Abstract
Statistical modeling techniques—and factor models in particular—are extensively used in practice, especially in the insurance and finance industry, where many risks have to be accounted for. In risk management applications, it might be important to analyze the situation when fixing the value of a weighted sum of factors, for example to a given quantile. In this work, we derive the -dimensional distribution corresponding to a n-dimensional i.i.d. standard Normal vector subject to the weighted sum constraint , where and . This law is proven to be a Normal distribution, whose mean vector and covariance matrix are explicitly derived as a function of . The derivation of the density relies on the analytical inversion of a very specific positive definite matrix. We show that it does not correspond to naive sampling techniques one could think of. This result is then used to design algorithms for sampling under constraint that or and is illustrated on two applications dealing with Value-at-Risk and Expected Shortfall.
1. Introduction
Factor models are extensively used in statistical modeling. In banking and finance, for instance, it is a standard procedure to introduce a dependence structure among loans (see, e.g., Li’s model Li (2016), but also Andersen and Sidenius (2004); Hull and White (2004); Laurent and Sestier (2016); Vrins (2009), just to name a few). In the popular case of a one-factor Gaussian copula model, the default of the i-th entity is jointly driven by a common risk factor, say Y, as well as an idiosynchratic risk, all being independent and Normally distributed. In multi-factor models, the common factor is replaced by a weighted sum of Normal risk factors representing different aspects of the global economy (like region, sector, etc.). The random vector can typically be expressed (via a Cholesky decomposition) as a weighted sum of n (or less) i.i.d. standard Normal factors . Interestingly, the asymptotic law (as the number of loans tends to infinity) of these portfolios can be derived analytically when only one systematic factor () is considered (see Vasicek (1991) in the case of homogeneous pools and Gordy (2003) for an extension to heterogeneous pools). However, the case requires numerical methods, typically Monte Carlo simulations. This raises the following question, whose practical interest will be illustrated with concrete examples: given a value c of a common factor where is a vector of non-zero weights, what is the distribution of ? In other words, how can we sample conditional upon ? It is of course straightforward to sample a vector of n Normal variables such that the weighted sum is c. One possibility is to sample a -dimensional i.i.d. standard Normal vector and then set (Method 1). Another possibility would be to draw a sample of a n-dimensional i.i.d. standard Normal vector and set (Method 2). Alternatively, one could just rescale such a vector and take (Method 3). However, as discussed in Section 3, none of these approaches yield the correct answer.
Conditional sampling methods have already been studied in the literature. One example is of course sampling random variables between two bounds, which is a trivial problem solved by the inverse transform, see e.g., the reference books Glasserman (2010) or Rubinstein and Kroese (2017). In the context of data acquisition, Pham (2000) introduces a clever algorithm to draw m samples from the n-dimensional Normal distribution subject to the constraint that the empirical (i.e., sample) mean vector and covariance matrix of these m vectors agree with their theoretical counterparts and , respectively. Very recently, Meyer (2018) introduced a method to draw n-dimensional samples from a given distribution conditional upon the fact that entries take known values. These works, however, do not provide an answer to the question we are dealing with. In particular, we do not put constraints on the average of sampled vectors, nor force some of their entries to take specific values, but instead work with a constraint on the weighted sum of the n entries of each of these vectors.
In this paper, we derive the -dimensional conditional distribution associated with the -slice of the n-dimensional standard Normal density when for all , . More specifically, we restrict ourselves to derive the joint distribution of where (as the distribution of can be obtained by simple rescaling of that of as where is an invertible diagonal matrix satisfying ). The result derives from the analytical properties of a square positive definite matrix having a very specific form. We conclude the paper with two sampling algorithms and two illustrative examples.
2. Derivation of the Conditional Density
The conditional distribution is derived by first noting that the conditional density takes the general form
where is the Dirac measure centered at 0. This expression is likely to be familiar to most readers but some technical details are provided in Appendix A.
We shall show that the random vector given is distributed as where the density of is a multivariate Normal with mean vector and covariance matrix respectively given by
Note that, in these expressions, the indices belong to and is the Kronecker symbol.
The denominator of Equation (1) collapses to the univariate centered Normal density with standard deviation evaluated at c, noted . Similarly, when , the numerator is just the product of univariate Normal densities. Using ,
Hence, when the vector meets the constraint, (1) looks like a -th dimensional Normal pdf:
where
On the other hand, the general expression of the Normal density of dimension with mean vector and covariance matrix whose inverse has entries noted by can be obtained by expanding the matrix form of the multivariate Normal:
where . To determine the expression of the covariance matrix and mean vector of the conditional density (4) (assuming it is indeed Normal), it remains to determine the entries of and by inspection, comparing the expression of conditional density in (4) with that of the multivariate Normal (5) and then to obtain by analytical inversion.
Leaving only as a factor in front of the exponential in (4), the independent term (i.e., the term that does not appear as a factor of any ) reads w.l.o.g. as
for any satisfying (note that the constant case might be a solution, but it is not guaranteed at this stage).
Comparing (4) and (5), it comes that the expression
must agree with
for all . Equating the terms in (6) and (7) uniquely determines the components of :
It remains to show that , in order to find the expressions of the s from the terms, provides the expression of by inverting and, finally, to check that the independent terms in (6) and (7) agree and that the implied ’s comply with . To that end, we rely on the following lemma.
Lemma 1.
Let denote a matrix with elements , for all . Define and . Then:
- (i)
- is positive definite;
- (ii)
- its determinant is given by
- (iii)
- the -element of the inverse is given by
The proof is given in Appendix B.
Observe now that takes the form with and for . We can call Lemma 1 to show that is symmetric and positive definite, proving that is a valid covariance matrix satisfying (notice however that in the summation and product indices agree with that of the ’s, i.e., range from 0 to , but the index of ranges from 1 to n). From Lemma 1 , as
We can then use Lemma 1 to determine , the elements of ,
This expression agrees with the right-hand side of (3). Finally, the mean vector is obtained by equating the terms in (6) and (7). Using that is symmetric, we observe that for all :
Hence, where is the m-dimensional column vector with m entries all set to 1 so that . It remains to check that these expressions for and also comply with the independent term. Equating the independent terms of (6) and (7) and calling (8) yields
which holds true provided that we take . This concludes the derivation of the conditional law as these ’s trivially comply with the constraint . This expression of corresponds to the right-hand side of (2).
3. Discussion
It is clear from (2) that the construction scheme based on the conditional distribution derived above (referred to as Method 4) is incompatible with the three other construction schemes discussed in the Introduction. Indeed, Method 1 yields , whereas Method 2 leads to . Finally, Method 3 corresponds to take as the ratio of two jointly Normal variables, for which it is known that the moments do not exist (for instance, the ratio of two independent and zero-mean Normal variables leads to a Cauchy distribution; see e.g., Fieller (1932) or more recently Cedilnik et al. (2004)). This is illustrated in Figure 1, which shows 250 samples of for these four methods in the bivariate case (). The same mismatch happens with the covariance, as shown in Figure 2 in the case: Method 1 yields , Method 2 leads to , the covariance is undefined for Method 3 and for Method 4 , from (3).
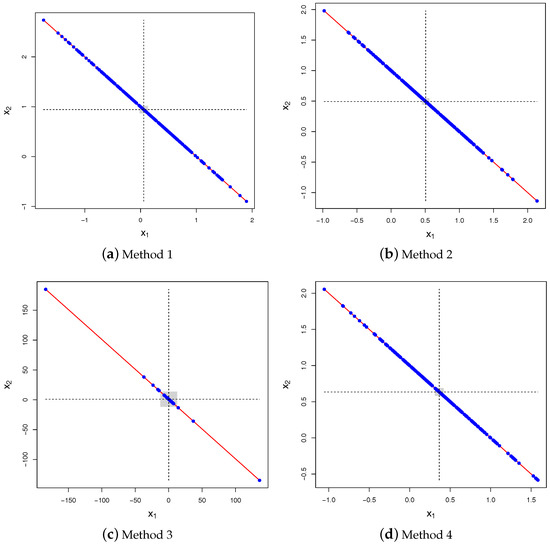
Figure 1.
Scatter plot of 250 samples drawn for the four methods with , , and . Method 4 yields the correct answer. The vertical and horizontal dashed lines show the empirical means of and for that specific run, respectively. The diagonal (red) solid line is . The horizontal and vertical widths of the gray rectangles show the confidence intervals () for both and based on 100 runs of 250 pairs each.
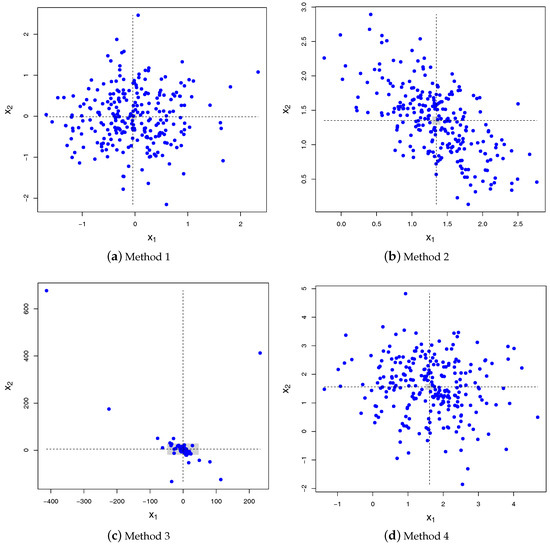
Figure 2.
Scatter plot of 250 samples drawn for the four methods with , , and . Method 4 yields the correct answer. Only the first two components of the vector are shown to enhance readability; the third component is set to . The vertical and horizontal dashed lines show the empirical means of and for that specific run, respectively. The horizontal and vertical widths of the gray rectangles show the confidence intervals () for both and based on 100 runs of 250 pairs each.
4. Sampling Algorithms
From the above result, it is easy to design sampling algorithms. We first derive an algorithm to sample a multivariate Normal distribution under a weighted sum constraint according to the density derived above (Algorithm 1). Next, we show that one can also easily extend this algorithm to sample the multivariate Normal distribution under an upperbound constraint on the weighted sum (Algorithm 2).
| Algorithm 1. Sampling of given . |
| 1. From the vector of weights and the constraint c, compute the -dimensional mean vector and symmetric matrix from (2) and (3); |
| 2. Compute the eigen decomposition of the covariance matrix ; |
| 3. Sample i.i.d. standard Normal variates ; |
| 4. Transform these variates using the mean vector and covariance matrix |
| 5. Enlarge the -dimensional vector with the n-th component to get , |
| 6. Return where for . |
The above algorithm can be extended to sample an n-th dimensional vector given . To that end, it suffices to first draw a sample from the conditional distribution of . Clearly, so that
From the inverse transform, the random variable
has cumulative distribution function whenever U is a Uniform- random variable. This leads to the following sampling procedure.
| Algorithm 2. Sampling of given . |
| 1. Draw a sample u from a Uniform- distribution; |
| 2. Draw a sample from the conditional law of given : |
| 3. Apply Algorithm 1 using as constraint (i.e., ); |
| 4. Return . |
Observe that it is very easy to adjust Algorithm 2 to deal with the alternative constraint . To that end, it suffices to replace by .
5. Applications
In this section, we provide two applications that are kept simple on purpose for the sake of illustration.
5.1. Conditional Portfolio Distribution
The application consists of computing the distribution of a portfolio conditional upon the fact that one stock reaches an extreme level, i.e., where is the -quantile of the random variable X. We consider K stocks with Normal dollar-returns and note J the dollar-return of a portfolio composed of these stocks with weigths . We postulate the following n-factor dependence structure:
where is the K-by- matrix of loadings, is the vector of n i.i.d. systematic standard Normal risk factors and the s, are the i.i.d. idiosynchratic standard Normal risk factors, independent from the s. Hence,
Set , and the K-by-n matrix made of the first n columns of . The portfolio return satisfies with
where the first term in the right-hand side of is the contribution of the n systematic factors and the second results from the K independent idiosynchratic components.
Let us now compute the conditional distribution of the portfolio given that is equal to its percentile , i.e., when
Noting , we conclude that
Applying the above result with , the density of the random vector conditional upon (9) is jointly Normal with mean vector and covariance matrix given by
where in . In order to find the joint distribution of , we need to correct for the scaling coefficients and disregard . Correcting for the scaling coefficients simply requires rescaling the entries of the mean vector and covariance matrix by and , respectively. The conditional distribution of is a n-dimensional Normal with mean vector and covariance matrix found by taking the first n entries of the above mean vector and the n-by-n upper-left of the covariance matrix. This leads to
The eigen decomposition of the covariance matrix is noted , so that where is a n-variate vector of independent standard Normal variables.
Let us note the vector whose j-th entry is set to 0, i.e., where is the j-th basis vector. Letting be a standard Normal random variable independent from ,
so that where
5.2. Expected Shortfall of a Defaultable Portfolio
The next example consists of approximating the Conditional Value-at-Risk (a.k.a. Expected Shortfall) associated with the portfolio of m defaultable assets in a multi-factor model. The total loss L on such a portfolio up to the time horizon T is the sum of the individual losses , where the contribution of the loss of the i-th asset is of the form , where is the weight of the asset in the portfolio and is the default time of the i-th obligor. Whereas the expected loss is independent from the possible correlation across defaults, it is a key driver of the Value-at-Risk, and hence of the economic and regulatory capital. Most credit risk models introduce such dependency by relying on latent variables, like , where the s are correlated random variables with cumulative distribution function F and is the marginal probability that under the chosen measure. The most popular choice (although debatable) is to rely on multi-factor Gaussian models, i.e., to consider , where is a n-dimensional vector of weights with norm smaller than 1, is the vector of n i.i.d. standard Normal systematic factors and the are i.i.d. standard Normal random variables independent from the s representing the idiosynchratic risks. Computing the Expected Shortfall in a multi-factor framework is very time-consuming as there is no closed-form solution and many simulations are required. A possible alternative to the plain Monte Carlo estimator is to rely on the ASRF model of Pykhtin, which can be seen as the single-factor model that “best” approximates the multi-factor model in the left tail, in some sense (see Pykhtin (2004) for details). The ASRF model thus deals with a loss variable relying on a single factor Y, but such that where L is the loss variable in the multi-factor model. By the law of large numbers, the idiosynchratic risks are diversified away for m large enough, so that conditional upon , the portfolio loss in the ASRF model converges almost surely, as , to with . Moreover, is a monotonic and decreasing function of x. Consequently, the Value-at-Risk of the ASRF model satisfies for m large enough. The asymptotic analytical expression is known as the large pool approximation (see e.g., Gordy (2003)). In the derivation of the ASRF analytical formula, Pykhtin implicitly models Y as a linear combination of the factors appearing in the multi-factor model, i.e., s.t. . One can thus draw samples for the s by using Algorithm 2 as follows: (i) draw a value for the standard Normal factor Y conditional upon , i.e., set with U a Uniform- random variable so that , and then (ii) sample conditional upon from the joint density derived in the paper. Therefore, we use as a proxy for the condition involved in the expected shortfall definition (observe that both L and depend on the same random vector ), but use the actual (multi-factor) loss to estimate the expected loss under this condition. In other words, we effectively compute as a proxy of the genuine Expected Shortfall, defined as , leading to a drastic reduction of the computational cost.
6. Conclusions
Many practical applications in the area of risk management deal with factor models, and often these factors are taken to be Gaussian. In various cases, it can be interesting to analyse the picture under some constraints on the weighted sum of these factors. This might be the case for instance when it comes to perform scenario analyses in adverse circumstances, to compute conditional risk measures or to speed up simulations (in the same vein as importance sampling). In this paper, we derive the density of a n-dimensional Normal vector with independent components subject to the constraint that the weighted sum takes a given value. It is proven to be a -multivariate Normal whose mean vector and covariance matrix can be computed in closed-form by relying on the specific structure of the (inverse) covariance matrix. This result naturally leads to various sampling algorithms, e.g., to draw samples with weighted sum being equal to, below or above a given threshold. Interestingly, the proposed scheme is shown to differ from various “standard rescaling” procedures applied to independent samples. Indeed, the latter fail to comply with the actual conditional distribution found, both in terms of expectation and variance.
Funding
This research has received no external funding.
Acknowledgments
The author is grateful to Damiano Brigo for interesting discussions around this question and to Monique Jeanblanc for suggestions about Appendix A.
Conflicts of Interest
The author declares no conflict of interest.
Appendix A. General Expression of the Conditional Density
Define , where has joint density f and is the density of Y. Let us note as the conditional expectation of given Y for some h:
The conditional density we are looking for is the function satisfying
for all c and every function h. By the law of iterated expectations, is defined as the function satisfying, for any function ,
A change of variable yields
This leads to
From (A1), the conditional density reads
or equivalently .
Appendix B. Proof of Lemma 1.
The matrix is the sum of two positive definite matrices: a diagonal matrix with strictly positive entries and a constant matrix with entries all set to . Hence, is positive definite, showing .
Let us now compute the determinant of . We proceed by recursion, showing that it is true for whenever it holds for . It is obvious to check that it is true for . The key point is to notice that it is enough to establish the following recursion rule:
We now apply the standard procedure for computing determinants, taking the product of each element of the last row of with the corresponding cofactor matrix and computing the sum. Recall that the cofactor matrix associated with is the submatrix obtained by deleting the i-th row and j-th column of Gentle (2007). This yields
where is the minor associated with the element of , i.e., the determinant of the cofactor matrix . Interestingly, the cofactor matrices take a form that is similar to . For instance, and is just with . Similarly, is the same as with provided that we shift all columns to the left, and put the last column back in first place (potentially changing the sign of the corresponding determinant), etc. More generally, for , the determinant of the cofactor matrix of , is exactly that of with if or that of with and when , up to some permutations of rows and columns. In fact:
The minor when can be obtained from the expression of provided that we adjust the sign and replace by 0:
(recall that is symmetric so that ). Therefore,
and this recursion is equivalent to .
Eventually, the expression of is given by times the adjunct matrix of , which is the (symmetric) cofactor matrix . Observe that the elements are given by . Using the minors expressions (A2) and (A3) derived above replacing m by yields:
This concludes the proof.
References
- Andersen, Leif B. G., and Jakob Sidenius. 2004. Extensions to the Gaussian copula: Random recovery and random factor loadings. Journal of Credit Risk 1: 29–70. [Google Scholar] [CrossRef]
- Cedilnik, Anton, Katarina Kosmelj, and Andrej Blejec. 2004. The distribution of the ratio of jointly Normal variables. Metodološki Zvezk 1: 99–108. [Google Scholar]
- Fieller, Edgar C. 1932. The distribution of the index in a normal bivariate population. Biometrika 23: 428–40. [Google Scholar] [CrossRef]
- Gentle, James E. 2007. Matrix Algebra: Theory, Computations, and Applications in Statistics. Berlin: Springer. [Google Scholar]
- Glasserman, Paul. 2010. Monte Carlo Methods in Financial Engineering. Berlin: Springer. [Google Scholar]
- Gordy, Michael B. 2003. A risk-factor model foundation for ratings-based bank capital rules. Journal of Financial Intermediation 12: 199–232. [Google Scholar] [CrossRef]
- Hull, John, and Alan White. 2004. Valuation of a CDO and an nth-to-default CDS without Monte Carlo simulation. Journal of Derivatives 12: 8–23. [Google Scholar] [CrossRef]
- Laurent, Jean-Paul, Michael Sestier, and Stéphane Thomas. 2016. Trading book and credit risk: how fundamental is the Basel review? Journal of Banking and Finance 73: 211–23. [Google Scholar] [CrossRef]
- Li, David X. 2016. On Default Correlation: A Copula Function Approach. Technical Report. Amsterdam: Elsevier. [Google Scholar]
- Meyer, Daniel W. 2018. (un)conditional sample generation based on distribution element trees. Journal of Computational and Graphical Statistics. [Google Scholar] [CrossRef]
- Pham, Dinh Tuan. 2000. Stochastic methods for sequential data assimilation in strongly nonlinear systems. Monthly Weather Review 129: 1194–207. [Google Scholar] [CrossRef]
- Pykhtin, Michael. 2004. Multifactor adjustment. Risk Magazine 17: 85–90. [Google Scholar]
- Rubinstein, Reuven Y., and Dirk Kroese. 2017. Simulation and the Monte Carlo Method. Hoboken: Wiley. [Google Scholar]
- Vasicek, Oldrich A. 1991. Limiting loan loss probability distribution. Finance, Economics and Mathematics. [Google Scholar] [CrossRef]
- Vrins, Frederic D. 2009. Double-t copula pricing of structured credit products—Practical aspects of a trustworthy implementation. Journal of Credit Risk 5: 91–109. [Google Scholar] [CrossRef]


© 2018 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).