
The Exponential Dispersion Family (EDF) Chain Ladder and Data Granularity


Abstract
1. Introduction
1.1. Background
“Annual exposure periods [accident periods] and development intervals are used in this example, but shorter periods can also be used; quarterly semi-annual or monthly periods are the most common, other than annual.”
“The difference between the payment year and the accident year is referred to as the development year. Other time periods can also be used particularly for short-tail classes.”
1.2. Purpose of the Paper
- The EDF chain ladder (Wüthrich and Merz 2008; Taylor 2009), where EDF refers to the exponential dispersion family; and
- The Mack chain ladder (Mack 1993).
1.3. Layout of the Paper
2. Notation and Mathematical Preliminaries
2.1. Fundamentals
2.2. Mesh Size
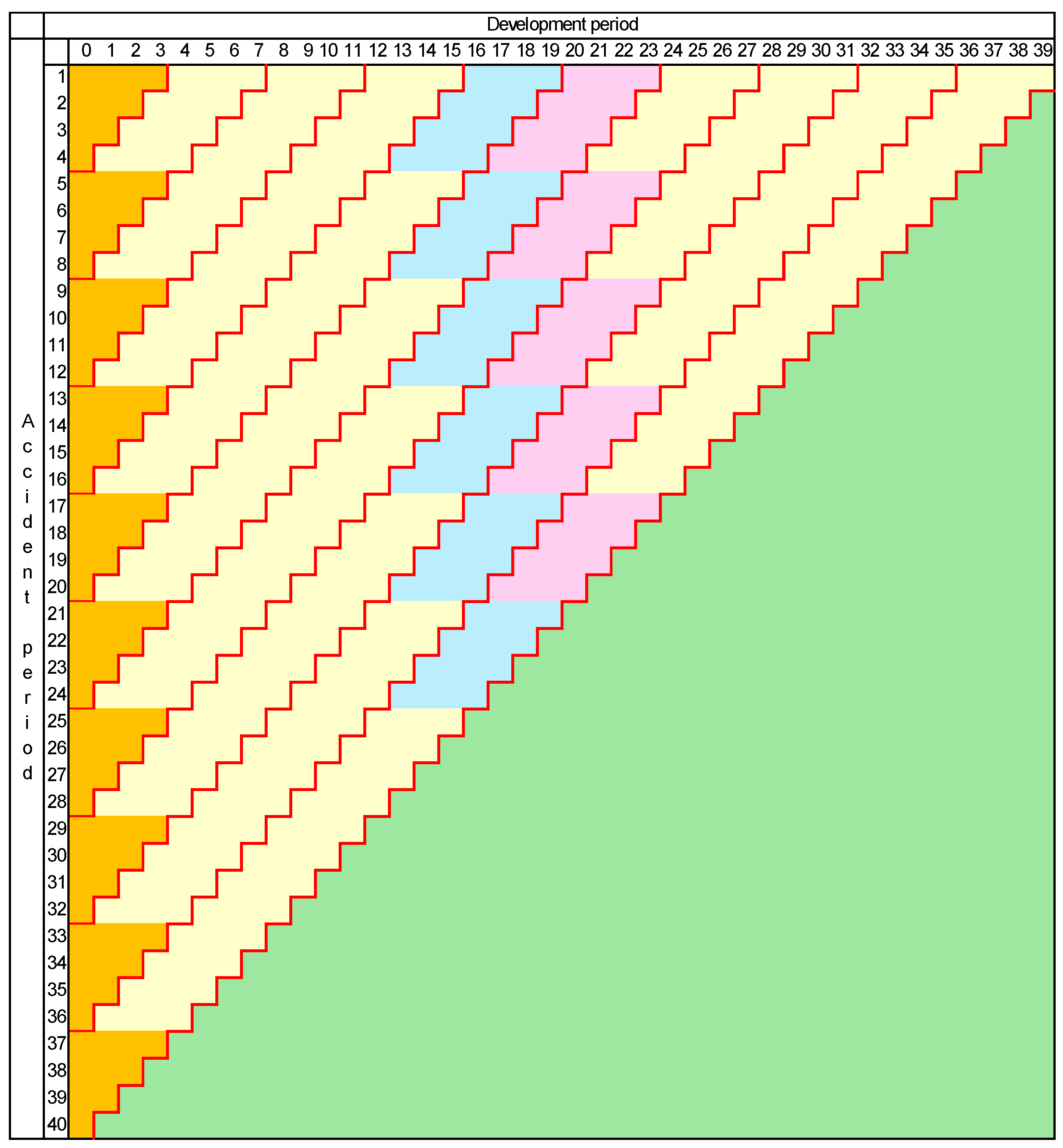
2.2.1. Preservation of Calendar Periods
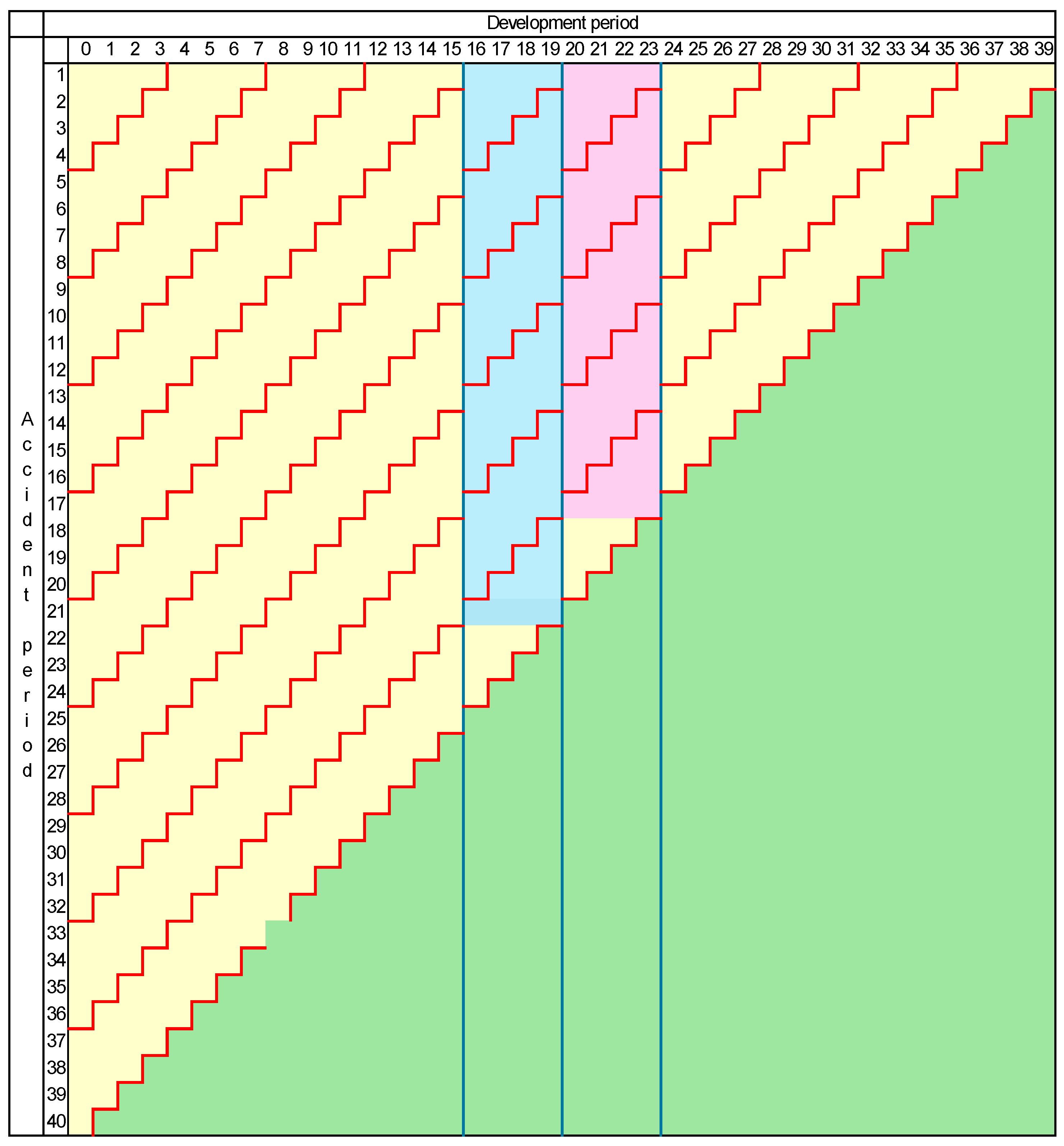
2.2.2. Preservation of Development Periods
2.3. Sufficient Statistics
2.3.1. Sufficiency
2.3.2. Generalized Linear Models
- the are stochastically independent real-valued random variables, each with range ;
- is the column -vector with components ;
- denotes a distribution from the exponential dispersion family (“EDF”) (Nelder and Wedderburn 1972) with mean and dispersion parameter
- is the column -vector with components ;
- is a column -parameter;
- X is an design matrix;
- is an invertible function, called the link function, with a subset of the real line, and operating component-wise in (11).
2.4. Notational Summary
3. EDF Chain Ladder
3.1. Model Assumptions
3.2. Parameter Estimation
3.3. Sufficient Statistics
- (a)
- For the only sufficient statistic for any or is the full data set ; there is no sufficient statistic that is a proper subset of .
- (b)
- For (Poisson chain ladder), the set is a sufficient statistic for .
3.4. Forecast Bias
3.4.1. Poisson Case
3.4.2. General EDF Case
3.5. Forecast Variance
3.5.1. Poisson Case
3.5.2. General EDF Case
4. Effects of Change of Mesh Size Under Preservation of Calendar Periods
4.1. Model Assumptions
4.1.1. EDF Chain Ladder
- (a)
- All observations are normally distributed (); or
- (b)
- All observations have common ratio of mean to variance.
4.1.2. Poisson Chain Ladder
4.1.3. Structure of Cell Means
- (a)
- is a scalar matrix, i.e., ;
- (b)
- for some constant .
4.2. Forecast Variance
- (a)
- is the unique MVUE of all unbiased estimators of , so conditioned;
- (b)
- is the unique MVUE of all unbiased estimators of , so conditioned;
- (c)
- .
5. Effects of Change of Mesh Size Under Preservation of Development Periods
5.1. Model Assumptions
5.1.1. EDF and Poisson Chain Ladder
5.1.2. Structure of Cell Means
- formulate a model of the incomplete larger-mesh development periods (which will not be informed by more granular data); or
- exclude the edge cells from the data set as uninformative.
5.2. Forecast Variance
- (a)
- is the unique minimum variance of all unbiased estimators of , so conditioned;
- (b)
- is the unique minimum variance of all unbiased estimators of , so conditioned;
- (c)
- .
6. Numerical Example
- As expected, the results for accident years 2 to 6 are not affected at all by the merger of development years 3 and 4, because their forecasts do not depend in any way on these development years;
- The results for accident years 8 to 10 are slightly affected by the omission of cell (7,3) from the modelling;
- The result for accident year 7 is substantially affected, with a noticeable change in forecast and a 44% increase in the associated standard deviation. This is the result of the loss of information of cell (7,3).
7. Discussion and Conclusions
- preserving calendar periods; and
- preserving development periods.
- Do the cells of the data triangle remain EDF under mesh enlargement?
- Do the cell expectations retain, under mesh enlargement, the multiplicative parameter structure required by the chain ladder model?
Funding
Data Availability Statement
Conflicts of Interest
References
- Cox, David R., and David V. Hinkley. 1974. Theoretical Statistics. London: Chapman and Hall. [Google Scholar]
- Das, Rituparna, Asif Iqbal Middya, and Sarbani Roy. 2022. High granular and short term time series forecasting of PM2.5 air pollutant—A comparative review. Artificial Intelligence Review 55: 1253–87. [Google Scholar]
- Elton, Edwin J., Martin J. Gruber, Christopher R. Blake, Yoel Krasny, and Sadi O. Ozelge. 2010. The effect of holdings data frequency on conclusions about mutual fund behavior. Journal of Banking & Finance 34: 912–22. [Google Scholar]
- Grolinger, Katarina, Alexandra L’Heureux, Miriam A. M. Capretz, and Luke Seewald. 2016. Energy forecasting for event venues: Big data and prediction accuracy. Energy and Buildings 112: 222–33. [Google Scholar] [CrossRef]
- Hart, David G., Robert A. Buchanan, and Bruce A. Howe. 1996. The Actuarial Practice of General Insurance, 5th ed. Sydney: Institute of Actuaries of Australia. [Google Scholar]
- Huang, Zhichuan, and Ting Zhu. 2016. Leveraging multi-granularity energy data for accurate energy demand forecast in smart grids. Paper presented at the 2016 IEEE International Conference on Big Data (Big Data), Washington, DC, USA, December 5–8; Piscatway: IEEE, pp. 1182–91. [Google Scholar]
- Jain, Rishi K., Kevin M. Smith, Patricia J. Culligan, and John E. Taylor. 2014. Forecasting energy consumption of multi-family residential buildings using support vector regression: Investigating the impact of temporal and spatial monitoring granularity on performance accuracy. Applied Energy 123: 168–78. [Google Scholar] [CrossRef]
- Kaplan, Edward L., and Paul Meier. 1958. Nonparametric estimation from incomplete observations. Journal of the American Statistical Association 53: 457–81. [Google Scholar] [CrossRef]
- Kim, Mingyung, Eric T. Bradlow, and Raghuram Iyengar. 2022. Selecting data granularity and model specification using the scaled power likelihood with multiple weights. Marketing Science 41: 848–66. [Google Scholar] [CrossRef]
- Lehmann, Erich L., and Henry Scheffé. 1950. Completeness, similar regions, and unbiased estimation-Part I. Sankhyā 10: 305–40. [Google Scholar]
- Lehmann, Erich L., and Henry Scheffé. 1955. Completeness, similar regions, and unbiased estimation. Part II. Sankhyā 15: 219–36. [Google Scholar]
- Li, Peikun, Chaoqun Ma, Jing Ning, Yun Wang, and Caihua Zhu. 2019. Analysis of prediction accuracy under the selection of optimum time granularity in different metro stations. Sustainability 11: 5281. [Google Scholar] [CrossRef]
- Lusis, Peter, Kaveh Rajab Khalilpour, Lachlan Andrew, and Ariel Liebman. 2017. Short-term residential load forecasting: Impact of calendar effects and forecast granularity. Applied Energy 205: 654–69. [Google Scholar]
- Mack, Thomas. 1993. Distribution-free calculation of the standard error of chain ladder reserve estimates. ASTIN Bulletin 23: 213–25. [Google Scholar]
- McCullagh, Peter, and John A. Nelder. 1989. Generalized Linear Models, 2nd ed. Boca Raton: Chapman & Hall. [Google Scholar]
- Nelder, John A., and Robert W. M. Wedderburn. 1972. Generalised linear models. Journal of the Royal Statistical Society. Series A 135: 370–84. [Google Scholar]
- Peterson, Timothy M. 1981. Loss Reserving: Property/Casualty Insurance. New York: Ernst & Whinney. [Google Scholar]
- Taylor, Greg C. 1985. Claim Reserving in Non-Life Insurance. Amsterdam: North-Holland. [Google Scholar]
- Taylor, Greg. 2000. Loss Reserving: An Actuarial Perspective. Boston: Kluwer Academic Publishers. [Google Scholar]
- Taylor, Greg. 2009. The chain ladder and Tweedie distributed claims data. Variance 3: 96–104. [Google Scholar]
- Taylor, Greg. 2011. Maximum likelihood and estimation efficiency of the chain ladder. ASTIN Bulletin 41: 131–55. [Google Scholar]
- Taylor, Greg. 2017. Existence and uniqueness of chain ladder solutions. ASTIN Bulletin 47: 1–41. [Google Scholar] [CrossRef]
- Taylor, Greg. 2021. A special Tweedie sub-family with application to loss reserving prediction error. Insurance: Mathematics and Economics 101B: 262–88. [Google Scholar] [CrossRef]
- Taylor, Greg, and Gráinne McGuire. 2023. Model error (or ambiguity) and its estimation, with particular application to loss reserving. Risks 11: 185. [Google Scholar] [CrossRef]
- Tweedie, Maurice C. K. 1984. An index which distinguishes between some important exponential families. In Statistics: Applications and New Directions, Proceedings of the Indian Statistical Golden Jubilee International Conference. Edited by Jayanta Kumar Ghosh and Jogabrata Roy. Kolkata: Indian Statistical Institute, pp. 579–604. [Google Scholar]
- Wang, Jue, Hao Zhou, Tao Hong, Xiang Li, and Shouyang Wang. 2020. A multi-granularity heterogeneous combination approach to crude oil price forecasting. Energy Economics 91: 104790. [Google Scholar] [CrossRef]
- Wang, Zongqiang, Yan Xian, Guoyin Wang, and Hong Yu. 2023. A Multi-granularity Network for Time Series Forecasting on Multivariate Time Series Data. Paper presented at the International Joint Conference on Rough Sets, Krakow, Poland, October 5–8; Cham: Springer Nature Switzerland, pp. 324–38. [Google Scholar]
- Wüthrich, Mario V., and Michael Merz. 2008. Stochastic Claims Reserving Methods in Insurance. Chichester: John Wiley & Sons Ltd. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
| Symbol | Introduced in Section | Interpretation |
|---|---|---|
| Section 2.1 | Accident period | |
| Section 2.1 | Development period | |
| Section 2.1 | Calendar period | |
| Section 2.1 | Amount of claim payments (random variable) made during development period of accident period | |
| Section 2.1 | Realization of the random variable | |
| Section 2.1 | Mean of | |
| Section 3.1 | Vector of the | |
| Section 2.1 | Upper triangle of observations (random variables) | |
| Section 2.1 | Lower triangle of observations (random variables) | |
| Section 2.1 | Realization of | |
| Section 2.1 | Cumulative claim payments (random variable) corresponding to (non-cumulative) | |
| Section 2.1 | Realization of | |
| Section 2.1 | Row of upper triangle | |
| Section 2.1 | Column of upper triangle | |
| Section 2.1 | Row sum of (over ) | |
| Section 2.1 | Column sum of (over ) | |
| Section 2.1 | Amount of outstanding losses (the loss reserve) for accident period | |
| Section 2.1 | Amount of outstanding losses (the loss reserve) for all accident periods | |
| Section 2.2 | Accident and development periods under changed mesh size | |
| Section 2.2 | Upper triangle under changed mesh size | |
| Section 2.2.2 | Partition of the interval , defining development periods under changed mesh | |
| Section 3.1 | EDF parameters for row and column effects in | |
| Section 3.4.1 | Loss reserve bias factor |
| Accident | Claim Payments in Development Year | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Year | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 1 | 5840 | 15,169 | 10,338 | 7518 | 5954 | 4451 | 2967 | 2135 | 1123 | 593 |
| 2 | 6205 | 15,311 | 10,682 | 7552 | 6080 | 4608 | 2990 | 2188 | 1185 | |
| 3 | 6254 | 15,915 | 11,107 | 8035 | 6217 | 4705 | 3130 | 2172 | ||
| 4 | 6349 | 16,180 | 11,272 | 7999 | 6375 | 4908 | 3193 | |||
| 5 | 7011 | 17,559 | 12,396 | 8967 | 7108 | 5272 | ||||
| 6 | 6755 | 17,464 | 12,180 | 8787 | 7061 | |||||
| 7 | 7277 | 18,481 | 12,511 | 9212 | ||||||
| 8 | 7525 | 18,714 | 13,134 | |||||||
| 9 | 7508 | 19,019 | ||||||||
| 10 | 7834 | |||||||||
| Accident | Forecast Outstanding Losses | Standard Deviation of Forecast | ||
|---|---|---|---|---|
| Year | ||||
| Unmerged | Merged | Unmerged | Merged | |
| 2 | 607 | 607 | 25 | 25 |
| 3 | 1835 | 1835 | 37 | 37 |
| 4 | 4137 | 4137 | 51 | 51 |
| 5 | 8036 | 8036 | 71 | 71 |
| 6 | 13,145 | 13,145 | 94 | 94 |
| 7 | 21,065 | 20,997 | 133 | 192 |
| 8 | 31,092 | 31,081 | 194 | 195 |
| 9 | 44,589 | 44,578 | 311 | 313 |
| 10 | 66,367 | 66,356 | 807 | 807 |
| Total | 190,871 | 190,771 | 1062 | 1087 |
| Accident | Forecast Outstanding Losses | Standard Deviation of Forecast | ||
|---|---|---|---|---|
| Year | ||||
| Unmerged | Merged | Unmerged | Merged | |
| 2 | 607 | 570 | 25 | 44 |
| 3 | 1835 | 1816 | 37 | 45 |
| 4 | 4137 | 4098 | 51 | 73 |
| 5 | 8036 | 8009 | 71 | 79 |
| 6 | 13,145 | 12,924 | 94 | 135 |
| 7 | 21,065 | 21,000 | 133 | 140 |
| 8 | 31,092 | 30,884 | 194 | 314 |
| 9 | 44,589 | 44,502 | 311 | 316 |
| 10 | 66,367 | 66,277 | 807 | 808 |
| Total | 190,871 | 190,079 | 1062 | 1178 |
| Accident | Standard Deviation of Forecast | Change Due to | |
|---|---|---|---|
| Years | |||
| Unmerged | Merged | Merger | |
| % | |||
| 2, 4, 6, 8 | 222 | 352 | 58 |
| 2 to 8 | 271 | 390 | 44 |
| All | 1062 | 1178 | 11 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Taylor, G. The Exponential Dispersion Family (EDF) Chain Ladder and Data Granularity. Risks 2025, 13, 65. https://doi.org/10.3390/risks13040065
Taylor G. The Exponential Dispersion Family (EDF) Chain Ladder and Data Granularity. Risks. 2025; 13(4):65. https://doi.org/10.3390/risks13040065
Chicago/Turabian StyleTaylor, Greg. 2025. "The Exponential Dispersion Family (EDF) Chain Ladder and Data Granularity" Risks 13, no. 4: 65. https://doi.org/10.3390/risks13040065
APA StyleTaylor, G. (2025). The Exponential Dispersion Family (EDF) Chain Ladder and Data Granularity. Risks, 13(4), 65. https://doi.org/10.3390/risks13040065