1. Introduction
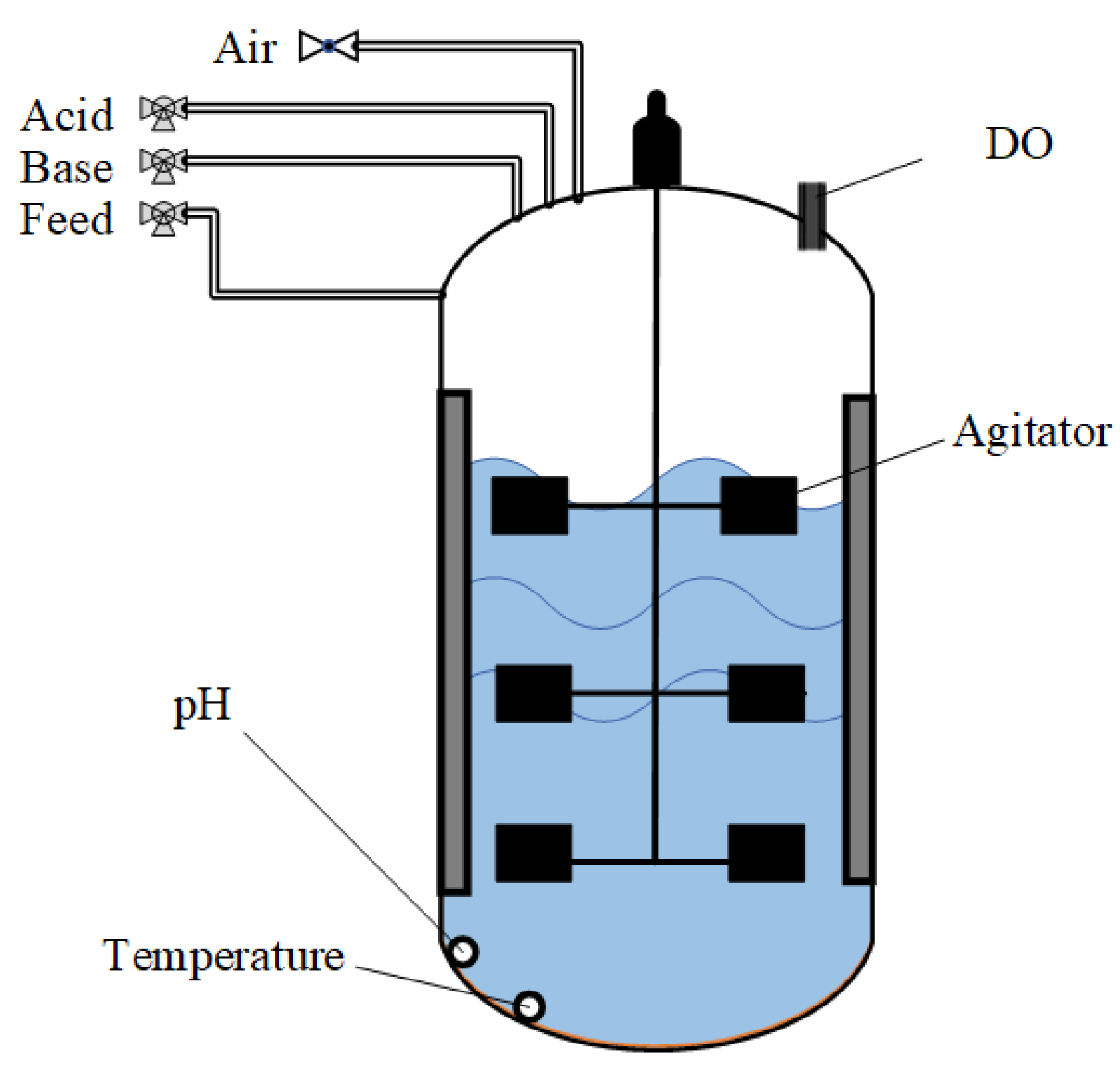
In recent decades, batch processes have been widely used in manufacturing products, which are indispensable in the modern landscape, ranging from food and pharmaceuticals to the most cutting-edge silicon [
1]. The overall normal operation of a specific batch process is essential for the concern of safety and profitability, and plays a central role in the ultimate success of a process [
2,
3,
4]. To this end, process monitoring is now an increasingly studied topic in batch process systems and has been improved by the great surge in data from real-world operations. Particularly, statistical process control (SPC), as an emerging technique, has found widespread applications in the field of process monitoring [
5,
6,
7,
8].
Generally, SPC attempts to monitor the data by mining the stable and event-sensitive patterns underlying the data, instead of relying on the complex process knowledge that is hard to obtain in practice. Due to this unique advantage, multivariate principal component analysis (MPCA) and multivariate partial least squares (MPLS) have been extensively used for fitting the cross- and auto-relations in the input data, which is also referred to as the issue of nonlinearities and dynamics underlying batch processes [
9,
10].
Actually, in real-world batch processes, there is a correlation between process data and historical data [
11]. Batch processes are typically dynamic in nature due to the chronological generation of process data [
12]. This results in the existence of nonlinear dynamics that not only reside in the time dimension but also in the batch dimension. To extract batch process data dynamics, researchers have successfully combined data augmentation techniques and SPC models, proposing the dynamic principal component analysis (DPCA) and dynamic kernel principal component analysis [
13,
14,
15]. However, these kind of approaches only consider correlations in the time dimension. Meanwhile, some researchers tried to construct 2D batch process monitoring models. Lu [
16] proposed a 2D sliding window in the time and batch directions and combined the sliding window with DPCA to capture the dynamic characteristics of the batch process. This approach assumes that 2D sliding windows are regular, whereas certain batch process dynamics may not be represented using regular sliding windows. For the determination of the shape of the sliding window, many different methods have been proposed by researchers. Yao [
17] proposed a method called region of support (ROS) to extract the dynamics of the batch process. The shape of the sliding window has been further defined with the support of ROS and this sliding window has an irregular shape. Jiang [
18] proposed a 2D-DCRL model and used DCCA to compute the correlation of samples in the time and batch dimensions to finalize the shape of the sliding window. Unlike the methods mentioned above, Ren [
19] performed data augmentation by sliding a window along the batch direction on the batch process data and then processed the data using an autoencoder based on a long short-term memory network to monitor the batch process.
The aforementioned 2D methods reshape sample data into a new matrix via specific regions or sliding windows, which is subsequently utilized for model training. However, these methods overlook the possibility of redundancy among samples within the sliding window. The determination of the sliding window’s shape in these methods is based on calculating the correlation between samples using a linear approach. Although these methods can select samples that are highly correlated with the current sample to form a 2D sliding window, this linear correlation may bring redundant information into the model. This redundancy is also reflected in the fact that the model assumes that all samples in the sliding window are of equal importance, which does not take full advantage of the correlation between the samples. In addition, neither the regular sliding windows nor the shaped sliding windows identified by data mining take into account the variation in the shape of the sliding window with respect to the time direction of the batch process. As a single batch process typically encompasses multiple phases characterized by distinct dynamics, it becomes necessary to adapt the sliding window’s configuration to align with the specific characteristics of each phase.
With the continual advancement in graph neural networks, graph-based neural network models have garnered significant attention in domains such as natural language processing and computer vision [
20,
21]. Particularly, graph models can use correlations between data to construct edges in a graph to extract structural information from the data [
22,
23]. Therefore, researcher have tried to apply graph neural network modeling to process monitoring. Zhang [
24] introduced the pruning graph convolutional network (PGCN) model for fault diagnosis, pioneering the fusion of a graph convolution network (GCN) with one-dimensional industrial process data. Liu [
25] determined the shape of a one-dimensional sliding window by analyzing sample autocorrelation. They constructed a graph using a sliding window and used a graph convolutional network for information aggregation and updating to reduce the dimension and reconstruct the original input. Moreover, the graph attention network (GAT) [
26], a classical model in the field of graph neural networks, demonstrates a remarkable capacity to extract vital information from raw data. This proficiency is attributed to the self-attention mechanism employed by GAT. By leveraging the graph structure, the self-attention mechanism efficiently filters out crucial information within the graph. It accomplishes this by computing attention weights for each node and its neighboring nodes, thereby mitigating the influence of redundant information on the model. Hence, GAT is more advantageous in extracting key information and reducing the interference of redundant information.
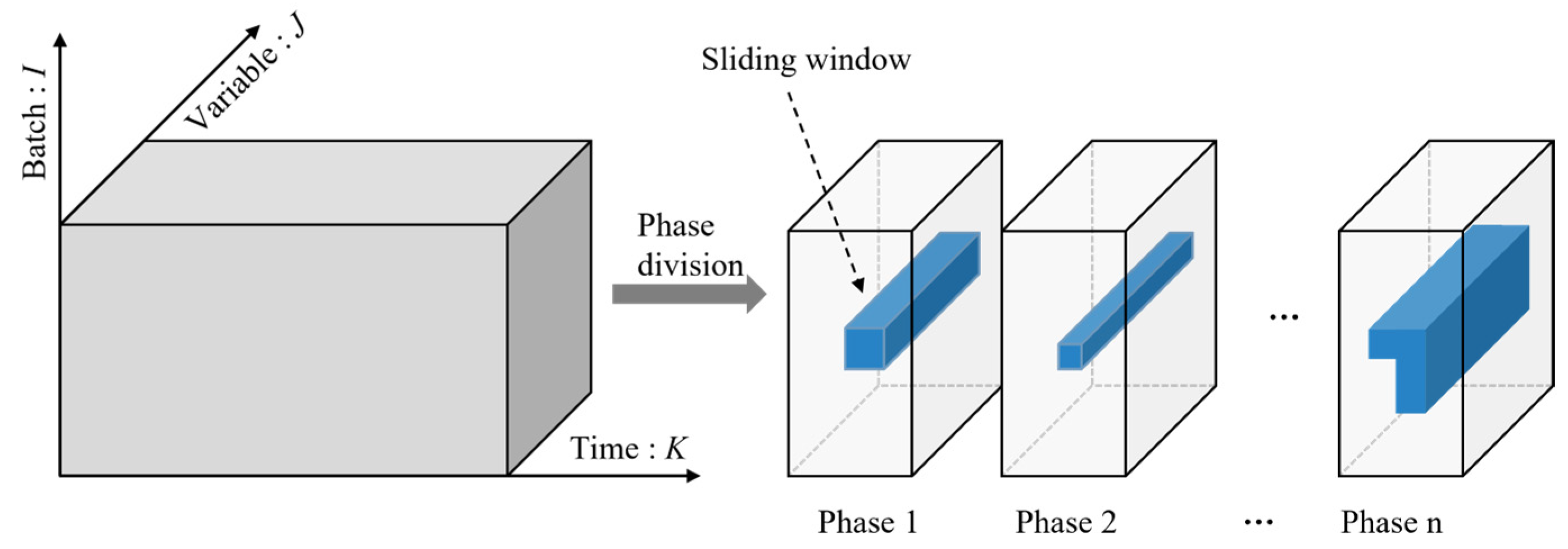
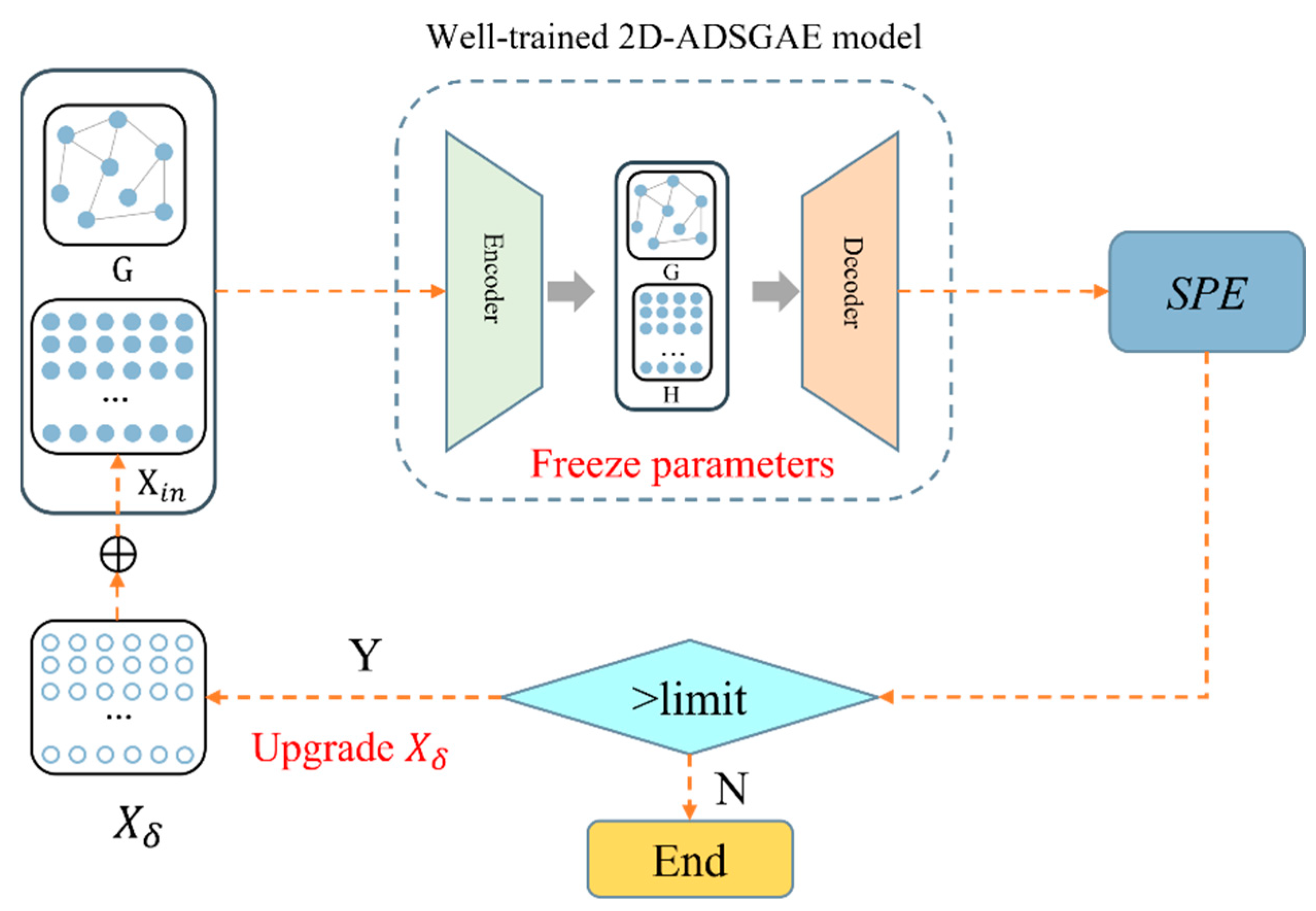
For those reasons, this paper proposes a new batch process monitoring method named attention-based two-dimensional dynamic-scale graph autoencoder (2D-ADSGAE), which combines GAT and SAE to construct an effective dynamic batch process monitoring model. In this work, the batch process is divided into different phases according to our proposed phase division method to determine the shape of the 2D sliding window at each phase, and then the normalized batch process data are used to construct the graph. The 2D-ADSGAE is a network with an encoder–decoder architecture, comprising multiple GAT layers. This method further extracts crucial information from the graph through attention mechanisms, reducing the impact of redundant information on the model. Network parameters are optimized by minimizing the reconstruction loss. Finally, a fault diagnosis method based on a deep reconstruction-based contribution (DRBC) plot is proposed to locate the fault variables and estimate the fault magnitude when a fault is detected. The contributions of this research are summarized as follows:
We devise a way to expound the heterogeneity of process dynamics that a batch process typically has across its time and batch direction, showcasing the necessity of updating receptive regions and assuaging redundancy for feature engineering.
Multi-phase sliding windows are utilized to construct the batch process data into a single graph with varying structures that are suitable for a graph neural networks-based model.
Additionally, the model’s practical applicability is demonstrated by analyzing the root cause of the faults through a comparison of the loss between inputs and reconstructions.
5. Conclusions
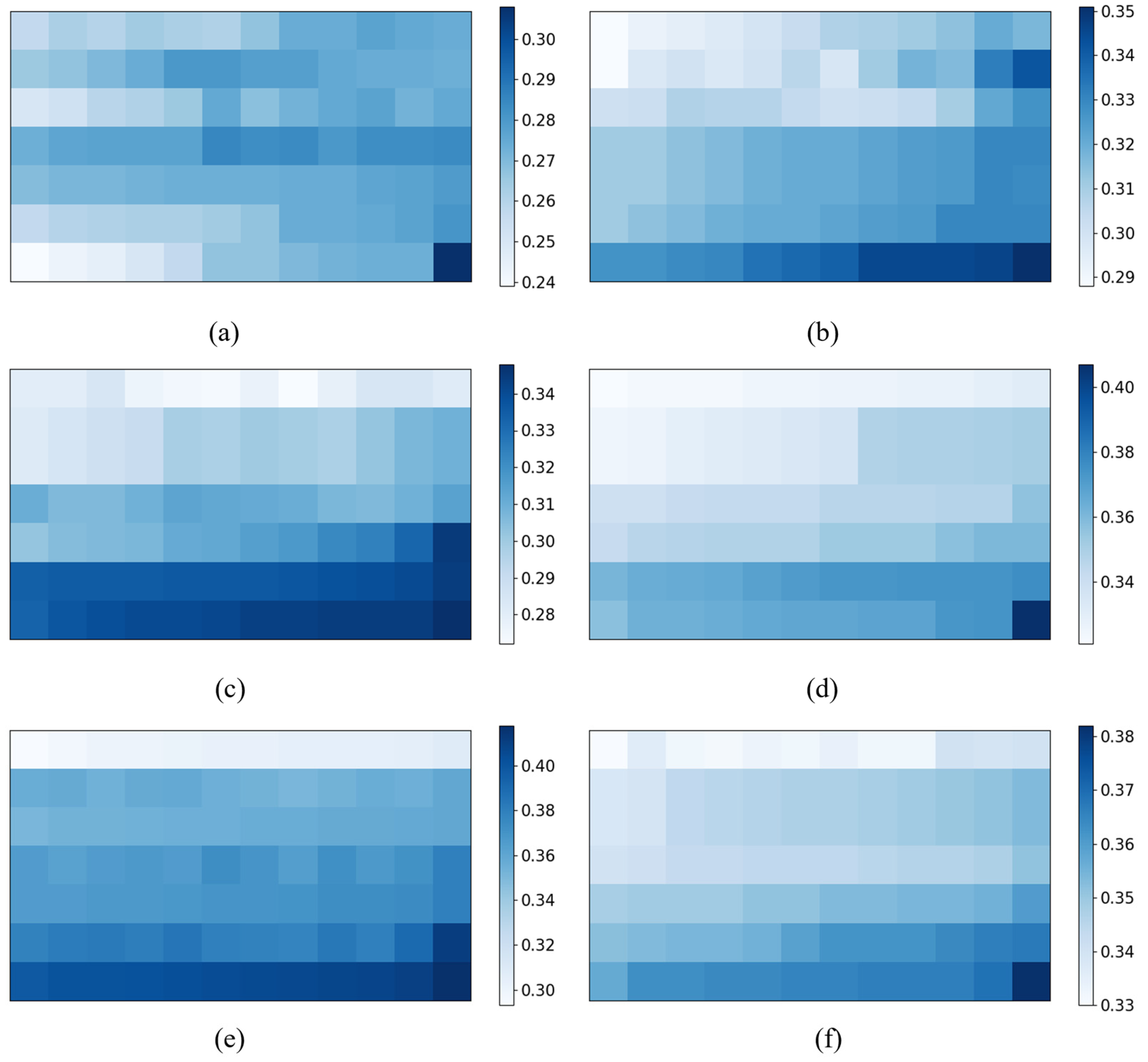
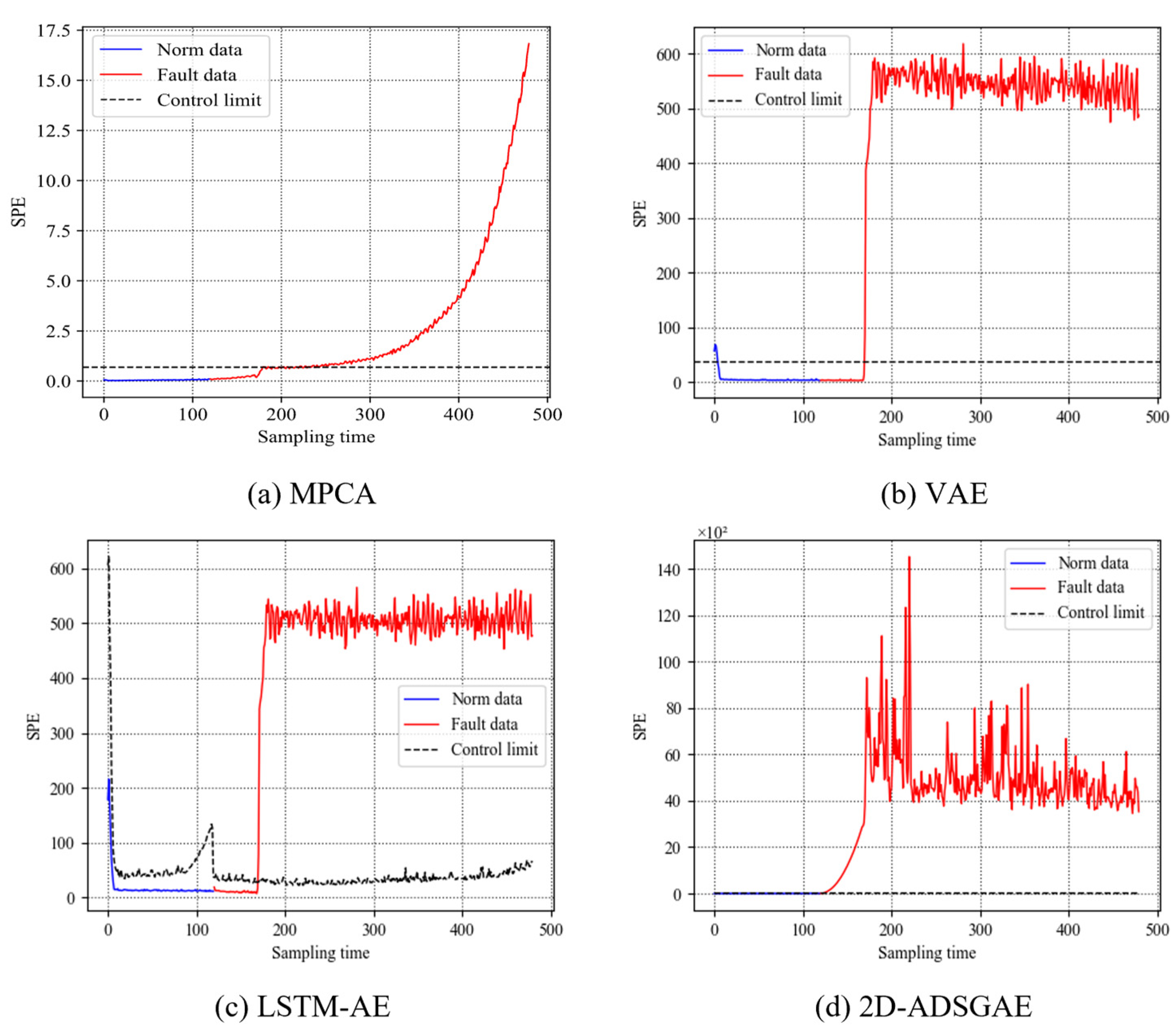
In this paper, a new 2D-ADSGAE model was proposed to extract nonlinearity and dynamics in batch processes. A method based on sample correlations within sliding windows was introduced for phase division. Through this method, we further determined the shape of the 2D sliding window within each phase, thereby establishing neighborhood information for nodes in the graph. The attention mechanism was employed to handle redundant information and nonlinear dynamics among samples within the sliding window. Additionally, a monitoring metric was established within the residual space. Finally, it was combined with DRBC for fault variable localization and analysis. The results of the two experiments demonstrate that 2D-ADSGAE outperforms the other models, significantly enhancing the fault detection accuracy and enabling the analysis and localization of fault variables.
Note that the proposed model does not distinguish between quality-related and non-quality-related faults, and this will be considered in our future work to further improve the monitoring capability of the model.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}