1. Introduction
The compatibility of penalized regularization with machine learning approaches allows for the successful treatment of various challenges in learning theory such as variable selection (see
Tibshirani (
1996)) and dimension reduction (see
Zou et al. (
2006)). The objective of many machine learning models used in mathematical finance is to predict asset prices by learning functions depending on stochastic inputs. In general, there is no guarantee that these stochastic factor models are consistent with no-arbitrage conditions. This paper introduces a novel penalized regularization approach to address this modelling difficulty in a manner consistent with financial theory. The incorporation of an arbitrage-penalty term allows various machine learning methods to be directly and coherently integrated into mathematical finance applications. We focus on regression-type model selection tasks in this article. However, the arbitrage-penalty can also be applied to other types of machine learning algorithms with financial applications.
To motivate our approach we first consider informally, similar to (
Björk 2009, Chapter 10), the following simple situation that will later be made more precise. Let
be a filtered probability space satisfying the usual conditions. Let
be an
-adapted real-valued stochastic process with continuous paths representing the price of a financial asset. Let
r be the constant risk-free interest rate and assume a fixed time interval
. Existence of a martingale measure
equivalent to the underlying real-world measure
implies absence of arbitrage. The price at time
of a derivative security with integrable payoff
at time
T is given by the risk-neutral pricing formula
With
we may express Equation (
1) under the real-world probability measure
as
Equivalently, the price given by Equation (
2) can be expressed under
by defining the state-price density process
. If
is the minimal martingale measure of
Schweizer (
1995) then the transformation
can be interpreted as finding the process closest to
which is a (local) martingale under
. The purpose of this paper is to find an analogue of the transformation (
3) in this setting when
is described by a stochastic factor model, as is the case with most machine learning approaches to mathematical finance. For example,
may be described by a deep neural network with stochastic inputs.
The above-ignored well-known results regarding the uniqueness of
(see
Schweizer (
1995)) and other important generalizations of the martingale approach to arbitrage theory. In particular, the more general setting for the fundamental theorem of asset pricing of
Delbaen and Schachermayer (
1998) implies that if “arbitrage”, in the sense of no-free lunch with vanishing risk, exists then the transformation (
3) is undefined. However, many machine learning approaches to mathematical finance may admit arbitrage so it is necessary to consider the general case. The arbitrage-regularization framework introduced in this paper integrates machine learning methodologies with the general martingale approach to arbitrage theory.
We consider a general framework for learning the arbitrage-free factor model that is most similar to a factor model within a prespecified class of alternative factor models. This search is optimized by minimizing a loss-function measuring the distance of the alternative model to the original factor model with the additional constraint that the market described by the alternative model is a local martingale under a reference probability measure.
The main theoretical results rely on asymptotics for the arbitrage-regularization penalty for selecting the optimal arbitrage-free model from a class of stochastic factor models. Relaxation of the asymptotic results necessary for practical implementation are presented. Throughout this paper, the bond market will serve as the primary example of our methods since no-arbitrage conditions for factor models are well understood, see
Filipović (
2001) and the references therein. Numerical results applying the arbitrage-regularization methodology are implemented using real data.
The remainder of this paper is organized as follows.
Section 2 states the arbitrage-regularization problem and presents an overview of relevant background on bond markets.
Section 3 develops the arbitrage-penalty and establishes the main asymptotic optimality results. Non-asymptotic relaxations of these results are also considered and linked with transaction costs.
Section 4 specializes the general results to bond markets and where a simplified expression for the arbitrage-penalty is obtained. Numerical implementations of the results are considered and the arbitrage-regularization methodology is used to generate new machine learning-based models consistent with no free lunch with vanishing risk (NFLVR) and the results are compared with classical term-structure models as benchmarks.
Section 5 concludes and
Appendix A contains supplementary material primarily required for the proofs, such as functional Itô calculus and
-convergence results. Proofs of the main theorems of the paper are included in
Appendix B.
2. The Arbitrage-Regularization Problem
For the remainder of the paper all stochastic processes described in this paper are defined on a common stochastic basis
. Let
be a probability measure equivalent to the reference probability measure
and
denotes the risk-free rate in effect at time
. Assume that there exists an asset whose price process, denoted by
, is a strictly positive
-martingale which serves as numéraire. Unless otherwise specified all the processes in this paper will be described under the martingale-measure for
, denoted
is defined by
The choice of the numéraire can be used to encode or remove any trend from the price processes being modelled. Price processes which are local martingales under
or
are usually only semi-martingales under the objective measure
. Further details on numéraires can be found in
Shreve (
2004).
We consider a large financial market
, indexed by a non-empty Borel subset
, were
D is a positive integer. For example,
may be used to represent a bond market where, using the parameterization of
Musiela and Rutkowski (
1997),
represents the collection of all possible maturities and
represents the time
t price of a zero-coupon bond with maturity
u.
For each
, the process
will be driven by a latent, possibly infinite-dimensional, factor process. In the case of the bond market, this latent process will be the forward-rate curve. Write
where
,
is a family of path-dependent functionals encoding the latent process into the asset price
,
is the factor model for the latent process, and
are the
-valued stochastic factors driving the latent process. Following
Fournie (
2010),
will be allowed to depend on the local quadratic-variation of the factor process
, denoted by
and defined by
where
denotes the usual quadratic-variation of the factor process
. It is instructive to note that the local quadratic-variation
is well-defined due to Assumption 1, imposed later.
In the case of the bond market,
will be the map taking a forward-rate curve, such as
, to the time
t price of a zero-coupon bond with maturity
u, as defined by
It will often be convenient to use the reparameterization of
Musiela and Rutkowski (
1997) and rewrite (
6) as
where
, for
, and represents the time to maturity of the bond.
In general,
will be allowed to depend on the path of
. Thus,
will be a path-dependent functional of regularity
in the sense of
Fournie (
2010) as discussed in
Appendix A.2. However, as in the bond market, if
depends only on the current value of
then the requirement that
be of class
, in the sense of
Fournie (
2010), is equivalent to it being of regularity
in the classical sense; where
. Therefore, the classical Itô-calculus would apply to
.
Analogously to
Björk and Christensen (
1999), the factor model
for the latent process will always be assumed to be suitably integrable and suitably differentiable. Specifically,
will belong to a Banach subspace
of
which can be continuously embedded within the Fréchet space
; where
is a Borel probability measure supported on
I,
is a Borel probability measure supported on
, and both
and
are equivalent to the corresponding Lebesgue measures restricted to their supports. Here,
is kept fixed.
An example from the bond modelling literature is the Nelson-Siegel model (see
Nelson and Siegel (
1987) and
Diebold and Rudebusch (
2013)), which expresses the forward-rate curve as a function of its level, slope, and curvature through the factor model. The Nelson-Siegel family is part of a larger class of affine term-structure models, in which, at any given time, the forward-rate curve is described in terms of a set of market factors as
where
d is a positive integer and
and
is a forward-rate curve typically calibrated to the data available at time
. Note that the forward-rate curves in (
7) are parameterized according to the change of variables in (6), however, since
represents all times to maturities these are indeed traded assets. However, as shown in
Filipović (
2001), the Nelson-Siegel model is typically not arbitrage-free therefore we would like to learn the closest arbitrage-free factor model, driven by the same stochastic factors. Therefore, given a non-empty and unbounded hypothesis class
of plausible alternative models, we optimize
where
is required to contain the (naive) factor model
and
is continuous and coercive loss function. For example,
ℓ may be taken to be the norm on
. Geometrically, (
8) describes a projection of
onto the (possibly non-convex) subset of
of factor models making each
into a
-local martingale for every
. The requirement that
contains the (naive) factor model
is for consistency, in order to ensure that for any arbitrage-free factor model
the solution to problem (
8) is itself.
In general, the problem described by (
8) may be challenging to implement as projections onto non-convex sets are intractable. In analogy with regularization literature, such as
Hastie et al. (
2015), instead we consider the following relaxation of problem (
8) which is more amenable to numerical implementation
where
is a family of functions from
to
taking value 0 if each
is a
-local martingale simultaneously for every value of
u and
is a meta-parameter determining the amount of emphasis placed on the penalizing factor models which fail to meet this requirement. Problem (
9) is called the
arbitrage-regularization problem.
At the moment, there are only two available lines of research which are comparable to the arbitrage-regularization problem. Results of the first kind, such as the arbitrage-free Nelson-Siegel model of
Christensen et al. (
2011a), provide closed-form case-by-case arbitrage-free variants of specific model only if they coincide with specific arbitrage-free HJM type factor models, such as those studied by
Björk and Christensen (
1999). However, the reliance on analytic methods typically limit this type of approach to simple or specific models and does not allow for a general or computationally viable solution to the problem. Moreover, arbitrage-free corrections derived in this way are not guaranteed to be optimal in the sense of (
8), or approximately optimal in the sense of (
9). This will be examined further in the numerics section of this paper.
The use of a penalty to capture no-arbitrage conditions has, to the best of the authors’ knowledge, thus far only been explored numerically by
Chen et al. (
2019) within the discrete-time portfolio optimization setting. A similar problem has been treated in
Chen et al. (
2006) for learning the equivalent martingale measure in the multinomial tree setting for stock prices. Our paper provides the first instance of a theoretical result in this direction as well as such a framework that applies to large-financial markets such as bond markets or which applies in the continuous-time setting.
Before presenting the main results we first state necessary assumptions.
Assumption 1. The following assumptions will be maintained throughout this paper.
- (i)
is an -valued diffusion process which is the unique strong solution towhere , is an -valued Brownian motion, the components are continuous, the components are measurable and such that the diffusion matrix is a continuous function of β for any fixed .
- (ii)
The stochastic differential equation (10) has a unique -valued solution for each . - (iii)
For every , is a non-anticipative functional in verifying the following “predictable-dependence” condition of Fournie (2010): for all and all , where is the set of -dimensional positive semi-definite matrices with real-coefficients,
The central problem of the paper will be addressed in full generality before turning to applications in term-structure models, in the next section.
3. Main Results
In this section, we show the asymptotic equivalence of problems (
8) and (
9) for general asset classes. This requires the construction of the penalty term
measuring how far a given factor model is from being a
-local martingale. The construction of
is made in two steps. First, a drift condition which guarantees that each
is simultaneously a
-local martingale is obtained. This condition generalizes the drift condition of
Heath et al. (
1992) and provides an analogue to the consistency condition of
Filipović and Teichmann (
2004). Second, the drift condition is used to produce the penalty term in (
9). Subsequently, the optimizers of (
9) will be used to asymptotically solve problem (
8).
Proposition 1 (Drift Condition).
The processes are -local-martingales, for each simultaneously, if and only ifis satisfied -a.s. for every and every , where and ∇ respectively denote the horizontal and vertical derivative of Fournie (2010) (see Appendix A.2 Equation (A3)). The drift condition in Proposition 1 implies that if
is such that the difference of the left and right-hand sides of (
11) is equal to 0,
-a.s. for all
then
is a
-local martingale simultaneously for all
. Thus,
is simultaneously a
-local martingale for all
if for every
the
-valued process
is equal to 0
-a.s, where
is defined using (
11) by
where
. The arbitrage-penalty is defined as follows.
Definition 1 (Arbitrage-Penalty).
Let be a family of -adapted -valued stochastic processes for whichholds for all , , , and -almost every . Then, for every , the family of functionsis said to define an arbitrage-penalty. Remark 1. Whenever fails to be integrable, we make the convention that .
The convergence of the optimizers of (
9) to the optimizers of (
8) is demonstrated in the next theorem. The proof relies on the theory of
-convergence, which is useful for interchanging the limit and an arginf operations.
Assumption 2. Assume that
- (i)
For every and -a.e. , the function is continuous on ,
- (ii)
is closed and non-empty.
Please note that both statements (i) and (ii) are with respect to the relative topology on .
Theorem 1. Under Assumption 2 the following hold:
- (i)
Equation (8) admits a minimizer on , - (ii)
- (iii)
If for every is lower-semi-continuous on then where is defined on as
Theorem 1 provides a theoretical means of asymptotically computing the optimizer
of problem (
8). In practice, this limit cannot always be computed and only very large values of
can be used. However, in reality trading does not occur in a friction-less market but every transaction placed at time
t incurs a cost
. Moreover, only a finite number of assets are traded.
Consider a market with frictions where only finitely many assets are traded. In this setting, an admissible strategy is an adapted, left-continuous of finite-variation process
whose corresponding wealth process is
-a.s. bounded below. In the context of this paper, the sub-market
with proportional transaction cost
is precisely such a market. Any such admissible strategy on this finite sub-market defines an admissible portfolio whose liquidation value, as defined by (
Guasoni 2006, Equation 2.2) and (
Guasoni 2006, Remark 2.4), is defined by
where
denote the optimizer of
9 for a fixed value of
,
denotes the weak derivative of
in the sense of measures, and
denotes its variation. The first term on the right-hand side of (
17) is the capital gains from trading, second represents the cost incurred from various transaction costs, and the last term represents the cost of instantaneous liquidation at time
t. Although more general transactions costs may be considered, the proportional transaction costs presented here are sufficient for the formulation of the next result.
The next result guarantees that the market model is arbitrage-free, granted that is large enough to cover the spread between and . The following assumption quantifies the requirement that be taken to be sufficiently large.
Assumption 3. There exists some and some such that for every , positive integer n, and every the following holds:
- (i)
- (ii)
Proposition 2. If for all times then for any admissible strategy θ trading , , then implies that
In the next section, we apply Theorem 1 and the arbitrage-regularization (
9) to the bond market.
4. Arbitrage-Regularization for Bond Pricing
As discussed in
Diebold and Rudebusch (
2013), affine term-structure models are commonly used in forward-rate curve modelling due to their tractability and the interpretability. In the formulation of
Björk and Christensen (
1999), as further developed in
Filipović (
2000);
Filipović et al. (
2010), affine term-structure models are characterized by (
7) together with the additional requirement that its stochastic factor process
follows an affine diffusion. By
Cuchiero (
2011) this means that the dynamics of
are given by
for some
matrices
and
, and some vectors
and
in
such that there exists a solution
to the following Riccati system
such that
has negative real part for all
,
,
, and
.
Fix meta-parameters
and
. For the next result, all the factor models will be taken as belonging to the weighted Sobolev space
with weight function
where
C is a unique constant ensuring that
and its weighted integral is equal to 1. Fix measures
on
and
on
. The space
is defined of all
-locally integrable,
k-times weakly differentiable functions
equipped with the norm:
where
is a multi-index,
, and
is the weak derivative of
f of order
defined by
Here,
is the space of all compactly supported functions with infinitely many derivatives. Furthermore,
k is required to satisfy
Remark 2. In the case where and , the Sobolev space is a reproducing kernel Hilbert space (see Nelson and Siegel (1987)) therefore point evaluation is a continuous linear functional and by (weighted) Morrey-Sobolev Theorem of Brown and Opic (1992) it can be embedded within a space of continuous functions. Therefore, given any and any -valued stochastic process , the process is a well-defined process in the following space of forward-rate curves of Filipović (2001) defined by Analytic tractability is ensured by requiring that the factor models considered for the arbitrage-regularization (
9) belong to the class
defined by
where
. This class of functions generalizes the Nelson-Siegel family (
7) discussed in the introduction.
Under these conditions the following theorem characterizes the asymptotic behavior of (
9) in
as solving problem (
8), given fixed meta-parameters
. Following
Filipović (
2001), it will be convenient to denote
Theorem 2. Let φ be given by (7), be as in (18), and fix . Then - (i)
For every there exists an element in minimizing where is defined by where , , , and , for .
- (ii)
The following inclusion holds
It may convenient to understand the
as a function of
when interpreting approximations of the limit (26) as a function of
. The following result removes the challenges posed by the unbounded interval
, in which
lies, by reparameterizing problem (
23) with a bounded meta-parameter
.
Corollary 1. Let φ be given by (7), be as in (18), ϕ be in , and fix . For every , define . Then minimizes (23) if and only if it minimizeswhere is as in (24). In particular, the following inclusion holdswhere is as in (16). Next, the arbitrage-regularization of forward-rate curves will be considered using deep learning methods.
4.1. A Deep Learning Approach to Arbitrage-Regularization
The flexibility of feed-forward neural networks (ffNNs), as described in the universal approximation theorems of
Hornik (
1991);
Kratsios (
2019b), makes the collection of ffNNs a well-suited class of alternative models for the arbitrage-regularization problem. In the context of this paper an ffNN is any function from
to
of the form
where each
for some
dimensional matrix
and some
, where
and
,
is a smooth activation-function, and • denotes component-wise composition. Fix integers
, and
. The set of all feed-forward neural networks with
for
,
, and fixed activation function
will be denoted by
.
To maintain analytic tractability, it will be required that our hypothesis class
consists of all
of the form
where
,
for all
, and where
denotes the transpose of
. The process
will be assumed to be a
d dimensional Ornstein-Uhlenbeck process and in particular will be of the form(
18). Therefore, the special class of models we consider here are of the form (
7).
It has been shown in
Rahimi and Recht (
2008), among others, that if a network is appropriately designed, then training only the final layer and suitably initializing the matrices
performs comparably well to networks with all the layers trained. More recently, the approximation capabilities of neural networks with randomized first few layers has is shown in
Gonon (
2020). This phenomenon was observed in numerous numerical studies, such as
Jaeger and Haas (
2004), where the entries of the matrices
are chosen entirely randomly. This practice has also become fundamental to feasible implementations of recurrent neural network (RNN) theory and reservoir computing, as studied in
Gelenbe (
1989), where training speed becomes a key factor in determining the feasibility of the RNN and reservoir computing paradigms.
The hypothesis class of alternative factor models to be considered in the arbitrage-regularization problem effectively reduces from (
28) to
where
and
is initialized through by
is a given factor model of the form (
21), and
is a uniform random sample on a non-empty compact subset of
;
. Thus, the optimization problem (
30) is random since it relies on randomly generated data points
. However, instead of initializing
in an ad-hoc random manner, the initialization (
30) guarantees that the shapes generated by (
29) are close to those produced by the naive factor model (
7). In this case, a brief computation shows that
simplifies to
where
with the integration is defined component-wise and
denotes the
entry of the vector
.
4.2. Numerical Implementations
The data-set for this implementation consists of German bond data for 31 maturities with observations obtained on 1273 trading days from January 4th 2010 to December 30th 2014. As is common practice in machine learning, further details of our code and implementation can be found on
Kratsios (
2019a). The code is relatively flexible and could be adapted to other bond-data sets.
The performance of the arbitrage-regularization methodology will now be applied to two factor models of affine type and its performance will be evaluated numerically. The first factor model is the commonly used dynamic Nelson-Siegel model of
Diebold and Rudebusch (
2013) and the second is a machine learning extension of the classical PCA approach to term-structure modeling. The performance of the arbitrage-regularization for each model will be benchmarked against both the original factor models and against the HJM-extension of the Vasiček model. The Vasiček model is a natural benchmark since, as shown in
Björk and Christensen (
1999), it is consistent with a low-dimensional factor model. Therefore, each of the factor models contains roughly the same number of driving factors which ensures that the comparisons are fair. Moreover, the numéraire process
will be taken to be the money-market and we take
. The meta-parameter
is taken to be
so that it is approximately 1.
As described in (
29)–(
31), the solution to the arbitrage-regularization (
9), will be numerically approximated using randomly initialized deep feed-forward neural networks. The initialization network
f of (
29) is selected to have fixed depth
, fixed height
and its weights are learned using the ADAM algorithm. The meta-parameters
and
are chosen empirically, and the parameters of the Ornstein-Uhlenbeck process are estimated using the maximum-likelihood. Once the model parameters have been learned, and the factor model optimizing (
9) has been learned, the day ahead predictions of the stochastic factors are obtained through Kalman filter estimates of the hidden parameters
for each of the factor models. In the case of the Vasiček model the unobservable short-rate parameter is also estimated using the Kalman filter (see
Bain and Crisan (
2009)). These day-ahead predictions are then fed into the factor model and used to compute the next-day bond prices. These predictions are then compared to the realized next-day bond prices.
4.2.1. Model 1: The Dynamic Nelson-Siegel Model (Practitioner Model)
The Nelson-Siegel family is a low-dimensional family of forward-rate curve models used by various central banks to produce forward-rate or yield curves. As discussed in
Carmona (
2014), Finland, Italy, and Spain are such examples with other countries such as Canada, Belgium, and France relying on a slight extension of this model. The Nelson-Siegel model’s popularity is largely due to its interpretable factors and satisfactory empirical performance. It is defined by
where, as discussed in
Diebold and Rudebusch (
2013), the first factor represents the long-term level of the forward-rate curve, the second represents its shape, the third represents its curvature, and
is a shape parameter; typically kept fixed.
Since market conditions are continually changing, the Nelson-Siegel model is typically extended from a static model to a dynamic model by replacing the static choice of
with a three-dimensional Ornstein-Uhlenbeck process and fixing the shape parameter
as in
Diebold and Rudebusch (
2013). However, as demonstrated in
Filipović (
2001), the dynamic Nelson-Siegel model does not admit an equivalent measure to
that makes the entire bond market simultaneously into local martingales. It was then shown in
Christensen et al. (
2011a) that a specific additive perturbation of the Nelson-Siegel family circumvents this problem, but empirically this is observed to come at the cost of reduced predictive accuracy. In our implementation, the parameters of the Ornstein-Uhlenbeck process driving
will be estimated using the maximum likelihood method described in
Meucci (
2005).
4.2.2. Model 2: dPCA (Machine-Learning Model)
The dynamic Nelson-Siegel model’s shape has been developed through practitioner experience. The second factor model considered here will be of a different type, with its factors learned algorithmically. As with (
32), consider a static three-factor model for the forward-rate curve of the form
where
are the first three principal components of the forward-rate curve calibrated on the first 100 days of data.
Subsequently, a time-series for the
parameters is generated, using the first 100 days of data, where on each day the
are optimizes according to the Elastic-Net (ENET) regression problem of
Hastie et al. (
2015) defined by
on rolling windows consisting of 100 data points and
are the available data-points on the forward-rate curve at time
t. The meta-parameters
and
are chosen by cross-validation on the first 100 training days and then fixed.
The ENET regression is used due to its factor selection abilities and computational efficiency. Next, analogously to the dynamic Nelson-Siegel model, an
-valued Ornstein-Uhlenbeck process
is calibrated, using the maximum likelihood methodology outlined in
Meucci (
2005) to the time-series
. These will provide the hidden stochastic factors in the dynamic PCA model (
33). Thus, the dPCA model is the factor model with stochastic inputs defined by
The resulting model differs from the dynamic Nelson-Siegel model in that its factors and dynamics are not chosen by practitioner experience but learned through the data and implicitly encode some path-dependence. However, as with the dynamic Nelson-Siegel model it falls within the scope of Theorem 2.
5. Discussion
The predictive performance of the Vasiček (Vasiček), dPCA, A-Reg(dPCA), the dynamic Nelson-Siegel Model (dNS), the arbitrage-free Nelson-Siegel model of
Christensen et al. (
2011a) (AFNS), and the arbitrage-regularization of the dynamic Nelson-Siegel Model (A-Reg(dNS)) is reported in the following tables. The predictive quality is quantified by the estimated mean-squared errors when making day-ahead predictions of the bond price for each maturity, for all but the first days in our data-set. The lowest estimated mean-squared errors recorded are highlighted using bold font and the second lowest estimated mean-squared errors on each maturity are emphasized using italics.
Table 1 evaluates the performance of the considered models on the short-mid end of the curve. Overall, the performance of all the models are generally comparable at the very short end but rapidly after the dPCA model begins to outperform the rest. The accuracy of the Vasiček model on small maturities is likely to it being a short-rate model.
In
Table 2 the dPCA model outperforms the rest by progressively larger margins. Most notably, in
Table 3 and
Table 4 which summarize the performance of the models for very long bong maturities the A-Reg(dPCA) model shows very low predictive error for a low number of factors while simultaneously being consistent with no-arbitrage conditions.
Even though arbitrage-free regularization does slightly reduce its accuracy, which is natural since it adds a constraint into an otherwise purely predictive process, the arbitrage-regularized dPCA model is still much more accurate than the rest.
An advantage of the A-Reg(dPCA) model is that it can accurately model the long-end of the forward-rate curve in an arbitrage-free manner. This fact is due to the dynamic factor selection properties of the dPCA model which otherwise could not have been used in a consistent manner if it were not for Theorem 2.
The numerical implementation highlights a few key facts about the arbitrage-regularization methodology. First, for nearly every maturity, the empirical performance of the arbitrage-regularization of a factor model is comparable to the original factor model. An analogous phenomenon was observed in
Devin et al. (
2010) when projecting infinite-dimensional arbitrage-free HJM models onto the finite-dimensional manifold of Nelson-Siegel curves. Therefore, correcting for arbitrage does not come at a significant predictive cost. However, it does come with the benefit of making the model theoretically sound and compatible with the techniques of arbitrage-pricing theory.
Second, since (
9) incorporates an additional constraint into the modeling procedure the arbitrage-regularization of a factor model has a reduction in performance as compared to the initial factor model. This phenomenon has also been observed empirically in
Christensen et al. (
2011a) for the arbitrage-free Nelson-Siegel correction of the dynamic Nelson-Siegel model. Therefore, one should not expect to improve on the predictive performance of the initial factor model by correcting for the existence of arbitrage.
Third, the empirical performance of A-Reg(dPCA) was significantly better than the empirical performance of the other arbitrage-free models, namely AFNS, A-Reg(dNS), and the Vasiček model, across nearly all maturities. This was especially true for mid and long maturity zero-coupon bonds. Moreover, the performance of A-Reg(dPCA) and dPCA were comparable. Similarly, for most maturities, the empirical performance of the AFNS, dNS, and A-Reg(dNS) models were all similar and notably lower than the performance of the A-Reg(dPCA), dPCA, and Vasiček models. This emphasizes the fact that arbitrage-regularization methodology produces performant models only if the original model itself produces accurate predictions. Therefore, it is up to the practitioner to make an appropriate choice of model. However, the methodology used to develop dPCA and A-Reg(dPCA) could be used as a generic starting point.
Since the arbitrage-regularization methodology applies to nearly any factor model, one may use any methodology to produce an accurate reference factor model and then apply arbitrage-regularization to make it theoretically consistent at a small cost in performance. This opens the possibility to applying machine learning models, such as dPCA, to finance without the worry that they are not arbitrage-free since their asymptotic arbitrage-regularization is well-defined. Furthermore, the flexibility of deep feed-forward neural networks allows for the efficient implementation of (
9).
The AFNS model proposes an arbitrage-free correction for the dynamic Nelson-Siegel. However, there is no guarantee that the AFNS corrects dNS optimally, and the predictive gap between these two models is documented in
Christensen et al. (
2011a). This is both echoed in
Table 2 and
Table 3. Furthermore, this is also reflected by Theorem 2 which guarantees asymptotic optimally of the A-Reg(dNS) model.
Unlike most regularization problems where there is a trade-off between the regularization term and the (un-regularized) objective function, the arbitrage-regularization requires
to be taken as close to 1 as possible. Since the limit (26) can only be approximated numerically
cannot be evaluated, however
can be taken to be arbitrarily close to, but less than, 1. This choice is justified by
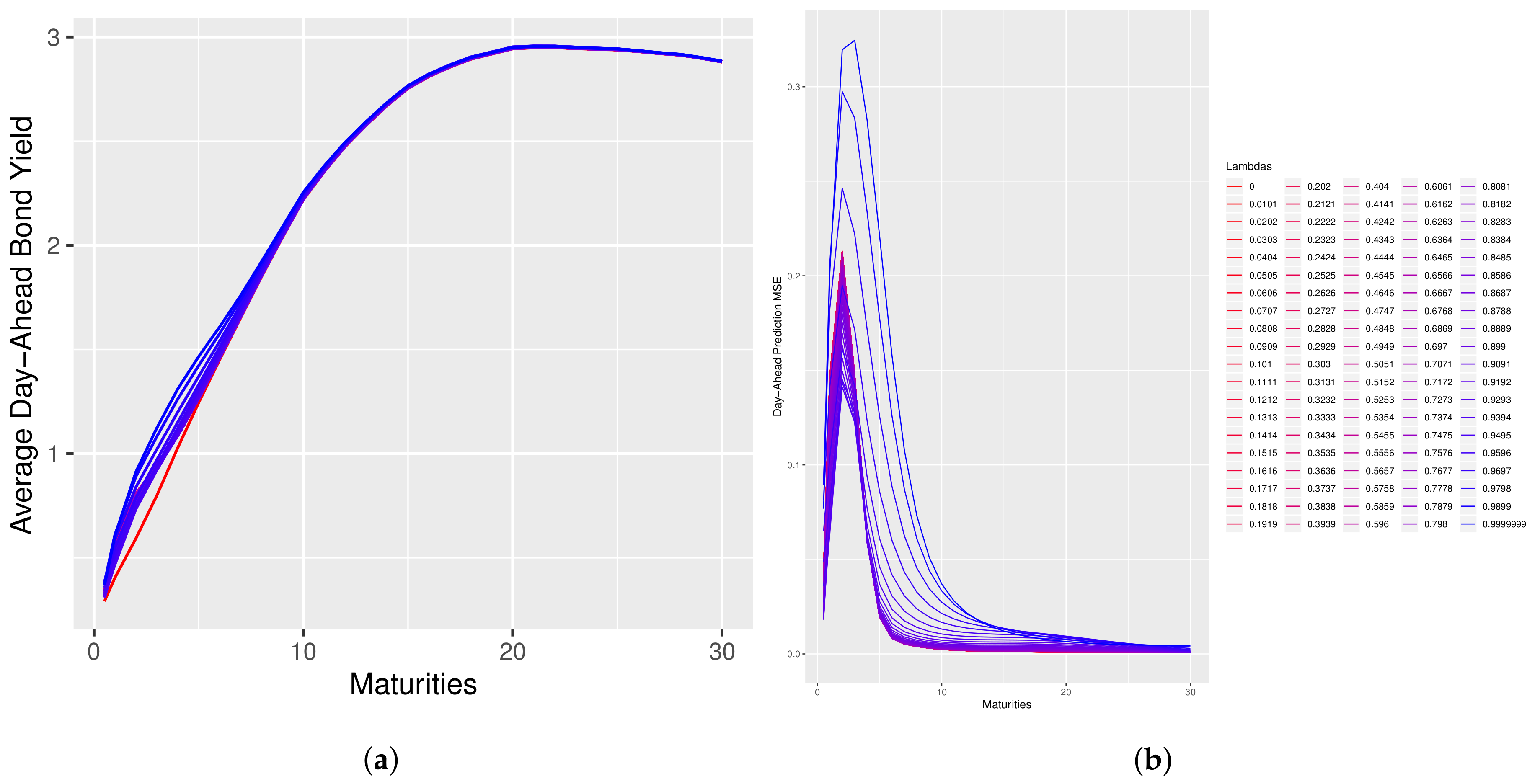
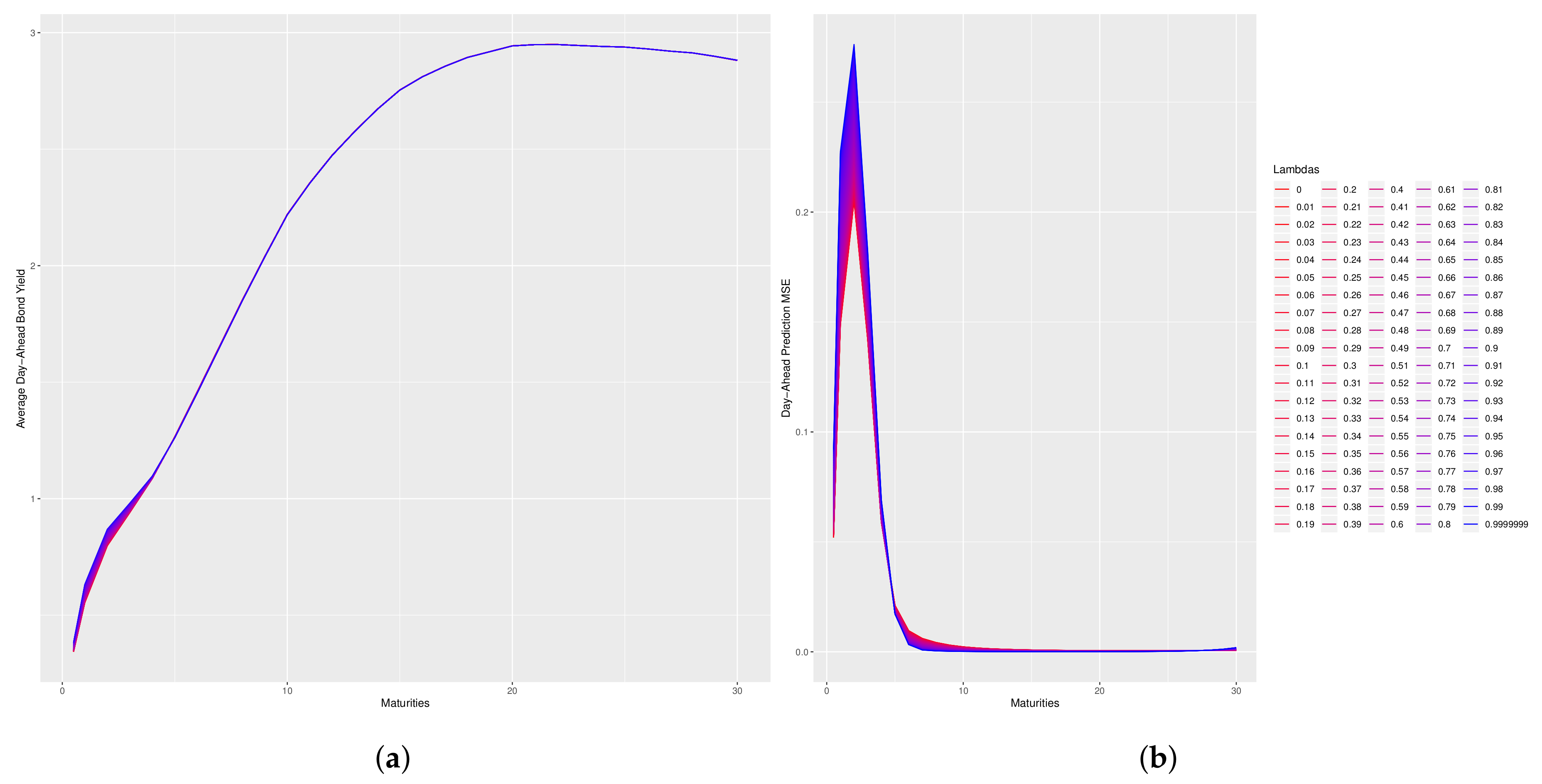
Figure 1 and
Figure 2 which illustrates that for values of
near 1 there is little change in the model’s predictive performance.
Figure 1 and
Figure 2 plot the change in the shape of the day-ahead predicted forward-rate curve and the change in the MSE of the day-ahead predicted bond prices as function of
. In those figures, the curves with a pink color correspond to low values of
and the curves progressing towards a blue color correspond to high values of lambda. Please note that in these plots, the reparameterization of Corollary 1 is used and an abuse of notation is made by using
to denote
.
In the case of the dNS model, an interesting property is that long-maturity bond prices do not change much, whereas short-maturity bond prices exhibit more dramatic changes. This property suggests that the dNS model is closer to being arbitrage-free on the long end of the curve than it is on the short end. This paper introduced a novel model-selection problem and provided an asymptotic solution in the form of the penalized optimization given by problem (
9). The problem was posed and solved in a generalized HJM-type setting, within Theorem 1 and specialized to the term-structure of interest setting in Theorem 2 where simple expressions for the penalty term were derived.
The key innovation of the paper was the construction of the penalty term
defining the arbitrage-regularization problem (
9). The construction of this term in Proposition 1 relied on the structure of the generalized HJM-type setting proposed in
Heath et al. (
1992) and generalized in (
4) which allowed one to encode the dynamics of a large class of factor models with stochastic inputs into the specific structure of any asset class.
The numerical feasibility of the proposed method was made possible by the flexibility of feed-forward neural networks, as demonstrated in
Hornik (
1991);
Kratsios (
2019b), which allowed the optimizer of the arbitrage-regularization problem (
9) to be approximated to arbitrary precision. In the numerics section of this paper, it was found that the arbitrage-regularization of a factor model does not heavily impact its predictive performance but does make it approximately consistent with no-arbitrage requirements.
In particular, the compatibility of the proposed approach with generic factor models with stochastic inputs allowed for the consistent use of factor models generated from machine learning methods. The A-Reg(dPCA) model is a novel example of such an approximately arbitrage-free model where the dynamics and factors were generated algorithmically instead of through practitioner experience.
The precise quantification of the approximate arbitrage-free property was made in Proposition 2. Thus, approximately arbitrage-free factor models under the stylized assumption of no transaction costs were indeed arbitrage-free when proportional transaction costs are in place, which is a more realistic assumption.
Finally, the arbitrage-regularization approach introduced in this paper opens the door to the compatible use of predictive machine-learning factor models with the no-free lunch with vanishing risk condition. The general treatment in Theorem 1 can be transferred to other asset classes and models generated from other learning algorithms. This approach can be an important new avenue of research lying at the junction of predictive machine learning and mathematical finance.






{kind=link}
{kind=link}