
A New Monitoring Method for the Injection Volume of Blast Furnace Clay Gun Based on Object Detection



Abstract
:1. Introduction
- This is the first time the task of monitoring the injection volume of a BF clay gun has been approached using computer vision. We propose a comprehensive solution, from data collection to model implementation, offering a novel perspective for future researchers.
- We propose PSCfrcn, composed of multi-stage positional encoding and two-branch self-challenge, which consistently improves the accuracy and stability of the objective detection model for the problem we address.
- We conduct extensive experiments on the clay gun dataset from actual industrial scenarios, and use various metrics to validate the performance improvements brought by our model.
2. Related Work
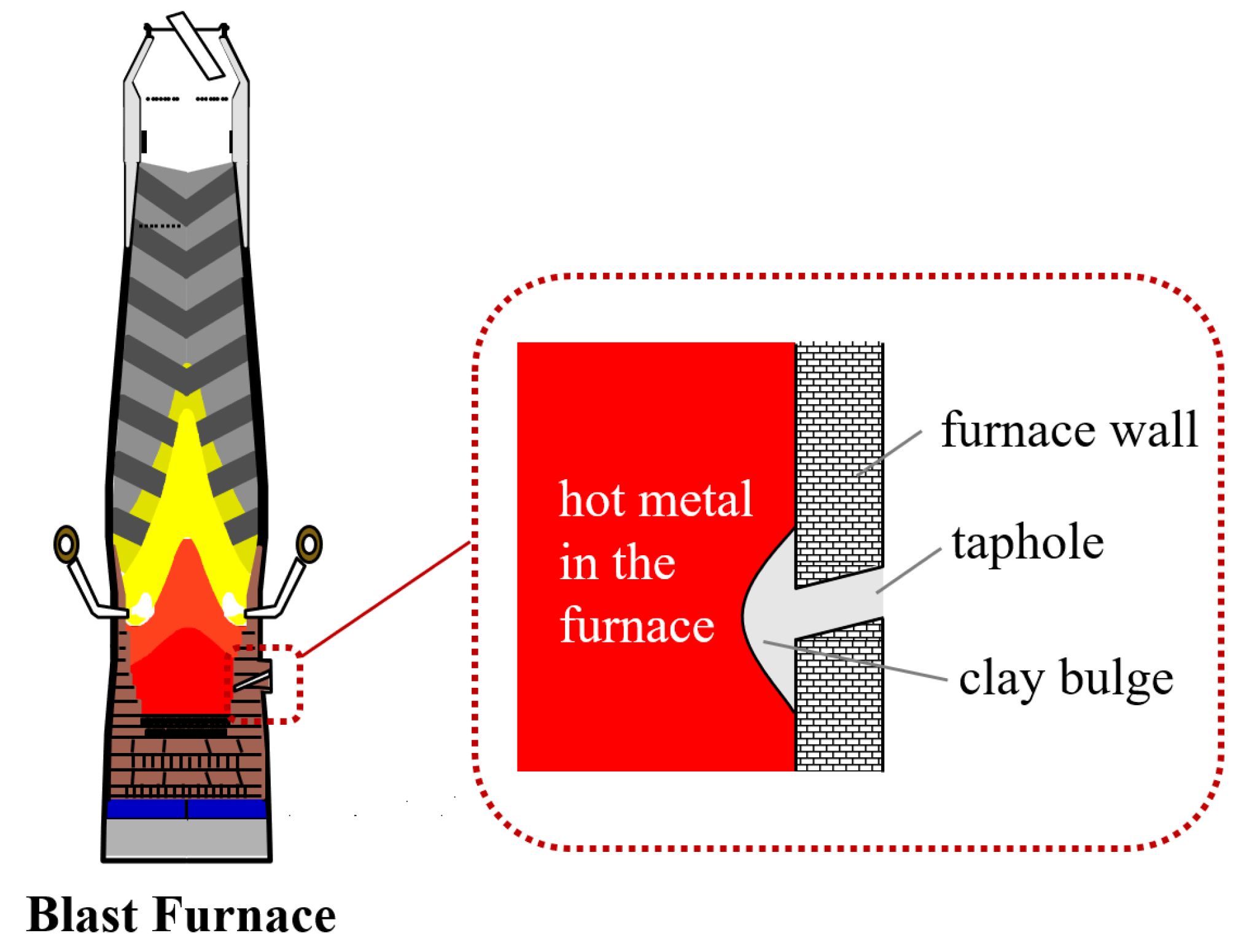
2.1. Injection Volume Monitoring of Clay Gun
2.2. Object Detection
3. Data Collection and Annotation
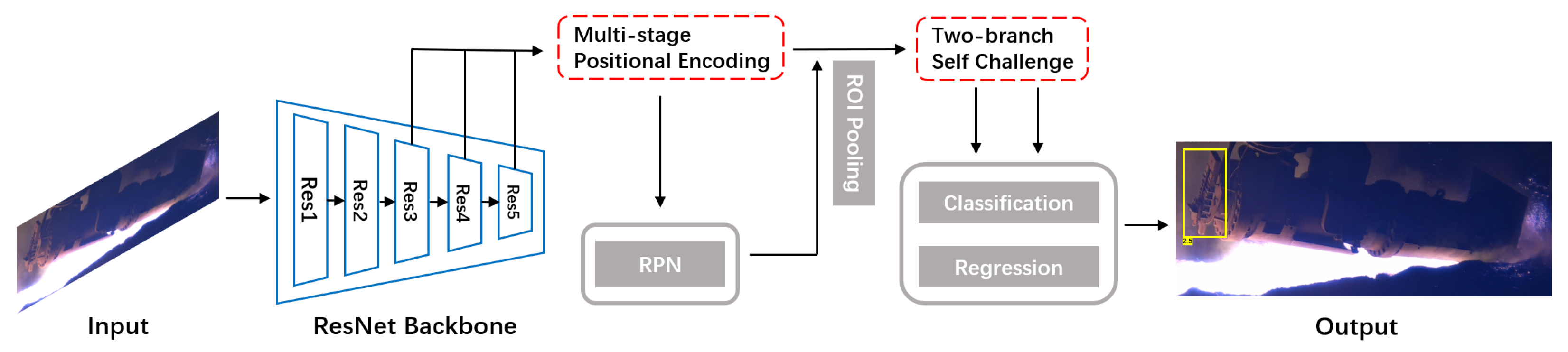
4. Our Model
4.1. Basic Model Selection
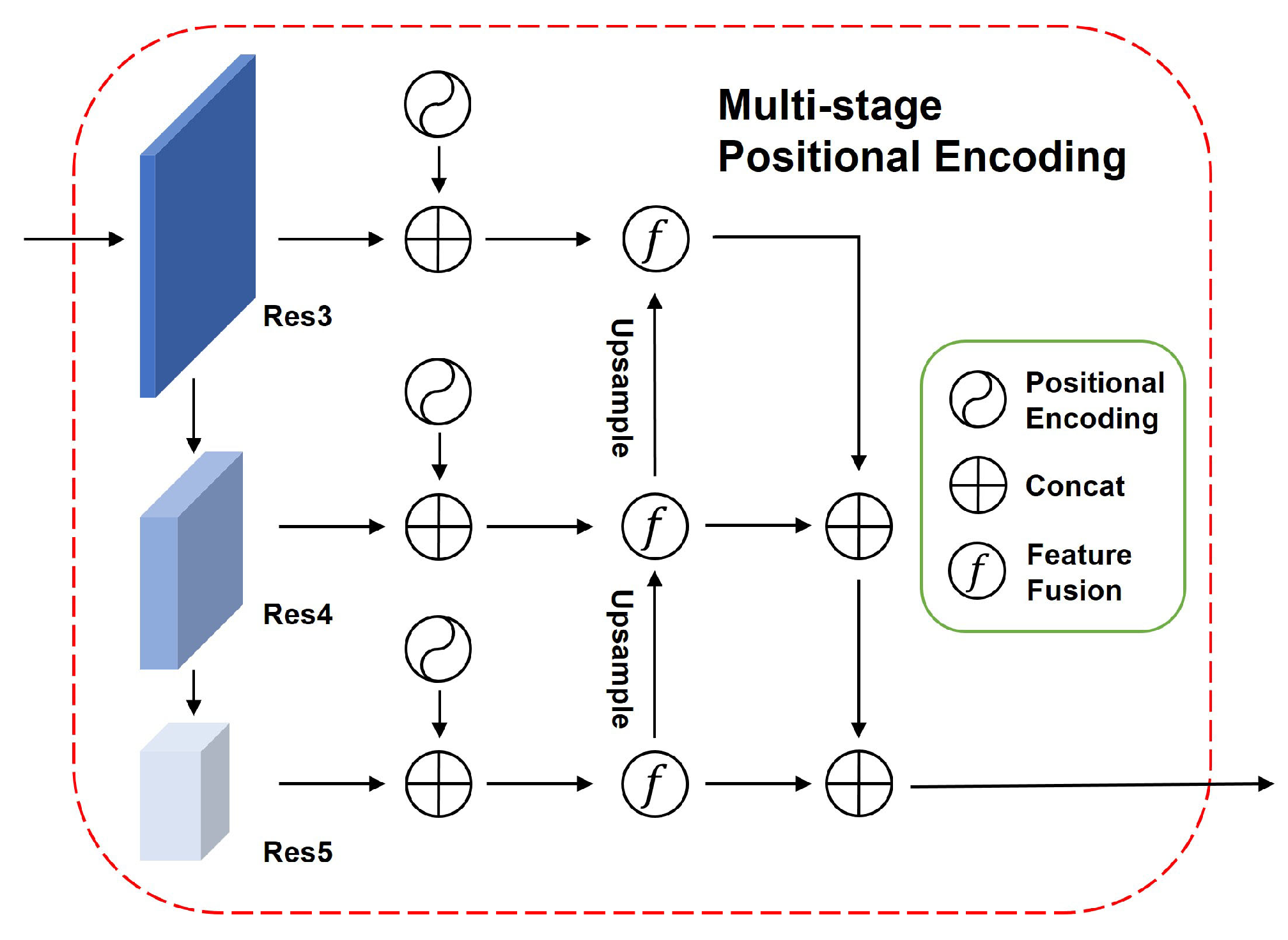
4.2. Multi-Stage PE
4.3. Two-Branch SC
| Algorithm 1 Two-branch SC. |
| Input: Dataset , percentage of batch to modify p, maximum number of epoches T, ROI features Z; Output: Last layer of our model ; Random initialize the model ; while do for every batch do Generate and by the locate strategy [30]; if then ▹ Use batch dropout Calculate the probabilities by Equations (8) and(9); Calculate the classification impact by Equation (10); Calculate the offsets by Equations (12) and (13); Calculate the regression impact by Equation (14); Update and by Equation (11); end if Obtain classification features and regression features ; Update by the gradient of the model; end for end while |
5. Method Validation
5.1. Data Preparation
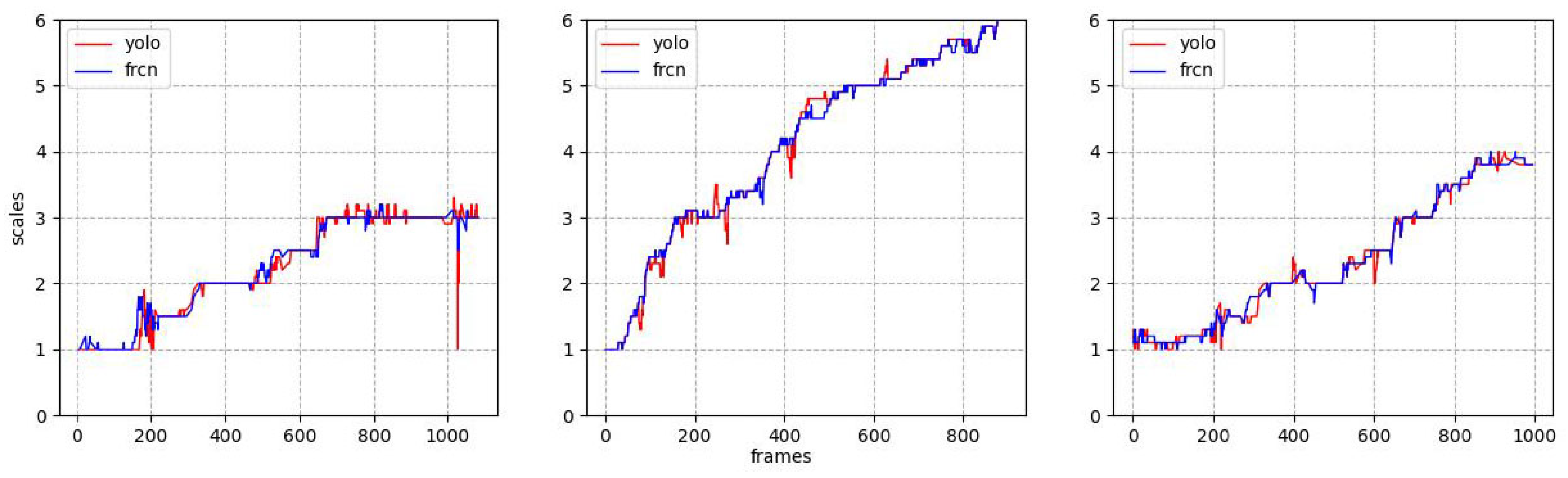
5.2. Evaluation Metrics
- Calculate the first-order derivative: Assume that the predicted vernier’s position of the frame is , the first-order derivative at a series of time points can be approximated by Equation (19):
- Calculate the standard deviation of the derivatives: For a series of derivative values , the 1st deriv. SD is calculated by Equation (20):where is the mean of the derivative values as Equation (21):
5.3. Experimental Results
5.4. Ablation Study
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Mousa, E. Modern blast furnace ironmaking technology: Potentials to meet the demand of high hot metal production and lower energy consumption. Metall. Mater. Eng. 2019, 25, 69–104. [Google Scholar] [CrossRef]
- Jiang, Z.; Dong, J.; Pan, D.; Wang, T.; Gui, W. A new monitoring method for the blocking time of the taphole of blast furnace using molten iron flow images. Measurement 2022, 204, 112155. [Google Scholar] [CrossRef]
- He, Q.; Liang, H.; Yan, B.; Guo, H. Angle Diagnosis of Blast Furnace Chute Through Deep Learning of Temporal Images. IEEE Trans. Instrum. Meas. 2024, 73, 1–11. [Google Scholar] [CrossRef]
- Mao, R. A survey Technology for the Dischapge capacity of blast furnace hydraulic clay gun. Metrol. Meas. Tech. 2021. [Google Scholar]
- Yi, A.; Wang, Z.; Ren, H. Application of intelligent measurement and control systems in blast furnace tapping machines and mud guns. Equip. Manag. Maint. 2021, 150–151. [Google Scholar] [CrossRef]
- Fang, W. Development of Mud Quantity Detection Device for Hydraulic Mud Cannon. Metall. Equip. 2023, 57–59. [Google Scholar]
- Liu, Q.; Zhang, S. Research on the Accurate Control of Sediment of Hydraulic Mud Cannon. Metal World 2022, 62–65. [Google Scholar]
- Sun, J.; Kong, J. Research and Application of Digital Mud Injection Detection Technology in Tapping Operations. In Proceedings of the Ironmaking Academic Exchange Conference in Shandong Province, Laiwu, China, 9–11 December 2009; Laiwu Steel Co., Ltd., Ironmaking Plant: Laiwu, China, 2009; pp. 187–188. [Google Scholar]
- Yu, C. Blast furnace mud gun play mud quantity indicating device improvement and application. Electron. Test 2013, 121–122. [Google Scholar]
- Li, Y.; Wang, Y.; Wang, W.; Lin, D.; Li, B.; Yap, K.H. Open World Object Detection: A Survey. arXiv 2024, arXiv:2410.11301. [Google Scholar]
- Redmon, J. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Ge, Z. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Law, H.; Deng, J. Cornernet: Detecting objects as paired keypoints. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. CenterNet++ for Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 3509–3521. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Duan, K.; Xie, L.; Qi, H.; Bai, S.; Huang, Q.; Tian, Q. Corner proposal network for anchor-free, two-stage object detection. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 399–416. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 213–229. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable detr: Deformable transformers for end-to-end object detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Jia, D.; Yuan, Y.; He, H.; Wu, X.; Yu, H.; Lin, W.; Sun, L.; Zhang, C.; Hu, H. Detrs with hybrid matching. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 19702–19712. [Google Scholar]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.H.; et al. Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 6881–6890. [Google Scholar]
- Zong, Z.; Song, G.; Liu, Y. Detrs with collaborative hybrid assignments training. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 6748–6758. [Google Scholar]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. Detrs beat yolos on real-time object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 16965–16974. [Google Scholar]
- Dosovitskiy, A. An image is worth 16×16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Qiao, L.; Zhao, Y.; Li, Z.; Qiu, X.; Wu, J.; Zhang, C. Defrcn: Decoupled faster r-cnn for few-shot object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 8681–8690. [Google Scholar]
- Vaswani, A. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; Girshick, R. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 16000–16009. [Google Scholar]
- Huang, Z.; Wang, H.; Xing, E.P.; Huang, D. Self-challenging improves cross-domain generalization. In Proceedings of the 16th European Conference of the Computer Vision (ECCV 2020), Glasgow, UK, 23–28 August 2020; Proceedings, Part II 16. Springer: Cham, Switzerland, 2020; pp. 124–140. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Yan, D.; Huang, J.; Sun, H.; Ding, F. Few-shot object detection with weight imprinting. Cogn. Comput. 2023, 15, 1725–1735. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual explanations from deep networks via gradient-based localization. Int. J. Comput. Vis. 2020, 128, 336–359. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Backbone | Accuracy (%) | mAP (%) | 1st Deriv. SD () | Params (M) | Inference Time (s) | |||
|---|---|---|---|---|---|---|---|---|---|
| All | 0.0 | 0.5 | mid | ||||||
| YOLOv5s | CSPDarknet | 72.41 | 68.43 | 70.04 | 69.18 | 66.09 | 12.10 | 7.2 | 0.013 |
| YOLOv5m | CSPDarknet | 78.37 | 75.11 | 77.86 | 74.77 | 72.72 | 7.86 | 21.2 | 0.022 |
| YOLOX-s [12] | Darknet | 76.13 | 70.96 | 74.55 | 71.54 | 66.81 | 10.63 | 9.0 | 0.016 |
| YOLOX-m [12] | Darknet | 81.44 | 76.43 | 79.11 | 76.37 | 73.82 | 6.72 | 25.3 | 0.030 |
| YOLOv8s | Darknet | 78.82 | 74.56 | 78.27 | 75.44 | 69.97 | 8.15 | 11.2 | 0.014 |
| YOLOv8m | Darknet | 85.52 | 80.27 | 81.98 | 80.92 | 77.91 | 4.94 | 25.9 | 0.027 |
| EfficientDet [31] | EfficientNet-D4 | 85.30 | 80.13 | 82.07 | 80.16 | 78.17 | 6.02 | 20.7 | 0.083 |
| EfficientDet [31] | EfficientNet-D5 | 86.07 | 80.92 | 81.89 | 81.72 | 79.14 | 5.14 | 33.7 | 0.138 |
| CenterNet-RT [15] | DLA34 | 84.72 | 79.06 | 80.53 | 79.10 | 77.54 | 5.31 | 26.5 | 0.045 |
| RT-DETR [24] | Res50 | 86.36 | 81.46 | 82.22 | 81.76 | 80.39 | 4.42 | 41.4 | 0.021 |
| Faster R-CNN † [16] | Res18 | 78.73 | 73.88 | 75.77 | 76.64 | 69.20 | 9.38 | 15.7 | 0.079 |
| Faster R-CNN † [16] | Res34 | 87.23 | 81.60 | 83.07 | 81.91 | 79.84 | 4.27 | 24.8 | 0.127 |
| Faster R-CNN † [16] | Res50 | 86.20 | 82.05 | 83.76 | 83.13 | 79.27 | 4.59 | 28.6 | 0.156 |
| FPN [17] | Res50 | 84.95 | 79.14 | 80.91 | 79.89 | 76.62 | 5.63 | 30.1 | 0.174 |
| CPN [18] | DLA34 | 83.68 | 78.57 | 80.14 | 79.48 | 76.07 | 6.21 | 19.8 | 0.237 |
| Faster R-CNN | Swin-T [26] | 86.61 | 81.28 | 82.58 | 82.20 | 79.08 | 4.85 | 34.6 | 0.286 |
| PSCfrcn † (ours) | Res34 | 90.58 | 84.53 | 86.26 | 84.29 | 83.05 | 3.76 | 24.8 | 0.128 |
| PSCfrcn † (ours) | Res50 | 89.76 | 84.29 | 85.72 | 85.35 | 81.79 | 3.92 | 28.6 | 0.158 |
| FRCN | Stages | mAP (%) | ||
|---|---|---|---|---|
| Block3 | Block4 | Block5 | ||
| ✓ | ✓ | 81.72 | ||
| ✓ | ✓ | 82.19 | ||
| ✓ | ✓ | 82.54 | ||
| ✓ | ✓ | ✓ | 82.71 | |
| ✓ | ✓ | ✓ | ✓ | 82.86 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Liang, H.; Guo, H.; Yan, B.; Xu, H. A New Monitoring Method for the Injection Volume of Blast Furnace Clay Gun Based on Object Detection. Processes 2025, 13, 1006. https://doi.org/10.3390/pr13041006
Zhang X, Liang H, Guo H, Yan B, Xu H. A New Monitoring Method for the Injection Volume of Blast Furnace Clay Gun Based on Object Detection. Processes. 2025; 13(4):1006. https://doi.org/10.3390/pr13041006
Chicago/Turabian StyleZhang, Xunkai, Helan Liang, Hongwei Guo, Bingji Yan, and Hao Xu. 2025. "A New Monitoring Method for the Injection Volume of Blast Furnace Clay Gun Based on Object Detection" Processes 13, no. 4: 1006. https://doi.org/10.3390/pr13041006
APA StyleZhang, X., Liang, H., Guo, H., Yan, B., & Xu, H. (2025). A New Monitoring Method for the Injection Volume of Blast Furnace Clay Gun Based on Object Detection. Processes, 13(4), 1006. https://doi.org/10.3390/pr13041006