
Data-Driven Method for Vacuum Prediction in the Underwater Pump of a Cutter Suction Dredger

Abstract
:1. Introduction
2. Research Object and Methodology
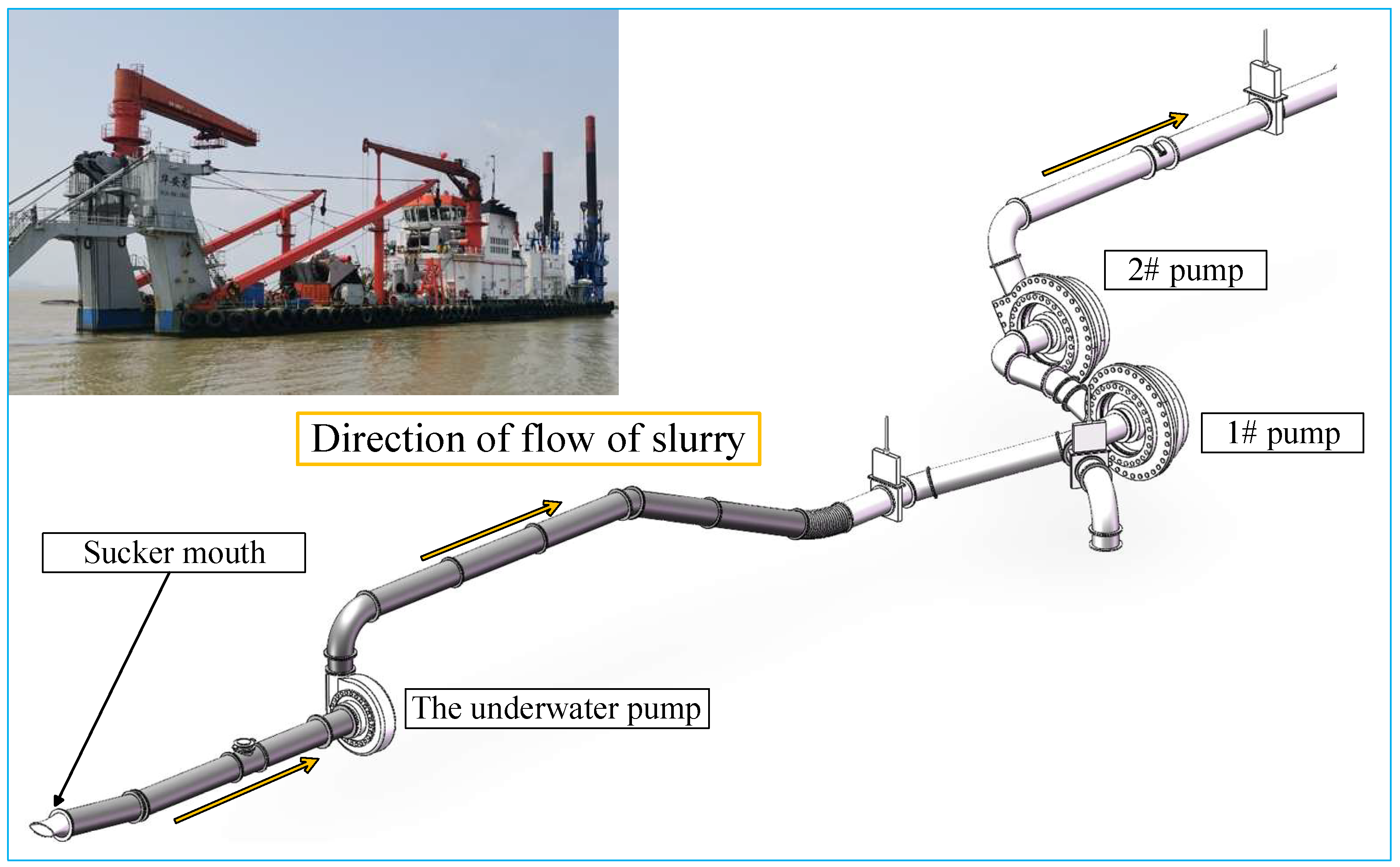
2.1. Construction Process for CSDs
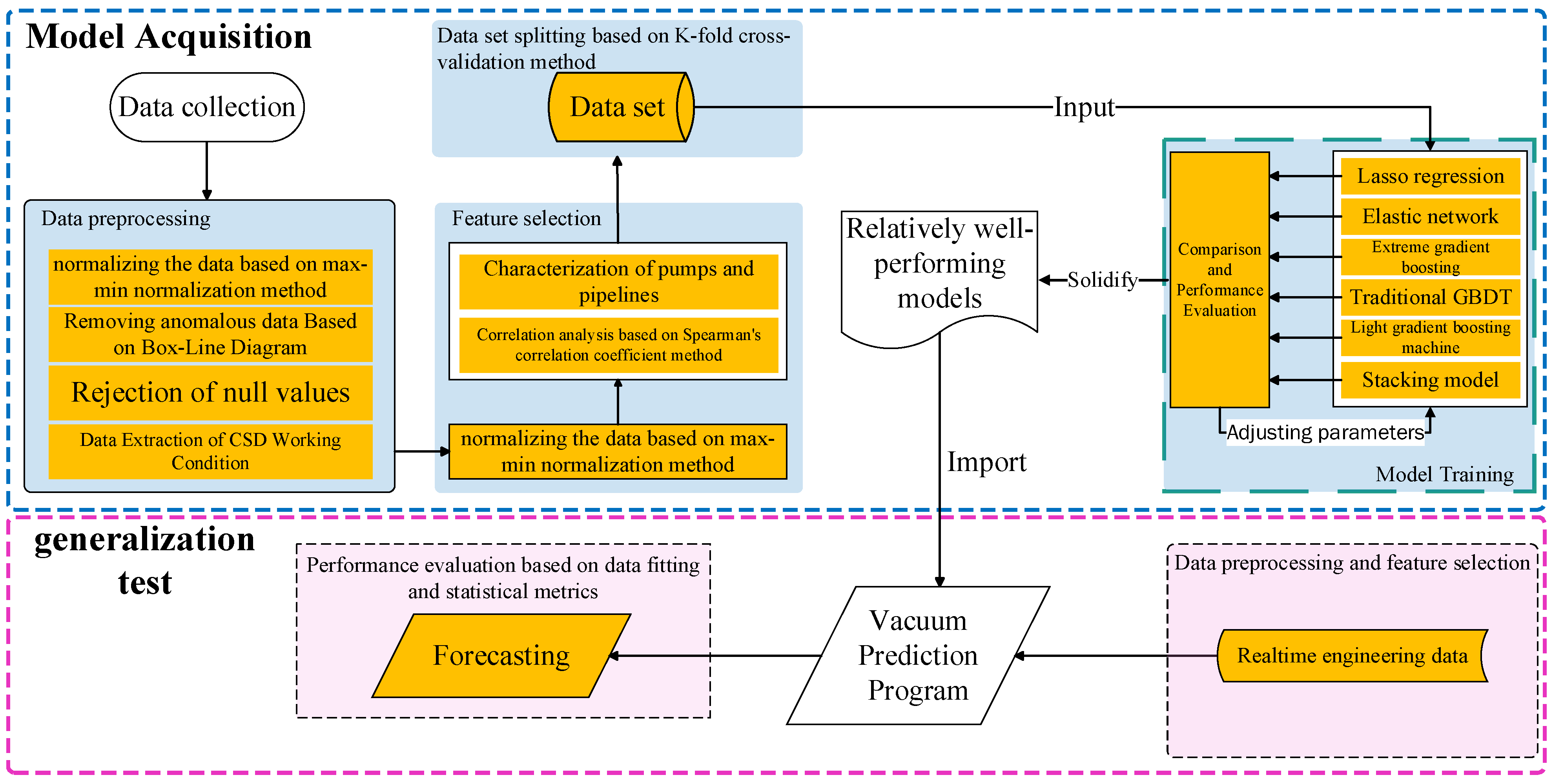
2.2. Methodology
3. Data Preprocessing
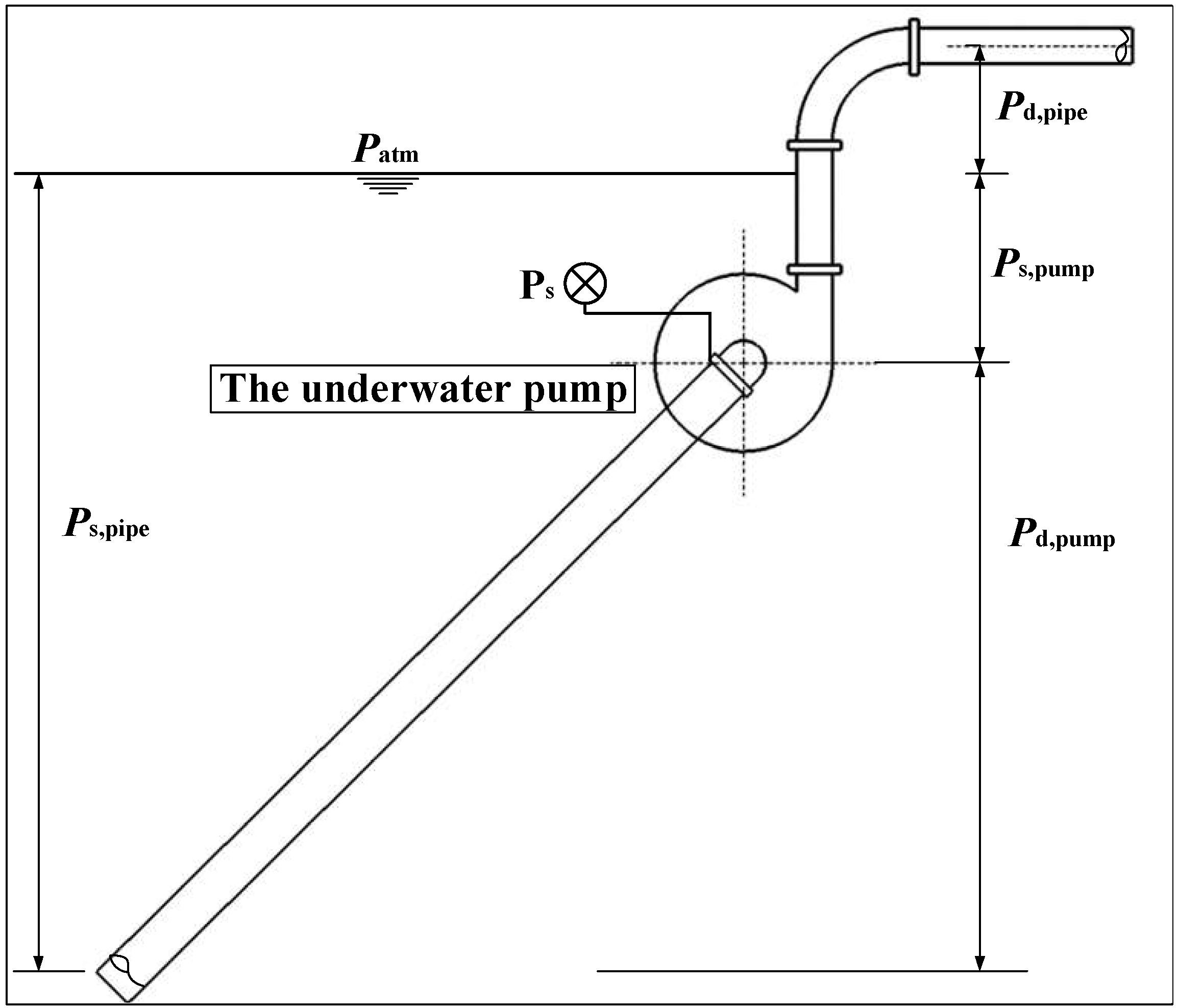
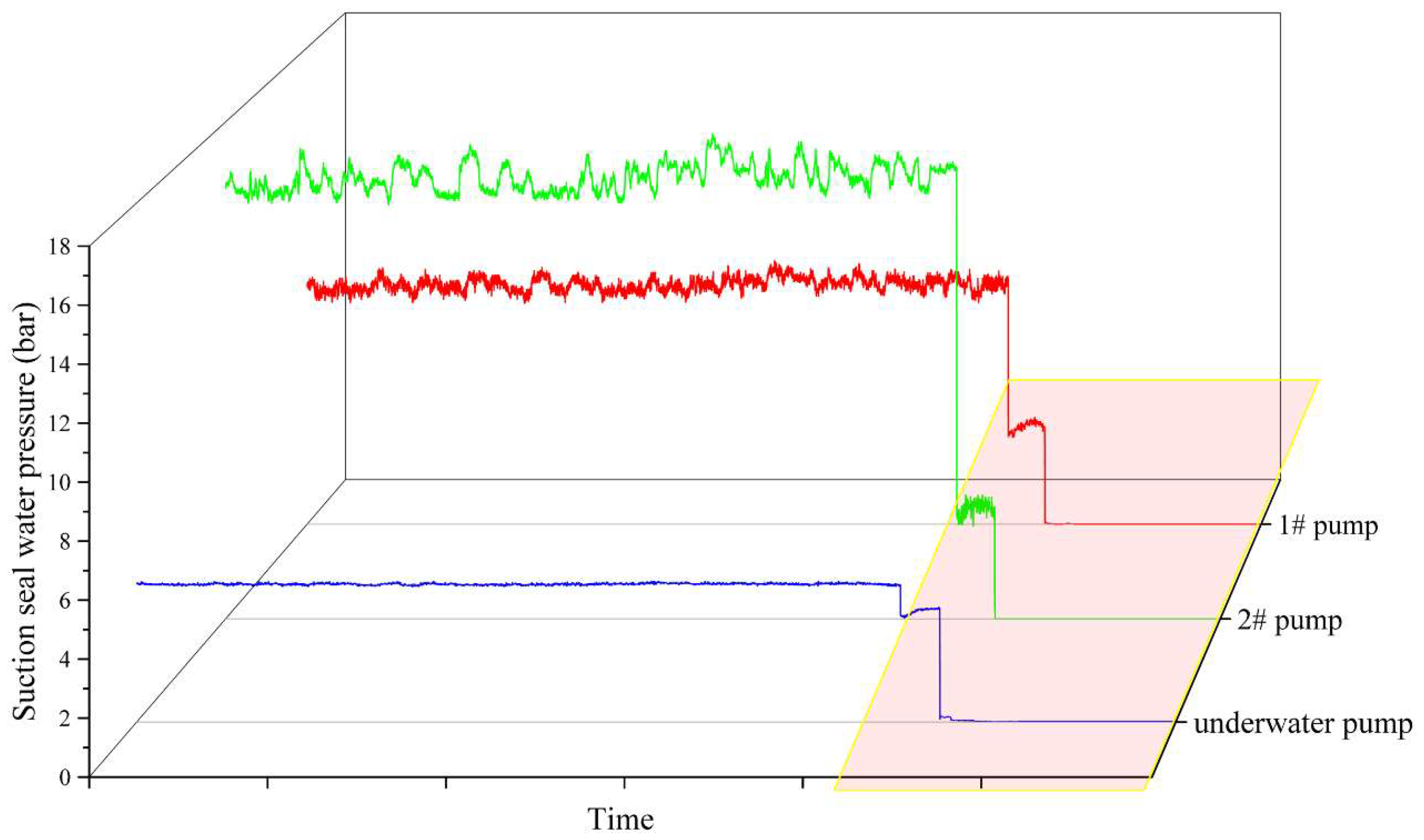
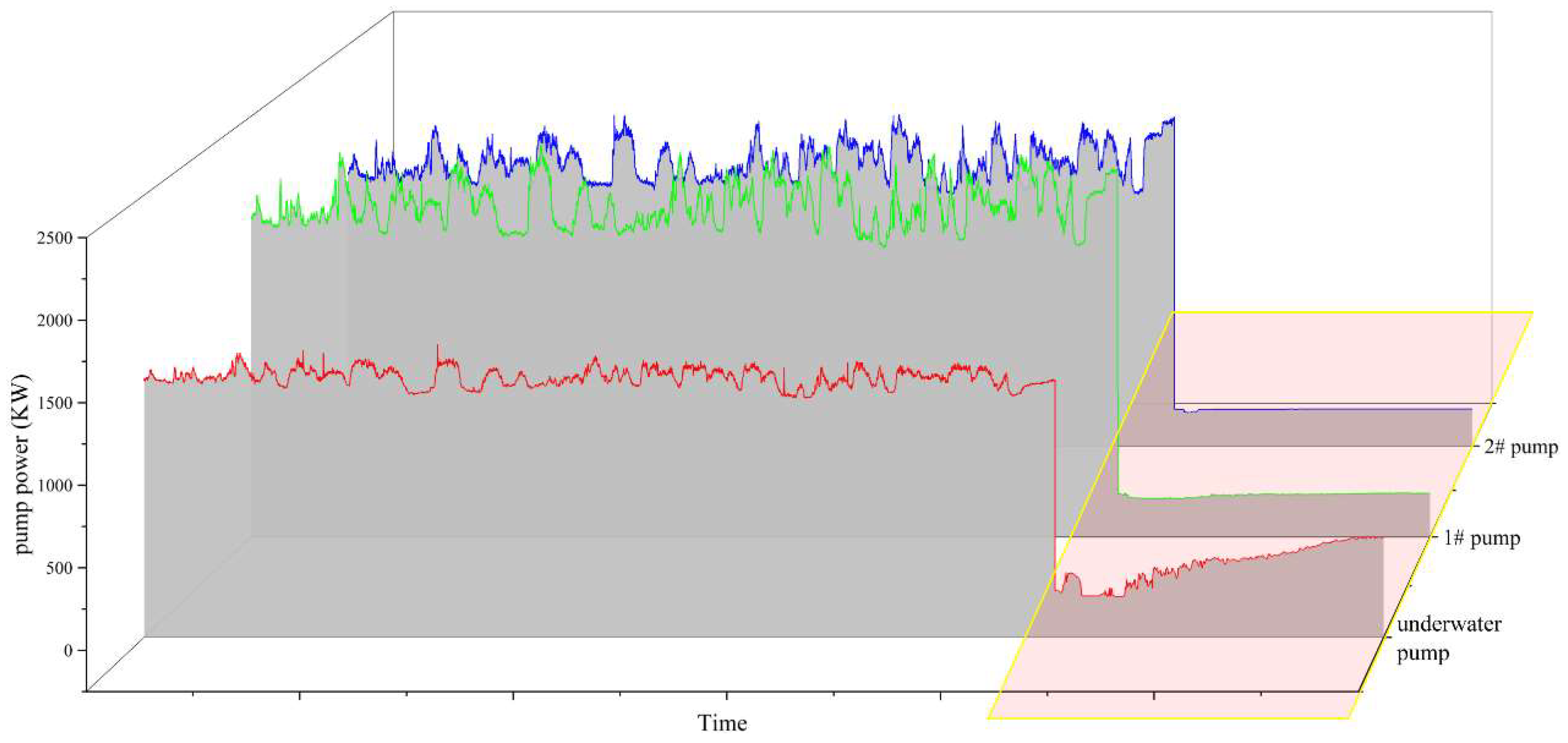
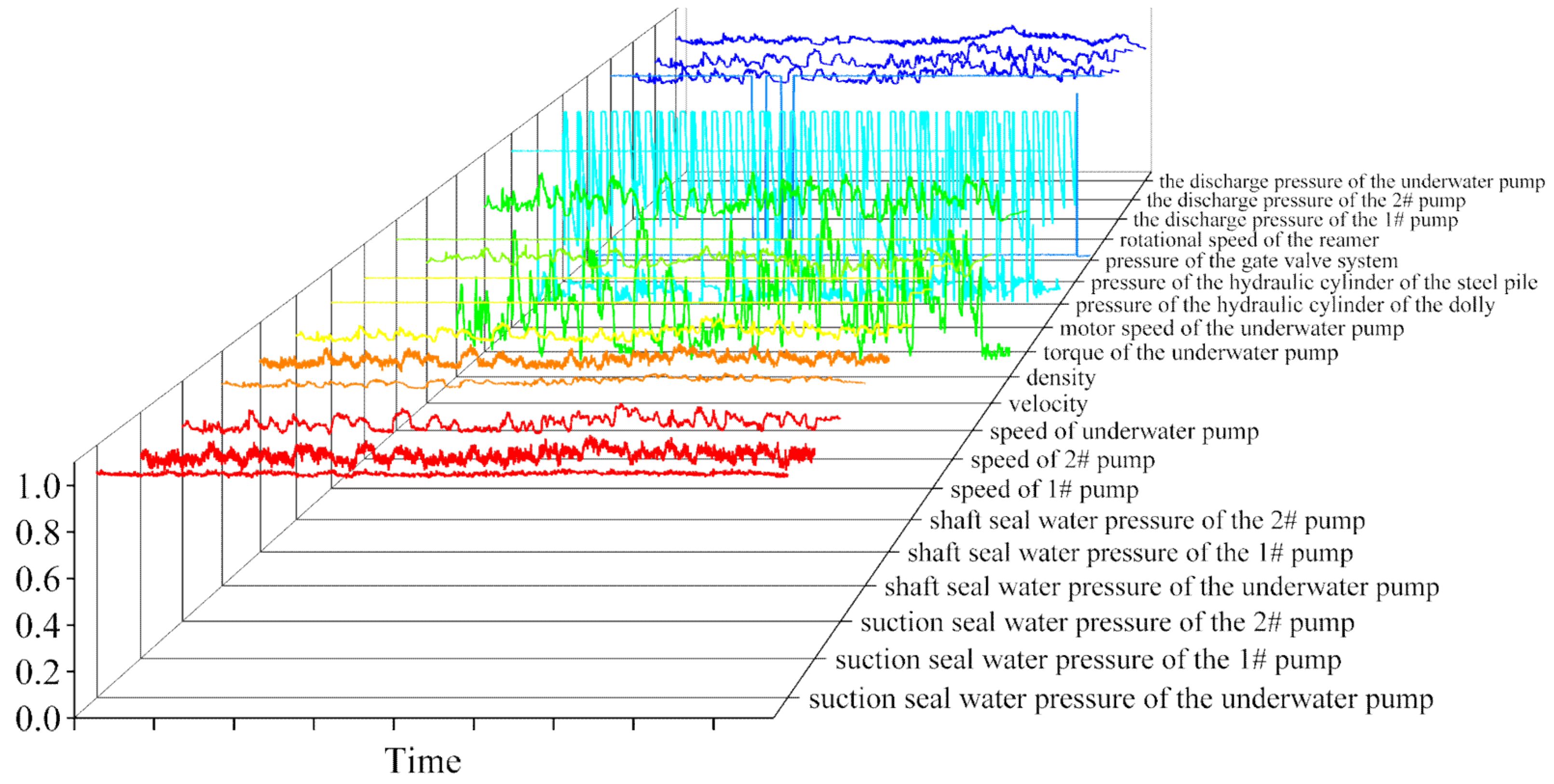
3.1. Data Observation and Extraction
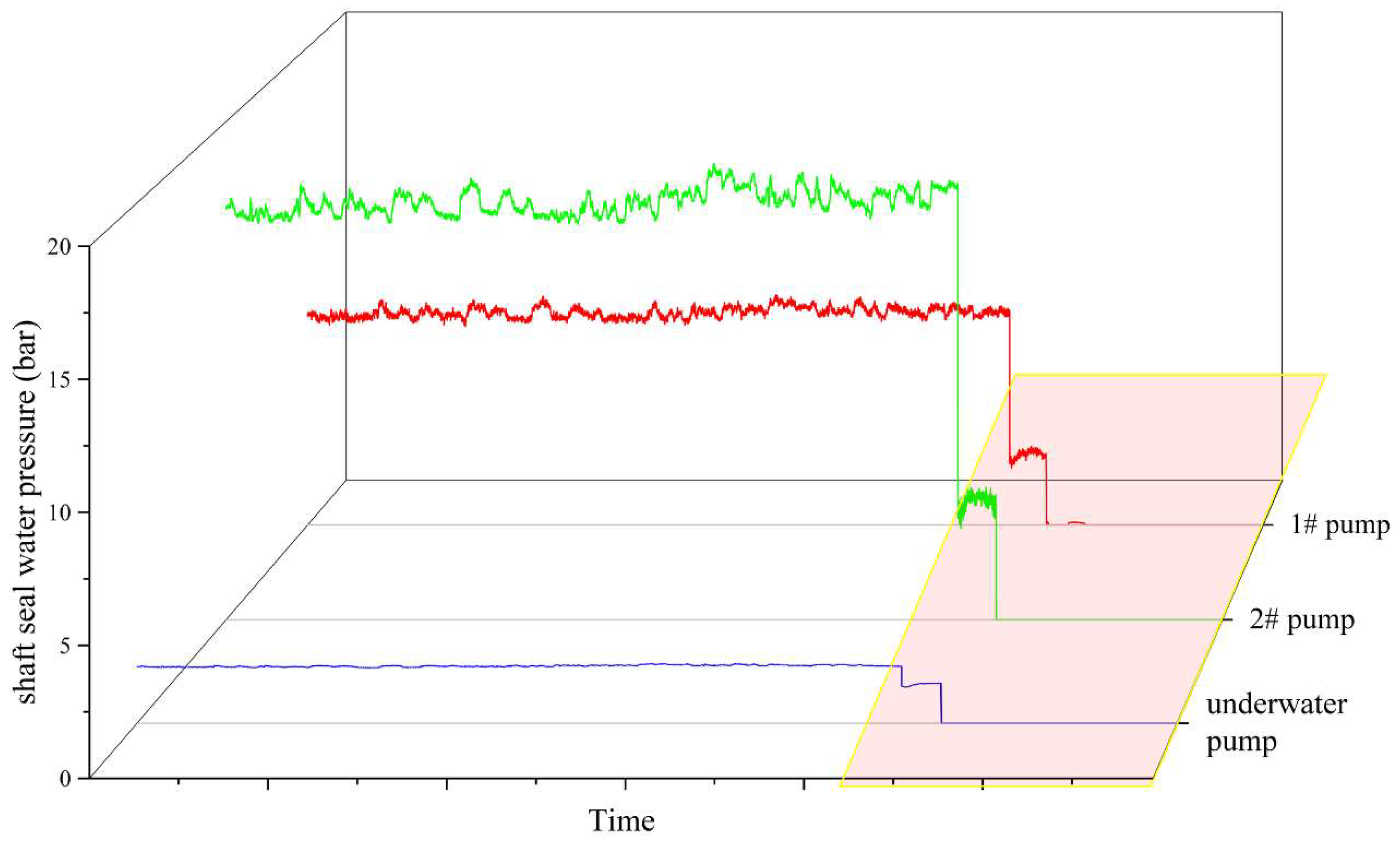
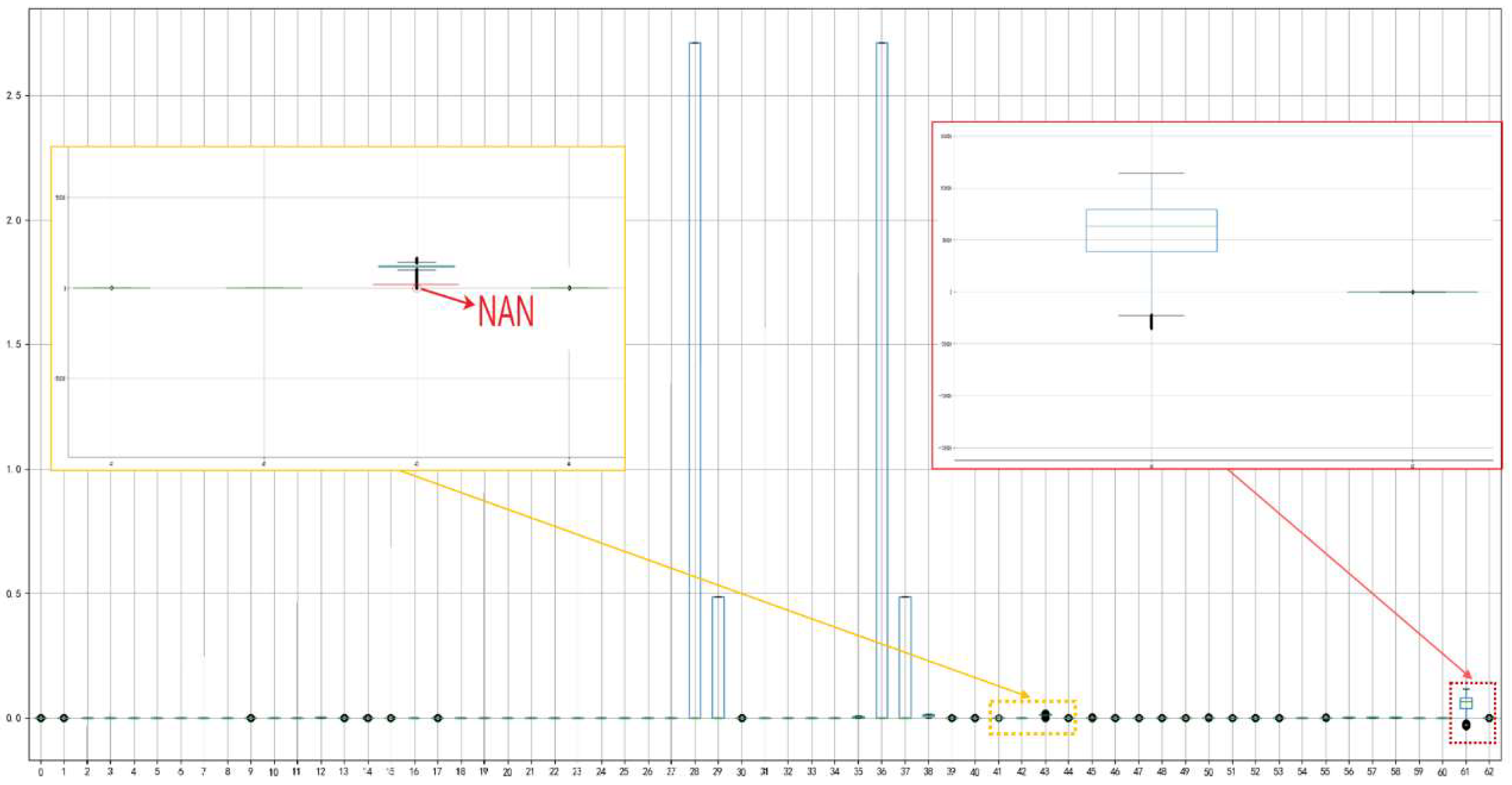
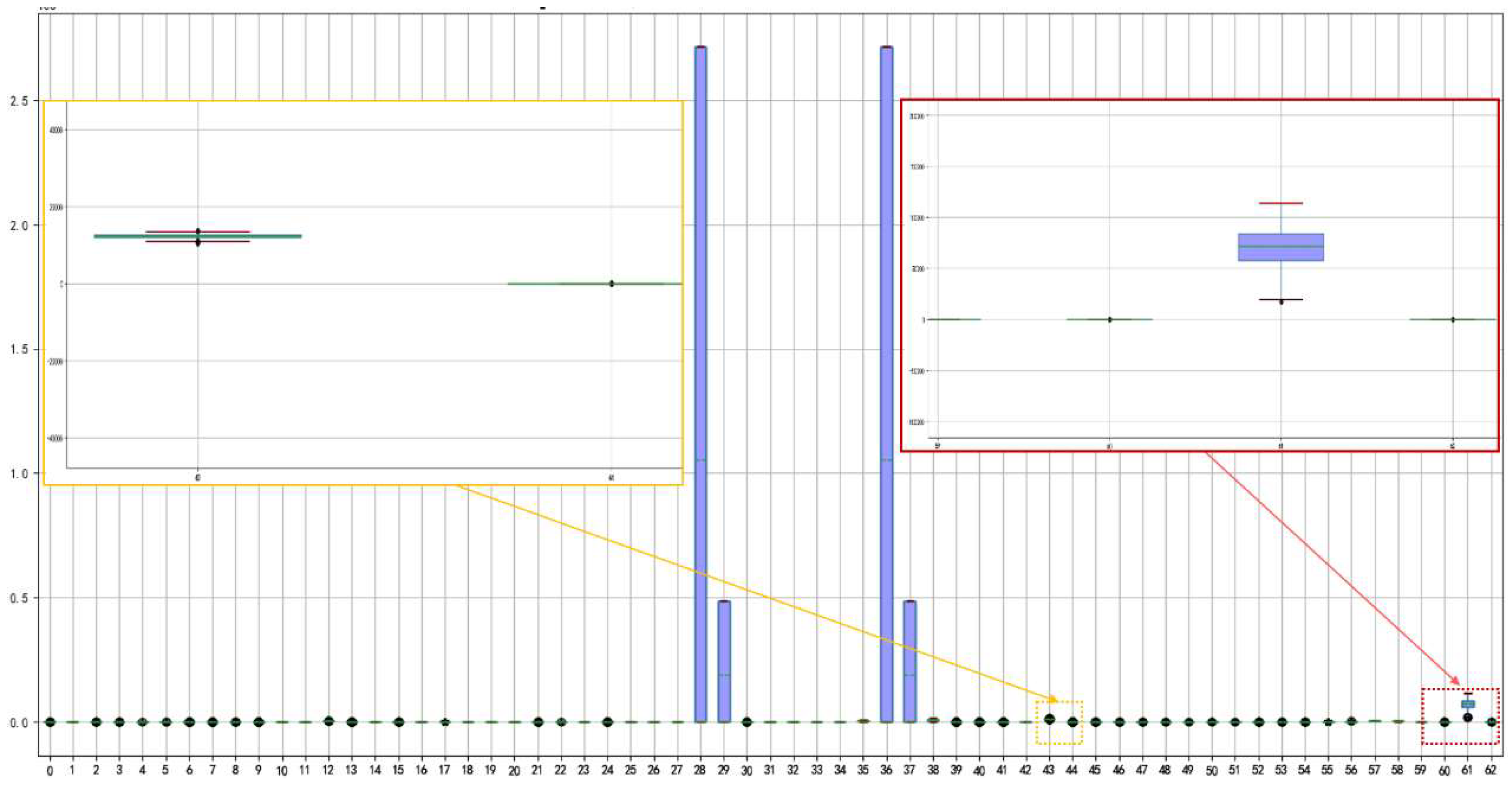
3.2. Handling of Missing Values and Outliers
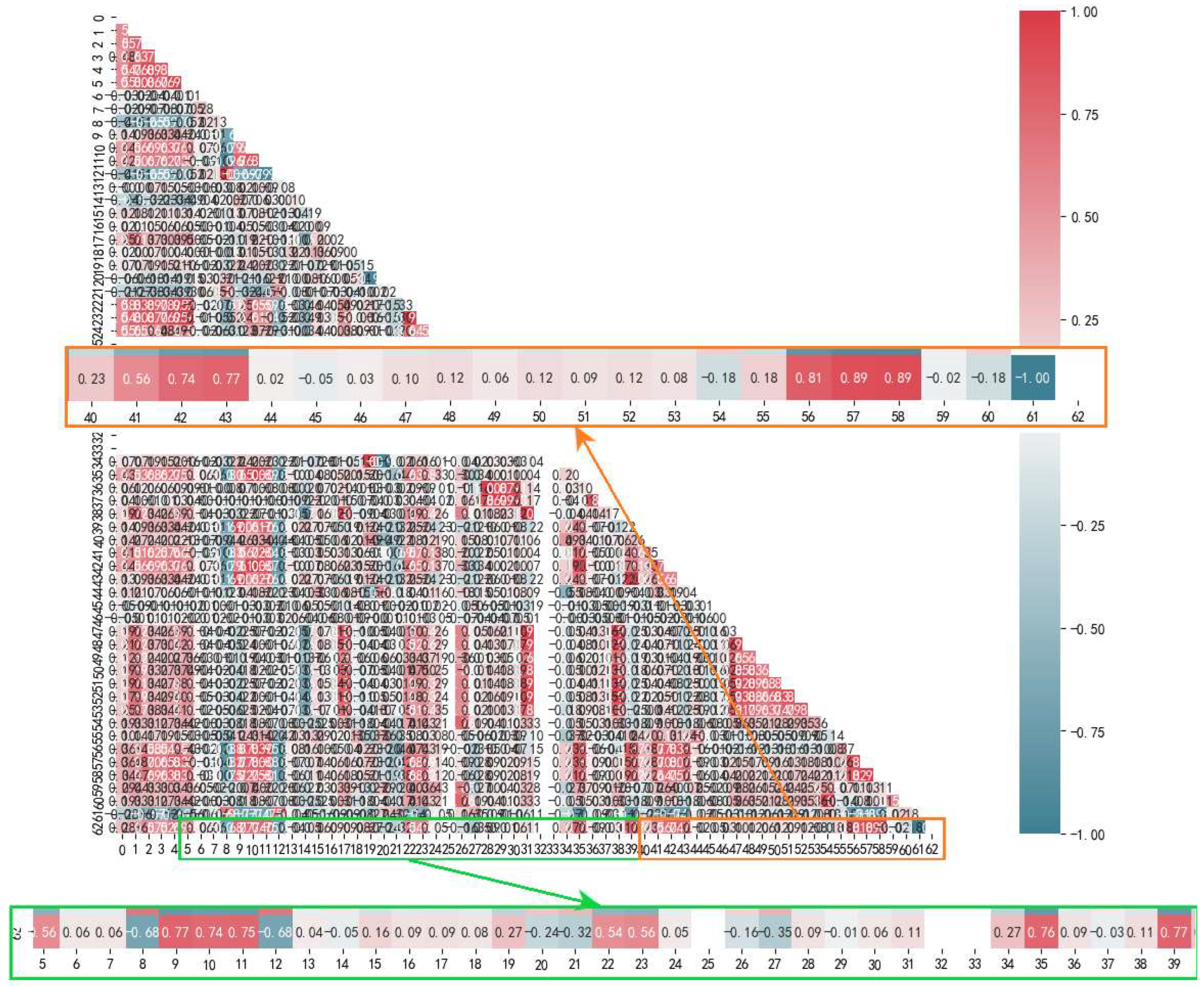
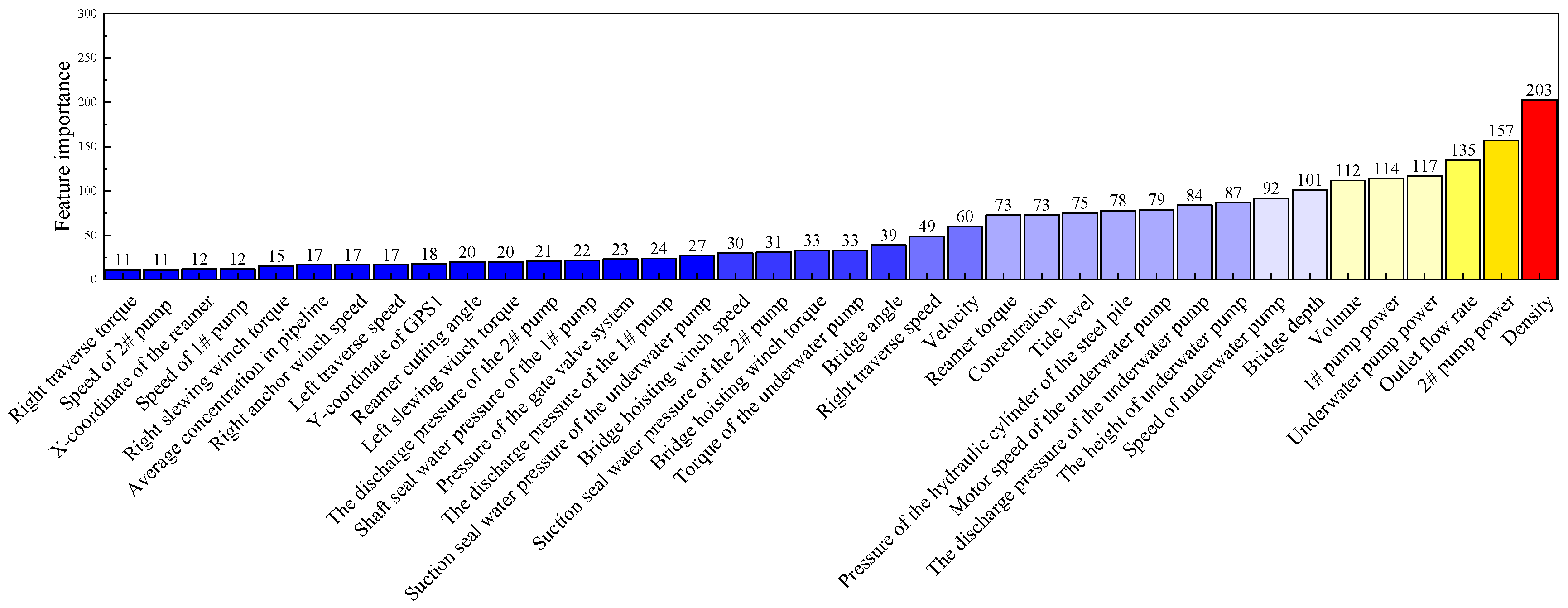
4. Correlation Analysis and Feature Selection
4.1. Data Normalization
4.2. Correlation Analysis
5. Model Training and Evaluation
5.1. Data Splitting
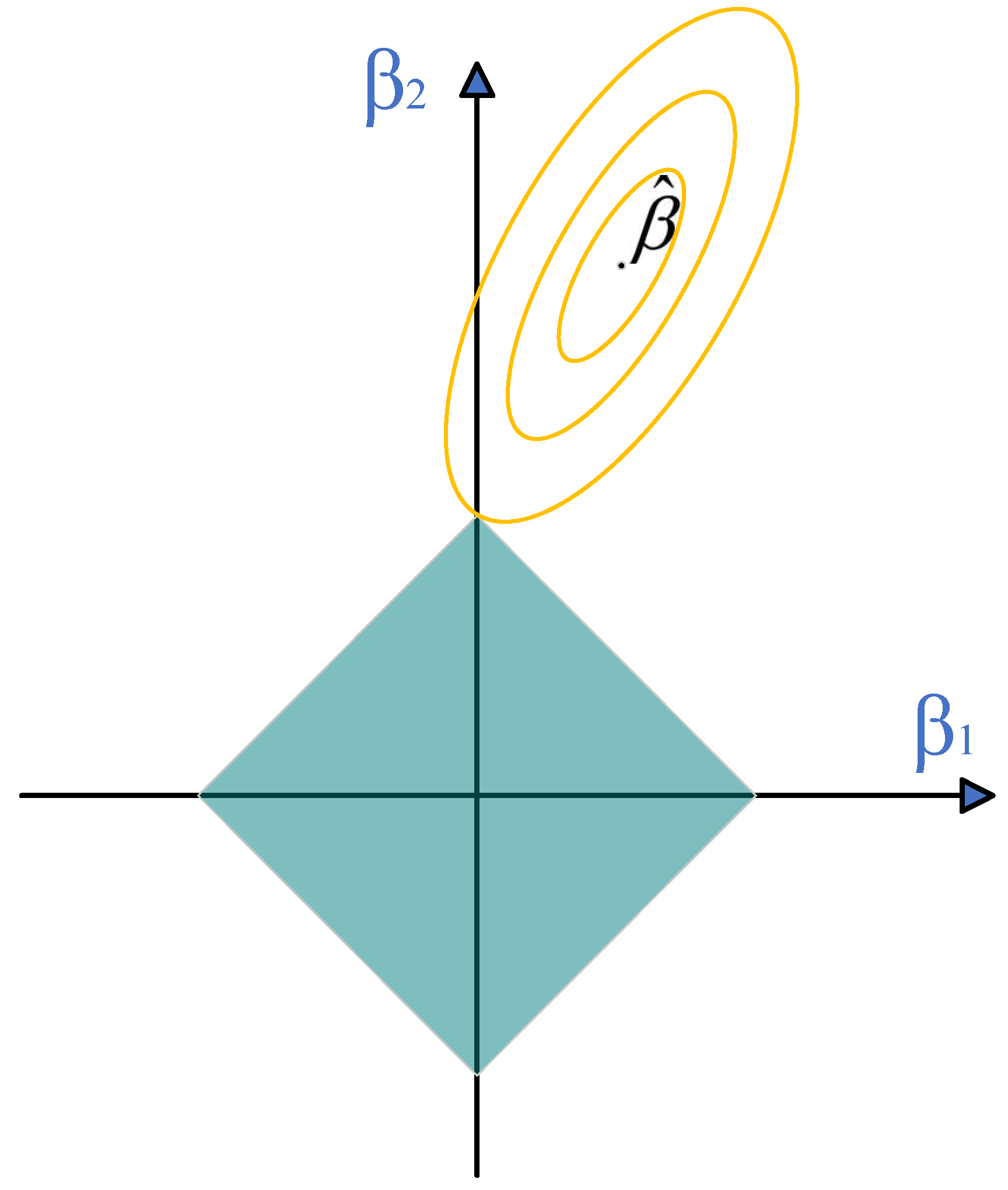
5.2. Lasso Regression
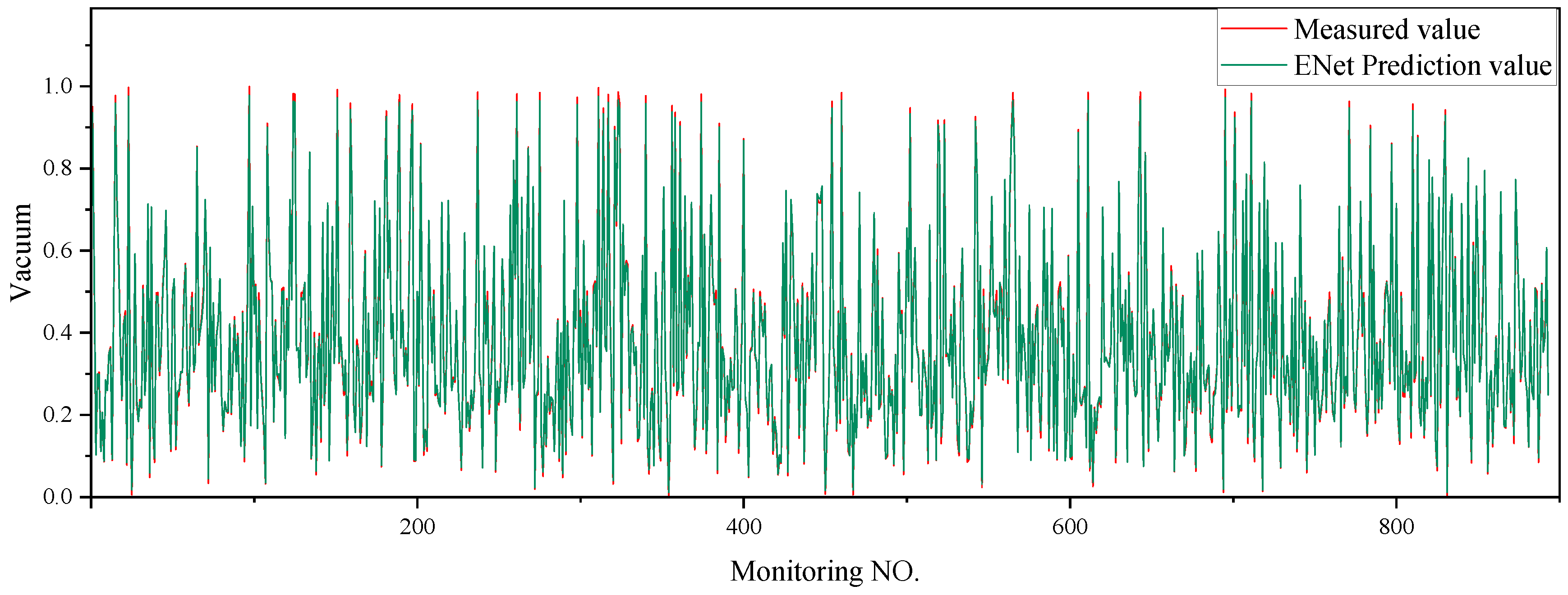
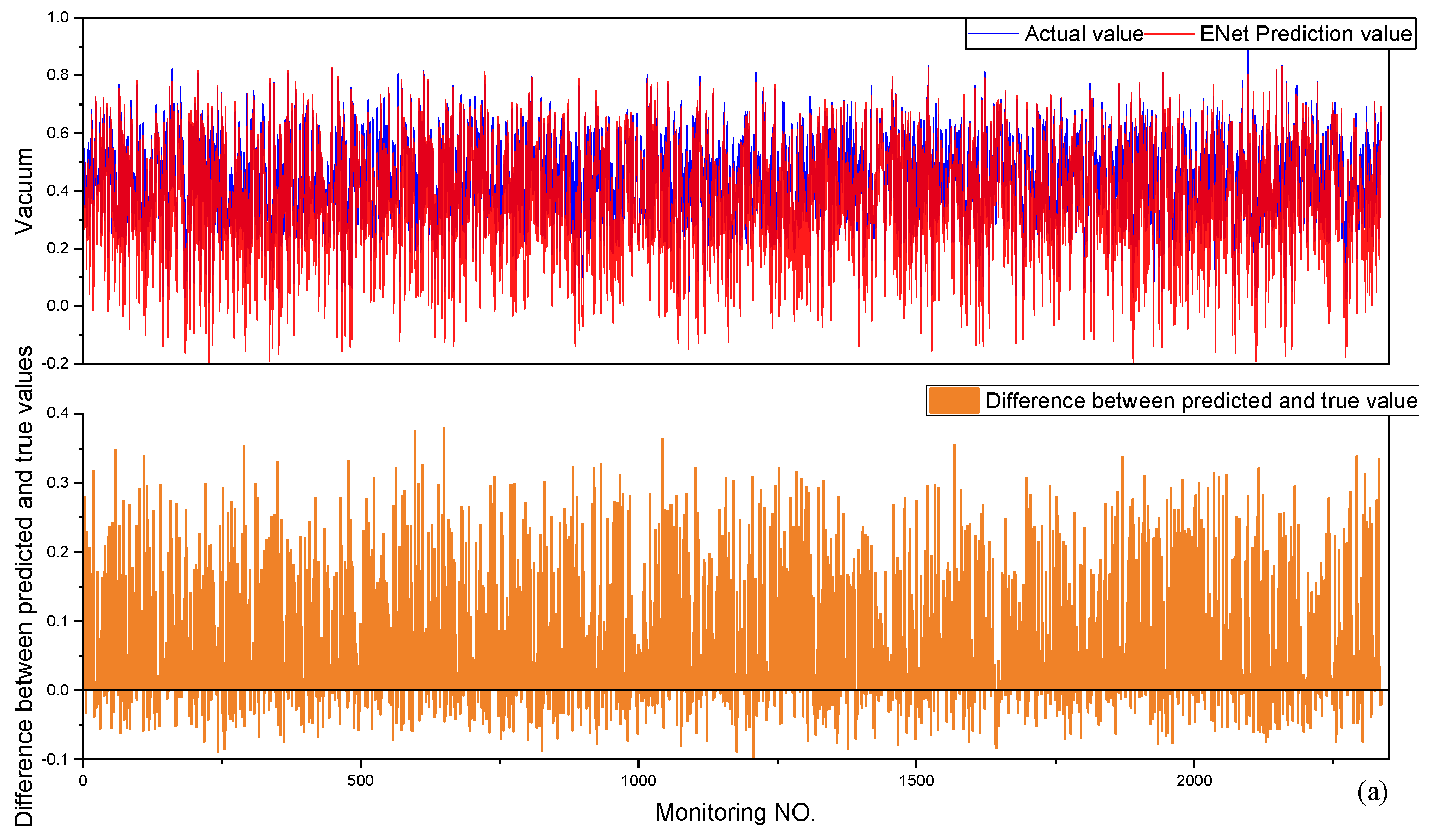
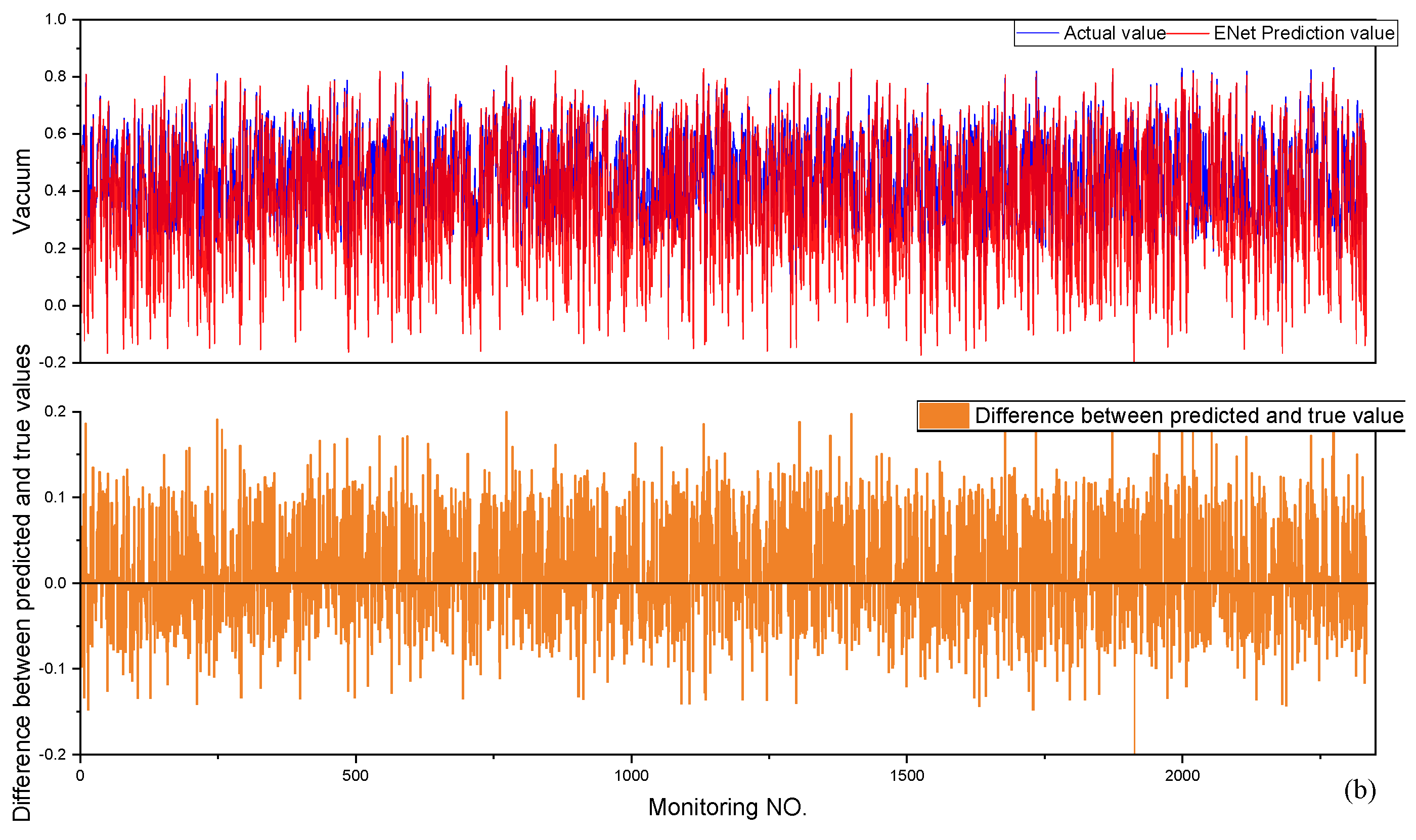
5.3. Elastic Network
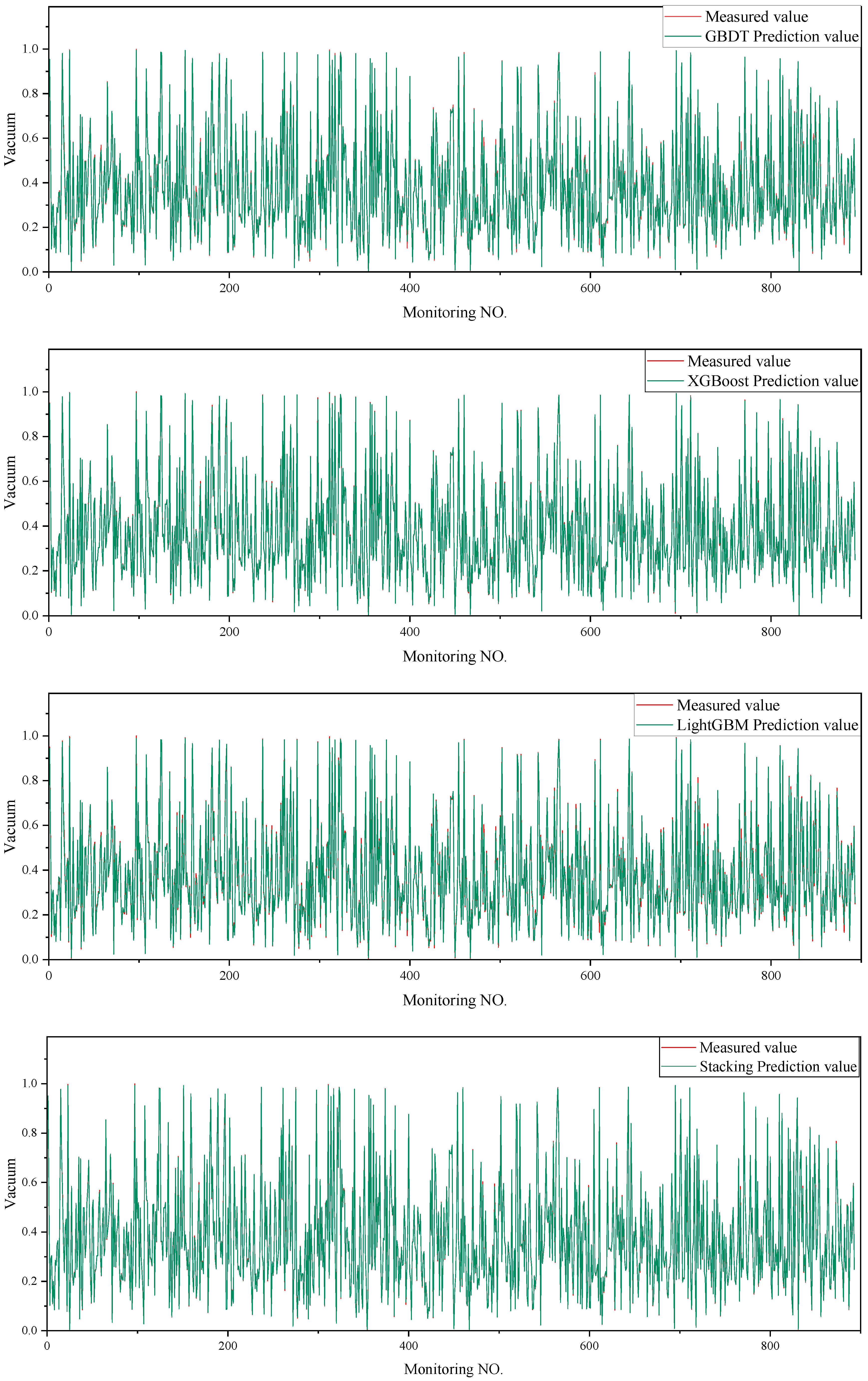
5.4. Traditional GBDT
- (1)
- For each sample (i = 1, 2 …, N), the residuals are calculated by:
- (2)
- The residuals obtained in the previous step are used as the new true values of the samples, and the data (i = 1, 2, …) are substituted to obtain a new regression tree, whose corresponding leaf node region is (j = 1, 2, …), where J is the number of leaf nodes of the regression tree t.
- (3)
- The best fit for the leaf region is calculated as follows:
- (4)
- The Strong Learner is updated as follows:
- (5)
- The Final Learner is calculated as follows:
5.5. Extreme Gradient Boosting
5.6. Light Gradient Boosting Machine
- (1)
- Introduction of the histogram algorithm. Continuous floating-point eigenvalues will be discretized into K integers, and at the same time, a histogram of width K will be constructed. When traversing the data, the discretized values will be used as indexes to accumulate statistics in the histogram. After traversing the data once, the histogram will be able to accumulate the required statistics, and then it will be traversed to find the optimal segmentation point according to the discrete values of the histogram [21].
- (2)
- Accelerated tree construction with the help of histogram difference. The histogram of a leaf can be obtained by the difference between the histogram of its father node and the histogram of its brother, which makes LightGBM twice as quick as other methods.
- (3)
- Leaf-wise leaf growth strategy with depth limitation. Most GBDT tools use the inefficient level-wise decision tree growth strategy to treat leaves in the same layer indiscriminately, which brings a lot of unnecessary overhead. In fact, many leaves have low splitting gain, and there is no need to search and split them, while LightGBM uses a depth-constrained grow-by-leaf algorithm.
- (4)
- One-sided gradient sampling algorithm. LightGBM is an algorithm that can better balance the amount of data and accuracy, from the point of view of reducing samples, excluding most of the small gradient samples, and using only the remaining samples to calculate the information gain.
- (5)
- Mutually exclusive feature bundling algorithm. LightGBM reduces the feature dimensions by means of feature bundling to improve computational efficiency. Usually, the bundled features are mutually exclusive, so that two bundled features will not lose information [22].
5.7. Stacking Model
6. Analysis of Results of Model Training
6.1. Model Parameter Optimization
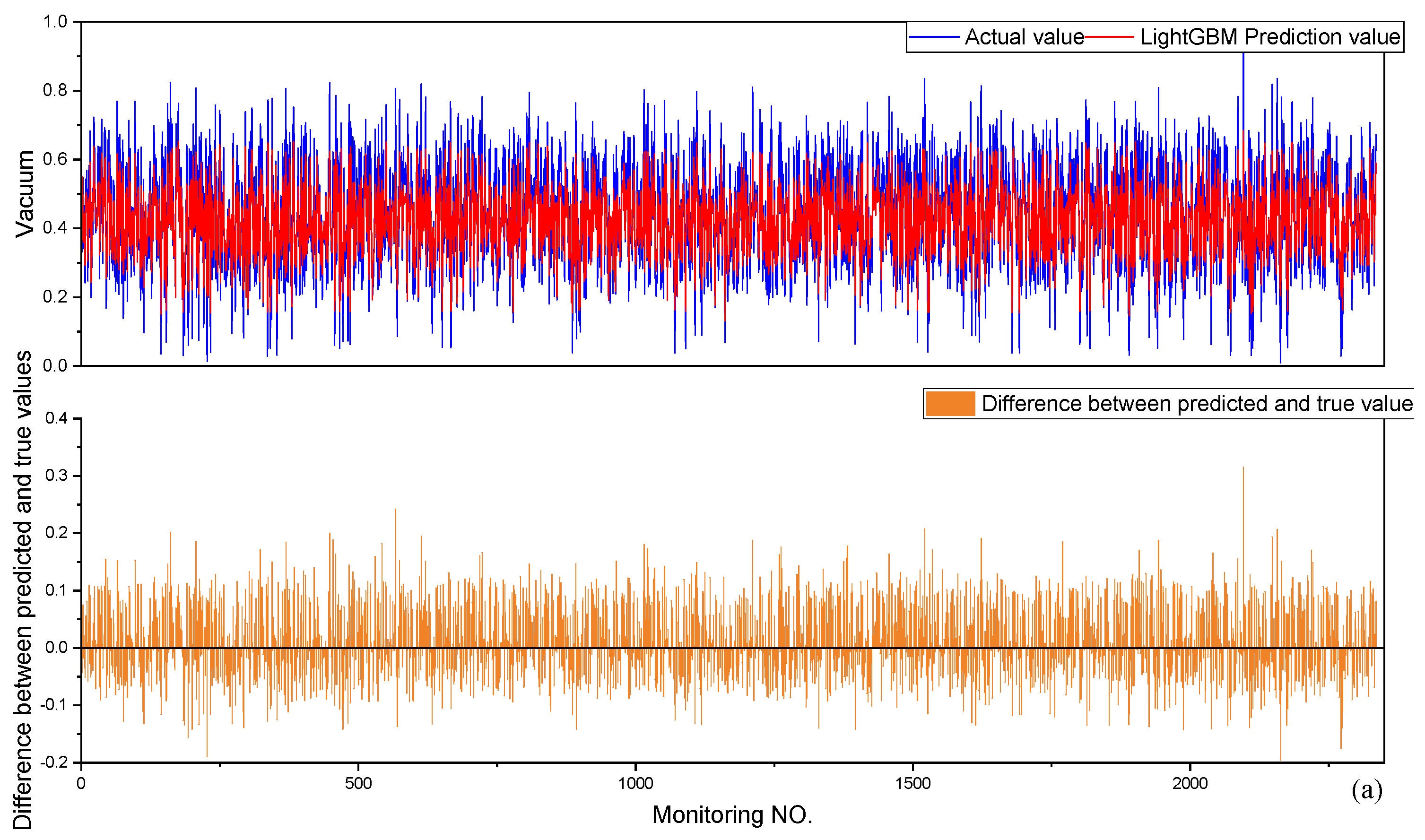
6.2. Model Evaluation
7. Model Generalization Capability Assessment and Application Methods
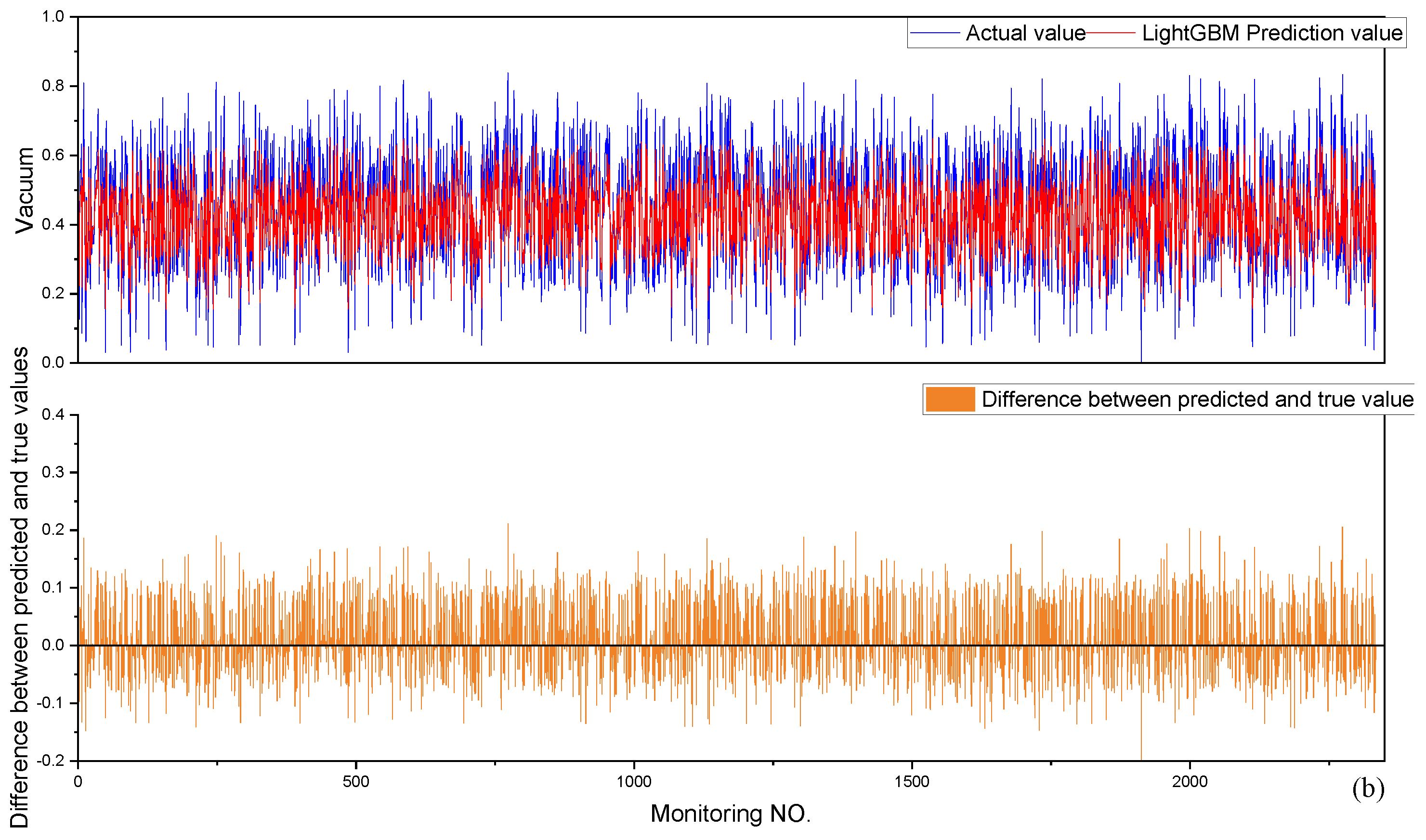
7.1. Assessment of Generalization Capacity
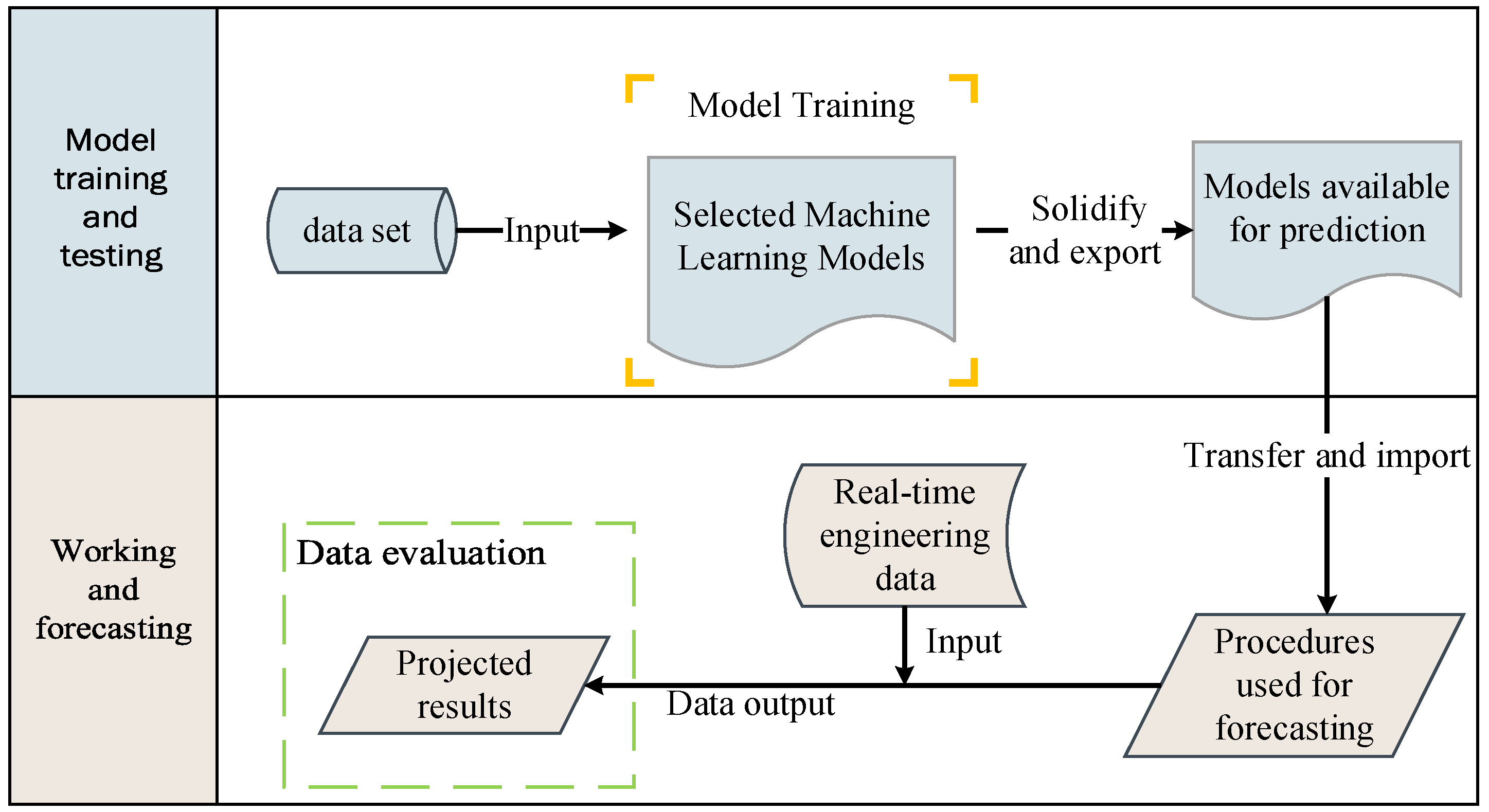
7.2. Engineering Methods
8. Conclusions
- (1)
- In this paper, theoretical engineering experience and Spearman’s correlation coefficient were jointly introduced into the feature selection process to reduce the dimensionality of the data;
- (2)
- This research included several rounds of training and testing similar to the work mentioned in this paper using several different datasets, and in the evaluation phase, we found that the results were similar to the experimental results presented in this paper, which supports the use of the model selection scheme we propose;
- (3)
- The results of the analysis in this study show that the main factors influencing the change in the vacuum level of the underwater pump of the CSD are the density, the flow rate, the bridge depth, the 1# pump power, the 2# pump power, the underwater pump power, the speed of the underwater pump and the height of the underwater pump;
- (4)
- In this paper, we propose evaluating the generalization ability based on the preferred model. We compared the generalization ability of the models with better performance in model training, and verified that LightGBM is suitable for predicting the vacuum level of the underwater pump of a CSD, as well as verifying the engineering feasibility of the method;
- (5)
- This paper proposes an engineering method for predicting the vacuum level of the underwater pump of a suction dredger based on the analyzed data, and also accordingly proposes a feasible engineering application scheme.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wang, B.; Fan, S.D.; Jiang, P.; Xing, T.; Fang, Z.L.; Wen, Q. Research on predicting the productivity of cutter suction dredgers based on data mining with model stacked generalization. Ocean Eng. 2020, 217, 108001. [Google Scholar] [CrossRef]
- Bai, S.; Li, M.C.; Kong, R.; Han, S.; Li, H.; Qin, L. Data mining approach to construction productivity prediction for cutter suction dredgers. Autom. Constr. 2019, 105, 102833. [Google Scholar] [CrossRef]
- Li, M.C.; Lu, Q.R.; Bai, S.; Zhang, M.X.; Tian, H.J.; Qin, L. Digital twin-driven virtual sensor approach for safe construction operations of trailing suction hopper dredger. Autom. Constr. 2021, 132, 103961. [Google Scholar] [CrossRef]
- Han, S.; Li, H.; Li, M.C.; Tian, H.J.; Qin, L.; Yu, Y.; Ma, J. Intelligent short-term forecasting for mud concentration in CSD dredging construction. Ocean Eng. 2022, 266, 113151. [Google Scholar] [CrossRef]
- Booyse, W.; Wilke, D.N.; Heyns, S. Deep digital twins for detection, diagnostics and prognostics. Mech. Syst. Signal Process. 2020, 140, 106612. [Google Scholar] [CrossRef]
- Shang, G.; Xu, L.Y.; Tian, J.Z.; Cai, D.W.; Xu, Z.; Zhou, Z. A real-time green construction optimization strategy for engineering vessels considering fuel consumption and productivity: A case study on a cutter suction dredger. Energy 2023, 274, 127326. [Google Scholar] [CrossRef]
- Lima, F.T.; Souza, V.M.A. A Large Comparison of Normalization Methods on Time Series. Big Data Res. 2023, 34, 100407. [Google Scholar] [CrossRef]
- Schober, P.; Boer, C.; Schwarte, L.A. Correlation Coefficients: Appropriate Use and Interpretation. Anesth. Analg. 2018, 126, 1763–1768. [Google Scholar] [CrossRef] [PubMed]
- Szmidt, E.; Kacprzyk, J.; Galichet, S.; Montero, J.; Mauris, G. The Spearman and Kendall rank correlation coefficients between intuitionistic fuzzy sets. In Proceedings of the 7th Conference of the European Society for Fuzzy Logic and Technology (EUSFLAT-2011) and LFA-2011, Aix-Les-Bains, France, 18–22 July 2011; pp. 521–528. [Google Scholar]
- Kou, G.; Lu, Y.Q.; Peng, Y.; Shi, Y. Evaluation of Classification Algorithms Using Mcdm and Rank Correlation. Int. J. Inf. Technol. Decis. Mak. 2012, 11, 197–225. [Google Scholar] [CrossRef]
- Xu, W.; Kang, Y.; Chen, L.; Wang, L.; Qin, C.; Zhang, L.; Liang, D.; Wu, C.; Zhang, W. Dynamic assessment of slope stability based on multi-source monitoring data and ensemble learning approaches: A case study of Jiuxianping landslide. Geol. J. 2023, 58, 2353–2371. [Google Scholar] [CrossRef]
- Liang, X.Y.; Jacobucci, R. Regularized Structural Equation Modeling to Detect Measurement Bias: Evaluation of Lasso, Adaptive Lasso, and Elastic Net. Struct. Equ. Model. A Multidiscip. J. 2020, 27, 722–734. [Google Scholar] [CrossRef]
- Liang, W.Z.; Luo, S.Z.; Zhao, G.Y.; Wu, H. Predicting Hard Rock Pillar Stability Using GBDT, XGBoost, and LightGBM Algorithms. Mathematics 2020, 8, 765. [Google Scholar] [CrossRef]
- Luo, X.; Xu, L.; Huang, P.; Wang, Y.; Liu, J.; Hu, Y.; Wang, P.; Kang, Z. Nondestructive Testing Model of Tea Polyphenols Based on Hyperspectral Technology Combined with Chemometric Methods. Agriculture 2021, 11, 673. [Google Scholar] [CrossRef]
- Wang, X.; Yang, Y.; Liu, J.; Wang, G. The stacking strategy-based hybrid framework for identifying non-coding RNAs. Brief. Bioinform. 2021, 22, bbab023. [Google Scholar] [CrossRef] [PubMed]
- Khan, A.Z. Regularization and Variable Selection via the Fixed-Shape Elastic Net and Exponential Norm. Master’s Thesis, King Fahd University of Petroleum and Minerals, Dhahran, Saudi Arabia, 2017. [Google Scholar]
- Zhang, W.; Wu, C.; Zhong, H.; Li, Y.; Wang, L. Prediction of undrained shear strength using extreme gradient boosting and random forest based on Bayesian optimization. Geosci. Front. 2021, 12, 469–477. [Google Scholar] [CrossRef]
- Chen, T.Q.; Guestrin, C.; Assoc Comp, M. XGBoost: A Scalable Tree Boosting System. In Proceedings of the KDD’16: The 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Zhou, J.; Qiu, Y.; Zhu, S.; Armaghani, D.J.; Khandelwal, M.; Mohamad, E.T. Estimation of the TBM advance rate under hard rock conditions using XGBoost and Bayesian optimization. Undergr. Space 2021, 6, 506–515. [Google Scholar] [CrossRef]
- Ke, G.L.; Meng, Q.; Finley, T.; Wang, T.F.; Chen, W.; Ma, W.D.; Ye, Q.W.; Liu, T.Y. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Hajihosseinlou, M.; Maghsoudi, A.; Ghezelbash, R. A Novel Scheme for Mapping of MVT-Type Pb-Zn Prospectivity: LightGBM, a Highly Efficient Gradient Boosting Decision Tree Machine Learning Algorithm. Nat. Resour. Res. 2023, 32, 2417–2438. [Google Scholar] [CrossRef]
- Goh, K.L.; Goto, A.; Lu, Y. LGB-Stack: Stacked Generalization with LightGBM for Highly Accurate Predictions of Polymer Bandgap. ACS Omega 2022, 7, 29787–29793. [Google Scholar] [CrossRef]
- Naimi, A.I.; Balzer, L.B. Stacked generalization: An introduction to super learning. Eur. J. Epidemiol. 2018, 33, 459–464. [Google Scholar] [CrossRef]
- Paz Sesmero, M.; Ledezma, A.I.; Sanchis, A. Generating ensembles of heterogeneous classifiers using Stacked Generalization. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2015, 5, 21–34. [Google Scholar] [CrossRef]
- Bai, S.; Li, M.; Song, L.; Ren, Q.; Qin, L.; Fu, J. Productivity analysis of trailing suction hopper dredgers using stacking strategy. Autom. Constr. 2021, 122, 103470. [Google Scholar] [CrossRef]
- Wang, B.; Fan, S.D.; Jiang, P.; Chen, Y.; Zhu, H.H.; Xiong, T. Cutting state estimation and time series prediction using deep learning for Cutter Suction Dredger. Appl. Ocean Res. 2023, 134, 103515. [Google Scholar] [CrossRef]
- Huang, H.; Li, J.; Yang, H.; Wang, B.; Gao, R.; Luo, M.; Li, W.; Zhang, G.; Liu, L. Research on prediction methods of formation pore pressure based on machine learning. Energy Sci. Eng. 2022, 10, 1886–1901. [Google Scholar] [CrossRef]
- Takele, Z.B.Z. Metaheuristic Based Stacked Generalization Algorithm. Master’s Thesis, State University of New York at Binghamton, Binghamton, NY, USA, 2018. [Google Scholar]
- Zhang, Y.; Wen, M.; Sun, Y.; Chen, H.; Cai, Y. Black Carbon Emission Prediction of Diesel Engine Using Stacked Generalization. Atmosphere 2022, 13, 1855. [Google Scholar] [CrossRef]
- Sandim, M.O. Using Stacked Generalization for Anomaly Detection. Master’s Thesis, Faculdade de Engenharia da Universidade do Porto, Porto, Portugal, 2017. [Google Scholar]






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Serial Number | Time | Shaft Seal Water Pressure of the Underwater Pump (Bar) | Suction Seal Water Pressure of the Underwater Pump (Bar) | … | Height of the Underwater Pump (m) | Suction Pressure (Pa) | Vacuum (Bar) |
|---|---|---|---|---|---|---|---|
| 1 | 2022-11-08 06:00:01 | 4.78 | 2.17 | … | 4.37 | 85,526.19 | 0.1559 |
| 2 | 2022-11-08 06:00:04 | 4.82 | 2.18 | … | 4.38 | 85,410.67 | 0.1570 |
| 3 | 2022-11-08 06:00:07 | 4.79 | 2.17 | … | 4.38 | 85,410.67 | 0.1570 |
| 4 | 2022-11-08 06:00:11 | 4.78 | 2.18 | … | 4.38 | 88,443.31 | 0.1271 |
| … | … | … | … | … | … | … | |
| 5955 | 2022-11-08 11:59:54 | 0.02 | 0 | … | −6.61 | −33,717.80 | 1.3327 |
| 5956 | 2022-11-08 11:59:57 | 0.02 | 0 | … | −6.62 | −34,557.10 | 1.3410 |
| 5957 | 2022-11-08 12:00:00 | 0.02 | 0 | … | −6.61 | −34,791.47 | 1.3433 |
| Model | Parameters |
|---|---|
| Lasso | α = 0.1; max_iter = 50 |
| Enet | α = 0.01; L1_ratio = 0.003; random_state = 3 |
| GBDT | rate = 0.05; max_depth = 4; n_estimators = 3000 |
| XGBoost | rate = 0.05; max_depth = 3; n_estimators = 2200 |
| LightGBM | rate = 0.05; n_estimators = 720; max_bin = 55; num_leaves = 5 |
| Modal | MAE | RMSE | Time | |
|---|---|---|---|---|
| Lasso | −0.000791 | 0.128561 | 0.160684 | 0.00099 |
| ENET | 0.997402 | 0.006231 | 0.008186 | 0.0360 |
| GBDT | 0.995463 | 0.008021 | 0.010819 | 12.7307 |
| XGBoost | 0.987243 | 0.012969 | 0.018142 | 0.4404 |
| LightGBM | 0.995764 | 0.008163 | 0.010454 | 0.1225 |
| Stacking | 0.997833 | 0.128561 | 0.007478 | 11.8235 |
| Model | MAE | RMSE | MSE | |
|---|---|---|---|---|
| ENET | 0.45282 | 0.09224 | 0.12548 | 0.01574 |
| 0.46916 | 0.09191 | 0.12522 | 0.01568 | |
| LightGBM | 0.82507 | 0.05839 | 0.07095 | 0.005034 |
| 0.82427 | 0.05991 | 0.07204 | 0.005190 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, H.; Yuan, Z.; Wang, W.; Chen, S.; Jiang, P.; Wei, W. Data-Driven Method for Vacuum Prediction in the Underwater Pump of a Cutter Suction Dredger. Processes 2024, 12, 812. https://doi.org/10.3390/pr12040812
Chen H, Yuan Z, Wang W, Chen S, Jiang P, Wei W. Data-Driven Method for Vacuum Prediction in the Underwater Pump of a Cutter Suction Dredger. Processes. 2024; 12(4):812. https://doi.org/10.3390/pr12040812
Chicago/Turabian StyleChen, Hualin, Zihao Yuan, Wangming Wang, Shuaiqi Chen, Pan Jiang, and Wei Wei. 2024. "Data-Driven Method for Vacuum Prediction in the Underwater Pump of a Cutter Suction Dredger" Processes 12, no. 4: 812. https://doi.org/10.3390/pr12040812