3.1. Case Study
The case building is a six-story retrofitted office building with a total floor area of 5700 m2 in Tianjin, China. The air conditioning area is approximately 4735 m2. A ground-coupled heat pump system is used to maintain indoor thermal comfort in the summer and winter. The ground-coupled heat pump system consists of two parallel heat pumps. The nominal cooling/heating capacity of heat pump A is 212 kW/213 kW, corresponding to nominal electricity consumption of 40.2 kW/48.6 kW. The nominal cooling/heating capacity of heat pump B is 140 kW/142 kW, corresponding to nominal electricity consumption of 24.2 kW/28.5 kW. The supply/return water temperatures of heat pump A and B during the cooling season are 7/12 °C and 14/19 °C, respectively. The supply/return water temperatures of heat pump A and B during the heating season are 40/35 °C. The test mainly focused on weekdays from 9:00 to 17:00 from 17 May to 19 August 2016, with a time interval of 0.5 h. Low-temperature water in the buried pipe was directly used to provide cooling for the building from 17 May to 20 June. Heat pump units A and B were mainly used to provide cooling for the building from 21 June to 19 August. Due to frequent starting and stopping of the soil source heat pump system on 19 August, the data on that date was abnormal and was excluded. Ultimately, the valid data for the test was from 17 May to 18 August 2016. The main test parameters were supply and return water temperature of the air conditioning system, flow rate, indoor temperature, and outdoor meteorological temperature.
When assessing the prediction accuracy of the model, this study omitted the building’s intrinsic thermal storage capacity and made the assumption that the measured instantaneous cooling supply from the heat pump system accurately represented the instantaneous cooling load of the test building. The expression for computing the cooling supply of the heat pump system is presented in Equation (47):
where
Qc (kW) is the cold load of the heat pump system,
G (m
3/h) is the circulating water flow rate of heat pump system,
cp,w (kJ/(kg·°C)) is the specific heat capacity of the chilled water,
ρw (kg/m
3) is the density of the chilled water,
Tre (°C) is the return water temperature of the heat pump system, and
Tsu (°C) is the water supply temperature of the heat pump system.
The detailed parameters of the test instrument (component), as shown in
Table 1.
Testing and the relative uncertainties of the calculated parameters, as shown in
Table 2.
As shown in
Table 2, the relative uncertainties of the tested and calculated parameters are within acceptable limits, so the tested and calculated data were highly reliable [
31]. The variation curves of outdoor temperature (
To) and relative humidity (
RHo) during the test period are shown in
Figure 7.
As shown in
Figure 7, the outdoor temperature and relative humidity ranged from 20.1 to 38.3 °C and 15.0 to 90.0%, respectively, from 17 May to 20 June. The average outdoor temperature and relative humidity were 29.0 °C and 39.7%, respectively, in this cooling stage. The outdoor temperature and relative humidity ranged from 23.3 to 40.1 °C and 29.0 to 100.0%, respectively, from 21 June to 18 August. The average outdoor temperature and relative humidity were 31.6 °C and 62.7%, respectively, in this cooling stage.
Figure 8 illustrates the variation curves of outdoor solar radiation intensity (
Io) and outdoor wind speed (
Vo) throughout the test period.
Figure 8 provides an overview of the solar radiation intensity and outdoor wind speed during the test period. Solar radiation intensity and outdoor wind speed ranged from 0 to 921.0 W/m² and 0 to 8.4 m/s, respectively, from 17 May to 20 June. The average values were 476.9 W/m² and 1.1 m/s, respectively, in this cooling stage. Meanwhile, solar radiation intensity and outdoor wind speed ranged from 1 to 925.0 W/m
2 and 0 to 4.9 m/s, respectively, from June 21 to August 18. The average values were 361.0 W/m
2 and 0.7 m/s, respectively, in this cooling stage.
It becomes evident that the average values of outdoor meteorological parameters, including outdoor temperature, relative humidity, solar radiation intensity, and wind speed, significantly differed between the two measured stages. This discrepancy underscores the varying impact of outdoor temperature, relative humidity, solar radiation intensity, and wind speed on the cooling load of the building during different cooling stages. For the sake of clarity, this study refers to the two test stages (from 17 May to 20 June and from 21 June to 18 August) as the early and middle cooling stages, respectively.
The building cooling load distribution during the test period is shown in
Figure 9.
As shown in
Figure 9, the building cooling load ranged from 49.7 to 133.5 kW with an average value of 72.8 kW in the early cooling stage, and from 112.5 to 346.5 kW with an average value of 169.1 kW in the middle cooling stage.
The variation curves of indoor temperature (
Ti) and relative humidity (
RHi) at the early and middle cooling stages are shown in
Figure 10.
As shown in
Figure 10, the indoor temperature and relative humidity ranged from 24.4 to 28.4 °C and 21.2 to 69.2%, respectively, in the early cooling stage. The average indoor temperature and relative humidity were 26.7 °C and 43.2%, respectively, in this cooling stage. The indoor temperature and relative humidity ranged from 24.0 to 26.1 °C and 54.0 to 81.0%, respectively, in the middle cooling stage. The average indoor temperature and relative humidity were 25.1 °C and 68.7%, respectively, in this cooling stage.
This study divides the measured data into two distinct sets: the training sample set and the test sample set. The test data from 17 May to 9 June and from 21 June to 2 August were employed as the training samples, while the test data from 10 June to 20 June and from 3 August to 18 August were used as the test samples.
To simplify the prediction model, a preliminary correlation analysis of the building cooling load and its influencing factors was conducted using SPSS software (SPSS 22). This analysis process aimed to identify and eliminate factors that displayed weaker correlations with the building cooling load [
39]. When performing a correlation analysis, the choice between the Pearson and the Spearman correlation coefficients depends on whether the independent and dependent variables follow bivariate normal distributions. In the case of normally distributed data, the Pearson correlation coefficient is selected to measure the degree of correlation, while the Spearman correlation coefficient is selected for non-normally distributed data.
The criterion for determining whether the test data conforms to a normal distribution is to see if the asymptotic significance index is greater than 0.05. If the value is greater than 0.05, the test data conforms to the normal distribution. The criterion for judging the correlation between the two factors is whether the significance index is greater than 0.01. If the significance index is less than 0.01, it indicates a significant correlation between two test factors.
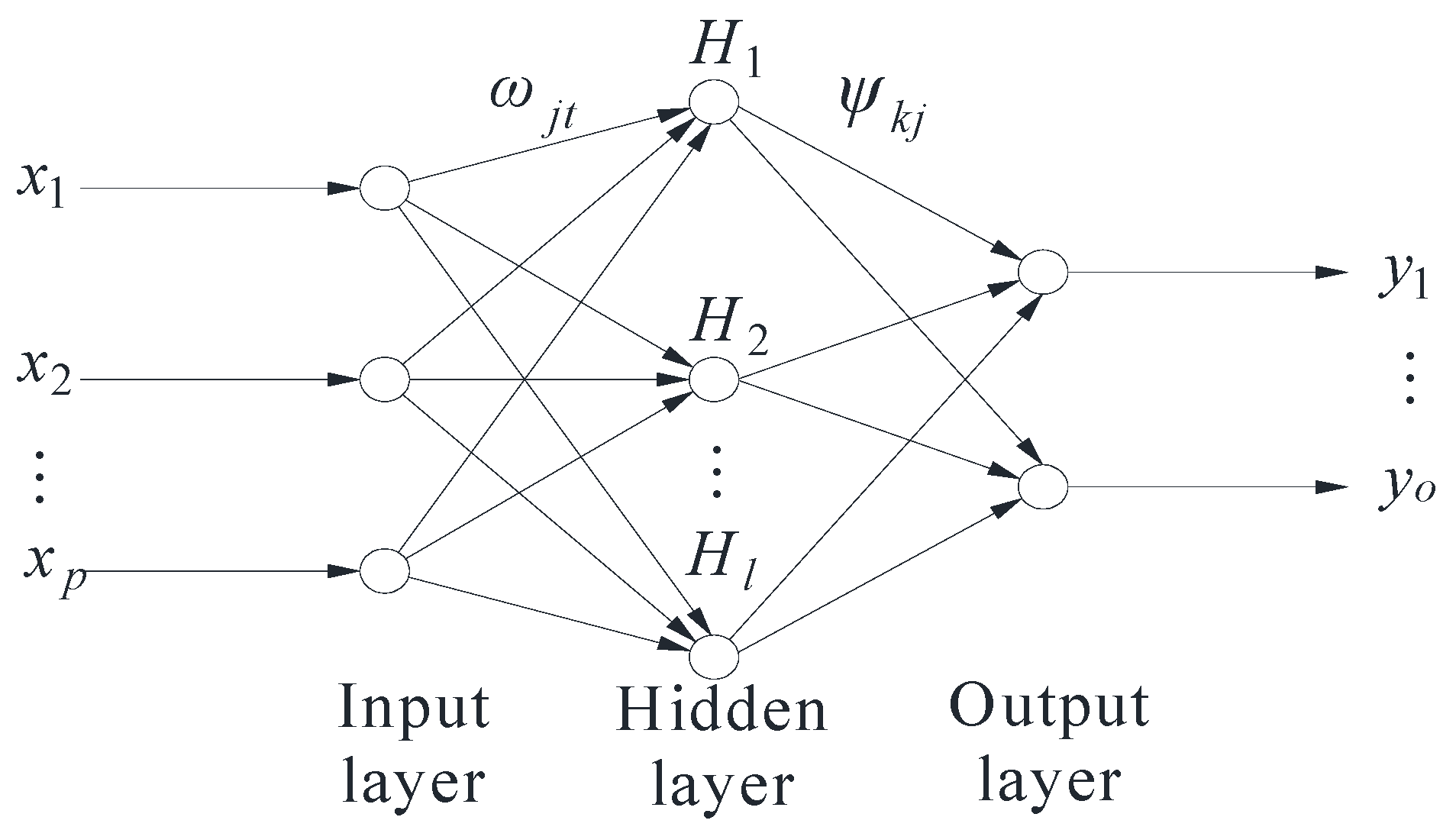
In this study, the transfer function for hidden layer neurons of the BPNN was selected as the S-type tangent function, while the transfer function for output layer neurons was chosen as the S-type logarithmic function. The Levenberg–Marquardt algorithm was employed for BPNN training and learning. The primary parameter settings for the genetic algorithm and BPNN are detailed in
Table 3 and
Table 4, respectively.
3.2. Cooling Load Prediction in the Early Cooling Stage
Using SPSS to process and analyze the sample data got the results of normal distribution detection of building cold load and its influencing factors at the early cooling stage, as shown in
Table 5. The results of correlation analysis between building cold load and its influencing factors at the early cooling stage are shown in
Table 6.
As shown in
Table 5, only the asymptotic significance index of outdoor temperature was greater than 0.05 in the early cooling stage. It meant that only outdoor temperature obeyed the normal distribution.
As shown in
Table 6, only the significance index of outdoor temperature was greater than 0.01, meaning that all parameters were significantly correlated with the building cooling load, except for outdoor temperature. This was because outdoor temperature was relatively low, which had a limited impact on the cooling load of the building in the early cooling stage. Therefore, outdoor relative humidity, solar radiation intensity, outdoor wind speed, indoor temperature, indoor relative humidity, and building cooling load at the previous moment were selected as the input variables of the prediction models in this cooling stage.
To evaluate the performance of the AIA prediction models improved by the sample similarity method, this study built eight contrast models. A comprehensive overview of different prediction models employed in the early cooling stage is provided in
Table 7.
The weight values for outdoor relative humidity, solar radiation intensity, outdoor wind speed, indoor temperature, indoor humidity and building cooling load at the previous moment were 0.1737, 0.1629, 0.1475, 0.1724, 0.1690, and 0.1745, respectively, calculated by the entropy weighting method. This study only selected historical samples with a comprehensive similarity coefficient greater than 0.6 as the similarity sample set.
As shown in
Figure 11,
Figure 12,
Figure 13,
Figure 14,
Figure 15,
Figure 16,
Figure 17,
Figure 18 and
Figure 19, the tendencies between the predicted and actual values of M1 to M8 were consistent. The
APE of M1, M2, M3, M4, M5, M6, M7, and M8 was mainly distributed between 6.0 and 13.3%, 2.6 and 10.8%, 1.6 and 6.5%, 2.1 and 6.5%, 1.4 and 6.3%, 1.2 and 5.4%, 1.1 and 6.5%, and 1.7 and 7.5%, respectively. The prediction error of each model only exceeded 30% at certain moments. This was because the main operating mode of the soil source heat pump system in the early cooling stage was that the low-temperature water in the outdoor buried pipe heat exchanger was directly supplied to the indoor floor radiation coil system. However, sometimes the operating staff switched the cooling mode. Low-temperature water was directly supplied to the indoor fan coil. The instantaneous heat transfer capacity of the fan coil was greater than that of the floor radiation coil. It caused an instantaneous increase of the building cooling load (this study assumed that the measured instantaneous cooling load of the heat pump system reflected the building’s cooling load). When the terminal was switched to floor radiation cooling mode, it also caused an instantaneous decrease of the building cooling load. In addition, there was an overall higher prediction error on 20 June. It could be attributed to the elevated outdoor temperature on that date, leading to a larger building cooling load. However, the cooling load in the training samples was lower than the actual cooling load measured on 20 June. Consequently, the AIA faced challenges in training and learning effectively, resulting in a higher prediction error on that date.
The training and prediction errors of different models at the early cooling stage are shown in
Table 8.
Table 8 provides insights into the cooling load predictions at the early cooling stage for M1 to M8. The training errors of M1 to M8 were relatively consistent. However, their prediction errors varied significantly. When the prediction models used the original data as the training samples, M5 yielded the best prediction accuracy, while the prediction accuracy of M1 was the worst. When the original data were pre-treated based on sample similarity,
MAPE,
R2, and
RMSE of M2 decreased from 11.5 to 8.8% (with a decrease of 23.5%), increased from 0.535 to 0.658 (with an increase of 23.0%), and decreased from 14.611 to 12.536 kW (with a decrease of 14.2%), respectively, compared to those of M1. It proves that the prediction accuracy of M2 had been greatly improved. Conversely, the
MAPE,
R2, and
RMSE of M4 increased from 7.2 to 8.3% (with an increase of 15.3%), decreased from 0.632 to 0.528 (with a decrease of 16.5%), and increased from 12.992 to 14.717 kW (with an increase 13.3%), respectively, compared to those of M3. It means that the prediction accuracy of the improved M4 had been decreased. The
MAPE,
R2, and
RMSE of M6 increased from 5.4 to 5.7% (with an increase of 5.6%), decreased from 0.811 to 0.782 (with a decrease of 3.6%), and increased from 9.319 to 10.007 kW (with an increase of 7.4%), respectively, compared to those of M5. The results of M6 were similar with those of M4, i.e., the prediction accuracy of M6 was decreased. M8 showed a substantial improvement, with its
MAPE,
R2, and
RMSE decreasing from 6.4 to 5.7% (with a decrease of 10.9%), increasing from 0.742 to 0.820 (with an increase of 10.5%), and decreasing from 10.881 to 9.101 kW (with a decrease of 16.4%), respectively, compared to those of M7.
3.3. Cooling Load Prediction in the Middle Cooling Stage
The outcomes of the normal distribution evaluation for the building’s cooling load and its impacting factors during the middle cooling stage are meticulously detailed in
Table 9. The results of the correlation analysis between the building’s cooling load and the pertinent factors for this cooling period are comprehensively expounded in
Table 10.
As shown in
Table 9, only the asymptotic significance index of outdoor temperature was greater than 0.05 in the middle cooling stage. The asymptotic significance indexes of the rest of the influencing factors were 0. It means that only outdoor temperature obeyed the normal distribution, and the rest of the parameters did not obey the normal distribution.
As shown in
Table 10, only the significance index of outdoor relative humidity was greater than 0.01, meaning that all parameters were significantly correlated with the building cooling load, except for outdoor relative humidity. It could be attributed to the limited dehumidification capacity of the soil source heat pump system. Changes of outdoor air relative humidity had a limited impact on the cooling load in the middle cooling stage. Therefore, outdoor temperature, solar radiation intensity, outdoor wind speed, indoor temperature, indoor relative humidity, and building cooling load at the previous moment were selected as the input variables of the prediction models in the middle cooling stage.
To evaluate the performance of the improved prediction model based on sample similarity, we built distinct control models for the middle cooling stage. Detailed specifications of the prediction models are provided in
Table 11.
The weight values for the input parameters, including outdoor temperature, solar radiation intensity, outdoor wind speed, indoor temperature and relative humidity, and building cooling load at the previous moment were 0.1767, 0.1741, 0.1544, 0.1753, 0.1685, and 0.1510, respectively, calculated by the entropy weighting method. This study only selected historical samples with a comprehensive similarity coefficient greater than 0.6 as the similarity sample set.
As shown in
Figure 20,
Figure 21,
Figure 22,
Figure 23,
Figure 24,
Figure 25,
Figure 26,
Figure 27 and
Figure 28, when prediction of the cooling load during the middle cooling stage was conducted, a general consistency in the trend between predicted and actual values of M1 to M8 was observed. Specifically, the
APE of M1 was primarily distributed within the range of 3.9 to 14.9%, while that of M2 was distributed within the range of 1.9 to 6.8%. The
APE of M3 was primarily distributed within the interval of 0.7 to 2.5%, and for M4, the
APE was distributed from 0.7 to 2.9%. The
APE of M5 primarily ranged from 0.6 to 2.3%. The
APE of M6 was mainly located between 0.6 and 2.1%. The
APE of M7 was mainly distributed within the range of 0.9 to 3.5%. The
APE of M8 was primarily located between 0.5 and 2.6%. The prediction error of each model only exceeded 30% at certain moments. This was because the main operating mode of the soil source heat pump system in this cooling stage was that heat pump A and B were combined for cooling. Sometimes the operating staff switched the working status of heat pumps A and B. The process of switching between heat pumps A and B required a certain amount of time to ensure system stability, which contributed to increasing prediction errors.
Table 12 presents the training and prediction errors of different models in the middle cooling stage.
As shown in
Table 12, when the original data were used as the training samples for the prediction models, the best prediction accuracy was obtained by M5, while the prediction accuracy of M1 was the worst. When the original data were pretreated using the sample similarity method, the
MAPE,
R2, and
RMSE of M2 decreased from 10.5 to 5.7% (with a reduction of 45.7%), increased from 0.850 to 0.893 (with an increase of 5.1%), and decreased from 25.580 to 21.588 kW (with a reduction of 15.6%), respectively, compared to that of M1. It means that the prediction accuracy of M2 had been greatly improved.
R2 and
RMSE of M4 were improved compared to those of M3, while the
MAPE got worse. The
MAPE,
R2, and
RMSE of M6 decreased from 2.6 to 2.5% (with a reduction of 3.8%), increased from 0.905 to 0.906 (with an increase of 0.1%), and decreased from 20.370 to 20.208 kW (with a reduction of 0.8%), respectively. It means that the prediction accuracy of M5 was slightly improved.
MAPE,
R2, and
RMSE of M8 decreased from 3.3 to 2.7% (with a reduction of 18.2%), increased from 0.904 to 0.906 (with an increase of 0.2%), and decreased from 20.467 to 20.247 kW (with a reduction of 1.1%), respectively, compared to those of M7. It proved that the prediction accuracy of M8 had been greatly improved.
In summary, the method of pretreating training samples based on sample similarity was highly effective in improving the prediction accuracy of BPNN and ELM models. However, this did not apply to GABPNN and SVR models. This was because the latter two neural networks inherently possess global optimization functions. The GABPNN utilizes the genetic algorithm to screen training samples, retaining the optimal individuals for network training. The SVR model ensures predictive accuracy through cross-validation for global validation. Excluding a part of the training samples makes it challenging to achieve global optimization in the training and learning of these two prediction models.































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}