Machine Learning for Multiple Yield Curve Markets: Fast Calibration in the Gaussian Affine Framework


Abstract
:1. Introduction
Related Literature
2. Gaussian Process Regression
3. The Single-Curve Vasiček Interest Rate Model
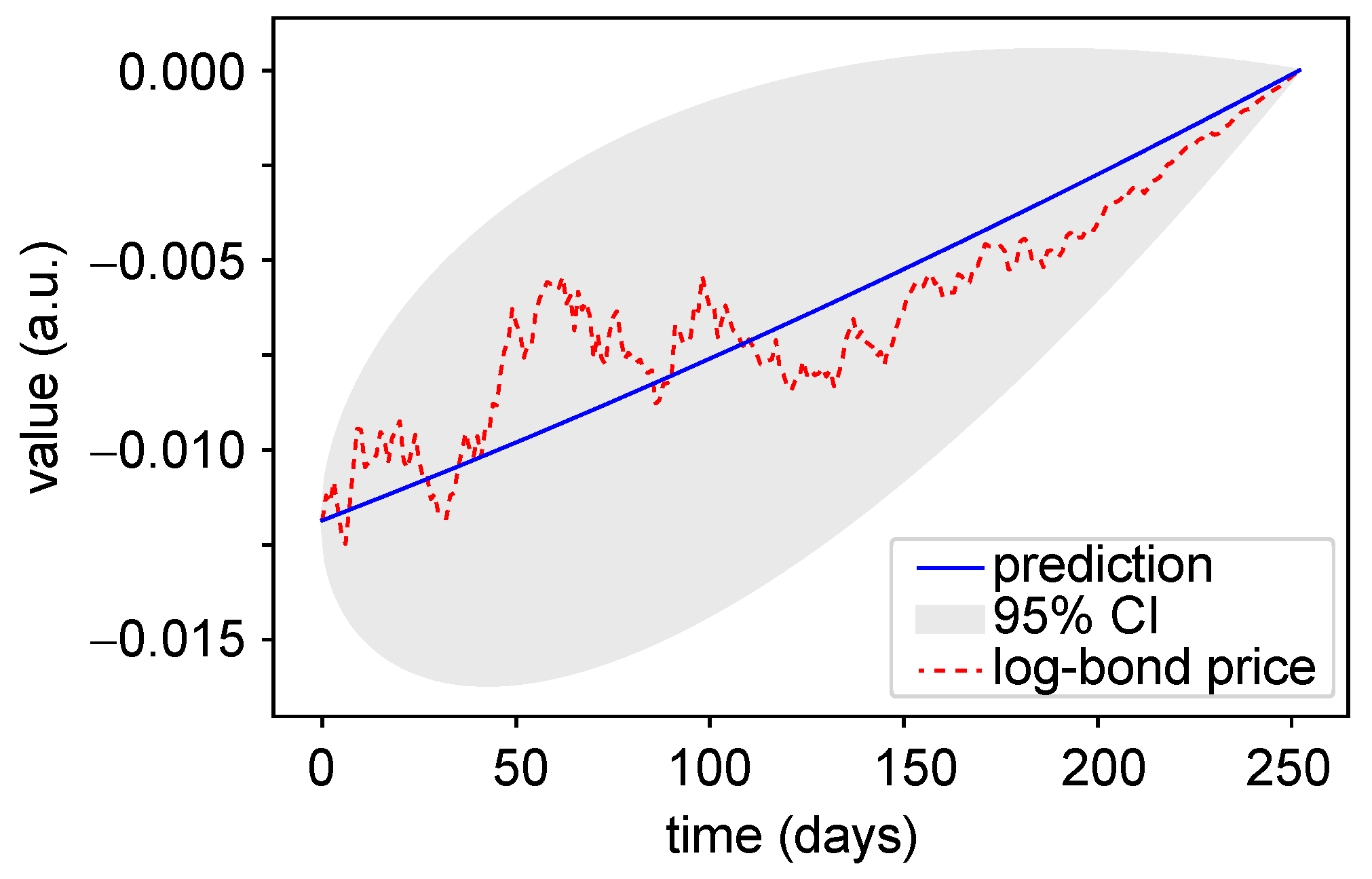
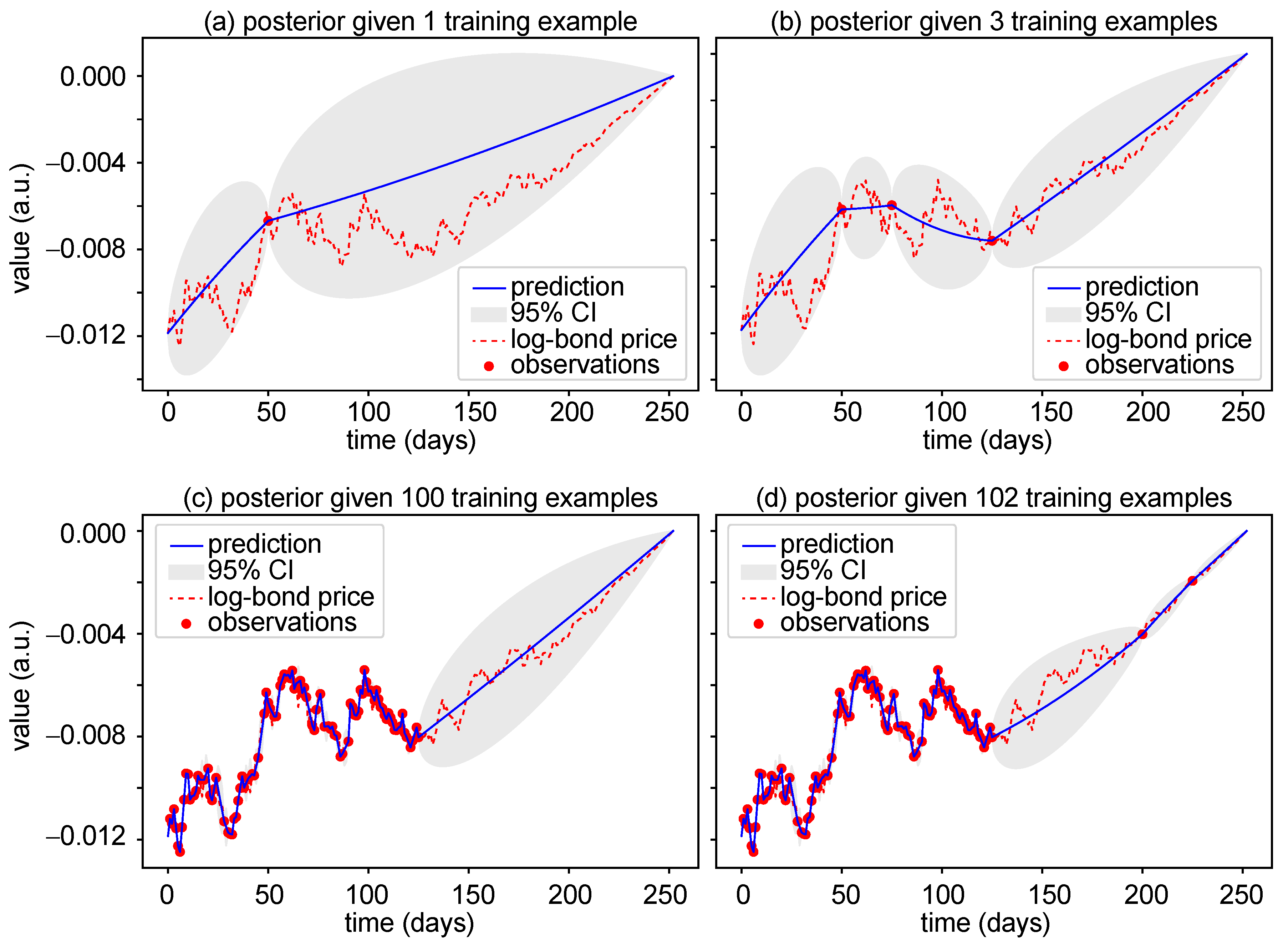
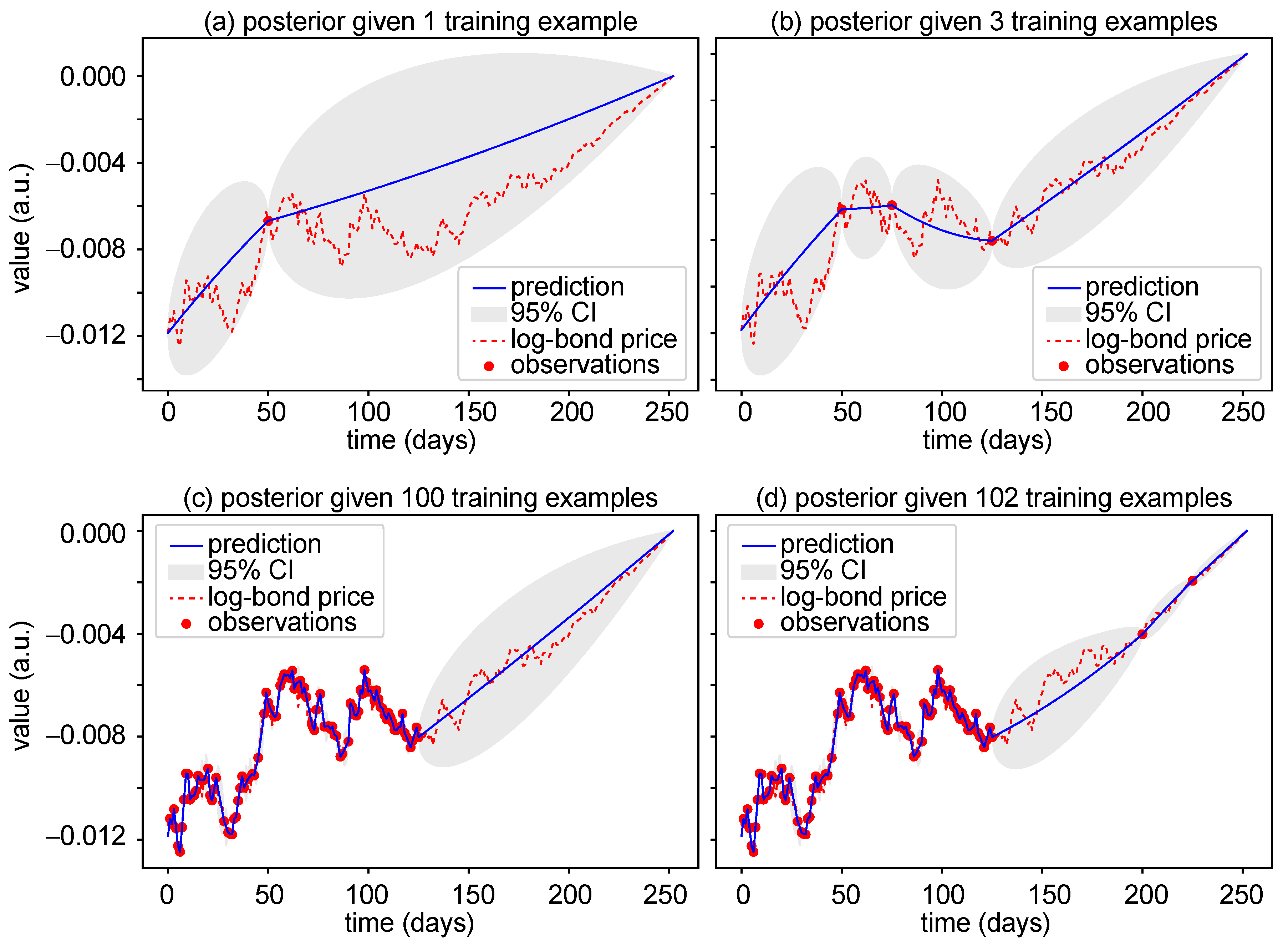
3.1. Prediction with Gaussian Processes Regression
3.2. Performance Measures
3.3. Calibration Results for the Vasiček Single-Curve Model
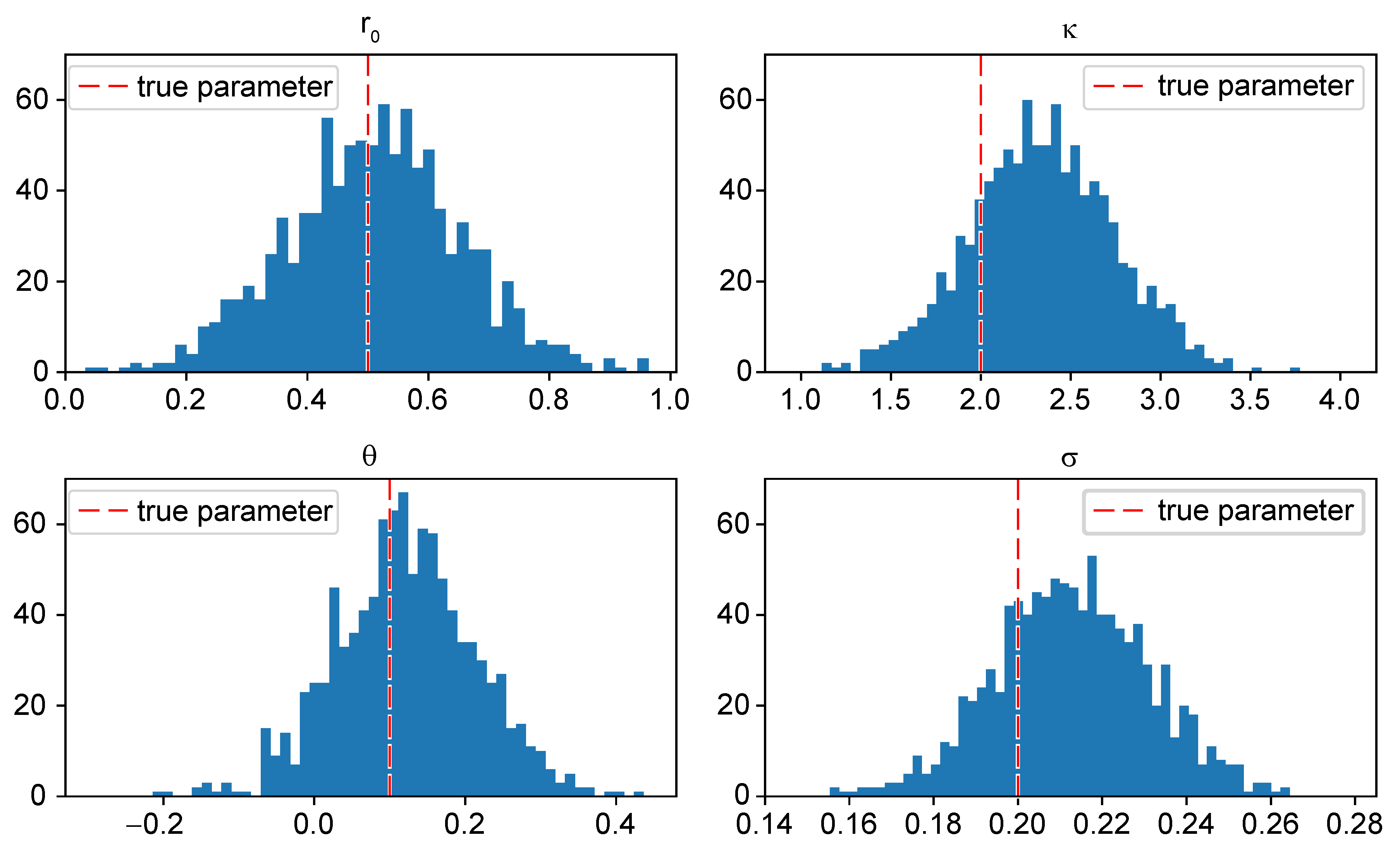
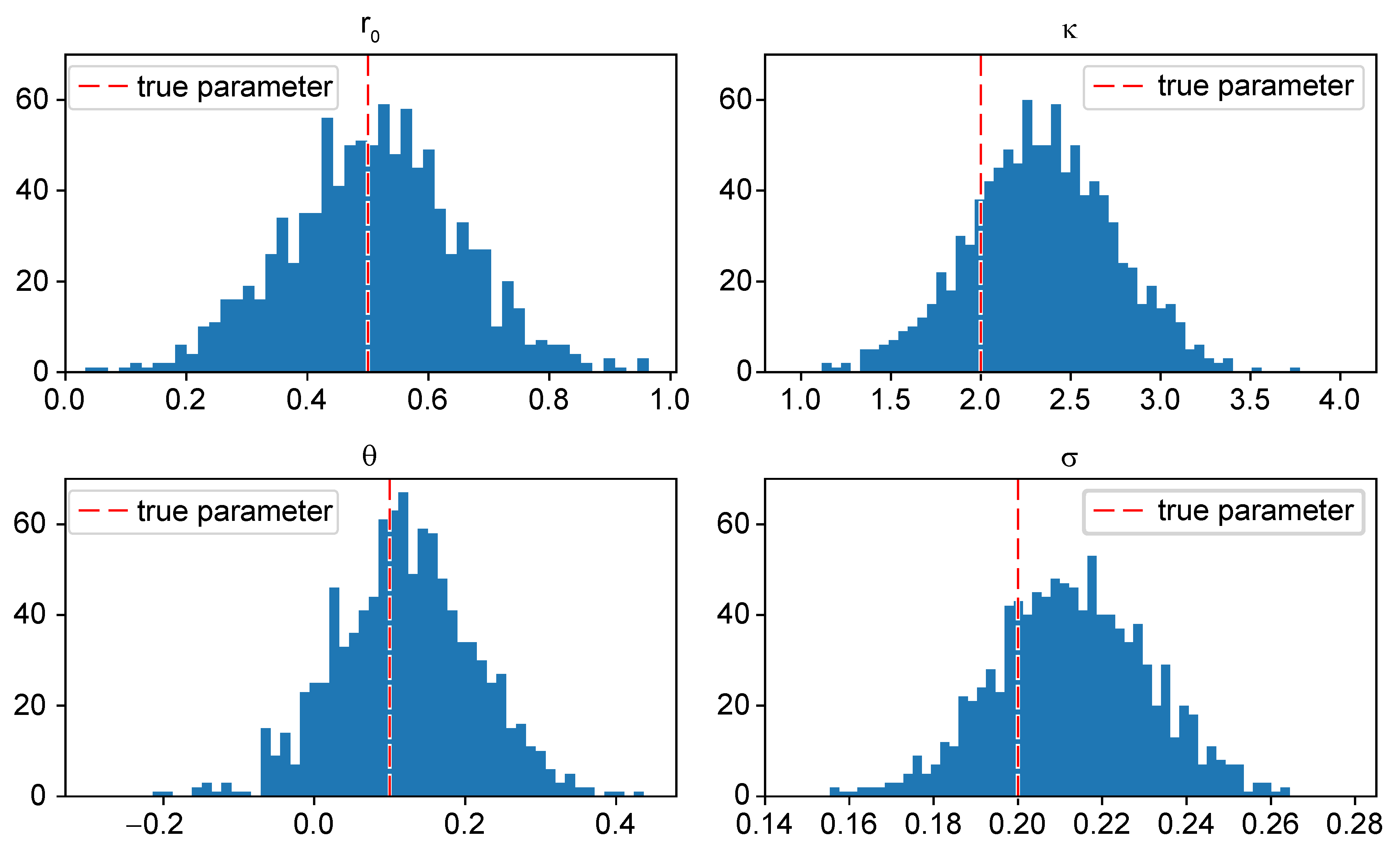
- The results of the calibration via the conjugate gradient optimization algorithm are very satisfying. In Figure 3, the learned parameters , , , and of 1000 simulated log-bond prices are plotted in 50-bin histograms. The red dashed lines in each sub-plot indicate the true model parameters.The mean and standard deviation of the learned parameters are summarized in Table 1. We observe that the mean of the learned parameters reaches the true parameters very closely while the standard deviation is reasonable.
- The results of the calibration via the Adam algorithm are satisfying, even though we note a shift of the mean reversion parameter and the volatility parameter . The learned parameters , , , and of 1000 simulated log-bond prices are plotted in 50-bin histograms in Figure 4 and summarized with their mean and standard deviation in Table 1. The Adam algorithm slowly reduces the learning rate over time to speed up the learning algorithm. Nonetheless, one needs to specify a suitable learning rate. If the learning rate is small, training is more reliable, but the optimization time to find a minimum can increase rapidly. If the learning rate is too big, the optimizer can overshoot a minimum. We tried different learning rates of 0.0001, 0.001, 0.01, 0.05, and 0.1. Finally, we decided in favor of a learning rate of 0.05 and performed the training over 700 epochs to achieve a suitable trade-off between accuracy and computation time. We expect the results to improve slightly with more epochs, at the expense of a longer training time.
4. Multi-Curve Vasiček Interest Rate Model
Calibration Results
- Considering the results of the calibration by means of the CG algorithm, we note several facts. In this regard, the mean and the standard deviation of the calibrated parameters can be found in Table 2. Figure 5 shows the learned parameters of the processes and in 50-bin histograms for 1000 simulations. The red dashed line in each of the sub-plots indicates the true model parameter value. First, except for the long term mean, the volatility for is higher than the one for . This implies more difficulties in the estimation of the parameters for , which is clearly visible in the results. For , we are able to estimate the parameters well (in the mean), with the most difficulty in the estimation of which shows a high standard deviation. For estimating the parameters of , we face more difficulties, as expected. The standard deviation of is very high—it is known from filtering theory and statistics that the mean is difficult to estimate, which is reflected here. Similarly, it seems difficult to estimate the speed of reversion parameter and we observe a peak around 0.02 in . This might be due to a local minimum, where the optimizer gets stuck.
- For the calibration results by means of the Adam algorithm, we note the following. The learned parameters are illustrated in a 50-bin histogram (see Figure 6), and mean and standard deviation of each parameter are stated in Table 2. After trying several learning rates of 0.0001, 0.001, 0.01, 0.05, and 0.1, we decided in favor of the learning rate 0.05 and chose 750 training epochs. While most mean values of the learned parameters are not as close to the true values as the learned parameters from the CG algorithm, we notice that the standard deviation of the learned parameters is smaller compared to the standard deviation of the learned parameters from the CG. Especially, comparing the values of in Figure 5 and Figure 6, we observe the different range of calibrated values.
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A. Proof of Proposition 2
Appendix B. Coding Notes and Concluding Remarks
References
- Brigo, D., and F. Mercurio. 2001. Interest Rate Models–Theory and Practice. Berlin: Springer Finance. [Google Scholar] [CrossRef]
- Cuchiero, C., C. Fontana, and A. Gnoatto. 2016. A general HJM framework for multiple yield curve modelling. Finance and Stochastics 20: 267–320. [Google Scholar] [CrossRef] [Green Version]
- Cuchiero, C., C. Fontana, and A. Gnoatto. 2019. Affine multiple yield curve models. Mathematical Finance 29: 1–34. [Google Scholar] [CrossRef] [Green Version]
- De Spiegeleer, J., D. B. Madan, S. Reyners, and W. Schoutens. 2018. Machine learning for quantitative finance: Fast derivative pricing, hedging and fitting. Quantitative Finance 18: 1635–43. [Google Scholar] [CrossRef]
- Dümbgen, M., and C. Rogers. 2014. Estimate nothing. Quantitive Finance 14: 2065–72. [Google Scholar] [CrossRef] [Green Version]
- Eberlein, E., C. Gerhart, and Z. Grbac. 2019. Multiple curve Lévy forward price model allowing for negative interest rates. Mathematical Finance 30: 1–26. [Google Scholar] [CrossRef] [Green Version]
- Fadina, T., A. Neufeld, and T. Schmidt. 2019. Affine processes under parameter uncertainty. Probability Uncertainty and Quantitative Risk 4: 1. [Google Scholar] [CrossRef] [Green Version]
- Filipović, D. 2009. Term Structure Models: A Graduate Course. Berlin: Springer Finance. [Google Scholar] [CrossRef]
- Fischer, B., N. Gorbach, S. Bauer, Y. Bian, and J. M. Buhmann. 2016. Model Selection for Gaussian Process Regression by Approximation Set Coding. arXiv, arXiv:1610.00907. [Google Scholar]
- Fontana, C., Z. Grbac, S. Gümbel, and T. Schmidt. 2020. Term structure modelling for multiple curves with stochastic discontinuities. Finance and Stochastics 24: 465–511. [Google Scholar] [CrossRef]
- Grbac, Z., A. Papapantoleon, J. Schoenmakers, and D. Skovmand. 2015. Affine libor models with multiple curves: Theory, examples and calibration. SIAM Journal on Financial Mathematics 6: 984–1025. [Google Scholar] [CrossRef]
- Grbac, Z., and W. Runggaldier. 2015. Interest Rate Modeling: Post-Crisis Challenges and Approaches. New York: Springer. [Google Scholar]
- Henrard, M. 2014. Interest Rate Modelling in the Multi-Curve Framework: Foundations, Evolution and Implementation. London: Palgrave Macmillan UK. [Google Scholar]
- Hölzermann, J. 2020. Pricing interest rate derivatives under volatility uncertainty. arXiv, arXiv:2003.04606. [Google Scholar]
- Jacod, J., and A. Shiryaev. 2003. Limit Theorems for Stochastic Processes. Berlin: Springer, vol. 288. [Google Scholar]
- Keller-Ressel, M., T. Schmidt, and R. Wardenga. 2018. Affine processes beyond stochastic continuity. Annals of Applied Probability 29: 3387–37. [Google Scholar] [CrossRef] [Green Version]
- Kingma, D.P., and J. Ba. 2014. Adam: A method for stochastic optimization. arXiv, arXiv:1412.6980. [Google Scholar]
- Mercurio, F. 2010. A LIBOR Market Model with Stochastic Basis. In Bloomberg Education and Quantitative Research Paper. Amsterdam: Elsevier, pp. 1–16. [Google Scholar]
- Nocedal, J., and S.J. Wright. 2006. Conjugate gradient methods. In Numerical Optimization. Berlin: Springer, pp. 101–34. [Google Scholar]
- Polak, E., and G. Ribiere. 1969. Note sur la convergence de méthodes de directions conjuguées. ESAIM: Mathematical Modelling and Numerical Analysis-Modélisation Mathématique et Analyse Numérique 3: 35–43. [Google Scholar] [CrossRef]
- Rasmussen, C.E., and C.K.I. Williams. 2006. Gaussian Processes for Machine Learning. Cambridge: MIT Press. [Google Scholar]
- Sousa, J. Beleza, Manuel L. Esquível, and Raquel M. Gaspar. 2012. Machine learning Vasicek model calibration with Gaussian processes. Communications in Statistics: Simulation and Computation 41: 776–86. [Google Scholar] [CrossRef] [Green Version]
- Sousa, J. Beleza, Manuel L. Esquível, and Raquel M. Gaspar. 2014. One factor machine learning Gaussian short rate. Paper presented at the Portuguese Finance Network 2014, Lisbon, Portugal, November 13–14; pp. 2750–70. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Params. | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Optimizer | Mean | StDev | Mean | StDev | Mean | StDev | Mean | StDev | |
| CG | 0.496 | 0.135 | 2.081 | 0.474 | 0.104 | 0.106 | 0.202 | 0.020 | |
| Adam | 0.510 | 0.144 | 2.339 | 0.403 | 0.121 | 0.093 | 0.213 | 0.018 | |
| True value | 0.5 | 2 | 0.1 | 0.2 | |||||
| Params. | |||||||||
| Optimizer | Mean | StDev | Mean | StDev | Mean | StDev | Mean | StDev | |
| CG | 0.477 | 0.119 | 1.994 | 0.781 | 0.101 | 0.121 | 0.150 | 0.033 | |
| Adam | 0.487 | 0.053 | 2.694 | 0.284 | 0.157 | 0.029 | 0.170 | 0.013 | |
| True value | 0.5 | 2 | 0.1 | 0.2 | |||||
| Params. | |||||||||
| Optimizer | Mean | StDev | Mean | StDev | Mean | StDev | Mean | StDev | |
| CG | 0.678 | 0.601 | 0.529 | 0.545 | 0.385 | 1.732 | 0.602 | 0.113 | |
| Adam | 0.477 | 0.139 | 0.813 | 0.277 | 0.876 | 0.254 | 0.640 | 0.055 | |
| True value | 0.7 | 0.5 | 0.03 | 0.8 | |||||
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gümbel, S.; Schmidt, T. Machine Learning for Multiple Yield Curve Markets: Fast Calibration in the Gaussian Affine Framework. Risks 2020, 8, 50. https://doi.org/10.3390/risks8020050
Gümbel S, Schmidt T. Machine Learning for Multiple Yield Curve Markets: Fast Calibration in the Gaussian Affine Framework. Risks. 2020; 8(2):50. https://doi.org/10.3390/risks8020050
Chicago/Turabian StyleGümbel, Sandrine, and Thorsten Schmidt. 2020. "Machine Learning for Multiple Yield Curve Markets: Fast Calibration in the Gaussian Affine Framework" Risks 8, no. 2: 50. https://doi.org/10.3390/risks8020050
APA StyleGümbel, S., & Schmidt, T. (2020). Machine Learning for Multiple Yield Curve Markets: Fast Calibration in the Gaussian Affine Framework. Risks, 8(2), 50. https://doi.org/10.3390/risks8020050