
Diesel Adulteration Detection with a Machine Learning-Enhanced Laser Sensor Approach

Abstract
:1. Introduction
2. Optical-Based Sensor Mechanism
3. Machine Learning Regression Models for Diesel Purity Prediction
- Incident angle from 10° to 40° with a 1° increment.
- Diesel sample depth from 1 cm to 5 cm with a 0.5 cm increment.
- Refractive index of the diesel sample from 1.4444 to 1.4604 with a increment to cover all possible adulterated diesel volume percentage.
3.1. Dataset Preparation and Partitioning
3.2. Normalization for Enhanced Model Performance
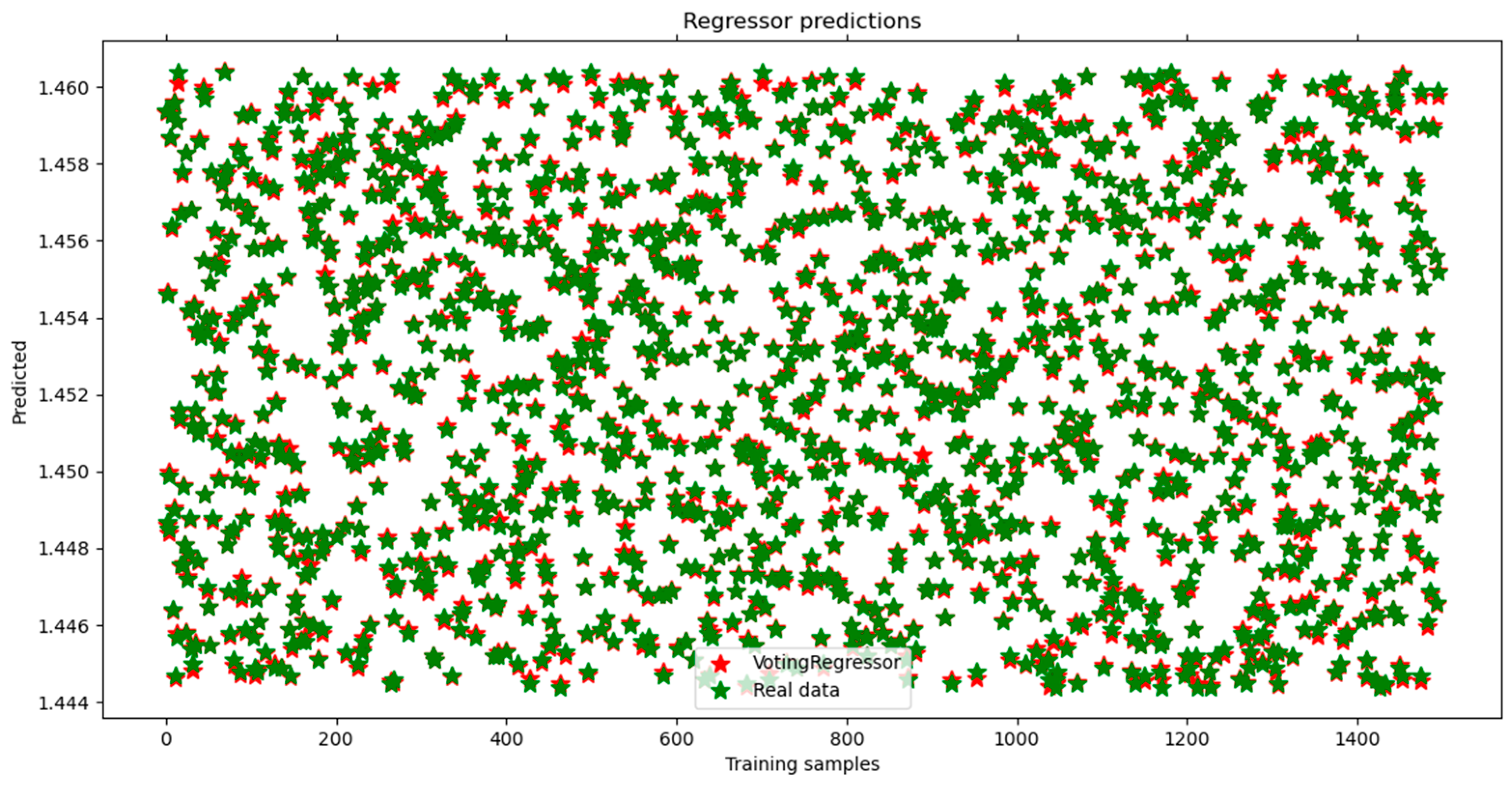
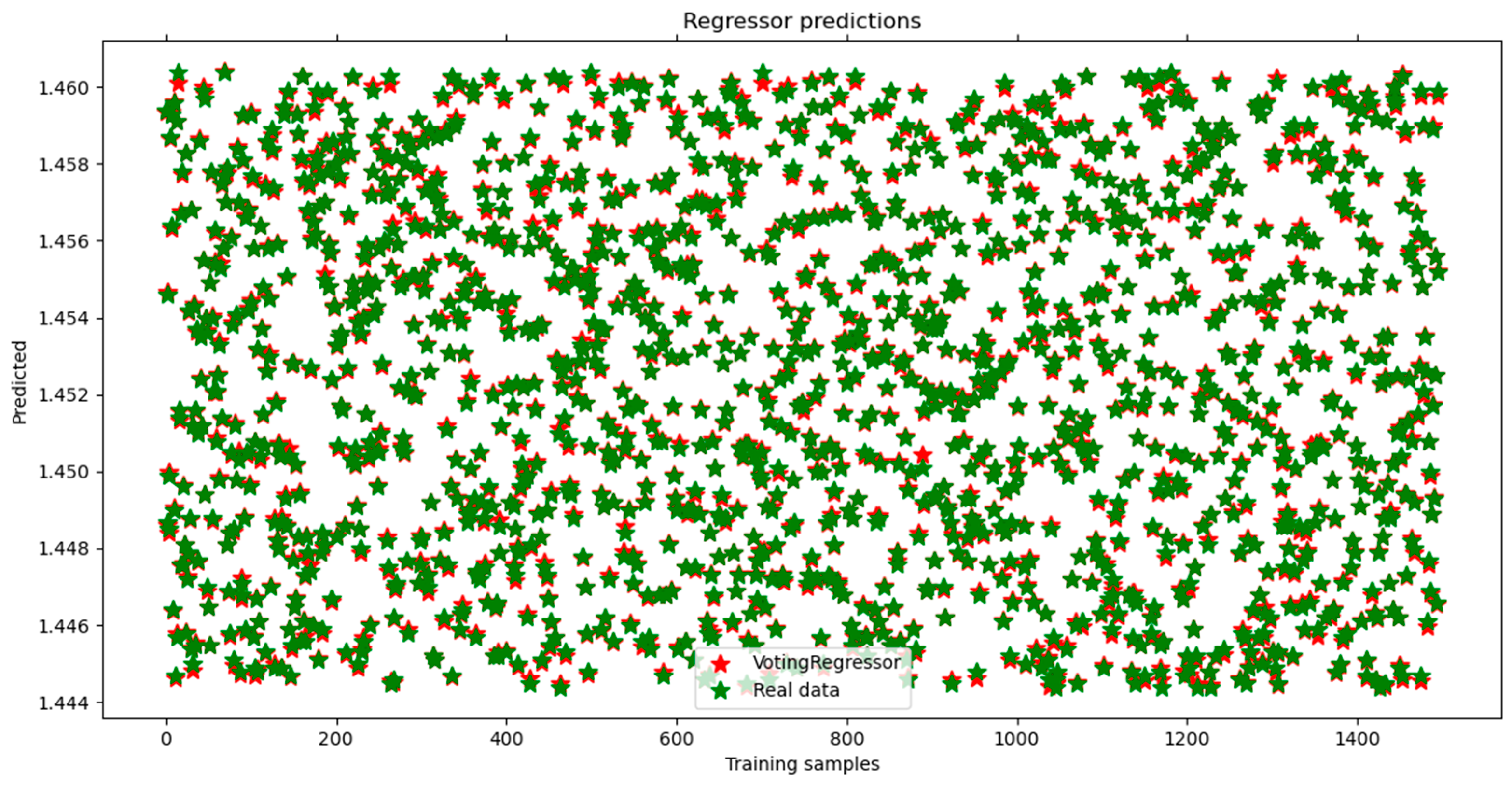
4. Results and Model Verification
5. Conclusions
- In contrast to traditional detection methods that are expensive, require extensive sample preparation, require skilled technicians, and are not adaptable for field testing or versatile in detecting various diesel adulterants, our suggested approach leverages the principles of optics of light reflection and refraction to create synthetic data for machine learning analysis.
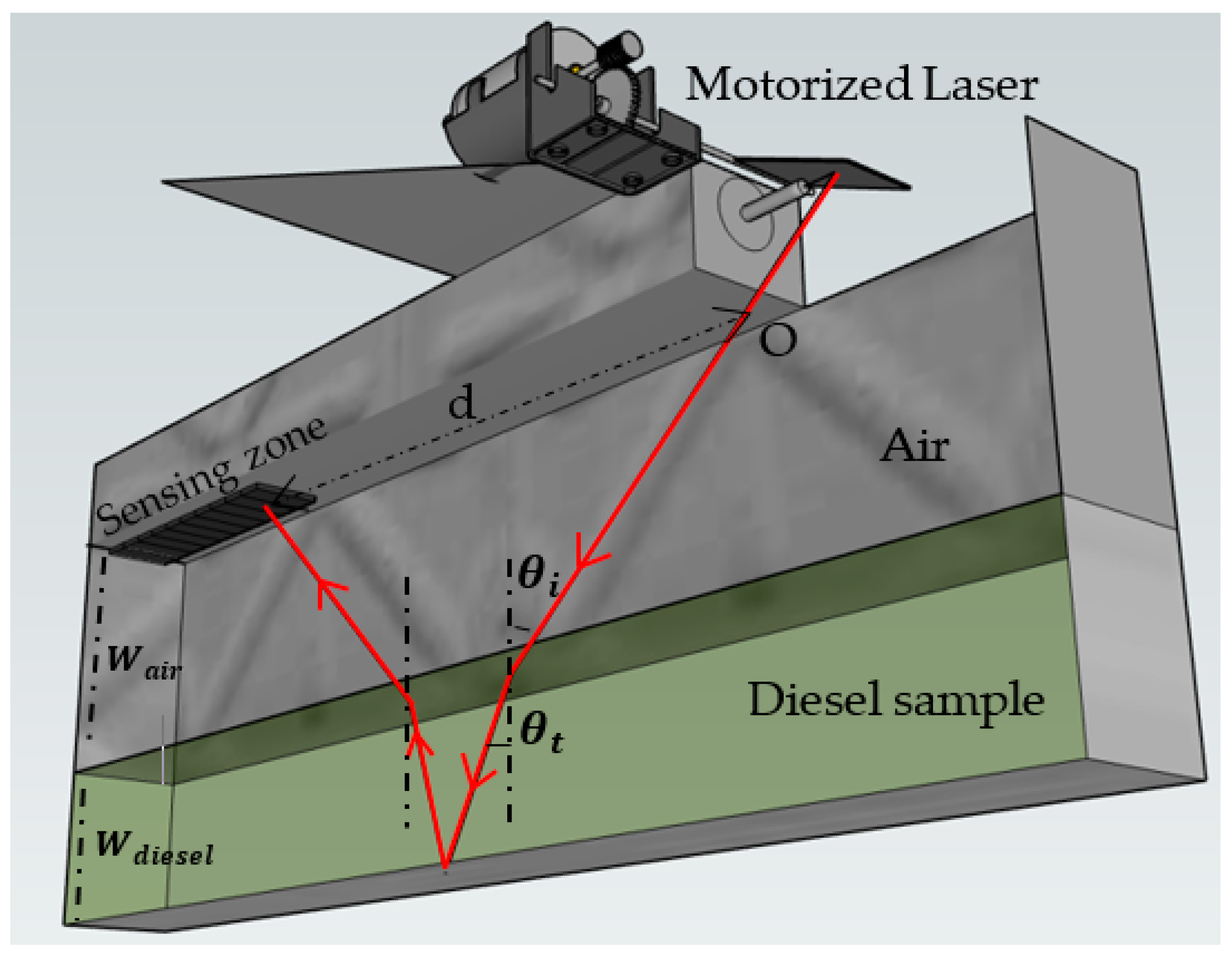
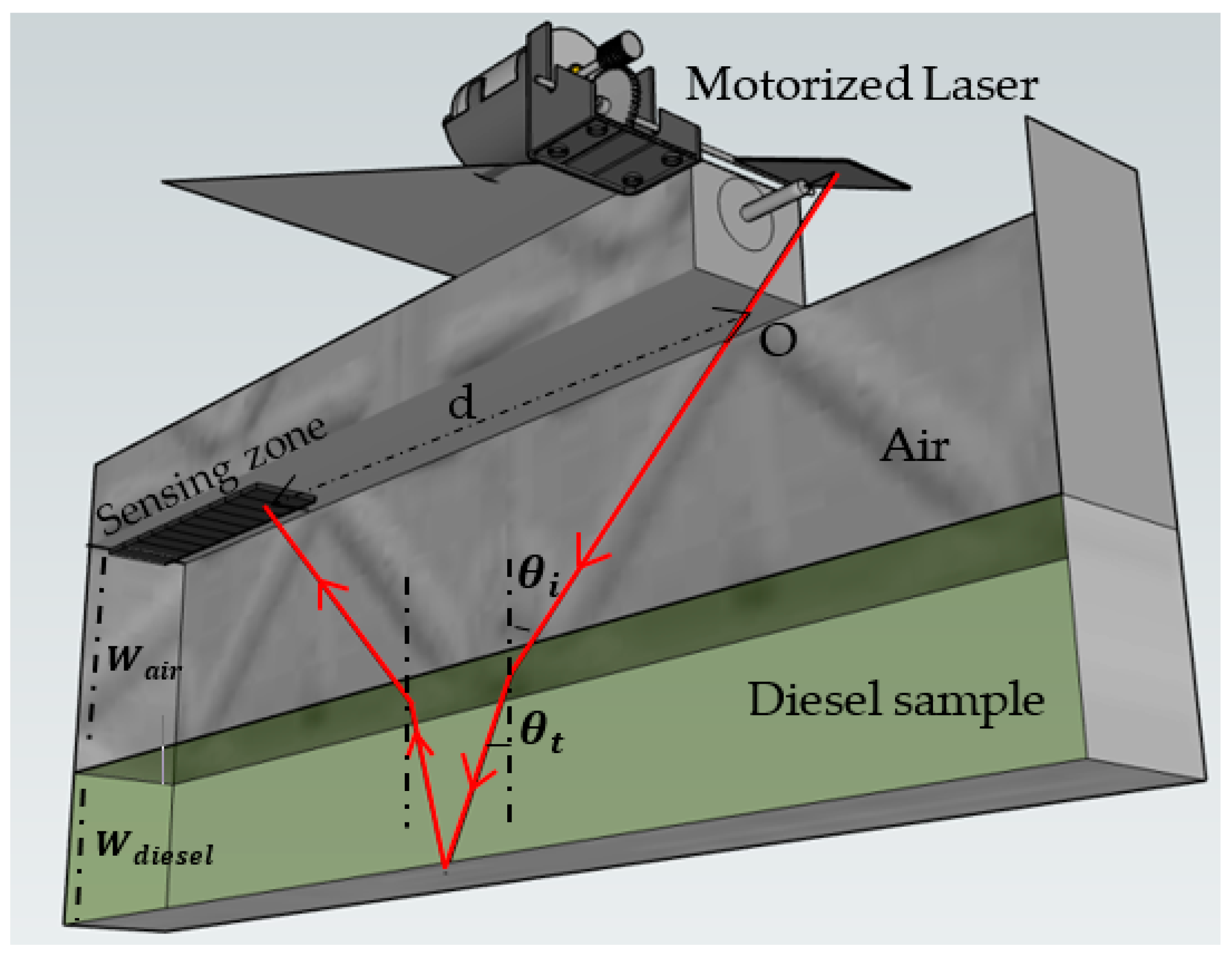
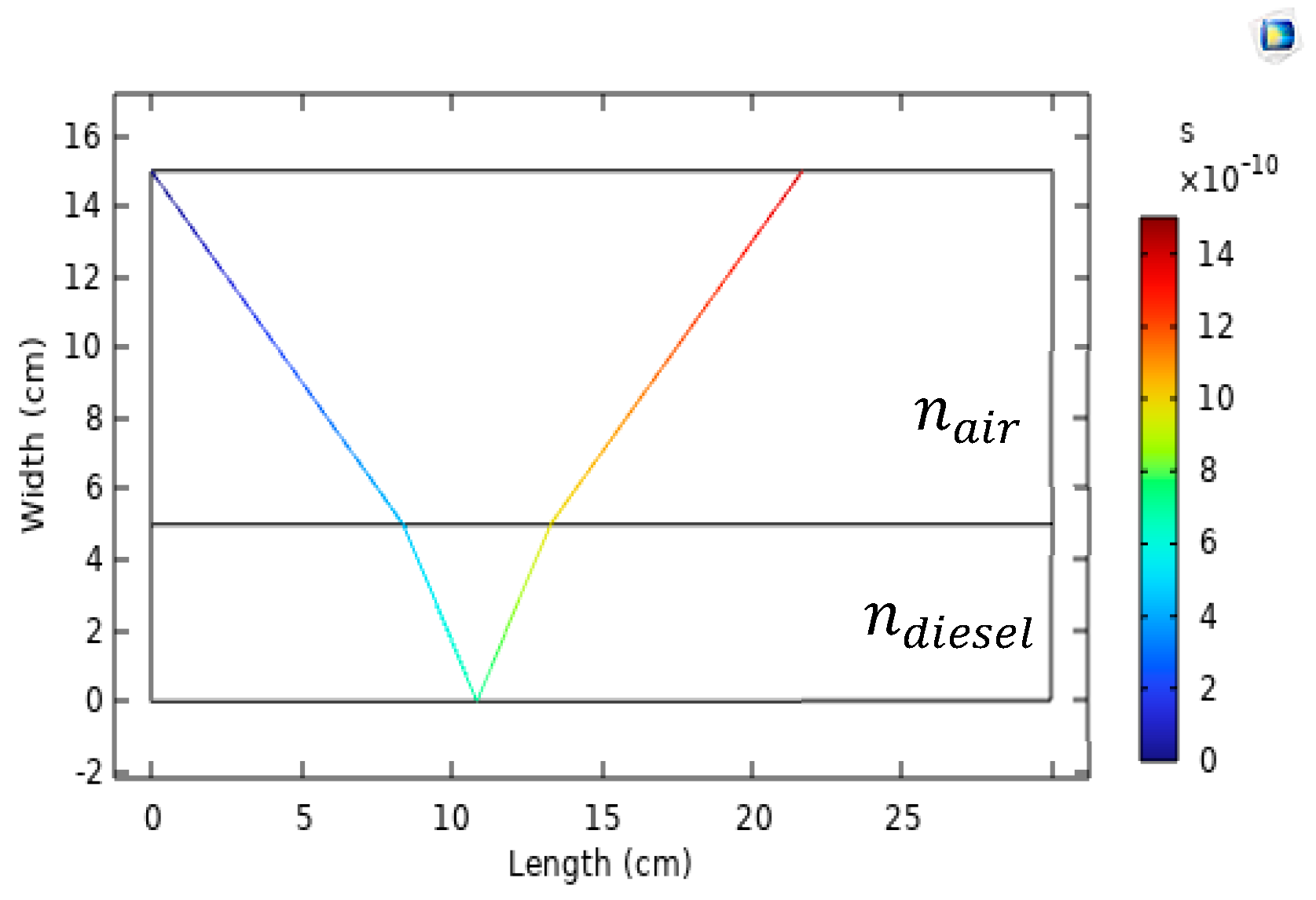
- Our laser-based sensor, designed using COMSOL, is composed of a simple setup involving a diesel-filled container and an overhead laser. The laser light, after refracting through the diesel, is measured for its reflection back to a sensor aligned with the laser.
- Various parameters are calculated, such as the distance from the laser to the point of light detection, angles of incidence, and diesel depth. These parameters are then utilized as synthetic data, streamlining the machine learning training phase, a typically laborious aspect of AI implementation, to predict adulteration levels across a spectrum from 0 to 100%.
- Different models have been tested to check the best performance looking at the hyperparameter metrics. The results validate our models’ high accuracy in predicting unseen data, as evidenced by an R-squared value of 0.999 and a mean absolute error of 0.074, confirming their potential for practical application.
- This sensor’s cost-effective and versatile design promotes its utility across various applications, making it a promising solution for affordable, low-cost Internet of Things technologies.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| SPR | Surface plasmon resonance |
| PCF | Photonic crystal fiber |
| IR | Infrared |
| PLS | Partial least squares |
| SVR | Support vector machine regression |
| MCR-ALS | Multivariate curve resolution with alternating least squares |
| AI | Artificial intelligence |
| ML | Machine learning |
| GEP | Gene expression programming |
| BSEC | Brake specific energy consumption |
| NOx | Nitrogen oxides |
| BTE | Brake thermal efficiency |
| UHC | Unburned hydrocarbon |
| CO | Carbon monoxide |
| NIR | Near-infrared |
| d | Light path from its point of entry to its intersection with the sensing zone |
| Refractive index of diesel | |
| Refractive index of kerosene | |
| Refractive index of air | |
| Refractive index of water | |
| Incident angle | |
| Transmitted angle | |
| Reflected angle | |
| Depth of air | |
| Depth of diesel sample | |
| Wavelength of light | |
| R-squared | |
| MSE | Mean squared error |
| MAE | Mean absolute error |
| RMSE | Root mean squared error |
References
- Vempatapu, B.P.; Kanaujia, P.K. Monitoring petroleum fuel adulteration: A review of analytical methods. TrAC—Trends Anal. Chem. 2017, 92, 1–11. [Google Scholar] [CrossRef]
- Mattheou, L.; Zannikos, F.; Schinas, P.; Karavalakis, G.; Karonis, D.; Stournas, S. Impact of using adulterated automotive diesel on the exhaust emissions of a stationary diesel engine. Glob. NEST J. 2018, 8, 291–296. [Google Scholar]
- Nurdin, H.; Hasanuddin, H.; Darmawi, D.; Prasetya, F. Analysis of Calorific Value of Tibarau Cane Briquette. Mater. Sci. Eng. Conf. Ser. 2018, 335, 012058. [Google Scholar] [CrossRef]
- International Council of Chemical Associations (US/ICCA) COCAM 3. 2012. Available online: https://hpvchemicals.oecd.org/UI/handler.axd?id=73b56220-3a8b-479b-b03c-99c7353bf4d6 (accessed on 7 April 2024).
- Yuan, W.; Hansen, A.C.; Zhang, Q. The specific gravity of biodiesel fuels and their blend with diesel fuel. Agric. Eng. Int. CIGR J. Sci. Res. Dev. 2004, 6. Available online: https://www.researchgate.net/publication/228589856_The_specific_gravity_of_biodiesel_fuels_and_their_blend_with_diesel_fuel (accessed on 7 April 2024).
- Obuchi, A.; Aoyama, H.; Ohi, A.; Ohuchi, H. Determination of polycyclic aromatic hydrocarbons in diesel exhaust particulate matter and diesel fuel oil. J. Chromatogr. A 1984, 312, 247–259. [Google Scholar] [CrossRef] [PubMed]
- Vempatapu, B.P.; Tripathi, D.; Kumar, J.; Kanaujia, P.K. Determination of Kerosene as an Adulterant in Diesel through Chromatography and High-Resolution Mass Spectrometry. SN Appl. Sci. 2019, 1, 637. [Google Scholar] [CrossRef]
- Chowdhury, M.; Gholizadeh, A.; Agah, M. Rapid Detection of Fuel Adulteration Using Microfabricated Gas Chromatography. Fuel 2021, 286, 119387. [Google Scholar] [CrossRef]
- Jabin, M.A.; Rana, M.J.; Al-Zahrani, F.A.; Paul, B.K.; Ahmed, K.; Bui, F.M. Novel Detection of Diesel Adulteration Using Silver-Coated Surface Plasmon Resonance Sensor. Plasmonics 2022, 17, 15–40. [Google Scholar] [CrossRef]
- Moura, H.O.; Câmara, A.B.; Santos, M.C.; Morais, C.L.; de Lima, L.A.; Lima, K.M.; de Carvalho, L.S. Advances in Chemometric Control of Commercial Diesel Adulteration by Kerosene Using IR Spectroscopy. Anal. Bioanal. Chem. 2019, 411, 2301–2315. [Google Scholar] [CrossRef] [PubMed]
- Cunha, D.A.; Neto, Á.C.; Colnago, L.A.; Castro, E.V.R.; Barbosa, L.L. Application of Time-Domain NMR as a Methodology to Quantify Adulteration of Diesel Fuel with Soybean Oil and Frying Oil. Fuel 2019, 252, 149. [Google Scholar] [CrossRef]
- de Aguiar, L.M.; Galvan, D.; Bona, E.; Colnago, L.A.; Killner, M.H.M. Data Fusion of Middle-Resolution NMR Spectroscopy and Low-Field Relaxometry Using the Common Dimensions Analysis (ComDim) to Monitor Diesel Fuel Adulteration. Talanta 2022, 236, 122838. [Google Scholar] [CrossRef] [PubMed]
- Cunha, D.A.; Montes, L.F.; Castro, E.V.R.; Barbosa, L.L. NMR in the Time Domain: A New Methodology to Detect Adulteration of Diesel Oil with Kerosene. Fuel 2016, 166, 78. [Google Scholar] [CrossRef]
- Verma, R.K.; Suwalka, P.; Yadav, J. Detection of Adulteration in Diesel and Petrol by Kerosene Using SPR Based Fiber Optic Technique. Opt. Fiber Technol. 2018, 43, 11. [Google Scholar] [CrossRef]
- Chauhan, M.; Khanikar, T.; Singh, V.K. PDMS Coated Fiber Optic Sensor for Efficient Detection of Fuel Adulteration. Appl. Phys. B 2022, 128, 109. [Google Scholar] [CrossRef]
- Roy, S. Fiber Optic Sensor for Determining Adulteration of Petrol and Diesel by Kerosene. Sens. Actuators B Chem. 1999, 55, 171. [Google Scholar] [CrossRef]
- Bell, J.; Gotor, R.; Rurack, K. Fluorescent Paper Strips for the Detection of Diesel Adulteration with Smartphone Read-Out. J. Vis. Exp. 2018, 141, 58019. [Google Scholar]
- Kanyathare, B.; Kuivalainen, K.; Räty, J.; Silfsten, P.; Bawuah, P.; Peiponen, K.E. A Prototype of an Optical Sensor for the Identification of Diesel Oil Adulterated by Kerosene. J. Eur. Opt. Soc. 2018, 14, 71. [Google Scholar] [CrossRef]
- Sadat, A. Determining the Adulteration of Diesel by an Optical Method. Int. J. Comput. Appl. 2014, 100, 17588. [Google Scholar] [CrossRef]
- Paiva, E.M.; Rohwedder, J.J.R.; Pasquini, C.; Pimentel, M.F.; Pereira, C.F. Quantification of Biodiesel and Adulteration with Vegetable Oils in Diesel/Biodiesel Blends Using Portable Near-Infrared Spectrometer. Fuel 2015, 160, 67. [Google Scholar] [CrossRef]
- Barra, I.; Mansouri, M.A.; Bousrabat, M.; Cherrah, Y.; Bouklouze, A.; Kharbach, M. Discrimination and Quantification of Moroccan Gasoline Adulteration with Diesel Using Fourier Transform Infrared Spectroscopy and Chemometric Tools. J. AOAC Int. 2019, 102, 966–970. [Google Scholar] [CrossRef] [PubMed]
- Pontes, M.J.C.; Pereira, C.F.; Pimentel, M.F.; Vasconcelos, F.V.C.; Silva, A.G.B. Screening Analysis to Detect Adulteration in Diesel/Biodiesel Blends Using Near Infrared Spectrometry and Multivariate Classification. Talanta 2011, 85, 2159–2165. [Google Scholar] [CrossRef]
- Kanyathare, B.; Asamoah, B.; Peiponen, K.E. Imaginary Optical Constants in Near-Infrared (NIR) Spectral Range for the Separation and Discrimination of Adulterated Diesel Oil Binary Mixtures. Opt. Rev. 2018, 26, 85–94. [Google Scholar] [CrossRef]
- Kumar, A.; Singh, V.R.; Parashar, D.C. Ultrasonic Detection of Adulteration in Diesel. Res. Ind. 1991, 36, 168–170. [Google Scholar]
- Bhowmik, S.; Paul, A.; Panua, R.; Ghosh, S.K.; Debroy, D. Artificial Intelligence Based Gene Expression Programming (GEP) Model Prediction of Diesel Engine Performances and Exhaust Emissions Under Diesosenol Fuel Strategies. Fuel 2019, 235, 317–325. [Google Scholar] [CrossRef]
- Babu, V.; Krishna, R.; Mani, N. Review on the Detection of Adulteration in Fuels through Computational Techniques. Mater. Today Proc. 2017, 4, 1723–1729. [Google Scholar] [CrossRef]
- De Matos, T.S.; Dos Santos, R.C.; De Souza, C.G.; De Carvalho, R.C.; De Andrade, D.F.; D’ávila, L.A. Determination of the Biodiesel Content on Biodiesel/Diesel Blends and Their Adulteration with Vegetable Oil by High-Performance Liquid Chromatography. Energy Fuels 2019, 33, 11310–11317. [Google Scholar] [CrossRef]
- Ejilah, I.R.; Olorunnishola, A.A.G.; Enyejo, L.A. A Comparative Analysis of the Combustion Behavior of Adulterated Kerosene Fuel Samples in a Pressurized Cooking Stove. Glob. J. Res. Eng. Mech. Mech. Eng. 2013, 13, 34–44. [Google Scholar]
- de Vasconcelos, F.V.C.; de Souza, P.F.B.; Pimentel, M.F.; Pontes, M.J.C.; Pereira, C.F. Using Near-Infrared Overtone Regions to Determine Biodiesel Content and Adulteration of Diesel/Biodiesel Blends with Vegetable Oils. Anal. Chim. Acta 2012, 716, 101–107. [Google Scholar] [CrossRef] [PubMed]
- Ogundare, F.; Adekola, F.; Oladosu, I. Compositions and photon mass attenuation coefficients of diesel, kerosene, palm and groundnut oils. Fuel 2019, 255, 115697. [Google Scholar] [CrossRef]
- Tran, N.; Chen, H.; Bhuyan, J.; Ding, J. Data Curation and Quality Evaluation for Machine Learning-Based Cyber Intrusion Detection. IEEE Access 2022, 10, 121900–121923. [Google Scholar] [CrossRef]
- Mourched, B.; Abdallah, M.; Hoxha, M.; Vrtagic, S. Machine-Learning-Based Sensor Design for Water Salinity Prediction: A Conceptual Approach. Sustainability 2023, 15, 11468. [Google Scholar] [CrossRef]
- Demircioğlu, U.; Sayil, A.; Bakır, H. Detecting Cutout Shape and Predicting Its Location in Sandwich Structures Using Free Vibration Analysis and Tuned Machine-Learning Algorithms. Arab. J. Sci. Eng. 2023, 49, 1611–1624. [Google Scholar] [CrossRef]
- Chugh, S.; Ghosh, S.; Gulistan, A.; Rahman, B.M.A. Machine Learning Regression Approach to the Nanophotonic Waveguide Analyses. J. Light. Technol. 2019, 37, 6080–6089. [Google Scholar] [CrossRef]
- Mourched, B.; Hoxha, M.; Abdelgalil, A.; Ferko, N.; Abdallah, M.; Potams, A.; Lushi, A.; Turan, H.I.; Vrtagic, S. Piezoelectric-Based Sensor Concept and Design with Machine Learning-Enabled Using COMSOL Multiphysics. Appl. Sci. 2022, 12, 9798. [Google Scholar] [CrossRef]
- Wang, Y.; Guo, J.; Yang, Z.; Dou, Y.; Chang, X.; Sun, R.; Zuo, G.; Yang, W.; Liang, C.; Hao, Y.; et al. Computer Prediction of Seawater Sensor Parameters in the Central Arctic Region Based on Hybrid Machine Learning Algorithms. IEEE Access 2020, 8, 213783–213798. [Google Scholar] [CrossRef]
- Ray Optics Module User’s Guide. COMSOL Multiphysics® v. 6.2. COMSOL AB, Stockholm, Sweden. 2023. Available online: https://doc.comsol.com/5.4/doc/com.comsol.help.roptics/RayOpticsModuleUsersGuide.pdf (accessed on 7 April 2024).
- Bhausaheb, M. Determination of Adulteration in Diesel by Refractive Index Measurements. Int. J. Appl. Chem. 2008, 4, 247–252. [Google Scholar]
- Kanyathare, B.; Peiponen, K.E. Hand-Held Refractometer-Based Measurement and Excess Permittivity Analysis Method for Detection of Diesel Oils Adulterated by Kerosene in Field Conditions. Sensors 2018, 18, 1551. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
{kind=link}
{kind=link}
| Range | Diesel Volume Percentage Adulteration |
|---|---|
| 1.4604 to 1.4588 | 0 (pure diesel) |
| 1.4587 to 1.4572 | 10 |
| 1.4571 to 1.4557 | 20 |
| 1.4556 to 1.4541 | 30 |
| 1.4540 to 1.4524 | 40 |
| 1.4523 to 1.4508 | 50 |
| 1.4507 to 1.4492 | 60 |
| 1.4491 to 1.4478 | 70 |
| 1.4477 to 1.4462 | 80 |
| 1.4461 to 1.4445 | 90 |
| ≤1.4444 | 100 (pure kerozene) |
| Input | Output | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| θi° | W (cm) | 1 | 1.5 | 2 | 2.5 | 3 | 3.5 | 4 | 4.5 | 5 | nd | Adulterated Diesel % |
| 10 | d (cm) | 5.17935546 | 5.12412847 | 5.06890149 | 5.01367451 | 4.95844752 | 4.90322054 | 4.84799356 | 4.79276657 | 4.73753959 | 1.4444 | 100 |
| 5.17854154 | 5.1229076 | 5.06727366 | 5.01163972 | 4.95600578 | 4.90037184 | 4.8447379 | 4.78910396 | 4.73347002 | 1.4492 | 60 | ||
| 5.17781708 | 5.1218209 | 5.06582473 | 5.00982856 | 4.95383238 | 4.89783621 | 4.84184004 | 4.78584387 | 4.72984769 | 1.4535 | 40 | ||
| 5.17666367 | 5.12009079 | 5.06351791 | 5.00694504 | 4.95037216 | 4.89379928 | 4.83722641 | 4.78065353 | 4.72408065 | 1.4604 | 0 | ||
| 15 | 7.86645862 | 7.78045004 | 7.69444146 | 7.60843288 | 7.5224243 | 7.43641572 | 7.35040714 | 7.26439856 | 7.17838999 | 1.4459 | 90 | |
| 7.8657839 | 7.77943797 | 7.69309203 | 7.6067461 | 7.52040016 | 7.43405423 | 7.34770829 | 7.26136236 | 7.17501642 | 1.4485 | 70 | ||
| 7.86408253 | 7.77688591 | 7.15694609 | 7.07622259 | 6.99549909 | 6.91477559 | 6.8340521 | 6.7533286 | 6.6726051 | 1.4551 | 30 | ||
| 7.86336562 | 7.77581054 | 7.15561411 | 7.07455762 | 6.99350112 | 6.91244463 | 6.83138814 | 6.75033164 | 6.66927515 | 1.4579 | 10 | ||
| 28 | 15.5735981 | 15.3847557 | 15.1959133 | 15.0070709 | 14.8182285 | 14.6293861 | 14.4405437 | 14.2517013 | 14.0628588 | 1.4475 | 80 | |
| 15.5712769 | 15.3812739 | 15.1912709 | 15.0012679 | 14.8112649 | 14.6212619 | 14.4312589 | 14.2412559 | 14.0512529 | 1.4519 | 50 | ||
| 15.5688679 | 15.3776603 | 15.1864528 | 14.9952452 | 14.8040377 | 14.6128301 | 14.4216226 | 14.230415 | 14.0392075 | 1.4565 | 20 | ||
| 15.5680341 | 15.3764097 | 15.1847853 | 14.9931608 | 14.8015364 | 14.609912 | 14.4182876 | 14.2266631 | 14.0350387 | 1.4581 | 10 | ||
| 40 | 24.4876426 | 24.1449694 | 23.8022962 | 23.459623 | 23.1169498 | 22.7742766 | 22.4316035 | 22.0889303 | 21.7462571 | 1.4456 | 90 | |
| 24.4834672 | 24.1387064 | 23.7939455 | 23.4491846 | 23.1044238 | 22.7596629 | 22.414902 | 22.0701412 | 21.7253803 | 1.4505 | 60 | ||
| 24.4812673 | 24.1354065 | 23.7895457 | 23.4436849 | 23.0978241 | 22.7519634 | 22.4061026 | 22.0602418 | 21.714381 | 1.4531 | 40 | ||
| 24.4787423 | 24.131619 | 23.7844957 | 23.4373724 | 23.0902491 | 22.7431258 | 22.3960025 | 22.0488792 | 21.7017559 | 1.4561 | 20 | ||
| MSE | RMSE | MAE | ||
|---|---|---|---|---|
| GradientBoostingRegressor | 0.9995755423 | 0.0000000090 | 0.0000948249 | 0.0000780582 |
| DecisionTreeRegressor | 0.9993493505 | 0.0000000138 | 0.0001174028 | 0.0001106952 |
| RandomForestRegressor | 0.9998072755 | 0.0000000041 | 0.0000638960 | 0.0000462553 |
| LinearRegression | 0.9976417782 | 0.0000000500 | 0.0002235102 | 0.0001711042 |
| ExtraTreesRegressor | 0.9999722953 | 0.0000000006 | 0.0000242260 | 0.0000124726 |
| VotingRegressor | 0.9997784577 | 0.0000000047 | 0.0000685067 | 0.0000536201 |
| Real | Predicted | Error % | |
|---|---|---|---|
| GradientBoostingRegressor | 1.4588 | 1.45887 | 0.00476 |
| 1.4491 | 1.44912 | 0.0014 | |
| 1.4567 | 1.45678 | 0.0052 | |
| 1.4486 | 1.4485 | 0.0069 | |
| 1.4538 | 1.4537 | 0.00688 | |
| DecisionTreeRegressor | 1.4588 | 1.4589 | 0.00685 |
| 1.4491 | 1.4492 | 0.0069 | |
| 1.4567 | 1.4568 | 0.00686 | |
| 1.4486 | 1.4485 | 0.0069 | |
| 1.4538 | 1.4537 | 0.00688 | |
| RandomForestRegressor | 1.4588 | 1.45882 | 0.00171 |
| 1.4491 | 1.44909 | 0.00035 | |
| 1.4567 | 1.45671 | 0.00103 | |
| 1.4486 | 1.44853 | 0.00511 | |
| 1.4538 | 1.4537 | 0.00715 | |
| LinearRegression | 1.4588 | 1.45926 | 0.03133 |
| 1.4491 | 1.44912 | 0.00116 | |
| 1.4567 | 1.45647 | 0.01558 | |
| 1.4486 | 1.44892 | 0.0221 | |
| 1.4538 | 1.45378 | 0.00127 | |
| ExtraTreesRegressor | 1.4588 | 1.45881 | 0.00082 |
| 1.4491 | 1.4491 | 1.07 × 10−13 | |
| 1.4567 | 1.4567 | 0.00027 | |
| 1.4486 | 1.44862 | 0.00138 | |
| 1.4538 | 1.45381 | 0.00103 | |
| VotingRegressor | 1.4588 | 1.45893 | 0.0091 |
| 1.4491 | 1.44913 | 0.00182 | |
| 1.4567 | 1.45665 | 0.0033 | |
| 1.4486 | 1.44861 | 0.00091 | |
| 1.4538 | 1.45374 | 0.00423 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mourched, B.; AlZoubi, T.; Vrtagic, S. Diesel Adulteration Detection with a Machine Learning-Enhanced Laser Sensor Approach. Processes 2024, 12, 798. https://doi.org/10.3390/pr12040798
Mourched B, AlZoubi T, Vrtagic S. Diesel Adulteration Detection with a Machine Learning-Enhanced Laser Sensor Approach. Processes. 2024; 12(4):798. https://doi.org/10.3390/pr12040798
Chicago/Turabian StyleMourched, Bachar, Tariq AlZoubi, and Sabahudin Vrtagic. 2024. "Diesel Adulteration Detection with a Machine Learning-Enhanced Laser Sensor Approach" Processes 12, no. 4: 798. https://doi.org/10.3390/pr12040798