
A Study of Text Vectorization Method Combining Topic Model and Transfer Learning


Abstract
:1. Introduction
- The topic model keyword extraction method is introduced into the text vectorization operation.
- The text vector that can deeply reflect the semantic relationship is generated by transferring the pretrained model.
- The above text vectorization method is applied to the calculation task of text similarity.
2. Literature Review
3. Materials and Methods
3.1. Word2vec
3.1.1. Continuous Bag of Words (CBOW)
3.1.2. Skip-Gram
3.2. Para2vec
3.2.1. Distributed Memory (DM)
3.2.2. Distributed Bag of Words (DBOW)
3.3. Topic Model
3.3.1. Latent Semantic Analysis (LSA)
3.3.2. Latent Dirichlet Allocation (LDA)
| Algorithm 1 Modeling based on LDA model. |
| Input: text set D; topic set T; word set W; parameters of Dirichlet distribution; length of each sentence . |
Output: allocation based on text-topic; allocation based on topic-word; probability density of topic; probability density of word; topic sequence t; sentence sequence d.
|
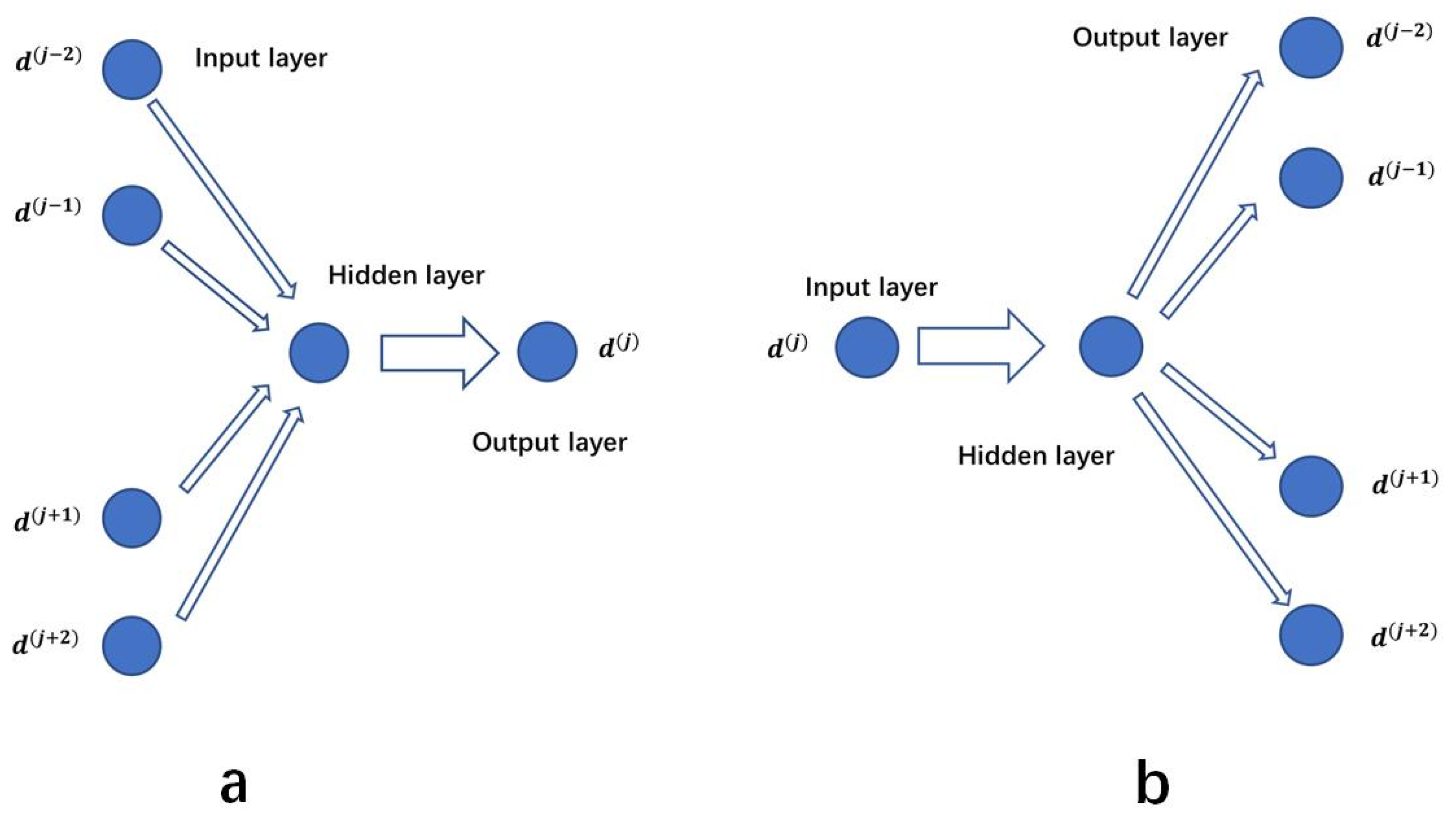
3.4. Pretrained Model and Transfer Learning
3.5. Text Similarity Calculation Based on Topic Modeling and Transfer-Learning-Based Text Vectorization (TTTV)
| Algorithm 2 Text similarity based on TTTV. |
| Input: text set D; number K of keywords. Output: similarity . 1: for each range do 2: for each range do 3: extract of through LDA. 4: end for 5: generate vector of text . 6: based on set through BERT. 7: end for 8: . 9: . 10: return . |
4. Experiment
4.1. Experimental Environment and Data
4.2. Experimental Setup and Analysis of Experimental Results
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Jeffrey, C. South Online resources for news about toxicology and other environmental topics. Toxicology 2001, 157, 153–164. [Google Scholar]
- Macskassy, S.A.; Hirsh, H.; Banerjee, A.; Dayanik, A.A. Converting numerical classification into text classification. Artif. Intell. 2003, 143, 51–77. [Google Scholar] [CrossRef] [Green Version]
- Qi, D.; Liu, X.; Yao, Y.; Zhao, F. Numerical characteristics of word frequencies and their application to dissimilarity measure for sequence comparison. J. Theor. Biol. 2011, 276, 174–180. [Google Scholar]
- Kang, X.; Ren, F.; Wu, Y. Exploring latent semantic information for textual emotion recognition in blog articles. IEEE/CAA J. Autom. Sin. 2018, 5, 204–216. [Google Scholar] [CrossRef]
- Tan, Z.; Chen, J.; Kang, Q.; Zhou, M.C.; Sedraoui, K. Dynamic embedding projection-gated convolutional neural networks for text classification. IEEE Trans. Neural Netw. Learn. Syst. 2021, 99, 1–10. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Le, Q.; Mikolov, T. Distributed Representations of Sentences and Documents. In Proceedings of the 31st International Conference on Machine Learning, Beijing, China, 21–26 June 2014. [Google Scholar]
- Kim, D.; Seo, D.; Cho, S.; Kang, P. Multi-co-training for document classification using various document representations: Tf–idf, lda, and doc2vec. Inform. Sci. 2019, 477, 15–29. [Google Scholar] [CrossRef]
- Gómez-Adorno, H.; Posadas-Durán, J.P.; Sidorov, G.; Pinto, D. Document embeddings learned on various types of n-grams for cross-topic authorship attribution. Computing 2018, 100, 741–756. [Google Scholar] [CrossRef]
- Zhang, Y.; Xu, B.; Zhao, T. Convolutional multi-head self-attention on memory for aspect sentiment classification. IEEE/CAA J. Autom. Sin. 2020, 7, 1038–1044. [Google Scholar] [CrossRef]
- Liu, H.; Chatterjee, I.; Zhou, M.C.; Lu, X.S.; Abusorrah, A. Aspect-based sentiment analysis: A survey of deep learning methods. IEEE Trans. Comput. Soc. Syst. 2020, 7, 1358–1375. [Google Scholar] [CrossRef]
- Lan, D.; Buntine, W.; Jin, H. A segmented topic model based on the two-parameter poisson-dirichlet process. Mach. Learn. 2010, 81, 5–19. [Google Scholar]
- Yang, Y.; Liu, Y.; Lu, X.; Xu, J.; Wang, F. A named entity topic model for news popularity prediction. Knowl.-Based Syst. 2020, 208, 106430. [Google Scholar] [CrossRef]
- Buiu, C.; Dnil, V.R.; Rdu, C.N. Mobilenetv2 ensemble for cervical precancerous lesions classification. Processes 2020, 8, 595. [Google Scholar] [CrossRef]
- Shin, S.J.; Kim, Y.M.; Meilanitasari, P. A holonic-based self-learning mechanism for energy-predictive planning in machining processes. Processes 2019, 7, 739. [Google Scholar] [CrossRef] [Green Version]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-Training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:1810.04805. [Google Scholar]
- Lai, P.T.; Lu, Z. Bert-gt: Cross-sentence n-ary relation extraction with bert and graph transformer. arXiv 2021, arXiv:2101.04158. [Google Scholar] [CrossRef]
- Abdulnabi, I.; Yaseen, Q. Spam email detection using deep learning techniques. Procedia Comput. Sci. 2021, 184, 853–858. [Google Scholar] [CrossRef]
- Boncalo, O.; Amaricai, A.; Savin, V.; Declercq, D.; Ghaffari, F. Check node unit for ldpc decoders based on one-hot data representation of messages. Electron. Lett. 2018, 51, 907–908. [Google Scholar] [CrossRef] [Green Version]
- Wu, L.; Hoi, S.; Yu, N.; Declercq, D.; Ghaffari, F. Semantics-preserving bag-of-words models and applications. IEEE Trans. Image Process. 2010, 19, 1908–1920. [Google Scholar]
- Lei, W.; Hoi, S. Enhancing bag-of-words models with semantics-preserving metric learning. IEEE Multimed. 2011, 18, 24–37. [Google Scholar]
- Bengio, Y.; Ducharme, R.; Vincent, P.; Jauvin, C. A neural probabilistic language model. J. Mach. Learn. Res. 2003, 3, 1137–1155. [Google Scholar]
- Ahn, G.; Lee, H.; Park, J.; Sun, H. Development of indicator of data sufficiency for feature-based early time series classification with applications of bearing fault diagnosis. Processes 2020, 8, 790. [Google Scholar] [CrossRef]
- Deerwester, S.; Dumais, S.T.; Furnas, G.W.; Landauer, T.K.; Harshman, R. Indexing by latent semantic analysis. J. Assoc. Inf. Sci. Technol. 2010, 41, 391–407. [Google Scholar] [CrossRef]
- Hofmann, T. Unsupervised learning by probabilistic latent semantic analysis. Mach. Learn. 2001, 42, 177–196. [Google Scholar] [CrossRef]
- Ozsoy, M.G.; Alpaslan, F.N.; Cicekli, I. Text summarization using latent semantic analysis. J. Inf. Sci. 2011, 37, 405–417. [Google Scholar] [CrossRef] [Green Version]
- Yong, W.; Hu, S. Probabilistic latent semantic analysis for dynamic textures recognition and localization. J. Electron. Imaging 2014, 23, 063006. [Google Scholar]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. Advances in Neural Information Processing Systems 14. In Proceedings of the Neural Information Processing Systems: Natural and Synthetic, NIPS 2001, Vancouver, BC, Canada, 3–8 December 2001. [Google Scholar]
- Kang, H.J.; Kim, C.; Kang, K. Analysis of the trends in biochemical research using latent dirichlet allocation (lda). Processes 2019, 7, 379. [Google Scholar] [CrossRef] [Green Version]
- Chao, C.; Zare, A.; Cobb, J.T. Partial membership latent dirichlet allocation. IEEE Trans. Image Process. 2015, 99, 1. [Google Scholar]
- Biggers, L.R.; Bocovich, C.; Ca Pshaw, R.; Eddy, B.P.; Etzkorn, L.H.; Kraft, N.A. Configuring latent dirichlet allocation based feature location. Empir. Softw. Eng. 2014, 19, 465–500. [Google Scholar] [CrossRef]
- Jia, Z. A topic modeling toolbox using belief propagation. J. Mach. Learn. Res. 2012, 13, 2223–2226. [Google Scholar]
- Zhu, X.; Jin, X.; Jia, D.; Sun, N.; Wang, P. Application of data mining in an intelligent early warning system for rock bursts. Processes 2019, 7, l55. [Google Scholar] [CrossRef] [Green Version]
- Yao, L.; Huang, H.; Chen, S.H. Product quality detection through manufacturing process based on sequential patterns considering deep semantic learning and process rules. Processes 2020, 8, 751. [Google Scholar] [CrossRef]
- Peters, M.; Neumann, M.; Iyyer, M.; Gardner, M.; Zettlemoyer, L. Deep Contextualized Word Representations. arXiv 2018, arXiv:1802.05365. [Google Scholar]
- Catelli, R.; Casola, V.; Pietro, G.D.; Fujita, H.; Esposito, M. Combining contextualized word representation and sub-document level analysis through bi-lstm + crf architecture for clinical de-identification. Knowl.-Based Syst. 2021, 213, 106649. [Google Scholar] [CrossRef]
- Subramanyam, K.K.; Sangeetha, S. Deep contextualized medical concept normalization in social media text. Procedia Comput. Sci. 2020, 171, 1353–1362. [Google Scholar] [CrossRef]
- Cen, X.; Yuan, J.; Pan, C.; Tang, Q.; Ma, Q. Contextual embedding bootstrapped neural network for medical information extraction of coronary artery disease records. Med Biol. Eng. Comput. 2021, 59, 1111–1121. [Google Scholar] [CrossRef]
- Feng, C.; Rao, Y.; Nazir, A.; Wu, L.; He, L. Pre-trained language embedding-based contextual summary and multi-scale transmission network for aspect extraction—Sciencedirect. Procedia Comput. Sci. 2020, 174, 40–49. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Llion Jones, L.; Aidan, N.; Gomez, A.N.; Kaiser, L. Attention Is All You Need. In Proceedings of the 31st Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Shan, Y.A.; Hl, B.; Sk, B.; Lx, A.; Jx, A.; Dan, S.B.; Lei, X.; Dong, Y. On the localness modeling for the self-attention based end-to-end speech synthesis. Neural Netw. 2020, 125, 121–130. [Google Scholar]
- Mo, Y.; Wu, Q.; Li, X.; Huang, B. Remaining useful life estimation via transformer encoder enhanced by a gated convolutional unit. J. Intell. Manuf. 2021, 2, 1997–2006. [Google Scholar] [CrossRef]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training; OpenAI: San Francisco, CA, USA, 2018. [Google Scholar]
- Yao, C.; Cai, D.; Bu, J.; Chen, G. Pre-training the deep generative models with adaptive hyperparameter optimization. Neurocomputing 2017, 247, 144–155. [Google Scholar] [CrossRef]
- Chan, Z.; Ngan, H.W.; Rad, A.B. Improving bayesian regularization of ann via pre-training with early-stopping. Neural Process. Lett. 2003, 18, 29–34. [Google Scholar] [CrossRef]
- Sun, S.; Liu, H.; Meng, J.; Chen, C.; Yu, Y. Substructural regularization with data-sensitive granularity for sequence transfer learning. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 2545–2557. [Google Scholar] [CrossRef] [PubMed]
- Ohata, E.F.; Bezerra, G.M.; Chagas, J.; Neto, A.; Albuquerque, A.B.; Albuquerque, V.; Filho, P.P.R. Automatic detection of COVID-19 infection using chest x-ray images through transfer learning. IEEE/CAA J. Autom. Sin. 2021, 8, 239–248. [Google Scholar] [CrossRef]
- Luo, X.; Li, J.; Chen, M.; Yang, X.; Li, X. Ophthalmic diseases detection via deep learning with a novel mixture loss function. IEEE J. Biomed. Health Inform. 2021, 25, 3332–3339. [Google Scholar] [CrossRef] [PubMed]
- Luo, X.; Sun, J.; Wang, L.; Wang, W.; Zhao, W.; Wu, J.; Wang, J.H.; Zhang, Z. Short-term wind speed forecasting via stacked extreme learning machine with generalized correntropy. IEEE Trans. Ind. Inf. 2018, 14, 4963–4971. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. Albert: A Lite Bert for Self-Supervised Learning of Language Representations. arXiv 2019, arXiv:1909.11942. [Google Scholar]
- Joshi, M.; Chen, D.; Liu, Y.; Weld, D.S.; Levy, O. Spanbert: Improving pre-training by representing and predicting spans. Trans. Assoc. Comput. Linguist. 2020, 8, 64–77. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Meaning |
|---|---|
| The component of the text sequence, which represents the word of the sentence | |
| Allocation probability when the topic corresponds to the word | |
| b | Distribution parameters of Dirichlet distribution obeyed by |
| The component of the topic sequence, which represents the topic corresponding to the word of the sentence | |
| Distribution probability of the topic to which the sentence belongs | |
| a | Distribution parameters of Dirichlet distribution obeyed by |
| Method | K = 3 | K = 4 | K = 5 | K = 6 | ||||||||
| P | R | F1 | P | R | F1 | P | R | F1 | P | R | F1 | |
| TFIDF | 0.67 | 0.11 | 0.19 | 0.75 | 0.17 | 0.27 | 0.80 | 0.22 | 0.35 | 0.83 | 0.28 | 0.42 |
| LSA | 0.67 | 0.11 | 0.19 | 0.50 | 0.11 | 0.18 | 0.60 | 0.17 | 0.26 | 0.67 | 0.22 | 0.33 |
| LDA | 0.66 | 0.11 | 0.19 | 0.75 | 0.17 | 0.27 | 0.60 | 0.17 | 0.26 | 0.67 | 0.22 | 0.33 |
| Method | K = 7 | K = 8 | K = 9 | K = 10 | ||||||||
| P | R | F1 | P | R | F1 | P | R | F1 | P | R | F1 | |
| TFIDF | 0.71 | 0.28 | 0.40 | 0.63 | 0.28 | 0.38 | 0.56 | 0.28 | 0.37 | 0.50 | 0.28 | 0.36 |
| LSA | 0.71 | 0.28 | 0.40 | 0.75 | 0.33 | 0.46 | 0.67 | 0.33 | 0.44 | 0.60 | 0.33 | 0.43 |
| LDA | 0.86 | 0.33 | 0.48 | 0.75 | 0.33 | 0.46 | 0.78 | 0.39 | 0.52 | 0.70 | 0.38 | 0.50 |
| Method | K = 11 | K = 12 | K = 13 | K = 14 | ||||||||
| P | R | F1 | P | R | F1 | P | R | F1 | P | R | F1 | |
| TFIDF | 0.45 | 0.28 | 0.34 | 0.42 | 0.28 | 0.33 | 0.46 | 0.33 | 0.39 | 0.50 | 0.39 | 0.44 |
| LSA | 0.55 | 0.33 | 0.41 | 0.50 | 0.33 | 0.40 | 0.46 | 0.33 | 0.39 | 0.43 | 0.33 | 0.38 |
| LDA | 0.82 | 0.50 | 0.62 | 0.75 | 0.50 | 0.60 | 0.77 | 0.56 | 0.65 | 0.79 | 0.61 | 0.69 |
| Method | K = 15 | K = 16 | K = 17 | K = 18 | ||||||||
| P | R | F1 | P | R | F1 | P | R | F1 | P | R | F1 | |
| TFIDF | 0.53 | 0.44 | 0.48 | 0.56 | 0.50 | 0.53 | 0.59 | 0.56 | 0.57 | 0.61 | 0.61 | 0.61 |
| LSA | 0.40 | 0.33 | 0.36 | 0.38 | 0.33 | 0.35 | 0.35 | 0.33 | 0.34 | 0.50 | 0.50 | 0.50 |
| LDA | 0.73 | 0.61 | 0.67 | 0.75 | 0.67 | 0.71 | 0.71 | 0.67 | 0.69 | 0.72 | 0.72 | 0.72 |
| Keyword Extraction | word2vec | para2vec | Pre-Trained | ||
|---|---|---|---|---|---|
| CBOW | Skip-Gram | DM | DBOW | BERT | |
| TFIDF | 0.68 | 0.67 | 0.81 | 0.79 | 0.82 |
| LSA | 0.71 | 0.72 | 0.82 | 0.82 | 0.83 |
| LDA | 0.78 | 0.79 | 0.83 | 0.84 | 0.86 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, X.; Yang, K.; Cui, T.; Chen, M.; He, L. A Study of Text Vectorization Method Combining Topic Model and Transfer Learning. Processes 2022, 10, 350. https://doi.org/10.3390/pr10020350
Yang X, Yang K, Cui T, Chen M, He L. A Study of Text Vectorization Method Combining Topic Model and Transfer Learning. Processes. 2022; 10(2):350. https://doi.org/10.3390/pr10020350
Chicago/Turabian StyleYang, Xi, Kaiwen Yang, Tianxu Cui, Min Chen, and Liyan He. 2022. "A Study of Text Vectorization Method Combining Topic Model and Transfer Learning" Processes 10, no. 2: 350. https://doi.org/10.3390/pr10020350
APA StyleYang, X., Yang, K., Cui, T., Chen, M., & He, L. (2022). A Study of Text Vectorization Method Combining Topic Model and Transfer Learning. Processes, 10(2), 350. https://doi.org/10.3390/pr10020350