
Capability Indices for Digitized Industries: A Review and Outlook of Machine Learning Applications for Predictive Process Control


Abstract
:1. Introduction
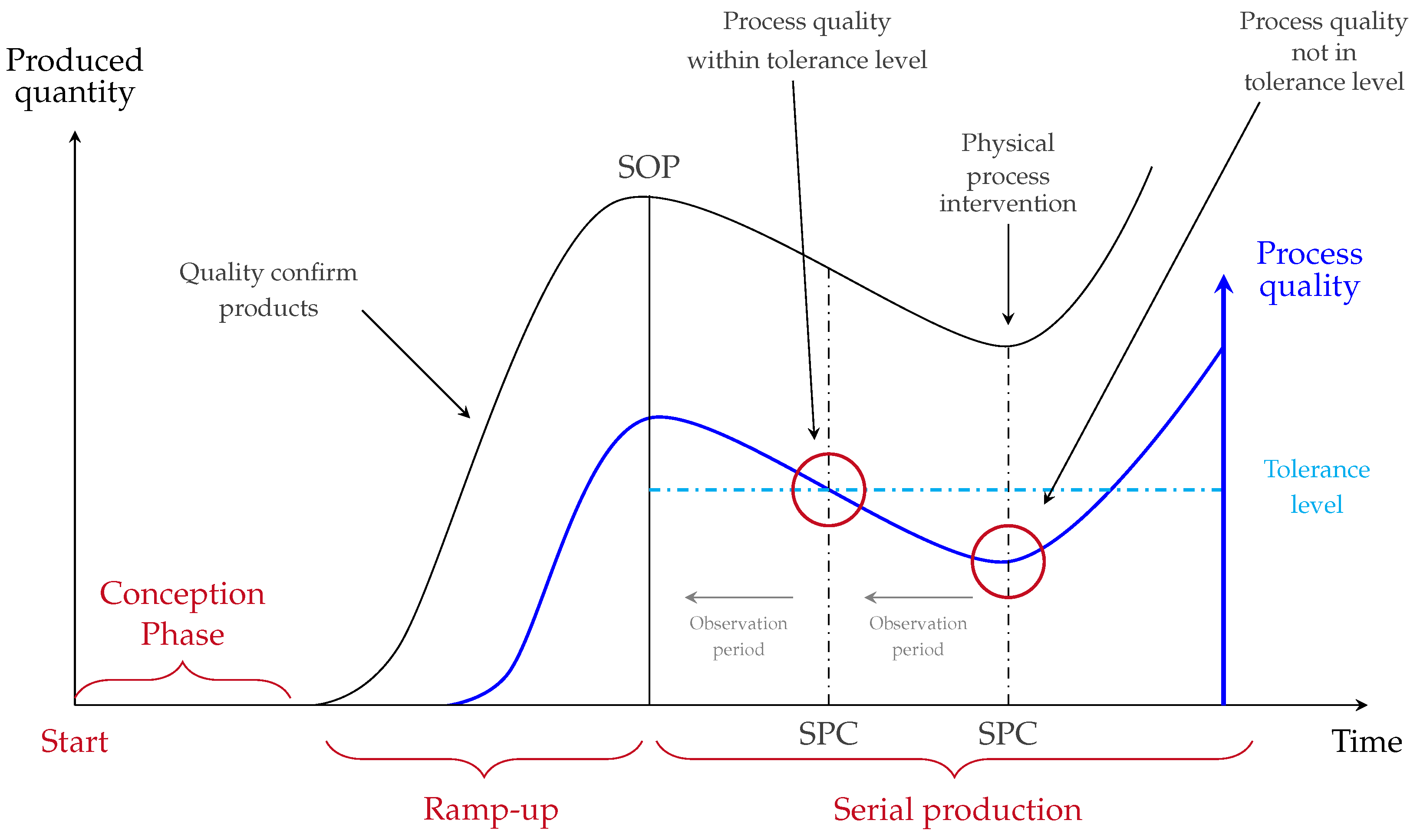
2. Background
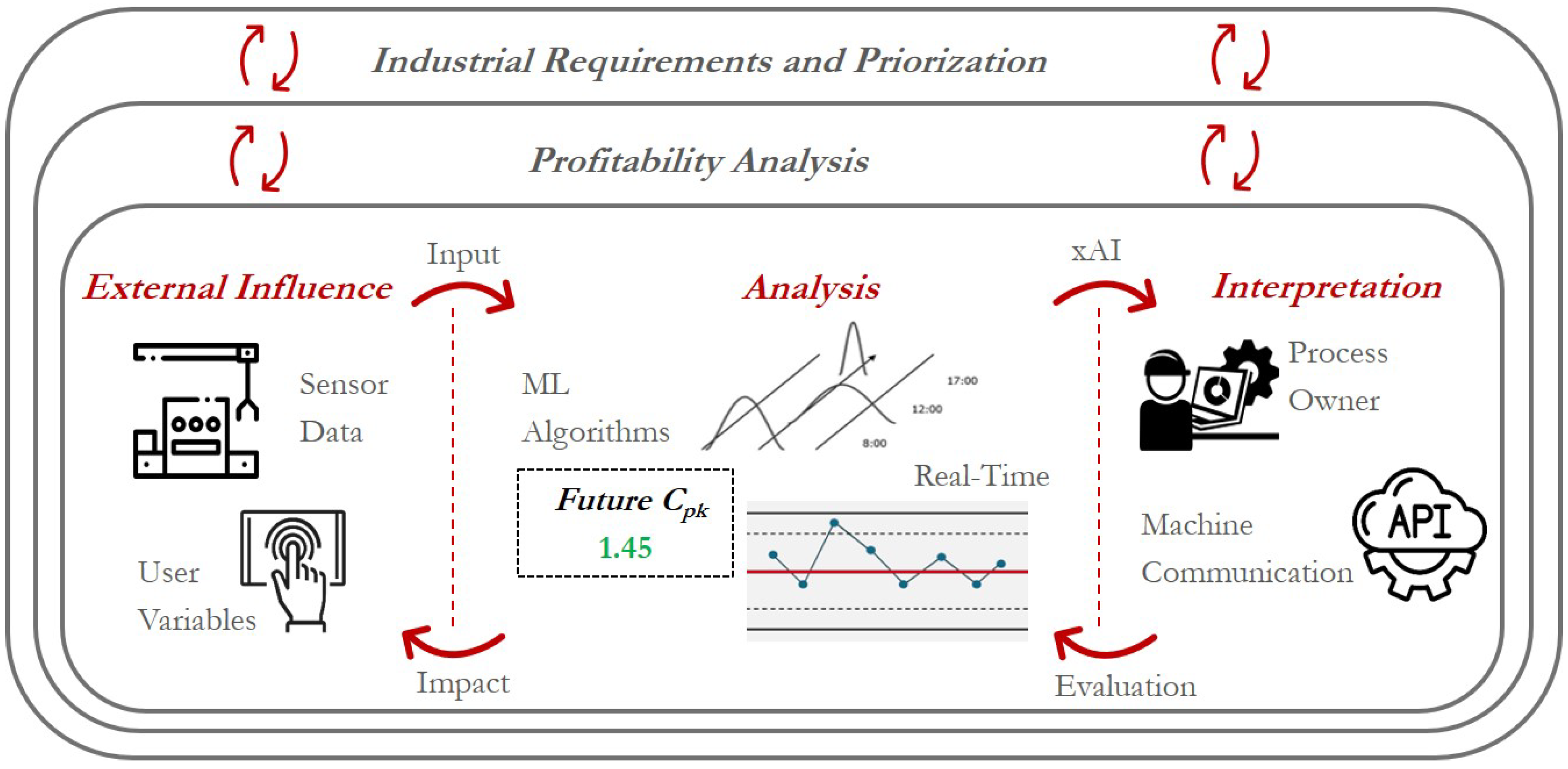
2.1. Interpretation of ML Applications in the Context of PPC
2.2. Scope and Aim of the Study
3. Methodology
4. Results
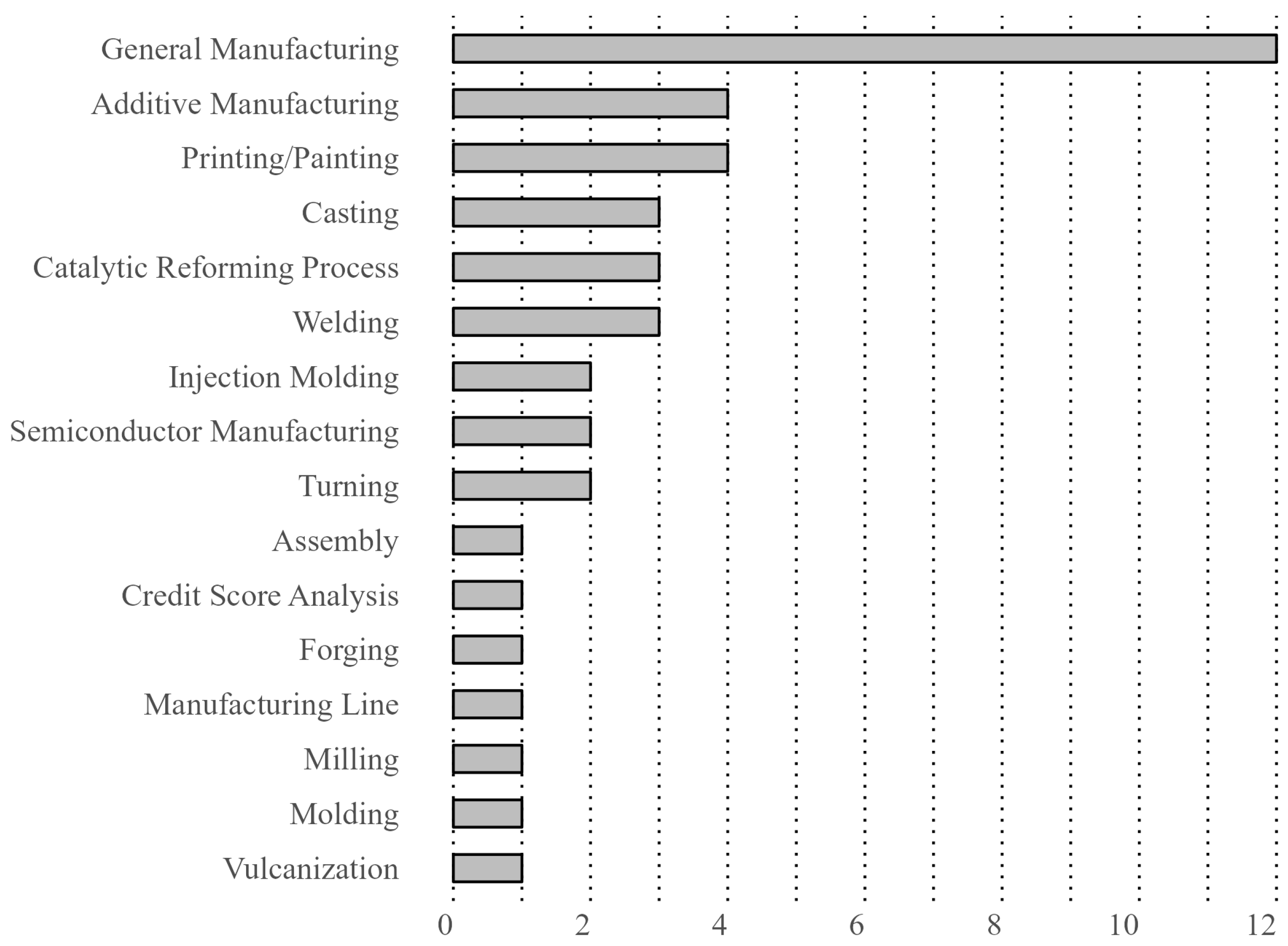
4.1. Industries
4.2. Data
4.3. Design of Experiments
4.4. Methodologies
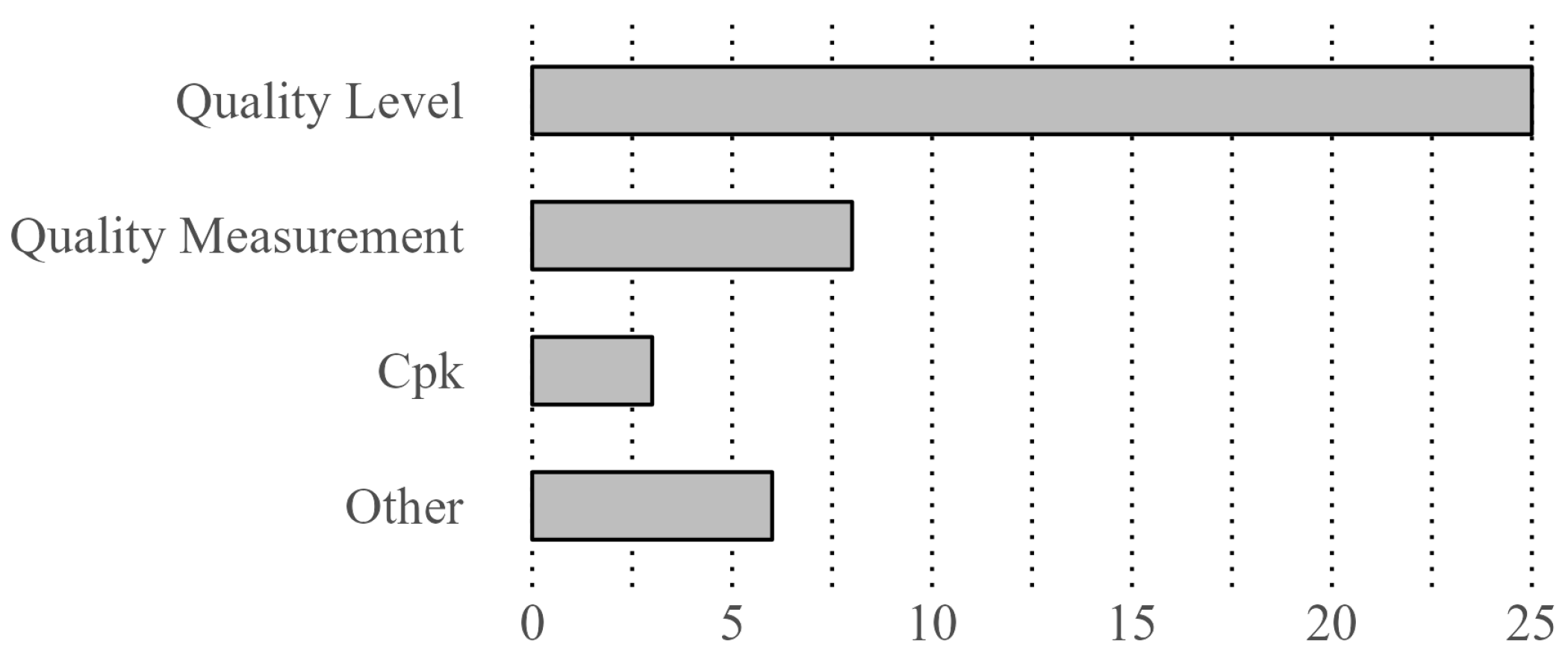
4.5. Dependent Variables
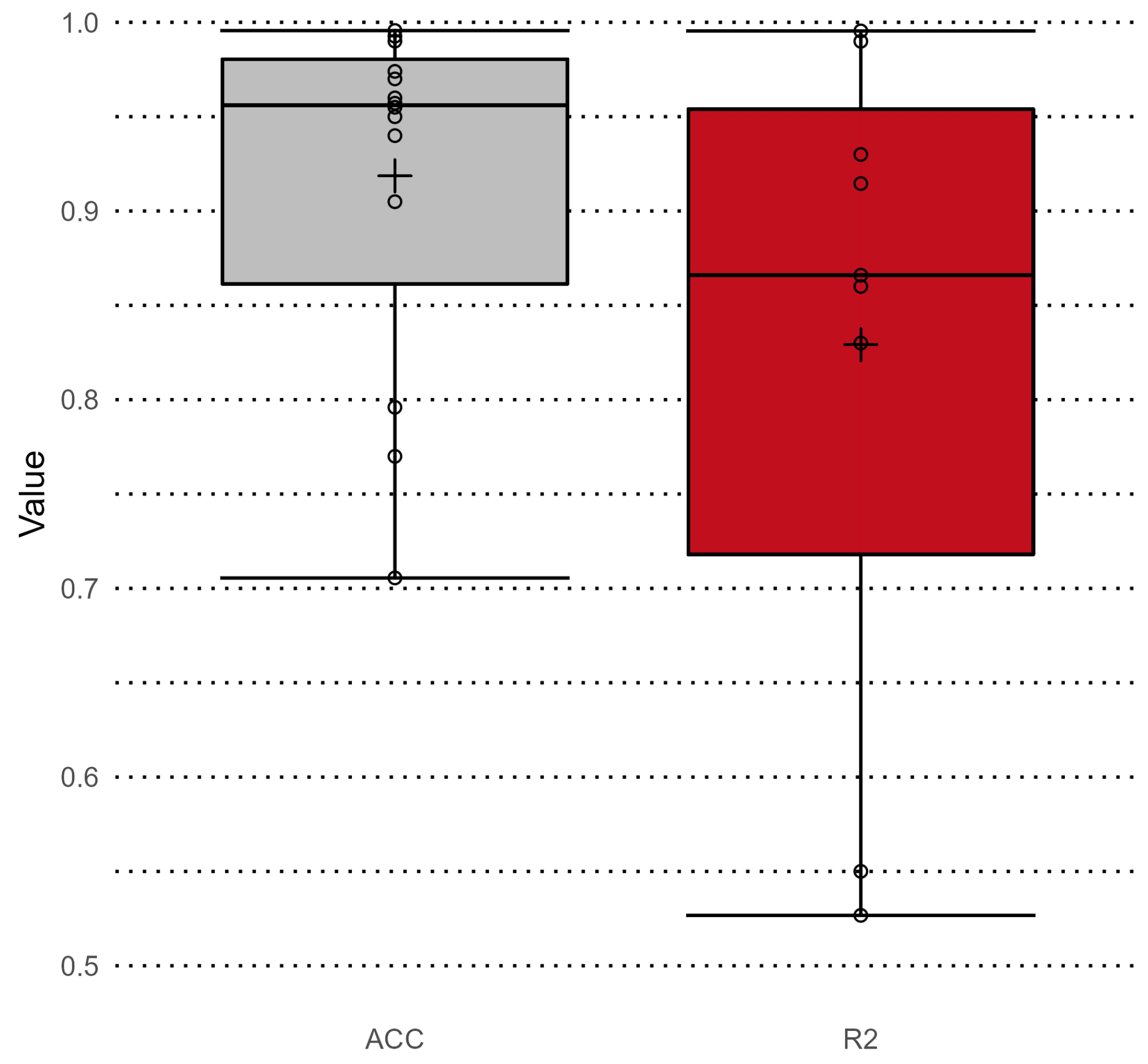
4.6. Model Performance
5. Analysis of Results
5.1. RQ1: Interpretation Domain—Humans
5.2. RQ1: Interpretation Domain—Machines
5.3. RQ2: Analysis Domain
5.4. RQ3: Domain of External Influence
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Goshime, Y.; Kitaw, D.; Jilcha, K. Lean manufacturing as a vehicle for improving productivity and customer satisfaction: A literature review on metals and engineering industries. Int. J. Lean Six Sigma 2019, 10, 691–714. [Google Scholar] [CrossRef]
- Kane, V.E. Process capability indices. J. Qual. Technol. 1986, 18, 41–52. [Google Scholar] [CrossRef]
- Tsung, F.; Li, Y.; Jin, M. Statistical process control for multistage manufacturing and service operations: A review and some extensions. Int. J. Serv. Oper. Inform. 2008, 3, 191–204. [Google Scholar] [CrossRef]
- Lee, S.M.; Lee, D.; Kim, Y.S. The quality management ecosystem for predictive maintenance in the Industry 4.0 era. Int. J. Qual. Innov. 2019, 5, 4. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, G.; Wang, J.; Sun, S.; Si, S.; Yang, T. Real-time information capturing and integration framework of the internet of manufacturing things. Int. J. Comput. Integr. Manuf. 2015, 28, 811–822. [Google Scholar] [CrossRef]
- Das, A.; Mondal, S.; Thakkar, J.; Maiti, J. A methodology for modeling and monitoring of centrifugal casting process. Int. J. Qual. Reliab. Manag. 2015, 32, 718–735. [Google Scholar] [CrossRef]
- Dombrowski, U.; Wullbrandt, J.; Krenkel, P. Industrie 4.0 in production ramp-up management. Procedia Manuf. 2018, 17, 1015–1022. [Google Scholar] [CrossRef]
- Guh, R.S. Integrating artificial intelligence into on-line statistical process control. Qual. Reliab. Eng. Int. 2003, 19, 1–20. [Google Scholar] [CrossRef]
- Wuest, T.; Irgens, C.; Thoben, K.D. An approach to monitoring quality in manufacturing using supervised machine learning on product state data. J. Intell. Manuf. 2014, 25, 1167–1180. [Google Scholar] [CrossRef]
- Lee, S.; Amin, R.W. Process tolerance limits. Total Qual. Manag. 2000, 11, 267–280. [Google Scholar] [CrossRef]
- Sharma, G.; Rao, P.S. A DMAIC approach for process capability improvement an engine crankshaft manufacturing process. J. Ind. Eng. Int. 2014, 10, 65. [Google Scholar] [CrossRef]
- Dietrich, E.; Conrad, S. Statistische Verfahren zur Maschinen-und Prozessqualifikation; Carl Hanser Verlag GmbH Co. KG: München, Germany, 2021; ISBN 978-3-446-46447-6. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J.; Hastie, T.; Tibshirani, R.; Friedman, J. Unsupervised learning. In The Elements of Statistical Learning; Springer: New York, NY, USA, 2009. [Google Scholar] [CrossRef]
- Mishra, N.; Rane, S.B. Prediction and improvement of iron casting quality through analytics and Six Sigma approach. Int. J. Lean Six Sigma 2019, 10, 189–210. [Google Scholar] [CrossRef]
- Senoner, J.; Netland, T.; Feuerriegel, S. Using explainable artificial intelligence to improve process quality: Evidence from semiconductor manufacturing. Manag. Sci. 2022, 68, 5704–5723. [Google Scholar] [CrossRef]
- Rehse, J.R.; Mehdiyev, N.; Fettke, P. Towards explainable process predictions for industry 4.0 in the dfki-smart-lego-factory. KI-Künstliche Intell. 2019, 33, 181–187. [Google Scholar] [CrossRef]
- Rudin, C.; Radin, J. Why are we using black box models in AI when we do not need to? A lesson from an explainable AI competition. Harv. Data Sci. Rev. 2019, 1, 1–9. [Google Scholar] [CrossRef]
- Hyun Park, S.; Seon Shin, W.; Hyun Park, Y.; Lee, Y. Building a new culture for quality management in the era of the Fourth Industrial Revolution. Total Qual. Manag. Bus. Excell. 2017, 28, 934–945. [Google Scholar] [CrossRef]
- Sharma, M.; Luthra, S.; Joshi, S.; Kumar, A. Implementing challenges of artificial intelligence: Evidence from public manufacturing sector of an emerging economy. Gov. Inf. Q. 2022, 39, 101624. [Google Scholar] [CrossRef]
- Okoli, C.; Schabram, K. A guide to conducting a systematic literature review of information systems research. Commun. Assoc. Inf. Syst. 2015, 37, 879–910. [Google Scholar] [CrossRef]
- Gusenbauer, M. Google Scholar to overshadow them all? Comparing the sizes of 12 academic search engines and bibliographic databases. Scientometrics 2019, 118, 177–214. [Google Scholar] [CrossRef]
- Vom Brocke, J.; Simons, A.; Riemer, K.; Niehaves, B.; Plattfaut, R.; Cleven, A. Standing on the shoulders of giants: Challenges and recommendations of literature search in information systems research. Commun. Assoc. Inf. Syst. 2015, 37, 9. [Google Scholar] [CrossRef]
- Cheng, W.K.; Azman, A.F.; Hamdan, M.H.; Mansa, R.F. Application of Six Sigma in oil and gas industry: Converting operation data into business value for process prediction and quality control. In Proceedings of the 2014 IEEE International Conference on Industrial Engineering and Engineering Management, Selangor, Malaysia, 9–12 December 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 148–153. [Google Scholar] [CrossRef]
- Schäfer, F.; Schwulera, E.; Otten, H.; Franke, J. From descriptive to predictive six sigma: Machine learning for predictive maintenance. In Proceedings of the 2019 Second International Conference on Artificial Intelligence for Industries (AI4I), Laguna Hills, CA, USA, 25–27 September 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 35–38. [Google Scholar] [CrossRef]
- Ke, K.C.; Huang, M.S. Quality classification of injection-molded components by using quality indices, grading, and machine learning. Polymers 2021, 13, 353. [Google Scholar] [CrossRef] [PubMed]
- Ismail, M.; Mostafa, N.A.; El-assal, A. Quality monitoring in multistage manufacturing systems by using machine learning techniques. J. Intell. Manuf. 2021, 33, 2471–2486. [Google Scholar] [CrossRef]
- Krauß, J.; Pacheco, B.M.; Zang, H.M.; Schmitt, R.H. Automated machine learning for predictive quality in production. Procedia CIRP 2020, 93, 443–448. [Google Scholar] [CrossRef]
- Zhang, S.; Gao, J.G.; Wang, H.; Zhang, X.Q. Position Tolerance Process Capability Prediction under Maximum Material Condition. Adv. Mater. Res. 2014, 945, 107–110. [Google Scholar] [CrossRef]
- Viharos, Z.J.; Jakab, R. Reinforcement learning for statistical process control in manufacturing. Measurement 2021, 182, 109616. [Google Scholar] [CrossRef]
- Teinemaa, I.; Dumas, M.; Rosa, M.L.; Maggi, F.M. Outcome-oriented predictive process monitoring: Review and benchmark. ACM Trans. Knowl. Discov. Data (TKDD) 2019, 13, 1–57. [Google Scholar] [CrossRef]
- Abbasi, B. A neural network applied to estimate process capability of non-normal processes. Expert Syst. Appl. 2009, 36, 3093–3100. [Google Scholar] [CrossRef]
- Nalbach, O.; Linn, C.; Derouet, M.; Werth, D. Predictive quality: Towards a new understanding of quality assurance using machine learning tools. In Proceedings of the Business Information Systems: 21st International Conference, BIS 2018, Berlin, Germany, 18–20 July 2018; pp. 30–42. [Google Scholar] [CrossRef]
- Schrunner, S.; Scheiber, M.; Jenul, A.; Zernig, A.; Kästner, A.; Kern, R. Towards a General Framework to Embed Advanced Machine Learning in Process Control Systems. arXiv 2021, arXiv:2103.13058. [Google Scholar] [CrossRef]
- Escobar, C.A.; Morales-Menendez, R.; Macias, D. Process-monitoring-for-quality—A machine learning-based modeling for rare event detection. Array 2020, 7, 100034. [Google Scholar] [CrossRef]
- Boaventura, L.L.; Ferreira, P.H.; Fiaccone, R.L. On flexible statistical process control with artificial intelligence: Classification control charts. Expert Syst. Appl. 2022, 194, 116492. [Google Scholar] [CrossRef]
- Köksal, G.; Batmaz, I.; Testik, M.C. A review of data mining applications for quality improvement in manufacturing industry. Expert Syst. Appl. 2011, 38, 13448–13467. [Google Scholar] [CrossRef]
- Afrasiab, H.; Khodaygan, S. Capability Prediction of Machining Processes Based on Uncertainty Analysis. Int. J. Mech. Mechatron. Eng. 2016, 10, 1262–1269. [Google Scholar] [CrossRef]
- Li, F.; Wu, J.; Dong, F.; Lin, J.; Sun, G.; Chen, H.; Shen, J. Ensemble machine learning systems for the estimation of steel quality control. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 2245–2252. [Google Scholar] [CrossRef]
- Zan, T.; Liu, Z.; Su, Z.; Wang, M.; Gao, X.; Chen, D. Statistical process control with intelligence based on the deep learning model. Appl. Sci. 2019, 10, 308. [Google Scholar] [CrossRef]
- Khoza, S.C.; Grobler, J. Comparing machine learning and statistical process control for predicting manufacturing performance. In EPIA Conference on Artificial Intelligence; Springer International Publishing: Cham, Switzerland, 2019. [Google Scholar] [CrossRef]
- Jeereddy, S.; Kennedy, K.; Duffy, E.; Walker, A.; Vorster, B. Machine learning use cases for smart manufacturing kpis. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 4375–4380. [Google Scholar] [CrossRef]
- Demircioglu Diren, D.; Boran, S.; Cil, I. Integration of machine learning techniques and control charts in multivariate processes. Sci. Iran. 2020, 27, 3233–3241. [Google Scholar] [CrossRef]
- Kahya, A.S.; Şişmanoğlu, S.; Erçin, Z.; Akdağ, H.C. Total Quality Management through Defect Detection in Manufacturing Processes Using Machine Learning Algorithms. In Proceedings of the International Symposium for Production Research 2019; Springer International Publishing: Cham, Switzerland, 2020. [Google Scholar] [CrossRef]
- Mabunda, M.R.; Mashamba, A. Predictive Process Control Framework for Online Quality Control in a Hot Rolling Mill. J. Hum. Earth Future 2022, 3, 263–279. [Google Scholar] [CrossRef]
- Qiu, P.; Xie, X. Transparent sequential learning for statistical process control of serially correlated data. Technometrics 2022, 64, 487–501. [Google Scholar] [CrossRef]
- Pheng, T.; Chuluunsaikhan, T.; Ryu, G.; Kim, S.H.; Nasridinov, A.; Yoo, K.H. Prediction of process quality performance using statistical analysis and long short-term memory. Appl. Sci. 2022, 12, 735. [Google Scholar] [CrossRef]
- Li, B.H.; Zhao, L.P.; Yao, Y.Y. Multiconditional machining process quality prediction using deep transfer learning network. Adv. Manuf. 2023, 11, 329–341. [Google Scholar] [CrossRef]
- Mahadevan, S.; Theocharous, G. Optimizing production manufacturing using reinforcement learning. In Proceedings of the FLAIRS Conference, Sanibel Island, FL, USA, 18–20 May 1998; Volume 372, p. 377, ISBN 978-1-57735-051-4. [Google Scholar]
- Kim, S.B.; Jitpitaklert, W.; Park, S.K.; Hwang, S.J. Data mining model-based control charts for multivariate and autocorrelated processes. Expert Syst. Appl. 2012, 39, 2073–2081. [Google Scholar] [CrossRef]
- Chou, S.H.; Chang, S.; Tsai, T.R.; Lin, D.K.; Xia, Y.; Lin, Y.S. Implementation of statistical process control framework with machine learning on waveform profiles with no gold standard reference. Comput. Ind. Eng. 2020, 142, 106325. [Google Scholar] [CrossRef]
- Kabasakal, İ.; Keskin, F.D.; Koçak, A.; Soyuer, H. A prediction model for fault detection in molding process based on logistic regression technique. In Proceedings of the International Symposium for Production Research 2019, Vienna, Austria, 28–30 August 2019; Springer International Publishing: Cham, Switzerland, 2020; pp. 351–360. [Google Scholar] [CrossRef]
- Li, J.; Liu, L.; Le, T.D.; Liu, J. Accurate data-driven prediction does not mean high reproducibility. Nat. Mach. Intell. 2020, 2, 13–15. [Google Scholar] [CrossRef]
- Xiao, X.; Waddell, C.; Hamilton, C.; Xiao, H. Quality prediction and control in wire arc additive manufacturing via novel machine learning framework. Micromachines 2022, 13, 137. [Google Scholar] [CrossRef] [PubMed]
- Crankshaw, D.; Gonzalez, J. Prediction-Serving Systems: What happens when we wish to actually deploy a machine learning model to production? Queue 2018, 16, 83–97. [Google Scholar] [CrossRef]
- Denkena, B.; Dittrich, M.A.; Wilmsmeier, S. Automated production data feedback for adaptive work planning and production control. Procedia Manuf. 2019, 28, 18–23. [Google Scholar] [CrossRef]
- Ziegler, D.; Peissner, M. Enabling Accessibility through Model-Based User Interface Development. In Proceedings of the AAATE Conference, Sheffield, UK, 11–15 September 2017; pp. 1067–1074. [Google Scholar] [CrossRef]
- Knowles, R.; Sanchez-Torron, M.; Koehn, P. A user study of neural interactive translation prediction. Mach. Transl. 2019, 33, 135–154. [Google Scholar] [CrossRef]
- Gupta, P.K.; Tyagi, V.; Singh, S.K. Predictive Computing and Information Security; Springer: Singapore, 2017. [Google Scholar] [CrossRef]
- Sadati, N.; Chinnam, R.B.; Nezhad, M.Z. Observational data-driven modeling and optimization of manufacturing processes. Expert Syst. Appl. 2018, 93, 456–464. [Google Scholar] [CrossRef]
- Chen, W.; Liu, H.; Qi, E. Discrete event-driven model predictive control for real-time work-in-process optimization in serial production systems. J. Manuf. Syst. 2020, 55, 132–142. [Google Scholar] [CrossRef]
- Tulkinbekov, K.; Kim, D.H. Blockchain-enabled approach for big data processing in edge computing. IEEE Internet Things J. 2022, 9, 18473–18486. [Google Scholar] [CrossRef]
- Ganapathy, A. Edge computing: Utilization of the internet of things for time-sensitive data processing. Asian Bus. Rev. 2021, 11, 59–66. [Google Scholar] [CrossRef]
- Qi, Q.; Xu, Z.; Rani, P. Big data analytics challenges to implementing the intelligent Industrial Internet of Things (IIoT) systems in sustainable manufacturing operations. Technol. Forecast. Soc. Chang. 2023, 190, 122401. [Google Scholar] [CrossRef]
- Rajagopal, R.; Del Castillo, E.; Peterson, J.J. Model and distribution-robust process optimization with noise factors. J. Qual. Technol. 2005, 37, 210–222. [Google Scholar] [CrossRef]
- Vilalta, R.; Apte, C.V.; Hellerstein, J.L.; Ma, S.; Weiss, S.M. Predictive algorithms in the management of computer systems. IBM Syst. J. 2002, 41, 461–474. [Google Scholar] [CrossRef]
- Ławryńczuk, M. Explicit nonlinear predictive control algorithms with neural approximation. Neurocomputing 2014, 129, 570–584. [Google Scholar] [CrossRef]
- Warriach, E.U.; Ozcelebi, T.; Lukkien, J.J. A comparison of predictive algorithms for failure prevention in smart environment applications. In Proceedings of the 2015 International Conference on Intelligent Environments, Prague, Czech Republic, 15–17 July 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 33–40. [Google Scholar] [CrossRef]
- Malyuta, D.; Açikmeşe, B.; Cacan, M. Robust model predictive control for linear systems with state and input dependent uncertainties. In Proceedings of the 2019 American Control Conference (ACC), Philadelphia, PA, USA, 10–12 July 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1145–1151. [Google Scholar] [CrossRef]
- Angione, C.; Lió, P. Predictive analytics of environmental adaptability in multi-omic network models. Sci. Rep. 2015, 5, 15147. [Google Scholar] [CrossRef]
- Muhr, D.; Tripathi, S.; Jodlbauer, H. An adaptive machine learning methodology to determine manufacturing process parameters for each part. Procedia Comput. Sci. 2021, 180, 764–771. [Google Scholar] [CrossRef]
- Wu, Z.; Rincon, D.; Christofides, P.D. Real-time adaptive machine-learning-based predictive control of nonlinear processes. Ind. Eng. Chem. Res. 2019, 59, 2275–2290. [Google Scholar] [CrossRef]
- Shahbazi, Z.; Byun, Y.C. Smart manufacturing real-time analysis based on blockchain and machine learning approaches. Appl. Sci. 2021, 11, 3535. [Google Scholar] [CrossRef]
- Kozłowski, E.; Mazurkiewicz, D.; Żabiński, T.; Prucnal, S.; Sęp, J. Machining sensor data management for operation-level predictive model. Expert Syst. Appl. 2020, 159, 113600. [Google Scholar] [CrossRef]
- Moldovan, D.; Cioara, T.; Anghel, I.; Salomie, I. Machine learning for sensor-based manufacturing processes. In Proceedings of the 2017 13th IEEE International Conference on Intelligent Computer Communication and Processing (ICCP), Cluj-Napoca, Romania, 7–9 September 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 147–154. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Forecasting Method | Description |
|---|---|
| Time Series Analysis | Utilizes historical data to predict future outcomes based on identified patterns and trends in the data over time. Commonly used methods include ARIMA and Exponential Smoothing [4]. |
| Regression Analysis | Employs statistical techniques to model the relationship between a dependent variable and one or more independent variables, enabling predictions based on this relationship [14]. |
| Machine Learning Models | Includes various algorithms such as neural networks, decision trees, and support vector machines that learn from data to make predictions, often outperforming traditional statistical methods in complex datasets [15]. |
| Ensemble Learning | Combines multiple machine learning models to improve prediction accuracy, including methods such as Random Forests and Gradient Boosting Machines [8]. |
| Simulation-based Forecasting | Involves creating models that simulate different scenarios to predict the impact of various factors on process outcomes, often used in conjunction with ML for more accurate predictions [5]. |
| Expert Systems | Utilizes rule-based systems that mimic the decision-making abilities of human experts to predict outcomes, often integrated with ML for enhanced decision support [6]. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mayer, J.; Jochem, R. Capability Indices for Digitized Industries: A Review and Outlook of Machine Learning Applications for Predictive Process Control. Processes 2024, 12, 1730. https://doi.org/10.3390/pr12081730
Mayer J, Jochem R. Capability Indices for Digitized Industries: A Review and Outlook of Machine Learning Applications for Predictive Process Control. Processes. 2024; 12(8):1730. https://doi.org/10.3390/pr12081730
Chicago/Turabian StyleMayer, Jan, and Roland Jochem. 2024. "Capability Indices for Digitized Industries: A Review and Outlook of Machine Learning Applications for Predictive Process Control" Processes 12, no. 8: 1730. https://doi.org/10.3390/pr12081730