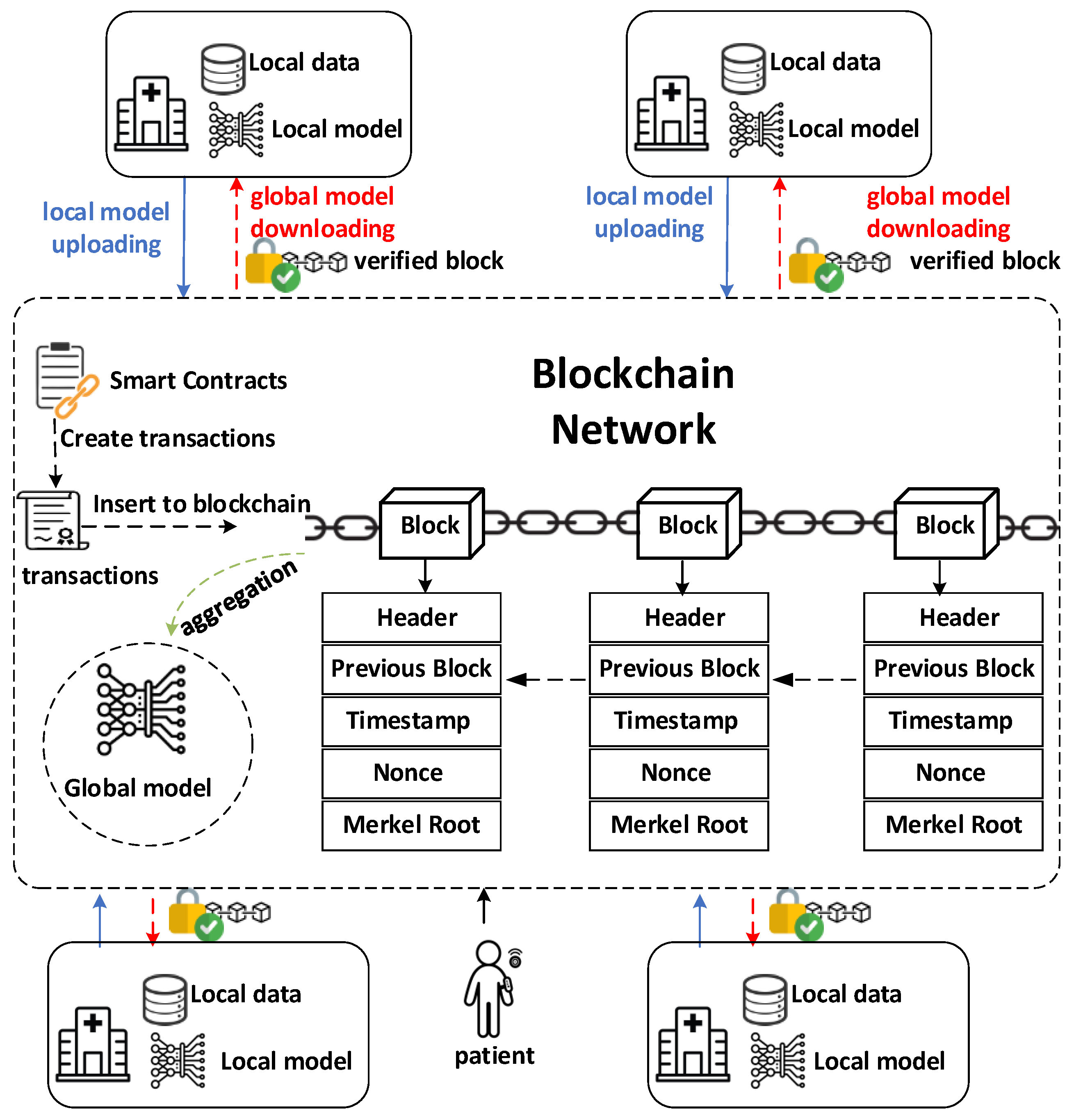
2.1. System Overview
2.2. Privacy Preservation
2.3. Secure Collaboration
2.3.1. Automating Security and Trust
- Submission of Model Updates: Healthcare providers, acting as federated learning clients, submit their locally trained model updates (e.g., gradients, weights) to the ModelUpdate contract. These updates are encrypted to ensure data privacy during transmission and storage on the blockchain.
- Authenticity Verification: The contract verifies the authenticity of each submitted update using digital signatures. Each participating healthcare provider has a unique cryptographic key pair, and the update is signed using their private key. The contract then uses the provider’s public key to verify the signature, ensuring that the update originated from an authorized participant.
- Validation and Integrity Checks: Before accepting an update, the contract performs various validation and integrity checks to ensure the quality and trustworthiness of the submitted model. These checks may include:
- (1)
- Data Validation: Verifying that the update adheres to the expected data format and structure.
- (2)
- Model Performance Metrics: Checking if the update meets certain performance criteria or thresholds to prevent the inclusion of potentially harmful or inaccurate models.
- (3)
- Dataset Verification: Ensuring that the update was trained on an authorized and relevant dataset, preventing the inclusion of models trained on biased or irrelevant data.
- Secure Aggregation: Once the updates are validated, the contract employs secure aggregation mechanisms to combine them into a new global model. This aggregation process may utilize techniques such as:
- (1)
- Federated Averaging: A simple and widely used approach that averages the model updates from different participants, weighted by the size of their local datasets.
- (2)
- Secure Multi-Party Computation (MPC): Enables the computation of the aggregated model without revealing the individual updates, ensuring data privacy.
- (3)
- Homomorphic Encryption: Allows computations to be performed directly on encrypted data, further enhancing privacy during aggregation.
- Consensus Mechanisms: The contract leverages the underlying blockchain’s consensus mechanism (e.g., Proof-of-Stake) to ensure agreement among network participants on the final aggregated model. This prevents malicious actors from manipulating the model or introducing biased updates.
- Model Distribution: After successful aggregation, the updated global model is securely distributed back to the participating healthcare providers, enabling them to continue local training and further refine the model in subsequent iterations.
2.3.2. Enhancing Security in Federated Learning
- Model Authentication: Blockchain verifies the identities of healthcare providers participating in federated learning, mitigating the risk of malicious actors or corrupted model updates.
- Secure Parameter Aggregation: Smart contracts provide a safe channel for model update exchange and aggregation. Advanced techniques like secure multi-party computation or homomorphic encryption can be integrated into the smart contract logic to ensure the confidentiality of updates during aggregation.
- Auditability and Quality Control: Storing model updates, metadata (e.g., hyperparameters, dataset origins), and aggregation outcomes on the blockchain creates an immutable audit trail. This promotes transparency and facilitates the investigation of anomalies. Smart contracts can enforce validation checks on model updates (for accuracy, fairness, or adherence to agreed-upon datasets) before they are accepted into the global model.
2.3.3. Empowering Patients with Data Sovereignty
2.4. Personalized Diabetes Prediction
2.5. Scalability Considerations
3. Results
3.1. Experimental Setup
3.1.1. Blockchain Network
- Platform: We utilized the Ethereum blockchain as the foundation for our decentralized network due to its mature ecosystem, extensive developer tools, and support for smart contracts.
- Nodes: We simulated a network of five participating nodes, each representing a healthcare provider or institution, to emulate a collaborative environment for data sharing and model training.
- Smart Contracts: We developed and deployed a suite of smart contracts on the Ethereum blockchain using the Solidity programming language. These contracts handle key functionalities such as user registration, authentication, data access control, model update management, and incentive mechanisms.
- Development Environment: The smart contracts were developed and tested using the Remix Integrated Development Environment (IDE) [38], which provides a user-friendly interface for interacting with and deploying smart contracts on the Ethereum network.
3.1.2. Dataset
- Source: We employed the publicly available diabetes prediction dataset [39], which comprises medical and demographic data from patients along with their diabetes status (positive or negative).
- Data Partitioning: To simulate a distributed data scenario, we partitioned the dataset into five distinct chunks, each assigned to a different node on the blockchain network. This emulates the real-world situation where healthcare providers hold their own portions of patient data.
- Data Preprocessing: Prior to model training, we performed comprehensive data preprocessing steps to ensure data quality and consistency:
- (1)
- Missing Value Handling: Missing values were addressed using imputation techniques [40] (e.g., mean/median replacement) or deletion based on the extent and distribution of missingness.
- (2)
- (3)
- Normalization and Scaling: Continuous features such as BMI and HbA1c levels were normalized and scaled to enhance model stability and convergence.
- (4)
- Class Imbalance Handling: To address the class imbalance in the dataset (fewer positive diabetes cases), we applied undersampling techniques [43] to create a more balanced distribution.
3.1.3. Model Selection and Training
- Algorithm: We chose the XGBoost algorithm [44] as our primary model due to its proven effectiveness in handling structured healthcare data and its ability to manage complex feature interactions.
- Hyperparameter Optimization: We utilized Optuna [45], a hyperparameter optimization framework, to fine-tune the XGBoost model and identify the most effective combination of hyperparameters to maximize performance metrics, such as the F1 score.
3.2. Blockchain-Based Federated Learning Workflow
3.3. Evaluation Results
3.3.1. Federated Learning Model Performance
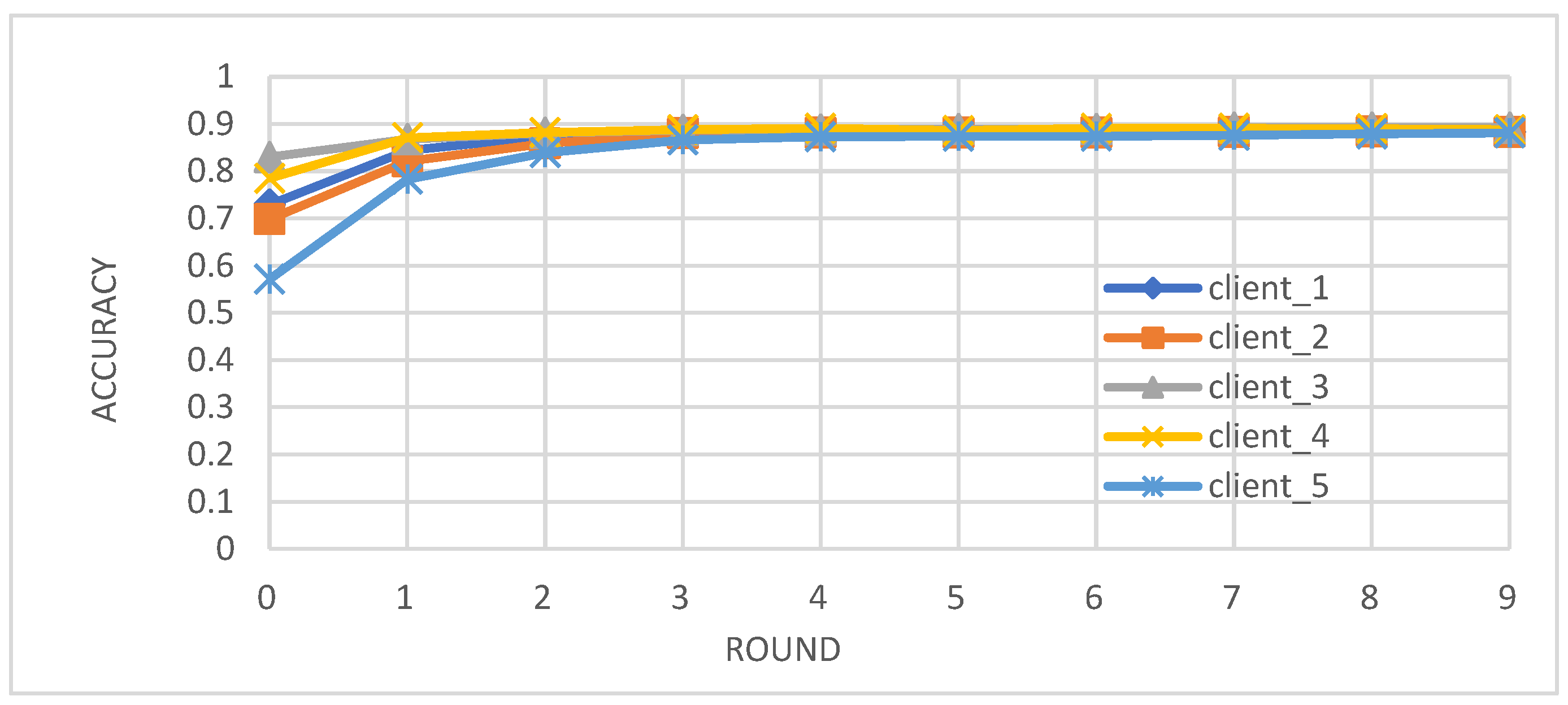
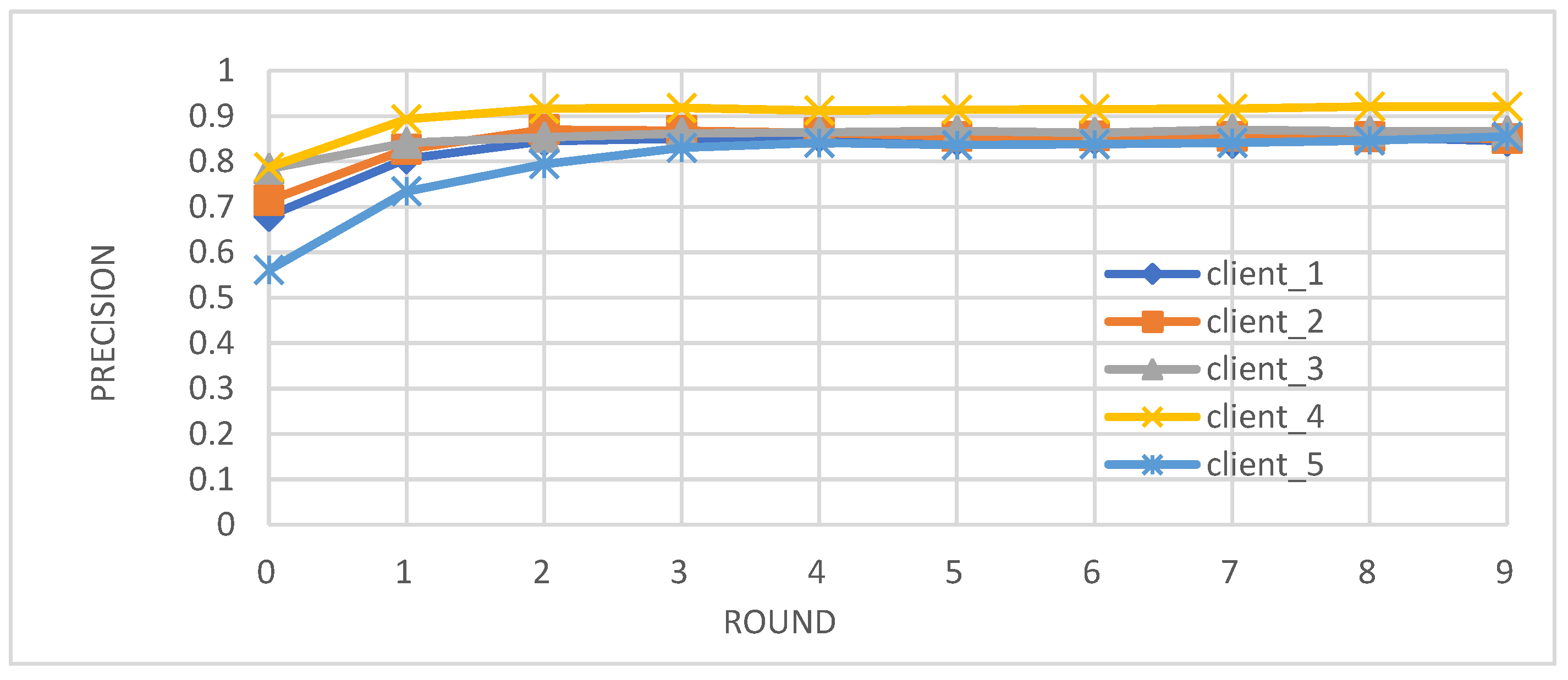
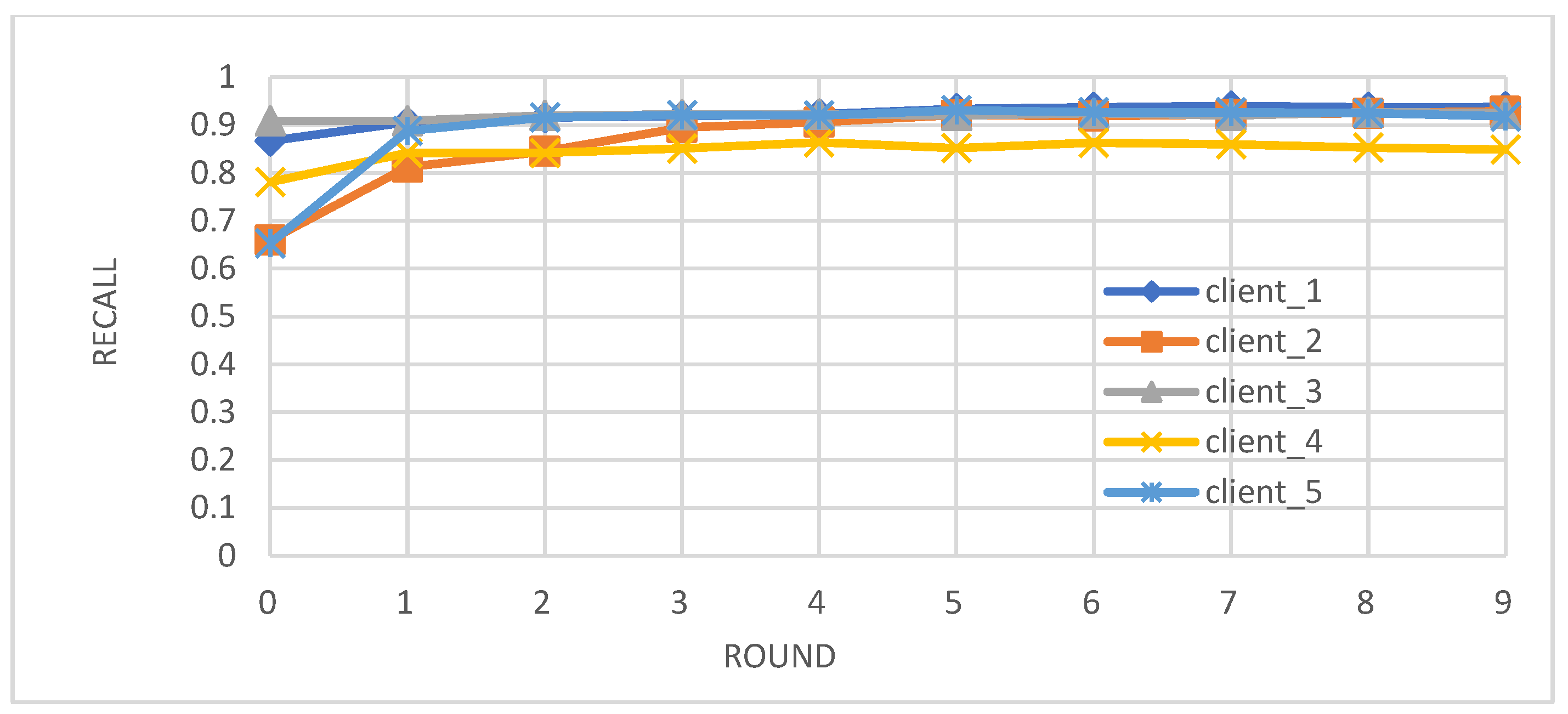
- Metrics: We evaluated the performance of the federated learning model on an independent test set using key metrics, including accuracy, precision, recall, and F1-score.
- Comparison with Centralized Learning: We also compared the communication overhead of our federated learning approach with that of centralized learning, demonstrating a significant reduction in communication costs (Figure 6).


3.3.2. Blockchain Smart Contract Evaluation with Use Cases
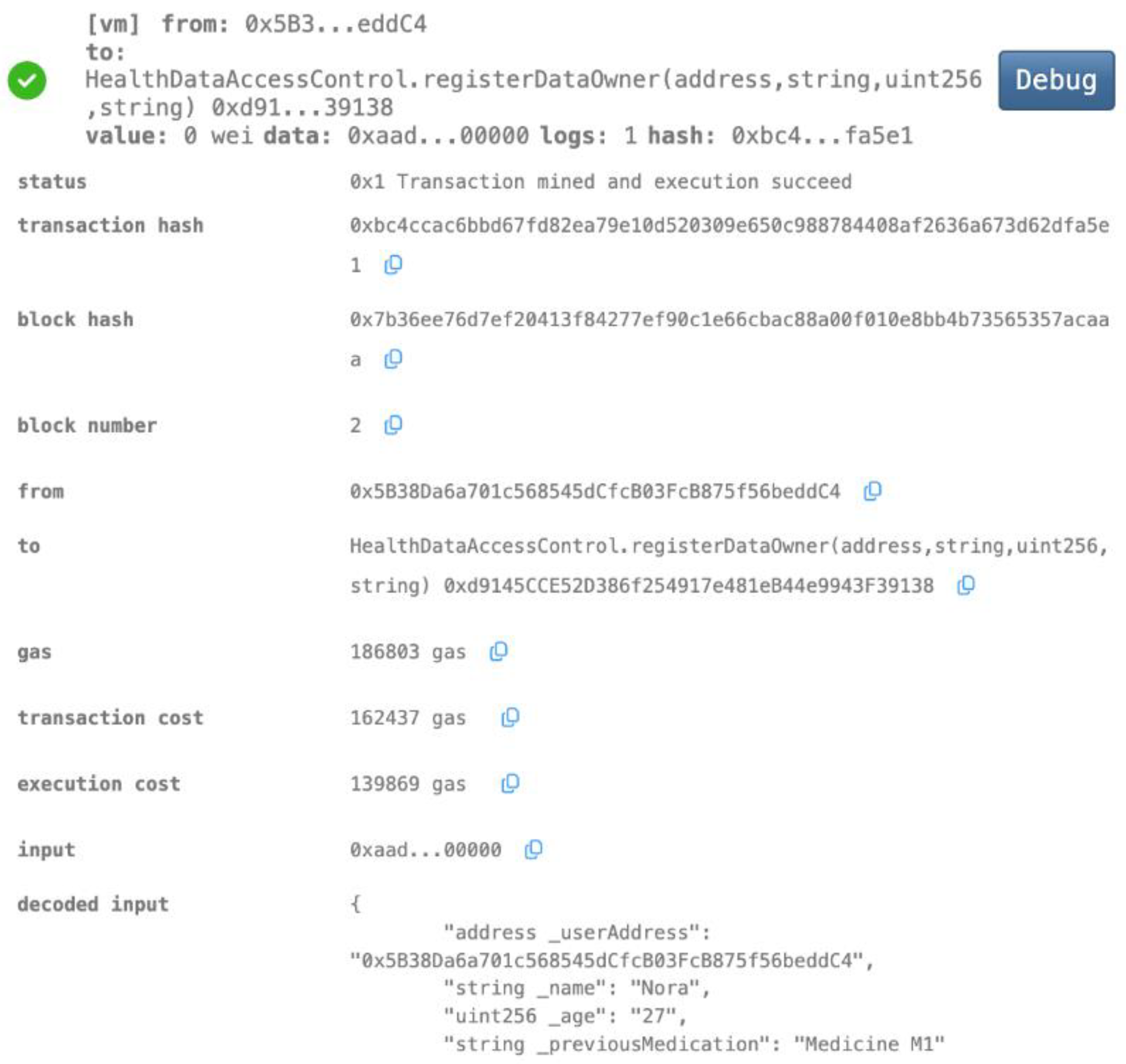
- Data Owner Registration
- Granting Access to Healthcare Providers


- Revoking Access

- Unauthorized Access Prevention

- Secure Model Aggregation of Federated Learning

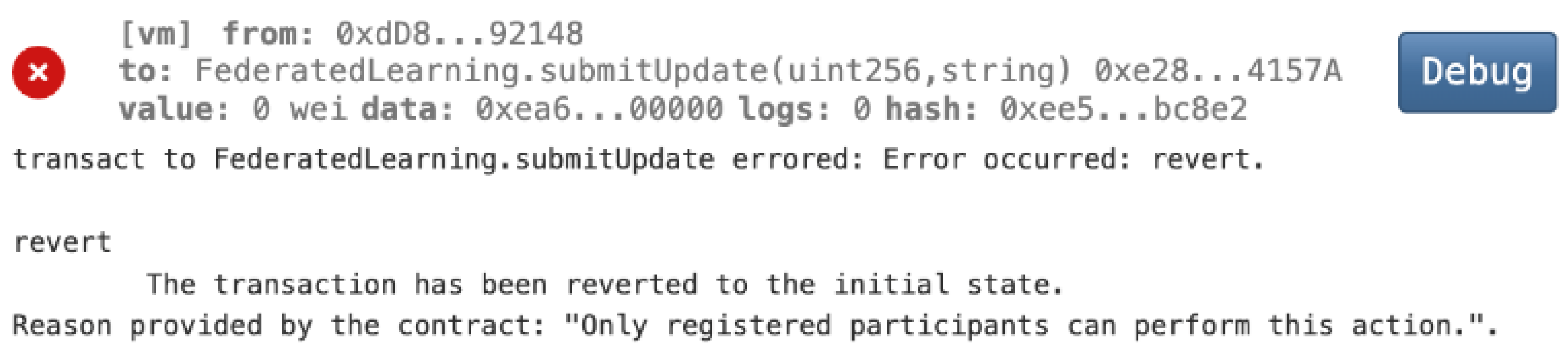
- Mitigating Malicious Model Updates of Federated Learning
4. Discussion
- (1)
- Enhanced Model Performance: The federated learning approach, as evidenced by the convergence of accuracy, precision, recall, and F1-score after just a few rounds (Figure 2, Figure 3, Figure 4 and Figure 5), demonstrates the power of collaborative learning from diverse data sources. This suggests that the model can effectively generalize to new, unseen data, making it a promising tool for real-world diabetes prediction.
- (2)
- Robust Privacy and Security: The implementation of smart contracts on the Ethereum blockchain ensured the secure management of patient data throughout the process. The use cases illustrated the efficacy of access control mechanisms in preventing unauthorized access and modification attempts (Figure 7, Figure 8, Figure 9 and Figure 10). Additionally, the secure aggregation of local models in federated learning further reinforced data privacy.
- (3)
- Reduced Communication Overhead: The significant reduction in communication overhead compared to centralized learning (Figure 6) not only improves efficiency but also minimizes potential data breaches. This is particularly important in healthcare settings, where privacy regulations and bandwidth limitations are critical considerations.
- (1)
- Secure model sharing: Blockchain’s immutable ledger ensures a transparent and tamper-proof record of model updates, safeguarding against unauthorized modifications.
- (2)
- Malicious update prevention: Simulated attacks, such as the injection of malicious model updates, were successfully thwarted by our smart contract’s data validation and integrity checks.
- (3)
- Access control: Smart contracts enforce strict authorization and access control, using token-based mechanisms and Solidity modifiers to prevent unauthorized actions and mitigate reentrancy attacks.
- (4)
- Transparency and traceability: The blockchain ledger’s transparency enables the tracking of all model updates and data access requests, ensuring auditability and accountability.
- (5)
- DoS mitigation: The Ethereum network’s gas fee requirement naturally limits the number of requests a single source can make, effectively mitigating Denial of Service (DoS) attacks.
- (6)
- MITM and replay attack prevention: Token-based authentication with private/public key verification secures communications within the network, preventing Man-in-the-Middle (MITM) and replay attacks.
- (7)
- Input validation and sanitization: Smart contracts rigorously validate and sanitize all incoming data, including model updates and patient consent, to prevent malicious data injection or manipulation.
- (8)
- Anomaly detection: The blockchain’s immutable ledger and transparent transaction history enable the implementation of anomaly detection mechanisms to identify and address suspicious activities or potential security breaches.
- (9)
- Blockchain-specific attack mitigation: We have considered potential blockchain-specific attacks such as 51% attacks and double-spending. Our framework leverages the security features of the underlying blockchain network and employs additional safeguards within the smart contract logic to mitigate these risks.
5. Conclusions
- Batching and Aggregation: Combining multiple model updates or data transactions into a single transaction to reduce the overall number of on-chain transactions and associated gas fees.
- Alternative Consensus Mechanisms: Exploring consensus mechanisms like Proof-of-Stake (PoS) or Delegated Proof-of-Stake (DPoS) that offer improved scalability compared to Ethereum’s current Proof-of-Work (PoW) mechanism.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Diabetes Facts and Figures. International Diabetes Federation. Available online: https://idf.org/about-diabetes/diabetes-facts-figures/ (accessed on 18 July 2024).
- Diabetes. Division of Global Health Protection. Global Health. CDC. Available online: https://www.cdc.gov/globalhealth/healthprotection/ncd/diabetes.html (accessed on 18 July 2024).
- Herman, W.H.; Ye, W.; Griffin, S.J.; Simmons, R.K.; Davies, M.J.; Khunti, K.; Rutten, G.E.H.M.; Sandbaek, A.; Lauritzen, T.; Borch-Johnsen, K.; et al. Early Detection and Treatment of Type 2 Diabetes Reduce Cardiovascular Morbidity and Mortality: A Simulation of the Results of the Anglo-Danish-Dutch Study of Intensive Treatment in People with Screen-Detected Diabetes in Primary Care (ADDITION-Europe). Diabetes Care 2015, 38, 1449–1455. [Google Scholar] [CrossRef] [PubMed]
- Dennis, J.M. Precision Medicine in Type 2 Diabetes: Using Individualized Prediction Models to Optimize Selection of Treatment. Diabetes 2020, 69, 2075–2085. [Google Scholar] [CrossRef]
- Hulsen, T.; Jamuar, S.S.; Moody, A.R.; Karnes, J.H.; Varga, O.; Hedensted, S.; Spreafico, R.; Hafler, D.A.; McKinney, E.F. From Big Data to Precision Medicine. Front. Med. 2019, 6, 34. [Google Scholar] [CrossRef]
- Thapa, C.; Camtepe, S. Precision Health Data: Requirements, Challenges and Existing Techniques for Data Security and Privacy. Comput. Biol. Med. 2021, 129, 104130. [Google Scholar] [CrossRef]
- Cushman, R.; Froomkin, M.; Cava, A.; Abril, P.; Goodman, K.W. Ethical, Legal and Social Issues for Personal Health Records and Applications. J. Biomed. Inform. 2010, 43, S51–S55. [Google Scholar] [CrossRef]
- Anand, D.; Khemchandani, V. Data Security and Privacy Functions in Fog Computing for Healthcare 4.0. In Studies in Big Data; Springer: Cham, Switzerland, 2020; Volume 76, pp. 387–420. [Google Scholar] [CrossRef]
- Huang, W.; Ye, M.; Shi, Z.; Wan, G.; Li, H.; Du, B.; Yang, Q. Federated learning for generalization, robustness, fairness: A survey and benchmark. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 1–20. [Google Scholar]
- HIPAA Home. HHS.Gov. Available online: https://www.hhs.gov/hipaa/index.html (accessed on 15 August 2024).
- General Data Protection Regulation (GDPR)—Legal Text. Available online: https://gdpr-info.eu/ (accessed on 15 August 2024).
- Sisodia, D.; Sisodia, D.S. Prediction of Diabetes Using Classification Algorithms. Procedia Comput. Sci. 2018, 132, 1578–1585. [Google Scholar]
- Santhanam, T.; Padmavathi, M.S. Application of K-Means and Genetic Algorithms for Dimension Reduction by Integrating SVM for Diabetes Diagnosis. Procedia Comput. Sci. 2015, 47, 76–83. [Google Scholar] [CrossRef]
- Maniruzzaman, M.; Kumar, N.; Menhazul Abedin, M.; Shaykhul Islam, M.; Suri, H.S.; El-Baz, A.S.; Suri, J.S. Comparative Approaches for Classification of Diabetes Mellitus Data: Machine Learning Paradigm. Comput. Methods Programs Biomed. 2017, 152, 23–34. [Google Scholar] [CrossRef]
- Yasashvini, R.; Raja Sarobin, M.V.; Panjanathan, R.; Graceline Jasmine, S.; Jani Anbarasi, L. Diabetic Retinopathy Classification Using CNN and Hybrid Deep Convolutional Neural Networks. Symmetry 2022, 14, 1932. [Google Scholar] [CrossRef]
- Mohsen, F.; Al-Absi, H.R.H.; Yousri, N.A.; El Hajj, N.; Shah, Z. A Scoping Review of Artificial Intelligence-Based Methods for Diabetes Risk Prediction. Npj Digit. Med. 2023, 6, 197. [Google Scholar] [CrossRef] [PubMed]
- Dubovitskaya, A.; Baig, F.; Xu, Z.; Shukla, R.; Zambani, P.S.; Swaminathan, A.; Jahangir, M.M.; Chowdhry, K.; Lachhani, R.; Idnani, N.; et al. ACTION-EHR: Patient-Centric Blockchain-Based Electronic Health Record Data Management for Cancer Care. J. Med. Internet Res. 2020, 22, e13598. [Google Scholar] [CrossRef] [PubMed]
- Al Mamun, A.; Azam, S.; Gritti, C. Blockchain-Based Electronic Health Records Management: A Comprehensive Review and Future Research Direction. IEEE Access 2022, 10, 5768–5789. [Google Scholar] [CrossRef]
- Mettler, M. Blockchain Technology in Healthcare: The Revolution Starts Here. In Proceedings of the 2016 IEEE 18th International Conference on e-Health Networking, Applications and Services (Healthcom), Munich, Germany, 14–16 September 2016; pp. 1–3. [Google Scholar] [CrossRef]
- Mayer, A.H.; da Costa, C.A.; Righi, R.d.R. Electronic Health Records in a Blockchain: A Systematic Review. Health Inform. J. 2020, 26, 1273–1288. [Google Scholar] [CrossRef]
- Ghadge, A.; Bourlakis, M.; Kamble, S.; Seuring, S. Blockchain Implementation in Pharmaceutical Supply Chains: A Review and Conceptual Framework. Int. J. Prod. Res. 2023, 61, 6633–6651. [Google Scholar] [CrossRef]
- Mazlan, A.A.; Daud, S.M.; Sam, S.M.; Abas, H.; Rasid, S.Z.A.; Yusof, M.F. Scalability Challenges in Healthcare Blockchain System-A Systematic Review. IEEE Access 2020, 8, 23663–23673. [Google Scholar] [CrossRef]
- Benaich, R.; El Mendili, S.; Gahi, Y. Advancing Healthcare Security: A Cutting-Edge Zero-Trust Blockchain Solution for Protecting Electronic Health Records. HighTech Innov. J. 2023, 4, 630–652. [Google Scholar] [CrossRef]
- Gazi, P.; Kiayias, A.; Zindros, D. Proof-of-Stake Sidechains. In Proceedings of the 2019 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 19–23 May 2019; pp. 139–156. [Google Scholar] [CrossRef]
- Sarani Rad, F.; Hendawi, R.; Yang, X.; Li, J. Personalized Diabetes Management with Digital Twins: A Patient-Centric Knowledge Graph Approach. J. Pers. Med. 2024, 14, 359. [Google Scholar] [CrossRef] [PubMed]
- Hendawi, R.; Li, J. Comprehensive Personal Health Knowledge Graph for Effective Management and Utilization of Personal Health Data. In Proceedings of the 2024 IEEE 1st International Conference on Artificial Intelligence for Medicine, Health and Care, AIMHC 2024, Laguna Hills, CA, USA, 5–7 February 2024; pp. 92–100. [Google Scholar] [CrossRef]
- Pandey, V.; Li, J.; Alian, S. Evaluation and Evolution of NAOnto—An Ontology for Personalized Diabetes Management for Native Americans. In Proceedings of the 7th International Conference on Computer and Communications, ICCC 2021, Chengdu, China, 10–13 December 2021; pp. 1635–1641. [Google Scholar] [CrossRef]
- Hendawi, R.; Alian, S.; Li, J. Breaking Down Barriers: Empowering Diabetes Patients with User-Friendly Medical Explanations. In Proceedings of the the 15th IEEE International Conference on Information and Communication Systems (ICICS 2024), Irbid, Jordan, 13–15 August 2024. [Google Scholar]
- Yi, X.; Paulet, R.; Bertino, E. Homomorphic Encryption; SpringerBriefs in Computer Science; Springer: Cham, Switzerland, 2014; pp. 27–46. [Google Scholar] [CrossRef]
- Knott, B.; Venkataraman, S.; Hannun, A.; Sengupta, S.; Ibrahim, M.; van der Maaten, L. CrypTen: Secure Multi-Party Computation Meets Machine Learning. Adv. Neural Inf. Process Syst. 2021, 34, 4961–4973. [Google Scholar]
- Schmidt, R.M. Recurrent Neural Networks (RNNs): A Gentle Introduction and Overview. arXiv 2019, arXiv:1912.05911. [Google Scholar]
- Fischer, T.; Krauss, C. Deep Learning with Long Short-Term Memory Networks for Financial Market Predictions. Eur. J. Oper. Res. 2018, 270, 654–669. [Google Scholar]
- Kotsiantis, S.B. Decision Trees: A Recent Overview. Artif. Intell. Rev. 2013, 39, 261–283. [Google Scholar] [CrossRef]
- Cutler, A.; Cutler, D.R.; Stevens, J.R. Random Forests. In Ensemble Machine Learning, 2nd ed.; Zhang, C., Ma, Y.Q., Eds.; Springer: New York, NY, USA, 2012; pp. 157–175. [Google Scholar] [CrossRef]
- Huang, S.; Nianguang, C.A.I.; Penzuti Pacheco, P.; Narandes, S.; Wang, Y.; Wayne, X.U. Applications of Support Vector Machine (SVM) Learning in Cancer Genomics. Cancer Genom. Proteom. 2018, 15, 41. [Google Scholar] [CrossRef]
- Kattenborn, T.; Leitloff, J.; Schiefer, F.; Hinz, S. Review on Convolutional Neural Networks (CNN) in Vegetation Remote Sensing. ISPRS J. Photogramm. Remote Sens. 2021, 173, 24–49. [Google Scholar] [CrossRef]
- Vujičić, D.; Jagodić, D.; Randić, S. Blockchain Technology, Bitcoin, and Ethereum: A Brief Overview. In Proceedings of the 2018 17th International Symposium on INFOTEH-JAHORINA (INFOTEH), East Sarajevo, Bosnia and Herzegovina, 21–23 March 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Remix—Ethereum IDE & Community. Available online: https://remix-project.org/?lang=en (accessed on 18 July 2024).
- Diabetes Prediction Dataset. Available online: https://www.kaggle.com/datasets/iammustafatz/diabetes-prediction-dataset/data (accessed on 18 July 2024).
- Zhang, Z. Missing Data Imputation: Focusing on Single Imputation. Ann. Transl. Med. 2016, 4, 9. [Google Scholar] [CrossRef]
- Seger, C. An Investigation of Categorical Variable Encoding Techniques in Machine Learning: Binary versus One-Hot and Feature Hashing. Bachelor’s Thesis, KTH Royal Institute of Technology, Stockholm, Sweden, 2018. [Google Scholar]
- Sadr, J.; Mukherjee, S.; Thoresz, K.; Sinha, P. The Fidelity of Local Ordinal Encoding. Adv. Neural Inf. Process Syst. 2001, 14, 1–8. [Google Scholar]
- Mohammed, R.; Rawashdeh, J.; Abdullah, M. Machine Learning with Oversampling and Undersampling Techniques: Overview Study and Experimental Results. In Proceedings of the 11th International Conference on Information and Communication Systems (ICICS), Irbid, Jordan, 7–9 April 2020; pp. 243–248. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining 2016, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar] [CrossRef]
- Akiba, T.; Sano, S.; Yanase, T.; Ohta, T.; Koyama, M. Optuna: A Next-Generation Hyperparameter Optimization Framework. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining 2019, Anchorage, AK, USA, 4–8 August 2019; pp. 2623–2631. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hasan, M.R.; Li, Q.; Saha, U.; Li, J. Decentralized and Secure Collaborative Framework for Personalized Diabetes Prediction. Biomedicines 2024, 12, 1916. https://doi.org/10.3390/biomedicines12081916
Hasan MR, Li Q, Saha U, Li J. Decentralized and Secure Collaborative Framework for Personalized Diabetes Prediction. Biomedicines. 2024; 12(8):1916. https://doi.org/10.3390/biomedicines12081916
Chicago/Turabian StyleHasan, Md Rakibul, Qingrui Li, Utsha Saha, and Juan Li. 2024. "Decentralized and Secure Collaborative Framework for Personalized Diabetes Prediction" Biomedicines 12, no. 8: 1916. https://doi.org/10.3390/biomedicines12081916
APA StyleHasan, M. R., Li, Q., Saha, U., & Li, J. (2024). Decentralized and Secure Collaborative Framework for Personalized Diabetes Prediction. Biomedicines, 12(8), 1916. https://doi.org/10.3390/biomedicines12081916