

A Multiobjective Variable Neighborhood Search with Learning and Swarm for Permutation Flowshop Scheduling with Sequence-Dependent Setup Times



Abstract
:1. Introduction
2. Literature Review of MOPFSP and Motivation
2.1. Literature Review of MOPFSP
2.2. Our Motivation
3. Proposed LS-MOVNS Algorithm
3.1. Traditional VNS
| Algorithm 1: Traditional VNS |
 |
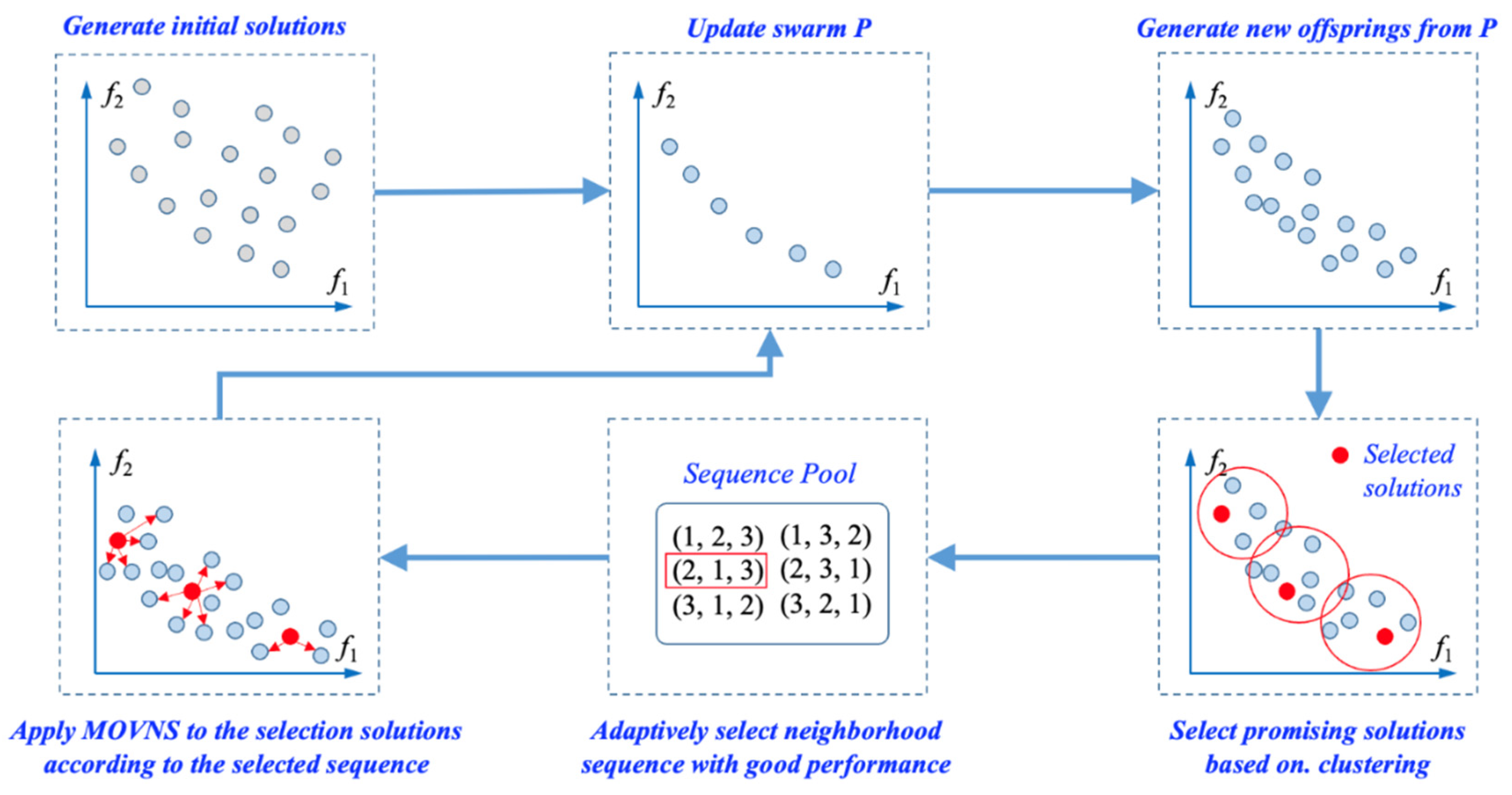
3.2. Overall Framework of the LS-MOVNS
| Algorithm 2: Overall framework of the LS-MOVNS |
 |
3.3. Initialization of the Swarm P
- Step 1.
- Calculate the total processing time of each job on all stages, and then sequence all the jobs in non-decreasing order according to the total processing time. Denote the obtained job sequence as Q. Set the partial solution S to be empty.
- Step 2.
- Insert the first two jobs in Q into the partial solution S so that the increased objective value is minimal, and then delete them from Q.
- Step 3.
- From the first job in Q, repeat the following procedure, i.e., insert the first job in Q into the partial solution S at the best position that gives the least increased objective function value, and then delete this job from Q, until Q is empty.
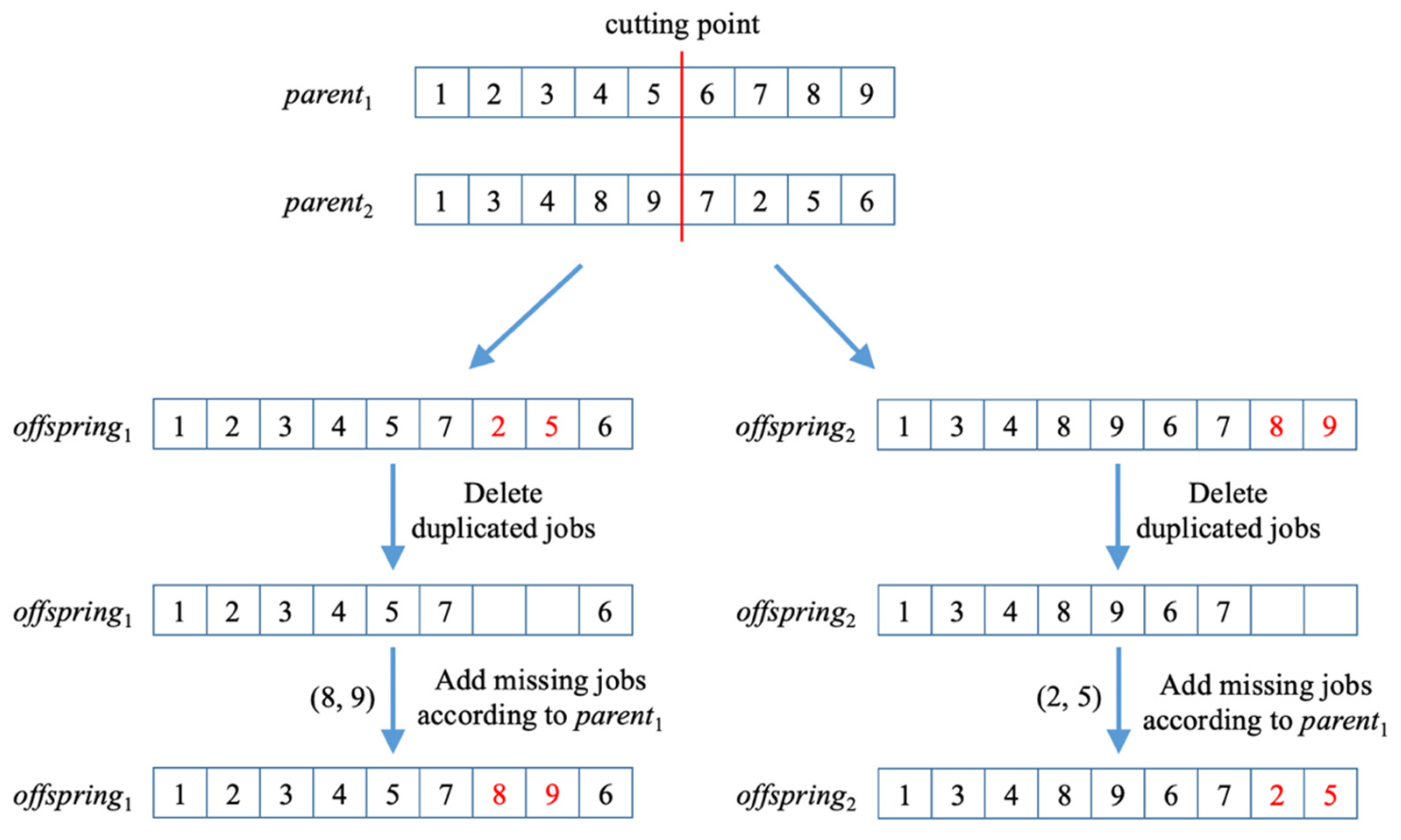
3.4. Generation of New Offspring Solutions
3.5. Selection of Promising Solutions with Clustering
3.6. Adaptive Selection of Neighborhood Sequence for MOVNS
- Swap: swap two jobs assigned at two different positions a and b in the solution (i.e., a job sequence).
- Insertion: remove a job from its current position a in the solution and then reinsert it to another position b.
- Two-Swap: perform two different swap moves in the solution.
3.7. Application of MOVNS
3.8. Update of Swarm P
- Step 1.
- If solution x is dominated by one solution in P, then solution x is discarded.
- Step 2.
- If solution x is not dominated by any solution in P, add it to P and then remove all solutions that are dominated by solution x from P.
- Step 3.
- If the number of solutions in P is larger than a given maximum size Nmax, calculate the crowding distance of all solutions in P, and iteratively remove the most crowded solution until |P| = Nmax.
4. Experimental Settings
4.1. Test Problems
4.2. Performance Metrics
4.3. Experiment Environment and Parameter Setting
4.4. Statistical Method for Performance Comparison
5. Experimental Results
5.1. Sensitivity Analysis of the Number of Clusters in LS-MOVNS
5.2. Effective Analysis of Learning-Based Selection of Solutions for MOVNS
5.3. Effective Analysis of the Adaptive Selection Strategy of Neighborhood Sequence
5.4. Effective Analysis of the Improved MOVNS
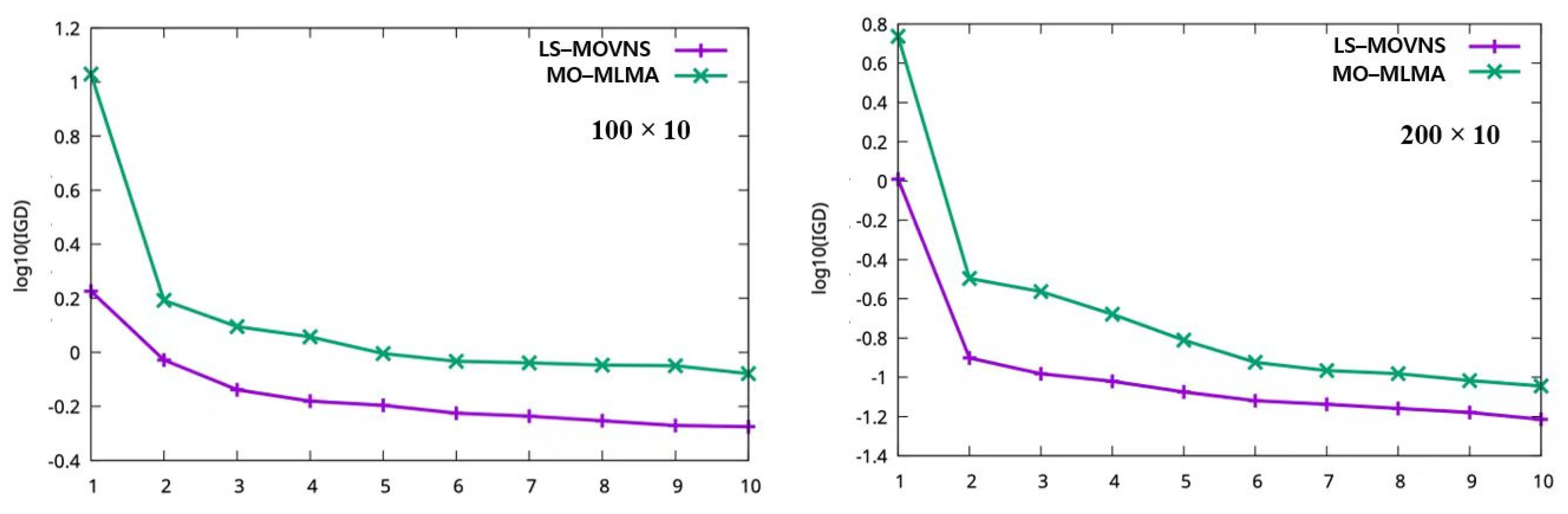
5.5. Comparison with Other Powerful Algorithms
6. Further Discussion
6.1. Computational Complexity
6.2. Stopping Criterion of Number of Function Evaluations
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Pan, Q.-K.; Ruiz, R. A comprehensive review and evaluation of permutation flowshop heuristics to minimize flowtime. Comput. Oper. Res. 2013, 40, 117–128. [Google Scholar] [CrossRef]
- Fernandez-Viagas, V.; Ruiz, R.; Framinan, J.M. A new vision of approximate methods for the permutation flowshop to minimise makespan: State-of-the-art and computational evaluation. Eur. J. Oper. Res. 2017, 257, 707–721. [Google Scholar]
- Ruiz, R.; Pan, Q.K.; Naderi, B. Terated Greedy methods for the distributed permutation flowshop scheduling problem. OMEGA—Int. J. Manag. Sci. 2019, 83, 213–222. [Google Scholar] [CrossRef]
- Pan, Q.-K.; Gao, L.; Wang, L.; Liang, J.; Li, X.-Y. Effective heuristics and metaheuristics to minimize total flowtime for the distributed permutation flowshop problem. Expert Syst. Appl. 2019, 124, 309–324. [Google Scholar]
- Li, J.-Q.; Song, M.-X.; Wang, L.; Duan, P.-Y.; Han, Y.-Y.; Sang, H.-Y.; Pan, Q.-K. Hybrid Artificial Bee Colony Algorithm for a Parallel Batching Distributed Flow-Shop Problem with Deteriorating Jobs. IEEE Trans. Cybern. 2020, 50, 2425–2439. [Google Scholar] [CrossRef] [PubMed]
- Meng, T.; Pang, Q.K. A distributed heterogeneous permutation flowshop scheduling problem with lot-streaming and carryover sequence-dependent setup time. Swarm Evol. Comput. 2021, 60, 100804. [Google Scholar] [CrossRef]
- Pan, Q.K.; Gao, L.; Li, X.Y.; Gao, K.Z. Effective metaheuristics for scheduling a hybrid flowshop with sequence-dependent setup times. Appl. Math. Comput. 2017, 303, 89–112. [Google Scholar] [CrossRef]
- Engin, O.; Guclu, A. A new hybrid ant colony optimization algorithm for solving the no-wait flowshop scheduling problems. Appl. Soft Comput. 2018, 72, 166–176. [Google Scholar] [CrossRef]
- Huang, Y.-Y.; Pan, Q.-K.; Huang, J.-P.; Suganthan, P.; Gao, L. An improved iterated greedy algorithm for the distributed assembly permutation flowshop scheduling problem. Comput. Ind. Eng. 2021, 152, 107021. [Google Scholar]
- Li, Y.-Z.; Pan, Q.-K.; Ruiz, R.; Sang, H.-Y. A referenced iterated greedy algorithm for the distributed assembly mixed no-idle permutation flowshop scheduling problem with the total tardiness criterion. Knowl. Based Syst. 2022, 239, 108036. [Google Scholar] [CrossRef]
- Perez-Gonzalez, P.; Fernandez-Viagas, V.; Framinan, J.M. Permutation flowshop scheduling with periodic maintenance and makespan objective. Comput. Ind. Eng. 2020, 143, 106369. [Google Scholar] [CrossRef]
- Brammera, J.; Lutzb, B.; Neumann, D. Permutation flow shop scheduling with multiple lines and demand plans using reinforcement learning. Eur. J. Oper. Res. 2022, 299, 75–86. [Google Scholar] [CrossRef]
- Libralesso, L.; Focke, P.A.; Secardina, A.; Josta, V. Iterative beam search algorithms for the permutation flowshop. Eur. J. Oper. Res. 2022, 301, 217–234. [Google Scholar]
- Silva, A.F.; Valente, J.M.; Schaller, J.E. Metaheuristics for the permutation flowshop problem with a weighted quadratic tardiness objective. Comput. Oper. Res. 2022, 140, 105691. [Google Scholar]
- Minella, G.; Ruiz, R.; Ciavotta, M. A Review and Evaluation of Multiobjective Algorithms for the Flowshop Scheduling Problem. INFORMS J. Comput. 2008, 20, 451–471. [Google Scholar] [CrossRef]
- Sun, Y.; Zhang, C.; Gao, L.; Wang, X. Multi-objective optimization algorithms for flow shop scheduling problem: A review and prospects. Int. J. Adv. Manuf. Technol. 2011, 55, 723–739. [Google Scholar]
- Varadharajan, T.; Rajendran, C. A multi-objective simulated-annealing algorithm for scheduling in flowshops to minimize the makespan and total flowtime of jobs. Eur. J. Oper. Res. 2005, 167, 772–795. [Google Scholar] [CrossRef]
- Pasupathy, T.; Rajendran, C.; Suresh, R. A multi-objective genetic algorithm for scheduling in flow shops to minimize the makespan and total flow time of jobs. Int. J. Adv. Manuf. Technol. 2006, 27, 804–815. [Google Scholar] [CrossRef]
- Geiger, M.J. On operators and search space topology in multi-objective flow shop scheduling. Eur. J. Oper. Res. 2007, 181, 195–206. [Google Scholar] [CrossRef]
- Motair, H.M. An Insertion Procedure to Solve Hybrid Multiobjective Permutation Flowshop Scheduling Problems. Ind. Eng. Manag. Syst. 2020, 19, 803–811. [Google Scholar] [CrossRef]
- Ishibuchi, H.; Yoshida, T.; Murata, T. Balance between genetic search and local search in memetic algorithms for multiobjective permutation flowshop scheduling. IEEE Trans. Evol. Comput. 2003, 7, 204–223. [Google Scholar]
- Arroyo, J.E.C.; Armentano, V.A. Genetic local search for multi-objective flowshop scheduling problems. Eur. J. Oper. Res. 2005, 167, 717–738. [Google Scholar]
- Rahimi-Vahed, A.R.; Mirghorbani, S.M. A multi-objective particle swarm for a flow shop scheduling problem. J. Comb. Optim. 2007, 13, 79–102. [Google Scholar]
- Framinan, J.M.; Leisten, R. A multi-objective iterated greedy search for flowshop scheduling with makespan and flowtime criteria. OR Spektrum 2008, 30, 787–804. [Google Scholar]
- Minella, G.; Ruiz, R.; Ciavotta, M. Restarted Iterated Pareto Greedy algorithm for multi-objective flowshop scheduling problems. Comput. Oper. Res. 2011, 38, 1521–1533. [Google Scholar]
- Chiang, T.-C.; Cheng, H.-C.; Fu, L.-C. NNMA: An effective memetic algorithm for solving multiobjective permutation flow shop scheduling problems. Expert Syst. Appl. 2011, 38, 5986–5999. [Google Scholar]
- Li, X.; Ma, S. Multi-Objective Memetic Search Algorithm for Multi-Objective Permutation Flow Shop Scheduling Problem. IEEE Access 2016, 4, 2154–2165. [Google Scholar] [CrossRef]
- Rajendran, C.; Ziegler, H. A multi-objective ant-colony algorithm for permutation flowshop scheduling to minimize the makespan and total flowtime of jobs. In Computational Intelligence in Flow Shop and Job Shop Scheduling; Chakraborty, U.K., Ed.; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Wang, X.; Tang, L. A machine-learning based memetic algorithm for the multi-objective permutation flowshop scheduling problem. Comput. Oper. Res. 2017, 79, 60–77. [Google Scholar]
- Fu, Y.; Wang, H.; Huang, M.; Wang, J. A decomposition based multiobjective genetic algorithm with adaptive multipopulation strategy for flowshop scheduling problem. Nat. Comput. 2019, 18, 757–768. [Google Scholar]
- Wang, Z.; Zhang, Q.; Li, H.; Ishibuchi, H.; Jiao, L. On the use of two reference points in decomposition based multiobjective evolutionary algorithms. Swarm Evol. Comput. 2017, 34, 89–102. [Google Scholar]
- Leung, M.-F.; Wang, J. A collaborative neurodynamic approach to multiobjective optimization. IEEE Trans. Neural Networks Learn. Syst. 2018, 29, 5738–5748. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Hu, T.; Tang, L. A multiobjective evolutionary nonlinear ensemble learning with evolutionary feature selection for silicon prediction in blast furnace, IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 2080–2093. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Dong, Z.; Tang, L.; Zhang, Q. Multiobjective multitask optimization-neighborhood as a bridge for knowledge transfer. IEEE Trans. Evol. Comput. 2022, in press. [Google Scholar] [CrossRef]
- de Siqueira, E.; Souza, M.; de Souza, S. A Multi-objective Variable Neighborhood Search algorithm for solving the Hybrid Flow Shop Problem. Electron. Notes Discret. Math. 2018, 66, 87–94. [Google Scholar] [CrossRef]
- Wang, X.; Tang, L. A population-based variable neighborhood search for the single machine total weighted tardiness problem. Comput. Oper. Res. 2009, 36, 2105–2110. [Google Scholar] [CrossRef]
- Wu, X.; Che, A. Energy-efficient no-wait permutation flow shop scheduling by adaptive multi-objective variable neighborhood search. Omega 2020, 94, 102117. [Google Scholar] [CrossRef]
- Zhang, X.; Chen, L. A general variable neighborhood search algorithm for a parallel-machine scheduling problem considering machine health conditions and preventive maintenance. Comput. Oper. Res. 2022, 143, 105738. [Google Scholar] [CrossRef]
- Yazdani, M.; Khalili, S.M.; Babagolzadeh, M.; Jolai, F. A single-machine scheduling problem with multiple unavailability constraints: A mathematical model and an enhanced variable neighborhood search approach. J. Comput. Des. Eng. 2017, 4, 46–59. [Google Scholar] [CrossRef]
- Garey, M.R.; Johnson, D.S.; Sethi, R. The complexity of flowhsop and jobshop scheduling. Math. Oper. Res. 1976, 1, 117–129. [Google Scholar] [CrossRef]
- Mladenovic, N.; Hansen, P. Variable neighborhood search. Comput. Oper. Res. 1997, 24, 1097–1100. [Google Scholar] [CrossRef]
- Nawaz, M.; Enscore, J.E.E.; Ham, I. A heuristic algorithm for the m machine, n job flowshop sequencing problem. Omega 1983, 11, 91–95. [Google Scholar]
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar]
- Taillard, E. Benchmarks for basic scheduling problems. Eur. J. Oper. Res. 1993, 64, 278–285. [Google Scholar]
- Zitzler, E.; Thiele, L.; Laumanns, M.; Fonseca, C.; da Fonseca, V. Performance assessment of multiobjective optimizers: An analysis and review. IEEE Trans. Evol. Comput. 2003, 7, 117–132. [Google Scholar]
- Schuetze, O.; Equivel, X.; Lara, A.; Coello Coello, C.A. Some comments on GD and IGD and relations to the Hausdorff distance, In Proceedings of the 12th Annual Conference Companion on Genetic and Evolutionary Computation, ACM. Online, 7 July 2010; pp. 1971–1974. [Google Scholar]
- Cruz-Rosales, M.H.; Cruz-Chávez, M.A.; Alonso-Pecina, F.; Peralta-Abarca, J.d.C.; Ávila-Melgar, E.Y.; Martínez-Bahena, B.; Enríquez-Urbano, J. Metaheuristic with Cooperative Processes for the University Course Timetabling Problem. Appl. Sci. 2022, 12, 542. [Google Scholar]
- Liu, Q.; Gui, Z.; Xiong, S.; Zhan, M. A principal component analysis dominance mechanism based many-objective scheduling optimization. Appl. Soft Comput. 2021, 113, 107931. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Problem (Jobs × Machines) | LS-MOVNSrand | Sig | LS-MOVNS | ||
|---|---|---|---|---|---|
| Mean | Std | Mean | Std | ||
| 20 × 5 | 1.79 × 10−2 | 1.4 × 10−2 | = | 1.76 × 10−2 | 1.0 × 10−2 |
| 20 × 10 | 2.21 × 10−2 | 6.7 × 10−3 | + | 1.93 × 10−2 | 6.2 × 10−3 |
| 20 × 20 | 5.58 × 10−2 | 2.8 × 10−2 | + | 5.36 × 10−2 | 3.6 × 10−2 |
| 50 × 5 | 2.44 × 10−2 | 2.4 × 10−2 | = | 2.39 × 10−2 | 2.3 × 10−2 |
| 50 × 10 | 3.30 × 10−2 | 3.9 × 10−2 | = | 3.25 × 10−2 | 3.2 × 10−2 |
| 50 × 20 | 3.87 × 10−2 | 2.1 × 10−2 | + | 3.64 × 10−2 | 1.5 × 10−2 |
| 100 × 5 | 2.31 × 10−2 | 4.1 × 10−2 | + | 2.00 × 10−2 | 4.5 × 10−2 |
| 100 × 10 | 4.65 × 10−2 | 2.1 × 10−2 | + | 3.92 × 10−2 | 1.2 × 10−2 |
| 100 × 20 | 2.47 × 10−2 | 5.6 × 10−3 | + | 1.99 × 10−2 | 4.1× 10−3 |
| 200 × 10 | 4.99 × 10−2 | 5.4 × 10−2 | + | 4.30 × 10−2 | 6.4 × 10−2 |
| 200 × 20 | 2.76 × 10−2 | 4.1 × 10−2 | + | 1.90 × 10−2 | 5.3 × 10−2 |
| Nos. +/−/= | 8/0/3 | ||||
| Problem (Jobs × Machines) | LS-MOVNSrand | Sig | LS-MOVNS | ||
|---|---|---|---|---|---|
| Mean | Std | Mean | Std | ||
| 20 × 5 | 5.39 × 10−1 | 2.1 × 10−1 | = | 5.36 × 10−1 | 2.4 × 10−1 |
| 20 × 10 | 4.61 × 10−1 | 2.2 × 10−1 | = | 5.07 × 10−1 | 2.1 × 10−1 |
| 20 × 20 | 3.21 × 10−1 | 3.4 × 10−1 | + | 3.43 × 10−1 | 3.1 × 10−1 |
| 50 × 5 | 4.61 × 10−1 | 3.8 × 10−1 | = | 5.65 × 10−1 | 3.7 × 10−1 |
| 50 × 10 | 4.45 × 10−1 | 4.1 × 10−1 | = | 4.42 × 10−1 | 4.5 × 10−1 |
| 50 × 20 | 3.71 × 10−1 | 2.5 × 10−1 | + | 4.05 × 10−1 | 1.9 × 10−1 |
| 100 × 5 | 5.12 × 10−1 | 4.3 × 10−1 | + | 5.91 × 10−1 | 3.9 × 10−1 |
| 100 × 10 | 4.08 × 10−1 | 2.2 × 10−1 | + | 4.24 × 10−1 | 1.7 × 10−1 |
| 100 × 20 | 4.41 × 10−1 | 5.4 × 10−1 | + | 4.95 × 10−1 | 6.0 × 10−1 |
| 200 × 10 | 5.56 × 10−1 | 4.9 × 10−1 | + | 6.07 × 10−1 | 4.5 × 10−1 |
| 200 × 20 | 5.94 × 10−1 | 2.6 × 10−1 | + | 6.57 × 10−1 | 1.4 × 10−1 |
| Nos. +/−/= | 7/0/4 | ||||
| Problem (Jobs × Machines) | LS-MOVNSrand_select | Sig | LS-MOVNS | ||
|---|---|---|---|---|---|
| Mean | Std | Mean | Std | ||
| 20 × 5 | 1.75 × 10−2 | 1.3 × 10−2 | = | 1.76 × 10−2 | 1.0 × 10−2 |
| 20 × 10 | 1.91 × 10−2 | 5.2 × 10−3 | = | 1.93 × 10−2 | 6.2 × 10−3 |
| 20 × 20 | 5.31 × 10−2 | 3.5 × 10−2 | = | 5.36 × 10−2 | 3.6 × 10−2 |
| 50 × 5 | 2.42 × 10−2 | 2.1 × 10−2 | = | 2.39 × 10−2 | 2.3 × 10−2 |
| 50 × 10 | 3.37 × 10−2 | 3.4 × 10−2 | + | 3.25 × 10−2 | 3.2 × 10−2 |
| 50 × 20 | 3.81 × 10−2 | 1.8 × 10−2 | + | 3.64 × 10−2 | 1.5 × 10−2 |
| 100 × 5 | 2.18 × 10−2 | 3.9 × 10−2 | + | 2.00 × 10−2 | 4.5 × 10−2 |
| 100 × 10 | 4.35 × 10−2 | 1.5 × 10−2 | + | 3.92 × 10−2 | 1.2 × 10−2 |
| 100 × 20 | 2.27 × 10−2 | 4.8 × 10−3 | + | 1.99 × 10−2 | 4.1× 10−3 |
| 200 × 10 | 4.62 × 10−2 | 6.1 × 10−2 | + | 4.30 × 10−2 | 6.4 × 10−2 |
| 200 × 20 | 2.31 × 10−2 | 3.7 × 10−2 | + | 1.90 × 10−2 | 5.3 × 10−2 |
| Nos. +/−/= | 7/0/4 | ||||
| Problem (Jobs × Machines) | LS-MOVNSfull | Sig | LS-MOVNS | ||
|---|---|---|---|---|---|
| Mean | Std | Mean | Std | ||
| 20 × 5 | 1.70 × 10−2 | 1.3 × 10−2 | – | 1.76 × 10−2 | 1.0 × 10−2 |
| 20 × 10 | 1.88 × 10−2 | 5.2 × 10−3 | – | 1.93 × 10−2 | 6.2 × 10−3 |
| 20 × 20 | 5.26 × 10−2 | 3.5 × 10−2 | – | 5.36 × 10−2 | 3.6 × 10−2 |
| 50 × 5 | 2.35 × 10−2 | 2.1 × 10−2 | = | 2.39 × 10−2 | 2.3 × 10−2 |
| 50 × 10 | 3.23 × 10−2 | 3.4 × 10−2 | = | 3.25 × 10−2 | 3.2 × 10−2 |
| 50 × 20 | 3.68 × 10−2 | 1.8 × 10−2 | = | 3.64 × 10−2 | 1.5 × 10−2 |
| 100 × 5 | 2.26 × 10−2 | 3.9 × 10−2 | + | 2.00 × 10−2 | 4.5 × 10−2 |
| 100 × 10 | 4.49 × 10−2 | 1.5 × 10−2 | + | 3.92 × 10−2 | 1.2 × 10−2 |
| 100 × 20 | 2.41 × 10−2 | 4.8 × 10−3 | + | 1.99 × 10−2 | 4.1× 10−3 |
| 200 × 10 | 4.83 × 10−2 | 6.1 × 10−2 | + | 4.30 × 10−2 | 6.4 × 10−2 |
| 200 × 20 | 2.47 × 10−2 | 3.7 × 10−2 | + | 1.90 × 10−2 | 5.3 × 10−2 |
| Nos. +/−/= | 5/3/3 | ||||
| Problem (Jobs × Machines) | RIPG [26] | Sig | MO-MLMA [30] | Sig | LS-MOVNS | |||
|---|---|---|---|---|---|---|---|---|
| Mean | Std | Mean | Std | Mean | Std | |||
| 20 × 5 | 1.85 × 10−2 | 1.2 × 10−2 | + | 1.72 × 10−2 | 1.4 × 10−2 | – | 1.76 × 10−2 | 1.0 × 10−2 |
| 20 × 10 | 2.16 × 10−2 | 5.1 × 10−3 | + | 1.98 × 10−2 | 5.1 × 10−3 | = | 1.93 × 10−2 | 6.2 × 10−3 |
| 20 × 20 | 5.67 × 10−2 | 2.1 × 10−2 | + | 5.33 × 10−2 | 3.2 × 10−2 | = | 5.36 × 10−2 | 3.6 × 10−2 |
| 50 × 5 | 3.04 × 10−2 | 2.7 × 10−2 | + | 2.53 × 10−2 | 2.1 × 10−2 | + | 2.39 × 10−2 | 2.3 × 10−2 |
| 50 × 10 | 3.62 × 10−2 | 3.3 × 10−2 | + | 3.24 × 10−2 | 2.8 × 10−2 | = | 3.25 × 10−2 | 3.2 × 10−2 |
| 50 × 20 | 4.07 × 10−2 | 1.8 × 10−2 | + | 3.78 × 10−2 | 2.1 × 10−2 | + | 3.64 × 10−2 | 1.5 × 10−2 |
| 100 × 5 | 2.44 × 10−2 | 4.4 × 10−2 | + | 2.16 × 10−2 | 5.1 × 10−2 | + | 2.00 × 10−2 | 4.5 × 10−2 |
| 100 × 10 | 4.70 × 10−2 | 2.5 × 10−2 | + | 4.12 × 10−2 | 1.1 × 10−2 | + | 3.92 × 10−2 | 1.2 × 10−2 |
| 100 × 20 | 2.53 × 10−2 | 5.1 × 10−3 | + | 2.23 × 10−2 | 3.7 × 10−3 | + | 1.99 × 10−2 | 4.1× 10−3 |
| 200 × 10 | 5.42 × 10−2 | 6.5 × 10−2 | + | 5.06 × 10−2 | 5.5 × 10−2 | + | 4.30 × 10−2 | 6.4 × 10−2 |
| 200 × 20 | 2.48 × 10−2 | 5.3 × 10−2 | + | 2.14 × 10−2 | 5.7 × 10−2 | + | 1.90 × 10−2 | 5.3 × 10−2 |
| Nos. +/−/= | 11/0/0 | 7/1/3 | ||||||
| Problem (Jobs × Machines) | RIPG [26] | Sig | MO-MLMA [30] | Sig | LS-MOVNS | |||
|---|---|---|---|---|---|---|---|---|
| Mean | Std | Mean | Std | Mean | Std | |||
| 20 × 5 | 5.25 × 10−1 | 1.7 × 10−1 | + | 5.51 × 10−1 | 1.9 × 10−1 | – | 5.36 × 10−1 | 2.4 × 10−1 |
| 20 × 10 | 4.88 × 10−1 | 2.6 × 10−1 | + | 5.04 × 10−1 | 3.4 × 10−1 | = | 5.07 × 10−1 | 2.1 × 10−1 |
| 20 × 20 | 3.14 × 10−1 | 1.6 × 10−1 | + | 3.47 × 10−1 | 1.0 × 10−1 | – | 3.43 × 10−1 | 3.1 × 10−1 |
| 50 × 5 | 4.85 × 10−1 | 3.5 × 10−1 | + | 5.45 × 10−1 | 2.5 × 10−1 | + | 5.65 × 10−1 | 3.7 × 10−1 |
| 50 × 10 | 4.10 × 10−1 | 4.1 × 10−1 | + | 4.46 × 10−1 | 3.8 × 10−1 | = | 4.42 × 10−1 | 4.5 × 10−1 |
| 50 × 20 | 3.48 × 10−1 | 2.6 × 10−1 | + | 3.97 × 10−1 | 3.1 × 10−1 | = | 4.05 × 10−1 | 1.9 × 10−1 |
| 100 × 5 | 5.46 × 10−1 | 3.6 × 10−1 | + | 5.73 × 10−1 | 4.6 × 10−1 | + | 5.91 × 10−1 | 3.9 × 10−1 |
| 100 × 10 | 3.69 × 10−1 | 2.5 × 10−1 | + | 4.06 × 10−1 | 2.2 × 10−1 | + | 4.24 × 10−1 | 1.7 × 10−1 |
| 100 × 20 | 4.38 × 10−1 | 5.0 × 10−1 | + | 4.78 × 10−1 | 4.5 × 10−1 | + | 4.95 × 10−1 | 6.0 × 10−1 |
| 200 × 10 | 5.36 × 10−1 | 2.4 × 10−1 | + | 5.72 × 10−1 | 3.3 × 10−1 | + | 6.07 × 10−1 | 4.5 × 10−1 |
| 200 × 20 | 5.92 × 10−1 | 2.3 × 10−1 | + | 6.26 × 10−1 | 1.2 × 10−1 | + | 6.57 × 10−1 | 1.4 × 10−1 |
| Nos. +/−/= | 11/0/0 | 6/2/3 | ||||||
| Problem (Jobs × Machines) | MO-MLMA [30] | Sig | LS-MOVNS | ||
|---|---|---|---|---|---|
| Mean | Std | Mean | Std | ||
| 20 × 5 | 1.84 × 10−2 | 1.8 × 10−2 | – | 1.96 × 10−2 | 1.4 × 10−2 |
| 20 × 10 | 2.07 × 10−2 | 4.3 × 10−3 | = | 1.98 × 10−2 | 4.7 × 10−3 |
| 20 × 20 | 5.62 × 10−2 | 2.5 × 10−2 | – | 5.84 × 10−2 | 2.1 × 10−2 |
| 50 × 5 | 2.81 × 10−2 | 3.7 × 10−2 | = | 2.73 × 10−2 | 3.4 × 10−2 |
| 50 × 10 | 3.81 × 10−2 | 3.6 × 10−2 | = | 3.68 × 10−2 | 4.1 × 10−2 |
| 50 × 20 | 4.15 × 10−2 | 2.4 × 10−2 | + | 3.92 × 10−2 | 2.6 × 10−2 |
| 100 × 5 | 2.92 × 10−2 | 3.2 × 10−2 | + | 2.65 × 10−2 | 3.7 × 10−2 |
| 100 × 10 | 4.77 × 10−2 | 2.1 × 10−2 | + | 4.37 × 10−2 | 2.5 × 10−2 |
| 100 × 20 | 2.86 × 10−2 | 3.2 × 10−3 | + | 2.52 × 10−2 | 3.7 × 10−3 |
| 200 × 10 | 5.43 × 10−2 | 4.7 × 10−2 | + | 4.74 × 10−2 | 4.3 × 10−2 |
| 200 × 20 | 2.51 × 10−2 | 3.9 × 10−2 | + | 2.28 × 10−2 | 4.4 × 10−2 |
| Nos. +/−/= | 6/2/3 | ||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, K.; Tian, H. A Multiobjective Variable Neighborhood Search with Learning and Swarm for Permutation Flowshop Scheduling with Sequence-Dependent Setup Times. Processes 2022, 10, 1786. https://doi.org/10.3390/pr10091786
Li K, Tian H. A Multiobjective Variable Neighborhood Search with Learning and Swarm for Permutation Flowshop Scheduling with Sequence-Dependent Setup Times. Processes. 2022; 10(9):1786. https://doi.org/10.3390/pr10091786
Chicago/Turabian StyleLi, Kun, and Huixin Tian. 2022. "A Multiobjective Variable Neighborhood Search with Learning and Swarm for Permutation Flowshop Scheduling with Sequence-Dependent Setup Times" Processes 10, no. 9: 1786. https://doi.org/10.3390/pr10091786
APA StyleLi, K., & Tian, H. (2022). A Multiobjective Variable Neighborhood Search with Learning and Swarm for Permutation Flowshop Scheduling with Sequence-Dependent Setup Times. Processes, 10(9), 1786. https://doi.org/10.3390/pr10091786