
A Machine Learning Approach for Predicting the Maximum Spreading Factor of Droplets upon Impact on Surfaces with Various Wettabilities




Abstract
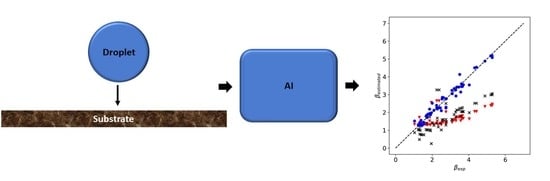
:
1. Introduction
2. Prediction of the Maximum Spreading Diameter
2.1. Scaling Analyses and Analytical Models
2.2. Data-Driven Models
3. Machine Learning Methods for Predicting Maximum Spreading Diameter
3.1. Multiple Linear Regression (MLR)
3.2. Regression Tree (RT)
3.3. Random Forest (RF)
3.4. Gradient Boost Regression Tree (GBRT)
3.5. Data Description and Processing
3.6. Feature Selection
3.7. ML Model Evaluation Metrics
4. Results and Discussion
4.1. Linear Regression Model (LRM)
4.2. Decision Tree (DT)
4.3. Random Forest (RF)
4.4. Gradient Boost Regression Tree (GBRT)
4.5. Importance of Features
5. Conclusions and Perspectives
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yarin, A. Drop Impact Dynamics: Splashing, Spreading, Receding, Bouncing…. Annu. Rev. Fluid Mech. 2006, 38, 159–192. [Google Scholar] [CrossRef]
- Josserand, C.; Thoroddsen, S. Drop Impact on a Solid Surface. Annu. Rev. Fluid Mech. 2016, 48, 365–391. [Google Scholar] [CrossRef] [Green Version]
- Danzebrink, R.; Aegerter, M.A. Deposition of micropatterned coating using an ink-jet technique. Thin Solid Film. 1999, 351, 115–118. [Google Scholar] [CrossRef] [Green Version]
- De Gans, B.J.; Duineveld, P.C.; Schubert, U.S. Inkjet printing of polymers: State of the art and future developments. Adv. Mater. 2004, 16, 203–213. [Google Scholar] [CrossRef]
- Fedorchenko, A.I.; Wang, A.B.; Wang, Y.H. Effect of capillary and viscous forces on spreading of a liquid drop impinging on a solid surface. Phys. Fluids 2005, 17, 093104. [Google Scholar] [CrossRef] [Green Version]
- Tembely, M.; Vadillo, D.; Soucemarianadin, A.; Dolatabadi, A. Numerical Simulations of Polymer Solution Droplet Impact on Surfaces of Different Wettabilities. Processes 2019, 7, 798. [Google Scholar] [CrossRef] [Green Version]
- Gomaa, H.; Tembely, M.; Esmail, N.; Dolatabadi, A. Bouncing of cloud-sized microdroplets on superhydrophobic surfaces. Phys. Fluids 2020, 32, 122118. [Google Scholar] [CrossRef]
- Liao, R.; Zuo, Z.; Guo, C.; Yuan, Y.; Zhuang, A. Fabrication of superhydrophobic surface on aluminum by continuous chemical etching and its anti-icing property. Appl. Surf. Sci. 2014, 317, 701–709. [Google Scholar] [CrossRef]
- Bhushan, B.; Jung, Y.C. Natural and biomimetic artificial surfaces for superhydrophobicity, self-cleaning, low adhesion, and drag reduction. Prog. Mater. Sci. 2011, 56, 1–108. [Google Scholar] [CrossRef] [Green Version]
- Yang, Z.; Liu, X.; Tian, Y. Hybrid Laser Ablation and Chemical Modification for Fast Fabrication of Bio-inspired Super-hydrophobic Surface with Excellent Self-cleaning, Stability and Corrosion Resistance. J. Bionic Eng. 2019, 16, 13–26. [Google Scholar] [CrossRef] [Green Version]
- Rioboo, R.; Tropea, C.; Marengo, M. Outcomes from a drop impact on solid surfaces. At. Sprays 2001, 11, 155–165. [Google Scholar] [CrossRef]
- Rioboo, R.; Marengo, M.; Tropea, C. Time evolution of liquid drop impact onto solid, dry surfaces. Exp. Fluids 2002, 33, 112–124. [Google Scholar] [CrossRef]
- Chandra, S.; Avedisian, C.T. On the collision of a droplet with a solid surface. Proc. R. Soc. A Math. Phys. Eng. Sci. 1991, 432, 13–41. [Google Scholar] [CrossRef]
- Pasandideh-Fard, M.; Qiao, Y.M.; Chandra, S.; Mostaghimi, J. Capillary effects during droplet impact on a solid surface. Phys. Fluids 1996, 8, 650–659. [Google Scholar] [CrossRef]
- Bayer, I.S.; Megaridis, C.M. Contact angle dynamics in droplets impacting on flat surfaces with different wetting characteristics. J. Fluid Mech. 2006, 558, 415–449. [Google Scholar] [CrossRef]
- Marengo, M.; Antonini, C.; Roisman, I.V.; Tropea, C. Drop collisions with simple and complex surfaces. Curr. Opin. Colloid Interface Sci. 2011, 16, 292–302. [Google Scholar] [CrossRef]
- Clanet, C.; Béguin, C.; Richard, D.; Quéré, D. Maximal deformation of an impacting drop. J. Fluid Mech. 2004, 517, 199–208. [Google Scholar] [CrossRef]
- Ukiwe, C.; Kwok, D.Y. On the maximum spreading diameter of impacting droplets on well-prepared solid surfaces. Langmuir 2005, 21, 666–673. [Google Scholar] [CrossRef]
- Du, J.; Wang, X.; Li, Y.; Min, Q.; Wu, X. Analytical Consideration for the Maximum Spreading Factor of Liquid Droplet Impact on a Smooth Solid Surface. Langmuir 2021, 37, 7582–7590. [Google Scholar] [CrossRef]
- Roisman, I.V.; Rioboo, R.; Tropea, C. Normal impact of a liquid drop on a dry surface: Model for spreading and receding. Proc. R. Soc. A Math. Phys. Eng. Sci. 2002, 458, 1411–1430. [Google Scholar] [CrossRef]
- Choudhury, R.; Choi, J.; Yang, S.; Kim, Y.J.; Lee, D. Maximum spreading of liquid drop on various substrates with different wettabilities. Appl. Surf. Sci. 2017, 415, 149–154. [Google Scholar] [CrossRef]
- Vadillo, D. Caractérisation des phénomènes Hydrodynamiques lors de l’impact de Gouttes sur Différents Types de Substrats. 2007. Available online: https://tel.archives-ouvertes.fr/tel-00178665/file/These_Vadillo.pdf (accessed on 15 April 2022).
- Seo, J.; Lee, J.S.; Kim, H.Y.; Yoon, S.S. Empirical model for the maximum spreading diameter of low-viscosity droplets on a dry wall. Exp. Therm. Fluid Sci. 2015, 61, 121–129. [Google Scholar] [CrossRef]
- Mao, T.; Kuhn, D.C.S.; Tran, H. Spread and rebound of liquid droplets upon impact on flat surfaces. AIChE J. 1997, 43, 2169–2179. [Google Scholar] [CrossRef]
- Brunton, S.L.; Noack, B.R.; Koumoutsakos, P. Machine Learning for Fluid Mechanics. Annu. Rev. Fluid Mech. 2020, 52, 477–508. [Google Scholar] [CrossRef] [Green Version]
- Tembely, M.; AlSumaiti, A.M.; Alameri, W. A deep learning perspective on predicting permeability in porous media from network modeling to direct simulation. Comput. Geosci. 2020, 24, 1541–1556. [Google Scholar] [CrossRef]
- Hassantabar, S.; Wang, Z.; Jha, N.K. SCANN: Synthesis of Compact and Accurate Neural Networks. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2021. Available online: https://arxiv.org/abs/1904.09090v2 (accessed on 15 April 2022). [CrossRef]
- Heidari, E.; Daeichian, A.; Sobati, M.A.; Movahedirad, S. Prediction of the droplet spreading dynamics on a solid substrate at irregular sampling intervals: Nonlinear Auto-Regressive eXogenous Artificial Neural Network approach (NARX-ANN). Chem. Eng. Res. Des. 2020, 156, 263–272. [Google Scholar] [CrossRef]
- Azimi Yancheshme, A.; Hassantabar, S.; Maghsoudi, K.; Keshavarzi, S.; Jafari, R.; Momen, G. Integration of experimental analysis and machine learning to predict drop behavior on superhydrophobic surfaces. Chem. Eng. J. 2021, 417, 127898. [Google Scholar] [CrossRef]
- Bartolo, D.; Josserand, C.; Bonn, D. Retraction dynamics of aqueous drops upon impact on non-wetting surfaces. J. Fluid Mech. 2005, 545, 329–338. [Google Scholar] [CrossRef] [Green Version]
- Laan, N.; De Bruin, K.G.; Bartolo, D.; Josserand, C.; Bonn, D. Maximum diameter of impacting liquid droplets. Phys. Rev. Appl. 2014, 2, 044018. [Google Scholar] [CrossRef] [Green Version]
- Salehi, H.; Burgueño, R. Emerging artificial intelligence methods in structural engineering. Eng. Struct. 2018, 171, 170–189. [Google Scholar] [CrossRef]
- Touzani, S.; Granderson, J.; Fernandes, S. Gradient boosting machine for modeling the energy consumption of commercial buildings. Energy Build. 2018, 158, 1533–1543. [Google Scholar] [CrossRef] [Green Version]
- Ha, S.; Jeong, H. Unraveling Hidden Interactions in Complex Systems With Deep Learning. Sci. Rep. Nat. 2021, 11, 12804. [Google Scholar] [CrossRef] [PubMed]
- Yuan, X.; Li, L.; Shardt, Y.A.W.; Wang, Y.; Yang, C. Deep Learning With Spatiotemporal Attention-Based LSTM for Industrial Soft Sensor Model Development. IEEE Trans. Ind. Electron. 2021, 68, 4404–4414. [Google Scholar] [CrossRef]
- Ou, C.; Zhu, H.; Shardt, Y.A.W.; Ye, L.; Yuan, X.; Wang, Y.; Yang, C. Quality-Driven Regularization for Deep Learning Networks and Its Application to Industrial Soft Sensors. IEEE Trans. Neural Netw. Learn. Syst. 2022, 1–11. [Google Scholar] [CrossRef]
- Zhu, H.H.; Zou, J.; Zhang, H.; Shi, Y.Z.; Luo, S.B.; Wang, N.; Cai, H.; Wan, L.X.; Wang, B.; Jiang, X.D.; et al. Space-efficient optical computing with an integrated chip diffractive neural network. Nat. Commun. 2022, 13, 1044. [Google Scholar] [CrossRef]
- Luo, S.; Zhang, Y.; Nguyen, K.T.; Feng, S.; Shi, Y.; Liu, Y.; Hutchinson, P.; Chierchia, G.; Talbot, H.; Bourouina, T.; et al. Machine Learning-Based Pipeline for High Accuracy Bioparticle Sizing. Micromachines 2020, 11, 1084. [Google Scholar] [CrossRef]
- Um, K.; Hu, X.; Thuerey, N. Liquid Splash Modeling with Neural Networks. Comput. Graph. Forum 2018, 37, 171–182. [Google Scholar] [CrossRef] [Green Version]
- Lee, W.J.; Na, J.; Kim, K.; Lee, C.J.; Lee, Y.; Lee, J.M. NARX modeling for real-time optimization of air and gas compression systems in chemical processes. Comput. Chem. Eng. 2018, 115, 262–274. [Google Scholar] [CrossRef]
- Antonini, C.; Amirfazli, A.; Marengo, M. Drop impact and wettability: From hydrophilic to superhydrophobic surfaces. Phys. Fluids 2012, 24, 102104. [Google Scholar] [CrossRef]
- Vadillo, D.C.; Soucemarianadin, A.; Delattre, C.; Roux, D.C. Dynamic contact angle effects onto the maximum drop impact spreading on solid surfaces. Phys. Fluids 2009, 21, 122002. [Google Scholar] [CrossRef]
- Eedi, H.; Kolla, M. Machine learning approaches for healthcare data analysis. J. Crit. Rev. 2020, 7, 806–811. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Schapire, R.E. The Strength of Weak Learnability. Mach. Learn. 1990, 5, 197–227. [Google Scholar] [CrossRef] [Green Version]
- Freund, Y.; Schapire, R.E. Experiments with a New Boosting Algorithm. In Proceedings of the 13th International Conference on Machine Learning, Bari, Italy, 3–6 July 1996; pp. 148–156. [Google Scholar]
- Natekin, A.; Knoll, A. Gradient boosting machines, a tutorial. Front. Neurorobot. 2013, 7, 1–21. [Google Scholar] [CrossRef] [Green Version]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Šikalo, Š.; Marengo, M.; Tropea, C.; Ganić, E.N. Analysis of impact of droplets on horizontal surfaces. Exp. Therm. Fluid Sci. 2002, 25, 503–510. [Google Scholar] [CrossRef]
- Roisman, I.V.; Opfer, L.; Tropea, C.; Raessi, M.; Mostaghimi, J.; Chandra, S. Drop impact onto a dry surface: Role of the dynamic contact angle. Colloids Surfaces A Physicochem. Eng. Asp. 2008, 322, 183–191. [Google Scholar] [CrossRef]
- Kim, H.Y.; Chun, J.H. The recoiling of liquid droplets upon collision with solid surfaces. Phys. Fluids 2001, 13, 643–659. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Investigation | Range of Weber Numbers | Range of Reynolds Numbers | Range of Equilibrium Contact Angles | Range of Values of Maximum Spreading Factors |
|---|---|---|---|---|
| Rioboo et al. [12] | 36–614 | 20–10,394 | 0–154 | 1.4–5.4 |
| Pasandideh-Fard et al. [14] | 27–641 | 213–5833 | 20–140 | 2.15–4.4 |
| Bayer et al. [15] | 11.5 | 1078 | 10–115 | 2.1–2.5 |
| Šikalo et al. [49] | 50–802 | 27–12,300 | 0–105 | 1.7–5.2 |
| Vadillo et al. and Vadillo [22,] | 0.21–12.4 | 39–2400 | 5–160 | 1.2 – 2.3 |
| Roisman et al. [50] | 0.88–7.9 | 400–1200 | 92 | 1.2–1.5 |
| Mao et al. [24] | 11–511 | 1966–13,297 | 37–97 | 1.65–4.94 |
| Kim and Chun [51] | 30–582 | 3222–14,191 | 6.2–87.5 | 2.3–5.1 |
| Antonini et al. [41] | 33 | 3379 | 99–164 | 1.8–2.45 |
| count | 204 | 204 | 204 | 204 |
| mean | 101.7 | 2551.3 | 49.7 | 2.5 |
| std | 170.1 | 3315.0 | 36.5 | 1.1 |
| min | 0.2 | 8.7 | 0.1 | 1.0 |
| 25% | 10.6 | 140.3 | 16.0 | 1.6 |
| 50% | 33.0 | 1046.3 | 48.5 | 2.2 |
| 75% | 117.1 | 3392.8 | 77.0 | 3.2 |
| max | 802.0 | 14,191.0 | 164.0 | 5.4 |
| Evaluation Metrics | LR | RT | RF | GBRT |
|---|---|---|---|---|
| R2-score | 0.777 | 0.885 | 0.953 | 0.963 |
| MAE | 0.413 | 0.308 | 0.165 | 0.148 |
| - | We | Re | |
|---|---|---|---|
| count | 62 | 62 | 62 |
| mean | 122.7 | 2722.2 | 47.8 |
| std | 191.2 | 3394.8 | 39.1 |
| min | 0.2 | 8.7 | 0.1 |
| max | 802.0 | 13,297.2 | 160.0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tembely, M.; Vadillo, D.C.; Dolatabadi, A.; Soucemarianadin, A. A Machine Learning Approach for Predicting the Maximum Spreading Factor of Droplets upon Impact on Surfaces with Various Wettabilities. Processes 2022, 10, 1141. https://doi.org/10.3390/pr10061141
Tembely M, Vadillo DC, Dolatabadi A, Soucemarianadin A. A Machine Learning Approach for Predicting the Maximum Spreading Factor of Droplets upon Impact on Surfaces with Various Wettabilities. Processes. 2022; 10(6):1141. https://doi.org/10.3390/pr10061141
Chicago/Turabian StyleTembely, Moussa, Damien C. Vadillo, Ali Dolatabadi, and Arthur Soucemarianadin. 2022. "A Machine Learning Approach for Predicting the Maximum Spreading Factor of Droplets upon Impact on Surfaces with Various Wettabilities" Processes 10, no. 6: 1141. https://doi.org/10.3390/pr10061141
APA StyleTembely, M., Vadillo, D. C., Dolatabadi, A., & Soucemarianadin, A. (2022). A Machine Learning Approach for Predicting the Maximum Spreading Factor of Droplets upon Impact on Surfaces with Various Wettabilities. Processes, 10(6), 1141. https://doi.org/10.3390/pr10061141